
This chapter covers fundamental topics related to networking in the Tcl language, with a focus on the TCP and UDP protocols. It outlines the basic abilities offered by Tcl, and the following chapters will gradually approach more advanced topics. The entire subject is far too extensive to be described in one book. We assume the reader has basic knowledge of these protocols and IP networking in general, and is familiar with core concepts such as client, server, peer, connection, and other similar ones.
The importance of network programming cannot be underestimated nowadays. Even if your application does not interact with the network directly, there is a set of tasks or features such as checking the online availability of the updates that implies the 'network awareness' of your software. The programming language you are going to use to develop this software should allow the handling of network operations in an easy and convenient fashion, and yes, Tcl is such a language, as it fits in well with the Internet philosophy.
In general, reading or writing from/to a file and sending/receiving data over/from the network are similar concepts, because of the universal abstract concept of channels. When you open a file in Tcl, you operate on the channel leading to that file—you read data from that channel, and write to that channel. When you open a TCP connection to the server, you also get a channel that is essentially identical in usage; you can also read from and write to it. Moreover, for all types of channels, you use the same set of commands such as puts, gets or read. This is the beauty of the Tcl architecture that makes networking so simple.
Of course, some differences must occur, as the underlying devices are significantly different between a file on the disk and the connection over a network. This chapter is going to present how to deal with such network communication.
In this chapter, we will learn about:
- Tcl native support for TCP—starting from most basic usage, more advanced items like nonblocking sockets along with event programming are presented. A separate section is dedicated to issues related to correct error handling, because in case of network communication, such situations are not rare. Finally, networking using threads is discussed.
- Programming based on UDP protocol is presented on the basis of the
TclUDPpackage. You will be able to get acquainted with both its similarities to and its differences from TCP programming, with the focus on avoiding possible pitfalls.
This chapter contains simple yet practical examples that not only illustrate the presented topics, but also form a good starting ground for further implementation of the network-related part of your application. As usual, we strongly encourage the reader not to settle for these examples, but to actively search for more examples over the Internet and write his/her own, as this is the best practical way to gain experience about the topic.
We will focus on the TCP and UDP protocols, but the Tcl architecture makes it extremely easy to operate on any protocol thanks to the ease with which it can be extended by additional packages. Support for UDP is a good example here, because it is provided by an external extension named TclUDP. By default, only TCP handling is built into the core of the Tcl interpreter.
TCP communication forms the basis of modern networking, so it is no surprise that we will start with it. The basic Tcl command to use in this topic is socket, and it is built into the Tcl interpreter core. A socket is an abstract term representing the endpoint of a bidirectional connection across the network. In this chapter, we will often use the terms socket and channel interchangeably, although the channel term is more general (not every channel is a socket, but every socket is a channel). We do this because the execution of socket will result in using channels—the effect of executing this command is usually opening the connection over the TCP protocol (socket supports only TCP) and returning a channel identifier, which may be used for sending or receiving data through that newly created channel, in terms of commands like read or puts. The command may be used in two flavors in order to create client-side or server-side sockets.
Client sockets serve as the connection opened from a client application to a server of your choice. On the contrary, a server socket does not connect to anything by itself, its primary task is to listen for incoming connections. Such connections will be accepted automatically, and a new channel will be created for each of them, enabling communication to each of the connecting clients.
Let's explain the details of TCP networking based on simple, yet working example code consisting of two parts: a server and a client.
First look at the server code stored in the server.tcl file:
socket -server serverProc 9876
puts "server started and waiting for connections..."
proc serverProc {channelId clientAddress clientPort} {
puts "connection accepted from $clientAddress:$clientPort"
puts "server socket details: [fconfigure $channelId -sockname]"
puts "peer socket details: [fconfigure $channelId -peername]"
after 5000 set cont 1; vwait cont
puts $channelId "thank you for connecting to our server!"
close $channelId
}
vwait forever
To create the listening socket, you have to use the socket command in the following format:
socket server procedureName ?options? port
The last argument is the value of the port on which the server will listen for connections. Throughout this chapter, the value 9876 will be used. Before this value, you can use optional parameters. To be more specific, only one option is available: -myaddr address, and it can be used if the computer where you run your server program has more than one IP interface, so you can specify on which IP address the server should accept connections.
The first parameter is the name of the command that will be called once a new connection is established. In our example, this procedure is called serverProc. The procedure has to accept three arguments: the identifier of the channel which can be used to send or receive data to/from the client program, the client IP address, and the port.
