
CHAPTER 4
A Look Back on Analytics: More Than One Hammer
“It does little good to forecast the future of … if the forecast springs from the premise that everything else will remain unchanged.”
—Alvin Toffler
The Third Wave
This chapter explores some of the pitfalls associated with traditional analytical environments and how modern data lakes attempt to remediate many of the gaps found in a data warehouse, especially in terms of handling unstructured data and providing support for artificial intelligence (AI). The lessons learned from the failures of previous analytics solutions reveal that further progress is necessary. Organizations need to develop a robust and modern information architecture. Newer solutions must address the needs of multiple personas along with data quality and data governance so that multiple forms of analytics, including AI, can be readily incorporated to yield a sustainable data and analytical environment.
Been Here Before: Reviewing the Enterprise Data Warehouse
Historically, organizations requiring analytics have turned to an enterprise data warehouse (EDW) for answers. The traditional EDW was used to store important business data and was designed to capture the essence of the business from other enterprise-based systems such as customer relationship management, inventory, and sales. These systems allowed analysts and business users to gain insight and to make important business decisions from the business's data.
For many years, techno-religious wars played out to see which employee had the most mettle to sway a direction, the winner to triumphantly select the enterprise's EDW deployment style. But as the technology landscape changed, driven in part by much higher data volumes from streaming data, social data feeds, and the magnitude of growth in connected devices, so rose the enterprise's expectations from data and analytics. IT departments began to realize that traditional EDW technologies, by themselves, were ill-suited to meet the newer and more complicated needs of the business.
The relational database, the tool of choice for most data warehouses, is still a viable technology for analytics. Even in the era of cloud computing, resilient cloud-native varieties do exist. However, relational technologies are being usurped by distributed ledgers (such as blockchains), graph databases, key-value databases, object databases, triplestores, document stores, wide-column stores, and so on—all seeking to offer alternative ways to store and retrieve corporate data.
The traditional EDW has ironically suffered heavily from its intended use. The relational model of data, the underpinning philosophy of the relational database, was first described by Ted Codd in the late 1960s. In the relational model, relations manifest as tables in a relational database. In turn, a table contains rows and columns. The table, rows, and columns all obey certain rules to retain the notion of being relational. The fact that the database was based on a formal model paved the way for data integrity (but not necessarily for data quality).
Codd set about establishing a number of rules to ensure the overall integrity of data within a relational database, and many are appropriate to many other database types as well.
These rules included the following:
- Rule 0: The foundation rule. For any system that is advertised as, or claims to be, a relational database management system, that system must be able to manage databases entirely through its relational capabilities.
- Rule 1: The information rule. All information in a relational database is represented explicitly at the logical level and in exactly one way—by values in tables.
- Rule 2: The guaranteed access rule. Each and every datum (atomic value) in a relational database is guaranteed to be logically accessible by resorting to a combination of table name, primary key value, and column name.
- Rule 3: The systematic treatment of null values rule. Null values (distinct from the empty character string or a string of blank characters and distinct from zero or any other number) are supported in fully relational database management systems (RDBMSs) for representing missing information and inapplicable information in a systematic way, independent of data type.
- Rule 4: The dynamic online catalog based on the relational model rule. The database description is represented at the logical level in the same way as ordinary data so that authorized users can apply the same relational language to its interrogation as they apply to the regular data.
- Rule 5: The comprehensive data sublanguage rule. A relational system may support several languages and various modes of terminal use (for example, the fill-in-the-blanks mode). However, there must be at least one language whose statements are expressible, per some well-defined syntax, as character strings and that is comprehensive in supporting all of the following items:
- Data definition
- View definition
- Data manipulation (interactive and by program)
- Integrity constraints
- Authorization
- Transaction boundaries (begin, commit, and rollback)
- Rule 6: The view-updating rule. All views that are theoretically updatable are also updatable by the system.
- Rule 7: Possible for high-level insert, update, and delete. The capability of handling a base relation or a derived relation as a single operand applies not only to the retrieval of data but also to the insertion, update, and deletion of data.
- Rule 8: The physical data independence rule. Application programs and terminal activities remain logically unimpaired whenever any changes are made in either storage representations or access methods.
- Rule 9: The logical data independence rule. Application programs and terminal activities remain logically unimpaired when information-preserving changes of any kind that theoretically permit unimpairment are made to the base tables.
- Rule 10: The integrity independence rule. Integrity constraints specific to a particular relational database must be definable in the relational data sublanguage and storable in the catalog, not in the application programs.
- Rule 11: The distribution independence rule. The data manipulation sublanguage of an RDBMS must enable application programs and terminal activities to remain logically unimpaired whether and whenever data are physically centralized or distributed.
- Rule 12: The nonsubversion rule. If a relational system has a low-level (single-record-at-a-time) language, that low level cannot be used to subvert or bypass the integrity rules and constraints expressed in the higher-level relational (multiple-records-at-a-time) language.
While not all databases, relational and nonrelational, adhere to these rules, fundamentally the rules apply in spirit to an information architecture and to what an information architecture seeks to accomplish.
In a relational database, a table is intended to store information about a particular type of thing, such as a customer, a product, or an order, and so on. Each row in the table is also intended to store information about the thing, such as an individual customer, an individual product, and an individual order. Each column of each row is intended to hold atomic pieces of data that describe the thing that the row now represents. And herein lies the crux of the EDW problem.
The problem was not, as may be initially thought, what to include in a primary key or even whether the data was properly normalized.
The problem was the atomic piece of data. Atomicity, as shown in Figure 4-1, caused, and still causes, table designers to limit their thinking for deploying business-oriented solutions.
The term atomic is used to connote the idea that a business concept must be expressed in its lowest common form of meaningful decomposition. Understanding the composition of data and what constitutes an atomic value can significantly aid in how you approach engineering features for an AI model.
