
CHAPTER 3
Exploration of MITRE Key Attack Vectors
Understanding MITRE ATT&CK
Today, organizations are digitally evolving by choosing among diverse technology options to store business-critical data. On the other hand, the cyberthreat landscape is expanding geographically and constantly looking for vulnerabilities in the security layers to perform security compromises. Cyberattackers are consistently staying a step ahead of the security measures taken by organizations and succeeding in their data breach menace.
To address today's challenges, the threat-hunting team needs to build a set of techniques to investigate and create a hypothesis of how attacks would work. This includes determining what artifacts are in the logs and the other parts of the systems such as volatile memory, Registry, bootloader, etc., that need to be analyzed. Organizations with an offense-focused team, like a pen-test group or a red team, have in-house experts who research and practice attacker techniques. Others may need to rely on researching published materials on attack techniques to create new hypotheses. For example, the MITRE ATT&CK framework, first released in 2013, is growing in popularity among researchers and security companies.
Regardless of what threat modeling techniques you pick up, the following questions should be answered:
- What is the defined scope and what should be worked on?
- What are the odds and what could fail or break?
- What is the action plan for them?
- Is our mitigation control effective enough?
MITRE ATT&CK is a globally accessible knowledge base of adversary tactics and techniques based on real-world observations. The ATT&CK knowledge base is used as a foundation for the development of specific threat models and methodologies in the private sector, in government, and in the cybersecurity product and service community.
With the creation of ATT&CK, MITRE is fulfilling its mission to solve problems for a safer world—by bringing communities together to develop more effective cybersecurity. ATT&CK is open and available to any person or organization for use at no charge.
The MITRE ATT&CK framework has gained a lot of attention and popularity in recent years. The ATT&CK framework is a series of matrices that break the hacking process down into tactic categories, based on the stages of the cyber kill chain. However, many companies are still navigating how to use it and what its implementation looks like. Initial questions may include those in the following sections.
What Is MITRE ATT&CK Used For?
Being a reference framework, ATT&CK is used to identify the root causes and data sources in an environment that, if prevented, would reduce the likelihood and capability of a successful hack. It's also a great starting point to get multiple teams on the same page, using the same terminology regarding a security-testing outlook. The framework includes information on threat actor groups, successful techniques they have previously executed in real-world breaches, information about software used in hacks, mapping of security vendors' software back to tactic detection and protection, and ultimately the data source where information on each tactic can be found in a network.
How Is MITRE ATT&CK Used and Who Uses It?
ATT&CK is a means of communication. It doesn't just give red and blue teams common terms, but it is also a conduit for other teams to interface with the security team. Using ATT&CK, security teams can easily explain strengths and weaknesses to leadership. In addition, they can learn to protect against something that they don't know about. If the security controls are reasonably mature, how does an organization determine how they would stand up to a real attack scenario?
How Is Testing Done According to MITRE?
ATT&CK is a tool to use when threat hunting for the unknown. It helps gauge a baseline to judge your current alerts to bridge the gap from what attackers are using and what the IDS/IPS is seeing. If you know certain techniques should be identified or blocked, you can verify that it is actually happening using that tool.
ATT&CK can be useful to cyberthreat intelligence as it describes adversarial behaviors in a standard fashion. Actors can be tracked with associations to techniques and tactics in ATT&CK that they have been known to utilize. This gives a roadmap to defenders to apply against their operational controls to see where they have weaknesses against certain actors and where they have strengths. Creating MITRE ATT&CK navigator entries for specific actors is a good way to visualize the environment's strengths and weaknesses against those actors or groups.
ATT&CK is valuable in a variety of everyday settings. Any defensive activities that reference attackers and their behaviors can benefit from applying ATT&CK's taxonomy. Beyond offering a common lexicon for cyber defenders, ATT&CK also provides a foundation for penetration testing and red teaming. This gives defenders and red teamers a common language when referring to adversarial behaviors.
What's most important to remember about implementing the MITRE ATT&CK Framework is that it is not a one-stop security shop. More squares filled in does not equal more protection, and technique visibility should always be verified with testing.
A list of tools that can help you accomplish this is available at MITRE ATT&CK® (https://attack.mitre.org). See Figure 3.1.
MITRE has techniques and sub-techniques. Techniques represent the broad action an adversary takes to achieve a tactical goal, whereas a sub-technique is a more specific adversary action.

Figure 3.1: Enterprise ATT&CK matrix with sub-techniques
Tactics
The highest level of organization in ATT&CK is tactics. The strategic goal of an attacker may be to extort ransom, steal information, or simply destroy an organization's IT environment. But attackers must reach a series of incremental, short-term objectives to achieve their ultimate, strategic goal.
MITRE ATT&CK® (https://attack.mitre.org) assigned a reference ID [TA*]
, representing different tactics and sub-tactics, which you can find at https://attack.mitre.org/tactic. Most attacks begin with trying to gain Initial Access (TA0001). Then other fundamental tactics, including Execution (TA0002) and Persistence (TA0003), are usually necessary intermediate goals no matter the end goal of the attack. An attacker trying to steal information will need to accomplish Collection (TA0009) and finally Understanding MITRE ATT&CK™ Exfiltration (TA0010). Attackers may engage many other tactics in order to reach their goal, such as hopping from system to system or account to account through Lateral Movement (TA0008) or attempting to hide from your monitoring through Defense Evasion (TA005).
Attackers may engage many other tactics in order to reach their goal. It's important to understand, though, that tactics are a classification and description of short-term intent. Tactics describe what the attacker is trying to do at any given phase of the attack—not how they are specifically going about it.
Techniques
While tactics specify what the attacker is trying to do, techniques describe the various technical ways attackers have developed to employ a given tactic. Similar to the tactics, techniques also carry a reference ID as [T*], which represents different techniques, which you can find at https://attack.mitre.org/techniques/enterprise). For instance, attackers usually want to maintain their presence in your network over reboots or logon sessions. This is Tactic TA0003: Persistence. But you can achieve persistence many ways. For instance, on Windows systems, you can leverage certain keys in the registry whose values are executed as system commands in connection with predictable events, such as system start or logon (which is the T1060 - Registry Run Keys/Startup Folder technique). Or you can simply install your malicious program as a system service using technique T1050: New Service. Another technique is T1103: AppInit DLLs, which is a way of getting every process that loads user32.dll to also load your malicious DLL. There are many more techniques, and others will be developed in the future, but they all revolve around giving the attacker persistent access to the victim's system or network. Hence, they are all grouped under the same tactic.
Some techniques help facilitate more than one tactic, and this is reflected in ATT&CK. For instance, T1050: New Service is listed under two tactics—Persistence and Privilege Escalation. For each technique, ATT&CK lists the applicable platforms (e.g., Windows and Linux), the permissions perquisite to exploiting the technique, sources of data for detecting the technique (e.g., logs), and a cross-reference to any related attack patterns in CAPEC, which is a related catalog of common attack patterns focused on application security.
Let's take a look at an example of how some of these changes demonstrate themselves in the latest version of the MITRE ATT&CK framework.
Figure 3.2 shows “Initial Access,” which is a tactic found on the ATT&CK Framework. In the previous version of the framework, Spear Phishing Attachment, Spear Phishing Link, and Spear Phishing via Service were techniques, and in the new version, they are all sub-techniques and consolidated under Phishing, which now exists at the Technique level. You can also see that Supply Chain Compromise and Valid Accounts added new sub-techniques that were not there previously. New sub-techniques were required across the entire framework to properly scale and respond to threats as they evolve.
Figure 3.2: The Initial Access tactic, found on the ATT&CK Framework
By combining existing similar sub-techniques into groups and developing new sub-techniques across the entire framework, MITRE has solved a problem with granularity and built a new framework that can continue to evolve and scale for years to come. ATT&CK's growth has resulted in techniques at different levels of granularity: some are very broad and cover a lot of activity, while others cover a narrow set of activity. They wanted to address the granularity challenge while also giving the community a more robust framework to build onto over time.
Applying ATT&CK tags to threat intelligence enables you to classify, correlate, and derive meaningful conclusions to help you prioritize responses and make better decisions. Incorporating ATT&CK into ThreatConnect Playbooks lets you automate how the framework is utilized in your workflow. You can find the public GitHub repository at https://github.com/ThreatConnect-Inc/threatconnect-playbooks. For example, notify your Security Operations team and add indicators to blocklists when incidents associated with tactics and techniques relevant to your organization occur.
The MITRE Enterprise matrix includes all tactics and techniques relevant to on-premise and cloud solutions. The MITRE framework also provides tactics and techniques that are relevant only to cloud solutions.
Figure 3.3 shows the tactics and techniques representing the MITRE ATT&CK Matrix for Enterprise covering cloud-based techniques. The matrix contains information for the following platforms: AWS, GCP, Azure, Azure AD, Office 365, and SaaS. Within the Cloud Matrix, you can go even further and pick up a specific cloud solution, such as O365.
Refer to Appendix G to learn more about the definitions of the MITRE Cloud Matrix tactics and its techniques.
Threat Hunting Using Five Common Tactics
In this section, we discuss the following five ATT&CK tactics and techniques because of their prevalence in attacks.
Figure 3.3: Tactics and techniques representing the MITRE ATT&CK® Matrix for Enterprise covering cloud-based techniques
| ID | TACTIC | TOP THREE TECHNIQUES |
|---|---|---|
| TA0004 | Privilege Escalation |
|
| TA0006 | Credential Access |
|
| TA0008 | Lateral Movement |
|
| TA0011 | Command and Control |
|
| TA0010 | Exfiltration |
|
Refer to Appendixes B to F to learn more about the definitions of these five ATT&CK tactics and techniques.
