
We've looked at the definition of performance, measuring performance complexity, and the different tools for measuring program performance. We've also gained insights by profiling code for statistics, memory usage, and so on.
We also saw a couple of examples of program optimization to improve the time performance of the code.
In this section, we will take a look at common Python data structures and discuss what their best and worst performance scenarios are and also discuss some situations of where they are an ideal fit and where they may not be the best choice.
Lists, dictionaries, and sets are the most popular and useful mutable containers in Python.
Lists are appropriate for object access via a known index. Dictionaries provide a near-constant time lookup for objects with known keys. Sets are useful to keep groups of items while dropping duplicates and finding their difference, intersection, union, and so on in near-linear time.
Let us look at each of these in turn.
Lists provide a near constant time O(1) order for the following operations:
However, lists perform badly (O(n)) in the following cases:
- Seeking an item via the
inoperator - Inserting at an index via the
.insertmethod
A list is ideal in the following cases:
- If you need a mutable store to keep different types or classes of items (heterogeneous).
- If your search of objects involves getting the item by a known index.
- If you don't have a lot of lookups via searching the list (item in list).
- If any of your elements are non-hashable. Dictionaries and sets require their entries to be hashable. So in this case, you almost default to using a list.
If you have a huge list—of, say, more than 100,000 items—and you keep finding that you search it for elements via the in operator, you should replace it with a dictionary.
Similarly, if you find that you keep inserting to a list instead of appending to it most of the time, you can think of replacing the list with deque from the collections module.
Dictionaries provide a constant time order for:
However, dictionaries take slightly more memory than lists for the same data. A dictionary is useful in the following situations:
A dictionary is also ideal where you load a lot of data uniquely indexed by keys from a source (database or disk) in the beginning of the application and need quick access to them—in other words, a lot of random reads as against fewer writes or updates.
The usage scenario of sets lies somewhere between lists and dictionaries. Sets are in implementation closer to dictionaries in Python—since they are unordered, don't support duplicate elements, and provide near O(1) time access to items via keys. They are kind of similar to lists in that they support the pop operation (even if they don't allow index access!).
Sets are usually used in Python as intermediate data structures for processing other containers—for operations such as dropping duplicates, finding common items across two containers, and so on.
Since the order of set operations is exactly the same as that of a dictionary, you can use them for most cases where a dictionary needs to be used, except that no value is associated to the key.
Examples include:
- Keeping heterogeneous, unordered data from another collection while dropping duplicates
- Processing intermediate data in an application for a specific purpose—such as finding common elements, combining unique elements across multiple containers, dropping duplicates, and so on
Tuples are an immutable version of lists in Python. Since they are unchangeable after creation, they don't support any of the methods of list modification such as insert, append, and so on.
Tuples have the same time complexity as when using the index and search (via item in tuple) as lists. However, they take much less memory overhead when compared to lists; the interpreter optimizes them more as they are immutable.
Hence tuples can be used whenever there are use cases for reading, returning, or creating a container of data that is not going to be changed but requires iteration. Some examples are as follows:
- Row-wise data loaded from a data store that is going to have read-only access. For example, results from a DB query, processed rows from reading a CSV file, and so on.
- A constant set of values that needs iteration over and over again. For example, a list of configuration parameters loaded from a configuration file.
- When returning more than one value from a function. In this case, unless one explicitly returns a list, Python always returns a tuple by default.
- When a mutable container needs to be a dictionary key. For example, when a list or set needs to be associated to a value as a dictionary key, the quick way is to convert it to a tuple.
The collection module supplies high performance alternatives to the built-in default container types in Python, namely list, set, dict, and tuple.
We will briefly look at the following container types in the collections module:
deque: An alternative to a list container supporting fast insertions and pops at either endsdefaultdict: A sub-class ofdictthat provides factory functions for types to provide missing valuesOrderedDict: A sub-class ofdictthat remembers the order of insertion of keysCounter: Adictsub-class for keeping count and statistics of hashable typesChainMap: A class with a dictionary-like interface for keeping track of multiple mappingsnamedtuple: A type for creating tuple-like classes with named fields
A deque or double ended queue is like a list but supports nearly constant (O(1)) time appends and pops from either side as opposed to a list, which has an O(n) cost for pops and inserts at the left.
