
LEARNING OBJECTIVES
To appreciate various dimensions along which approaches to reuse may be classified
To be aware of a number of composition-based and generation-based reuse techniques
To see how reuse can be incorporated into the software life cycle
To recognize the relation between reuse and various other software engineering concepts and techniques
To understand the major factors that impede successful reuse
Note
If we estimate the programmer population at three million people, and furthermore assume that each programmer writes 2 000 lines of code per year, 6 000 million lines of code are produced each year. There is bound to be a lot of redundancy in them. Reuse of software or other artifacts that are produced in the course of a software development project, may lead to considerable productivity improvements and, consequently, cost savings. This chapter gives an overview of reuse issues. Chapters 18 and 19 discuss two reuse technologies in more details: components and services.
Meanwhile Daedalus, tired of Crete and of his long absence from home, was filled with longing for his own country, but he was shut in by the sea. Then he said: 'The king may block my way by land or across the ocean, but the sky, surely, is open, and that is how we shall go. Minos may possess all the rest, but he does not possess the air.' With these words, he set his mind to sciences never explored before, and altered the laws of nature. He laid down a row of feathers, beginning with tiny ones, and gradually increasing their length, so that the edge seemed to slope upwards. In the same way, the pipe which shepherds used to play is built up from reeds, each slightly longer than the last. Then he fastened the feathers together in the middle with thread, and at the bottom with wax; when he had arranged them in this way, he bent them round into a gentle curve, to look like real birds' wings.
Ovid: Metamorphoses, VIII, 183–194.
Daedalus deserves a place in the mythology of software engineering. In King Minos' days, software did not exist; and yet the problems and notions which we still find in today's software engineering existed. One example is the construction of complex systems. Daedalus certainly has a track record in that field. He successfully managed a project that can stand a comparison with today's software development projects: the construction of the Labyrinth at Knossos.
After a while, Daedalus wanted to leave Crete, as narrated above in Ovid's words. King Minos, however, did not want to let him go. We know how the story continues: Daedalus flies with his son Icarus from Crete. Despite his father's warnings, Icarus flies higher and higher. He gets too close to the sun and the wax on his wings melts. Icarus falls into the sea and drowns. Daedalus safely reaches the mainland of Italy.
Daedalus' construction is interesting from the point of view of reuse. The fact that it concerns hardware rather than software is not important here. What concerns us in the present framework is the application of certain principles in the construction:
reuse of components: Daedalus used real feathers;
reuse of design: he imitated real wings;
glue to connect the various components: at that time, people used wax to glue things together. The quality of the glue has a great impact on the reliability of the end product.
Through a justified and determined application of these principles, a successful and ambitious project (Daedalus' flight to Italy) was realized. An effort to storm heaven with insufficient technology turned into a disaster (Icarus' fall into the sea).
We make a small jump in history, to the end of the 1970s. The software crisis has been rampant for many years. The demand for new applications far surpasses the ability of the collective workforce in our field. This gap between demand and supply is still growing. Software reuse is one of the paths being explored in order to achieve a significant increase in software productivity.
Why code well-known computations over and over again? Cannot reliability and productivity be drastically increased by using existing high-quality software components?
It sounds too good to be true. But it isn't that simple. The use of existing software components requires standardization of naming and interfaces. The idea of gluing components together is not directly transferable to software.
Is software reuse a myth or can it really be achieved? In the following sections, we give an overview of the developments, opportunities, and expectations of software reusability. A tentative conclusion is that we should not expect miracles. By patiently developing a sound reuse technology, a lot of progress is possible. There is no philosopher's stone. There are, however, a great number of different developments that may reinforce and supplement one another.
The modern view does not restrict the notion of software reuse to component reuse. Design information can be reused also, as can other forms of knowledge gathered during software construction.
Software reuse is closely related to software architecture. A software architecture provides a context for the development of reusable building blocks. Conversely, a software architecture provides a skeleton into which building blocks can be incorporated. Attention to architectural issues is a prime software reuse success factor. A new style of software development, emphasizing component reuse within an architectural framework, is emerging. It is known as Component-Based Software Engineering (CBSE). Developments in interface technology such as provided by middleware interface description languages provide additional leverage for CBSE. Components that are dynamically discovered and deployed are called services. These two specific reuse technologies are discussed more extensively in Chapters 18 and 19.
Closely coupled to software reuse is software flexibility. Software is continuously adapting to changed circumstances. In developing the next release of a system, we would like to reuse as much as possible from the present release. This is sometimes considered to be software reuse. Flexibility aspects have been extensively discussed in previous chapters, notably Chapters 6 and 11, albeit not explicitly in the context of reusability.
Various aspects of software reuse are discussed in Sections 17.1 to 17.4. Section 17.1 discusses the main dimensions along which reuse approaches can be distinguished. Section 17.2 elaborates upon one of these dimensions, the type of product to be reused. Section 17.3 discusses another of these dimensions, namely the various process models incorporating reuse. Specific tools and techniques to support reuse are the topic of Section 17.4. Section 17.5 addresses the perspectives of software reuse. In particular, a domain-oriented, evolutionary approach is advocated. Finally, non-technical aspects of software reuse are addressed in Section 17.6.
Software reuse has many dimensions or facets. The main dimensions along which approaches to software reuse can be distinguished are listed in Table 17.1. We discuss each of these dimensions in turn, by highlighting essential characteristics of extreme positions along the axes. Most reuse systems, however, exhibit a mixture of these characteristics. For example, a typical reuse system may use a combination of a compositional and a generative approach.
Table 17.1. Reuse dimensions
Dimension | Description |
|---|---|
Substance | components, concepts, procedures |
scope | horizontal or vertical |
approach | planned, systematic or ad hoc, opportunistic |
technique | compositional or generative |
usage | black-box, as-is or white-box, modified |
product | code, object, design (architecture), text, ... |
The first dimension along which approaches to reuse may differ concerns the substance, the essence of the things that are reused. Most often, the things being reused are components. A component can be any piece of program text: a procedure, a module, an object-oriented class, etc. Components can be generic (data structures, such as binary trees or lists, widgets for graphical user interfaces, or sorting routines) or domain-specific. A point of recurring concern when reusing components is their quality, in particular their reliability. Instead of encapsulating a chunk of knowledge as a component in some programming language, we may also describe it at a more abstract level, for example as a generic algorithm, or a concept. Finally, rather than reusing product elements, we may also reuse process elements, such as procedures on how to carry out an inspection or how to prototype. To be able to do so, these process elements have to be formally captured, for example in a process model.
