
15
Putting the pieces together
This chapter covers
- A bells-and-whistles version of ServiceMonitor
- Whether to use modules
- What an ideal module might look like
- Keeping module declarations clean
- Comparing the module system to build tools, OSGi, and microservices
Now that we’ve covered pretty much everything there is to know about the module system, it’s time to wrap things up. In this final chapter, I want to connect the dots and give a few pieces of advice for creating awesome modular applications.
The first step is to show you an example of how the various features discussed throughout the book can come together by applying most of them to the ServiceMonitor application (section 15.1). Then I’ll take a deep dive into a number of more general concerns that will help you decide whether to even create modules, what to aim for when doing so, and how to carefully evolve your module declarations so they stay squeaky clean (section 15.2). I’ll close with a review of the technology landscape surrounding the module system (section 15.3) and my vision for Java’s modular ecosystem (section 15.4).
15.1 Adding bells and whistles to ServiceMonitor
Chapter 2 showed the anatomy of the ServiceMonitor application. In section 2.2, you created simple modules that only used plain requires and exports directives. Since then, we’ve not only discussed those in detail but also explored the module system’s more-advanced features. We’ve looked at each of them individually, but now I want to put them all together.
To enjoy the ServiceMonitor application in all its glory, check out the repository’s features-combined branch. The following listing contains the declarations for all the modules in ServiceMonitor.
Listing 15.1 ServiceMonitor, using advanced features presented throughout the book
module monitor.observer {
exports monitor.observer;
exports monitor.observer.utils ①
to monitor.observer.alpha, monitor.observer.beta;
}
module monitor.observer.alpha {
requires monitor.observer;
provides monitor.observer.ServiceObserverFactory ②
with monitor.observer.alpha.AlphaServiceObserverFactory;
}
// [...] ③
module monitor.statistics {
requires transitive monitor.observer; ④
requires static stats.fancy; ⑤
exports monitor.statistics;
}
module stats.fancy {
exports stats.fancy;
}
module monitor.persistence {
requires transitive monitor.statistics; ④
requires hibernate.jpa; ⑥
exports monitor.persistence;
opens monitor.persistence.entity; ⑦
}
module monitor.rest {
requires transitive monitor.statistics; ④
requires spark.core; ⑥
exports monitor.rest;
}
module monitor {
requires monitor.observer;
requires monitor.statistics;
requires monitor.persistence;
requires monitor.rest;
uses monitor.observer.ServiceObserverFactory; ②
}
If you compare this listing to listing 2.2 or look at figure 15.1, you can see that the fundamental structure of ServiceMonitor has stayed pretty much the same. But looking closer, you can see a number of improvements. Let’s go over them one by one.

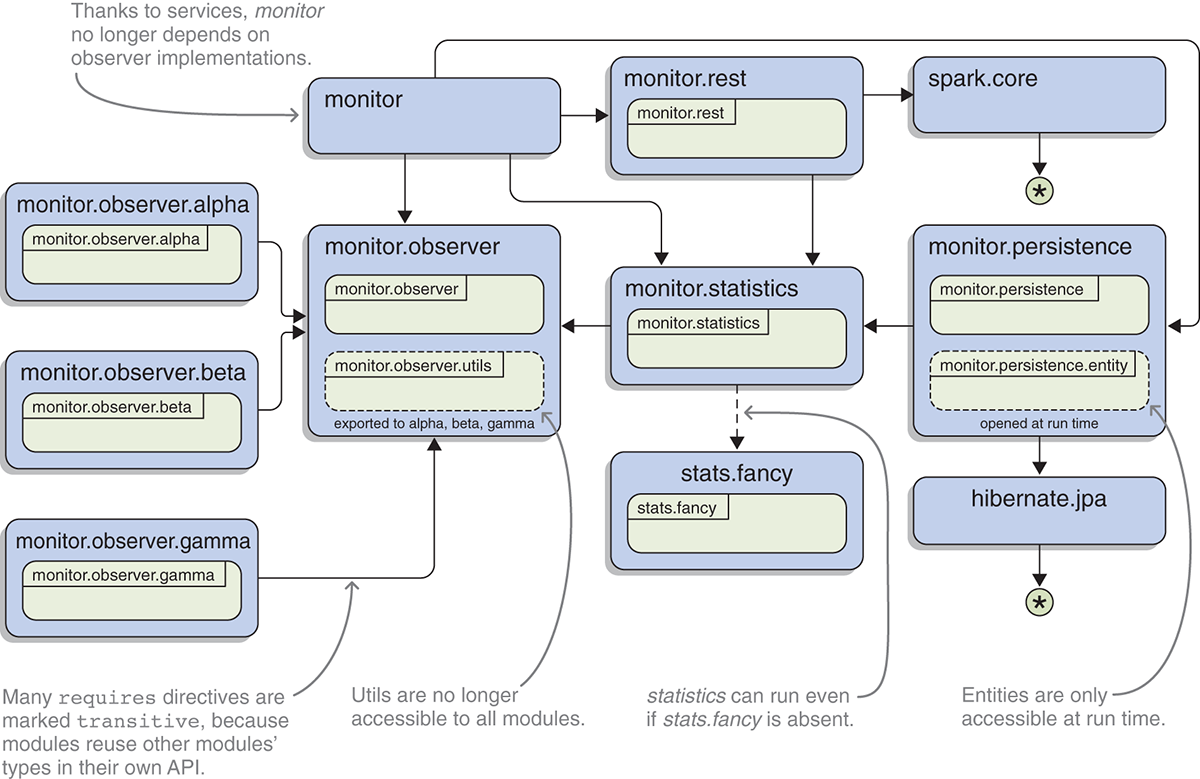
Figure 15.1a Comparison of module graphs for the ServiceMonitor application depending on feature use. The first variant only uses plain exports and requires directives (a), whereas the second makes full use of refined dependencies and exports as well as services (b). (The basic variant has been extended to include the same modules and packages as the advanced one.)
