
CHAPTER 10
A Journey's End: An IA for AI
“Some principal characteristics of the Information Age are extreme complexity and extreme rates of change.”
—Clive Finkelstein
Enterprise Architecture for Integration
While the number and variety of use cases for artificial intelligence (AI) can be safely predicted at ∞, the ideas expressed in this book can successfully be applied to address extreme situations, whether in business, military defense, counterintelligence, child safety, or deep space.
Today, space agencies believe they have a good handle on things up to an altitude of 2000 km above the planet—the ceiling height of low earth orbit (LEO). The International Space Station, for example, operates within LEO. Above that altitude, less and less is known, especially about the long-term impact of deep space on the human body. For instance, within LEO, some astronauts experience a syndrome known as visual impairment intracranial pressure (VIIP), which negatively impacts the astronaut's ability to see properly. While technological advancements now allow astronauts to carry a single pair of glasses with an adjustable prescription (a dialable lens), the precise causes behind the syndrome are not fully understood. If we don't understand everything that occurs within LEO, moving into deep space for longer-term travel certainly can pose an additional set of health risks.
Imagine that you're part of a team tasked with planning to take an astronaut to Mars, a journey filled with actual unknown unknowns. Each unknown that manifests itself might need some form of remediation that needs to be addressed in near real time, but sending and receiving a message to the spaceship (including any code changes) could take over six minutes—and that's if the communication signal traveled at the speed of light.
A weekly development sprint would likely prove impractical for all but minor cases. Even CI/CD approaches could be a stretch in terms of latency. That said, many of the techniques that have been described in this book can be used for adaptive deployment solutions as well as agile ones. In deep space, where lives would be continually at risk and the ability to respond must occur within an incredibly short window, the use of machine learning models that can be trained with minimal data or function on unsupervised learning would be essential. The use of data zones and data topographies along with data models that avoid hard-coding can provide for the flexible and timely responses necessary to keep the astronauts alive and such a mission on track.
This chapter serves to pull together a series of techniques that can be used for both normal use cases as well as extreme ones, with the necessary considerations for composing an information architecture to support the activities associated with model development and deployment with AI. The information architecture required for AI needs to incorporate a data topology and a highly distributed computing environment. Smarter data science initiatives understand that data-intensive AI deployments must be able to support the real-time event-driven business needs that are often required when operationally infusing AI as a means to improve the effectiveness and performance of an organization.
Development Efforts for AI
Traditional software engineering practices rely on functional decompositions to identify the scope of each computer program that needs to be written. Expected program behaviors for each program are designed into every given solution. Any deviation from the expected behavior of a computer program is, by definition, a software defect. The power of an AI model inherently lies in the ability of the model to learn and incrementally adapt without the need for a traditional computer program.
An AI model is not engineered in the traditional sense of system design. AI models are set to learn via complex neural networks with no guarantees as to the precise functional operation. The organization's data is used to help the models determine how they should behave. In this regard, data has become a new way to create a specification.
Testing a system using traditional verification techniques is not likely to work as well with AI, since there are no hard and fast rules for what must occur. Models are, by nature, pattern-based and not rules-based. Added complexity comes from the statistical nature of machine learning algorithms that can select outputs for a given input based on calculated confidence levels versus the deterministic methods that are used by traditional rule-based systems.
The personalization of outputs produced by AI models that can match specific user needs can introduce further challenges over traditional software engineering practices. The correctness of the output may be decided by the subjectivity of the business user looking at the outcome. Furthermore, traditional user acceptance tests can appear to be impractical—as traditional tests have been based on the consistency of rule-based outcomes and AI's pattern-based outcome may not yield an identical outcome each and every time.
The traditional means to recognize a defect can change with the use of AI. Unintended model consequences such as bias and other emergent behaviors may need to play out in production and not in a controlled test environment. With AI, continuous learning can manifest as a series of behavioral changes that occur over time within a system.
While traditional software systems paid attention to usability, reliability, and operational performance, AI systems often require an intensive and continual effort to focus on trust. Trust is a topic that can cover a range of areas that include human oversight, robustness, data privacy, fairness, ethics, transparency, and accountability.
Machine learning models are likely to be built using machine learning libraries with little attention paid to traditional techniques associated with software engineering practices. The variability associated with AI places a renewed emphasis on the need for an information architecture that can serve as a means to impose aspects of predictability for a solution that includes models whose results are not in and of themselves predictable, in other words, how an information architecture is a singular enabler for smarter data science.
The broader view of developing machine learning applications includes other activities beyond the development of the model itself. Also required are activities such as data preparation; building, training, and testing a model; DevOps/MLOps and DataOps; as well as all deployment and production monitoring activities related to AI.
Data preparation activities can often consume upward of 70 percent of the effort related to model development. For AI models and AI-infused applications, appropriate efforts to perform data preparation are required as a means to help avoid unintended bias and to help ensure fairness and trust. Feature extraction is a critical task in the data preparation process, which can help remove redundant data dimensions, unwanted noise, and other properties that can otherwise degrade model performance.
Building, training, and testing a model are required activities toward producing the best model that can meet the perceived requirements from your organization's available data. In practice, data scientists are likely to leverage various frameworks such as TensorFlow, PyTorch, and Scikit-Learn when the models are actually created. Each type of framework can provide some tooling to help support the coding process. However, if and when a model does not produce any identifiable errors, the model may still not be suitable for the intended deployed purpose.
Another important core activity in the building of a machine learning model is the separation of the training data from the validation data. The separation is required to help adequately evaluate the model's ability to generalize. Cross-validation is a practice that data scientists often follow to help with model validation. As a rule of thumb, approximately 70 percent of the available data is set aside for model training purposes, and the remaining 30 percent is set aside for model validation. Debugging an AI model can be complex since the model's behavior cannot ultimately be based on the inferred code and the training data.
When a machine learning model is deemed ready, the model can be infused into a software application. The technique of using black-box testing can help to evaluate whether the model is good enough for deployment. The use of black-box testing is to know the output or the outcome, but not to explicitly reveal how the output or the outcome was determined.
MLOps and DataOps activities also need to keep the model and training data versions synchronized so that any future changes to the model can be adequately tracked. Overall, AI development can be considered different from that of traditional software development because:
- Managing the AI data lifecycle can be more challenging when compared with other software engineering efforts that do not include machine learning.
- Model creation and reuse can require different skillsets that may not be directly comparable to other skillsets that participate in traditional software projects.
- AI components can be more challenging to manage than traditional software assets due to the difficulty in isolating inappropriate, undesirable, or erroneous behaviors.
If, for example, an AI model was built to identify objects in an image, a generative adversarial network (GAN) model could be used. Generative modeling involves the use of a model to generate new examples that could plausibly come from an existing distribution of samples. The new examples could include generated images that are similar but specifically different from a dataset of existing images.
A GAN model is a generative model that is trained using two neural network models. One of the models is known as the generator model and learns how to generate new plausible samples. The other model is known as the discriminator and learns to differentiate between generated examples and real examples.
Based on the results of testing with training datasets that include images, the accuracy of identifying a given object within the image would yield a given probability. When the model is ready for deployment, the accuracy might be found to be significantly less than during the training phase. The disparity is probably associated with drift. Data drift denotes a change in the data distribution during deployment as compared to the distribution of data that was used during the training phase of the model.
How quickly drift can be detected is impacted by the following:
- The data that is used in the learning process can have a high number of dimensions. Finding the difference between the learning data and the production data's distribution can be difficult to identify.
- At deployment time, the data is typically not labeled. Direct measurements of the model's performance may not be possible.
- Experimental design can require advanced sequential test analysis to help retain statistical power, the absence of which can make repeated measurements tricky to achieve.
Avoiding data drift issues can require a high degree of engineering. In the model building process, maintaining a clear separation of training data and validation data is necessary, even though the training data and the validation data can be sampled from the same distribution. Careful selection of black-box test data is critical so that the data can best reflect the data that is expected at the time of deployment.
Traditional software development has mature processes to capture and persist critical artifacts such as requirements, designs, code versions, test cases, deployment data, and so on. By contrast, the process used for developing models may not permit the permanent storage of the training data as a critical artifact.
In practice, the restriction may be due to large datasets that are required for training, limited data access, or licensing terms that prohibit the data from being used beyond the training period.
Data can also vary over time, which can make the preservation of data less relevant for use later. If capturing and preserving all the data that is necessary for training and testing a model is impractical, the ability to reproduce or post-audit the models may be impeded.
Data preparation is an activity that can be underrated in the efforts to produce a model. Data preparation holds the key to a more reliable model building regimen and can affect the final predictive accuracy more so than the actual modeling. Like modeling, data preparation can also contain parameters that are subject to tuning. Data preparation must be understood as a process that must be optimized, cross-validated, and deployed jointly with data modeling to ensure proper applicability.