The scope of software reuse can be horizontal or vertical. In horizontal reuse, components are generic. They can be used across a variety of domains. A library of mathematical subroutines or GUI widgets is a typical example of horizontal reuse. In vertical reuse, components within a particular application domain are sought for. This often involves a thorough domain analysis to make sure that the components do reflect the essential concepts of the domain. The choice of a particular domain incurs a challenging tradeoff: if the domain is narrow, components can be made to fit precisely and the pay-off is high when these components are reused. On the other hand, the chance that these components can be reused outside this narrow domain is fairly small. The reverse holds for large domains.
Software reuse may be undertaken in a planned, systematic way or it may be done in an ad hoc, opportunistic fashion. Planned reuse involves substantial changes in the way software is developed. Extra effort is needed to develop, test, and document reusable software. Specific process steps must be introduced to investigate opportunities to reuse existing components. The economics of software development change, since costs and benefits relate to more than just the present project. Planned reuse requires a considerable investment up front. For a while, extra effort is needed to develop reusable components. Only at a later stage can the benefits be reaped. With the opportunistic approach, individuals reuse components when and if they happen to know of their existence, and when and if these components happen to fit. In this approach, components are not developed with reuse in mind. Populating a library with a large enough number of reusable components is often a problem when using the opportunistic approach. In the process-model perspective, the planned and opportunistic approaches to reuse are known as software development for reuse and software development with reuse, respectively.
In a composition-based technology, reuse is achieved by (partly) composing a new system from existing components. The building blocks used are passive fragments that are copied from an existing base. Retrieval of suitable components is a major issue here. In a generation-based technology, it is much more difficult to identify the components that are being reused. Rather, the knowledge reused (usually domain-specific) is to be found in a program that generates some other program. In a generation-based technology, reusable patterns are an active element used to generate the target system. Prime examples of these two technologies are subroutine libraries and application generators, respectively.
In a black-box reuse approach, elements are reused as-is: they are not modified to fit the application in which they are going to be incorporated. Often, the person reusing the component does not know the internals of the element. Commercial off-the-shelf (COTS) components are a prime example of this approach. Quality and the legal aspects of such components are critical issues. In a white-box approach, elements can be modified before they are incorporated. White-box reuse is most often done in combination with an opportunistic approach. Black-box reuse is 'safer' in that components reused as-is usually have fewer faults than components that are changed before being reused.
Finally, we may categorize reuse approaches according to the type of product that is reused: source code, design, architecture, object, text, and so on. Most often, some form of source code is the reuse product. There is a strong trend to capture reusable design knowledge in the form of design patterns and software architectures; see Chapter 11. Text is a quite different kind of reusable product, for instance in the form of pieces of documentation. The 'user manual' of a modern airplane, for example, easily runs to thousands of pages. Quite likely, each airplane is unique in some aspects and so is its documentation. By developing reusable pieces of documentation, the user manual can be constructed by assembling it from a huge number of documentation fragments.
Libraries with ready-to-use pieces of code, such as those for numerical or statistical computations, have been with us for a long time and their use is widespread. This form of software reuse is not necessarily suited for other domains. In other domains we may be better off reusing 'skeleton' components, i.e. components in which some details have not been filled in yet. In an environment in which the same type of software is developed over and over again, these skeletons may be molded in a reusable design. A similar technique is to reuse the architecture of a software system, as is found in the construction of compilers, for example. These are all examples of composition-based reuse techniques.
By incorporating domain knowledge in supporting software, we arrive at the area of application generators and fourth-generation languages. These are examples of generation-based reuse techniques.
No one in his right mind will think of writing a routine to compute a cosine. If it is not built into the language already, there is bound to be a library routine cos. By investigating the question of why the reuse of mathematical functions is so easy, we come across a number of stumbling blocks that hamper the reuse of software components in other domains:
a well-developed field, with a standardized terminology: 'cosine' means the same to all of us;
a small interface: we need exactly one number to compute a cosine;
a standardized data format: a real number may be represented in fixed point, floating point, or double precision, and that's about all.
Reuse of subroutines works best in an application domain that is well disclosed, one whose notions are clear and where the data to be used is in some standardized format.
The modern history of software reuse starts with McIlroy (1968), who envisaged a bright future for a software component technology at the NATO software engineering conference. In his view, it should be possible to assemble larger components and systems from a vast number of ready-to-use building blocks, much like hardware systems are assembled using standard components. We haven't got there yet. In order for large-scale reuse of software components to become feasible, we first have to solve the following problems:
Searching: We have to search for the right component in a database of available components, which is only possible if we have proper methods available to describe components. If you do not know how to specify what you are looking for, there is little chance you will find it.
Understanding: To decide whether some component is usable, we need a precise and sufficiently complete understanding of what the component does.
Adaptation: The component selected may not exactly fit the problem at hand. Tinkering with the code is not satisfactory and is, in any case, only justified if it is thoroughly understood.
Composition: A system is wired from many components. How do we glue the components together? We return to this topic in Section 17.4.1 and, more extensively, in Chapter 18.
To ease the searching process, hardware components are usually classified in a multilevel hierarchy. Since the naming conventions in that field have been standardized, people are able to traverse the hierarchy. At the lowest level, alternative descriptions of components are given, such as a natural language description, logic schema, and timing information, which describe different aspects of the components. These alternative descriptions further improve the user's understanding of these components.
Several efforts have been made to classify software components in a hierarchical fashion as well. One such effort is described in (Booch, 1987). In his taxonomy (see Figure 17.1), a component is first described by the abstraction it embodies. Secondly, components are described by their time and space behavior, for instance, whether or not objects are static in size or handle their own memory management.
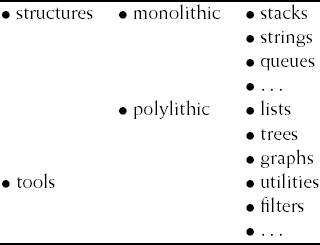
The retrieval problem for software components is very similar to that for textual sources in an ordinary library. Quite a number of classification, or indexing, techniques have been developed for the latter type of problem. Figure 17.2 identifies the main indexing techniques.
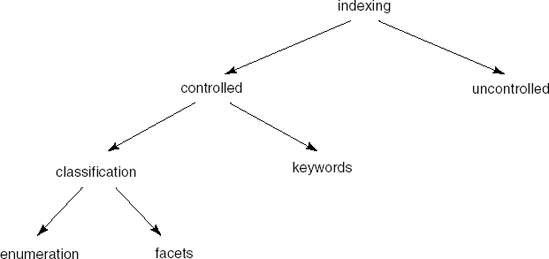
An indexing scheme is either controlled or uncontrolled. In a controlled indexing scheme, classifiers are chosen from a finite set of terms. This set of terms may be predefined and immutable. It may also change over time, though only in a controlled way. With controlled indexing, a list of synonyms is often provided to make both searching and indexing more flexible. In an uncontrolled indexing scheme, there is no restriction on the number of terms. Uncontrolled indexing is mostly done by extracting terms from the entity to be indexed. For example, the terms that occur most frequently can be taken as index terms. An advantage of uncontrolled indexing is that it can be done automatically. A disadvantage is that semantic knowledge is lost.