To some businesspeople, the term mailing address can be considered atomic (refer to Figure 4-1). However, a mailing address, in the United States, could be decomposed as street number, street name, city, state, and ZIP code. But then, the street name could also be further decomposed into a pre-direction, the street name, a post-direction, and a suite or apartment number.
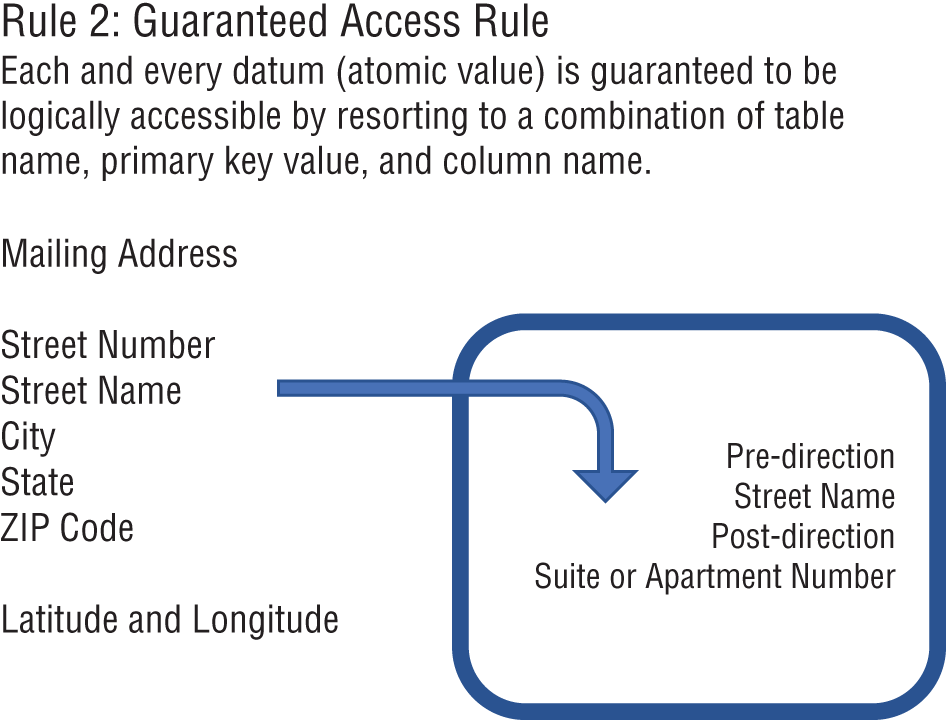
Figure 4-1: Reviewing atomic data
In fact, the U.S. Postal Service further defines alternative atomic rules that include general addresses versus rural route addresses versus post office box addresses. The Postal Service also delineates rules of format between business addresses and residential addresses.
But while there are all of these different approaches to representing a mailing address, two other atomic values could act as a surrogate: a latitude and a longitude.
Even the notion of a mailing address, from an atomic aspect, is therefore distinct from other uses of an address such as a billing address or for a mobile location. One must also consider that not all addresses represent a geographically fixed location.
In another example, a person's name can be decomposed into first name, middle name, and last name with honorifics such as Mr., Mrs., and Dr. also separated along with any separation for name suffixes, such as academic achievements (e.g., Ph.D.), honorary titles (e.g., K.B.E), professional title (e.g., CPA), or generational title (e.g., Sr., Jr., and III)—leading to column design that may begin as follows:
- Order_Name_Prefix
- Order_Name_First
- Order_Name_Middle
- Order_Name_Last
- Order_Name_Suffix
Depending on cultural needs, the previous approach can also be too restrictive. In some cultures, a last name can contain many names representing paternal or maternal lineage. But across different cultures, the sequence in how portions of a name are represented may vary too. All of these factors played heavily into where people drew the line as to how the guaranteed access rule should be interpreted and applied.
In many cases, too many designers choose to hard-code atomic attributes to the prevailing business vernacular rather than to pursue more forgiving (and adaptive) abstractions. The adopted practices created a technique that served to literally hard-code the business to a point in time and prevented an easier route to making changes to a database schema. The binding nature of data was also addressed in Chapter 2, “Framing Part I: Considerations for Organizations Using AI.”
Following on from the “gender” example that was used in Chapter 2, if an organization wanted to add a biology or a sex code to a table that already had an existing gender code, this could be simply accomplished by using a structured query language (SQL) statement named ALTER. The ALTER statement would allow someone to specify the table name and to provide the new column name with an appropriately designated data type, such as string or numeric.
However, what proved to be difficult was the time required to effect the change when a table contained billions of stored rows and when potentially hundreds of application programs and procedures were dependent and tied to the original schema.
Atomicity was relentlessly infused as a best practice. Few practitioners took note that concepts such as the built-in data type TIMESTAMP were themselves not atomic. The TIMESTAMP data type could be decomposed by the query language and even participate in temporal (time-series) equations—but a column with this data type was not technically atomic in its representation. While subtle, this meant that people referred to designs as having certain characteristics that they, in fact, did not have.
Later, character large objects (CLOBs) and binary large objects (BLOBs) were introduced as data types that were highly suited for nonatomic attributes and concepts. These data types were essentially NoSQL friendly. Relational technology was essentially doomed by best practices that ended up paving the way for future nimbler and more adaptive techniques and technologies.
Some successful implementations broke away from the atomic column-defined design model when using a relational database. For example, Initiate Systems, bought by IBM in 2010, used alternative design techniques in its relational database Master Data Management offering that were driven by external metadata. The metadata was managed externally to the table and allowed the column structure to be inferred and interpreted through the metadata. Ultimately, though, the inherent schema-on-write best practice of relational databases was perceived as being far too slow and restrictive to address constant business changes.