The development of essential elements for an information architecture must be able to address the data preparation, model development, and xOps practices over time to ensure integrity and viability.
Essential Elements: Cloud-Based Computing, Data, and Analytics
An information architecture for AI is framed around three essential elements. The elements are cloud, data, and analytics. (As an element, the word cloud is used in the broader sense of cloud enablement rather than a specific type of cloud.) The three elements are also critical to achieving any organizational goal that contributes toward digital transformation. Cloud, data, and analytic elements can overlap and intersect with each other. The intersections serve to indicate capabilities that would need to be provided to ensure a robust implementation. For example, the intersections can illuminate cross-element operational needs for interoperability, governance, security, and workload balancing.
Earlier chapters in this book have mentioned that not all data is created equal. Similarly, inequality applies to clouds and to analytics—in that not all clouds and not all machine learning models are created equal.
Figure 10-1 shows an overarching cloud topography. The topography is tightly aligned to the data topography specified with the data topology presented in earlier chapters. (The data topology incorporated a zone map, data flows, and the data topography.) The three elements of the cloud topography are cloud computing, fog computing, and mist computing.
Each element shares a common set of facets: the inclusion of hardware, the ability to run software, the accessibility to a communications network, and the means to store information. All elements of the cloud topography can be provisioned either through a public provider, through a private provider, or be self-provided.
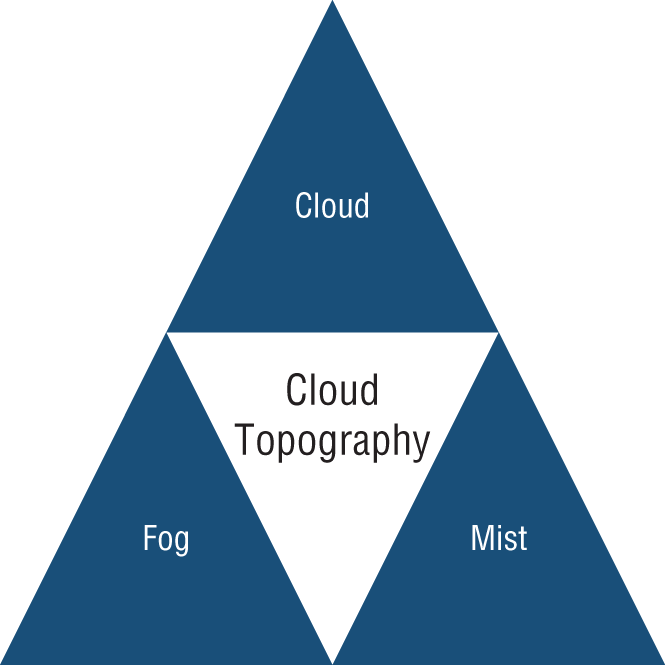
Figure 10-1: Cloud topography
A public cloud provider offers computing services over the public Internet. Examples of public cloud providers include Amazon Web Services, Google Cloud Platform, Microsoft Azure, and IBM Cloud. Typically, a public cloud provider can save an organization from having to purchase or license their own hardware and application infrastructures. Additionally, a public cloud provider can often take on the responsibility to manage and maintain a given environment on behalf of an organization.
Through the use of a public cloud, some software products can be deployed faster than when an organization uses traditional on-premise infrastructures. Invariably, a public cloud provider caters to higher levels of elasticity and scalability to satisfy the organization's resource needs during times of peak demand. A public cloud provider is typically associated with the cloud element in the cloud topography.
A private cloud provider offers computing services to select users, often a single organization, instead of the general public. The computing services are typically made available over the public Internet or through a private internal network. Private cloud computing can provide organizations with some of the benefits associated with a public cloud, such as self-service, scalability, and elasticity, without the burden of having to share certain infrastructural resources.
Additional controls and customization are also advantages for using a private cloud provider over the use of dedicated resources from computing infrastructures hosted by an organization's own data center. Private clouds can also provide improvements in the level of security and privacy through a combination of the organization's own firewalls with a private cloud-hosted firewall. The use of a private cloud provider would typically require an organization to maintain the same technical staffing levels that would have been necessary with the use of a traditional data center.
Two cloud service models that are commonly used with a private cloud include infrastructure as a service (IaaS) and platform as a service (PaaS). IaaS is designed to allow an organization to use infrastructure resources such as compute, network, and storage as a service. PaaS is designed to let an organization deliver everything from a relatively simple standalone cloud-based application to a complex enterprise system.
Private clouds, when combined with public clouds, establish a hybrid cloud solution. A hybrid cloud can often support the means to cloud burst. With cloud bursting, an organization can seek to scale computing services to a public cloud when the computing demand increases beyond the thresholds of the private cloud. A private cloud provider can be associated with two of the three cloud topography elements: the cloud and the fog.
Self-provided is provisioned by the organization and traditionally involves an on-premise data center. Due to the advent of portable computing such as autonomous vehicles, laptop computing, and smart devices such as tablets and mobile telephones, many self-provided computing capabilities are distributed outside of the physical data center. Self-provided capabilities are often distributed to the elements fog and mist within the cloud topography model.
The elements in the cloud topography infer a hierarchy of capability in terms of the amount of computing power, the elasticity in the possible number of execution nodes, and the overall capacity to store data for on-demand use. Understanding the differences and the benefits is critical for the development of the information architecture.
The topography elements cloud, fog, and mist represent classes of computing and not a given number of instances that may ultimately be deployed or accessible. Each deployed instance is considered a node. Physically, an organization may choose to implement zero, one, or more cloud nodes; zero, one, or more fog nodes; and zero, one, or more mist nodes.
Mist nodes can number into the tens of thousands—perhaps millions. An IoT sensor is not, by itself, regarded as a mist node. However, should the sensor be directly attached to compute, network, and storage capabilities, then the IoT sensor could participate as a recognized mist node. In a retail store, a handheld smart device used for physical inventory control could participate as one of the mist nodes.
A retailer, for example, may choose to use a cloud node to help with managing order replenishment functions and a fog node in an organization's primary data center to run a campaign management function. The retailer may also choose to set up each of their stores with a dedicated micro data center to act as independent fog nodes. As each store, in this example, acts as a fog node, each store can operationally function as an independent entity in the case of a network outage. The ability to function independently provides a degree of operational resiliency. In this example, the primary data center and the stores are all representative of different fog nodes. The key tenancy across the cloud topography is to be able to operate in a disconnected mode. Operating in a disconnected mode is to indicate that some level of business continuity can be provided even when there is a network outage.
The ability to run AI models locally is an aspect that should be taken into consideration when constructing an information architecture. Local is contextual to where a model runs and can be independently applied to each node type.
A disconnected cloud is local for the models that run on that cloud without the need to pull or distribute data beyond the one cloud. A fog is local if the models that run on the fog node do not need to interoperate or depend on other nodes to perform a score, etc. A mist is local to the models that run on that one smart device so long as there is not a need for additional inbound or outbound data to be transmitted.
The following are the general characteristics of cloud, fog, and mist:
- Cloud
- Regional or global
- Managed
- Virtual
- Bare metal
- One or more data centers
- Scalable and elastic
- Unlimited storage
- Fog
- Localization
- Low-latency
- Dedicated
- A single data center
- Restricted scalability and elasticity
- Restricted storage
- Mist
- Edge
- Ultra-localization
- Personal computing
- Little or no scalability or elasticity
- Limited storage
While consideration can be given for each node to operate in a disconnected mode, a deployment can further consider peer-to-peer communications across each node type: across clouds, across fogs, and across mists. Peer-to-peer communication is separate from that of cloud to fog connectivity, fog to mist connectivity, and cloud to mist connectivity.
Comprehensive enterprise-grade deployments can be achieved and configured to cater to disparate and high-demand workloads with infused AI capabilities inside of business applications. A potential use of the fog node is to assign this type of node with a traditional enterprise data center. The data center is often referred to as on-premise or on-prem computing.
On-prem computing may include the use of mainframe computing, such as an IBM Z series computer that has the ability to provide complete data encryption on all data at rest and inflight. On-prem computing may include other server types such as those that use IBM's Power-based chips or even smaller servers that are based on x86 or Nvidia chipsets. (x86 is a family of instruction set architectures that are based on Intel's 8086 microprocessor.)
Servers that are deployed on-premise, whether as a single server or in a cluster, can be reviewed for horizontal and vertical scaling. But at any given point in time, there are likely to be physical limits as to the degree of scalability that can be achieved. The aspect of a physical and known limitation is the primary characteristic that distinguishes a fog node from a cloud node.