In controlled indexing, one option is simply to use a list of keywords. This list is not ordered and there are no relations between the keywords. An advantage of this scheme is that it is easy to extend the set of index terms. In a classification scheme, on the other hand, the set of index terms is structured in some way. One way of doing so is through some enumerated hierarchical structure, as in Figures 17.1 and 17.2. The power of a hierarchical scheme is its structure. This same structure, however, is also a weakness.
An enumerated scheme offers one specific view on the structure of a domain. Figure 17.1 offers one such view on the domain of generic data structures. Figure 17.3 offers an alternative view on that same domain. In the latter scheme, the structural relationships between elements of a compound data structure have been used to set up the taxonomy. For example, there is a 1–1 relationship between elements of a linear structure such as a list or queue. The taxonomies in Figures 17.1 and 17.3 both seem to be reasonable. Each of them can be used effectively, provided the user knows how the hierarchy is organized.
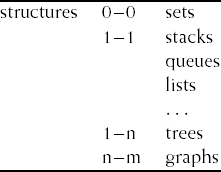
This phenomenon holds for component hierarchies in general. If you do not know how the hierarchy is organized, there is little chance that you will be able to find the component you were looking for.
Strictly enumerative schemes use a predefined hierarchy and force you to search for a node that best fits the component to be classified. Though cross-references to other nodes can be included, the resulting network soon becomes fairly complicated. Facetted classification has certain advantages over the enumerative classification used in the examples of Figures 17.1 and 17.3. A faceted classification scheme uses a number of different characteristics, or facets, to describe each component. For example, components in a UNIX environment could be classified according to the action they embody, the object they manipulate, the data structure used, and the system they are part of. Classifying a component is then a matter of choosing an n-tuple which best fits that component.
The essence of an indexing technique is to capture the relevant information of the entities to be classified. This requires knowledge of the kind of questions users will pose, as well as knowledge of the users' search behavior. This is difficult, which makes the development of an indexing language a far from trivial undertaking. Librarians know this. Software engineers responsible for a library of reusable components should know this too. Any user of the Internet will have experienced that finding something that exactly fits your needs is a very difficult task.
The examples contained in Figures 17.1 and 17.3 are somewhat misleading, in that the components found at the leaf nodes of the hierarchy embody abstractions that are all too well known. In other domains, there will be less mutual understanding as regards primitive concepts and their naming. Therefore, setting up a usable taxonomy, i.e. defining an indexing language, is likely to be much more difficult in other domains.
Once a set of candidate components has been found, we need to evaluate these components for their suitability in the current reuse situation. The main types of information useful for such an evaluation are:
Quality information, for example, a rating for each ISO 9126 quality characteristic (see Chapter 6)
Administrative information, such as the name and address of the developer, the component's modification history, and information on the price of reuse
Documentation about what the component does and details about the internals of the component (if it may be adapted)
Interface information (most often about the types of parameters)
Test information, to help with testing the component in the reuse situation, such as a set of test cases with the associated expected results.
Valuable quality information is also provided by comments about the reuse history of the component: successful experiences,[30] critical notes about circumstances in which reuse was found to be less successful, and so on.
One further observation that can be made about the reuse of components regards their granularity. The larger a component is, the larger the pay-off will be once it is reused. On the other hand, the reusability of a component decreases as its size grows, because larger components tend to put larger constraints on their environment. This is analogous to Fisher's fundamental theorem of biology: the more an organism is adapted to some given environment, the less suited it is for some other environment.
Some actual experiences suggest that practical, useful component libraries will not contain a huge number of components. For example, Prieto-Diaz (1991a) reports that the asset collection of GTE went from 190 in 1988 to 128 in 1990. Poulin (1999) asserts that the best libraries range from 30 components to, in rare cases, as many as 250 components. For that reason, the classification and retrieval of components is often not the main impediment to a successful reuse program. Rather, filling the library with the right components is the real issue. This aspect will be taken up again in Section 17.5.
More detailed technical characteristics of components, their forms, their development and composition, are discussed in Chapter 18.
In the preceding section, we silently assumed library components to be ready-to-use pieces of code. The applicability of a component can be increased by leaving certain details unspecified. Templates or skeletons are 'unfinished' components. By instantiating them, i.e. by filling in the holes, a (re)usable component results.
An example of a possible template is a procedure that implements the quicksort algorithm. Details such as the bounds of the array to be sorted, the type of the array elements, and the relational operator used to compare array elements, are not important for the essence of the algorithm.
As more and more details are left open, a template can be applied more generally. However, there is a price to be paid. The cost of obtaining a complete application is likely to increase in proportion to the number of holes to be filled in.
Templates need not be constrained to just subroutines. It is realistic to think of a template that can be instantiated into a full program for a very specific application domain. Such templates are called application generators and are discussed in Section 17.2.4.
For each problem, we must look for an architecture which best fits that problem. An inappropriate architecture can never be the basis for a good system. The situation becomes rather different if a problem recurs over and over again in different variants. If a useful standard architecture exists for a particular type of problem, it can be applied in all future variants.
A prime area within computer science where a software architecture is routinely reused is in building compilers. Most compilers are built out of the same components: a lexical analyzer, a parser, a symbol table, a code generator, and a few others. There exist certain well-defined types of parser, such as LL(1) or LALR(1) parsers. There is a large body of theory about how compilers function and this theory is known to the people building compilers. In this way, a generally accepted standard architecture for compilers has evolved. Obviously, it has never been proved that this is the only, or best, way to build a compiler. But it constitutes a sound and well-known method of attacking problems in a notoriously difficult domain.
Large-scale reuse of architecture is still seldom found in other areas. The main reason is that a similar body of shared, crystallized knowledge just does not yet exist for most domains. We may, however, observe that this situation is changing rapidly. In many fields, people are explicitly building such a body of knowledge and molding it into the form of a software architecture. It may be called a domain-specific software architecture (DSSA), a product-line architecture (in which case the architecture provides the basis for a family of similar systems), or an application framework (if the emphasis is on the rapid generation of an application from existing building blocks); see also Chapter 11.
Application generators write programs. An application generator has a fair amount of application-domain knowledge. Usually, the application domain is quite narrow. In order to obtain a program, one obviously needs a specification of that program. Once the specification is available, the program is generated automatically.
The principle being used is the same as that behind a generic package or template: the actual program to be generated is already built into the application generator. Instantiation of an actual program is done by filling in a number of details. The difference is that the size of the code delivered is much bigger with an application generator than with a template. Also, the details are generally provided at a higher level of abstraction, in terms of concepts and notions drawn from the application domain.
