
Chapter 2. Basic Types. Expressions
If you’ve ever programmed in C, C++, Java, or C#, you’ll feel right at home understanding D’s basic types and expressions—fortunately with quite a few home improvements. Manipulating values of basic types is the bread and butter of many programming tasks, and a language’s offering interacting with your personal preferences can go a long way toward making your life either pleasant or miserable. There is no perfect approach; many desiderata are conflicting, which brings the subjective factor into play. In turn, that makes it impossible for a language to find a solution that pleases everyone. Too strict a system puts the burden in the wrong place as the programmer must fight the compiler into accepting the simplest idioms; make it too lax, and all of a sudden you’re on the wrong side of verifiability, efficiency, or both.
D’s basic type system works little wonders inside the boundaries dictated by its membership in the family of statically typed, compiled languages. Type inference, value range propagation, various operator overloading decisions, and a carefully designed web of automatic conversions work together to make D’s type system a thorough, discreet assistant that starts nagging and asking for attention mostly when it has a real reason.
The fundamental types can be classified in the following categories:
- The type without a value:
void, which fills in for cases where a type is formally required but no meaningful value is ever produced - Boolean type:
bool, with two possible values,trueandfalse - Integral types:
byte,short,int, andlong, and their unsigned counterpartsubyte,ushort,uint, andulong - Real floating-point types:
float,double, andreal - Character types:
char,wchar, anddchar, which are numeric but are understood by the language to be encodings of Unicode strings
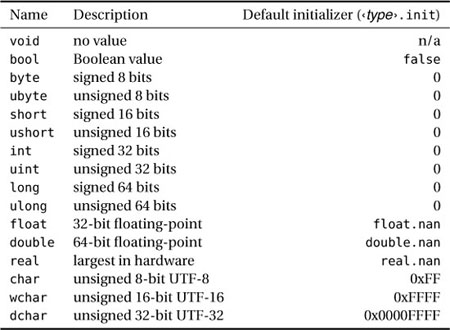
Table 2.1 briefly describes the garden variety of basic types, with their sizes and default initializers. In D, all variables are initialized if you just define them without initializing. The default value is accessible as ‹type›.init; for example, int.init is zero.
2.1 Symbols
A symbol is a case-sensitive string of characters starting with a letter or an underscore followed by any number of letters, underscores, or digits. The only exception to this rule is that symbols starting with two underscores are reserved by the D implementation. Symbols starting with only one underscore are allowed and actually are a popular convention for denoting member variables.
An interesting detail about D symbols is that they are international: in the definition above, “letter” means not only the Roman alphabet letters A through Z and a through z, but also universal characters as defined by the C99 standard [33, Annex D].
For example, abc, α5, _, Γ_1, _AbC, Ab9C, and _9x are valid symbols, but 9abc, __, and __abc are not.
If a symbol is prefixed by a dot .likeThis, then the symbol is looked up at module scope, not at the current lexically nested scope. The prefix dot operator has the same precedence as a regular symbol.
2.1.1 Special Symbols
Certain symbols, shown in Table 2.2, are language-reserved keywords. User code cannot define them in any circumstance.

A few symbols are recognized as primitive expressions. The special symbol this denotes the current object inside a method’s definition; super restricts both static and dynamic lookup to the base subobject of the current object, as Chapter 6 discusses. The $ symbol is valid only inside an index expression or a slice expression and evaluates to the length of the array being indexed. The null symbol denotes a null object, array, or pointer.
The typeid(T) primary expression returns information about the type T (consult your implementation’s documentation for more information).
2.2 Literals
2.2.1 Boolean Literals
The bool literals are true and false.
2.2.2 Integral Literals
D features decimal, octal, hexadecimal, and binary integral literals. A decimal constant is a sequence of digits optionally suffixed by L, U, u, LU, Lu, UL, or uL. The type of decimal literals is deduced as follows:
- No suffix: the type is the first of
intandlongthat can accommodate the value. U/uonly: the type is the first ofuintandulongthat can accommodate the value.Lonly: the type islong.- Both
U/uandL: the type isulong.
For example:
auto
a = 42, // a has type int
b = 42u, // b has type uint
c = 42UL, // c has type ulong
d = 4000000000, // long; wouldn't fit in an int
e = 4000000000u, // uint; it does fit in a uint
f = 5000000000u; // ulong; wouldn't fit in a uint
You can freely insert underscores in a number (just not in the first position lest you’d actually create an identifier). Underscores are helpful in writing large numbers clearly:
To write a hexadecimal integral literal, use the prefix 0x or 0X followed by a sequence of the letters 0–9, a–f, A–F, or _. A leading 0 followed by a possibly empty sequence of 0–7 or _ forms an octal literal. Finally, you can create binary literals with 0b or 0B followed by a string of 0s, 1s, and again underscores. All of these literals can be suffixed similarly to the decimal constants, and the rules governing their types are identical to those for decimal literals.
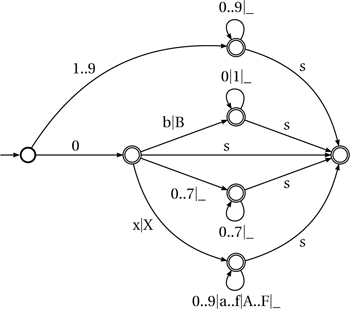
Figure 2.1, worth the proverbial 1024 words, defines the syntax of integral literals concisely and rigorously. The rules of walking the automaton are: (1) each edge consumes the input corresponding to its label; (2) the automaton tries to consume as much input as possible.1 Stopping in a final (i.e., doubly circled) state means that a number was successfully parsed.
Figure 2.1. Understanding D integral literals. The automaton tries to take successive steps (consuming the input corresponding to the edge taken) until it must stop. Stopping in a terminal (doubly circled) state means that a number was successfully parsed. s stands for the suffix, which can be U|u|L|UL|uL|Lu|LU.
2.2.3 Floating-Point Literals
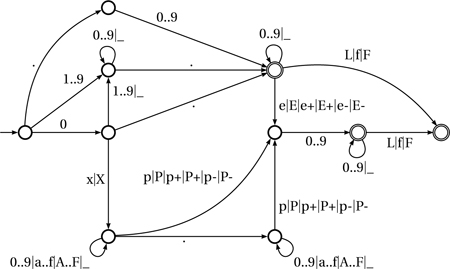
Floating-point literals can be decimal or hexadecimal. Decimal floating-point literals are easy to define in terms of the just-defined integral literals: a decimal floating-point literal consists of a decimal literal that may also contain one dot (.) in any position, optionally followed by an exponent and/or a suffix. The exponent is one of e, E, e+, E+, e-, or E- followed by an unsigned decimal literal. The suffix can be f, F, or L. Obviously, at least one of ., e/E, or f/F must be present, lest the floating-point number quite literally miss the point and become an integral literal. The f/F suffix, when present, forces the type of the literal to float, and L forces it to real. Otherwise, the literals type is double.