The availability of storage in the cloud, fog, and mist is critical to AI in terms of data inputs and model outputs. Figure 10-2 shows the cloud topography juxtaposed between the inherent compute capabilities and the storage capabilities required for advanced analytics.
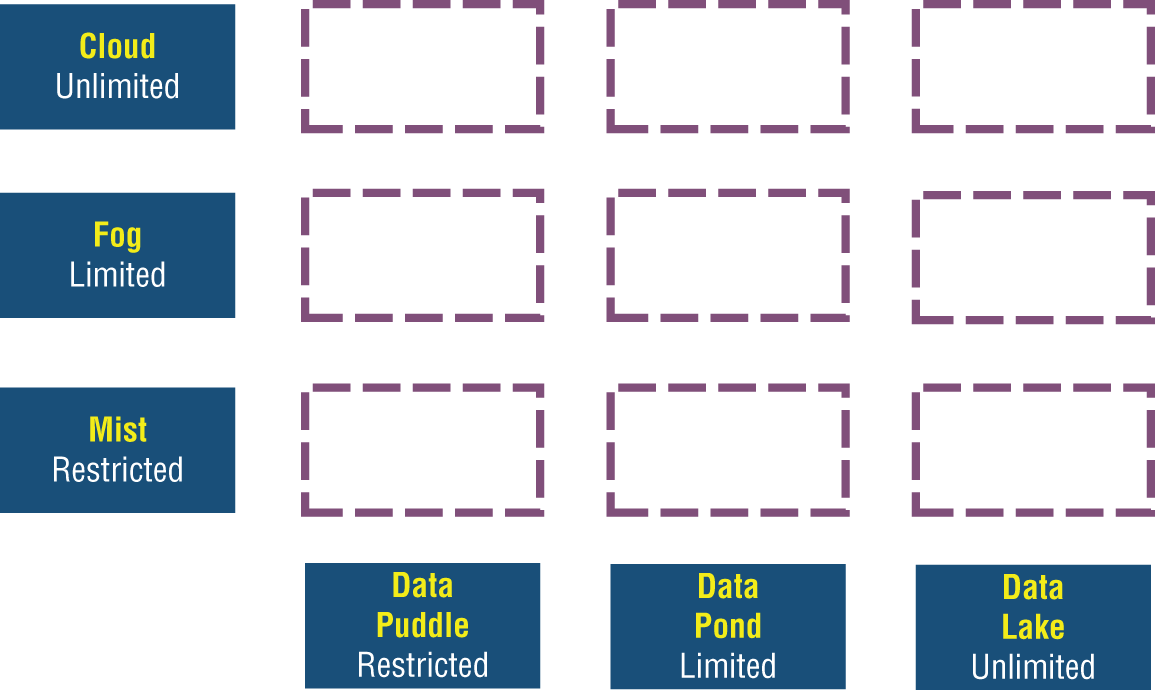
Figure 10-2: Compute and storage capabilities
Intersections: Compute Capacity and Storage Capacity
In Figure 10-2, the compute capabilities associated with cloud, fog, and mist computing are shown along the y-axis, and the candidate storage capabilities—the data lake, the data pond, and the data puddle—are shown along the x-axis. The compute capabilities of the cloud are labeled as being unrestricted. The compute capabilities for the fog are marked as being limited, while the mist capabilities are labeled as being restricted. While there are physical limits associated with each public cloud provider or private cloud provider, a single organization is unlikely to press those limits. Therefore, from the perspective of the organization, the limits are labeled as unrestricted.
The fog is restricted in the sense that an organization's data center cannot organically grow without addressing a number of constraints. The constraints are associated with locational limits, floor space limits, and power consumption limits. As such, the fog node is regarded as being limited. The mist is viewed as being restricted because many smart devices cannot be expanded beyond their purchased configurations.
The storage capabilities follow a similar hierarchical pattern to the compute capabilities. Here the data lake is considered unrestricted, as the lake is primarily associated with the storage capabilities coming from the cloud. A data pond has limited storage as the data pond is primarily associated with the storage capabilities of the fog. The data puddle is restricted and is primarily associated with the storage capabilities of the mist.
Each axis has representations for unrestricted, limited, and restricted capabilities. For the unrestricted compute power of the cloud, the cloud is capable of spanning more than one organizationally sized data center. The storage for the cloud can be very large and possibly exceed one brontobyte. (One brontobyte is 1,237,940,039,285,380,274,899,124,224 bytes.) The processing power of the cloud is able to run as many containers as necessary for a cloud-native application.
The limited compute power of the fog can be expressed as being equivalent to one data center, while the storage for the fog is likely to be less than one exabyte. (One exabyte is 1,152,921,504,606,846,976 bytes.) The processing power of the fog is able to run a reasonable or limited number of containers that might be necessary for a cloud-native-styled application.
The restricted compute power of the mist can be expressed as being less than one data center, while the storage for the mist is likely to be less than ten terabytes. (Ten terabytes are 10,099,511,627,776 bytes.) The processing power of the mist is only a few containers for a cloud-native-styled application.
The capacity of storage for the cloud, fog, or mist is independent of whether the data is held in a transient or persistent state. Transient capacity is often data that is being held in memory or data that is inflight. Persistent capacity is typically data that is held on recoverable media and is at rest.
The primary intersections between the nodes and the storage form natural use cases. These use cases are as follows:
- Cloud ➪ data lake
- Fog ➪ data pond
- Mist ➪ data puddle
The secondary intersections between the nodes and the storage form alternative use cases. The alternative use cases are as follows:
- Fog ➪ data lake
- Mist ➪ data pond
The tertiary intersections between the nodes and the storage form possible but ill-suited use cases. These use cases include the following:
- Cloud ➪ data pond
- Cloud ➪ data puddle
- Fog ➪ data puddle
An intersection that does not meaningfully work in any capacity between the nodes and the storage is as follows:
- Mist ➪ data lake
Each node is often focused on various aspects of an ability to scale, the ability to provide elasticity, and the ability to offer resilience, continuity, and security. Each node is capable of accentuating one or more of these aspects. The cloud node maximizes scalability and elasticity. The fog node maximizes security, while the mist node maximizes resilience. Along with the areas of focus lies an ability to run certain types of AI models. This ability has some fundamental distinctions that relate to the intensity of the analytics.
Analytic Intensity
The analytic intensity that is shown in Figure 10-3 is based on the ability to provision computer power and on having access to large data stores (whether transient or persistent) for a given model to act upon. A mist node is not going to have, nor is the mist intended to have, the same computing power or the same ability to locally store extremely large data stores as the cloud. Therefore, the analytical intensity is naturally lighter in weight, especially when directly compared to other fog and cloud nodes.
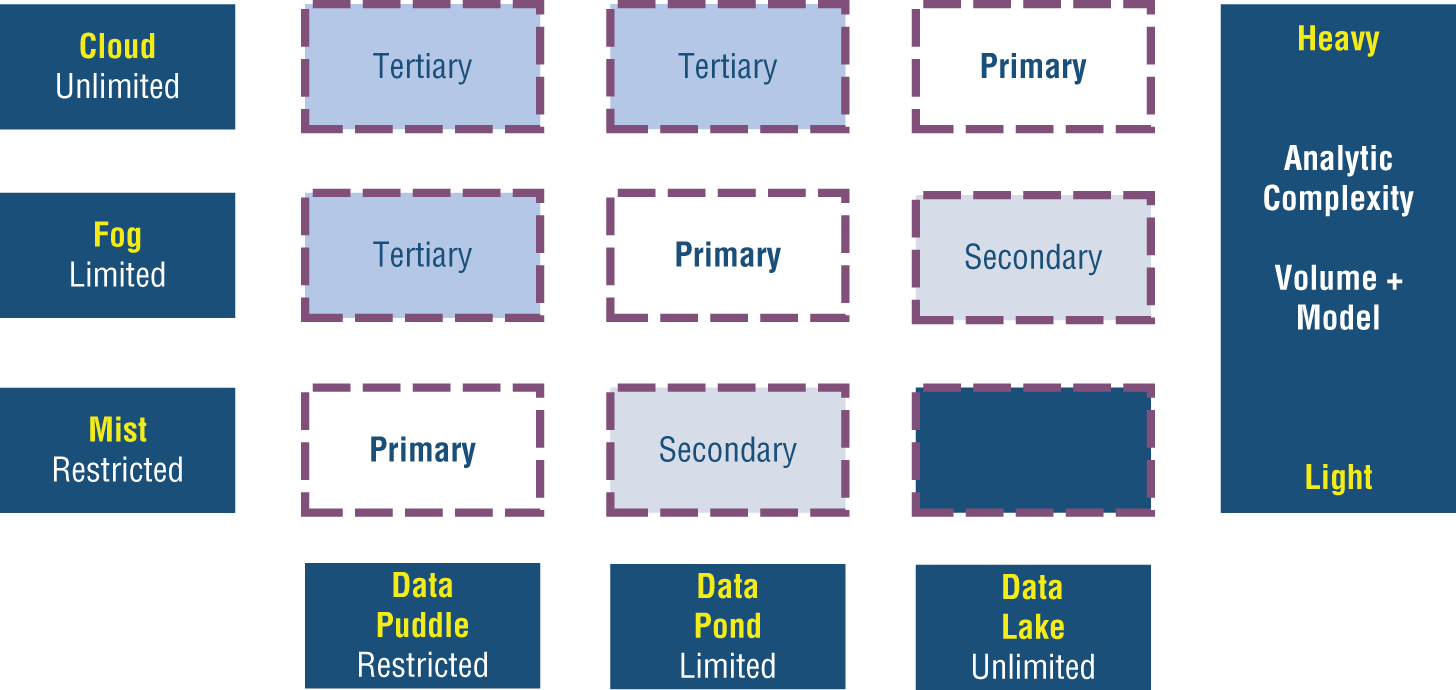
Figure 10-3: Analytic intensity
A fog node can achieve moderate analytic intensity, and a cloud node can achieve a level of heavy and complex analytic intensity for running AI models.
