
31
–––––––––––––––––––––––
Virtualization Techniques for Graphics Processing Units
Pavan Balaji, Qian Zhu, and Wu-Chun Feng
31.1 INTRODUCTION
General-purpose graphics processing units (GPGPUs or GPUs) are becoming increasingly popular as accelerator devices for core computational kernels in scientific and enterprise computing applications. The advent of programming models such as NVIDIA's CUDA [1], AMD/ATI's Brook + [2], and Open Computing Language (OpenCL) [3] has further accelerated the adoption of GPUs by allowing many applications and high-level libraries to be ported to them [4‒7]. While GPUs have heavily proliferated into high-end computing systems, current programming models require each computational node to be equipped with one or more local GPUs, and application executions are tightly coupled to the physical GPU hardware. Thus, any changes to the hardware (e.g., if it needs to be taken down for maintenance) require the application to stall.
Recent developments in virtualization techniques, on the other hand, have advocated decoupling the application view of “local hardware resources” (such as processors and storage) from the physical hardware itself; that is, each application (or user) gets a “virtual independent view” of a potentially shared set of physical resources. Such decoupling has many advantages, including ease of management, ability to hot-swap the available physical resources on demand, improved resource utilization, and fault tolerance.
For GPUs, virtualization technologies offer several benefits.GPU virtualization can enable computers without physical GPUs to enjoy virtualized GPU acceleration + ability provided by other computers in the same system. Even in a system where all computers are configured with GPUs, virtualization allows allocating more GPU resources to applications that can be better accelerated on GPUs, thus improving the overall resource utilization.
However, with the current implementations of GPU programming models, such virtualization is not possible. To address this situation, we have investigated the role of accelerators, such as GPUs, in heterogeneous computing environments. Specifically, our goal is to understand the feasibility of virtualizing GPUs in such environments, allowing for compute nodes to transparently view remote GPUs as local virtual GPUs. To achieve this goal, we describe a new implementation of the OpenCL programming model, called virtual OpenCL (VOCL). The VOCL framework provides the OpenCL-1.1 API but with the primary difference that it allows an application to view all GPUs available in the system (including remote GPUs) as local virtual GPUs. VOCL internally uses the message-passing interface (MPI) [8] for data management associated with remote GPUs and utilizes several techniques, including argument caching and data pipelining, to improve performance.
We note that VOCL does not deal with using GPUs on virtual machines, which essentially provide operating system (OS)-level or even lower-level virtualization techniques (i.e., full or paravirtualization). Instead, it deals with user-level virtualization of the GPU devices themselves. Unlike full or paravirtualization using virtual machines, VOCL does not handle security and OS-level access isolation. However, it does provide similar usage and management benefits and the added benefit of being able to transparently utilize remote GPUs. As shown in Figure 31.1, VOCL allows a user to construct a virtual system that has, for example, 17 virtual GPUs even though no physical machine in the entire system might have 17 colocated physical GPUs.
We describe here the VOCL framework and the optimizations used to improve its performance. Next, we present a detailed evaluation of the framework, including a microbenchmark evaluation that measures data transfer overheads to and from GPUs associated with such virtualization and a detailed profiling of overheads for many OpenCL functions. We also evaluate the VOCL framework with real application kernels, including SGEMM/DGEMM, N-body computations, matrix transpose kernels, and the Smith‒Waterman application from biology. We observe that for compute-intensive kernels (high ratio of computation required to data movement between host and GPU), VOCL's performance differs from native OpenCL performance by only a small percentage. However, for kernels that are not as compute intensive (low ratio of computation required to data movement between host and GPU) and where the PCI-Express bus connecting the host processor to the GPU is already a bottleneck, such virtualization does have some impact on performance, as expected.
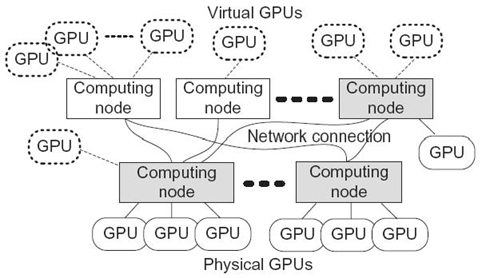
FIGURE 31.1. Transparent GPU virtualization.
The rest of the chapter is organized as follows Section 31.2 provides an overview of the GPU architecture and the OpenCL programming model. Sections 31.3 and Section 31.4 describe the VOCL framework, its implementation, and the various performance optimization techniques we used Section 31.5 presents the performance evaluation. Section 31.6 describes related work, and Section 31.7 presents our conclusions.
31.2 BACKGROUND
In this section, we provide a brief overview of the NVIDIA GPU architecture and the OpenCL programming model.
An NVIDIA GPU consists of single-instruction multiple-data (SIMD) streaming multiprocessors (SMs), and each SM contains a few scalar processors. A GPU has a multilevel memory hierarchy, which includes on-chip memory and off-chip memory. On-chip memory contains private local memory, shared memory, texture memory, and constant memory. Off-chip memory includes local memory and global memory. On-chip memory has low access latency, but its size is small. In contrast, off-chip memory is large, but the access latency is high. In addition, on the latest generation of NVIDIA Fermi architecture, L1 and L2 caches are provided to access the off-chip memory more efficiently, particularly for irregular access.
OpenCL [3] is a framework for programming heterogeneous computing systems. It provides functions to define and control the programming context for different platforms. It also includes a C-based programming language for writing kernels to be executed on different platforms such as the GPU, CPU, and Cell Broadband Engine (Cell BE) [9]. A kernel is a special function called on the host and executed on the device in heterogeneous systems. Usually, the data-parallel and compute-intensive parts of applications are implemented as kernels to take advantage of the computational power of the GPU. A kernel consists of a few workgroups, with each workgroup consisting of work items. Work items in a workgroup are organized as groups (called warps), and the same instructions are executed across them if there are no divergent branches. However, if different threads execute different instructions, they are serialized, thus losing performance.
The current implementations of the OpenCL programming model only provide capabilities to utilize accelerators installed locally on a compute node.
31.3 VOCL FRAMEWORK
The VOCL framework consists of the VOCL library on the local node and a VOCL proxy process on each remote node, as shown in Figure 31.2. The VOCL library exposes the OpenCL API to applications and is responsible for sending information about the OpenCL calls made by the application to the VOCL proxy using MPI and for returning the proxy responses to the application. The VOCL proxy is essentially a service provider for applications, allowing them to utilize GPUs remotely. The proxies are expected to be set up initially (e.g., by the system administrator) on all nodes that would be providing virtual GPUs to potential applications. The proxy is responsible for handling messages from the VOCL library, executing the actual kernel on physical GPUs, and sending results back to the VOCL library. When an application wants to use a virtual GPU, its corresponding VOCL library would connect to the appropriate proxy, utilize the physical GPUs associated with the proxy, and disconnect when it is done.
