
Chapter 6. Classes. Object-Oriented Style
Object-oriented programming (OOP) has evolved through the years from an endearing child to an annoying pimple-faced adolescent to the well-adjusted individual of today. Nowadays we have a better understanding of not only the power but also the inherent limitations of object technology. This in turn made the programming community aware that a gainful approach to creating solid designs is to combine the strengths of OOP with the strengths of other paradigms. That trend is quite visible—increasingly, today’s languages either adopt more eclectic features or are designed from the get-go to foster OOP in conjunction with other programming styles. D is in the latter category, and, at least in the opinion of some, it has done a quite remarkable job of keeping different programming paradigms in harmony. This chapter explores D’s object-oriented features and how they integrate with the rest of the language. For an in-depth treatment of object orientation, a good starting point is Bertrand Meyer’s classic Object-Oriented Software Construction [40] (for a more formal treatment, see Pierce’s Types and Programming Languages [46, Chapter 18]).
6.1 Classes
The unit of object encapsulation in D is the class. A class defines a cookie cutter for creating objects, defining how they look and feel. A class may specify constants, perclass state, per-object state, and methods. For example:
class Widget {
// A constant
enum fudgeFactor = 0.2;
// A shared immutable value
static immutable defaultName = "A Widget";
// Some state allocated for each Widget object
string name = defaultName;
uint width, height;
// A static method
static double howFudgy() {
return fudgeFactor;
}
// A method
void changeName(string another) {
name = another;
}
// A non-overridable method
final void quadrupleSize() {
width *= 2;
height *= 2;
}
}
Creation of an object of type Widget is achieved with the new expression new Widget (§ 2.3.6.1 on page 51), which you’d usually invoke to store its result in a named object. To access a symbol defined inside Widget, you need to prefix it with the object you want to operate on, followed by a dot. In case the accessed member is static, the class name suffices. For example:
unittest {
// Access a static method of Widget
assert(Widget.howFudgy() == 0.2);
// Create a Widget
auto w = new Widget;
// Play with the Widget
assert(w.name == w.defaultName); // Or Widget.defaultName
w.changeName("My Widget");
assert(w.name == "My Widget");
}
Note a little twist. The code above used w.defaultName instead of Widget.defaultName. Wherever you access a static member, an object name is as good as the class name. This is because the name to the left of the dot guides name lookup first and (if needed) object identification second. w is evaluated whether it ends up being used or not.
6.2 Object Names Are References
Let’s conduct a little experiment:
import std.stdio;
class A {
int x = 42;
}
unittest {
auto a1 = new A;
assert(a1.x == 42);
auto a2 = a1;
a2.x = 100;
assert(a1.x == 100);
}
This experiment succeeds (all assertions pass), revealing that a1 and a2 are not distinct objects: changing a2 in fact went back and changed a1 as well. The two are only two distinct names for the same object, and consequently changing a2 affected a1. The statement auto a2 = a1; created no extra object of type A; it only made the existing object known by another name. Figure 6.1 illustrates this fact.
Figure 6.1. The statement auto a2 = a1; only adds one extra name for the same underlying object.
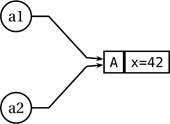
This behavior is consistent with the notion that all class objects are entities, meaning that they have “personality” and are not supposed to be duplicated without good reason. In contrast, value objects (e.g., built-in numbers) feature full copying; to define new value types, struct (Chapter 7) is the way to go.
So in the world of class objects there are objects, and then there are references to them. The imaginary arrows linking references to objects are called bindings—we say, for example, that a1 and a2 are bound to the same object, or have the same binding. The only way you can work on an object is to use a reference to it. As far as the object itself is concerned, once you have created it, it will live forever in the same place. What you can do if you get bored with some object is to bind your reference to another object. For example, consider that you want to swap two references:
unittest {
auto a1 = new A;
auto a2 = new A;
a1.x = 100;
a2.x = 200;
// Let's swap a1 and a2
auto t = a1;
a1 = a2;
a2 = t;
assert(a1.x == 200);
assert(a2.x == 100);
}
Instead of the last three lines we could have availed ourselves of the universal routine swap found in the module std.algorithm by calling swap(a1, a2), but doing the rewiring explicitly makes what’s going on clearer. Figure 6.2 illustrates the bindings before and after swapping.
Figure 6.2. The bindings before and after swapping two references. The swapping process changes the way references are wired to the objects; the objects themselves stay in the same place.

The objects themselves stay put, that is, their locations in memory never change after creation. Just as remarkably, the object never goes away—once it’s created, you can count on it being there forever. (A garbage collector recycles in the background memory of objects that are not used anymore.) The references to the objects (in this case a1 and a2) can be convinced to “look” elsewhere by rebinding them. When the runtime system figures out that an object has no more references bound to it, it can recycle the object’s memory, an activity known as garbage collection. Such a behavior is fundamentally different from value semantics (e.g., int), in which there is no indirection and no rebinding—each name is stuck directly to the value it manipulates.
A reference that is not bound to any object is a null reference. Upon default initialization with .init, class references are null. A reference can be compared to null and assigned from null. The following assertions succeed:
unittest {
A a;
assert(a is null);
a = new A;
assert(a !is null);
a = null;
assert(a is null);
a = A.init;
assert(a is null);
}
Accessing a member of an unbound (null) reference results in a hardware fault that terminates the application (or, on some systems and under certain conditions, starts the debugger). If you try to access a non-static member of a reference and the compiler can prove statically that the reference would definitely be null, it will refuse to compile the code.
In an attempt to not annoy you too much, the compiler is conservative—if a reference may be null but not always, the compiler lets the code go through and defers any errors to runtime. For example:
A a;
if (‹condition›) {
a = new A;
}
...
if (‹condition›) {
a.x = 43; // Fine
}
The compiler lets such code go through even though it’s possible that ‹condition› changes value between the two evaluations. In the general case it would be very difficult to verify proper object initialization, so the compiler assumes you know what you’re doing except for the simplest cases where it can vouch that you are trying to use a null reference in a faulty manner.
D’s reference semantics approach to handling class objects is similar to that found in many object-oriented languages. Using reference semantics and garbage collection for class objects has both positive and negative consequences, including the following:
+ Polymorphism. The level of indirection brought by the consistent use of references enables support for polymorphism. All references have the same size, but related objects can have different sizes even though they have ostensibly the same type (through the use of inheritance, which we’ll discuss shortly). Because references have the same size regardless of the size of the object they refer to, you can always substitute references to derived objects for references to base objects. Also, arrays of objects work properly even when the actual objects in the array have different sizes. If you’ve used C++, you sure know about the necessity of using pointers with polymorphism, and about the various lethal problems you encounter when you forget to.
+ Safety. Many of us see garbage collection as just a convenience that simplifies coding by relieving the programmer of managing memory. Perhaps surprisingly, however, there is a very strong connection between the infinite lifetime model (which garbage collection makes practical) and memory safety. Where there’s infinite lifetime, there are no dangling references, that is, references to some object that has gone out of existence and has had its memory reused for an unrelated object. Note that it would be just as safe to use value semantics throughout (have auto a2 = a1; duplicate the A object that a1 refers to and have a2 refer to the copy). That setup, however, is hardly interesting because it disallows creation of any referential structure (such as lists, trees, graphs, and more generally shared resources).
– Allocation cost. Generally, class objects must reside in the garbage-collected heap, which generally is slower and eats more memory than memory on the stack. The margin has diminished quite a bit lately but is still nonzero.
– Long-range coupling. The main risk with using references is undue aliasing. Using reference semantics throughout makes it all too easy to end up with references to the same object residing in different—and unexpected—places. In Figure 6.1 on page 177, a1 and a2 may be arbitrarily far from each other as far as the application logic is concerned, and additionally there may be many other references hanging off the same object. Interestingly, if the referred object is immutable, the problem vanishes—as long as nobody modifies the object, there is no coupling. Difficulties arise when one change effected in a certain context affects surprisingly and dramatically the state as seen in a different part of the application. Another way to alleviate this problem is explicit duplication, often by calling a special method clone, whenever passing objects around. The downside of that technique is that it is based on discipline and that it could lead to inefficiency if several parts of an application decide to conservatively clone objects “just to be sure.”
Contrast reference semantics with value semantics à la int. Value semantics has advantages, notably equational reasoning: you can always substitute equals for equals in expressions without altering the result. (In contrast, references that use method calls to modify underlying objects do not allow such reasoning.) Speed is also an important advantage of value semantics, but if you want the dynamic generosity of polymorphism, reference semantics is a must. Some languages tried to accommodate both, which earned them the moniker of “impure,” in contrast to pure object-oriented languages that foster reference semantics uniformly across all types. D is impure and up-front about it. You get to choose at design time whether you use OOP for a particular type, in which case you use class; otherwise, you go with struct and forgo the particular OOP amenities that go hand in hand with reference semantics.
6.3 It’s an Object’s Life
Now that we have a general notion of objects’ whereabouts, let’s look in detail at their life cycle. To create an object, you use a new expression:
import std.math;
class Test {
double a = 0.4;
double b;
}
unittest {
// Use a new expression to create an object
auto t = new Test;
assert(t.a == 0.4 && isnan(t.b));
}
Issuing new Test constructs a default-initialized Test object, which is a Test with each field initialized to its default value. Each type T has a statically known default value, accessible as T.init (see Table 2.1 on page 30 for the .init values of basic types). If you’d prefer to initialize some member variables to something other than their types’ .init value, you can specify a statically known initializer when you define the member, as shown in the example above for a. The unittest above passes because a is explicitly initialized with 0.4, and b is left alone so it is implicitly initialized with double.init, which is “Not a Number” (NaN).
6.3.1 Constructors
Of course, most of the time initializing fields with some statically known values is not enough. To execute code upon the creation of an object, you can use special functions called constructors. A constructor is a function with the name this that declares no return type:
class Test {
double a = 0.4;
int b;
this(int b) {
this.b = b;
}
}
unittest {
auto t = new Test(5);
}
As soon as a class defines at least one constructor, the implicit default constructor is not available anymore. With Test defined as above, trying
does not work anymore. This interdiction was intended to help avoiding a common bug: a designer carefully defines a number of constructors with parameters but forgets all about the default constructor. As is often the case in D, such protection for the forgetful is easy to avoid by simply telling the compiler that yes, you did remember:
class Test {
double a = 0.4;
int b;
this(int b) {
this.b = b;
}
this() {} // Default constructor,
// all fields implicitly initialized
}
Inside a method—except static ones; see § 6.5 on page 196—the reference this is implicitly bound to the object receiving the call. That reference is occasionally useful, as in the example above that illustrates a common naming convention in constructors: if a parameter is meant to initialize a member, give it the same name and disambiguate the member from the parameter by prefixing the former with an explicit reference to this. Without the prefix this, a parameter hides the homonym members.
Although you can modify this.field for any field, you can never rebind this itself, which effectively behaves like an rvalue:
class NoGo {
void fun() {
// Let's just rebind this to a different object
this = new NoGo; // Error! Cannot modify 'this'!
}
}
The usual function overloading rules (§ 5.5 on page 142) apply to constructors: a class may define any number of constructors as long as they have distinct signatures (different in the number of parameters or in the type of at least one parameter).
6.3.2 Forwarding Constructors
Consider a class Widget that defines two constructors:
class Widget {
this(uint height) {
this.width = 1;
this.height = height;
}
this(uint width, uint height) {
this.width = width;
this.height = height;
}
uint width, height;
...
}
The code above is quite repetitive and gets only worse for larger classes, but fortunately one constructor may defer to another:
class Widget {
this(uint height) {
this(1, height); // Defer to the other constructor
}
this(uint width, uint height) {
this.width = width;
this.height = height;
}
uint width, height;
...
