
This chapter covers the concept of input validation and shows you practical ways to sanitize the data coming into your application. If you learn only one thing from this book, let it be this: If you sanitize each and every piece of data that comes into your application, you will prevent a lot of the most common types of attacks.
So far we’ve kept things simple and allowed only one input field in the guestbook—a text area for comments. In this chapter, we’re going to give visitors the capability to enter their names as well.
Let’s take a look at the new feature code:
<?php
// Create user interface
$html = beginHtml();
$html .= "Please enter your comment here: ";
$html .= "<textarea rows="20" cols="10" name="comment">
";
$html .= "Would you like to sign your comment? ";
$html .= "<input type="text" name="name">
";
$html .= endHtml();
print $html;
// Pull user input into a local variable
if($_POST['comment']) {
$comment = $_POST['comment'];
}else {
errorHandler("Please enter a comment");
}
If ($_POST['name']) {
$name = $_POST['name'];
}
// Entering a name is optional so we won't complain
// if they leave it blank
// Store comment and name in the database
saveComment($comment, $name);
// HTML functions
function beginHtml() {
return "<head><title>Guestbook</title></head><body>
";
}
function endHtml() {
return "</body></html>";
}
// Database functions
Function saveComment($comment, $name) {
// Do something here
}
?>
As you can see, we’ve added very few lines of code to the application, but we’ve also introduced an additional level of vulnerability by doubling the amount of data we ask for from the user. When we created the guestbook in Chapter 2, “Error Handling,” we added a check to make sure the users didn’t enter a blank comment. In this chapter, we’ll take that one step further and verify that the data they gave us in the comment and name fields actually looks like a comment and a name.
Anytime you give users the capability to send comments, complaints, or suggestions, be prepared for a pretty wide range of replies. A lot of what you get will be quite reasonable in length—two or three sentences. Sometimes you’ll get a lot more—enough to overrun the physical limits of your database or the operating system. Lengthy input won’t always come from hackers trying to break your application; some users simply have a lot to say.
The problem with excessively long inputs is that when they exceed the limits of the data type you use to store them, you run into buffer overflows, which can expose the underlying server to the user—not generally a good idea. Refer back to Chapter 4, “Buffer Overflows and Variable Sanitation,” for more information on buffer overflows.
Even if user input doesn’t exceed built-in data type limits, excessively large input can be a warning flag that something strange is going on. For example, spammers often exploit text input fields, entering PHP commands that are passed directly to the mail transport system. Testing for input length on the name field will give you an instant warning if someone is trying to use your application to send spam.
In some cases that’s a big assumption! But most of the time you can make some educated guesses about the data you expect from your users. For example, you know that a name will include upper- and lowercase letters and possibly a hyphen and/or an apostrophe. Most names do not include other symbols such as @, $, , &, or *. They probably won’t include numbers either.
You can also guess at the length of the data. Some people have long names, but you can guess at the upper limit of name length. Fifty characters is generally a reasonable limit. The trick here is to set a limit long enough to accommodate your users, but short enough to foil injection attacks. Setting length limits alone isn’t enough to consider user input safe, but when you combine length limits with assumptions about the makeup of the data, you can be fairly certain that what you’re getting is legitimate.
Every database allows you to set constraints on the length of the data you can store. Many also enable you to place additional constraints on columns. For example, in MySQL (the most commonly used open-source database management system and the one we’re using for the guestbook application), char and varchar data types have a hard limit of 255 bytes, or 2,040 characters. A hacker can do a lot of damage in 2,040 characters, so you can also set your own limits on the length of data you will allow in any given column.
Why bother to place constraints on the database when you know you’re going to validate every piece of user input long before it ever hits the database? There are two good reasons:
• Documentation: It’s a lot easier to export your database schema and include it in your data dictionary than it is to slog through your code six months from now trying to figure out why user inputs are being randomly rejected.
• Last line of defense: Of course you will validate every single piece of user input that comes into your application. Right? That’s the goal, but the reality is that developers—even the best of us—are still human. We miss things. We get rushed and cut corners just to get the job done. We have the best of intentions to go back and add validation after we get the alpha release sent out, but that doesn’t always happen. Putting length constraints on the database is kind of like making nightly backups—you don’t expect to need the backup, but you wouldn’t dream of running a Web server without that safety net. You don’t start out expecting to leave out input validation code, but it happens sometimes. That’s why you give yourself a backup by placing constraints on the database.