An application generator can be employed in each domain with a structure such that complicated operations within that domain can be largely automated. One example is the production of graphical summaries from a database. So-called compiler compilers are another typical example of application generators: given a grammar (i.e. the details) of some programming language, a parser for that language is produced.
Fourth-generation languages or very-high-level languages (VHLLs) are often mentioned in the same breath with application generators. Fourth-generation languages offer programming constructs at a much higher level than third-generation programming languages. Model-driven development/architecture (MDD/MDA) may be seen as the ultimate form of this; see also Section 3.4.
Expressions from a given application domain can be directly phrased in the corresponding fourth-generation language. Consequently, the fourth-generation language must have knowledge of that application domain. This generally means that fourth-generation languages are only suited for one specific, limited, domain.
There is no fundamental difference between fourth-generation languages and application generators. When one wants to stress the generative capabilities of a system, the term application generator is mostly applied. The term fourth-generation language highlights the high-level programming constructs being offered. For many such systems, the terms are used interchangeably.
Application generators and fourth-generation languages potentially offer a number of cost savings, since implementation details need not be bothered with: less code is written, the software is more comprehensible, there are fewer errors, and the software is easier to maintain. In practice, this theory often does not come up to expectations. For one thing, the user may want something which is not offered by the system. In that case, a piece of handwritten code must be added to the software being generated automatically. By doing this, one of the main advantages of using fourth-generation languages, easily comprehensible programs at a high level of abstraction, is lost.
Reuse affects the way we develop software. We may distinguish two main process models incorporating reuse:
software development with reuse, and
software development for reuse.
Both these approaches to reuse may be combined with any of the software life cycle models discussed earlier. Also, combinations of the 'with' and 'for' reuse models are possible.
The software-development-with-reuse model may be termed a passive approach to reuse. It presupposes a repository with a number of reusable assets. At some point during the development process, this repository is searched for reusable assets. If they are found, they are evaluated for their suitability in the situation at hand and, if the evaluation yields a positive answer, the reusable assets are incorporated. The process does not actively seek to extend the repository. As a side effect of the present project, we may add elements to the repository, but no extra effort is spent in doing so. For instance, we do not put in extra effort to test the component more thoroughly, to document it more elaborately, or to develop a more general interface to it. From a reuse perspective, the software-development-with-reuse approach is an opportunistic approach.
A pure software-development-with-reuse model is routinely applied in, e.g. circumstances where we need some mathematical routine. If our project requires some numerical interpolation routine, we search a mathematical library. We may find some routine which uses Gaussian interpolation, fits our needs, and decide to incorporate it. Most likely, the project will not result in a new interpolation routine to be included in the library.
Development with reuse is most often applied at the component level. It has its main impact, therefore, during the architectural design stage when the global decomposition into components is decided upon. We search the repository for suitable candidates, evaluate them, and possibly include them in our architecture. This is a cyclical process, since we may decide to adjust the architecture because of characteristics of the components found. The resulting process model is depicted in Figure 17.4. The model includes some further communication links between later phases of the software development life cycle and the repository. These reflect less far-reaching adaptations to the process model. For example, the repository may contain test cases that can be retrieved and used when testing the system, or we may be able to add our own test results to the repository.
The software-development-for-reuse process model constitutes an active approach to reuse. Rather than merely searching an existing base, we develop reusable assets. The software-development-for-reuse approach is thus a planned approach to reuse. Again, this approach most often involves reusable components, and we illustrate the approach by considering that situation. During architectural design, extra effort is now spent to make components more general, more reusable. These components are then incorporated into the repository, together with any information that might be of help at a later stage, when searching for or retrieving components. Software-development-for-reuse thus incurs extra costs to the present project. These extra costs are only paid back when a subsequent project reuses the components.
Software-development-for-reuse process models (see Figure 17.5) may differ with respect to the point in time at which components are made reusable and incorporated in the repository. In one extreme form, reusable components are extracted from the system after it has been developed. This may be termed the a posteriori approach. In an a priori software-development-for-reuse approach, reusable components are developed before the system in which they are to be used. The latter approach has become known as the software factory approach.
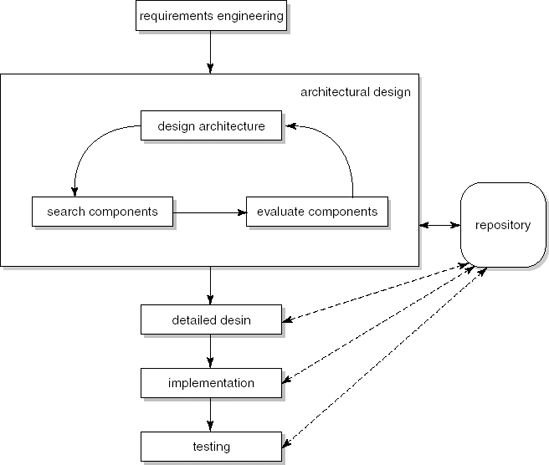
If the architecture is developed for one specific problem, chances are that peculiarities of that situation creep into the architecture. As a result, components identified might fit the present situation very well, but they might not fit a similar future situation. The extra effort spent to make these components reusable then might not pay off. To prevent this, development for reuse generally involves a different requirements engineering process as well. Rather than only considering the present situation, the requirements for a family of similar systems are taken into account. So, instead of devising an architecture for the library of our own department, we may decide to develop an architecture which fits the other departments of our university as well. We may even decide to develop an architecture for scientific libraries in general. This more general requirements engineering process is known as domain engineering. The resulting architecture is also termed a product-line architecture; see also Section 18.4.
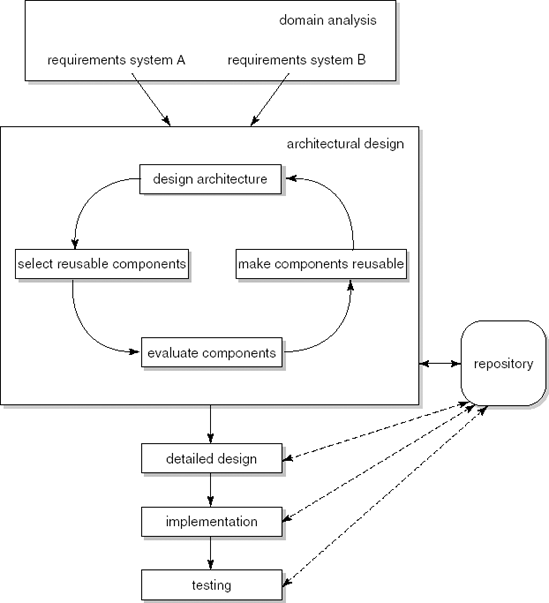
A disadvantage of the model depicted in Figure 17.5 is that the development of components and the development of applications are intertwined. This may lead to tensions. For example, a manager responsible for the delivery of an application may be reluctant to spend resources on developing reusable components. An alternative form of the software-development-for-reuse model therefore is to have separate life cycle processes for the development of reusable components and the development of applications. This latter form is discussed in Section 18.3.