Deques also support operations such as rotation for moving k elements from back to front and reverse with an average performance of O(k). This is often slightly faster than the similar operation in lists, which involves slicing and appending:
def rotate_seq1(seq1, n):
""" Rotate a list left by n """
# E.g: rotate([1,2,3,4,5], 2) => [4,5,1,2,3]
k = len(seq1) - n
return seq1[k:] + seq1[:k]
def rotate_seq2(seq1, n):
""" Rotate a list left by n using deque """
d = deque(seq1)
d.rotate(n)
return dBy a simple timeit measurement, you should find that deques have a slight performance edge over lists (about 10-15%), in the above example.
Default dicts are
dict sub-classes that use type factories to provide default values to dictionary keys.
A common problem one encounters in Python when looping over a list of items and trying to increment a dictionary count is that there may not be any existing entry for the item.
For example, if one is trying to count the number of occurrences of a word in a piece of text:
counts = {}
for word in text.split():
word = word.lower().strip()
try:
counts[word] += 1
except KeyError:
counts[word] = 1We are forced to write code like the preceding or a variation of it.
Another example is when grouping objects according to a key using a specific condition, for example, trying to group all strings with the same length to a dictionary:
cities = ['Jakarta','Delhi','Newyork','Bonn','Kolkata','Bangalore','Seoul']
cities_len = {}
for city in cities:
clen = len(city)
# First create entry
if clen not in cities_len:
cities_len[clen] = []
cities_len[clen].append(city)A defaultdict container solves these problems elegantly by defining a type factory to supply the default argument for any key that is not yet present in the dictionary. The default factory type supports any of the default types and defaults to None.
For each type, its empty value is the default value. This means:
0 → default value for integers
[] → default value for lists
'' → default value for strings
{} → default value for dictionariesThe word-count code can then be rewritten as follows:
counts = defautldict(int)
for word in text.split():
word = word.lower().strip()
# Value is set to 0 and incremented by 1 in one go
counts[word] += 1Similarly, for the code which groups strings by their length we can write this:
cities = ['Jakarta','Delhi','Newyork','Bonn','Kolkata','Bangalore','Seoul']
cities_len = defaultdict(list)
for city in cities:
# Empty list is created as value and appended to in one go
cities_len[len(city)].append(city)
OrderedDict is a sub-class of dict that remembers the order of the insertion of entries. It kind of behaves as a dictionary and list hybrid. It behaves like a mapping type but also has list-like behavior in remembering the insertion order plus supporting methods such as popitem to remove the last or first entry.
>>> cities = ['Jakarta','Delhi','Newyork','Bonn','Kolkata','Bangalore','Seoul']
>>> cities_dict = dict.fromkeys(cities)
>>> cities_dict
{'Kolkata': None, 'Newyork': None, 'Seoul': None, 'Jakarta': None, 'Delhi': None, 'Bonn': None, 'Bangalore': None}
# Ordered dictionary
>>> cities_odict = OrderedDict.fromkeys(cities)
>>> cities_odict
OrderedDict([('Jakarta', None), ('Delhi', None), ('Newyork', None), ('Bonn', None), ('Kolkata', None), ('Bangalore', None), ('Seoul', None)])
>>> cities_odict.popitem()
('Seoul', None)
>>> cities_odict.popitem(last=False)
('Jakarta', None)You can compare and contrast how the dictionary changes the order around and how the OrderedDict container keeps the original order.
This allows for a few recipes using the OrderedDict container.
Let us modify the cities list to include duplicates:
>>> cities = ['Jakarta','Delhi','Newyork','Bonn','Kolkata','Bangalore','Bonn','Seoul','Delhi','Jakarta','Mumbai'] >>> cities_odict = OrderedDict.fromkeys(cities) >>> print(cities_odict.keys()) odict_keys(['Jakarta', 'Delhi', 'Newyork', 'Bonn', 'Kolkata', 'Bangalore', 'Seoul', 'Mumbai'])
See how the duplicates are dropped but the order is preserved.
