
Chapter 7. Other User-Defined Types
Much good software can be written by using classes, primitive types, and functions. Classes and functions parameterized with types and values make things even better. But oftentimes it becomes painfully obvious that classes are not the ultimate type abstraction device, for a few reasons.
First, classes obey reference semantics, which may force them to represent many designs poorly and with considerable overhead. An entity as simple as a Point with 2-D or 3-D coordinates becomes practically difficult to model with a class if there are more than a few million of them, which puts the designer in the dreaded position of choosing between good abstraction and reasonable efficiency. Also, in linear algebra, aliasing is a huge hassle. You’d have a difficult time convincing a mathematician or a scientific programmer that assigning two matrices by using a = b should make a and b refer to the same actual matrix instead of making a an independent copy of b. Even a type as simple as an array would incur overhead to model as a class when compared to D’s lean and mean abstraction (Chapter 4). Sure, arrays could be “magic,” but experience has shown time and again that offering many magic types that are unattainable to user code is a frustrating proposition and a sign of poor language design. The payload of an array is two words, so allocating a class object and using an extra indirection would mean large space and time overheads for all of arrays’ primitives. Even a type as simple as int cannot be expressed as a class in a cheap and elegant manner, even if we ignore the issue of operator convenience. A class such as BigInt faces again the issue that a = b does something very different from the corresponding assignment for ints.
Second, classes have an infinite lifetime, which means they make it difficult to model resources with an emphatically finite lifetime and in relatively scarce supply, such as file handles, graphics handles, mutexes, sockets, and such. Dealing with such resources with classes puts a permanent strain on your attention because you must remember to free the encapsulated resources in a timely manner by using a method such as close or dispose. The scope statement (§ 3.13 on page 84) often helps, but it is very useful to encapsulate such scoped semantics once and for all in a type.
Third, classes are a relatively heavy and high-level abstraction mechanism, so they aren’t particularly convenient for expressing lightweight abstractions such as enumerated types or alternate names for a given type.
D wouldn’t be true to form as a system-level programming language if it offered classes as the sole abstraction mechanism. In addition to classes, D has in store structs (value types wielding most of classes’ power, but with value semantics and without polymorphism), enums (lightweight enumerated types and simple constants), unions (low-level overlapped storage for unrelated types), and ancillary type definition mechanisms such as alias. This chapter looks at each of these in turn.
7.1 structs
struct allows defining simple, encapsulated value types. A good model to keep in mind is int: an int value consists of 4 bytes supporting certain operations. There is no hidden state and no indirection in an int, and two ints always refer to distinct values.1 The charter of structs precludes dynamic polymorphism, override for functions, inheritance, and infinite lifetime. A struct is but a glorified int.
Recall that classes have reference semantics (§ 6.2 on page 177), meaning that you always manipulate an object via a reference to it, and that copying references around actually just adds more references to the same object, without duplicating the actual object. In contrast, structs are value types, meaning essentially they behave “like int”: names are stuck to the values they represent, and copying struct values around actually copies entire objects, not only references.
Defining a struct is very similar to defining a class, with the following differences:
structreplacesclass.- Inheritance of classes and implementation of interfaces are not allowed, so a
structcannot specify: BaseType, Interface, and obviously there’s nosuperto refer to inside astruct. overrideis not allowed forstructmethods—all methods arefinal(you may redundantly specifyfinalwith astruct’s method).- You cannot use
synchronizedwith astruct(see Chapter 13). - A
structis not allowed to define the default constructorthis()(an issue that deserves an explanation, to come in § 7.1.3.1 on page 244). - Inside a
structyou can define the postblit constructorthis(this)(we’ll get to that in § 7.1.3.4 on page 245). - The
protectedaccess specifier is not allowed (it would imply there exist derivedstructs).
Let’s define a simple struct:
struct Widget {
// A constant
enum fudgeFactor = 0.2;
// A shared immutable value
static immutable defaultName = "A Widget";
// Some state allocated for each Widget object
string name = defaultName;
uint width, height;
// A static method
static double howFudgy() {
return fudgeFactor;
}
// A method
void changeName(string another) {
name = another;
}
}
7.1.1 Copy Semantics
The few surface differences between structs and classes are consequences of deeper semantic differences. Let’s reenact an experiment we first carried out with classes in § 6.2 on page 177. This time we create a class and a struct containing the same fields, and we experiment with the copy behavior of the two types:
class C {
int x = 42;
double y = 3.14;
}
struct S {
int x = 42;
double y = 3.14;
}
unittest {
C c1 = new C;
S s1; // No new for S: stack allocation
auto c2 = c1;
auto s2 = s1;
c2.x = 100;
s2.x = 100;
assert(c1.x == 100); // c1 and c2 refer to the same object...
assert(s1.x == 42); // ...but s2 is a true copy of s1
}
With struct there are no references that you bind and rebind by using initialization and assignment. Any name of a struct value is associated with a distinct value. Defining auto s2 = s1; copies the entire struct object wholesale, field by field. As discussed, struct objects have value semantics and class object have reference semantics. Figure 7.1 shows the state of affairs after having just defined c2 and s2.
Figure 7.1. Evaluating auto c2 = c1; for a class object c1 and auto s2 = s1; for a struct object s1 has very different effects because of the reference nature of classes and the value nature of structs.
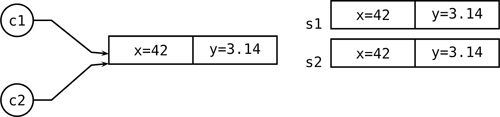
Unlike c1 and c2, which have the ability to bind to any object, s1 and s2 are simply inextricable names given to existing objects. There is no way two names could refer to the same struct object (unless you use alias, which defines simple equivalent symbols; see § 7.4 on page 276) and you cannot have a name without a struct attached to it—the comparison s1 is null is nonsensical and a compile-time error.
7.1.2 Passing struct Objects to Functions
Because of value semantics, struct objects are copied into functions by value.
struct S {
int a, b, c;
double x, y, z;
}
void fun(S s) { // fun receives a copy
...
}
To pass a struct object by reference, use ref arguments (§ 5.2.1 on page 135):
Speaking of ref, this is passed inside the methods of a struct S as a hidden ref S parameter.
7.1.3 Life Cycle of a struct Object
Unlike class objects, struct objects do not have an infinite lifetime. They obey very precise scoped lifetime semantics, akin to the lifetime of transitory function (stack) objects.
To create a struct object, just use its name as you’d use a function:
import std.math;
struct Test {
double a = 0.4;
double b;
}
unittest {
// Use the struct name as a function to create an object
auto t = Test();
assert(t.a == 0.4 && isnan(t.b));
}
Calling Test() creates a struct object with all fields default-initialized. In our case, that means t.a is 0.4 and t.b is left as double.init.
The calls Test(1) and Test(1.5, 2.5) are also allowed and initialize the object’s fields in the order of their declarations. Continuing the previous example:
unittest {
auto t1 = Test(1);
assert(t1.a == 1 && isnan(t1.b));
auto t2 = Test(1.5, 2.5);
assert(t2.a == 1.5 && t2.b == 2.5);
}
The syntactic difference between the expression creating a struct object—Test(‹args›)—and the expression creating a class object—new Test(‹args›)—may be jarring at first. D could have dropped the new keyword entirely when creating class objects, but that new reminds the programmer that a memory allocation operation (i.e., nontrivial work) takes place.
7.1.3.1 Constructors
You may define constructors for structs in a manner similar to class constructors (§ 6.3.1 on page 181):
struct Test {
double a = 0.4;
double b;
this(double b) {
this.b = b;
}
}
unittest {
auto t = Test(5);
}
The presence of at least one constructor disables all of the field-oriented constructors discussed above:
auto t1 = Test(1.1, 1.2); // Error!