15.1.1 Diversified dependencies
One change that’s easy to spot are the requires transitive and requires optional directives. Although plain requires directives are the right choice in most cases, a significant portion of dependencies are a little more complicated.
The most obvious case is optional dependencies, where a module uses types from another module and hence needs to be compiled against it, but the dependency may still be absent at run time. This is exactly the case for monitor.statistics and stats.fancy, so the dependency is established with a requires static directive.
The module system will then enforce the presence of stats.fancy when compiling monitor.statistics (which makes sense, because otherwise compilation would fail) and will add a reads edge from monitor.statistics to stats.fancy if the latter made it into the module graph (which also makes sense, because otherwise monitor.statistics couldn’t access types from stats.fancy). But stats.fancy may not make it into the module graph, in which case monitor.statistics has to handle its absence.
Listing 15.2 Checking whether the optional dependency stats.fancy is present
private static boolean checkFancyStats() {
boolean isFancyAvailable = isModulePresent("stats.fancy");
String message = "Module 'stats.fancy' is"
+ (isFancyAvailable ? " " : " not ")
+ "available.";
System.out.println(message);
return isFancyAvailable;
}
private static boolean isModulePresent(String moduleName) {
return Statistician.class
.getModule()
.getLayer()
.findModule(moduleName)
.isPresent();
}
Optional dependencies are discussed in detail in section 11.2.
The other case is a little less obvious than optional dependencies, but no less common—maybe even more so. The module monitor.rest, for example, has this method in its public API:
public static MonitorServer create(Supplier<Statistics> statistics) {
return new MonitorServer(statistics);
}
But Statistics comes from monitor.statistics, so any module using rest needs to read statistics or it can’t access Statistics and thus can’t create a MonitorServer. In other words, rest is useless to modules that don’t also read statistics. In the ServiceMonitor application, this happens surprisingly often: every module that requires at least one other module and exports a package ends up being in that situation.
That’s considerably more frequent than out in the wild and only happens that often because the modules are so small that almost all of their code is public API—it would be surprising if they didn’t constantly expose their dependencies’ types in their own APIs. So although this occurs more rarely in practice, you can still expect to see it on a daily basis—in the JDK, roughly 20% of the dependencies are exposed.
To not keep users guessing about which other modules they need to require explicitly, which is cumbersome and bloats module declarations, the module system offers requires transitive. Because rest requires transitive statistics, any module reading rest also reads statistics, and thus users of rest are spared the guesswork. Implied readability is discussed in detail in section 11.1.
15.1.2 Reduced visibility
Another change from the application’s original versions in section 2.2 is that its modules work harder to reduce their API surface. The updated modules use considerably fewer plain exports directives:
- Thanks to services, the observers no longer have to export their implementations.
- By using qualified exports, the package
monitor.observer.utilsin monitor.observer is only accessible to a selected set of modules. - monitor.persistence opens its entity package instead of exporting it, thus only making it available at run time.
These changes reduce the amount of code that’s readily accessible for any random module, which means developers can change more code inside a module without having to worry about the effects on downstream consumers. Reducing the API surface this way is a boon for the maintainability of frameworks and libraries, but large applications with many modules can also benefit. Section 11.3 introduces qualified exports, and section 12.2 explores open packages.
15.1.3 Decoupled with services
The only structural change of the module graph (compared to section 2.2) is that monitor no longer directly depends on the observer implementations. Instead, it only depends on the module providing the API, monitor.observer, and it uses ServiceObserverFactory as a service. All three implementing modules provide that service with their specific implementations, and the module system connects the two sides.
This is much more than just an aesthetic improvement. Thanks to services, it’s possible to configure aspects of the application’s behavior—which kinds of services it can observe—at launch time. New implementations can be added and obsolete ones can be removed by adding or removing modules that provide that service—no changes of monitor are required, and hence the same artifacts can be used without having to rebuild them. To learn all about services, check out chapter 10.
15.1.4 Loads code at run time with layers
Although services allow us to define the application’s behavior at launch time, we even went one step further. It isn’t visible in the module declarations, but by enabling the monitor module to create new layers, we made it possible for the application to start observing services at run time for which it didn’t even have the ServiceObserver implementation when it launched. On demand, monitor will create a new module graph and, together with a new class loader, load additional classes and update its list of observers.
Listing 15.3 Creating a new layer with the graph created for modules on those paths
private static ModuleLayer createLayer(Path[] modulePaths) {
Configuration configuration = createConfiguration(modulePaths);
ClassLoader thisLoader = getThisLoader();
return getThisLayer()
.defineModulesWithOneLoader(configuration, thisLoader);
}
private static Configuration createConfiguration(Path[] modulePaths) {
return getThisLayer()
.configuration()
.resolveAndBind(
ModuleFinder.of(),
ModuleFinder.of(modulePaths),
Collections.emptyList()
);
}
Such behavior is particularly interesting for applications that aren’t frequently redeployed and where restarts are inconvenient. Complex desktop applications come to mind, but a web backend that runs on the customer’s premises and needs to be comprehensibly configurable could also qualify. For a discussion of what layers are and how to create them, see section 12.4.