The procedure serverProc first prints out some details about the client—its IP address and port. Next, it prints information about the server and client sockets, illustrating the usage of fconfigure command (described later in this paragraph). After this, some time-consuming data processing is simulated, by forcing the execution to be suspended for 5 seconds. After that time, it writes a 'thank you' message to the channel, effectively sending it to the client and closing the channel (and thereby, a TCP network connection).
The server socket will listen for the connection only when the Tcl event loop is enabled (otherwise, the the program would end), so the last line enters the event loop with the vwait forever command.
The typical output produced by that code is:
c: cl_bookchapter6TCPsocketsfirstExample>tclsh85 server.tcl
server started and waiting for connections...
connection accepted from 127.0.0.1:1234
server socket details: 127.0.0.1 localhost 9876
peer socket details: 127.0.0.1 localhost 1234
As you can see, the server socket details returned by fconfigure $channelId sockname reflect the actual configuration of that socket.
Note that the port from which client connection comes is generally random. In this case it was forced to 1234, however. You can also see that both the server and client were executed on the same machine, effectively using 127.0.0.1 as the IP address.
The client code, saved in client.tcl file, is as follows:
set serverChannel [socket myport 1234 localhost 9876] set startTime [clock seconds] puts "client socket details: [fconfigure $serverChannel -sockname]" puts "peer socket details: [fconfigure $serverChannel -peername]" puts [read $serverChannel] puts "execution has been blocked for [expr [clock seconds] - $startTime] seconds" close $serverChannel
First let's present the output produced by this client code:
c: cl_bookchapter6TCPsocketsfirstExample >tclsh85 client.tcl
client socket details: 127.0.0.1 localhost 1234
peer socket details: 127.0.0.1 localhost 9876
thank you for connecting to our server!
execution has been blocked for 5 seconds
What happens in the client code is that in the first line we create a TCP connection towards the localhost:9876 socket and save the channel reference in the serverChannel variable. We also store the current time (expressed in seconds) to calculate how long we had to wait for the answer from the server. The code prints out some details about the connection. In general, fconfigure allows us to get/set various options for a channel. As the types of channels may be very different (the vs.network file), at first glance, the task seems to be impossible. The beauty of this command is that although it operates on an abstract term of channels, depending on the underlying type, it supports a wide set of options. In the case of network channels, the command has new configuration options:
-sockname—returns the details about the 'closer' end of the connection, that is about the socket used by the client: the IP address, the name of the host, and the number of the port. The data is returned as a three-element list. In this example, the client connects to the server from the port 1234, because this value was forced along with themyportoption for thesocketcommand. In general, if this option is omitted, its value would be randomly chosen by the operating system.-peername—similar to previous option, but the data returned is related to second end of the connection. We can see that we are indeed connected to port 9876, the same one where the server is listening for connections. This option can not be used on the channel identifier returned directly by thesocket servercommand, as it is not connected to anything and cannot be used to send or receive any data—it will only listen for incoming connections.-error—returns the current error status for the connection. If there is no error, an empty string is returned.
Next, we read data from the network connection as we would do for any other type of channel—in this case, using the read command. This command reads all the data until the end-of-file marker (in this case, caused by close $channelId being executed on the server's side).
As we know, the server waits for 5 seconds before sending any answer. This effectively causes blocking of the entire client application, because execution hangs at the read command waiting for the data. In many cases such a behavior is unacceptable; therefore an alternative was introduced—nonblocking sockets.
The concept of a nonblocking socket is rather simple—instead of executing the command that would wait for (and therefore block), and eventually read the data, you just register a procedure that should be called when there is some data to be read (in other words, when the channel becomes readable). It is the duty of the underlying nonblocking I/O subsystem to call this procedure. The advantages are obvious—your code does not block, is more responsive (which is crucial in the case of GUI-based applications) and may do some other work in the meantime. It can also handle multiple connections at the same time. As for the drawbacks, the code may become a bit more complicated, but this is not something you could not handle.
First, let's modify the server code a little:
socket -server serverProc 9876
puts "server started and waiting for connections..."
proc serverProc {channelId clientAddress clientPort} { after 5000 set cont 1; vwait cont
puts -nonewline $channelId "12345"
flush $channelId
after 5000 set cont 1; vwait cont
puts $channelId "6789"
flush $channelId
after 5000 set cont 1; vwait cont
puts $channelId "thank you for connecting to our server!"
close $channelId
}
vwait forever
Now it returns 2 lines, wherein the first line is produced in two phases—first it sends 12345, but without the end-of-line character (the -nonewline option for puts), and after 5 seconds, the rest of line 6789. Following that it sends the line identical to the earlier one (also without the newline character), and closes the connection. Each time, the flush command is executed to make sure the data is sent—otherwise, the data could be buffered. Effectively, it takes 15 seconds to finish sending the data, and we would like to have client code that will not be blocked for that long.
The following is the client-side code that will not be blocked, due to usage of event programming:
set serverChannel [socket -async localhost 9876]
fconfigure $serverChannel -blocking 0
fileevent $serverChannel readable [list readData $serverChannel]
proc readData {serverChannel} {
global end
set startTime [clock seconds]
set data [read $serverChannel]
if {[eof $serverChannel]} { close $serverChannel
set end 1
break
}
puts "read: $data"
puts "execution has been blocked for [expr [clock seconds] - $startTime] seconds"
}
vwait end
The first line is almost identical to that of the previous example, with the difference that the -async option is used. This option causes the socket command to not wait until the connection is established, and to exit immediately. This may matter in the case of slow, overloaded networks.
The next line causes the channel to be switched from the default blocking mode to nonblocking. In this mode, the command operating on this channel will not block—for example read will return only the data that is available at the moment in the input buffer, without waiting for the "end of the file" notification. The nonblocking mode will only make sense when Tcl enters the event loop, which is why the last line calls vwait end, effectively causing the interpreter to wait until the end variable is written.
Once we know that reading commands will not wait for data, there must be another way to cause the client to react once the data is available. The fileevent command is useful for achieving this. By using this command, you can have your code executed only when some event related to the channel occurs. The command accepts the following as parameters:
- The channel identifier
writableorreadable, corresponding to the appropriate event- The code to execute once that event has occurred:
fileevent $serverChannel readable [list readData $serverChannel]
For example, the preceding code causes the readData command to be executed always when the channel becomes readable, that is, when there is some data to be read from it.
Handling the writable event is important when creating the socket with the -async option. As mentioned before, the socket command will end immediately, and the socket creation may be delayed (due to some network operations). Therefore, once it is ready to transmit your data, you will be notified with that event.
The readData command reads the data using the read command, calculates the time spent on this task, and if the channel was closed, also correctly closes this side of the channel and sets the end variable to 1, which causes the client code to leave the event loop and end as a result.
The closure of the channel is detected using the eof command—eof $serverChannel returns 1 if the end of file event occurred during the most recently read operation on the channel.
The output from this client-side code is:
c: cl_bookchapter6TCPsocketsfirstExample>tclsh85 client_async1.tcl
read: 12345
execution has been blocked for 0 seconds
read: 6789
execution has been blocked for 0 seconds
read: thank you for connecting to our server!
execution has been blocked for 0 seconds
What we have achieved is that there is no single line in the code which would block waiting for any network connection related event. The output clearly illustrates that read does not block, but returns any data that came from the server.
More interesting is the behavior of the gets command. As we know, this command reads the entire line from the channel or the blocks. In nonblocking mode, when there is data available for reading, but it does not constitute the full line, gets will return an empty string without removing this data from the input buffer. Let's modify the readData procedure slightly:
proc readData {serverChannel} {
global end
puts "noOfChars: [gets $serverChannel data]"
puts "fblocked: [fblocked $serverChannel]"
puts "eof: [eof $serverChannel]"
if {![fblocked $serverChannel]} {
if {[eof $serverChannel]} {
close $serverChannel
set end 1
break
}
puts "read: $data"
}
}
We have removed the time calculations and replaced read with gets. The procedure also introduces us to the fblocked command. The command returns 1 in case there is some data to read from the channel, but it is not sufficient for the reading command. The typical example is just gets, which attempts to read the entire line, and when only the characters 12345 without newline character at the end are available, the gets command will read an empty string and return -1 as the read character count, leaving the data in the buffer, and causing fblocked to report properly.
c: cl_bookchapter6TCPsocketsfirstExample>tclsh85 client_async2.tcl
noOfChars: -1
fblocked: 1
eof: 0
noOfChars: 9
fblocked: 0
eof: 0
read: 123456789
noOfChars: 39
fblocked: 0
eof: 0
read: thank you for connecting to our server!
noOfChars: -1
fblocked: 0
eof: 1
Detecting the end of transmission may be a little tricky. In the current example, the server at the end sends the entire line (with the newline character at the end), so gets is able to read it properly. Following that, the channel is closed, resulting in another execution of the readData procedure on the client's side. This time gets also returns -1 as the number of characters read, but the channel is not blocked, and eof indicates that the connection is terminated.
So far so good, but what if the server sends the last line without the newline marker:
puts -nonewline $channelId "thank you for connecting to our server!"
flush $channelId
close $channelId
In this case, the client would get the following:
c: cl_bookchapter6TCPsocketsfirstExample>tclsh85 client_async2.tcl
noOfChars: -1
fblocked: 1
eof: 0
noOfChars: 9
fblocked: 0
eof: 0
read: 123456789
noOfChars: -1
fblocked: 1
eof: 0
noOfChars: 39
fblocked: 0
eof: 1
As you can see, the last call to gets resulted in 39 characters of data being read. However, in parallel, it caused eof to report 1, effectively causing the read data to be discarded. This allows a mistake in the logic of the readData function, which checks for the end of file first. A better design would include checking if gets returns a value other than -1:
proc readData {serverChannel} {
global end
set noOfChars [gets $serverChannel data]
puts "noOfChars: $noOfChars"
puts "fblocked: [fblocked $serverChannel]"
puts "eof: [eof $serverChannel]"
if {![fblocked $serverChannel]} {
if {$noOfChars!=-1} {
puts "read: $data"
}
if {[eof $serverChannel]} {
close $serverChannel
set end 1
break
}
}
}
This makes the usage of fblocked redundant, because gets returns -1 also when it was unable to read the entire line. Finally, the procedure would look like:
proc readData {serverChannel} {
global end
set noOfChars [gets $serverChannel data]
if {$noOfChars!=-1} {
puts "read: $data"
}
if {[eof $serverChannel]} {
close $serverChannel
set end 1
break
}
}
Up until this moment, we have been sending text data without paying attention to the formatting. When network communication occurs between potentially heterogenic systems, this subject must be considered more carefully. Let's illustrate these concepts using the example of uploading files to the server. For the sake of simplicity, the communication will be one way only, and for every file the following information will be sent:
- The file name encoded in UTF-8
- The size of the file
- The binary content of the file
The protocol we have just proposed allows you to send any number of files using a single TCP connection. On the server side, the uploaded files will be stored in the uploaded directory.
Firstly, let's look at the client-side code:
set serverChannel [socket -async 127.0.0.1 9876]
fconfigure $serverChannel -blocking 0
fileevent $serverChannel writable [list socketWritable $serverChannel]
set end 0
set files [list tcl_logo.gif Tcl.png]
proc socketWritable {serverChannel} {
variable files
variable end
if {[llength $files]!=0} {
set fileName [lindex $files 0]
set files [lreplace $files 0 0]
uploadFile $fileName $serverChannel
} else {
close $serverChannel
set end 1
}
}
proc uploadFile {fileName serverChannel} {
fconfigure $serverChannel -encoding utf-8
fconfigure $serverChannel -translation auto
fileevent $serverChannel writable ""
set fileSize [file size $fileName]
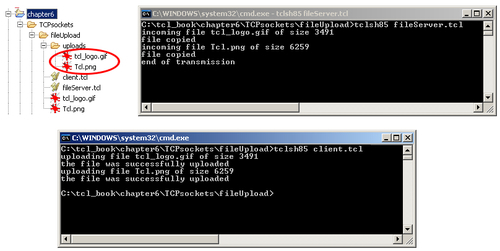
puts "uploading file $fileName of size $fileSize"
puts $serverChannel $fileName
puts $serverChannel $fileSize
set fileInput [open $fileName r]
fconfigure $fileInput -translation binary
fconfigure $serverChannel -translation binary
fcopy $fileInput $serverChannel -size $fileSize -command [list fileUploaded $fileInput $serverChannel]
}
TCP networkingbinary data, transferringproc fileUploaded {fileInput serverChannel size} {
puts "the file was successfully uploaded"
close $fileInput
fileevent $serverChannel writable [list socketWritable $serverChannel]
}
vwait end
In this case, we are uploading two graphical files, both containing the Tcl logo (taken from http://www.demailly.com/tcl/about/logos.html and from Wikipedia respectively). The names of these files are stored in files list.
Every time the TCP channel opened to the server becomes writable, the socketWritable procedure is called. If there are any files on the list to be sent, the procedure pops the first element from the files list and calls the uploadFile procedure; otherwise, it closes the connection and writes the end variable, effectively causing the client code to exit the event loop and terminate.
The uploadFile procedure first configures the data encoding for the channel. As usual, fconfigure is used to set two new options: -encoding (described in detail in Chapter 5, Data Storage) and -translation. The second option is related to the fact that—for historical reasons—on various platforms newline characters are presented differently. Internally, Tcl always stores the newline indicator as a single LF (line feed, the ASCII code 0x0A), just as on Unix systems. However, on other systems, the following combinations are used:
CRLFon Windows and DOSCRon Mac OS
CR is the carriage return character, coded as 0x0D.
For every read or written newline character, Tcl will convert it from/to the form specified by the channel configuration. The valid values for -translation are:
cr, crlf, orlf—corresponds to the appropriate combinations of CR, CRLF, or LF characters respectively.auto—the format is chosen automatically depending on the underlying platform where the script is executed. This is the default value of the translation mode.binary—the translation of newline characters is disabled, and the channel encoding is set tobinary, that is, any additional character conversions are disabled. This mode is extremely important when you are sending binary data, which could be easily damaged by the unnecessary conversion.
It is worth noting that fconfigure allows separate configuration of the input and output modes by specifying two values. The configuration of the channel encoding or translation can be modified dynamically at any time. We will use this later to set the socket channel to binary mode after the filename and size have been sent, but before the file data is sent.
In our example, we set the translation mode to lf, so effectively, no translation will occur, because this is the way Tcl stores newline characters. The encoding is set to UTF-8.
Following this, file events for the network channel are temporarily disabled, and the filename and size are sent to the server, both as the separate lines (no -nonewline option for puts).
To copy the content of the file, a handy command called fcopy will be used, which copies data from an input channel to an output channel. The format of the command follows:
fcopy inputChannel outputChannel ?-size numberOfBytes? ?-command commandName?
By default, the command will copy the data until end of file occurs, but this behavior can be altered by specifying the -size parameter—in this case, the command will copy only a numberOfBytes.
Normally, the command would block until the copying operation is completed, but in case the -command parameter is used, it will end immediately and the commandName command will be called once the data is copied.
In our example, we are using both options: we copy only the exact amount of bytes, that is, the size of the file, and on completion, the fileUploaded procedure will be called. The input channel allows us to read data from the file (returned by the open command). The output is the TCP channel to the server. Both channels are configured as binary at the moment.
During the fcopy operation, no other input/output operations are allowed on the involved channels, which is why we disabled the writable events earlier.
Once the file content is sent to the server using the TCP socket channel, the fileUploaded procedure closes the file channel and restores the handling of the writable events, allowing the repetition of the entire operation for the next filename in the list.
The server code that is able to understand the protocol described is:
socket -server serverProc 9876
proc serverProc {channelId clientAddress clientPort} {
while {true} {
fconfigure $channelId -encoding utf-8
fconfigure $channelId -translation lf
set fileName [gets $channelId]
set fileSize [gets $channelId]
if {[eof $channelId]} {
puts "end of transmission"
break
}
puts "incoming file $fileName of size $fileSize"
set fileOutput [open "uploads/$fileName" w]
fconfigure $fileOutput -translation binary
fconfigure $channelId -translation binary
fcopy $channelId $fileOutput -size $fileSize
puts "file copied"
close $fileOutput
}
close $channelId
}
vwait forever
All server logic is contained in the serverProc procedure. The server is designed to accept transmission of multiple files, so it enters an "infinitive" loop (while {true}). In each iteration, the channel is first configured to read text data from it. Then the name and size of file that is about to be uploaded are read. If any of these operations encounter the end of the file, the loop will be ended by calling the break command.
Following that, the file output channel is opened (all the incoming files will be stored in the uploads directory), and both this and the network channel are set to binary mode. Then the job of copying the data is done by the fcopy command, this time working in the blocking mode, because the -command parameter was not specified. Finally, the iteration ends with closure of the file.
If you exit the loop, the network channel will be closed and the serverProc procedure terminated.
The result of running the described example is illustrated in the following screenshot:
Network operations are especially vulnerable to various kinds of errors, so if you wish to create reliable application, proper handling of such a situation is indispensable. The basis of this is appropriate reaction to a writable event. The issue is that the channel is considered writable not only when it is possible to write to it, but also if some error occurred on the underlying device/file. Once an error occurs, your script will get a bunch of writable events to handle. Therefore, the proper implementation of the handler command must check the error condition, using the fconfigure $socket -error command.
Let's discuss error related issues using the following example:
if {[catch {
TCP networkingerror related issuesset serverChannel [socket -async somehostname.com 9876] } e]} { puts $e
exit 1
}
fconfigure $serverChannel -blocking 0
fileevent $serverChannel writable [list socketWritable $serverChannel]
fileevent $serverChannel readable [list socketReadable $serverChannel]
set timer [after 5000 [list timeout $serverChannel]]
proc timeout {serverChannel} {
fileevent $serverChannel writable ""
catch {close $serverChannel}
puts "custom timeout"
}
proc socketWritable {serverChannel} {
variable timer
set error [fconfigure $serverChannel -error]
switch $error {
TCP networkingerror handling"connection timed out" -
"connection refused"
{
after cancel $timer
catch {close $serverChannel}
}
""
{
puts "all OK"
after cancel $timer
}
default
{
puts $error
}
}
}
proc socketReadable {serverChannel} {
set error [fconfigure $serverChannel -error]
if {$error == ""} {
catch {gets $serverChannel}
if {[eof $serverChannel]} {
puts "the remote peer closed the connection"
catch {close $serverChannel}
}
}
}
vwait forever
The socket command may throw an error—for example, if the specified target host domain name is invalid. In order to handle it properly, the catch command must be used.
Another important issue is timeouts. The network may be slow, or the target server may be unresponsive. If you do not want to rely on system defaults, there is no other way to specify your user-defined timeout value in Tcl. However, a little trick with after may be used. In our example, we decided that we would like to terminate it 5 seconds after the initial attempt to connect—the timeout procedure was executed to do so. First, we need to unregister ourselves from any new writable events and then close the channel. Note that the closing operation may also throw some errors (for example, the channel may already have been closed), so it is good practice to wrap it into catch. The same applies to commands such as gets or puts. So that we can cancel the timer in case the connection is successful, we store it in the $timer variable.
Once the writable event occurs, the socketWritable procedure is called. First, the current error status of the $serverChannel socket is retrieved by calling fconfigure $serverChannel error, and then it's stored in the $error variable. If there is no error, an empty string is returned, and in the consecutive switch block, the "all OK" message is printed and the timeout timer is cancelled. If the returned string is not empty, it means that some error occurred, for example:
- Connection refused—the server refused the connection
- Connection timed out—the system-defined timeout has occurred
In case of these errors, the timer is cancelled and the channel closed manually. For any other non-empty error messages, the script (default section) will simply print out the error message, but of course, the appropriate clean-up actions can also be done here.
The other important situation is detecting that the remote peer has closed the connection. This case can only be handled in the procedure called for readable events—socketReadable in this example. This procedure first checks for errors, just as socketWritable does. Following that, some input operation must be called (in this case, gets), because without it, the eof command would not notify that the EOF state occurred, as mentioned earlier,. Once it is detected, the channel is closed. Note that any concurrent puts $serverChannel operations will throw an error if the channel was closed, so this should also be handled properly with a catch.
The following table sums up the most common issues along with the ways of detecting them:
|
Issue |
Detection |
|---|---|
|
Initial connecting issues |
• writable event along with appropriate error information from |
|
Peer disconnected |
Detectable only in the readable event handler using |
|
Transmission errors |
When you are working with channels of various types, and especially the network type, all modern programming languages take advantage of buffering techniques that increase performance and make I/O operations more effective. As already mentioned in Chapter 2, Advanced Tcl features, Tcl is no exception. From the sender's point of view, the buffering is an automated process, where the data written with a puts command is not sent over the channel immediately, but rather gathered in internal memory (buffer) and transmitted in bulk, making the communication more effective. Each channel has its own buffer.
Basically, there are two commands allowing direct interaction with output buffers. The first is fconfigure with appropriate options—it allows either buffering configuration or reading of the existing parameters (assuming that $channel is a valid channel handle):
fconfigure $channel bufferingmode—allows you to set the buffering for$channelin one of the following modes:full—the data will be stored in the buffer until it is completely full (or until theflushcommand is executed) and then sent to the channelline—the data is flushed (sent) any time the newline character occurs in input datanone—the data is flushed automatically after each output operation- If the
modeis omitted, the command will return the actual value of the buffering mode.
fconfigure $channel buffersizesize—allows you to define the size of the buffer, between ten bytes and one million bytes. Returns the current size if the last parameter is omitted.
In many cases of network programming, you would like the data to be sent right after you write it to the channel, so the none mode is useful here. All the more, it helps beginners to avoid some confusion—they may start writing networking code and may spend a considerable amount of time wondering why the data is not sent immediately or received in bulk different from those defined by the sender. Unless performance becomes an issue, setting buffering to none may be considered to be the best option.
The second command is flush $channel, and the result of calling it is a dump of the data stored in the buffer directly to the channel represented by the $channel handle. The command will block if the channel is in the blocking mode, until the data is transmitted.
Many languages focus on blocking the network model and using threads to handle each connection individually. Tcl also allows this model, using threads and transferring channels between threads. This concept was introduced in Chapter 2.
Using threads provides the benefit of being easier to write. However, it consumes more resources and makes it more difficult to provide scalability to a high number of simultaneous connections.
However, in some cases, it is a good idea to use this model for network connections in Tcl. One example can be when operations related to each connection can be blocked for a long period of time and/or a large amount of data processing needs to occur. Using threads allows one blocking operation not to block other ones from being completed and allows us to take advantage of newer CPUs that offer multiple cores, which can be more effective for data computations. As each thread or process can only use up one core of a processor, using multiple threads will allow us to perform calculations on multiple cores and/or processors.
For the purpose of this book, we'll create an example that uses threads and Tcl's thread pool. We'll use the thread pool to process requests from clients. Thread pools allow us to run commands within separated threads. It passes the specified job to the first available thread or spawns a new thread if it is needed. Jobs are specified as Tcl scripts to be run, so it is intuitive to use them. We also provide initialization and clean-up scripts for the thread.
The requests that the clients send will be read from the main thread and once read, the request itself along with the channel is passed to child thread, which handles the request and sends back the response. This optimizes how child threads are used—we do not need to make a thread wait until all data is readable, but instead use a single thread for reading all the incoming data.
The request is sent in such a way that a line indicating the number of bytes to read, as plaintext, is sent first and is followed by the specified number of bytes of the request itself.
Let's start with creating the server. We'll need to set up our namespace and load the Thread package first:
package require Thread
namespace eval tpserver {}
Next we'll set up a new thread pool. We use the command tpool::create for this purpose, which returns the new thread pool's identifier. We store it in tpserver::tpool variable for later use.
set tpserver::tpool [tpool::create -initcmd [list source server-threads.tcl]]
Several options can be passed to the tpool::create command. The options -initcmd and -exitcmd specify commands that will be run in the new thread after it is created and before it is deleted accordingly. The options -minworkers and -maxworkers define how many threads should be running, and their values default to 0 and 4 accordingly. This means that, at most, four threads will be used and no thread will be created if not required. The -idletime option specifies a time (in seconds) after which a thread is terminated if it is not used. If not specified, threads are deleted as soon as they have no jobs to perform.
For this example, we specify a command to run to initialize the thread and use the default values for the remaining options. Child threads that will be used for operations will need to have their own code, which is responsible for handling requests. We have the thread source file called server-threads.tcl, which contains the code to run and respond to requests.
We now need to write the code for handling incoming connections. This code will be running in the main thread and will read the request using events. After reading the request, we'll add a job to the thread pool.
We start by setting the channel to the nonblocking mode and set up automatic translation of newline characters. We also set up a readable event so that whenever anything is sent, the command is run:
proc tpserver::accept {chan args} {
fconfigure $chan -buffering none -blocking 0
-translation auto
fileevent $chan readable
[list tpserver::readInfo $chan]
}
We'll then execute the command for reading the first line that specifies number of bytes. We check if the end of file has been received first. If so, we will close the channel and exit.
proc tpserver::readInfo {chan} {
if {[eof $chan]} {
catch {close $chan}
return
}
Following that, we try to read the line. If a complete line is not available, the gets command will return -1 and we'll wait for next readable event.
if {[gets $chan line] < 0} {
return
}
In the next step we try to remove all the whitespace around the number of bytes and check if it is a valid integer. If not, we close the channel immediately and return.
set bytes [string trim $line "
"]
if {![string is integer -strict $bytes]} {
catch {close $chan}
return
}
After getting a valid number of bytes to read, we convert the channel into binary mode and set up a new readable event, which will read the specified amount of bytes.
fconfigure $chan -translation binary fileevent $chan readable [list tpserver::readData $chan $bytes ""] }
The command for reading data accepts the number of bytes left to be read and the data read so far. For the initial event, we'll set up the specified number of bytes and empty the buffer. The subsequent events will be set up with data read so far until the specified number of bytes has been read.
The command to read data also begins by checking if the end of the file has been reached:
proc tpserver::readData {chan numBytes data} {
if {[eof $chan]} {
catch {close $chan}
return
}
Next we try to read data from the channel. If that fails, we close the channel immediately and return.
if {[catch {
set d [read $chan $numBytes]
}]} {
catch {close $chan}
return
}
Following that, we append the data that was read to the buffer and calculate the new number of bytes remaining—by taking the difference between the number of bytes read now and the previous value.
append data $d
set numBytes [expr {$numBytes - [string length $d]}]
If we have read the entire request, we remove the readable event and invoke the command to handle the request:
if {$numBytes <= 0} {
fileevent $chan readable [list]
tpserver::handleRequest $chan $data
} else {
Otherwise, we set up a new readable event with the current data buffer and the remaining number of bytes to read:
fileevent $chan readable [list tpserver::readData $chan $numBytes $data] } }
When a complete request has been read, we will use the thread pool to deploy it. We first invoke the tls::detach command, which detaches a channel from the current thread. After this command, the current thread can no longer access the channel.
proc tpserver::handleRequest {chan data} {
variable tpool
thread::detach $chan
We then post a new job to be performed in the thread pool—the command to handle the response to a request along with request already read. We specify the channel to use and the request.
tpool::post -nowait -detached $tpool [list tpserver::respond $chan $data] }
After that, this connection is handled by one of the threads in the thread pool.
Finally, we need to set up a listening connection to accept the requests:
socket -server tpserver::accept 12345
We now need to set up the server-threads.tcl file that handles responding to the requests.
We'll start by creating the respond command. It needs to attach to the channel using the tls::attach command. After running this command, the specified channel can be used like any other channel in this thread.
proc tpserver::respond {chan data} {
thread::attach $chan
We will then run the command to handle the response and catch any potential errors. If the command does not fail, the result variable will store the value returned by the respondHandle command. If there are any errors, result will store the error information.
set c [catch {
respondHandle $data
} result]
In the next step, we try to send the results as a list of two elements—the result from the catch command and the result or error, depending on value of the c variable.
catch {
puts -nonewline $chan [list $c $result]
flush $chan
}
We wrap writing output in a catch command because the write might fail, either because the client has already closed the channel or because of network issues.
Finally, we try to close the channel:
catch {close $chan}
}
We then need to write the command that handles the request itself.
proc tpserver::respondHandle {data} { return [eval $data]
}
While the respondHandle command can perform any action, for the purpose of this example, it simply evaluates the Tcl code sent by a remote peer.
Finally, we need to create a client that will allow us to send a command to any host and port, and will allow us to specify a callback to be run whenever results are available.
We'll start by creating a namespace for our client.
namespace eval tpclient {}
Following that, we'll create the command to send a request to the server. It accepts the host and the port, the request and callback data to invoke when results are retrieved, or if sending the request fails.
The callback will be run with two additional arguments specified—whether an error was encountered (true indicating an error and false indicating a successful request), followed by either error information or the result from the server.
We start by trying to open a TCP connection to a remote system and setup a channel for sending binary data:
proc tpclient::sendRequest {host port data callback} {
if {[catch {
set chan [socket $host $port]
fconfigure $chan -blocking 0 -buffering none
-translation binary
Then we send the request by sending the length of the request followed by the request itself:
puts -nonewline $chan "[string length $data] $data"
Finally, we set up a readable event to read results as soon as they are available:
fileevent $chan readable [list tpclient::readResponse $chan "" $callback]
If any of these operations fail, we close the channel if it was open and invoke the callback, specifying an error:
}]} {
catch {close $chan}
{*}$callback true "Unable to connect"
}
}
The command to read the response is written in a similar way to the command to read a request on the server—it reads the data and passes the current buffer to the next readable event. We also pass the callback command as the argument.
We start by trying to read data from the channel:
proc tpclient::readResponse {chan data callback} {
if {[catch {
set d [read $chan]
}]} {
If the read fails, the callback is invoked with an error indication.
catch {close $chan}
{*}$callback true "Unable to read data"
return
}
Otherwise, we append the newly read data to the buffer and check if the end of file message has been received:
append data $d
if {[eof $chan]} {
If the end of file has been reached, we close the channel. We then take the first index of the resulting list as an indication of an error and the actual data as the second element of the list and invoke the callback with this data:
catch {close $chan}
set error [lindex $data 0]
set data [lindex $data 1]
{*}$callback $error $data
} else {
Otherwise, we set up a new readable event with the current buffer:
fileevent $chan readable [list tpclient::readResponse $chan $data $callback] } }
Further, we can invoke the command to send a request to the server, specifying the expr {1+1} command to be run and the requestCallback command to be run as the callback:
tpclient::sendRequest 127.0.0.1 12345
{expr {1+1}}
requestCallback
We used 127.0.0.1, but if the server is located on any other machine, its IP address or hostname should be specified.
The callback itself simply prints either an error indication or a result from the command:
proc requestCallback {error data} {
if {$error} {
puts "Error: $data"
} else {
puts "Result: $data"
}
exit 0
}
Depending on whether the server (saved in server.tcl in the source code examples for this chapter) is running or not, the result should be either one of the following commands:
c: cl_bookchapter6TCPsockets hreads>tclsh85 client.tcl
Error: Unable to connect
or:
c: cl_bookchapter6TCPsockets hreads> tclsh85 client.tcl
Result: 2
Even though this example only does 1+1, using a thread pool to perform tasks can be useful if you need to offer functions that either use blocking functions (such as getting data from a database) or use CPU intensive operations (such as calculating an MD5 from a large file). Imposing limits on the number of threads itself prevents us from using up all available resources on one type of functionality.
Documentation for the Thread package as well as thread pools can be found on Tcl's wiki page - http://wiki.tcl.tk/thread in the Documentation section.