When any of the nodes are planned to be interoperative, the intensity can be reevaluated. For the purposes of the information architecture, the analytic intensity is viewed as a single node provisioning the data and running the AI model.
Interoperability Across the Elements
For an organization sensitive to network latencies, multiple cloud providers might be leveraged for performing cloud computing. An organization is likely to choose a provider's cloud zones that are located nearer to its operational locations to reduce latency times. For other organizations, multiple cloud providers might be used to keep the processing of data isolated within a political or country border for regulatory purposes. Still, other organizations might elect to use multiple cloud providers to force an additional layer of workload distribution across the application portfolio.
The fog compute node can take on multiple characteristics. The use of a traditional on-premise data center to support all back-office operations is one such characteristic. A larger organization ordinarily uses multiple data centers that are configured to take on the workload of another data center should an outage of some type arise. Each data center would be an independent fog node with regard to an information architecture. Depending on the industry and the needs of an organization, additional fog computing nodes may be established.
A hospital system with hospitals throughout a country might choose to have a fog node located within each hospital or leverage a regional setup to support several hospitals that have a geographical proximity. An oil and gas company might choose to have a fog node located on each oil rig; a shipping company might decide to have a fog node located on each tanker or cargo ship. A university might choose to have a fog node on each campus; a manufacturer might want to have a fog node in each plant; a retailer, in each store; and a government might elect to provide each agency or ministry with its own fog computing nodes.
In many instances, a fog node may make use of a private Long-Term Evolution (LTE) network for wireless broadband communication. Private networks can help support remote locations and may provide higher degrees of resilience.
The mist compute node is the lightest node of the three elements. The mist node typically represents the most restriction in terms of compute processing capabilities. As previously stated, a mist node can be a smart device such as a tablet computer or a mobile telephone handset. Additionally, a mist node might be the computing power located in the trunk of a police car. A passenger vehicle might be a mist node and able to operate in peer-to-peer relationships with other vehicles through a vehicle area network (VAN).
Indeed, an autonomous vehicle would be a mist node and must be able to unequivocally operate in a disconnected mode. Mist nodes that can participate in a wireless fifth-generation (5G) network are likely to play an increasing role in taking on distributed workload across the elements. The massive capacity provided by 5G networks means that many more machines, objects, and devices can also be simultaneously interconnected. 5G is designed to support high gigabyte per second transfer rates and provide for ultra-low latency.
In a hierarchical communication flow, the mist compute nodes can provide data to the fog node or directly to the cloud node. In turn, the fog compute node can provide data to the cloud node.
The communication flows for advanced configurations can be more elaborate by providing for the following:
- Bidirectional communication flows
- Peer-to-peer communication flows
Figure 10-4 shows all of the communication flows. The complexity to instantiate each flow can be significant when taking into account data governance, data security, data privacy, and the overall orchestration of the distributed workload. But, being able to deploy AI models to operate singularly or in ensemble patterns across the distributed nodes and close to the data can provide unbridled deployment opportunities and can be expressed through the information architecture.

Figure 10-4: Communication flows
The ability to communicate peer-to-peer means that network traffic is not forced to unnecessarily traverse the communication map in a rigid up and down manner. Because all three elements (cloud, fog, and mist) have compute capability, predictions, scores, or signals from AI models can be transmitted without having to transmit individual data points unnecessarily.
A mist node could collect sensor readings and continuously run a model on each data point. Only when necessary would the mist need to send a score or a signal to the cloud or the fog. Additionally, the compute capability of the mist means that various data points can be aggregated prior to any transmission to reduce network traffic, or alternatively, all of the data points can be communicated with either in real time or via a planned lag to avoid peak communication times.
The flexibility in the paradigm should allow for quicker business decisions. In all likelihood, those business decisions are going to be automated decisions where the ability to react close to real time can bode well for an organization and create significant advantages in terms of competitiveness, cost savings, or improved safety.
The fog may be used to correlate data from multiple mist nodes for decision-making based on predictions, and the cloud may correlate data points from multiple fog nodes for decision-making that may be more diagnostic in nature.
The machine learning models at each node are reflective of the computing power, storage capabilities, and any inherent latencies. Each model is optimized to the node, and the node is reflective of the context for which the prediction is sought.
The overall topography is deliberately highly distributed. But individual application or system needs within the topography can certainly be centralized to an appropriate node. Not every application needs to scale, and not every application needs elastic computing; some workloads can be highly predictable and stable. For machine learning, the key is to tailor the models to fit the node.
Overall, the communication across the nodes is to foster interoperability and to foster ensemble modeling where predictions from other distributed nodes might be highly relevant in decision-making. The counter aspect of interoperability is to understand what is needed to provide resilience. Balancing the two provides for many options to support real-time, near real-time, and batch needs for machine learning in all application types.
By architecting the communication paths, the actual flight paths provide areas of interest to exploit machine learning in terms of activities for preflight, inflight, and postflight predictions.
Data Pipeline Flight Paths: Preflight, Inflight, Postflight
The preflight, inflight, and postflight flightpaths give an indication of when a machine learning model can be initiated relative to the flow of data. Three flights are identified as follows:
- Preflight: Predictions in the split moment before the flow begins
- Inflight: Predictions that occur during the flow and while the data is still regarded as being transient between a start point and an endpoint
- Postflight: Predictions that occur after the flow ends
At each flight stage lies the opportunity to perform machine learning and the means to predict or trigger an appropriate signal (see Figure 10-5). Preflight data, or source data, may be in-memory or persistent data. A preflight prediction might seek to understand the quality of the source data and potentially interpolate any missing values prior to sending the data. A preflight model may also determine that transmitting data is unwarranted and hold back the data.
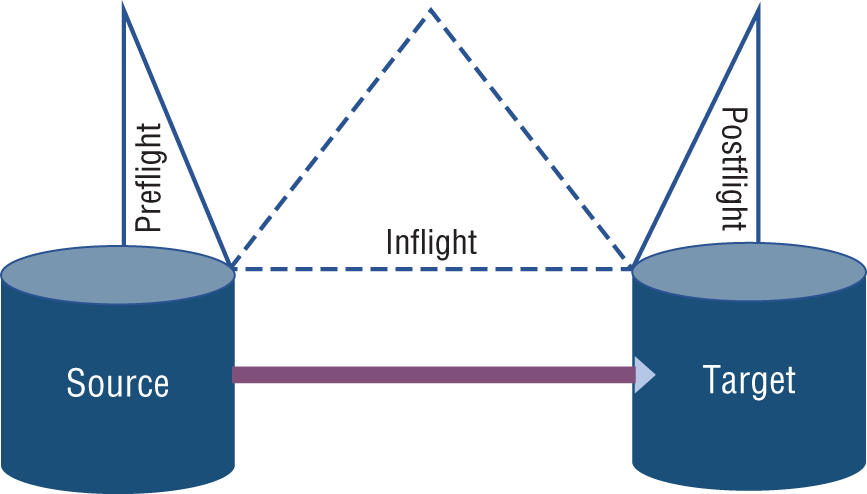
Figure 10-5: Flight paths for model execution
Inflight prediction occurs while the data is transient between begin and endpoints. Inflight prediction offers closer to real-time prediction and decision-making. Most IoT data is streamed, and IoT data is a prime candidate to have inflight predictions infused into the transferring of data. Inflight prediction can allow a model to uncover potential anomalies in the data so that other processing events can be triggered in a timely manner. Inflight prediction also accommodates proactive business decision-making.