Many organizations are already collecting the logs and information that match the data sources necessary to detect these techniques. Explore each one of these techniques in-depth, highlighting how the attackers use them and how you can detect them. Identify which logs you need to collect and what you need to look for in those logs.
Privilege Escalation
Privilege escalation is a common way for attackers to gain unauthorized access to systems within a security perimeter. Attackers start by finding weak points in an organization's defenses and gaining access to a system. In many cases, that first point of penetration will not grant attackers with the level of access or data they need. Especially nowadays, removing the local admin is one of the best practices to reduce the attack surface. Hence, attacks need to escalate the privilege from a normal user to a higher privilege or admin in order to gain more permissions or obtain access to additional, more sensitive systems.
In some cases, attackers attempting privilege escalation find the “doors are wide open”—inadequate security controls, or failure to follow the principle of least privilege, with users having more privileges than they actually need. In other cases, attackers exploit software vulnerabilities, or use specific techniques to overcome an operating system's permissions mechanism.
Privilege escalation consists of techniques that adversaries use to gain higher-level permissions on a system or network. Adversaries can often enter and explore a network with unprivileged access but require elevated permissions to follow through on their objectives. Common approaches are to take advantage of system weaknesses, misconfigurations, and vulnerabilities.
There are many privilege escalation methods in Windows operating systems. Here is a brief review of the top three common methods.
- Access Token Manipulation: Adversaries may modify access tokens to operate under a different user or system security context to perform actions and bypass access controls. Windows uses access tokens to determine the ownership of a running process. A user can manipulate access tokens to make a running process appear as though it is the child of a different process or belongs to someone other than the user that started the process. When this occurs, the process also takes on the security context associated with the new token.
- Bypass User Account Control: Adversaries may bypass UAC mechanisms to elevate process privileges on a system. Windows User Account Control (UAC) allows a program to elevate its privileges (tracked as integrity levels ranging from low to high) to perform a task under administrator-level permissions, possibly by prompting the user for confirmation. The impact to the user ranges from denying the operation under high enforcement to allowing the user to perform the action if they are in the local administrators group and click through the prompt or allowing them to enter an administrator password to complete the action.
- DLL Search Order Hijacking: Adversaries may execute their own malicious payloads by hijacking the search order used to load DLLs. Windows systems use a common method to look for required DLLs to load into a program. Hijacking DLL loads may be for the purpose of establishing persistence as well as elevating privileges and/or evading restrictions on file execution.
Refer to Appendix B to learn more about the definitions of the Privilege Escalation tactic and its techniques.
Case Study
A leading organization in Asia produces and sells passenger tickets with a magnetic strip to their train and bus commuters. Customers can buy unregistered tickets directly from a retail store, or from the train or bus station. Customers can register the card online using a unique ID such as email address and bank account details (credit or debit card number), which can also automatically add money when the card balance meets a certain threshold.
A hacker somehow stole unique customer ID and bank details from the organization's database. The hacker used that stolen information to top up unregistered zero-balance tickets that he purchased from a retail store. He started selling these topped-up tickets in retail stores and online at a discounted price. For example, the hacker added $100 to an unregistered ticket using someone else's credit or debit card and sold the ticket with a 20% discount, i.e., $80. In the customer's bank transaction, there was a record reflecting the credit or debit card transaction; however, they did not initiate it. The hacker carried out this activity for a while until the organization realized the large volume of customers that were impacted.
The ticket was a genuine one, and the organization was liable to its customers, including financial loss. The organization had a substantial financial loss and reputational damage, as customers were worried about the data breach of their identity and payment details.
The organization realized the cause of the compromise in their infrastructure related to API and the web server. The use of information technology applications and services without explicit IT department approval also caused this compromise. They decided to implement security testing and the software development cycle that includes the API.
Credential Access
Credential access consists of techniques for stealing credentials like account names and passwords. Techniques used to get credentials include keylogging or credential dumping. Using legitimate credentials can give adversaries access to systems, make them harder to detect, and provide the opportunity to create more accounts to help achieve their goals.
Here is a brief review of the top three common credential access methods.
- Credential Dumping: Adversaries attempt to dump credentials to obtain account login and credential information, normally in the form of a hash or a cleartext password, from the operating system and software. Credentials can then be used to perform lateral movement and access restricted information.
- Password Cracking: Adversaries may use password cracking to attempt to recover usable credentials, such as plaintext passwords, when credential material such as password hashes are obtained. OS credential dumping is used to obtain password hashes, which may only get an adversary so far when pass the hash is not an option. Techniques to systematically guess the passwords used to compute hashes are available, or the adversary may use a precomputed rainbow table to crack hashes. Cracking hashes is usually done on adversary-controlled systems outside of the target network. The plaintext password resulting from a successfully cracked hash may be used to log in to systems, resources, and services.
- Man in the Middle: Adversaries may attempt to position themselves between two or more networked devices using a man-in-the-middle (MiTM) technique to support follow-on behaviors such as network sniffing or transmitted data manipulation. By abusing features of common networking protocols that can determine the flow of network traffic (e.g., ARP, DNS, LLMNR, etc.), adversaries may force a device to communicate through an adversary-controlled system so they can collect information or perform additional actions.
Refer to Appendix C to learn more about the definitions of the Credential Access tactic and its techniques.
Case Study
Credential stuffing is a brute force technique and a common type of attack that many popular brands have been caught up in. In credential stuffing, adversaries may use credentials obtained from breach dumps of unrelated accounts to gain access to target accounts through credential overlap. Occasionally, large numbers of username and password pairs are dumped online when a website or service is compromised, and the user account credentials accessed. The information may be useful to an adversary attempting to compromise accounts by taking advantage of the tendency for users to use the same passwords across personal and business accounts.
Uber was severely punished following its deception over a data breach that occurred in 2016. The company was fined a total of $1.2 million from separate regulators in the UK and the Netherlands, although both penalties resulted from the same incident.
An investigation from the UK's Information Commissioner's Office (ICO) found that an attacker gained access to Uber's data storage through credential stuffing. They used an Uber employee's previously exposed credentials from other websites to access their GitHub account.
Once inside this account, the attacker found login details to the Amazon Web Service S3 buckets where Uber's data was stored. This allowed them to steal data for 57 million Uber users, including both drivers and riders. The attackers then reached out to Uber and demanded a $100,000 payment for information on how they were able to access the S3 buckets. Uber paid up, making the payment seem as though it was part of their bug bounty program, but it did not make the matter fully public. The company didn't end up revealing the details of the breach until about a year later, in late 2017. The hacking incident and its resulting cover-up led to Uber being punished for several different reasons: for poor security practices, for late notification, and for being deceptive about the so-called bug bounty.
Despite the seemingly low rate of success, the sheer scale of credential stuffing makes it incredibly effective for hackers and devastatingly costly for users and companies.
Lateral Movement
Lateral movement consists of techniques that adversaries use to enter and control remote systems on a network. Following through on their primary objective often requires exploring the network to find their target and subsequently gaining access to it. Reaching their objective often involves pivoting through multiple systems and accounts to gain control. Adversaries might install their own remote access tools to accomplish lateral movement or use legitimate credentials with native network and operating system tools, which may be stealthier.
Adversaries may use alternate authentication material, such as password hashes, Kerberos tickets, and application access tokens, to move laterally within an environment and bypass normal system access controls. Here is a brief review of the top three common methods:
- Pass the Hash: Adversaries may “pass the hash” using stolen password hashes to move laterally within an environment, bypassing normal system access controls. Pass the hash (PtH) is a method of authenticating as a user without having access to the user's cleartext password. This method bypasses standard authentication steps that require a cleartext password, moving directly into the portion of the authentication that uses the password hash. In this technique, valid password hashes for the account being used are captured using a Credential Access technique. Captured hashes are used with PtH to authenticate as that user. Once authenticated, PtH may be used to perform actions on local or remote systems.
- Application Access Token: Adversaries may use stolen application access tokens to bypass the typical authentication process and access restricted accounts, information, or services on remote systems. These tokens are typically stolen from users and used in lieu of login credentials.
- Pass the Ticket: Adversaries may “pass the ticket” using stolen Kerberos tickets to move laterally within an environment, bypassing normal system access controls. Pass the ticket (PtT) is a method of authenticating to a system using Kerberos tickets without having access to an account's password. Kerberos authentication can be used as the first step to lateral movement to a remote system.
Refer to Appendix D to learn more about the definitions of the Lateral Movement tactic and its techniques.
Case Study
A recent attack from the PARINACOTA group, known for human-operated attacks that deploy the Wadhrama ransomware, is notable for its use of multiple methods for lateral movement (see Figure 3.4). After gaining initial access to an Internet-facing server via RDP brute force, the attackers searched for additional vulnerable machines in the network by scanning on ports 3389 (RDP), 445 (SMB), and 22 (SSH).
The adversaries downloaded and used Hydra to brute force targets via SMB and SSH. In addition, they used credentials that they stole through credential dumping using Mimikatz to sign into multiple other server machines via Remote Desktop. On all additional machines they were able to access, the attackers performed mainly the same activities, dumping credentials and searching for valuable information.