With schema-on-write approaches, enterprises must design the data model and articulate the analytical needs before loading any data into the traditional EDW. In other words, each enterprise must know ahead of time how it plans to use the data. For many organizations, this approach can be highly constraining.
Beginning with the use of eXtensible Markup Language (XML), smaller data stores benefited from using a far less rigid and formalized method for describing a structure. By using flat files, programmers could work around formal database administrator (DBA) groups, and, at the time, DBAs were happy to give up control of flat-file designs as they were often just viewed as tinker toys compared to a real database.
Soon after the insurgence of XML, database technologies that could support a schema-less-write began to appear in the marketplace. A schema-less-write could be used to extract data from a source and then place that data into a data store without first transforming the data in a way that would have been necessary with a traditional EDW.
The newer approaches to managing data began to highlight some of the drawbacks associated with the traditional methods used in the creation of an analytical environment.
Drawbacks of the Traditional Data Warehouse
The simplified EDW architecture shown in Figure 4-2 helps to illustrate some of the drawbacks associated with the traditional EDW. There are three major areas for data stores: the staging area, the normalized data stores, and the marts.

Figure 4-2: Simplified information architecture for an EDW
The staging area was used as a transition area between the source data and the data being formally incorporated into the data warehouse environment for end-user access. The normalized area is a broad array of cross-subject area domain models for the enterprise to support general analytical needs, while the mart area is comprised of discrete models to address certain types of specific analytical needs.
Each data store area required its own distinct data model for which multiple data models could actually be created: a conceptual data model, a logical data model, and a physical data model. In all, some organizations attempted to build nine different models to support the hypothetical architecture that is shown in Figure 4-2.
The approach to designing the staging data may have been based on a denormalized design inherited from multiple source systems and accompanied by separate conceptual, logical, and physical models. The normalized data may have used a normalized design and also be accompanied by separate conceptual, logical, and physical models. The mart data may have used a star schema or snowflake design and also is supported by a cadre of underlying models.
Approaches to normalization, denormalization, and even star schemas boil down to affinities between concepts and whether to organize the concepts together or separately and with what degree of applied rigor. In each case, the physical data model would be the source for the writing or generating data definition language (DDL) so that the necessary tables can be installed.
In addition to the three data store areas, three separate data integration processes are required: one to move data into the staging area, another to move data into the normalized area, and a third to move data into the marts. These processes are often referred to as or extract, transform, and load (ETL). There are variants such as ELT: extract, load, and then transform.
Each operational source, data file, or relational table requires its own ETL line. Figure 4-2 illustrates why a schema-on-write approach for the traditional EDW can consume a tremendous amount of time and cost in extensive data modeling and data preparation.
Under the guise of data governance, many organizations invested in a paradigm known as analysis paralysis. Resulting standardization or governance committees were formed, and they met to deliberate over standards and terminology—sometimes for years and without actually completing all of the tasks at hand.
For example, the outcome of lengthy deliberation for defining what a customer actually means to an organization may result in a definition such as “a party that has purchased, been shipped, or used products.” While this might be amenable to an IT department, most business-facing employees found little value or meaning with such lackluster and terse definitions.
A committee process normally involves creating many up-front definitions. Before formally beginning, committees must often deliberate upon the problems they want to solve. Then, the committee must decide what types of business questions are likely to be frequently asked. The committee process is perceived to help ensure that the correct supporting data can be identified. From that, a committee will commission the design of a database schema capable of supporting the questions brought to light by the committee.
Because of the time and energy to onboard new data sources, after a schema has been finalized, a committee can spend an inordinate amount of time deciding what information should be included and what information should be excluded from a data warehouse. Such a time-intensive process helped to render the traditional EDW fairly static in composition and content.
If a committee became gridlocked, meaningful work and progress could stall. In some organizations, gridlocks have been known to drag on for many months. A gridlock can be short-circuited when a committee member, sometimes dubbed as the 800-pound gorilla in the room, decides to simply edict an answer.
However, such answers can often be biased and can be detrimental to both the short-term and long-term success of an EDW. The lack of success is evident by the consistency of EDW project failures, as reported by numerous advisory services.
The question must be asked as to why an organization would use a committee as a means to create an EDW. The answer is twofold.
First, the enterprise aspect of a traditional EDW denotes that it represents the entire enterprise and that the enterprise nature of the warehouse would prevent it from becoming another siloed function or siloed data store. Second, as a best practice, the hierarchical organization chart used by all major organizations is based on lines of business (which are themselves silos that are created by following a best practice on organizational models) where only one enterprise-wide decision-maker actually exists, the company president.
As repeatedly asking the organization's president to decide on what should or should not go into a data warehouse is probably not a viable option, committees were therefore established as a way to facilitate a cross line-of-business activity. In a matrixed organization where employees may report into multiple managers, interlocking, or the coordination with others, becomes a surrogate means to provision a committee or governance authority.
Using a traditional EDW approach, business analysts and data scientists cannot consistently seek answers to ad hoc questions from the data. A business analyst or data scientist would have to form a hypothesis ahead of creating the requisite data structures and analytics so as to test out their hypothesis. A restrictive aspect of the EDW was that analytic users had to follow a predefined path of access to the data so as to avoid performance or response time issues. System administrators often canceled wayward (or ad hoc) requests because they were seen as consuming too many computer resources.
The only feasible analytic results that were consistently produced by a traditional EDW were those that the EDW had been explicitly designed to return. Certainly, this is not an issue if the original hypothesis was absolutely correct and the underlying business (and the business-side business model) is stagnant from one year to the next. The closed-loop techniques adopted by EDW designers can be restrictive for a business that consistently requires new ways to view data and new data to support a changing business landscape.
