
It would be hard to talk about data storage and not mention relational databases. In this section, we will briefly review how Tcl interacts with different databases. We assume the reader is familiar with database concepts and SQL. If not, you can either skip this section, or learn about the topic from other sources first.
For demonstration purposes, in every database described, we will setup a database named Bookstore with the following tables and sample data:
CREATE DATABASE Bookstore
CREATE TABLE Books
(
title varchar(255),
isbn varchar(255),
PRIMARY KEY (isbn)
);
CREATE TABLE Persons
(
name varchar(255),
surname varchar(255),
CONSTRAINT pk PRIMARY KEY (name, surname)
);
CREATE TABLE Authors
(
book_id varchar(255),
name varchar(255),
surname varchar(255),
FOREIGN KEY (book_id) REFERENCES Books(isbn),
FOREIGN KEY (name, surname) REFERENCES Persons(name, surname)
);
INSERT INTO Persons VALUES ('Piotr','Beltowski'),
INSERT INTO Persons VALUES ('Wojciech','Kocjan'),
INSERT INTO Books VALUES ('Tcl Network Programming','978-1-849510-96-7'),
INSERT INTO Books VALUES ('Learning Nagios 3.0','978-1-847195-18-0'),
INSERT INTO Authors VALUES ('978-1-847195-18-0', 'Wojciech','Kocjan'),
INSERT INTO Authors VALUES ('978-1-849510-96-7', 'Wojciech','Kocjan'),
INSERT INTO Authors VALUES ('978-1-849510-96-7', 'Piotr','Beltowski'),
The structure of the tables and data are meant to reflect the current achievements of the authors of this book.
In the following sections we are going to discuss databases that can be divided into two general types:
- Client-server databases such as MySQL or PostgreSQL. In this case, the connection is done over network (in case of remote db) or local socket to the database server that is running as completely separate program. This solution is more flexible, but vulnerable to connectivity problems or low network performance that can really be a bottleneck. The main benefit is that the server where the database is running usually offers reasonable computing performance, so performing operations on large volume of data shouldn't be a problem. It also allows more efficient use of multiple applications using the same database.
- Embedded databases such as SQLite and mk4tcl. However, the latter does not support SQL and therefore is beyond the scope of this chapter. Such a database runs as a part of your application and is closed once you terminate the application. The data is usually stored in a local file or even in memory. This type of database is perfect for use when you are developing a standalone, single-user application.
MySQL is one of the most popular free databases. To work with it from Tcl, you can use the mysqltcl package that constitutes Tcl interface towards the database. The home page of this extension is located at http://www.xdobry.de/mysqltcl/index.html, and you can find the full manual here. Below we will briefly present how to use this package.
Assume that the database is installed on localhost, port 3306, the user name is root and the password is toor. To start working with it, we will first have to connect to it:
package require mysqltcl
set m [::mysql::connect -host localhost -port 3306 -user root -password toor]
The first line loads the package, the next one connects to the database using the mysql::connect command, and stores the connection handle in m variable for future usage. The options for the connecting command are rather self explanatory.
To select the database, use the mysql::use command with the handle and the DB name:
::mysql::use $m Bookstore
Assume we want to retrieve the details (title and ISBN number) of the books authored by Wojciech Kocjan. To facilitate this, first store the appropriate SQL query in the query variable:
set query "SELECT Books.title, Books.isbn FROM Books, Authors WHERE Authors.surname = 'Kocjan' AND Books.isbn = Authors.book_id"
To send the query to the server, we will use the mysql::sel function. This command is only for SELECT queries, and accepts the following parameters: the connection handle, the query string, and optionally:
-list—this command will return the list of lists, where every list corresponds to one resulting row. For example:puts [::mysql::sel $m $query -list]The preceding command will output:
{{Learning Nagios 3.0} 978-1-847195-18-0} {{Tcl Network Programming} 978-1-849510-96-7}-flatlist—all rows will be concatenated into one single list:puts [::mysql::sel $m $query -flatlist]
And it returns:
{Learning Nagios 3.0} 978-1-847195-18-0 {Tcl Network Programming} 978-1-849510-96-7Such a list may be a perfectly suitable for use with a
foreachstatement, to iterate over the results.