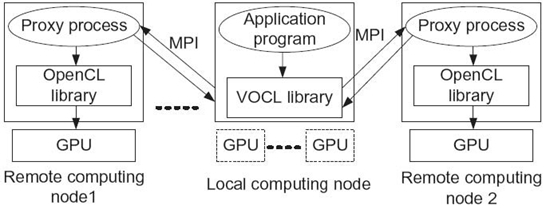
FIGURE 31.2. Virtual OpenCL framework.
We chose OpenCL as the programming model for two reasons. First, OpenCL provides general support for multiple accelerators (including AMD/ATI GPUs, NVIDIA GPUs, Intel accelerators, and the Cell BE), as well as for general-purpose multicore processors. By supporting OpenCL, our VOCL framework can support transparent utilization of varieties of remote accelerators and multicore processors. Second, OpenCL is primarily based on a library-based interface rather than a compiler-supported user interface such as CUDA. Thus, a runtime library can easily implement the OpenCL interface without requiring the design of a new compiler.
31.3.1 VOCL Library
VOCL is compatible with the native OpenCL implementation available on the system with respect to its abstract programming interface (API) as well as its abstract binary interface (ABI). Specifically, since the VOCL library presents the OpenCL API to the user, all OpenCL applications can use it without any source code modification. At the same time, VOCL is built on top of the native OpenCL library available on the system and utilizes the same OpenCL headers on the system. Thus, applications that have been compiled with the native OpenCL infrastructure need only to be relinked with VOCL and do not have to be recompiled. Furthermore, if the native OpenCL library is a shared library and the application has opted to do dynamic linking of the library (which is the common usage mode for most libraries and default linker mode for most compilers), such linking can be performed at runtime just by preloading the VOCL library through the environment variable LD_PRELOAD.
The VOCL library is responsible for managing all virtual GPUs exposed to the application. Thus, if the system has multiple nodes, each equipped with GPUs, the VOCL library is responsible for coordinating with the VOCL proxy processes on all these nodes. Moreover, the library should be aware of the locally installed physical GPUs and call the native OpenCL functions on them if they are available.
31.3.1.1 VOCL Function Operations When an OpenCL function is called, VOCL performs the following operations:
- Check whether the physical GPU to which a virtual GPU is mapped is local or remote.
- If the virtual GPU is mapped to a local physical GPU, call the native OpenCL function and return.
- If the virtual GPU is mapped to a remote physical GPU, check whether the communication channels between applications and proxy processes have been connected. If not, call the
MPI_Comm_connect()function to establish the communication channel. - Pack the input parameters of the OpenCL functions into a structure and call
MPI_Isend()to send the message (referred to as control message) to the VOCL proxy. Here, a different MPI message tag is used for each OpenCL function to differentiate them. Call MPI_Irecv()to receive output and error information from the proxy process, if necessary.Call MPI_Wait()when the application requires completion of pending OpenCL operations (e.g., in blocking OpenCL calls or flush calls).
This functionality is illustrated in Figure 31.3.

FIGURE 31.3. Pseudocode for the function clSetKernelArg().
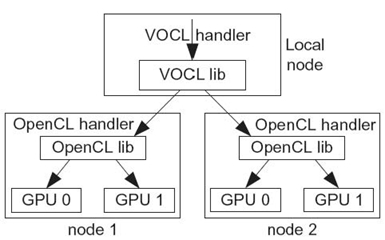
FIGURE 31.4. Multiple-level handler translation.
31.3.1.2 Multiple-Level Handle Translation In OpenCL, kernel execution is performed within a host-defined context, which includes several objects such as devices, program objects, memory objects, and kernels. A context can contain multiple devices; therefore, objects such as programs and memory buffers within the context need to be mapped onto a specific device before computation can be performed. In environments where a node is equipped with multiple physical GPUs, to do this mapping, the OpenCL library includes additional information in each object that lets it identify which physical GPU the object belongs to. For example, when OpenCL returns a memory object (i.e., cl_mem), this object internally has enough information to distinguish which physical GPU the memory resides on.
With VOCL, since the physical GPUs might be located on multiple physical nodes, the VOCL library might internally be coordinating with the native OpenCL library on multiple nodes (through the VOCL proxy). Thus, VOCL needs to add an additional level of virtualization for these objects to identify which native OpenCL library to pass each object to. We show this in Figure 31.4. Specifically, within VOCL, we define an equivalent object for each OpenCL object. Together with the native OpenCL handler, the VOCL object contains additional information to identify which physical node (and thus, which native OpenCL library instance) the object corresponds to.
31.3.2 VOCL Proxy
The VOCL proxy is responsible for (1) receiving connection requests from the VOCL library to establish communication channels with each application process, (2) receiving inputs from the VOCL library and executing them on its local GPUs, (3) sending output and error codes to the VOCL library, and (4) destroying the communication channels after the program execution has completed.
31.3.2.1 Managing Communication Channels Communication channels between the VOCL library and VOCL proxy are established and destroyed dynamically. Each proxy calls MPI_Comm_accept() to wait for connection requests from the VOCL library. When such a request is received, a channel is established between them, which is referred to as the control message channel. Once the application has completed utilizing the virtual GPU, the VOCL library sends a termination message to the proxy. Then MPI_Comm_disconnect() is called by both the VOCL library and the VOCL proxy to terminate the communication channel.
In the VOCL framework, each application can utilize GPUs on multiple remote nodes. Similarly, GPUs on a remote node can be used by multiple applications simultaneously. In addition, applications may start their execution at different times. Thus, the proxy should be able to accept connection requests from application processes at any arbitrary time. To achieve this, we used an additional thread at the proxy that continuously waits for new incoming connection requests. When a connection request is received, this thread updates the communication channels such that messages sent by the VOCL library can be handled by the main proxy process, and the thread waits for the next connection request.
31.3.2.2 Handling Native OpenCL Function Calls Once a control message channel is established between the VOCL proxy and the VOCL library, the proxy preposts buffers to receive control messages from the VOCL library (using nonblocking MPI receive operations). Each VOCL control message is only a few bytes large, so the buffers are preposted with a fixed maximum buffer size that is large enough for any control message. When a control message is received, it contains information on what OpenCL function needs to be executed as well as information about any additional input data that needs to be sent to the physical GPU. At this point, if any data needs to be transferred to the GPU, the proxy posts additional receive buffers to receive this data from the VOCL library. It is worth noting that the actual data communication happens on a separate communicator to avoid conflicts with control messages; this communicator will be referred to as the data channel.
Specifically, for each control message, the proxy process performs the following steps:
- When a control message is received, the corresponding OpenCL function is determined based on the message tag. Then the proxy process decodes the received message according to the OpenCL function. Depending on the specific OpenCL function, other messages may be received as inputs for the function execution in the data channel.
