
Metakit is an embeddable database library which was created by the Netherlands based programmer Jean-Claude Wippler (Note that he is also one of the authors of TclKit, so it's no surprise that these two technologies are commonly used together.). In this section, we are going to explain how it works. This information is not crucial for building the standalone binaries, so you may skip it, but we do recommend that you take the time to get more familiar with it for at least one reason—whenever you use the TclKit, you will already have a Metakit within easy reach, so it is always useful to know about the possibilities it offers.
- Extreme portability—the entire database is stored in one file
- Platform independence—the file containing the database can be used directly on any other platform (such as Unix, Windows, Macintosh, and others) without any conversion
- High efficiency in typical operations, thanks to the specific internal format
- The ability to embed it in C++, Python, and Tcl based applications
- Support for transactions
- A small footprint—the library itself has a size of about 125 KB
The Metakit database format involves relational and hierarchical concepts. It introduces slightly different terminologywhen compared to typical relational databases.
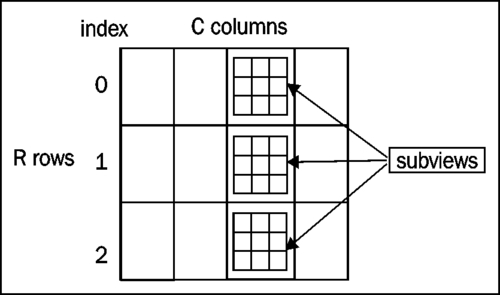
The most basic concept is a view, and it is nothing more than collection of rows (similar to a "table of records" in database terminology). A specific row is pointed out by an index (its values start from zero). Each row consists of a fixed number of cells, so basically a view is an RxC matrix, where 'R' is the number of rows and 'C' the number of columns (each cell belongs to some column). All cells belonging to the same column share the same data type (that is, they are homogenous):
- string
- numeric
- raw data (untyped)
- subview (nested view)
A subview is nothing more than a view nested inside another view. The availability of such nesting gives great flexibility to Metakit, and is also its biggest difference from traditional relational databases.
What is interesting is that data from a column is stored contiguously in the Metakit file. This is the opposite of a traditional database organization, where data is stored in a row-like perspective— where data from one specific row are adjacent to each other. The Metakit way means that the performance of adding / deleting rows is lower, but in return, loops iterating on data from a column are extremely fast.
The complete documentation of Metakit, along with downloads and support information is available at http://www.equi4.com/metakit/index.html.
Mk4tcl is an extension that allows operations on Metakit databases from Tcl scripts. The homepage, containing full documentation, is located at http://www.equi4.com/metakit/tcl.html. We do not intend to duplicate it, we will just review the most important Tcl commands introduced by this extension.
If you are using the prepared Tcl distribution, there is a good chance that the extension is already a part of it. Otherwise, you will have to download the extension from its homepage and install it. To start using the extension, you have to load it in your script using:
package require Mk4tcl
To operate on data files, use the mk::file command with the appropriate arguments. Mk4tcl introduces the concept of a tag—that is, an identifier for an opened data file.
To create or open an existing Metakit file, use mk::file open, for example:
mk::file open myTag myDatabase.mk
Here the tag is named myTag and the data file myDatabase.mk. Note that unless you use the option nocommit, all pending changes will be saved to file when it is closed.
Other uses of mk::file include:
mk::file close myTag—closes the data file identified bymyTagmk::file commit myTag—commits all changes, this is useful whennocommitis used. The other scenario when this may be useful is if you want to explicitly commit data—for example, before some time-consuming operations take place. Autocommit is done within the event loop, so it wouldn't occur in this situation, and if the user aborts the program, the data can be lost.mk::file rollback myTag—drops all pending changesmk::file views myTag—returns a list of views defined in the data file
To specify a view or a row with in a view, you can use a path. The way to construct a path can be easily described using the following examples:
myTag.myView—specifies the top-level view calledmyViewin database referred to by usingmyTagmyTag.myView!R—specifies a row; R is a row number, starting from zeromyTag.myView!R.subview—denotes an entiresubviewin the row R ofmyViewmyTag.myView!R.subview!S—denotes row S in asubviewin row R ofmyView
To operate on a view, use the mk::view command. In the following commands, myTag.myView is an example of the path denoting the view, and it will sometimes be referred to by using path to make the syntax more readable:
mk::view size myTag.myViewreturns the number of rows in the view namedmyViewin the data file identified withmyTagmk::view layout myTag.myViewreturns the current data structure of the view namedmyViewin the data file identified withmyTag- The same
layoutcommand may be used to define a data structure:mk::view layout myTag.people {name birthYear:I}This command defines a
peopleview with two columns—name and birth year. Note that the second one is of type integer (with suffix :I). The other suffixes are::S—string (default type):L—64-bit integer (long) value:F—single-precision floating point value (32 bits):D—double-precision floating point value (64 bits):B—binary (un-typed) value
If the suffix is not specified, it defaults to a string.