Notably, the attackers were particularly interested in a server that did not have Remote Desktop enabled. They used WMI in conjunction with PsExec to allow remote desktop connections on the server and then used netsh to disable blocking on port 3389 in the firewall. This allowed the attackers to connect to the server via RDP.
They eventually used this server to deploy ransomware to a huge portion of the organization's server machine infrastructure. The attack, an example of a human-operated ransomware campaign, crippled much of the organization's functionality, demonstrating that detecting and mitigating lateral movement is critical.
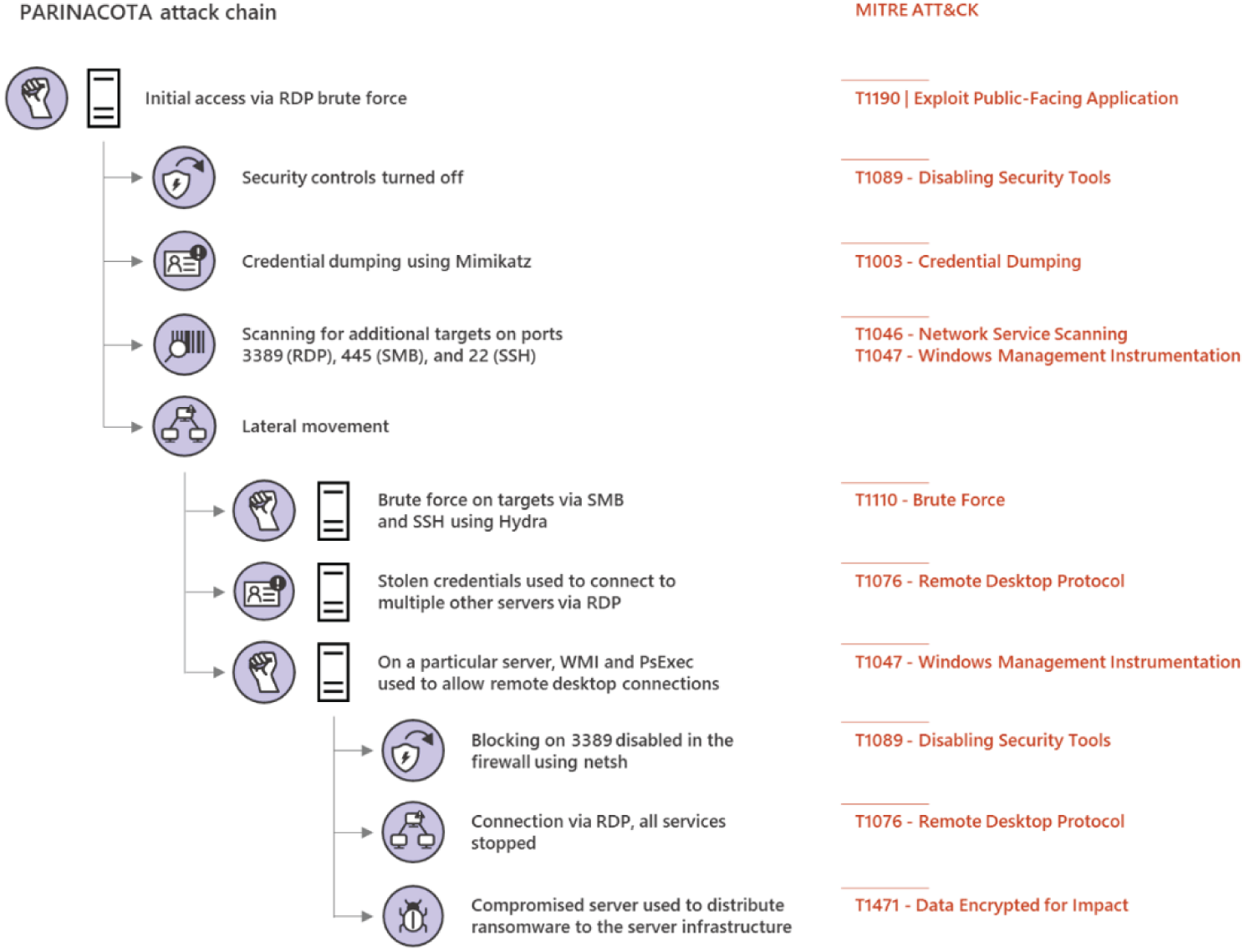
Figure 3.4: PARINACOTA attack with multiple lateral movement methods
Command and Control
Command and control consists of techniques that adversaries may use to communicate with systems under their control within a victim network. Adversaries commonly attempt to mimic normal, expected traffic to avoid detection. There are many ways an adversary can establish command and control with various levels of stealth depending on the victim's network structure and defenses:
- Connection Proxy: This technique is used by attackers to facilitate the Command-and-Control Tactic (TA0011), which represents how adversaries communicate with systems under their control within a target network. There are many ways an adversary can establish command and control with various levels of covertness, depending on system configuration and network topology. Due to the wide degree of variation available to the adversary at the network level, only the most common factors were used to describe the differences in command and control. There are still a great many specific techniques within the documented methods, largely due to how easy it is to define new protocols and use existing, legitimate protocols and network services for communication.
- Non-standard Ports: Adversaries may communicate using a protocol and port paring that are typically not associated. For example, HTTPS over port 8088[1] or port 587[2] as opposed to the traditional port 443. Adversaries may make changes to the standard port used by a protocol to bypass filtering or muddle analysis/parsing of network data.
- One-way Communication: Adversaries may use an existing, legitimate external web service as a means for sending commands to a compromised system without receiving return output over the web service channel. Compromised systems may leverage popular websites and social media to host command and control (C2) instructions. Those infected systems may opt to send the output from those commands back over a different C2 channel, including to another distinct web service. Alternatively, compromised systems may return no output at all in cases where adversaries want to send instructions to systems and do not want a response.
Refer to Appendix E to learn more about the definitions of the Command and Control tactic and its techniques.
Case Study
The professional service firm, which is the second-most targeted industry for cybersecurity attacks, was using SaaS solutions for business productivity. They did not deploy multifactor authentication across all employees except the IT department. They realized they had not received payment from a couple of customers to whom they issued invoices. First, they validated with the bank to ensure any delay from the bank side to reflect the amount if the customer had already paid. Their bank confirmed that they had not received payments from the customers. Then the professional service firm reached out to the customer's finance department. The customer finance team confirmed they paid based on the invoice and new account details provided. The professional service firm's finance team ensured that no account change was initiated from their end. So, they launched a full investigation of this incident.
Although there was a security policy to change the password every 90 days, a senior executive in the firm requested an exception overruling this policy. Around 20 senior executives got a similar exception. During the cyber team investigation, they found the executive's password was leaked to multiple sites. It was evident that a hacker dumped the executive's password. The hacker accessed the Practice Lead's email account, for which he had not changed his password for the past couple of years. The hacker set up “forward rule” in the senior executive's email account so that all emails that the senior executive received were forwarded to the hacker's personal email. As the executive did not attempt to change the password for more than two years, the hacker spent ample time waiting for the right opportunity to strike.
The senior executive sent invoices to customers. When the firm's finance team sent invoices to the senior executive by email attachment, they were forwarded to the hacker's email. The hacker picked a few emails with the invoice attached and amended the account information where the customer was expected to make the payment. The hacker logged in to the senior executive's email account and sent the invoice with altered account information and called out the account number change in the email. The customer had no reason to be suspicious as the email they received was from the genuine source that they regularly work with.
As a result of this incident, the professional service firm had to report to the local privacy commissioner. The challenge was that they could not determine the scope of the impact, as they had no idea how long the hacker was active in the network and whether other user credentials were compromised. The incident was exposed to the market and the professional service firm had to send one-to-one communication to around 2,000 customers to explain the situation. In addition to financial and reputational damage, it was an embarrassing situation for the professional service firm, as they tell their customers about the importance of security measures, but failed to implement a strict and universal security policy within their own organization.
Exfiltration
Exfiltration consists of techniques that adversaries use to steal data from your network. Once they've collected data, adversaries often package it to avoid detection while removing it. This can include compression and encryption. Techniques for getting data out of a target network typically include transferring it over their command and control channel or an alternate channel and may also include putting size limits on the transmission.
- Automation Exfiltration: Adversaries may exfiltrate data, such as sensitive documents, through the use of automated processing after being gathered during collection.
- Exfiltration Over Alternative Protocol: Once an attacker obtains the desired information, the attacker must get that data out of the victim's network without being noticed. This is part of the Exfiltration Tactic (TA0010) and a common technique is the Exfiltration Over Alternative Protocol, where the exfiltration is performed with a different protocol from the main command and control protocol or channel. The data is likely to be sent to an alternate network location from the main command and control server. Alternate protocols include FTP, SMTP, HTTP/S, DNS, or some other network protocol. Different channels could include Internet web services such as cloud storage.
- Transfer Data to Cloud Account: Adversaries may exfiltrate data by transferring the data, including backups of cloud environments, to another cloud account they control on the same service to avoid typical file transfers/downloads and network-based exfiltration detection. A defender who is monitoring for large transfers outside the cloud environment through normal file transfers or over command and control channels may not be watching for data transfers to another account within the same cloud provider. Such transfers may utilize existing cloud provider APIs and the internal address space of the cloud provider to blend into normal traffic or avoid data transfers over external network interfaces.
Refer to Appendix F to learn more about the definitions of the Data Exfiltration tactic and its techniques.
