
14
–––––––––––––––––––––––
Privacy and Confidentiality in Cloud Computing
Khaled M. Khan and Qutaibah Malluhi
14.1 INTRODUCTION
Cloud computing is an emerging computation model in which applications, data, computational processes, computing resources, and operating platforms are offered to consumers as services. This model provides the opportunity for utility-like virtually unlimited computational power and capacity at a lower cost with greater flexibility as well as elasticity. This new paradigm promotes and facilitates cost-effective outsourcing of computations and data in a shared infrastructure, enabling enterprises to cut information technology costs while focusing on their core business functionalities. Therefore, enterprises are increasingly becoming interested in running their business applications on the cloud.
In spite of the obvious benefits offered by this open computing environment, privacy and confidentiality of consumers'data and processes are the paramount concerns for propelling cloud computing adoption in a wider scale. Cloud computing poses several privacy and confidentiality challenges that can be the major stumbling blocks for moving applications into the cloud. These concerns include the risk of data breaches, malicious corruption of computed results, uncertainty about data privacy, and lack of consumer control on their data assets residing on third-party infrastructure. Consumers'data processed by cloud computing are often sensitive, such as containing commercial secrets, information of national security importance, legal requirements related to privacy laws that pertain to medical records, financial records, or educational records.
Consumers of cloud computing often do not want their data as well as computed output to be seen by the server. This is an issue of data confidentiality. For example, Alice likes to have the computational services of cloud computing but does not want the cloud computing server to “see,” “know,” or “derive” anything about her input data, processing model, and output data. In other words, cloud servers are supposed to process consumers'data without “seeing” and “comprehending” the actual input and output.
In the database context, there must be assurances that the cloud data center is provably unable to identify individuals with sensitive information. This is an issue of privacy because privacy laws are usually applicable to individually identifiable data. In such privacy and confidentiality requirements, pooling storage resources with consumers'data and their manipulation on the providers'servers raise serious concerns regarding data privacy and confidentiality. These issues force security experts to rethink and reconsider the existing practices in light of this new frontier of privacy and confidentiality problems previously unaccounted for [1]. In cloud environments, flexible and dynamic resource allocation must occur in real time based on events and security policy on a scale that no provider has yet materialized [2]. The challenges are to ensure that appropriate technologies are in place to prevent cloud providers from seeing consumer queries, identifying individuals with sensitive data, and seeing and using consumers'data in a way not agreed upon.
The privacy concern is often addressed with contractual agreements such as service level agreements (SLAs). Interestingly, SLAs might not work for consumers because these are more related to providing compensation to consumers when a violation occurs rather than prevention of privacy and confidentiality violation. Consumers are usually more concerned about the loss of data privacy and not about compensation after the data breach because, for most enterprises, privacy breaches of enterprise data are often irreparable and priceless [3]. In contrast, this chapter focuses more on the concept of prevention rather than on being compensated after privacy and confidentiality breaches. We discuss technological solutions that could enhance consumers'confidence in cloud computing by enabling them to outsource their computational needs with privacy and confidence on the cloud. We are interested in solutions that minimize or even eliminate the utilization of expensive encryption in order to make them more practical.
14.2 CLOUD STAKEHOLDERS AND COMPUTATIONAL ASSETS
Cloud computing is still an evolving paradigm. To understand the entire spectrum of privacy and confidentiality issues of this paradigm, we need to recognize its landscape such as its stakeholders and their computational assets. In this context, computational assets refer to data and processes such as algorithms or specific computing models. Privacy and confidentiality issues are closely related to customers of cloud computing and their computational assets. Figure 14.1 depicts various stakeholders of cloud computing and their computational assets.
14.2.1 Stakeholders
Cloud computing can have two major stakeholders at different levels of its abstraction: provider and consumer.
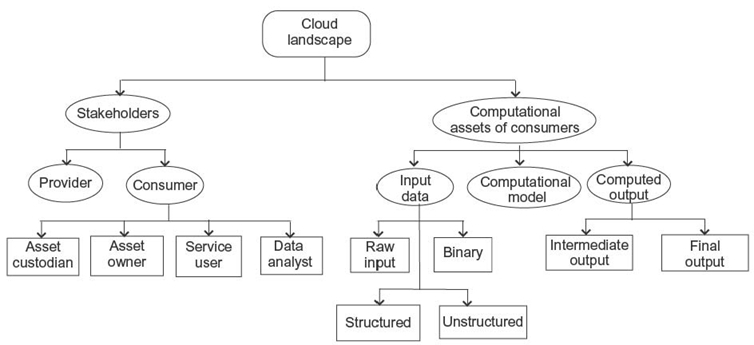
FIGURE 14.1. Cloud stakeholders and their computational assets.