It would appear that hexadecimal floating-point constants are an oddity, but they turn out to be very useful in writing constants precisely. Internally, floating-point values are stored in base 2, so a real number expressed in base 10 involves a base conversion, which is approximate because 10 is not a power of 2. In contrast, hexadecimal notation allows you to write down floating-point numbers exactly as they will be represented. A full treatise on how floating-point numbers are stored is beyond the scope of this book, but all D implementations are guaranteed to use the IEEE 754 format, for which plentiful good references are just a Web search away (e.g., look for “IEEE 754 floating-point format”).
A hexadecimal floating-point constant consists of the prefix 0x or 0X followed by a string of hexadecimal digits containing a dot in any position. Then comes the mandatory exponent, which is introduced by one of p, P, p+, P+, p-, or P- followed by decimal (not hexadecimal!) digits. Only the so-called mantissa—the fractional portion before the exponent—is expressed in hexadecimal; the exponent itself is a decimal integer. The exponent of a hexadecimal floating-point constant represents the exponent of 2 in the final number (not 10 as in the decimal case). Finally, the optional suffix f, F, or L completes the constant.2 Let’s look at some relevant examples:
auto
a = 1.0, // a has type double
b = .345E2f, // b = 34.5 has type float
c = 10f, // c has type float due to suffix
d = 10., // d has type double
e = 0x1.fffffffffffffp1023, // e is the largest double
f = 0XFp1F; // f = 30.0 has type float
Figure 2.2 on the facing page concisely describes D’s floating-point literals. The rules for walking the automaton are the same as for the integral constants automaton: transition is made on reading characters in the literal and the longest path is attempted. The automaton representation clarifies a few points that would be tedious to describe informally: For example, 0x.p1 and even 0xp1 are legal, albeit odd, ways of expressing zero, but constructs such as 0e1, .e1, and 0x0.0 are disallowed.
Figure 2.2. Understanding floating-point literals.
2.2.4 Character Literals
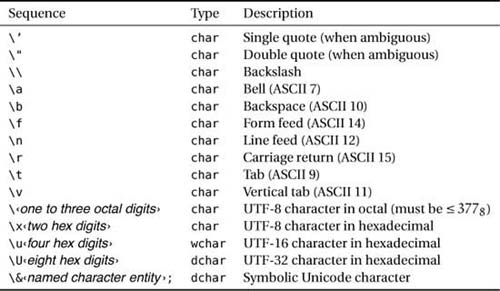
A character literal is one character enclosed in single quotation marks, as in 'a'. The actual quote character must be escaped by a backslash, as in '''. In fact, like other languages, D defines a number of escape sequences, and Table 2.3 on page 36 shows them all. In addition to the standard fare of control characters, D defines ways to form Unicode characters by using one of the notations 'u03C9' (u followed by exactly four hex digits), 'U0000211C' (U followed by exactly eight hex digits), or '©' (a named entity starting with & and ending with ;). The first one is Unicode for ω, the second is a nicely calligraphed ![]() , and the last one is the dreaded copyright symbol ©. Search the Net for “Unicode table” in case you’re in need of a complete list.
, and the last one is the dreaded copyright symbol ©. Search the Net for “Unicode table” in case you’re in need of a complete list.
2.2.5 String Literals
Now that we know how to represent characters, literal strings are a breeze. D is great at manipulating strings, and that is partly because of its powerful ways of representing string literals. Just like other string-bashing languages, D differentiates between quoted strings (inside which the escape sequences in Table 2.3 on the following page apply) and What You See Is What You Get (WYSIWYG) strings (which the compiler just parses blindly, without attempting to decipher escape sequences). The WYSIWYG style is very useful for representing strings that would require a flurry of escapes, two notorious examples being regular expressions and Windows path names.
Quoted strings are sequences of characters enclosed in double quotation marks, "like this". All escape sequences in Table 2.3 on the next page are meaningful inside a quoted string. Strings of all kinds are automatically concatenated when juxtaposed:
auto crlf = "
";
auto a = "This is a string with "quotes" in it, and also
a newline, actually two" "
";
The line break after also in the code above is intentional: a string literal can embed a newline (an actual newline in the source code, not a backslash followed by an n), which will be stored as such.
2.2.5.1 WYSIWYG, Hex, and imported String Literals
WYSIWYG strings either start with r" and end with a " (r"like this"), or start and end with a backquote ('like that'). Any character (aside from the respective terminating characters) can occur within a WYSIWYG string and is stored at face value. This implies that you cannot represent, say, the double quote character itself within a double-quoted WYSIWYG string. That’s not a big problem because you can concatenate literal strings obtained with various syntaxes. For example:
For practical purposes, you can consider that a double quote inside an r"string" is encoded by the sequence ‹" '" '"›, and that a backquote inside a 'string' is encoded as ‹'" '" '›. Happy quote counting.
D defines a third kind of literal string: a hex string, which is a string of hex digits and (ignored) whitespace, delimited by x" and ". Hex strings are useful for defining raw data; the compiler makes no attempt whatsoever to interpret the contents as Unicode characters or anything else but hexadecimal digits. Spaces inside a hex string are ignored.
auto
a = x"0A", // Same as "x0A"
b = x"00 F BCD 32"; // Same as "x00xFBxCDx32"
In case your hacker mind immediately started thinking about embedding binary resources into D programs, you’ll be happy to hear about a very powerful means to define a string: from a file!
During compilation, x will be initialized with the actual contents of the file resource.bin. (This is not the same as C’s #include facility because the above includes the file as data, not code.) For safety reasons, only relative paths are accepted and the search paths are controlled via a compiler switch. The reference implementation dmd uses the -J flag to control string include paths.
The string resulting from an import is not checked for UTF-8 correctness. This is intentional in order to allow importing binary resources.
2.2.5.2 Type of a Literal String
What’s the type of a literal string? Let’s run a simple experiment:
import std.stdio;
void main() {
writeln(typeid(typeof("Hello, world!")));
}
The built-in operator typeof fetches the type of an expression, and typeid makes that type into a printable string. Our little program prints
revealing that literal strings are arrays of immutable characters. In fact, the type string that we used in our code examples is a shortcut notation for the longer type immutable(char)[]. Let’s look in detail at these three aspects of string literal types: immutability, length, and base character type.
Immutability
Literal strings live in “read-only” memory. That doesn’t necessarily mean they are stored on actual non-erasable memory chips or in memory protected by the operating system, but it does mean that the language makes a pledge against overwriting of the string’s memory. The immutable keyword embodies that pledge by disallowing, during compilation, any operation that would modify the contents of an immutable piece of data:
auto a = "Nobody can change me";
a[0] = 'X'; // Error! Cannot modify an immutable string!