Case Study
An oil and gas facility had two high-tech exercise bicycles that were connected to the Internet and communicating through insecure methods. These were not segmented from corporate IT resources and thus presented the attacker with a network path to the organization's critical assets.
Awake Security identified that the two exercise bikes were sending unencrypted HTTP traffic to the Internet, and used basic authentication (a weak authentication method that exposes the username and password). Both machines were sitting on the corporate network and exfiltrating data out to the Internet. Additionally, they appeared to be unpatched, leaving the facility wide open to attack. (See https://awakesecurity.com/case-studies/iot-unsecured-iot-devices-used-for-data-exfiltration/.)
The firm's IT and security teams were completely unaware of these devices being on the network, since existing security and configuration management tools were blind to these unmanaged IoT devices.
Awake automatically looks for weak and insecure authentication mechanisms, the use of cleartext credentials, and for sensitive data leaving the network. These activities triggered an adversarial model in the Awake Security Platform, which alerted the security team about the insecure IoT devices.
The MITRE ATT&CK Framework is growing in popularity among researchers and security companies. It provides a detailed explanation of the hows and whys of specific attacker techniques. ATT&CK describes the purpose of the technique, the types of platforms, potential mitigations, and references to online reports.
Other Methodologies and Key Threat-Hunting Tools to Combat Attack Vectors
In this section, we discuss other leading methodologies and key threat-hunting tools to combat attack vectors outside of MITRE ATT&CK Framework tactics and techniques. We explicitly look at the Zero Trust and the cloud-based Defense in Depth strategy, and we introduce the Microsoft and AWS threat-hunting tools to analyze events and logs.
Zero Trust
Before the Internet, we created networks protected by firewalls, using a methodology called castle defenses. But then the Internet started to enable us to really transform how we did things. Now, in an organization, user population spans across employees, partners, and contractors, and they are all bringing their own devices. They store sensitive data in transformative cloud services. They connect devices deployed in our supply chains, dealers, factories, vehicles, and buildings. They even share users, devices, apps, and data with our partners and vendors. Furthermore, the bolt on security tools added over the years to combat new threats is now aging and not able to keep up with the new and emerging threats. We can see this simply by seeing the number of data breaches. So, Microsoft and many other industry players are leading a new approach to modernize cybersecurity using a comprehensive Zero Trust model adapt to the changing world and protect assets, data, and customers wherever they are.
We're living in a new reality. Those old assumptions will not keep us secure in the new world. We can no longer believe everything behind the corporate firewall is safe. We need new principles to protect us.
- Verify explicitly. Always authenticate and authorize based on all available data points, including user identity, location, device health, service or workload, data classification, and anomalies.
- Use least privileged access. Limit user access with Just In Time and Just Enough Access (JIT/JEA) to protect both data and productivity.
- Assume breach. Minimize blast radius for breaches and employ security strategy to prevent lateral movement.
Zero Trust is a security methodology that requires all users, even those inside the organization's enterprise network, to be authenticated, authorized, and continuously validating security configuration and posture, before being granted or keeping access to applications and data (Figure 3.5). Zero Trust is not simply a tool or product. It packages a set of existing technologies and processes like multi-factor authentication, identity and access management, and data analytics to provide defense-in-depth to thwart adversaries even after they've breached networks.
Figure 3.5: Zero Trust is a security methodology with several aspects.
To cut through the complexity, simply put, Zero Trust is next-generation defense-in-depth risk-based security—a journey toward intelligent security for an organization where we move away from a trust-by-default perspective to a trust-by-exception one.
An integrated capability to automatically manage those exceptions and alerts is important so you can more easily find and detect threats, respond to them, and prevent or block undesired events across your organization. This provides visibility across your environment and allows leveraging automation to make intelligent risk-based access decisions. It's not a point solution, but a holistic modular approach that adapts and grows with you and your business.
Zero Trust is one of the most effective ways for organizations to control access to their networks, applications, endpoints, identity, infrastructure, and data. It combines a wide range of preventative techniques including identity verification, micro segmentation, endpoint security, and least privilege controls to deter would-be attackers and limit their access in the event of a breach.
This added layer of security is critical as companies increase the number of endpoints within their network and expand their infrastructure to include cloud-based applications and servers. Both of these trends make it more difficult to establish, monitor, and maintain secure perimeters. Furthermore, a borderless security strategy is especially important for those organizations that have a global workforce and offer employees the ability to work remotely.
By segmenting the network and restricting user access, Zero Trust security helps the organization contain breaches and minimize potential damage. This is an important security measure as some of the most sophisticated attacks are orchestrated by internal users.
Zero Trust is targeted at both outside attackers that have already breached the network and malicious insiders, and is designed to prevent them from moving laterally through the network as they seek out sensitive data. For example, Edward Snowden had legitimate credentials to operate as a subcontractor within the National Security Agency's network. There was no way to know, however, that he was downloading top-secret material about NSA surveillance programs because there wasn't an additional micro-perimeter that prevented downloads without proper authentication. Zero Trust would have hypothetically uncovered or prevented his activities through the principle known as least privilege, which gives users the least network privileges they need to access the data, applications, and services necessary to do their job.
Cloud deployments are excellent candidates for implementing Zero Trust concepts. If the cloud infrastructure itself is ever compromised, a Zero Trust–compliant architecture provides protection from adversaries seeking to entrench themselves in our virtual network. Different organizational requirements, existing technology implementations, and security stages affect how the Zero Trust model implementation takes place. Integration between multiple technologies, like endpoint management and SIEM, helps make implementations simple, operationally efficient, and adaptive.
While commercial clouds offer an excellent opportunity to scale capability and control costs, they pose risks since we do not control the infrastructure and there may be delays in communicating compromises. The assumption Zero Trust makes—that you are compromised—is particularly suited to cloud infrastructures.
Threat Intelligence and Zero Trust
Threat intelligence provides two main benefits to organizations:
- It helps inform organizations about threats.
- It gives you a language for communicating threats and their impact within your organization.
Threat intelligence as a Zero Trust control is about helping you understand the specific threats that you need to protect for the specific environments that you're protecting. Once you've deployed Zero Trust controls, you're going to have network segments that have different purposes or serve the business in different ways. Each of these is going to face different risks. For example, in a network or in a server environment, you're not likely to have users opening and clicking phishing emails, but in a user environment, it's quite likely you will.
Having a better know-how for the different tactics, techniques, and procedures that are being leveraged against your organizations within your region are going to help you protect these individual siloed environments and prioritize your mitigation strategy for each of them. In many ways, threat intelligence provides you the justification for your security budget.
As you mature in your journey, you are going to realize the need for specific types of intelligence about more specific types of threat; this is where you will now need to subscribe to paid or open-source threat intel feed or from a specific technology vendor. Organizations will likely engage with many different sources of threat intelligence. This is key to building a foundation of understanding, and again, the language for communicating internally and the risks that your organization faces.
The most important thing to understand when you're dealing with threat intelligence is that it's collected from many disparate sources (open sourced and paid). The analysis and outcome and, truly, even the confidence in what you receive may vary greatly.
Build Cloud-Based Defense-in-Depth
The last section outlined three principles of Zero Trust—verify explicitly, least privilege access, and assume breach. The guiding principle is assume breach, which is an extension of the defense-in-depth strategy. By constantly challenging the security capabilities, organizations can stay ahead of emerging threats.
There is no perfect defense. Even cutting the network cables between systems isn't enough to stop attackers from getting in. Attackers are strongly motivated to invent new ways to sneak or smash their way into our networks and steal our stuff. The better strategy we need is to assume breach and realize that any control can be overcome. See Figure 3.6.