14.2.1.1 Provider Cloud providers typically own and manage cloud computing resources such as hardware, networks, and systems software. They serve cloud consumers by offering services such as on-demand utility computing, storage, data processing, software services, infrastructure, and operating platform.
14.2.1.2 Consumer Cloud consumers are the entities that consume cloud services offered by providers (such as software as a service and database as a service) by outsourcing their computational needs. We can classify cloud consumers into four broader groups: asset custodian, asset owner, service user, and data analyst:
- Asset Custodian. This is the entity that produces, manipulates, and stores data on behalf of someone else but does not own them, such as a hospital, which is the custodian of patients'data. A data custodian usually manages data of multiple owners who might have access to their data consigned to the cloud.
- Asset Owner. This entity is described by data or to whom the data belong. For example, a patient is the owner of his or her own medical records. Any disclosure of data may affect the privacy of the owner. It is also not uncommon that the data owner and the data custodian are the same entity. Owners could have either direct or indirect access to their data stored in the cloud through their asset custodian.
- Service User. Service users only consume the services provided by the cloud without providing input data or computational models. They are the passive consumers of the cloud without owning any data.
- Data Analyst. Data analysts periodically use data available on cloud for their own purposes. They usually perform various data mining operations such as analyzing patterns, finding trends, and computing forecasts on data stored on the cloud. Typically, various government agencies fall in this category of the stakeholder. Data analysts analyze populated data on the cloud for various purposes. They can also make available their analysis results on the cloud so that service users could use the results.
14.2.2 Computational Assets of Consumers
The outsourcing of consumers'computational assets involves three types of entities that, in most cases, are considered sensitive and should be kept private and/or confidential:
- Input Data. The input data submitted to cloud by consumers often represent information that are sensitive such as business secrets, private information about individuals, national security information, and strategic information. Input data submitted to cloud computing for processing or storage can be classified into four major groups:
- raw data (e.g., scientific data, matrices, series of numbers, and stream of characters)
- structured (e.g., relational database and complex data structures)
- unstructured (e.g., narrative texts)
- binary (e.g., multimedia objects and images).
- Computational Models.Consumers may also use their own customized computational models that embody consumer-specific algorithms, simulations, analyses, processes, and so on. These are often private and confidential in a sense that a disclosure of such models may make consumers lose their competitive advantage or may put them in disadvantageous situations financially and/or legally.
- Computed Output Data. Results produced by cloud servers can be classified into two broad categories:
- intermediate output
- final output.
These are also considered confidential. The cloud server should not be able to deduce any knowledge out of the computed intermediate or final output.
14.3 DATA PRIVACY AND TRUST
Consumers'computational assets can be sensitive, such as containing commercial secrets involving national security-related information, or subject to legal requirements and regulatory compliances such as the Health Insurance Portability and Accountability Act (HIPAA) legislation for health records, Gramm‒Leach‒Bliley Act for financial records, or Family Education Rights and Privacy Act (FERPA) for student records. For example, consumers in the European Union (EU) having contract with cloud providers located outside the EU/European Economic Area (EEA) are subject to the EU regulations on export of personal data [4]. Cloud computing is being criticized by privacy advocates for greater control by the companies hosting the cloud services (i.e., cloud providers), and, thus, they can monitor at will, lawfully or unlawfully, the consumers'communication and data.
Cloud consumers have many reasons to be concerned regarding their data and computational models consigned on the cloud:
- Loss of Control. Consumers'loss of control on their data and processes once they are on the cloud, and fear of overdependence on third party for manipulating their data stored on remote machines are serious concerns.
- Leakage of Information. The possibility of leakage of consumers'proprietary information to competitors such as revealing business secrets, corporate strategy, and data owners'private information may drive the consumers'decision to use the cloud.
