
Chapter 2. Foundational Concepts
In the previous chapter you learned the foundations of Git, its characteristics and typical application of version controlling your projects. It probably sparked your curiosity and left you with a good number of questions. For instance, how does git keep track revisions of the same file at every commit on your local development machine? What are the contents of the hidden .git directory and its significance? How is a commit ID generated and why does it look gibberish and should you take note of it?
If you have used another Version Control System, such as SVN or CVS, you may notice that some of the commands described in the last chapter likely seemed familiar. Although Git serves the same function and provides all the operations you expect from a modern Version Control System, an exception to this notion will be that the inner workings and principles of Git differ in some fundamental and surprising ways.
In this chapter, we explore why and how Git differs by examining the key components of its architecture and some important concepts. We will focus on the basics, common terminologies, the relation between git objects and how they are utilized, all through the lens of a single repository. The fundamentals you learn in this chapter apply just the same, when you will work with multiple interconnected repositories.
Repositories
A Git repository is simply a key-value pair database containing all the information needed to retain and manage the revisions and history of files in a project. A Git repository retains a complete copy of the entire project throughout its lifetime. However, unlike most other Version Control Systems, the Git repository not only provides a complete working copy of all the files stored in the project, but also a copy of the repository (key-value pair database) itself with which to work.
Figure 2-1 helps illustrate the explanation:
. ├── my_website │ └── .git │ └── Hidden git objects └── index.html

Note
We use the term repository to describe the entire project and its key-value pair database as a single unit
Besides file data and repository metadata, git also maintains a set of configuration values within each repository. We have already worked with some of these in the previous chapter, in specific the repository user’s name and email address. These configuration settings are not propagated from one repository to another during a clone, or duplicating operation. Instead, Git manages and inspects configuration and setup information on a per-environment, per-user, and per-repository basis.
Within a repository, Git maintains two primary data structures, the object store and the index. All of this repository data is stored at the root of your working directory in the hidden subdirectory named .git
The object store is designed to be efficiently copied during a clone operation as part of the mechanism that supports a fully distributed Version Control System. The index is transitory information, is private to a repository, and can be created or modified on demand as needed.
The next two sections describe the object store and index in more detail.
Git Object Store
At the heart of Git’s repository implementation is the object store. It contains your original data files and all the log messages, author information, dates, and other information required to rebuild or restore any version or branch of the project to a specific state in time.
Git places only four types of objects in the object store: the blobs, trees, commits, and tags. These four atomic objects form the foundation of Git’s higher level data structures.
- Blobs
-
Each version of a file is represented as a blob. Blob, a contraction of “binary large object,” is a term that’s commonly used in computing to refer to some variable or file that can contain any data and whose internal structure is ignored by the program. A blob is treated as being opaque. A blob holds a file’s data but does not contain any metadata about the file or even its name.
- Trees
-
A tree object represents one level of directory information. It records blob identifiers, path names, and a bit of metadata for all the files in one directory. It can also recursively reference other (sub)tree objects and thus build a complete hierarchy of files and subdirectories.
- Commits
-
A commit object holds metadata for each change introduced into the repository, including the author, committer, commit date, and log message. Each commit points to a tree object that captures, in one complete snapshot, the state of the repository at the time the commit was performed. The initial commit, or root commit, has no parent. Most commits have one commit parent, although later in the book we explain how a commit can reference more than one parent.
- Tags
-
A tag object assigns an arbitrary yet presumably human readable name to a specific object, usually a commit. Although
9da581d910c9c4ac93557ca4859e767f5caf5169refers to an exact and well-defined commit, a more familiar tag name likeVer-1.0-Alphamight make more sense!
Note
These four objects are immutable. Note that only an annotated tag is immutable, a lightweight tag is not
Over time, all the information in the object store changes and grows, tracking and modeling your project edits, additions, and deletions. To use disk space and network bandwidth efficiently, Git compresses and stores the objects in packfiles, which are also placed in the object store.
Index
The index stores binary data and is private to your repository. The content of the index is temporary and describes the structure of the entire repository at a specific moment in time. More specifically, it provides a cached representation of all the blob objects which reflects the current state of the project you are working on.
The information in the index is transitory, meaning it’s a dynamic stage between your project’s working directory (file system) and the repository’s object store (repository commit history). As such the index is also labeled as the “Staging Directory” interchangeably.
Figure 2-2 provides a visual representation of this concept:
.