15.1.5 Handles dependencies on plain JARs
Another detail that isn’t obvious from the module declarations is the modularization status of ServiceMonitor’s third-party dependency. Neither the Hibernate version nor the Spark version it uses is modularized yet, and they still ship as plain JARs. Because explicit modules require them, they need to be on the module path, though, where the module system turns plain JARs into automatic modules.
So although ServiceMonitor is fully modularized, it can nonetheless depend on non-modularized JARs. Looking at this from the ecosystem-wide perspective, where the JDK modules sit at the bottom and application modules are at the top, this is effectively a top-down modularization effort.
Automatic modules in particular are covered in section 8.3, but all of chapter 8 applies here. If you want to catch up on modularization strategies, check out section 9.2.
15.2 Tips for a modular application
Throughout the book, we’ve spent a lot of time looking at how to use the module system’s various tools to solve individual problems. That’s obviously the most important task of a book about the JPMS, but I won’t let you go without taking at least a quick inventory of the toolbox as a whole.
The first question is, do you even want to use these tools? Without the metaphor, do you want to create modules (section 15.2.1)? Once that’s settled, we’ll take a shot at defining what an ideal module might look like (section 15.2.2). We’ll then focus on how to keep module declarations in tip-top shape (section 15.2.3) and which changes might break your users’ code (section 15.2.4).
15.2.1 Modular or not?
After all you’ve learned about the module system—its features, its drawbacks, its promises, and its restrictions—maybe you’re still asking yourself whether you should modularize your JARs. In the end, only you and your team can answer that for your project, but I can give you my thoughts on the topic.
As I’ve expressed throughout the book, I’m convinced that the module system offers lots of benefits that are important to libraries, frameworks, and most nontrivial applications. Particularly strong encapsulation, decoupling via services (although that can also be done without modules, albeit less comfortably), and application images stand out to me.
What I like best, though, are the module declarations themselves: they’re at all times a true representation of your project’s architecture and will provide considerable benefits to every developer and architect who works on those aspects of their system, thus improving its overall maintainability. (I go deeper into this topic in section 15.2.3.)
When it comes to modularizing existing projects, the answer is much more “it depends.” The amount of work that needs to be done is much more apparent, but the benefits are just as tangible. In fact, the more work that has to be done, the higher the payoff will usually be. Think about it: which applications are the hardest to modularize? Those that consist of more artifacts, are more entangled, and are less maintainable. But these are also exactly the ones that stand to gain the most from having their structure investigated and worked on. So be careful when somebody assumes the modularization of an existing project has low costs and high benefits (or the other way around).
If you’re working on a project that has users outside your team, such as a library or a framework, you should also take their needs into account. Even if modularization doesn’t seem worth it to you, they stand to benefit considerably from it.
15.2.2 The ideal module
Suppose you’ve made your decision and have gone with modules. What’s the ideal module? What are you shooting for when cutting modules and writing declarations? Once again, there’s no one-size-fits-all answer, but there are a number of signals you can keep on your radar:
- Module size
- API surface
- Coupling between modules
Before discussing each of these in turn, I want to add that even if you have a notion of what an ideal module is, it’s unlikely that you’ll churn out one after another. Particularly if you start by modularizing an existing project, chances are you’ll create some ugly modules on the way.
If you’re working on an application, you don’t have to worry about that—you can easily refactor modules as you go. For library and framework developers, life is tougher. As you’ll see in section 15.2.4, many refactoring steps can break your users’ code, so you have much less freedom to evolve.
Now, let’s turn to the three signals you can observe to judge a module’s quality: size, surface, and coupling.
Keep your modules small(ish)
Module declarations give you a great tool to analyze and sculpt the boundaries between modules, but they’re relatively blind to what goes on within a module. Packages have circular dependencies? All classes and members are public? It’s a big ball of mud? That may hurt during development, but your module declarations won’t reflect it.
That means the more module declarations you have, the more insight into and control over your code’s structure you have (see figure 15.2). On the other hand, there’s a one-to-one relationship between modules, JARs, and (typically) build-tool projects, so a higher number of module declarations also means increased maintenance efforts and longer build times. It’s clearly a trade-off.

Figure 15.2 These package relationships are arguably somewhat chaotic. With just two modules (top), that doesn’t become apparent, though. It’s only when trying to create more modules (bottom) that the problems become obvious. The additional module boundaries provided that insight.
Still, as a general rule of thumb, prefer smaller modules over larger ones. Once a module’s lines of code get into five digits, you may want to think about cutting it apart; when the module crosses into six digits, I recommend seriously considering it. If it’s seven digits, you’re likely to have some serious refactoring work ahead of you. (If you have trouble breaking cyclic dependencies between classes, check out section 10.2.5, where you use services to do just that.)
What belongs together? When cutting a cohesive module in two, you’re bound to end up with a pretty large API surface between the pieces—which brings us to the next aspect we need to discuss.
Keep the API surface small
How do plain and qualified exports compare? Within a project, there isn’t much of a difference. When it comes to entangling two modules, it doesn’t really matter whether the export was qualified. That said, a qualification at least indicates that an API may not have been designed for general use, which is useful information, particularly in larger projects.
