
5.3 Results
We compare the inference performance of the C3NET [12] for four mutual information estimators. We simulated gene expression datasets for random graphs for different edge densities. We studied the global inference performance and structural characteristics of the inferred networks.
5.3.1 Global Network Inference Performance
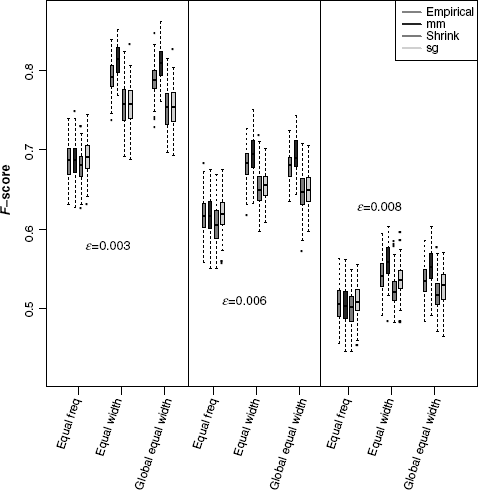
We study the influence of four different mutual information estimators on the C3NET network inference performance. We use the F-score measure to measure the performance for C3NET network inference from simulated gene expression data. First, we compared the impact of three discretization methods for each estimator. For the three network types the equal width and global equal width discretization showed the highest inference accuracy for C3NET compared to the equal frequency discretization.
The equal and global equal width discretization favor the Miller–Madow estimator followed by the empirical estimator to be most beneficial for the C3NET inference performance. The Schürmann–Grassberger and Shrink estimator perform worse. However, the Schürmann–Grassberger performs better than the Shrink estimator (Fig. 5.9). For the equal frequency discretization, we do not observe a substantial difference of the inference performance for the empirical, Miller–Madow, Shrink, and Schürmann–Grassberger estimator (Fig. 5.9).
Figure 5.9 The influence of different discretization methods on the global network inference accuracy F-score measure for three Erdös–Renyi networks using four MI estimators. The simulated gene expression datasets have a sample size of 200.
Further, we studied the influence of the estimators for each of the discretization methods on the sample size (equal frequency discretization Fig. 5.10, equal width discretization Fig. 5.11, global equal width discretization Fig. 5.12). For all network types, the inference performance increases with the sample size. The Miller-Madow estimator in combination with the equal width and global equal width discretization is the most beneficial setting for the inference performance of C3NET.
Figure 5.10 The influence of equal frequency discretization method on the global network inference accuracy F-score measure for three Erdös–Renyi networks using four MI estimators.
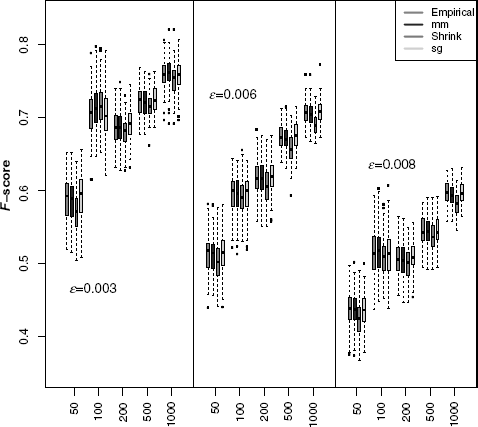
Figure 5.11 The influence of equal width discretization method on the global network inference accuracy F-score measure for three Erdös–Renyi networks using four MI estimators.
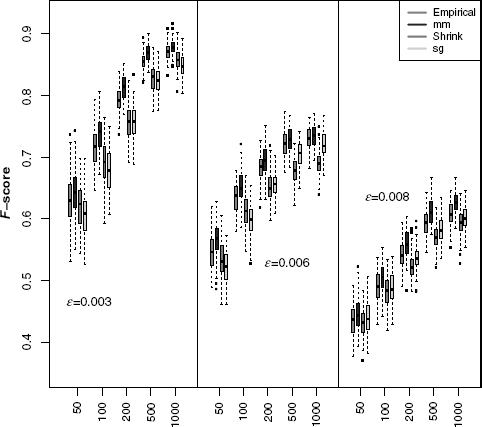
Figure 5.12 The influence of global equal width discretization method on the F-score for three Erdös–Renyi networks using four MI estimators.