└── repository
├── .git/
└── Index
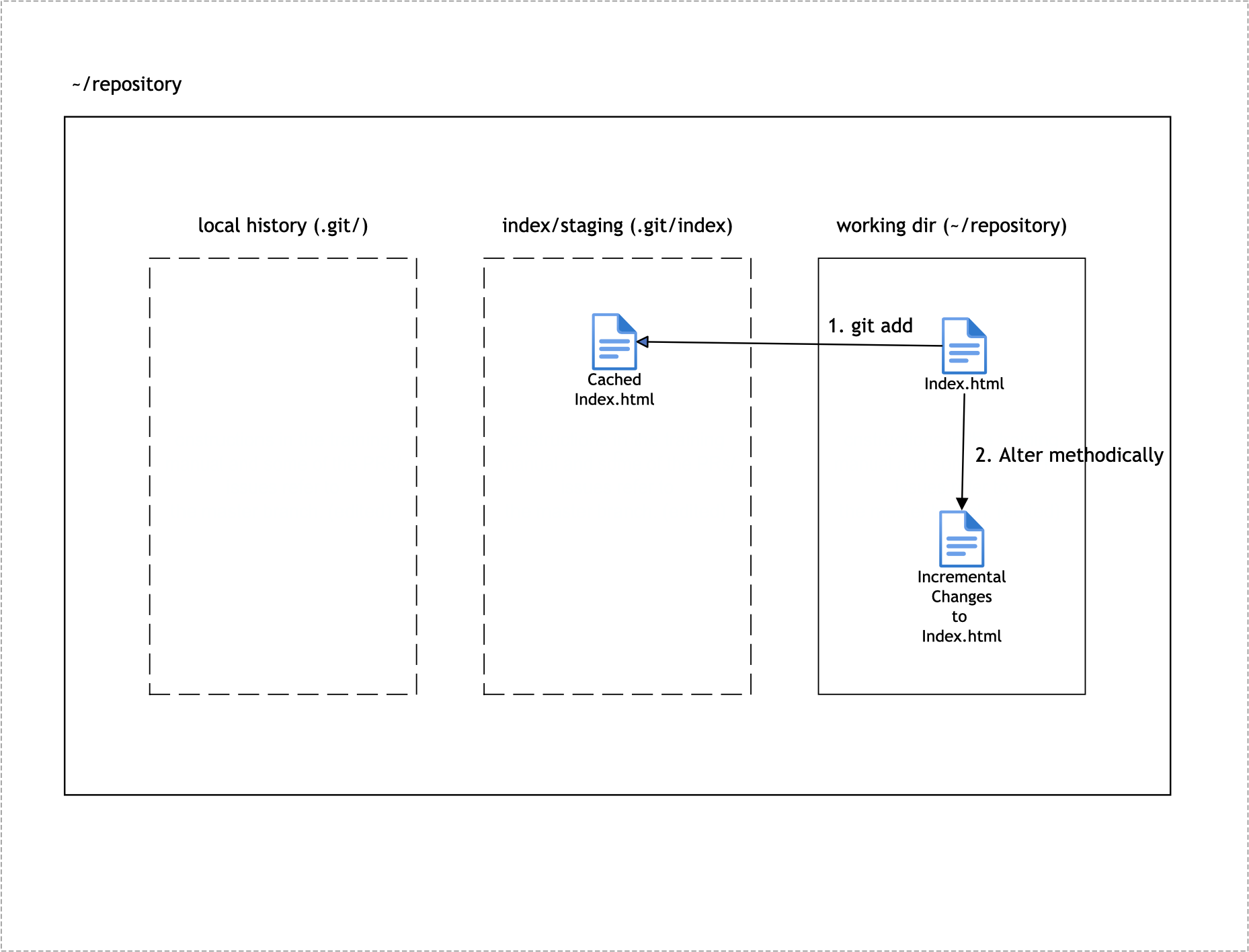
The index is one of the key distinguishing features of Git. This is because you are able to alter the content of the index methodically, allowing you to have finer control over what content will be stored in the next commit. In short, the index allows a separation between incremental development steps and the committal of those changes.
Here’s how it works. As a software engineer you usually add, delete or edit a file or a set of files. These are changes that affect the current state of the repository. Next you will need to execute the git add command to stage these changes in the index. Then the index keeps records of those changes and keeps them safe until you are ready to commit them. Git also allows you to remove changes recorded in the index. Thus the index allows a gradual transition of the repository (curated by you) from an older version to a newer updated version.
As you’ll see in Chapter: Merges, the index also plays an important role in a merge operation, allowing multiple versions of the same file to be managed, inspected, and manipulated simultaneously.
Content-Addressable Database
Git is also described as a content addressable storage system. This is because the object store is organized and implemented to store key value pairs of each object it generates under the hood when you are version controlling your project. Each object in the object store is associated with a unique name produced by applying SHA1 to the content of the object, yielding a SHA1 hash value.
Git uses the complete content of an object to generate the SHA1 hash value. This hash value is believed to be effectively unique to that particular content at a specific state in time, thus the SHA1 hash is used as a sufficient index or name for that object in git’s object store. Any tiny change to a file causes the SHA1 hash to change, causing the new version of the file to be indexed separately.
SHA1 values are 160-bit values that are usually represented as a 40-digit hexadecimal number, such as 9da581d910c9c4ac93557ca4859e767f5caf5169. Sometimes, during display, SHA1 values are abbreviated to a smaller, easier to reference prefix. Git users speak of the term SHA1, hash code, and sometimes object ID interchangeably.
Git Tracks Content
Git is much more than a Version Control System, based on what we learnt in the earlier section, it will help to understand the inner mechanics of Git when you think of Git as a content tracking system.
This distinction, however subtle, guides much of the design principle of Git and is perhaps the key reason it can perform internal data manipulations with relative ease without compromising performance when done right. Yet, this is also perhaps one of the most difficult concepts for new users of Git to grasp, so some exposition is worthwhile.
Git’s content tracking is manifested in two critical ways that differ fundamentally from almost all other1 version control systems.
-
First, Git’s object store is based on the hashed computation of the contents of its objects, not on the file or directory names from the user’s original file layout.
-
Second, Git’s internal database efficiently stores every version of every file—not their differences—as files go from one revision to the next.
Let’s explore this a little more. When Git places a file into the object store, it does so based on the hash of the data (file content) and not on the name of the file (file metadata). In fact, Git does not track file or directory names, which are associated with files in secondary ways. The data is stored as a blob object in the object store. Again, Git tracks content instead of files.
If two separate files have exactly the same content, whether in the same or different directories, Git only stores a single copy of that content as a blob within the object store. Git computes the hash code of each file according solely to its content, determines that the files have the same SHA1 values and thus the same content, and places the blob object in the object store indexed by that SHA1 value. Both files in the project, regardless of where they are located in the user’s directory structure, use that same object for content.