As we mentioned previously, verifying the length of user input is useful, but it’s not a complete solution. In the guestbook, we have only two inputs, so it’s fairly easy to describe the content of the data we expect:
• Name: Can contain upper- and lowercase letters, and the symbols - and 'are also acceptable. Acceptable length is between 2 and 30 characters.
• Comment: Can contain upper- and lowercase letters, numbers, and most symbols. Should not contain HTML or scripting commands. Acceptable length is between 1 and 256 characters. Why 256 characters? That’s the maximum length for a varchar column set by MySQL. MySQL can store longer varchars, but it allocates an extra byte per row for that column. If you need the extra space, by all means use it, but 256 characters is more than sufficient for what we’re doing here, so there’s no reason to take up the extra storage space.
Now that we know what good data should look like, we need to put the code in place to enforce our assumptions—and that means delving into regular expressions. You may be a regex wizard, and if so feel free to skip the next section. We mere mortals need to refresh our memories occasionally, and that’s what the next section is all about. We don’t have the space in this book to include a complete treatment of regular expressions, but there are quite a few great reference books available if you need more in-depth information. We’ve listed our favorite regex handbooks in the Appendix.
At this point, we’ve identified what types of characters are acceptable and how much data we will accept for each input field. The problem is this: How do we enforce these dictates? Regular expressions and taintedness to the rescue!
Tainted is a strong word, suggesting images of destroyed reputations and social diseases. As such, it seems appropriate for describing data that’s guilty until proven innocent.
Are we being too suspicious here? Unreasonable even? After all, isn’t Western civilization built on the concept of “innocent until proven guilty”? We have no argument with that idea as applied to individuals, but data is another story. To keep your application as secure as possible, you have to assume that any data that doesn’t originate within your application is tainted—even restricted inputs such as checkboxes and radio buttons. A sophisticated hacker can still use those to send bad data to your application.
Only after you validate the data by passing it through a regular expression can you assume the data is safe to use. This chapter will show you exactly how to use regular expressions to validate the data coming into your application. The first step in this process is to keep tainted data—data you haven’t yet validated—separate from data you’ve proven to be good and nonmalicious. One easy way to keep tainted and validated data separate is to use naming conventions. For example, you might read all POST data into variables with the tainted_varname convention:
After you validate that the data is in fact what you expect, you can move the data to normal variables:
$name
$comment
This way, if you ever find yourself using a variable with the tainted_ prefix, you know you’re doing something wrong.
Note
Using a prefix like tainted_ is purely an application-level convention. PHP doesn’t assign any special meaning to tainted_. You could just as easily prefix tainted variables with the name of your cat (although that naming convention may not be quite as clear to anyone else who reads your code).
How do you prove the innocence of tainted data? Bring on the regular expressions!
A regular expression—or regex for the geeks among us (you know who you are!)—is simply a language used to describe a pattern of characters. For example, you may want to know whether or not the data in $tainted_name matches the conditions you’ve declared for a name:
• 2–30 characters long
• Can contain upper- and lowercase characters
• Can contain the characters - and '
What we end up with is a regular expression that looks something like this:
^[a-zA-Z-']{2,30}$
Note that this isn’t the only way to write this regex. It’s not even the most efficient way to write it, depending on your regex engine. But it is fairly straightforward and easy to understand, so we’ll sacrifice some efficiency for clarity this time.
Before you declare in utter disbelief, “Clarity? Are they nuts? That looks like a core dump!” let’s attack this just like any other programming problem, and remember: PHP looked like utter nonsense the first time you saw it, too. We’ll start by breaking the regex down into bite-sized chunks.
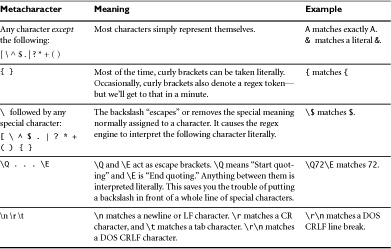
• ^: In this case (yes, there are exceptions to this rule), since we’re outside a character class, the ^ symbol simply means “Begin at the beginning.” It matches the beginning of the string. Inside a character class, the ^ symbol has no special meaning.
• [ ]: The square brackets tell us that we’re dealing with the description of a range of characters or a list. (In this case, it’s both.)