The successor environment to the data warehouse was the data lake, and it sought to eliminate many of the issues just described as both structured and unstructured data could be readily ingested—without any data modeling or standardization. Structured data from conventional databases can be placed into the rows of the data lake table in a largely automated process. Technologies associated with the data lake were also better prepared to handle big data.
Because the schema for storing data does not need to be defined up front, expensive and time-consuming modeling is not needed (or can be deferred). Once data is in the data lake, analysts can annotate or choose which tag and tag groups to assign. The tags are typically pulled from the source's table-based information. Data can receive multiple tags, and tags can be changed or added over time.
Paradigm Shift
Driven both by the enormous data volumes associated with big data and by the perceived lower cost of ownership, schema-less-write technologies such as Hadoop found open doors in many organizations.
In 2010, Pentaho's James Dixon wrote about the limitations of the EDW and the benefits of Hadoop. He more or less stated that in the EDW, the standard way to handle reporting and analysis is to identify the most interesting attributes and to aggregate these attributes into a data mart. There are several problems with this approach. First, only a subset of the attributes can be examined, so only predetermined questions can be answered. Second, the data is aggregated so that visibility into the lowest levels are lost.
Based on the requirement needs of the modern organization and to address the problems of the traditional EDW, Dixon created a concept called the data lake to describe an optimal solution, which he expressed through this analogy:
If you think of a data mart as a store of bottled water—cleansed and packaged and structured for easy consumption—the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.
While the term has caught on and has continued to gain in popularity as a concept, data lake projects have not all been smooth sailing. Many data lakes have been turned into data swamps—an all but useless collection of data where any hope of performing analytics has become all but lost. When a data lake becomes a data swamp, starting a new data lake project is simpler than attempting to drain (otherwise known as reorganizing) the swamp.
Modern Analytical Environments: The Data Lake
Many modern analytical environments primarily seek to address big data. One of the approaches to managing big data is the data lake, a central location in which to store the enterprise's data, regardless of its source and format.
The data lake technology of choice has been to sit on top of the Hadoop Distributed File System (HDFS) or cloud object storage. The data can be structured or unstructured and can be used by a variety of storage and processing tools to extract result sets.
For example, cloud object storage aids with managing the needs associated with aggressive storage capacity growth demands by enabling capacity-on-demand and other benefits. Similarly, the scalability, simplicity, and accessibility for managing storage on public, private, and on-premise clouds are compelling.
Cloud object storage normally has the following traits:
- Provides a cost-efficient storage capability that can supersede some of the complexities and restrictions associated with older file systems that support network attached storage (NAS) and storage array networks (SANs).
- Provides any time and any device storage access via HTTP protocols and can be delivered via a storage-as-a-service (SaaS) application.
- Provides for elastic and on-demand services. Cloud object storage systems do not use directory hierarchy and can provide for location transparency without imposed limits on the number of files that can be maintained, mandate a threshold as to how large a file can grow, or place a restriction on the amount of space that can be allocated.
- Helps to eliminate hot spots and provides for near-linear performance as nodes are added. A cloud object storage cluster is symmetrical, which allows for the workload to be automatically load balanced across the nodes in the cluster.
- Helps to avoid the need for cloud backup and recovery as the entire cloud object storage cluster is an online, scalable file repository.
When the big data era began, it was defined by volume, variety, velocity, and veracity. Data lakes became a welcoming beacon for managing these types of data traits because the underlying storage mechanisms were far more flexible than those that had been used to support an EDW.
- Volume: Large
Making petabytes and exabytes a viable storage number
- Variety: Unbounded
Making it possible to store structured, semistructured, and richly varied unstructured data that included text, documents, audio, video, and images
- Velocity: Tolerable
Broad acceptance of eventually consistent data copies across the distributed storage made HDFS and cloud object storage an underpinning for capturing data associated with devices and sensors associated with the Internet of Things (IoT)
- Veracity: Naivety
Believing the enterprise was capable of deriving insights from inconsistent content
If data lakes could put out a flashing neon sign, it would likely read “All data is welcome” as a mark of its intended flexibility and capability. Data lakes have arisen as a dominant alternative to the traditional EDW, especially as organizations seek to expand their mobile, IoT, and multicloud data footprints.
The following are some of the benefits you would experience in building a data lake:
- Deriving business value from any type of data
- Persisting any type of data format
- Hoarding data without having to understand its immediate utility
- Refining data as understanding, need, and insight improves
- Fewer restrictions on how data can be queried
- Not restricted to proprietary tools to gain insight into what the data means
- Data can be democratized (allow for nonspecialists to be able to gather and analyze data without requiring outside help) and helping data silos to be eradicated.
- Democratized access can provide a single, unified view of data across the organization.
- Supports complete analytical needs from traditional business intelligence to AI
As indicated earlier in Figure 4-2, several distinct styles of table design emerged to support the EDW. As previously discussed, one style was based on a normalized model of data. The target level of normalization that was sought by many practitioners was third normal form, often abbreviated as 3NF. Third normal form defined design guidelines for associating data to a table's primary key. As data is inert, the data itself could not tell whether it was in or out of 3NF, and practitioners who cited their designs as conforming with 3NF were, at times, making invalid claims.
Other popular data modeling techniques for the EDW include the previously mentioned star schema and snowflake. The star schema and the snowflake were typically known as a data mart. The normalized model and the data mart can co-exist in an information architecture for data warehousing. But the differences between an EDW and a data lake can be significant.
While machine learning and AI models invariably use denormalized data, understanding the process and mechanics associated with normalization can pay huge dividends when examining results from the execution of a model—especially in terms of identifying false positives in pattern detection.
By Contrast
While both the EDW and the data lake cater to an organization's analytical needs, how those needs are met have more than a semantic difference. As the E in EDW stands for enterprise, the approach organizations took to schema design in the traditional EDW was (and is) often based on establishing a unifying canonical model. Canonical data models are normally developed to present data entities and relationships in a simple and singular form—which may often result in a series of designs that represent a lowest-common denominator.