Because Git uses the hash of a file’s complete content as the name for that file, it must operate on each complete copy of the file. It cannot base its work or its object store entries on only part of the file’s content nor on the differences between two revisions of that file. Using the earlier example of two separate files having exactly the same content, if one of those files changes, Git computes a new SHA1 for it, determines that it is now a different blob object, and adds the new blob to the object store. The original blob remains in the object store for the unchanged file to use.
For this reason, your typical view of a file—that it has revisions and appears to progress from one revision to another revision—is simply an artifact. Git computes this history as a set of changes between different blobs with varying hashes, rather than storing a file name and set of differences directly. It may seem odd, but this feature allows Git to perform certain tasks with ease.
Figure 2-3 provides a visual representation of this concept:

Figure 2-1. Blob Object
Pathname Versus Content
As with many other Version Control Systems, Git needs to maintain an explicit list of files that form the content of the repository. However, this need not require that Git’s manifest be based on file names. Indeed, Git treats the name of a file as a piece of data that is distinct from the contents of that file. In this way, it separates index from data in the traditional database sense. It may help to look at Table 1.Table 2-1, which roughly compares Git to other familiar systems.
| System | Index mechanism | Data store |
|---|---|---|
Relational database |
Indexed Sequential Access Method (ISAM) |
Data records |
Unix file system |
Directories (/path/to/file) |
Blocks of data |
Git |
.git/objects/`hash`, tree object contents |
Blob objects, tree objects |
The names of files and directories come from the underlying filesystem, but Git does not really care about the names. Git merely records each pathname and makes sure it can accurately reproduce the files and directories from its content, which is indexed by a hash value. This set of information is stored in the Git object store as the tree object.
Git’s physical data layout isn’t modeled after the user’s file directory structure. Instead, it has a completely different structure that can, nonetheless, reproduce the user’s original file and directory layout in a project. Git’s internal structure is a more efficient data structure for its own internal operations and storage considerations.
When Git needs to create a working directory, it says to the filesystem: “Hey! I have this big blob of data that is supposed to be placed at pathname path/to/directory/file. Does that make sense to you?” The filesystem is responsible for saying “Ah, yes, I recognize that string as a set of subdirectory names, and I know where to place your blob of data! Thanks!”
Figure 2-4 provides a visual representation of this concept:

Figure 2-2. Tree Object
Packfiles
Next, let’s look at how Git stores the blob and tree objects in it’s object store. Also if you’re following closely, you might think that Git is implementing an inefficient method to store the complete content of every version of every file directly in it’s object store. Even if Git compresses the files, it is still inefficient to have the complete content of different versions of the same file, for instance what if we only add, say, one line to a file, Git will still store the complete content of both versions.
Luckily, that’s not how Git internally stores the objects in it’s database. Instead, Git uses a more efficient storage mechanism called packfiles. Git uses zlib2 a free software which implements the DEFLATE algorithm3 to compress each object prior to storing it in it’s object store. We will be diving deeper into packfiles in Chapter: Remote Repositories.
Tip
For efficiency, Git’s algorithm by design generates deltas against larger object to be mindful of the space it takes up to save a compressed file. This size optimization is also true for many other delta algorithms because removing data is considered cheaper than adding data in a delta object.
Take note that packfiles are stored in the object store alongside the other objects. They are also used for efficient data transfer of repositories across a network.
Visualizing Git Object Store
Now that we know how Git efficiently stores it’s objects, let’s visualize how Git objects fit and work together to form a complete system.
-
The blob object is at the “bottom” of the data structure; it references no other git objects and is referenced only by tree objects. It can be considered as a leaf-node in relation to the tree object. In the figures that follow, each blob is represented by a rectangle.
-
Tree objects point to blobs and possibly to other trees as well. Any given tree object might be pointed at by many different commit objects. Each tree is represented by a triangle.