If the third parameter is omitted, the resulting rows can be retrieved using the following commands:
mysql::fetch—at every call to this command, retrieves one row of the result:mysql::sel $m $query while {[llength [set row [mysql::fetch $m]]]>0} { puts "[lindex $row 0] --> [lindex $row end]" }And the output is:
Learning Nagios 3.0 --> 978-1-847195-18-0 Tcl Network Programming --> 978-1-849510-96-7mysql::map—this command maps every column from the resulting row to the variable and executes the provided script, from which these variables can be accessed. For example lets map the columns to variables namedtitleandisbn, and then print them out:mysql::sel $m $query mysql::map $m [list title isbn] { puts "$title --> $isbn" }The result will be the same as in previous example:
Learning Nagios 3.0 --> 978-1-847195-18-0 Tcl Network Programming --> 978-1-849510-96-7
Both of these commands process one row at a time.
There is also another way to retrieve the result, with mysql::receive. The major difference is that this command does not buffer (cache) any data on the client side, but receives it directly from the server. This offers much better performance when a large number of results is received from the server.
When compared to fetch and map, it is not required to call sel first, as it accepts the query string directly:
mysql::receive $m $query [list title isbn] {
puts "$title --> $isbn"
}
The output is identical to previous script. The command is very similar to foreach in the sense that it accepts a list of variables to assign values to.
If you would like to execute some SQL query other then SELECT, use mysql::exec:
::mysql::exec $m "INSERT INTO Persons VALUES ('John','Smith')"
::mysql::exec $m "INSERT INTO Authors VALUES ('978-1-849510-96-7', 'James T.','Kirk')"
This command returns the number of affected rows. The second call to the command will fail, as there is no record for James T. Kirk in the Persons table, so a foreign key constraint fails. To avoid execution interruption, you could use the appropriate catch clause.
Once you have finished working with the database, it is a good idea to disconnect and free the resources, by using the command:
mysql::close $m
The support for PostgreSQL database is far better, than the support for MySQL, because we can choose from 2 available:
- The first one is
pgtcl(http://pgtcl.projects.postgresql.org/), and its newer versionpgtcl-ng(http://pgtclng.projects.postgresql.org/). This extension is built using native code, so you have to pick the correct version for your platform, or compile one from the source code. Once you do this, you will be rewarded with the high performance of this solution. - The second extension is
pgintcl(http://pgintcl.projects.postgresql.org/). This one is written in pure Tcl language, so it is portable and independent of the operating system and hardware you are using. Internally it uses TCP/IP protocol to connect to and carry on a dialogue with the database (so it is tightly related to the version of PostgreSQL protocol). The main disadvantage of this extension is its performance—it is slower than the previous extension, because native binary code will always perform better than Tcl-based code.
The good news is that both of these extensions share almost the same command set, so from the programmer's point of view there is almost no difference in usage. The first one, pgtcl, is loaded with:
package require Pgtcl
While to use pgintcl you have to call:
package require pgintcl
As usual, we are not going to duplicate the extension's manual it's already written by the extension's authors, and you can find it on appropriate homepages, but to make the reader aware of such a solution and get him familiar with it, we will be presenting the following example code:
package require pgintcl
set p [pg_connect -conninfo {dbname=bookstore host=127.0.0.1 port=5432 user=root password=toor}]
set query "SELECT Books.title, Books.isbn FROM Books, Authors WHERE Authors.surname = 'Kocjan' AND Books.isbn = Authors.book_id"
pg_select $p $query result {
puts "$result(title) --> $result(isbn)"
}
pg_execute -array result $p $query {
puts "$result(title) --> $result(isbn)"
}
set handle [pg_exec $p "INSERT INTO Persons VALUES ('John','Smith')"]
puts [pg_result $handle -status]
set handle [pg_exec $p "INSERT INTO Authors VALUES ('978-1-849510-96-7', 'James','T. Kirk')"]
puts [pg_result $handle -status]
pg_disconnect $p
In this case, we use pgintcl, but as mentioned before, you can easily switch to pgtcl by modifying the first line.
The example itself does the same operations as in case of the one presented in MySQL section.