- Regulatory Compliance. The potential of transborder data movement among cooperating service providers may not be supportive to regulatory compliance such as HIPAA because data located in different countries may be governed by different jurisdictions.
- Legal Liability. Compromising private information caused by cloud providers may lead to embarrassments and lawsuits against the consumers and/or providers. Compliance with privacy laws may make it illegal to share data with others such as third-party cloud providers.
Therefore, an important requirement on cloud environments is that the cloud servers learn nothing about the customer's input data, the computational models, and the computed results. The servers of the cloud provider process consumers'data without seeing it, as well as without comprehending the meaning of the computed products. The consumer needs to query the database from time to time but without revealing to the remote server either the queries or the results. Another requirement is that private data are not compromised by preventing linking sensitive information to individuals.
14.4 A CLOUD COMPUTING EXAMPLE
Let us consider an example in order to flesh out the roles of different stakeholders of cloud computing and the privacy and confidentiality issues in relation to outsourcing of scientific computing and relational databases. Figure 14.2 illustrates the scenario of cloud computing with
- different types of stakeholders and their roles
- their outsourcing needs
- their privacy and/or confidentiality requirements.
In this scenario, we can find different stakeholders with their role and security requirements: CloudLab (the provider), MatrixCom (consumer and asset owner), ImageGE (consumer and asset owner), Penrith Hospital (consumer but not asset owner), Medi Insurance (data analyst), a medicine manufacturer (service user), and patients (asset owner, but not cloud consumer).
14.4.1 Scientific Computing: Matrix Multiplication
Imagine a company called MatrixCom that handles expensive algebraic computations such as convolution and deconvolution involving multiplications of large matrices. For MatrixCom, the input values of the matrices as well as output are sensitive, and should remain confidential. MatrixCom, an asset owner in this case, is considering to outsource all computationally expensive matrix multiplication tasks to CloudLab (a cloud provider) in a manner that ensures its following data confidentiality and integrity requirements:
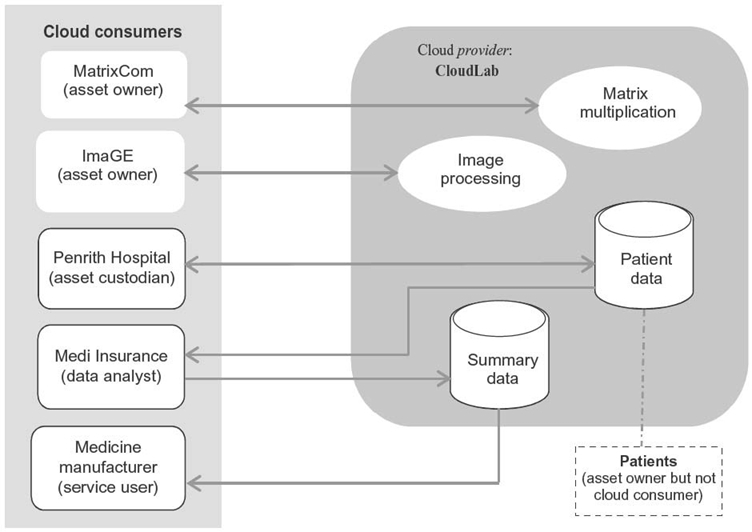
FIGURE 14.2. A cloud computing scenario with stakeholders and their computational assets.
- Confidentiality. The servers of the provider CloudLab learn nothing about the input matrices, intermediate output, and the computed output matrix. For example, CloudLab is required to multiply two n × n matrices A and B sent by MatrixCom. CloudLab should not be allowed to learn any of A B, or the C. MatrixCom should be able to hide A and B by doing no more than linear work in terms of the size of matrices A and B.
- Integrity of Output. The cloud consumer MatrixCom requires the computation to be done in such a way that it is able to detect with high probability if the servers of CloudLab did carry out the computations correctly and without cheating. The cloud server may cheat by not carrying out the full expensive computation to save resources; that is, MatrixCom should also be able to validate with high probability that the generated output matrix C is equal to A × B.
- Efficiency. To hide its data and to validate the integrity of the output, MatrixCom should not be required to perform expensive operations that will negate the benefits of outsourcing. Therefore, MatrixCom should only do O(n2) operations. Otherwise, outsourcing would not make sense because hiding the input and output data will be as expensive as (or will have similar complexity to) performing the computation itself. In addition, hiding the input and output should not require the server to do operations that have higher complexity than the intended matrix multiplication operation (e.g., the server should not take more than O(n3) if the brute force matrix multiplication algorithm is used).