Postflight prediction occurs at the target. The target may be in-memory or persistent data. Postflight data affords the most comprehensive models but at a potential cost of latency.
At each flight stage, data can be correlated with other data to extend features that are used with machine learning. Depending on the technology used for inflight processing, the data may be multicast to many targets. For example, a fog node can multicast to mist nodes, or a fog node can multicast to each cloud node. Multicasting is the distribution of data that occurs simultaneously to multiple endpoints and is not serialized.
The flights can occur across the cloud, fog, and mist nodes as well as within the cloud, fog, or mist. Therefore, the flight paths can be interzonal or intrazonal. The types of data held in each node place a different impact on data management.
Data Management for the Data Puddle, Data Pond, and Data Lake
Data management within the data topology can include operational data stores as well as other data stores to encompass advanced analytics such as the data puddle, the data pond, and the data lake. The puddle, pond, and lake have discrete analytic uses and can support discrete capabilities.
The data puddle is characterized by the predominant use of in-memory and flash storage media. Data tends to be raw sensor data, and the machine learning models tend to be primitive in nature and are also restricted by the availability of data to make certain predictions or assertions.
The data pond is characterized by the ability to handle raw sensor data, structured data, and limited unstructured data. The machine learning models are broader when compared to the data puddle. Improved storage capability accommodates reasonable amounts of historical data.
The data lake is characterized by the ability to handle any data type and provide meaningful and contextual data to a mixed and broad set of end-user needs and machine needs, too. The data lake can also address the needs of delta lakes that seek to provide alternative levels of data consistency. The machine learning capabilities extend to all forms of advanced analytics, including predictive, diagnostic, prescriptive, sensemaking, cognitive, augmented intelligence, and AI.
For a manufacturer, examples of data that may feed the mist's data puddle include the following: localized ambient temperature, localized humidity, roller speeds, thermal images, vibration (seismic) activity, acoustic sound waves, identifiers and parts associated with an assembly or a subassembly, an operator, a shift, measures that may be taken in time increments (e.g., every second), measures that may be taken in length increments (e.g., every 30 centimeters/one foot), the recording of a transaction, etc.
Examples of data that may be used to feed the fog's data pond for a manufacturer include data sent from mist compute nodes, ambient temperature outside a manufacturing plant, humidity outside a manufacturing plant, lighting conditions, manufacturing schedule for material and resources, motion detection, etc.
A manufacturer may use the cloud's data lake for data sent from mist and fog compute nodes, bills of lading, bills of material, maintenance reports for plant machinery, warranty claims against shipped products, etc.
Conversely, a social services agency might use the data puddle to predict activities during a site visit, and the data pond may be used to perform predictions during regular intake or eligibility processes. The data lake may be used to predict citizen outcomes by performing longitudinal assessments.
In viewing the needs of an organization, the machine learning models may be accompanied by descriptive analytics as well, but all analytics need to be placed within the context of the organizational needs, the content of the data, and the needs of the user or machine.
Driving Action: Context, Content, and Decision-Makers
Harold Leavitt's 1964 paper, “Applied Organization Change in Industry,” introduced a four-part model for interactions within an organization.
- Structure: How people are organized
- Tasks: How people perform their work
- People: The individuals who are tasked to perform work
- Technology: Tools that people use to conduct work
Nowadays, the model is commonly condensed into three parts: people, process, and technology. How people should perform their work and what work they should perform are still critical organizational questions. With increased levels of automation through AI, machines can be added to the people aspect so that people can be further generalized and recast as decision-makers. The generalization of decision-maker, therefore, refers to either a person or a machine. Decision-making is an activity that can be collaborative between people, between machines, or between people and machines.
Processes help decision-makers work better. Processes define and standardize work, preventing people from reinventing the wheel every time a task is begun and allowing for machines to work in a predictable manner.
Technology can help decision-makers work faster and smarter. Business outcomes need to be accomplished in a manner that is faster, more efficient, and better than with an older version of the technology. But questions can arise about the need to become faster, to be more efficient, to be better.
If organizations are not fast enough, additional automation from machine learning should be sought. Machines would then act as the decision-maker and be further supported by processes and technology. If organizations are not sufficiently efficient, then seeking the means to optimize tasks and processes can further be explored—processes would need to leverage additional utility from any decision-makers as well as technology. If organizations are not being innovative and creating new value (being better), then rethinking the use of technology along the lines of hyper-distributed computing models using cloud, fog, and mist computing can provide new opportunities—technology becomes the means to provide new methods for processes and decision-makers.
While broader IT themes can be aligned to decision-makers, processes, and technology, data-centric discussions around machine learning can be centered on the topics of context and content, as well as decision-makers. As shown in Figure 10-6, context, content, and decision-makers are used to help drive prediction, automation, and optimization for data-intensive work activities.
- Context: Alignment of machine learning with business goals, funding, politics, culture, technology, resources, and constraints
- Content: Subject-matter objectives, document and data types, volume, existing structure, governance, and ownership
- Decision-makers: Audience, collaboration, tasks, needs, information-seeking behavior, and experience
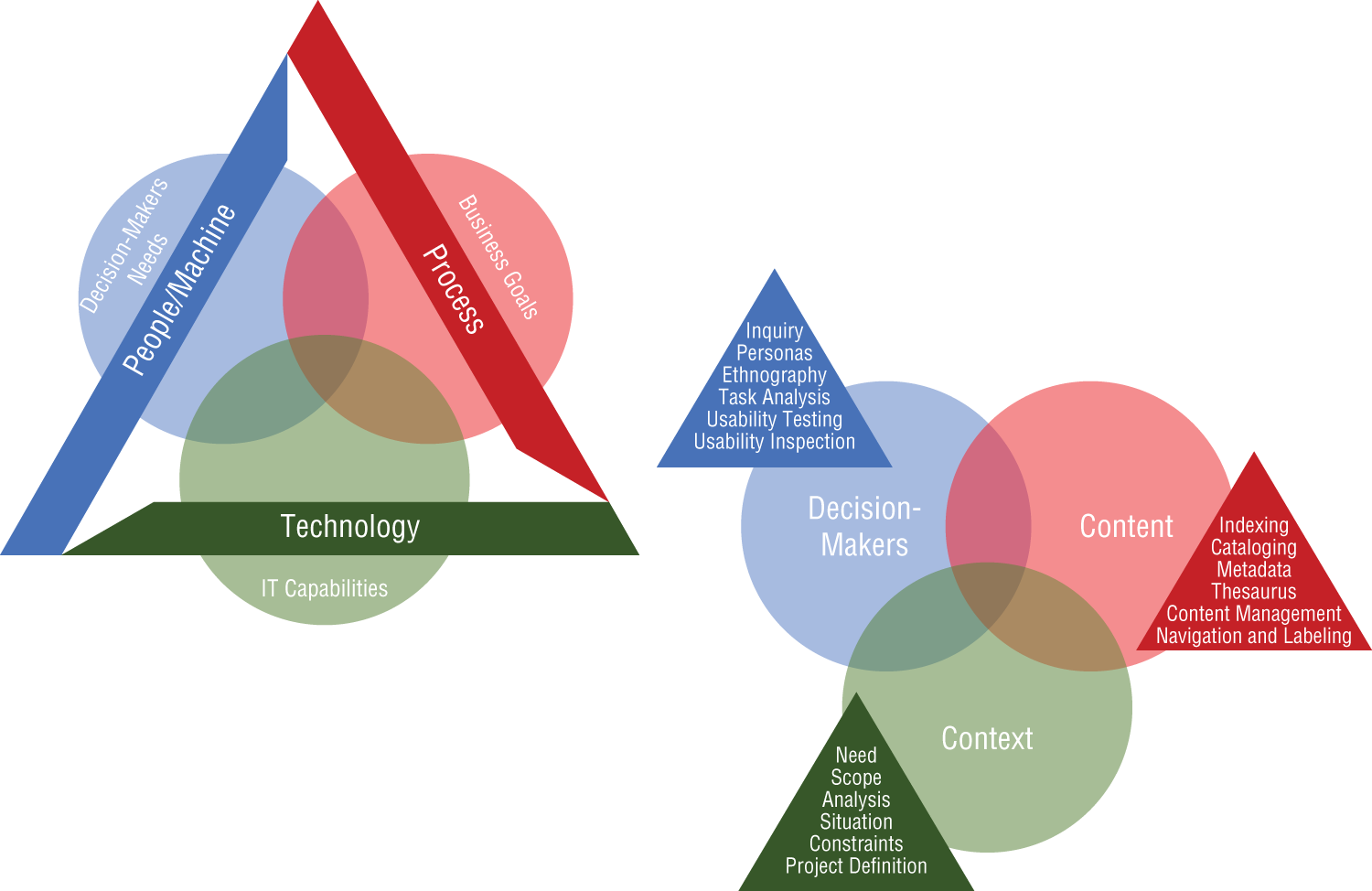
Figure 10-6: Driving prediction, automation, and optimization
While the use of a given technology and any newly adopted business processes are all susceptible to future change, the context-content-decision-makers paradigm is sufficiently acute to be directly associated with a given point in time. As such, while an outcome is within the bounds of reasonableness, the outcome itself may be something that is not repeated in the same way. This is an inherent by-product of using continuous learning with machine learning, addressed earlier in this chapter.