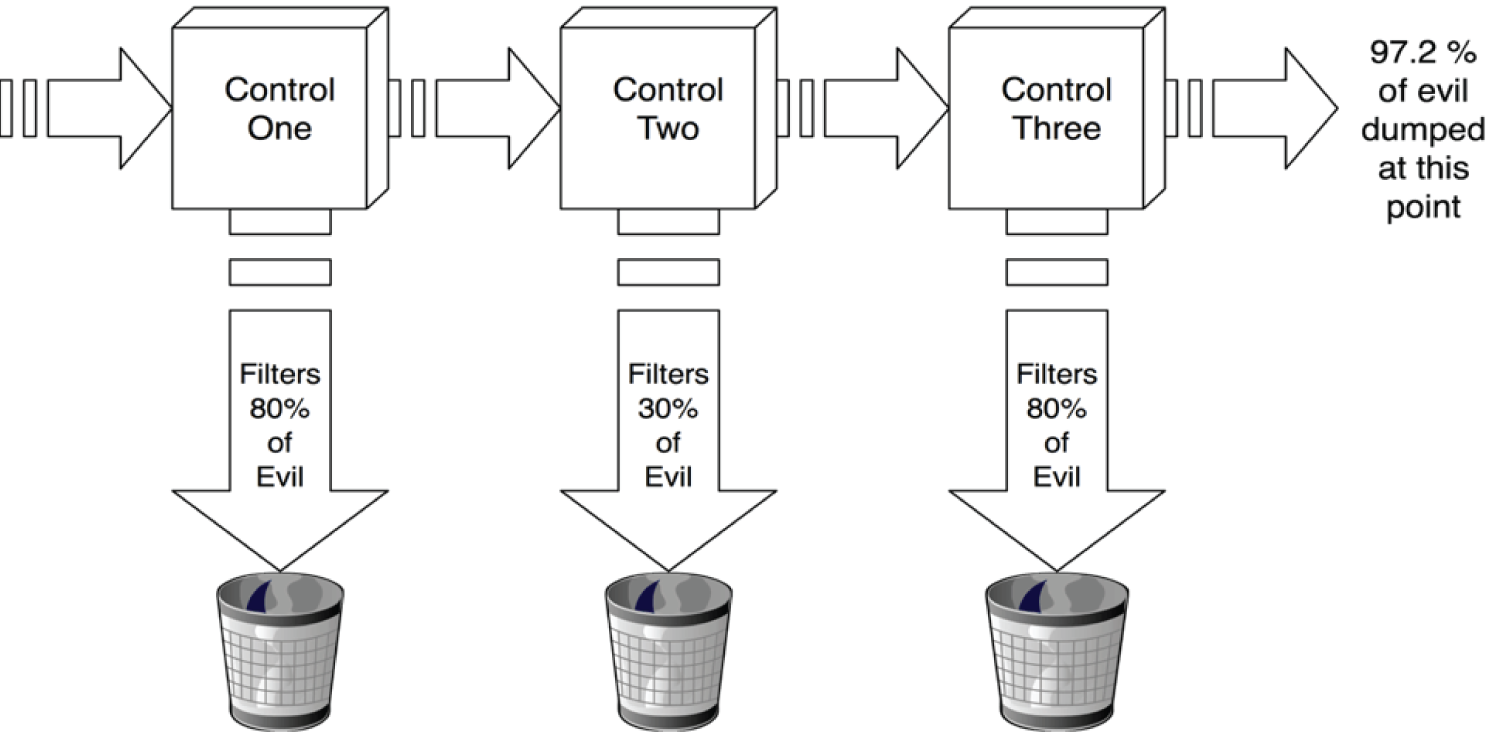
Figure 3.6: Control number filters
Say you've got a hundred attacks coming into your organization at a given moment. Control One filters out 80% of threats to give you only 20 attacks to worry about. Not bad. And then Control Two whacks nearly a third of those. Now the total has dropped to 13. Not a great control, but it still reduced things a bit. Finally, Control Three takes another 80% off that, dropping the number of attacks to just 3. By overlapping these three limited controls, you've created a single control that's 97% effective.
In today's cloud-enabled world, the perimeter of the network is an increasingly blurry line. Defense-in-depth involves defining a clear separation of “inside” and “outside” network operations and building multiple lines of defense separating the two. While some security controls are not applicable to implementing defense-in-depth in the cloud, it is possible to apply a variety of requirements. While a cloud consumer cannot implement physical controls (due to lack of physical access to cloud servers), they can implement both technical and administrative controls based upon the type of cloud architecture in use. Controls can be classified as external or internal to the cloud environment:
- External Cloud Security: The first step in implementing cloud-based defense-in-depth is identifying the use of each cloud resource and the associated level of appropriate security and trust. For example, an IaaS cloud environment such as AWS, and Azure being used to host a public website has very different requirements than environments hosting databases containing sensitive or confidential information. The security needs of each resource should be considered separately, and the controls applied to each environment must be commensurate with the level of risk associated with an exposure. Ideally, public-facing and internal resources should be kept in cloud environments completely isolated from one another unless absolutely necessary to do otherwise. If isolation is impossible, strictly defined interconnections should be utilized and can be implemented using both the tools available within the CSP's management interface as well as third-party tools, which can be integrated into the environment. An important part of external cloud security is locking down access to the cloud systems. One of the advantages of the cloud is that it can be accessed from anywhere; however, this also presents security concerns. Regardless of the technology implemented, all organizations should implement strong authentication controls, including multifactor authentication. Organizations with multiple cloud presences should implement a Cloud Access Security Broker (CASB) tool to ensure Identity and Access Management controls are applied consistently across all cloud resources.
- Internal Cloud Security: Cloud resources should also have strong internal security. “Compartmentalization” is often used to segregate data and services that do not need to be stored in the same location or accessed by the same groups of individuals. Within a virtual machine, access should be limited based upon the principles of need-to-know and least privilege to minimize the impact of a potential breach. For example, Amazon S3 buckets should always be set to private with access granted on an individual basis—a very common misconfiguration enables S3 buckets, often containing sensitive information, to be accessed by anyone. Sensitive information should be encrypted whether “at-rest” (being stored) or “in-transit” (being transmitted) with keys stored within the organizational network, not on cloud servers. All connections to cloud resources should use encrypted protocols like SSH and HTTPS or be tunneled using a VPN connection if possible.
Monitoring the cloud for potential threats will help you stay situationally aware of when your defense strategies fail so you can quickly mitigate a threat before it becomes a compromise.
There is no cut-and-copy checklist on what controls and defenses to leverage. It's going to vary based on an organization's business, technological infrastructure, culture, and relevant threats. The key is analyzing and understanding the threats you face and the assets you care about, and then applying divergent but overlapping controls to remediate as much risk as you can. The good news is that a coordinated collection of useful but imperfect defenses is not only more effective than a single bulletproof control, it's a lot more attainable.
Analysis Tools
Threat hunters can bring a wide range of tools to bear to analyze complex datasets from multiple sources, from scripts parsing raw data, to a full Security Information and Event Management (SIEM) that provides ad hoc and complex searching, reporting, and investigations. The decision is usually about setup complexity, cost, and the need to scale as the team grows. In the following section, two common threat-hunting platforms offered by Microsoft and Amazon are introduced for the benefit of starting points in collecting all relevant events and logs for further threat hunting and analytics.
Microsoft Tools
Microsoft Azure Sentinel (see Figure 3.7) is a scalable, cloud-native SIEM and Security Orchestration, Automation, and Response (SOAR) solution. Azure Sentinel delivers intelligent security analytics and threat intelligence across the enterprise, providing a single solution for alert detection, threat visibility, proactive hunting, and threat response.
Azure Sentinel is your bird's-eye view across the enterprise alleviating the stress of increasingly sophisticated attacks, increasing volumes of alerts, and long resolution time frames. You can:
- Collect data at cloud scale across all users, devices, applications, and infrastructure, both on-premises and in multiple clouds.
- Detect previously undetected threats and minimize false positives using Microsoft's analytics and unparalleled threat intelligence.
- Investigate threats with artificial intelligence and hunt for suspicious activities at scale, tapping into years of cybersecurity work at Microsoft.
- Respond to incidents rapidly with built-in orchestration and automation of common tasks.
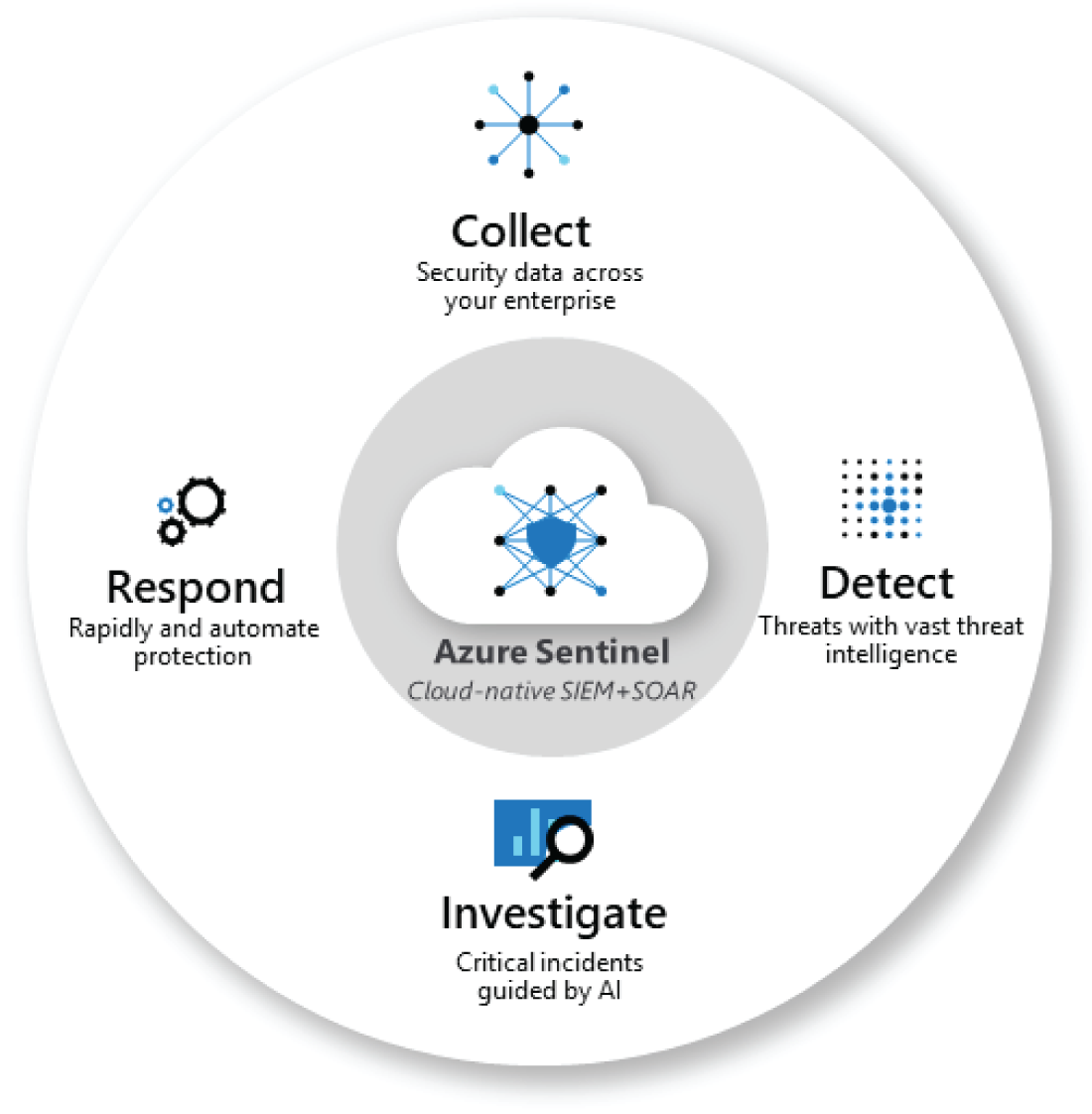
Figure 3.7: Microsoft Azure Sentinel
Building on the full range of existing Azure services, Azure Sentinel natively incorporates proven foundations, like log analytics and logic apps. Azure Sentinel enriches your investigation and detection with AI and provides Microsoft's threat intelligence stream and enables you to bring your own threat intelligence.
