
CHAPTER
5
Data Layer

Traditionally, companies scaled their databases vertically by buying stronger servers, adding random access memory (RAM), installing more hard drives, and hoping that the database engine they used would be able to utilize these resources and scale to their needs. This worked in most cases, and only the largest and most successful companies needed horizontal scalability. All of that changed with the rise of the Internet, social networks, and the globalization of the software industry, as the amounts of data and concurrent users that systems need to support have skyrocketed. Nowadays systems with millions of users and billions of database records are the norm, and software engineers need to have a better understanding of the techniques and tools available to solve these scalability challenges.
In previous chapters we scaled the front-end and web services layers by pushing the state out of our servers so that we could treat them as stateless clones and simply add more servers whenever we needed to scale. Now it is time to tackle the problem of scaling the data layer so that it will be horizontally scalable and so that it will not create a system bottleneck.
Depending on your business needs, required scalability of your application, and your data model, you can use either a traditional relational database engine like MySQL or a more cutting-edge nonrelational data store. Both of these approaches have benefits and drawbacks, and I will try to objectively present both of these as complementary solutions to different application needs. Let’s first look at the scalability of relational database engines using the example of a MySQL database.
Scaling with MySQL
MySQL is still the most popular database, and it will take a long time before it becomes irrelevant. Relational databases have been around for decades, and the performance and scalability that can be achieved with MySQL is more than most web startups would ever need. Even though scaling MySQL can be difficult at times and you may need to plan for it from day one, it can be done and dozens of the world’s biggest startups are successfully doing it, for example, Facebook,L35 Tumblr,L33 and Pintrest.L31 Let’s get started by looking at replication as one of the primary means of scaling MySQL.
Replication
Replication usually refers to a mechanism that allows you to have multiple copies of the same data stored on different machines. Different data stores implement replication in different ways. In the case of MySQL, replication allows you to synchronize the state of two servers, where one of the servers is called a master and the other one is called a slave. I will discuss different topologies that allow you to synchronize the state of more than two MySQL servers later in this chapter, but the core concept focuses on replicating content between a master and a slave.
When using MySQL replication, your application can connect to a slave to read data from it, but it can modify data only through the master server. All of the data-modifying commands like updates, inserts, deletes, or create table statements must be sent to the master. The master server records all of these statements in a log file called a binlog, together with a timestamp, and it also assigns a sequence number to each statement. Once a statement is written to a binlog, it can then be sent to slave servers.
Figure 5-1 illustrates how statement replication works. First the client connects to the master server and executes a data modification statement. That statement is executed and written to a binlog file. At this stage the master server returns a response to the client and continues processing other transactions. At any point in time the slave server can connect to the master server and ask for an incremental update of the master’s binlog file. In its request, the slave server provides the sequence number of the last command that it saw. Since all of the commands stored in the binlog file are sorted by sequence number, the master server can quickly locate the right place and begin streaming the binlog file back to the slave server. The slave server then writes all of these statements to its own copy of the master’s binlog file, called a relay log. Once a statement is written to the relay log, it is executed on the slave data set, and the offset of the most recently seen command is increased.
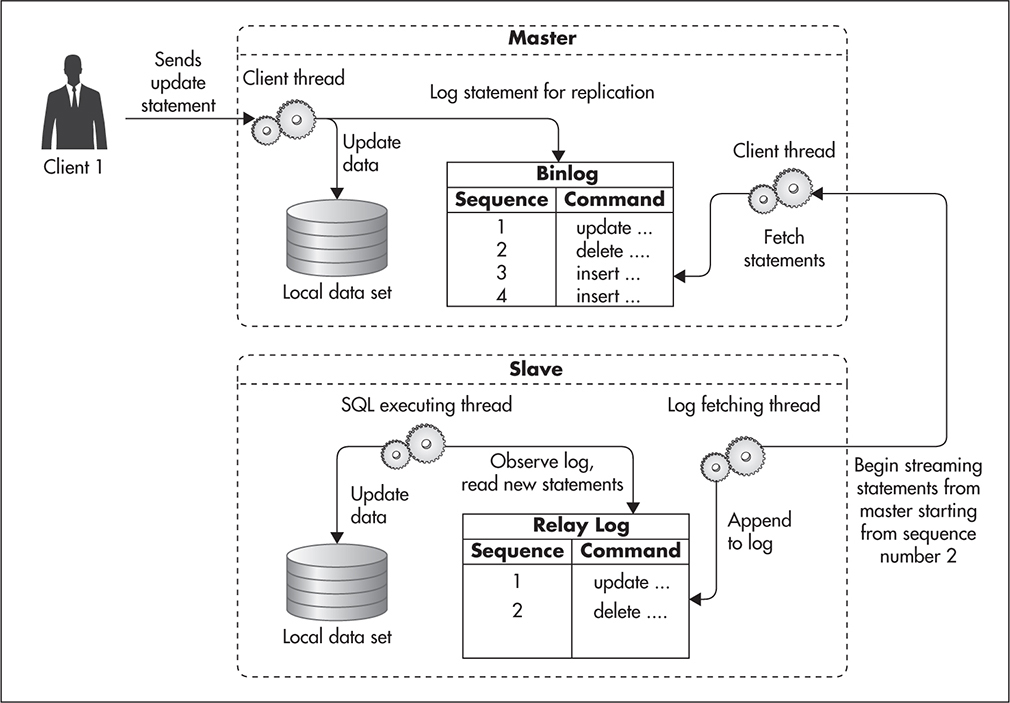
Figure 5-1 MySQL replication
An important thing to note here is that MySQL replication is asynchronous. That means that the master server does not wait for slave to get the statements replicated. The master server writes commands to its own binlog, regardless if any slave servers are connected or not. The slave server knows where it left off and makes sure to get the right updates, but the master server does not have to worry about its slaves at all. As soon as a slave server disconnects from the master, the master forgets all about it. The fact that MySQL replication is asynchronous allows for decoupling of the master from its slaves—you can always connect a new slave or disconnect slaves at any point in time without affecting the master.
Because replication is asynchronous and the master does not need to keep track of its slaves, this allows for some interesting topologies. For example, rather than having just a single slave server, you can create multiple slave replicas and distribute read queries among them. In fact, it is a common practice to have two or more slaves for each master server.
Figure 5-2 shows a master server with multiple slave machines. Each of the slave servers keeps track of the last statement that was replicated. They all connect to the master and keep waiting for new events, but they do not interact with each other. Any slave server can be disconnected or connected at any point in time without affecting any other servers.
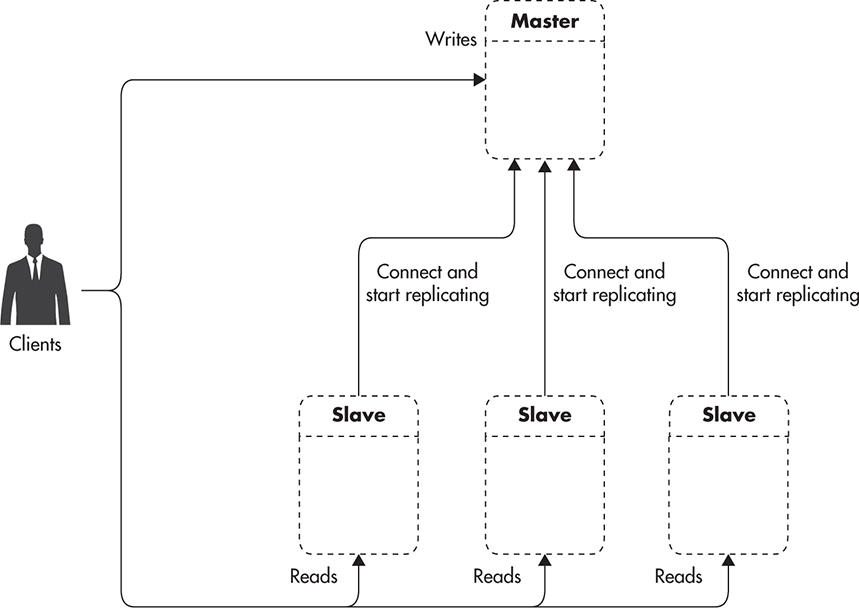
Figure 5-2 MySQL replication with multiple slaves
Having more than one slave machine can be useful for a number of reasons:
![]() You can distribute read-only statements among more servers, thus sharing the load among more machines. This is scaling by adding clones (explained in Chapter 2) applied to database engines, as you add more copies of the same data to increase your read capacity.