The basis for using machine learning is that it provides an ability to identify and react to patterns and not rules. While a pattern may span time, a pattern may alternatively be anchored to a single point in time.
Content is highly volatile in terms of accumulated knowledge. The discussion of statistics in Chapter 8, “Valuing Data with Statistical Analysis and Enabling Meaningful Access,” included differences between a sample set and a population set. While a population is always complete at a given moment in time, the population set in many business scenarios is subject to an impending change.
The content associated with a given point in time is not likely to be the same as the content associated with a different point in time. Aspects of past, present, and future provide for a shifting lens. What is the future becomes the now, and the now becomes the past. The content relative to the past, present, and future is time-oriented to a single point in time. Past, present, and future impact context too. What a cohort or a given individual is likely to do (the future) is quite different than what a cohort or a given individual has done (the past). The situation is further compounded by what a given cohort or a given individual is currently doing (the present).
Context is attributable to a task at hand and frames the rationale for gathering content and even sets the validity of participation by decision-makers. While people-process-technology looks at addressing decisions over time, context-content-decision-makers look at addressing a decision for a point in time. Even if a decision were to change over time, the ability to ensure that a decision is appropriate for a point in time is critical.
Keep It Simple
When building and deploying a data topology, remember that the data topology is likely to evolve over time. Working to overcome any inherent weaknesses associated with your data topology should be part of a long-term plan for success. First and foremost is an understanding of whether a data topology is being represented within your organization as a concept or part of a fleshed-out information architecture.
The data zones must be able to support over-time and point-in-time needs, which means that the data must be well organized and be to practical extents immutable so that scenarios can be reconstructed—for which OpenScale can be meaningfully leveraged.
Although sensitive data, data privacy, and data security can all be addressed in the context of an information architecture, these topics can still be challenging for a comprehensive enterprise deployment. An aspect of establishing a leaf-level data zone is to focus on simplifying data sensitivity, data privacy, data security, and even data governance at the expense of adding another copy of the data that may on the surface appear redundant or a replica. Simplification is also complementary to providing a hyper-personalized dataset to support the needs of any decision-maker (person or machine).
Consider a raw data zone that contains both sales data and human resource data. In most situations, it would be reasonable to expect that a sales analyst would want to consume only sales data and not the human resource data. On the other hand, a human resource analyst is likely to solely focus on the human resource data. In terms of the two analysts, their activities are not heavily intermixed or interlocked.
However, when combining human resource data with sales data to track employee performance, there could be a valid reason to comingle the data. Comingled or correlated data is likely to be highly sensitive, requiring additional controls. How best to apply security for any correlated data would remain an important task to resolve, especially as the correlated data may flow into and across other data zones. Separating data into data zones that can be overlaid with straightforward security profiles can aid protection and also mean that machine learning models only consume relevant features.
Transitive closure was initially discussed in Chapter 8 with the Eminem example. The issue of transitive closure is how the use of nondemocratized data can pose significant security challenges. Transitive closure could come into a situation where multiple tables or datasets need to be accessed and, depending upon the privileges of what data can be visible and by whom, means that any activity associated with data discovery can equate to a scenario of data vulnerability. See Figure 10-7.
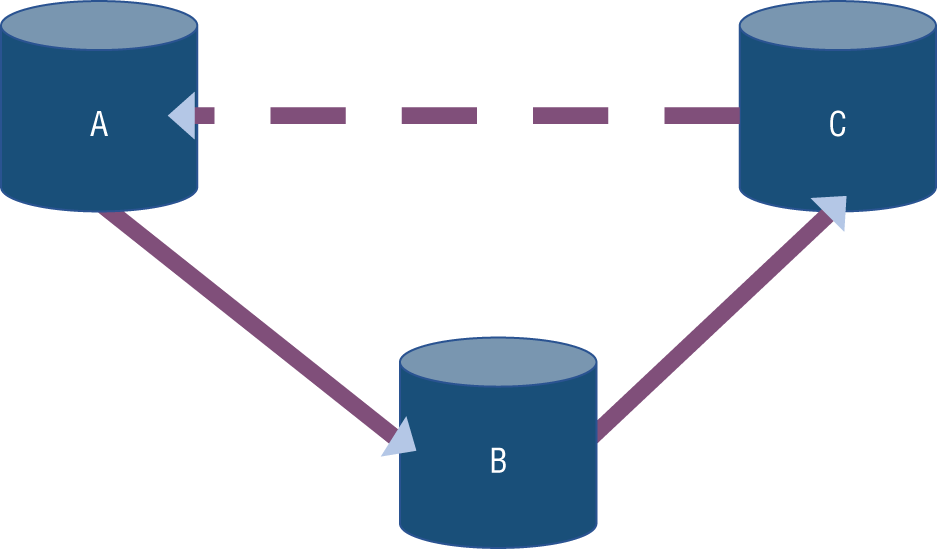
Figure 10-7: Transitive closure and access privileges
In Figure 10-7, if the data from dataset A can be matched against data from dataset B, which in turn can be matched against the data in dataset C, then A and C can be asserted to be equivalent even if the matching logic is insufficient to yield a direct match against datasets A and C.
If a user does not have permission to see the data in dataset B, should that user be allowed to know that A and C have equivalency, especially if the outcome is advantageous to the organization? Beyond securing access privileges to the datasets, the privileges would need to carry through into any indexing technology.
Within the context of machine learning, machine learning is a subfunction of all the possible functions that consume data to achieve an outcome. Ultimately, the data zones need to be placed in the frame of context, content, and decision-makers.
Before trying to understand the data in the context of an information architecture, a formal approach for establishing a data topology must be set in place. The purpose of each data zone should be deliberate and should not be construed as being arbitrary. The use of data zones should serve to foster a sense of simplicity within the overall information architecture.
A data topology is a method and approach for classifying and clustering data coupled with all the essential data flows exposed. The resulting outcome from a data topology must attempt to create a zone map that is sustainable over time and one that should be unaffected by the continuous change of data characteristics that come from volume, variety, velocity, veracity, and perceived value. Any continuous change should not result in the loss of affinity between content and context. Protecting affinity may require the need to silo certain aspects of the data.
The Silo Is Dead; Long Live the Silo
Mentioning a data silo in negative terms is likely to be received with cheers. The dastardly silo, a blight to progress and momentum. Bah humbug!
In the nomenclature of a data topology, data is literally organized as silos. However, unlike the negative silo, the silos of the data topology are intended for planned interoperability through design and not by happenstance. The human body can be used analogously (see the sidebar “The Body as a Myriad of Silos”) to highlight the positive aspects of establishing specialized silos that are designed with interoperability in mind.
Each nonleaf zone and leaf-level zone in the data topology promotes a level of purposeful isolation, redundancy, and duplication. Zones are directly used to promote agility and flexibility—for the business and for IT developers—but are established at the expense of creating silos. Silos are also paramount to the ideas behind managing a data value chain: keeping the raw data zone separate from the refined data zone and separate from personalized data zones.
Singularly, the means to address and apply interoperability, a concept that is manifest through the data flows of the data topology, is what can separate good silos from bad silos. Silos are often thought of as being in a closed environment that cannot readily participate with anything that is external. But if a silo is deliberately designed to foster accessibility through integration or interoperability, the silo can become a technique of leverage and a tangible asset. Only when interoperability with data is a core discipline can an organization become agile in more than just name.
On a diagram, a data flow is normally illustrated as a line. Potentially, the line is also given an arrowhead to indicate a direction. Literally, mastering lines is one of the keys to successfully establishing and deploying an information architecture. A diagram is likely to contain more lines than any other graphical symbol, so mastering how each line can be supported is an imperative for any squad. For example, even a traditionally styled high-level conceptual diagram, as shown in Figure 10-8, contains more lines than the other symbols. In an actual deployment, you'll find the actual number of lines will significantly grow.