In this section, we consider a few concepts, methods and techniques that have a positive impact on software reuse. In doing so, we reconsider the approaches discussed in the previous section, thus establishing a relation between the reusable software assets discussed in the previous section and the notions discussed here.
The relation between different modules of a system can be formally expressed in a module interconnection language (MIL). A MIL is an important tool when designing and maintaining large systems consisting of many different modules. A MIL description is a formal description of the global structure of a software system. It can be used to verify the integrity of the system automatically. It can also be used to check whether the various modules conform to the agreed interfaces.
Figure 17.6 contains a small fragment of (hypothetical) MIL code to illustrate the general flavor. The example concerns the structure of a Key Word In Context (KWIC) index program using abstract data types (see (Parnas, 1972) for the description of this problem and its solutions). For each component, it specifies what the component provides to its environment and what it requires from its environment. The overall result is a complete 'uses' structure of the system. For each component, one or more implementations are also indicated. The composition given at the end of the description selects a number of building blocks defined previously.
MILs originated as a consequence of the separation between programming-in-the-small and programming-in-the-large. The essential ideas behind the development of MILs are:
A separate language for system design: A MIL is not a programming language. Rather, it describes desirable properties of modules that are to become part of the system being considered.
Static type-checking between different modules: This automatically guarantees that different modules obey the interface. An interface can only be changed after the corresponding change has been realized in the design.
Design and binding of modules in one description: In the early days of programming-in-the-large the various modules of a system were assembled by hand. Using a MIL, it is done automatically.
Version control: Keeping track of the different versions of (parts of) a system during development and maintenance requires a disciplined approach.
A number of different MILs have been developed. The basic concepts, however, are the same:
resources: everything that can have a name in a programming language (constants, types, variables, and procedures) and can be made available by a module for use in another module;
modules: make resources available or use them;
systems: groups of modules which together perform a well-defined task. To the outside world, a system can be viewed as a single module.

The coupling between modules can be modeled as a graph: the nodes of the graph denote modules while the (directed) edges denote the 'uses' relation. Depending on the sophistication of the MIL, this graph can be a tree, an acyclic directed graph, or a directed graph without any restrictions.
To describe the architecture of a system, we need more than is generally provided by a MIL. MILs emphasize components and uses relations between components. In particular, MILs neither treat connectors as first-class citizens nor describe the architectural configuration (topology) of the system. MILs have evolved into architecture description languages (ADLs) that express the latter aspects also.
Figure 17.7 contains part of a (hypothetical) ADL-description of the same KWIC-index program using abstract data types. It defines Store as a component with an abstract data type interface. It also lists the various methods, with their signatures, that make up this interface. The main program, kwic, is a component too. Its interface is defined to be of type filter; both its input and output are streams of characters. The implementation part of kwic lists all components and connectors as instances of certain types of component or connector. Furthermore, all connections are made explicit, so that the topology of the system is completely specified. For example, a procedure call connector has two ends: a defining end and a calling end. The defining end of P in Figure 17.7 is connected to the routine Putchar of module Store, while its calling end is connected to the output routine of module Input.
MILs and ADLs generally have the same limitations: they only engage themselves in the syntax of interfaces. Whether the resources passed on are meaningful or not cannot be assessed.
With respect to the previous section we may note that MILs and ADLs fit in well with forms of reuse where design plays an essential role.
In the object-oriented paradigm, it is often stated that two objects, a client and a server, have agreed upon some contract, whereby the client object is allowed to request certain services from the server object. A natural next step is to isolate the contents of this contract, or interface, from both client and server. This is essentially what happens in the Common Object Request Broker Architecture, CORBA.[31] CORBA has been developed by the Object Management Group (OMG), a multivendor effort to standardize object-oriented distributed computing. JavaBeans and Microsoft's COM and .NET are similar solutions to the problem of connecting components with a very long wire.


CORBA interfaces are expressed in the Interface Definition Language (IDL). Figure 17.8[32] contains part of such an interface definition for the KWIC index program using abstract data types. IDL is a strongly typed language; it is not case-sensitive; and its syntax resembles that of C++. The interface construct collects operations that form a natural group. Typically, the operations of one abstract data type constitute such a group. For each operation, the result type is given, followed by the operation names, and finally the parameters. A result type of void indicates that no value is returned. Parameters are prefixed by either in, out, or inout, denoting an input, output, or input-output parameter.
Note the similarity between the texts of Figures 17.6, 17.7 and 17.8. Each of these figures expresses interfaces of components, though with a slightly different syntax and for slightly different purposes.
Middleware primarily shields underlying technology such as hardware, the operating system, and the network. It is a bridging technology. A key driver of middleware is to realize interoperability between independently developed pieces of a software system. It is often used as an integration technology in enterprise information systems. Component models on the other hand emphasize achieving certain quality properties for a collection of components that together make up a system. Component models generally focus on the conventions that components running on top of the middleware must satisfy. Some types of middleware can thus be part of a component model. The Corba Component Model (CCM) is a very relaxed component model. It imposes few constraints on top of its request-response type of interaction. Other component models offer a lot more, though. Component models are discussed in Section 18.2.
In any reuse technology, the building blocks being reused, whether in the form of subroutines, templates, transformations, or problem solutions known to the designers, correspond to crystallized pieces of knowledge, which can be used in circumstances other than the ones for which they were envisaged originally.
A central question in all the reuse technologies discussed above is how to exploit some given set of reusable building blocks. This is most paramount in various projects in the area of component libraries, where the main goal is to provide ways of retrieving a useable component for the task at hand.
Alternatively, we may look at software reusability from an entirely different angle: what building blocks do we need in order to be able to use them in different applications?
Reuse is not the same as reusability. Reuse of software is only profitable if the software is indeed reusable. The second approach addresses the question of how to identify a useful, i.e. reusable, collection of components in an organized way. Such a collection of reusable components is tied to a certain application domain.
When trying to identify a reusable set of components, the main question is to decide which components are needed. A reusable component is to be valued, not for the trivial reason that it offers relief from implementing the functionality yourself, but for offering a piece of the right domain knowledge, the very functionality you need, gained through much experience and an obsessive desire to find the right abstractions.
Components should reflect the primitive notions of the application domain. In order to be able to identify a proper set of primitives for a given domain, considerable experience with software development for that domain is needed. While this experience is being built up, the proper set of primitives will slowly evolve.
Actual implementation of those primitives is of secondary importance. A collection of primitives for a given domain defines an interface that can be used when developing different programs in that domain. The ideas, concepts, and structures that play an important role in the application domain have to be present in the interface. Reuse of that interface is more important than reuse of its implementation. The interface structures the software. It offers a focal point in designing software for that application area.