As few applications could conform to the structure of a canonical model, a production EDW often provided a warehousing environment had limited use. The EDW also paved the way for the establishment of the departmental data warehouse (DDW), where the implemented data model was never intended to have enterprise-wide appeal and thus had a stronger affinity to the source schemas or the schemas of the supported transactional applications. Both the EDW and the DDW always made use of a predefined schema.
The operational data store (ODS) was also the result of the limitations to a canonical approach to data modeling but also required schemas to be predefined. The ODS was often built to support intraday analytical needs for front-office applications. Today, the ODS can be replaced with hybrid transactional/analytical processing (HTAP) database technologies.
In many organizational implementations, the EDW was designed only to collect data that is controlled for quality and conforms with the enterprise data model. As a result, the traditional EDW was only able to address a limited number of questions, specifically, the preconceived questions that the environment was theoretically capable of answering.
Once implemented, the traditional EDW also proved difficult to manage. At one point, the research and advisory firm Gartner cautioned that more than 50 percent of data warehouse projects would have limited acceptance. Later, another advisory service, Dresner, found that only 41 percent of survey respondents considered their data warehouse projects to be successful, and Forrester reported that 64 percent of analytics users had trouble relating the data that was available to the business questions they were trying to answer. More recently, Forbes has commented that the trend is not dissipating: “For too many companies, the data warehouse remains an unfulfilled promise.”
Indigenous Data
While the data warehouse often focused a tremendous amount of effort on recasting data into new data models, the data lake inherently onboards data in its original form. Little or no preprocessing is performed for adapting the structure to an enterprise schema—this does not imply that data is not subsequently cleansed or standardized. The structure of the data collected for the data lake is not always known when it is fed into the data lake. The structure is often found only through discovery, when the data is read.
Flexibility is one of the biggest advantages of the data lake. By allowing data to remain in its native format, the data can often be made available for analysis in a much quicker time frame and in greater quantities. But, acting on the flexibility in this manner can be a double-edged sword, resulting in the following problems:
- Too much dirty data as few controls are put into place to reject redundant copies of data, to reject data from unauthorized sources, or to refine the numerous and various anomalies that are often found in source systems
- Trouble with actually collecting data resulting from a lack of data governance to ensure repeatable and consistent feed schedules are put in place
- Trouble with users accessing data due to few controls being placed on publishing a schema design or when a change occurs on a schema
- Not realizing value beyond the collection of data for the sake of collecting data without business objectives in place or identified
- Limited business value beyond keyword search because the data may not easily lend itself to analytics or AI
- Difficulty in properly securing the data lake because the security profiles of different stakeholders, custodians, and users were not sufficiently captured prior to onboarding the data
Cleansing and reconciling data from its contributing sources is central to understanding the differences between an EDW and a data lake. The primary purpose of the traditional EDW is to provide for reliable, consistent, and accessible data to business users in support of decision-making, especially for lawful actions, performance tracking, and problem determination. The data lake's primary purpose was to expand on the type of data that could be collected and made available to the organization. In addition, the data lake was meant to also provide higher degrees of flexibility, to reduce the amount of time spent in system design and on development lifecycles.
The EDW's detailed data originates from operational (largely transactional) systems. The data is often subdivided (especially in the data mart) and summarized (aggregated) by the time the data is accessed by a user. The discussion of data zones in Chapter 5, “A Look Forward on Analytics: Not Everything Can Be a Nail,” further elaborates on some of the data characteristics within the data lake and illustrates some of the differences to the EDW.
Attributes of Difference
In contrast to the EDW, a data lake is often defined by several key attributes. The first of these key attributes is the ability to collect anything and everything. Please note that there is a difference between an ability to collect anything and everything and then acting on that ability. Prudence should be used as to what data to place into a data lake. Citing, again, the discussion on data zones in Chapter 5, specific areas can be carved out within a data lake to better manage data that is of an exploratory nature.
The data lake persists both the inbound raw data and any data that has been subsequently processed. Second, a data lake is also characterized by a dive-in-anywhere approach. As access paths are not predefined, users are free to refine, explore, and enrich data based on their terms, implying that a data lake can be cobbled together without much forethought or planning. While the data lake serves to mitigate some of the shortcomings associated with the EDW, an absence of an information architecture does not help with the success rate of a data lake.
Another key attribute is flexible access. Flexible access accommodates multiple data access patterns across a shared infrastructure that may stretch over a hybrid cloud or a multicloud approach and includes batch processing, interactive processing, online processing, cognitive search, in-memory data access, and so on.
The final key attribute of the data lake is that many of the elements are available through open source technologies and not solely on the availability of proprietary software.
Elements of the Data Lake
Data lakes were born out of the big data movement with the notion that a single shared data repository was a necessity. Because of the affinity between big data and the data lake, the technology of choice for many organizations was Hadoop. A repository built to conform to the Hadoop framework would, as previously mentioned, likely sit on top of HDFS or cloud object storage. In a hybrid or multicloud environment, there may be a need for more than one data lake, although a single data lake can span multiple topographies and will be covered in more detail in Chapter 5 on data topologies. In spanning more than one cloud deployment, a data lake can be partitioned to optimize analytic and AI functions for the supported users and the applications.
Hadoop data lakes often aimed to preserve data in its original form and to capture changes to data and contextual semantics throughout the data's lifecycle. This approach can be especially useful for compliance and internal auditing activities that need to have insight into the changing characteristics of the data and the analytical demands.
In contrast to the traditional EDW, there can be numerous challenges to piecing together a longitudinal perspective of the data after the data has undergone transformations, aggregations, and updates, resulting from a loss of provenance at the column or row level.