}
There are certain limitations when it comes to calling constructors explicitly à la this(1, h). First, you can issue such a call only from within another constructor. Second, if you decide to make such a call, you must convince the compiler that you’re making exactly one such call throughout your constructor, no matter what. For example, this constructor would be invalid:
this(uint h) {
if (h > 1) {
this(1, h);
}
// Error! One path skips constructor
}
In the case above, the compiler figures there are cases in which another constructor is not called and flags that situation as an error. The intent is to have a constructor either carry the construction itself or forward the task to another constructor. The situations in which a constructor may or may not choose to defer to another constructor are rejected.
Invoking the same constructor twice is incorrect as well:
You don’t want a doubly initialized object any more than one you forgot to initialize, so this case is also flagged as a compile-time error. In short, a constructor is allowed to call another constructor either exactly zero times or exactly one time. This claim is verified during compilation by using simple flow analysis.
6.3.3 Construction Sequence
In all languages, object construction is a bit tricky. The construction process starts with a chunk of untyped memory and deposits in it information that makes that chunk look and feel like a class object. A certain amount of magic is always needed.
In D, object construction takes the following steps:
- Allocation. The runtime allocates on the heap a chunk of raw memory large enough to store the non-
staticfields of the object. All class-based objects are dynamically allocated—unlike in C++, there is no way to allocate a class object on the stack. If allocation fails, construction is abandoned by throwing an exception. - Field initialization. Each field is initialized to its default value. As discussed above, the default field value is the one specified in the field declaration with
= valueor, absent that, the.initvalue of the field’s type. - Branding. After default field initialization has taken place, the object is branded as a full-fledged
T, even before the actual constructor gets called. The branding process is implementation-dependent and usually consists of initializing one or more hidden fields with type-dependent information. - Constructor call. Finally, the compiler issues a call to the applicable constructor. If the class defines no constructor, this step is skipped.
Since the object is considered alive and well right after the default field initialization, it is highly recommended that the field initializers always put the object in a meaningful state. Then, the actual constructor does adjustments that put the object in an interesting state (which is, of course, also meaningful).
In case your constructor reassigns some fields, the double assignment should not be an efficiency problem. Most of the time, if the body of the constructor is simple enough, the compiler should be able to figure out that the first assignment is redundant and perform the dark-humored “dead assignment elimination” optimization.
If efficiency is an absolutely essential concern, you may specify = void as a field initializer for certain fields, in which case you must be very careful to initialize that member in the constructor. You might find = void useful with fixed-size arrays. It is difficult for the compiler to optimize double initialization of all array elements, so you can give it a hand. The code below efficiently initializes a fixed-size array with 0.0, 0.1, 0.2, . . ., 1.28:
class Transmogrifier {
double[128] alpha = void;
this() {
foreach (i, ref e; alpha) {
e = i * 0.1;
}
}
...
}
Sometimes, a design may ask for certain fields to be left deliberately uninitialized. For example, Transmogrifier may track the already used portion of alpha in a separate variable usedAlpha, initially zero. The object primitives know that only the portion of alphas from zero up to a size usedAlpha are actually initialized:
class Transmogrifier {
double[128] alpha = void;
size_t usedAlpha;
this() {
// Leave usedAlpha = 0 and alpha uninitialized
}
...
}
Initially usedAlpha is zero, which is all the initialization that Transmogrifier needs. As usedAlpha grows, the code must never read elements in the interval alpha[usedAlpha .. $] before writing them. This is, of course, stuff that you, not the compiler, must ensure—which illustrates the inevitable tension that sometimes exists between efficiency and static verifiability. Although such optimizations are often frivolous, there are cases in which unnecessary compulsive initializations could sensibly affect bottom-line results, so having an opt-in escape hatch is reassuring.
6.3.4 Destruction and Deallocation
D maintains a garbage-collected heap for all class objects. Once an object is successfully allocated, it may be considered to live forever as far as the application is concerned. The garbage collector recycles the memory used by an object only when it can prove there are no more accessible references to that object. This setup makes for clean, safe class-based code.
For certain classes, it is important to have a hook on the termination process so they can free additional resources that they might have acquired. Such classes may define a destructor, introduced as a special function with the name ~this:
import core.stdc.stdlib;
class Buffer {
private void* data;
// Constructor
this() {
data = malloc(1024);
}
// Destructor
~this() {
free(data);
}
...
}
The example above illustrates an extreme situation—a class maintaining its own raw memory buffer. Most of the time a class would use properly encapsulated resources, so there is little need for defining destructors.
6.3.5 Tear-Down Sequence
Like construction, tearing an object down follows a little protocol:
- Right after branding (step 3 in the construction process) the object is considered alive and put under the scrutiny of the garbage collector. Note that this happens even if the user-defined constructor throws an exception later. Given that default initialization and branding cannot fail, it follows that an object that was successfully allocated is considered a full-fledged object as far as the garbage collector is concerned.
- The object is used throughout the program.
- All accessible references to the object are gone; no code could possibly reach the object anymore.
- At some implementation-dependent point, the system acknowledges that the object’s memory may be recycled and invokes its destructor.
- At a later point in time (either immediately after calling the destructor or later on) the system reuses the object’s memory.
One important detail regarding the last two steps is that the garbage collector makes sure that an object’s destructor can never access an already deallocated object. It is possible to access an already destroyed object, just not deallocated; in D, destroyed objects hold their memory for a short while, until their peers get destroyed. If that were not the case, destroying and deallocating objects that refer to each other in a cycle (e.g., circular lists) would be impossible to implement safely.
The life cycle described above may be amended in several ways. First, it is very possible that an application ends before ever reaching step 4. This is often the case for small applications running on systems with enough memory. In that case, D assumes that exiting the application will de facto free all resources associated with it, so it does not invoke any destructor.
Another way to amend the life cycle of an object is to explicitly invoke its destructor. This is accomplished by calling the clear function defined in module object (the standard library module that is imported automatically in any compilation).
unittest {
auto b = new Buffer;
...
clear(b); // Get rid of b's extra state
... // b is still usable here
}
By calling clear(b), the user expresses the intent to explicitly invoke b’s destructor (if any), obliterate that object’s state with Buffer.init, and call Buffer’s default constructor. However, unlike in C++, clear does not dispose of the object’s own memory and there is no delete operator. (D used to have a delete operator, but it was deprecated.) You still can free memory manually if you really, really know what you’re doing by calling the function GC.free() found in the module core.memory. Freeing memory is unsafe, but calling clear is safe because no memory goes away so there’s no risk of dangling pointers. After clear(obj), the object obj remains eminently accessible and usable for any purpose, even though it does not contain any interesting state. For example, the following is correct D code:
unittest {
auto b = new Buffer;
auto b1 = b; // Extra alias for b
clear(b);
assert(b1.data is null); // The extra alias still refers to
// the (valid) chassis of b
}
So after you invoke clear, the object is still alive and well, but its destructor has been called and the object is now carrying its default-constructed state. Interestingly, during the next garbage collection, the destructor of the object is called again. This is because, obviously, the garbage collector has no idea in what state you have left the object.
Why this behavior? The answer is simple—divorcing object tear-down from memory deallocation gives you manual control over expensive resources that the object might control (such as files, sockets, mutexes, and system handles) while at the same time ensuring memory safety. You will never create dangling pointers by using new and clear. (Of course, if you get your hands greasy by using C’s malloc and free or the aforementioned GC.free, you do expose yourself to the dangers of dangling pointers.) Generally, it is wise to separate resource disposal (safe) with memory recycling (unsafe). Memory is fundamentally different from any other resource because it is the physical support of the type system. Deallocate it unwittingly, and you are liable to break any guarantee that the type system could ever make.
6.3.6 Static Constructors and Destructors
Inside a class and essentially anywhere in D, static data must always be initialized with compile-time constants. To allow for an orderly means to execute code during thread startup, the compiler allows defining the special function static this(). The code doing module-level and class-level initialization is collected together, and the runtime support library proceeds with static initialization in an orderly fashion.
Inside a class you can define one or more default constructors prefixed by static:
class A {
static A a1;
static this() {
a1 = new A;
}
...
static this() {
a2 = new A;
}
static A a2;
}
Such functions are called static class constructors. When loading the application and before executing main, the compiler executes each static class constructor in turn, in the order they appeared in the source code. In the example above, a1 will be initialized before a2. The order of execution of static class constructors in distinct classes inside the same module is again dictated by the lexical order. Static class constructors in unrelated modules are executed in an unspecified order. Finally and most interestingly, static class constructors of classes that are in interdependent modules are ordered to eliminate the possibility of a class ever being used before its static this() has run.
initialization orderHere’s how the ordering works. Consider class A defined in module MA and class B defined in module MB. The following situations may occur:
- At most one of
AandBdefines a static class constructor. Then there is no ordering to worry about. - Neither
MAnorMB imports the other. Then the ordering is unspecified—any order works because the two modules don’t depend on each other. MA importsMB. ThenA’s static class constructors run beforeB’s.MB importsMA. ThenB’s static class constructors run beforeA’s.MA importsMBandMB importsMA. Then a “cyclic dependency” error is signaled and execution is abandoned during program loading.
This reasoning does not really depend on classes A and B, just on the modules themselves and their import relationships. Chapter 11 discusses the matter in detail.
If any static class constructor fails by throwing an exception, the program is terminated. If all succeed, classes are also given a chance to clean things up during thread shutdown by defining static class destructors, which predictably look like this:
class A {
static A a1;
static ~this() {
clear(a1);
}
...
static A a2;
static ~this() {
clear(a2);
}
}
Static destructors are run during thread shutdown. Within each module they are run in reverse order of their definition. In the example above, a2’s destructor will get called before a1’s. When multiple modules are involved, the order of modules invoking static class destructors is the exact reverse of the order in which the modules were given a chance to call their static class constructor. It’s reversed turtles, all the way up.
6.4 Methods and Inheritance
We’re now experts in creating and obliterating objects, so let’s take a look at using them. Most of the interaction with an object is carried out by calling its methods. (In some languages that activity is known as “sending messages” to the object.) A method definition looks much like a regular function definition, the only difference being that it occurs inside a class. To focus the description on an example, say you build a Rolodex application that allows you to store and display contact information. The unit of information—one virtual business card—could then be a class Contact. Among other things, it might define a method specifying the background color used when displaying the contact:
class Contact {
string bgColor() {
return "Gray";
}
}
unittest {
auto c = new Contact;
assert(c.bgColor() == "Gray");
}
The interesting part starts when you decide that a class should inherit another. For example, certain contacts are friends, and for those we use a different background color:
class Friend : Contact {
string currentBgColor = "LightGreen";
string currentReminder;
override string bgColor() {
return currentBgColor;
}
string reminder() {
...
return currentReminder;
}
}
By declaring inheritance from Contact through the notation : Contact, an instance of class Friend will contain everything that a Contact has, plus Friend’s additional state (in this case, currentBgColor) and methods (in this case, reminder).
We call Friend a subclass of Contact and Contact a superclass of Friend. By virtue of subclassing, you can substitute a Friend value wherever a Contact value is expected:
unittest {
Friend f = new Friend;
Contact c = f; // Substitute a Friend for a Contact
auto color = c.bgColor(); // Call a Contact method
}
If the substituted Friend would behave precisely like a Contact, there would be little if any impetus to use Friends. One key feature of object technology is that it allows a derived class to override functions in the base class and therefore customize behavior in a modular manner. Predictably, overriding is introduced with the override keyword (in Friend’s definition of bgColor), which indicates that calling c.bgColor() against an object of type Contact that was actually substituted with an object of type Friend will always invoke Friend’s version of the method. Friends will always be Friends, even when the compiler thinks they’re simple Contacts.
6.4.1 A Terminological Smörgåsbord
Object technology has had a long and successful history in both academia and industry. Consequently, it has been the focus of much work and has spawned a fair amount of terminology, which can get confusing at times. Let’s stop for a minute to review the nomenclature.