14.4.1.1 Current Practices Several techniques for secure outsourcing of matrix multiplications exist in the literature [5, 6]. In Reference 5, simple protocols for matrix multiplications that satisfy the above requirements have been presented. These protocols disguise the input/output matrices by shuffling the matrix elements and by adding or multiplying them by random values. These protocols are efficient. However, they suffer from very weak protection as they can easily be attacked.
Relevant and much more secure techniques in the literature include homomorphic encryption and server-aided secret computation [7], which are considered to be expensive. Other relevant work includes protocols for secure multiparty computation and secure function evaluation [8]. However, these protocols do not satisfy the requirements of asymmetric load distribution between the consumer and the server, and the ability to validate the produced output. Researchers have also addressed similar solutions for other types of scientific computations (e.g., DNA analysis [9] and linear programming [10]).
The technique proposed in Reference 11 uses a scheme that requires more than one server. Servers need to perform expensive homomorphic encryptions. The approach is vulnerable to collusion by the participating servers to learn the input. In the classical homomorphism approach [12], the server can perform certain selected operations on data while it remains encrypted; the data owner needs only to decrypt the data received from the server to get the real data. The homomorphic encryption used in Reference 13 requires communication between two participating servers, which may lead to learning the data. The approach also suffers from the need for expensive computation.
14.4.1.2 Proposed Approach We envision a framework without any expensive encryption where consumers could only do work that is linear (or close to linear) in the size of their inputs, and the cloud servers do all of the superlinear computational burden. We need techniques that are more efficient and practical than the current state of the art.
In this section, we present a simple protocol as an example for a matrix multiplication that satisfies all the MatrixCom requirements. This protocol is based on the concept of orthogonal matrices. An orthogonal matrix is a matrix whose inverse is its transpose. Therefore, if matrix X is an orthogonal matrix, we have X−1 = XT. Let

where P1, P2,…, Pk are 2 × 2 orthogonal matrices. Each Pi is generated from a random value θi as computed in Equation (14.2):

It can easily be verified that Pi is orthogonal and, subsequently, P is also orthogonal. In other words, we have it as shown in Equation (14.3):
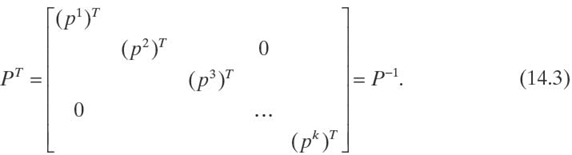
Based on the above basic equations, we can outline the following protocol for secure matrix multiplication on the cloud.
14.4.1.3 Protocol Description A consumer wants to compute C = A × B.
- The consumer generates
- P, Q, and R, which are random orthogonal matrices generated as indicated in the above equations
- T and U, which are matrices generated by random shuffling of the rows of the identity matrix I.
- The consumer computes A′, B′ as follows:
- A′ = (T × Q) × A × R
- B′ = RT × B × (U × P).
- The consumer sends A', B'to the provider.
- The provider calculates C′ = A′ × B′ and returns the result C′ to the consumer.
- The consumer can find the values of A × B as follows:
- A × B = (T × Q)T × C ′ × (U × P)T.
Notice that the consumer computes:
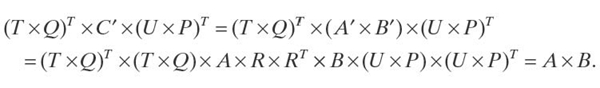
Also, notice that the consumer does not need more than O(n2) because of the following:
- Multiplication by T and U has the effect of shuffling the rows of the matrix and is done in O(n2).
- Multiplication by P, Q, and R is O(n2) because every column or row of these matrices has at most two nonzero elements.
- Cheating detection can be done in O(n2) in the same way as presented in Reference 11.