Figure 10-8: A proliferation of lines serves to highlight the need for line management as a formal discipline.
A line is likely to hold true even if the underlying technology or data payloads are subject to change, so line mastering must include the use of agile and adaptive processes. For simplicity within a data topology and an information architecture, separate diagrams should be used to decompose any line. By removing technology overlays from lines, you can start to create diagrams that are more stable over time.
Commonly, lines across a data topology or information architecture may use a disparate set of technologies. For example, you may decide to use Change Data Capture technologies to move committed business transactions, streaming technologies for IoT feeds, event queues, message queues, bulk loads, micro-batches, and even software products such as Apache Spark, Apache Kafka, Apache Nifi, IBM Streams, IBM DataStage, and so on.
The design and creation of data silos—if planned, managed, and interoperable—will provide you with a corporate advantage and not a disadvantage for your information architecture. Realistically, the advantage is predicated on your mastering the lines that connect each silo: the data pipelines and flows whether preflight, inflight, or postflight. Understanding the data flows begins with building a taxonomy for the data topology.
Taxonomy: Organizing Data Zones
A data topology for an information architecture can be expressed via a taxonomy. The root layer expresses the scope and boundary of the data topology. Multiple roots can exist within an enterprise or the ecosystem of the enterprise. When multiple root zones exist, a meta-zone model can be established to describe the intent and purpose of each of the multiple root zones. This can be especially useful if there are any overlaps between root zones.
The ecosystem of an enterprise may include outside partners and stakeholders and their respective enterprises. Establishing a root zone from the ecosystem perspective can provide for a broader holistic view of the data that the organization needs and can use to achieve higher levels of benefit.
Associated with the data topology root is a definition of the scope and the intended boundary. The root zone should be absent of any physical data store. The root zone is an aggregate zone. The root establishes the theoretical limit of knowledge for the analytical environment and models: the boundary of what is knowable.
The root zone is not limited to the natural boundary of the organization. The root zone can indeed encompass all operational, nonoperational, and analytical data zones but can fully encompass the enterprise. Additionally, the root zone can encompass the ecosystem that may include vendors, partners, etc.
The root zone can also contain any other type of data that can be identified and zoned, such as third-party data, social media, weather data, etc. What is knowable is critical to building a fully featured model.
In Figure 10-9, styles A and B reflect alternative representations and show the use of establishing a subzone. Below the root zone in style A are six different nonleaf zones: weather (from an outside source), operational data (internally sourced), a data lake, two data ponds, and a data puddle. Style B clusters the data lake, the data ponds, and the data puddle below a common nonleaf zone for analytics. The lake, ponds, and puddle are now subzones of the analytics nonleaf zone. Overall, style A and style B both reflect zone maps.
Figure 10-9: Taxonomic representation
Figure 5-11 in Chapter 5 showed a third style for representing zones that used a box-in-box style to represent the root zone and nonleaf zones. The hierarchical style and the box-in-box styles can be intermixed.
As virtualized access services or technologies may be used within a zone map, Figure 10-10 illustrates a dashed-line grouping technique that can be especially useful when the subzones are known to exist in different locations or they make use of multiple technologies.
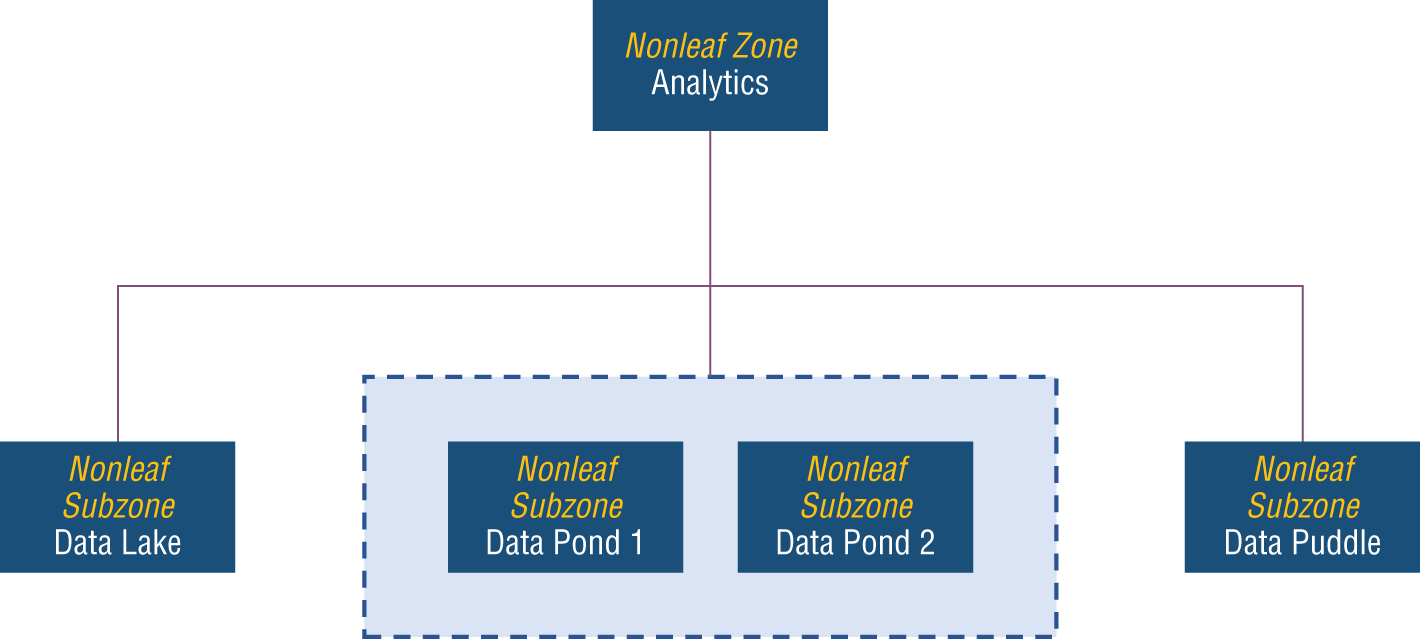
Figure 10-10: Virtualized data zones
The two data ponds in Figure 10-10 are likely to exist in separate fog nodes, but the data scientist might be interested to know that the information architecture has been established with a virtualization capability so that both ponds can be accessed as a singularity for data science activities.
As stated, the leaf zone should be the zone that identifies a specific instantiation of data. Leaves should be established to help drive simplicity in managing data. Reasons to establish an independent leaf zone can include ensuring privacy, providing security, offering personalization, addressing democracy, adding curation, incorporating ingestion, improving refinement, provisioning sandboxes, establishing exploration and discovery, etc.
Other zones may be created for distinct types of data, such as video, audio, and images. Persisted videos may have a series of complex security requirements for viewing. For example, a video of a hospitalized patient may reveal the patient's name and date of birth on a visible wristband and serve to violate specific medical regulations. Here separate zones can be established to simplify security with one zone set to incorporate videos without identifiable personal information and a different zone for videos that contain personally identifiable information. Deep learning can be used to determine whether a video contains identifiable information and route inflight videos to the correct leaf zone.
The dashed-line technique can further delineate hybrid cloud and multicloud approaches to data management, where data is also kept physically separated to address regulatory or compliance needs.
The use of data zones should result from a deliberate thought process to develop a cohesive classification approach based on subject areas for managing data in an information architecture. The number and type of data zones should be aligned to the business and be defined in a manner that illustrates how business value is to be derived.
Aligning a data zone to value can help eliminate any arbitrary data storage. All data stores should have an identified owner in the unified data governance function. The following is a list of criteria to help determine when to use subzones within a zone:
- A leaf-level data zone is easier to manage if there is only one underlying technology.
- To avoid complicated security models or a high mixture of redacted/obfuscated data with nonredacted/obfuscated data, consider the creation of separate subzones.
- Storing duplicate or redundant data is not an issue if managed, and the data governance facility provides the appropriate level of visibility.
- Data sharing is not the driving force in decision-making for a data zone. Any opportunity for data sharing is a derivative of a zone map. Therefore, decision-making precedes data sharing in zonal decisions.
- The impetus behind the creation of a data zone is to ultimately provide a user with the wealth of information needed to carry out their analytic responsibilities with a means that is as simple as possible.
- Users should be grouped into communities of interest to ascertain like needs and data sharing opportunities.
- A community of interest is permitted to contain only a single decision-maker.
- Each data zone should be aligned to one or more communities of interest.
- A community of interest may exclusively contain internal users, external users, or machines.
- Subzones can be created to work with or workaround firewall issues.
- Any data is subject to levels of granularity and representation.
- Subzones can be created to accommodate the needs of granularity or representation.