Orchestration and job scheduling capabilities are also important elements of the data lake. Within the Hadoop framework, these capabilities are often provided through the use of YARN, which is an acronym for Yet Another Resource Negotiator. YARN is a generic and flexible framework to administer the computing resources in the Hadoop cluster.
YARN provides resource management by using a central platform to deliver tools for consistent operations, security, and data governance. The tools are used across Hadoop clusters and ensure that the analytic workflows have access to the data and the required computing resources. Figure 4-3 shows the architecture for YARN.
The architecture shows specialized application clients submitting processing jobs to YARN's resource manager, which works with ApplicationMasters and NodeManagers to schedule, run, and monitor the jobs.
YARN containers are typically set up in nodes and scheduled to execute jobs only if there are system resources available for them. Hadoop supports creating opportunistic containers that can be queued up at NodeManagers to wait for resources to become available. An opportunistic container concept aims to optimize the use of cluster resources and, ultimately, increase overall processing throughput.
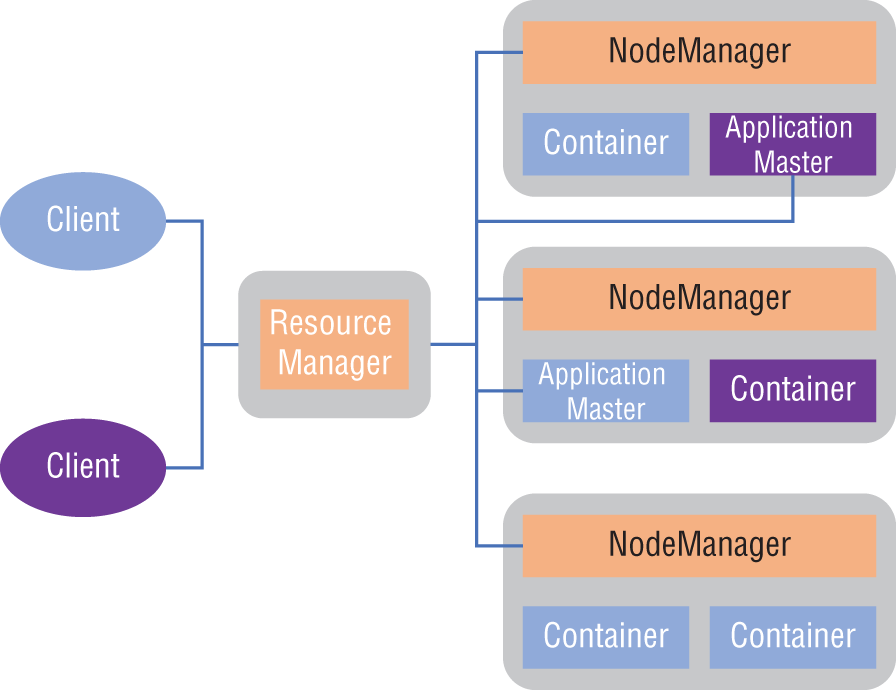
Figure 4-3: YARN architecture
Easy user access is one of the premises associated with a data lake due to the fact that organizations can preserve the data in its original form. This is opposite of the canonical data model approach that was previously described for EDWs. Data lakes seek to provide a set of applications or workflows for consuming, processing, and acting upon the data. Whether the data is structured, semistructured, or unstructured, the data is typically loaded and stored in its raw form.
By leveraging the raw data, the data lake offers data owners the chance to readily consolidate customer, supplier, and operations data, thereby eliminating many of the roadblocks that inhibit sharing data. However, in practice, the raw data is as much an inhibitor to the various data owners. The inherent nature of the raw data can prevent any easy consolidation and may serve to limit the number of data sharing opportunities, especially when using a self-service model.
The paradox between providing a means to consolidate data easily and the raw data preventing easy consolidation is that the raw data brought into the data lake can suffer from many traditional data quality issues seen in many systems. The promise of easy data consolidation requires that the raw ingested data of the data lake contain a level of data quality that is deemed reasonably accurate and consistent. Invariably, many organizations have business data that contains a series of significant data quality issues. If these issues are transferred into the data lake, they persist and are not always easily overcome.
The challenges that the EDW tried to proactively overcome are often addressed reactively within the data lake environment. Reactively addressing data quality issues means that AI models can be erroneously trained on big data, and other analytic processes can lead to misleading insights.
The New Normal: Big Data Is Now Normal Data
Since the dawning of the computer era for mass commercial business purposes—which began in the mid-1960s with the introduction of the IBM 360—provisioning reports for analytical and insight purposes has been critical.
The genesis for the data warehouse began in the late-1980s and was quickly adopted as the de facto environment type for producing (seemingly) complex analytics and reports. But in the era of big data, where traditional complex analytics have taken a back seat to higher-levels of complex analytics—prescriptive analytics, machine learning, cognitive analytics, and AI, along with much higher volumes of data and broader varieties of data—the traditional EDW environment is overwhelmed and sometimes ill-suited.
Initially, big data was data that was deemed either too large or too complex for traditional data-processing methods to handle. As previously indicated, big data was often characterized by volume, variety, velocity, and veracity. Over time, these characteristics became accepted as the new normal.
In the face of this new normal, organizations were faced with the need to continuously change and adapt traditional EDW data models as well as manipulate the rigid field-to-field data integration mappings, all of which proved highly cumbersome. The move toward data lakes was a direct result of recognizing the necessity for a different analytical paradigm for end users and one that was already better equipped to handle big data.
Another weakness in the EDW model was the organization's sole reliance on IT departments to perform any manipulation or enrichment to the data. The dependency arose from the inflexible designs, system complexities, and misguided perception that human error could be eradicated from the environment. On the surface, data lakes were an easy answer for solving these types of challenges because they were not tied to any rigidity associated with a single data model.