-
A circle represents a commit. A commit points to one particular tree that is introduced into the repository by the commit.
-
Each tag is represented by a parallelogram. Each tag can point to, at most, one commit.
The branch is not a fundamental Git object, yet it plays a crucial role in naming commits. Each branch is pictured as a rounded rectangle.
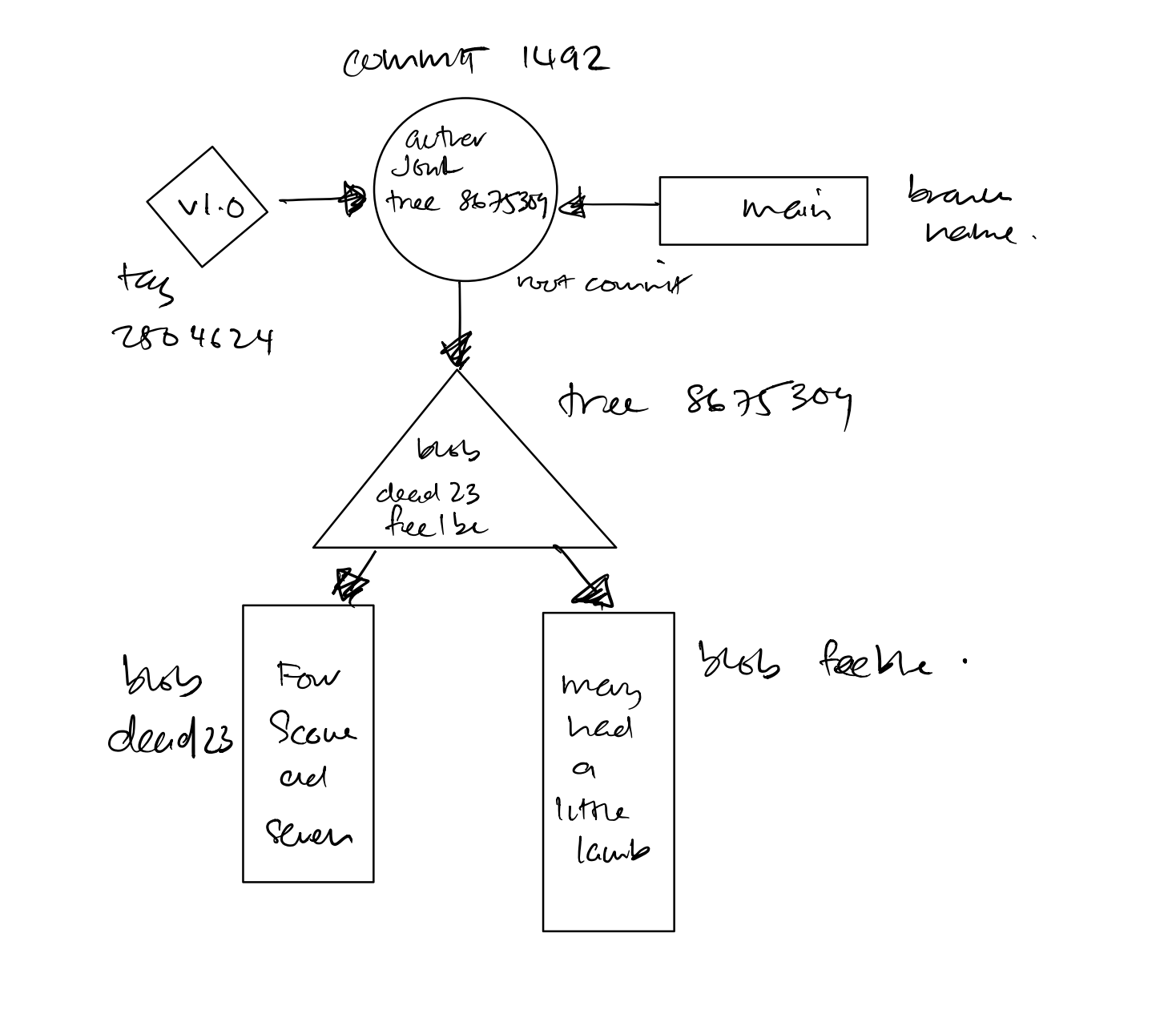
Figure 2-3. Git objects
. └── ~/project ├── .git │ └── .git/objects/* ├── file dead23 └── file feeb1e
Figure 2-5 captures how all the pieces fit together. This diagram shows the state of a repository after a single, initial commit added two files. Both files are in the top-level directory. Both the master branch and a tag named V1.0 point to the commit with ID 1492.
Now, let’s make things a bit more complicated. Let’s leave the original two files as is, adding a new subdirectory with one file in it. The resulting object store looks like Figure 2-6 below.
.
└── ~/project
├── .git
│ └── .git/objects/*
├── file dead23
├── file feeb1e
└── newsubdir
└── file 1010b

As in the previous picture, the new commit has added one associated tree object to represent the total state of directory and file structure. Because the top-level directory is changed by the addition of the new subdirectory, the content of the top-level tree object has changed as well, so Git introduces a new tree, cafed00d.
However, the blobs dead23 and feeb1e didn’t change from the first commit to the second. Git realizes that the IDs haven’t changed and thus can be directly referenced and shared by the new cafed00d tree.
Pay attention to the direction of the arrows between commits. The parent commit or commits come earlier in time. Think of it as a DAG Diagram: A directed acyclic graph where each node is directed from an earlier node in a single direction to form its topological ordering of the graph.
Therefore, in Git’s implementation, each commit points back to its parent or parents. Many people get confused because the state of a repository is conventionally portrayed in the opposite direction: as a dataflow from the parent commit to child commits. In other words, ordered from left to right, the right most commit in DAG diagram represent the latest state of a repository.
In Chapter: Commits, we extend these pictures to show how the history of a repository is built up and manipulated by various commands.
Git Internals: Concepts at Work
With some tenets out of the way, let’s peek under the hood and see how all these concepts fit together in a git repository. We will start by creating a new repository and inspect the internal files and object store in much greater detail. We do this by starting at the bottom of Git’s data structure and work our way up in the object store.
Before we go any further, it is important to know that Git has a few categories of commands to implement it’s inner mechanics. To get a detailed categorized list of all the commands, type in git help -a in your terminal. Git commands are categorized as follows :
-
Main Porcelain Commands (High level commands for routine Git operations)
-
Ancillary Commands (Commands that help query Git’s internal data store)
-
Low-level Commands (Plumbing Commands for internal Git Operations)
-
External Commands (Commands that extent the standard Git Operations)
-
Commands to act as a bridge with selected version control tool (Interacting with Others Commands)
-
Command Aliases (Custom aliases created by users to mask complex Git commands)
Typically, for our daily use and interaction with Git, we will mostly use a subset of the main porcelain commands. In this section, we will be using some low-level or plumbing commands to better understand Git Internals.
Inside the .git Directory
To begin, initialize an empty repository using git init and then run the tree .git command to reveal what’s created.
$mkdir /tmp/hello$cd /tmp/hello$git initInitialized empty Git repository in /tmp/hello/.git/ # List all the files in the current directory $tree .git.git ├── HEAD ├── config ├── description ├── hooks │ ├── applypatch-msg.sample │ ├── commit-msg.sample │ ├── fsmonitor-watchman.sample │ ├── post-update.sample │ ├── pre-applypatch.sample │ ├── pre-commit.sample │ ├── pre-merge-commit.sample │ ├── pre-push.sample │ ├── pre-rebase.sample │ ├── pre-receive.sample │ ├── prepare-commit-msg.sample │ ├── push-to-checkout.sample │ └── update.sample ├── info │ └── exclude ├── objects │ ├── info │ └── pack └── refs ├── heads └── tags
As you can see, .git contains a lot of stuff. The files are displayed based on a template directory that you can adjust if desired by passing in the --template=<template_directory> option. For example, if you prefer to create a new repository which implements custom git-hooks, you may point to a template which is already preconfigured with custom directory structure and git-hook files to begin with. We will discuss more on git-hooks in Chapter: Hooks.
Note
Depending on the version of Git you are using, your actual manifest may look a little different. For example, older versions of Git do not use a .sample suffix on the .git/hooks files. You can learn more about the command by running man git-init in the command-line.
In general, you don’t have to view or manipulate the files in .git directory. These “hidden” files are considered part of Git’s plumbing or configuration commands.
Initially, the .git/objects directory (the directory for all of Git’s objects) is empty, except for a few placeholders.
$ find .git/objects
.git/objects
.git/objects/pack
.git/objects/info
Let’s now carefully create a simple object:
$echo "hello world" > hello.txt$git add hello.txt
If you typed “hello world” exactly as it appears here (with no changes to spacing or capitalization), then your objects directory should now look like this:
$ find .git/objects
.git/objects
.git/objects/3b
.git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad
.git/objects/pack
.git/objects/info
Note that there is only one object at this point in time, the blob object with a SHA1 ID generated based on content of the file hello.txt. All this looks pretty mysterious. But it’s not, as the following sections explain.
Blob Objects and Hashes
When we created the file hello.txt and staged it in the index directory using git add, git internally created a blob object. At this point, Git doesn’t care that the filename is hello.txt. Git cares only about what’s inside the file: the sequence of 12 bytes that represent “hello world” and the terminating newline (the same blob created earlier). Git performs a few operations on this blob, calculates its SHA1 hash, and enters it into the object store as a file named after the hexadecimal representation of the hash.
The hash in this case is 3b18e512dba79e4c8300dd08aeb37f8e728b8dad. The 160 bits of an SHA1 hash correspond to 20 bytes, which takes 40 bytes of hexadecimal to display, so the content is stored as .git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad.
Git inserts a / after the first two digits to improve filesystem efficiency. (Some filesystems slow down if you put too many files in the same directory; making the first byte of the SHA1 into a directory is an easy way to create a fixed, 256-way partitioning of the namespace for all possible objects with an even distribution.)
You can verify that the content in the file is not changed by Git (it’s still the same comforting “hello world”) by using the generated hash value to extract out the content from the object store, utilizing a low-level plumbing command.
# Using the git cat-file command $ git cat-file -p 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello world
Or
# Using the git hash-object command $ echo "hello world" | git hash-object --stdin 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
Tip
Git also knows that 40 characters is a bit chancy to type by hand, so it provides a command to look up objects by a unique prefix of the object hash:
$ git rev-parse 3b18e512d 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
Next we move up the data structure to understand how path and filenames are stored by Git.
Tree Object and Files
Now that the “hello world” blob is safely ensconced in the object store, let’s take a look at how it is associated with a filename. Git wouldn’t be very useful if it couldn’t find files by name.
As mentioned before, Git tracks the pathnames of files through another kind of object called a tree. When you use git add, Git creates an object for the contents of each file you add, but it doesn’t create an object for your tree right away. Instead, it updates the index. The index is found in .git/index and keeps track of file pathnames and corresponding blobs. Each time you run commands such as git add, git rm, or git mv, Git updates the index with the new pathname and blob information.
Whenever you want, you can create a tree object from your current index by capturing a snapshot of its current information with the low-level git write-tree command. An action which you will rarely execute in your typical daily git rendezvous.
At the moment, the index contains exactly one file, hello.txt.
$ git ls-files -s
100644 3b18e512dba79e4c8300dd08aeb37f8e728b8dad 0 hello.txt
Here you can see the association of the file, hello.txt, and the 3b18e5… blob.
Next, let’s capture the index state and save it to a tree object:
$git write-tree68aba62e560c0ebc3396e8ae9335232cd93a3f60 $find .git/objects.git/objects .git/objects/68 .git/objects/68/aba62e560c0ebc3396e8ae9335232cd93a3f60 .git/objects/pack .git/objects/3b .git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad .git/objects/info
Now there are two objects: the “hello world” blob object at 3b18e5 and a new one, the tree object, at 68aba6. As you can see, the SHA1 object name corresponds exactly to the subdirectory and filename in .git/objects.
But what does a tree look like? Because it’s an object, just like the blob, you can use the same low-level plumbing command to view it.
$ git cat-file -p 68aba6
100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello.txt
The contents of the object should be easy to interpret. The first number, 100644, represents the file attributes of the object in octal, which should be familiar to anyone who has used the Unix chmod command. Here, 3b18e5 is the object name of the hello world blob, and hello.txt is the name associated with that blob.
It is now easy to see that the tree object has captured the information that was in the index when you ran git ls-files -s.
A Note on Git’s Use of SHA1
Before inspecting the contents of the tree object in more detail, let’s re-emphasize an important feature of SHA1 hashes:
$git write-tree68aba62e560c0ebc3396e8ae9335232cd93a3f60 $git write-tree68aba62e560c0ebc3396e8ae9335232cd93a3f60 $git write-tree68aba62e560c0ebc3396e8ae9335232cd93a3f60
From the example above, every time you compute another tree object for the same index (no adding or removing of files), the SHA1 hash remains exactly the same. Git doesn’t need to recreate a new tree object. If you’re following these steps at the computer, you should be seeing exactly the same SHA1 hashes as the ones published in this book.
In this sense, the hash function is a true function in the mathematical sense: For a given input, it always produces the same output. Such a hash function is sometimes called a digest to emphasize that it serves as a sort of summary of the hashed object. This is also true for any hash function, even the lowly parity bit, has this property.