• a-zA-Z: Match any character between lowercase a and lowercase z and uppercase A and uppercase Z. In other words, match any alphabetic character regardless of case.
• { }: The curly brackets tell us we’re looking at how many characters the previous pattern should match. In this case we’re telling it to match between 2 and 30 characters (coincidentally, the length constraints we’ve declared for a name).
• $: The dollar sign means “The end.” It matches the end of the string. By placing the ^ at the beginning and the $ at the end, we know that the entire string matches—there’s nothing extra hiding out that we didn’t catch.
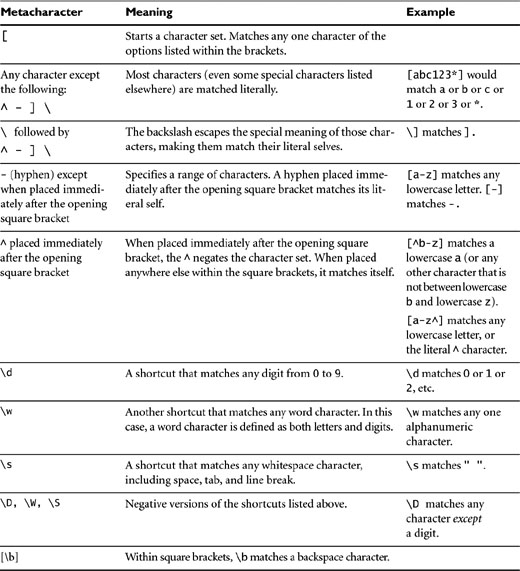
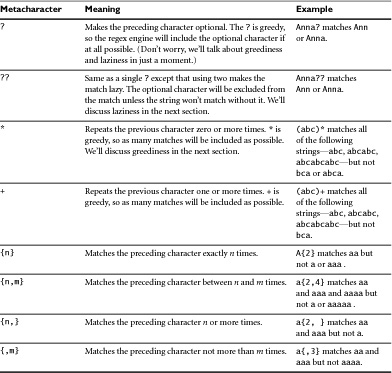
There is a lot of obscure notation involved in writing a regular expression, as well as a few shortcuts you can take. In Tables 5.1 through 5.4 we’ve broken down the most common parts of regular expression notation so you can get started writing regexes right away.
Using the concepts and metacharacters listed here, you can construct just about any regular expression you’ll need to validate user input. To get you started, we’ve listed some of the most commonly used validation expressions.

Greedy and lazy are two terms you’ll see quite a bit in any discussion of regular expressions. Depending on the discussion, you may also see a few other insulting terms, but in this case we’re not trying to be rude. Greedy and lazy are simply terms to describe how certain regular expression modifiers behave.
You already know that the + modifier tells the regular expression engine to match the preceding character one or more times. Therefore, if our pattern is
<.+>
and our test string is
$string = "<abc>DEF</abc>def"
we might expect that the pattern would match the first substring within the angle brackets:
<abc>DEF</abc>def
In reality, because the plus is greedy, it will attempt to match as much of the string as possible. When the regular expression engine encounters the first angle bracket, which matches the beginning of the pattern, it will continue to try to match the rest of the string, until matching causes the entire string to fail. When the engine reaches a point in the string where it can no longer match, it will backtrack to the last point in the string that successfully matched. This is how the engine will process our example string:
The < character in our pattern is a literal, so it will match the first angle bracket in the string. The dot will match any character in the string except a newline. The dot will match the a immediately following the angle bracket. The plus character causes the dot to repeat, matching the b and c characters as well. The dot will also match the > character and will continue to match until it reaches the end of the string.
At this point, our pattern will attempt to match the entire string:
<abc>DEF</abc>def
Unfortunately, the newline character at the end of the string doesn’t match the last character in the pattern (the >), so the engine will backtrack, removing one character at a time from the match until it reaches the > character. In the end, the greedy plus causes the pattern to match as much of the string as possible:
<abc>DEF</abc>def
The most common greedy modifiers are the plus (+), star (*), and curly brackets ({ }).