Libraries and frameworks, unlike applications, always have to think about how their exports impact projects depending on them. In this scenario, a qualified export to other modules within the same project is the same as if the package wasn’t exported at all, which is definitely a win. In summary, qualified exports still contribute to the API surface: almost as much as regular exports within a project, but considerably less so across project boundaries.
Keep coupling to a minimum
Pick two random pieces of code—it doesn’t matter whether they’re methods, classes, or modules. Everything else being equal, the one with fewer dependencies is more maintainable. The reason is simple: the more dependencies it has, the more changes are in a position to break it.
It goes beyond plain dependencies, though: it’s more generally a matter of coupling. If a module not only depends on another, but actively uses all of the dozen packages it exports, the two modules are more tightly coupled. This is even truer if qualified exports are part of the mix, because they essentially say, “This isn’t a properly supported API, but I’ll let you use it anyway.”

Figure 15.3 Even though both graphs have the same number of nodes, they vary considerably in complexity. The one on the left has about as many edges as nodes, whereas the one on the right has about one edge per pair of nodes. If a new node was added, the left graph would get one or maybe two new edges, whereas the right graph would get about six.
One good way to decouple modules are services, as explained in chapter 10. Not only do they break the direct dependency between modules, but they also require you to have a single type through which you can access the entire API. If you don’t turn that type into a kraken that connects to dozens of other types, this will greatly reduce the coupling between the modules.
This should be the litmus test: Can you create a service type with a reasonably small API? Does it look like it might be used or provided by more than just one module on each side?
If you’re unsure, have a look around the JDK. The official documentation lists the services a module uses or provides, and you can use your IDE to look at the user’s and implementation’s code.
Listen to your module declaration
Also note that the three signals (size, surface, and cohesion) will often work against one another. As an extreme example, take an application that consists of just one module. It very likely has no API; and with just one artifact, there’s not much coupling going on. At the other extreme, a code base where each package is in its own module is full of small modules with small API surfaces. These extremes are, of course, ridiculous, but they illustrate the problem: this is a balancing act.
15.2.3 Take care of your module declarations
If you’re building a modular project, module declarations are easily the most important .java files in your code base. Each of them represents an entire JAR, which will likely consist of dozens, hundreds, or maybe even thousands of source files. Even more than merely representing them, the modular declarations govern how the module interacts with other modules.
So, you should take good care of your module declarations! Here are a few things to look out for:
- Keep declarations clean.
- Comment declarations.
- Review declarations.
Let’s take these one by one.
Clean module declarations
Module declarations are code and should be treated as such, so make sure your code style is applied. Consistent indentation, line length, bracket positions, and so forth—these rules make as much sense for declarations as they do for any other source file.
In addition, I strongly recommend that you structure your module declarations instead of putting directives in random order. All declarations in the JDK as well as in this book have the following order:
requires, includingstaticandtransitiveexportsexports toopensopens tousesprovides
The JDK always puts an empty line between blocks to keep them apart—I only do that when there are more than a few directives.
Going further, you could define how to order directives within the same block. Lexicographically is an obvious choice, although for requires I first list internal dependencies and then external ones.
Commenting module declarations
Opinions on code documentation, like Javadoc or inline comments, vary wildly, and this isn’t the place to make my argument for why it’s important. But whatever your team’s position on comments is, extend it to module declarations.
If you like the idea that each abstraction has a sentence or a small paragraph explaining its meaning and importance, consider adding a Javadoc comment to each module:
/**
* Aggregates service availability data points into statistics.
*/
module monitor.statistics {
// ...
}
The JDK has such a comment or a longer one on each module.
Even if you don’t like writing down what a module does, most people agree that documenting why a specific decision was made has value. In a module declaration, that could mean adding an inline comment
- To an optional dependency, to explain why the module might be absent
- To a qualified export, to explain why it isn’t a public API, but was still made accessible to specific modules
- To an open package, explaining which frameworks are planned to access it
In the JDK, you’ll occasionally find comments like this one in jdk.naming.rmi:
// temporary export until NamingManager.getURLContext uses services
exports com.sun.jndi.url.rmi to java.naming;
Generally speaking, my recommendation is this: every time you make a decision that isn’t immediately obvious, add a comment. Every time a reviewer asked why some change was made, add a comment. Doing that can help your fellow developers—or yourself two months down the road.
Reviewing module declarations
Module declarations are the central representation of your modular structure, and examining them should be an integral part of any kind of code review you do. Whether it’s looking over your changes before a commit or before opening a pull request, wrapping up after a pair-programing session, or during a formal code review—any time you inspect a body of code, pay special attention to module-info.java:
- Are added dependencies really necessary? Are they in line with the project’s underlying architecture? Should they be exposed with
requires transitivebecause their types are used in the module’s API? - If a dependency is optional, is the code prepared to handle its absence at run time? Are there knock-on effects, like missing transitive dependencies that the optional dependency implied readability on?
- Could a new dependency be replaced with a service?
- Are added exports really necessary? Are all public classes in the newly exported packages ready for public use, or do they need to be shuffled around to reduce the API surface?
- If an export is qualified, does that make sense, or is it just a cop-out to get access to an API that was never meant to be public?
- Is the type used as a service designed to be an integral part of the application’s infrastructure?
- Were any changes made that can negatively affect downstream consumers that aren’t part of the build process? (See section 15.2.4 for more on that.)
- Is the module declaration styled and commented according to the team’s requirements?