Liberation from the Rigidity of a Single Data Model
Because data can be unstructured as well as structured, a data lake can be used to persist anything from blog posts to product reviews to order taking and order fulfillment. Because the data lake is not driven by a canonical data model, the data does not have to be stored in a uniform manner.
For example, one data source may render gender as “male” and “female,” another data source might use an encoding technique such as “m” and “f,” and a third system may choose to distinguish between biology and societal gender preferences and persist the information as two separate concepts. A system that uses both biology and gender may choose to represent the biology at birth and the gender to represent the individual's portrayal in society; this also includes the ability for a system to recognize gender neutrality.
Onboarding three or more different data source techniques such as streaming, bulk-batch, micro-batch, message queues, etc., in a traditional EDW can be considered problematic; in a data lake, however, you can put all sorts of data into a single repository without worrying about schemas that define the integration points between different datasets.
This approach affords the ability that not every user must conform to using data that is not helpful in making their job easier and more efficient. In the discussion on data zones in Chapter 7, “Maximizing the Use of Your Data: Being Value Driven,” we'll cover how the zones can be developed to provide curated data. Data that has been curated makes it easier to consume data in a meaningful and useful manner.
Streaming Data
Once a capability of a select few organizations like stock markets, space agencies, and Formula 1 racers, tapping into streaming data has transcended from being a rare use case.
Streamed data can be brought into the data lake to cover a variety of near-real time or trending data needs from video and audio feeds, social media content, log data, news feeds, surveillance, machine operations (such as an engine from an in-flight airplane), and business transactions.
As the quote in Chapter 2 from Alvin Toffler stated, organizations are having to make decisions at “a faster and faster pace.” Streaming data affords decisions to be made faster as analytics can be performed on many streams while the data is transient and still inflight. Being able to assess data while the data is still inflight reduces the need to wait for data to be written to a database. Technologies suitable for the task at hand can reduce latencies associated with decision-making.
Suitable Tools for the Task
While a traditional EDW can meet the needs of some business users for general types of business intelligence activity like aggregation and ranking, the use of tools like Spark, MapReduce, Pig, and Hive in the preparation of data for analysis for an EDW can take far more time than performing the actual analytics.
In a data lake, the data can often be processed more efficiently through these tools without requiring excessive preparation work. As data lakes do not enforce a rigid metadata schema, integrating data can involve fewer steps. Schema-on-read allows users to build custom schemas into their queries upon query execution for easier accessibility.
Easier Accessibility
By using infrastructures designed for big data, ever-larger data volumes can be managed for all forms of analytics, including cognitive analytics and AI. Unlike the potential monolithic view of a single enterprise-wide data model, the data lake accommodates delaying any data modeling activities. Data modeling can be delayed until the end user actually intends to use the data.
The delay may be seen as creating opportunities for enhanced operational insights through the lens of just-in-time data discovery practices. This type of advantage is perceived to grow with increasing data volumes and data varieties along with an increase in the richness of the metadata.
Reducing Costs
Because of economies associated with open source distributions and the use of the infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS) computing models, data lakes built on Hadoop clusters can be less expensive than comparable on-premise solutions using a commercial relational database.
However, an unmanaged data lake can become more expensive than it needs to be because of the relatively easy tendency to hoard data. Waiting for data to be discovered in a data lake carries a certain number of organizational risks as well as potential rewards. For example, all of the data in the data lake can be subject to search during an e-discovery process for litigation purposes. Not knowing if any of the data that was persisted conflicts with regulatory or compliance requirements is not normally viewed as a sufficient legal defense.
Scalability
Big data is typically defined as an intersection between volume, variety, and velocity. Traditional EDWs are notorious for not being able to scale beyond a certain volume due to restrictions within the architecture. Data processing in an EDW can take so long that organizations are prevented from exploiting all of their data to its fullest extent. Using Hadoop, petabyte-scale and beyond data lakes are more cost-efficient and relatively simple to build and maintain at the level of scale that is organizationally desired.
Veracity and value were two other v words that became associated with the big data movement. In a number of ways, veracity and value only highlighted the gap between the promise of the data lake and the realization that some other approach would ultimately be needed.
Data Management and Data Governance for AI
If an organization uses data and advanced analytics, especially AI, for mission-critical purposes, then data management and data governance cannot be lax or ad hoc.
While the traditional EDW was initially embraced because of the formal processes and strict controls, the processes themselves became overwhelmed by the growth in data volume as well as the speed required to handle the ingestion rates along with the broad variety of data types. A knee-jerk reaction for using the data lake is another type of extreme: a convenient place to dump gobs and gobs of data.
Early adopters of the data lake were likely to exhibit the tendency to load data without any attempt to manage the data using a formalized process. Although this type of situation may still exist as organizations go through the trials and errors of using a data lake, the dumping ground for data is rarely considered an optimal business choice.
In situations where the data has not been standardized, where data errors are unacceptable, and when the accuracy of the data is regarded as more than just a high priority, a data dump will work against any organizational efforts to derive value from the data lake.
The data lake can still be a data lake even if it borrows certain formalities from a traditional EDW. A data lake is intended to be flexible, scalable, and cost-effective, but it can also adopt some of the disciplines from a traditional EDW, especially practices associated with data management and data governance.
Incorporating data management and data governance disciplines into the data lake environment requires organizations to avoid the temptation to freely load data at will. While machine learning techniques can sometimes help discover structures in large volumes of disorganized and uncleansed data, this is not something that can ordinarily be left to the unsupervised learning techniques of AI.
Even the most sophisticated inference engine would require a place to start in the vast amounts of data that comprise a data lake. Based on the potential volume, an inference engine would, in all likelihood, need to ignore some of the data. Organizations can run the risk that parts of the data lake may result in data that becomes stagnant and isolated—also known as dark data. In addition, the data lake may contain data with so little context or structure that even the most specialized automated tools, or data scientists, can find the terrain tough to rationalize.