Connect To All Your Data
To on-board Azure Sentinel, you first need to connect to your security sources. Azure Sentinel comes with a number of connectors for Microsoft solutions, available out-of-the-box and providing real-time integration, including Microsoft 365 Defender (formerly Microsoft Threat Protection) solutions, and Microsoft 365 sources, including Office 365, Azure AD, Microsoft Defender for Identity (formerly Azure ATP), Microsoft Cloud App Security, and more. In addition, there are built-in connectors to the broader security ecosystem for non-Microsoft solutions. You can also use common event format, Syslog, or REST-API to connect your data sources with Azure Sentinel. See Figure 3.8.
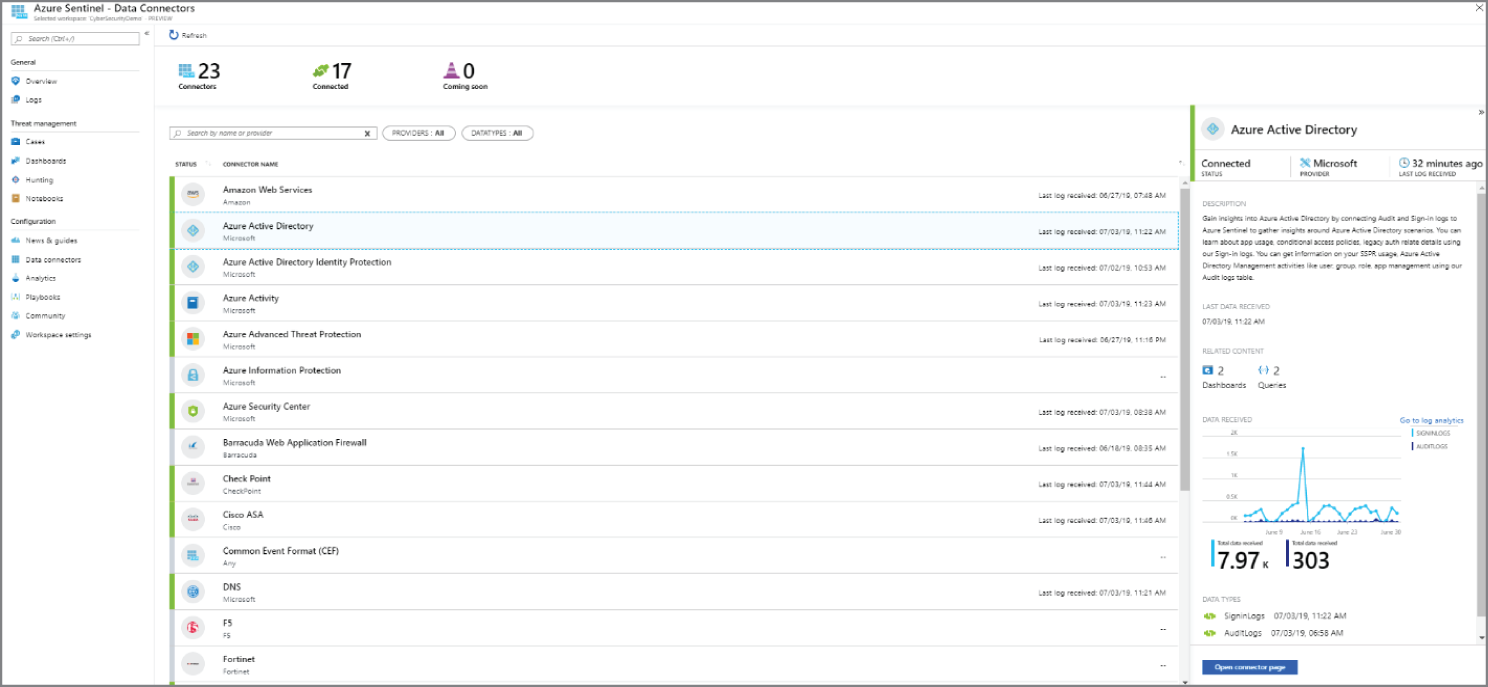
Figure 3.8: Azure Sentinel Data Connectors
Workbooks
After you have connected your data sources to Azure Sentinel, you can monitor the data using the Azure Sentinel integration with Azure Monitor Workbooks, which provides versatility in creating custom workbooks (see Figure 3.9). While Workbooks are displayed differently in Azure Sentinel, it may be useful for you to see how to create interactive reports with Azure Monitor workbooks. Azure Sentinel allows you to create custom Workbooks across your data, and also comes with built-in workbook templates to allow you to quickly gain insights across your data as soon as you connect a data source.
Analytics
To help you reduce noise and minimize the number of alerts you have to review and investigate, Azure Sentinel uses analytics to correlate alerts into incidents. Incidents are groups of related alerts that together create an actionable possible threat that you can investigate and resolve (see Figure 3.10). Use the built-in correlation rules as-is, or use them as a starting point to build your own. Azure Sentinel also provides machine learning rules to map your network behavior and then look for anomalies across your resources. These analytics connect the dots, by combining low-fidelity alerts about different entities into potential high-fidelity security incidents.
Figure 3.9: Azure Sentinel Workbooks
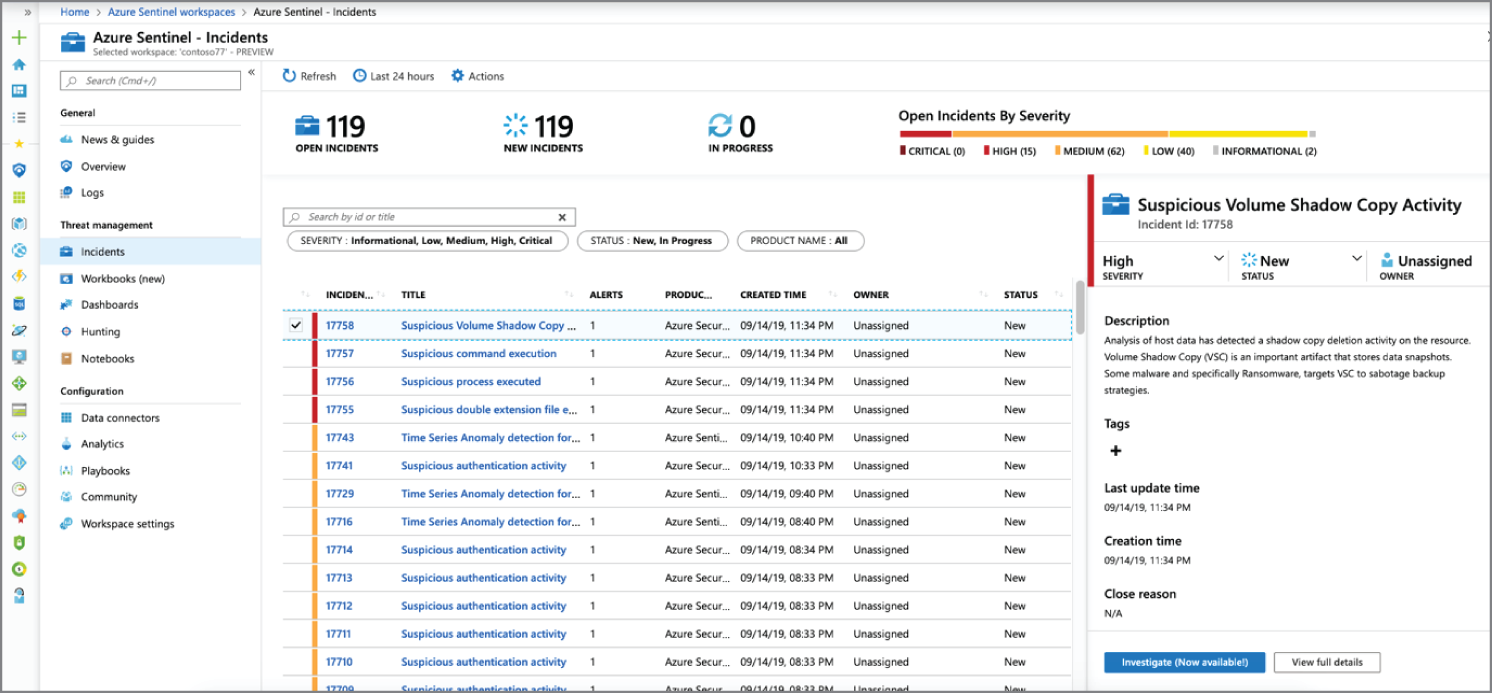
Figure 3.10: Azure Sentinel Incidents
Security Automation and Orchestration
Automate your common tasks and simplify security orchestration with playbooks that integrate with Azure services as well as your existing tools. Built on the foundation of Azure Logic Apps, Azure Sentinel's automation and orchestration solution provides a highly extensible architecture that enables scalable automation as new technologies and threats emerge. To build playbooks with Azure Logic Apps, you can choose from a growing gallery of built-in playbooks. These include more than 200 connectors for services such as Azure functions. The connectors allow you to apply any custom logic in code, ServiceNow, Jira, Zendesk, HTTP requests, Microsoft Teams, Slack, Windows Defender ATP, and Cloud App Security.