If a class D directly inherits a class B, D is called a subclass of B, a child class of B, or a class derived from B. Conversely, B is called a superclass, parent class, or base class of D.
A class X is a descendant of class B if and only if either X is a child of B, or X is a descendant of a child of B. This definition is recursive, which, put another way, means that if you walk up X’s parent and then X’s parent’s parent and so on, at some point you’ll meet B.
This book uses the notions of parent/child and ancestor/descendant throughout because these phrases distinguish the notion of direct versus possibly indirect inheritance more precisely than the terms superclass/subclass.
Oddly enough, although classes are types, subtype is not the same thing as subclass (and supertype is not the same thing as superclass). Subtyping is a more general notion that means a type S is a subtype of type T if a value of type S can be safely used in all contexts where a value of type T is expected. Note that this definition does not require or mention inheritance. Indeed, inheritance is but one way of achieving subtyping, but there are other means in general (and in D). The relationship between subtyping and inheritance is that the descendants of a class C plus C itself are all subtypes of C. A subtype of C that is different from C is a proper subtype.
6.4.2 Inheritance Is Subtyping. Static and Dynamic Type
Let’s exemplify how inheritance induces subtyping. As mentioned, an object of the derived class is always substitutable for an object of the base class:
class Contact { ... }
class Friend : Contact { ... }
void fun(Contact c) { ... }
unittest {
auto c = new Contact; // c has type Contact
fun(c);
auto f = new Friend; // f has type Friend
fun(f);
}
Although fun expects a Contact object, passing f is fair game because Friend is a subclass (and therefore a subtype) of Contact.
When subtyping is in effect, it is very often possible that the actual type of an object is partially “forgotten.” Consider:
class Contact { string bgColor() { return ""; } }
class Friend : Contact {
override string bgColor() { return "LightGreen"; }
}
unittest {
Contact c = new Friend; // c has type Contact
// but really refers to a Friend
assert(c.bgColor() == "LightGreen");
// It's a friend indeed!
}
Given that c has type Contact, it could be used only in ways any Contact object could be used, even though it has been bound to an object of type Friend. For example, you can’t call c.reminder because that method is specific to Friend and not present in Contact. However, the assert above shows that friends will always be friends: calling c.bgColor reveals that the Friend-specific method gets called. As discussed in the section on construction (§ 6.3 on page 181), once an object is constructed it will just live forever, so the Friend object created with new never goes away. The interesting twist that occurs is that the reference c bound to it has type Contact, not Friend. In that case we say that c has static type Contact and dynamic type Friend. An unbound (null) reference has no dynamic type.
Teasing out the Friend that’s hiding under the disguise of a Contact—or in general a descendant from an ancestor—is a bit more elaborate. For one thing, the operation may fail: what if this contact didn’t really refer to a Friend? Most of the time, the compiler wouldn’t be able to tell. To do such extraction you’d need to rely on a cast:
unittest {
auto c = new Contact; // c has static and dynamic type Contact
auto f = cast(Friend) c;
assert(f is null); // f has static type Friend and is unbound
c = new Friend; // Static: Contact, dynamic: Friend
f = cast(Friend) c; // Static: Friend, dynamic: Friend
assert(f !is null); // Passes!
}
6.4.3 Overriding Is Only Voluntary
The override keyword in the signature of Friend.bgColor is required, which at first sight is a bit annoying. After all, the compiler could figure out that overriding is in effect all by itself and wire things appropriately. So why was override deemed necessary?
The answer is related to maintainability. Indeed, the compiler has no trouble figuring out automatically which methods you wanted to override. The problem is, it has no means to determine which methods you did not mean to override. Such a situation may occur when you change the base class after having defined the derived class. Imagine, for example, that class Contact initially defines only the bgColor method and you derive Friend from it and override bgColor as shown in the snippet above. You may also define another method in Friend, such as Friend.reminder, which allows you to retrieve reminders about that particular friend. If later on someone else (including you three months later) defines a reminder method for Contact with some other meaning, you now have the odd bug that calls to Contact.reminder get routed through Friend.reminder when passed to a Contact or a Friend, something that Friend was unprepared for.
The converse situation is just as pernicious, if not more so. Say, for example, that after the initial design, Contact decides to remove a method or change its name. The designer would have to manually go through all of Contact’s derived classes and decide what to do with the now orphaned methods. This is a highly error-prone activity and is sometimes impossible to carry out in its entirety when parts of a hierarchy are not writable by the base class designer.
So requiring override allows you to modify base classes without risking unexpected harm to derived classes.
6.4.4 Calling Overridden Methods
Sometimes, an overriding method wants to call the very method it is overriding. Consider, for example, a graphical widget Button that inherits a Clickable class. The Clickable class knows how to dispatch button presses to listeners but is not concerned with visual effects at all. To introduce visual feedback, Button overrides the onClick method defined by Clickable and introduces the visual effects part but also wants to invoke Clickable.onClick to carry out the dispatch part.
class Clickable {
void onClick() { ... }
}
class Button : Clickable {
void drawClicked() { ... }
override void onClick() {
drawClicked(); // Introduce graphical effect
super.onClick(); // Dispatch click to listeners
}
}
To call the overridden method, use the predefined alias super, which instructs the compiler to access a method as it was defined in the parent class. You are free to call any method, not only the method being currently overridden (for example, you can issue super.onDoubleClick() from within Button.onClick). To be entirely honest, the accessed symbol doesn’t even have to be a method name; it could be a field name as well, or really any symbol. For example:
class Base {
double number = 5.5;
}
class Derived : Base {
int number = 10;
double fun() {
return number + super.number;
}
}
Derived.fun accesses its own member and also the member in its base class, which incidentally has a different type.
The general means to access members in ancestors is to use Classname.membername. In fact, super is nothing but an alias for whatever name the current base class has. In the example above, writing Base.number is entirely equivalent to writing super.number. The obvious difference is that super leads to more maintainable code: if you change the base of a class, you don’t need to search and replace names.
With explicit class names, you can jump more than one inheritance level. Explicitly qualifying a method name with super or a class name is also a tad faster because the compiler knows exactly which function to dispatch to. If the symbol involved is anything but an overridable method, the explicit qualification affects only visibility but not speed.
Although destructors (§ 6.3.4 on page 186) are just methods, destructor call handling is a bit different. You cannot issue a call to super’s destructor, but when calling a destructor (either during a garbage collection cycle or in response to a clear(obj) request), D’s runtime support always calls all destructors all the way up in the hierarchy.
6.4.5 Covariant Return Types
Continuing the example with Widget, TextWidget, and VisibleTextWidget, consider that you want to add code that duplicates a Widget. In that case, if the duplicated object is a Widget, the copy will also be a Widget; if it is a TextWidget, the copy will be a TextWidget as well; and so on. A way to achieve proper duplication is by defining a method duplicate in the base class and by requiring every derived class to implement it:
class Widget {
...
this(Widget source) {
... // Copy state
}
Widget duplicate() {
return new Widget(this); // Allocates memory
// and calls this(Widget)
}
}
So far, so good. Let’s look at the corresponding override in the TextWidget class:
class TextWidget : Widget {
...
this(TextWidget source) {
super(source);
... // Copy state
}
override Widget duplicate() {
return new TextWidget(this);
}
}
Everything is correct, but there is a notable loss of static information: TextWidget.duplicate actually returns a Widget object, not a TextWidget object. But the result type of TextWidget.duplicate is TextWidget as long as we look inside that function. However, that information is lost as soon as TextWidget.duplicate returns because the return type of TextWidget.duplicate is Widget—the same as Widget.duplicate’s return type. Therefore, the following code does not work, although in a perfect world it should:
void workWith(TextWidget tw) {
TextWidget clone = tw.duplicate(); // Error!
// Cannot convert a Widget to a TextWidget!
...
}
To maximize the availability of static type information, D defines a feature known as covariant return types. As snazzy as it sounds, covariance of return types is rather simple: if a base type returns some class type C, an overriding function is allowed to return not only C, but any class derived from C. With this feature, you can declare TextWidget.duplicate to return TextWidget. Just as important, sneaking “covariant return types” into a conversation makes you sound pretty cool. (Kidding. Really. Do not attempt.)
6.5 Class-Level Encapsulation with static Members
Sometimes it’s useful to encapsulate not only fields and methods, but regular functions and (gasp) global data inside a class. Such functions and data should have no special property aside from being scope inside the class. To share regular functions and data among all objects of a class, introduce them with the static keyword:
class Widget {
static Color defaultBgColor;
static Color combineBackgrounds(Widget bottom, Widget top) {
...
}
}
Inside a static method, there is no this reference. This is because, again, static methods are regular functions scoped inside a class. It logically follows that you don’t need an object to access defaultBgColor or call combineBackgrounds—you just prefix them with the class’s name:
unittest {
auto w1 = new Widget, w2 = new Widget;
auto c = Widget.defaultBgColor;
// This works too: w1.defaultBgColor;
c = Widget.combineBackgrounds(w1, w2);
// This works too: w2.combineBackgrounds(w1, w2);
}
If you use an object instead of the class name when accessing a static member, that’s fine, too. Note that the object value is still computed even though it’s not really needed:
// Creates a Widget and throws it away
auto c = (new Widget).defaultBgColor;
6.6 Curbing Extensibility with final Methods
There are times when you actively want to disallow subclasses from overriding a certain method. This is a common occurrence because some methods are not meant as customization points. Such methods may call customizable methods, but there may often be cases when you want to keep certain control flows unchanged. (The Template Method design pattern [27] comes to mind.) To prevent inheriting classes from overriding a method, prefix its definition with final.
For example, consider a stock ticker application that wants to make sure it updates the on-screen information whenever a stock price has changed:
class StockTicker {
final void updatePrice(double last) {
doUpdatePrice(last);
refreshDisplay();
}
void doUpdatePrice(double last) { ... }
void refreshDisplay() { ... }
}
The methods doUpdatePrice and refreshDisplay are overridable and therefore offer customization points to subclasses of StockTicker. For example, some stock tickers may introduce triggers and alerts upon certain changes in price or display themselves in specific colors. But updatePrice cannot be overriden, so the caller can be sure that no stock price gets updated without an accompanying update of the display. In fact, just to be sticklers for correctness, let’s define updatePrice as follows:
final void updatePrice(double last) {
scope(exit) refreshDisplay();
doUpdatePrice(last);
}
With scope(exit) in tow, the display is properly refreshed even if doUpdatePrice throws an exception. This approach really ensures that the display reflects the latest and greatest state of the object.
There is a perk associated with final methods that is almost dangerous to know, because it could easily lure you toward the dark side of premature optimization. The truth is, final methods may be more efficient. This is because non-final methods go through one indirection step for each call, a step that ensures the flexibility brought about by override. For some final methods that indirection is still necessary. For example, a final override of a method is normally still subject to indirect calls when invoked via a base class object; in general the compiler still wouldn’t know where the call goes. But if the final method is also a first introduced method (not an override of a base class’ method), then whenever you call it, the compiler is 100% sure where the call will land. So final non-override methods are never subjected to indirect calls; instead, they enjoy the same calling convention, low overhead, and inlining opportunities as regular functions. It would appear that final non-override methods are much faster than others, but this margin is eroded by two factors.
First, the baseline call overhead is assessed against a function that does nothing. To assess the overhead that matters, the actual time spent inside the function must be considered in addition to the invocation overhead. If the function is very short, the relative overhead can be considerable, but if the function does some nontrivial work, the relative overhead decreases quickly until it falls into the noise. Second, a variety of compiler, linker, and runtime optimization techniques work aggressively to minimize or eliminate the dispatch overhead. You’re definitely much better off starting with flexibility and optimizing sparingly, instead of crippling your design from day one by making it unduly rigid for the sake of a potential future performance issue.
If you’ve used Java and C#, final is immediately recognizable because it has the same semantics in those languages. If you compare the state of affairs with C++, you’ll notice an interesting change of defaults: in C++ methods are final by default if you don’t use any annotation, and non-final if you explicitly annotate them with virtual. Again, at least in this case it was deemed that it is better to default on the side of flexibility. You may want to use final primarily in support of a design decision, and only seldom as a means to shave off some extra cycles.
6.6.1 final Classes
Sometimes you want a class to be the final word on a subject. You can achieve that by marking an entire class as final:
class Widget { ... }
final class UltimateWidget : Widget { ... }
class PostUltimateWidget : Widget { ... } // Error!
// Cannot inherit from a final class
A final class cannot be inherited from—it is a leaf in the inheritance hierarchy. This can sometimes be an important design device. Obviously, all of a final class’ methods are implicitly final because no overriding would ever be possible.
An interesting secondary effect of final classes is a strong implementation guarantee. Client code that uses a final class can be sure that said class’ methods have known implementations with guaranteed effects that cannot be tweaked by some subclass.
6.7 Encapsulation
One hallmark of object-oriented design, and of other design techniques as well, is encapsulation. Objects encapsulate their implementation details and expose only well-defined interfaces. That way, objects reserve the freedom to change a host of implementation details without disrupting clients. This leads to more decoupling and consequently fewer dependencies, confirming the adage that every design technique is, at the end of the day, aimed at dependency management.
In turn, encapsulation is a manifestation of information hiding, a general philosophy in designing software. Information hiding prescribes that various modular elements in an application should focus on defining and using abstract interfaces for communicating with one another, while hiding the details of how they implement the interfaces. Often, the details are related to data layout, for which reason “data hiding” is a commonly encountered notion. Focusing on data hiding alone, however, misses part of the point because a component may hide a variety of information, such as design decisions or algorithmic strategies.
Today, encapsulation sounds quite attractive and perhaps even obvious, but much of that is the result of accumulated collective experience. Things weren’t that clear-cut in the olden times. After all, information is ostensibly a good thing and the more you have of it the better off you are, so why would you want to hide it?
Back in the 1960s, Fred Brooks (author of the seminal book The Mythical Man-Month) was an advocate of a transparent, white-box, “everybody knows everything” approach to designing software. Under his management, the team building the OS/360 operating system received documentation of all design details of the project on a regular basis through a sophisticated hard copy annotation method [13, Chapter 7]. The project enjoyed qualified success, but it would be tenuous to argue that transparency was a positive contributor; more plausibly, it was a risk minimized by intensive management. It took a revolutionary paper by David L. Parnas [44] to forever establish the notion of information hiding in the community lore. Brooks himself commented in 1995 that his advocacy of transparency was the only major element of The Mythical Man-Month that hadn’t withstood the test of time. But the information hiding concept was quite controversial back in 1972, as witnessed by this comment by a reviewer of Parnas’ revolutionary paper: “Obviously Parnas does not know what he is talking about because nobody does it this way.” Funnily enough, only a decade later the tide had reversed so radically, the same paper almost got trivialized: “Parnas only wrote down what all good programmers did anyway” [32, page 138].
Getting back to encapsulation as enabled by D, you can prefix the declaration of any type, data, function, or method with one of five access specifiers. Let’s start from the most reclusive specifier and work our way up toward notoriety.
6.7.1 private
The label private can be specified at class level, outside all classes (module-level), or inside a struct (Chapter 7). In all contexts, private has the same power: it restricts symbol access to the current module (file).
This behavior is unlike that in other languages, which limit access to private symbols to the current class only. However, making private module-level is consistent with D’s general approach to protection—the units of protection are identical to the operating system’s unit of protection (file and directory). The advantage of file-level protection is that it facilitates collecting together small, tightly coupled entities that have a given responsibility. If class-level protection is needed, simply put the class in its own file.
6.7.2 package
The label package can be specified at class level, outside all classes (module-level), or inside a struct (Chapter 7). In all contexts, package introduces directory-level protection: all files within the same directory as the current module have access to the symbol. Subdirectories or the parent directory of the current module’s directory have no special privileges.
6.7.3 protected
The protected access specifier makes sense only inside a class, not at module level. When used inside of some class C, the protected access specifier means that access to the declared symbol is reserved to the module in which C is defined and also to C’s descendants, regardless of which modules they’re in. For example:
class C {
// x is accessible only inside this file
private int x;
// This file plus all classes inheriting C directly or
// indirectly may call setX()
protected void setX(int x) { this.x = x; }
// Everybody may call getX()
public int getX() { return x; }
}
Again, the access protected grants is transitive—it goes not only to direct children, but to all descendants that ultimately inherit from the class using protected. This makes protected quite generous in terms of giving access away.
6.7.4 public
Public access means that the declared symbol is accessible freely from within the application. All the application has to do is gain visibility to the symbol, most often by importing the module that defines it.
In D, public is also the default access level throughout. Since the order of declarations is ineffectual, a nice style is to put the visible interface of a module or class toward the beginning, then restrict access by using (for example) private: and continue with definitions. That way, the client only needs to look at the top of a file or class to learn about its accessible entities.
6.7.5 export
It would appear that public is the rock bottom of access levels, the most permissive of all. However, D defines an even more permissive access: export. When using export with a symbol, the symbol is accessible even from outside the program it’s defined in. This is the case with shared libraries that expose interfaces to the outside world. The compiler carries out the system-dependent steps required for a symbol to be exported, often including a special naming convention for the symbol. At this time, D does not define a sophisticated dynamic loading infrastructure, so export is to some extent a stub waiting for more extensive support.
6.7.6 How Much Encapsulation?
One interesting question we should ask ourselves is: How do the five access specifiers compare? For example, assuming we have already agreed that information hiding is a good thing, it is reasonable to infer that private is “better” than protected because it is more restrictive. Continuing along that line of thought, we might think that protected is better than public (heck, public sets the bar pretty low, not to mention export). It is unclear, however, how to rate protected in comparison to package. Most important, such a qualitative analysis does not give an idea of how much of a hit the design takes if, for example, it decides to loosen the restrictiveness of a symbol. Is protected closer to private, closer to public, or smack in the middle of the scale? And what’s the scale after all?
Back in December 1999, when everybody else was worried about Y2K, Scott Meyers was worried about encapsulation, or more exactly, about coding techniques that could maximize it. In his subsequent article [41], Meyers proposes a simple criterion for devising the “amount” of encapsulation of an entity: if we were to change that entity, how much code would be affected? The less code is affected, the more encapsulation has been achieved.
Having a means to measure the degree of encapsulation clarifies things a lot. Without a metric, a common assessment is that private is good, public is bad, and protected is sort of halfway in between. As people are optimistic by nature, protected has been for many of us a feel-good-within-bounds protection level, kind of like drinking responsibly.
Another aspect we can use in assessing the degree of encapsulation is control, that is, the influence you can exercise over the code that may be affected by a change. Do you know (or can you cheaply find) the code affected by a change? Do you have the rights to modify that code? Can others add to that code? The answers to these questions define degrees of control.
For starters, consider private. Modifying a private symbol affects exactly one file. A source file has on the order of a thousand lines; smaller files are common, whereas much larger files (e.g., 10,000 lines) would become difficult to manage. You have control over that file by the sheer fact that you’re changing it, and you could easily restrict others’ access to it by the use of file attributes, version control, or team coding standards. So private offers excellent encapsulation: little code affected and good control over that code.
When you use package-level access, all files within the same directory would be affected by the change. We can estimate that the files grouped in a package have about one order of magnitude more lines (for example, it’s reasonable to think of a package containing on the order of ten modules). Correspondingly, it costs to mess with package symbols: a change affects an order of magnitude more code than a similar change against a private symbol. Fortunately, however, you have good control over the affected code because, again, the operating system and various version control tools allow directory-level control over adding and changing files.
Sadly, protected protects much less than it would appear. First off, protected marks a definite departure from the confines of private and package: any class situated anywhere in a program can gain access to a protected symbol by simply inheriting a descendant of the class defining it. You don’t have fine-grained control over inheritance, except through the all-or-none attribute final. It follows that if you mess with a protected symbol, you affect an unbounded amount of code. To add insult to injury, not only do you have no ability to limit who inherits from your class, but you could also break code that you yourself don’t have the right to fix. (Think, for example, of changing a library symbol that affects applications elsewhere.) The reality is as grim as it is crisp: as soon as you step outside private and package, you’re out in the wild. Using protected offers hardly any protection.
How much code do you need to inspect when changing a protected symbol? That would be all of the descendants of the class defining the symbol. A reasonable ballpark is one order of magnitude above a package size, or a few hundreds of thousands of lines. Tools that index source code and track a class’ descendants can help a lot here, but at the end of the day, a change of a protected symbol potentially affects large amounts of code.
Using public does not change much in terms of control, but it does add one extra order of magnitude to the bulk of the code potentially affected. Now it’s not only a class’ descendants, it’s the entire code of the application. And finally, export adds one interesting twist to the situation—it’s all binary applications using your code as a binary library, so you’re not only looking at code that you can’t modify, it’s code you can’t even look at because it may not be available in source form.
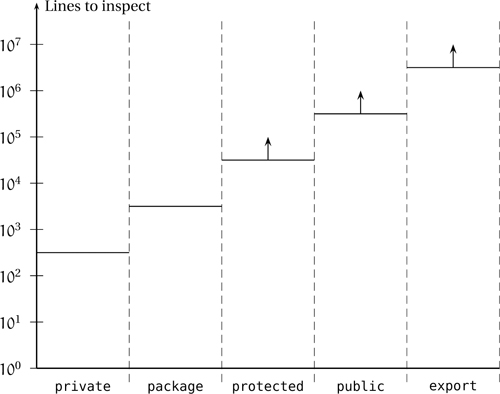
Figure 6.3 on the following page illustrates these ballpark approximations by plotting the potentially affected lines of code for each access specifier. Of course, the amounts are guesstimates and could vary wildly, but the rough proportions should not be affected too much. The vertical axis uses logarithmic scale and the steps suggest a linear trend, so each time you give up one iota of access protection, you must work about ten times harder to keep things in sync. The upward-pointing arrows suggest loss of control over the affected code. One corollary is that protected is not smack in between private and public—it’s much more like public so you should treat it as such (that is, with atavistic fear).
Figure 6.3. Ballpark estimates of lines of codes potentially affected by altering a symbol for each protection level. The vertical axis uses logarithmic scale, so each relaxation of encapsulation makes things worse by an order of magnitude. The upward-pointing arrows symbolize the fact that the amount of code affected by protected, public, and export is not under the control of the coder who maintains the symbol.
6.8 One Root to Rule Them All
Some languages define a root class for all other classes, and D is among them. The root of everything is called Object. If you define a class like this:
to the compiler things are exactly as if you wrote
Other than the automatic rewrite above, Object is not very special—it’s a class like any other. Your implementation defines it in a module called object.di or object.d, which is imported automatically in every module you compile. You should easily find and inspect that module by navigating around the directory in which your D implementation resides.
There are several advantages to having a root for all classes. An obvious boon is that Object can introduce a few universally useful methods. Below is a slightly simplified definition of the Object class:
class Object {
string toString();
size_t toHash();
bool opEquals(Object rhs);
int opCmp(Object rhs);
static Object factory(string classname);
}
Let’s look closer at the semantics of each of these symbols.
6.8.1 string toString()
This returns a textual representation of the object. By default it returns the class name:
// File test.d
class Widget {}
unittest {
assert((new Widget).toString() == "test.Widget");
}
Note that the name of the class comes together with the name of the module the class is defined in. By default, the module name is the same as the file name, a default that can be changed with a module declaration (§ 11.1.8 on page 348).
6.8.2 size_t toHash()
This returns a hash of the object as an unsigned integral value (32 bits on 32-bit machines, 64 bits on 64-bit machines). By default, the hash is computed by using the bitwise representation of the object. The hash value is a concise but inexact digest of the object. One important requirement is consistency: If toHash is called twice against a reference without an intervening change to the state of the object, it should return the same value. Also, the hashes of two equal objects must be equal, and the hash values of two distinct (non-equal) objects are unlikely to be equal. The next section discusses in detail how object equality is defined.
6.8.3 bool opEquals(Object rhs)
This returns true if this considers that rhs is equal to it. This odd formulation is intentional. Experience with Java’s similar function equals has shown that there are some subtle issues related to defining equality in the presence of inheritance, for which reason D approaches the problem in a relatively elaborate manner.
First off, one notion of equality for objects already exists: when you compare two references to class objects a1 and a2 by using the expression a1 is a2 (§ 2.3.4.3 on page 48), you get true if and only if a1 and a2 refer to the same object, just as in Figure 6.1 on page 177. This notion of object equality is sensible, but too restrictive to be useful. Often, two actually distinct objects should be considered equal if they hold the same state. In D, logical equality is assessed by using the == and != operators. Here’s how they work.
Let’s say you write ‹lhs› == ‹rhs› for expressions ‹lhs› and ‹rhs›. Then, if at least one of ‹lhs› and ‹rhs› has a user-defined type, the compiler rewrites the comparison as object.opEquals(‹lhs›, ‹rhs›). Similarly, ‹lhs› != ‹rhs› is rewritten as !object.opEquals(‹lhs›, ‹rhs›). Recall from earlier in this section that object is a core module defined by your D implementation and implicitly imported in any module that you build. So the comparisons are rewritten into calls to a free function provided by your implementation and residing in module object.
The equality relation between objects is expected to obey certain invariants, and object.opEquals(‹lhs›, ‹rhs›) goes a long way toward ensuring correctness. First, null references must compare equal. Then, for any three non-null references x, y, and z, the following assertions must hold true:
// The null reference is singular; no non-null object equals null
assert(x != null);
// Reflexivity
assert(x == x);
// Symmetry
assert((x == y) == (y == x));
// Transitivity
if (x == y && y == z) assert(x == z);
// Relationship with toHash
if (x == y) assert(x.toHash() == y.toHash());
A more subtle requirement of opEquals is consistency: evaluating equality twice against the same references without an intervening mutation to the underlying objects must return the same result.
The typical implementation of object.opEquals eliminates a few simple or degenerate cases and then defers to the member version. Here’s what object.opEquals may look like:
// Inside system module object.d
bool opEquals(Object lhs, Object rhs) {
// If aliased to the same object or both null => equal
if (lhs is rhs) return true;
// If either is null => non-equal
if (lhs is null || rhs is null) return false;
// If same exact type => one call to method opEquals
if (typeid(lhs) == typeid(rhs)) return lhs.opEquals(rhs);
// General case => symmetric calls to method opEquals
return lhs.opEquals(rhs) && rhs.opEquals(lhs);
}
First, if the two references refer to the same object or are both null, the result is trivially true (ensuring reflexivity). Then, once it is established that the objects are distinct, if one of them is null, the comparison result is false (ensuring singularity of null). The third test checks whether the two objects have exactly the same type and, if they do, defers to lhs.opEquals(rhs). And a more interesting part is the double evaluation on the last line. Why isn’t one call enough?
Recall the initial—and slightly cryptic—description of the opEquals method: “returns true if this considers that rhs is equal to it.” The definition cares only about this but does not gauge any opinion rhs may have. To get the complete agreement, a handshake must take place—each of the two objects must respond affirmatively to the question: Do you consider that object your equal? Disagreements about equality may appear to be only an academic problem, but they are quite common in the presence of inheritance, as pointed out by Joshua Bloch in his book Effective Java [9] and subsequently by Tal Cohen in an article [17]. Let’s restate that argument.
Getting back to an example related to graphical user interfaces, consider that you define a graphical widget that could sit on a window:
class Rectangle { ... }
class Window { ... }
class Widget {
private Window parent;
private Rectangle position;
... // Widget-specific functions
}
Then you define a class TextWidget, which is a widget that displays some text.
How do we implement opEquals for these two classes? As far as Widget is concerned, another Widget that has the same state is equal:
// Inside class Widget
override bool opEquals(Object rhs) {
// The other must be a Widget
auto that = cast(Widget) rhs;
if (!that) return false;
// Compare all state
return parent == that.parent
&& position == that.position;
}
The expression cast(Widget) rhs attempts to recover the Widget from rhs. If rhs is null or rhs’s actual, dynamic type is not Widget or a subclass thereof, the cast expression returns null.
The TextWidget class has a more discriminating notion of equality because the right-hand side of the comparison must also be a TextWidget and carry the same text.
// Inside class TextWidget
override bool opEquals(Object rhs) {
// The other must be a TextWidget
auto that = cast(TextWidget) rhs;
if (!that) return false;
// Compare all relevant state
return super.opEquals(that) && text == that.text;
}
Now consider a TextWidget tw superimposed on a Widget w with the same position and parent window. As far as w is concerned, tw is equal to it. But from tw’s viewpoint, there is no equality because w is not a TextWidget. If we accepted that w == tw but tw != w, that would break reflexivity of the equality operator. To restore reflexivity, let’s consider making TextWiget less strict: inside TextWidget.opEquals, if comparison is against a Widget that is not a TextWidget, the comparison just agrees to go with Widget’s notion of equality. The implementation would look like this:
// Alternate TextWidget.opEquals -- BROKEN
override bool opEquals(Object rhs) {
// The other must be at least a Widget
auto that = cast(Widget) rhs;
if (!that) return false;
// Do they compare equal as Widgets? If not, we're done
if (!super.opEquals(that)) return false;
// Is it a TextWidget?
auto that2 = cast(TextWidget) rhs;
// If not, we're done comparing with success
if (!that2) return true;
// Compare as TextWidgets
return text == that.text;
}
Alas, TextWidget’s attempts at being accommodating are ill advised. The problem is that now transitivity of comparison is broken: it is easy to create two TextWidgets tw1 and tw2 that are different (by containing different texts) but at the same time equal with a simple Widget object w. That would create a situation where tw1 == w and tw2 == w, but tw1 != tw2.
So in the general case, comparison must be carried out both ways—each side of the comparison must agree on equality. The good news is that the free function object.opEquals(Object, Object) avoids the handshake whenever the two involved objects have the same exact type, and even any other call in a few other cases.
6.8.4 int opCmp(Object rhs)
This implements a three-way ordering comparison, which is needed for using objects as keys in associative arrays. It returns an unspecified negative number if this is less than rhs, an unspecified positive number if rhs is less than this, and 0 if this is considered unordered with rhs. Similarly to opEquals, opCmp is seldom called explicitly. Most of the time, you invoke it implicitly by using one of a < b, a <= b, a > b, and a >= b.
The rewrite follows a protocol similar to opEquals, by using a global object.opCmp definition that intermediates communication between the two involved objects. For each of the operators <, <=, >, and >=, the D compiler rewrites the expression a ‹op› b as object.opCmp(a, b)‹op› 0. For example, a < b becomes object.opCmp(a, b) < 0.
Implementing opCmp is optional. The default implementation Object.opCmp throws an exception. In case you do implement it, opCmp must be a “strict weak order,” that is it must satisfy the following invariants for any non-null references x, y, and z.
// 1. Reflexivity
assert(x.opCmp(x) == 0);
// 2. Transitivity of sign
if (x.opCmp(y) < 0 && y.opCmp(z) < 0) assert(x.opCmp(z) < 0);
// 3. Transitivity of equality with zero
if ((x.opCmp(y) == 0 && y.opCmp(z) == 0) assert(x.opCmp(z) == 0);
The rules above may seem a bit odd because they express axioms in terms of the less familiar notion of three-way comparison. If we rewrite them in terms of <, we obtain the familiar properties of strict weak ordering in mathematics:
// 1. Irreflexivity of '<'
assert(!(x < x));
// 2. Transitivity of '<'
if (x < y && y < z) assert(x < z);
// 3. Transitivity of '!(x < y) && !(y < x)'
if (!(x < y) && !(y < x) && !(y < z) && !(z < y))
assert(!(x < z) && !(z < x));
The third condition is necessary for making < a strict weak ordering. Without it, < is called a partial order. You might get away with a partial order, but only for restricted uses; most interesting algorithms require a strict weak ordering. If you want to define a partial order, you’re better off giving up all syntactic sugar and defining your own named functions distinct from opCmp.
Note that the conditions above focus only on < and not on the other ordering comparisons because the latter are just syntactic sugar (x > y is the same as y < x, x <= y is the same as !(y > x), and so on).
One property that derives from irreflexivity and transitivity, but is sometimes confused with an axiom, is antisymmetry: x < y implies !(y < x). It is easy to verify by reductio ad absurdum that there can never be x and y such that x < y and y < x are simultaneously true: if that were the case, we could replace z with x in the transitivity of < above, obtaining
The tested condition is true by the hypothesis, so the assert will be checked. But it can never pass because of irreflexivity, thus contradicting the hypothesis.
In addition to the restrictions above, opCmp must be consistent with opEquals:
The relationship with opEquals is relaxed: it is possible to have classes for which x <= y and y <= x are simultaneously true, so common sense would dictate they are equal. However, it is not necessary that x == y. A simple example would be a class that defines equality in terms of case-sensitive string matching, but ordering in terms of case-insensitive string matching.
6.8.5 static Object factory(string className)
This is an interesting method that allows you to create an object given the name of its class. The class involved must accept construction without arguments; otherwise, factory throws an exception. Let’s give factory a test drive.
// File test.d
import std.stdio;
class MyClass {
string s = "Hello, world!";
}
void main() {
// Create an Object
auto obj1 = Object.factory("object.Object");
assert(obj1);
// Now create a MyClass
auto obj2 = cast(MyClass) Object.factory("test.MyClass");
writeln(obj2.s); // Writes "Hello, world!"
// Attempting factory against nonexistent classes returns null
auto obj3 = Object.factory("Nonexistent");
assert(!obj3);
}
Having the ability to create an object from a string is very useful for a variety of idioms, such as the Factory design pattern [27, Chapter 23] and object serialization. On the face of it, there’s nothing wrong with
However, it is possible that later on you will change your mind and decide a derived class TextWidget is better for the task at hand, so you need to change the code above to
The problem is that you need to change the code. Doing surgery on code for new functionality is bad because it is liable to break existing functionality. Ideally you’d only need to add code to add functionality, thus remaining confident that existing code continues to work as usual. That’s when overridable functions are most useful—they allow you to customize code without actually changing it, by tweaking specific and well-defined customization points. Meyer nicely dubbed this notion the Zen-sounding Open/Closed Principle [40]: a class (and more generally a unit of encapsulation) should be open for extension, but closed for modification. The new operator works precisely against all that because it requires you to change the initializer of w if you want to tweak its behavior. A better solution would be to pass the name of the class to be created from the outside, thus decoupling widgetize from the choice of the exact widget to use:
void widgetize(string widgetClass) {
Widget w = cast(Widget) Object.factory(widgetClass);
... use w ...
}
Now widgetize is relieved of the responsibility for choosing which concrete Widget to use. There are some other ways of achieving flexible object construction that explore the design space in different directions. For a thorough discussion of the matter, you may want to peruse the dramatically entitled “Java’s new considered harmful” [4].
6.9 Interfaces
Most often, class objects contain state and define methods that work with that state. As such, a given object acts at the same time as an interface to the outside world (through its public methods) and as an encapsulated implementation of that interface.
Sometimes, however, it is very useful to separate the notion of interface from that of implementation. Doing so is particularly useful when you want to define communication among various parts of a large program. A function trying to operate on a Widget is solely preoccupied with Widget’s interface—Widget’s implementation is irrelevant by the very definition of encapsulation. This brings to the fore the notion of a completely abstract interface, consisting only of the methods that a class must implement, but devoid of any implementation. That entity is called an interface.
D’s interface definitions look like restricted class definitions. In addition to replacing the keyword class with interface, an interface definition needs to obey certain restrictions. You cannot define any non-static data in an interface, and you cannot specify an implementation for any overridable function. It is legal to define static data and final functions with implementation inside an interface. For example:
interface Transmogrifier {
void transmogrify();
void untransmogrify();
final void thereAndBack() {
transmogrify();
untransmogrify();
}
}
This is everything a function using Transmogrifier needs to compile. For example:
void aDayInLife(Transmogrifier device, string mood) {
if (mood == "play") {
device.transmogrify();
play();
device.untransmogrify();
} else if (mood == "experiment") {
device.thereAndBack();
}
}
Of course, given that at the moment there is no definition for Transmogrifier’s primitives, there is no sensible way to call aDayInLife. So let’s create an implementation of the interface:
class CardboardBox : Transmogrifier {
override void transmogrify() {
// Get in the box
...
}
override void untransmogrify() {
// Get out of the box
...
}
}
The implementation of an interface uses the same syntax as regular inheritance. With a CardboardBox at hand, we can now issue a call such as
Any implementation of an interface is a subtype of that interface, so it converts automatically to it. We used that by simply passing a CardboardBox object in lieu of the Transmogrifier expected by aDayInLife.
6.9.1 The Non-Virtual Interface (NVI) Idiom
One presence that may seem unfamiliar is the final function in the Transmogrifier interface. What happened to waxing poetic about abstract, unimplemented functionality? If the interface is abstract, it behooves it to define no implementation.
In 2001, Herb Sutter wrote an article [52] that put forward an interesting observation, which he later resumed in a book [55, Item 39]. Overridable methods defined by an interface (such as transmogrify and untransmogrify in our example) fulfill a double role. First, they are elements of the interface itself, that is, what calling code uses in order to get things done. Second, such methods are also customization points because that’s what inheriting classes define directly. It may be useful, Sutter argued, to distinguish between the two categories: an interface may define some low-level abstract methods that are to be implemented later, plus higher-level, visible, non-overridable methods that client code may use. The two sets may or may not overlap, but it would be a net loss to consider them equal.
There are many benefits to making a distinction between what the client sees and what the implementor defines. The approach allows you to design interfaces that are at the same time implementation-friendly and client-friendly. An interface that conflates the needs of the implementation and the needs of clients must compromise between serving the needs of the two. Too much focus on implementation leads to overly pedestrian, verbose, and low-level interfaces that invite code duplication in client code, whereas too much focus on client code leads to large, loose, redundant interfaces that specify convenience functions in addition to essential primitives. With the Non-Virtual Interface (NVI) idiom, you can afford to make life easier for both. For example, Transmogrifier.thereAndBack offers callers a convenience function that is specified in terms of primitive operations.
The then-nascent idiom was in keeping with the Template Method pattern that prescribes fixed high-level operations with customized intermediate steps, but it seemed particular enough to receive its own name, which came out to be Non-Virtual Interface (NVI). Unfortunately, although NVI has since become a widely used pattern, it has remained a convention among good designers more than a language-assisted means to enforce design consistency. Language support for NVI has been lacking, mostly because the definition of some popular OOP languages has predated (and conditioned) the better understanding of OOP design that led to NVI. So Java does not support NVI at all, C# supports it scarcely (yet uses it extensively as a design guideline), and C++ allows good convention-helped support but, however, no strong guarantees to callers or implementors.
D fully supports NVI by providing specific guarantees when interfaces use access specifiers. Consider, for example, that the author of Transmogrifier is worried about incorrect use—what if people call transmogrify and then forget to untransmogrify? Let’s expose only thereAndBack to clients, while still requiring implementations to define transmogrify and untransmogrify:
interface Transmogrifier {
// Client interface
final void thereAndBack() {
transmogrify();
untransmogrify();
}
// Implementation interface
private:
void transmogrify();
void untransmogrify();
}
The Transmogrifier interface made the two primitives private. This setup makes for a very interesting design: a class that implements Transmogrifier must define transmogrify and untransmogrify but is unable to call them. In fact, nobody outside Transmogrifier’s module could ever call the two primitives. The only way to call them is indirectly, by using the high-level routine thereAndBack, which is the very point of the design: well-defined access points and a well-structured flow around the calls through said access points. The language thwarts casual attempts at breaking this guarantee. For example, an implementing class may not relax the protection level of transmogrify and untransmogrify:
class CardboardBox : Transmogrifier {
override private void transmogrify() { ... } // Fine
override void untransmogrify() { ... } // Error!
// Cannot change protection of untransmogrify
// from private to public!
}
Of course, since after all it’s your implementation, you can make a primitive public if you so want, but you’d have to give it a different name:
class CardboardBox : Transmogrifier {
override private void transmogrify() { ... } // Fine
override private void untransmogrify() { // Fine
doUntransmogrify();
}
override void doUntransmogrify() { ... } // Fine
}
Now users of CardboardBox can call doUntransmogrify, which does the same thing as untransmogrify. But the important point is that void untransmogrify() with that specific name and signature could not be directly exposed by an implementing class. So client code would never access the private functionality specified under the private name. If an implementation wishes to define and document an alternate function, that’s its decision.
A second way in which D enforces consistency of NVI is by disabling hijacking of final methods: no implementor of Transmogrifier can define a method that effectively hijacks thereAndBack. For example:
class Broken : Transmogrifier {
void thereAndBack() {
// Why not do it twice?
this.Transmogrifier.thereAndBack();
this.Transmogrifier.thereAndBack();
}
// Error! Cannot hijack final method Transmogrifier.thereAndBack
...
}
If such hiding were allowed, a client with knowledge that Broken implements Transmogrifier cannot assuredly call obj.thereAndBack() against an obj of type Broken; there would be no confidence that thereAndBack does what it is supposed to do as prescribed and documented by Transmogrifier. Of course, client code could call obj.Transmogrifier.thereAndBack() to make sure that the call is routed properly, but such attention-driven designs are never too appealing. After all, a good design doesn’t wait for you to lower your guard to strike you with puzzling behavior. Bottom line—if an interface defines a public function, that stays visible as it is through all of its implementations. If the implementation is also final, there is no way for an implementing class to intercept such a call to it. An implementation, however, could define a function with the same name as long as there is no potential conflict. For example:
class Good : Transmogrifier {
void thereAndBack(uint times) {
// Why not do it multiple times?
foreach (i; 0 .. times) {
thereAndBack();
}
}
...
}
The case above is allowed because there is never a risk of confusion: a call is either spelled as obj.thereAndBack() and goes to Transmogrify.thereAndBack, or as obj.thereAndBack(n) and goes to Good.thereAndBack. To wit, the implementation of Good.thereAndBack does not need to qualify its internal call to the homonym interface function.
6.9.2 protected Primitives
Making an overridable function private in an interface is sometimes more restrictive than needed. For example, it prevents an implementation from calling the super function, as shown here:
class CardboardBox : Transmogrifier {
private:
override void transmogrify() { ... }
override void untransmogrify() { ... }
}
class FlippableCardboardBox : CardboardBox {
private:
bool flipped;
override void transmogrify() {
enforce(!flipped, "Can't transmogrify: "
"box is in time machine mode");
super.transmogrify(); // Error! Cannot invoke private
// method CardboardBox.transmogrify!
}
}
When the cardboard box is flipped, it can’t function as a transmogrifier—as we all know, in that case it’s a boring ol’ time machine. FlippableCardboardBox enforces that fact, but on the normal path it is unable to call its parent’s version. What to do?
One solution would be to use the renaming trick illustrated above with doUntransmogrify, but that gets repetitive if you need to do it for several methods. A simpler solution is to relax the access of the two overridables in Transmogrifier from private to protected:
interface Transmogrifier {
final void thereAndBack() { ... }
protected:
void transmogrify();
void untransmogrify();
}
With protected access, an implementation is now able to call its parent’s implementation. Note that strengthening protection is also illegal. If an interface defined a method, an implementation cannot lay stronger protection claims on that method. For example, given the Transmogrifier that defines both transmogrify and untransmogrify as protected, this code would be in error:
class BrokenInTwoWays {
public void transmogrify() { ... } // Error!
private void untransmogrify() { ... } // Error!
}
It would be technically feasible to allow both relaxation and strengthening of an interface’s requirements in an implementation, but that would hardly serve any good design purposes. An interface expresses an intent, and a reader should only absorb the definition of the interface to fully use it, whether or not the static type of the implementor is available.
6.9.3 Selective Implementation
It is sometimes possible that two interfaces define ambiguous public final methods:
interface Timer {
final void run() { ... }
...
}
interface Application {
final void run() { ... }
...
}
class TimedApp : Timer, Application {
... // Cannot define run()
}
In cases like these, TimedApp is unable to define its own run() because it would actually hijack two methods, and in all likelihood two hijacks are worse than one. Eliminating one final in either Timer or Application would not help the situation because one hijack remains active. If both were non-final, we’re in good shape—TimedApp.run implements Timer.run and Application.run simultaneously.
To access those methods for app of type TimedApp, you’d have to write app.Timer.run() and app.Application.run() for Timer’s and Application’s version, respectively. TimedApp could define its own functions that forward to these as long as they do not hijack run().
6.10 Abstract Classes
Often, a base class is unable to provide any sensible implementation for some or all of its methods. A thought would be to convert that class to an interface, but sometimes it would be very helpful to have that class define some state and non-final methods, privileges not allowed to interfaces. Here’s where abstract classes come to the rescue: they are almost like regular classes, with the liberty to leave functions unimplemented by declaring them using the abstract keyword as prefix.
As illustration, consider the time-honored example featuring a hierarchy of shape objects that participate in a vector-oriented drawing program. The hierarchy is rooted in class Shape. Any shape has a bounding rectangle, so Shape may want to define it as a member variable (something that an interface would not be able to do). On the other hand, Shape must leave some methods, such as draw, undefined because it is unable to implement them sensibly. Those methods are supposed to be implemented by Shape’s descendants.
class Shape {
protected Rectangle _bounds;
abstract void draw();
bool overlaps(Shape that) {
return _bounds.left <= that._bounds.right &&
_bounds.right >= that._bounds.left &&
_bounds.top <= that._bounds.bottom &&
_bounds.bottom >= that._bounds.top;
}
}
Method draw is abstract, which means three things. First, the compiler does not expect that Shape implements draw. Second, the compiler disallows instantiation of Shape. Third, the compiler disallows instantiation of any descendant of Shape that does not implement (directly or indirectly in an ancestor) the draw method. The “directly or indirectly” part means that the implementation requirement is not transitive; for example, if you define a class RectangularShape inheriting Shape that implements draw, you are not required to reimplement it in RectangularShape’s descendants.
If the compiler does not expect an implementation for an abstract method, that doesn’t mean you can’t provide one if you so wish. You could provide, for example, an implementation for Shape.draw. Clients can call it by explicitly qualifying the call as in this.Shape.draw().
The overlaps method is at the same time implemented and overridable, an interesting detail. By default, overlaps approximates the intersection of two shapes as the intersection of their bounding rectangles. This is inaccurate for most non-rectangular shapes; for example, two circles may not overlap, even though their bounding boxes do.
A class that has at least one abstract method is itself called an abstract class. If class RectangularShape inherits abstract class Shape without overriding all of Shape’s abstract methods, RectangularShape is also abstract and passes the requirement of implementing those abstract methods down to RectangularShape’s descendants. In addition, RectangularShape is allowed to introduce new abstract methods. For example:
class Shape {
// As above
abstract void draw();
...
}
class RectangularShape : Shape {
// Inherits one abstract method from Shape
// and introduces one more
abstract void drawFrame();
}
class Rectangle : RectangularShape {
override void draw() { ... }
// Rectangle is still an abstract class
}
class SolidRectangle : Rectangle {
override void drawFrame() { ... }
// SolidRectangle is concrete:
// no more abstract functions to implement
}
Most interestingly, a class may decide to reintroduce a function as abstract, even though it was previously overriden and implemented! The code below introduces an abstract class, derives a concrete class from it, and then derives an abstract class from the concrete class, all on account on a single method.
class Abstract {
abstract void fun();
}
class Concrete : Abstract {
override void fun() { ... }
}
class BornAgainAbstract : Concrete {
abstract override void fun();
}
You can finalize an implementation of an abstract method . . .
class UltimateShape : Shape {
// This is the last word about method draw
override final void draw() { ... }
}
... but for obvious reasons you can’t define a method that is at the same time abstract and final.
If you want to introduce a bunch of abstract methods, you can reuse the abstract keyword in a manner similar to a protection specifier (§ 6.7.1 on page 200):
class QuiteAbstract {
abstract {
// Everything in this scope is abstract
void fun();
int gun();
double hun(string);
}
}
There’s no way to turn off abstract inside an abstract scope, so this definition is incorrect:
class NiceTry {
abstract {
void fun();
final int gun(); // Error!
// Cannot define a final abstract function!
}
}
You can use abstract as a label:
class Abstractissimo {
abstract:
// Everything below is abstract
void fun();
int gun();
double hun(string);
}
Once you introduce abstract:, it’s impossible to turn it off.
Finally, you can label an entire class as abstract:
abstract class AbstractByName {
void fun() {}
int gun() {}
double hun(string) {}
}
In light of the crescendo of abstract uses above, it might appear that making an entire class abstract really pulls the big guns by making every single method in that class abstract. Nope. That would actually be too coarse to be of any use. What abstract does in front of a class is to simply prevent client code from instantiating it—you can instantiate only non-abstract classes derived from it. Continuing the AbstractByName example above:
unittest {
auto obj = new AbstractByName; // Error! Cannot instantiate
// Abstract class AbstractByName!
}
class MakeItConcrete : AbstractByName {
}
unittest {
auto obj = new MakeItConcrete; // OK
}
6.11 Nested Classes
Nested classes are an interesting feature that deserves special attention. They are useful as building blocks for important idioms, such as multiple subtyping (discussed in the next section).
A class may define another class right inside of it:
class Outer {
int x;
void fun(int a) { ... }
// Define an inner class
class Inner {
int y;
void gun() {
fun(x + y);
}
}
}
A nested class is just an ordinary . . . wait a minute! How come Inner.gun has access to Outer’s non-static member variables and methods? If Outer.Inner were simply a classic class definition scoped inside Outer, it could not possibly fetch data and call methods of the Outer object. In fact, where does that object come from? Let’s just create an object of type Outer.Inner and see what happens:
unittest {
// Nagonna work
auto obj = new Outer.Inner;
obj.gun(); // This should crash the world because there's no
// Outer.x or Outer.fun in sight - there's no Outer at all!
}
Since this code creates only an Outer.Inner but not an Outer, the only allocated data is whatever Outer.Inner defines (i.e., y) but not what Outer defines (i.e., x).
However, surprisingly, the class definition does compile, and the unittest does not. What is happening?
First off, you can never create an Inner object without an Outer object, a limitation that makes a lot of sense since Inner has magical access to Outer’s state and methods. Here’s how you correctly create an Outer.Inner object:
unittest {
Outer obj1 = new Outer;
auto obj = obj1.new Inner; // Aha!
}
The very syntax of new is indicative of what’s happening: creating an object of type Outer.Inner necessitates the preexistence of an object of type Outer. A reference to that object (in our case obj1) is surreptitiously stored in the Inner object as a language-defined property called outer. Then, whenever you use a member of Outer such as x, the access is rewritten as this.outer.x. Initialization of the hidden back reference stored in the inner object occurs right before that inner object’s constructor gets called, so the constructor itself has immediate access to the outer object’s members. Let’s actually test all that by making a few changes to the Outer/Inner example:
class Outer {
int x;
class Inner {
int y;
this() {
x = 42;
// x or this.outer.x are the same thing
assert(this.outer.x == 42);
}
}
}
unittest {
auto outer = new Outer;
auto inner = outer.new Inner;
assert(outer.x == 42); // inner changed outer
}
If you create the Outer.Inner object from within a non-static member function of Outer, there is no need to prefix the new expression with this. because that’s implicit. For example:
class Outer {
class Inner { ... }
Inner _member;
this() {
_member = new Inner; // Same as this.new Inner
assert(_member.outer is this); // Check the link
}
}
6.11.1 Classes Nested in Functions
Nesting a class inside a function works surprisingly similarly to nesting a class inside another class. A class planted inside a function can access that function’s parameters and local variables:
void fun(int x) {
string y = "Hello";
class Nested {
double z;
this() {
// Access to parameter
x = 42;
// Access to local variable
y = "world";
// Access to own members
z = 0.5;
}
}
auto n = new Nested;
assert(x == 42);
assert(y == "world");
assert(n.z == 0.5);
...
}
Classes nested inside functions are particularly useful when you have a function that returns a class type and you want to inherit that type and tweak its behavior. Consider:
class Calculation {
double result() {
double n;
...
return n;
}
}
Calculation truncate(double limit) {
assert(limit >= 0);
class TruncatedCalculation : Calculation {
override double result() {
auto r = super.result();
if (r < -limit) r = -limit;
else if (r > limit) r = limit;
return r;
}
}
return new TruncatedCalculation;
}
The truncate function overrides the result method of a Calculation class to truncate it within limits. There’s a very subtle aspect to the workings of truncate: note how the override of result uses the limit parameter. That’s not too odd as long as TruncatedCalculation is used within truncate, but truncate returns a TruncatedCalculation to the outside world. A simple question would be: Where does limit lie after truncate returns? Normally a function’s parameters and local variables live on the stack and disappear when the function returns. In this case limit gets used after truncate has long returned, so limit had better sit somewhere; otherwise, the entire code would fall apart by unsafely accessing disposed stack memory.
The example does work properly, with a little help from the compiler. Whenever compiling a function, the compiler searches and detects non-local escapes—situations when a parameter or a local variable remains in use after the function has returned. If such an escape is detected, the compiler switches that function’s allocation of local state (parameters plus local variables) from stack allocation to dynamic allocation. That way the limit parameter of truncate successfully survives the return of truncate and can be used by TruncatedCalculation.
6.11.2 static Nested Classes
Let’s face it: nested classes are not quite what they seem to be. They would appear to simply be regular classes defined inside classes or functions, but they clearly aren’t regular: the particular new syntax and semantics, the magic .outer property, the modified lookup rules—nested classes are definitely unlike regular classes.
What if you do want to define a bona fide class inside another class or in a function? Overuse of the static keyword comes to the rescue: just prefix the class definition with static. For example:
class Outer {
static int s;
int x;
static class Ordinary {
void fun() {
writeln(s); // Fine, access to static value is allowed
writeln(x); // Error! Cannot access non-static member x!
}
}
}
unittest {
auto obj = new Outer.Ordinary; // Fine
}
A static inner class being just a regular class, it does not have access to the outer object simply because there isn’t any. However, by virtue of its scoping, the static inner class does have access to the static members of the enclosing class.
6.11.3 Anonymous Classes
A class definition that omits the name and the : in its superclass specification introduces an anonymous class. Such classes must always be nested (non-statically) inside functions, and the only use you can make of them is to create a new one right away:
class Widget {
abstract uint width();
abstract uint height();
}
Widget makeWidget(uint w, uint h) {
return new class Widget {
override uint width() { return w; }
override uint height() { return h; }
...
};
}
The feature works a lot like anonymous functions. Creating an anonymous class is equivalent to creating a new named class and then instantiating it. The two steps are merged into one. This may seem an obscure feature with minor savings, but it turns out many designs use it extensively to connect observers to subjects [7].
6.12 Multiple Inheritance
D models single inheritance of classes and multiple inheritance of interfaces. This is a stance similar to Java’s and C#’s, but different from the path that languages such as C++ and Eiffel took.
An interface can inherit any number of interfaces. Since it is unable to implement any overridable function, an inheriting interface is simply an enhanced interface that requires the sum of primitives of its base interfaces, plus potentially some of its own. Consider:
interface DuplicativeTransmogrifier : Transmogrifier {
Object duplicate(Object whatever);
}
The interface DuplicativeTransmogrifier inherits Transmogrifier, so anyone implementing DuplicativeTransmogrifier must also implement all of Transmogrifier’s primitives, in addition to the newly introduced duplicate. The inheritance relationship works as expected—you can pass around a DuplicativeTransmogrifier wherever a Transmogrifier is expected, but not vice versa.
Generally, an interface may inherit any number of interfaces, with the expected accumulation of required primitives. Also, a class may implement any number of interfaces. For example:
interface Observer {
void notify(Object data);
...
}
interface VisualElement {
void draw();
...
}
interface Actor {
void nudge();
...
}
interface VisualActor : Actor, VisualElement {
void animate();
...
}
class Sprite : VisualActor, Observer {
void draw() { ... }
void animate() { ... }
void nudge() { ... }
void notify(Object data) { ... }
...
}
Figure 6.4 on the next page displays the inheritance hierarchy coded above. Interfaces are encoded as ovals, and classes are encoded as rectangles.
Figure 6.4. A simple inheritance hierarchy featuring multiple inheritance of interfaces.
Let’s now define a class Sprite2. Sprite2’s author has forgotten that VisualActor is an Actor, so Sprite2 inherits Actor directly in addition to Observer and VisualActor. Figure 6.5 on the following page shows the resulting hierarchy.
Figure 6.5. An inheritance hierarchy featuring a redundant path (in this case the link from Sprite2 to Actor). Redundant paths are not a liability, but eliminating them is often trivial and leads to a cleaner design and a reduction in object size.
A redundant path in a hierarchy is immediately recognizable as a direct connection with an interface that you also inherit indirectly. Redundant paths do not pose particular problems, but in most implementations they add to the size of the final object, in this case Sprite2.
There are cases in which you inherit the same interface through two paths, but it’s impossible to remove either of the paths. Consider that we first add an ObservantActor interface that inherits Observer and Actor:
interface ObservantActor : Observer, Actor {
void setActive(bool active);
}
interface HyperObservantActor : ObservantActor {
void setHyperActive(bool hyperActive);
}
Then we define Sprite3 to implement ObservantActor and VisualActor:
class Sprite3 : HyperObservantActor, VisualActor {
override void notify(Object) { ... }
override void setActive(bool) { ... }
override void setHyperActive(bool) { ... }
override void nudge() { ... }
override void animate() { ... }
override void draw() { ... }
...
}
This setup changes things quite a bit (Figure 6.6). If Sprite3 wants to implement both HyperObservantActor and VisualActor, it ends up implementing Actor twice, through different paths, and there is no way to eliminate that. Fortunately, however, the compiler does not have a problem with that—repeated inheritance of the same interface is allowed. However, repeated inheritance of the same class is not allowed, and for that reason D disallows any multiple inheritance of classes altogether.
Figure 6.6. A hierarchy with multiple paths between nodes (in this case Sprite3 and Actor). This setup is usually known as a “diamond inheritance hierarchy” because, in the absence of HyperObservantActor, the two paths between Sprite3 and Actor would describe a diamond shape. In the general case, such hierarchies may have a variety of shapes. The indicative feature is the presence of multiple indirect paths from one node to another.
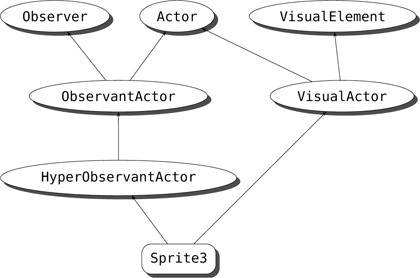
Why the discrimination? What is so special about interfaces that makes them more amenable to multiple inheritance than classes? The full explanation would be quite elaborate, but in short, the essential difference between an interface and a class is that the latter may contain state. More to the point, a class may contain modifiable state. In contrast, an interface does not hold its own state; there is some bookkeeping associated with each implemented interface (in many implementations, a pointer to a “virtual table”—an array of pointers to functions) but that pointer is identical for all occurrences of an interface inside a class, never changes, and is under the compiler’s control. Taking advantage of these restrictions, the compiler actually plants multiple copies of that bookkeeping information in the class, but the class could never tell.
Historically, there has been a huge amount of debate about the merits and demerits of multiple inheritance. That debate has not converged and probably won’t converge any time soon, but one thing that is generally agreed upon is that it’s difficult to implement multiple inheritance in a way that’s at the same time simple, efficient, and useful. Some languages do not have efficiency as a prime concern so they opt for the extra expressiveness brought about by multiple inheritance. Some others want to achieve some basic performance premises, such as contiguous objects or rapid function dispatch, and consequently limit the flexibility of possible designs. One interesting design that shares most advantages of multiple inheritance without its woes is Scala’s mixins, which essentially are interfaces packaged with default implementations. D’s approach is to allow multiple subtyping—that is, subtyping without inheritance. Let’s see how that works.
6.13 Multiple Subtyping
Let’s continue building on the Shape example and say we’d like to define Shape objects that can be stored in a database. We find a beautifully crafted database persistence library that seems to suit our purposes very well, with only one small hitch—it requires each storable object to inherit a class called DBObject.
class DBObject {
private:
... // State
public:
void saveState() { ... }
void loadState() { ... }
...
}
This situation could be modeled in a number of ways, but let’s face it—if language limitations were not an issue, a quite natural approach would be to define a class StorableShape that “is a” Shape and a DBObject at the same time. The shapes hierarchy would be rooted in StorableShape. Then, when you need to draw a StorableShape, it would look and feel like a Shape; when you want to maneuver it in and out of a database, it will behave like a DBObject all right. That would mean multiple inheritance of classes, which is verboten in D, so we need to look for alternative solutions.
Fortunately, the language comes to the rescue with a general and very useful mechanism: multiple subtyping. A class can specify that it is a subtype of any other class, without needing to inherit from it. All you’d need to do is specify an alias this declaration. The simplest example would go like this:
class StorableShape : Shape {
private DBObject _store;
alias _store this;
this() {
_store = new DBObject;
}
...
}
StorableShape inherits and “is a” Shape, but is also a DBObject. Whenever conversion from StorableShape to DBObject is requested, or whenever a member of StorableShape is looked up, the member _store also has a say in the matter. Requests that match DBObject are automatically redirected from this to this._store. For example:
unittest {
auto s = new StorableShape;
s.draw(); // Calls a Shape method
s.saveState(); // Calls a DBObject method
// Gets rewritten as s._store.saveState()
Shape sh = s; // Normal upcast derived -> base
DBObject db = s; // Rewritten as DBObject db = s._store
}
Effectively, a StorableShape is a subtype of DBObject, and the _store member is the DBObject subobject of the StorableShape object.
A class could introduce any number of alias this declarations, thus subtyping any number of types.
6.13.1 Overriding Methods in Multiple Subtyping Scenarios
Things couldn’t be so simple, could they? They aren’t, because StorableShape was cheating all along. Yes, with the alias _store this declaration in tow, a StorableShape is nominally a DBShape, but it cannot directly override any of its methods. Clearly Shape’s methods can be overridden as usual, but where’s the place where DBObject.saveState could be overridden? Returning _store as a pseudo subobject is a copout—in fact, there isn’t much about _store that’s linked to its StorableShape outer object, at least not unless we do something about it. Let’s see what that something consists of.
The exact point where the original StorableShape definition cheated was at the initialization of _store with new DBObject. That completely disconnects the subobject _store from the StorableShape outer object that is supposed to override methods in DBObject. So what we need to do is to define a new class MyDBObject inside StorableShape. That class would store a back reference to the StorableObject outer object and would override whichever methods need overriding. Finally, inside the overriden methods, MyDBObject has access to the full StorableObject, and everything can be done as if full-fledged multiple inheritance were in action. Cool!
If the phrase “outer object” rang a bell from upstream in this chapter, you have noticed one of the most serendipitous occurrences in the annals of computing. Nested classes (§ 6.11 on page 222) fit the need for multiple subtyping so well, you’d think they’re a deus ex machina trick. In fact, nested classes (inspired by Java) predate the alias this feature by years.
Using a nested class makes overriding with alias this extremely simple. All you need to do in this case is define a nested class that inherits DBObject. Inside that class, you override any method of DBObject you wish, and you have full access to DBObject’s public and protected definitions and all definitions of StorableShape. If it were any easier, it’d be illegal in at least a few states.
class StorableShape : Shape {
private class MyDBObject : DBObject {
override void saveState() {
// Access DBObject and StorableShape
...
}
}
private MyDBObject _store;
alias _store this;
this() {
// Here's the crucial point where the link is made
_store = this.new MyDBObject;
}
...
}
Crucially, _store has access to the outer StorableShape object. As discussed in § 6.11 on page 222, creating a nested class will surreptitiously store the outer object (in our case this) inside the nested class. The notation this.new MyDBObject just attempted to make it very clear that this conditions the creation of the new MyDBObject object. (In fact, this., being implicit, is not required in that case.)
The only rub is that members of DBObject would mask members of StorableShape. For example, let’s say both DBObject and Shape defined a member variable called _name:
class Shape {
protected string _name;
abstract void draw();
...
}
class DBObject {
protected string _name;
void saveState() { ... }
void loadState() { ... }
...
}
When using multiple subtyping with class MyDBObject nested inside StorableShape, the member DBObject._name hides StorableShape._name. So if code inside MyDBObject simply uses _name, that will refer to DBObject._name:
class StorableShape : Shape {
private class MyDBObject : DBObject {
override void saveState() {
// Modify Shape._name for the outer Shape object
this.outer._name = "A";
// Modify DBObject._name for the base object
_name = "B";
// Just to make the point clear
assert(super._name == "B");
}
}
private MyDBObject _store;
alias _store this;
this() {
_store = new MyDBObject;
}
...
}
6.14 Parameterized Classes and Interfaces
Sometimes you need to parameterize a class or an interface with a statically known entity. Consider, for example, defining a stack interface. The interface should be parameterized with the type stored in the stack so we avoid duplication (StackInt, StackDouble, StackWidget . . .). To define a parameterized interface in D you go like this:
interface Stack(T) {
@property bool empty();
@property ref T top();
void push(T value);
void pop();
}
The syntax (T) introduces a type parameter to Stack. Inside Stack, you use T as you’d use any type. To use Stack in client code, you need to specify an argument, much as you’d have to pass an argument to a one-parameter function when you call it. You pass the argument by using the binary operator ! like this:
unittest {
alias Stack!(int) StackOfInt;
alias Stack!int SameAsAbove;
...
}
Where there’s only one argument (as is the case with Stack), the parentheses around it can be omitted.
A logical next step would be to implement the interface in a class. The implementation should ideally also be generic (not specialized for a particular element type), so we define a parameterized class StackImpl that takes type parameter T, passes it to Stack, and uses it inside the implementation. Let’s actually implement a stack using an array as back end:
class StackImpl(T) : Stack!T {
private T[] _store;
@property bool empty() {
return _store.empty;
}
@property ref T top() {
assert(!empty);
return _store.back;
}
void push(T value) {
_store ~= value;
}
void pop() {
assert(!empty);
_store.popBack();
}
}
Using StackImpl is as much fun as implementing it:
unittest {
auto stack = new StackImpl!int;
assert(stack.empty);
stack.push(3);
assert(stack.top == 3);
stack.push(5);
assert(stack.top == 5);
stack.pop();
assert(stack.top == 3);
stack.pop();
assert(stack.empty);
}
Once you instantiate a parameterized class, it is a class all right, so StackImpl!int is a class like any other. This particular class implements Stack!int because the cookie cutter StackImpl(T) pasted int in lieu of T everywhere in its definition.
6.14.1 Heterogeneous Translation, Again
Now that we talked about hatching actual types out of parameterized types, let’s take a closer look at instantiation mechanics. We first discussed the notion of heterogeneous translation (as opposed to homogeneous translation) in § 5.3 on page 138, in the context of type-parameterized functions. To recap, in homogeneous translation the language infrastructure adopts a common format for all values (e.g., everything is an Object) and then adjusts generic (type-parameterized) code to that common format under the hood. Adjustments may include casting types back and forth and “boxing” some types to make them obey the common value format, then “unboxing” them when user code asks for them. The process is typesafe and entirely transparent. Java and C# use heterogeneous translation for their parameterized types.
Under a homogeneous approach, all StackImpls for all types would share the same code for their method implementations. More important, there’s no distinction at the type level—the dynamic types of StackImpl!int and StackImpl!double are the same. The translator essentially defines one interface for all Stack!T and one class for all StackImpl!T. These types are called erased types because they erase any T-specific information. Then, the translator skillfully replaces code using Stack and StackImpl with various Ts to use only those erased types. The static information about whatever types client code uses with Stack and StackImpl is not preserved; that information is used for static typechecking and then promptly forgotten—or better put, erased. This process comes with its problems on account of the simple fact that there is some loss of information. A simple example is that you cannot overload a function on Stack!int versus Stack!double—they have the same type. Then there are deeper soundness issues that are discussed and partially addressed in the research literature [14, 1, 49].
A heterogeneous translator (such as C++’s template mechanism) approaches things differently. To a heterogeneous translator, Stack is not a type; it’s a means to create a type. (Extra indirection for the win: a type is a blueprint of a value, and a parameterized type is a blueprint of a type.) Each instantiation of Stack!int, Stack!string, or whatever types you need throughout your application, will generate a distinct type. The heterogeneous translator generates all of these types by copying and pasting Stack’s body while replacing T with whatever type you are using Stack with. This approach is liable to generate more code, but it’s also more powerful because it preserves static type information in full. Besides, given that heterogeneous translation generates specialized code for each case, it may generate faster code.
D uses heterogeneous translation throughout, which means that Stack!int and Stack!double are distinct interfaces, and also that StackImpl!int is a distinct type from StackImpl!double. Apart from originating in the same parameterized type, the types are unrelated. (You could, of course, relate them somehow by, for example, having all Stack instantiations inherit a common interface.) Given that StackImpl generates one battery of methods for each type it’s instantiated with, there is quite some binary code duplication, which is jarring particularly since the generated code may often be, in fact, identical. A clever compiler could merge all of the identical functions into one (at the time of this writing, the official D compiler does not do that, but such merging is a proven technology in the more mature C++ compilers).
A class may have, of course, more than one type parameter, so let’s showcase this with an interesting twist in StackImpl’s implementation. Instead of tying the storage to an array, we could hoist that decision outside of StackImpl. Of all an array’s capabilities, StackImpl uses only empty, back, ~=, and popBack. Let’s then make the container decision an implementation detail of StackImpl:
class StackImpl(T, Backend) : Stack!T {
private Backend _store;
@property bool empty() {
return _store.empty;
}
@property ref T top() {
assert(!empty);
return _store.back;
}
void push(T value) {
_store ~= value;
}
void pop() {
assert(!empty);
_store.popBack();
}
}
6.15 Summary
Classes are the primary mechanism for implementing object-oriented design in D. They consistently use reference semantics and are garbage-collected.
Inheritance is the enabler of dynamic polymorphism. Only single inheritance of state is allowed, but a class may inherit many interface types, which have no state but may define final methods.
Protection rules follow operating system protection (directories and files).
All classes inherit class Object defined in module object provided by the implementation. Object defines a few important primitives, and the module object defines pivotal functions for object comparison.
A class may define nested classes that automatically store a reference to their parent class, and static nested classes that do not.
D fully supports the Non-Virtual-Interface idiom and also a semi-automated mechanism for multiple subtyping.