An LRU cache gives preference to entries that are recently used (accessed) and drops those entries that are least used. This is a common caching algorithm used in HTTP caching servers such as Squid and in places where one needs to keep a limited size container that keeps recently accessed items preferentially over others.
Here we make use of the behavior of OrderedDict: when an existing key is removed and re-added, it is added at the end (the right side):
class LRU(OrderedDict):
""" Least recently used cache dictionary """
def __init__(self, size=10):
self.size = size
def set(self, key):
# If key is there delete and reinsert so
# it moves to end.
if key in self:
del self[key]
self[key] = 1
if len(self)>self.size:
# Pop from left
self.popitem(last=False)Here is a demonstration:
>>> d=LRU(size=5)
>>> d.set('bangalore')
>>> d.set('chennai')
>>> d.set('mumbai')
>>> d.set('bangalore')
>>> d.set('kolkata')
>>> d.set('delhi')
>>> d.set('chennai')
>>> len(d)
5
>>> d.set('kochi')
>>> d
LRU([('bangalore', 1), ('chennai', 1), ('kolkata', 1), ('delhi', 1), ('kochi', 1)])Since a key mumbai was set first and never set again, it became the leftmost one and got dropped off.
A counter is a subclass of a dictionary to keep a count of hashable objects. Elements are stored as dictionary keys and their counts get stored as the values. The Counter class is a parallel for multisets in languages such as C++ or Bag in languages such as Smalltalk.
A counter is a natural choice for keeping the frequency of items encountered when processing any container. For example, a counter can be used to keep the frequency of words when parsing text or the frequency of characters when parsing words.
For example, both of the following code snippets perform the same operation but the counter one is less verbose and compact.
They both return the most common 10 words from the text of the famous Sherlock Holmes Novel, The Hound of Baskervilles from its Gutenberg version online:
- Using the
defaultdictcontainer in the following code:import requests, operator text=requests.get('https://www.gutenberg.org/files/2852/2852-0.txt').text freq=defaultdict(int) for word in text.split(): if len(word.strip())==0: continue freq[word.lower()] += 1 print(sorted(freq.items(), key=operator.itemgetter(1), reverse=True) [:10]) - Using the
Counterclass in the following code:import requests text = requests.get('https://www.gutenberg.org/files/2852/2852-0.txt').text freq = Counter(filter(None, map(lambda x:x.lower().strip(), text.split()))) print(freq.most_common(10))
A ChainMap is a dictionary-like class that groups multiple dictionaries or similar mapping data structures together to create a single view that is updateable.
All of the usual dictionary methods are supported. Lookups search successive maps until a key is found.
The ChainMap class is a more recent addition to Python, having been added in Python 3.3.
When you have a scenario where you keep updating keys from a source dictionary to a target dictionary over and over again, a ChainMap class can work in your favor in terms of performance, especially if the number of updates is large.
Here are some practical uses of a ChainMap:
- A programmer can keep the
GETandPOSTarguments of a web framework in separate dictionaries and keep the configuration updated via a singleChainMap. - Keeping multilayered configuration overrides in applications.
- Iterating over multiple dictionaries as a view when there are no overlapping keys.