14.4.2 Scientific Computing: Image Processing
An image processing company ImaGE deals with various image-related operations ranging from image template matching, sharpening the edges of objects, reducing random noise, correcting the unequal illumination in large digital images, and so on. In image matching, the template represented as a kernel or filter is a description of the object to be matched in the image. ImaGE requires mathematical computations such as convolving the original image with an appropriate filter kernel, producing the filtered image, and correlating the template with the image. Correlation and convolution are basic operations that the company ImaGE needs to extract from or to match particular information in images. Correlation is usually used to find locations in an image. These operations have two main features: shift invariant and linear. In shift-invariant operation, the same operation is performed at every point in the image, whereas in linear operation, every pixel is replaced with a linear combination of its neighbors. The output values of the convolution are simple linear combinations of certain input pixel values.
However, the image convolution requires ImaGE computers to perform an enormous amount of calculations. For example, when a 1024 × 1024 pixel image is convolved with a 64 × 64 pixel filter, more than a billion multiplications and additions are needed (i.e., 64 × 64 × 1024 × 1024). ImaGE considers outsourcing its image processing to CloudLab because operations tend to be computationally intensive and their data are often captured by computationally weak hardware. The confidentiality requirements of ImaGE are the following:
- The server of CloudLab will not know the values of the original image and the filter.
- The server will also not know the values of the output convolved image.
14.4.2.1 Current Approaches In current approaches, encryption of images is usually used to make the images secure during the communication process. However, the research on hiding the actual pixel values of images from the server is still in the infancy stage. In one approach, the random splitting of the image into several pieces is used to hide the pixel; however, this approach is not very effective in securing the pixel values.
14.4.2.2 Proposed Approach In our vision, we believe that a template matching operation requires computing a difference measure between the template and all possible portions of the image that could match the template. Various difference measures have different mathematical as well as computational properties. More precisely, let Q be an m × m matrix (the image) and P an n × n matrix (the template represented as in a filter), n ≤ m. The entries of both Q and P come from some s-element alphabet A = a1, a2,…, as, where the ai's are typically positive integer values. The goal is then to compute an (m − n + 1) × (m − n + 1) matrix C, where C(i, j) is of the form C(i, j) = 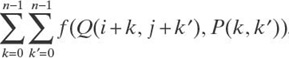 , for some function f, 0 ≤ i, j ≤ m − n.
, for some function f, 0 ≤ i, j ≤ m − n.
A method similar to matrix multiplications can be used for the Euclidean distance metric that corresponds to f(x, y) = (x − y)2.
In order to hide the actual values of the original image and the filter from the server without encryptions, we adopt the similar approach as proposed for matrix multiplications in the previous section. According to our approach, the pixel values of the rows and columns of images are randomly shuffled, scaled, and additively split. These could be augmented with an efficient image splitting technique in which the images are randomly split into several pieces and sent to the server piece by piece. When CloudLab returns the processed pieces of images to ImaGE, it needs to reconstruct the image by computing the pieces together, which should not require ImaGE heavy computing efforts.
14.4.3 Database Outsourcing: Query Processing on Relational Databases
Consider a database-as-a-service model offered by CloudLab. Penrith Hospital likes to use this service in order to outsource its patients'clinical data for storage and query processing. The clinical data include patients'illnesses, prescribed medications to patients, doctor's name, patients'personal information, treatment dates, and so on. In this case, Penrith Hospital is the consumer of CloudLab, whereas patients are the owners of data processed by CloudLab (but not the consumers of this CloudLab service). Penrith Hospital is also the custodian of the patients'clinical data, which are considered sensitive and private, and patients should not be identified with their clinical data to any entities without their consent. Penrith Hospital is liable to patients for data privacy; therefore, it requires the following in order to preserve confidentiality and privacy of its patients'data:
- CloudLab should be prevented from seeing clinical information of any patients and from linking their identity with sensitive information such as their illness and drugs prescribed.
- CloudLab should enable third-party data users or data analysts such as government agencies to access parts of the patients'data without violating privacy restrictions. Data analysts could perform, for example, statistical operations on patients'clinical databases without knowing clinical information about individuals or the identity of the patients.
- Penrith Hospital should be able to fully query its database. The database queries should substantially be processed by the CloudLab servers. Penrith Hospital should perform small amounts of computing to get the final answers of queries that are partially (but substantially) processed by the servers.