You can distribute read-only statements among more servers, thus sharing the load among more machines. This is scaling by adding clones (explained in Chapter 2) applied to database engines, as you add more copies of the same data to increase your read capacity.
![]() You can use different slaves for different types of queries. For example, you could use one slave for regular application queries and another slave for slow, long-running reports. By having a separate slave for slow-running queries, you can insulate your application from input/output (I/O)–intensive queries, improving the overall user experience.
You can use different slaves for different types of queries. For example, you could use one slave for regular application queries and another slave for slow, long-running reports. By having a separate slave for slow-running queries, you can insulate your application from input/output (I/O)–intensive queries, improving the overall user experience.
![]() You can use the asynchronous nature of MySQL replication to perform zero-downtime backups. Performing a consistent backup of a slave machine is simple—all you need to do is shut down the MySQL process, copy the data files to your archive location, and start MySQL again. As soon as MySQL starts, it connects to its master and begins catching up on any statements that it might have missed.
You can use the asynchronous nature of MySQL replication to perform zero-downtime backups. Performing a consistent backup of a slave machine is simple—all you need to do is shut down the MySQL process, copy the data files to your archive location, and start MySQL again. As soon as MySQL starts, it connects to its master and begins catching up on any statements that it might have missed.
![]() If one of your slaves dies, you can simply stop sending requests to that server (taking it out of rotation) until it is rebuilt. Losing a slave is a nonevent, as slaves do not have any information that would not be available via the master or other slaves. MySQL servers do not keep track of each other’s availability, so detection of server failure must be performed on the database client side. You can either implement it in your application logic or use a smart proxy/load balancer that can detect slave failures.
If one of your slaves dies, you can simply stop sending requests to that server (taking it out of rotation) until it is rebuilt. Losing a slave is a nonevent, as slaves do not have any information that would not be available via the master or other slaves. MySQL servers do not keep track of each other’s availability, so detection of server failure must be performed on the database client side. You can either implement it in your application logic or use a smart proxy/load balancer that can detect slave failures.
One of the main reasons why people use replication in MySQL and other data stores is to increase availability by reducing the time needed to replace the broken database. When using MySQL replication, you have two main failure scenarios that you need to be ready to recover from: failure of a slave and failure of a master.
Slave failures are usually not a big concern, as they can be handled quickly. All you need to do is stop sending queries to the broken slave to end the outage. You may still have reduced capacity, but the availability of the system is restored as soon as you take the slave server out of rotation. At a later point in time you can rebuild the slave server and add it back into rotation.
HINT
It is important to remember that rebuilding a MySQL slave is a manual process, and it requires a full backup of the database to be taken from the master or one of the remaining slaves. MySQL does not allow you to bootstrap a slave from an empty database. To be able to start a slave and continue replicating statements from the master, you need a consistent backup of all the data and a sequence number of the last statement that was executed on the database before taking the backup. Once you have a backup and a sequence number, you can start the slave and it will begin catching up with the replication backlog. The older the backup and the busier the database, the longer it will take for the new slave to catch up. In busy databases, it can take hours before a slave manages to replicate all data updates and can be added back into rotation.
Rebuilding slaves can seem like a lot of trouble, but a scenario that is even more complex to recover from is master failure. MySQL does not support automatic failover or any mechanism of automated promotion of slave to a master. If your master fails, you have a lot of work ahead of you. First, you need to find out which of your slaves is most up to date (which slave has the highest statement sequence number). Then you need to reconfigure it to become a master. If you have more than one slave, you need to make sure that they are identical to your new master by either rebuilding them all from the backup of the new master or by manually tweaking binlog and relay log files to align all servers to the exact same state. Finally, you need to reconfigure all remaining slaves to replicate from the new master. Depending on the details of your configuration, this process may be a bit simpler or a bit more complicated, but it is still a nightmare scenario for most engineers.
The difficulty of recovering from master failure brings us to another interesting replication deployment topology called master-master. In this case you have two servers that could accept writes, as Master A replicates from Master B and Master B replicates from Master A. MySQL replication allows for that type of circular replication, as each statement written to a master’s binlog includes the name of the server it was originally written to. This way, any statement that is sent to Server A is replicated to Server B, but then it does not replicate back to Server A, as Server A knows that it already executed that statement.
Figure 5-3 shows what master-master deployment looks like. All writes sent to Master A are recorded in its binlog. Master B replicates these writes to its relay log and executes them on its own copy of the data. Master B writes these statements to its own binlog as well in case other slaves want to replicate them. In a similar way, Master A replicates statements from Master B’s binlog by appending them to its own relay log, executing all new statements, and then logging them to its own binlog.
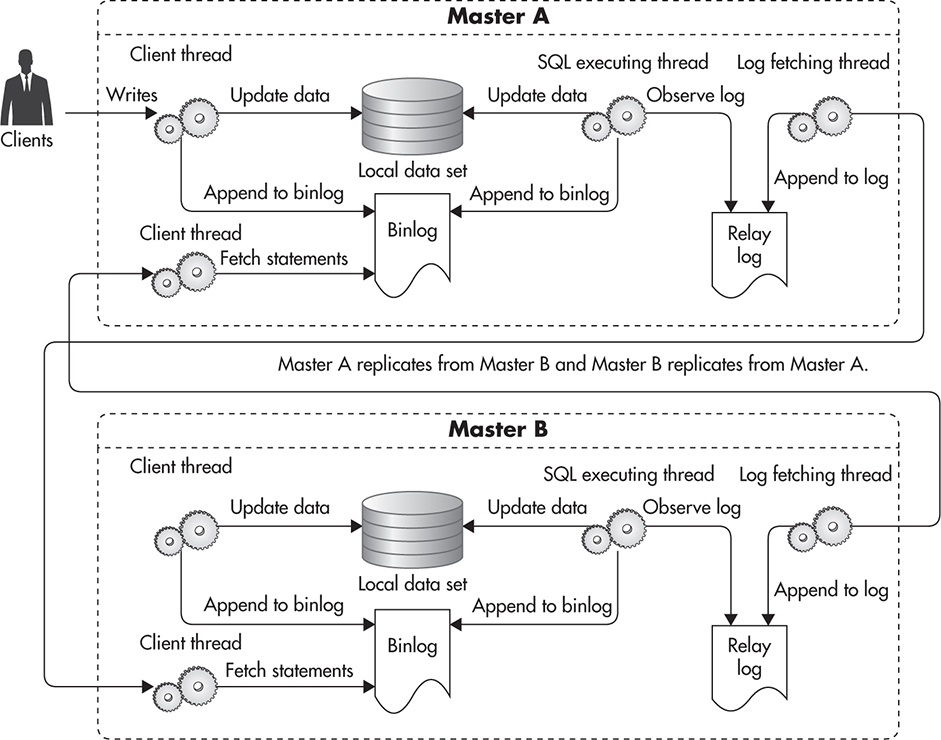
Figure 5-3 MySQL master-master replication
This topology is more complicated, but it can be used for faster master failover and more transparent maintenance. In case of Master A failure, or any time you need to perform long-lasting maintenance, your application can be quickly reconfigured to direct all writes to Master B.
Figure 5-4 shows how you can create two identical server groups with Master A and Master B each having an equal number of slaves. By having the same number of slaves, your application can be running with equal capacity using either of the groups. That, in turn, means that in case of Master A failure, you can quickly fail over to use Master B and its slaves instead.
