
IN THIS CHAPTER
Making the Words and Pictures Make Sense
Translation Issues
Localization Issues
Configuration and Compatibility Issues
How Much Should You Test?
Si eres fluente en más de un idioma y competente probando programas de computadora, usted tiene una habilidad muy deseada en el mercado.
Wenn Sie eine zuverläßig Software Prüferin sind, und fließend eine fremd sprache, ausser English, sprechen können, dann können Sie gut verdienen.
Translated roughly from Spanish and German, the preceding two sentences read: If you are a competent software tester and are fluent in a language other than English, you have a very marketable skill set.
Most software today is released to the entire world, not just to a certain country or in a specific language. Microsoft shipped Windows XP with support for 106 different languages and dialects, from Afrikaans to Hungarian to Zulu. Most other software companies do the same, realizing that the U.S. English market is less than half of their potential customers. It makes business sense to design and test your software for worldwide distribution.
This chapter covers what's involved in testing software written for other countries and languages. It might seem like a straightforward process, but it's not, and you'll learn why.
Highlights of this chapter include
Why just translating is not enough
How words and text are affected
Why footballs and telephones are important
The configuration and compatibility issues
How large of a job testing another language is
Have you ever read a user's manual for an appliance or a toy that was poorly converted word for word from another language? “Put in a bolt number five past through green bar and tighten no loose to nut.” Got it?
That's a poor translation, and it's what software can look like to a non-English speaker if little effort is put into building the software for foreign languages. It's easy to individually convert all the words, but to make the overall instructions meaningful and useful requires much more work and attention.
Good translators can do that. If they're fluent in both languages, they can make the foreign text read as well as the original. Unfortunately, what you'll find in the software industry is that even a good translation isn't sufficient.
Take Spanish, for example. It should be a simple matter to convert English text to Spanish, right? Well, which Spanish are you referring to? Spanish from Spain? What about Spanish from Costa Rica, Peru, or the Dominican Republic? They're all Spanish, but they're different enough that software written for one might not be received well by the others. Even English has this problem. There's not just American English, there's also Canadian, Australian, and British English. It would probably seem strange to you to see the words colour, neighbour, and rumour in your word processor.
What needs to be accounted for, besides the language, is the region or locale—the user's country or geographic area. The process of adapting software to a specific locale, taking into account its language, dialect, local conventions, and culture, is called localization or sometimes internationalization. Testing the software is called localization testing.
Although translation is just a part of the overall localization effort, it's an important one from a test standpoint. The most obvious problem is how to test something that's in another language. Well, you or someone on your test team will need to be at least semi-fluent in the language you're testing, being able to navigate the software, read any text it displays, and type the necessary commands to run your tests. It might be time to sign up for the community college course in Slovenian you always wanted to take.
NOTE
It's important that you or someone on your test team be at least a little familiar with the language you're testing. Of course, if you're shipping your program in 32 different languages, they may be difficult. The solution is to contract out this work to a localization testing company. Numerous such companies worldwide can perform testing in nearly any language. For more information, search the Internet for “localization testing.”
It's not a requirement that everyone on the test team speak the language that the software is being localized into; you probably need just one person. Many things can be checked without knowing what the words say. It would be helpful, sure, to know a bit of the language, but you'll see that you might be able to do a fair amount of the testing without being completely fluent.
The most straightforward example of a translation problem that can occur is due to something called text expansion. Although English may appear at times to be wordy, it turns out that when English is translated into other languages, often more characters are necessary to say the same thing. Figure 10.1 shows how the size of a button needs to expand to hold the translated text of two common computer words. A good rule of thumb is to expect up to 100 percent increase in size for individual words—on a button, for example. Expect a 50 percent increase in size for sentences and short paragraphs—typical phrases you would see in dialog boxes and error messages.

Figure 10.1. When translated into other languages, the words Minimize and Maximize can vary greatly in size often forcing the UI to be redesigned to accommodate them.
Because of this expansion, you need to carefully test areas of the software that could be affected by longer text. Look for text that doesn't wrap correctly, is truncated, or is hyphenated incorrectly. This could occur anywhere—onscreen, in windows, boxes, buttons, and so on. Also look for cases where the text had enough room to expand, but did so by pushing something else out of the way.
Another possibility is that this longer text can cause a major program failure or even a system crash. A programmer could have allocated enough internal memory for the English text messages, but not enough for the translated strings. The English version of the software will work fine but the German version will crash when the message is displayed. A white-box tester could catch this problem without knowing a single word of the language.
Chapter 5, “Testing the Software with Blinders On,” briefly discussed the ASCII character set. ASCII can represent only 256 different characters—not nearly enough to represent all the possible characters in all languages. When software started being developed for different languages, solutions needed to be found to overcome this limitation. An approach common in the days of MS-DOS, but still in use today, is to use a technique called code pages. Essentially, a code page is a replacement ASCII table, with a different code page for each language. If your software runs in Quebec on a French PC, it could load and use a code page that supports French characters. Russian uses a different code page for its Cyrillic characters, and so on.
This solution is fine, although a bit clunky, for languages with less than 256 characters, but Japanese, Chinese, and other languages with thousands of symbols cause problems. A system called DBCS (for Double-Byte Character Set) is used by some software to provide more than 256 characters. Using 2 bytes instead of 1 byte allows for up to 65,536 different characters.
Code pages and DBCS are sufficient in many situations but suffer from a few problems. Most important is the issue of compatibility. If a Hebrew document is loaded onto a German computer running a British word processor, the result can be gibberish. Without the proper code pages or the proper conversion from one to the other, the characters can't be interpreted correctly, or even at all.
The solution to this mess is the Unicode standard.
Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language. | ||
| --“What is Unicode?” from the Unicode Consortium website, www.unicode.org | ||
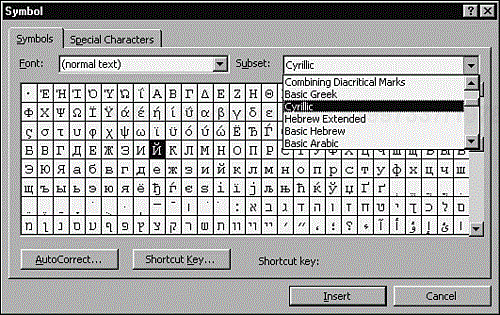
Because Unicode is a worldwide standard supported by the major software companies, hardware manufacturers, and other standards groups, it's becoming more commonplace. Most major software applications support it. Figure 10.2 shows many of the different characters supported. If it's at all possible that your software will ever be localized, you and the programmers on your project should cut your ties to “ol' ASCII” and switch to Unicode to save yourself time, aggravation, and bugs.
In English, it's Search. In French, it's Réchercher. If the hotkey for selecting Search in the English version of your software is Alt+S, that will need to change in the French version.
In localized versions of your software, you'll need to test that all the hotkeys and shortcuts work properly and aren't too difficult to use—for example, requiring a third keypress. And, don't forget to check that the English hotkeys and shortcuts are disabled.
A common problem with localized software, and even non-localized software, is in its handling of extended characters. Referring back to that ancient ASCII table, extended characters are the ones that fall outside the normal English alphabet of A–Z and a–z. Examples of these would be the accented characters such as the é in José or the ñ in El Niño. They also include the many symbol characters such as ![]()
![]()
![]() that aren't on your typical keyboard. If your software is properly written to use Unicode or even if it correctly manages code pages or DBCS, this shouldn't be an issue, but a tester should never assume anything, so it's worthwhile to check.
that aren't on your typical keyboard. If your software is properly written to use Unicode or even if it correctly manages code pages or DBCS, this shouldn't be an issue, but a tester should never assume anything, so it's worthwhile to check.
The way to test this is to look for all the places that your software can accept character input or send output. In each place, try to use extended characters to see if they work just as regular characters would. Dialog boxes, logins, and any text fields are fair game. Can you send and receive extended characters through a modem? Can you name your files with them or even have the characters in the files? Will they print out properly? What happens if you cut, copy, and paste them between your program and another one?
Related to extended characters are problems with how they're interpreted by software that performs calculations on them. Two examples of this are word sorting and upper- and lowercase conversion.
Does your software sort or alphabetize word lists? Maybe in a list box of selectable items such as filenames or website addresses? If so, how would you sort the following words?
Kopiëren | Reiste |
Ärmlich | Arg |
Reiskorn | résumé |
Reißaus | kopieën |
reiten | Reisschnaps |
reißen | resume |
If you're testing software to be sold to one of the many Asian cultures, are you aware that the sort order is based on the order of the brush strokes used to paint the character? The preceding list would likely have a completely different sort order if written in Mandarin Chinese. Find out what the sorting rules are for the language you're testing and develop tests to specifically check that the proper sort order occurs.
The other area where calculation on extended characters breaks down is with upper- and lowercase conversion. It's a problem because the “trick” solution that many programmers learn in school is to simply add or subtract 32 to the ASCII value of the letter to convert it between cases. Add 32 to the ASCII value of A and you get the ASCII value of a. Unfortunately, that doesn't work for extended characters. If you tried this technique using the Apple Mac extended character set, you'd convert Ñ (ASCII 132) to § (ASCII 164) instead of ñ (ASCII 150)—not exactly what you'd expect.
Sorting and alphabetizing are just two examples. Carefully look at your software to determine if there are other situations where calculations are performed on letters or words. Spell-checking perhaps?
A huge issue for translation is that some languages, such as Hebrew and Arabic, read from right to left, not left to right. Imagine flipping your entire user interface into a mirror image of itself.
Thankfully, most major operating systems provide built-in support for handling these languages. Without this, it would be a nearly impossible task. Even so, it's still not a simple matter of translating the text. It requires a great deal of programming to make use of the OS's features to do the job. From a testing standpoint, it's probably safe to consider it a completely new product, not just a localization.
Another translation problem occurs when text is used in graphics. See Figure 10.3 for several examples.

The icons in Figure 10.3 are the standard ones for selecting Bold, Italic, Underline, and Font Color. Since they use the English letters B, I, U, and A, they'll mean nothing to someone from Japan who doesn't read English. They might pick up on the meaning based on their look—the B is a bit dark, the I is leaning, and the U has a line under it—but software isn't supposed to be a puzzle.
The impact of this is that when the software is localized, each icon will have to be changed to reflect the new languages. If there were many of these icons, it could get prohibitively expensive to localize the program. Look for text-in-graphic bugs early in the development cycle so they don't make it through to the end.
The final translation problem to cover is a white-box testing issue—keep the text out of the code. What this means is that all text strings, error messages, and really anything that could possibly be translated should be stored in a separate file independent of the source code. You should never see a line of code such as:
Print "Hello World"
Most localizers are not programmers, nor do they need to be. It's risky and inefficient to have them modifying the source code to translate it from one language to another. What they should modify is a simple text file, called a resource file, that contains all the messages the software can display. When the software runs, it references the messages by looking them up, not knowing or caring what they say. If the message is in English or Dutch, it gets displayed just the same.
That said, it's important for white-box testers to search the code to make sure there are no embedded strings that weren't placed in the external file. It would be pretty embarrassing to have an important error message in a Spanish program appear in English.
Another variation of this problem is when the code dynamically generates a text message. For example, it might piece together snippets of text to create a larger message. The code could take three strings:
“You pressed the”
a variable string containing the name of the key just pressed
“key just in time!”
and put them together to create a message. If the variable string had the value “stop nuclear reaction,” the total message would read:
You pressed the stop nuclear reaction key just in time!
The problem is that the word order is not the same in all languages. Although it pieces together nicely in English, with each phrase translated separately, it could be gibberish when stuck together in Mandarin Chinese or even German. Don't let strings crop into the code and don't let them be built up into larger strings by the code.
As mentioned previously, translation issues are only half the problem. Text can easily be translated and allowances made for different characters and lengths of strings. The difficulty occurs in changing the software so that it's appropriate for the foreign market.
REMINDER
Remember those terms from Chapter 3, “The Realitites of Software Testing”: precision, accuracy, and reliability and quality?
Well translated and tested software is precise and reliable, but, if the programmers don't consider localization issues, it's probably not accurate or of high quality. It might look and feel great, read perfectly, and never crash, but to someone from another locale, it might just seem plain–old wrong. Assuring that the product is correctly localized gets you to this next step.
What would you think of a new software encyclopedia for the U.S. English market if it had the content shown in Figure 10.4?
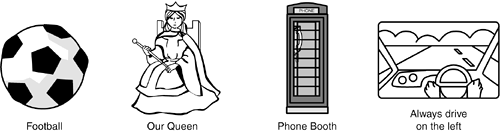
In the United States, a soccer ball isn't the same thing as a football! You don't drive on the left! These may not seem right to you, but in other countries they would be perfectly accurate. If you're testing a product that will be localized, you need to carefully examine the content to make sure it's appropriate to the area where it will be used.
Content is all the other “stuff” besides the code that goes into the product (see Chapter 2, “The Software Development Process”). The following list shows various types of content that you should carefully review for localization issues. Don't consider it a complete list; there can be many more examples depending on the product. Think about what other items in your software might be problematic if it was sent to another country.
Sample documents | Icons |
Pictures | Sounds |
Video | Help files |
Maps with disputed boundaries | Marketing material |
Packaging | Web links |
A NOSE TOO LONG
In 1993, Microsoft released two products for kids called Creative Writer and Fine Artist. These products used a helper character named McZee to guide the kids through the software. A great deal of research went into the design of McZee to select his look, color, mannerisms, personality, and so on. He turned out to be a rather strange looking fellow with buck teeth, dark purple skin, and a big nose.
Unfortunately, after a great deal of work was done drawing the animations that would appear on the screen, a call came in from one of Microsoft's foreign offices. They had received a preliminary version of the software and after reviewing it said that it was unacceptable. The reason: McZee's nose was too long. In their culture, people with large noses weren't common and, right or wrong, they associated having a large nose with lots of negative stereotypes. They said that the product wouldn't sell if it was localized for their locale.
It would have been way too costly to create two different McZees, one for each market, so the artwork completely to that point was thrown out, and McZee had his first nose job.
The bottom line is that the content that goes with the software, whether it's text, graphics, sounds, or whatever, is especially prone to having localization issues. Test the content with an eye for these types of problems and, if you're not experienced with the culture of the locale that the software is destined for, be sure to call in someone who is.
Different locales use different formats for data units such as currency, time, and measurement. Just as with content, these are localization, not translation, issues. An American English publishing program that works with inches couldn't simply undergo a text translation to use centimeters. It would require code changes to alter the underlying formulas, gridlines, and so on.
Table 10.1 shows many of the different categories of units that you'll need to become familiar with if you're testing localized software.
Table 10.1. Data Format Considerations for Localized Software
Fortunately, most operating systems designed for use in multiple locales support these different units and their formats. Figure 10.5 shows an example from Windows. Having this built-in support makes it easier, but by no means foolproof, for programmers to write localized software.
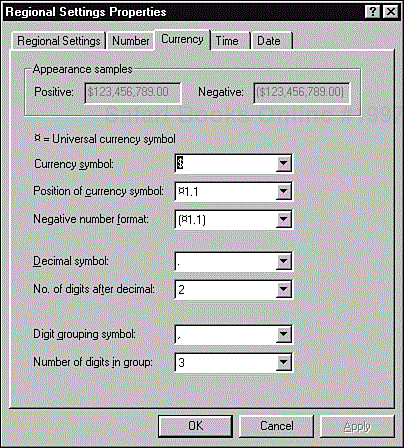
Figure 10.5. The Windows Regional Settings options allow a user to select how numbers, currency, times, and dates will be displayed.
NOTE
How a unit is displayed isn't necessarily how it's treated internally by the software. For example, the Date tab on the Regional Settings program shows a short date style of m/d/yy. That doesn't imply that the operating system handles only a 2-digit year (and hence is a Y2K bug). In this case, the setting means only a 2-digit year is displayed. The operating system still supports a 4-digit year for computations—more things to consider when testing.
If you're testing localized software, you'll need to become very familiar with the units of measure used by the target locale. To properly test the software, you'll need to create different equivalence partitions of test data from the ones you create for testing the original version of the software.
The information covered in Chapters 8, “Configuration Testing,” and 9, “Compatibility Testing,” on configuration and compatibility testing is very important when testing localized versions of software. The problems that can crop up when software interacts with different hardware and software are amplified by all the new and different combinations. Performing this testing isn't necessarily more difficult, just a bit larger of a task. It can also tax your logistical skills to locate and acquire the foreign version of hardware and software to test with.
Windows XP supports 106 different languages and 66 different keyboard layouts. It does this, as shown in Figure 10.6, through the Keyboard Properties dialog via Control Panel. The drop-down list for languages runs from Afrikaans to Ukrainian and includes eight different versions of English other than American English (Australian, British, Canadian, Caribbean, Irish, Jamaican, New Zealand, and South African), five different German dialects, and 20 different Spanish dialects.
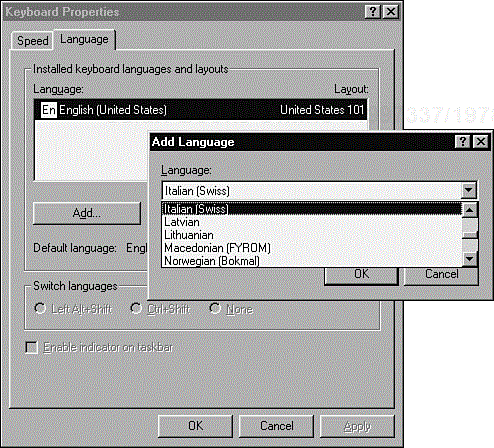
Figure 10.6. Windows supports the use of different keyboards and languages through the Keyboard Properties dialog.
Figure 10.7 shows examples of three different keyboard layouts designed for different countries. You'll notice that each has keys specific to its own language, but also has English characters. This is fairly common, since English is often spoken as a second language in many countries, and allows the keyboard to be used with both native and English language software.
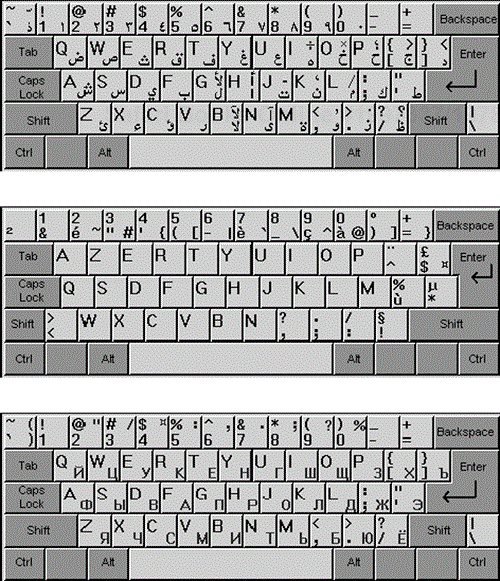
Figure 10.7. The Arabic, French, and Russian keyboards support characters specific to those languages. (www.fingertipsoft.com)
Keyboards are probably the piece of hardware with the largest language dependencies, but depending on what you're testing, there can be many others. Printers, for example, would need to print all the characters your software sends to them and properly format the output on the various paper sizes used in different countries. If your software uses a modem, there might be issues related to the phone lines or communication protocol differences. Basically, any peripheral that your software could potentially work with needs to be considered for a place in your equivalence partitions for platform configuration and compatibility testing.
NOTE
When designing your equivalence partitions, don't forget that you should consider all the hardware and software that can make up the platform. This includes the hardware, device drivers for the hardware, and the operating system. Running a French printer on a Mac, with a British operating system, and a German version of your software might be a perfectly legitimate configuration for your users.
Just as with platform configuration testing, compatibility testing of data takes on a whole new meaning when you add localization to the equation. Figure 10.8 shows how complex it can get moving data from one application to another. In this example, a German application that uses metric units and extended characters can move data to a different French program by saving and loading to disk or using cut and paste. That French application can then export the data for import to yet another English application. That English program, which uses English units and non-extended characters, can then move it all back to original German program.
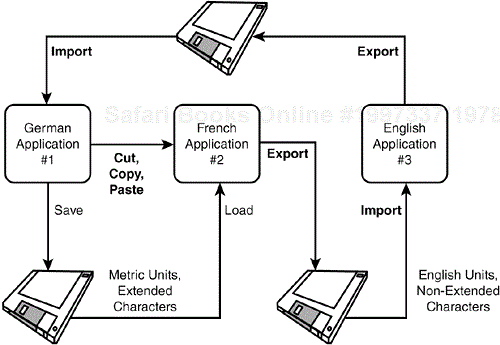
During this round and round of data transfers, with all the conversions and handling of measurement units and extended characters, there are numerous places for bugs. Some of these bugs might be due to design decisions. For example, what should happen to data moved from one application to another if it needs to change formats? Should it be automatically converted, or should the user be prompted for a decision? Should it show an error or should the data just move and the units change?
These important questions need to be answered before you can start testing the compatibility of your localized software. As soon as you have those specifications, your compatibility testing should proceed as it normally would—just with more test cases in your equivalence partitions.
The big uncertainty that looms over localization testing is in determining how much of the software you should test. If you spent six months testing the American English version, should you spend six months testing a version localized into French? Should you spend even more because of additional configuration and compatibility issues?
This complex issue comes down to two questions:
Was the project intended to be localized from the very beginning?
Was programming code changed to make the localized version?
If the software was designed from the very beginning to account for all the things discussed in this chapter, the risk is much smaller that a localized version will be very buggy and require lots of testing. If, on the other hand, the software was written specifically for the U.S. English market and then it was decided to localize it into another language, it would probably be wise to treat the software as a completely new release requiring full testing.
NOTE
The amount of localization testing required is a risk-based decision, just as all testing is. As you gain experience in testing, you'll learn what variables go into the decision-making process.
The other question deals with what needs to change in the overall software product. If the localization effort involves changing only content such as graphics and text—not code—the test effort can sometimes be just a validation of the changes. If, however, because of poor design or other problems, the underlying code must change, the testing needs take that into account and check functionality as well as content.
IS IT LOCALIZABLE?
One method used by teams who know they are going to localize their product is to test for localizability. That is, they test the first version of the product, assuming that it will eventually be localized. The white-box testers examine the code for text strings, proper handling of units of measure, extended characters, and other code-level issues. They may even create their own “fake” localized version. The black-box testers carefully review the spec and the product itself for localizing problems such as text in graphics and configuration issues. They can use the “fake” version to test for compatibility.
Eventually, when the product is localized, many of the problems that would have shown up later have already been found and fixed, making the localization effort much less painful and costly.
Ha Ön egy rátermett és képzett softver ismer?, és folyékonyan beszél egy nyelvet az Angolon kívül, Ön egy nagyon piacképes szakképzett személy.
That's the same first sentence of this chapter—only written in Hungarian this time. Don't worry if you can't read it. You've learned in this chapter that knowing the language is only part of the overall testing required for a localized product. Much work can be done by checking the product for localizability and for testing language-independent areas.
If you are fluent in a language other than English, keep reading this book, and learn all you can about software testing. With the global economy and the worldwide adoption of technology and computers you will, as the Hungarian phrase roughly says, “have a very marketable skill set.”
For more information on localization programming and testing for Windows, visit www.microsoft.com/globaldev. For the Mac, consult the Apple website, developer.apple.com/intl/localization/tools.html. Linux programmers and testers can find localization information at www.linux.com/howtos/HOWTO-INDEX/other-lang.shtml.
These quiz questions are provided for your further understanding. See Appendix A, “Answers to Quiz Questions,” for the answers—but don't peek!