
7
PRODUCT BACKLOG MANAGEMENT
QUIZ
To set the stage for this chapter, try answering each of the following statements with Agree or Disagree. Answers appear at the end of the chapter.
Statement |
Agree |
Disagree |
The Product Backlog replaces the need for any other requirement documents. |
|
|
Agile requirements must be no more than a few sentences. |
|
|
User story is synonymous with Product Backlog item. |
|
|
Defects should not be in the Product Backlog because they are triaged by the Development Team. |
|
|
The Development Team should not allow any Product Backlog items into the Sprint unless they meet a definition of “Ready.” |
|
|
A Product Backlog can be made up of tests. |
|
|
WHAT IS A REQUIREMENT?
According to Merriam-Webster, a requirement is:
a : something wanted or needed : NECESSITY
b : something essential to the existence or occurrence of something else : CONDITION.1
A requirement is not a document. It exists whether it has been captured or not. It may not even be known yet. This adds to the complexity of developing a software product. The best you can do is to keep inspecting and adapting in an empirical way.
All requirements fall into one of these categories:
1. How/why someone uses the system 5 Functional
2. How the system should behave 5 Nonfunctional (stability, usability, performance, etc.)
3. The rules that surround the existing business domain (e.g., formulas, processes, laws, etc.)
The level of detail needed depends on your goal (see Figure 7-1). Is there value in the requirement itself? Or are you simply concerned with not forgetting something?

Figure 7-1 What is your goal for documenting requirements?
In some situations, the requirement document may have value to the business. If lives are on the line, you may need to specify more detail. Fixed price vendor contracts may need more documentation.
However, the reality of the vast majority of product development work today is that more value comes in representing stakeholder needs (or what they think they need) than in capturing detail.
Rather than worrying about requirements ambiguity and documentation, which in itself could be quite wasteful, strive to represent, or tag, the functionality.
Instead, consider creating a big to-do list for the product where the intent is not to capture detail; the intent is to not forget to ask all the right questions, either upfront or somewhere down the road.
Think about it: How much detail do you put into your personal to-do lists? Each to-do list item is nothing more than a reminder to get something done.
The details will be captured along the way, while you strive to better understand the underlying customer need, as acceptance criteria, tests, diagrams, conversations, and so on.
In Scrum, the Product Owner’s “to-do list” is the Product Backlog.
PRODUCT BACKLOG
From the Scrum Guide
The Product Backlog is an ordered list of everything that is known to be needed in the product. It is the single source of requirements for any changes to be made to the product. The Product Owner is responsible for the Product Backlog, including its content, availability, and ordering.2
So what exactly do you put into a Product Backlog?

Figure 7-2 Valid Product Backlog items
As Figure 7-2 shows, the Product Backlog is open to all types of work:
![]() Feature Requests: Any request from a stakeholder (e.g., “I want admin access.” “I want to be able to sort this list.”)
Feature Requests: Any request from a stakeholder (e.g., “I want admin access.” “I want to be able to sort this list.”)
![]() Nonfunctional Requirements: Qualities of the system (e.g., Performance, Scalable to 2,000 concurrent users, Legal Terms & Conditions)
Nonfunctional Requirements: Qualities of the system (e.g., Performance, Scalable to 2,000 concurrent users, Legal Terms & Conditions)
![]() Experiments: Functionality that is released to production to test the marketplace (e.g., New UI, User Survey, Analytics); also, experiments can be “enabling constraints,” as described in Chapter 5
Experiments: Functionality that is released to production to test the marketplace (e.g., New UI, User Survey, Analytics); also, experiments can be “enabling constraints,” as described in Chapter 5
![]() User Stories: Placeholders for conversations; popular in the agile community
User Stories: Placeholders for conversations; popular in the agile community
![]() Bugs/Defects: Problems that have arisen from a previous release
Bugs/Defects: Problems that have arisen from a previous release
![]() Use Cases: List of actions between an actor and a system (not as common these days)
Use Cases: List of actions between an actor and a system (not as common these days)
![]() Capabilities: Different ways or channels to access existing functionality (e.g., mobile, web, cloud services, public API)
Capabilities: Different ways or channels to access existing functionality (e.g., mobile, web, cloud services, public API)
As a framework, Scrum does not prescribe any real method or template for Product Backlog items. However, the vast majority of Scrum Teams populate their Product Backlogs with user stories.
USER STORIES
Before user stories, requirement-capturing techniques were seen as a communication channel with the intent to gather as much information as possible.
A common approach to capturing requirements was use cases. Use cases were originally developed and used by Ivar Jacobson in 1986. They became popular in the 1990s by practitioners of the Unified Process (UP) and Unified Modelling Language (UML). Use cases break requirements into more manageable pieces (scenarios) and describe a specific behavior from the context of an actor working with a system. They also provide a mechanism to get into a lot of detail, which if you aren’t careful can generate unnecessary documentation and actually reduce communication. The creation of a single use case could occupy a team for months before it is handed over for development.
Admittedly, use cases were never meant to be exhaustive documents. They were meant to be built iteratively as development was happening. However, too many organizations were writing tedious use cases that added little or no value and resulted in a lot of rework.
In an effort to fight back against the amount of unnecessary detail in use cases, user stories were introduced by the Extreme Programming community in the 1990s, with the intent to “force” brevity and create purposeful ambiguity. The idea is that this ambiguity would result in more face-to-face communication.
 I often get asked what the difference is between a use case and a user story? The way I see it, a user story describes one flow through a use case. A use case often has a happy path, a couple of alternative or error paths, and a few exceptional paths. Often I see value in implementing the happy path first to validate the underlying assumption. Once we implement the first complete scenario and have received feedback that we are on the right track, we can then go ahead and implement the other paths.
I often get asked what the difference is between a use case and a user story? The way I see it, a user story describes one flow through a use case. A use case often has a happy path, a couple of alternative or error paths, and a few exceptional paths. Often I see value in implementing the happy path first to validate the underlying assumption. Once we implement the first complete scenario and have received feedback that we are on the right track, we can then go ahead and implement the other paths.
User stories are best explained with the Three Cs:3
![]() Card: Legend has it that when approached by eager entrepreneurs looking for an investor, Andrew Carnegie’s standard response was to ask them to write their ideas on the back of their business cards. If he liked it, he would call them back. Given this opportunity, what do you suppose they would focus on?
Card: Legend has it that when approached by eager entrepreneurs looking for an investor, Andrew Carnegie’s standard response was to ask them to write their ideas on the back of their business cards. If he liked it, he would call them back. Given this opportunity, what do you suppose they would focus on?
One would imagine they would be desperately trying to communicate value and make it interesting enough for a follow-up conversation.
This same principle applies to user stories, which are commonly captured using a 3" × 5" card and a felt-tip marker. They are not the requirements. They are instead a tag that represents value to the business and a promise of a future conversation, the second C.
![]() Conversation: Teams often say that the area that needs the most improvement is communication. By being purposefully ambiguous and intriguing, user stories are designed to increase conversations. This can be tremendously freeing when creating Product Backlogs and when new requirements arise. It allows you to not stress about the details right away and instead quickly jot something down as a placeholder for a future conversation, at which point you will fill in the details. The details are captured as the final C.
Conversation: Teams often say that the area that needs the most improvement is communication. By being purposefully ambiguous and intriguing, user stories are designed to increase conversations. This can be tremendously freeing when creating Product Backlogs and when new requirements arise. It allows you to not stress about the details right away and instead quickly jot something down as a placeholder for a future conversation, at which point you will fill in the details. The details are captured as the final C.
![]() Confirmation: Rather than endlessly repeating the same conversations, agile teams capture details of a user story just in time. This detail is typically captured as acceptance criteria before a team takes on the story. Acceptance criteria is what the Product Owner, representing the stakeholders, deems as necessary to consider the story accepted.
Confirmation: Rather than endlessly repeating the same conversations, agile teams capture details of a user story just in time. This detail is typically captured as acceptance criteria before a team takes on the story. Acceptance criteria is what the Product Owner, representing the stakeholders, deems as necessary to consider the story accepted.
A good rule is to limit the acceptance criteria to the back of the user story card. If more room is needed, the story may need to be broken into smaller stories.
A popular and simple template for user stories, first used by Connextra and popularized by Mike Cohn in User Stories Applied,4 is shown in Figure 7-3.

Figure 7-3 Popular user story template
![]() As a <role/persona> (who?): The focus is on a stakeholder, not just a user. Keep in mind that not all value is directed at a user of the system. For example, a company’s lawyer would see the value in a “terms and conditions” user story, whereas it could be a distraction for an actual user. Try to identify specific roles from the business domain and avoid using generic roles like “user” or technical roles like “Product Owner,” “Scrum Master,” or “Developer.”
As a <role/persona> (who?): The focus is on a stakeholder, not just a user. Keep in mind that not all value is directed at a user of the system. For example, a company’s lawyer would see the value in a “terms and conditions” user story, whereas it could be a distraction for an actual user. Try to identify specific roles from the business domain and avoid using generic roles like “user” or technical roles like “Product Owner,” “Scrum Master,” or “Developer.”
I once saw a t-shirt at a conference that read something like this: “There are only two kinds of businesses on earth who call their users “user”: software and illegal drugs.”
![]() I want <behavior> (what?): This is a business-oriented workflow or action that describes the requested feature. You should avoid technical actions, such as “I want to create a database” or “I want to refactor that nasty piece of code.” These technical actions are solution oriented and should be done instead as part of a separate, more business-oriented user story.
I want <behavior> (what?): This is a business-oriented workflow or action that describes the requested feature. You should avoid technical actions, such as “I want to create a database” or “I want to refactor that nasty piece of code.” These technical actions are solution oriented and should be done instead as part of a separate, more business-oriented user story.
![]() So that <the value>) (why?): This is a crucial, yet often forgotten, part of a user story. The better you can communicate the reason for the requested functionality, the better decisions and assumptions will be made by all involved. If this seems challenging to create, then it may be telling you something about the validity of the user story.
So that <the value>) (why?): This is a crucial, yet often forgotten, part of a user story. The better you can communicate the reason for the requested functionality, the better decisions and assumptions will be made by all involved. If this seems challenging to create, then it may be telling you something about the validity of the user story.
Figure 7-4 provides an example.

