
Open-Source Software
Jagdish Gediya*; Jaswinder Singh*; Prabhakar Kushwaha*; Rajan Srivastava*; Zening Wang† * NXP Semiconductors, Automotive Division, Noida, India
† NXP Semiconductors, Microcontroller Division, Shanghai, China
Abstract
In the last 2 decades, open-source software has been adopted widely by many companies due to its significant advantages over proprietary alternatives. Many companies use open-source software to build commercial products and services because it helps achieve faster times to market and reduces development costs. Open-source software is reliable and secure because the global community has contributed to its development and thorough review. This chapter covers open-source operating systems like “Linux” and “FreeRTOS” as well as the open-source boot loader “U-Boot.” Linux is an open-source operating system that is widely used in embedded system as well as servers, desktops, and mobile devices. U-Boot is an open-source boot loader widely used in embedded systems, supporting a number of architectures. FreeRTOS is an open-source real-time kernel developed for small embedded systems.
Keywords
Operating systems; Linux; Router; Security; Architecture; Embedded system; Open source
1 Linux
Linux is one of the most widely used software operating systems across all relevant market segments. Here are a couple of examples that represent the success of Linux: it is used in all 500 of the fastest supercomputers across the world [1]; and 85% of mobile phones are now shipped with Android which is based on Linux [2]. In whatever market segments Linux has entered, it has become the most dominant operating system. Fig. 1 shows the domains in which Linux is being used today.
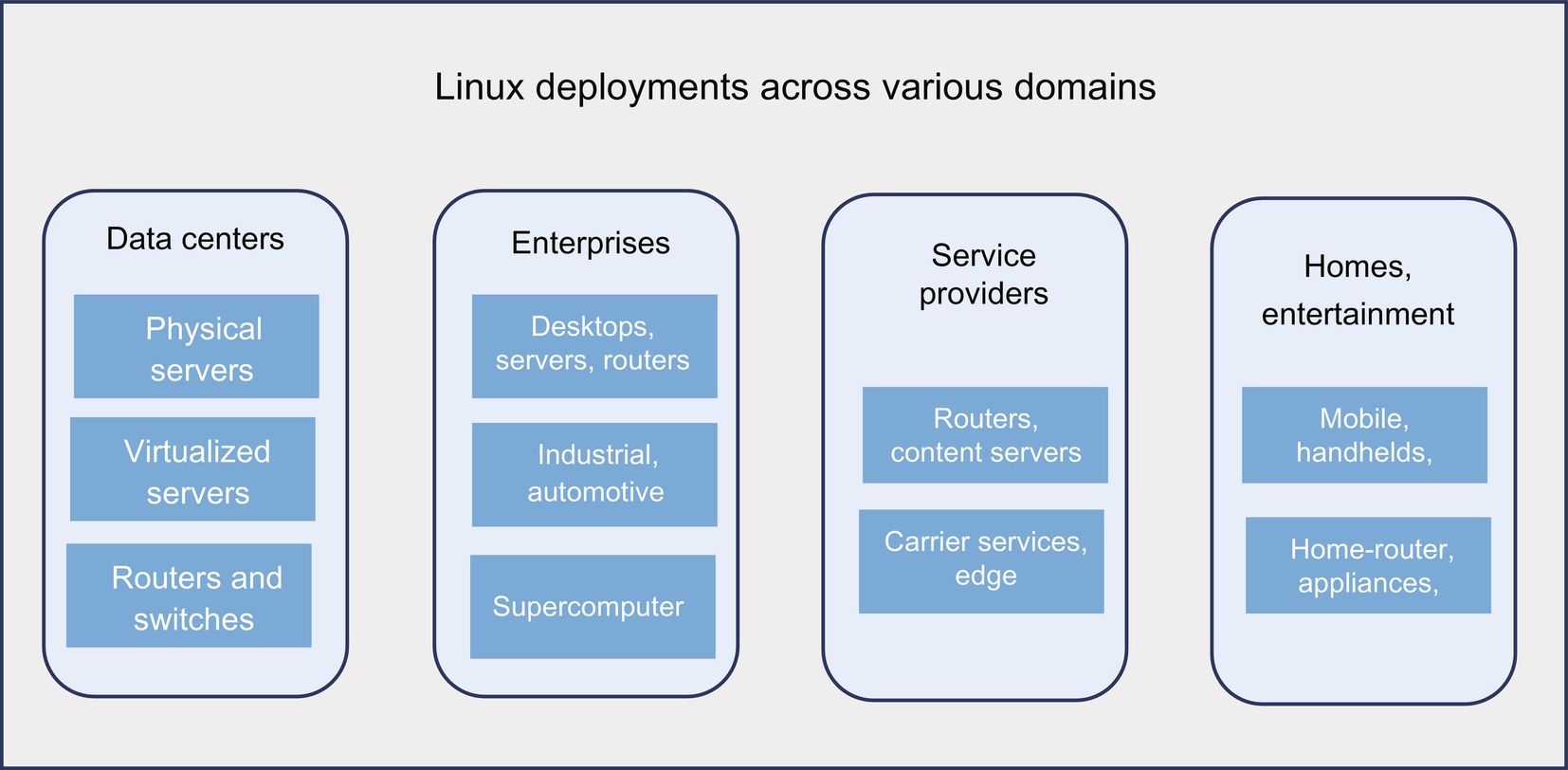
This chapter starts with a brief outline of the Linux journey since its conception. It goes on to explore salient features of Linux to explain why it has become the operating system of choice throughout the world of embedded systems.
1.1 History of Linux
Linux was initially developed as a hobby activity by software enthusiast Linus Torvalds in the early 1990s. He shared this operating system (which he called “Linux”) publicly. Due to its GPL aspect (described later in this chapter), it quickly became very popular among the open-source community. Primarily developed for the desktop environment, it was soon adopted by other uses. Toward the late 1990s and early 21st century, most of the biggest commercial desktop suppliers started shipping desktops with preloaded Linux to avoid the need for costly commercial desktop operating systems.
1.1.1 Reason for the Exponential Acceptance of Linux
Linux is one of the most successful products of the open-source software movement driven by the GNU. The availability of the entire source code of the Linux kernel, along with its very visionary licensing approach, has been driving the success of Linux for more than two decades. Since its source code was publicly available immediately after its origination in the early 1990s, many people became Linux experts, creating and adding useful features to it. Under the guidance of strictly disciplined Linux source code maintenance, Linux became an extremely feature-rich and stable operating system within a couple of years of its inception.
Another major reason for the success of Linux was its “free” availability. Because of an existing monopoly by the de facto leader of desktop operating systems, desktop vendors were looking for options to remove the existing omnipresent operating system. In the late 1990s, desktop PCs started to become a commodity. This put pressure on desktop vendors to reduce costs so that the global availability of desktops could be increased. Linux-based desktops were less costly as Linux was freely available for commercial deployment.
Another movement progressed in parallel—in the domain of research. Supercomputer developers wanted an operating system that they could personally tweak to meet their requirements. Linux came to the rescue. All these factors helped make Linux more feature rich, stable, and popular.
1.1.2 Linux and Embedded Systems
Before Linux, commercial operating systems dominated the entire embedded world. In the late 1990s and early 21st century, there were a good number of embedded devices that needed highly feature-rich operating system to support their many features. Prime uses of such products were enterprise and home routers and set-top boxes. We will consider home routers to explain how the transition from commercial operating systems to Linux happened. Routers were supposed to provide networking layers for Ethernet/ATM/Wifi interfaces along with offering various flavors of network security. These embedded devices used commercial operating systems. Commercial operating systems had small footprints and needed very small RAM and flash storage—these reasons were enough for commercial operating systems to capture the embedded market.
Once desktops started arriving in households, the need for home routers became a necessity. The burden of cost reduction started building on home router providers. After the dot-com bubble burst, enterprise routers also started facing cost pressures. One of the major areas that could offer significant cost reduction was the operating system. Vendors were paying heavy royalties to commercial operating system providers. Linux was not feasible for routers because of its big memory footprint. Constant reductions in the cost of flash storage and SDRAM in the early 21st century made it feasible to accommodate Linux within routers [3]. Soon after this, an open-source forum, named OpenWrt, was set up, focusing on Linux deployments in Wi-Fi routers, in 2004.
The remainder of this chapter focuses on the important features of Linux that mean it can be used in various embedded-world use cases.
1.2 How Embedded Linux is Different From Linux?
“Linux” is generally used for desktop computers and servers. These machines are “general-purpose” machines that can do any type of job with reasonable efficiency: spreadsheets, word processing, browsing, games, network access, etc. Since these systems support all kinds of possible use cases, the operating system software also includes such probable features that may be used.
On the other hand, embedded systems are generally customized for one or more specific use cases. In such systems, operating systems also need to be customized based on the requirement to increase throughput performance and decrease memory footprint. During this customization, unwanted software is removed and the configuration of the rest of the software is matched to meet specific use cases. Linux, which is customized for a given use case, is referred to as embedded Linux.
1.3 Major Features of Linux
Most other embedded operating systems are custom solutions for a limited set of use cases. Linux has been designed as a general-purpose operating system and consequently it has most of its features available in desktop, as well as embedded, operating systems.
This section will describe some salient features of Linux.
1.3.1 Portability
Linux is a highly portable operating system, something that is very clear from the list of supported CPU architectures (see subsequent text). Most parts of the core kernel (that includes scheduler, memory management, device driver frameworks, interrupt framework) are written in such a way that can work on any underlying CPU. In addition to the core kernel, most of the drivers for onboard and on-chip devices run without any modifications on any CPU architecture.
1.3.1.1 Supported CPU Architectures
Today Linux is available for all general CPU architectures, for example, for several years it has supported Intel x86, PowerPC, ARM, and MIPS, to name but a few. Linux supports almost all variants of these architectures. For example, it supports all the major cores of Power Architecture: e500, e550, e5500, e6500, etc.
1.3.1.2 POSIX Compliance
There are challenging situations when precompiled applications supported on one operating system fail to execute (or even compile) on other operating systems. This happens because of the incompatibility of system calls (name or prototype of system call) between two operating systems. POSIX standard is meant to establish compatibility between operating systems. This means if an organization has software that is written for any non-Linux POSIX operating system, that application can be reused to run on Linux since most parts of Linux are POSIX compliant.
1.3.2 Support of a Wide Variety of Peripheral Devices
Linux provides excellent support for various communication interfaces, e.g., Ethernet, 802.11 Wi-Fi, Bluetooth, ATM. All popular storage devices are supported: USB storage, Secure Disk (SD), SATA, SSD, SCSI, RAID, etc. For onboard connectivity, it provides support for I2C, SPI (serial peripheral interface), PCIe, etc.
In summary, if you are planning to use any existing on-chip or onboard hardware in your system, it’s very likely that its stable driver already exists in Linux. Device drivers contribute 60% of Linux source code—24 million lines of code in Linux kernel 4.19.
1.3.3 Complete Network Stack Solution
For end-to-end connectivity, Linux has a very rich network stack: TCP/UDP, IPv4/v6. Linux has a very feature-rich network stack that is also optimized for throughput performance.
Most of today’s high-speed networking devices have network traffic accelerators—these accelerators perform checksum, TCP functions, and even bridging-routing functions. Linux network and device driver frameworks easily support these proprietary accelerators.
1.3.4 Variety of Task Schedulers
The job of task schedulers in operating systems is to execute a task at an appropriate moment. There are scenarios in which a use case demands a specific way of task scheduling. In case of a multiuser system, the CPU should be allocated in a round-robin way to each of the users so that no user feels excessive delays in completion of his or her tasks.
In the case of a desktop with a single user, if the user is running multiple tasks, such as a browser, a word processor, or a print job, they want to see progress in each of these jobs, in parallel; in addition to this the user wants the mouse pointer to immediately change its position on the desktop monitor when the mouse is moved on a mouse mat.
In real-time systems, the task schedule must ensure that real-time jobs finish their work within bounded timelines. For example, in a cellular 4G world, the base station is supposed to transmit the “subframe” exactly at the time defined in the 3GPP specifications. This transmission can only afford delays of less than a microsecond—if the base station incurs higher delays it causes system failure.
For each of the above examples, a custom task scheduler is required. Linux provides task schedulers for each of the above scenarios, and more.
1.3.5 Security
Security is a prime concern when everything is connected—be it the security of the connected device or the security of the data that is being processed by the device. Linux (with the help of underlying CPU architecture) ensures that a device boots with genuine software and also provides enough hooks that prevent the execution of undesired software.
For secure data transfers, Linux provides for the support of security protocols like Ipsec.
Another aspect of security are the firewalls in gateway/router devices. Linux has performance-optimized solutions to ensure that internal/LAN users are not impacted by malicious activities initiated outside of the LAN.
Not only does Linux provide a highly optimized stack to enable the above but it also has a good framework to support proprietary crypto hardware accelerators.
1.3.6 User Space Drivers
Traditionally, device drivers were written to execute in the Linux kernel. Some of the drivers need lots of information to be exchanged with their corresponding user space software. For example, a network interface driver must exchange vast volumes of data each second between the kernel and a webserver running in user space. As we will see later in this chapter, this kind of design incurs a huge penalty on CPU horsepower—Linux provides a user space driver framework where the network driver executes in user space.
1.3.7 Endianness
Some of the product vendors want to use the same onboard and/or on-chip devices on different CPU architectures. For example, a vendor may want to use the same USB device in two separate product lines, one that uses big-endian CPUs and other that uses little-endian CPUs. Maintaining two separate drivers for the same device to handle this situation is a costly proposition. The same scenario arises when one product line uses 32-bit CPU architecture and another uses 64-bit CPU architecture.
The Linux device driver framework and coding practices ensure that when a new driver is added in Linux, endianness and CPU bus sizes of devices do not demand modifications in the drivers.
1.3.8 Debuggability
The success of a design depends on how easily it can be debugged. Debugging doesn’t only mean debugging of the hang/crash of software, it also refers to finding places where optimizations can be made for better performance. Linux has several kinds of debugging mechanisms available to developers for various types of issues in networking, file systems, synchronization mechanisms, device drivers, Linux initialization, and schedulers. The debug features allow developers to inspect what is happening in the system in online mode (while Linux is running) and in offline mode (i.e., take the logs and review them separately).
1.4 Benefits of Using Linux
Use of Linux instead of other operating systems (commercial and noncommercial) brings many benefits. The main benefit comes from a reduction in product cost, however, there are several other benefits as well. This section describes the main benefits of using Linux in embedded devices.
1.4.1 Free of Cost
Linux is freely available to everyone—individuals or commercial/noncommercial companies. One can use it as it is; one can modify and sell the modified Linux—no money needs to be paid to Linux or anyone else. All versions of Linux are free for use—long-term stable (LTS) versions or non-LTS versions.
Note that it’s not only the Linux kernel that is free, its entire ecosystem is also free, for example, the GNU toolchain that compiles the Linux kernel, the GDB debugger, and root file systems (buildroot, Yocto, OpenWrt, ubuntu, etc.) are all free.
1.4.2 Time to Market
In today’s competitive market, return on investment (ROI) also depends on how early you bring your product to market. Software development and testing needs a considerable amount of time in terms of product development therefore it’s very important to reduce the software cycle.
Most CPU architectures (old, latest, and upcoming) are generally available in Linux. This means that with Linux you get an operating system that has already been tested for your specific CPU architecture. As mentioned in an earlier section of this chapter, Linux is already deployed in a variety of market segments. This means that required features are likely to be already available in Linux. These aspects reduce the overall product development time.
Other things that reduce time to market include:
- 1. Quick software team ramp-up. There are many white papers, articles, and videos available on Linux that can be used to quickly ramp-up a project.
- 2. Linux has a vast open-source community. If software developers face an issue, they can generally do a search on the web and most of the time find some forum or group that has already discussed/solved a particular issue—or can assist through web-posts or chat.