Lazy modifiers work in exactly the opposite way as greedy ones. They stop as soon as they reach a matching section of the string. To make our example pattern lazy rather than greedy, we’ll add a ? character to modify the +, making our pattern look like this:
<.+?>
In this case, the .+ combination will attempt to match as few times as possible. The minimum number of matches (designated by the +) is one, so the engine will attempt to match the first < and one character following it:
<abc>DEF</abc>def
The next character, b, doesn’t match the next literal in the pattern (>), so the engine forces the .+ to expand to include one more character:
<abc>DEF</abc>def
Again, the c doesn’t match the next literal, so it is also added to the .+ match:
<abc>DEF</abc>def
Finally, the pattern reaches a character that matches > and the engine returns the match:
<abc>DEF</abc>def
Using a lazy modifier isn’t usually the most efficient way to write a regular expression, but it works and is usually a lot simpler and clearer to read than the alternatives. Unless you’re working with very large strings or very complex patterns, you probably won’t notice the extra CPU cycles required to process an inefficient regex. You will notice, and appreciate, a clean, easy-to-read, and easy-to-maintain regex a year or two from now when you go back to modify or maintain your code. If you do run into a situation where regular expression efficiency is an issue, you’ll want to find one of the more in-depth regular expression reference books available. We’ve listed our favorites in the Appendix.
Now that you understand how regular expressions work, we’ll give you a few of the ones we use most often for input validation. Table 5.5 provides a handy reference for some of the common input validation patterns.
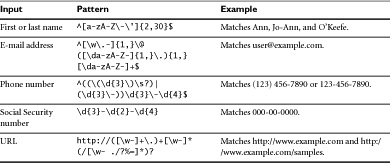
How does all this apply to real applications? The most common way you’ll use regular expressions is to sanitize variables and user input. Here’s a quick example of how we use regular expressions in the sample guestbook application:
function check_comment($tainted_comment) {
$pattern = ""/^[ws.,!?&|]*$/-;
if(preg_match($pattern, $tainted_comment) != 0) {
return $tainted_comment;
} else {
return FALSE;
}
}
We’ll discuss this particular function in more detail later in the book, but for now it’s enough to show how a regular expression works within a real application. The preg_match() function takes two arguments—the regular expression pattern and the string to check. We could have inserted the regex directly into the function call, but it’s often easier to read the code (and maintain it later) if the regex is pulled out into a variable, as we have done here.
PHP has two basic mechanisms for handling regular expressions: POSIX and PCRE. POSIX is an older implementation of regular expression syntax and is not safe for binary strings. The POSIX regular expression engine expects a text string, which for most circumstances is a perfectly appropriate expectation. You won’t normally put binary data, such as a JPEG file, through a regular expression. Unfortunately, regular expressions are often the front line of defense between raw user input and your application, which means that anything a user decides to throw at your application will hit the regex. If you use POSIX regular expressions in PHP and a user submits a nontext character, such as the NULL character, your regular expressions will not evaluate correctly. Here’s an example:
$pattern = '^[A-Za-z]*$'; // Matches any upper- or lowercase character
With normal input, the results are as expected:
$text_string = 'Hello';
ereg( $text_string, $pattern ); // This evaluates to TRUE
$numeric_string = '1234';
ereg( $numeric_string, $pattern ); // This evaluates to FALSE
The string containing nothing but alphabetic characters evaluated to TRUE—it passed through the regex—but the string containing numbers evaluated to FALSE. So far, so good. What happens if a user submits binary data to this regular expression?
$mixed_string = 'Hello'.chr(0); // chr(0) adds a NULL byte
ereg( $mixed_string, $pattern ); // This evaluates to TRUE
The mixed string should evaluate to FALSE. It contains a character that doesn’t fall within the specified range: A–Z and a–z. Unfortunately, in practice, this string containing a binary NULL byte will evaluate to TRUE. In our example, it doesn’t really matter all that much. The binary character is just a NULL byte. The real problem comes when a malicious user comes along and sends binary-encoded data—such as a virus program—to our application. If we’re using POSIX regular expressions, they will let the binary data pass right through.
The best way to defend against this problem is to use PCRE regular expressions, which handle binary data correctly. That’s what we’ve done throughout our example application. The main difference you’ll notice is that we use the preg_match() function rather than ereg(). Of course, PCRE functions have their own limitations, mostly based on the size of the patterns and strings they can handle, but in real life you’ll probably never run into problems unless you start writing patterns that span 30 pages of text.
In this chapter, we’ve discussed the important concept of input validation. If you sanitize each and every piece of data that comes into your application, you will have prevented many of the most common types of attacks. We also went over how to use regular expressions as a tool for sanitizing input.