The C3NET infers a sparse network with maximal one edge for each gene. Due to the limited number of edges in an inferred C3NET network, more densely connected network structure cannot be inferred. This effect can be observed in Figures 5.9 –5.12, where the performance for the network inference is decreasing with an increasing edge density.
5.3.2 Local Network Inference Performance
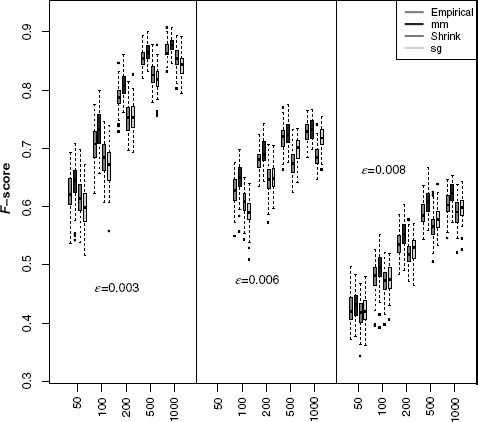
In the previous section, we studied the impact of MI estimators on the global network inference performance of C3NET. When global measures are used, we measure the average influence of the MI estimators on the inference performance for all edges. Local network-based measures allow to study the local network inference performance for different edge classes. We use the D1 measure to classify edges in the three Erdös–Rènyi reference networks into two edge classes connected to nodes with a low (Class I) and a high (Class II) edge degree. For each dataset, we obtain a measure for the true positive rate from the Bootstrap generated ensemble of networks. We compare the distribution of median true positive rates for D1 Class I and D1 Class II for 100 datasets for each network. In Figures 5.13 and 5.14, we show the distribution of the median true positive rate for the three simulated gene expression datasets and different sample sizes for the two classes in D1. The Class I edges show a high inference performance for the D1 measure, while Class II edges have a low inference performance. With increasing edge density and increasing sample size the true positive rate for Class I edges approaches 1 while for Class II the true positive rate approaches 0.
Figure 5.13 Class I edges (according to D1) in the three Erdös–Renyi networks using four different MI estimators. Simulated gene expression datasets for Erdös–Renyi networks with edge density ![]() for sample sizes ranging from 50 to 1000 samples.
for sample sizes ranging from 50 to 1000 samples.
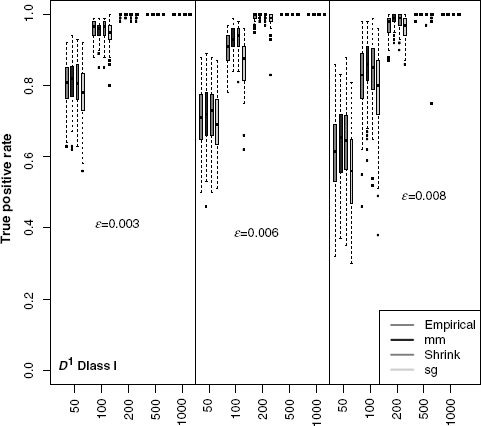
Figure 5.14 Class II edges (according to D1) in the three Erdös–Renyi networks using four different MI estimators. Simulated gene expression datasets for Erdös–Renyi networks with edge density ![]() for sample sizes ranging from 50 to 1000 samples.
for sample sizes ranging from 50 to 1000 samples.
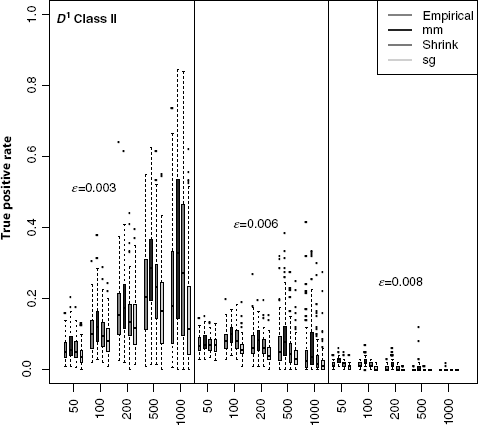
For Class I edges, the true positive rates among MI estimators do not show a substantial difference, while the Schürmann–Grassberger estimator has the tendency to perform worse than the other MI estimators. For Class II edges, the Miller–Madow estimators shows the best inference performance. We performed the same analysis using the D2 measure (not shown). The D1 and D2 measure show similar results for the relative performance of the four MI estimators.