- A
ChainMapclass keeps the previous mappings in its maps attribute. However, when you update a dictionary with mappings from another dictionary, the original dictionary state is lost. Here is a simple demonstration:>>> d1={i:i for i in range(100)} >>> d2={i:i*i for i in range(100) if i%2} >>> c=ChainMap(d1,d2) # Older value accessible via chainmap >>> c[5] 5 >>> c.maps[0][5] 5 # Update d1 >>> d1.update(d2) # Older values also got updated >>> c[5] 25 >>> c.maps[0][5] 25
A namedtuple is like a class with fixed fields. Fields are accessible via attribute lookups like a normal class but are also indexable. The entire namedtuple is also iterable like a container. In other words, a namedtuple behaves like a class and a tuple combined in one:
>>> Employee = namedtuple('Employee', 'name, age, gender, title, department')
>>> Employee
<class '__main__.Employee'>Let's create an instance of Employee:
>>> jack = Employee('Jack',25,'M','Programmer','Engineering')
>>> print(jack)
Employee(name='Jack', age=25, gender='M', title='Programmer', department='Engineering')We can iterate over the fields of the instance, as if it is an iterator:
>>> for field in jack: ... print(field) ... Jack 25 M Programmer Engineering
Once created, the
namedtuple instance, like a tuple, is read-only:
>>> jack.age=32 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: can't set attribute
To update values, the _replace method can be used. It returns a new instance with the specified keyword arguments replaced with new values:
>>> jack._replace(age=32) Employee(name='Jack', age=32, gender='M', title='Programmer', department='Engineering')
A namedtuple is much more memory-efficient when compared to a class which has the same fields. Hence a namedtuple is very useful in the following scenarios:
- A large amount of data needs to be loaded as read-only with keys and values from a store. Examples are loading columns and values via a DB query or loading data from a large CSV file.
- When a lot of instances of a class need to be created but not many write or set operations need to be done on the attributes. Instead of creating class instances,
namedtupleinstances can be created to save on memory. - The
_makemethod can be used to load an existing iterable that supplies fields in the same order to return anamedtupleinstance. For example, if there is anemployees.csvfile with the columns name, age, gender, title, and department in that order, we can load them all into a container ofnamedtuplesusing the following command line:employees = map(Employee._make, csv.reader(open('employees.csv'))
Before we conclude our discussion on the container data types in Python, let us take a look at an important probabilistic data structure named Bloom Filter. Bloom filter implementations in Python behave like containers, but they are probabilistic in nature.
A bloom filter is a sparse data structure that allows us to test for the presence of an element in the set. However, we can only positively be sure of whether an element is not there in the set—that is, we can assert only for true negatives. When a bloom filter tells us an element is there in the set, it might be there—in other words, there is a non-zero probability that the element may actually be missing.
Bloom filters are usually implemented as bit vectors. They work in a similar way to a Python dictionary in that they use hash functions. However, unlike dictionaries, bloom filters don't store the actual elements themselves. Also elements, once added, cannot be removed from a bloom filter.
Bloom filters are used when the amount of source data implies an unconventionally large amount of memory if we store all of it without hash collisions.
In Python, the pybloom package provides a simple bloom filter implementation (however, at the time of writing, it doesn't support Python 3.x, so the examples here are shown in Python 2.7.x):
$ pip install pybloom
Let us write a program to read and index words from the text of The Hound of Baskervilles, which was the example we used in the discussion of the Counter data structure, but this time using a bloom filter:
# bloom_example.py
from pybloom import BloomFilter
import requests
f=BloomFilter(capacity=100000, error_rate=0.01)
text=requests.get('https://www.gutenberg.org/files/2852/2852-0.txt').text
for word in text.split():
word = word.lower().strip()
f.add(word)
print len(f)
print len(text.split())
for w in ('holmes','watson','hound','moor','queen'):
print 'Found',w,w in fExecuting this, we get the following output:
$ python bloomtest.py 9403 62154 Found holmes True Found watson True Found moor True Found queen False
Note
The words holmes, watson, hound, and moor are some of the most common in the story of The Hound of Baskervilles, so it is reassuring that the bloom filter finds these words. On the other hand, the word queen never appears in the text so the bloom filter is correct on that fact (true negative). The number of the words in the text is 62,154, out of which only 9,403 got indexed in the filter.
Let us try and measure the memory usage of the bloom filter as opposed to the Counter. For that we will rely on memory profiler.