// No constructor matches Test(double, double)
static Test t2 = { 0.0, 1.0 }; // Error!
// No constructor matches Test(double, double)
There is an important exception: the compiler always defines the no-arguments constructor.
Also, user code is unable to define the no-arguments constructor:
struct Test {
double a = 0.4;
double b;
this() { b = 0; } // Error!
// A struct cannot define the default constructor!
}
Why this limitation? It all has to do with T.init, the default value that every type defines. T.init must be statically known, which contradicts the existence of a default constructor that executes arbitrary code. (For classes, T.init is the null reference, not a default-constructed object.) For all structs, the default constructor initializes an object with each field default-initialized.
7.1.3.2 Forwarding Constructors
Let’s copy the example from § 6.3.2 on page 183 and change class to struct.
struct Widget {
this(uint height) {
this(1, height); // Defer to the other constructor
}
this(uint width, uint height) {
this.width = width;
this.height = height;
}
uint width, height;
...
}
The code runs without other modification. Just like classes, structs allow one constructor to forward to another, and with the same restrictions.
7.1.3.3 Construction Sequence
Classes need to worry about allocating dynamic memory and initializing their base sub-object (§ 6.3.3 on page 184). Things are considerably simpler for structs because the memory allocation step is not implicit in the construction sequence. The steps taken toward constructing a struct object of type T are
- Copy
T.initover the memory that will contain the object by using raw memory copying (à lamemcpy). - Call the constructor, if applicable.
If some or all of a struct’s fields are initialized with = void, the work in the first step can be reduced, but that is seldom a concern and often just a way to introduce subtle bugs into your code (however, do refer to the Transmogrifier example on page 185 for a plausible case).
7.1.3.4 The Postblit Constructor this(this)
Let’s say we want to define an object that holds a private array inside and exposes a limited API for that array:
struct Widget {
private int[] array;
this(uint length) {
array = new int[length];
}
int get(size_t offset) {
return array[offset];
}
void set(size_t offset, int value) {
array[offset] = value;
}
}
There is a problem with Widget as defined: copying Widget objects creates a long-distance dependency between copies. Consider:
unittest {
auto w1 = Widget(10);
auto w2 = w1;
w1.set(5, 100);
w2.set(5, 42); // Sets w1.array[5] as well!
assert(w1.get(5) == 100); // Fails!?!
}
Where’s the problem? Copying w1 into w2 is “shallow,” that is, field-by-field, without transitively copying whatever memory may be indirectly referenced by each field. Copying an array does not allocate a new array; it only copies the bounds of the array (§ 4.1.4 on page 98). After the copy, w1 and w2 do contain distinct array fields, but they refer to the same region of memory. Such objects that are value types but contain indirect shared references could jokingly be called “clucts”: a hybrid of structs with their value semantics and classes with their reference semantics.2
Oftentimes, structs want to define real value semantics, which means that a copy becomes entirely independent from its source. To do so, define a postblit constructor like this:
struct Widget {
private int[] array;
this(uint length) {
array = new int[length];
}
// Postblit constructor
this(this) {
array = array.dup;
}
// As before
int get(size_t offset) { return array[offset]; }
void set(size_t offset, int value) { array[offset] = value; }
}
A postblit constructor intervenes during object copying. When initializing a struct object tgt from another object src of the same type, the compiler takes the following steps:
- Copy the raw memory of
srcover the memory oftgt. - For each transitive field (i.e., field of field of ...) that defines method
this(this), call it bottom up (innermost fields first). - Call method
this(this)againsttgt.
The name postblit comes from blit, a popular abbreviation of “BLock Transfer,” which meant raw memory copying. The language does the courtesy of raw copying objects upon initialization and offers a hook right after that. In the example above, the postblit constructor takes the now aliased array and makes it into a full-blown copy, ensuring that from here on the source and the target Widget objects have nothing in common. With the postblit constructor in effect, this test now passes:
unittest {
auto w1 = Widget(10);
auto w2 = w1; // this(this) invoked here against w2
w1.set(5, 100);
w2.set(5, 42);
assert(w1.get(5) == 100); // Pass
}
The postblit constructor calls are consistently inserted whenever you copy objects, whether or not a named variable is explicitly created. For example, passing a Widget by value to a function also involves creating a copy.
void fun(Widget w) { // Pass by value
w.set(2, 42);
}
void gun(ref Widget w) { // Pass by reference
w.set(2, 42);
}
unittest {
auto w1 = Widget(10);
w1.set(2, 100);
fun(w1); // A copy is created here
assert(w1.get(2) == 100); // Pass
gun(w1); // No copy
assert(w1.get(2) == 42); // Pass
}
The second step (the part with “transitive field”) of the postblit copy process deserves a special mention. The rationale for that behavior is encapsulation—the postblit constructor of a struct object must be called even when the struct is embedded in another struct object. Consider, for example, that we make Widget a member of another struct, which in turn is a member of yet another struct:
struct Widget2 {
Widget w1;
int x;
}
struct Widget3 {
Widget2 w2;
string name;
this(this) {
name = name ~ " (copy)";
}
}
Now, if you want to copy around objects that contain Widgets, it would be pretty bad if the compiler forgot to properly copy the Widget subobjects. That’s why when copying objects of type Widget2, a call to this(this) is issued for the w subobject, even though Widget2 does not intercept copying at all. Also, when copying objects of type Widget3, again this(this) is invoked for the field w of field w2. To clarify:
unittest {
Widget2 a;
a.w1 = Widget(10); // Allocate some data
auto b = a; // this(this) called for b.w
assert(a.w1.array !is b.w1.array); // Pass
Widget3 c;
c.w2.w1 = Widget(20);
auto d = c; // this(this) for d.w2.w
assert(c.w2.w1.array !is d.w2.w1.array); // Pass
}
In brief, if you define the postblit constructor this(this) for a struct type, the compiler makes sure that the postblit is invoked consistently whenever the object is copied, be it stand-alone or part of a larger struct object.
7.1.3.5 The Whys of this(this)
What was the rationale behind the postblit constructor? There is no precedent for this(this) in other languages. Why not just pass the source object to the target object (the way C++ does it)?
// This is not D
struct S {
this(S another) { ... }
// Or
this(ref S another) { ... }
}
Experience with C++ has shown that excessive copying of objects is a prime source of inefficiency in C++ programs. To mitigate that loss in efficiency, C++ established cases in which calls to the copy constructor could be elided by the compiler. The elision rules have quickly gotten fairly complicated and still do not cover all cases, leaving the problem unsolved. The upcoming C++ standard addresses those issues by defining a new type “rvalue reference,” which allows user-controlled copy elision at the cost of even more language complication.
Because of postblit, D’s approach to copy elision is simple and largely automated. First off, D objects must be relocatable, that is, location-independent: an object can be moved around memory by using raw memory move without its integrity being affected. The restriction, however, means that objects may not embed so-called internal pointers, addresses of sub-parts of the object. This is a technique that is never indispensable, so D simply rules it out. It is illegal to create objects with internal pointers in D, and the compiler and runtime subsystem are free to assume observance of this rule. Relocatable objects give the compiler and the runtime subsystem (for example, the garbage collector) great opportunities to make programs faster and more compact.
With relocatable objects in place, object copying becomes a logical extension of object moving: the postblit constructor this(this) makes copying equivalent to a move plus an optional user-defined hook. That way, user code does not have the opportunity to change the fields of the source object, which is good because copying should not affect the source, but it does have the opportunity to fix up fields that should not indirectly share state with the source object. To elide copies, the compiler is free to not insert the call to this(this) whenever it can prove the source of the copy will not be used after the copying process. Consider, for example, a function that returns a Widget (as defined above) by value:
Widget hun(uint x) {
return Widget(x * 2);
}
unittest {
auto w = hun(1000);
...