- Once all of the input data are available, the native OpenCL function is executed.
- Once the native OpenCL function completes, the proxy packs the output and sends it back to the VOCL library.
- If dependencies exist across different functions or if the current function is a blocking operation, the proxy waits for the current operation to finish and the result is sent back to the VOCL library before the next OpenCL function isprocessed. On the other hand, if the OpenCL function is nonblocking, the proxy will send out the return code and continue processing other functions.
- Another nonblocking receive will be issued to replace the processed control message.
Since the number of messages received is not known beforehand, the proxy process uses a continuous loop waiting to receive messages. It is terminated by a message with a specific tag. Once the termination message is received, the loop is ended and the MPI communicator released.
This functionality is illustrated in Figure 31.5.

FIGURE 31.5. Pseudocode of the proxy process.
31.4 VOCL OPTIMIZATIONS
For each OpenCL function, the input data and the kernel program must be transferred to the proxy on the remote node, and the output sent back to the local node once the remote processing has completed. The data that need to be transferred for various OpenCL functions can vary from a single variable with only a few bytes to a data chunk of hundreds of megabytes. Furthermore, depending on the function, data may be transferred to the CPU memory of the remote node (e.g., inputs to the OpenCL API functions) or to the GPU memory (e.g., inputs to the kernel). Data transfer time depends on the data size and the network bandwidth between the local and remote nodes. Such overhead varies significantly and can be smaller than, equal to, or even larger than the actual OpenCL function execution time. The number of times that an OpenCL function is called also affects the overhead of the total program execution time.
Table 31.1 shows the OpenCL functions and their invocation counts in the Smith‒Waterman application for aligning a pair of 6K- letter genome sequences. The functions in Table 31.1a, c are essentially used for initializing and finalizing the OpenCL environment, and the number of times they occur is independent of the number of problem instances that are executed. Therefore, from an optimization perspective, these are less critical and thus are of little interest (their overhead is amortized for reasonably long-running applications—e.g., anything more than few tens of seconds). Functions in Table 31.1b, on the other hand, are core functions whose performance directly impacts the overall application performance.
TABLE 31.1. OpenCL API Functions Used in Smith‒Waterman
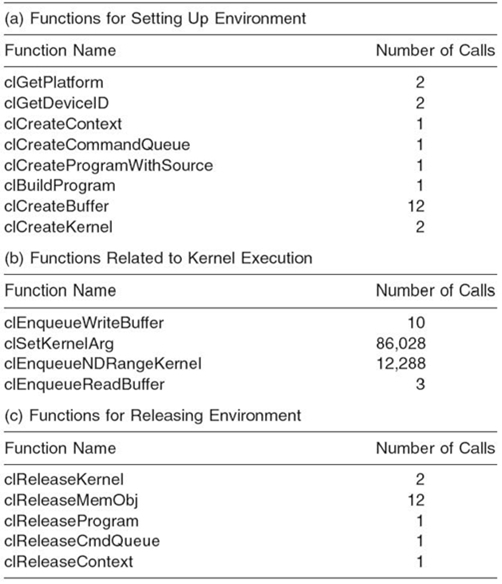
TABLE 31.2. Overhead (in ms) of API Functions Related to Kernel Execution
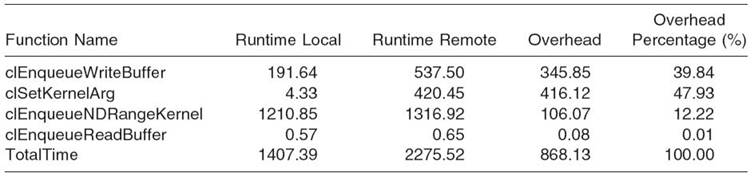
In Table 31.2, we compare the OpenCL function call overheads for VOCL (using a remote GPU) versus the native OpenCL library for aligning 6K base-pair sequences on an NVIDIA Tesla M2070 GPUs with the QDR InfiniBand as the network connection between different nodes. In general, such overhead is caused mainly by the data transfer between the local host memory and the GPU memory. For instance, in clEnqueueWriteBuffer, data transfer from the host memory to the GPU memory accounts for about 39.84% of the total overhead. Since the size of the data transferred in the reverse direction from the GPU memory to the local host memory is small, it accounts for less than 1% of the total overhead. The number of function invocations also affects the overhead. In this example, clSetKernelArg() has an overhead of 416.12 ms, which accounts for 47.93% of the total overhead for the Smith‒Waterman execution. The reason is that, although the overhead of each call is small, the function is called more than 86,000 times (the kernel is called 12,288 times, and seven parameters have to be set for each call).
TABLE 31.3. Overhead (in ms) of API Functions Related to Kernel Execution with Kernel Argument Caching Optimization
To reduce these overheads, we have implemented three optimizations: (1) kernel argument caching, (2) improvement to the bandwidth by pipelining data transfer between the local host memory and the GPU memory, and (3) modifications to error handling.
31.4.1 Kernel Argument Caching
The basic idea of kernel argument caching is to combine the message transfers for multiple clSetKernelArg() calls. Instead of sending one message for each call of clSetKernelArg(), we send kernel arguments to the remote node only once for every kernel launch, irrespective of how many arguments the kernel has. Since
all arguments should be set before the kernel is launched, we just cache all the arguments locally at the VOCL library. When the kernel launch function is called, the arguments are sent to the proxy. The proxy performs two steps on being notified of the kernel launch: (1) It receives the argument message and sets the individual kernel arguments, and (2) it launches the kernel.
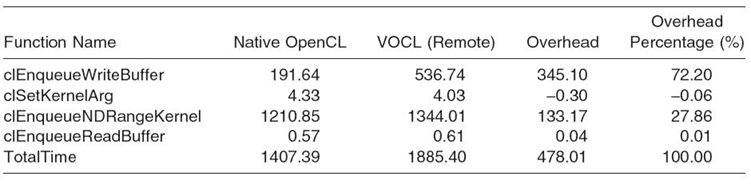
Table 31.3 shows the execution time of Smith‒Waterman for aligning 6K base pair sequences using our kernel argument caching approach. As we can see in the table, the execution time of clSetKernelArg() is reduced from 420.45 ms (Table 31.2) to 4.03 ms (Table 31.3). We notice a slight speedup compared with native OpenCL; the reason is that, with VOCL, the arguments are cached in host memory and are not passed to the GPU immediately. We also notice a slightly higher overhead for the kernel execution time (increase from 1344.01 to 1316.92 ms), which is due to the additional kernel argument data passed to the proxy within this call. On the whole, the total execution time of the four kernel execution-related functions decreases from 2275 to 1885 ms, or by 17.1%.