- All data flows to populate a data zone must be predetermined to minimize any side effects and to avoid undesirable outcomes.
- Not all data is created equal, and not all data zones are created equal. So, apply a zone toward a fit-for-purpose paradigm.
- Zones represent an area of specialization.
- Always strive for holistic (overall) simplicity.
All leaf zones must be instantiated in some capacity and fit into an overall platform or solution.
Capabilities for an Open Platform
An information architecture (IA) for AI is ultimately an aggregation of integrated (cohesive and associative) artifacts. The information architecture consists of a number of models, one of which is the data topology and includes the zone maps and data flows.
In developing solutions using machine learning, the practice is not defined solely by a series of algorithms that conform to a given syntax. For example, the following code snippet is just one aspect of a machine learning activity that needs to be addressed by a data scientist and other IT and business professionals responsible for managing a production environment:
#apply a light gradient boost modelimport lightgbm as lgbtrain_data = lgb.Dataset(x_train, label=y_train)#define parametersparams = {'learning_rate':0.001}model = lgb.train(params, train_data, 100)y_pred = model.predict(x_test)for i in range(0,185):if y_pred[i]>= 0.5:y_pred[i] = 1else:y_pred[i] = 0
Machine learning can involve many activities, including the following:
- Data preparation
- Ingesting data
- Exploring data
- Cleansing data
- Model development
- Engineer features
- Train
- Tune and test
- Deployment
- Publish
- Consume
- Monitor
The activities listed previously culminate in the following tenets:
- Accessibility: Data is ready for consumption by machine learning models.
- Trustworthiness: Higher levels of data quality are being realized, data provenance has been added to all data assets, and all AI outcomes can be adequately explained. AI is not regarded as a black-box event.
- Resiliency: An AI environment can operate and perform at scale and is always available.
- Measurability: All activity can be monitored and measured.
- Promoting innovation through evolution: Outcomes are delivered, and the outcomes continually serve to provide a positive impact on the business.
A deployed solution or platform for an information architecture that supports AI should probably be unified around open source assets with a philosophy of embracing hybrid data management. For a modern environment that leverages cloud, fog, or mist computing, a solution should also seek to take advantage of a microservices-based architecture for additional agility and scalability. An open source solution also means that many capability extensions can be incorporated without the need to scrap and rework major portions of the solution.
Core capabilities of a given platform would provide an affinity to the AI ladder that was outlined earlier in the book, namely, the means to collect, organize, analyze, and infuse data for purposes of providing business benefit through AI.
- Collect data of any type regardless of where the data is physically sourced.
- Organize data into trusted and curated digital assets that are business-aligned.
- Analyze data in smarter ways with machine learning and deep learning.
A deployed solution should also be able to augment AI with additional analytic capabilities so as to provide the means to develop complete insight for any decision-maker. Analytic capabilities should address the following:
- Descriptive analytics
- Diagnostic analytics
- Predictive analytics
- Prescriptive analytics
- Sensemaking
- Machine learning models
- Deep learning models
AI itself is an aggregate analytic capability that consists of one or more of the following characteristics:
- Deep learning
- Predictive analytics
- Machine learning
- Translation
- Classification and clustering
- Information extraction
- Natural language processing
- Speech to text
- Text to speech
- Expert systems
- Planning, scheduling, and optimization
- Robotics
- Image recognition
- Machine vision
A deployment in support of AI should include the following:
- Hybrid data management to manage multiple data store technologies
- Unified data governance to ensure planning, oversight, and control over the management of data in the data topology
- Relationships to schema designs, though not the schema designs themselves
- The identification of all technologies involved in exercising the data flows and managing transient and persistent data
- The identification of all technologies involved in providing a secured environment that can ensure privacy and confidentially, inhibit unauthorized access, and provide for logging and auditing of all activities
- The policies and standards to control the analytic environment
- The identification of tools to support all analytics, including self-service tools
- The means to catalog all assets for purposes of discovery as separate from other data governance provisions
- Guidance as to acceptable data quality for purposes of reducing the risk associated with decision-making as a result of cultivating insights
Other areas of a deployment should incorporate the following:
- Search engines
- Cognitive classification
- Inference engines
- File retrieval
- Data discovery
- Data retrieval
- Naming conventions
- Indexing methods
- Registries
- Ontologies
- Taxonomies
- Vocabularies for metadata management
- Data standards
- Middleware
- Data vaults
- Format standards
- Change control
As your organization begins to accelerate its transformations to predict and reshape future business outcomes, attention will gravitate toward higher-value work. The need to automate experiences through AI will grow ever more critical. To implement AI successfully, across an open platform, the platform should help with supporting the data topology to address data complexity, aid with applying collaborative data science, and foster trustworthiness in the outcome from each and every model, every time.
Summary
The Ladder to AI is a progressive concept toward smarter data science by helping organizations understand that they cannot leapfrog reasonable practices for basic and advanced data analytics by going directly to AI. IA for AI is a progressive architecture to build out analytic capabilities that include AI and deep learning. In essence, there is a deep sense that one reaches the ability to enact AI through a prescriptive journey: a journey to AI.
Some organizations might be tempted to rush into AI before reaching a critical mass of automated processes and mastering structured analytics. IA for AI is a means to avoid impenetrable black-box systems, cumbersome cloud computational clusters, and a vast plethora of redundant open source toolkits.
By building on a good analytic foothold, organizations should be able to make breakthroughs in complex and critical areas by layering in AI capabilities. But without basic automation, strategic visions for solving complex problems could prove to be elusive. Only after processes critical to achieving an efficient ingestion and data distribution (data flows) mechanism exist can AI be used to yield insights that all organizations are likely to demand.
Organizations do not need to build a repository of pure golden records or establish a definitive and declarative source of truth. Absolute precision in data accuracy is not a de facto standard; the diligent avoidance of fixable data garbage, however, should be a requirement. A schema-less-write approach to data management should not be an excuse for organizational laziness in the data management of an analytical environment within an information architecture.
AI is useful for analyzing a wide set of data and for incorporating diverse data sources such as social media, call center notes, images, open-ended surveys, videos, and electronic body language. The better the data is organized, the quicker an organization can realize value. The use of AI can beget organizational change, and an organization must remain ready and able to change in order to maintain relevance.
Successful organizations on the AI ladder do not skip the basics and understand the need to invest the time, money, and energy to be prepared with sufficiently automated and structured data analytics to maximize the benefit of AI.
This chapter discussed some of the challenges with the software development lifecycle for developing machine learning models, especially in terms of testing models. IBM's OpenScale can assist with testing and evaluating the performance and explainability of a model in production.
For developing an information architecture for AI, a backdrop for a heavily distributed architecture was discussed that involved cloud, fog, and mist computing. Incorporating a rich deployment capability into the information architecture means that applications infused with AI can provide capabilities for systems of engagement and aid in IoT applications for real-time event processing that harnesses machine learning.
Correlating analytical environments to the capabilities of the cloud, fog, and mist maps additional opportunities for an information architecture to bring AI closer to the data. The distributed computing model provides a means to introduce resiliency and continuity into an information architecture while still providing AI-infused competences. The flight paths further offer insight as to when to use AI to act on data.
Data management and the methodical use of siloed data stores can help to maximize the opportunity to serve data in a meaningful way to users across any specialized need that may arise. Provisioning data to users should use the most appropriate database technology, whether that is a graph database, a relational database, a document store, and so on.
The taxonomy for organizing data zones also showed how to address virtualization and federation. Pulling everything together is the need for a technology platform that supports collecting, organizing, analyzing, and infusing AI models with data and applications together.
The journey toward smarter data science incorporates the need to establish an information architecture for artificial intelligence—an IA for AI. For your organization to begin succeeding with enterprise-grade data and AI projects, multicloud deployment models with cloud, fog, and mist computing will be essential. By following the prescriptive approach outlined by the AI ladder, organizations can be prescriptive in their model deployments. As data is digitized, it means that a copy can be taken without the fear of loss or degradation. Organizations need to take advantage of the fact that copying data doesn't suffer from a generational loss to provision data in a meaningful and manageable way across a zone map—though applying a transformation or exercising a compression algorithm might result in some data loss.
Change is an inevitable consequence of life for people and for organizations. While change cannot be avoided, how we set ourselves up to respond to change can be premeditated. Many aspects of our organizational IT work can be designed to be adaptive in nature, rather than continuously reworked, reintegrated, and redeployed. Creating zones for a data topology should allow for adaptation as much as possible. So too should our work in designing data assets and machine learning models. Embracing the notion of the silo as being paramount to addressing specialization within the organization is critical, as well as becoming knowledgeable in all aspects of data for business use.