For example, if you create the exact same content as another developer, regardless of where or when or how both of you work, an identical hash is proof enough that the full content is identical, too. In fact, Git treats them as identical and this notion is extremely important.
But hold on a second—aren’t SHA1 hashes unique? What happened to the trillions of people with trillions of blobs per second who never produce a single collision? This is a common source of confusion among new Git users. So read on carefully, because if you can understand this distinction, then everything else in this chapter is easy.
Identical SHA1 hashes in this case do not count as a collision. It would be a collision only if two different objects produced the same hash. Here, you created two separate instances of the very same content, and the same content always has the same hash.
Git depends on another consequence of the SHA1 hash function: it doesn’t matter how you got a tree called 68aba62e560c0ebc3396e8ae9335232cd93a3f60. If you have it, you can be extremely confident it is the same tree object that, say, another reader of this book has. Consider the following:
-
Scenario 1 - Bob might have created the tree by combining commits A and B from Jennie and commit C from Sergey on a shared repository
-
Scenario 2 - You on the other hand, working in that same shared repository, might have created the same tree but via a different path, you might have got commit A from Sue and an update from Lakshmi that combines commits B and C.
The results are the same for the generated tree object in both scenarios, this facilitates distributed development with Git.
If you are asked to look for object 68aba62e560c0ebc3396e8ae9335232cd93a3f60 and can find such an object, then, because SHA1 is a cryptographic hash, you can be confident that you are looking at precisely the same data from which the hash was created.
The converse is also true: If you don’t find an object with a specific hash in your object store, then you can be confident that you do not hold a copy of that exact object. In sum, you can determine whether your object store does or does not have a particular object even though you know nothing about its (potentially very large) contents. The hash thus serves as a reliable label or name for the object.
Tree Hierarchies
In our examples from the previous section, we only have information regarding a single file, but in actuality projects contain complex, deeply nested directories that are refactored and moved around over time. In this section we will be creating a new subdirectory that contains an identical copy of the hello.txt file in order to see how Git handles this scenario:
$pwd/tmp/hello $mkdir subdir$cp hello.txt subdir/$git add subdir/hello.txt$git write-tree492413269336d21fac079d4a4672e55d5d2147ac $git cat-file -p 4924132693100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad hello.txt 040000 tree 68aba62e560c0ebc3396e8ae9335232cd93a3f60 subdir
The new top-level tree contains two items: the original hello.txt file as well as the new subdir directory, which is of type tree instead of blob.
Look closer at the object name of subdir, do you notice anything unusual? Indeed It’s none other than our old friend, the SHA1 68aba62e560c0ebc3396e8ae9335232cd93a3f60!
How can this be you ask? Well, the new tree for subdir contains only one file, hello.txt, and that file contains the same old “hello world” content. So the `subdir` tree is exactly the same as the older, top-level tree! And yes, you are correct to point out that it is for this reason alone, it has the same SHA1 object name as before: traits of a true function in the mathematical sense.
Let’s look at the .git/objects directory and see what this most recent change affected:
$ find .git/objects
.git/objects
.git/objects/49
.git/objects/49/2413269336d21fac079d4a4672e55d5d2147ac
.git/objects/68
.git/objects/68/aba62e560c0ebc3396e8ae9335232cd93a3f60
.git/objects/pack
.git/objects/3b
.git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad
.git/objects/info
There are still only three unique objects: a blob containing “hello world”; a tree containing hello.txt, which contains the text “hello world” plus a new line; and a second tree that contains another reference to hello.txt along with the first tree.
Figure 2-7 illustrates this concept:
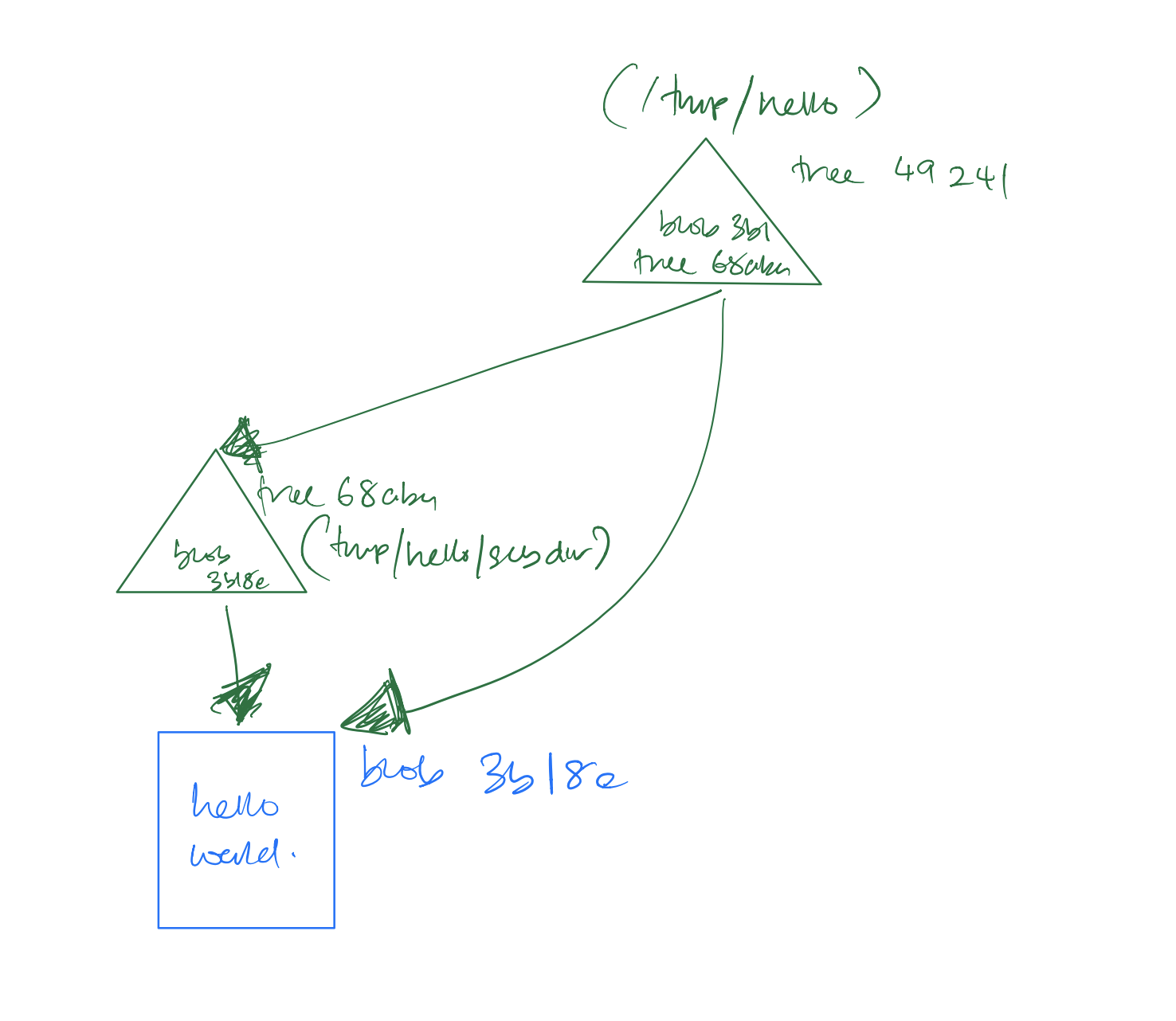
Figure 2-4. Tree Hierarchies
Commit Objects
The next object to discuss is the commit. Now that hello.txt_ has been added with the git add command and the tree object has been produced with git write-tree, we can create a commit object using low-level plumbing commands like this:
$ echo -n "Commit a file that says hello
" | git commit-tree 492413269336d21fac079d4a4672e55d5d2147ac
3ede4622cc241bcb09683af36360e7413b9ddf6c
The result will look something like this:
$ git cat-file -p 3ede462
tree 492413269336d21fac079d4a4672e55d5d2147ac
author Jon Loeliger <[email protected]> 1220233277 -0500
committer Jon Loeliger <[email protected]> 1220233277 -0500
Commit a file that says hello
Figure 2-8 illustrates this concept:
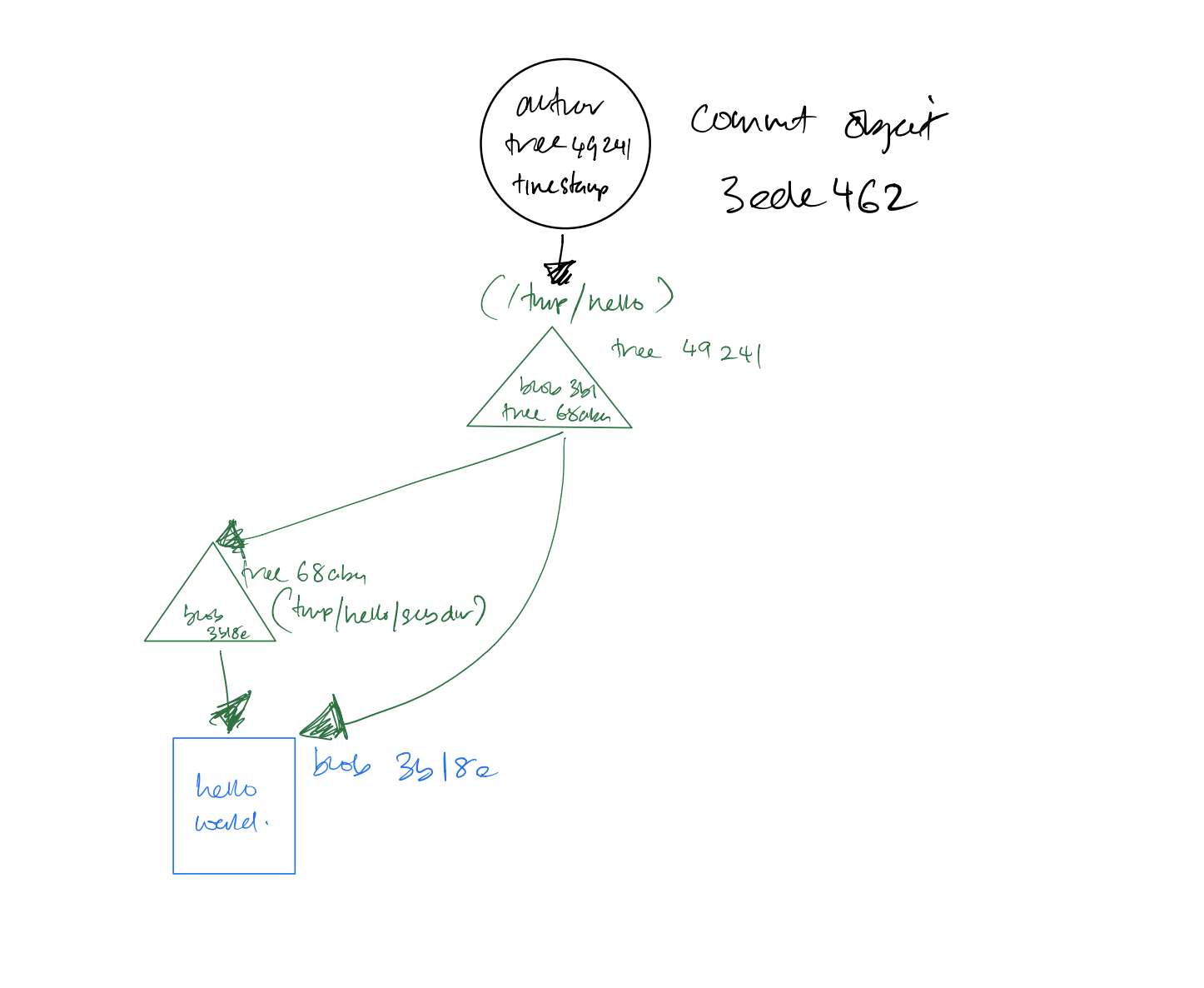
Figure 2-5. Commit Object
If you’re following along on your computer, you probably find that the commit object you generated does not have the same identical value as the one in this example. If you’ve understood everything so far, the reason for that should be obvious: Our commit object, it’s not the same as your commit object.
Your commit object contains your name and the time you made the commit, whereas our commit object contains a different timestamp and author name, so of course it is different.
On the other hand, your commit does have the same tree. This is why commit objects are separate from their tree objects: different commits often refer to exactly the same tree. When that happens, Git is smart enough to transfer around only the new commit object, which is tiny, instead of the entire tree and blob objects, which are probably much larger.
In real life, you can (and should!) pass over the low-level plumbing commands git write-tree and git commit-tree used in the examples. You can just use the porcelain git commit command. You don’t need to remember all those plumbing commands to be a perfectly happy Git user.
In essence, a basic commit object is fairly simple, and it’s the last ingredient required for a real Version Control System. The commit object just shown, is the simplest possible one, containing:
-
The name of a tree object that actually identifies the associated files
-
The name of the person who composed the new version (the author) and the time when it was composed
-
The name of the person who placed the new version into the repository (the committer) and the time when it was committed
-
A description of the reason for this revision (the commit message)
By default, the author and committer are the same; there are a few situations where they’re different.
Tip
You can use the command git show --pretty=fuller to see additional details about a given commit.
A more closer to home use case is when a project contains multiple commits. In such a situation, when you make a new commit in the project, you can give it one or more parent commits. Given this context, consider the most recent commit (or its associated tree object) in the project. Because it contains, as part of its content, the hash of its parent commits and of its tree and that in turn contains the hash of all of its subtrees and blobs recursively through the whole data structure, it follows by induction that the hash of the original commit uniquely identifies the state of the whole data structure rooted at that commit.
By following back through the chain of parents, you can discover the history of your project, thus the term commit history. Commit objects are also stored in a graph structure, although it’s completely different from the structures used by tree objects. More details about commits and the commit graph are given in the Commits chapter.
Tag Objects
Finally, the last object Git manages is the tag. Although Git implements only one kind of tag object in it’s object store, Git supports two basic tag types, usually called a lightweight and an annotated tag.
Lightweight tags are simply references to a commit object and are usually considered private to a repository. Lightweight tags are not stored as permanent objects in the object store.
An annotated tag is more substantial and creates an object. It contains a message, supplied by you, and can be digitally signed using a GnuPG key according to RFC4880.
Git treats both lightweight and annotated tag names equivalently for the purposes of associating a commit with meaningful human readable name. However, by default, many Git commands work only on annotated tags, because they are considered “permanent immutable” objects.
Tip
Typical use case for an annotated tag is when you are creating a specific release version for your projects. Whereas lightweight tags are in the light of a bookmark as a temporary label attached to a commit object.
You create an annotated, unsigned tag with a message on a commit using the git tag command:
$ git tag -a V1.0 3ede462
Git will launch your configured default editor after the command is issued and you may provide a tag message to complete the operation.
To view the newly created tag object, you may do so via the git cat-file -p command, but what is the SHA1 of the tag object? To find it, use the Tip from “Blob Objects and Hashes”:
$git rev-parse V1.06b608c1093943939ae78348117dd18b1ba151c6a $git cat-file -p 6b608cobject 3ede4622cc241bcb09683af36360e7413b9ddf6c type commit tag V1.0 tagger Jon Loeliger <[email protected]> Sun Oct 26 17:07:15 2008 -0500 Tag version 1.0
In addition to the log message and author information, the tag refers to the commit object 3ede462.
Git usually tags a commit object, which points to a tree object, which encompasses the total state of the entire hierarchy of files and directories within your repository.
Recall from Figure 2-3 that the V1.0 tag points to the commit named 1492, which in turn points to a tree (8675309) that spans multiple files. Thus, the tag simultaneously applies to all files of that tree.
This is unlike CVS, for example, which will apply a tag to each individual file and then rely on the collection of all those tagged files to reconstitute a whole tagged revision. And whereas CVS lets you move the tag on an individual file, Git requires a new commit, encompassing the file state change, onto which the tag will be moved.
Summary
We have discussed the inner workings of Git to an elaborate extent, let’s now recap the key takeaways from this chapter. We started at the high level of a repository where we learnt about the various working directory Git replies upon, mainly the Index, Working directory and the local history. We continued to dive into the Git Object Store, where we analyzed each of the Immutable Git Objects: During which we also learnt how to interact with those internal objects directly using low-level git commands that you would rarely use on a daily basis. Grasping this concept should highlight the fact that Git as a concept is merely a simple content addressable database whereby its innermechnics are somewhat direct yet may at times be complex to comprehend. We’ve also described visually the relationship between the objects in Git’s Object Store to help establish a good foundation for the next Chapters in Part 2: Fundamentals of Git.
1 Monotone, Mercurial, OpenCMS, and Venti are notable exceptions here.
3 https://tools.ietf.org/html/rfc1951
4 https://www.schneier.com/blog/archives/2005/02/cryptanalysis_o.html
6 https://github.com/git/git/blob/master/Documentation/technical/hash-function-transition.txt or https://git-scm.com/docs/hash-function-transition