
Appendix B
Possibility–Probability Transformation
The presentation in this appendix is taken from Flage et al. (2013). Procedures for the transformation from a possibilistic representation to a probabilistic one, and vice versa, have been suggested: see, for example, Dubois et al. (1993). The transformations are not one-to-one, and in going from possibility (probability) to probability (possibility) some information is introduced (lost) in the transformation procedure. However, certain principles can be adopted so that there is minimum loss (introduction) of (artificial) information.
With possibility–probability/probability–possibility transformations, uncertainty propagation can be performed within a single calculus, using Monte Carlo sampling when transforming possibility distributions into probability distributions and fuzzy methods for the converse.
In this appendix we review the possibility–probability transformation method applied in Chapters 8–11 in Part III. Probability–possibility transformation is not considered; we refer to Dubois et al. (1993) for an overview of such methods.
We consider the transformation from a possibility distribution into a probability distribution. The transformation is based on given principles and ensures consistency to the extent that there is no violation of the formal rules connecting probability and possibility when possibility and necessity measures are understood as upper and lower probabilities, and so that the transformation is not arbitrary within the constraints of these rules. Nevertheless, as noted by Dubois et al. (1993):
going from a probabilistic representation to a possibilistic representation, some information is lost because we go from point-valued probabilities to interval-valued ones; the converse transformation adds information to some possibilistic incomplete knowledge. This additional information is always somewhat arbitrary.
Given the interpretation of possibility and necessity measures as upper and lower probabilities, a possibility distribution π induces a family P (π) of probability measures. Since there is not a one-to-one relation between possibility and probability, a transformation of a possibility distribution π into a probability measure P can therefore only ensure that:
- P is a member of P (π); and
- P is selected among the members of P (π) according to some principle (rationale); for example, “minimize the information content of P,” in some sense.
We will deal with probability densities. In the following h denotes the probability density associated with a probability measure P.
Different possibility–probability transformations have been suggested in the literature. Dubois et al. (1993) argue that the following should be basic principles for such transformations.
![]()
![]()
![]()
The following transformation method is presented by Dubois et al. (1993).
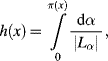
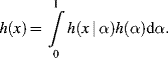
![]()
Dubois, D., Prade, H., and Sandri, S. (1993) On possibility/probability transformations, in R. Lowen and M. Roubens (eds.) Fuzzy Logic: State of the Art, Kluwer Academic, Dordrecht, pp. 103–112.
Flage, R., Baraldi, P., Aven, T., and Zio, E. (2013) Probabilistic and possibilistic treatment of epistemic uncertainties in fault tree analysis. Risk Analysis, 33 (1), 121–133.