31.4.2 Data Transfer Pipelining
Two types of data need to be transferred between the VOCL library and the VOCL proxy. The first type is the input arguments to the OpenCL functions; this type of data is transferred from the local host memory to the remote host memory. The size of such input arguments is at most a few hundred bytes. For the proxy, once the input data are received, the corresponding OpenCL functions are executed, and the output (if any) is returned to the VOCL library. Such data transfers cause negligible overhead.
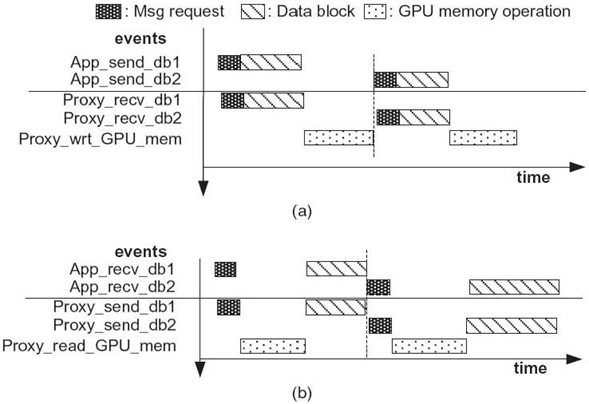
FIGURE 31.6. Blocking data transmission scenarios. (a) Blocking write to the GPU memory.(b) Blocking read from the GPU memory.
The second type is the input data used by the compute kernel, which are transferred from the local host memory to the remote GPU memory. Such data transfer has two stages: (1) between the VOCL library and the VOCL proxy, and (2) between the VOCL proxy and the GPU. In a naive implementation of VOCL, these two stages would be serialized. Such an implementation, though simple, has three primary problems. First, the size of the data transferred to the GPU memory can be several gigabytes. So, for each data transfer, an appropriate sized memory region needs to be allocated at the VOCL proxy before the data can be transmitted. Second, there is no pipelining of the data transfer between the two stages, thus causing loss of performance. Third, since the temporary buffer used for storing data at the VOCL proxy is dynamically allocated and freed, this buffer is not statically registered with the local GPU device and has to be registered for each data transfer 1; this causes additional loss of performance. This nonpipelined model is illustrated in Figure 31.6.
In order to optimize the data transfer overhead within VOCL, we designed a data pipelining mechanism (Fig 31.7). In this approach, the VOCL proxy maintains a buffer pool, where each buffer in this buffer pool is of size B bytes. This buffer pool is statically allocated and maintained at the VOCL proxy; thus, it does not encounter the buffer allocation or buffer registration overheads that we face in the nonpipelined approach. When the VOCL library needs to write some user data to the GPU, it segments this data into blocks of size at most B bytes and transfers them to the VOCL proxy as a series of nonblocking sends. The VOCL proxy, on receiving each block, initiates the transfer of that data block to the GPU. The read operation is similar but in the opposite direction. Figure 31.8 illustrates this buffer pool model utilized in VOCL. In the example shown, data segments 1 and 2 are smaller than the maximum size of each buffer in the buffer pool. Thus, they are transmitted as contiguous blocks. Data segment 3, however, is larger than the maximum size and hence is segmented into smaller blocks. Since the number of buffers in the pool is limited, we reuse buffers in a circular fashion. Note that before we reuse a buffer, we have to ensure that the previous data transfers (both from the network transfer as well as the GPU transfer) have been completed. The number of buffers available in the pool dictates how often we need to wait for such completion and thus has to be carefully configured.
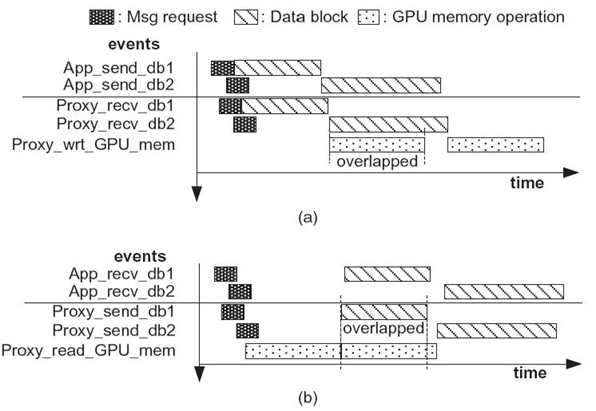
FIGURE 31.7. Nonblocking data transmission scenarios. (a) Nonblocking write to the GPU memory. (b) Nonblocking read to the GPU memory.

FIGURE 31.8. Buffer pool on proxy processes.
We also note that, at the VOCL proxy, the tasks of sending/receiving data from the VOCL library and of writing/reading data from the GPU are performed by two different threads. This allows each thread to perform data movement in a dedicated manner without having to switch between the network communication and GPU communication. This approach allowed us to further improve the data transfer performance by a few percent.
31.4.3 Error Return Handling
Most OpenCL functions provide a return code to the user: either CL_SUCCESS or an appropriate error code. Such return values, however, are tricky for VOCL to handle, especially for nonblocking operations. The OpenCL specification does not define how error codes are handled for nonblocking operations; that is, if the GPU device is not functional, is a nonblocking operation that tries to move data to the GPU expected to return an error?
While the OpenCL specification does not describe the return value in such cases, current OpenCL implementations do return an error. For VOCL, however, since every OpenCL operation translates into a network operation, significant overhead can occur for nonblocking operations if the VOCL library has to wait until the OpenCL request is transferred over the network, a local GPU operation is initiated by the VOCL proxy, and the return code sent back.
We believe this is an oversight in the OpenCL specification since all other specifications or user documents that we are aware of (including MPI, CUDA, and InfiniBand) do not require nonblocking operations to return such errors—the corresponding wait-for-completion operation can return these errors at a later time. In our implementation, therefore, we assume this behavior and return such errors during the corresponding wait operation.
31.5 EXPERIMENTAL EVALUATION
In this section, we evaluate the efficiency of the proposed VOCL framework. First, we analyze the overhead of individual OpenCL operations with VOCL. Then, we quantitatively evaluate the VOCL framework with several application kernels: SGEMM/DGEMM, matrix transpose, N-body [10], and Smith‒Waterman [11, 12], of which SGEMM/DGEMM and N-body are compute intensive, while the others are data-transfer bound.
The compute nodes used for our experiments are connected with QDR InfiniBand. Each node is installed with two Magny-core AMD CPUs with host memory of 64 GB and two NVIDIA Tesla M2070 GPU cards, each with 6-GB global memory. The two GPU cards are installed on two different PCIe slots, one of which shares the PCIe bandwidth with the InfiniBand adapter as shown in Figure 31.9. The computing nodes are installed with the Centos Linux OS and the CUDA 3.2 toolkit. We use the MVAPICH2 [13] MPI implementation. Each of our experiments was conducted three times and the average reported.
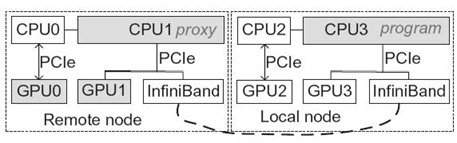
FIGURE 31.9. GPU confi guration and the scenario for the bandwidth rest.