For example, if you use the ServiceNow ticketing system, you can use the tools provided to use Azure Logic Apps to automate your workflows and open a ticket in ServiceNow each time a particular event is detected. See Figure 3.11.
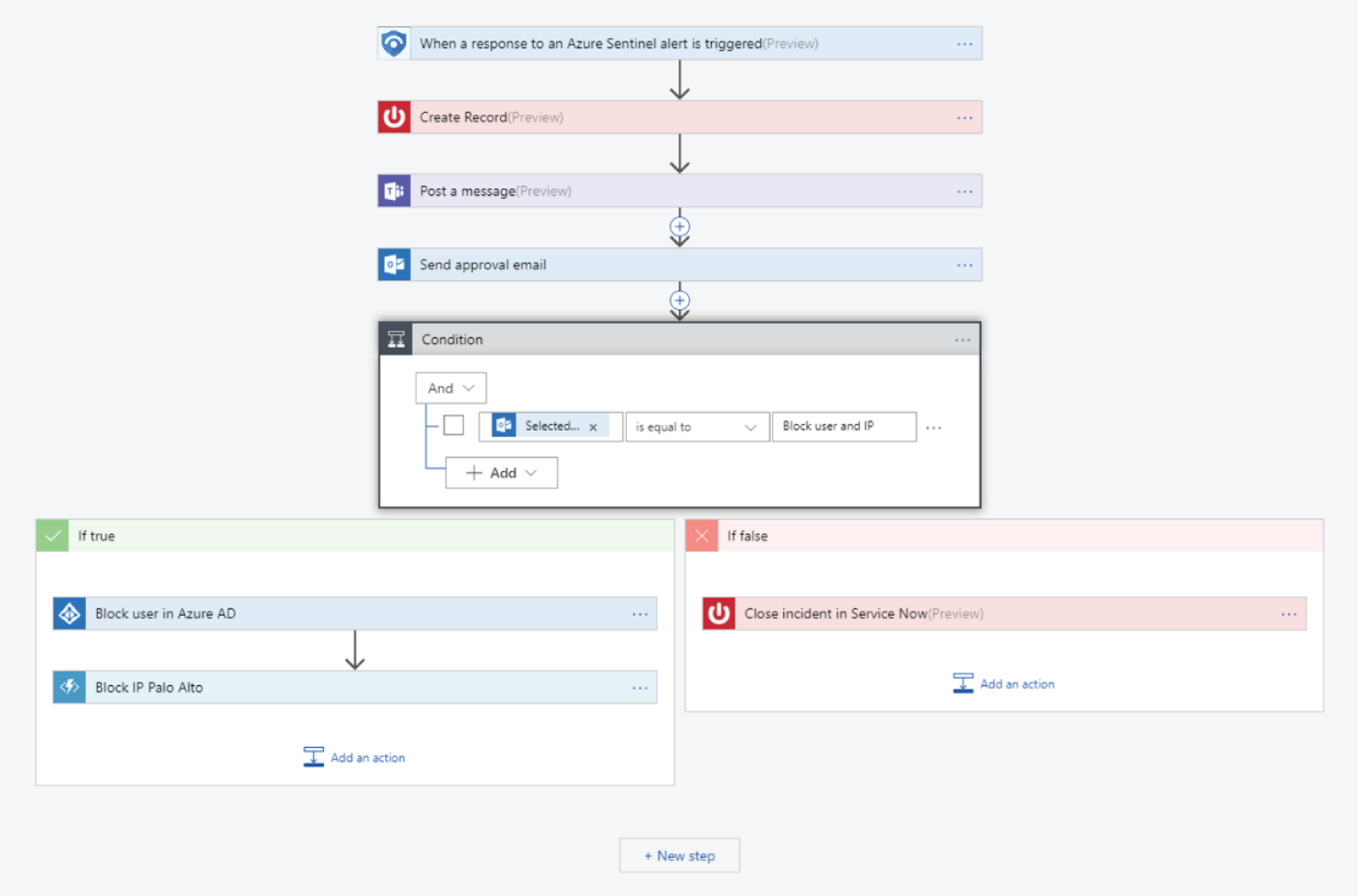
Figure 3.11: Security Orchestration Playbook
Threat hunting is all about proactive analysis of data to detect the anomalous behavior that is undetectable by the security products. As the threat-hunting team's analytics become more sophisticated, it may begin developing a set of repeatable analytics, enrichments, or data gathering steps. If it's repeatable and articulate, it can be automated. SOAR leverages the data storage and enrichment of the SIEM, understands basic rules of infrastructure integration, and allows the easy buildout of playbooks to automate a course of action. Gathering potential logs to analyze and automating the enriching processes when necessary could save threat hunters tedious and repetitive work. It could also help provide quicker triage. The SIEM with a SOAR could significantly improve speed to analysis. Taking the playbook a step further, it's possible to use data pushed to the SIEM and SOAR, such as the SQL injection detection logs from the WAF, and initiate an action.
This automated response action allows the team to limit what passive data has to be managed, and makes it easier to correlate the process logs returned with the suspicious SQL injection attacks.
Investigation
Currently in preview, Azure Sentinel's deep investigation tools help you to understand the scope and find the root cause of a potential security threat. You can choose an entity on the interactive graph to ask interesting questions for a specific entity, and drill down into that entity and its connections to get to the root cause of the threat. See Figure 3.12.
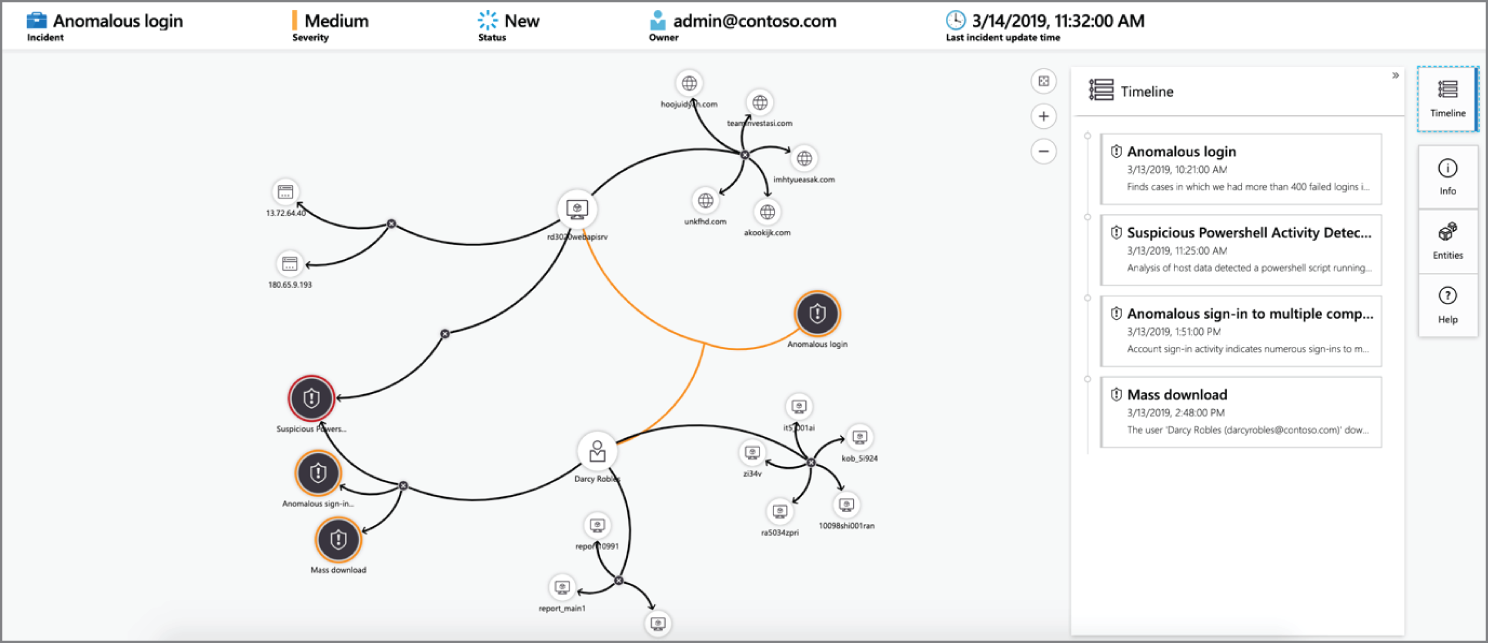
Figure 3.12: Interactive Graph for Investigation
Hunting
Azure Sentinel's powerful hunting search-and-query tools, based on the MITRE framework, enable you to proactively hunt for security threats across your organization's data sources, before an alert is triggered (see Figure 3.13). After you discover which hunting query provides high-value insights into possible attacks, you can also create custom detection rules based on your query, and surface those insights as alerts to your security incident responders. While hunting, you can create bookmarks for interesting events, enabling you to return to them later, share them with others, and group them with other correlating events to create a compelling incident for investigation.