To define a
peopleview with the subviewaddresses(containing the columnscity, street,andnumber), use the following command:mk::view layout myTag.people {name birthYear:I {addresses {city street number:I}}}What is more interesting is that this command may also be used to dynamically change the structure of the existing view— to add new or remove existing columns without losing other data.
Once you have opened the data file and defined the view, it is time to operate on the data. You can start operating on rows with the mk::row command:
mk::row append myTag.myViewappends new rows, for example:mk::row append myTag.people name "John Smith" birthYear 1945Note that you can also refer to a new, as yet undefined column, thereby effectively creating it. By default, the type of that column's data is string, unless an appropriate suffix is used.
mk::row delete pathdeletes the row pointed to by the path.mk::row createcreates a temporary row stored in memory and returns a unique path:set tempPath [mk::row create name "Will Bush" birthYear 1980]mk::row insert path 1 tempPathinserts a temporary row into the view in a position specified bypath. 1is the number of copies (the row may be inserted in multiple copies)mk::row replace path tempPathreplaces the row with a new onemk::row delete pathdeletes the row
To get values from the row, use the mk::get path command. It returns a list of column names and values.
To set values in an already existing row, you can use the mk::set path command like this:
mk::set path name "George S." birthYear 1978
The path must denote the row number (in the myTag.myView!R format). If that row does not exist, it will be created. If you use a value higher than the index of the last row, the gap will be filled in with rows of empty values.
Knowing all this, lets consider the following example code:
package require Mk4tcl
proc printRows {path rows} {
foreach i $rows {
puts [mk::get $path!$i]
}
}
mk::file open myTag myDatabase.mk
mk::view layout myTag.people {name birthYear:I}
mk::row append myTag.people name "George S." birthYear 1978
mk::row append myTag.people name "John Gray" birthYear 1973 sex male
mk::row append myTag.people name "Jeniffer Snake" birthYear 1982 sex female
mk::row append myTag.people name "Judith Brow" birthYear 1987 sex female
mk::set myTag.people!9 name "Johnny B." birthYear 1977 sex male
This set of instructions will create a database stored in the myDatabase.mk file and put inside it a total of 10 rows.
For easy selection of rows, use the mk::select path ?options? command. The command returns a list of row numbers that matched the selection criteria, which was specified in the options arguments. By default, the command will select all rows:
set rows [mk::select myTag.people]
printRows myTag.people $rows
The previous command will result in the following output:
name {George S.} birthYear 1978 sex {}
name {John Gray} birthYear 1973 sex male
name {Jeniffer Snake} birthYear 1982 sex female
name {Judith Brow} birthYear 1987 sex female
name {} birthYear 0 sex {}
name {} birthYear 0 sex {}
name {} birthYear 0 sex {}
name {} birthYear 0 sex {}
name {} birthYear 0 sex {}
name {Johnny B.} birthYear 1977 sex male
There is no point in doubling the documentation and describing all options of mk::select. Instead, we will show an example of the usage of some of them:
- Use
-minand-maxto specify a range of allowed values:set rows [mk::select myTag.people -min birthYear 1975 -max birthYear 1985] printRows myTag.people $rowsThis will result in selecting all the people born within 1975 and 1985:
name {George S.} birthYear 1978 sex {}
name {Jeniffer Snake} birthYear 1982 sex female
name {Johnny B.} birthYear 1977 sex male
- Use
-exactfor an exact match:set rows [mk::select myTag.people -exact sex female] printRows myTag.people $rowsThe preceding command will find all women:
name {Jeniffer Snake} birthYear 1982 sex female
name {Judith Brow} birthYear 1987 sex female
- You can also use wildcard matching with
-glob:set rows [mk::select myTag.people -glob name J*] printRows myTag.people $rowsThe result of this command will be:
name {John Gray} birthYear 1973 sex male
name {Jeniffer Snake} birthYear 1982 sex female
name {Judith Brow} birthYear 1987 sex female
name {Johnny B.} birthYear 1977 sex male
- Also, in order to use regular expressions, we use the following command:
set rows [mk::select myTag.people -regexp name John.*] printRows myTag.people $rowsThe matching rows are:
name {John Gray} birthYear 1973 sex male
name {Johnny B.} birthYear 1977 sex male