14.4.3.1 Current Practices Known techniques to prevent a third party from seeing confidential information in outsourced data include using encryption, or information hiding techniques on data such as perturbation, generalization, and swapping [14]. Databases can be stored on cloud servers in encrypted form. However, encrypted databases do not allow query processing on the server. Data anonymization models like k-anonymity [15] and l-diversity [16, 17] have been developed to provide guarantees of privacy protection [14]. Some anonymization techniques such as order-preserving partial encryption, anatomy, and generalization enable partial query processing on the server but with data loss. In Reference 18, a bucketization technique has been proposed to enable a third party to partially execute data owners'queries on the encrypted database to get the actual result of the queries.
TABLE 14.1. Original Table with Identifying and Sensitive Data
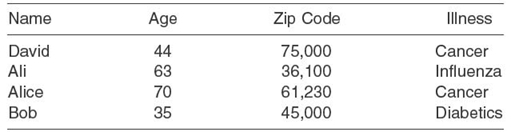
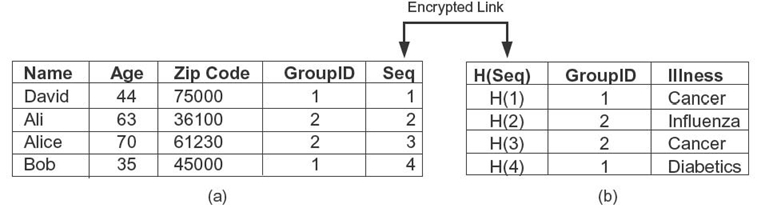
FIGURE 14.3. Partitioned tables into identifying and sensitive information. (a) Identifying information. (b) Sensitive information.
14.4.3.2 Proposed Approach Most of the above techniques usually lead to information loss (e.g., information is lost when an address is generalized to/replaced by a zip code). In contrast, we are aiming for using an advanced anonymization technique such as proposed in Reference 19 that would enable private database outsourcing without or with minimum loss of information while enabling query processing on the server. Advanced anonymization techniques should ensure no data loss in order to provide regular full query processing on the database while preserving data privacy. Let us consider an example. Table 14.1 depicts a database of patients that Penrith Hospital stores on CloudLab. The illness of the individual patient is considered sensitive as well as private to the patient. The table contains identifying information such as name, age, and zip code of the patient, and sensitive information such as illness.
Applying the anatomy model [15] and anonymization technique [19] to the table, the consumer, Penrith Hospital, separates sensitive data (illness) from the identifying information of the patient (name, age, zip code), divides the tuples into groups, and stores them on CloudLab, as shown in Figure 14.3.
In the basic anatomy model, the consumer, Penrith Hospital, loses the information linking individuals to their illness. Therefore, we propose an approach in which Penrith Hospital maintains an encrypted link between these two tables by using a unique key enabling join of the tables. The efficient symmetric encryption techniques can be used for encrypting this link. The symmetric encryption key is only known to Penrith Hospital; servers of CloudLab have no knowledge about the key. In this case, the data are minimally encrypted. The identifying and sensitive information in isolation, such as the two tables (Figure 14.3 a, b, respectively) in Figure 14.3, do not violate the privacy constraints. An example of a privacy constraint is k-anonymity, which requires that any tuple in the table cannot be linked with less than k individuals. It is clear that, in Figure 14.3, the records satisfy the 2-anonymity constraint. However, only the authorized consumer (i.e., Penrith Hospital) with the key will have full access to the database and can have queries that link these two tables (i.e., links corresponding tuples from the two tables). The service provider (or the third-party user) can only have anonymized (e.g., 2-anonymous) information from these partitioned data. This approach enables the server to partially execute queries of the consumer, who has the key to link the partitioned tables [19]. The consumer gets partial results that can be used to easily extract the intended result through decrypting the hidden link between the partial results. Since the server would not have access to identifiable data, it would not be protected from being subject to violation of privacy laws.
14.5 CONCLUSION
The privacy and confidentiality model of cloud computing should focus more on the prefailure rather than the postfailure of cloud services. Therefore, it is quite vital that clouds should provide technological guarantees in addition to contractual agreements to consumers that their data as well as processing always remain private and confidential on the cloud. This chapter has provided some efficient techniques for private and confidential manipulation of consumer data on the cloud without expensive cryptographic processing. It also shows that much of the controlling power remains in the hand of cloud consumers whose data should be protected. With the proposed technologies, the consumer is able to decide which part of its data could be revealed to the servers. The proposed approaches advocate for improving the efficiency by minimizing the use of expensive encryption to preserve privacy and confidentiality and by shipping the expensive data processing operations to the more powerful cloud servers (rather than performing them on the weak consumer machines). These methods will promote the consumers'trust in the cloud and will allow cloud providers to ensure secure and trustworthy services.
ACKNOWLEDGMENTS
This publication was made possible by the support of a National Priorities Research Program grant from the Qatar National Research Fund (QNRF). The statements made herein are solely the responsibility of the authors.
REFERENCES
[1] A. Ghosh and I. Arce, “In cloud computing we trust but should we?” IEEE Security and Privacy, November/December 2010, pp. 14‒16.
[2] P. Banarjee, et al., “Everything as a service: Powering the new information economy,” IEEE Computer, 44(3): 36‒43, 2011.
[3] K. Khan and Q. Malluhi, “Establishing trust in cloud computing,” September/October 2010.
[4] T. Helbing, “How the new EU rules on data export affect companies in and outside the EU.” Available at http://www.thomashelbing.com/en.
[5] M. Atallah, K. Pantazopoulos, J. Rice, and E. Spafford, “Secure outsourcing of scientific computations,” Advances in Computers, 54(6): 215‒272, 2001.
[6] K. Frikken and M. Atallah, “Securely outsourcing linear algebra computations,” Proceedings of the 5th ACM Symposium on Information, Computer and Communications Security (AsiaCCS 2010), Beijing, China, April 2010.
[7] P. Beguin and J. Quisquater, “Fast server-aided RSA signatures secure against active attacks,” in CRYPT0 95, pp. 57‒69, 1995.
[8] A. Yao, “Protocols for secure computation,” Proceedings of the 23rd Annual IEEE Symposium on Foundations of Computer Science, pp. 160‒164, 1982.
[9] M. Blanton and M. Aliasgari, “Secure outsourcing of DNA searching via finite automata,” in Annual IFIP Conference on Data and Applications Security (DBSec '10), pp. 49‒64, June 2010.
[10] C. Wang, K. Ren, and J. Wang, “Secure and practical outsourcing of linear programming in cloud computing,” 30th IEEE International Conference on Computer Comm. (INFOCOM '11), Shanghai, China, April 2011.
[11] D. Benjamin and M. Atallah, “Private and cheating-free outsourcing of algebraic computations,” in 6th Annual Conference on Privacy, Security, and Trust (PST 2008), pp. 240‒245. Fredericton, New Brunswick, Canada, 2008.
[12] R. Rivest, L. Adleman, and M. Dertouzos, “On data banks and privacy homomorphisms,” in Foundations of Secure Computation (R. DeMillo, D. Dobkin, A. Jones, and R. Lipton, eds.), New York: Academic Press, pp. 169‒180, 1978.
[13] M. Atallah and J. Li, “Secure outsourcing of sequence comparisons,” International Journal of Information Security, 4(4): 277‒286, 2005.
[14] B. Hore, S. Mehrotra, and H. Hacigumus, Managing and querying encrypted data in Handbook of Database Security: Applications and Trends, pp. 163‒190, 2007. Available at http://dx.doi.org/10.1007/978-0-387-48533-17.
[15] X. Xiao and Y. Tao, “Anatomy: Simple and effective privacy preservation,” Proceedings of the 32nd International Conference on Very Large Databases (VLDB 2006), Seoul, Korea, September 2006.
[16] M. Machanavajjhala, et al., “l-Diversity: Privacy beyond k-anonymity,” ACM Transactions on Knowledge Discovery from Data (TKDD), 1(1): 1‒52, 2007.
[17] L. Sweeney, “k-Anonymity: A model for protecting privacy,” International Journal on Uncertainty, Fuzziness and Knowledge-Based Systems, 10(5): 557‒570, 2002.
[18] H. Hacigumus, B. Iyer, and S. Mehrotra, “Executing SQL over encrypted data in the database-service-provider model,” in Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, June 4‒6, pp. 216‒227, 2002. Available at http://doi.acm.org/10.1145/564691.564717.
[19] A. Nergiz and C. Clifton, “Query processing in private data outsourcing using anonymization,” Proceedings of the Conference on Database Security (DBSec 2011), Lecture Notes in Computer Science, pp. 138‒153. 2011.