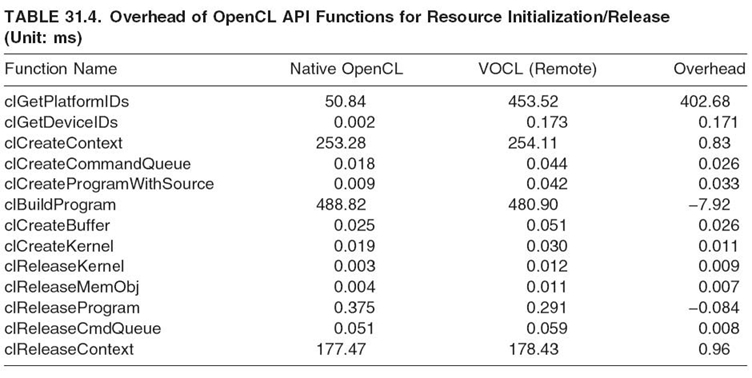
TABLE 31.4. Overhead of OpenCL API Functions for Resource Initialization/Release(Unit: ms)
31.5.1 Microbenchmark Evaluation
In this section, we study the overhead of various individual OpenCL operations using the SHOC benchmark suite [14] and a benchmark suite developed within our group.
31.5.1.1 Initialization/Finalization Overheads In this section, we study the performance of initializing and finalizing OpenCL objects within the VOCL framework. These functions are listed in Table 31.4. As we can notice in the table, for most functions, the overhead caused by VOCL is minimal. The one exception to this is the clGetPlatform() function, which has an overhead of 402.68 ms. The reason for this overhead is that clGetPlatform is typically the first OpenCL function executed by the application in order to query the platform. Therefore, the VOCL framework performs most of its initialization during this function, including setting up the MPI communication channels, as described in Section 31.3.
The overall overhead caused by all the initialization and finalization functions together is a few hundred milliseconds. However, this overhead is a one-time overhead unrelated to the total program execution time. Thus, in practice, for any program that executes for a reasonably long time (e.g., a few tens of seconds), these overheads play a little role in the noticeable performance of VOCL.
31.5.1.2 Performance of Kernel Execution on the GPU Kernel execution on the GPU would be the same no matter which host processor launches the kernel. Thus, utilizing remote GPUs via VOCL should not affect the kernel execution on the GPU card. By evaluating the SHOC microbenchmark [14] with VOCL, we verified that the maximum flops, on-chip memory bandwidth, and off-chip memory bandwidth are the same as native OpenCL. These results are not provided here because they show no useful difference in performance.
31.5.1.3 Data Transfer between Local Host Memory and GPU Memory In this section, we measure the data transfer bandwidth achieved for GPU write and read operations using VOCL. The experiment is performed with different message sizes. For each message size, a window of 32 messages is issued in a nonblocking manner, followed by a flush operation to wait for their completion. This is repeated for a large number of iterations, and the bandwidth is calculated as the total data transferred per second. A few initial “warm-up” iterations are skipped from the timing loop.
Figure 31.10 shows the performance of native OpenCL, VOCL when using a local GPU (legend “VOCL (local)”), and VOCL when using a remote GPU (legend “VOCL (remote)”). Native OpenCL only uses the local GPU. Two scenarios are shown—bandwidth between CPU3 and GPU0 (Fig 31.10 c, d) and between CPU3 and GPU1 (Fig. 31.10 a, b); see Figure 31.9. In our experiments, the VOCL proxy is bound to CPU1. For native OpenCL, the application process is bound to CPU1.
As shown in the figures, VOCL-local has no degradation in performance as compared to native OpenCL, as expected. VOCL-remote, however, has some degradation in performance because of the additional overhead of transmitting data over the network. As the message size increases, the bandwidth increases for native OpenCL as well as VOCL (both local and remote). However, VOCL-remote saturates at a bandwidth of around 10‒25% lesser than that of native OpenCL. Comparing the bandwidth between GPU0 and GPU1, we notice that the absolute bandwidth of native OpenCL as well as VOCL (local and remote) is lesser when using GPU0 as compared to GPU1. The reason for this behavior is that data transmission between CPU1 and GPU0 requires additional hops compared to transmission between CPU1 and GPU1, causing some drop in performance. This lower absolute performance also results in lesser difference between VOCL-remote and native OpenCL (10% performance difference, as compared to the 25% difference when transmitting from CPU1 to GPU1). The results for reading data from the GPU are similar.
We also note that the shared PCIe between the network adapter and GPU1 does not degrade performance because, for most communications, the direction of data transfer to/from the network and to/from the GPU does not conflict. Specifically, when the application is writing data to the GPU, the proxy reads the data from the network and writes it to the GPU. Similarly, when the application is reading data from the GPU, the proxy reads the data from the GPU and writes it to the network. Since PCIe is a bidirectional interconnect, data transfers in opposite directions do not share the bandwidth. This allows transfers to/from GPU1 to achieve a higher bandwidth as compared with GPU0. Consequently, the performance difference for VOCL is higher for GPU1 than for GPU0.
For the remaining results, we use GPU1 because of the higher absolute performance it can achieve.
31.5.2 Evaluation with Application Kernels
In this section, we evaluate the efficiency of the VOCL framework using four application kernels: SGEMM/DGEMM, N-body, matrix transpose, and Smith‒Waterman. Table 31.5 shows the computation to memory access ratios for these four kernels. The first two kernels, SGEMM/DGEMM and N-body, can be classified as compute intensive based on their computational requirements, while the other two require more data movement.