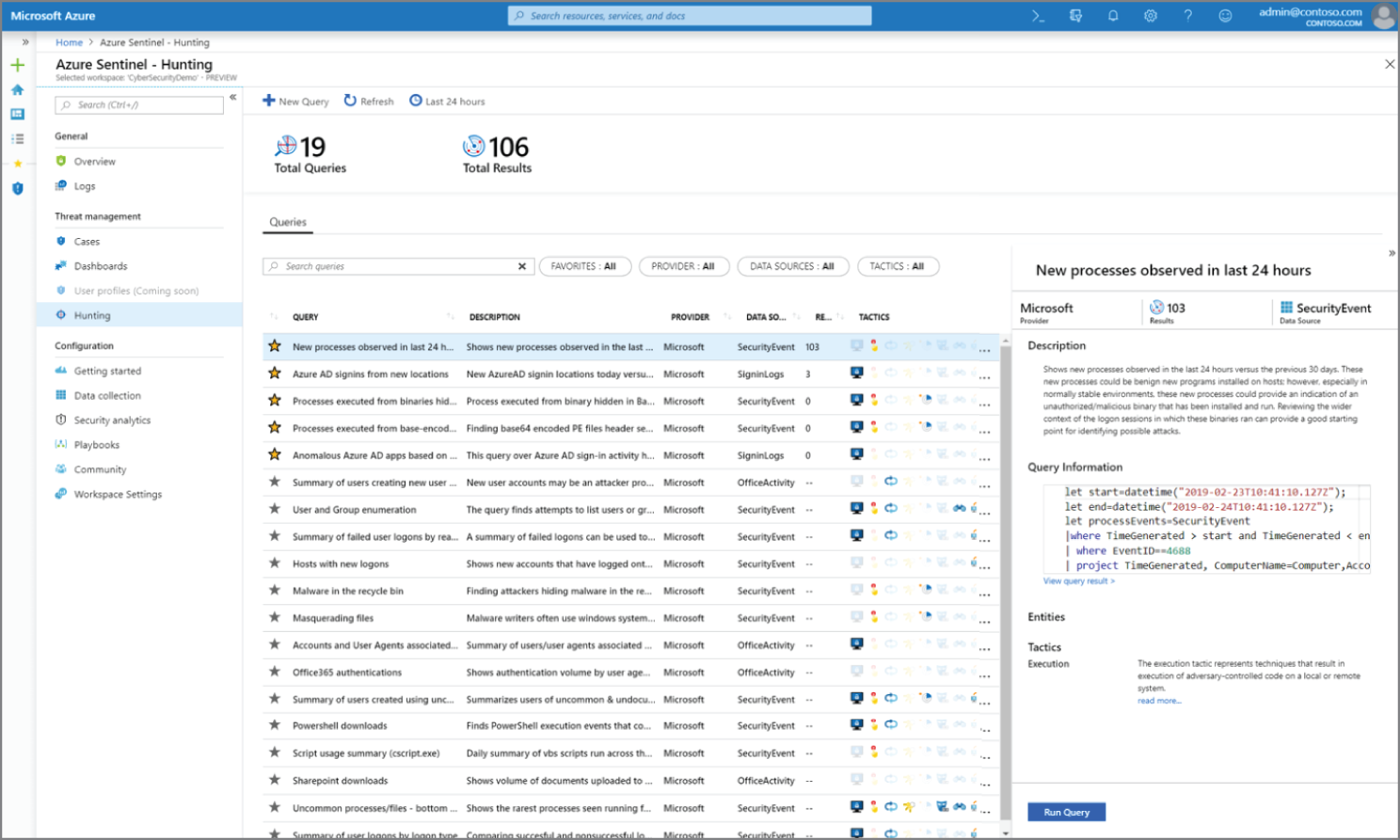
Figure 3.13: Azure Sentinel's hunting tools
Community
The Azure Sentinel community is a powerful resource for threat detection and automation. Microsoft security analysts constantly create and add new workbooks, playbooks, hunting queries, and more, posting them to the community for you to use in your environment. You can download sample content from the private community GitHub repository to create custom workbooks, hunting queries, notebooks, and playbooks for Azure Sentinel. See Figure 3.14.
Figure 3.14: Azure Sentinel Community
AWS Tools
Amazon Web Services (AWS) provides several services that can be used and chained together for scripts and analytical use.
Analyzing Logs Directly
Amazon CloudWatch is the core service for monitoring an AWS environment, because it is easy to get up and running and provides basic metrics, alarming, and dashboards (Figure 3.15). Amazon CloudWatch and AWS CloudTrail can be used together to interact directly with collected data. AWS offers methods of exporting Amazon CloudWatch logs, collected from custom applications to Amazon S3, AWS Lambda, or the Amazon ElasticSearch Service.
Figure 3.15: Amazon CloudWatch
AWS provides another service called Amazon Athena, which runs SQL queries against data in an Amazon S3 bucket (Figure 3.16). Customers build virtual tables that organize and format the underlying log data inside the bucket objects. It takes time to ensure that data is formatted and managed. Amazon GuardDuty is a managed service that is evaluating a growing number of findings that detect adversary behaviors and alerting the customer. Amazon GuardDuty evaluates potential behaviors by analyzing Amazon Virtual Private Cloud (VPC) Flow Logs. A similar real-time VPC flow logs analysis engine can be created using AWS Lambda, Amazon Kinesis, Amazon S3, Amazon Athena, and Amazon QuickSight.
Figure 3.16: The Amazon Athena service
SIEMs in the Cloud
As a threat-hunting team starts to build a corpus of analytics that it wants to run repeatedly, or as its investigating, monitoring, and reporting needs become more comprehensive, a full SIEM is likely of interest. Several cloud-specific services, as well as traditional on-premises SIEMs, work with cloud infrastructure. The threat-hunting team should focus on developing and managing a tactical SIEM, which could be different from the SIEM an SOC might use. The tactical SIEM will likely have unstructured data, a shorter retention policy than the SOC's SIEM, and the ability to easily determine what the infrastructure looked like in the recent past.
In the cloud, good data management strategy should be implemented to be cost-effective, with pay-per-usage pricing. Generally, free or open source solutions tend to take more time and expertise to set up and maintain, but they are more customizable and cost little or nothing. Commercial solutions may cost more, but may come with better support, easy access to purpose-built connectors, and more reporting options.
After the tactical SIEM is stood up; the data is gathered, translated, and enriched; and mechanisms for analytics and reporting are in place, the threat-hunting team will start to discover repeated steps, analytics, or actions. The emerging service that integrates with the SIEM, called Security Orchestration Automation and Response (SOAR), can be helpful there.
ElasticSearch, a favorite of the open source community, boasts a significant user base and supports plug-ins for data importing, translating, and easy displaying with the Kibana application. AWS provides a managed Amazon ElasticSearch Service to make it easy to set up and run the search engine without having to do all the management heavy lifting. The company behind ElasticSearch, Elastic, has released a new app called the Elastic SIEM that is more focused on the security operations. Other products, such as ones from Sumo Logic and Splunk, also integrate directly with AWS and provide even richer and more full-featured analytic platforms.
Summary
- ATT&CK can be used many different ways to improve cybersecurity efforts. This chapter focused on explaining how you can leverage ATT&CK tactics and techniques to enhance, analyze, and test your threat-hunting efforts.
- We are in the early days of threat hunting, specifically in cloud environments. Organizations are moving away from traditional server-based infrastructure into serverless, event-driven architectures that rely on native cloud services.
- Threat hunters adapt their processes, tools, and techniques to identify and neutralize the threats in the cloud infrastructure landscape. Proper strategy ensures the right data is collected, enriched, and available to the tools the threat-hunting team uses to tease out suspicious anomalies from the vast and ever-changing infrastructure.
- Your threat-hunting process is always growing and adapting to new information, increasing experience, and the changing threat landscape.
Resources
Understanding MITRE ATT&CK References:
https://attack.mitre.org/https://www.cynet.com/network-attacks/privilege-escalation/https://www.sisainfosec.com/downloads/Case-Study/mitigating-privilege-escalation-attack-by-user-behaviour-analysis-and-threat-hunting.pdf
Case Study References:
https://awakesecurity.com/case-studies/iot-unsecured-iot-devices-used-for-data-exfiltration/https://gallery.logrhythm.com/independent-white-papers/uws-using-mitre-attack-in-threat-hunting-and-detection-white-paper.pdfhttps://www.comparitech.com/blog/information-security/credential-stuffing-attacks/https://www.microsoft.com/security/blog/2020/06/10/the-science-behind-microsoft-threat-protection-attack-modeling-for-finding-and-stopping-evasive-ransomware/
AWS Tools Reference:
Zero Trust References:
https://breakingdefense.com/2020/01/disa-embraces-zero-trust-might-stop-the-next-snowden/https://www.crowdstrike.com/epp-101/zero-trust-security/#:~:text=Zero%20Trust%20also%20prevents%20attacks,and%20minimizes%20the%20attack%20surface
Defense-in-depth References:
https://www.f5.com/labs/articles/cisotociso/build-defense-in-depth-with-dissimilar-protectionshttps://www.avertium.com/cloud-security-using-defense-in-depth/
Microsoft Tools Reference: