
IN THIS CHAPTER
Getting Your Bugs Fixed
Isolating and Reproducing Bugs
Not All Bugs Are Created Equal
A Bug's Life Cycle
Bug-Tracking Systems
If you stand back and look at the big picture of software testing, you'll see that it has three main tasks: test planning, actual testing, and the subject of this chapter—reporting what you find.
On the surface, it may seem as though reporting the problems you discover would be the easiest of the three. Compared to the work involved in planning the testing and the skills necessary to efficiently find bugs, telling the world that you found something wrong would surely be a simpler and less time-consuming job. In reality, it may be the most important—and sometimes most difficult—task that you, as a software tester, will perform.
In this chapter you'll learn why reporting what you find is such a critical task and how to use various techniques and tools to ensure that the bugs you find are clearly communicated and given the best chance of being fixed the way they should.
Highlights of this chapter include
Why all bugs aren't always fixed
What you can do to make it more likely that the bugs you find are fixed
What techniques you can use to isolate and reproduce a bug
What a bug's life is like from birth to death
How to track the bugs you find manually or with a database
Way back in Chapter 3, “The Realities of Software Testing,” you learned that despite your best efforts at planning and executing your tests, not all the bugs you find will be fixed. Some may be dismissed completely, and others may be deferred or postponed for fixing in a subsequent release of the software. At the time, it may have been a bit discouraging or even frightening to think that such a concept was a possibility. Hopefully, now that you know a great deal more about software testing, you can see why not fixing all the bugs is a reality.
The reasons listed in Chapter 3 for not fixing a bug were
There's not enough time. Every project always has too many software features, too few people to code and test them, and not enough room left in the schedule to finish. If you're working on a tax-preparation program, April 15 isn't going to move—you must have your software ready in time.
It's really not a bug. Maybe you've heard the phrase, “It's not a bug, it's a feature!” It's not uncommon for misunderstandings, test errors, or spec changes to result in would-be bugs being dismissed as features.
It's too risky to fix. Unfortunately, this is all too often true. Software is fragile, intertwined, and sometimes like spaghetti. You might make a bug fix that causes other bugs to appear. Under the pressure to release a product under a tight schedule, it might be too risky to change the software. It may be better to leave in the known bug to avoid the risk of creating new, unknown ones.
It's just not worth it. This may sound harsh, but it's reality. Bugs that would occur infrequently or appear in little-used features may be dismissed. Bugs that have workarounds, ways that a user can prevent or avoid the bug, often aren't fixed. It all comes down to a business decision based on risk.
One more item should be added to this list that can often be the contributing reason for all of them:
Ineffective bug reporting. The tester didn't make a strong enough case that a particular bug should be fixed. As a result, the bug was misunderstood as not being a bug, was deemed not important enough to delay the product, was thought to be too risky to fix, or was just plain considered to be not worth fixing.
As in the case with Chicken Little, running around screaming that the sky is falling is usually not an effective approach for communicating a problem (unless, of course, the sky really is falling and it's obvious that it is). Most bugs that you find won't be as dramatic as this. They will require you to clearly and succinctly communicate your findings to the team making the fix/no-fix judgment so that they have all the information they need to decide what to do.
NOTE
Because of all the different software development models and possible team dynamics, it's impossible to tell you exactly how the fix/no-fix decision-making process will work for your team or project. In many cases, the decision lies solely with the project manager, in others it's with the programmer, and in others, it's left to a committee.
What is universal, though, is that some person or group of people will review the bugs you report and determine whether they will be fixed. The information you provide that describes the bug is used to make that decision.
You don't need to be a lawyer or an ex-debate team captain to know how to persuade everyone that your bugs need to be fixed. Common sense and basic communication skills will take you a long way. Later in this chapter you'll learn about the different systems for bug logging and tracking, but for now, consider these fundamental principles for reporting a bug:
Report bugs as soon as possible. This has been discussed many times before, but it can't be emphasized enough. The earlier you find a bug, the more time that remains in the schedule to get it fixed. Suppose that you find an embarrassing misspelling in a Help file a few months before the software is released. That bug has a very high likelihood of being fixed. If you find the same bug a few hours before the release, odds are it won't be fixed. Figure 19.1 shows this relationship between time and bug fixing on a graph.
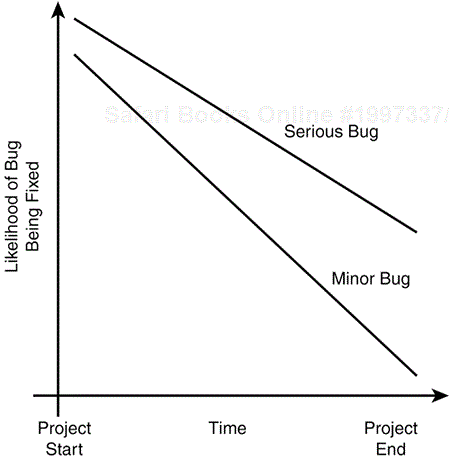
Figure 19.1. The later a bug is found, the less likely it is to be fixed, especially if it's a very minor bug.
This may seem strange—the bug is still the same bug whether you find it today or three months from now. Ideally, it shouldn't matter when it's found, just what the bug is. In reality, however, the risks of fixing that bug go up over time and increasingly weigh on the decision-making process.
Effectively describe the bugs. Suppose that you were a programmer and received the following bug report from a tester: “Whenever I type a bunch of random characters in the login box, the software starts to do weird stuff.” How would you even begin to fix this bug without knowing what the random characters were, how big a bunch is, and what kind of weird stuff was happening?
Be nonjudgmental in reporting bugs. It's easy for testers and programmers to form an adversarial relationship. Reread Chapter 3 if you forget why. Bug reports can be viewed by the programmers and others on the development team as the tester's “report card” on their work so they need to be nonjudgmental, nonpersonal, and noninflammatory. A bug report that says, “Your code for controlling the printer is terrible, it just plain doesn't work. I can't believe that you even checked it in for testing,” would be out of line. Bug reports should be written against the product, not the person, and state only the facts. No gloating, no grandstanding, no personalizing, no egos, no accusations. Tact and diplomacy are what matters.
Follow up on your bug reports. One thing worse than not finding an important bug is finding a bug, reporting it, and then forgetting about it or losing track of it. You've learned that testing software is hard work, so don't let the results of your labor, the bugs you find, become neglected. From the moment you find a bug, it's your responsibility to make sure that it's reported properly and given the attention that it needs to be addressed. A good tester finds and logs lots of bugs. A great tester finds and logs lots of bugs but also continues to monitor them through the process of getting them fixed. You'll learn more about this later in the chapter.
These principles—report bugs as soon as possible, effectively describe them, be nonjudgmental in reporting them, and follow up on them—should be common sense. You could apply these rules to almost any communications task. It's sometimes difficult, though, in the rush to create a product to remember to apply them to your testing. However, if you want to be effective at reporting your bugs and getting them fixed, these are fundamental rules to follow.
You've just learned that to effectively report a bug, you need to describe it as obvious, general, and reproducible. In many cases this is easy. Suppose that you have a simple test case for a painting program that checks that all the possible colors can be used for drawing. If each and every time you select the color red the program draws in the color green, that's an obvious, general, and reproducible bug.
What would you do, though, if this incorrect color bug only occurs after you've run several of your other test cases and doesn't occur if you run the specific failing test case directly after rebooting the machine? What if it seems to occur randomly or only during a full moon? You'd have some sleuthing to do.
Isolating and reproducing bugs is where you get to put on your detective hat and try to figure out exactly what the steps are to narrow down the problem. The good news is that there's no such thing as a random software bug—if you create the exact same situation with the exact same inputs, the bug will reoccur. The bad news is that identifying and setting up that exact situation and the exact same inputs can be tricky and time consuming. Once you know the answer, it looks easy. When you don't know the answer, it looks hard.
NOTE
Some testers are naturally good at isolating and reproducing bugs. They can discover a bug and very quickly narrow down the specific steps and conditions that cause the problem. For others, this skill comes with practice after finding and reporting many different types of bugs. To be an effective software tester, though, these are skills that you'll need to master, so take every opportunity you can to work at isolating and reproducing bugs.
A few tips and tricks will give you a good start if you find a bug that seems to take numerous steps to reproduce or can't seem to be reproduced at all. If you run into such a situation, try the suggestions in this list as a first step in isolating the bug:
Don't take anything for granted. Keep notes of everything you do—every step, every pause, everything. It's easy to leave out a step or add one unintentionally. Have a co-worker watch you try the test case. Use a keystroke and mouse recording program so that you can record and playback your steps exactly. Use a video camera to record your test session if necessary. The goal is to make sure that every detail of the steps necessary to cause the bug are visible and can be analyzed from a different view.
Look for time-dependent and race condition problems. Does the bug occur only at a certain time of day? Maybe it depends on how quickly you enter the data or the fact that you're saving data to a slower floppy instead of a fast hard drive. Was the network busy when you saw the bug? Try your test case on slower or faster hardware. Think timing.
White-box issues of boundary condition bugs, memory leaks, and data overflows can be slow to reveal themselves. You might perform a test that causes data to be overwritten but you won't know it until you try to use that data—maybe in a later test. Bugs that don't appear after a reboot but only after running other tests are usually in this category. If this happens, look at the previous tests you've run, maybe by using some dynamic white-box techniques, to see if a bug has gone unnoticed.
State bugs show up only in certain states of the software. Examples of state bugs would be ones that occur only the first time the software is run or that occur only after the first time. Maybe the bug happens only after the data was saved or before any key was pressed. State bugs may look like a time-dependent or race condition problem but you'll find that time is unimportant—it's the order in which things happen, not when they happen.
Consider resource dependencies and interactions with memory, network, and hardware sharing. Does the bug occur only on a “busy” system that's running other software and communicating with other hardware? In the end, the bug may turn out to be a race condition, memory leak, or state bug that's aggravated by the software's dependency or interaction with a resource, but looking at these influences may help you isolate it.
Don't ignore the hardware. Unlike software, hardware can degrade and act unpredictably. A loose card, a bad memory chip, or an overheated CPU can cause failures that look like software bugs but really aren't. Try to reproduce your bugs on different hardware. This is especially important if you're performing configuration or compatibility testing. You'll want to know if the bug shows up on one system or many.
If, after your best attempts at isolating the bug, you can't produce a short, concise set of steps that reproduce it, you still need to log the bug so you don't risk losing track of it. It's possible that with just the information you've learned a programmer may still be able to figure out what the problem is. Since the programmer is familiar with the code, seeing the symptom, the test case steps, and especially the process you took attempting to isolate the problem, may give him a clue where to look for the bug. Of course, a programmer won't want to, nor should he have to, do this with every bug you find, but sometimes those tough ones to isolate require a team effort.
You would probably agree that a bug that corrupts a user's data is more severe than one that's a simple misspelling. But, what if the data corruption can occur only in such a very rare instance that no user is ever likely to see it and the misspelling causes every user to have problems installing the software? Which is more important to fix? The decisions become more difficult.
Of course, if every project had infinite time, both problems would be fixed, but that's never the case. As you learned earlier in this chapter, trade-offs must be made and risks must be taken in every software project to decide what bugs to fix and what bugs not to fix or to postpone to a later release of the software.
When you report your bugs, you'll most often have a say in what should happen to them. You'll classify your bugs and identify in a short, concise way what their impact is. The common method for doing this is to give your bugs a severity and a priority level. Of course, the specifics of the method vary among companies, but the general concept is the same:
Severity indicates how bad the bug is; the likelihood and the degree of impact when the user encounters the bug.
Priority indicates how much emphasis should be placed on fixing the bug and the urgency of making the fix.
The following list of common classification of severity and priority should help you better understand the difference between the two. Keep in mind, these are just examples. Some companies use up to ten levels and others use just three. No matter how many levels are used, though, the goals are the same.
System crash, data loss, data corruption, security breach
Operational error, wrong result, loss of functionality
Minor problem, misspelling, UI layout, rare occurrence
Suggestion
Immediate fix, blocks further testing, very visible
Must fix before the product is released
Should fix when time permits
Would like to fix but the product can be released as is
A data corruption bug that happens very rarely might be classified as Severity 1, Priority 3. A misspelling in the setup instructions that causes users to phone in for help might be classified as Severity 3, Priority 2.
What about a release of the software for testing that crashes as soon as you start it up? Probably Severity 1, Priority 1. If you think a button should be moved a little further down on the page you might classify it as Severity 4, Priority 4.
As you learned in the discussion of the DREAD formula in Chapter 13, “Testing for Software Security,” security issues can be difficult to classify. A specific vulnerability could be very hard to expose but, if it is, could allow hackers access to the information in millions of personal accounts. That would most likely be a Severity 1, Priority 1 bug.
Severity and Priority are vital pieces of information to the person or team reviewing the bug reports and deciding what bugs should be fixed and in what order. If a programmer has 25 bugs assigned to him, he should probably start working on the Priority 1's first, instead of just fixing the easiest ones. Similarly, two project managers—one working on game software and another on a heart monitor—would use this same information but could make different decisions based on it. One would likely choose to make the software look the best and run the fastest; the other would choose to make the software as reliable as possible. The severity and priority information is what they would use to make these decisions. You'll see later in this chapter how these fields are used in a real bug-tracking system.
NOTE
A bug's priority can change over the course of a project. A bug that you originally labeled as Priority 2 could be changed to Level 4 as time starts to run out and the software release date looms. If you're the software tester who found the bug, you need to continually monitor the bug's status to make sure that you agree with any changes made to it and to provide further test data or persuasion to get it fixed.
In entomology (the study of real, living bugs), the term life cycle refers to the various stages that an insect undergoes over its life. If you think back to your high school biology class, you'll remember that the life cycle stages for most insects are the egg, larvae, pupae, and adult. It seems appropriate, given that software problems are also called bugs, that a similar life cycle system is used to identify their stages of life. A software bug's stages don't exactly match a real bug's, but the concept is the same. Figure 19.2 shows an example of the simplest, and most optimal, software bug life cycle.
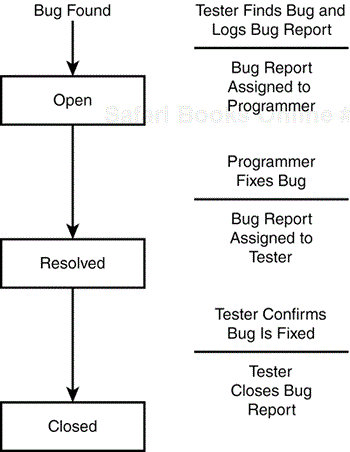
This example shows that when a bug is first found by a software tester, a report is logged and assigned to a programmer to be fixed. This state is called the open state. Once the programmer fixes the code, he assigns the report back to the tester and the bug enters the resolved state. The tester then performs a verification test to confirm that the bug is indeed fixed and, if it is, closes the report. The bug then enters its final state, the closed state.
In many instances, this is as complicated as a software bug's life cycle gets: a bug report is opened, resolved, and closed. In some situations, though, the life cycle gets a bit more complicated, as shown in Figure 19.3.
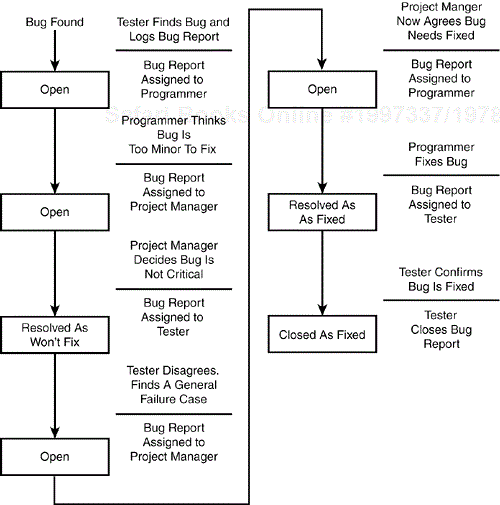
Figure 19.3. A bug's life cycle can easily become very complicated if the bug-fixing process doesn't occur as smoothly as expected.
In this case, the life cycle starts out the same with the tester opening the bug report and assigning it to the programmer, but the programmer doesn't fix the bug. He doesn't think it's bad enough to fix and assigns the report to the project manager to decide. The project manager agrees with the programmer and places the bug report in the resolved state as a “won't-fix” bug. The tester disagrees, looks for and finds a more obvious and general case that demonstrates the bug, reopens the report, and assigns it to the project manager. The project manager, seeing the new information, agrees and assigns it to the programmer to fix. The programmer fixes the bug, resolves it as fixed, and assigns the report to the tester. The tester confirms the fix and closes the bug report.
You can see that a bug might undergo numerous changes and iterations over its life, sometimes looping back and starting the life cycle all over again. Figure 19.4 takes the simple model of Figure 19.2 and adds to it the possible decisions, approvals, and looping that can occur in most projects. Of course, every software company and project will have its own system, but this figure is fairly generic and should cover most any bug life cycle that you'll encounter.
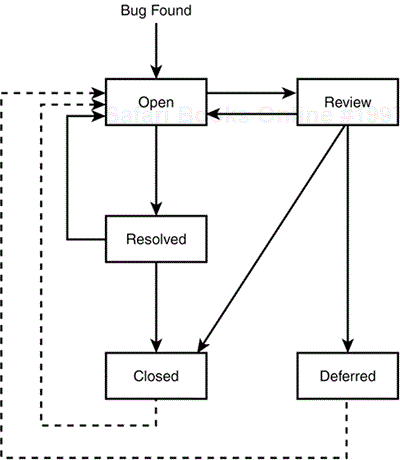
Figure 19.4. This generic bug life-cycle state table covers most of the possible situations that can occur.
This generic life cycle has two additional states and extra connecting lines. The review state is where the project manager or the committee, sometimes called a Change Control Board, decides whether the bug should be fixed. In some projects all bugs go through the review state before they're assigned to the programmer for fixing. In other projects, this may not occur until near the end of the project, or not at all. Notice that the review state can also go directly to the closed state. This happens if the review decides that the bug shouldn't be fixed—it could be too minor, is really not a problem, or is a testing error. The other added state is deferred. The review may determine that the bug should be considered for fixing at some time in the future, but not for this release of the software.
The additional line from the resolved state back to the open state covers the situation where the tester finds that the bug hasn't been fixed. It gets reopened and the bug's life cycle repeats. The two dotted lines that loop from the closed state and the deferred state back to the open state rarely occur but are important enough to mention. Since a tester never gives up, it's possible that a bug that was thought to be fixed, tested, and closed could reappear. Such bugs are often called regressions. It's also possible that a deferred bug could later be proven serious enough to fix immediately. If either of these situations occurs, the bug is reopened and started through the process again.
Most project teams adopt rules for who can change the state of a bug or assign it to someone else. For example, maybe only the project manager can decide to defer a bug or only a tester is permitted to close a bug. What's important is that once you log a bug, you follow it through its life cycle, don't lose track of it, and provide the necessary information to drive it to being fixed and closed.
By now it should be clear that the bug-reporting process is a complex beast that requires a great deal of information, a high level of detail, and a fair amount discipline to be effective. Everything you've learned so far in this chapter sounds good on the surface, but to put it into practice requires some type of system that allows you to log the bugs you find and monitor them throughout their life cycle. A bug-tracking system does just that.
The remainder of this chapter will discuss the fundamentals of a bug-tracking system and give you examples of using a paper-based approach and a full-fledged database. Of course what you use will likely be customized and specific to your company or project, but in general, the concepts are consistent across the software industry so you should be able to apply your skills to just about any system you're asked to use.
Your good friend, the IEEE 829 Standard for Software Test Documentation, defines a document called the Test Incident Report whose purpose is “to document any event that occurs during the testing process which requires investigation.” In short, to log a bug.
Reviewing the standard is a good way to distill what you've learned about the bug-reporting process so far and to see it all put into one place. The following list shows the areas that the standard defines, adapted and updated a bit, to reflect more current terminology.
Identifier. Specifies an ID that's unique to this bug report that can be used to locate and refer to it.
Summary. Summarizes the bug into a short, concise statement of fact. References to the software being tested and its version, the associated test procedure, test case, and the test spec should also be included.
Incident Description. Provides a detailed description of the bug with the following information:
Date and time
Tester's name
Hardware and software configuration used
Inputs
Procedure steps
Expected results
Actual results
Attempts to reproduce and description of what was tried
Other observations or information that may help the programmer locate the bug
Impact. The severity and priority as well as an indication of impact to the test plan, test specs, test procedures, and test cases.
The IEEE 829 standard doesn't define the format that the bug report should take, but it does give an example of a simple document. Figure 19.5 shows what such a paper bug report can look like.

Figure 19.5. A sample bug report form shows how the details of a bug can be condensed to a single page of data.
Notice that this one-page form can hold all the information necessary to identify and describe a bug. It also contains fields that you can use to track a bug through its life cycle. Once the form is filed by the tester, it can be assigned to a programmer to be fixed. The programmer has fields where she can enter information regarding the fix, including choices for the possible resolutions. There's also an area where, once the bug is resolved, the tester can supply information about his efforts in retesting and closing out the bug. At the bottom of the form is an area for signatures—in many industries, you put your name on the line to reflect that a bug has been resolved to your satisfaction.
For very small projects, paper forms can work just fine. As recently as the early 1990s, even large, mission-critical projects with thousands of reported bugs used paper forms for bug reporting and tracking. There still may be pockets of this today.
The problem with paper forms is that, well, they're paper, and if you've ever walked into a paper-run office and asked someone to find something, you know how inefficient such a system can be. Think about the complex bug life cycles that can occur (an example of which was shown in Figure 19.3), and you'll wonder how a paper system can work. What if someone wanted to know the status of Bug #6329 or how many Priority 1 bugs were left to fix? Thank goodness for spreadsheets and databases.
Just as with the test case and test procedure documents described in Chapter 18, “Writing and Tracking Test Cases,” there's no reason that the IEEE 829 standard can't be brought up-to-date and adapted to work with modern systems. After all, the information for tracking bugs, the data put on the form shown in Figure 19.5, is just text and numbers—a perfect application for a database. Figure 19.6 shows such an automated bug reporting and tracking system that represents the type you might encounter in your work.
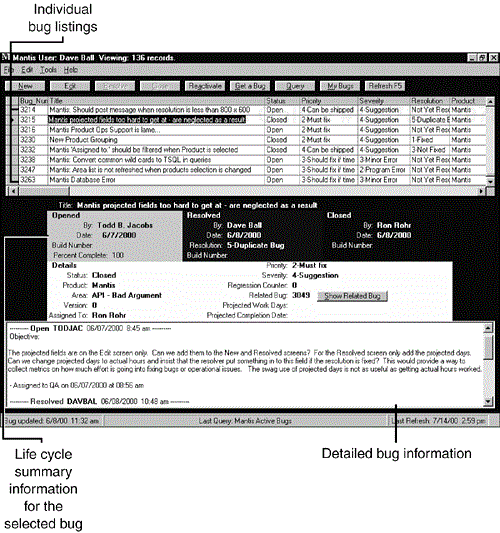
Figure 19.6. The main window of a typical bug-reporting database shows what an automated system can provide. (Mantis bug database images courtesy of Dave Ball and HBS International, Inc.)
Figure 19.6 shows a top-level view of a bug database containing 3,263 bugs. The individual bugs, their IDs, titles, status, priority, severity, and resolution are shown in a simple listing at the top third of the screen. Further information about the selected bug entry is then shown on the bottom part of the screen. At a glance you can see who opened the bug, who resolved it, and who closed it. You can also scroll through details that were entered about the bug as it went through its life cycle.
Notice that at the top of the screen there is a series of buttons that you can click to create (open) a new bug or to edit, resolve, close, or reactivate (reopen) an existing bug. The next few pages will show you the windows that appear when you select each option.
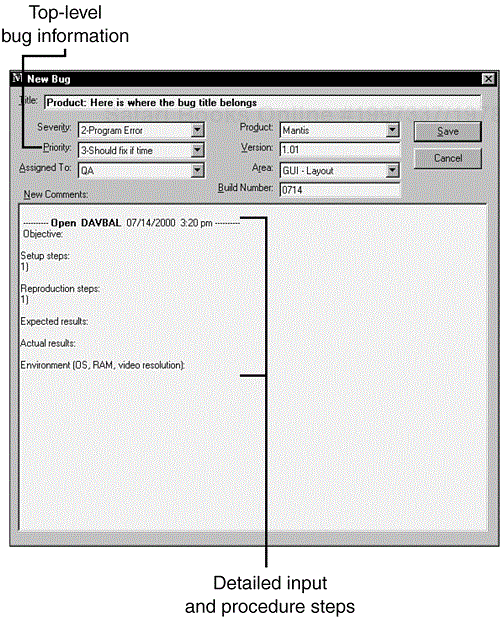
Figure 19.7 shows the New Bug dialog box, in which information is entered to log a new bug into the system. The top-level description of the bug includes its title, severity, priority, software version info, and so on. The comment field is where you would enter the details of how the bug was discovered. This database conveniently prefills the comment area with headers that guide you in providing the necessary information. If you're entering a new bug, all you need to do is follow the prompts—entering your test's objective, the setup steps, the steps that reproduce the bug, what result you expected, what result you saw, and what hardware and software configurations you were using when you saw the bug.
Once a bug is entered, and really anytime during its life cycle, new information may need to be added to clarify the description, change the priority or severity, or make other minor tweaks to the data. Figure 19.8 shows the window that provides this functionality.

Notice that this dialog box provides additional data fields over what the new bug window provided. Editing a bug allows you to relate this bug to another one if you find one that seems similar. A programmer can add information about how much progress he's made in fixing the bug and how much longer it will take. There's even a field that can put the bug “on hold,” sort of freezing it in its current state in the life cycle.
An important feature shown in Figure 19.8 is in the Comments section. Each time a bug is modified, when it's opened, edited, resolved, and closed, that information is recorded in the comment field. At a glance you can see what states the bug has been through over its life.
Figure 19.9 shows the dialog box used when someone, usually the programmer or project manager, resolves a bug. A drop-down list provides different resolution choices from Fixed to Can't Fix to Duplicate. If the bug is fixed, the build—or version number that will contain the fix—is entered, and information about what was fixed or how the fix was made is added to the comment field. The bug is then reassigned to the tester for closing.
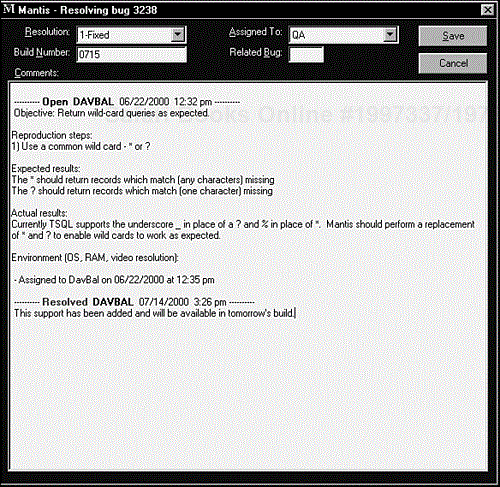
Figure 19.9. The Resolving dialog box is typically used by the programmer to record information regarding the bug fix.
Many bug databases track not just comments about the fix, but also details of exactly what the programmers did to make the fix. The line of code, the module, and even the type of error can be recorded as it often provides useful information to the white-box tester.
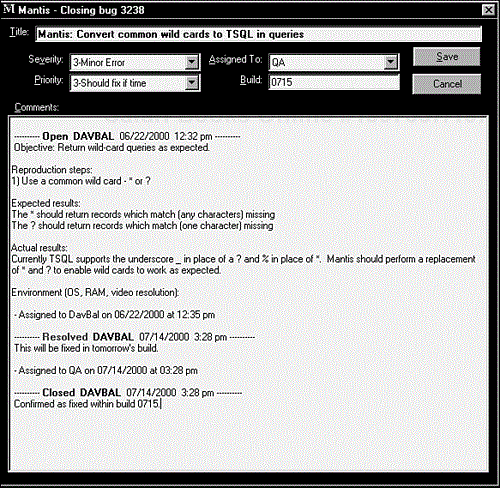
After a bug is resolved, it's typically assigned back to you, the tester, for closing. Figure 19.10 shows the bug Closing dialog box. Because the database tracked every modification to the bug report since it was opened, you can see the decisions that were made along the way and what exactly was fixed. It's possible that the bug wasn't fixed the way you expected, maybe a similar bug had been found and added by another tester, or maybe the programmer made a comment about the fix being risky. All this information will assist you when you retest the bug to make sure it's fixed. If it turns out that it's not fixed, you simply reopen the bug to start the life cycle over again.
Once you use a real bug-tracking database, you'll wonder how a software project's bugs could ever have been managed on paper. A bug-tracking database provides a central point that an entire project team, not just the testers, can use to communicate the status of the project, tell who's assigned what tasks to perform, and, most importantly, assure that no bug falls through the cracks. It's the culmination of everything you've learned in this chapter about how to report the bugs you find.
This chapter started out with an excerpt from the kids' story about Chicken Little that described her reaction when an acorn unexpectedly fell on her head. She thought she had discovered a serious problem—a Severity 1, Priority 1 bug—and immediately began running around screaming that the sky was falling.
As a software tester, it's sometimes easy to get caught up in the moment when you find that something in the program you're testing doesn't work as expected. What you've learned in this chapter is that there's a formal process that should be followed to properly isolate, categorize, record, and track the problems you find to ensure that they're eventually resolved and, hopefully, fixed.
Chicken Little has never read Chapter 19, so she didn't know what to do other than tell everyone she met what she thought was happening. She was wrong, of course. The sky wasn't falling. If she had at least stopped to isolate and reproduce the problem, she would have discovered that it wasn't really a problem at all—it was by design that the nut fell from the tree. In the end, her panic and naïveté did her in. (If you're unfamiliar with the story, she and her barnyard friends eventually meet a hungry fox who invites them into his den to hear their story).
The moral of all this is that to be an effective tester, you need to not just plan your testing and find bugs, but also to apply a methodical and systematic approach to reporting them. An exaggerated, poorly reported, or misplaced bug is no bug at all—and surely one that won't be fixed.
These quiz questions are provided for your further understanding. See Appendix A, “Answers to Quiz Questions,” for the answers—but don't peek!