The level of data quality in the data can deteriorate over time, and the deterioration can potentially escalate as the volume of data accumulates in the data lake. When similar semantic questions are asked in a slightly different way and yield different answers, users may begin to distrust the data lake or require that the data lake be metaphorically “drained” and begun all over again.
Tools that were used with the traditional EDW can often be applied or adapted for use in the data lake. Invariably, a big data equivalent tool or a specialized data connector can be found. As the marketplace for big data matures, so too will the capabilities that are offered. Evolving capabilities would include the means to allow data—whether written via a schema-on-write approach or through a schema-less-write (schema-on-read)—to be readily cataloged across a hybrid or multicloud environment. Other necessary capabilities would also include improved support for the management of workflows and to assist in the improvement of data quality regardless of where the data is located. Such capabilities would further foster the ability to infuse AI into more applications.
Schema-on-Read vs. Schema-on-Write
This is an oversimplified but useful characterization: the EDW centered on schema-on-write, and the data lake has centered upon schema-on-read.
Some of the advantages associated with a schema-on-write approach include the following:
- The location of the data is known.
- The structure is optimized for predefined purposes.
- The SQL queries are reasonably simple.
- Response times are often very fast.
- Checking the data's quality is an important requisite function.
- Business rules are used to help ensure integrity.
- Answers are largely seen as being precise and trustworthy.
These are some of the disadvantages associated with a schema-on-write approach:
- Data is modified and structured to serve a specific purpose and predefined need.
- There can be certain limitations placed on how long a query can run.
- There can be certain limitations on writing complex queries without the aid of a stored procedure or a program.
- ETL processes and validation rules can take a long time to build.
- Certain ETL processes—due in part to the nature of batch processing—can take a long time to execute.
- ETL processes can take a long time to be adapted to address new needs.
The following are some of the advantages that can be associated with a schema-on-read approach:
- Query capabilities can be flexible.
- Different types of data that are generated by different types of sources can all be stored in the same location.
- The previous two points allow for querying multiple data stores and types at the same time.
- This approach more readily supports agile development approaches.
- This approach more easily accommodates unstructured data.
These are some of the disadvantages associated with a schema-on-read approach:
- The data may not be subjected to data cleaning or data rationalization/validation processes.
- Some necessary data may be missing, duplicated, or invalid.
- The SQL queries can become complex—taking time to write and time to execute.
Schema-on-write has been an accepted approach since the inception of hierarchical databases such as IBM's IMS database and IBM's relational database Db2 and its forerunner, System R. Before any data is written in the database, the structure of that data is strictly defined, and that metadata is stored and tracked. The schema, comprising the columns, rows, tables, and relationships, is defined for the specific purpose that the database is intended to address. Data is filled into its predefined positions within the schema. In the majority of cases, the data is cleansed, transformed, and made to fit in the structure before the information is persisted.
Schema-on-read is a concept where the programmer is not burdened with knowing what is going to happen to the data before persistence takes place. Data of many types, sizes, shapes, and structures can be thrown into the data storage system or data lake. Only at the time that the data is to be accessed is the schema structure required.
In essence, the two approaches represent opposite ends of a shared spectrum. In earnest, a data-centered environment that supports analytics and AI is likely to benefit from an appropriate blend of the two approaches that is anchored toward providing value to the organization based on organizational business objectives. Rather than establishing a mind-set as to which is better, a mind-set as to which is prudent might yield better odds that a data-centered environment can result in business success.
Data lake successes have not been unilateral. Benefits of the data lake have often been voiced by IT and not because of realized outcomes experienced by a business. While EDWs often started life under a “build it and they will come” mentally, data lakes have often been set up without specific goals in mind other than to build a single corporate version of the truth and to finally democratize the corporate data asset. The downside of many data lakes has been that their setup has been neither strategically aligned to the business nor sufficient in tactical innovation.
Often data lakes succeed where the approach is not enterprise-wide and where specific analytic use cases are specifically being addressed. The use cases tend to be oriented to smaller business groups within a department or line of business.
Realistically, both the EDW and the data lake are infrastructures. As an infrastructure, neither one is a substitute for being an isolated and disenfranchised strategy. In Chapter 5, design considerations for a data lake implementation are explored within the context of information architecture. Backboning a data lake, especially one that is intended to promote advanced analytics and AI with an information architecture, can reinvigorate the data management program to look more closely at all of the aspects that contribute toward a successful analytical platform.
Summary
While half of the EDWs that were attempted have reportedly failed to succeed, the number of data lake and big data projects that have been attempted have outpaced the EDW in terms of failure. As expressed in the introduction, Gartner analysts have, in the past, projected that the failure rate of data lakes may be as high as 60 percent. However, that number was subsequently regarded as being too much on the conservative side, with the actual failure rate being much closer to 85 percent.
Interestingly, the higher rate of failure for data lakes and big data initiatives has not been attributed to technology but rather to the technologists who have applied the technology.
For much the same reasons that the EDW failed, the underlying approaches taken by practitioners in the era of data lakes and big data have failed to fully understand the nature of the enterprise or the business of the organization, that change is stochastic and can be gargantuan, that data quality really does matter, and that the techniques applied to schema design and an information architecture can have consequences in how readily the environment can be adapted.
While new technologies can provide many new and tangible advantages, technologies are not always impervious to how they are deployed and can have difficulty being impervious to the data they have to ingest.
Only the organization can control how data is entered and how and what data is entered changes over time. In some ways, an organization can be thought of as a fragile entity. Rarely does it stay the same for any length of time. Creating design solutions against a moving target has proven to be difficult, but the challenge is not insurmountable. Some of the potential methods to combat organizational volatility when providing advanced analytics and AI capabilities to the organization are themes discussed in the next chapter.