The immutable keyword is a type qualifier (Chapter 8 discusses qualifiers) that operates on whatever type comes to its right, obeying parentheses. If you say immutable(char)[] str, then the characters in str are not individually mutable, but str can be made to refer to a different string:
immutable(char)[] str = "One";
str[0] = 'X'; // Error! Can't assign immutable(char)!
str = "Two"; // Fine, rebind str
On the other hand, if the parentheses are not present, immutable will qualify the entire array:
Immutability has many virtues. To wit, immutable provides enough guarantees to allow indiscriminate data sharing across module and thread boundaries (Chapter 13). Since the characters of a string are not changeable, there is never contention, and sharing is safe and efficient.
Length
The length of the literal string (which is 13 for "Hello, world!") is obviously known during compilation. It might seem natural, then, to give the most precise type to each string; for example, "Hello, world!" could be typed as char[13], that is, an array of exactly 13 characters. However, experience with the Pascal language has shown that static sizes are highly inconvenient. Therefore, in D the type of literals does not include length information. However, if you really want a fixed-size string you can create one by specifying it explicitly:
Fixed-size array types T[N] are implicitly convertible to dynamically sized array types T[] for all types T. Information is not lost in the process because dynamically sized arrays remember their length:
import std.stdio;
void main() {
immutable(char)[3] a = "Hi!";
immutable(char)[] b = a;
writeln(a.length, " ", b.length); // Prints "3 3"
}
Base Character Type
Last but not least, string literals can have either char, wchar, or dchar as their base character type. You don’t need to use the long-winded type names: string, wstring, and dstring are handy aliases for immutable(char)[], immutable(wchar)[], and immutable(dchar)[], respectively. If the literal string contains at least a 4-byte character dchar, it is of type dstring; otherwise, if the literal contains at least a 2-byte character wchar, it is of type wstring; otherwise the string is of familiar type string. If a different type of string from the one inferred is expected, a literal will silently comply, as in this example:
wstring x = "Hello, wide world!"; // UTF-16-encoded
dstring y = "Hello, even wider world!"; // UTF-32-encoded
In case you want to override string type inference, you can suffix a string literal with either c, w, or d, which, similarly to the homonym character literal suffixes, force the type of the string literal to string, wstring, and dstring, respectively.
2.2.6 Array and Associative Array Literals
Strings are a particular kind of arrays featuring their own literal syntax; now, how do we express array literals of other types, for example, int or double? An array literal is represented as a comma-separated sequence of values enclosed in square brackets:
auto somePrimes = [ 2u, 3, 5, 7, 11, 13 ];
auto someDoubles = [ 1.5, 3, 4.5 ];
The size of the array is computed from the length of the comma-separated list. Unlike string literals, array literals are not immutable, so you can change them after initialization:
auto constants = [ 2.71, 3.14, 6.023e22 ];
constants[0] = 2.21953167; // The "moving sofa" constant
auto salutations = [ "hi", "hello", "yo" ];
salutations[2] = "Ave Caesar";
Notice how you can reassign a slot in salutations, but you cannot alter the content of the string stored in the slot. This is to be expected because membership in an array does not change what you can do with a string.
The element type of the array is determined by agreement among all elements of the array, which is computed by means of the conditional operator ?: (anticipating § 2.3.16). For a literal lit of more than one element, the compiler applies the expression true ? lit[0] : lit[1] and stores the type of that expression as a type L. Then for each ith element lit[2] up to the last element in lit, the compiler computes the type of true ? L.init : lit[i] and stores that type back in L. The final L is the element type of the array.
This sounds a whole lot more complicated than it really is, which is simply that the element type of the array is established by a Polish democracy consensus—a type is found to which all elements agree to implicitly convert. For example, the type of [ 1, 2, 2.2 ] is double, and the type of [ 1, 2, 3u ] is uint because taking ?: between an int and a uint yields a uint.
Associative array literals are defined with the following syntax:
auto famousNamedConstants =
[ "pi" : 3.14, "e" : 2.71, "moving sofa" : 2.22 ];
Each slot in an associative array literal has the form key : value. The key type of the associative array literal is computed by conceptually putting all keys in one array and computing the type of that array as discussed above. The value type is computed in a similar fashion. Once the key type K and the value type V are computed, the literal is typed as V[K]. The type of famousNamedConstants is, for example, double[string].
2.2.7 Function Literals
In some languages, each function has a name chosen at the point of its definition; subsequent calls of that function use its name. Other languages offer the possibility to define anonymous functions (also known as lambda functions) right at the point of their use. Such a feature is useful in powerful idioms using higher-order functions, that is, functions that take as parameters and/or return other functions. D’s function literals offer the ability to define an anonymous function in situ wherever a function name is expected.
This chapter’s sole preoccupation is to show how function literals are defined, at the expense of showcasing some interesting use cases. For illustrations of the powerful uses of this mighty feature, please accept a rain check, to be redeemed in Chapter 5. Here’s the basic syntax of a function literal:
auto f = function double(int x) { return x / 10.; };
auto a = f(5);
assert(a == 0.5);
Function literal definitions follow the same syntax as regular function definitions, the only difference being that the keyword function precedes the definition and that the name is missing. The code above doesn’t even use much anonymity because the anonymous function is immediately bound to the symbol f. The type of f is “pointer to function taking an int and returning a double.” That type itself is spelled as double function(int) (notice that the keyword function got swapped after the return type), so an equivalent definition of f would be
The seemingly odd swap of function and double actually makes everybody’s life considerably easier because it allows distinguishing a function literal from its type. To easily remember things: in a literal function comes first, whereas in the type of a function, function replaces the name of the function.
To simplify definition of a function literal, you can omit the return type and the compiler will deduce it for you because it has the body available straightaway:
Our function literal above uses only its own parameter x, so its meaning can be figured by looking inside the body of the function literal alone, and not the environment in which it is used. But what if the function literal needs to use data present at the point of call yet not passed as a parameter? In that case you must replace function with delegate:
int c = 2;
auto f = delegate double(int x) { return c * x / 10.; };
auto a = f(5);
assert(a == 1);
c = 3;
auto b = f(5);
assert(b == 1.5);
The type of f is now double delegate(int). All type deductions for function apply unchanged to delegate. This raises a legitimate question: Given that delegates can do anything functions do (after all, a delegate can but is not obligated to use variables within its environment), why bother with functions in the first place? Can’t we just use delegates throughout? The answer is simple: efficiency. Clearly delegate has access to more information, so by some immutable law of nature, it must pay for that access. In practice, the size of function is that of a pointer, while delegate is twice as big (one pointer for the function, the other for the environment).
2.3 Operators
The following subsections describe in detail all of D’s operators, in decreasing order of precedence. This order corresponds to the natural order in which you’d group together and compute small subexpressions in increasingly larger chunks.
Operators are tightly linked to two orthogonal notions: lvalues versus rvalues and numeric conversion rules. The following two subsections introduce the needed definitions.
2.3.1 Lvalues and Rvalues
Many operators work only when their left-hand side satisfies certain conditions. For example, there isn’t a need for a sophisticated justification to deem the assignment 5 = 10 invalid. For an assignment to succeed, the left-hand side operator must be an lvalue. It’s about time we defined lvalues precisely (together with rvalues, their complement). Historically, the terms originated indeed from the position of values in an assignment expression such as a = b: a stands on the left-hand side so it’s an lvalue, and b stands on the right-hand side, hence it’s an rvalue.
Defined by sheer enumeration, lvalues are composed of
- All variables, including function parameters, even if they cannot be effectively modified (e.g., are qualified with
immutable) - Elements of arrays and associative arrays
structandclassfields (which we’ll discuss later)- Function returns of
reftype (which we’ll discuss even later).
Any lvalue can act as an rvalue. Rvalues also comprise everything not explicitly mentioned above, such as literals, enumerated values (introduced with enum; see § 7.3 on page 272) and the result of expressions such as x + 5. Notice that being an lvalue is a necessary, but not sufficient, condition to allow assignment: several other semantic checks must be satisfied, such as access rights (Chapter 6) and mutability rights (Chapter 8).
2.3.2 Implicit Numeric Conversions
We’ve touched on the topic of implicit conversions already, so it’s time for a thorough treatment. As far as numeric conversions go, there really are only a few simple rules to remember:
- If a numeric expression compiles in the C language and also compiles in D, its type will be the same in both languages (note that not all C expressions must be accepted by D).
- No integral value converts implicitly to a narrower one.
- No floating-point value converts implicitly to an integral value.
- Any numeric value (integral or floating-point) converts implicitly to any floating-point value.
Rule 1 makes things just a tad more complicated than they would otherwise be, but D overlaps enough with C and C++ to inspire people to simply copy and paste entire functions into D programs. Now it’s all right if D occasionally refuses to compile certain constructs for safety or portability reasons; but if it compiled that 2000-line encryption package and ran it with different results, life would definitely not be good for the hapless victim. However, rule 2 tightens the screws more than C and C++. So when porting code, the occasional diagnostic will point you to rough portions of code and prompt you to insert the appropriate checks and explicit casts.
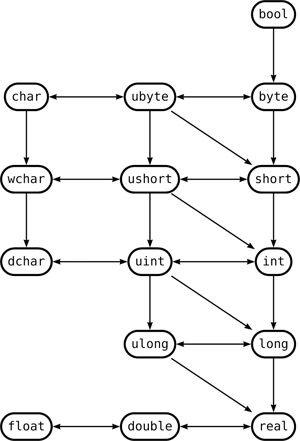
Figure 2.3 on the next page illustrates the conversion rules for all numeric types. In a conversion, the shortest path is taken; when two paths have equal length, the result of the conversion is the same. Regardless of the number of steps, the conversion is considered a one-step process, and there are no priorities or orderings among conversions—either a type converts to another or not.
Figure 2.3. Implicit integral conversions. A type is automatically convertible to another type if and only if there is a directed path in the graph from the source type to the destination type. The shortest path is taken, and conversion is considered one-step regardless of the actual path length. Conversions in the opposite directions are possible if value range propagation (§ 2.3.2.1 on the previous page) verifies validity.
2.3.2.1 Value Range Propagation
By the rules described above, a banal number such as 42 would be considered unequivocally of type int. Now consider the following equally banal initialization:
Following the inexorable laws of typechecking, 42 is first recognized as an int. That int is subsequently assigned to x, a process that incurs a coercion. Allowing such an unqualified coercion is dangerous (there are many ints that can’t actually fit in a ubyte). On the other hand, requiring a cast for code that is so obviously correct would be thoroughly unpleasant.
D breaks this conundrum in an intelligent way inspired by a compiler optimization known as value range propagation: each value in an expression is associated with a range consisting of the minimum and maximum possible values. These bounds are tracked during compilation. When some value is assigned to a narrower type, the compiler allows the assignment if and only if the value’s range fits within the target type. For a constant such as 42, obviously the minimum and maximum possible values are 42 and 42, so the assignment goes through.
Of course, that trivial case could have been figured much more easily, but value range propagation checks correctness in much more interesting situations. Consider a function that extracts the least significant and the most significant bytes from an int:
The code is correct regardless of the input value val. The first expression masks the value eliminating all high-order bits, and the second shifts the expression such that the most significant byte of val migrates to the least significant byte, and everything else is zeroed.
Indeed, the compiler types fun correctly because in the first case it computes the range of val & 0xFF between 0 and 255 regardless of val, and in the second case it computes the range of val >>> 24, again from 0 through 255. If you tried operations yielding values that don’t necessarily fit in a ubyte (such as val & 0x1FF or val >>> 23), the compiler would not have accepted the code.
Value range propagation “understands” all arithmetic and logic operations; for example, a uint divided by 100,000 will always fit within a ushort and also works correctly in complex expressions, such as a masking followed by a division. For example:
In the example above, the & operator sets the bounds to 0 through 0xF0F0, which is 61,680 in decimal. Then the division sets the bounds to 0 through 205. Any number within that range fits in a ubyte.
Using value range propagation to differentiate between correct and incorrect narrowing conversions is an imperfect, conservative mechanism. For one thing, tracking of value ranges is carried only myopically, inside an expression but not across consecutive expressions. For example:
void fun(int x) {
if (x >= 0 && x < 42) {
ubyte y = x; // Error!
// Cannot coerce int to ubyte!
...
}
}
Clearly the initialization is correct, but the compiler does not recognize it. It could, but that would complicate the implementation and slow down the compilation process. It was decided to go with the less sensitive per-expression value range propagation. Experience with the feature as implemented reveals that this conservative estimate tends to remove most undue coercion errors in a program. For the remaining false positives, you may want to use the cast expression (§ 2.3.6.7 on page 53).
2.3.3 Typing of Numeric Operators
Many of the coming sections introduce operators applicable to numeric types. The type of the value yielded by operators on numbers is computed by using a few rules. They aren’t the best rules that could be devised but are simple enough, uniform, and systematic.
The type yielded by unary operators is the same as the operand, except for the negation operator !, to be defined in § 2.3.6.6 on page 53, which always yields bool. For binary operators, the type of the result is computed as follows:
- If at least one participant in the operator application has a floating-point type, then the result type is that of the largest floating-point type involved.
- Otherwise, if at least one participant has type
ulong, the other is implicitly converted toulongprior to the application and the result has typeulong. - Otherwise, if at least one participant has type
long, the other is implicitly converted tolongprior to the application and the result has typelong. - Otherwise, if at least one participant has type
uint, the other is implicitly converted touintprior to the application and the result has typeuint. - Otherwise, implicitly convert both operands to
intand apply the operator. The result has typeint.
All implicit conversions take the shortest path depicted in Figure 2.3 on page 44. This is an important detail; consider, for example, the following:
In the division operation, 10 has type int and according to the rules above x is implicitly converted to int prior to the operation. Figure 2.3 shows several possible paths, among which are the direct conversion ushort → int and the slightly longer (one hop) ushort → short → int. The second is undesirable because converting 60000 to short yields -5536, which is further promoted to an int and causes the assert to fail. Choosing the shortest path in the conversion graph ensures better value preservation.
2.3.4 Primary Expressions
Primary expressions are atoms of evaluation. We’ve already met with symbols (§ 2.1 on page 30), the Boolean literals true and false (§ 2.2.1 on page 32), integral literals (§ 2.2.2 on page 32), floating-point literals (§ 2.2.3 on page 33), character literals (§ 2.2.4 on page 34), string literals (§ 2.2.5 on page 35), array literals (§ 2.2.6 on page 39), and function literals (§ 2.2.7 on page 40); they are all primary expressions, as is the literal null. The following subsections describe the other primary subexpressions: assert expressions, mixin expressions, is expressions, and parenthesized expressions.
2.3.4.1 The assert Expression
Several expressions and statements, including assert itself, use the notion of nonzero values. These values can be of (a) numeric or character type, in which case nonzero has the obvious meaning; (b) Boolean type (nonzero means true); or (c) array, reference, and pointer types (nonzero means non-null).
The expression assert(expr) evaluates expr. If expr is nonzero, there is no effect. Otherwise, the assert expression throws an exception of type AssertError. The form assert(expr, message) makes message (which must be convertible to a string type) part of the error message contained within the AssertError object. (message is not evaluated if expr is nonzero.) In all cases, assert’s own type is void.
When you want to build a program for ultimate efficiency, the D compiler offers a switch (-release for the reference implementation dmd) to ignore all assert expressions in a module (not evaluate expr at all). As such, assert should be seen as a debugging tool and not a means for testing conditions that might legitimately fail. For the same reason it’s incorrect to put expressions with side effects inside assert expressions if the program behavior depends on those side effects. For more details about release builds, refer to Chapter 11.
The case assert(false), assert(0), or in general assert against a statically known zero value is handled in a particular manner. That assertion is always enabled (regardless of build flags) and issues the HLT machine code instruction that abruptly stops execution of the process. Such an interrupt may prompt the operating system to generate a core dump or to start the debugger on the offending line.
Foreshadowing the logical OR expression (§ 2.3.15 on page 59), a simple idiom for always evaluating an expression and asserting on its result is (expr) || assert(false).
Chapter 10 discusses in depth assert and other mechanisms for ensuring program correctness.
2.3.4.2 The mixin Expression
If expressions were various kinds of screwdrivers, mixin would be a power screwdriver with exchangeable heads, adjustable clutch, a brain surgery adapter, built-in wireless camera, and speech recognition. It’s that powerful.
In short, the mixin expression allows you to make a string into executable code. The expression’s syntax is mixin(expr), where expr must be a compile-time-known string. The restriction rules out dynamic scripting abilities such as reading a string from the terminal and interpreting it; no, D is not an interpreted language, and neither does it make the compiler part of the standard runtime support. The good news is that D does run a full-fledged interpreter during compilation, which means that you can build strings in ways as sophisticated as needed.
The ability to manipulate strings and transform them into code during compilation enables the creation of the so-called domain-specific embedded languages, fondly called DSELs by their fans. A typical DSEL implemented in D would accept DSEL statements as a string literal, process it during compilation, create the corresponding D code in string form, and use mixin to transform the string into D. As fancy as they sound, DSELs are very down-to-earth and practical. Good examples of useful DSELs are SQL commands, regular expressions, and grammar specifications (à la yacc). In fact, if you’ve ever used printf, you did DSELs. The format specifier used by printf is really a small language that specializes in describing textual data layouts.
D allows you to create any DSEL without using any additional tools (parsers, binders, code generators, ...); to wit, the standard library function bitfields (in module std.bitmanip) accepts bit field definitions and generates optimal D code for reading and writing them, even though the language itself does not support bit fields.
2.3.4.3 is Expressions
The is expressions answer queries about types (“Does a type called Widget exist?” or “Does Widget inherit Gadget?”) and are an important part of D’s powerful compile-time introspection. Evaluation of all is expressions occurs during compilation and returns an answer to a query as a bool constant. There are multiple forms of is expressions, as shown below.
- The forms
is(Type)andis(Type Symbol)check whether a type exists. The type may be illegal or, most often, just not exist. For example:
bool
a = is(int[]), // True, int[] is a valid type
b = is(int[5]), // True, int[5] is also valid
c = is(int[-3]), // False, array size is invalid
d = is(Blah); // False (if Blah wasn't defined)In all cases,
Typemust be syntactically valid even if it is semantically invalid; for example,is([]x[])is a compile-time error, not afalseconstant. In other words, you can make queries only about things that syntactically look like types.If
Symbolis present, it becomes an alias ofTypein thetruecase. This can be useful ifTypeis long and complicated. The as-yet-unseenstatic ifstatement distinguishes thetruecase from thefalseone. Chapter 3 discussesstatic ifin full detail, but the basic plot is simple—static ifevaluates a compile-time expression and compiles the controlled statement only if the expression istrue.
static if (is(Widget[100][100] ManyWidgets)) {
ManyWidgets lotsOfWidgets;
...
} - The forms
is(Type1 == Type2)andis(Type1 Symbol == Type2)yieldtrueifType1is identical toType2. (They might have different names through the use ofalias.)
If
Symbolis present, it becomes an alias ofType1in thetruecase. - The forms
is(Type1 : Type2)andis(Type1 Symbol : Type2)yieldtrueifType1is identical to, or implicitly convertible to,Type2. For example:
bool
a = is(int[5] : int[]), // True, int[5] convertible to int[]
b = is(int[5] == int[]), // False; they are distinct types
c = is(uint : long), // True
d = is(ulong : long); // TrueAgain, if
Symbolis present and theisexpression evaluates totrue,Symbolbecomes an alias ofType1. - The forms
is(Type == Kind)andis(Type Symbol == Kind)check the kind ofType. A kind is one of the following keywords:struct,union,class,interface,enum,function,delegate, andsuper. The expression istrueifTypeis of the respective kind. If present,Symbolis defined depending on the kind, as shown in Table 2.4.Table 2.4. Bindings for
Symbolin the formis(Type Symbol == Kind)
2.3.4.4 Parenthesized Expressions
Parentheses override usual precedence order: for any expression ‹expr›, (‹expr›) is a primary expression.
2.3.5 Postfix Expressions
2.3.5.1 Member Access
The member access operator a . b accesses the member named b within the object or type a. If a is a complicated value or type, it may be parenthesized. b can also be a new expression (see Chapter 6).
2.3.5.2 Increment and Decrement
All numeric and pointer types support the postincrement operator (lval++) and the postdecrement operator (lval--) with semantics similar to the homonym operators found in C and C++: evaluating postincrement or postdecrement increments lval but yields a copy of it before the modification. lval must be an lvalue. (For the related preincrement and predecrement operators see § 2.3.6.3 on page 53.)
2.3.5.3 Function Call
The familiar function call operator fun() invokes function fun. The syntax fun(‹comma-separated list›) also passes fun an argument list. All arguments are evaluated left to right before fun gets invoked. The function type must be in agreement with the number and types of the values in the argument list. If the function was defined with the @property attribute, specifying the function name alone is equivalent to invoking that function without any arguments. Usually fun is the name of a defined function, but it may also be a function literal (§ 2.2.7 on page 40) or an expression yielding a pointer to a function or delegate. Chapter 5 describes functions in detail.
2.3.5.4 Indexing
The expression arr[i] accesses the ith (zero-based) element of array or associative array arr. If the array is non-associative, i must be of an integral type. Otherwise, i must be implicitly convertible to arr’s key type. If the indexing expression is on the left-hand side of an assignment operation (e.g., arr[i] = e) and a is an associative array, the expression inserts an element in the array if it wasn’t present. In all other cases, if i does not refer to an existing element of arr, the expression throws a RangeError object. The expression arr[i] also works if arr has pointer type and i has integral type. Pointer indexing is unchecked. Certain build modes (release unsafe builds; see § 4.1.2 on page 95) may disable bounds checking for non-associative arrays altogether.
2.3.5.5 Array Slices
If arr is a linear (non-associative) array, the expression arr[i .. j] returns an array referring to a window inside arr starting at index i and ending at (without including) index j. The bounds i and j must be convertible to integral types. The expression arr[] takes a slice of arr as large as arr itself. No actual data is copied, so modifying the array returned by the slice operator modifies arr’s contents. For example:
int[] a = new int[5]; // Create an array of five integers
int[] b = a[3 .. 5]; // b refers to the last two elements of a
b[0] = 1;
b[1] = 3;
assert(a == [ 0, 0, 0, 1, 3 ]); // a was modified
If i > j or j > a.length, the operator throws a RangeError object. Otherwise, if i == j, an empty array is returned. The expression arr[i .. j] also works if arr has pointer type and returns an array reflecting the memory region from arr + i up to (and excluding) arr + j. If i > j, a RangeError object is thrown, but otherwise range slicing from pointers is unchecked. Again, release unsafe builds (§ 4.1.2 on page 95) may disable all bounds checking for slices.
2.3.5.6 Nested Class Creation
An expression of the form a.new T, where a is of class type, creates an object of type T whose definition is nested inside a’s definition. If it is confusing, it is because classes, nested classes, and even new expressions haven’t been defined yet. The definition of the new expression is right around the corner (§ 2.3.6.1), but for the definition of classes and nested classes please wait until Chapter 6 (specifically § 6.11 on page 222). Until then, this paragraph is a placeholder inserted for completeness purposes.
2.3.6 Unary Expressions
2.3.6.1 The new Expression
A new expression has one of the following forms:
new (‹addr›)opt ‹Type›
new (‹addr›)opt ‹Type›(‹arglist›opt)
new (‹addr›)opt ‹Type›[‹arglist›]
new (‹addr›)opt ‹AnonymousClass›
Let’s ignore the optional (‹addr›) for the moment. The first two forms new T and new T(‹arglist›opt) dynamically allocate an object of type T. The latter form optionally passes some arguments to T’s constructor. (The forms new T and new T() are entirely equivalent and create a default-initialized object.) We haven’t yet looked at types with constructors, so let’s defer that discussion to the treatment of classes in Chapter 6 (specifically § 6.3 on page 181) and of other user-defined types in Chapter 7 (see § 7.1.3 on page 243). Let’s also defer anonymous class allocation (last line above) to Chapter 6, § 6.11.3 on page 226.
Here, let’s focus on allocating the already familiar arrays. The expression new T[n] allocates a contiguous chunk of memory large enough to accommodate n objects back to back, fill those slots with T.init, and return a handle to them in the form of a T[] value. For example:
The same result can be achieved with a slightly different syntax:
This time, the expression is interpreted as new T(4), where T is int[]. Again, the net result is an array of four elements handled by arr, which has type int[].
The second form is actually more generous than the first. If you want to allocate an array of arrays, you can specify multiple arguments in the parentheses. They count as dimension initializers, in row order. For example, here’s how you allocate an array of four arrays, each having eight elements:
auto matrix = new int[][](4, 8);
assert(matrix.length == 4);
assert(matrix[0].length == 8);
The first line in the snippet above supplants the more verbose
auto matrix = new int[][](4);
foreach (ref row; matrix) {
row = new int[](8);
}
All allocations discussed so far grab memory off the garbage-collected heap. Memory that becomes unused and inaccessible to the program is automatically recycled. The runtime support of the reference implementation offers a number of specialized primitives for manipulating garbage-collected memory in module core.gc, including changing the size of an already allocated block or manually freeing memory. Manual memory management is risky, so you should avoid it unless absolutely necessary.
The optional address addr passed right after the new keyword introduces a construct known as placement new. The semantics of new(addr) T in that case is different: instead of allocating memory for a new object, just create an object in place at the given address addr. This is a low-level feature that does not occur in normal code; for example, you could use it if you want to allocate memory off C’s heap with malloc and then use it to store D values.
2.3.6.2 Address and Dereference
Since pointers are a future topic, we’ll just mention the dual operators address-of and dereference in passing. The expression &lval fetches the address of lval (as its name suggests, lval must be an lvalue) and returns a pointer of type T*, for lval of type T.
The converse operator *p dereferences a pointer in a way that cancels out & and makes *&lval the same as lval. A detailed discussion of pointers is intentionally deferred to Chapter 7 because you should be able to write a great deal of good D code without relying on pointers—a low-level and dangerous feature par excellence.
2.3.6.3 Preincrement and Predecrement
The expressions ++lval and --lval respectively increment and decrement lval and also offer as a result the freshly changed value of lval. lval must have numeric or pointer type.
2.3.6.4 Bitwise Complement
The expression ~a toggles (reverses) every bit in a and has the same type as a itself. a must have integral type.
2.3.6.5 Unary Plus and Unary Minus
The expression +val does nothing noteworthy—it’s present for completeness only. The expression -val computes 0 - val and applies to numeric types.
One surprising behavior of unary minus is that, when applied to an unsigned value, it still yields an unsigned value (according to the rules in § 2.3.3 on page 45). For example, -55u is 4_294_967_241, which is uint.max - 55 + 1.
The fact that unsigned types are not really natural numbers is a fact of life. In D and many other languages, two’s complement arithmetic with its simple overflow rules is an inescapable reality that cannot be abstracted away. One way to think of -val for any integral value val is to consider it a short form of ~val + 1; in other words, flip every bit in val and then add 1 to the result. This manipulation does not raise particular questions about the signedness of val.
2.3.6.6 Negation
The expression !val has type bool and yields false if val is nonzero (see the definition of nonzero 46) and true otherwise.
2.3.6.7 Cast Expressions
The cast operator is like the mighty and well-intended lamp genie hurrying to save the day. Much like a cartoonish lamp genie, the cast is mischievous, hard of hearing, and prone to taking advantage of poorly worded wishes by fulfilling them all too mechanically—often with disastrous consequences.
That being said, casts can occasionally be useful when the static type system isn’t smart enough to keep pace with your exploits. The cast syntax is cast(Type) a. There are several kinds of casts, ranked below in decreasing order of safety:
- Reference casts allow you to convert among references to
classandinterfaceobjects. These casts are always checked dynamically. - Numeric casts coerce data from any numeric type to any other numeric type.
- Array casts allow you to convert across different array types, as long as the total size of the source array is divisible by the element size of the target array.
- Pointer casts take a pointer to one type and transform it into a pointer to another type.
- Pointer-numeric casts deposit a pointer into an integral type large enough to hold it, and vice versa.
Be extremely careful with all unchecked casts, particularly the last three, which may violate the integrity of the type system.
2.3.7 The Power Expression
The power expression has the form base ^^ exp and raises base to the power of exp. Both base and exp must be of numeric type. The offered functionality is the same as that of the library function pow(base, exp) found in C’s and D’s standard libraries (consult your documentation for the std.math module). However, certain numeric applications do benefit from the syntactic simplification.
Raising zero to power zero is one, and raising zero to any nonzero power is zero.
2.3.8 Multiplicative Expressions
The multiplicative expressions are multiplication (a * b), division (a / b), and remainder (a % b). They operate on numeric types only.
If b is zero in the integral operation a / b or a % b, a hardware exception is thrown. If the division would yield a fractional number, it is always truncated toward zero (for example, 7 / 3 yields 2 and -7 / 3 yields -2). The expression a % b is defined such that a == (a / b) * b + a % b, so 7 % 3 yields 1 and -7 / 3 yields -1.
D also defines modulus for floating-point numbers. The definition is more involved. When at least one of a and b is a floating-point value in a % b, the result is the largest (in absolute value) floating-point number r satisfying the following conditions:
aandrdo not have opposite signs.ris smaller thanbin absolute value,abs(r) < abs(b).- There exists an integer
qsuch thatr == a - q * b.
If such a number cannot be found, a % b yields the Not A Number (NaN) special value.
2.3.9 Additive Expressions
The additive expressions are addition a + b, subtraction a - b, and concatenation a ~ b.
Addition and subtraction operate on numeric types only. The type of the result is determined as described in § 2.3.3 on page 45.
Concatenation requires that at least one of a and b be an array type holding elements of some type T. The other value must be either an array of T or a value implicitly convertible to type T. The result is a new array composed of the juxtaposition of a and b.
2.3.10 Shift Expressions
There are three shift operators in D, all taking two integral values: a << b, a >> b, and a >>> b. In all cases, b must be of an unsigned type; if all you have is a signed value, you must cast it to an unsigned type (likely after ensuring that b >= 0; shifting by a negative amount yields an unspecified value). a << b shifts a to the left (i.e., in the direction of a’s most significant bit) by b bits, and a >> b shifts a to the right by b bits. If a is negative, shifting preserves its sign.
a >>> b is an unsigned shift regardless the signedness of a. This means that a zero will be shifted into a’s most significant bit, guaranteed. To exemplify the sometimes surprising effects of shifts over signed numbers:
int a = -1; // That's 0xFFFF_FFFF
int b = a << 1;
assert (b == -2); // 0xFFFF_FFFE
int c = a >> 1;
assert (c == -1); // 0xFFFF_FFFF
int d = a >>> 1;
assert(d == +2147483647); // 0x7FFF_FFFF
Shifting by more than the number of bits in a’s type is disallowed during compilation if b is a statically known value, and it leaves an implementation-dependent value in a if b is a runtime value:
int a = 50;
uint b = 35;
a << 33; // Compile-time error
auto c = a << b; // Implementation-defined result
auto d = a >> b; // Implementation-defined result
In all cases, the type of the result is determined according to the rules in § 2.3.3 on page 45.
A historically popular use of shifting was as an inexpensive integral multiplication by 2 (a << 1) or division by 2 (a >> 1)—or, in general, multiplication and division by various powers of 2. This technique has gone the way of the videotape. Just write a * k or a / k; as long as k is a compile-time-known quantity, your trusty compiler will generate the optimal code for you with shift and all, without you having to worry about getting the sign subtleties right. Shift happens.
2.3.11 in Expressions
If key is a value of type K and map is an associative array of type V[K], then key in map yields a value of type V* (pointer to V). If the associative array contains the pair ‹key, val›, then the pointer points to val. Otherwise, the pointer yielded is null.
For the converse negative test, you may of course write !(key in map) but also the terser form key !in map, which has the same precedence as key in map.
Why all the pointer aggravation instead of just having a in b yield a bool? It’s for efficiency. Oftentimes, you want to look up an index in an associative array and use the mapped element if present. A possibility would be
double[string] table;
...
if ("hello" in table) {
++table["hello"];
} else {
table["hello"] = 0;
}
The problem with the code above is that it performs two lookups on the successful path. Using the returned pointer, the code can be written more efficiently like this:
double[string] table;
...
auto p = "hello" in table;
if (p) {
++* p;
} else {
table["hello"] = 1;
}
2.3.12 Comparison Operators
2.3.12.1 Comparing for Equality
a == b, of type bool, has the following semantics: First, if the two operands don’t have the same type, an implicit conversion brings them to the same type. Then the operands are compared for equality as follows:
- For integral types and pointers, equality is defined as an exact bitwise comparison of the bit pattern of the values.
- For floating-point types,
-0is considered equal to+0, and NaN is considered unequal to NaN.3 In all other cases equality is defined as bit pattern equality. - For objects of
classtype, equality is defined with the help of theopEqualsoperator (see § 6.8.3 on page 205). - For arrays, equality means element-for-element equality.
- For objects of
structtype, equality is by default defined as field-for-field equality. User-defined types may override this behavior (see Chapter 12).
The form a != b tests for non-equality.
The expression a is b compares for alias equality and returns true if a and b refer to the same actual object.
- If
aandbare arrays or class references, the result istrueif and only ifaandbare two names for the same actual object; - Otherwise,
a is bis the same asa == b.
We haven’t looked into classes yet, but an example with arrays should be helpful:
import std.stdio;
void main() {
auto a = "some thing";
auto b = a; // a and b refer to the same array
a is b && writeln("Yep, they're the same thing really");
auto c = "some (other) thing";
a is c || writefln("Indeed... not the same");
}
The code above prints both messages because a and b are bound to the same actual array, whereas c is bound to a different one. In general, it’s possible that the content of two arrays is equal (so a == c is true), but they point to different regions of memory so they fail the a is c test. Of course, if a is c is true, definitely a == c is true as well, unless you bought your RAM chips at a very, very deep discount.
The inequality operator a !is b is shorthand for !(a is b).
2.3.12.2 Comparing for Ordering
D defines the expressions a < b, a <= b, a > b, and a >= b, of type bool, with the usual meanings: less than, less than or equal, greater than, greater than or equal. When numbers are compared, one of them must be implicitly convertible to the other’s type. For floating-point operands, -0 and 0 are considered equal so -0 < 0 yields false, whereas 0 <= -0 yields true. All ordering comparison operators return false whenever at least one of their operands is a NaN (as paradoxical as this might seem).
As always, NaNs tend to mess things up whenever legit floating-point numbers are trying to have a good time. All comparisons that receive at least one NaN engenders a floating-point exception. That is not an actual exception in the usual programming language terminology, but a hardware-level state that can be checked explicitly. D offers an interface with the floating-point hardware via the std.c.fenv module.
2.3.12.3 Non-associativity
One important characteristic of all of D’s comparison operators is that they are not associative. Any chaining of comparison operations, such as a <= b < c, is illegal.
One simple way to define comparison operators is to have them yield bool. Boolean values can be compared themselves, which would create the unfortunate state of affairs that a <= b < c does not have the meaning expected by the little mathematician inside all of us struggling to get out. Instead, the expression would be parsed as (a <= b) < c, or “Compare the Boolean resulting from a <= b with c.” For example, 3 <= 4 < 2 would yield true! Such semantics is almost never what you’d want.
A possible solution would be to allow a <= b < c and impart to it the intuitive mathematical meaning, which is a <= b && b < c, with the perk that b gets evaluated only once. Languages such as Python and Perl 6 have embraced this semantics, allowing arbitrary chains of comparisons such as a < b == c > d < e. D, on the other hand, has a different heritage. Allowing C expressions but with subtly different semantics (albeit arguably in the right direction) would add more confusion than convenience, so D chose to simply disallow the construct.
2.3.13 Bitwise OR, XOR, AND
Expressions a | b, a ^ b, and a & b evaluate the OR, XOR, and AND bitwise operations, respectively. Both sides are evaluated (no short-circuit) even when the result would be entirely determined by one side alone.
Both a and b must have integral types. The type of the result is determined according to § 2.3.3 on page 45.
2.3.14 Logical AND
In light of the above, it should come as no surprise that the semantics of the expression a && b depends on the type of b.
- If the type of
bis notvoid, then the expression has typebool. Ifais nonzero, the expression evaluatesband yieldstrueif and only ifbis nonzero. Otherwise, the expression evaluates tofalse. - If
bhas typevoid, the expression has typevoidas well. Ifais nonzero,bis evaluated. Otherwise,bis not evaluated.
Using && with a void expression on the right-hand side is useful as shorthand for an if statement:
2.3.15 Logical OR
The semantics of the expression a || b depends on the type of b.
- If the type of
bis notvoid, then the expression has typebool. Ifais nonzero, the expression evaluates totrue. Otherwise, the expression evaluatesband yieldstrueif and only ifbis nonzero. - If
bhas typevoid, the expression has typevoidas well. Ifais nonzero,bis not evaluated. Otherwise,bis evaluated.
The second instance is useful for handling contingency cases:
2.3.16 The Conditional Operator
The conditional operator is an if-then-else expression with the syntax a ? b : c, with which you might be familiar already. If a is nonzero, the conditional expression evaluates and yields b; otherwise, the expression evaluates and yields c. The compiler makes heroic efforts to find the “tightest” common type of b and c, which becomes the type of the conditional expression. That type (let’s call it T) is computed by using a simple algorithm (shown below with examples):
- If
aandbhave the same type,Tis that type; - else if
aandbare integrals, first promote anything smaller than 32-bit toint, then chooseTas the larger type, with a preference for unsigned type if tied in size; - else if one is an integral and the other is a floating-point type,
Tis the floating-point type; - else if both have floating-point types,
Tis the larger of the two; - else if the types have a common supertype (e.g., base class),
Tis that supertype (we will return to this topic in Chapter 6); - else try implicitly converting
atob’s type andbtoa’s type; if exactly one of these succeeds,Tis the type of the successful conversion target; - else the expression is in error.
Moreover, if b and c have the same type and are both lvalues, the result is an lvalue as well, allowing you to write
int x = 5, y = 5;
bool which = true;
(which ? x : y) += 5;
assert(x == 10);
Many generic programming idioms use the conditional operator to assess the common type of two values.
2.3.17 Assignment Operators
Assignment operators take the form a = b or a ω= b, where ω stands for one of the following: ^^, *, /, %, +, -, ~, <<, >>, >>>, |, ^, &, and “obligatory use of Greek letters in a programming book.” The previous sections have already introduced the stand-alone versions of these operators.
The semantics of a ω= b is identical to that of a = a ω b, with the notable difference that a is evaluated only once (imagine a and b as arbitrarily complex expressions, as in array[i * 5 + j] *= sqrt(x)).
Regardless of the precedence of ω, the precedence of ω= is the same as that of = itself, just below the conditional operator (discussed just above) and a notch tighter than the comma operator’s precedence (discussed just below). Also, regardless of ω’s associativity, all ω = operators (and also =) collectively associate right to left; for example, a /= b = c -= d is the same as a /= (b = (c -= d)).
2.3.18 The Comma Operator
Expressions separated by commas are evaluated in sequence. The result of the entire expression is the result of the rightmost expression. Example:
After the snippet above is executed, the values of a, b, and c are 10, 7, and 8, respectively.
2.4 Summary and Quick Reference
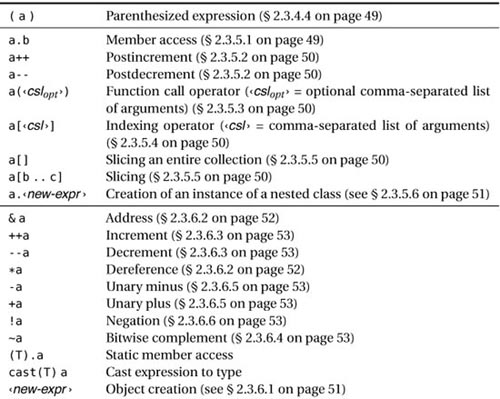
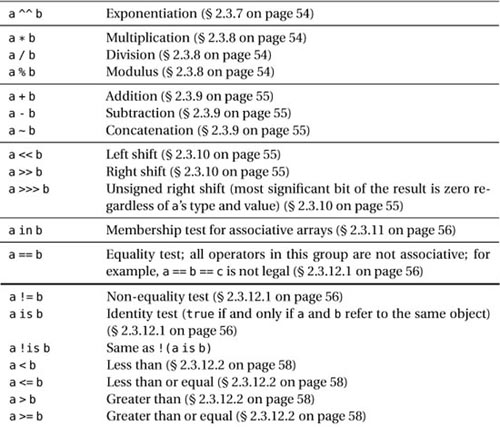
This about concludes D’s rich ways to build expressions. Table 2.5 summarizes all of D’s operators and is the place to which you may want to return whenever you’re in need of a quick reference.
Table 2.5. Expressions in decreasing order of precedence


![]()