A diligent review is particularly important because IDEs offer quick fixes that let developers edit declarations at a distance by exporting packages or adding dependencies with a simple command. I appreciate those features, but they make careless editing more likely; thus it’s all the more important to ensure that nothing sneaks by unnoticed.
Investing time into reviewing module descriptors may sound like a lot of additional work. First, I would argue whether it’s a lot, particularly compared to the effort that goes into developing and reviewing the rest of the code base. More important, though, I don’t see it as an additional task—instead I see it as an opportunity.
15.2.4 Breaking code by editing module declarations
As with any other source file, changing a module declaration can have unintended and possibly breaking effects on other code. More than that, though, the declaration is the distillation of your module’s public API and so has a much higher impact than any random class.
If you develop an application and all consumers of your module are part of the same build process, then breaking changes can’t slip by unnoticed. Even for frameworks and libraries, such changes can be detected with thorough integration tests.
- New module name
- Fewer exported packages
- Different provided services
- Editing dependencies
As you’ll see, all of these changes can cause compile errors or unexpected run-time behavior in downstream projects. As such, they should always be considered breaking changes, so if you use semantic versioning, a major version bump is in order. This doesn’t mean making other changes in your module declarations can’t also cause problems, but they’re much less likely; so, let’s focus on these four.
Impact of a new module name
Changing a module’s name will immediately break all modules that depend on it—they will need to be updated and rebuilt. That’s the least of the problems it can cause, though.
Much more dangerous is the modular diamond of death (see section 3.2.2) it may create when some project transitively depends on your module twice: once with the old name and once with the new name. That project will have a hard time including your new version in its build and may well have to resort to eschewing the update just because of the changed name.
Be aware of this, and try to minimize renames. You may still have to do it occasionally, in which case you can try to mitigate the effects by creating an aggregator module with the old name (explained in section 11.1.5).
Impact of exporting fewer packages
It should be obvious why “unexporting” packages causes problems: any module that uses types in these packages will fail to access them at compile time and run time. If you want to go this route, you should first deprecate those packages and types to give your users time to move away from them before they’re removed.
This only fully applies to plain exports directives:
- Qualified exports usually only export to other modules you control, which are likely part of your build and thus updated at the same time.
- Open packages are usually geared toward a specific framework or piece of code that’s intended to reflect over them. That code is rarely part of your users’ modules, so they won’t be impacted by closing the package.
Generally speaking, I wouldn’t consider removing qualified exports or opened packages a breaking change. Specific scenarios may go against that rule of thumb, though, so watch out for them and think things through when making such a change.
Impact of adding and removing services
With services, the situation is a little less clear-cut. As described in section 10.3.1, service consumers should always be prepared to handle the absence of service providers; similarly, they shouldn’t break when an additional provider is suddenly returned. But that only really covers that applications shouldn’t crash because the service loader returned the wrong number of providers.
It’s still conceivable, maybe even likely, that an application misbehaves because a service was there in one version and isn’t in another. And because service binding happens across all modules, this may even impact code that doesn’t directly depend on you.
Impact of editing dependencies
The last point on the list, dependencies in all their forms, is also a gray area. Let’s start with requires transitive. Section 11.1.4 explains that users should only rely on a dependency you let them read if they use it in the direct vicinity of your module. Assuming you stopped exposing the dependency’s types and your users updated their code, removing transitive from the exports directive shouldn’t impact them.
On the other hand, they may not know about or heed that recommendation, so keeping them from reading that dependency still requires them to update and rebuild their code. Hence I’d still consider it a breaking change.
It’s also possible to come up with scenarios where removing or even adding other dependencies can cause problems, even though that shouldn’t be observable from outside your module:
- Adding or removing plain
requiresdirectives changes optional dependency resolution and service binding. - Making a dependency optional (or going the other way) can also change which modules make it into the module graph.
So although requires and requires static can change the module graph and thus impact modules that are totally unrelated to you, this isn’t a common case. By default, I wouldn’t consider such changes to be breaking.
15.3 The technology landscape
After I first introduced the module system in section 1.4, I thought you might have a few questions about how it relates to the rest of the ecosystem. As you may recall, they went like this:
- Don’t Maven, Gradle, and others already manage dependencies?
- What about OSGi? Why not just use that?
- Isn’t a module system overkill in times where everybody writes microservices?
I’ll answer these now.
15.3.1 Maven, Gradle, and other build tools
The Java ecosystem is in the lucky position to have a few powerful, battle-tested build tools like Maven and Gradle. They’re not perfect, of course, but they’ve been building Java projects for more than 10 years, so they clearly have something going for them.
As the name implies, a build tool’s main job is to build a project, which includes compiling, testing, packaging, and distributing it. Although the module system touches on a lot of these steps and requires some changes in the tools, it doesn’t add any capabilities to the platform that make it compete with them in this area. So when it comes to building a project, the relation between the Java platform and its build tools remains much the same.
If you want to learn more about Gradle, check out Manning’s very hands-on Gradle in Action (Benjamin Muschko, 2014, www.manning.com/books/gradle-in-action). Unfortunately, I can’t recommend any book on Maven that I’ve had the chance to at least flip through.
Dependency Management
Build systems usually perform another task, and now Java 9+ performs it, too: dependency management. As section 3.2 discusses, reliable configuration aims at making sure dependencies are present and unambiguous, so that the application becomes more stable—Maven or Gradle will do the same for you. Does that mean the module system replaces build tools? Or is it too late to the game, and these features are useless? On the surface, it seems as though the module system duplicates the build tools’ functionality; but when you look closer, you can see that the overlap is small.