First it connects to the database by calling pg_connect. The -conninfo argument specifies the list of connection options in form of key=value pairs. The full list of options may depend on version of the database, but the most common options are:
|
Key |
Description |
|---|---|
|
|
The name of the database to connect to |
|
|
The host name or address where the server is running and listening for connections |
|
|
The TCP port to connect to |
|
|
The username used for the authorization |
|
|
The user's password |
If the values contain spaces, they should be entered in single quotes, following the typical escaping rules (\ for and ' for ')
The next command, pg_select, is used to execute the query and work on the results. The command accepts the following attributes:
- The handle for the connection, returned by
pg_connect - The query string (this command accepts only SELECT queries)
- The name of the array, where the results of the query will be stored. Array keys are named after appropriate columns of returned rows.
- The script that will be executed for each row of the returned data. The script can be omitted, which makes sense in cases where only one row will be returned.
Next, another type of command—pg_execute—is used. The syntax is similar to the syntax of the previous command, but the order of arguments is different—first you have to specify the array name, which is done with -array argument. This command also accepts queries other than SELECT, and in such a case it simply returns the number of affected rows. In the case of a SELECT query, the (optional) script is executed for every row.
Once retrieving of the data is demonstrated, we attempt to execute some other types of query—in this case INSERT. To send a command to the database server, use the pg_exec command, with the handle and appropriate command string. The command returns another handle, this time to the result object, which can be further examined with the pg_result command. To use pg_result, you have specify the mentioned handle and which of the result attributes you would like to retrieve. For example, pg_result $handle status will return the status (for other options, see the manual).
In our example the first INSERT query will succeed, and the next one will fail, which maps directly to the code's output:
Learning Nagios 3.0 --> 978-1-847195-18-0
Tcl Network Programming --> 978-1-849510-96-7
Learning Nagios 3.0 --> 978-1-847195-18-0
Tcl Network Programming --> 978-1-849510-96-7
PGRES_COMMAND_OK
PGRES_FATAL_ERROR
At the end, we close connection to the database server with pg_disconnect.
SQLite is a free SQL database engine that has gained wide popularity among Tcl users. The reason for this is that it does not require installation or configuration, or dedicated server—you just start using it locally as an embedded database. It is fast, compact, efficient and very handy when it comes to rapid prototyping of the application, and this is the task which often happens in Tcl world. The details of SQLite can be found on its home webpage http://www.sqlite.org/.
What is particularly important from a Tcler's point of view is that SQLite was originally created as a Tcl extension, so it is supported in Tcl from the very beginning. It was meant to be very easy to use from Tcl code, and of course provides a comprehensive interface in terms of Tcl commands. As you will see, the usage is so simple that eventually even the most zealous antagonist will start using it as a default way to store application data.
To start using it, you have to load the appropriate package:
package require sqlite3
SQLite stores all data in database files. The file name can be anything, but by convention the extension for the file is .db. The following command connects to the file bookstore.db (or creates one if it does not exist) and defines the command named bs for handling the database from that file:
sqlite3 bs bookstore.db
Note that if you do not specify an absolute path to the file, it will be created in the current working directory of your Tcl interpreter. There is also the possibility to create and use a database that is stored in memory—in this case, instead of the filename, use :memory: as the name.
Once the database is opened, it is accessible via the command defined in the opening call; in our example the command is bs. Note that you have complete freedom in choosing the command name. What is more, you can open the same database more than once, each one with different command. You can consider a command name as the equivalent of a connection handle. Such a command provides a set of methods, where the most important is named eval. This method allows executing SQL queries on the database. The syntax is as follows:
bs eval sqlQuery ?arrayName? ?script?
sqlQueryis a string containing an SQL query. Usually it is put in curly brackets {} to avoid Tcl substitution, because SQLite has the unique feature of understanding Tcl variables, so even though the variable will not be substituted by Tcl interpreter, the database engine will replace it properly with the correct value.arrayNameis an optional name of the array where the columns from each result row will be stored (see the example below). Column names are used as array keys. Note that not every SQL query must return results.scriptis an optional Tcl script that will be executed for each result row.