For this test, we will rewrite the code using the Counter class as follows:
# counter_hound.py
import requests
from collections import Counter
@profile
def hound():
text=requests.get('https://www.gutenberg.org/files/2852/2852-0.txt').text
c = Counter()
words = [word.lower().strip() for word in text.split()]
c.update(words)
if __name__ == "__main__":
hound()And the one using the bloom filter as follows:
# bloom_hound.py
from pybloom import BloomFilter
import requests
@profile
def hound():
f=BloomFilter(capacity=100000, error_rate=0.01)
text=requests.get('https://www.gutenberg.org/files/2852/2852-0.txt').text
for word in text.split():
word = word.lower().strip()
f.add(word)
if __name__ == "__main__":
hound()Here is the output from running the memory profiler for the first one:
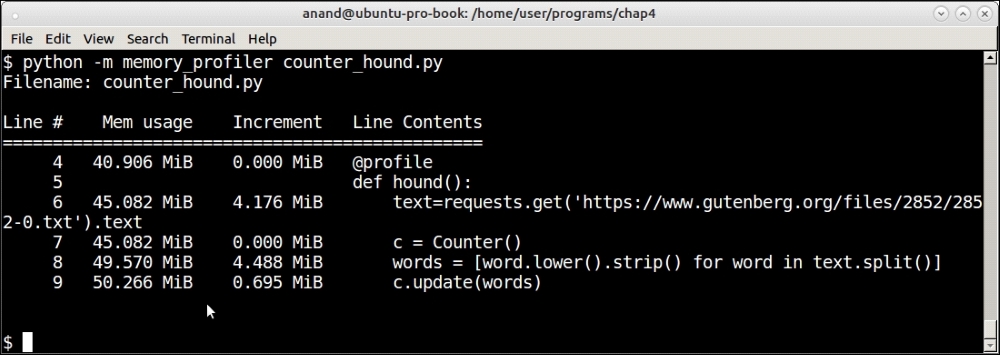
Memory usage by the Counter object when parsing the text of The Hound of the Baskervilles
The following result is for the second one:
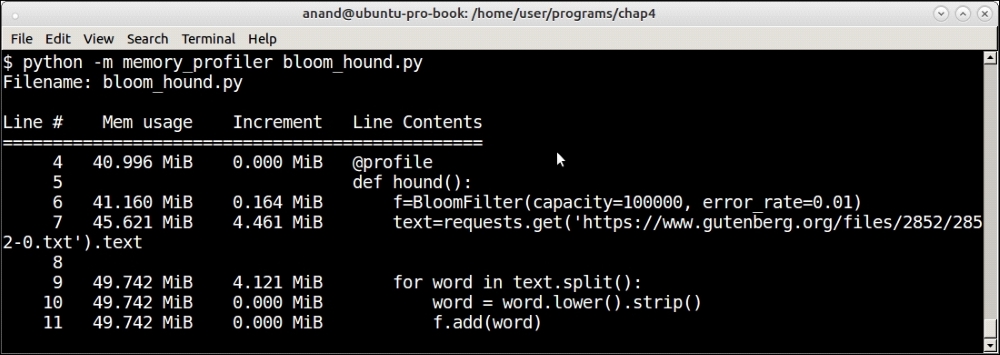
Memory usage by the Bloom filter for parsing text of The Hound of the Baskervilles
The final memory usage is roughly the same at about 50 MB each. In the case of the Counter, nearly no memory is used when the Counter class is created but close to 0.7 MB is used when words are added to the counter.
However, there is a distinct difference in the memory growth pattern between both these data structures.
In the case of the bloom filter, an initial memory of 0.16 MB is allotted to it upon creation. The addition of the words seems to add nearly no memory to the filter and hence to the program.
So when should we use a bloom filter as opposed to, say, a dictionary or set in Python? Here are some general principles and real-world usage scenarios:
- When you are fine with not storing the actual element itself but only interested in the presence (or absence) of the element. In other words, where your application use case relies more on checking the absence of data than its presence.
- When the size of your input data is so large that storing each and every item in a deterministic data structure (as a dictionary or hashtable) in memory is not feasible. A bloom filter takes much less data in memory as opposed to a deterministic data structure.
- When you are fine with a certain well-defined error rate of false positives with your dataset—let us say this is 5% out of 1,000,000 pieces of data—you can configure a bloom filter for this specific error rate and get a data hit rate that will satisfy your requirements.
Some real-world examples of using bloom filters are as follows: