
Chapter 8. Abuse Cases[1]
![Abuse CasesAbuse casesAbuse casesoverviewMisuse cases.Abuse cases.Touchpointslist ofabuse casesUMLUse casesAbuse cases.Parts of this chapter appeared in original form in IEEE Security & Privacy magazine co-authored with Paco Hope and Annie Anton [Hope, McGraw, and Anton 2004].](http://imgdetail.ebookreading.net/software_development/21/0321356705/0321356705__software-security-building__0321356705__graphics__205fig01.gif)
To kill, you must know your enemy, and in this case my enemy is a varmint. And a varmint will never quit—ever. They’re like the Viet Cong—Varmint Cong. So you have to fall back on superior intelligence and superior firepower. And that’s all she wrote. | ||
| --BILL MURRAY (AS CARL SPACKLER IN CADDYSHACK) | ||
Software development is all about making software do something. People who build software tend to describe software requirements in terms of what a system will do when everything goes right—when users are cooperative and helpful, when environments are pristine and friendly, and when code is defect free. The focus is on functionality (in a more perfect world). As a result, when software vendors sell products, they talk about what their products do to make customers’ lives easier—improving business processes or doing something else positive.
Following the trend of describing the positive, most systems for designing software also tend to describe features and functions. UML, use cases, and other modeling and design tools allow software people to formalize what the software will do. This typically results in a description of a system’s normative behavior, predicated on assumptions of correct usage. In less fancy language, this means that a completely functional view of a system is usually built on the assumption that the system won’t be intentionally abused. But what if it is? By now you should know that if your software is going to be used, it’s going to be abused. You can take that to the bank.
Consider a payroll system that allows a human resources department to control salaries and benefits. A use case might say, “The system allows users in the HR management group to view and modify salaries of all employees.” It might even go so far as to say, “The system will only allow a basic user to view his or her own salary.” These are direct statements of what the system will do.
Savvy software practitioners are beginning to think beyond features, touching on emergent properties of software systems such as reliability, security, and performance. This is mostly due to the fact that more experienced software consumers are beginning to say, “We want the software to be secure” or “We want the software to be reliable.” In some cases, these kinds of wants are being formally and legally applied in service-level agreements (SLAs) and acceptance criteria regarding various system properties.[2] (See the box Holding Software Vendors Accountable for an explanation of SLAs and software security.)
The problem is that security, reliability, and other software -ilities are complicated. In order to create secure and reliable software, abnormal behavior must somehow be anticipated. Software types don’t normally describe non-normative behavior in use cases, nor do they describe it with UML; but we really need some way to talk about and prepare for abnormal behavior, especially if security is our goal. To make this concrete, think about a potential attacker in the HR example. An attacker is likely to try to gain extra privileges in the payroll system and remove evidence of any fraudulent transaction. Similarly, an attacker might try to delay all the paychecks by a day or two and embezzle the interest that is accrued during the delay. The idea is to get out your black hat and think like a bad guy.
Surprise! You’ve already been thinking like a bad guy as you worked through previous touchpoints. This chapter is really about making the idea explicit. When you were doing source code analysis with a tool, the tool pumped out a bunch of possible problems and suggestions about what might go wrong, and you got to decide which ones were worth pursuing. (You didn’t even have to know about possible attacks because the tool took care of that part for you.) Risk analysis is a bigger challenge because you start with a blank page. Not only do you have to invent the system from whole cloth, but you also need to anticipate things that will go wrong. Same goes for testing (especially adversarial testing and penetration testing). The core of each of these touchpoints is in some sense coming up with a hypothesis of what might go wrong. That’s what abuse cases are all about.
Abuse cases (sometimes called misuse cases as well) are a tool that can help you begin to think about your software the same way that attackers do. By thinking beyond the normative features and functions and also contemplating negative or unexpected events, software security professionals come to better understand how to create secure and reliable software. By systematically asking, “What can go wrong here?” or better yet, “What might some bad person cause to go wrong here?” software practitioners are more likely to uncover exceptional cases and frequently overlooked security requirements.
Think about what motivates an attacker. Start here.... Pretend you’re the bad guy. Get in character. Now ask yourself: “What do I want?” Some ideas: I want to steal all the money. I want to learn the secret ways of the C-level execs. I want to be root of my domain. I want to reveal the glory that is the Linux Liberation Front. I want to create general havoc. I want to impress my pierced girlfriend. I want to spy on my spouse. Be creative when you do this! Bad guys want lots of different things. Bring out your inner villain.
Now ask yourself: “How can I accomplish my evil goal given this pathetic pile of software before me? How can I make it cry and beg for mercy? How can I make it bend to my iron will?” There you have it. Abuse cases.
Because thinking like an attacker is something best done with years of experience, this process is an opportune time to involve your network security guys (see Chapter 9). However, there are alternatives to years of experience. One excellent thought experiment (suggested by Dan Geer) runs as follows. I’ll call it “engineer gone bad.” Imagine taking your most trusted engineer/operator and humiliating her in public—throw her onto the street, and dare her to do anything about it to you or to your customers. If the humiliated street bum can do nothing more than head banging on the nearest wall, you’ve won. This idea, in some, cases may be even more effective than simply thinking like a bad guy—it’s turning a good guy into a bad guy.
The idea of abuse cases has a short history in the academic literature. McDermott and Fox published an early paper on abuse cases at ACSAC in 1999 [McDermott and Fox 1999]. Later, Sindre and Opdahl wrote a paper that explained how to extend use case diagrams with misuse cases [Sindre and Opdahl 2000]. Their basic idea is to represent the actions that systems should prevent in tandem with those that it should support so that security analysis of requirements is easier. Alexander advocates using misuse and use cases together to conduct threat and hazard analysis during requirements analysis [Alexander 2003]. Others have since put more flesh on the idea of abuse cases, but, frankly, abuse cases are not as commonly used as they should be.
Security is not a feature that can be added to software. There is no convenient “security” pull-down menu where security can be selected and magic things happen. Unfortunately, many software producers mistakenly rely solely on plonking functional security features and mechanisms, such as cryptography, somewhere in their software, and they assume that the security needs are in this way addressed everywhere. Too often product literature makes broad feature-based claims about security such as “Built with SSL” or “128-bit encryption included,” and these represent the vendor’s entire approach for securing the product. This is a natural and forgivable misconception, but it is still a concerning problem.
Security is an emergent property of a system, not a feature. This is similar to how “being dry” is an emergent property of being inside a tent in the rain. The tent keeps people dry only if the poles are stabilized, vertical, able to support the weight of wet fabric, and so on. Likewise, the tent must have waterproof fabric that has no holes and is large enough to protect all the people who want to stay dry. Lastly, all the people who want to be dry must remain under the tent the entire time it is raining. Whereas it is important to have poles and fabric, it is not enough to say, “The tent has poles and fabric, thus it keeps you dry!” This sort of claim, however, is analogous to the claims software vendors make when they highlight numbers of bits in keys and the use of particular encryption algorithms. It is true that cryptography of one kind or another is usually necessary in order to create a secure system, but security features alone are not sufficient for building secure software.
Because security is not a feature, it can’t be “bolted on” after other software features are codified. Nor can it be “patched in” after attacks have occurred in the field. Instead, security must be built in from the ground up—considered a critical part of the design from the very beginning (requirements specification) and included in every subsequent development phase all the way through fielding a complete system.
Sometimes this involves making explicit tradeoffs when specifying system requirements. For example, ease of use may be paramount in a medical system meant to be used by secretaries in a doctor’s office. Complex authentication procedures, such as obtaining and using a cryptographic identity, can be hard to use [Gutmann 2004]. But regulatory pressures from HIPPA and California’s privacy regulations (SB 1386) force designers to negotiate a reasonable tradeoff.
To extend this example, consider that authentication and authorization can’t stop at the “front door” of a program. Technical approaches must go far beyond the obvious features, deep into the many-tiered heart of a software system to be secure enough.
The best, most cost-effective approach to software security incorporates thinking beyond white hat normative features by donning a black hat and thinking like a bad guy, and doing this throughout the development process. Every time a new requirement, feature, or use case is created, someone should spend some time thinking about how that feature might be unintentionally misused or intentionally abused. Professionals who know how features are attacked and how to protect software should play an active role in this kind of analysis (see Chapter 9).
Attackers are not standard-issue customers. They are bad people with malicious intent who want your software to act in some unanticipated way—to their benefit. An attacker’s goal is to think of something you didn’t think of and exploit it in a way you didn’t expect—to the gain of the attacker and probably to your detriment. If the development process doesn’t address unexpected or abnormal behavior, then an attacker usually has plenty of raw material to work with.
Attackers are creative. Despite this creativity, we can be sure that some well-known locations will always be probed in the course of attacks: boundary conditions, edges, intersystem communication, and system assumptions. Clever attackers always try to undermine the assumptions a system is built on. For example, if a design assumes that connections from the Web server to the database server are always valid, an attacker will try to make the Web server send inappropriate requests in order to access valuable data. If software design assumes that Web browser cookies are never modified by the client before they are sent back to the requesting server (in an attempt to preserve some state), attackers will intentionally cause problems by modifying cookies.
When we are the designers and analyzers of a system, we’re in a great position to know our systems better than potential attackers do. We should leverage this knowledge to the benefit of security and reliability. We can do this by asking and answering some critical questions:
What assumptions are implicit in our system?
What kinds of things would make our assumptions false?
What kinds of attack patterns will an attacker bring to bear?
Unfortunately, a system’s creators rarely make the best security analysts for their own systems. This is precisely because it is very hard to consciously note and consider all assumptions (especially in light of thinking like an attacker). Fortunately, these professionals, instead, make excellent subject matter experts to be powerfully combined with security professionals. Together this team of system experts and security analysts can ferret out base assumptions in a system under analysis and think through the ways an attacker will approach the software.
The simplest, most practical method for creating abuse cases is usually through a process of informed brainstorming. There exist a number of theoretical methods that involve fully specifying a system with rigorous formal models and logics, but such activities are extremely time and resource intensive. The good news is that formal methods are often unnecessary in the real world. A more practical approach that covers a lot of ground more quickly involves forming brainstorming teams that combine security and reliability experts with system designers. This approach relies heavily on experience and expertise.
To guide such brainstorming, software security experts ask many questions that help identify the places where the system is likely to have weaknesses. This activity mirrors the kind of thinking that an attacking adversary performs. Abuse is always possible at the places where legitimate use is possible. Such brainstorming involves a careful look at all user interfaces (including environment factors) as well as functional security requirements and considers what things most developers assume a person can’t or won’t do. These can’ts and won’ts take many forms, such as: “Users can’t enter more than 50 characters because the JavaScript code won’t let them.” “The user doesn’t understand the format of the cached data. They can’t modify it.” Attackers, unfortunately, make can’ts and won’ts happen with some regularity.
All systems have more places that can be attacked than obvious front doors, of course. Where can a bad guy be positioned? On the wire? At a workstation? In the back office? Any communications line between two endpoints or two components is a place where an attacker can try to interpose. What can a bad guy do? Watch communications traffic? Modify and replay such traffic? Read files stored on the workstation? Change registry keys or configuration files? Be the DLL? Be the “chip”? (Note that all of these kinds of attacks are person-in-the-middle attacks, sometimes called PIMs or interposition attacks.) Many of these attacks are elegantly explained in the book How to Break Software Security [Whittaker and Thompson 2003].
One of the goals of abuse cases is to decide and document a priori how the software should react to illegitimate use. The process of specifying abuse cases makes a designer differentiate appropriate use from inappropriate use very clearly. Approaching this problem involves asking the right questions. For example, how can the system distinguish between good and bad input? How can the system tell that a request is coming from a legitimate Java applet and not from a rogue application replaying traffic? Trying to answer questions like these helps software designers explicitly question design and architecture assumptions. This puts the designer squarely ahead of the attacker by identifying and fixing a problem before it can even be created!
System architects and project managers often respond to the very idea of abuse cases by claiming, “But no one would do these things.” Interestingly, these claims are correct if the worldview is limited to legitimate users. Virtually any system that has value, however, can be abused. Few systems operate securely in a free-for-all permissions environment, despite how much trust designers may want to place on the users. This problem is exacerbated by the rush to move software into a highly distributed, network-based model. Limiting system activity to legitimate users may be possible on a secure proprietary network, but it is categorically impossible on the Internet. The fact is that malicious users do exist in both kinds of environment, and it is often straightforward to thwart a significant portion of them.
Unfortunately, abuse cases are only rarely used in practice even though the idea seems natural enough. Perhaps a simple process model will help clarify how to build abuse cases and thereby fix the adoption problem. Figure 8-1 shows a simple process model.
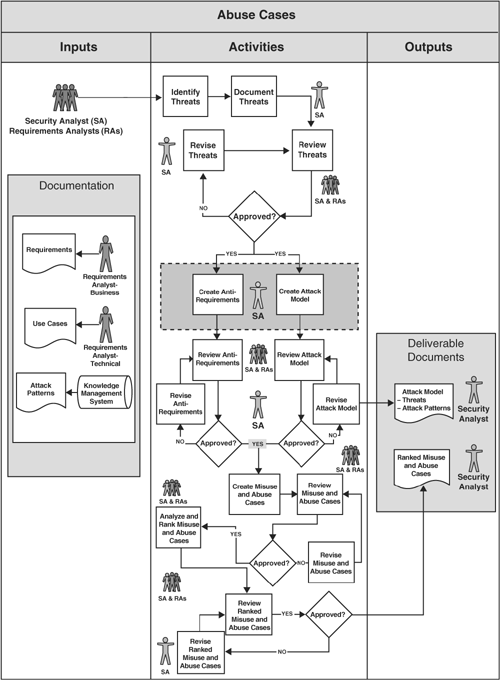
Abuse cases are to be built by a team of requirements people and security analysts (called RAs and SAs in the picture). This team starts with a set of requirements, a set of standard use cases (or user stories), and a list of attack patterns.[3] This raw material is combined by the process I describe to create abuse cases.
The first step involves identifying and documenting threats. Note that I am using the term threat in the old-school sense. A threat is an actor or agent who carries out an attack. Vulnerabilities and risks are not threats.[4] Understanding who might attack you is really critical. Are you likely to come under attack from organized crime like the Russian mafia? Or are you more likely to be taken down by a university professor and the requisite set of overly smart graduate students all bent on telling the truth? Thinking like your enemy is an important exercise. Knowing who your enemy is likely to be is an obvious prerequisite.
Given an understanding of who might attack you, you’re ready to get down to the business of creating abuse cases. In the gray box in the center of Figure 8-1, the two critical activities of abuse case development are shown: creating anti-requirements and creating an attack model.
When developing a software system or a set of software requirements, thinking explicitly about the things that you don’t want your software to do is just as important as documenting the things that you do want. Naturally, the things that you don’t want your system to do are very closely related to the requirements. I call them anti-requirements. Anti-requirements are generated by security analysts, in conjunction with requirements analysts (business and technical), through a process of analyzing requirements and use cases with reference to the list of threats in order to identify and document attacks that will cause requirements to fail. The object is explicitly to undermine requirements.
Anti-requirements provide insight into how a malicious user, attacker, thrill seeker, competitor (in other words, a threat) can abuse your system. Just as security requirements result in functionality that is built into a system to establish accepted behavior, anti-requirements are established to determine what happens when this functionality goes away. When created early in the software development lifecycle and revisited throughout, these anti-requirements provide valuable input to developers and testers.
Because security requirements are usually about security functions and/or security features, anti-requirements are often tied up in the lack of or failure of a security function. For example, if your system has a security requirement calling for use of crypto to protect essential movie data written on disk during serialization, an anti-requirement related to this requirement involves determining what happens in the absence of that crypto. Just to flesh things out, assume in this case that the threat in question is a group of academics. Academic security analysts are unusually well positioned to crack crypto relative to thrill-seeking script kiddies. Grad students have a toolset, lots of background knowledge, and way too much time on their hands. If the crypto system fails in this case (or better yet, is made to fail), giving the attacker access to serialized information on disk, what kind of impact will that have on the system’s security? How can we test for this condition?
Abuse cases based on anti-requirements lead to stories about what happens in the case of failure, especially security apparatus failure.
An attack model comes about by explicit consideration of known attacks or attack types. Given a set of requirements and a list of threats, the idea here is to cycle through a list of known attacks one at a time and to think about whether the “same” attack applies to your system. Note that this kind of process lies at the heart of Microsoft’s STRIDE model [Howard and LeBlanc 2003]. Attack patterns are extremely useful for this activity. An incomplete list of attack patterns can be seen in the box Attack Patterns from Exploiting Software [Hoglund and McGraw 2004] on pages 218 through 221. To create an attack model, do the following:
Together, the resulting attack model and anti-requirements drive out abuse cases that describe how your system reacts to an attack and which attacks are likely to happen. Abuse cases and stories of possible attacks are very powerful drivers for both architectural risk analysis and security testing.
The simple process shown in Figure 8-1 results in a number of useful artifacts. The simple activities are designed to create a list of threats and their goals (which I might call a “proper threat model”), a list of relevant attack patterns, and a unified attack model. These are all side effects of the anti-requirements and attack model activities. More important, the process creates a set of ranked abuse cases—stories of what your system does under those attacks most likely to be experienced.
As you can see, this is a process that requires extensive use of your black hat. The more experience and knowledge you have about actual software exploit and real computer security attacks, the more effective you will be at building abuse cases (see Chapter 9).
Cigital reviewed a client-server application that manipulated a financially sensitive database, finding a classic software security problem. In this case, the architecture was set up so that the server counted on a client-side application to manage all of the data access permissions. No permissions were enforced on the server itself. In fact, only the client had any notion of permissions and access control. To make matters worse, a complete copy of the sensitive database (only parts of which were to be viewed by a given user with a particular client) was sent down to the client. The client program ran on a garden-variety desktop PC. This means that a complete copy of sensitive data expressly not to be viewed by the user was available on that user’s PC in the clear.
If the user looked in the application’s cache on the hard disk and used the unzip utility, the user could see all sorts of sensitive information that should not have been allowed to be seen. It turns out that the client also enforced which messages were sent to the server, and the server honored these messages independent of the user’s actual credentials. The server was assuming that any messages coming from the client had properly passed through the client software’s access control system (and policy) and were, therefore, legitimate. By either intercepting network traffic, corrupting values in the client software’s cache, or building a hostile client, a malicious user could inject data into the database that no user was even supposed to read (much less write).
For this simple example, we’ll choose to think about a legitimate user (gone bad) as the threat. The Make the Client Invisible attack pattern is particularly relevant to this system (as are a number of others). In this case, the server trusts the client to provide correct messages. However, this trust is mostly unfounded since creating a malicious client (either by sniffing traffic and building an attack generator or by reverse-engineering the real client) is so easy. This attack pattern leads to an abuse case describing what happens when a malicious client interacts with the server.
From the anti-requirements side of the story, we consider what happens when an attacker bypasses the access control “security mechanism” built into the client software. In this case, the mechanism is laid bare to attack on a standard PC belonging to the attacker. The resulting abuse case describes why this security mechanism is inadequate and most likely results in a major design change.
Determining the can’ts and won’ts is often difficult for those who think only about positive features. Some guidance exists in the form of attack patterns. Attack patterns are like patterns in sewing—a blueprint for creating a kind of attack. Everyone’s favorite software security example, the buffer overflow, follows several different standard patterns. Patterns allow for a fair amount of variation on a theme. They can take into account many dimensions, including timing, resources required, techniques, and so forth. Attack patterns can be used to guide abuse case development.
Security requirements specify the security apparatus for software systems. In addition to capturing and describing relevant attacks, abuse cases allow an analyst to think carefully through what happens when these functional security mechanisms fail or are otherwise compromised.
Clearly, generating abuse cases is important. The main benefit of abuse cases is that they provide essential insight into a system’s assumptions and how attackers will approach and undermine them. Of course, like all good things, abuse cases can be overused (and generated forever with little impact on actual security). A solid approach to this technique requires a combination of security expertise and subject matter expertise to prioritize abuse cases as they are generated and to strike the right balance between cost and value.
[1] Parts of this chapter appeared in original form in IEEE Security & Privacy magazine co-authored with Paco Hope and Annie Anton [Hope, McGraw, and Anton 2004].
[2] Note that in many of these instances it is still left up to the software developer to define “secure” and “reliable” and then create secure and reliable software.
[3] Attack patterns à la Exploiting Software [Hoglund and McGraw 2004] are not the only source to use for thinking through possible attacks. A good low-octane substitute might be the STRIDE model list of attack categories: Spoofing, Tampering, Repudiation, Information disclosure, Denial of service, and Elevation of privilege. Cycling through this list of six attack categories one at a time is likely to provide insight into your system. For more on STRIDE, see [Howard and LeBlanc 2003].
[4] Microsoft folks use the term threat incorrectly (and also very loudly). When they say “threat modeling,” they really mean “risk analysis.” This is unfortunate.