First, the module system has no way to uniquely identify or locate artifacts. Most notable is that it has no concept of versions, which means given a few different versions of the same artifact, it can’t pick the right one. This situation will result in an error precisely because it’s ambiguous.
And although many projects will choose a module name that has the chance to be unique (like reversing a domain name the project is associated with), there is no instance like Maven Central to ensure that, which makes the module name insufficient for uniquely identifying a dependency. Speaking of remote repositories like Maven Central, the module system has no capabilities to connect to them. So although both the module system and build tools manage dependencies, the former performs on a level that’s too abstract to replace the latter.
Build systems do have a considerable shortcoming, though: they ensure that dependencies are present during compilation and can even deliver them to your doorstep, but they don’t manage the application’s launch. If the tool is unaware of an indirectly required dependency (due to use of Maven’s provided or Gradle’s compileOnly), or a library gets lost on the way from build to launch, you’ll only find out at run time, most likely by a crashing application. The module system, on the other hand, manages direct and transitive dependencies not only at compile time but also at run time, ensuring reliable configuration across all phases. It’s also better equipped to detect ambiguities like duplicate artifacts or artifacts containing the same types. So even when you zoom in on dependency management, both technologies are different; the only overlap is that both list dependencies in some form.
Encapsulation, services, and linking
Moving away from dependency management, we quickly find features of the module system that build tools can’t compete with. Most notable is strong encapsulation (see section 3.3), which enables libraries to hide implementation details from other code at compile time and run time—something Maven or Gradle can’t even dream of promising. This strictness will take a while to get used to, but in the long run, the JDK, frameworks, libraries, and even large applications will benefit from clearly distinguishing supported and internal APIs and making sure the latter aren’t accidentally relied on. In my opinion, strong encapsulation alone is worth the move to the module system.
Looking over the more-advanced features, two particularly interesting ones stand out as being beyond the build tools’ reach. First, the module system can operate as a service registry in the service locator pattern, allowing you to decouple artifacts and to implement applications that make it easy to use plugins (see chapter 10). Second is the ability to link desired modules into a self-contained runtime image, giving you the opportunity to make deployments slimmer and easier (see chapter 14).
In summary, except for a small overlap in dependency management, build tools and the module system don’t compete but should instead be seen as complementary. Figure 15.4 shows this relationship.

Figure 15.4 Build tools (left) and the module system (right) have very different feature sets. The only similarities are that both record dependencies (build tools by globally unique identifiers plus versions; the JPMS just by module names) and can verify them for compilation. Their handling of dependencies is very different, and beyond that they have virtually nothing in common.
15.3.2 OSGi
The Open Service Gateway initiative (OSGi) is shorthand for both an organization (the OSGi Alliance) and the specification it creates. It’s also somewhat imprecisely applied to the different implementations of that specification, which is how I use it in this section.
OSGi is a module system and service platform on top of the Java Virtual Machine that shares parts of its feature set with the JPMS. If you know a few things about OSGi or have been using it, you may wonder how it compares to Java’s new module system, and maybe whether it’s replaced by it. But you may also wonder why the latter was even developed—couldn’t Java just use OSGi?
I’m not an OSGi expert, but during my research I paged through Manning’s OSGi in Depth and liked it (Alexandre de Castro Alves, 2011, www.manning.com/books/osgi-in-depth). Consider turning to it if you need more than the Java Platform Module System can offer you.
Why doesn’t the JDK use OSGi?
Why doesn’t the JDK use OSGi? The technical answer to this question comes down to the way OSGi implements its feature set. It heavily leans on class loaders, which we briefly discussed in sections 1.2 and 1.3.4, and of which OSGi creates its own implementations. It uses one class loader per bundle (modules are called bundles in OSGi) and in this way controls, for example, which classes a bundle can see (to implement encapsulation) or what happens when a bundle is unloaded (which OSGi allows—more on that later).
What may seem like a technical detail has far-reaching consequences. Before the JPMS, Java placed no limitations on the use of class loaders, and using the reflection API to access classes by name was common practice.
If the JPMS required a specific class-loader architecture, Java 9+ would drastically break the JDK, many existing libraries and frameworks, and critical application code. Java 9+ still poses migration challenges, but incompatibly changing the class-loader API would be even more disruptive and not replace these challenges but come on top of them. As a consequence, the JPMS operates below class loaders, as shown in figure 15.5.

Figure 15.5 OSGi (left) is built on top of the JVM, which forced it to use existing functionality, mainly the class-loading infrastructure, to implement its feature set. The module system (right), on the other hand, was implemented within the JVM and operates below class loading, keeping systems built on top of it working as before.
Another consequence of using class loaders for module isolation is that although OSGi uses them to reduce the visibility of classes, they can’t reduce accessibility. What do I mean by that? Say a bundle lib contains a type Feature from a package that isn’t exported. Then OSGi makes sure code in another bundle app can’t “see” Feature, meaning, for example, that Class.forName("org.lib.Feature") will throw a ClassNotFoundException. (Feature isn’t visible.)
But now assume lib has an API that returns a Feature as an Object, in which case app can get an instance of the class. Then app can call featureObject.getClass().newInstance() and create a new Feature instance. (Feature is accessible.)
As discussed in section 3.3, the JPMS wants to ensure strong encapsulation, and what OSGi has to offer isn’t strong enough. If you create a situation like earlier, with two JPMS modules app and lib and a type Feature that lib contains but doesn’t export, app can successfully get a class instance with Class.forName("org.lib.Feature") (it’s visible) but can’t call newInstance() on it (it isn’t accessible). Table 15.1 juxtaposes the differences of OSGi and JPMS.
| OSGi | JPMS | |
Limits visibility (Class::forName fails) |
✔ | ✘ |
Limits accessibility (Class::newInstance fails) |
✘ | ✔ |
Can the JPMS replace OSGi?
Can the JPMS replace OSGi? No.
The JPMS was primarily developed to modularize the JDK. It covers all the modularity basics—some of them, like encapsulation, arguably better than OSGi—but OSGi has a lot of features the JPMS doesn’t need and thus doesn’t have.
To name a few, with OSGi, due to its class-loader strategy, you can have the same fully qualified type in several bundles. This also makes it possible to run different versions of the same bundle at the same time. In that vein, with OSGi, exports and imports can be versioned, letting bundles express what version they are and which versions their dependencies should be. If the same bundle is required in two different versions, OSGi can make that work.
Another interesting difference is that in OSGi, a bundle usually expresses dependencies on packages instead of bundles. Although both are possible, the former is the default. This makes dependencies more robust with regard to replacing or refactoring bundles, because it doesn’t matter where a package comes from. (In the JPMS, on the other hand, a package must be in one of the required modules, so moving a package into another module or exchanging one module for another with the same API will cause problems.)
A big feature set of OSGi revolves around dynamic behavior, where its roots as an Internet of Things service gateway clearly show and where the implementation via class loaders enables powerful capabilities. OSGi allows bundles to appear, disappear, and even be updated at run time, exposing an API that lets dependencies react accordingly. This is great for applications running across multiple devices but can also come in handy for single-server systems that want to reduce downtime to a minimum.
The bottom line is that if your project is already using OSGi, chances are high that you’re relying on features the JPMS doesn’t have. In that case, there’s no reason to switch to Java’s native module system.
Does OSGi obviate the JPMS?
Does OSGi obviate the JPMS? No.
Although what I just presented sounds a lot like OSGi is better than the JPMS for every use case, OSGi has never seen wide adoption. It has carved out a niche and is successful in it, but it has never become a default technology (unlike IDEs, build tools, and logging, to name a few examples).
The main reason for that lack of wide adoption is complexity. Whether it’s perceived or real, whether it’s inherent to modularity or accidental to OSGi, is secondary to the fact that the majority of developers see OSGi’s complexity as a reason not to use it by default.
The JPMS is in a different position. First, its reduced feature set (particularly, no version support, and dependencies on modules, not packages) makes it less complex. In addition, it benefits from being built into the JDK. All Java developers are exposed to the JPMS to some degree, and more senior developers in particular will explore how it can help them with their projects. This more intense use will also spur good tool integration.
So if a team already has the skills and tools and is already running on top of the JPMS, why not go all the way and modularize the entire application? This step builds on existing knowledge, incurs less additional complexity, and requires no new tools, while giving a lot of benefits.
In the end, even OSGi stands to profit from the JPMS, because Java 9+ will put modularity on the map much as Java 8 did with functional programming. Both releases are exposing mainstream Java developers to new ideas and are teaching them an entirely new skill set. At some point, when a project stands to benefit from functional programming or more powerful modularity, its developers climb enough of the learning curve to evaluate and maybe use “the real thing.”
Are JPMS and OSGi compatible?
Are JPMS and OSGi compatible? In a sense, yes. Applications developed with OSGi can run on top of Java 9+ just as they did on earlier versions. (To be more precise, they will run in the unnamed module, which section 8.2 explains in detail.) OSGi incurs no migration efforts, but the application code faces the same challenges as other code bases.
In another sense, the verdict isn’t in yet. Whether OSGi will allow us to map bundles to JPMS modules is still an open question. For now, OSGi uses no capabilities of the JPMS and continues to implement its features itself. It’s also not clear whether adapting OSGi to the JPMS would be worth the considerable engineering cost.
15.3.3 Microservices
The relationship between the module system and microservices architecture has two very different aspects:
- Are microservices and the module system in competition? How do they compare?
- Does the module system concern you if you go with microservices?
We’ll look at both in this section.
If you’re not familiar with the microservices architecture, you can safely skip this section. If you want to learn more, there are tons of great microservice books out there. To back up my claims, I skimmed Manning’s Microservices in Action and can recommend it (Morgan Bruce and Paulo A. Pereira, 2018, www.manning.com/books/microservices-in-action).
Microservices vs. the JPMS
In general, it’s fair to say that the module system’s benefits have a larger effect, the bigger the project is. So when everybody is talking about microservices, isn’t a module system for large applications the proverbial lipstick on a pig? The answer depends on how many projects will end up being structured as microservices, and that is, of course, a huge discussion in itself.
Some believe microservices are the future and sooner or later all projects will start out that way—it’s all microservices! If you’re in that camp, you may still implement your services in Java 9+, and the module system will affect you, but, of course, much less than it affects monolithic projects. We’ll discuss that in the next section.
Others have a more cautious opinion. Like all architecture styles, microservices have both advantages and disadvantages, and a trade-off must be made between them with the project’s requirements in mind. Microservices shine particularly brightly in rather complex projects that have to sustain high loads, where their ability to scale is almost unrivaled.
This scalability is paid for with operational complexity, though, because running a multitude of services requires much more knowledge and infrastructure than putting a handful of instances of the same service behind a load balancer. Another drawback is that getting service boundaries wrong, which is more likely the less the team knows about the domain, is more expensive to fix in microservices than in a monolith.
The critical observation is that the price for the complexity (Martin Fowler calls it the microservices premium) must always be paid, but the benefits are only reaped once a project is large enough. This factor has convinced many developers and architects that most projects should start as a monolith and move toward splitting off services, maybe eventually ending in microservices, once circumstances require it.
Martin Fowler, for examples, relates the following opinions of his colleagues (in https://martinfowler.com/bliki/MonolithFirst.html; emphasis mine):
You shouldn’t start a new project with microservices, even if you’re sure your application will be big enough to make it worthwhile. […] The logical way is to design a monolith carefully, paying attention to modularity within the software, both at the API boundaries and how the data is stored. Do this well, and it’s a relatively simple matter to make the shift to microservices.
By now, the emphasized phrases should be familiar: careful design, modularity, boundaries—these are all properties that the module system promotes (see section 1.5). In a microservice architecture, service dependencies should be clear (cue reliable configuration) and ideally decoupled (service loader API); furthermore, all requests must go through public APIs (strong encapsulation). Carefully using the module system can lay the groundwork for a successful migration to microservices if and when the time for that comes. Figure 15.6 shows the importance of this careful design.

Figure 15.6 Given two hypothetical migrations of a monolithic application to microservices, would you rather start with a sizable square of mud (left) or a properly modularized code base (right)?
Notwithstanding the module system’s focus on larger projects, even small services can benefit from embracing modules.
Microservices with the JPMS
If your project went with microservices and you’re implementing some of them on top of Java 9+ because you want to benefit from improved security and performance, you’ll necessarily interact with the module system because it’s operating within the JVM that’s running your code. One consequence is that the potentially breaking changes discussed in chapters 6 and 7 still apply to the services in question and need to be mended. It’s also likely that most of your dependencies will be turned into modules over time, but as section 8.1.3 describes, that doesn’t force you to package your artifacts as modules.
If you decide to keep all JARs on the class path, strong encapsulation isn’t enforced between them. So within that set of JARs, access to internal APIs as well as reflection, for example from frameworks into your code, will continue to work. In this scenario, your exposure to the module system is limited to the changes it had on the JDK.
The other route you could take would be to use your services and dependencies as modules, at which point you’d be fully integrated into the module system. Of its various benefits, the most relevant may end up being the scalable platform briefly described in section 1.5.5 and thoroughly explored in chapter 14, which allows you to use jlink.
With jlink, you can create a small runtime image with just the right set of platform modules to support your application, including your modules, which can cut image size by up to 80%. Furthermore, when linking the required modules together, jlink can analyze the bytecode with the knowledge that it sees the entire application and can thus apply more aggressive optimizations, leading to even smaller image sizes and slightly improved performance. You also get other benefits: for example, being sure you only use your dependencies’ public APIs.
15.4 Thoughts on a modular ecosystem
Java 9+ is a massive release. Although lacking in new language features, it packs a lot of powerful improvements and additions. But all of those improvements are eclipsed by the Java Platform Module System. It’s easily both the most anticipated and the most contentious feature of Java 9+, not least because of the migration challenges it causes.
Despite the sometimes-rocky start on the way to the modular future, well-known libraries and frameworks were quick to support Java 9+, and since then there’s been no sign of that trend slowing down. What about older, less-well-supported projects? Although some may find new maintainers, even if just to get them to work on a current Java release, the long tail of Java projects may thin out.
That will surely disgruntle some developers whose code bases depend on such projects. That’s understandable—nobody likes having to change working code without apparent benefit. At the same time, the exodus of some incumbents will give other projects the chance to sweep up their users. And who knows? Maybe they’ll see a benefit from switching after all.
Once the big wave of upgrading to Java 9+ is behind us and projects start raising their baseline to Java 9+, you’ll begin to see more and more modular JARs being publicly available. Thanks to the module system’s support for incremental and decentralized modularization, this process requires comparatively little coordination between projects. It also gives you the opportunity to start modularizing your project right now.
To what end? Unlike more flashy features like lambda expressions and streams in Java 8 or local variable type inference in Java 10, the module system’s effect on your code base will be subtle. You won’t be able to look at a few lines of code and be content with its beauty. You won’t notice suddenly that you’re having more fun when coding.
No, the module system’s benefits are on the other end of the spectrum. You’ll catch more errors early due to reliable configuration. You’ll avoid missteps due to having better insight into your project architecture. You won’t so readily entangle your code, and you won’t accidentally depend on your dependencies’ internals.
It’s the moody parts of software development that the JPMS will improve. The module system is no panacea: you still have to put in the hard work to properly design and arrange your artifacts; but with the module system on hand, this effort will have fewer pitfalls and more shortcuts along the way.
As more and more of the ecosystem’s artifacts become modular, this effect will only get stronger, until one day we’ll ask ourselves how we ever coded without the module system. What was it like, back in the day when the JVM turned our carefully designed dependency graph into a ball of mud?
It will feel strange, thinking back. As strange as writing a Java class without private. Can you imagine what that would be like?
Summary
- Design your module system carefully.
- Microservices and the JPMS complement each other.
- OSGi and the JPMS also complement each other.
And now—thank you very much for reading this book. It was a pleasure to write for you. I’m sure we’ll see each other again!