}
A naïve approach would be to simply create a Widget object inside hun and then copy it into w by using a bitwise copy followed by a call to this(this). But this is wasteful because D assumes objects to be relocatable, so then why not simply move the moribund temporary created by hun into w? Nobody could really tell because there’s no use of the temporary after hun returns. If a tree falls in the forest and nobody hears it, there should be no problem with moving the tree instead of copying it. A similar but not identical example is shown here:
Widget iun(uint x) {
auto result = Widget(x * 2);
...
return result;
}
unittest {
auto w = iun(1000);
...
}
In this case, again, result is gone after iun returns, so a call to this(this) is unnecessary. Finally, a subtler case is the following:
This case is tricky to rid of a call to this(this). It is possible that ‹code2› continues using w, in which case moving it out from the unittest into jun would be incorrect.3
In view of all of the considerations above, D takes the following stance on copy elision:
- All anonymous rvalues are moved, not copied. A call to
this(this)is never inserted when the source is an anonymous rvalue (i.e., a temporary as featured in the functionhunabove). - All named temporaries that are stack-allocated inside a function and then
returned elide a call tothis(this). - There is no guarantee that other potential elisions are observed.
Sometimes, however, we actively want to order the compiler to perform a move. This is in fact doable via the move function defined in the standard library module std.algorithm:
import std.algorithm;
void kun(Widget w) {
...
}
unittest {
auto w = Widget(1000);
... // ‹code1›
// Call to move inserted
kun(move(w));
assert(w == Widget.init); // Passes
... // ‹code2›
}
Using move ensures that w will be moved, and that an empty, default-constructed Widget replaces w’s contents. By the way, this is one place where the existence of a stateless non-throwing default constructor (§ 7.1.3.1 on page 244) called Widget.init comes in really handy. Without that, there might be no way to put the source of a move in a well-defined, empty state.
7.1.3.6 Destruction and Deallocation
A struct may define a destructor, spelled like ~this():
import std.stdio;
struct S {
int x = 42;
~this() {
writeln("An S with payload ", x, " is going away. Bye!");
}
}
void main() {
writeln("Creating an object of type S.");
{
S object;
writeln("Inside object's scope");
}
writeln("After object's scope.");
}
The program above reliably prints
Creating an object of type S.
Inside object's scope
An S with payload 42 is going away. Bye!
After object's scope.
Any struct object obeys scoped lifetime, meaning that its lifetime effectively ends at the end of the object’s scope. More specifically:
- The lifetime of a non-
staticobject defined inside a function ends at the end of the current scope, before allstructobjects defined before it. - The lifetime of an object defined as a member inside another
structends immediately after the enclosing object’s lifetime. - The lifetime of an object defined at module scope is infinite. If you want to call that object’s destructor, you must do so in a module destructor (§ 11.3 on page 356).
- The lifetime of an object defined as a member inside a
classends at the point the enclosing object’s memory is collected.
The language guarantees calling ~this automatically at the end of a struct object’s lifetime, which is very handy if you want to automatically carry out operations like closing files and freeing any sensitive resources.
The source of a copy that uses this(this) obeys its normal lifetime rules, but the source of an elided copy that is moved through memory does not have its destructor called.
Deallocation of a struct object is conceptually carried out immediately after destruction.
7.1.3.7 Tear-Down Sequence
By default, struct objects are destroyed in the exact opposite order of their creation. For example, the last struct object defined in a scope is the first to be destroyed:
import std.conv, std.stdio;
struct S {
private string name;
this(string name) {
writeln(name, " checking in.");
this.name = name;
}
~this() {
writeln(name, " checking out.");
}
}
void main() {
auto obj1 = S("first object");
foreach (i; 0 .. 3) {
auto obj = S(text("object ", i));
}
auto obj2 = S("last object");
}
The program above prints
first object checking in.
object 0 checking in.
object 0 checking out.
object 1 checking in.
object 1 checking out.
object 2 checking in.
object 2 checking out.
last object checking in.
last object checking out.
first object checking out.
As expected, the first object created is the last object to be destroyed. A loop enters and exits the scope of the controlled statement at each pass through the loop.
You can invoke a struct object’s destructor explicitly by calling clear(obj). We got acquainted with the clear function on page 187. There, clear was useful for resetting class objects to their default-constructed state. For struct objects, clear does a similar deed: it invokes the destructor and then copies .init over the bits of the object. The result is a valid object, just one that doesn’t hold any interesting state.
7.1.4 Static Constructors and Destructors
A struct may define any number of static constructors and destructors. This feature is virtually identical to the homonym feature we introduced for classes in § 6.3.6 on page 188.
import std.stdio;
struct A {
static ~this() {
writeln("First static destructor");
}
...
static this() {
writeln("First static constructor");
}
...
static this() {
writeln("Second static constructor");
}
...
static ~this() {
writeln("Second static destructor");
}
}
void main() {
writeln("This is main speaking");
}
No pairing is needed between static constructors and static destructors. Before evaluating main, the runtime support boringly executes all static constructors in the order of their definition. After main terminates, the runtime support just as boringly executes all static destructors in the opposite order of their definition. The program above writes
First static constructor
Second static constructor
This is main speaking
Second static destructor
First static destructor
The order of execution of static constructors and destructors is well defined (as above) within a module, but not always across modules. The order of execution of static constructors and destructors across modules is defined on page 189.
7.1.5 Methods
structs may define member functions, also known as methods. Since there is no inheritance and no overriding for structs, struct methods are only little more than regular functions.
For a struct type S, non-static methods take a hidden parameter this by reference (equivalent to a ref S parameter). Inside a method, name lookup proceeds as with classes: parameters hide homonym member names, and member names hide homonym module-level names.
void fun(int x) {
assert(x != 0);
}
// Illustrating name lookup rules
struct S {
int x = 1;
static int y = 324;
void fun(int x) {
assert(x == 0); // Fetch parameter x
assert(this.x == 1); // Fetch member x
}
void gun() {
fun(0); // Call method fun
.fun(1); // Call module-level fun
}
// unittests may be struct members
unittest {
S obj;
obj.gun();
assert(y == 324); // "Member" unittests see static data
}
}
Also featured above is a unittest defined inside a struct. Such member unittests have no special status but are very convenient to insert after each method definition. Code inside a member unittest enjoys the same name visibility as regular static methods—for example, the unittest above does not have to prefix the static member y with S, just as a static method wouldn’t.
A few special methods are worth a closer investigation. They are the assignment operator opAssign used for =, the equality operator opEquals used for == and ! =, and the ordering operator opCmp used for <, <=, >=, and >. This topic really belongs in Chapter 12 because it concerns operator overloading, but these operators are special because the compiler may generate them automatically with a specific behavior.
7.1.5.1 The Assignment Operator
By default, if you say
struct Widget { ... } // Defined as in § 7.1.3.4 on page 245
Widget w1, w2;
...
w1 = w2;
then the assignment is done member by member. This may cause trouble with the type Widget discussed in § 7.1.3.4 on page 245. Recall that Widget holds a private int[] member that was supposed to be distinct for each Widget object. Assigning w2 to w1 field by field assigns w2.array to w1.array—a simple assignment of array bounds, without actually copying the array contents. This needs fixing because what we want is to create a duplicate of the array in the source Widget and assign that duplicate to the target Widget.
User code can intercept assignment by defining the method opAssign. Essentially, an assignment lhs = rhs is translated into lhs.opAssign(rhs) if lhs defines opAssign with a compatible signature (otherwise, it performs the default field-by-field assignment if lhs and rhs have the same type). Let’s define Widget.opAssign:
struct Widget {
private int[] array;
... // this(uint), this(this), etc.
ref Widget opAssign(ref Widget rhs) {
array = rhs.array.dup;
return this;
}
}
The assignment operator returns a reference to this to allow chained assignments à la w1 = w2 = w3, which the compiler rewrites into w1.opAssign(w2.opAssign(w3)).
There is one problem left. Consider the assignment
Widget w;
...
w = Widget(50); // Error!
// Cannot bind an rvalue of type Widget to ref Widget!
The problem is that opAssign as defined expects a ref Widget, that is, an lvalue of type Widget. To accept assignment from rvalues in addition to lvalues, Widget must define two assignment operators:
import std.algorithm;
struct Widget {
private int[] array;
... // this(uint), this(this), etc.
ref Widget opAssign(ref Widget rhs) {
array = rhs.array.dup;
return this;
}
ref Widget opAssign(Widget rhs) {
swap(array, rhs.array);
return this;
}
}
There’s no more .dup in the version taking an rvalue. Why? Well, the rvalue (with its array in tow) is practically owned by the second opAssign: it was copied prior to entering the function and will be destroyed just before the function returns. This means there’s no more need to duplicate rhs.array because nobody will miss it. Swapping rhs.array with this.array is enough. When opAssign returns, rhs goes away with this’s old array, and this stays with rhs’s old array—perfect conservation of state.
We now could remove the first overload of opAssign altogether: the one taking rhs by value takes care of everything (lvalues are automatically converted to rvalues). But keeping the lvalue version allows for a useful optimization: instead of .duping the source, opAssign can check whether the current array has space for accommodating the new contents, in which case an overwrite is enough.
// Inside Widget ...
ref Widget opAssign(ref Widget rhs) {
if (array.length < rhs.array.length) {
array = rhs.array.dup;
} else {
// Adjust length
array.length = rhs.array.length;
// Copy array contents (§ 4.1.7 on page 100)
array[] = rhs.array[];
}
return this;
}
7.1.5.2 Comparing structs for Equality
Objects of struct type can be compared for equality out of the box with == and ! =. Comparison is carried out member by member and yields false if at least two corresponding members in the compared objects are not equal, and true otherwise.
struct Point {
int x, y;
}
unittest {
Point a, b;
assert(a == b);
a.x = 1;
assert(a != b);
}
To define a custom comparison routine, define the opEquals method:
import std.math, std.stdio;
struct Point {
float x = 0, y = 0;
// Added
bool opEquals(ref const Point rhs) const {
// Perform an approximate comparison
return approxEqual(x, rhs.x) && approxEqual(y, rhs.y);
}
}
unittest {
Point a, b;
assert(a == b);
a.x = 1e-8;
assert(a == b);
a.y = 1e-1;
assert(a != b);
}
Compared to opEquals for classes (§ 6.8.3 on page 205), opEquals for structs is much simpler because it doesn’t need to worry about correctness in the presence of inheritance. The compiler simply rewrites a comparison of struct objects into a call to opEquals. Of course, structs must still define a meaningful opEquals: reflexive, symmetric, and transitive. It must be said that, although Point.opEquals looks quite sensible, it fails the transitivity test. A better test would compare two Points truncated to their most significant bits; that test could be made transitive more easily.
When a struct contains members that define opEquals but it does not itself define opEquals, comparison will still invoke opEquals for the members that define it. Continuing the Point example above:
struct Rectangle {
Point leftBottom, rightTop;
}
unittest {
Rectangle a, b;
assert(a == b);
a.leftBottom.x = 1e-8;
assert(a == b);
a.rightTop.y = 5;
assert(a != b);
}
Given two Rectangles a and b, evaluating a == b is equivalent to evaluating
which in turn is rewritten as
a.leftBottom.opEquals(b.leftBottom) &&
a.rightTop.opEquals(b.rightTop)
The example also reveals that comparison is carried out in field declaration order (i.e., leftBottom before rightTop) and stops early if two fields are not equal because of the short-circuit evaluation of &&.
7.1.6 static Members
A struct may define static data and static member functions. Save for their scoped visibility and observance of access rules (§ 7.1.7 on the next page), static member functions have the same regime as regular functions. There is no hidden this parameter and no other special mechanism involved.
Similarly, static data members have a regime much like module-level global data (§ 5.2.4 on page 137), save for visibility and access imposed by the struct defining them.
import std.stdio;
struct Point {
private int x, y;
private static string formatSpec = "(%s %s)
";
static void setFormatSpec(string newSpec) {
... // Check the format spec for correctness
formatSpec = newSpec;
}
void print() {
writef(formatSpec, x, y);
}
}
void main() {
auto pt1 = Point(1, 2);
pt1.print();
// Call static member by prefixing it with either Point or pt1
Point.setFormatSpec("[%s, %s]
");
auto pt2 = Point(5, 3);
// The new spec affects all Point objects
pt1.print();
pt2.print();
}
The program above predictably prints
7.1.7 Access Specifiers
struct types obey the access specifiers private (§ 6.7.1 on page 200), package (§ 6.7.2 on page 200), public (§ 6.7.4 on page 201), and export (§ 6.7.5 on page 201) the same way as class types do. For structs, protected does not make sense because structs have no inheritance.
You may want to refer to the respective sections for the full story. Here, let’s just briefly recap the meaning of each access specifier:
struct S {
private int a; // Accessible within this file and S's methods
package int b; // Accessible within this file's directory
public int c; // Accessible from within the application
export int d; // Accessible outside the application
// (where applicable)
}
Again, export, although syntactically allowed anywhere an access specifier is allowed, has semantics that are at the discretion of the implementation.
7.1.8 Nesting structs and classes
Often, it is convenient for a struct to internally define other structs or classes. For example, a tree container may choose to expose a struct shell with a simple searching interface but use polymorphism inside to define the nodes of the tree.
struct Tree {
private:
class Node {
int value;
abstract Node left();
abstract Node right();
}
class NonLeaf : Node {
Node _left, _right;
override Node left() { return _left; }
override Node right() { return _right; }
}
class Leaf : Node {
override Node left() { return null; }
override Node right() { return null; }
}
// Data
Node root;
public:
void add(int value) { ... }
bool search(int value) { ... }
}
Similarly, structs may be nested inside other structs ...
struct Widget {
private:
struct Field {
string name;
uint x, y;
}
Field[] fields;
public:
...
}
... and, finally, structs may be nested within classes:
class Window {
struct Info {
string name;
Window parent;
Window[] children;
}
Info getInfo();
...
}
Unlike classes nested within classes, nested structs and nested classes within structs don’t contain any hidden member outer—there is no special code generated. The main design goal of nesting such types is to enforce the desired access control.
7.1.9 Nesting structs inside Functions
Recall from § 6.11.1 on page 223 that nested classes enjoy special, unique properties. A nested class gets to access the enclosing function’s parameters and local variables. If you return a nested class object, the compiler even creates a dynamically allocated function frame such that the function’s locals and parameters survive beyond the end of the function.
For conformity and consistency, D offers similar amenities to structs nested inside functions. A nested struct can access the enclosing function’s parameters and locals:
void fun(int a) {
int b;
struct Local {
int c;
int sum() {
// Access parameter, variable, and Local's own member
return a + b + c;
}
}
Local obj;
int x = obj.sum();
assert(Local.sizeof == 2 * size_t.sizeof);
}
unittest {
fun(5);
}
Nested structs embed the magic “frame pointer” that allows them to access outer values such as a and b in the example above. Because of that extra state, the size of a Local object is not 4 as one might expect, but 8 (on a 32-bit machine) to account for the frame pointer. If you want to define a nested struct without that baggage, just prefix struct with static in the definition of Local, which makes Local a regular struct and consequently prevents it from accessing a and b.