Using the eval method is simple. For example to create a table called Books, all you need to do is:
bs eval {
CREATE TABLE Books
(
title varchar(255),
isbn varchar(255),
PRIMARY KEY (isbn)
);
}
Of course all SQL commands could be placed in a single bs eval call. In the rest of this paragraph we assume that bookstore.db database is populated with the example SQL structures presented at the beginning. Note that by default SQLite does not honor FOREIGN KEY constraints, and it must be enabled (the best option is to do it right after opening database) with the command:
bs eval {PRAGMA foreign_keys = ON;}
If the SQL query does return some results, the eval method will return a flat Tcl list containing all result records, suitable for using in a foreach loop:
set query "SELECT Books.title, Books.isbn FROM Books, Authors WHERE Authors.surname = 'Kocjan' AND Books.isbn = Authors.book_id" puts [bs eval $query]
The result from this query is as follows:
{Learning Nagios 3.0} 978-1-847195-18-0 {Tcl Network Programming} 978-1-849510-96-7
The following illustrates how to use a script passed as additional argument for eval:
bs eval $query {
puts "$title --> $isbn"
}
The script contained in {} is executed for every row. To access the returned data, use the variables named after appropriate column names. Note that instead of column names, identifiers specified with the SQL keyword AS can be used:
set query2 "SELECT Books.title AS TheTitle, Books.isbn AS ISBN_Number FROM Books, Authors WHERE Authors.surname = 'Kocjan' AND Books.isbn = Authors.book_id"
bs eval $query2 {
puts "$TheTitle --> $ISBN_Number"
}
Using the array name is also trivial:
bs eval $query result {
puts "$result(title) --> $result(isbn)"
}
In this case, the array name is result, and the keys for the array are named title and isbn. In all three examples, the output produced will be the same:
Learning Nagios 3.0 --> 978-1-847195-18-0 Tcl Network Programming --> 978-1-849510-96-7
As mentioned before, eval handles any SQL query, for example a query of type INSERT:
bs eval {INSERT INTO Persons VALUES ('John','Smith')}
In the case of such queries, eval does not return any value, but it can throw an error. For example, if the presented line were called second time, the PRIMARY KEY constraint would cause a failure, resulting in:
columns name, surname are not unique
while executing
"bs eval {INSERT INTO Persons VALUES ('John','Smith')}"
As usual, such Tcl errors can be handled programmatically by using a catch command.
SQLite's origins in Tcl brings interesting feature—you are able to use Tcl variables directly in SQL queries:
set a 2
set b 3
set c "1+1"
puts [bs eval {SELECT $a + $b, $c}]
This will output: 5 1+1
When a query is put in curly braces, variables are not expanded by Tcl, but SQLite is able to map them to Tcl variables—its one of the reasons why SQLite3 is so popular in the Tcl world.
To close the database, use the close method:
bs close
As a result, the command controlling the database—in this case bs—is also deleted.
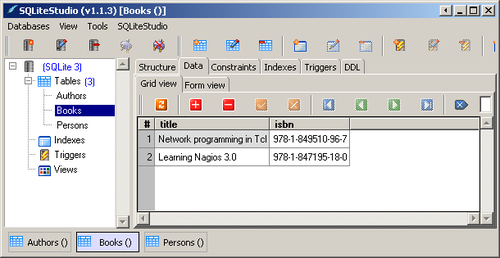
SQLite database is so popular among Tcl users that a group of management tools aimed to facilitate the daily work were created. We would like to present one of them - SQLiteStudio, created by Pawel Salawa, available at http://sqlitestudio.one.pl/. Why do we mention this particular tool? It is a free, advanced, GUI based, cross-platform database manager, written in Tcl and offered in the form of a single standalone executable binary file (thanks to Starpack technology). What is more, you can easily download the source code and analyze it. SQLiteStudio offers you a number of features:
- Open an existing database file or create new one
- View and modify the structure of a database, for example to add new tables
- Display and modify (add, delete, edit) data values stored in the database
- Work with triggers, views and indexes
For illustration, in the below screenshot the bookstore.db database is loaded into SQLiteStudio, and data from table Books is displayed:
There are of course a lot of other database engines, and the majority of them have some kind of Tcl bindings—for example Oratcl for Oracle or db2tcl for DB2. We should also keep in mind that Tcl world has another interesting database solution—Metakit, described in Chapter 3.
The last thing to mention is that you are also able to use ODBC data sources, by using tclodbc extension (http://sourceforge.net/projects/tclodbc/). It is supported for Unix and Windows, and allows you to connect to any database management system that provides ODBC interface.