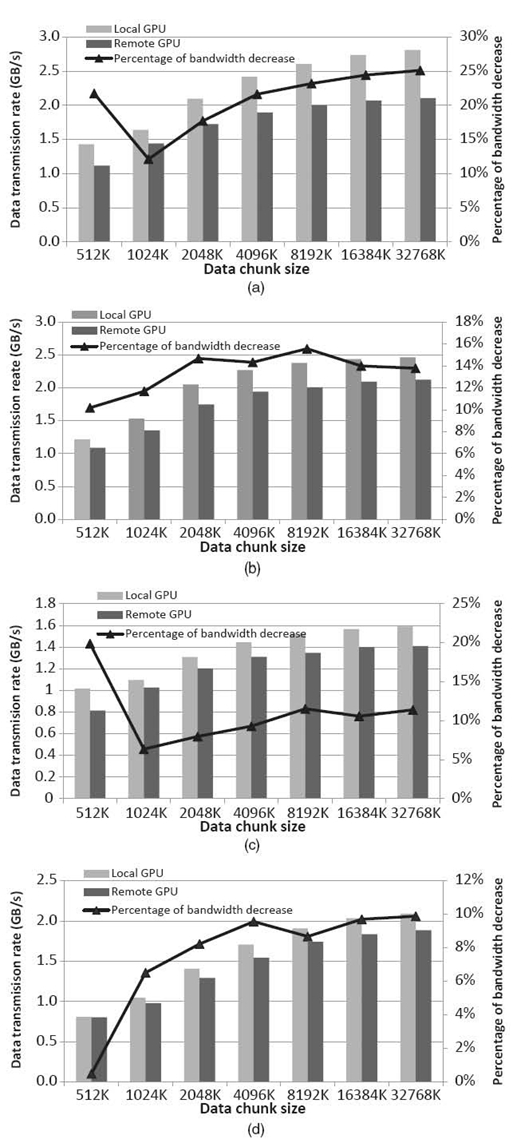
FIGURE 31.10. Bandwidth between host memory and device memory for nonblocking data transmission. (a) Bandwidth from host memory to device memory (local transmission is from CPU1 to GPU1, and remote transmission is from CPU3 to GPU1). (b) Bandwidth from device memory to host memory (local transmission is from GPU1 to CPU1, and remote is from GPU1 to CPU3). (c) Bandwidth from host memory to device memory (local transmission is from CPU1 to GPU0, and remote transmission is from CPU3 to GPU0). (d) Bandwidth from device memory to host memory (local transmission is from GPU0 to CPU1, and remote transmission is from GPU0 to CPU3).
TABLE 31.5. Computation and Memory Access Complexities of the Four Applications

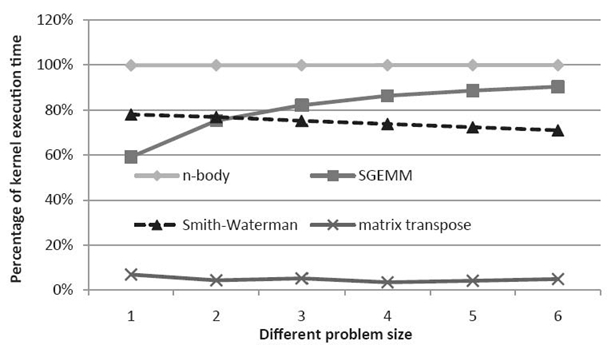
FIGURE 31.11. Percentage of the kernel execution time in the single-precision case.
This difference in the computational intensity of these four kernels is further illustrated in Figure 31.11, where the percentage of time spent on computation for each of these kernels is shown. As we can see in the figure, the N-body kernel spends almost 100% of its time computing. SGEMM/DGEMM spend a large fraction of time computing, and this fraction increases with increasing problem size. Matrix transpose spends a very small fraction of time computing. While Smith‒Waterman spends a reasonable amount of time computing (70‒80%), most of the computational kernels it launches are very small kernels that, as we will discuss later, are harder to optimize because of the large number of small message transfers they trigger.
Next, we evaluate the overhead of program execution time with different problem sizes. Recall that the program execution time in this experiment includes the data
transfer time, kernel argument setting, and kernel execution. We ran both the single-precision and double-precision implementations of all application kernels except Smith‒Waterman since sequence alignment scores are usually stored as integers or single-precision floats in practice. We ran multiple problem instances in a nonblocking manner to pipeline data transfer and kernel execution. After we issue all nonblocking function calls, the OpenCL function clFinish() is called to ensure that all computations and data transfers have been completed before measuring the overall execution time. We also profile the percentage of the kernel execution in the total execution time to show the relationship between the percentage of kernel
execution time and overall overhead caused by using remote GPUs.
Figure 31.12 shows the performance and the overhead of the application kernels for single-precision computations. We notice that the performance of native OpenCL is identical to that of VOCL-local; this is expected as VOCL does not do any additional processing in this case. For VOCL-remote, however, the performance depends on the application. For compute-intensive algorithms, the overhead of VOCL is very small, 1‒4% for SGEMM and nearly 0% for N-body. This is because, for these applications, the total execution time is dominated by the kernel execution. For SGEMM, we further notice that the overhead decreases with increasing problem size. This is because the computation time for SGEMM increases as O(N3), while the amount of data that needs to be transferred only increases as O(N2); thus, the computation time accounts for a larger percentage of the overall execution for larger problem sizes.
For data-intensive algorithms, the overhead of VOCL is higher. For matrix transpose, for example, this is between 20% and 55%, which is expected because it spends a large fraction of its execution time in data transfer (based on Fig. 31.11, matrix transpose spends only 7% of its time computing). With VOCL-remote, this data has to be transmitted over the network, causing significant overhead. For Smith‒Waterman, the overhead is much higher and closer to 150%. This is because of two reasons. First, since the VOCL proxy is a multithreaded process, the MPI implementation has to be initialized to support multiple threads. It is well known in the MPI literature that multithreaded MPI implementations can add significant overhead in performance, especially for small messages [15‒18]. Second, Smith‒Waterman relies on a large number of kernel launches for a given amount of data [12]. For a 1K sequence alignment, for example, more than 2000 kernels are launched, causing a large number of small messages to be issued, which, as mentioned above, cause a lot of performance overhead. We verified this by artificially initializing the MPI library in single-threaded mode and noticed that the overhead with VOCL comes down to around 35% by doing so.2
Figure 31.13 shows the performance and the overhead of the application kernels for double-precision computations. The observed trends for double precision are nearly identical to the single-precision cases. This is because the amount of data transferred for double-precision computations is double that of single-precision computations; and on the NVIDIA Tesla M2070 GPUs, the double-precision computations are about twice as slow as single-precision computations. Thus, both the computation time and the data transfer time double, resulting in no relative difference. On other architectures, such as the older NVIDIA adapters where the double-precision computations were much slower than the single-precision computations, we expect this balance to change and the relative overhead of VOCL to reduce.
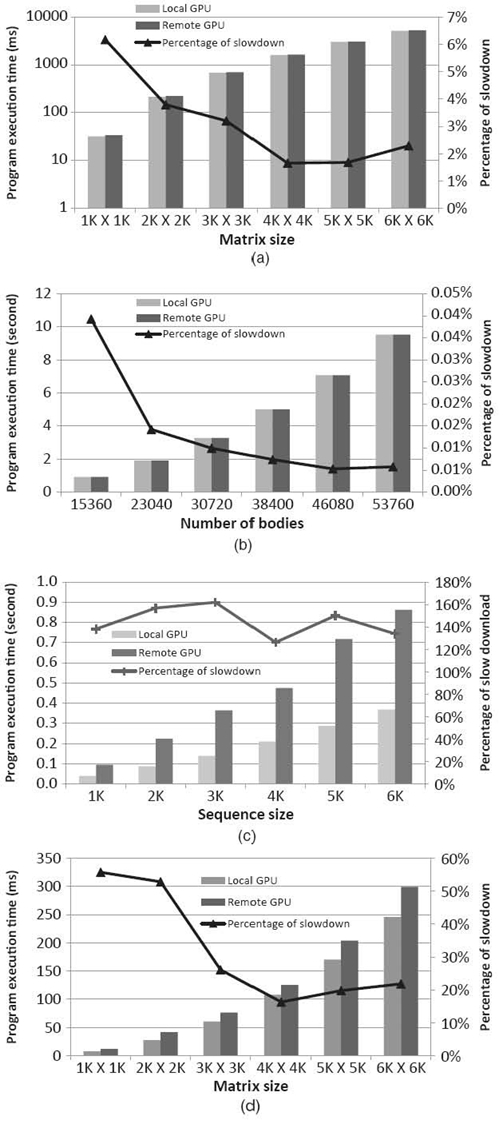
FIGURE 31.12 Overhead in total execution time for single-precision computations. (a) SGEMM. (b) N-body. (c) Smith‒Waterman. (d) Matrix transpose.
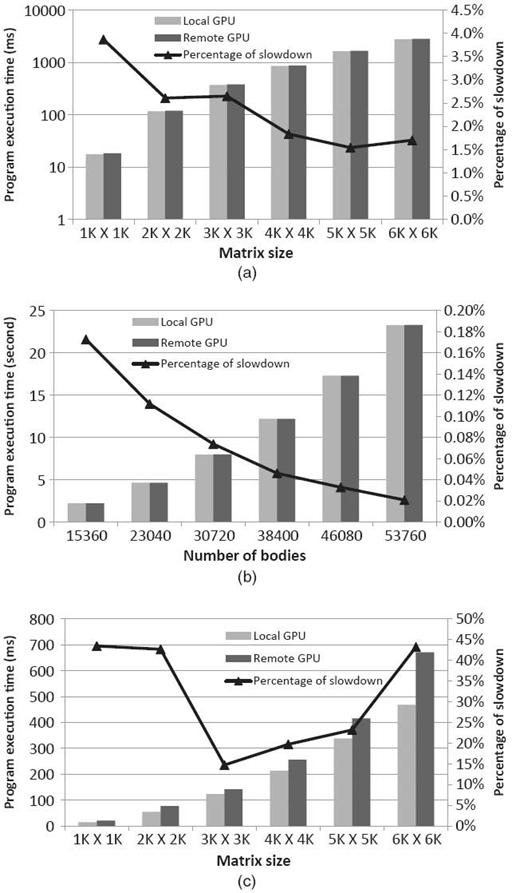
FIGURE 31.13. Overhead in total execution time for double-precision computations.
31.5.3 Multiple Virtual GPUs
OpenCL allows applications to query for the available GPUs and to distribute their problem instances on them. Thus, with native OpenCL, an application can query for all the local GPUs and utilize them. With VOCL, on the other hand, the application would have access to all the GPUs in the entire system; thus, when the application executes the resource query function, it would look like it has a very large number of GPUs.
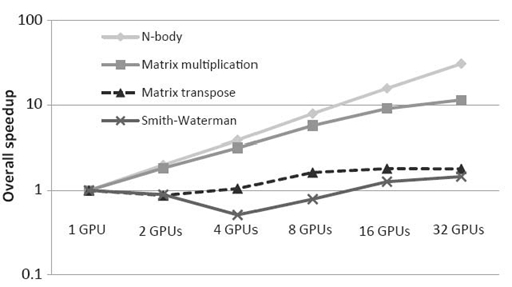
FIGURE 31.14 Performance improvement with multiple virtual GPUs utilized (single precision).
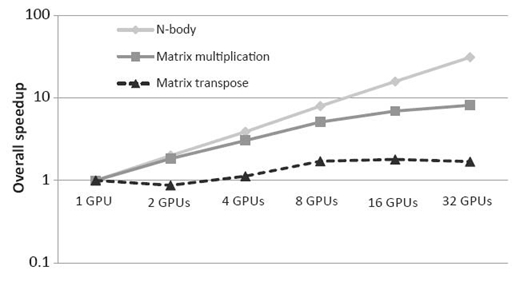
FIGURE 31.15 Performance improvement with multiple virtual GPUs utilized (double precision).
In this section, we perform experiments with a setup that has 16 compute nodes, each with two local GPUs; thus, with VOCL, it would appear that the applications running in this environment have 32 local (virtual) GPUs. Thus, the application can distribute its work on 32 GPUs instead of the 2 GPUs that it would use with native OpenCL. Figure 31.14 shows the total speedup achieved with 1, 2, 4, 8, 16, and 32 virtual GPUs utilized. With one and two GPUs, only local GPUs are used. In the other cases, two of the GPUs are local, and the remaining are remote.
As shown in the figure, for compute-intensive applications such as SGEMM and N-body, the speedup can be significant; for instance, with 32 GPUs, the overall speedup of N-body is about 31-fold. For SGEMM, the overall speedup is 11.5 (some scalability is lost because of the serialization of the data transfer through a single network link). For data-intensive applications such as matrix transpose and Smith‒Waterman, on the other hand, there is almost no performance improvement; in fact, the performance degrades in some cases. The reason for this behavior is that most of the program execution time is for data transfer between the host memory and the device memory. As data transfer is serialized to different GPUs, program execution still takes approximately the same amount of time as with the single GPU case.
Figure 31.15 illustrates a similar experiment, but for double-precision computations. Again, we notice almost identical trends as single-precision computations because there is no relative difference in data transfer time and computation time, as explained in Section 31.5.2.
31.6 RELATED WORK
Several researchers have studied GPU virtualization and data transfer between computing nodes and GPUs.
Lawlor proposed the cudaMPI library, which provides an MPI-like message passing interface for data communication across different GPUs [19]. They compared the performance of different approaches for inter-GPU data communication and suggested various data transfer strategies. Their work is complementary to VOCL and can be adopted in our framework for efficient data transfer.
Athalye et al. designed and implemented a preliminary version of GPU-aware MPI (GAMPI) for CUDA-enabled device-based clusters. It is a C library with an interface similar to MPI, allowing application developers to visualize an MPI-style consistent view of all GPUs within a system. With such API functions, all GPUs, local or remote, in a cluster can be used in the same way. This work provides a general approach for using both local and remote GPUs. However, their solution requires invoking GPUs in a way different from the CUDA or OpenCL programming models, and thus is nontransparent. In comparison, our framework supports both local and remote GPUs without any source code modification. To the best of our knowledge, ours is the first research effort that proposes a transparent virtualization mechanism for utilization of remote GPUs.
Duato et al. [21] presented a GPU virtualization middleware that makes remote CUDA-compatible GPUs available to all compute nodes in a cluster. They implemented the software on top of TCP sockets to ensure portability over commodity networks. Similar to the work by Athalye et al., API functions have to be called explicitly for data transfer between the local node and the remote node. Thus, additional efforts are needed to modify the GPU programs to use their virtualization middleware. Further, this work requires all CUDA kernels to be separated into a different file, so this file can be shipped to the remote node and executed. This is a fundamental limitation of trying to utilize remote GPUs with the CUDA programming model because of its dependency on a compiler. With OpenCL, on the other hand, the compilation of the computational kernel is embedded into the runtime library, thus allowing such virtualization to be done transparently.
Shi et al. [22] proposed a framework that allows high-performance computing applications in virtual machines to benefit from GPU acceleration, where a prototype system was developed on top of KVM and CUDA. This work considers OS -level virtualization of GPUs installed locally, and the overhead comes from the usage of virtual machines. Therefore, GPUs that can be used in vCUDA are restricted by local GPUs. In contrast, our VOCL framework provides the transparent utilization of both local and remote GPUs. Overhead in VOCL applies only to remote GPUs, which comes from data transfer between the local and remote nodes.
In summary, the proposed VOCL framework provides a unique and interesting enhancement to the state of art in GPU virtualization.
31.7 CONCLUDING REMARKS
GPUs have been widely adopted to accelerate general-purpose applications. However, the current programming models, such as CUDA and OpenCL, can support usage of GPUs only on local computing nodes. In this chapter, we described the VOCL framework to support the transparent utilization of GPUs allowing applications to use local or remote GPUs. Performance measurements demonstrate that, for compute-intensive kernels, VOCL has no performance overheads compared to native OpenCL.
REFERENCES
[1] NVIDIA, NVIDIA CUDA Programming Guide-3.2. November 2010. Available at http://developer.download.nvidia.com/compute/cuda/3_2_prod/toolkit/docs/CUDA_C_Programming_Guide.pdf.
[2] AMD/ATI, Stream Computing User Guide. April 2009. Available at http://developer. amd.com/gpu_assets/Stream_Computing_User_Guide.pdf.
[3] Khronos OpenCL Working Group, The OpenCL Specification. June 2011. Available at http://www.khronos.org/registry/cl/specs/opencl-1.1.pdf.
[4] S.A. Manavski and G. Valle, “CUDA compatible GPU cards as efficient hardware accelerators for Smith‒Waterman sequence alignment,” BMC Bioinformatics, 9, 2008.
[5] Y. Munekawa, F. Ino, and K. Hagihara, “Design and implementation of the Smith‒Waterman algorithm on the CUDA-compatible GPU,” in Proceedings of the 8th IEEE International Conference on BioInformatics and BioEngineering, pp. 1‒6, October 2008.
[6] C.I. Rodrigues, D.J. Hardy, J.E. Stone, K. Schulten, and W.W. Hwu, “GPU acceleration of cutoff pair potentials for molecular modeling applications,” in Proceedings of the Conference on Computing Frontiers, pp. 273‒282, May 2008.
[7] M.G. Striemer and A. Akoglu, “Sequence alignment with GPU: Performance and design challenges,” in IPDPS, May 2009.
[8] Message Passing Interface Forum, The Message Passing Interface (MPI) Standard. Available at http://www.mcs.anl.gov/research/projects/mpi.
[9] T. Chen, R. Raghavan, J. Dale, and E. Iwata, “Cell Broadband Engine architecture and its first implementation,” in IBM developerWorks, November 2005.
[10] L. Nyland, M. Harris, and J. Prins, “Fast N-body simulation with CUDA,” in GPU Gems, Vol. 3. 677‒695. 2007.
[11] T. Smith and M. Waterman, “Identification of common molecular subsequences,” Journal of Molecular Biology, 147 (1): 195‒197, 1981.
[12] S. Xiao, A. Aji, and W. Feng, “On the robust mapping of dynamic programming onto a graphics processing unit,” Proceedings of the International Conference of Parallel and Distributed System, December 2009.
[13] Network-Based Computing Laboratory, MVAPICH2 (MPI-2 over OpenFabrics-IB, OpenFabrics-iWARP, PSM, uDAPL and TCP/IP). Available at http://mvapich.cse.ohio-state.edu/overview/mvapich2.
[14] A. Danaliszy, G. Mariny, C. McCurdyy, J.S. Meredithy, P.C. Rothy, K. Spaffordy, V. Tipparajuy, and J.S. Vetter, The Scalable Heterogeneous Computing (SHOC) Benchmark Suite. March 2010. Proceedings of the 3rd Workshop on General-Purpose Computation on Graphics Processing Units, pp. 63‒74, 2010.
[15] P. Balaji, D. Buntinas, D. Goodell, W. Gropp, and R. Thakur, “Toward efficient support for multithreaded MPI communication,” inProceedings of the 15th EuroPVM/MPI, pp. 120‒129, September 2008.
[16] P. Balaji, D. Buntinas, D. Goodell, W. Gropp, and R. Thakur, “Fine-grained multithreading support for hybrid threaded MPI programming,” International Journal of High Performance Computing Applications (IJHPCA), 24 (1): 49‒57, 2009.
[17] G. Dozsa, S. Kumar, P. Balaji, D. Buntinas, D. Goodell, W. Gropp, J. Ratterman, and R. Thakur, “Enabling concurrent multithreaded MPI communication on multicore petascale systems,” in Proceedings of the 15th EuroMPI, pp. 11‒20, September 2010.
[18] D. Goodell, P. Balaji, D. Buntinas, G. Dozsa, W. Gropp, S. Kumar, B.R. de Supinski, and R. Thakur, “Minimizing MPI resource contention in multithreaded multicore environments,” in Proceedings of the IEEE International Conference on Cluster Computing, pp. 1‒8, September 2010.
[19] O.S. Lawlor, “Message passing for GPGPU clusters: cudaMPI,” in IEEE Cluster PPAC Workshop, 1‒8, August 2009.
[20] A. Athalye, N. Baliga, P. Bhandarkar, and V. Venkataraman, GAMPI is GPU Aware MPI—A CUDA Based Approach. May 2010.
[21] J. Duato, F.D. Igual, R. Mayo, A.J. Pena, E.S. Quintana-Orti, and F. Silla, “An efficient implementation of GPU virtualization in high performance clusters,” Lecture Notes in Computer Science, 6043: 385‒394, 2010.
[22] L. Shi, H. Chen, and J. Sun, “vCUDA: GPU accelerated high performance computing in virtual machines,” IEEE Transactions on Computers, 99: 804‒816, 2011.
1All hardware devices require the host memory to be registered, which includes pinning virtual address pages from swapping out, as well as caching virtual-to-physical address translations on the device.
2Note that, in this case, the VOCL proxy can accept only one connection request each time it is started. After an application fi nishes its execution and disconnects the communication channel, we would need to restart the proxy process for the next run, a process that is unusable in practice. We only tried this approach to understand the overhead of using a multithreaded versus a single-threaded MPI implementation.