Chapter 3. Statements
This chapter contains the obligatory definitions for all statements that D defines. D builds on the C family’s look and feel—there’s if, while, for, and others. However, there are a few new, interesting statements and tweaks on the existing statements. In case you are likely to get bored by the inevitable litany describing each statement in detail, here are some “deltas”—interesting bits original to D.
If you want to conditionally compile code, static if (§ 3.4 on page 68) may be of interest. Its usefulness goes well beyond simple flag-directed customizations; if you use generic code in any capacity, static if is an enormous boon. The switch statement (§ 3.5 on page 71) looks and acts much like its C counterpart but works with strings, too, and allows you to match entire ranges at once. For correctly handling small closed sets of values, final switch (§ 3.6 on page 72) may be of interest; it works with enumerated types and forces you to handle each and every one of the possible values. The foreach statement (§ 3.7.4 to 3.7.5 on pages 74–75) is very handy for straight iterations, whereas the classic for is more general but a bit more verbose. The mixin statement (§ 3.12 on page 82) expands predefined boilerplate code. The scope statement (§ 3.13 on page 84) greatly simplifies writing correct transactional code with correct error recovery by replacing convoluted try/catch/finally statements that you’d otherwise have to write.
3.1 The Expression Statement
As mentioned before (§ 1.2 on page 5), an expression becomes a statement if you append a semicolon to it:
However, not just any expression can become a statement. If the resulting statement has no effect, as in
then the compiler issues an error.
3.2 The Compound Statement
The compound statement is a (possibly empty) sequence of statements enclosed in curly braces. The statements are executed in sequence. The braces introduce a lexical scope: symbols defined inside a compound statement are not visible outside of it.
A symbol defined inside a scope hides a homonym symbol hanging outside all scopes:
uint widgetCount;
...
void main() {
writeln(widgetCount); // Writes the global symbol
auto widgetCount = getWidgetCount();
writeln(widgetCount); // Writes the local symbol
}
The first call to writeln prints the global widgetCount symbol and the second accesses the locally defined widgetCount. Should there be a need for accessing the global symbol after it has been masked, prefixing it with a dot—as in writeln(.widgetCount)—will do, as first mentioned on page 31. However, it is illegal to define a symbol that would mask a symbol in an enclosing compound statement:
void main() {
auto widgetCount = getWidgetCount();
// Let's now open a nested block
{
auto widgetCount = getWidgetCount(); // Error!
}
}
As long as masking does not occur, it’s legal to reuse the same symbol in different compound statements:
The rationale of this setup is simple. Allowing global symbol masking is necessary for writing good modular code that’s assembled out of separately compiled parts; you don’t want the addition of a global variable to suddenly render various innocent bystanders uncompilable. On the other hand, enclosing-scope masking is useless as a modularity device (as there’s never a case of a compound statement spanning multiple modules in D) and most often indicates either an oversight aspiring to become a bug, or a cancerous function that’s grown out of control.
3.3 The if Statement
Various examples have already used D’s if statement, which is pretty much what you’d expect:
or
One detail about the statements controlled by if is worth noting. Unlike other languages, D does not have an “empty statement” construct; in particular, a colon present by itself is not a statement and will be flagged as an error. This design automatically steers programmers away from bugs like
code that looks obviously silly when it’s short and when you’ve been primed for it, but not so much so when the expression is longer, the entire construct is buried in swaths of code, and it’s two o’clock in the morning. If you do want to control an empty statement with an if, you may want to use the closest approximation of an empty statement—a compound statement with no statements inside:
which is useful as you refactor code and occasionally comment in and out various portions of code.
The else clause always binds to the closest if, so the following code is correctly indented:
if (a == b)
if (b == c)
writeln("All are equal");
else
writeln("a is different from b. Or is that so?");
The second writeln kicks in when a == b and b != c because the else binds to the innermost (second) if. If you instead want to bind the else to the first if, “buffer” the second if with a pair of braces:
if (a == b) {
if (b == c)
writeln("All are equal");
else
writeln("a is different from b");
}
Cascading multiple if-else statements is achieved in the time-honored C style:
auto opt = getOption();
if (opt == "help") {
...
} else if (opt == "quiet") {
...
} else if (opt == "verbose") {
...
} else {
stderr.writefln("Unknown option '%s'", opt);
}
3.4 The static if Statement
Now that we’ve gotten warmed up a bit with some simple statements (thanks for suppressing that yawn), let’s take a look at something just a bit more unusual.
If you want to “comment out” (or not) some statements depending on a compile-time Boolean condition, then the static if statement1 comes in handy. For example:
enum size_t
g_maxDataSize = 100_000_000,
g_maxMemory = 1_000_000_000;
...
double transmogrify(double x) {
static if (g_maxMemory / 4 > g_maxDataSize) {
alias double Numeric;
} else {
alias float Numeric;
}
Numeric[] y;
... // Complicated computation
return y[0];
}
The static if statement is a compile-time selector, much like C’s #if construct. When encountering a static if, the compiler evaluates the controlling expression. If the expression is nonzero, the corresponding code is compiled; otherwise, the code corresponding to the else clause (if any) gets compiled. In the example above, static if is used to switch between a memory-saving operation mode (by using the smaller float) and an accurate mode (by using the more precise double). Uses of considerably more power and expressiveness are possible inside generic code.
The expression tested by static if is any if-testable expression that can be evaluated during compilation. Allowed expressions include a large subset of the language, including arithmetic on all numeric types, array manipulation, is expressions that operate on types (§ 2.3.4.3 on page 48), and even function calls, an absolutely remarkable feature called compile-time function evaluation. Chapter 5 discusses compile-time evaluation in depth.
Peeling Braces
There’s a glaring oddity about the transmogrify example. See, the numeric type is introduced inside a pair of { and } braces. As such, it should be visible only locally inside that scope (and consequently invisible to the enclosing function), thus foiling our entire plan quite thoroughly. Such behavior would also render the promising static if statement practically useless. For that reason, static if uses braces for grouping, but not for scoping. As far as scope and visibility are concerned, static if peels the outermost braces away, if any (they are not required when you have only one controlled statement; our example above uses them only out of stylistic obsession). If you do want braces, just add another pair:
import std.stdio;
void main() {
static if (real.sizeof > double.sizeof) {{
auto maximorum = real.max;
writefln("Really big numbers - up to %s!", maximorum);
}}
... /* Maximorum is invisible here */ ...
}
The Statement That Wasn’t
What is the name of this chapter? “Statements.” What is the name of this section? “The static if Statement.” You’re right to be a little surprised hearing that static if is not only a statement but also a declaration. The non-statement-ness of static if shows not only in the peeling braces behavior, but also in the fact that static if can occur anywhere a declaration may occur, and that includes module, struct, and class levels, which are inaccessible to statements; for example, we could define numeric globally by simply pulling the pertinent code outside transmogrify as follows:
enum size_t
g_maxDataSize = 100_000_000,
g_maxMemory = 1_000_000_000;
...
// The declaration of Numeric will be seen at module scope
static if (g_maxMemory / 4 > g_maxDataSize) {
alias double Numeric;
} else {
alias float Numeric;
}
double transmogrify(double x) {
Numeric[] y;
... // Complicated computation
return y[0];
}
Two ifs, One else
static if does not come with a corresponding static else. Instead, it just reuses the regular else. Logically, else binds to the nearest if, be it static or regular:
if (a)
static if (b) writeln("a and b are nonzero");
else writeln("b is zero");
3.5 The switch Statement
It’s best to illustrate switch with a quick example:
import std.stdio;
void classify(char c) {
write("You passed ");
switch (c) {
case '#':
writeln("a hash sign.");
break;
case '0': .. case '9':
writeln("a digit.");
break;
case 'A': .. case 'Z': case 'a': .. case 'z':
writeln("an ASCII character.");
break;
case '.', ',', ':', ';', '!', '?':
writeln("a punctuation mark.");
break;
default:
writeln("quite a character!");
break;
}
}
The general form of the switch statement is
‹expression› can have numeric, enumerated, or string type. ‹statement› may contain labels defined as follows:
case‹e›:Jump here if ‹expression›
==‹e›. To use the comma operator (§ 2.3.18 on page 60) ine, you need to wrap the entire expression in parentheses.case‹e1›, ‹e2›, ..., ‹en›:Each ‹ek› is an expression. The construct is equivalent to
case‹item1›:case‹item2›:, ...,case‹itemn›:.case‹e1›:.. case‹e2›:Jump here if ‹expression›
>=‹e1› and ‹expression›<=‹e2›.default:Jump here if no other jump was taken.
In all of these tests, ‹expression› is evaluated only once. The expression in each case label is any legal expression comparable for equality with ‹expression›, and also for inequality if the .. syntax is used. Usually the case expressions are compile-time constants, but D allows variables, too, and guarantees lexical-order evaluation up to the first match. After evaluation, a jump is taken to the corresponding case or default label and execution proceeds from there. Just as in C and C++, execution inside the switch does not automatically stop when the next case label is reached; you must insert a break if you want that to happen. This arguably suboptimal behavior was decided in order to not surprise programmers coming from other languages.
For labels evaluated during compilation, it is enforced that no overlap exists. For example, this code is illegal:
switch (s) {
case 'a' .. case 'z': ... break;
// Trying a special case for 'w'
case 'w': ... // Error! Case labels cannot overlap!
}
If no jump is taken at all, a runtime exception is thrown. This is to prevent the common programming error of overlooking a subset of values. If there is no such danger, insert a default: break; in the controlled statement, thus nicely documenting your assumption. Check the next section for a static enforcement of the same condition.
3.6 The final switch Statement
It is often the case that switch is used in conjunction with enumerated types and is meant to handle all of their possible values. If, during maintenance, the number of cases is changing, all of the dependent switch statements suddenly fall out of sync and must be manually searched for and modified.
Now clearly the scalable solution is to replace tag-based switching with virtual function dispatch; that way there’s no more need to handle all different cases in one place, but instead the processing is distributed across different interface implementations. However, it is a reality of life that defining interfaces and classes incurs a high initial effort, which switch-based solutions may avoid. For such situations, the final switch statement comes in handy by statically forcing the case labels to cover all possible values of an enumerated type:
enum DeviceStatus { ready, busy, fail }
...
void process(DeviceStatus status) {
final switch (status) {
case DeviceStatus.ready:
...
case DeviceStatus.busy:
...
case DeviceStatus.fail:
...
}
}
Say that code maintenance adds another possible device status:
After that change, attempting to recompile process is met with refusal on the following grounds:
The final switch statement requires that all labels of the enum be explicitly handled. Ranged case labels of the form case ‹e1›: .. case ‹e2› : or the default label are disallowed.
3.7 Looping Statements
3.7.1 The while Statement
Yes, you are absolutely right:
Execution starts by evaluating ‹expression›. If it is nonzero, ‹statement› is executed and the cycle resumes with another evaluation of ‹expression›. Otherwise, the while statement is done and execution flows past it.
3.7.2 The do-while Statement
If a loop with at least one execution is needed, the do-while statement comes in handy:
Notice the required semicolon at the end of the construct. Again, ‹statement› must be non-empty. The do-while statement is equivalent to a while statement that forces one initial execution of ‹statement›.
3.7.3 The for Statement
The for statement has the syntax
Any and all of ‹decl-expr›, ‹expr1›, and ‹expr2› can be missing; if ‹expr1› is missing, it is considered to be true. The ‹decl-expr› construct either introduces a value declaration (such as auto i = 0; or float w;) or is an expression followed by ; (such as i = 10;). The semantics is similar to that of the homonym construct in other languages: ‹decl-expr› is evaluated first, then ‹expr1› is evaluated; as long as it is true, ‹statement› is executed, then ‹expr2›, after which the cycle resumes by evaluating ‹expr1› again.
3.7.4 The foreach Statement
The most convenient, safe, and often fast means to iterate is the foreach statement, which comes in several flavors. The simplest form of foreach is
The two expressions must be of numeric or pointer types. Simply put, ‹symbol› spans the interval from (and including) ‹expression1› to (and excluding) ‹expression2›. This informal explanation achieves conciseness at the expense of leaving out quite a few details; for example, is ‹expression2› evaluated only once or multiple times throughout? Or what happens if ‹expression1› >= ‹expression2›? Such details can be easily figured out by looking at the semantically equivalent code below. The technique of expressing high-level constructs in terms of equivalent constructs in a simpler (sub)language is called lowering and will be put to good use throughout this chapter.
{
auto __n = ‹expression2›;
auto ‹symbol› = true ? ‹expression1› : ‹expression2›;
for (; ‹symbol› < __n; ++‹symbol›) ‹statement›
}
where __n is a symbol generated by the compiler, guaranteed to never clash with other symbols (“fresh” symbol in compiler writer lingo).
(What do the top braces do? They ensure that ‹symbol› doesn’t leak past the foreach statement, and also that the entire construct is a single statement.)
It’s now clear that both ‹expression1› and ‹expression2› are evaluated only once, and ‹symbol›’s type is computed according to the rules of the ternary operator (§ 2.3.16 on page 59)—that’s why the ?: is there, as it has no runtime role. The careful type conciliation made by ?: ensures that some potential confusion between numbers of different sizes and precisions, as well as conflicts between signed and unsigned types, are properly prevented or at least exposed.
It is also worth mentioning that the compiler doesn’t enforce a specific type for __n; consequently, you can make this form of foreach work with a user-defined type too, as long as that type defines operators for less-than comparison and increment (we’ll learn how to do that in Chapter 12). Better yet, if the type does not define less-than comparison but does define comparison for equality, the compiler automatically replaces < with != in the lowering. In that case, the range cannot be checked for validity so you must make sure that the upper limit can be reached by starting from the lower limit and applying ++ repeatedly. Otherwise, the iteration may go astray.2
You can specify an actual type with ‹symbol›. That type is often redundant, but it is useful when you want to ensure that the iterated type fits a certain expectation, solve a signed/unsigned ambiguity, or insert an implicit conversion:
import std.math, std.stdio;
void main() {
foreach (float elem; 1.0 .. 100.0) {
writeln(log(elem)); // Logarithms in single precision
}
foreach (double elem; 1.0 .. 100.0) {
writeln(log(elem)); // Double precision
}
foreach (elem; 1.0 .. 100.0) {
writeln(log(elem)); // Same
}
}
3.7.5 foreach on Arrays
Moving on to a different form of foreach, here’s a form that works with arrays and slices:
‹expression› must be of array (linear or associative), slice, or user-defined type. Chapter 12 will deal with the latter case, so for now let’s focus on arrays and slices. After ‹expression› is evaluated once, a reference to it is stored in a private temporary. (The actual array is not copied.) Then ‹symbol› is bound in turn to each element of the array and ‹statement› is executed. Just as with the range foreach, you can specify a type in front of ‹symbol›.
The foreach statement assumes there will be no changes in the array length during iteration; if you plan otherwise, you may want to use a plain for loop and the appropriate amount of care.
Updating during Iteration
Assigning to ‹symbol› inside ‹statement› is not reflected in the array. If you do want to change the element being iterated, define ‹symbol› as a reference type by prefixing it with ref or ref ‹type›. For example:
void scale(float[] array, float s) {
foreach (ref e; array) {
e *= s; // Updates array in place
}
}
You could specify a full type with ref, such as ref float e in the code above. However, this time the type match must be exact; conversions don’t work with ref!
float[] arr = [ 1.0, 2.5, 4.0 ];
foreach (ref float elem; arr) {
elem *= 2; // Fine
}
foreach (ref double elem; arr) { // Error!
elem /= 2;
}
The reason is simple: to ensure proper assignment, ref counts on and exact match of representation; although you can create a double from a float at any time, you can’t use a double assignment to update a float for multiple reasons, the simplest one being that they don’t even have the same size.
Where Was I?
Sometimes, having access to the iteration index is useful. You can bind a symbol to it with the form
So you can write
void print(int[] array) {
foreach (i, e; array) {
writefln("array[%s] = %s;", i, e);
}
}
This function prints the contents of an array as actual D code: print([5, 2, 8]) produces
Accessing the iteration index becomes much more interesting with associative arrays:
void print(double[string] map) {
foreach (i, e; map) {
writefln("array['%s'] = %s;", i, e);
}
}
Now calling print(["Moon": 1.283, "Sun": 499.307, "Proxima Centauri": 133814298.759]) prints
array['Proxima Centauri'] = 1.33814e+08;
array['Sun'] = 499.307;
array['Moon'] = 1.283;
Notice how the order of elements is not the same as the order specified in the literal. In fact, if you experiment with the same code on a different implementation or version of the same implementation, you may experience a different ordering. This is because associative arrays use several occult techniques to make storage and retrieval of elements efficient, at the expense of guaranteed ordering.
The type of the index and that of the element are deduced. Alternatively, you can impose them by specifying types for one or both of ‹symbol1› and ‹symbol2›. However, ‹symbol1› can never be a ref type.
Shenanigans
Arbitrarily changing the underlying array during iteration has the following possible effects:
- Array mutates in place: Iteration will “see” mutation to not-yet-visited slots of the array.
- Array changes in size: Iteration will iterate up to the length that the array had upon loop entry. It’s possible that the size change moves the new array to a different region of memory, in which case subsequent mutation of the array is invisible to the iteration, and also subsequent mutations effected by the iteration itself are not visible to the array. Not recommended because the rules that trigger moving the array are implementation-dependent.
- Array is deallocated or shrunk in place using low-level allocation control functions: You wanted ultimate control and efficiency and you took the time to read about low-level allocation control in your implementation’s documentation. It can only be assumed that you know what you’re doing, and that you are a boring date for anyone who hasn’t written a garbage collector.
3.7.6 The continue and break Statements
The continue statement forces a jump to the end of the statement controlled by the innermost while, do-while, for, or foreach statement. The loop skips the rest of its controlled statement and proceeds to the next iteration.
The break statement forces a jump right after the innermost while, do-while, for, foreach, switch, or final switch statement, effectively ending its execution.
Both statements accept an optional label, which allows specifying which exact statement to effect. Labeled break and continue greatly simplify the expression of complex iteration patterns without state variables and without having to resort to you-know-which statement, which is described in the next section.
void fun(string[] strings) {
loop: foreach (s; strings) {
switch (s) {
default: ...; break; // Break the switch
case "ls": ...; break; // Break the switch
case "rm": ...; break; // Break the switch
...
case "#": break loop; // Ignore rest of strings (break foreach)
}
}
...
}
3.8 The goto Statement
In the wake of global warming, there’s no point in adding any more heat to the debate around goto. Suffice it to say that D does provide it in the following form:
where the symbol ‹label› must be visible in the function where goto is called. A label is defined implicitly by prefixing a statement with a symbol followed by a colon. For example:
There cannot be multiply-defined labels in the same function. Another restriction is that a goto cannot skip the definition point of a value that’s visible at the landing point, even when that value is not used. For example:
void main() {
goto target;
int x = 10;
target: {} // Error! goto bypasses definition of x!
}
Finally, a goto cannot cross an exception boundary, a restriction that § 3.11 on page 81 will explain. Other than that, goto obeys remarkably few restrictions, and that’s precisely what makes it dangerous. goto can jump all over the place: forward or backward, in and out of if statements, and in and out of loops, including the infamous forward jump into the middle of a loop.
However, in D not everything bearing the goto name is dangerous. Inside a switch statement, writing
jumps to the corresponding case ‹expression› label, and
jumps to the default label. While these jumps are not much more structured than any other gotos, they are easier to follow because they are localized and can make switch statements substantially simpler:
enum Pref { superFast, veryFast, fast, accurate,
regular, slow, slower };
Pref preference;
double coarseness = 1;
...
switch (preference) {
case Pref.fast: ...; break;
case Pref.veryFast: coarseness = 1.5; goto case Pref.fast;
case Pref.superFast: coarseness = 3; goto case Pref.fast;
case Pref.accurate: ...; break;
case Pref.regular: goto default;
default: ...
...
}
With labeled break and continue (§ 3.7.6 on page 78), exceptions (§ 3.11 on the next page), and the advanced flow control statement scope (§ 3.13 on page 84), finding good justification becomes increasingly difficult for goto aficionados.
3.9 The with Statement
The Pascal-inspired with statement allows working on a specific object comfortably. The statement
first evaluates ‹expression› and then makes the resulting object’s members the topmost visible symbols inside ‹statement›. We’ve met struct in the first chapter, so let’s look at a short example involving a struct:
import std.math, std.stdio;
struct Point {
double x, y;
double norm() { return sqrt(x * x + y * y); }
}
void main() {
Point p;
int z;
with (p) {
x = 3; // Assigns p.x
p.y = 4; // It's fine to still use p explicitly
writeln(norm()); // Writes p.norm, which is 5
z = 1; // z is still visible
}
}
Changes to the fields are reflected directly in the object that with operates on—with recognizes and preserves the fact that p is an lvalue.
If one symbol made visible through with shadows a symbol defined earlier in the function, the compiler does not allow access for ambiguity reasons. Assuming the same definition of Point, the following code does not compile:
void fun() {
Point p;
string y = "I'm here to make a point (and a pun).";
with (p) {
writeln(x, ":", y); // Error!
// p.y is not allowed to shadow y!
}
}
However, the error is always signaled on actual, not potential, ambiguity. For example, if the with statement above did not use y at all, the code would have compiled and run, in spite of the latent ambiguity. Also, replacing writeln(x, ":", y) with writeln(x, ":", p.y) also works because the explicit qualification of y eliminates any possibility of ambiguity.
A with statement can mask module-level (e.g., global) symbols. Accessing the symbols masked by a with statement is possible with the syntax .symbol.
Notice that you can make multiple members implicit by writing
There is no ambiguity-related danger in using nested withs because the language disallows shadowing of a symbol introduced by an outer with by a symbol introduced by an inner with. In brief, in D a local symbol can never shadow another local symbol.
3.10 The return Statement
To immediately return a value from the current function, write
The statement evaluates ‹expression› and then returns it to the caller, implicitly converted (if needed) to the function’s returned type.
If the current function has type void, ‹expression› must either be omitted or consist of a call to a function that in turn has type void.
It is illegal for the execution flow to exit a non-void function without a return. This is hard to enforce effectively during compilation, so you might see the compiler complain unnecessarily on rare occasions.
3.11 The throw and try Statements
D supports error handling via exceptions. An exception is initiated by the throw statement and handled via the try statement. To throw an exception, you typically write
The SomeException type must inherit the built-in class Throwable. D does not support throwing arbitrary types, partly because choosing a specific root type makes it easy to support chaining exceptions of different types together, as we’ll see in a minute.
To handle an exception or at least be aware of it, use the try statement, which generally looks like this:
try ‹statement›
catch (‹E1› ‹e1›) ‹statement1›
catch (‹E2› ‹e2›) ‹statement2›
...
catch (‹En› ‹en›) ‹statementn›
finally ‹statementf›
All controlled statements must be block statements; that is, they must be enclosed by braces. The finally clause, as well as any and all of the catch clauses, can be omitted, but the try statement must have at least one catch or the finally clause. ‹Ek› are types that, as mentioned, must inherit Throwable. The symbol names ‹ek› bind to the exception object being caught and can be missing.
The semantics is as follows. First, ‹statement› is executed. If it throws an exception (let’s call it ‹ex› of type ‹Ex›), then types ‹E1›, ‹E2›, ..., ‹En› are tentatively matched against ‹Ex›. The first type ‹Ek› that is ‹Ex› or a class derived from it “wins.” The symbol ‹ek› is bound to the exception object ‹ex› and ‹statementk› is executed. The exception is considered already handled, so if ‹statementk› throws itself an exception, that exception will not be dispatched among the current exception’s catch blocks. If no type ‹Ek› matches, ‹ex› continues up the call stack to find a handler.
The finally clause ‹statementf›, if present, is executed in absolutely all cases, whether an exception ends up being thrown or not, and even if a catch clause catches an exception and then throws another. It is essentially guaranteed to be executed (barring, of course, infinite loops and system calls causing program termination). If ‹statementf› throws an exception ‹ef›, that exception will be appended to the current exception chain. Chapter 9 contains full information about D’s exception model.
A goto statement (§ 3.8 on page 78) cannot jump inside any of ‹statement›, ‹statement1›, ..., ‹statementn›, and ‹statementf›, except if the goto also originates in that statement.
3.12 The mixin Statement
We saw in Chapter 2 (§ 2.3.4.2 on page 47) that mixin expressions allow you to transform strings known during compilation in D expressions that are compiled just like regular code. mixin statements take that one step further—you can use mixin to generate not only expressions, but also declarations and statements.
Consider, for example, that you want to compute the number of nonzero bits in a byte really fast. This count, also known as the Hamming weight, is useful in a number of applications such as encryption, distributed computing, and approximate database searches. The simplest method of counting the nonzero bits in a byte is by successively accumulating the least significant bit and shifting the input number. A faster method was first suggested by Peter Wegner [60] and popularized by Kernighan and Ritchie in their K&R classic [34]:
uint bitsSet(uint value) {
uint result;
for (; value; ++result) {
value &= value - 1;
}
return result;
}
unittest {
assert(bitsSet(10) == 2);
assert(bitsSet(0) == 0);
assert(bitsSet(255) == 8);
}
This method is faster than the naïve one because it makes only exactly as many iterations as bits are set. But bitsSet still has control flow; a faster method is to simply do a table lookup. For best results, let’s fill the table during compilation, which is where a mixin declaration may greatly help. The plan is to first generate a string that looks like a declaration of a table and then use mixin to compile that string into regular code. The table generator may look like this:
import std.conv;
string makeHammingWeightsTable(string name, uint max = 255) {
string result = "immutable ubyte["~to!string(max + 1)~"] "
~name~" = [ ";
foreach (b; 0 .. max + 1) {
result ~= to!string(bitsSet(b)) ~ ", ";
}
return result ~ "];";
}
Calling makeHammingWeightsTable("t") returns the string "immutable ubyte[256] t = [ 0, 1, 1, 2, ..., 7, 7, 8, ];". The immutable qualifier (Chapter 8) states that the table never changes after the initialization. We first met the library function to!string on page 16—it converts anything (in this case the uint returned by bitsSet) into a string. Once we have the needed code in string format, defining the table is only one step away:
mixin(makeHammingWeightsTable("hwTable"));
unittest {
assert(hwTable[10] == 2);
assert(hwTable[0] == 0);
assert(hwTable[255] == 8);
}
You may build tables of virtually any size, but careful testing is always recommended—too large tables may actually become slower than computation because of cache effects.
Finally, with the reluctance of an aikido trainer recommending pepper spray in class, it should be mentioned that combining string import (§ 2.2.5.1 on page 37) with mixin declarations offers the lowest form of modularity: textual inclusion. Consider:
The import expression reads the text of file widget.d into a literal string, and immediately after that, the mixin expression transforms that string into code. Use such a trick only after you’ve convinced yourself that your path to glory in hacking depends on it.
3.13 The scope Statement
The scope statement is original to D, although its functionality can be found with slight variations in other languages, too. With scope, it is very easy to write exception-safe code in D and, most important, to also read and understand it later. The correctness of code using scope can be achieved with other means; however, the result is inscrutable except for the most trivial examples.
Writing
allows you to plant ‹statement› to be executed when control flow leaves the current scope. It does what the finally clause of a try statement does, but in a much more scalable manner. Using scope(exit) comes in handy when you want to make sure you “remember” to leave something in good order as you leave a scope. For example, say you have a “verbose” flag in an application that you want to temporarily disable. Then you can write
bool g_verbose;
...
void silentFunction() {
auto oldVerbose = g_verbose;
scope(exit) g_verbose = oldVerbose;
g_verbose = false;
...
}
The rest of silentFunction can contain arbitrary code with early returns and possibly exceptions, in full confidence that, come hell or high water, g_verbose will be properly restored when silentFunction’s execution ends.
More generally, let us define a lowering for scope(exit), that is, a systematic means for rewriting code using scope(exit) as equivalent code containing other statements, such as try. We already used lowering informally when explaining the for statement in terms of the while statement, and then the foreach statement in terms of the for statement.
Consider a block containing a scope(exit) statement:
Let’s pick the first scope in the block, so we can assume that ‹statements1› itself does not contain scope (but ‹statement2› and ‹statements3› might). Lowering transforms the code into this:
Following the transform, ‹statements3› and ‹statement2› are further lowered because they may contain additional scope statements. (The lowering always ends because the fragments are always strictly smaller than the initial sequence.) This means that code containing multiple scope(exit) statements is well defined, even in weird cases like scope(exit) scope(exit) scope(exit) writeln("?"). In particular, let’s see what happens in the interesting case of two scope(exit) statements in the same block:
Let’s assume that all statements do not contain additional scope(exit) statements. After lowering we obtain
{
‹statements1›
try {
‹statements3›
try {
‹statements5›
} finally {
‹statement4›
}
} finally {
‹statement2›
}
}
The purpose of showing this unwieldy code is to figure out the order of execution of multiple scope(exit) statements in the same block. Following the flow shows that ‹statement4› gets executed before ‹statement2›. In general, scope(exit) statements execute in a stack, LIFO manner, the reverse of their order in the execution flow.
It is much easier to track the flow of the scope version than that of the equivalent try/finally code; simply reaching a scope statement guarantees that its controlled statement will be executed when the scope exits. This allows you to achieve exception safety in your code not through awkwardly nested try/finally statements, but simply by ordering straight-line statements appropriately.
The previous example also shows a very nice property of the scope statement: scalability. scope shines best when its formidable scalability is taken into account. (After all, if all we needed was one occasional scope, we already had the linguistic means to write its lowered equivalent by hand.) Achieving the functionality of several scope(exit) statements requires a linear growth in code length when using scope(exit) itself, and a linear growth in both length and depth of code when using the equivalent try-based code; the depth scales very poorly, in addition to sharing real estate with other compound statements such as if or for. C++-style destructors (also supported by D; see Chapter 7) offer a scalable solution, too, as long as you are able to discount the cost of defining new types; but if a class must be defined mostly for its destructor’s sake (ever felt a need for a class like CleanerUpper?), then its scalability is even worse than that of inline try statements. In short, if classes were vacuum welding and try/finally were chewing gum, then scope(exit) would qualify as a quick-dry epoxy glue.
The scope(success) ‹statement› schedules ‹statement› for execution only in the case when the current scope will ultimately be exited normally, not by throwing. The lowering of scope(success) is as follows:
becomes
{
‹statements1›
bool __succeeded = true;
try {
‹statements3›
} catch(Exception e) {
__succeeded = false;
throw e;
} finally {
if (__succeeded) ‹statement2›
}
}
Again, ‹statement2› and ‹statements3› must undergo further lowering until they contain no more scope statements.
Moving on to a gloomier form, executing scope(failure) ‹statement› guarantees that ‹statement› will be executed if and only if the current scope is exited by throwing an exception.
The lowering of scope(failure) is almost identical to that of scope(exit)—it just negates the test of __succeeded. The code
becomes
{
‹statements1›
bool __succeeded = true;
try {
‹statements3›
} catch(Exception e) {
__succeeded = false;
throw e;
} finally {
if (!__succeeded) ‹statement2›
}
}
followed by further lowering of ‹statement2› and ‹statements3›.
There are many places where scope statements can be put to good use. Consider, for example, that you want to create a file transactionally—that is, if creating the file fails, you don’t want a partially created file on the disk. You could go about it like this:
import std.contracts, std.stdio;
void transactionalCreate(string filename) {
string tempFilename = filename ~ ".fragment";
scope(success) {
std.file.rename(tempFilename, filename);
}
auto f = File(tempFilename, "w");
... // Write to f at your leisure
}
scope(success) sets the goal of the function early on. The equivalent scope-less code would be much more convoluted, and indeed, many programmers would be simply too busy making the blessed thing work on the normal path to put in extra work for supporting unlikely cases. That’s why the language should make it as easy as possible to handle errors.
One nice artifact of this style of programming is that all error-handling code is concentrated in transactionalCreate’s prologue and does not otherwise affect the main code. As simple as it stands, transactionalCreate is rock-solid: you are left with either a good file or a fragment file, but not a corrupt file claiming to be correct.
3.14 The synchronized Statement
The synchronized statement has the form
synchronized effects scoped locking in multithreaded programs. Chapter 13 defines the semantics of synchronized.
3.15 The asm Statement
D would not respect its vow to be a system-level programming language without allowing some sort of interface with assembly language. So if you enjoy getting your hands dirty, you’ll be glad to hear that D has a very carefully defined embedded assembly language for Intel x86. Better yet, D’s x86 assembler language is portable across virtually all D implementations working on x86 machines. Given that assembly language depends on only the machine and not the operating system, this looks like a “duh” sort of feature but you’d be surprised. For historical reasons, each operating system defines its own incompatible assembly language syntax, so, for example, you couldn’t get any Windows assembler code working on Linux because the syntaxes are entirely different (arguably gratuitously). What D does to cut that Gordian knot is to not rely on a system-specific external assembler. Instead, the compiler truly parses and understands assembler language statements. To write assembler code, just go
or
The symbols normally visible just before asm are accessible inside the asm block as well, ensuring that the assembler can access D entities. This book does not cover D’s assembler language, which should look familiar to anyone who’s used any x86 assembler; consult D’s assembler documentation [12] for the full story.
3.16 Summary and Quick Reference
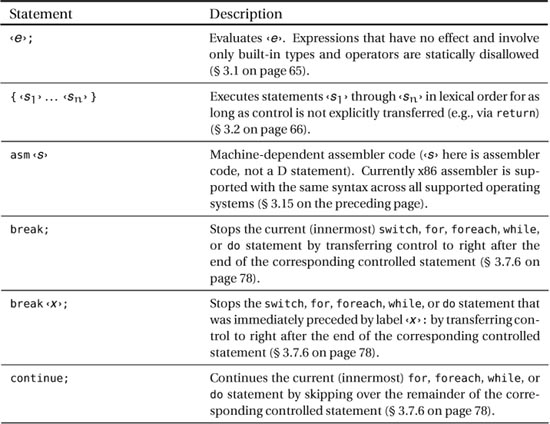
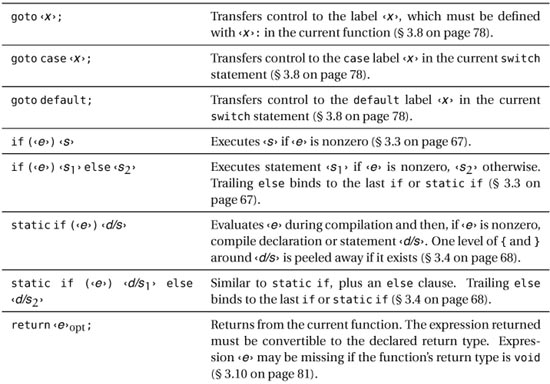
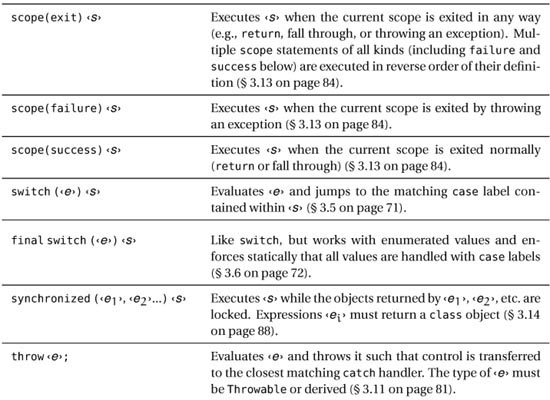
D offers the usual suspects in terms of statements, plus a few interesting newcomers such as static if, final switch, and scope. Table 3.1 is a quick reference for all of D’s statements, favoring brevity at the expense of ultimate precision and excruciating detail (for those, refer to the respective sections of this chapter).
Table 3.1. Statements cheat sheet (‹s› means statement, ‹e› means expression, ‹d› means declaration, ‹x› means symbol)