Aside from avoiding a gratuitous limitation when compared with nested classes, nested structs are of little use. Nested struct objects cannot be returned from functions because the caller doesn’t have access to their type. If a design gets to use sophisticated nested structs, it implicitly fosters complex functions, which should at best be avoided in the first place.
7.1.10 Subtyping with structs. The @disable Attribute
Although structs don’t feature inheritance and polymorphism, they still support the alias this feature, first introduced in § 6.13 on page 230. By using alias this, you can have a struct subtype any other type. For example, let’s define a simple type called Final that behaves much like a class reference—except you can never rebind it! Here’s an example of using Final:
import std.stdio;
class Widget {
void print() {
writeln("Hi, I'm a Widget. Well, that's about it.");
}
}
unittest {
auto a = Final!Widget(new Widget);
a.print(); // Fine, just print a
auto b = a; // Fine, a and b are bound to the same Widget
a = b; // Error!
// opAssign(Final!Widget) is disabled!
a = new Widget; // Error!
// Cannot assign to rvalue returned by get()!
}
The purpose of Final is to be a special kind of class reference that first binds to some object and then never lets go of it. Such “faithful” references are useful in many designs.
The first step is to get rid of assignment. The problem is, the assignment operator is automatically generated if missing, so Final must kindly instruct the compiler to not do that. To effect that, use the @disable attribute:
struct Final(T) {
// Disable assignment
@disable void opAssign(Final);
...
}
You may use @disable to remove other generated functions, such as comparison.
So far, so good. To implement Final!T, we need to make sure that the type subtypes T by using alias this but not offer an lvalue. A mistaken design looks like this:
// Mistaken design
struct Final(T) {
private T payload;
this(T bindTo) {
payload = bindTo;
}
// Disable assignment
@disable void opAssign(Final);
// Subclass T
alias payload this;
}
Final holds its value in the payload member and initializes it in the constructor. It also effectively disables assignment by declaring opAssign but never defining it. That way, clients attempting to assign to objects of type Final!T will either have no access (because of private) or encounter a link-time error.
The mistake of Final is to introduce alias payload this. Here’s a unittest that accomplishes something it’s not supposed to:
class A {
int value = 42;
this(int x) { value = x; }
}
unittest {
auto v = Final!A(new A(42));
void sneaky(ref A ra) {
ra = new A(4242);
}
sneaky(v); // Hmm...
assert(v.value == 4242); // Passes?!?
}
The workings of alias payload this are quite simple. Whenever a value obj of type Final!T is used in a context that would be illegal for its type, the compiler rewrites obj as obj.payload. (In other words, it makes obj.payload an alias of obj, hence the name and syntax of the feature.) But obj.payload is direct access to a field of obj and as such it’s an lvalue. That lvalue is bound to sneaky’s ref parameter and therefore allows sneaky to overwrite v’s field directly.
To fix that, we need to alias the object to an rvalue. That way, we get full functionality, but the reference stored in payload is impossible to touch. Binding to an rvalue is very easy by using a @property that returns payload by value:
struct Final(T) {
private T payload;
this(T bindTo) {
payload = bindTo;
}
// Disable assignment by leaving opAssign undefined
private void opAssign(Final);
// Subclass T, but do not allow rebinding
@property T get() { return payload; }
alias get this;
}
The crucial new element is that get returns a T, not a ref T, so payload cannot be rebound. Of course, the object that payload refers to can be modified (for ways to prevent that, refer to const and immutable in Chapter 8 on page 287). The charter of Final is now fulfilled. First, Final!T behaves like a T for any class type T. Second, once you bind a Final!T to some object in the constructor, there is no way to rebind it to any other object. To wit, the killer unittest does not compile anymore because the call sneaky(v) is now illegal: an rvalue of type A (obtained from v implicitly via v.get) cannot be bound to ref A as sneaky needs for its dirty deeds.
There is one little fly left in this ointment—really just a small Drosophila melanogaster—that we ought to remove. Whenever a type such as Final uses alias get this, extra attention must be paid to Final’s own symbols masking homonym symbols defined by the aliased type. For example, say we use Final!Widget and Widget itself defines a property called get:
class Widget {
private int x;
@property int get() { return x; }
}
unittest {
auto w = Final!Widget(new Widget);
auto x = w.get; // Gets the Widget in Final,
// Not the int in Widget
}
To avoid such collisions, we need to use a naming convention, and a solid one is to simply use the name of the type in the name of the transparent property:
struct Final(T) {
private T Final_payload;
this(T bindTo) {
Final_payload = bindTo;
}
// Disable assignment
@disable void opAssign(Final);
// Subclass T, but do not allow rebinding
@property T Final_get() { return Final_payload; }
alias Final_get this;
}
With this convention in action, the risk of unintended collisions is diminished. (Of course, on occasion you actively want to intercept certain methods and carry them in the intercepter.)
7.1.11 Field Layout. Alignment
How are fields laid out in a struct object? D is very conservative with structs—it lays their contents in the same order as that specified in the struct definition but is still free to insert padding between fields. Consider:
If the compiler were to lay fields exactly with the sizes prescribed by A, b would sit at the object’s address plus 1 (a char occupies exactly 1 byte). This is problematic because most contemporary computer systems fetch data in 4- or 8-byte increments, with the restriction that they can fetch only from addresses that are multiples of 4 or 8, respectively. Let’s assume an object of type A sits at a “good” address, for example, a multiple of 8. Then b’s address would definitely be in a bad part of town. What the processor needs to do to fetch b is quite onerous—stitch the value of b by assembling byte-size pieces of it. To add insult to injury, depending on the compiler and the underlying hardware architecture, the entire operation may be performed in response to a “misaligned memory access” kernel trap, which has its own (and way larger) overhead [28]. This is definitely not a beans-counting matter—the extra gymnastics could easily dampen access speed by many orders of magnitude.
For that reason, today’s compilers lay out structures with padding. The compiler inserts additional bytes into the object to ensure that all fields are situated at advantageous offsets. Then, allocating objects at addresses that are multiple of the word size ensures fast access to all of their members. Figure 7.2 illustrates the padded layout of A.
Figure 7.2. Padded layout for an object of type A. The hashed areas are paddings inserted for proper alignment. The compiler inserts two holes into the object adding 6 bytes of slack space, or 50% of the total object size.
![]()
The resulting layout has quite a bit of padding (the hashed bytes). In the case of a class, the compiler has the freedom to reorder fields, but with a struct you may want to pay attention to the layout of data if memory consumption is important. A better choice of field ordering would be to place the int first, followed by the two chars, which would fit in 64 bits including 2 bytes of padding.
Each field of an object has a compile-time-known offset from the starting address of the object. That offset is always the same for all objects of the same type within a given program (it may change from one compilation to the next, but not from one run to the next). The offset is user-accessible as the .offsetof property implicitly defined for any field in a class or struct:
import std.stdio;
struct A {
char a;
int b;
char c;
}
void main() {
A x;
writefln("%s %s %s", x.a.offsetof, x.b.offsetof, x.c.offsetof);
}
The reference implementation prints 0 4 8, revealing the layout in Figure 7.2 on the previous page. It is a bit awkward that you need to create an object of type A just to access some static information about it, but the syntax A.a.offsetof does not compile. A trick that can be used, however, is to use A.init.a.offsetof, which is enough to fetch the offset associated with each member as a compile-time constant.
import std.stdio;
struct A {
char a;
int b;
char c;
}
void main() {
// Access field offsets without an object
writefln("%s %s %s", A.init.a.offsetof,
A.init.b.offsetof, A.init.c.offsetof);
}
D guarantees that all of the padding bytes are consistently filled with zeros.
7.1.11.1 The align Attribute
If you want to override the compiler’s choice of alignment, which influences the padding inserted, you can use an align modifier with your field declaration. Such a necessity may occur when you want to interact with a piece of hardware or a binary protocol that specifies a specific alignment. Here’s what an align specifier looks like:
With the specification above, the fields of A are laid out without gaps between them. (There may still be a gap at the end of the object.) The argument of align is the maximum alignment of the field, so the effective alignment will likely not go beyond the natural alignment of the field’s type. To get the natural alignment of a type T, use the compiler-defined property T.alignof. So if you specify, for example, align(200) instead of align(1) for b above, the effective alignment obtained is 4, the same as for int.alignof.
You may use align with an entire class definition:
When specified with a struct, align sets the default alignment to a specific value. You may override that default with individual align attributes inside the struct definition. If you specify only align without a number for a field of type T, that counts as align(T.alignof)—in other words, it resets the alignment of that field to its natural alignment.
align is not supposed to be used with pointers and references. The garbage collector assumes that all references and pointers are aligned at size_t size. The compiler does not enforce this restriction because generally you could have pointers and references that are not garbage-collected. So this definition is highly dangerous because it compiles warning-free:
If the code above assigns obj.next = new Node (i.e., fills obj.next with a garbage-collected reference), then chaos is bound to occur: the misaligned reference goes under the radar of the garbage collector, memory gets recycled, and obj.next is a dangling reference.
7.2 unions
C-style unions are also accepted in D, though it should be mentioned that they should be used rarely and with extreme care.
A union is akin to a struct in which all members start at the same address. This makes their storage overlap, meaning that it’s your responsibility as the union’s user to always read the same exact type you wrote. At any given time, only one member of a union value is valid.
union IntOrFloat {
int _int;
float _float;
}
unittest {
IntOrFloat iof;
iof._int = 5;
// Read only iof._int, but not iof._float
assert(iof._int == 5);
iof._float = 5.5;
// Read only iof._float, not iof._int
assert(iof._float == 5.5);
}
Since int and float both have the same exact size (4 bytes), they will precisely overlap inside IntOrFloat. The details of their layout, however, are not specified—for example, _int and _float may use different endianness: _int’s most significant byte might be at the lowest address and _float’s most significant byte (the one containing the sign and most of the exponent) may be at the highest address.
unions are not tagged, meaning that the union object itself does not contain a “tag,” that is a means to distinguish which member is the good one. The responsibility of correct use falls straight on the user’s shoulders, which makes unions quite an unpleasant means to build any kind of larger abstraction.
Upon definition without initialization, a union object has its first field initialized with its .init value, so after default construction the first member is readable. To initialize the first field with something other than .init, specify the desired initializer in brackets:
A static union object may have another field initialized by using the following syntax:
Truth be told, many uses of union actually use it to read different types from those written in the first place, in order to achieve certain system-dependent manipulation of representation. Because of that, the compiler will not denounce even the detectable misuses of unions. For example, the code below passes compilation and even the assert on an Intel 32-bit machine:
unittest {
IntOrFloat iof;
iof._float = 1;
assert(iof._int == 0x3F80_0000);
}
A union may define member functions and generally any members a struct may define but cannot define constructors and destructors.
The most frequent (or, better put, least infrequent) use of union is as an anonymous member inside a struct, as shown here:
import std.contracts;
struct TaggedUnion {
enum Tag { _tvoid, _tint, _tdouble, _tstring, _tarray }
private Tag _tag;
private union {
int _int;
double _double;
string _string;
TaggedUnion[] _array;
}
public:
void opAssign(int v) {
_int = v;
_tag = Tag._tint;
}
int getInt() {
enforce(_tag == Tag._tint);
return _int;
}
...
}
unittest {
TaggedUnion a;
a = 4;
assert(a.getInt() == 4);
}
(Details on enum are forthcoming in this chapter; refer to § 7.3.)
The example above is the absolute classic use of union as a helper in defining a so-called discriminated union, aka tagged union or algebraic type. TaggedUnion encapsulates an unsafe union within a safe box that keeps track of the last type assigned. Upon initialization, the value of Tag is Tag._void, meaning that the object is effectively uninitialized. When you assign to the union, opAssign kicks in and sets the type of the object appropriately. To complete the implementation, you may want to define opAssign(double), opAssign(string), and opAssign(TaggedUnion[]) as well, together with the corresponding getXxx() functions.
The union member is anonymous, meaning that it is at the same time a type definition and a member definition. The anonymous union is allocated as a regular member inside the struct, and its members are directly visible inside the struct (as the methods of TaggedUnion illustrate). Generally you may define both anonymous structs and anonymous unions and nest them as you want.
Finally, you should know that union is not as evil as it may seem. Using a union instead of type punning with cast is often good communication etiquette between you and the compiler. A union of a pointer and an integral clarifies to the compiler that it should be conservative and not collect that pointer. If you store the pointer in an integral and cast it occasionally back to the pointer’s type, the results are undefined because the garbage collector might have collected the memory associated with that surreptitious pointer.
7.3 Enumerated Values
Types that can take only a few discrete values turn out to be very useful—so useful, in fact, that Java ended up adding enumerated types to the core language after heroically trying for years to emulate them with an idiom [8]. Good enumerated types are not easy to define, either—enum has a fair share of oddities in C++ and (particularly) C. D tried to leverage the advantage of hindsight in defining a simple and useful enum facility.
Let’s start at the beginning. The simplest use of enum is just “Let me enumerate some symbolic values,” without associating them with a new type:
Type deduction works for enum as it does for auto, so in the example above pi and euler have type double and greet has type string. If you want to define one or more enums of a specific type, specify one right after the enum keyword:
enum float verySmall = 0.0001, veryBig = 10000;
enum dstring wideMsg = "Wide load";
Enumerated values are constant; using them is essentially equivalent to using the literals they stand for. In particular, the supported operations are the same—for example, you cannot take the address of pi much as you cannot take the address of 3.14:
auto x = pi; // Fine, x has type double
auto y = pi * euler; // Fine, y has type double
euler = 2.73; // Error!
// Cannot modify enum value!
void f(ref double x) {
...
}
fun(pi); // Error!
// Cannot take the address of 3.14!
As shown above, the type of an enum value is not limited to int but also encompasses double and string. Exactly what types can be used with enum? The answer is simple: any primitive and struct type may be used with enum. There are only two requirements for an enum value initializer:
- The initializer must be computable during compilation.
- The type of the initializer must allow copying, that is, not
@disable this(this)(§ 7.1.3.4 on page 245).
The first requirement ensures the enum value does not depend on any runtime parameter. The second requirement makes sure that you can actually create copies of the value; a copy will be created whenever you use the enum.
You may not define an enumerated value of class type because class objects must always be created with new (aside from the uninteresting null value), and new is not computable during compilation. It wouldn’t be a surprise if that restriction were lifted or relaxed in the future.
Let’s create and use an enum of struct type:
struct Color {
ubyte r, g, b;
}
enum
red = Color(255, 0, 0),
green = Color(0, 255, 0),
blue = Color(0, 0, 255);
Whenever you use, for example, green, the code will behave as if you pasted Color(0, 255, 0) instead of the symbolic name.
7.3.1 Enumerated Types
You can give a collection of enumerated values a named type:
Once you ascribe a name to a collection of enums, they may not be of different types; all must share the same type because users may subsequently define and use values of that type. For example:
OddWord w;
assert(w == OddWord.acini); // Default initializer is
// the first value in the set: acini
w = OddWord.aprosexia; // Always use type name to qualify the
// value name
// (it's not what you might think btw)
int x = w; // OddWord is convertible to int
// but not vice versa
assert(x == 3); // Values are numbered 0, 1, 2, ...
The type of a named enum is automatically deduced as int. Assigning a different type is done like this:
With the new definition (byte is called the base type of OddWord), the enum symbols still have the same values, just a different storage. You may make the type double or real as well, and the values ascribed to the symbols are still 0, 1, and so on. But if you make the base type of OddWord a non-numeric type such as string, you must specify initializers for all values because the compiler does not have a natural succession to follow.
Returning to numeric enums, if you assign a specific value to any value, that resets the internal step counter used by the compiler to assign values to symbols. For example:
enum E { a, b = 2, c, d = -1, e, f }
assert(E.c == 3);
assert(E.e == 0);
There is no conflict if two enum symbols end up having the same value (as is the case with E.a and E.e). You may actually create equal values without even meaning to, because of floating-point types’ unwavering desire to surprise the unwary:
The problem illustrated above is that the largest int that can be precisely represented by a float is 16_777_216, and going beyond that will have increasingly large ranges of integers represented by the same float number.
7.3.2 enum Properties
Each enumerated type E defines three properties: E.init is equal to the first value that E defines, E.min is the smallest value defined by E, and E.max is the largest value defined by E. The last two values are defined only if E has as base type a type that allows comparison with < during compilation.
You are free to define your own min, max, and init values inside an enum, but that is unrecommended: generic code often counts on such values having specific semantics.
One commonly asked question is: Would it be possible to get to the name of an enumerated value? It is indeed possible and actually easy, but the mechanism used is not built in but instead relies on compile-time reflection. The way compile-time reflection works is to expose, for some enumerated type Enum, a compile-time constant __traits(allMembers, Enum) that contains all members of Enum as a tuple of strings. Since strings can be manipulated at compile time as well as runtime, this approach gives considerable flexibility. For example, at the expense of anticipating just a bit, let’s write a function toString that returns the string corresponding to an enumerated value. The function is parameterized on the type of the enum.
string toString(E)(E value) if (is(E == enum)) {
foreach (s; __traits(allMembers, E)) {
if (value == mixin("E." ~ s)) return s;
}
return null;
}
enum OddWord { acini, alembicated, prolegomena, aprosexia }
void main() {
auto w = OddWord.alembicated;
assert(toString(w) == "alembicated");
}
The not-yet-introduced element above is mixin("E." ~ s), which is a mixin expression. A mixin expression takes a string known during compilation and simply evaluates it as an ordinary expression within the current context. In our case, we build such an expression from the name of the enum E, the member selector ., and the name of the enum value iterated by s. In our case, s will successively take the values "acini", "alembicated", ..., "aprosexia". The constructed string will therefore be "E.acini" and so on, evaluated by mixin to the actual values corresponding to those symbols. As soon as the passed-in value is equal to one of those values, the function returns. Upon passing an illegal value, toString may throw; to simplify matters we chose to just return the null string.
The function toString featured above is already implemented by the standard library module std.conv, which deals with general conversion matters. The name is a bit different—you’d have to write to!string(w) instead of toString(w), which is a sign of flexibility (you may also call to!dstring(w) or to!byte(w), etc.). The same module defines the reciprocal function that converts a string to an enum; for example, to!OddWord("acini") returns OddWord.acini.
7.4 alias
We’ve met size_t—the type of an unsigned integral large enough to hold the size of any object—on a few occasions already. The type size_t is not defined by the language; it simply morphs into one of uint or ulong, depending on the host machine’s address space (32 versus 64 bits, respectively).
If you opened the installation-provided file object.d (or object.di) that is included with your D installation, you’d find a declaration that may look like this:
The .sizeof property gauges the size in bytes of a type, in this case int. Any other type could replace int above; it’s not that type that matters, but instead the type of its size, fetched with typeof. The compiler measures object sizes using uint on 32-bit architectures, and ulong on 64-bit architectures. Consequently, the alias statement introduces size_t as a synonym for either uint or ulong.
The general syntax of the alias declaration is not any more complex than is shown above:
‹existingSymbol› may be anything that has a name. It could be a type, a variable, a module—if something has a symbolic name, it can be aliased. For example:
import std.stdio;
void fun(int) {}
void fun(string) {}
int var;
enum E { e }
struct S { int x; }
S s;
unittest {
alias object.Object Root; // Root of all classes
alias std phobos; // Package name
alias std.stdio io; // Module name
alias var sameAsVar; // Variable
alias E MyEnum; // Enumerated type
alias E.e myEnumValue; // Value of that type
alias fun gun; // Overloaded function
alias S.x field; // Field of a struct
alias s.x sfield; // Field of an object
}
The rules for using an alias are simple: use the alias wherever the aliased symbol would make sense. That’s what the compiler does—it conceptually rewrites the name of the alias into the aliased symbol. Even the error messages or the debugged program may “see through” aliases and show the original symbols, which may seem surprising. An example is that you may see immutable(char)[] instead of string in some error messages or debug symbols, but showing one or the other is up to the implementation.
An alias may “double-alias” something that was aliased before, for example:
Nothing special there, just the usual rules: at the point of MyInt’s definition, Int is replaced with the symbol it aliases, which is int.
alias is frequently used to give shorter names to complex symbol chains, or in conjunction with overloaded functions from different modules (§ 5.5.2 on page 146).
Another frequent use of alias is with parameterized structs and classes. For example:
// Define a container class
class Container(T) {
alias T ElementType;
...
}
unittest {
Container!int container;
Container!int.ElementType element;
...
}
Here, if Container hadn’t exposed the alias ElementType, there would have been no reasonable way for the outside world to access the argument bound to Container’s T parameter. T is visible only inside Container, but not from the outside—Container!int.T does not compile.
Finally, alias is very helpful in conjunction with static if. For example:
// This is object.di
// Define the type of the difference between two pointers
static if (size_t.sizeof == 4) {
alias int ptrdiff_t;
} else {
alias long ptrdiff_t;
}
// Use ptrdiff_t ...
The alias declaration of ptrdiff_t binds it to different types depending on which branch of the static if was taken. Had there been no possibility of doing the binding, code that needed such a type would have had to stay inside the two branches of the static if.
7.5 Parameterized Scopes with template
The entities introduced so far that facilitate compile-time parameterization (akin to C++ templates or Java and C# generics) are functions (§ 5.3 on page 138), parameterized classes (§ 6.14 on page 233), and parameterized structs, which follow the same rules as parameterized classes. Sometimes, however, you want to do some compile-time type manipulation that does not result in defining a function, struct, or class. One such entity (widely used in C++) selects one type or another depending on a statically known Boolean condition. There is no new type being defined and no function being called, only an alias for one of two existing types.
For situations in which compile-time parameterization is needed without defining a new type or function, D defines parameterized scopes. Such a parameterized scope is introduced like this:
The above is actually the skeleton for the compile-time selection mechanism just discussed. We’ll get to the implementation shortly, but before that let’s focus on the declaration proper. A template declaration introduces a scope with a name (Select in this case) and compile-time parameters (in this case, a Boolean and two types). A template declaration may occur at module level, inside a class definition, inside a struct definition, and inside another template declaration, but not inside a function definition.
Inside the body of the parameterized scope, any normally accepted declaration is allowed, and parameter names may be used. From the outside, whatever declarations are inside the scope may be accessed by prefixing them with the name of the scope and a ., for example, Select!(true, int, double).foo. In fact, let’s complete the definition of Select right away so we can play with it:
template Select(bool cond, T1, T2) {
static if (cond) {
alias T1 Type;
} else {
alias T2 Type;
}
}
unittest {
alias Select!(false, int, string).Type MyType;
static assert(is(MyType == string));
}
Note that we might have used a struct or a class to achieve the same effect. After all, such types may define an alias inside, which is accessible with the usual dot syntax:
struct /* or class */ Select2(bool cond, T1, T2) { // Or class
static if (cond) {
alias T1 Type;
} else {
alias T2 Type;
}
}
unittest {
alias Select2!(false, int, string).Type MyType;
static assert(is(MyType == string));
}
Arguably that would be an unsavory solution. For example, imagine the documentation of Select2: “Do not create objects of type Select2! It is defined only for the sake of the alias inside of it!” Having a specialized mechanism for defining parameterized scopes clarifies intent and does not leave any room for confusion and misuse.
A template scope may introduce not only an alias, but really any declaration whatsoever. Let’s define another useful template, this time one that yields a Boolean telling whether a given type is a string of any width or not.
template isSomeString(T) {
enum bool value = is(T : const(char[]))
|| is(T : const(wchar[])) || is(T : const(dchar[]));
}
unittest {
// Non-strings
static assert(!isSomeString!(int).value);
static assert(!isSomeString!(byte[]).value);
// Strings
static assert(isSomeString!(char[]).value);
static assert(isSomeString!(dchar[]).value);
static assert(isSomeString!(string).value);
static assert(isSomeString!(wstring).value);
static assert(isSomeString!(dstring).value);
static assert(isSomeString!(char[4]).value);
}
Parameterized scopes may be recursive; for example, here’s one possible implementation of the factorial exercise:
template factorial(uint n) {
static if (n <= 1)
enum ulong value = 1;
else
enum ulong value = factorial!(n - 1).value * n;
}
Although perfectly functional, factorial above is not the best approach in this case. When computing values during compilation, you may want to consider compile-time evaluation, described in § 5.12. Unlike the factorial template above, a factorial function is more flexible because it can be evaluated during compilation as well as runtime. The template facility is best used only for manipulating types the way Select and isSomeString do.
7.5.1 Eponymous templates
A template may define any number of symbols, but as the examples shown above suggest, most of the time it defines exactly one. A template is usually defined to do one thing exactly, and to expose the result of its labor as a sole symbol, such as Type in the case of Select or value in the case of isSomeString.
The need to remember and always mention that symbol at the end of instantiation can become jarring. Commonly people would simply forget to append .Type and would wonder why Select!(cond, A, B) yields a mysterious error message.
D helps here with a simple rule that has come to be known as “the eponymous template trick”: if a template defines a symbol of the same name as the template itself, any subsequent use of the template name will automatically append that symbol to any use of the template. For example:
template isNumeric(T) {
enum bool isNumeric = is(T : long) || is(T : real);
}
unittest {
static assert(isNumeric!(int));
static assert(!isNumeric!(char[]));
}
Now whenever some code uses isNumeric!(T), the compiler automatically rewrites that as isNumeric!(T).isNumeric and saves the user the tedium of appending some redundant symbol to the name of the template.
A template using the eponymous trick may define other names inside, but those are simply inaccessible from the outside. This is because the compiler does the rewrite very early in the name lookup process. The only way to access such symbols is from within the template itself. For example:
template isNumeric(T) {
enum bool test1 = is(T : long);
enum bool test2 = is(T : real);
enum bool isNumeric = test1 || test2;
}
unittest {
static assert(isNumeric!(int).test1); // Error!
// Type bool does not define a property called test1!
}
The error message is caused by the eponymous rule: the compiler expands isNumeric!(int) into isNumeric!(int).isNumeric before doing anything else. Then the user code tries to fetch isNumeric!(int).isNumeric.test1, which is tantamount to fetching member test1 off a bool value, hence the error message. Long story short, use eponymous templates if and only if you want the template to expose exactly one symbol. That is the case more often than not, which makes eponymous templates very popular and convenient.
7.6 Injecting Code with mixin templates
Certain designs require adding boilerplate code (such as data definitions and method definitions) to one or more class implementations. Typical examples include support for serialization, the Observer design pattern [27], and event passing in windowing systems.
Inheritance could be used for such endeavors, but the single inheritance of implementation model makes it impossible for a given class to save on more than one source of boilerplate. Sometimes it is best to have a mechanism that simply dumps some predefined code into a class, pretty much as if it were written by hand.
Here’s where mixin templates come to the rescue. It is worth noting that as of today, this feature is mainly experimental. It is possible that a more general AST macro facility will replace mixin templates in a future revision of the language.
A mixin template is defined much like the parameterized scope (template) just discussed. For example, a mixin template that introduces a variable, a getter, and a setter may look like this:
mixin template InjectX() {
private int x;
int getX() { return x; }
void setX(int y) {
... // Checks
x = y;
}
}
Once defined, the mixin template can be inserted in several places:
// Inject at module scope
mixin InjectX;
class A {
// Inject into a class
mixin InjectX;
...
}
void fun() {
// Inject into a function
mixin InjectX;
setX(10);
assert(getX() == 10);
}
The code above now defines the variable and the two associated functions at module level, inside class A, and inside fun, pretty much as if the body of InjectX were pasted by hand. In particular, descendants of A can override getX and setX as if A itself defined them. Copy and paste without the unpleasant duplication.
Of course, the next logical step is to reckon that InjectX takes no compile-time parameters but has the air of someone who could—and indeed it does:
mixin template InjectX(T) {
private T x;
T getX() { return x; }
void setX(T y) {
... // Checks
x = y;
}
}
Now usage of InjectX passes the argument like this:
which actually brings us to the ambiguity—what if you have the two instantiations above, and then you want to use getX? There are two functions with that name, so clearly there is an ambiguity problem. To solve that, D allows you to introduce scope names with mixin instantiation:
With these definitions in hand, you get to unambiguously access members introduced by the two mixins by using regular scope resolution:
MyInt.setX(5);
assert(MyInt.getX() == 5);
MyDouble.setX(5.5);
assert(MyDouble.getX() == 5.5);
So mixin templates are only almost like copy and paste; you get to copy and paste multiple times and specify which instance you are referring to.
7.6.1 Symbol Lookup inside a mixin
The biggest difference between a mixin template and a regular template (as defined in § 7.5 on page 278), and potentially the most prone to confusion, is lookup.
Templates are entirely modular: code inside a template looks up symbols at the template’s definition site. This is a desirable property because it means you can absorb and understand a template by just analyzing its definition.
In contrast, a mixin template looks up symbols at the instantiation site, which means that you need an understanding of the context in which you use the mixin template to figure out what its behavior will be.
To illustrate the difference, consider the example below, which offers symbols with the same name at both the definition site and the instantiation site:
import std.stdio;
string lookMeUp = "Found at module level";
template TestT() {
string get() { return lookMeUp; }
}
mixin template TestM() {
string get() { return lookMeUp; }
}
void main() {
string lookMeUp = "Found at function level";
alias TestT!() asTemplate;
mixin TestM!() asMixin;
writeln(asTemplate.get());
writeln(asMixin.get());
}
The output is
The propensity of mixin templates to pick up local symbols confers on them some expressiveness but also makes them difficult to follow. Such behavior makes mixin templates of limited applicability; you may want to think twice before reaching for this particular tool in your toolbox.
7.7 Summary and Reference
Not all abstraction needs can be satisfactorily covered by classes, in particular finegrained objects, scoped resources, and value types. structs fill that void. In particular, constructors and destructors allow easy definition of scoped resource types.
unions are a low-level feature that allows you to keep the compiler in known overlapped storage for various types.
Enumerations are simple user-defined discrete values. An enum may be assigned a new type, which strengthens the typechecking for the values defined within that type.
alias is a very useful means to associate one symbol with another. Oftentimes the aliased symbol is long and complicated or is computed within a nested entity and must be exposed as a simple name.
Parameterized scopes using template are very useful for defining compile-time computations such as type introspection and type traits. Eponymous templates allow you to offer abstractions in a highly convenient, encapsulated form.
Parameterized scopes are also offered in the form of experimental mixin templates, which behave much like simple macros. A full AST macro feature might replace mixin templates.