- 3. Linux’s debugging is very feature rich. It can easily help localize problems.
1.4.3 No “Vendor Lock-in”
If a product manufacturer deploys a commercially available operating system in a product, the product manufacturer will have to customize the application software for that particular operating system. Additionally, the software team within the product development organization will have to create expertise in that particular operating system.
Now, if the product manufacturer has to come up with a new product, they will have to use the same commercial operating system since their workforce is already trained in that particular operating system. Even if the product needs a different operating system due to its specific needs, the product manufacturer will prefer to reuse their trained workforce to reduce product development costs. If the manufacturer decides to change the operating system, they will have to retrain the workforce and recustomize the application software for a new operating system.
On the other hand, the vendor of the commercial operating system may take undue advantage of the dependence of the product manufacturer on this operating system.
With Linux, there is no “lock-in” with any operating system vendor. This is because Linux expertise can help in tailoring Linux for different use cases. Therefore retraining of the workforce is not required. Also, there are many software vendors that offer Linux-based software—if a product manufacturer wants to outsource software work, they will have variety of choices for selecting software providers.
1.4.4 Highly Stable Operating System
The Linux open-source community is supposed to be one of the biggest open-source communities. Every new software feature (whether a driver, new framework, new scheduler) undergoes strict reviews by the community. These reviewers and repo maintainers are mostly subject-matter experts and they ensure that new proposed code changes comply with all the rules set by Linux.
Once a Linux version is released, it’s tested by several members in the community. Each day, the community keeps adding patches to the mainline Linux and each night the “Linux-next” is tested on a wide range of platforms touching all CPU architectures and almost all features.
The outcome of this effort is that every version of Linux is very stable.
1.4.5 Low Maintenance
There are two aspects of software maintenance that this section describes and in both cases the product vendor achieves low-cost maintenance.
1.4.5.1 Supporting Software Releases After Shipping the Product
Suppose you delivered a production software release and a customer finds a bug. If this issue is a result of core kernel components, you will easily find it discussed on several Internet chat forums. Sometimes, you’ll find the fix for such issues in newer Linux kernel versions—it’s up to the software developer whether he or she wants to backport the fix to the desired kernel version or migrate the entire software to a new Linux kernel version.
Even if an issue relates to an interface between a component written personally and a Linux kernel framework, you will find matching discussions on the Internet because similar issues are likely to have arisen in similar components written by others.
You can take hints from preexisting discussions (or newer Linux versions) and provide fixes to your customers.
1.4.5.2 Keeping Your Own Drivers up to Date With the Latest Kernel
Supposed a vendor ships a software product and plans to ship the next product a few years after the first. Also suppose a vendor has created a lot of new drivers for the first product. When the vendor starts product development for the second product, they have two options:
- 1. Use the same software driver and same Linux kernel version as in the first product.
- 2. Use a new Linux version and port the previously created driver to the new kernel.
Option 2 is the right choice for most as new Linux kernel versions include a lot of new features and bug fixes for previous versions. Porting of your own drivers will require some effort because of the probability that a new kernel framework and features will make your existing drivers incompatible. Linux comes to the rescue of driver developers: one can write the driver, test it, and then get the driver included within the mainline Linux kernel. Once the mainline kernel includes a driver (irrespective of who has written the driver), all new kernel versions always ensure that all the existing drivers are ported to the next kernel version—this forward porting is done by the open-source Linux community.
1.5 Linux Architecture
Linux is designed in a modular way. This approach helps to make it portable across various hardware components and scalable across various use cases. A complete kernel is written in C language (except for very low–level CPU init code that is written in assembly language) making it easily understandable to those who don’t understand the complex constructs of object-oriented languages.
A very high-level overview of the Linux kernel architecture is depicted in Fig. 2.

In Linux-based systems, CPU cores execute in two modes:
- 1. Privileged mode. In this mode, software executes with unrestricted privileges. In this mode of execution, the CPU allows software to access all hardware resources. The entire Linux kernel executes in this mode.
- 2. Unprivileged mode. The Linux kernel creates a permission setting for all hardware resources and, based on the developer’s choice, removes restrictions on some of the resources. Software that runs in unprivileged mode is permitted to access those resources that Linux configures for unrestricted accesses. In Fig. 2, “Apps” running in user space can access kernel resources by directly invoking Linux system calls or by invoking libc (or glibc)-provided API calls. In the latter case, libc (or glibc) invokes a Linux system call. “Drivers” in user space can directly access hardware (more on this later in the chapter), can access a Linux system call, or can access libc (or glibc) APIs. libc (or glibc) is an example library running in user space—there are many more such user space libraries.
1.5.1 Linux Kernel Components
The Linux kernel is composed of several components and in a typical Linux configuration all these components are essential.
1.5.1.1 Device Driver Framework
75% of overall Linux code is for device drivers. This is not a surprise since Linux is ported on a wide range of systems and this deployment has led to the inclusion of drivers of most devices on such systems. These devices include high-complexity hardware like Ethernet and graphics as well as low-complexity devices like EEPROM. To ensure all varieties of devices are plugged into Linux properly, Linux has a device driver framework.
Linux has a generic driver infrastructure that provides a base framework for all kinds of devices. For example, a “struct device” is required by all drivers to help driver modules organize generic resources like interrupts, the bus-type on which such devices exist, and hooks for power management.
The generic driver framework provides further frameworks for each type of device. For example, there is an Ethernet device framework that provides for common jobs associated with a typical Ethernet driver. Any hardware that has Ethernet can leverage from this framework: the actual Ethernet driver becomes smaller in size due to the Ethernet driver framework. Also, the author of an Ethernet device driver does not need to worry about exactly how the driver will exchange Ethernet frames with Linux’s network stack.
Fig. 3 shows only a few of the many example device driver frameworks that exist. There are many more in the kernel. Details can be seen in the Linux source tree (visit/drivers at top level directory of the Linux tree).

1.5.1.2 Schedulers
Linux supports several types of task scheduling and one or more can be used at runtime since most of the schedulers are compiled in. Linux assigns a priority to each thread. Here, thread refers to a kernel thread as well as a user thread (please note that even if a user doesn’t create an explicit thread via invocation of pthread_create() in his user space program, Linux still considers that process as a thread). This approach of threading allows a very fine control on scheduling priorities across the entire system.
‘chrt’ is the user program that lets you change the priority of a thread at runtime (the same effect can be made from within the source code of the programs as well). For a high-priority thread, FIFO (first in, first out) should be used for scheduling policy. For a periodic event that needs a fixed amount of processing after the event occurs, DEADLINE scheduling policy should be used. For regular processing (e.g., running a web server or a driver thread) the default scheduling policy OTHER or RR (round-robin) is used.
Note that initially, Linux was not designed to be an RTOS (real-time operating systems) where hard timelines can be met. Gradually, as Linux became popular in embedded domains, some real-time aspects were added from time-to-time to make scheduling and execution more deterministic with respect to timelines. Even today, Linux doesn’t guarantee bounded latencies. If your product needs bounded latencies, you can apply a very popular Linux patch “PREEMPT_RT”—more on this patch comes later in the chapter.
1.5.1.3 Interrupt
Devices and timers need CPU attention so that some important actions can be performed at a CPU through an interrupt subroutine of the interrupting device. To simplify interrupt initialization and runtime interrupt handling, Linux implements an interrupt management subsystem. Linux manages the low-level details of interrupt management which makes drivers of interrupt controllers and drivers of devices simpler.
This subsystem provides a user interface to check on the statistics of interrupts in the system at runtime and to get/set interrupt affinity to cores.
1.5.1.4 Memory Management
Memory management is comprised of two parts: virtual memory management and memory allocation management. To a good extent, virtual memory management depends on the underlying CPU architecture. Memory allocation management is independent of hardware unless some hardware accelerators are added to the hardware for this purpose. The Linux memory management subsystem is responsible for memory allocations to user space programs as well as kernel space software. For throughput-sensitive modules like Ethernet drivers and network stacks, Linux defines options like slab/slub/slob allocators.
1.5.1.5 Communication Protocol Stack
Linux has native implementations of various types of connectivity protocols like TCP/IP, Wi-Fi, Bluetooth, ATM, MPLS, X25, and so on. This section describes the most commonly used stacks only.
Linux has full networking support—the TCP/IP stack for IPv4 and IPv6. For data protection, Linux has IPsec support using software- based crypto; Linux also has a security framework for systems with hardware-based crypto.
In addition to this, Linux also has the excellent support of a firewall to protect LAN from externally initiated malicious traffic. This framework in Linux is called “NETFILER.” It also lets you enable NAT (Network Address Translation) that allows a Linux device to work as a gateway so that local devices can access the Internet even with their local IP addresses.
In addition to networking, it also supports bridging and 802.1Q-based VLANs.
Linux supports traffic classification for a wide variety of rules of bridged and routed traffic.
1.5.1.6 User Interface (UI)
Linux implements a system call interface between the Linux kernel and user space applications, allowing the Linux kernel to be managed. Typically, shells (e.g., bash) use this system call interface to communicate with the Linux kernel for various configurations. There are device-specific, open-source programs that let the user configure the device; e.g., “ethtool” is used to configure an Ethernet interface. The Linux kernel also provides a well-organized file system “sysfs” that lets the user manage various devices and kernel configurations via the “/sys” directory at the shell prompt.
1.6 Build Environment
This section describes kernel compilation and the root filesystem. The Linux kernel is generally compiled (or cross compiled) on a host x86 machine. Some new embedded systems (e.g., NXP’s QorIQ Layerscape series) let you compile the kernel even on the target device.
1.6.1 Kernel Compilation
GNU GCC toolchain, an open-source compilation toolchain, is generally used to compile and link the Linux kernel to all popular CPU architectures. You may also use a commercial toolchain.
Before you compile the kernel, you should configure the kernel to match your CPU architecture by running “make menuconfig” at the top-level directory of the Linux kernel tree on your build machine. This command allows the user to select the CPU architecture of the target, kernel configuration (e.g., virtual memory page size and endianness), protocol stack configuration (e.g., IPv6/v6, firewall), and hardware devices that are present in the system—you may include, exclude, or customize kernel features using “make menuconfig.” Subsequent execution of “make” compiles and links the kernel.
1.6.2 Root Filesystem
The Linux kernel alone is not very interesting—it’s an operating system without any user-friendly shell interface. Root filesystem provides user-friendly applications, including shells, management applications for devices (e.g., ethtool for Ethernet interfaces), kernel configurations (e.g., “top” to check CPU usage), network stacks (e.g., “ip” for IPv4/IPv6-related configuration), and runtime libraries. Based on user choice, it may include a compiler toolchain and a gdb debugger as well!
There are several ways in which users can generate a root filesystem. This section describes Yocto, one of the most popular frameworks for generating a root filesystem.
1.6.2.1 Yocto
Yocto is an open-source project, sponsored by the Linux Foundation, that provides utilities to create, customize, and build a Linux distribution for an embedded system; the Linux distribution includes boot firmware, the Linux kernel, and a root filesystem. Yocto also allows a user to set up a build environment on a host x86 machine or a target system.
Yocto lets a user fine-tune the root filesystem based on user choice: if the system has very limited interfaces and small memories, the user can generate a tiny root filesystem—in this case the Yocto framework excludes undesired software from the root filesystem. If the target is heavily loaded with memory, the root filesystem can be made extremely feature rich—in this case the root filesystem will be huge!
1.7 Customizing Linux
The default Linux configuration includes many features that are generally required in desktop environments. Embedded devices generally provide a fixed set of capabilities, for example, a router supports routing and IP security–related features, it probably does not need to include graphics, sound, storage features, etc.
Linux provides the means to modulate the kernel so that a designer can attain specific, desired behavior. This section describes how Linux can be configured for desired use cases.
1.7.1 Low Memory Footprint
Low-end embedded devices support a limited set of features. To reduce the cost of these products they have the lowest possible memory resources. Full-blown Linux needs several megabytes of persistent storage (i.e., flash or other media) and several hundred bytes of runtime space (i.e., RAM). It is generally the Linux kernel and root filesystem that take up almost all the memory spaces in a typical embedded system.
- 1. Optimizing Linux. Linux can easily be fine-tuned to meet these limited resources so that it can fit in much smaller persistent and runtime memories. At compiling time, a designer can specify desirable and undesirable features using “make menuconfig.” Linux classifies all features in a hierarchical order that allows a designer to either completely remove a feature or remove only part of a feature. For example, you can remove the complete network stack, or just remove IPv6 and retain IPv4. Even within IPv4 you can pick and choose specific features. The compiled Linux image will contain only the selected features.
- 2. Optimizing the root filesystem. This is the biggest memory consumer in most embedded systems. Yocto is the most popular root filesystem builder for Linux-based embedded system products and a full Yocto root filesystem may take up to several hundreds of megabytes of persistent storage. Yocto provides designers with a customization option that allows making a small root filesystem. This is described in more detail later in the chapter.
1.7.2 Boot Performance
When you turn on your home router, you want it to become operational instantly. This is where boot performance comes in, that is, how quickly the software1 completes all of its initialization. To reduce the boot time, the first thing that a software designer must do is remove undesired software components as described in the previous text.
The next phase of optimization is product specific. Linux starts its multitasking subsystem (i.e., scheduler) very early in its Linux init: boot-critical jobs should be implemented in separate sets of threads and the remainder of jobs should be placed in other threads. If some part of the init system is CPU intensive, and you are operating a multicore system, then you can implement such functions in separate kernel threads and distribute these threads to separate cores. Modules, that are not important for the init system should be moved to separate kernel threads and assigned low priority.
1.7.3 High Throughput Performance
In some categories of products performance is critical. For example, a router is generally expected to route network traffic at Ethernet line rates; similarly, a storage device (USB pen drive) is expected to read/write files as early as possible. There are several options available in Linux that can be enabled at compile and/or runtime to achieve maximum throughput performance.
1.7.3.1 Core Affinity
In SMP systems, the Linux scheduler generally tries to assign a newly ready thread to a CPU core that is currently free. In some cases, designers know that if a job is affined to a specific core, the performance will be better. Linux provides for a runtime user interface (via/proc. files) to allow you to play with the system to discover what affinity configuration works best for your product. Once your experiments yield the right results, you may affine tasks either at compile time or at init time to achieve the discovered affinities of various threads.
1.7.3.2 Interrupt Coalescing
In network-based systems, CPU cores experience interrupts at very high speed when the system is put under heavy load. For example, if a router is subject to small Ethernet frames at maximum supported Ethernet speed, CPU cores become overwhelmed by excessive context switches between their regular task execution and interrupt processing.
The Linux network device driver subsystem provides for a “NAPI” interface that lets the network device driver process tons of network packets using a single interrupt: while these packets are being processed, interrupts are kept disabled from network interface hardware. This “NAPI” feature increases network throughput manifold.
1.7.3.3 User Space Mapping of Buffers
Generally, user space modules are not permitted to read-write memory resources owned by the kernel. If user space software wants to transfer some memory buffer to a kernel driver, the kernel driver first copies the contents from the user space buffer to the kernel driver- allocated buffer. The same copy operation is required when the kernel driver wants to pass on a buffer to a user space module. This works fine for the user space modules that have a small number of buffers to be transmitted between user and kernel spaces. If the volume of such transfers is big then it consumes many CPU cycles doing a memory copy between the user and kernel buffers.
Linux provides an “mmap” feature that allows user space software to read-write a memory space owned by the kernel. Using “mmap,” a user space module can pass on any amount of content to the kernel (and vice versa) without the need for a memory copy.
1.7.3.4 User Space Drivers
Traditionally, device drivers were developed in the Linux kernel. Some of the drivers were complex and when these buggy drivers misbehaved, by accessing memory which a driver was not supposed to access, the result was catastrophic—the entire Linux kernel could hang or crash. This was a problem—no one wanted a crashed/hung system, not even during the software development phase.
There was one further challenge—users didn’t want the source code of their driver or software to be publicly available as advised by Linux’s GPL license. Hence, such users started looking for alternative ways of using their drivers on Linux-based systems.
User space drivers came to the rescue in these scenarios. In the case of user space drivers, the driver software runs in user space as an application program. User space software doesn’t fall under GPL so the user can retain the privacy of their source code in their modules. Also, if the user space driver tries to misbehave by accessing unauthorized regions, Linux detects this and prevents the driver from doing so.
Linux makes this possible by exposing a specific device’s configuration space (generally, memory-mapped device configuration registers) and DMA-capable RAM to user space. Since a user space driver can access its device’s memory space and DMA-capable regions without involving the Linux kernel, these drivers are very useful in case the device processes a lot of traffic. For example, Ethernet interfaces need huge amounts of network-level processing to cater to network traffic at line rate. In such cases user space network drivers and stacks are becoming popular in the open-source world—DPDK, an open-source project, uses user space drivers to provide maximum throughput. Interrupt handling is a challenge as interrupts force the CPU to enter supervisory mode—hence interrupt routines cannot be implemented completely in user space. The solution to this issue is to have a small Linux kernel driver for the device with an extremely small interrupt subroutine to just notify the user space driver of the interrupt event. Another approach could be to disable the interrupt and let the user space driver do the polling for events. Some solutions use a mix of the two approaches: (1) during high-traffic conditions, use polling mode in user space and keep the interrupt disabled; and (2) during scarce traffic, enable the interrupt and wait for notification from the kernel driver of the device.
The Linux kernel provides “UIO” and “vfio” frameworks to help develop user space drivers.
1.7.4 Latencies
Real-time systems need bounded latencies for handling some of events. Linux, using its default configuration, cannot ensure bounded latencies. The default scheduling scheme in Linux is a sort of nonpreemptive round-robin—if some task is running and a higher priority task becomes runnable due to some event, this new high-priority task will have to wait for the existing low-priority task to complete its scheduling quota. Linux provides some kernel configurations (CONFIG_PREEMPT…) to make scheduling more deterministic.
If you want Linux to be completely deterministic during scheduling, to ensure bounded latencies, you can use another open-source project “PREEMPT_RT.” This is a decade-old project for making Linux an “RTOS”—gradually features of the PREEMPT_RT projects are moving into mainline Linux.
1.8 Linux Development and its Open-Source Ecosystem
According to Greg Kroah-Hartman (one of the maintainers of Linux), 4300 Linux developers from 530 different companies had contributed to Linux by 2017. This represents the biggest collaborative software project. Coordinating among so many developers across the globe needs a well-defined workflow and discipline.
This section describes how the Linux community releases Linux versions and describes other relevant open-source projects. This section also looks at a few forums that are promoting open-source projects.
1.8.1 Linux Versions
Like other open-source communities, Linux developers send, review, and approve features and bug fixes via email. These changes are sent to the community in the form of a “patch” or “patch-set.” Every 2 to 3 months, a Linux kernel maintainer adds the approved features and fixes to the existing kernel and comes up with a candidate release for the new Linux kernel version. Once the release candidate is found to be stable enough, a formal Linux kernel release is announced.
Linux kernel version numbers use a template like “a.b.c.,” where a, b, and c are natural numbers. For example, the latest Linux version as of October 2018 is 4.18.0. These Linux versions are also called stable kernel releases.
1.8.2 Long-Term Support (LTS) Linux Version
These are the Linux versions that are maintained by Linux maintainers over the long term (approximately 2 years). Every year, one of the stable Linux releases is chosen as an LTS Linux version.
1.8.3 Related Open-Source Communities
The open-source community has created several forums to promote open-source projects, some of these are working around Linux. This section describes a couple of these forums.
1.8.3.1 Linux Foundation
Its primary focus is to build ecosystems around open-source projects to accelerate the commercial adoption of open-source projects. For example, to make Linux suitable for automotive and carrier markets, the Linux Foundation created AGL (Automotive Grade Linux) and CGL (Carrier Grade Linux) working groups. The objectives of such working groups are to identify the gaps in open-source projects like Linux for their deployment in specific market segments. Once the gaps are identified, these groups try to create the requisite groups to fill such gaps.
1.8.3.2 Linaro
Linaro works to promote open-source projects like Linux for various market segments for ARM's generic core–based systems.
1.8.4 Linux-Based Distributions
1.8.4.1 Android
Android is a Linux-based distribution deployed on most smartphones, tablets, and wearables. In its core, Android uses the Linux kernel with some modifications. These Linux modifications are maintained by the Android team and some of these features have been gradually included in Linux.
Android generally uses one of the latest LTS (long-term support) kernel versions of Linux.
1.8.4.2 Ubuntu
Ubuntu is one of the most popular open-source Linux distributions mainly targeted at desktops and servers. Ubuntu is released every 6 months and has LTS (long-term support) for 5 years. Thanks to its popularity, Ubuntu has been ported to several high-end embedded systems based on ARM and Power architectures.
There are many other open-source distros that are based on Linux.
1.9 Coding Guidelines
Linux expects that developers should write the Linux kernel code in such a way that code is as generic as possible (i.e., independent of any specific hardware architecture), is readable, and avoids unnecessary complexity. These guidelines ensure that Linux code is maintainable over the long term and that it increases code reusability across multiple types of hardware. These guidelines are strictly enforced during the patch review process that takes place during patch upstreaming.
Let us see how a good driver code ensures that the Linux driver is usable across two different CPU architectures. “QorIQ” devices from Freescale (now part of NXP) include an Ethernet controller ETSEC, its software driver “gianfar” can be found in the drivers/net/ethernet/freescale/directory of the Linux kernel source. The gianfar driver is written in such a way that whether the CPU core executes in little- endian mode or in big-endian mode, the same driver source code is used. See the code-snippet from gianfar.h below (this is the kernel recommended coding guideline for endian-safe drivers):

The ETSEC Ethernet Controller is a big-endian module in several SoC devices of NXP irrespective of whether the CPU cores in those SoC execute in big-endian or little-endian mode. The above driver uses the gfar_write() accessor function (shown in the above code snippet) to write ETSEC configuration registers and this accessor in turn uses an endianness- safe Linux provided accessor iowrite32be()—the Linux accessor is compiled according to the CPU core’s endianness defined during the compilation of Linux.
Below is an incorrect driver snippet for the same action completed in the previous snippet. Technically, the snippet given below will work but this code includes undesired complexity in terms of its handling of endianness.

If a developer sends a patch like the incorrect code-snippet above, reviewers are likely to reject it.
Some important coding style suggestions can be found in a file available in the Linux source: Documentation/process/coding-style.rst.
1.10 Code Review in the Upstream Community
Linux mandates code reviews in the open-source community. The community helps to provide a better coding style, find potential bugs, and identify better architecture frameworks. It eventually makes the code generic enough to be used by the entire Linux community.
Also, if the feature is new or covers several areas of interest then it is easy to find help with testing it within the community.
Let’s consider a few examples of how community reviews help with the betterment of a patch.
- 1. Example 1 Upstream review of “Upstreaming imx7ulp lpuart support.” This feature took four rounds of reviews (which means the author had to send four versions of the patch).

Each revision improved the code in the following manner:- • Round 1: Code clean up and architecture improvement.
- • Round 2: Better coding style, eEliminate one unnecessary global variable, make unchangeable variables to “Const.”
- • Round 3: Better architecture and performance improvement, better driver design to handle different types of SoC devices (e.g., Layerscape lpuart), baud rate calculation algorithm improvement, elimination of another global variable which usually a bad design for per-device routines is.
- • Round 4: Fix a small bug caught by 0-day Robot (Community CI).
The patch after four rounds of reviews, i.e., the final version [4], had the following improvements compared with the initial version [5]:- • Readability—cleaner code.
- • Efficiency—better performance.
- • Stability—better stability for different types of SoC devices.
- • Scalability—easier to add new types of support for devices.
- • Maintainability—better architecture and driver design.
Below is a snapshot of a partial patch showing the differences between initial v1 and final v4: note that the color bar to the right of the snapshot identifies the big differences.

- 2. Example 2: Upstream review of “Upstreaming imx8qxp clock support.” This feature took eight rounds of reviewing.
 Each revision improved the code in the following manner:
Each revision improved the code in the following manner:- • Round 1: Code clean up and reorganization.
- • Round 2: Better coding style, better namespace for exported functions, put device specific SCU service API into device driver.
- • Round 3: Proper prefix for exported structure names.
- • Round 4: Update header-file path.
- • Round 5: Fix potential bugs (memory leak), add more code comments, add missing lock and more code clean up.
- • Round 6: Significant architecture improvement, architecture redesign to address a workaround issue, clearer component separation.
- • Round 7: Use new kernel API.
- • Round 8: Add enough comments to code and clean up the code further.
The patch after eight rounds of reviews, i.e., the final version [6], had the following improvements compared with the initial version [7]:- • Readability—cleaner code.
- • Efficiency—better performance.
- • Stability—better stability for different types of SoC devices.
- • Scalability—easier to add new types of device support.
- • Maintainability—better architecture and driver design.
To conclude, if the author of the code undertakes all the recommended coding guidelines and various aspects described in this section the code will be accepted by the open-source maintainer in a short period of time. These community reviews help to make code generic and help maintainers gain enough confidence for a change set.
1.11 License
Linux comes under GPL (GNU General Public License) version 2. This license allows anyone to use Linux source code as it is, modify it, and redistribute it (in original and/or modified forms) to others for commercial and noncommercial purposes. GPL asks that if you have modified the Linux source and redistributed it then you are bound to publish the distributed software in source format. It also imposes some restrictions on how you may link non-GPL software with Linux. Details of these GPL version 2 rules can be found in COPYING file present in the top-level directory of the Linux source.
2 U-Boot
2.1 U-Boot and its Applicability to Several Types of Devices
A boot loader is a critical piece of software running on any system. Whenever a computing system is initially powered on, the first piece of code to be loaded and run is the boot loader. It provides an interface for the user to load an operating system and applications.
The open-source ecosystem has lots of boot loaders like GRUB, UEFI, RedBoot, Yaboot, etc. However, U-Boot or Das U-Boot is the most commonly used open-source cross-platform boot loader. It is commonly used in embedded systems with the prime objective of configuring systems and loading next-level operating systems. It supports multiple architectures and has a large following by hardware manufacturers.
U-Boot boot loader typically is loaded by a system’s Boot ROM from various boot sources, commonly nonvolatile memory such as NOR flash, SD cards, and SPI flash during power on—taking control of the hardware. Once U-Boot starts execution, it configures the hardware to load next-level images from onboard storage or from a network and then starts loading next-level images. After loading next-level images, U-Boot transfers execution control to next-level executable images. U-Boot also provides users with a “shell”-like interface so that users can play with the hardware configuration before next-level images take over.
2.2 Major Features of U-Boot
Broadly speaking, the major features of U-Boot are multiple boot sources, image upgrades, its shell (user interface), environment variables, scripts, stand-alone applications, and operating system boot commands.
2.2.1 Multiple Boot Source Support
A boot source is a nonvolatile onboard memory from where hardware loads U-Boot into preinitialized memory or transfers control directly for in-place execution (also known as XIP). Later sections in this chapter will share further details on this topic.
U-Boot supports booting from NOR, Serial NOR, SD/MMC, DSPI, NAND, etc.—some systems support multiple boot sources in the same U-Boot executable image while some systems support only one boot source in one U-Boot executable. Once U-Boot executes, it can load next-level images from a desired boot source—U-Boot makes this decision based on the user configuration saved in its “environment variables” (see later sections of this chapter for more on environment variables).
2.2.2 Shell (User Interface)
U-Boot provides a shell (also known as a command-line interface) over its serial interface which lets users manage various U-Boot attributes (e.g., which boot source to use for loading next-level images). This command-line interface provides lots of commands depending upon compile-time configuration. Major supported commands are flash read/write, networking (mdio, dhcp, tftp, ping, etc.), i2c, sdhc, usb, pcie, sata, and memory operations. Users can use these commands to configure the system and access I/O devices. Memory tests can also be initiated using the U-Boot shell.
U-Boot also supports commands for the management of environment variables and the display of runtime system configuration.
2.2.3 Environment Variables
These variables control the hardware configuration and boot behavior. Environment variables are usually stored on nonvolatile memory—they are given a default value at compile time, based on a user’s choice for that specific system. Users can also modify these variables at runtime (using U-Boot shell) and save them to nonvolatile memory.
Runtime control and configuration environment variables consist of variables such as the IP address, UART baud rates, Linux bootargs, system MAC address, and bootcmd.
Boot-time control and configurations changes the way devices boot. For example, SDRAM configurations (ECC on/off, type of interleaving) modifies the way SDRAM is initialized during boot-sequence.
2.2.4 Scripts
The scripting feature of U-Boot allows storing multiple command sequences in a plain text file. This plain text file, can be run at the U-Boot user shell by simply invoking the “source” command followed by the script’s name. This allows the user to run multiple command sequences in one go.
2.2.5 Stand-Alone Applications
U-Boot supports “stand-alone” applications. These applications can be loaded dynamically during U-Boot execution by bringing in RAM via network or nonvolatile memory. These stand-alone applications can have access to the U-Boot console, I/O functions, and memory allocations.
Stand-alone applications use a jump table, provided by U-Boot, to use U-Boot services.
2.2.6 Operating System Boot Commands
The U-Boot command “bootm” allows booting of next-level executable images (typically an operating system) preloaded in RAM—an operating system image can be obtained via RAM from a network or from onboard nonvolatile memory.
U-Boot also supports file systems. This way, rather than requiring the data that U-Boot will load to be stored at a fixed location on the storage device, U-Boot can read the file system on nonvolatile storage to search for and load specific files (e.g., the kernel and device tree). U-Boot supports all commonly used file systems like btrfs, cramfs, ext2, ext3, ext4, FAT, FDOS, JFFS2, Squashfs, UBIFS, and ZFS.
An operating system boot command is intelligent enough to perform all required prerequisites for operating system boot, such as device tree fix-up, required operating system image and file system uncompressing, and architecture-specific hardware configuration (cache, mmu). Once all prerequisites are completed, it transfers control to the operating system.
2.2.7 Autoboot
This feature allows a system to automatically boot to a next-level image (such as Linux or any user application) without the need for user commands. If any key is pressed before the boot delay time expires, U-Boot stops the autoboot process, provides a U-Boot shell prompt, and waits forever for a user command.
2.2.8 Sandbox U-Boot
The “sandbox” architecture of U-Boot is designed to allow U-Boot to run under Linux on almost any hardware. It is achieved by building U-Boot as a normal C application with a main () and normal C libraries. None of U-Boot’s architecture-specific code is compiled as part of the sandbox U-Boot.
The purpose of running sandbox U-Boot under Linux is to test all the generic code—code that is not specific to any one architecture. It helps in creating unit tests which can be run to test upper level code.
The reader is referred to U-Boot documentation for further information on sandbox U-Boot.
2.3 U-Boot Directory Organization
U-Boot code and directory organization is very similar to Linux with customization for boot loaders.
| arch/ | Architecture-specific files |
| arc/ | Files generic to ARC architecture |
| arm/ | Files generic to ARM architecture |
| m68k/ | Files generic to m68k architecture |
| microblaze/ | Files generic to microblaze architecture |
| mips/ | Files generic to MIPS architecture |
| nds32/ | Files generic to NDS32 architecture |
| nios2/ | Files generic to Altera NIOS2 architecture |
| openrisc/ | Files generic to OpenRISC architecture |
| powerpc/ | Files generic to PowerPC architecture |
| riscv/ | Files generic to RISC-V architecture |
| sandbox/ | Files generic to HW-independent “sandbox” |
| sh/ | Files generic to SH architecture |
| x86/ | Files generic to x86 architecture |
| api/ | Machine/arch-independent API for external apps |
| board/ | Board dependent files |
| cmd/ | U-Boot commands functions |
| configs/ | Board default configuration files |
| disk/ | Code for disk drive partition handling |
| doc/ | Documentation |
| drivers/ | Drivers for on-chip and onboard devices |
| dts/ | Contains Makefile for building internal U-Boot fdt. |
| examples/ | Example code for stand-alone applications, etc. |
| fs/ | Filesystem code (cramfs, ext2, jffs2, etc.) |
| Include/ | Header files |
| licenses | Various license files |
| net/ | Network-stack code |
| post/ | Power on self-test |
| scripts/ | Various build scripts and Makefiles |
| tools/ | Tools to build S-Record or U-Boot images, etc. |
CPU architecture–related code is placed in the arch/folder, while board-related code is placed the board/folder. The folder include/configs contains platform- or system-related header files. It can be used by the user to customize U-Boot for features and commands supported on a platform.
Other folders are self-explanatory, the top-level README file can be referred to for further details.
2.4 U-Boot Architecture and Memory Footprint
U-Boot supports two types of architecture: the single-stage boot loader and two-stage boot loader. The architecture you use depends on the size and nature of the memory available in the hardware. The following sections consider these two types of architecture as well as their applicability.
2.4.1 Single-Stage Boot Loader
If hardware (SoC or board) has XIP (eXecute In Place) nonvolatile (NV) storage, single-stage U-Boot architecture is preferred. In this architecture the entire U-Boot software is compiled into a single U-Boot binary. This single U-Boot binary is stored in XIP NV memory. During a system boot, the hardware transfers control to the abovementioned XIP memory; consequently, U-Boot executes from this memory and configures other desired hardware blocks. In the last stage of execution, U-Boot relocates to a bigger RAM. If the bigger RAM is SDRAM, then U-Boot first configures the SDRAM hardware and then relocates itself from the NV memory to RAM. A detailed flow diagram of this process is given in Fig. 4.

The relocated U-Boot has access to the complete SDRAM, allowing the initialization of the complete system, including drivers, such as USB, PCIe, SATA, and Ethernet. Once all the initialization is completed, U-Boot enters an infinite loop, waiting for user input. Further execution is controlled by the user. Alternatively, relocated U-Boot loads next-level images.
The approximate size of the single-stage boot loader for NXP’s QorIQ LS2080ARDB platform is 700 kB.
In terms of design considerations for single-stage boot loader architecture, U-Boot performs some of the tasks before relocation and the remaining tasks after relocation. Execution from XIP NV memory is generally much slower than execution from SRAM or SDRAM. Hence, the user will have to carefully design what should be included in the phase before relocation.
2.4.2 Two-Stage Boot Loader
If the hardware (SoC or board) does not have XIP (eXecute In Place) nonvolatile (NV) storage but has internal SRAM, then two-stage U-Boot architecture is preferred. In this architecture U-Boot is compiled into two sets of binaries known as SPL (Secondary Program Loader) and U-Boot. Here, the SPL and U-Boot binary are stored in nonvolatile memory (such as SD and SPI).
SPL binary is loaded into internal SRAM by the system’s BootROM. BootROM further transfers control to SPL. SPL, executing from internal SRAM, configures SDRAM. Once SDRAM is configured it copies U-Boot into SDRAM and transfers control to U-Boot. A detailed flow diagram of this process is given in Fig. 5.

Once U-Boot gets control, it initializes some of the hardware components like USB, PCIe, SATA, Ethernet etc. After complete initialization, U-Boot enters an infinite loop, waiting for user input. Further execution is controlled by the user. A detailed flow diagram of this process is given in Fig. 6.

The approximate sizes of the two-stage boot loaders for NXP’s ARMv8 LS2080ardb platforms are ~ 75 kB for SPL and ~ 700 kB for U-Boot.
The beauty of U-Boot is that its size is controlled by the user at compile time. Users can customize its size based on system requirements by removing compile-time config options.
Note: selection of type of boot architecture.
- The type of boot stage loader used for U-Boot depends upon the system’s hardware configurations. If the system’s hardware has XIP (eXecute In Place) flash, like NOR flash, then a single-stage boot loader can be used.
- However, for cases where a system’s hardware does not have XIP (eXecute In Place) memory and has internal RAM of limited size, then the default U-Boot may not be able to fit into the internal RAM. In this case a two-stage boot loader is the best option, i.e., having a small SPL loading normal U-Boot in SDRAM.
2.5 Fast Boot Approach
Because of widespread deployment across various market segments, U-Boot has a large array of features. These features have made U-Boot a little bulky, resulting in slow boot progress. This slow speed is not acceptable to some systems in the production environment, hence the need for a U-Boot that boots very rapidly.
U-Boot’s fast boot approach is known as falcon mode. This mode is only available in SPL. It has been introduced to speed up the booting process, allowing the loading/executing of next-level images without a full-blown U-Boot. SPL plays key role here configuring SDRAM. It further copies the operating system image to SDRAM and completes all the prerequisites of an operating system boot. Once all the operating system prerequisites are complete, control is transferred. Fig. 7 represents falcon mode.

The reader is referred to the U-boot documentation for falcon mode implementation and support.
2.6 Secure Boot
Secure boot or chain-of-trust boot is a mechanism for authenticating and optionally decrypting next-level images while still allowing them to be field upgraded. This feature allows product vendors to ensure that the shipped hardware always executes “genuine” software images (“genuine” software here refers to the software that was distributed/shipped by the specific vendor only).
U-Boot’s secure boot depends on two major technologies: cryptographic hashing (e.g., SHA-1) and public key cryptography (e.g., RSA). These two cryptography technologies help product vendors in distributing authentic images, having them verified on target before they are used by the hardware after power-on.
Images can be stored one after another and signed using the cryptographic algorithms mentioned above. For added security the images can be encrypted. After power-on, the hardware authenticates the first image (i.e., U-Boot) and then—if required—decrypts the U-Boot. If hardware finds the U-Boot image to be genuine, it starts U-Boot execution. Next, U-Boot authenticates the next-level image (typically the operating system) and, if desired, decrypts it. U-Boot passes on execution control to the next-level image only if it finds that it is successfully authenticated.
Secure boot is an optional feature—designers need to implement the complete U-Boot flow for the secure boot feature.
2.7 Supported Architectures and Operating Systems
U-boot supports various computer architectures including 68k, ARM, Blackfin, MicroBlaze, MIPS, Nios, SuperH, PPC, RISC-V, and x86. It also supports almost all variants of these architectures. For example, it supports all the major cores of Power Architecture: e500, e550, e5500, e6500, etc.
U-Boot is mainly used to boot Linux. Considering that Linux supports a variety of computer architectures, it does all the required architecture-specific configurations and device tree fix-ups for Linux booting.
Also, U-Boot supports various flavors or distributions of Linux, such as Ubuntu and Suse. U-Boot does not inherently support different Linux distributions. To support these distributions, U-Boot runs a layer of abstraction (EFI). This abstraction (EFI) layer is used by GRUB2 to launch Linux distributions.
2.8 Open-Source Community and New Upcoming Features
U-Boot is maintained by Wolfgang Denx and hosted at www.denx.de/wiki/U-Boot. All discussions, developments, and reviews occur via a U-Boot mailing list [8]. These discussions and developments can be seen on patchwork [9].
The open-source community is continuously evolving U-Boot with the support of new architecture/hardware and features. Considering that the organization of U-Boot is very much the same as Linux, the community used to sync U-Boot’s code-base with the Linux code-base, allowing many features to be ported to U-Boot.
U-Boot has lots of new, upcoming features, such as driver model, SPI-NAND framework, EFI layer enhancement for distribution, and device trees for all supported architectures.
2.9 Licensing Information—Commercial Aspects
U-Boot is free software. It has been copyrighted by Wolfgang Denk and many others who have contributed code. It can be redistributed and/or modified under the terms of version 2 of the GNU General Public License as published by the Free Software Foundation. This license does not cover “stand-alone” applications that use U-Boot services by means of the jump table provided by U-Boot exactly for this purpose.
Any organization or individual can freely download this software and customize it for their desired system. Such customized U-Boot software may then be distributed commercially and noncommercially. Organizations and individuals can also send their customized U-Boot back to the mainline U-Boot for long-term maintenance.
3 FreeRTOS
3.1 About FreeRTOS
FreeRTOS is a portable, open-source and tiny footprint real-time kernel developed for small embedded systems commonly used in wearable devices, smart lighting solutions, and IoT solutions.
The FreeRTOS kernel was originally developed by Richard Barry around 2003. Later, the FreeRTOS project was developed and maintained by Real Time Engineers Ltd., a company founded by Richard Barry. In 2017 Real Time Engineers Ltd. passed control of the FreeRTOS project to Amazon Web Services (AWS), however, it is still an open-source project.
FreeRTOS can be built with many open-source compilers, like GCC, as well as many commercial compilers. It supports various architectures, such as ARM, x86, and PowerPC. The FreeRTOS “port” is a combination of one of the supported compilers and architectures. FreeRTOS files that are common to all ports conform to MISRA coding standard guidelines. However, there are a few deviations from MISRA standards.
The FreeRTOS footprint depends on architecture, compiler, and kernel configuration. With full optimizations and the least kernel configurations, its footprint can be as low as ~ 5 kB [10].
3.2 Licensing
FreeRTOS is provided under an MIT opensource license [11]. Earlier, FreeRTOS kernel versions prior to V10.0.0 were provided under a modified GPLv2 license.
3.3 Commercial Aspects
FreeRTOS has commercial licensing available in form of OpenRTOS. OpenRTOS is the commercial version of FreeRTOS that provides a warranty and dedicated support.
SAFERTOS is a derivative of FreeRTOS designed to meet the requirements of industrial, medical, and automotive standards. It is precertified for standards such as IEC 61508-3 SIL 3 and ISO 26262 ASIL D.
OpenRTOS and SAFERTOS aren’t open source.
3.4 Supported Architectures
There are wide range of architectures supported by FreeRTOS, such as ARM7, ARM9, ARM Cortex-M, ARM Cortex R, ARM Cortex-A, AVR, PIC, PowerPC, and x86.
3.5 FreeRTOS Architecture
Fig. 8 describes the FreeRTOS source code directory structure. The source directory contains the common kernel source code and portable layer. The demo directory contains the demo application projects targeted at a specific port.

Fig. 9 describes the typical architecture of a FreeRTOS-based system.

3.6 Portability
Basically, the FreeRTOS kernel has three files called tasks.c, queue.c, and list.c. These three files are present in the source directory. Additional files, i.e., event_groups.c, timers.c, and croutine.c, are only required if software timer, event group, or coroutine functionality are needed. All these files are common between all ports.
Apart from common files, FreeRTOS needs compiler- and architecture-specific code—called port. This code is available in the Source/portable/[compiler]/[architecture] directories, e.g., Source/portable/GCC/ARM_CM4F.
New FreeRTOS ports can also be developed [12].
Each FreeRTOS project requires a file called FreeRTOSConfig.h which contains different configuration macros. This file is used to customize the FreeRTOS kernel.
3.7 Features
3.7.1 Scheduling
FreeRTOS doesn’t have any restrictions on the number of real-time tasks that can be created and the number of task priorities that can be used. Multiple tasks can have the same priorities too.
A task can have one of these states: running, ready, blocked, or suspended.
The scheduling algorithm is based on the configUSE_PREEMPTION and configUSE_TIME_SLICING values in FreeRTOSConfig.h (Table 1).
Table 1
| configUSE_PREEMPTION | configUSE_TIME_SLICING | Scheduling Algorithm |
|---|---|---|
| 0 | Any value | Context switch occurs only when the RUNNING state task enters the Blocked state or the RUNNING state task explicitly yields by calling taskYIELD(). Tasks are never preempted. |
| 1 | 0 | A new task is selected to run only if higher priority tasks enter READY state or a running task enters the blocking or suspended state. |
| 1 | 1 | Preempt the running tasks if higher priority tasks enter the READY state. Running tasks enter READY state and higher priority tasks enter the RUNNING state. Equal priority tasks share an equal amount of processing time if they are in READY state. Time slice ends at each tick interrupt. Scheduler selects a new task to enter the RUNNING state during RTOS tick interrupt. |
3.7.2 Low Power
FreeRTOS supports tickless idle mode for low-power implementation. A developer can use the idle task hook to enter low-power state. However, power saving using this method is limited because periodically the tick interrupt will be served, hence exit and entry to low-power mode will be frequent. It may introduce an overhead instead of power saving if the tick interrupt frequency is too high. The FreeRTOS tickless idle mode stops the tick interrupt during an idle task to overcome this issue.
FreeRTOS provides for an idle task hook function which is called from the idle task. An application author can use this hook function to enter the device into low-power mode.
3.7.3 Debugging
FreeRTOS provides a mechanism for stack overflow detection. An application needs to provide the stack overflow hook function with a specific prototype and name. The kernel calls the hook function if the stack pointer has a value outside the valid range.
The FreeRTOS kernel contains different types of trace macros that are defined empty by default. An application writer can redefine these macros according to their need to collect application behavioral data.
3.7.4 IPC and Synchronizations
FreeRTOS supports various intertask communication mechanisms like stream and message buffers, task notifications, queues, and event groups.
FreeRTOS supports many synchronization primitives like binary semaphores, counting semaphores, mutexes, and recursive mutexes.
3.7.5 Memory Management
FreeRTOS supports creating different objects, such as tasks, queues, timers, and semaphores, either by using dynamic memory or by an application provided in static memory.
FreeRTOS supports five dynamic memory allocation implementations, i.e., heap_1, heap_2, heap_3, heap_4, and heap_5, which are in the Source/Portable/MemMang directory. An application writer must include only one of these memory allocation implementations in a project.
heap_1 is the simplest and the only implementation which doesn’t allow freeing of memory. heap_2 allows freeing memory but doesn’t concatenate adjacent free blocks. heap_3 is wrapper around standard "malloc" and "free" interfaces provided by compiler. heap_4 concatenates adjacent blocks to avoid fragmentation. heap_5 allows spanning the heap over multiple nonadjacent memory and concatenates adjacent blocks to avoid fragmentation.
It is also possible to provide your own implementation.
3.8 FreeRTOS + Ecosystem
There are many add-on software products that are either open source or proprietary, such as filesystems, networking stacks, networking security libraries, command line Interfaces, and I/O frameworks, available to debug and develop FreeRTOS-based embedded systems more rapidly. The source code for these add-on software products is available under the FreeRTOS-Plus/Source directory.
3.9 Debugging
FreeRTOS is widely used in small embedded systems. As a result, FreeRTOS awareness is widely supported in many IDEs, such as DS-5 studio from ARM and Kinetis Design Studio from NXP.
Using these FreeRTOS-aware IDEs and powerful hardware debuggers, like DSTREAM from ARM, application writers can get all the required data for debugging, such as task lists and their status, timer information, queue status, and current data in the queue.
FreeRTOS also provides a mechanism to debug stack overflow problems. However, this mechanism has limitations on certain architectures where the CPU throws exceptions against stack corruption before FreeRTOS checks for an overflow.
Application developers can redefine and use FreeRTOS trace macros to obtain application behavioral data.
3.10 Support
FreeRTOS has a support forum https://sourceforge.net/p/freertos/discussion/ for associated discussions.
Questions
- 1. Describe how embedded Linux is different from general Linux.
- 2. What are pros and cons of implementing a device driver in a Linux kernel vs. a user space?
- 3. What kind of customizations are available in Linux? Explain performance-related customization.
- 4. What is the significance of the coding guidelines for developers?
- 5. What are the benefits of upstream code reviewing. Explain providing one suitable example?
- 6. Why does U-Boot have a two-stage boot load flow for some products and a three-stage boot load flow for others?
- 7. In what types of device would you use FreeRTOS over Linux?
- 8. What are different scheduling algorithms supported in FreeRTOS?