Figure 7-4 Example user story
INVEST is a useful mnemonic established by Bill Wake in Extreme Programming Explored.5 It can be used to inspect the quality of your user story by validating it against each of the following (in Bill Wake’s words):
![]() Independent
Independent
Independent stories are the easiest to work with. That is, we’d like them to not overlap in concept, and we’d like to be able to schedule and implement them in any order.
You can’t always achieve this; once in a while we may say things like “3 points for the first report, then 1 point for each of the others.”
![]() Negotiable . . . and Negotiated
Negotiable . . . and Negotiated
A good story is negotiable. It is not an explicit contract for features; rather, details will be co-created by the customer and programmer during development. A good story captures the essence, not the details. Over time, the card may acquire notes, test ideas, and so on, but we do not need these to prioritize or schedule stories.
![]() Valuable
Valuable
A story needs to be valuable. We do not care about value to just anybody; it needs to be valuable to the customer. Developers may have (legitimate) concerns, but these should be framed in a way that makes the customer perceive them as important.
![]() Estimable
Estimable
A good story can be estimated. We do not need an exact estimate, but just enough to help the customer rank and schedule the story’s implementation. Being estimable is partly a function of being negotiated, as it’s hard to estimate a story we do not understand. It is also a function of size: Bigger stories are harder to estimate. Finally, it’s a function of the team: what’s easy to estimate will vary depending on the team’s experience.
![]() Small
Small
Good stories tend to be small. Stories typically represent at most a few person-weeks’ worth of work. (Some teams restrict them to a few person-days of work.) Above this size, it seems to be too hard to know what’s in the story’s scope. Saying, “it would take me more than month” often implicitly adds, “as I do not understand what-all it would entail.” Smaller stories tend to get more accurate estimates.
![]() Testable
Testable
A good story is testable. Writing a story card carries an implicit promise: “I understand what I want well enough that I could write a test for it.” Several teams have reported that by requiring customer tests before implementing a story, the team is more productive. “Testability” has always been a characteristic of good requirements; actually writing the tests early helps us know whether this goal is met.
Another well-known acronym is DEEP6:
![]() Detailed Enough—acceptance criteria to get started
Detailed Enough—acceptance criteria to get started
![]() Emergent—The Product Backlog is never “complete”; it is refined over time
Emergent—The Product Backlog is never “complete”; it is refined over time
![]() Estimated Relatively—sized in terms of effort
Estimated Relatively—sized in terms of effort
![]() Prioritized Ordered—by value, risk, cost, dependencies, etc.
Prioritized Ordered—by value, risk, cost, dependencies, etc.
NONFUNCTIONAL REQUIREMENTS
Requirements that fall into any of the following categories are considered nonfunctional:
![]() Usability
Usability
![]() Scalability
Scalability
![]() Portability
Portability
![]() Maintainability
Maintainability
![]() Availability
Availability
![]() Accessibility
Accessibility
![]() Supportability
Supportability
![]() Security
Security
![]() Performance
Performance
![]() Cost
Cost
![]() Legal and Compliance
Legal and Compliance
![]() Cultural
Cultural
That is, they exist because of the fact that a system exists, as opposed to functional requirements, which may exist whether or not you have a system. For example, the need for depositing money into a bank account exists in the client banking business domain whether or not an ATM exists. But having an ATM introduces new nonfunctional requirements around security, accessibility, and usability.
In other words, functional requirements describe what the system should do, whereas nonfunctional requirements describe what the system should be.
Highlighting these nonfunctional concerns is important as they drive many key architectural decisions.
How do you capture nonfunctional requirements?
Capture your nonfunctional requirements in one of the following three ways:
1. As a Product Backlog item
As nonfunctional requirements do have direct value to the business, it is perfectly acceptable to capture them on the Product Backlog, possibly even as user stories as represented in Figure 7-5.

Figure 7-5 Nonfunctional requirement as user story
2. As acceptance criteria
Another option for nonfunctional requirements is to capture them as acceptance criteria for a particular Product Backlog item. That way, the nonfunctional requirement is completed as part of a larger functional item and may affect the effort needed to complete it.
For example, a functional “Login” Product Backlog item, could have the following nonfunctional acceptance criteria:
![]() Login happens within two seconds.
Login happens within two seconds.
![]() Password is masked.
Password is masked.
3. As part of the definition of “Done”
If the same nonfunctional acceptance criteria seem to apply across most of your Product Backlog items then consider anchoring it in the definition of “Done” as they are omnipresent.
For example:
![]() All pages must load within three seconds.
All pages must load within three seconds.
![]() Content must appear in both English and German.
Content must appear in both English and German.
I like to put the nonfunctional requirements (listed as NFR) on a separate document or, even better, on the wall to be present and visible at all times. We label each NFR with a letter of the alphabet. Then as we refine and have conversations about the Product Backlog items, we can refer to the list of NFRs and include the labels as acceptance criteria (see Figure 7-6). When estimating each Product Backlog item, we can consider the additional NFR effort in our estimate. If any NFRs are added or removed, we would likely need to reestimate the item.
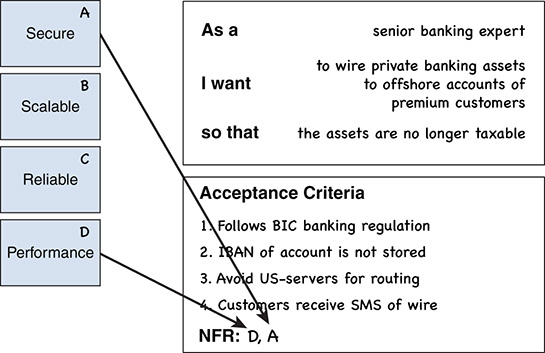
Figure 7-6 Example of tying nonfunctional requirements to Product Backlog items
EPICS
Stories that are too large to implement in one Sprint are commonly referred to as epics (long stories). Having epics in your Product Backlog is not necessarily a bad thing. In fact, epics are often a crucial building block in a wide-reaching Product Backlog. However, at some point, you need to split the epic into more manageable stories.
I personally do not care whether you call them epics, stories, or doohickeys. I just see them as Product Backlog items of various sizes. If a Product Backlog item cannot be turned into “Done” by the end of the Sprint, it is too large. Refine it, until it is the right size.
How large is too large?
One fairly widespread rule in the agile community is that if a story—a Product Backlog item—cannot be completed within one Sprint, then it is an epic. However, having just one big story in a Sprint is problematic: The success of the Sprint now hinges on the completion of that single story, so you put a lot more at risk. The other inevitable result is that all the testing for the story (and for the whole Sprint) will happen at the end of the Sprint. This unbalance of focus areas can create a lot of churn within the Development Team, making it more impossible to produce a bug-free “Done” increment within the Sprint.
So what can you do?

Figure 7-7 Epics broken down by story across architectural layers
Well, you break it down some more. A good number is to have between 6 and 12 Product Backlog items in the forecast for the Sprint. This also means that shorter Sprints will have smaller Product Backlog items. For a two-week Sprint, this means that every couple of days a Product Backlog item should be “Done,” which helps spread testing throughout the Sprint. Development Teams that can achieve this will realize that they should actually release within the Sprint instead of delaying value until the end.
How do you split a story?
This can be a challenge for many teams. Remember, Product Backlog items should be valuable to the customer, which means each story slice has to still demonstrate some value, however small. For this reason, stories that are broken down by technology component (UI, Database, etc.) are considered invalid (see Figure 7-7).
The best place to start is with the acceptance criteria. You will learn more about how to write acceptance criteria later, but for now all you need to know is that they are the conditions of satisfaction for the stakeholders, not just the user.
A Development Team along with the Product Owner should ask: “What are we going to demonstrate to prove this story is complete?”
The resulting answer should be a concrete list of items that the stakeholders deem valuable (see Figure 7-8). Therefore, each and every one can then be translated into its own separate story.
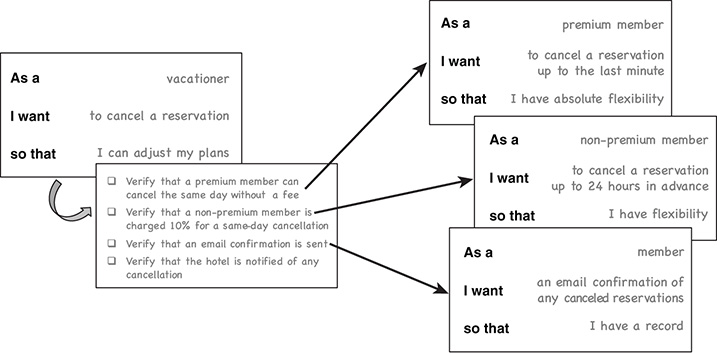
Figure 7-8 Simple example of breaking user stories down from acceptance criteria
 I often get pushback from Scrum Teams that are just starting out. They insist that the story is way too complex to be broken down. Instead of pushing back too strongly, I’ve started instead to ask them about the acceptance criteria for the epic story. In no time at all, they rattle off a dozen different things that are important to the stakeholders and therefore have supplied a dozen different ways to break down the epic.
I often get pushback from Scrum Teams that are just starting out. They insist that the story is way too complex to be broken down. Instead of pushing back too strongly, I’ve started instead to ask them about the acceptance criteria for the epic story. In no time at all, they rattle off a dozen different things that are important to the stakeholders and therefore have supplied a dozen different ways to break down the epic.
When do you break down epics?
Remember the Three Cs of user stories? The purpose of the card is to have a conversation. Epics that are far down in the Product Backlog are likely not being talked about too much. As the epics move further up the Product Backlog, more conversations happen about them and are captured as acceptance criteria on the back of the card. Once that card starts to fill up with acceptance criteria—a sign that an epic is getting closer to the top of the Product Backlog—you break it down. This could likely happen during refinement or even Sprint Planning.
Let’s take a closer look at acceptance criteria.
ACCEPTANCE CRITERIA
Acceptance criteria define what the customer will see to approve the work as being complete. They can be written as test cases or something less detailed. Although acceptance criteria are owned by the Product Owner, it is crucial to involve the whole Scrum Team (and even some stakeholders) when defining them.
I never actually write acceptance criteria on the back of a physical card. It is far from practical as you keep turning the card over and over again. However, the mindset remains. I like to find a way to limit the number of acceptance criteria, either by number of items or amount of text. In Figure 7-9, you can see an example of a template that limits the number of acceptance criteria (to nine). One of my biggest issues with agile management software tools is that it does not limit the amount of text (space-boxing) for user story descriptions and acceptance criteria.

Figure 7-9 Example of Product Backlog item with acceptance criteria
Here are three common ways of writing acceptance criteria:
Test That . . .
Start each acceptance criteria with the words “Test that . . .” This gets people into a testing mindset right off the bat. For each Product Backlog item, what will be tested to ensure the item is “Done”?
Demonstrate That . . .
Start each acceptance criteria with the words “Demonstrate that . . .” This gets people thinking about the Sprint Review and what they would want to show to stakeholders that demonstrates value. In a way, the Scrum Team is writing the script for the Sprint Review. You can hand out a list of acceptance criteria in the Sprint Review and go through them one by one. An example of this is in Figure 7-9, where we added “Demonstrate that . . .” to the acceptance criteria section.
Given, When, Then (Gherkin syntax)
Gherkin syntax serves two purposes—documentation and automated tests. The grammar is readable by anyone, yet it is also parsable by test automation tools, like Cucumber.7
Given <a precondition>
When <a user action occurs>
Then <an expected result>
Good acceptance criteria should be SMART and SAFE:8
![]() SMART
SMART
![]() Specific—what is the outcome?
Specific—what is the outcome?
![]() Measurable—how can the outcome be measured?
Measurable—how can the outcome be measured?
![]() Attainable—is it attainable with the current setup (skills, technology, etc.)?
Attainable—is it attainable with the current setup (skills, technology, etc.)?
![]() Relevant—is it aligned with the objective?
Relevant—is it aligned with the objective?
![]() Time-Bound—at which point in time can the outcome be measured?
Time-Bound—at which point in time can the outcome be measured?
![]() SAFE
SAFE
![]() Success—what is the success criteria for the Product Backlog item? For example, an ATM user receives a receipt of the transaction.
Success—what is the success criteria for the Product Backlog item? For example, an ATM user receives a receipt of the transaction.
![]() Advance—what has to happen before the success outcome can be reached? For example, an ATM user accepts the terms and conditions.
Advance—what has to happen before the success outcome can be reached? For example, an ATM user accepts the terms and conditions.
![]() Failure—what could go wrong, and how can you cope with it? For example, an ATM user does not have enough money in his account—prompt for another amount.
Failure—what could go wrong, and how can you cope with it? For example, an ATM user does not have enough money in his account—prompt for another amount.
![]() Error—what are the error situations that are out of our control? For example, there isn’t enough cash in the ATM machine—display “out of service” message.
Error—what are the error situations that are out of our control? For example, there isn’t enough cash in the ATM machine—display “out of service” message.
SPIKES
Every once in a while, usually in early Sprints, a Scrum Team will encounter a Product Backlog item that they cannot break down any further. This is typically because the team does not yet know enough about the technology or domain.
A spike is a research Product Backlog item whose goal is to learn more about what is needed to complete the requested functionality.
Spikes are typically very simple proof of concepts that are likely to be thrown away after they have served their purpose. The ultimate goal of a spike is to reduce risk through experimentation, allowing us to make better product decisions sooner.
Caution
The danger with spikes is that they may, like anything, become abused. Every Sprint ends up with a spike story, and before long teams start planning whole spike Sprints. As spikes do not produce any immediate value to the business, this is a slippery slope. Use them, but do not abuse them.
Good reason for a spike: Download and install a candidate third-party API to see if it meets our performance needs. This would allow the Scrum Team to decide whether to attempt the feature or not.
Poorer reason for a spike: Research a feature so that the Development Team can feel more confident with their estimates. This is likely more about fear of failure than experimentation and does not necessarily help the Scrum Team make decisions.
I have seen a waterfall approach hidden behind “analyze,” “design,” “implement,” and “test” Product Backlog items instead of actual functionality being “Done” at the end of the Sprint.
A preferred approach is to both research and implement the Product Backlog item in the same Sprint. If both cannot be completed within the Sprint, then the whole Product Backlog item goes back on the Product Backlog, and the Development Team completes it in a future Sprint. The team is no worse off than if they had preemptively separated the story into different Sprints.
It is worth repeating that this focus on completing valuable quality increments every single Sprint is essential to the agility of Scrum Teams and the business as a whole. Each Sprint results in an Increment, which from the stakeholders’ point of view is “Done.”
PRODUCT BACKLOG ORDERING
The 2011 Scrum Guide’s description of Product Backlogs replaces the word “prioritize” with “order.” The reason for this was that “priority” was too often equated with business value and categorizations such as High, Medium, Low, or MoSCoW9 (Must, Should, Could, Won’t).
The last time I reviewed a company’s “H-M-L prioritized” Product Backlog, I did a count of the categories. Eighty percent of them were High, 10 percent Medium, 10 percent Low. Rather than spend a lot of wasted effort prioritizing a long list in this manner, it is much simpler to just acknowledge that they are all important to the business and ask, “Which do we want to do first?”
While business priority is important, it is not the only variable that affects the order in which you pull things off the Product Backlog.
To properly order your Product Backlog, you need to consider many aspects:
![]() Business Value
Business Value
The value created from implementing the feature: revenue, cost saving, customer retention, prospect customers, and future opportunity. Features that map closest to the product vision likely rank highest here. Example: A “make payment” feature that generates direct revenue
![]() Risk
Risk
The importance of a Product Backlog item in terms of exposure to a harmful situation. This includes both business and technical risk. The higher the risk, the higher it should be in the Product Backlog. Business risk example: A feature that must be implemented before a regulatory deadline Technical risk example: Implementing new technology on which a feature depends without knowing whether the technology solution will even work
![]() Cost/Size
Cost/Size
The cost of implementing a feature. This is mostly (but not exclusively) associated with the effort and time that the Development Team needs to build it.
![]() Dependency
Dependency
Regardless of value, risk, and cost/size, sometimes a feature cannot be done before another. These can be both business and organizational dependencies.Business example: An authentication feature that must be completed before anyone can use the more valuable features Organizational example: A feature that depends on another downstream team creating a service for your team to use
As you can see, many forces are at play. Consider the following formula:
(Business Value 1 Risk) / Size 5 Order Rank
By finding a way to enumerate each of these variables, you can create an order ranking system in which the higher the number, the higher the item will be in the Product Backlog (see Figure 7-10). Then make adjustments based on identified dependencies.

Figure 7-10 Value, risk, and size (cost) as dimensions for Product Backlog ordering
By focusing on smaller valuable features, you risk that the large yet valuable items get ignored. As these are likely the more strategic initiatives, identifying them and breaking them into smaller (right-sized) deliverables becomes an important part of refining the Product Backlog.
My family wants to renovate our kitchen. But because it is such a daunting task, we keep putting it off. It is important and strategic, but is just not getting done. The solution? Break it down into smaller tasks. Could we start with getting some people in to provide suggestions and cost estimates? That would get the ball rolling, and if we determine that the costs and risks are manageable, we will commit to the new kitchen and start to break it down into smaller tasks. Before you know it, we will have a new kitchen. Maybe.
Items that are low value, low risk, yet cost very little (left side of Figure 7-10) should not necessarily be ignored either. Consider these as “fun-sized” and work on them if there is extra capacity or they can be taken by newer Development Team members who are still getting comfortable working with the product. Some organizations even open-source these items to other groups within the organization or even to the public.
Obviously, the risky items that have little value (the right side of Figure 7-10) should be ignored.
This formulaic approach to ordering could be a good start. Just do not consider it a magic formula to which you are bound. Ordering the Product Backlog is more of a nondeterministic problem. You shouldn’t strive for the best answer as it likely does not exist. Aim for a good answer and trust the empirical process of inspecting and adapting. A good Product Owner, with help from the Development Team, can use intuition and experience to order the Product Backlog just as effectively.
With this in mind, spending a lot of time ordering the bottom half of the Product Backlog can be considered somewhat wasteful. Focus instead on the order for the next few Sprints. Since you are refining as you go, the rest will work itself out.
Ordering the Product Backlog will open up many important conversations within your Scrum Team (and with stakeholders) that will clarify assumptions, misconceptions, and dependencies and thereby reduce accidental complexity. This process itself generates lots of value.
MEASURING VALUE, RISK, AND SIZE
In the previous section, this formula to consider when ordering your Product Backlog was introduced:
(Business Value 1 Risk) / Size 5 Order Rank
This formula may seem straightforward, but where do the numbers come from?
Value
If you can determine the monetary value amount of the Product Backlog item (e.g., this feature will make $300,000), then that would be ideal. However, it is rarely that easy.
Other approaches use somewhat arbitrary numbers to indicate value, much like with relative effort sizing. The number range does not matter as much as getting stakeholders engaged and using the wisdom of the crowd. There are plenty of facilitation techniques for this, such as:
![]() Business Value Game10
Business Value Game10
Use planning poker to estimate value instead of size
![]() Buy-a-Feature11
Buy-a-Feature11
Innovation Game using money to purchase features
![]() 20/20 Vision12
20/20 Vision12
Innovation Game for simple ordering of a Product Backlog
![]() Thirty-Five13
Thirty-Five13
Collaboration activity for ordering
Using these democratic and inclusive processes with stakeholders for assigning business value to Product Backlog items has two main benefits for Product Owners:
1. They get a better overall sense of what their stakeholders are thinking.
2. Their stakeholders feel more included and heard.
Remember that business value is not the only factor when ordering a Product Backlog. Risk, cost, and technical dependency also play their parts.
Risk
The easiest way to measure risk is with a simple Low, Medium, High ranking provided by the Scrum Team. To use this system in the formula cited above, assign a number to each risk rating (e.g., L51, M55, H510). Ultimately, the scale you use to represent risk depends on other factors: How important is risk for your product? What scale are you using for value?
Risk may not even need to be considered for certain products, while others may want to give risk more weight and more ranges.
Size
The most common scale to use when assigning relative size estimates to Product Backlog items is the Fibonacci sequence (1, 2, 3, 5, 8, 13, etc.). The next chapter on release management will get more into the reasons for relative estimation. For the purposes of ordering a Product Backlog, just know that the size of an item is a factor. However, what you name the unit that represents its size is not that important (often it is called a point or story point).
Imagine you have two Product Backlog items, PBIa and PBIb. PBIa is more valuable to the business while PBIb is cheaper but addresses a bigger risk. Which should you do first? Let’s apply the formula:
PBIa → (25 value 1 5 risk) / 8 size 5 3.75 order rank
PBIb → (15 value 1 10 risk) / 5 size 5 5 order rank
In this case, PBIb ranks higher on the Product Backlog as it addresses a large risk and is relatively cheap to implement.
This can be a handy technique, but like everything it can be taken too far. As a Product Owner, are you now stuck with the order derived from this formula? Of course not. Like any tool, if it makes your job easier, then keep using it. If you want to move a few things around after the formula ranking, then feel free.
Keep in mind that this formula does not take dependencies into account. It may be a good idea to have your Scrum Team make a pass over the ordered Product Backlog to reorder based on technical and business dependencies.
Refinement is a great opportunity to revisit this ordering each Sprint.
“DONE”
In this section, we define “Done” and then work through an example of “Done.”
DEFINITION OF “DONE”
When you get a bathroom remodeled, buy a new car, or dine in a nice restaurant, you have certain expectations about the end product. Despite the best intentions, if the customer expectations do not align with the producer’s understanding of those expectations, then conflict and unhappiness generally follow. Whether a tile doesn’t quite line up, the car is dirty, or the dinner plate is not prewarmed, you are disappointed.
A clearly communicated and shared set of expectations creates the transparency needed to avoid this problem.
Software is no different. Whether you purchase a software package, consume a product as a service, or implement against an external API, you have certain expectations about quality, performance, and support. These expectations define what it means to be truly “Done.”
What should “Done” include? The answer depends on the context. Good candidates are:
![]() thoroughly tested
thoroughly tested
![]() integrated
integrated
![]() documented
documented
![]() releasable
releasable
Sound good? Well, how much testing? How much documentation? Is there a difference if you are building a dating website or a vital medical product? There is not one universal definition of “Done” for all possible products. However, you need to ensure that “Done” allows for continuous releases without disappointing your customers and other stakeholders and is clearly communicated and understood by all people involved.
From the Scrum Guide
When a Product Backlog item or an Increment is described as “Done,” everyone must understand what “Done” means. Although this may vary significantly per Scrum Team, members must have a shared understanding of what it means for work to be complete, to ensure transparency.14
This shared understanding, with the goal of transparency, is manifested in the definition of “Done.”
When do you get to “Done”? Scrum indicates that the Increment must be “Done” by the end of the Sprint. However, waiting until the very end to get to “Done” can be risky. A Development Team can hedge their bets by getting each Product Backlog item to “Done” throughout the Sprint. The moment a Product Backlog item meets the definition of “Done,” it is then considered part of the Increment. The sooner they can achieve this within a Sprint, the better (see Figure 7-11).

Figure 7-11 Continuously “Done” versus “Done” once at Sprint end
Consider this list of “Done” elements:
![]() Unit tested
Unit tested
![]() Code reviewed
Code reviewed
![]() Matches code style guide
Matches code style guide
![]() No known defects
No known defects
![]() Checked into main dev branch
Checked into main dev branch
![]() Public API documented
Public API documented
![]() Acceptance tests pass
Acceptance tests pass
![]() Product Owner approved
Product Owner approved
![]() Regression tests pass
Regression tests pass
![]() Release notes updated
Release notes updated
![]() Performance tests pass
Performance tests pass
![]() User guide updated
User guide updated
![]() Support guide updated
Support guide updated
![]() Security tests pass
Security tests pass
![]() Compliance documentation updated
Compliance documentation updated
At what point could your Development Team realistically do these? Every time they complete a Sprint Backlog item? A Product Backlog item? At the end of a Sprint for the overall Increment? Or will it have to wait until just before a release?
What if you placed them in a chart like the one in Figure 7-12?

Figure 7-12 Being “Done” more often reduces risk and promotes continuous delivery.
In an ideal world, all of these items would be completed at the Sprint Backlog item level. The introduction of practices like automation and the elimination of wasteful bureaucratic activities could make it a reality, but likely the extra effort could reduce your ROI, at least in the short term.
The further down the line you go in Figure 7-12, the more risk you introduce. Anything in the “Release” level is a huge risk, as you are indicating that those items cannot be addressed within a Sprint and would have to wait until right before a major release. So how far up the line can you push these activities? What can you do to move them up a level? If it takes two weeks to do regression testing, then likely you cannot complete it within a Sprint. However, delaying regression testing to the very end is risky. Your Scrum Team should be focusing on all the elements in the “Release” level and asking what practices they can put in place to move them up. In the case of regression testing, automation can make a big difference. But do not just settle for doing regression testing once a Sprint for the Increment. What would it take to get all the regression tests running every time the Development Team completes a Product Backlog item? Or what about every time a programmer checks in code? This is how a Scrum Team gets closer to continuous delivery.
So what’s the difference between acceptance criteria and the definition of “Done”? The definition of “Done” is for the whole Increment. Acceptance criteria are specific to a single Product Backlog item. To realize the value of a Product Backlog item, you must fulfill all of its acceptance criteria plus what is in the definition of “Done.” If you throw out the Product Backlog item, you also throw out its acceptance criteria. The definition of “Done” stays. In other words, the definition of “Done” is the global acceptance criteria.
The definition of “Done” addresses two aspects. One is what is required from a good engineering point of view, the technical aspects of the Development Team. The other, albeit smaller, aspects are domain requirements like regulations, laws, and so on. The latter need to be communicated to the Development Team so that they can figure out a way to address them correctly from their point of view (see Figure 7-13).
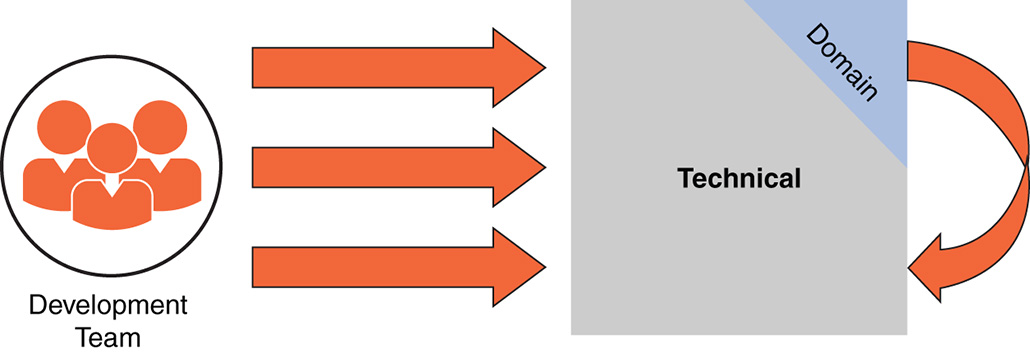
Figure 7-13 Division between technical and domain areas of definition of “Done”
How often does the definition of “Done” change? Again, it depends. Whenever there are new insights about the product and its quality, it is time to change the definition of “Done.” Usually more changes occur in the beginning since a lot of learning happens in the first Sprints, especially on the technical side. The domain aspect often changes whenever marketplace or internal/external regulatory requirements are introduced. Nonfunctional requirements (performance, usability, legal, etc.) often find themselves on the definition of “Done.” The definition of “Done” grows over time (see Figure 7-14).

Figure 7-14 Definition of “Done” growing over time
Think of the definition of “Done” as the code (as in rules, not programming) of quality that everyone commits to. Unlike professions such as doctors, plumbers, and accountants, the software development industry has no universally agreed-upon document to protect it when under pressure to deliver more, faster. At least when a Scrum Team (and the development organization) within a company sets its own standards of quality, they have something to point to when asked to do something that could compromise the quality of the product. As part of continuous improvement, the Sprint Retrospective is a good place to amend the definition of “Done.”
EXAMPLE DEFINITION OF “DONE”
What “Done” means may vary wildly from team to team. Following are example definitions of “Done” from valued trainer colleagues:
![]() Barry Overeem:
Barry Overeem:
![]() Created design
Created design
![]() Updated documentation
Updated documentation
![]() Tested
Tested
![]() Approved by Product Owner
Approved by Product Owner
![]() Clear on “how to demo” at Sprint Review
Clear on “how to demo” at Sprint Review
![]() Francois Desrosiers:
Francois Desrosiers:
![]() Code review done
Code review done
![]() Unit tests done
Unit tests done
![]() BDD tests done based on the acceptance criteria
BDD tests done based on the acceptance criteria
![]() Documentation done (based on the documentation that the client defined as essential and valuable)
Documentation done (based on the documentation that the client defined as essential and valuable)
![]() Features tested/approved by the PO or business analyst
Features tested/approved by the PO or business analyst
![]() Features deployed in the staging environment
Features deployed in the staging environment
![]() Source code of the feature is in the proper branch
Source code of the feature is in the proper branch
![]() Jeronimo Palacios:
Jeronimo Palacios:
![]() It works
It works
![]() Passes the acceptance criteria
Passes the acceptance criteria
![]() It is in production
It is in production
![]() Peer reviewed
Peer reviewed
![]() Covered by tests
Covered by tests
![]() Passes all the tests
Passes all the tests
![]() Merged into Master
Merged into Master
![]() No apparent bugs
No apparent bugs
![]() Accepted by the PO
Accepted by the PO
![]() API documented
API documented
![]() Anything not trivial commented
Anything not trivial commented
![]() Argument for binaries documented
Argument for binaries documented
![]() Fredrik Wendt:
Fredrik Wendt:
![]() Everything is version controlled
Everything is version controlled
![]() Code reviewed
Code reviewed
![]() Automated tests setup
Automated tests setup
![]() Solution shared with full team
Solution shared with full team
![]() Live/in production
Live/in production
![]() Vincent Tence:
Vincent Tence:
![]() All automated tests pass
All automated tests pass
![]() The application supports the expected load
The application supports the expected load
![]() Response time is within accepted limits
Response time is within accepted limits
![]() Manual tests are conclusive
Manual tests are conclusive
![]() Exploratory tests are conclusive
Exploratory tests are conclusive
![]() Development Team is satisfied with test coverage
Development Team is satisfied with test coverage
![]() The application has been translated to French and English
The application has been translated to French and English
![]() The application is accessible and available on all supported devices
The application is accessible and available on all supported devices
![]() Release notes are up-to-date and ready for publication
Release notes are up-to-date and ready for publication
![]() Online help is up-to-date with latest features
Online help is up-to-date with latest features
![]() Ops diagnostic can be done efficiently and timely
Ops diagnostic can be done efficiently and timely
![]() Ops Team is confident they can operate and support the application
Ops Team is confident they can operate and support the application
![]() Revision history is exploitable
Revision history is exploitable
![]() Development Team can set up a new development environment automatically
Development Team can set up a new development environment automatically
![]() New key learnings and design decisions are documented
New key learnings and design decisions are documented
![]() Development Team is satisfied with the new user experience
Development Team is satisfied with the new user experience
![]() Codebase is in a better state than before
Codebase is in a better state than before
![]() Development Team is satisfied with new code quality
Development Team is satisfied with new code quality
![]() Ops Team can roll back to a previous version retaining all data
Ops Team can roll back to a previous version retaining all data
![]() Application is available in Pre-Production environment
Application is available in Pre-Production environment
![]() No new security vulnerability has been introduced
No new security vulnerability has been introduced
![]() Development Team can reproduce identical deployment
Development Team can reproduce identical deployment
![]() Ralph Jocham:
Ralph Jocham:
![]() Compliant to development standards
Compliant to development standards
![]() Passes code analysis
Passes code analysis
![]() Documented (Scenario, SAD, Test Case, Interfaces)
Documented (Scenario, SAD, Test Case, Interfaces)
![]() Reviewed or pair programmed
Reviewed or pair programmed
![]() Automatic Unit Tests (for non UI, i.e. tier containing business logic has a test coverage of 95 percent or higher)
Automatic Unit Tests (for non UI, i.e. tier containing business logic has a test coverage of 95 percent or higher)
![]() Automatic Selenium Tests; each usage scenario has at least one Selenium test
Automatic Selenium Tests; each usage scenario has at least one Selenium test
![]() Automatic Appium Tests on target device
Automatic Appium Tests on target device
![]() All text is internationalized
All text is internationalized
![]() No known bugs exist
No known bugs exist
Figure 7-15 shows a useful definition of “Done” template for multiple teams working on one product. It defines common elements across the teams, but also leaves autonomy in how they work within each Development Team.

Figure 7-15 Definition of “Done” template
Why Is This Important for the Product Owner?
As a Product Owner, some of these “Done” elements are obvious. You need to have an integrated product, you need to have the required level of documentation and compliance, and you definitely want some degree of testing. But why should you be concerned about programming elements like coding standard adherence? Why is it important for you that a method is no longer than 12 lines and that lines do not have more than 80 characters? Why should you, as a Product Owner, be aware of these points or even enforce them?
Look at it this way: Why do you change the oil in your car on a regular basis? Why do you check the pressure in your tires on a regular basis or bring the car in for service? As a driver, you only want to get from point A to B; that’s where the value is for you. However, if you do not pay regular attention to maintenance, eventually the negligence will catch up to you and will result in being broken down on the side of the road with high repair costs. It is the same for software. If you do not maintain it on a regular basis, you will accrue lots of technical debt—slowing development, reducing innovation, and costing far more in the long run.
For that reason, it is important for a Product Owner to understand the technical concepts of the definition of “Done” and be aware that they could have dire consequences in the long run. That is why you want to know about them and track them. If this is not already happening, then ask your Development Team to start measuring them and to maybe add the measurements into the automated continuous integration environment, which will let everybody know the moment the Development Team checks in any code that violates the definition of “Done.”
This is like being notified from your car dashboard the moment something goes wrong. Ultimately, a good definition of “Done” creates transparency for the Product Owner, the Development Team, and the stakeholders.
“READY” IS A MINDSET
Working with a self-organizing Development Team is powerful, and you will be amazed at what they can deliver. However, even self-organization has its limits.
Garbage IN → Garbage OUT
If you feed garbage into the Sprint, you most likely will get garbage as output.
In other words, if you are not “Ready” at the beginning of the Sprint, you won’t be “Done” at the end of the Sprint.
Mise en place is a French culinary phrase that roughly translates to “putting in place” or “everything in its place,” which refers to organizing your kitchen before you start cooking. Essentially you make sure that you have all the required ingredients in sufficient amounts, the right equipment ready to go, oven preheated, and so forth. Imagine halfway through baking your grandmother’s famous apple crumble pie you discover that you do not have enough apples. You would have to run out and buy more, but once you return the already cut apples may have turned brown. If you want raving reviews, that surely is not going to get you there. Once you put everything in its place and make sure you have the tools and infrastructure, you are ready to roll.
What is the equivalent in software product development? Well, it is not as simple as laying everything out in front of you. Software product development is complex, abstract, and less tangible. That means “Ready” is also less tangible. Even if the Product Backlog items have been broken down, estimated, and given clear acceptance criteria, you still may not know how to implement the Product Backlog item.
Jeff Patton includes a useful metaphor in his story-mapping book15 that emphasizes the importance of “conversation” in the Three Cs (card, conversation, confirmation). He tells a story about showing a vacation picture to a friend, a picture like the one in Figure 7-16 showing Ralph and a few friends on vacation.
You see a photo of Ralph being surprised by a handful of colorful birds. For Ralph, it is more. It is a memory he can relive by looking at it. He was there to experience the moment, the location, the story about how the birds found him, the sound of the birds, the noise they made (they were deafening), their smell (they were pungent), and their rather sharp claws that left scratch marks on his skin that remained visible days later.

Figure 7-16 Ralph on vacation with birds
For the rest of us, it is just a photo; for Ralph, it is a vivid memory. That is what Product Backlog items are. Think about them as memories you create for each Development Team member. Apart from the size, estimate, and acceptance criteria, it does not matter that much what is written on the card. What matters is the narrative behind the card. Put enough on the Product Backlog item card to remember, but make sure the narrative sticks so that it can be recalled if it becomes part of the Sprint Goal.
In other words, getting a Product Backlog item “Ready” is about communicating the story behind the picture in a way that the Development Team can act on it.
GETTING TO READY
What exactly does “Ready” entail? There are three minimum needs that each Product Backlog item should meet before being tackled in a Sprint:
1. Small enough to be completed within one Sprint
2. Sized so that you can get an idea about the overall effort of the whole Product Backlog
3. Just enough detail (acceptance criteria) so that it can act as confirmation that the Product Backlog item is functioning as intended
On top of that, you may even refer to architectural constraints, business rules, UX designs, dependencies, and more, based on the needs of the product and the Scrum Team.
None of this has to be perfect. The Development Team just has to know enough to make a forecast in Sprint Planning. This may vary from Scrum Team to Scrum Team.
Scrum does not define the concept of “Ready.” The Scrum Guide considers Product Backlog items that can be “Done” within one Sprint as “Ready.” Why? “Done” is a black-and-white checklist; you can check each point off with a yes or a no. One or more no’s mean that you are not fulfilling the definition of “Done” and are not releasable. “Ready,” on the other hand, is not a checklist but a helpful guide during refinement that may not always be achievable. Defining “Ready” should not mean that a Development Team cannot attempt a Product Backlog item that is not 100 percent “Ready.”
Definition of “Ready” warning: I have worked with Development Teams that would refuse to accept a Product Backlog item into a Sprint if it didn’t meet their definition of “Ready.” While that seems reasonable at first, what I noticed was that this document started to become a gate or even a contract that shifted the mindset of the Development Team—a mindset that was less agile. Remember the third value from the Agile Manifesto, “Customer Collaboration over Contract Negotiation”? The definition of “Ready” cannot be used as a contract. If a Product Owner wakes up in the middle of the night before a Sprint Planning session with the greatest idea ever, shouldn’t he be able to take it to his Development Team the next day to be considered for the upcoming Sprint? Even if it hasn’t been fully vetted with the definition of “Ready”? The warning here is to treat “Ready” as a guideline, not a concrete contract that could decrease true collaboration.
The important thing is that “Ready” is a mindset, a common understanding to be reached within the Scrum Team. It doesn’t matter whether the content is in the form of a user story, a sentence, or a rough sketch. What does matter is that each Development Team member understands the intention of the Product Backlog item and feels good about starting it. So on top of the three points shown earlier: small enough for one Sprint, sized, and just enough detail, consider a fourth point:
4. Understood by the Development Team
Once this state is reached, feel free to make the Product Backlog item part of your Sprint Goal.

Figure 7-17 Using a “Ready” line for Product Backlog items
I once worked with a Scrum Team that had a great idea. They added a “Ready” line to their Product Backlog wall, which was arranged similarly to a story map. After each refinement session, Product Backlog items moved further up the wall as they were estimated, split into more cards, and had acceptance criteria added.
At some point, the card was close but still underneath the black “Ready” line. Only after the Development Team and Product Owner considered it “Ready” was the card moved above the line to be brought into one of the upcoming Sprints. Figure 7-17 shows an example of this.
LEAN REQUIREMENTS MANAGEMENT
There is nothing worse than when a beautiful piece of hard work has to be thrown out.
I once had a project canceled after my team and I worked overtime for three months. We lived in the office, apart from going home to get fresh clothes and to kiss our families twice a week. After a “successful” beta-launch, the project was canceled the very next day because of fear about possible patent infringement litigation. What a WASTE!
Instead of being driven by activities like planning, analysis, design, implementation, and testing, where your batch size is the whole product, it is good to have a Product Backlog that allows you to think in value. That is one reason it is important for the Product Owner to always keep the Product Backlog ready and ordered. The Product Backlog is emergent, so that the details come into focus as the Scrum Team works through it. The longer they can wait, the better decisions they will make.
This essentially means that the first reasonable moment to make a decision is the last responsible one.
Last Responsible Moment (LRM)
A strategy of not making a premature decision but instead delaying commitment and keeping important and irreversible decisions open until the cost of not making a decision becomes greater than the cost of making a decision.16
This enables you to keep the unknown-unknowns, the complexity, vague for as long as reasonable. But once the time is right, you go deep. You go from a “mile wide and inch deep” to “an inch wide and a mile deep.” You do this just in time and then go ahead and create another Increment with exactly what you specified a little earlier. This way you delay to avoid creating waste.
In other words, have just enough of your Product Backlog “Ready” for the next few Sprints. Anything else is considered waste.
Lean manufacturing or lean production, pioneered by Toyota, is a systematic method that minimizes waste without sacrificing productivity.
Lean defines seven areas of waste. An easy way to remember them is by thinking of wasteful TIM WOOD, as outlined in Table 7-1.
Table 7-1 TIMWOOD Mnemonic Device
Transport |
Moving work between phases. In software product development, this equates to handoffs between people and departments. |
Inventory |
Unnecessary storage. In software, this equates to any work—requirements, specifications, source code, tests—that has not yet been released and used by the customer. |
Motion |
Doing the same thing again and again, like manual regression testing. Task switching is another example of motion waste (e.g., on-product index). |
Waiting |
Anything that causes idle time like waiting for people (skills), data, system availability; in short, it is related to dependency management. |
Overproduction |
Unused features (e.g., usage index). |
Overprocessing |
Work not adding value or helping the product. Unnecessary documents, unnecessary meetings, or shuffling people between teams so that they have to relearn over and over. |
Defects |
Bugs. |
Anything that does not add value is considered waste. In Japanese this is called muda. Lean differentiates between two kinds of muda:
![]() Muda Type I—Non-value-added activity, necessary for product or customer. For example, compliance documentation.
Muda Type I—Non-value-added activity, necessary for product or customer. For example, compliance documentation.
![]() Muda Type II—Non-value-added activity, unnecessary for product or customer. The aim is to eliminate this type of waste.
Muda Type II—Non-value-added activity, unnecessary for product or customer. The aim is to eliminate this type of waste.
STORY MAPPING
Typically, Product Backlogs are represented as one-dimensional priority queues. The enforced order is helpful as it requires you, the Product Owner, to make tough decisions because no one Product Backlog item can be as important as another. This provides valuable insight about how to proceed. However, sometimes it is helpful to add other dimensions to the Product Backlog for themes, customer segments, releases, and so on.
Story mapping, originally developed by Jeff Patton,17 is a powerful tool to discover the right solution for your users and evolves as you gain insights. It is the process of visualizing your product from the initial vision, to user key activities, and viable releases (see Figure 7-26). A story map becomes a multidimensional map that tells the story of the overall product and provides a development strategy for fast learning.

Figure 7-18 Structure of a story map
STEPS TO CREATING A STORY MAP
The steps involved in creating a story map are covered in this section.
1. Key Activities—The Backbone
Try to see the whole picture from a bird’s eye view, the backbone (see Figure 7-26). Identify your users and their high-level key activities. Look to your Business Model Canvas as a source for this information. Customer segments could identify users, and value propositions could be candidate activities. See the business modeling section of Chapter 2.
2. Epics—The Walking Skeleton
Break down these high-level activities into epics to form the walking skeleton of your story map (see Figure 7-26).
3. User Stories—The Map of Your Most Important User
Once you have the walking skeleton, take the most important user you can think of and map out the user stories for this user for a typical day with your product. The flow of the user stories is from left to right. Identifying your most important user should be straightforward if you have already crafted a product vision. See the product vision section of Chapter 2.
4. Discover Additional Key Activities
Often, many user stories belong together and can be grouped as an activity that folds back into your backbone. This is an iterative process as more and more stories and activities emerge over time (see Figure 7-18). Activities may come first or may be identified in retrospect by grouping existing user stories.
5. Enhance the Map with Additional Users
Once you have developed a story map for your most important and critical user, go ahead and do the same for other users based on their importance. There is no point in getting into detailed mappings for users whose needs you are not yet willing to address. Again, use the flow from left to right and add their activities and tasks. Make sure each “user” of a task is clearly identifiable.
EXPLORE THE STORY MAP
Next you want to engage in some exploration of the story maps.
1. Fill in and Refine the Story Map
Break down large user stories into smaller ones and add more detail. This splitting of user stories could be for different users, different flow alternatives, and more. Other cards get rewritten as understanding grows. All these changes mean that the story map is changing again and again.
2. Think Outside the Box
Try to come up with all great possibilities you can think of and try them out on your story map. Do not be restricted while you do this. Later will be the time to triage the story map. Also, do not forget to think about all the things that can go wrong.
![]() Think outside the box to come up with cool product ideas.
Think outside the box to come up with cool product ideas.
![]() What are the variations the users expect from the product?
What are the variations the users expect from the product?
![]() What are the exceptional paths for all the things that can go wrong, and how would the user recover?
What are the exceptional paths for all the things that can go wrong, and how would the user recover?
![]() Are there other users, and how would they like to use the product?
Are there other users, and how would they like to use the product?
3. Collect Feedback
Tell this story map to others who have experience in that domain and understand the needs of the users. Use their input to refine the story map. Also, run the story map by your Development Team to learn about risks, dependencies, and available technologies. Again, this process is iterative.
4. Group It by Releases
The whole story map is likely too much for one release. Move more important user stories higher up and move less essential stories further down to form groups by releases. Think about the resulting story map as a different kind of roadmap where the first release is your Minimal Viable Product (MVP).
STORY MAPS AND PRODUCT BACKLOGS
How do story maps tie together with a Product Backlog?
The short answer is perfectly. As described in the Product Backlog section, the Product Backlog reflects all the work the Development Team needs to do. The Product Backlog is a one-dimensional priority queue. The story map expresses the vast amount of work from the Product Backlog in more than one dimension. What the Scrum Team needs to do is to project the story map into your Product Backlog (see Figure 7-19). The resulting order has to reflect what best maximizes value generation, risk mitigation, and technical dependencies for fast learning.
You may also discover constraints, which is work that slows or halts other Product Backlog items (or user stories) from being completed. Constraints could be technical or something else.

Figure 7-19 Story map projected into Product Backlog
THE PAST AND THE FUTURE
In certain situations, such as the replacement of an existing product, it is a good exercise to first map the current-reality story map and then the future story map. Contrasting both points of views helps to understand and frame the delta and resulting work for the desired outcome.
IMPACT MAPPING
Requirements can end up as an overzealous shopping list. If you feel that you only have one chance to voice your needs, you may try to prepare for all possible contingencies. This approach, when combined with a defined process in which the whole product is being delivered as one big batch, poses two big problems:
1. No big picture (vision)
2. No learning (validation)
How does impact mapping address these points? Impact mapping is a strategic planning technique that prevents companies from getting lost while building a product. Each assumption is clearly communicated. Each of the team’s activities is clearly focused and aligned toward one of those clear business objectives. As each activity is clearly directed toward an objective, it can be measured and validated while working on it. This allows for more effective roadmapping.
On top of this, working in Sprints with “Done” Increments at the end of each Sprint facilitates ongoing learning about what the Scrum Team builds and how they work together. This covers customer feedback, scope, tests, integration, and many more elements. This feedback allows for validated learning. Those learnings in turn drive the scope and roadmap.
This approach of having a clear vision and thinking in value with the measurable business objectives based on continuous validation allows you to deliver even large interdependent products in an environment of constant change.
Also, as all decisions are being validated, this process leads to better choices regarding the roadmap and the scope within, which in turn causes less scope creep and waste along the way.
In his popular book Start with Why,18 Simon Sinek makes the strong argument that you should always start with “Why” as described in his Golden Circle (see Figure 7-20).
What |
Every company on earth knows “What” services or products they do. |
How |
Some companies know “How” they do it. This sets them apart from the rest and makes them somewhat special. |
Why |
Very few organizations know “Why” they are doing what they are doing. The “Why” is not about making money. Money follows result. The “Why” is the reason the company exists. |

Figure 7-20 Golden Circle
Impact mapping builds and extends this thinking by using the “Why” to identify the right scope and how to validate it. This is achieved by adding the question of “Who” is going to benefit (see Figure 7-21).
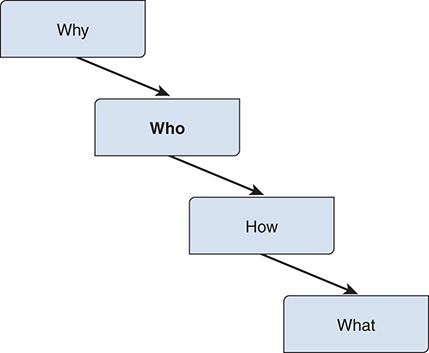
Figure 7-21 Impact mapping driven by the person being impacted
I like to think about it the following way: Because of what we do, we improve someone’s life. It might not be much—having to click one button instead of two, say—but it is still an improvement. Try to think about “Who” this person is and “how” you will improve her life.
If “Why” is the goal you want to achieve along with a value metric to validate the business objective and the “Who” is the actor performing the act, you can identify “How” you can achieve this impact. Once the impact is identified, you can come up with “What” is needed. This is your deliverable. The resulting impact map allows you to compare the various options and measure the outcome (see Figure 7-22).
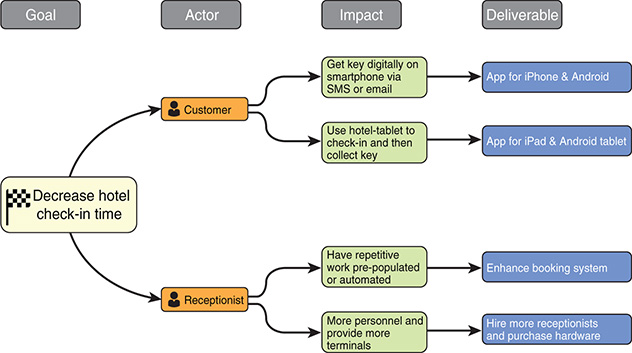
Figure 7-22 Impact map example
Each deliverable in turn can be broken down into tangible Product Backlog items, in the form of user stories, for example (see Figure 7-23). Given that the goal, the actor, and the deliverable are established, defining the Product Backlog items is more straightforward.

Figure 7-23 Product Backlog item as user story from impact map
SUCCESS CRITERIA
Impact mapping is a powerful way to come up with the right deliverables to achieve a specific goal. Still, wouldn’t it be great to quantify upfront how success can be measured (see Figure 7-24)?
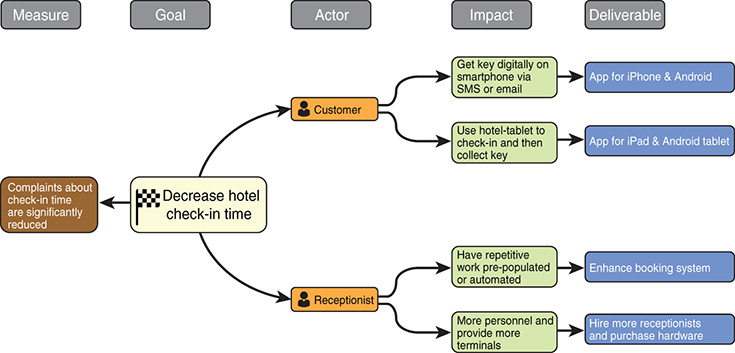
Figure 7-24 Success criteria as measure of impact validation
Think about a measure and how it will validate your targeted impact. This practice is useful as it enforces defining value validation measures and the resulting metrics upfront. This is a good mechanism to tie your measures back to your EBMgt metrics: in this case, customer happiness.
Figure 7-25 shows a way of making this transparent by creating a different view of your Product Backlog
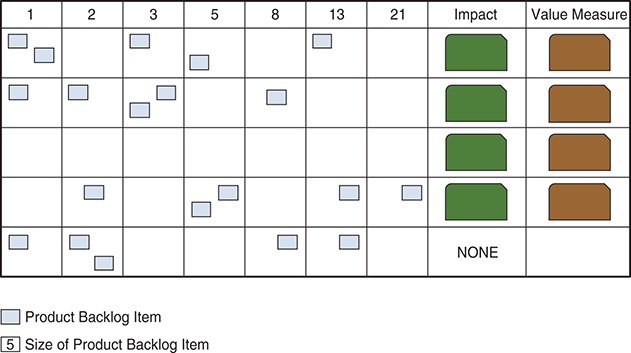
Figure 7-25 Assigning Product Backlog items to impacts
Each Product Backlog Item gets associated with an impact, and each impact has a clear measure for validation. By having the Product Backlog item sized, it helps to derive the anticipated overall effort and resulting cost.
The goal is to have each Product Backlog item associated with an impact. There may be some work that cannot be associated. That is acceptable as long as you can still justify its existence, which could lead to newly discovered impacts.
SPECIFICATION BY EXAMPLE
As formality increases, tests and requirements become indistinguishable. At the limit, tests and requirements are equivalent.19
—Robert Martin and Grigori Melnik
Let’s break that quote down. Formality does not mean that you drill down with a big upfront design effort to specify everything in the Product Backlog. It means that you remove enough ambiguity from a Product Backlog item just in time to be “Ready” for it to be developed with minimal waste.
Requirements have a tendency to be abstract. At the beginning, this is a good thing as it leaves your options open while you are deriving scope from rather broad goals or a product vision.
However, the further a Product Backlog item moves up the Product Backlog, the more it needs to be “Ready” to be consumed within a Sprint. By the time a requirement has tests written for it, it becomes much more precise (see Figure 7-26). This is where tests and requirements become indistinguishable. Once there is something as precise as a test, why is the requirement needed anymore? The test is the requirement and the requirement is the test. Eliminating the need for separate requirements reduces waste. As tests are constantly being executed, they are much more likely to be kept up to date than a requirements document.

Figure 7-26 Different levels and granularities of “Ready”
At the same time, the human brain is not that great at dealing with lots of information at once. This means that when you do need more precision, it should be done just before putting the effort into developing it.
I was once a developer/architect for a large product. We were about five months in (five Sprints) when I found myself working on this one feature. I thought I understood it fairly well and knocked it out in a couple of days. I submitted it to our QA person through our tracking tool. Not 10 minutes later, I was notified that my feature failed the tests. Perplexed, I contacted the QA person who showed up at my desk to with a three-page test case in hand. She pointed to where I went wrong. My response was a common one from programmers like me, “What? I didn’t know it was supposed to do that. Where did this come from?” She explained to me that she had met with the Product Owner weeks prior who helped her write the test case. I felt wronged since I had only started the feature days prior and asked, “Next time, can I have this before starting? Or can you just invite me to your meeting?” What I realized in that moment was that from my perspective, I wasn’t looking at a test case, I was looking at the requirements. These were the answers to the test, which would have assured me passing and saved everybody a lot of time.
You get to that level of precision by breaking down a requirement into all possible scenarios and by illustrating them. Each scenario will be illustrated with at least one concrete example and more if needed. This process of illustrating is a team effort so that all relevant perspectives are considered. The resulting examples then guide the Development Team to implement the requirement—and these examples also guide the testing effort. Both development and testing get the information from the same source. You succeed in removing all ambiguity by having tests as requirements and requirements as tests. In other words, executable requirements.
Once you reach this level of precision, it is fairly easy to automate them in a meaningful way. Specification by Example exploits this formality and formulates requirements by writing automatable tests. These automated tests can then function as executable documentation (see Figure 7-27).

Figure 7-27 Examples driving requirements and tests20
Examples sound nice, but how do you get there? Get familiar with the concept of the Triad.21 The Triad is made up of a representative for each the following domains:
![]() Business
Business
![]() Development
Development
![]() Testing
Testing
In Scrum, these roles would be covered by the Product Owner and/or a subject-matter expert for the business domain, and a programmer and tester from the Development Team. As you can see, these three domains can be easily covered by a cross-functional Scrum Team. Together, they will refine and illustrate the requirements and all acceptance criteria with specific examples.
Consider the Triad to be the amalgam between the why and the what from the business perspective and the how from the development perspective. Therefore, on the Agile Testing Quadrants, described first by Brian Marick22 in 2003, they reside in Quadrant 2 (see Figure 7-28). With the evolution of agile, Quadrant 2 has emerged as the most important area for testing.

Figure 7-28 Agile Testing Quadrants and the Three Cs or Triad
The benefits of using Specification by Example and to illustrate the requirements with examples are numerous.
This tight collaboration between the three domains is a great antidote for misunderstanding. It prevents bugs and subsequent bug fixes. This leads to less rework, higher product quality, and faster turnaround times.
Also, often not as obvious, it allows for concurrent work on Product Backlog items within a Sprint because of better alignment of the activities of the various roles like programmers, testers, and business analysts in the cross-functional Development Team.
Ultimately, Specification by Example gets all on the same page. Everyone may think they know what is meant by acceptance criteria such as:
“When users log in with invalid credentials, they should get a warning message.”
In reality, that statement could mean entirely different things to different people. Invalid password? Invalid e-mail? Incorrect role? No password? Too many attempts? What message? The same message every time?
Simply asking, “Could you give me some real examples that you would try to prove this works?” could resolve much ambiguity. Table 7-2 presents such examples.
Table 7-2 Specification by Example example
Username |
Password |
Result |
Message |
suzieq |
Wr0ngP@ss |
fail |
“Incorrect Password. Please try again.” |
suzieb |
R1ghtP@ss |
fail |
“No user with name “suzieb.” Please try again.” |
suzieq |
fail |
“Please enter a password.” |
|
bobbyg |
R1ghtP@ss |
fail |
“You are not authorized for this system. Please contact your supervisor.” |
These examples are of data that you would need to gather at some point in the development of this particular feature anyway (while writing unit tests, adding test data, exploratory testing, etc.). Pulling at least some of this data together earlier in the development cycle is the essence of Specification by Example. These are no longer tests, they are executable requirements.
There are plenty of opportunities within Scrum to create and expand these examples. Product Backlog refinement, Sprint Planning, or even during the Sprint when the Development Team starts work on a new Product Backlog item.
A while back, I was on a team that developed forensic software helping validate laboratories so that they could submit findings to court. As a laboratory, you have to prove that you will get the right and correct result over and over again. This also meant that the product we developed had to be FDA compliant. It had to consider all the applicable laws and other regulations and provide guidance for those laboratories in order to become validated. While it was an exciting product to be a part of, it was way above my pay grade. My uncertainty in programming certain features caused me to go and see our business analyst over and over again. “Gloria could you quickly explain once more how this works?” was my usual question. At some point Gloria, I guess she was fed up, handed me a spreadsheet which contained all the important information about certain calculations (see Figure 7-29). Instead of having only the abstract theory, I had concrete specific examples for all possible cases. These examples helped me, as a programmer, implement the functionality correctly the first time. Once I was done, our testers used the same spreadsheet to test the product.
In this project, we discovered Specification by Example the hard way. Once we came up with this approach—to illustrate our requirements with lots of examples in spreadsheets—our productivity and product quality went up by leaps and bounds.
Those spreadsheets were actually our documentation and placed in our version control system in which a small self-developed program read out the input values and performed and compared the results with the spreadsheet. Whenever parts of the spreadsheet created unexpected behavior of some of the assays, we received an updated spreadsheet. This spreadsheet then replaced the existing one, and we just reran all the tests. If something failed, we saw it immediately and could start to have conversations with the right people.

Figure 7-29 Life science Specification by Example example
Think about the Specification by Example development flow the following way: First you create the high-level Product Backlog item, a user story, for example. This user story then gets refined and illustrated with examples until it is considered “Ready” and becomes part of the Sprint forecast. Then each example gets turned into an automated functional test,23 and for each of the tests, the functionality is developed, driven by unit tests (aka TDD—Test-Driven Development) as in Figure 7-30.

Figure 7-30 Putting Specification by Example and Test-Driven Development together
QUIZ REVIEW
Compare your answers from the beginning of the chapter to the ones below. Now that you have read the chapter, would you change any of your answers? Do you agree with the answers below?
Statement |
Agree |
Disagree |
The Product Backlog replaces the need for any other requirement documents. |
|
|
Agile requirements must be no more than a few sentences. |
|
|
User story is synonymous with Product Backlog item. |
|
|
Defects should not be in the Product Backlog because they are triaged by the Development Team. |
|
|
The Development Team should not allow any Product Backlog items into the Sprint unless they meet a definition of “Ready.” |
|
|
A Product Backlog can be made up of tests. |
|
|
____________________________
1. Merriam-Webster Collegiate Dictionary, 10th edition.
2. Ken Schwaber and Jeff Sutherland, The Scrum Guide (November 2017), 15.
3. Ron Jeffries, “Essential XP: Card, Conversation, Confirmation,” RonJeffries.com, August 30, 2001, http://ronjeffries.com/xprog/articles/expcardconversationconfirmation/.
4. Mike Cohn, User Stories Applied (Boston: Addison-Wesley, 2004), 135.
5. William C. Wake, Extreme Programming Explored (Boston: Addison-Wesley, 2002).
6. Mike Cohn, “Make the Product Backlog DEEP,” Mountain Goat Software (blog), December 14, 2009, https://www.mountaingoatsoftware.com/blog/make-the-product-backlog-deep
7. Cucumber Ltd.’s homepage, accessed March 1, 2018, http://cucumber.io.
8. This acronym was first defined by Jef Newsom, one of the founders of Improving Enterprises.
9. “The DSDM Agile Project Framework (2014 Onwards),” chap. 10, Agile Business Consortium, accessed March 15, 2018, https://www.agilebusiness.org/content/moscow-prioritisation.
10. “Business Value Game,” agile42, accessed March 1, 2018, http://www.agile42.com/en/agile-coaching-company/agile-scrum-tools/business-value-game/.
11. “Buy a Feature,” Innovation Games, accessed March 1, 2018, http://www.innovationgames.com/buy-a-feature/.
12. “20/20 Vision,” Innovation Games, accessed March 1, 2018, http://www.innovationgames.com/2020-vision/.
13. “Thirty-five,” TastyCupcakes.org, accessed March 1, 2018, http://tastycupcakes.org/2012/10/thirty-five/.
14. Schwaber and Sutherland, Scrum Guide, 18.
15. Jeff Patton, User Story Mapping: Discover the Whole Story, Build the Right Product (Sebastopol, CA: O’Reilly Media, 2014), https://jpattonassociates.com/user-story-mapping/.
16. Agile Glossary Definitions, s.v. “last responsible moment (LRM),” Innolution.com, assessed March 1, 2018, http://www.innolution.com/resources/glossary/last-responsible-moment-lrm.
17. Patton, User Story Mapping, https://jpattonassociates.com/user-story-mapping/.
18. Simon Sinek, Start with Why: How Great Leaders Inspire Everyone to Take Action (New York: Penguin Group, 2009).
19. Robert C. Martin and Grigori Melnik, “Tests and Requirements, Requirements and Tests: A Mobius Strip, IEEE Software 25, no. 1 (2008): 54–59.
20. https://less.works/less/technical-excellence/specification-by-example.html.
21. The term “Triad,” created by Ken Pugh, is a more common term for the “Three Amigos,” created around 2009 by George Dinwiddie.
22. “My Agile Testing Project,” Exampler Consulting, August 21, 2003, http://www.exampler.com/old-blog/2003/08/21.1.html#agile-testing-project-1.
23. Often this is called ATDD (Acceptance Test-Driven Development).