
6
Universality of Consensus
6.1 Introduction
In Chapter 5, we considered a simple technique for proving statements of the form “there is no wait-free implementation of X by Y.” We considered object classes with deterministic sequential specifications.1 We derived a hierarchy in which no object from one level can implement an object at a higher level (see Fig. 6.1). Recall that each object has an associated consensus number, which is the maximum number of threads for which the object can solve the consensus problem. In a system of n or more concurrent threads, it is impossible to construct a wait-free implementation of an object with consensus number n from an object with a lower consensus number. The same result holds for lock-free implementations, and henceforth unless we explicitly state otherwise, it will be implied that a result that holds for wait-free implementations holds for lock-free ones.
Figure 6.1. Concurrent computability and the universality hierarchy of synchronization operations.
| Consensus Number | Object |
| 1 | atomic registers |
| 2 | getAndSet(), getAndAdd(), Queue, Stack |
| m | (m,m(m + 1)/2)-register assignment |
| ∞ | memory-to-memory move, compareAndSet(), Load-Linked/StoreConditional2 |
2 See Appendix B for details.
The impossibility results of Chapter 5 do not by any means imply that wait-free synchronization is impossible or infeasible. In this chapter, we show that there exist classes of objects that are universal: given sufficiently many of them, one can construct a wait-free linearizable implementation of any concurrent object.
A class is universal in a system of n threads if, and only if it has a consensus number greater than or equal to n. In Fig. 6.1, each class at level n is universal for a system of n threads. A machine architecture or programming language is computationally powerful enough to support arbitrary wait-free synchronization if, and only if it provides objects of a universal class as primitives. For example, modern multiprocessor machines that provide a compareAndSet() operation are universal for any number of threads: they can implement any concurrent object in a wait-free manner.
This chapter describes how to use consensus objects to build a universal construction that implements any concurrent object. The chapter does not describe practical techniques for implementing wait-free objects. Like classical computability theory, understanding the universal construction and its implications will allow us to avoid the na![]() e mistake of trying to solve unsolvable problems. Once we understand why consensus is powerful enough to implement any kind of object, we will be better prepared to undertake the engineering effort needed to make such constructions efficient.
e mistake of trying to solve unsolvable problems. Once we understand why consensus is powerful enough to implement any kind of object, we will be better prepared to undertake the engineering effort needed to make such constructions efficient.
6.2 Universality
A class C is universal if one can construct a wait-free implementation of any object from some number of objects of C and some number of read–write registers. Our construction uses multiple objects of class C because we are ultimately interested in understanding the synchronization power of machine instructions, and most machines allow their instructions to be applied to multiple memory locations. We allow an implementation to use multiple read–write registers because it is convenient for bookkeeping, and memory is usually in plentiful supply on modern architectures. To avoid distraction, we use an unlimited number of read–write registers and consensus objects, leaving the question of recycling memory as an exercise. We begin by presenting a lock-free implementation, later extending it to a slightly more complex wait-free one.
6.3 A Lock-Free Universal Construction
Fig. 6.2 shows a generic definition for a sequential object, based on the invocation–response formulation of Chapter 3. Each object is created in a fixed initial state. The apply() method takes as argument an invocation which describes the method being called and its arguments, and returns a response, containing the call’s termination condition (normal or exceptional) and the return value, if any. For example, a stack invocation might be push() with an argument, and the corresponding response would be normal and void.
![]()
Figure 6.2 A Generic sequential object: the apply() method applies the invocation and returns a response.
Figs. 6.3 and 6.4 show a universal construction that transforms any sequential object into a lock-free linearizable concurrent object. This construction assumes that sequential objects are deterministic: if we apply a method to an object in a particular state, then there is only one possible response, and one possible new object state. We can represent any object as a combination of a sequential object in its initial state and a log: a linked list of nodes representing the sequence of method calls applied to the object (and hence the object’s sequence of state transitions). A thread executes a method call by adding the new call to the head of the list. It then traverses the list, from tail to head, applying the method calls to a private copy of the object. The thread finally returns the result of applying its own operation. It is important to understand that only the head of the log is mutable: the initial state and nodes preceding the head never change.

Figure 6.3 The Node class.

Figure 6.4 The lock-free universal algorithm.
How do we make this log-based construction concurrent, that is, allow threads to make concurrent calls to apply()? A thread attempting to call apply() creates a node to hold its invocation. The threads then compete to append their respective nodes to the head of the log by running an n-thread consensus protocol to agree which node was appended to the log. The inputs to this consensus are references to the threads' nodes, and the result is the unique winning node.
The winner can then proceed to compute its response. It does so by creating a local copy of the sequential object and traversing the log, following next references from tail to head, applying the operations in the log to its copy, finally returning the response associated with its own invocation. This algorithm works even when apply() calls are concurrent, because the prefix of the log up to the thread’s own node never changes. The losing threads, which were not chosen by the consensus object, must try again to set the node currently at the head of the log (which changes between attempts) to point to them.
We now consider this construction in detail. The code for the lock-free universal construction appears in Fig. 6.4. A sample execution appears in Fig. 6.5. The object state is defined by a linked list of nodes, each one containing an invocation. The code for a node appears in Fig. 6.3. The node’s decideNext field is a consensus object used to decide which node is appended next in the list, and next is the field in which the outcome of that consensus, the reference to the next node, is recorded. The seq field is the node’s sequence number in the list. This field is zero while the node is not yet threaded onto the list, and positive otherwise. Sequence numbers for successive nodes in the list increase by one. Initially, the log consists of a unique sentinel node with sequence number 1.
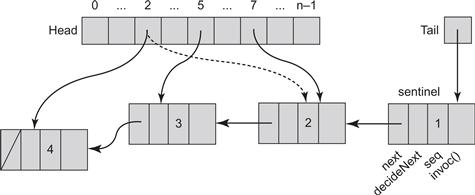
Figure 6.5 Execution of the lock-free universal construction. Thread 2 appends the second node in the log winning consensus on decideNext in the sentinel node. It then sets the node's sequence number from 0 to 2, and refers to it from its entry in the head[] array. Thread 7 loses the decideNext consensus at the sentinel node, sets the next reference and sequence number of the decided successor node to 2 (they were already set to the same values by thread 2), and refers to the node from its entry in the head[] array. Thread 5 appends the third node, updates its sequence number to 3 and updates its entry in the head[] array to this node. Finally, thread 2 appends the fourth node, sets its sequence number to 4, and refers to it from its entry in the head[] array. The maximal value in the head array keeps track of the head of the log.
The hard part about designing the concurrent lock-free universal construction is that consensus objects can be used only once. 3
In our lock-free algorithm in Fig. 6.4, each thread allocates a node holding its invocation, and repeatedly tries to append that node to the head of the log. Each node has a decideNext field, which is a consensus object. A thread tries to append its node by proposing as input to a consensus protocol on the head’s decideNext field. Because threads that do not participate in this consensus may need to traverse the list, the result of this consensus is stored in the node’s next field. Multiple threads may update this field simultaneously, but they all write the same value. When the thread’s node is appended, it sets the node’s sequence number.
Once a thread’s node is part of the log, it computes the response to its invocation by traversing the log from the tail to the newly added node. It applies each of the invocations to a private copy of the object, and returns the response from its own invocation. Notice that when a thread computes its response, all its predecessors' next references must already be set, because these nodes have already have been added to the head of the list. Any thread that added a node to the list has updated its next reference with the result of the decideNext consensus.
How do we locate the head of the log? We cannot track the head with a consensus object because the head must be updated repeatedly, and consensus objects can only be accessed once by each thread. Instead, we create a per-thread structure of the kind used in the Bakery algorithm of Chapter 2. We use an n-entry array head[], where head[i] is the last node in the list that thread i has observed. Initially all entries refer to the tail sentinel node. The head is the node with the maximum sequence number among the nodes referenced in the head[] array. The max() method in Fig. 6.3 performs a collect, reading the head[] entries and returning the node with the highest sequence number.
The construction is a linearizable implementation of the sequential object. Each apply() call can be linearized at the point of the consensus call adding the node to the log.
Why is this construction lock-free? The head of the log, the latest node appended, is added to the head[] array within a finite number of steps. The node’s predecessor must appear in the head array, so any node repeatedly attempting to add a new node will repeatedly run the max() function on the head array. It detects this predecessor, applies consensus on its decideNext field, and then updates the winning node’s fields, and including its sequence number. Finally, it stores the decided node in that thread’s head array entry. The new head node always eventually appears in head[]. It follows that the only way a thread can repeatedly fail to add its own node to the log is if other threads repeatedly succeed in appending their own nodes to the log. Thus, a node can starve only if other nodes are continually completing their invocations, implying that the construction is lock-free.
6.4 A Wait-Free Universal Construction
How do we make a lock-free algorithm wait-free? The full wait-free algorithm appears in Fig. 6.6. We must guarantee that every thread completes an apply() call within a finite number of steps, that is, no thread starves. To guarantee this property, threads making progress must help less fortunate threads to complete their calls. This helping pattern will show up later in a specialized form in other wait-free algorithms.
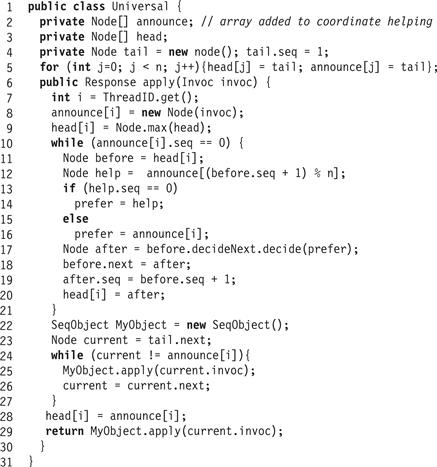
Figure 6.6 The wait-free universal algorithm.
To allow helping, each thread must share with other threads the apply() call that it is trying to complete. We add an n-element announce[] array, where announce[i] is the node thread i is currently trying to append to the list. Initially, all entries refer to the sentinel node, which has a sequence number 1. A thread i announces a node when it stores the node in announce[i].
To execute apply(), a thread first announces its new node. This step ensures that if the thread itself does not succeed in appending its node onto the list, some other thread will append that node on its behalf. It then proceeds as before, attempting to append the node into the log. To do so, it reads the head[] array only once (Line 9), and then enters the main loop of the algorithm, which it executes until its own node has been threaded onto the list (detected when its sequence number becomes non zero in Line 10). Here is a change from the lock-free algorithm. A thread first checks to see if there is a node that needs help ahead of it in the announce[] array (Line 12). The node to be helped must be determined dynamically because nodes are continually added to the log. A thread attempts to help nodes in the announce[] array in increasing order, determined by the sequence number modulo the width n of the announce[] array. We will prove that this approach guarantees that any node that does not make progress on its own will eventually be helped by others once its owner thread’s index matches the maximal sequence number modulo n. If this helping step were omitted, then an individual thread could be overtaken an arbitrary number of times. If the node selected for help does not require help (its sequence number is non zero in Line 13), then each thread attempts to append its own node (Line 16). (All announce[] array entries are initialized to the sentinel node which has a non zero sequence number.) The rest of the algorithm is almost the same as in the lock-free algorithm. A node is appended when its sequence number becomes non zero. In this case, the thread proceeds as before to compute its result based on the immutable segment of the log from the tail to its own node.
Fig. 6.7 shows an execution of the wait-free universal construction in which, starting from the initial state, thread 5 announces its new node and appends it to the log, and pauses before adding the node to head[]. Thread 7 then takes steps. The value of (before.seq + 1) mod n is 3, so thread 7 tries to help thread 2. Thread 7 loses the consensus on the sentinel node’s decideNext reference since thread 5 already won it, and thus completes the operations of thread 5, setting the node’s sequence number to 2 and adding thread 5’s node to the head[] array. Now imagine that thread 3 immediately announces its node. Then thread 7 succeeds in appending thread 3’s node, but again pauses immediately after setting thread 3’s node’s sequence number to 3, but before adding it to head[]. Now thread 3 wakes up. It will not enter the main loop because its node’s sequence number is non zero, but will continue to update head[] at Line 28 and compute its output value using a copy of the sequential object.
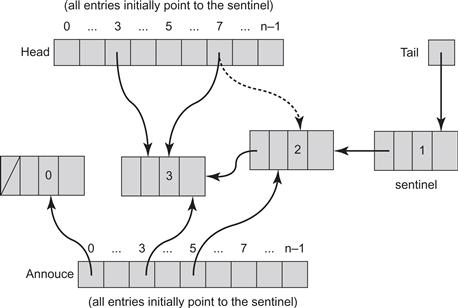
Figure 6.7 Execution of the wait-free universal construction. Thread 5 announces its new node and appends it to the log, but halts before adding the node to the head[] array. Another thread 7 will not see thread 5's node in the head[] array, and will attempt to help thread (before.seq + 1 mod n), which is equal to 3. When attempting to help thread 3, thread 7 loses the consensus on the sentinel node's decideNext reference since thread 5 already won. Thread 7 therefore completes updating the fields of thread 5's node, setting the node's sequence number to 2, and adding the node to the head[] array. Notice that thread 5's own entry in the head[] array is not yet set to its announced node. Next, thread 2 announces its node and thread 7 succeeds in appending thread 3's node, setting thread 3's node's sequence number to 3. Now thread 3 wakes up. It will not enter the main loop because its node's sequence number is non zero, but will continue to update the head[] array and compute its output value using a copy of the sequential object.
There is a delicate point to understand about these modifications to the lock-free algorithm. Since more than one thread can attempt to append a particular node to the log, we must make sure that no node is appended twice. One thread might append the node, and set the node’s sequence number, at the same time that another thread appended the same node and set its sequence number. The algorithm avoids this error because of the order in which threads read the maximum head[] array value and the sequence number of a node in the announce[] array. Let a be a node created by thread A and appended by threads A and B. It must be added at least once to head[] before the second append. Notice, however, that the before node read from head[A] by B (Line 11) must be a itself, or a successor of a in the log. Moreover, before any node is added to head[] (either in Line 20 or in Line 28), its sequence number is made non zero (Line 19). The order of operations ensures that B sets its head[B] entry (the entry based on which B ’s before variable will be set, resulting in an erroneous append) in Lines 9 or 20, and only then validates that the sequence number of a is non zero in Lines 10 or 13 (depending whether A or another thread performs the operation). It follows that the validation of the erroneous second append will fail because the sequence number of node a will already be non zero, and it will not be added to the log a second time.
Linearizability follows because no node is ever added twice, and the order in which nodes are appended to the log is clearly compatible with the natural partial order of the corresponding method calls.
To prove that the algorithm is wait-free, we need to show that the helping mechanism will guarantee that any node that is announced is eventually added to the head[] array (implying that it is in the log) and the announcing thread can complete computation of its outcome. To assist in the proof, it is convenient to define some notation. Let max(head[]) be the node with the largest sequence number in the head[] array, and let “c ∈ head[]” denote the assertion that node c has been assigned to head[i], for some i.
An auxiliary variable (sometimes called a ghost variable) is one that does not appear explicitly in the code, does not alter the program’s behavior in any way, yet helps us reason about the behavior of the algorithm. We use the following auxiliary variables:
![]() concur(A) is the set of nodes that have been stored in the head[] array since thread A ’s last announcement.
concur(A) is the set of nodes that have been stored in the head[] array since thread A ’s last announcement.
![]() start(A) is the sequence number of max(head[]) when thread A last announced.
start(A) is the sequence number of max(head[]) when thread A last announced.
The code reflecting the auxiliary variables and how they are updated appears in Fig. 6.8. For example, the statement
![]()
means that the node after is added to concur(j) for all threads j. The code statements within the angled brackets are considered to be executed atomically. This atomicity can be assumed because auxiliary variables do not affect the computation in any way. For brevity let us slightly abuse the notation by letting the function max() applied to a node or array of nodes return the maximal among their sequence numbers.
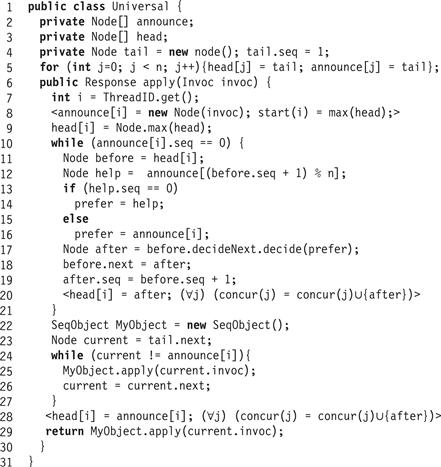
Figure 6.8 The wait-free universal algorithm with auxiliary variables. Operations in angled brackets are assumed to happen atomically.
Notice that the following property is invariant throughout the execution of the universal algorithm:
![]() (6.4.1)
(6.4.1)
Lemma 6.4.1
For all threads A, the following claim is always true:
![]()
Proof
If |concur(A)| > n, then concur(A) includes successive nodes b and c (appended to the log by threads B and C) whose respective sequence numbers plus one modulo n are equal to A − 1 and A (note that b and c are the nodes thread B and C added to the log, not necessarily the ones they announced). Thread C will, based on the code of Lines 12 through 16, append to the log a node located in A ’s entry in the announce[] array. We need to show that when it does so, announce[A] was already announced, so c appends announce[A], or announce[A] was already appended. Later, when c is added to head[] and ![]() , announce[A] will be in head[] as the Lemma requires.
, announce[A] will be in head[] as the Lemma requires.
To see why announce[A] was already announced when C reached Lines 12 through 16, notice that (1) because C appended its node c to b, it must have read b as the before node in Line 11, implying that B appended b before it was read from head[] by C in Line 11, and (2) because b is in concur(A), A announced before b was added to head[]. From (1) and (2) by transitivity it follows that A announced before C executed Lines 12 through 16, and the claim follows.
Lemma 6.4.1 places a bound on the number of nodes that can be appended while a method call is in progress. We now give a sequence of lemmas showing that when A finishes scanning the head[] array, either announce[A] is appended, or head[A] lies within n + 1 nodes of the end of the list.
Lemma 6.4.2
The following property always holds:
![]()
Proof
The sequence number for each head[i] is nondecreasing.
Lemma 6.4.3
The following is a loop invariant for Line 13 of Fig. 6.3(i.e., it holds during each iteration of the loop):
![]()
where j is the loop index.
In other words, the maximum sequence number of head[A] and all head[] entries from the current value of j to the end of the loop never become smaller than the maximum value in the array when A announced.
Proof
When j is 0, the assertion is implied by Lemma 6.4.2. The truth of the assertion is preserved at each iteration, when head[A] is replaced by the node with the sequence number ![]() .
.
Lemma 6.4.4
The following assertion holds just before Line 10:
![]()
Proof
Notice that head[A] is set to point to A ’s last appended node either in Line 20 or Line 28. Thus, after the call to Node.max() at Line 9, max(head[A],head[0], …, head[n − 1]) is just head[A].seq, and the result follows from Lemma 6.4.3.
Lemma 6.4.5
The following property always holds:
![]()
Proof
The lower bound follows from Lemma 6.4.4, and the upper bound follows from Eq. 6.4.1.
Theorem 6.4.1
The algorithm in Fig. 6.6 is correct and wait-free.
Proof
To see that the algorithm is wait-free, notice that A can execute the main loop no more than n + 1 times. At each successful iteration, head[A]. seq increases by one. After n + 1 iterations, Lemma 6.4.5 implies that
![]()
Lemma 6.4.1 implies that announce[A] must have been added to head[].
6.5 Chapter Notes
The universal construction described here is adapted from Maurice Herlihy’s 1991 paper [62]. An alternative lock-free universal construction using load-linked–store-conditional appears in [60]. The complexity of this construction can be improved in several ways. Yehuda Afek, Dalia Dauber, and Dan Touitou [3] show how to improve the time complexity to depend on the number of concurrent threads, not the maximum possible number of threads. Mark Moir [118] shows how to design lock-free and wait-free constructions that do not require copying the entire object. James Anderson and Mark Moir [11] extend the construction to allow multiple objects to be updated. Prasad Jayanti [80] shows that any universal construction has worst-case Ω(n) complexity, where n is the maximal number of threads. Tushar Chandra, Prasad Jayanti, and King Tan [26] identify a large class of objects for which a more efficient universal construction exists.
Exercise 76. Give an example showing how the universal construction can fail for objects with nondeterministic sequential specifications.
Exercise 77. Propose a way to fix the universal construction of Figure 6.8 to work for objects with nondeterministic sequential specifications.
Exercise 78. In both the lock-free and wait-free universal constructions, the sequence number of the sentinel node at the tail of the list is initially set to 1. Which of these algorithms, if any, would cease to work correctly if the sentinel node’s sequence number was initially set to 0?
Exercise 79. Suppose, instead of a universal construction, you simply want to use consensus to implement a wait-free linearizable register with read() and compareAndSet() methods. Show how you would adapt this algorithm to do so.
Exercise 80. In the construction shown here, each thread first looks for another thread to help, and then tries to to append its own node.
Suppose instead, each thread first tries to append its own node, and then tries to help the other thread. Explain whether this alternative approach works. Justify your answer.
Exercise 81. In the construction in Fig. 6.4 we use a “distributed” implementation of a “head” reference (to the node whose decideNext field it will try to modify) to avoid having to create an object that allows repeated consensus. Replace this implementation with one that has no head reference at all, and finds the next “head” by traversing down the log from the start until it reaches a node with a sequence number of 0 or with the highest non zero sequence.
Exercise 82. A small addition we made to the wait-free protocol was to have a thread add its newly appended node to the head array in Line 28 even though it may have already added it in Line 20. This is necessary because, unlike in the lock-free protocol, it could be that the thread’s node was added by another thread in Line 20, and that “helping” thread stopped at Line 20 right after updating the node’s sequence number but before updating the head array.
1. Explain how removing Line 28 would violate Lemma 6.4.4.
Exercise 83. Propose a way to fix the universal construction to work with a bounded amount of memory, that is, a bounded number of consensus objects and a bounded number of read–write registers.
Hint: add a before field to the nodes and build a memory recycling scheme into the code.
Exercise 84. Implement a consensus object that is accessed more than once by each thread using read() and compareAndSet() methods, creating a “multiple access” consensus object. Do not use the universal construction.
1 The situation with nondeterministic objects is significantly more complicated.
3 Creating a reusable consensus object, or even one whose decision is readable, is not a simple task. It is essentially the same problem as the universal construction we are about to design. For example, consider the queue-based consensus protocol in Chapter 5. It is not obvious how to use a Queue to allow repeated reading of the consensus object state after it is decided.