In (Sikkel and van Vliet, 1988), such a collection of primitives is called a domain-oriented virtual machine (DOVM). A domain is a 'sphere or field of activity or influence'. A domain is defined by consensus and its essence is the shared understanding of some community. It is characterized by a collection of common notions that show a certain coherence, while the same notions do not exist or do not show that coherence outside the domain. Domains can be taken more or less broadly. Example domains are, for instance:
accounting software,
accounting software for multinationals,
accounting software for multinationals, developed by Soft Ltd.
All accounting software will incorporate such notions as 'ledger' and 'balance'. Accounting software for multinationals will have some notions in common that do not exist in accounting systems for the grocery store or the milkman, such as provisions for cross-border cash flow. Representation of notions in software developed by Soft Ltd. will differ from those of other firms because of the use of different methodologies or conventions.
The essential point is that certain notions play an important role in the domain in question. Those notions also play a role in the software for that domain. If we want to attain reuse within a given domain, these domain-specific notions are important. These notions have certain semantics which are fixed within the domain, and are known to people working in that domain. These semantically primitive notions should be our main focus in trying to achieve reusability.
For most domains, it is not immediately clear which primitives are the right ones. It is very much a matter of trial and error. By and by, the proper set of primitives show themselves. As a domain develops, we may distinguish various stages:
At the start, there is no clear set of notions and all software is written from scratch. Experience slowly builds up, while we learn from previous mistakes.
At the second stage, similar problems are being recognized and solved in a similar way. The first semantic primitives are recognized. By trial and error, we find out which primitives are useful and which are not.
At the third stage, the domain is ripe for reuse. A reasonable amount of software has been developed, the set of concepts has stabilized, there are standard solutions for standard problems.
Finally, the domain has been fully explored. Software development for the domain can largely be automated. We do not program in the domain any more. Instead, we use a standard interface formed by the semantic primitives of the domain.
Most reuse occurs at the last stage, by which time it is not recognized as such. A long time ago, computers were programmed in assembly language. In high-level languages, we 'just write down what we want' and the compiler makes this into a 'real' program. This is generally not seen as reuse any more. A similar phenomenon occurs in the transition from a third-generation language to a fourth-generation language.
From the reusability point of view, the above classification is one of a normal, natural, evolution of a domain. The various stages are categorized by reuse at qualitatively different levels:
at the first stage, there is no reuse;
at the second stage, reuse is ad hoc;
at the third stage, reuse is structured. Existing components are reused in an organized way when new software is being developed;
at the fourth stage, reuse is institutionalized and automated. Human effort is restricted to the upper levels of abstraction.
Within a given domain, an informal language is used. In this informal domain language, the same thing can be phrased in quite different ways, using concepts that are not sharply defined. Yet, informal language is understandable, because the concepts refer to a universe of discourse that both speaker and listener share.
Concepts in a formal language do not refer to experience or everyday knowledge. They merely have a meaning in some formal system. A virtual machine is such a formal system and its language is a formal language.
To formalize a domain is to construct a formal (domain) language that mimics an existing informal language. We then have to choose from the different semantic primitives that exist informally. Sometimes also, it is convenient to add new primitives that fit neatly within the formalized domain.
As an example of the latter, consider the domain of computerized typesetting. Part of formatting a document concerns assembling words into lines and lines into paragraphs. The sequence of words making up a paragraph must be broken into lines such that the result is typographically pleasing. Knuth and Plass (1981) describe this problem in terms of 'boxes', 'glue', and 'penalties'. Words are contained in boxes, which have a certain width. White space between words is phrased in terms of glue, which may shrink or stretch. A nominal amount of white space between adjacent words is preferred and a penalty of 0 is associated with this nominal spacing. Putting words closer together (shrinking the glue), or wider apart (stretching the glue), incurs a non-negative penalty. The more this glue is stretched or shrunk, the higher the penalty. The penalty associated with formatting a complete paragraph in some given way then is the sum of the penalties associated with the inter-word spacing within that formatted paragraph. The problem may now be rephrased as: break the paragraph into lines such that the total penalty is minimal. (Note that penalties may also be associated with other typographically less-desirable properties, such as hyphenation.) The notions 'box', 'glue', and 'penalty' give a neat formalization to certain aspects of typography. They also lead to an efficient solution for the above problem, using a dynamic programming technique.
In practice, formalizing is not a one-shot activity. Rather, it is an iterative process. The formalized version does not exactly describe the informal language. It fixes one possible interpretation. If we study its semantics, it may have some undesirable aspects. In due course, an acceptable compromise is reached between those who use the language (in higher domains) and those who implement it (in lower domains). Once the formal domain language is fixed, it also affects the informal domain language. People working within the domain start to use the primitives of the formal language.
It is now clear that it is, in general, not wise to go directly from stage one (no reuse) to stage three (structured reuse). Formalization has much in common with standardization. It has a solidifying effect on the semantic primitives of the domain. Our notion of these primitives changes, because we do not any longer consider them as coming from the intuitive universe of discourse, but as being based on the underlying formalism. A crucial question, namely whether we formalized the right semantic primitives, then becomes harder to answer.
Stage two (ad hoc reuse) is crucial. In this stage, we get insight into the application domain and discover useful semantic primitives. This experience, both in working with the primitives and in implementing them, is of vital importance for the formalization of the domain in the right way.
The above discussion suggests an evolutionary approach to reuse. To start with, potentially reusable building blocks can be extracted from existing software products. While gaining experience with the reuse of these building blocks, better insight is obtained and better abstractions of concepts and mechanisms from the application domain are discovered. The library of reusable building blocks thus evolves and stabilizes over time.
This evolutionary process can be structured and guided through domain analysis, a process in which information used in developing software for a particular domain is identified, captured, structured, and organized for further reuse. Domain analysts and domain experts may use a variety of sources when modeling a domain, including expert knowledge, existing implementations and documentation. They extract and abstract the relevant information and encapsulate them in reusable building blocks.
Domain analysis often results not only in a collection of reusable building blocks. It also yields a reusable architecture for that domain: the domain-specific software architecture, product-line architecture, or application framework mentioned in Section 17.2.3. To increase the reusability of these building blocks across different operating systems, networks, and so on, they are put on top of some middleware platform.
The problem is not lack of technology but unwillingness to address the most important issues influencing software reuse: managerial, economic, legal, cultural, and social.
Prieto-Diaz (1991b)
Myth #1: Software reuse is a technical problem.
Tracz (1988)
Until now, we have discussed only the technical aspects of software reuse. Software engineering is not only concerned with technical aspects but with people and other environmental aspects as well.
By being embedded within a society, the field of software engineering will also be influenced by that society. Software reuse in the US is likely to be different from software reuse in Japan or Europe. Because of cultural differences and different economic structures, it is not a priori clear that, say, the Toshiba approach to reuse can be copied by Europeans, with the same results.
Though our discussion so far has concerned the technical aspects of software reuse, it is not complete without a few words on non-technical issues. These nontechnical issues are intimately intertwined with the more technical ones. Various practitioners in the field of software reuse have argued that the technology needed for software reuse is available, but that the main problems inhibiting a prosperous reuse industry are non-technical in nature.
Successful reuse programs share the following characteristics:
Unconditional and extensive management support. A reuse program requires changes in the way software is developed. Management commitment is essential for making such changes work. In particular, building a base of reusable assets requires an initial investment which may not pay off for some time.
Establishment of an organizational support structure. The organization must provide the initiative for the reuse program, funding, and policies. A separate body is needed to assess potential candidates for inclusion in the reuse library. A librarian is needed to maintain the library.
Incremental program implementation. A first catalog with potential reusable assets can be built at a relatively low cost. Positive experiences with such an initial library will raise awareness and provide the necessary incentives (and funding) to expand the library, devise a classification scheme, etc.
Significant success, both financial and organizational. Raytheon for example reports a 50% increase in productivity over a period of several years.
Compulsory or highly incentivized. Programmers suffer from the 'not invented here' syndrome. By creating an environment that values both the creation of reusable software and the reuse of software, an atmosphere is established in which reuse may become a success.
Domain analysis was conducted either consciously or unconsciously. Domain analysis identifies the concepts and mechanisms underlying some well-understood domain. This way, the really useful concepts are captured in reusable resources.
Explicit attention to architectural issues, such as a common architecture across a product line.
Some of the non-technical aspects are discussed in the subsections below.
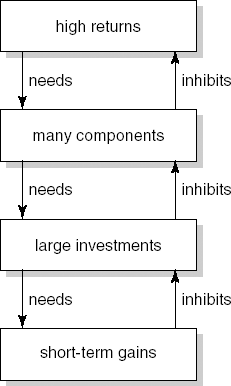
Reuse does not come for free. In a traditional development environment, products are tailored to the situation at hand. Similar situations are likely to require slightly different products or product components. For a software component to become reusable, it has to be generalized from the situation at hand, thoroughly documented and tested, incorporated in a library and classification scheme, and maintained as a separate entity. This requires an initial investment, which only starts to pay off after a certain period of time. One of the real dangers for a software reuse program is that it gets trapped in a devil's loop of the kind depicted in Figure 17.9.
The major factors that determine the cost of a reusable building block are:
the initial development cost of that component,
the direct and indirect costs of including the component in a library, and
the cost of (possibly) adapting the component and incorporating it into the system under development.
It is obvious that the development of a reusable component is more costly than the development of a nonreusable component with the same functionality. Estimates of this extra cost vary from 50% to 100% (see also Section 7.1.5 on the COCOMO 2 cost estimation model). It depends on the usage frequency of the component whether its development eventually pays off.
More immediate returns on investment can be obtained if the reuse program starts small, with an initial library whose members are extracted from existing products. Expansion of the program can then be justified on the basis of positive early experiences. But even then, non-project-specific funds must be allocated to the reuse program.
The economic consequences of software reuse go beyond cost savings in production and maintenance. The nature of the software development process itself changes. Software becomes a capital good. High initial costs are coupled with returns over a longer time period. The production of software thus becomes a capital-intensive process (Wegner, 1984). The production of non-reusable software, on the other hand, is a labor-intensive process. Many man-months are spent, but the profits are reaped as soon as the project is finished.
Whereas labor-intensive software production tends to concentrate on finishing the project at hand on time and within budget, capital-intensive software production takes into account long-term business concerns such as the collective workers' knowledge and the collection of reusable assets. The software factory paradigm discussed earlier in this chapter as well as the various approaches emphasizing the architecture of a software system fit this view of the software development organization.
Getting software reuse off the ground cannot depend on spontaneity. Rather, software production ought to be organized so that reuse is promoted. In Chapter 3, we noted that the traditional waterfall model tends to impede software reuse. In the waterfall model, emphasis is placed on measuring and controlling project progress. The product quality with respect to reusability is hard to measure. There is no real incentive to pursue reusability, since the primary (and often the only) goal is to finish the current project within time and budget. There is no motivation to make the next project look good. Consequently, software reusability tends to have a low priority.
If reuse is not a clear objective of our software development process, it is bound to remain accidental. Programmers tinker with code they have written before if and when they happen to notice similarities between successive problems. This unplanned approach to reuse is also known as code scavenging or code salvaging. This is distinct from the process of reusing software that was designed to be reused. In the life cycle perspective, this shows up as the difference between software-development-with-reuse and software-development-for-reuse.
In software-development-for-reuse, software reuse has been incorporated in the software development process. In this process model, reusable assets are actively sought. The concepts and mechanisms underlying some domain are identified and captured in reusable resources. The focus of software management then shifts from the delivery of individual products to maintaining and nurturing a rich collection of reusable artifacts. Some of the successful reuse programs, such as those reported in (Prieto-Diaz, 1991b), have followed this approach.
The library of reusable assets itself needs to be managed. An organizational infrastructure must be created which makes the library accessible (through documentation and classification schemes), assesses candidates for inclusion in the library, maintains and updates the library, etc. A separate organizational role, the librarian, may be created for this purpose. Its tasks resemble that of a database administrator.
One type of reuse only mentioned in passing is reuse of good people. Expert designers are worth their weight in gold. Every average programmer is capable of writing a complicated, large program. In order to obtain a better, smaller, more elegant, radically new solution for that same problem, we need a person who has bright ideas from time to time.
A major problem in our field is that managers are rated higher than programmers or designers. If you are really good, you will sooner or later, but usually sooner, rise in the hierarchy and become part of the management. According to (Brooks, 1987), there is only one way to counteract this phenomenon. To ensure that bright people remain system designers, we need a dual ranking scheme, one in which good designers have the same job prospects as good managers. Once again: the software process must be reconsidered as one of growing both people and the base of reusable assets (Curtis, 1989).
Reusing other people's code would prove that I don't care about my work. I would no more reuse code than Hemingway would reuse other authors' paragraphs.
Cox (1990)
Software reuse means that programmers have to adapt, incorporate, or rejuvenate software written by other programmers. There are two important psychological aspects to this process:
Are programmers willing to do so?
Are they capable of doing so?
The first aspect is often mentioned as a major stumbling-block to establishing a positive attitude towards software reuse. Barnes and Bollinger (1991) phrase this problem of image as follows: 'Anyone who has ever gone to an auto salvage yard to pick up a spare part for his old car ''knows'' what reuse is.'
Many authors suggest a solution to this problem that is both simple and effective: change the programming culture. The experiences at Raytheon and other places suggest that it is indeed possible, given the right incentives and, more importantly, a management attitude that pays attention to longer-term goals and developers' expectations about the nature of their work.
Research into the comprehensibility of software, such as reported in (Soloway and Ehrlich, 1984), shows that programmers use certain standard schemes in standard situations. Experienced programmers tend to get confused when a known problem has been tackled using (to them) non-standard solutions. As a consequence, the reusability of components is likely to be increased if the components embody abstractions the programmers are familiar with. Domain analysis addresses the same issues by trying to identify the notions that are shared by experts in a particular domain.
One side-effect of the use of standard designs and standard components is the increased comprehensibility of the resulting software. Once all programmers get used to the same house style, all programs read as if they were written by one team. Any team can understand and adapt a program written by another team. This effect is stronger if we are able to explicitly name these larger constructs, as is done with design patterns and architectural styles.
Reuse projects vary considerably in a number of dimensions:
The thing to be reused may be a concrete component such as a piece of code or a software architecture, a more abstract concept, or even a process element such as a procedure to handle change requests.
The scope of reuse may be horizontal or vertical. In horizontal reuse, components are generic. In vertical reuse, they are domain-specific.
The approach to reuse may be planned or opportunistic. In planned reuse, software is designed to be reused. In opportunistic reuse, software is reused haphazardly, if and when we happen to know of its existence, if and when it happens to fit the current situation. Planned reuse is software development for reuse, opportunistic reuse is software development with reuse.
Reuse may be compositional or generative. A composition-based technology aims at incorporating existing components into software to be newly developed. In a generation-based technology, the knowledge reused is to be found in some program that generates some other program.
Reuse may be black-box or white-box. In black-box reuse, elements are reused as-is. In white-box reuse, they may be adapted to fit the situation at hand.
Classification schemes for reusable elements resemble those for textual sources in an ordinary library. They vary from a simple Key Word In Context approach to fully automated keyword retrieval from existing documentation, and may even involve elaborate knowledge of the application domain. With respect to retrieval, systems may employ an extensive thesaurus to relate similar terms or offer browsing facilities to inspect 'similar' components.
Software reusability is an objective, rather than a field. It emerged as an issue within software engineering, not because of its appeal as a scientific issue per se, but driven by the expected gain in software development productivity.
The history of software reuse starts in 1968. At the first software engineering conference, McIlroy already envisaged a bright future for a software component technology, somewhat similar to that for hardware components. The first conference specifically devoted to software reuse was held in 1983 (ITT, 1983). Since then, the topic has received increased attention. Over the years, a shift in research focus can be observed from domain-independent technical issues, such as classification techniques and component libraries, to domain-specific content issues, such as architectural frameworks and domain analysis.
A central question in all reuse technologies discussed is how to exploit some set of reusable building blocks. As argued in Section 17.5, an equally important question is which building blocks are needed to start with. Answering the latter question requires a much deeper understanding of the software design process than we currently have.
Successful reuse programs share a number of characteristics:
unconditional and extensive management support,
an organizational support structure,
incremental program implementation,
significant success, both financial and organizational,
compulsory or highly incentivized,
domain analysis conducted either consciously or unconsciously,
explicit attention to architectural issues.
Reuse is not a magic word with which the productivity of the software development process can be substantially increased at a stroke. But we do have a sufficient number of departure-points for further improvements to get a remunerative reuse technology off the ground. Foremost amongst these are the attention to non-technical issues involved in software reuse and an evolutionary approach in conjunction with a conscientious effort to model limited application domains.
The modern history of software reuse starts at the first NATO software engineering conference (McIlroy, 1968). The first conference specifically devoted to software reuse was held in 1983 (ITT, 1983). (Biggerstaff and Perlis, 1989) and (Freeman, 1987) are well-known collections of articles on software reuse. (Karlsson, 1995) is a good textbook on the subject. It is the result of an Esprit project called REBOOT. Amongst other things, it describes the software-development-with-reuse and software-development-for-reuse process models. (Reifer, 1997) and (Mili et al., 2002) are other textbooks on software reuse. Frakes and Kang (2005) discuss the status of software reuse research.
The various reuse dimensions are discussed in (Prieto-Diaz, 1993). A survey of methods for classifying reusable software components is given in (Frakes and Gandel, 1990). Advice on when to choose black-box reuse or white-box reuse is given in (Ravichandran and Rothenberger, 2003). Selby (2005) discusses fault characteristics of black-box versus white-box reuse. The application of faceted classification to software reuse is described in (Prieto-Diaz, 1991a).
(Prieto-Diaz and Neighbors, 1986) gives an overview of Module Interconnection Languages. (Medvidovic and Taylor, 1997) gives an overview of major types of Architecture Description Languages. CORBA is described in (Siegel, 1995). (Emmerich et al., 2007) give an excellent overview of research on middleware. References for component-based software engineering are given at the end of Chapter 18.
The non-technical nature of software reuse is discussed in (Tracz, 1988) and (Fafchamps, 1994). Software reuse success factors are discussed in (Prieto-Diaz, 1991b), (Rine and Sonnemann, 1998), (Fichman and Kemerer, 2001), (Morisio et al., 2002a), and (Rothenberger et al., 2003). Models to quantify reuse levels, maturity, costs and benefits are discussed in (Frakes and Terry, 1996). The Raytheon approach to software reuse is described in (Lanergan and Grasso, 1984). Experiences with successful reuse programs are collected in (Schaeffer et al., 1993), (Software, 1994b), and (JSS, 1995b).
What is the difference between composition-based reuse and generation-based reuse?
What is a faceted classification scheme?
What is the difference between horizontal and vertical reuse?
Describe the software-development-with-reuse process model. Where does it differ from the software-development-for-reuse process model?
Discuss the main differences between module interconnection languages (MILs) and architecture description languages (ADLs). How do these differences relate to software reuse?
How does CORBA promote reuse?
To what extent do you consider a domain-independent library of reusable software components a realistic option?


window management systems;
(2D) computer graphics;
user-interface development systems;
office automation;
salary administration;
hypertext systems.
components developed by yourself which you reused more than once, and
components developed by others and reused by you.
To what extent does the 'not-invented-here' syndrome apply to your situation? Is reuse in your situation accidental or deliberate? Were the components designed for reuse or was it, rather, a form of code scavenging?
[30] Be careful though. The software that caused the Ariane 5 disaster was reused from the Ariane 4 and never caused any problems there (Lions, 1996); see also Section 1.4.1. This phenomenon may be termed the antidecomposition property of software reuse: if a component has been successfully used in some environment, this does not imply that it can be successfully reused in some other environment.
[31] CORBA, ORB, Object Request Broker, OMG-IDL, CORBAservices and CORBAfacilities are trademarks of the Object Management Group.
[32] Reserved words are printed in bold for legibility.