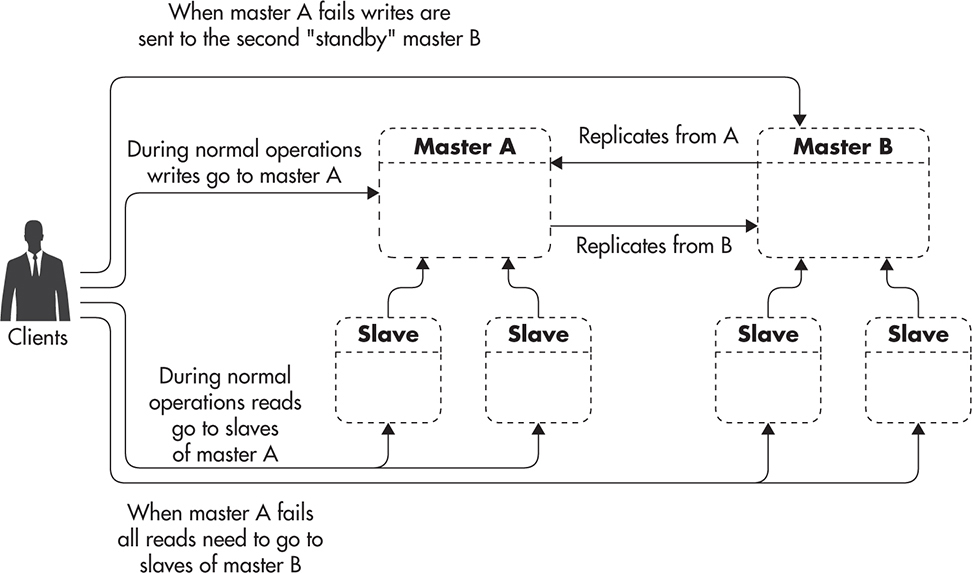
Figure 5-4 MySQL master-master failover
Having identical groups of servers in a master-master configuration allows you to switch between groups with minimal downtime. For example, if you need to upgrade your software or hardware on your master databases, you may need to shut down each server for an hour at a time to do the work, but you may be able to do it with just a few seconds of application downtime. To achieve that, you would upgrade one server group at a time. First, you upgrade the standby Master B and its slaves. Then, you stop all the writes coming into the Master A database, which begins the downtime. Then you wait just long enough for all the writes to replicate from Master A to Master B. You can then safely reconfigure your application to direct all writes to Master B, as it has already replicated all previous commands and there is no risk of conflicts or update collisions. By reconfiguring the application, you end the downtime, since reads and writes are accepted again. Finally, you can perform maintenance on Master A and its slaves. Figure 5-5 shows the timing of each of the steps and the total downtime.

Figure 5-5 Maintenance failover timeline
Although in theory, it is also possible to write to both servers at the same time, I would advise against it due to a much higher complexity and risk of data inconsistency. It is not safe to simply start sending writes to either of the masters without additional configuration and use case analysis. For example, if you wanted to send writes to both masters at the same time, you would need to use auto-increment and UUID() in a specific way to make sure you never end up with the same sequence number being generated on both masters at the same time. You can also run into trouble with data inconsistency. For example, updating the same row on both masters at the same time is a classic race condition leading to data becoming inconsistent between masters. Figure 5-6 shows a sequence of events leading to both master servers having inconsistent data.
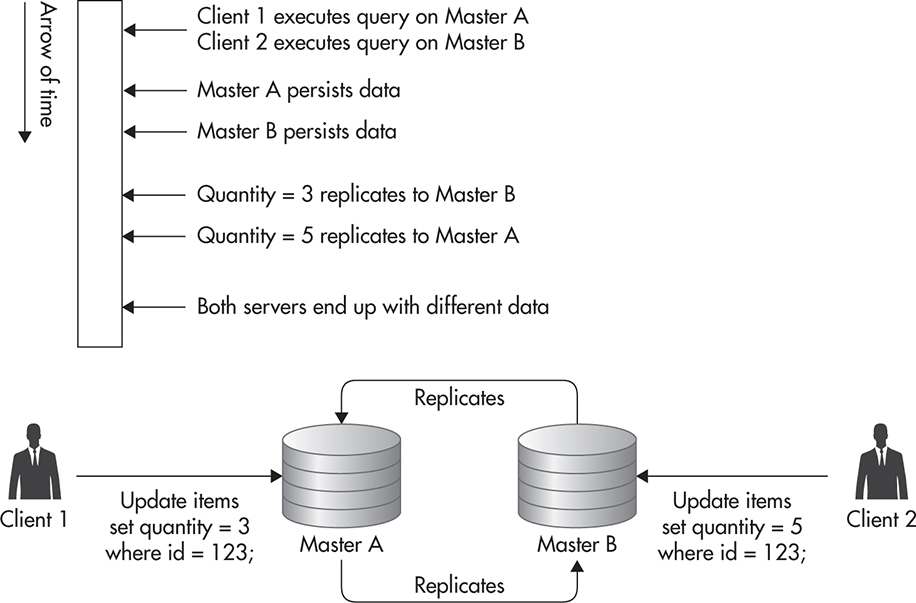
Figure 5-6 Update collision
Although master-master replication can be useful in increasing the availability of your system, it is not a scalability tool. Even if you took all the precautions and managed to write to both masters at the same time, you would not be able to scale using this technique. There are two main reasons why master-master replication is not a viable scalability technique:
![]() Both masters have to perform all the writes. The fact that you distribute writes to both master servers from your application layer does not mean that each of them has less to do. In fact, each of the masters will have to execute every single write statement either coming from your application or coming via the replication. To make it even worse, each master will need to perform additional I/O to write replicated statements into the relay log. Since each master is also a slave, it writes replicated statements to a separate relay log first and then executes the statement, causing additional disk I/O.
Both masters have to perform all the writes. The fact that you distribute writes to both master servers from your application layer does not mean that each of them has less to do. In fact, each of the masters will have to execute every single write statement either coming from your application or coming via the replication. To make it even worse, each master will need to perform additional I/O to write replicated statements into the relay log. Since each master is also a slave, it writes replicated statements to a separate relay log first and then executes the statement, causing additional disk I/O.
![]() Both masters have the same data set size. Since both masters have the exact same data set, both of them will need more memory to hold ever-growing indexes and to keep enough of the data set in cache. As your data set grows, each of your masters needs to grow with it (by being scaled vertically).
Both masters have the same data set size. Since both masters have the exact same data set, both of them will need more memory to hold ever-growing indexes and to keep enough of the data set in cache. As your data set grows, each of your masters needs to grow with it (by being scaled vertically).
In addition to master-master replication, you can use MySQL ring replication, where instead of two master servers, you chain three or more masters together to create a ring. Although that might seem like a great idea, in practice, it is the worst of the replication variants discussed so far. Figure 5-7 shows what that topology looks like.

Figure 5-7 MySQL ring replication
Not only does ring replication not help you scale writes, as all masters need to execute all the write statements, but it also reduces your availability and makes failure recovery much more difficult. By having more masters, statistically, you have a higher chance of one of them failing; at the same time, ring topology makes it more difficult to replace servers and recover from failures correctly.L36
Replication lag is a measurement of how far behind a particular slave is from its master. Any time you execute a write on the master, your change becomes visible as soon as the transaction commits. Although data is already updated on the master and can be read from there, it cannot be seen on the slave until the statement is replicated and executed there as well. When hosting your system on a decent network (or cloud), your replication lag should be less than a second. That means that any time you write to the master, you should expect your read replicas to have the same change less than a second later.
Another interesting fact is that ring replication significantly increases your replication lag, as each write needs to jump from master to master until it makes a full circle. For example, if the replication lag of each of your servers was 500 ms, your total lag would be 1.5 s in a four-node configuration, as each statement needs to be replicated three times before being visible to all of the servers.
It is worth pointing out that any master-master or ring topology makes your system much more difficult to reason about, as you lose a single source of truth semantics. In regular master-slave replication, you can always query the master to get the most recent data. There is no way that the master would be behind or that you would read some stale data, with writes being in flight between servers, as all the writes are sent by the application to the same machine. That allows you to be sure that any time you ask the master for data, you will get the most recent version of it. By allowing writes to be sent to multiple masters at the same time, with asynchronous replication in between them, you lose this kind of consistency guarantee. There is no way for you to query the database for the most recent data, as writes propagate asynchronously from each server. No matter which server you ask, there may be an update on its way from the master that cannot be seen yet. That, in turn, prevents the overall consistency of your system. I will discuss the nature and challenges of this type of consistency (called eventual consistency) later in this chapter.
Replication Challenges
The most important thing to remember when scaling using replication is that it is only applicable to scaling reads. When using replication, you will not be able to scale writes of your MySQL database. No matter what topology you use, replication is not the way to scale writes, as all of your writes need to go through a single machine (or through each machine in case of multimaster deployments). Depending on your deployment, it may still make sense to use replication for high availability and other purposes, but it will not help you scale write-heavy applications.
On the other hand, replication is an excellent way of scaling read-heavy applications. If your application does many more reads than writes, replication is a good way to scale. Instead of a single server having to respond to all the queries, you can have many clones sharing the load. You can keep scaling read capacity by simply adding more slaves, and if you ever hit the limit of how many slaves your master can handle, you can use multilevel replication to further distribute the load and keep adding even more slaves. By adding multiple levels of replication, your replication lag increases, as changes need to propagate through more servers, but you can increase read capacity, which may be a reasonable tradeoff. Figure 5-8 shows how you can deploy multiple levels of slaves to further scale the read capacity.

Figure 5-8 Multilevel MySQL replication
Another thing worth knowing is that replication is a great way to scale the number of concurrently reading clients and the number of read queries per second, but it is not a way to scale the overall data set size. For example, if you wanted to scale your database to support 5,000 concurrent read connections, then adding more slaves or caching more aggressively could be a good way to go. On the other hand, if you wanted to scale your active data set to 5TB, replication would not help you get there. The reason why replication does not help in scaling the data set size is that all of the data must be present on each of the machines. The master and each of its slaves need to have all of the data. That, in turn, means that a single server needs to write, read, index, and search through all of the data contained in your database.
Active data set is all of the data that must be accessed frequently by your application. It is usually difficult to measure the size of the active data set precisely because data stores do not report this type of metric directly. A simple way of thinking about the active data set is to imagine all of the data that your database needs to read from or write to disk within a time window, like an hour, a day, or a week.
It is important to think about your data access patterns and the active data set size, because having too much active data is a common source of scalability issues. Having a lot of inactive data may increase the size of your database indexes, but if you do not need to access that data repeatedly, it does not put much pressure on your database. Active data, on the other hand, needs to be accessed, so your database can either buffer it in memory or fetch it from disk, which is usually where the bottleneck is. When the active data set is small, the database can buffer most of it (or all of it) in memory. As your active data set grows, your database needs to load more disk blocks because your in-memory buffers are not large enough to contain enough of the active disk blocks. At a certain point, buffers become useless and all that database ends up doing is performing random disk I/O, trying to fetch the disk blocks necessary to complete application requests.
To explain better how an active data set works, let’s consider an example. If you had an e-commerce website, you might use tables to store information about each purchase. This type of data is usually accessed frequently right after the purchase and then it becomes less and less relevant as time goes by. Sometimes you may still access older transactions after a few days or weeks to update shipping details or to perform a refund, but after that, the data is pretty much dead except for an occasional report query accessing it. This type of active data set behaves like a time window. It moves with time, but it does not grow aggressively as long as the number of purchases per day does not grow. Figure 5-9 illustrates transactions by their creation time, with data being accessed in the last 48 hours highlighted.
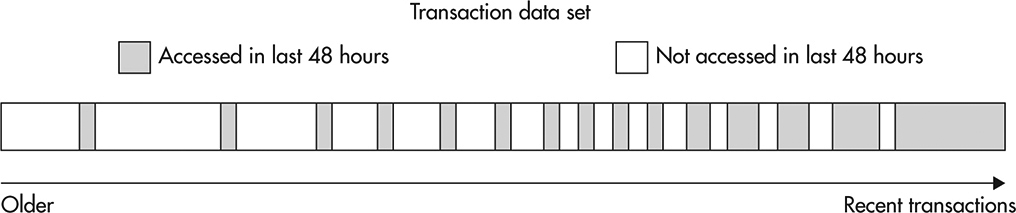
Figure 5-9 Active and inactive data
Let’s now consider a different example showing an access pattern that could result in an unlimited active data set growth. If you built a website that allowed users to listen to music online, your users would likely come back every day or every week to listen to their music. In such case, no matter how old an account is, the user is still likely to log in and request her playlists on a weekly or daily basis. As the user base grows, the active data set grows, and since there is no natural way of deactivating the data over time, your system needs to be able to sustain the growth of the active data set. I will discuss how to deal with active data set growth later in this chapter, but for now let’s remember that replication is not a way to solve this problem.
Another thing to remember when working with MySQL replication is that slaves can return stale data. MySQL replication is asynchronous, and any change made on the master needs some time to replicate to its slaves. It is critical to remember that, as you can easily run into timing issues where your code writes to the master and then it performs a read on a slave to fetch the same data. In such a scenario, depending on the replication lag, the delay between requests, and the speed of each server, you may get the freshest data or you may get stale data, as your write may still be replicating to the slave.
During normal operations, the replication lag can be as low as half a second, but it does not mean that you can depend on it to be that low all the time. The reason why replication lag can suddenly increase is that MySQL replication runs as a single thread on slaves. Although the master can process multiple updates in parallel, on slaves, all these statements are executed one at a time. That “gotcha” in MySQL replication is often a source of bugs and outages during database maintenance because a long-running update like an alter table statement blocks replication of all the tables for as long as the statement takes to execute, which can be seconds, minutes, or even hours.
To prevent these timing issues, one approach is to cache the data that has been written on the client side so that you would not need to read the data that you have just written. Alternatively, you can send critical read requests to the master so that they would always result in the most up-to-date data. Finally, you can try to minimize the replication lag to reduce the chance of stale data being read from slaves. For example, to make sure your alter table statements do not block replication, you can issue them on the master with binlog disabled and manually execute them on each slave as well. This way, altering a large table would not block writes to other tables and all servers would end up with the same schema.
It is critical not to underestimate the complexity and cost of MySQL replication, as it can be a serious challenge for less experienced administrators and you need to have a much deeper understanding of MySQL replication and MySQL itself to manage and use replication in a safe manner.
There are many ways in which you can break MySQL replication or end up with inconsistent data. For example, using functions that generate random numbers or executing an update statement with a limit clause may result in a different value written on the master and on its slaves, breaking the consistency of your data. Once your master and your slaves get out of sync, you are in serious trouble, as all of the following update/insert/delete statements may also behave differently on each of the servers because they may be affected by the difference in state. This can result in hard-to-debug problems, ghostlike bugs, and replication repeatedly breaking, as statements execute successfully on the master but then throw errors on the slave, stopping the replication process.
Although some open-source tools like pt-table-checksum or pt-table-sync can help you discover and fix such problems, there is no high-availability autopilot built into MySQL replication. If things break, you are the one who will have to fix them, and it may require a great deal of knowledge, experience, and time to get there.
Considering that managing MySQL replication is fairly involved, it can be a good strategy to use a hosted MySQL solution like Amazon RDS (Amazon Relational Database Service) or Rackspace Cloud Database to reduce the burden. Especially if you work for a young startup and you need to get to market as fast as possible, you may be better off using hosted MySQL rather than learning and doing everything by yourself. Hosted MySQL usually comes with a lot of useful features, such as setting up replication, automated backups, and slave bootstrapping with a click of a button. Some of the providers support more advanced features, such as automated failover to another availability zone, but you may still get into trouble if your replicas get out of sync, so learning more about MySQL would still be needed.
Even though I focused on MySQL replication in this section, a lot of the information covered here applies to other data stores as well. Replication is usually implemented as asynchronous propagation of changes from a single master to one or many slaves. Details of the implementation are usually different, making some of the challenges easier and others harder to overcome, but they all carry the same scalability benefits of distributing read queries among more machines and allowing you to offload slow queries and backups to separate servers. Whether you use replication in MySQL, Redis, MongoDB, or Postgres, you will not be able to scale writes or your data set size using it. Let’s now have a look at the second main scalability technique, which is data partitioning, also known as sharding.
Data Partitioning (Sharding)
Data partitioning is one of the three most basic scalability techniques listed in Chapter 2 (next to functional partitioning and scaling by adding clones). The core motivation behind data partitioning is to divide the data set into smaller pieces so that it could be distributed across multiple machines and so that none of the servers would need to deal with the entire data set. By dividing the data set into smaller buckets and assigning each bucket to a single server, servers become independent from one another, as they share nothing (at least in the simple sharding scenario). Without data overlap, each server can make authoritative decisions about data modifications without communication overhead and without affecting availability during partial system failures.
People often refer to data partitioning as sharding, and although the exact origin of this term is not clear, some people believe that it originated in the 1990s from Ultima Online. Ultima Online was the first massively multiplayer online role-playing game, and it required so many resources that developers decided to divide the world of the game into isolated, independent servers (also called shards). In the world of the game, they explained the existence of these independent parallel worlds using a compelling storyline of a world crystal being shattered, creating alternative realities. Each world was independent, and characters were bound to exist within a single shard without the ability to interact across shards.
Regardless of its origin, sharding can be explained using a metaphor of transporting a sheet of glass. The larger the sheet, the more difficult it is to handle and transport due to its size and weight. As soon as you shatter the glass into small pieces, however, you can transport it more easily. No matter how large the original sheet, you can fill buckets, trucks, or other containers of any size and transport it bit by bit rather than having to deal with it all at once. If the sheet of glass was your data set, then your buckets are servers running your data store, and sharding is the act of breaking the monolithic piece of data into tiny portions so that they can be poured into containers of any size.
Choosing the Sharding Key
The core idea of sharding is to divide the data in some way so that each server would get only a subset of it. At the same time, when you need to access the data to read or write it, you should be able to ask only the server who has the information you need rather than talking to all the servers and trying to figure out who has the data you are interested in. Being able to locate the shard on which the data lives without having to ask all the servers is what sharding keys are used for.
A Sharding key is the information that is used to decide which server is responsible for the data that you are looking for. The way a sharding key is used is similar to the way you interact with object caches. To get data out of the cache, you need to know the caching key, as that is the only way to locate the data. A sharding key is similar—to access the data, you need to have the sharding key to find out which server has the data. Once you know which server has the data, you can connect to it and issue your queries.
To illustrate it better, let’s consider an example of an e-commerce website again. If you were building a large-scale e-commerce website, you could put all of the user data into a single MySQL database and then host it on a single machine. Figure 5-10 shows how that might look. In this configuration, you do not need to decide which server to talk to, as there is only one server and it contains all of the data.
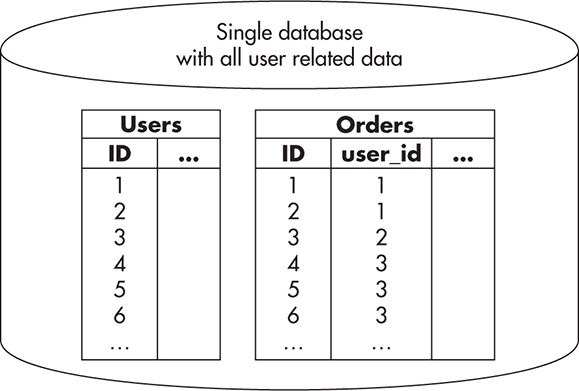
Figure 5-10 User database without sharding
If you wanted to scale the data size beyond a single server, you could use sharding to distribute it among multiple MySQL database servers. Any time you want to use sharding, you need to find a way to split your data set into independent buckets. For example, since in traditional online stores, users do not need to interact with each other, you could assign each user to one of the shards without sacrificing functionality. By doing this, you can easily distribute your users among many servers, and any time you want to read or write data related to a particular user, you would only need to talk to one of the servers.
Once you decide how to split the data, you then need to select the sharding key. If you shard based on the user, your sharding key would be something that identifies the user, for example, an account ID (also known as a user ID). Once you decide upon the sharding key, you also need to choose an algorithm, which will allow you to map the sharding key value to the actual server number. For the sake of simplicity, let’s say that you wanted to have only two shards; in this case, you could allocate all of the users with even user IDs to shard 1 and all of the users with odd user IDs to shard 2. Figure 5-11 shows the process of mapping the user data to the server number.

Figure 5-11 Mapping the sharding key to the server number
By performing a split and then selecting the sharding key and a mapping method, your data does not have to live on a single machine any more. Each machine ends up with roughly the same amount of data, as you assign new users to one of the servers based on the user ID. In addition, each piece of data lives on one machine only, making your database servers share nothing and giving them authority over the data that they have.
Figure 5-12 shows how a sharded MySQL database could look. Each user is allocated to a single database server based on the user ID. Any time you want to access a user’s data, you would take the user ID and check whether it is odd or even to find out which database server this user belongs to. Once you know the server number, you simply connect to it and perform your database queries as if it was a regular database. In fact, MySQL does not need any special configuration, as it does not know that sharding is applied to the data set. All of the sharding logic lives in your application and the database schema is identical on all of the shards.

Figure 5-12 User database with sharding
If you look more closely at Figure 5-12 you may notice that order IDs are not unique across shards. Since IDs are generated using auto_increment and databases do not know anything about one another, you get the same IDs generated on each of the servers. In some cases, this may be acceptable, but if you wanted to have globally unique IDs, you could use auto_increment_increment and auto_increment_offset to make sure that each shard generates different primary keys.
HINT
Sharding can be implemented in your application layer on top of any data store. All you need to do is find a way to split the data so it could live in separate databases and then find a way to route all of your queries to the right database server. The data store does not need to support sharding for your application to use it, but some data stores provide automatic sharding and data distribution out of the box. I will discuss automatic sharding in more detail later in this chapter.
I used user ID as the sharding key in this example, as it usually allows you to create many tiny buckets rather than a few large ones. Sharding into a small number of large buckets may not let you distribute the data evenly among multiple machines. For example, if you sharded the data based on the user’s country of origin, you would use country_code as your sharding key and then map country_code to a server number. This might look like it gives you the same result, but it does not. If you shard by the country of origin, you are likely to have an uneven distribution of data. Some countries will have a majority of your users and others will have very few, making it harder to ensure equal distribution and load. By splitting your data into large buckets, you can also end up in a situation where one bucket becomes so large that it cannot be handled by a single machine any more. For example, the number of users from the United States can grow beyond the capacity of a single server, defeating the purpose of sharding altogether. Figure 5-13 shows how sharding by country code can cause some servers to be overloaded and others to be underutilized. Although the number of countries is equal, the amount of data is not.
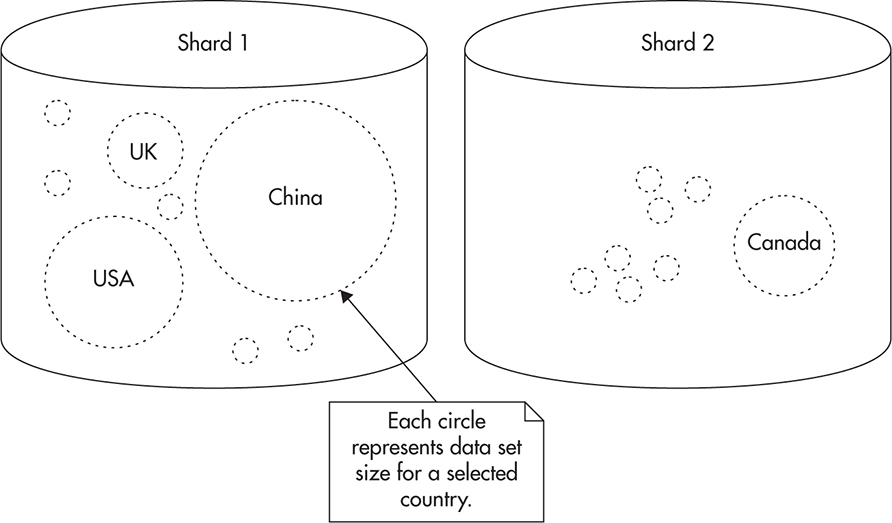
Figure 5-13 Uneven distribution of data
When you perform sharding, you should try to split your data set into buckets of similar size, as this helps to distribute the data evenly among your servers. It is usually not possible to ensure equal size of your data buckets, but as long as your buckets are small and you have a lot of them, your servers will still end up with a pretty good overall data distribution.
Advantages of Sharding
As you can probably already see, the most important advantage of sharding is that when applied correctly, it allows you to scale your database servers horizontally to almost any size.
To have a truly horizontally scalable system, all of your components need to scale horizontally. Without sharding, you are most likely going to hit MySQL scalability limits no matter what you do. Sooner or later, your data size will be too large for a single server to manage or you will get too many concurrent connections for a single server to handle. You are also likely to reach your I/O throughput capacity as you keep reading and writing more data (there is always a limit to how many hard drives you can connect to a single database server).
By using application-level sharding, none of the servers need to have all of the data. This allows you to have multiple MySQL servers, each with a reasonable amount of RAM, hard drives, and central processing units (CPUs) and each of them being responsible for a small subset of the overall data, queries, and read/write throughput. By having multiple servers, you can scale the overall capacity by adding more servers rather than by making each of your servers stronger.
Since sharding splits data into disjointed subsets, you end up with a share-nothing architecture. There is no overhead of communication between servers, and there is no need for cluster-wide synchronization or blocking. Each database server is independent as if it was a regular MySQL instance and it can be managed, optimized, and scaled as a regular MySQL server would be.
Another advantage of sharding is that you can implement it in the application layer and then apply it to any data store, regardless of whether it supports sharding out of the box or not. You can apply sharding to object caches, message queues, nonstructured data stores, or even file systems. Any place that requires lots of data to be persisted, managed, and searched through could benefit from data partitioning to enable scalability.
Challenges of Sharding
Unfortunately, sharding does not come without its costs and challenges. Implementing sharding in your application layer allows you to scale more easily, but it adds a significant amount of work and complexity. Although it might sound like adding a sharding key and routing queries among more machines should be easy to do, in reality, it requires a lot of extra code and makes things much more complex.
One of the most significant limitations that come with application-level sharding is that you cannot execute queries spanning multiple shards. Any time you want to run such a query, you need to execute parts of it on each shard and then somehow merge the results in the application layer. In some cases, that might be easy to do, but in others, it might be prohibitively difficult.
To illustrate it better, let’s consider an example. If you had an e-commerce website and you sharded the data across multiple database servers based on the user ID (like we did in previous examples in this chapter), you could easily access data of a particular user, but you would not be able to run queries that span multiple users. If you wanted to find the most popular item in the last seven days, you would need to run your query on each of the shards and then compute the correct result in the application. Even in such a simple scenario, it is very easy to make wrong assumptions and write invalid code, as most of us are not used to working with sharding and disjointed data sets. If all of the data was hosted on a single machine, all you would need to do to get the item with the highest number of sales is run a query similar to Listing 5-1.
Listing 5-1 Example of a simple GET request

With that mind-set, you might assume that all you need to do is run the same query on each of your servers and pick the highest of the values. Unfortunately, that would not guarantee a correct result. If you had two servers and each of them had top sales data, as is shown in Table 5-1, your code would return an incorrect value. Running the query on each of the servers and picking the highest value would result in returning item_id=2, as it had 16 sales on shard B. If you looked at the data more closely, though, you would realize that item_id=5 had a higher overall sales number of 23.
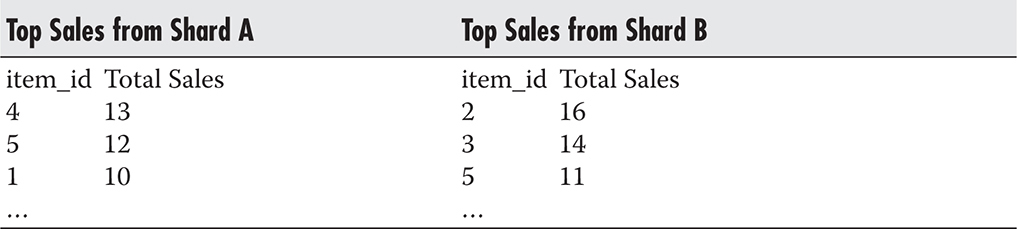
Table 5-1 Summarized Data from Each of the Shards
As you can see, dealing with disjointed data sets and trying to execute queries across shards can be tricky. Although Listing 5-1 shows one of the simplest examples imaginable, you may need to fetch a much larger data set from each of the servers and compute the final result in the application layer to guarantee correctness. As your queries become more complex, that can become increasingly difficult, making complex reports a serious challenge.
The term ACID transaction refers to a set of transaction properties supported by most relational database engines. A stands for Atomicity, C for Consistency, I for Isolation, and D for Durability. An atomic transaction is executed in its entirety. It either completes or is rejected and reverted. Consistency guarantees that every transaction transforms the data set from one consistent state to another and that once the transaction is complete, the data conforms to all of the constraints enforced by the data schema. Isolation guarantees that transactions can run in parallel without affecting each other. Finally, durability guarantees that data is persisted before returning to the client, so that once a transaction is completed it can never be lost, even due to server failure. When people say that a certain data store supports ACID transactions, they mean that each transaction executed by that data store provides all of the ACID guarantees.
Another interesting side effect of distributing data across multiple machines is that you lose the ACID properties of your database as a whole. You can still depend on ACID transactions on each of the shards, but if you needed to make changes across shards, you would lose the ACID properties. Maintaining ACID properties across shards requires you to use distributed transactions, which are complex and expensive to execute (most open-source database engines like MySQL do not even support distributed transactions). For example, if you had to update all of the orders of a particular user, you could do it within the boundaries of a single server, thus taking advantage of ACID transactions. However, if you needed to update all of the orders of a particular item, you would need to send your queries to multiple servers. In such a case, there would be no guarantee that all of them would succeed or all of them would fail. You could successfully execute all of the queries on Shard A, committing the transaction, and then fail to commit your transaction on Shard B. In such a case, you would have no way to roll back queries executed on Shard A, as your transaction had already completed.
Another challenge with sharding in your application layer is that as your data grows, you may need to add more servers (shards). Depending on how you map from sharding key to the server number, it might be surprisingly difficult to add more servers to your sharded deployment.
At the beginning of this section, I explained that the sharding key is used to map to a server number. The simplest way to map the sharding key to the server number is by using a modulo operator. In the first example of this section, I had two shards and I decided to direct users with odd user IDs to Shard A and users with even user IDs to Shard B, which is a modulo 2 mapping.
Modulo(n,x) is the remainder of the division of x by n. It allows you to map any integer number to one of the numbers in range from 0 to n–1. For example, if you had six servers, you would use modulo(6, userId) to calculate the server number based on the user ID.
The problem with modulo-based mapping is that each user is assigned to a particular server based on the total number of servers. As the total number of servers changes, most of the user–server mappings change. For example, if you had three servers, numbered 0, 1, and 2, then user_id=8 would be mapped to the last server as modulo(3,8)=2. If you now added a fourth server, you would have four servers numbered 0, 1, 2, and 3. Executing the same mapping code for the same user_id=8 would return a different result: modulo(4,8)=0.
As you can see, adding a server could become a huge challenge, as you would need to migrate large amounts of data between servers. You would also need to do it without losing track of which user’s data should be migrated to which server. When scaling your system horizontally, scaling events should be much cheaper and simpler than that; that is why we need to look for alternatives.
One way to avoid the need to migrate user data and reshard every time you add a server is to keep all of the mappings in a separate database. Rather than computing server number based on an algorithm, we could look up the server number based on the sharding key value. In our e-commerce example, we would need a separate data store with mappings of user_id to server number. Figure 5-14 shows how mappings could be stored in a data store and looked up by the application (mappings could be cached in the application to speed up the mapping code).
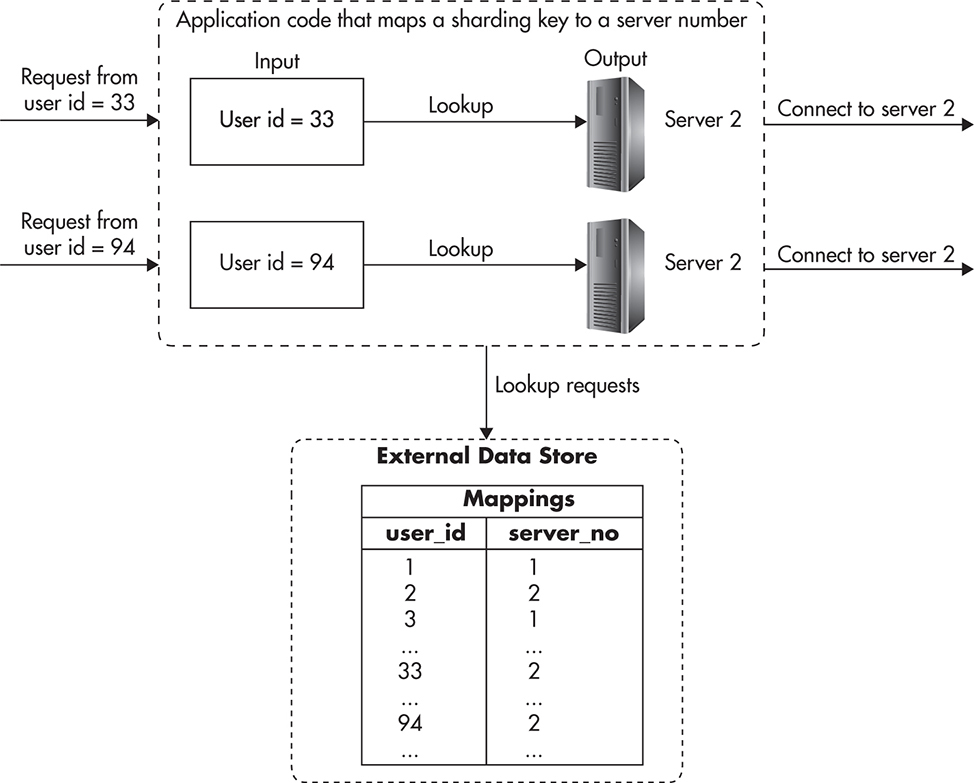
Figure 5-14 External mapping data store
The benefit of keeping mapping data in a database is that you can migrate users between shards much more easily. You do not need to migrate all of the data in one shot, but you can do it incrementally, one account at a time. To migrate a user, you need to lock its account, migrate the data, and then unlock it. You could usually do these migrations at night to reduce the impact on the system, and you could also migrate multiple accounts at the same time, as there is no data overlap.
By keeping mappings in a database, you also benefit from additional flexibility, as you can cherry-pick users and migrate them to the shards of your choice. Depending on the application requirements, you could migrate your largest or busiest clients to separate dedicated database instances to give them more capacity. Conversely, if high activity was not a good thing, you could punish users for consuming too many resources by hosting them together with other noisy users.
Since mapping data needs to be stored somewhere, you could either use MySQL itself to store that data or use an alternative data store. If you wanted to keep mapping data in MySQL, you could deploy a MySQL master server that would be the source of truth for the mapping table and then replicate that data to all of the shards. In this scenario, any time you create a new user, you need to write to the global master. Then the user entry replicates to all of the shards, and you can perform read-only lookups on any of the shards. Figure 5-15 shows how that could be done.

Figure 5-15 Master of all the shards
This is a relatively simple approach, as you add one more MySQL instance without introducing any new technologies. Since the mapping data set is small, it should not be a serious challenge to cache most of it in memory and replicate it quickly to all of the shards, but that is assuming you do not create thousands of mappings per second.
Depending on your infrastructure, adding another MySQL instance could be a good idea, but if you already used another highly scalable data store (I will talk about these later in this chapter), you may also consider keeping the mapping data there rather than writing it to all of the shards. Keeping mappings in a separate data store increases the complexity of your system as you need to deploy, manage, and scale yet another data store instance, but if you were already using one, it could be a relatively easy way out.
Luckily, there is one more solution to sharding that reduces the risk of resharding at relatively low cost and with minimal increase of complexity. In this scenario, you use the modulo function to map from the sharding key value to the database number, but each database is just a logical MySQL database rather than a physical machine. First, you decide how many machines you want to start with. Then you forecast how many machines you may realistically need down the road.
For example, you estimate that you will need two servers to start with and you will never need more than 32 machines in total (32 shards). In such a situation, you create 16 databases on each of the physical servers. On Server A you name them db-00 … db-15 and on Server B you name them db-16 … db-31. You then deploy the exact same schema to each of these databases so that they are identical. Figure 5-16 shows how such a deployment might look.
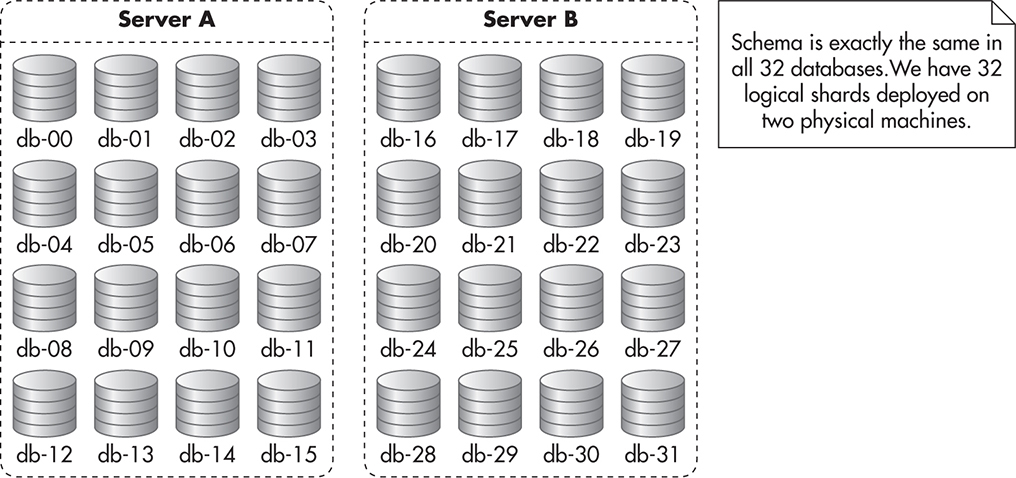
Figure 5-16 Initial deployment of multidatabase sharded solution
At the same time, you implement mapping functions in your code that allow you to find the database number and the physical server number based on the sharding key value. You implement a getDbNumber function that maps the sharding key value (like a user ID) to the database number (in this case, 32 of them) and getServerNumber, which maps the database number to a physical server number (in this case, we have two). Listing 5-2 shows how all of the mapping code would look initially.

You can then deploy your application and begin operation. As your database grows and you need to scale out, you simply split your physical servers in two. You take half of the logical database and move it to new hardware. At the same time, you modify your mapping code so that getServerNumber would return the correct server number for each logical database number. Figure 5-17 shows how your deployment might look after scaling out to four physical servers.
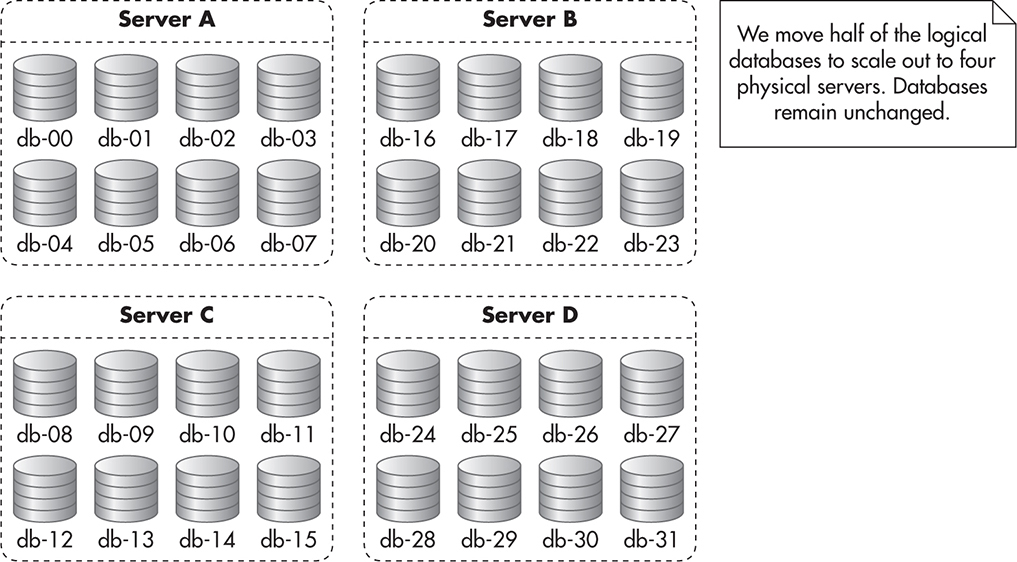
Figure 5-17 Multidatabase sharded solution after scaling-out event
Although adding multiple databases on each machine is slightly more complicated than a simple sharded deployment, it gives you much more flexibility when it comes to scaling out. Being able to double your capacity by simply copying binary database backups and updating a few lines of code is a huge time saver. It is also much easier and safer to perform, as you do not need to update, insert, or delete any data for the migration to be completed. All you do is move the entire MySQL database from one server to another.
Another benefit of this approach is that you can scale out relatively quickly with minimal amount of downtime. With good planning, you should be able to complete such a scaling-out event in less than a couple of minutes downtime. The actual scaling-out procedure might look as follows:
![]() First, you set up your new servers as replicas of your current shards.
First, you set up your new servers as replicas of your current shards.
![]() Then you need to stop all writes for a brief moment to allow any in-flight updates to replicate.
Then you need to stop all writes for a brief moment to allow any in-flight updates to replicate.
![]() Once slaves catch up with masters, you disable replication to new servers, as you do not want them to continue replicating the data that they will not be responsible for.
Once slaves catch up with masters, you disable replication to new servers, as you do not want them to continue replicating the data that they will not be responsible for.
![]() You can then change the configuration of your application to use new servers and allow all traffic.
You can then change the configuration of your application to use new servers and allow all traffic.
A challenge that you may face when working with application-level sharding is that it may be harder to generate an identifier that would be unique across all of the shards. Some data stores allow you to generate globally unique IDs, but since MySQL does not natively support sharding, your application may need to enforce these rules as well.
If you do not care how your unique identifiers look, you can use MySQL auto-increment with an offset to ensure that each shard generates different numbers. To do that on a system with two shards, you would set auto_increment_increment=2 and auto_increment_offset=1 on one of them and auto_increment_increment=2 and auto_increment_offset=2 on the other. This way, each time auto-increment is used to generate a new value, it would generate even numbers on one server and odd numbers on the other. By using that trick, you would not be able to ensure that IDs are always increasing across shards, since each server could have a different number of rows, but usually that is not be a serious issue.
Another simple alternative to generating globally unique IDs is to use atomic counters provided by some data stores. For example, if you already use Redis, you could create a counter for each unique identifier. You would then use Redis’ INCR command to increase the value of a selected counter and return it in an atomic fashion. This way, you could have multiple clients requesting a new identifier in parallel and each of them would end up with a different value, guaranteeing global uniqueness. You would also ensure that there are no gaps and that each consecutive identifier is bigger than the previous ones.
HINT
An interesting way of overcoming the complexity of application-level sharding is to push most of its challenges onto the cloud hosting provider. A good example of how sharding can be made easier for developers is by using Azure SQL Database Elastic Scale. Azure SQL Database Elastic Scale is a set of libraries and supporting services that take responsibility for sharding, shard management, data migration, mapping, and even cross-shard query execution. Rather than having to implement all of this code and supporting tools yourself, you can use the provided libraries and services to speed up your development and avoid painful surprises. Although the Azure SQL Database is using a custom version of SQL Server (not MySQL), it is worth mentioning it here, as it is a great example of how cloud-hosting providers expand their support for scalability.L13
As you can see, a lot of challenges come with application-level sharding. Let’s now have a quick look at how you could combine replication, sharding, and functional partitioning to enable a MySQL-based system to scale efficiently.
Putting It All Together
As I mentioned earlier, scalability can be boiled down to three underlying techniques: scaling by adding copies of the same thing, functional partitioning, and data partitioning. All of these techniques could be applied to a MySQL-based system to allow it to scale. Imagine again that you are hosting an e-commerce website. This time, we will look at the bigger picture and we will discuss how different scalability techniques complement each other.
If you were to build an e-commerce system, you could design it in a simple way where you only have one web service containing all of the functionality of the application. You could also have that web service talk to a single MySQL database for all of its persistence needs. In such a simple scenario, your system might look similar to Figure 5-18.
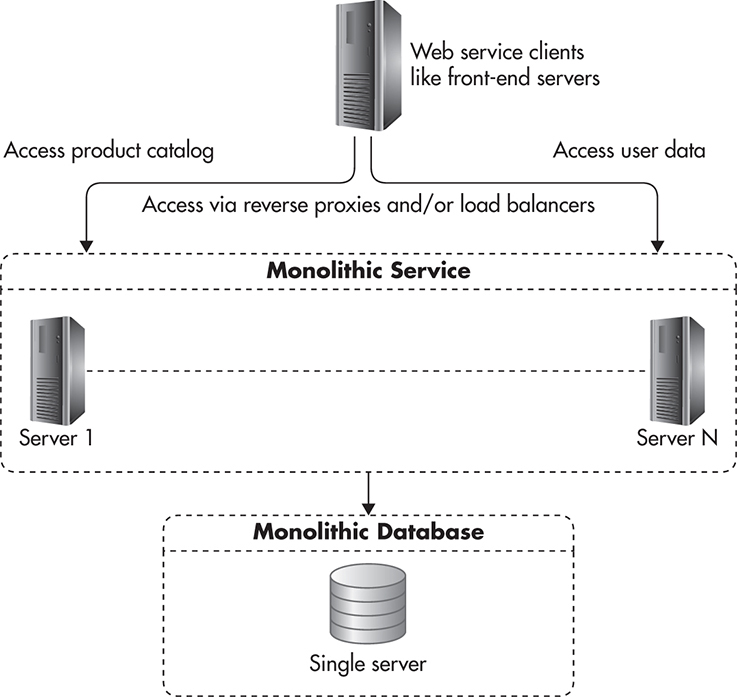
Figure 5-18 Single service and single database
Assuming that your web service was stateless, you could scale the web service machines, but you would not be able to scale your database past a single server. If your application was performing many more reads than writes, you could scale reads by adding read replica servers. These servers would have an exact copy of the data that the master database has, thus allowing you to scale by adding more copies of the same thing. In this configuration, your system might look like Figure 5-19.
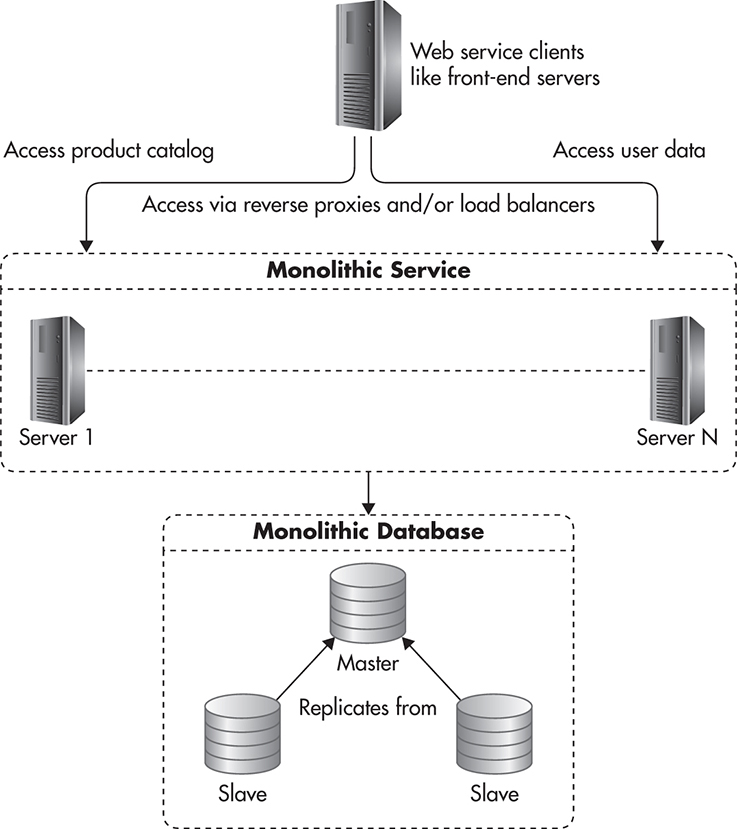
Figure 5-19 Scaling catalog by adding replicas
Now, if that was not enough to scale your system, you might decide to split it into two functional components by performing functional partitioning. For example, you could decide to store all of the user-centric data on one database and the rest of the data in a separate database. At the same time, you would split the functionality of your web services layer into two independent web services: ProductCatalogService and CustomerService. ProductCatalogService would be responsible for managing and accessing information about products, categories, and promotions and CustomerService would be responsible for user accounts, orders, invoices, and purchase history. After performing functional partitioning, your system might look like Figure 5-20.
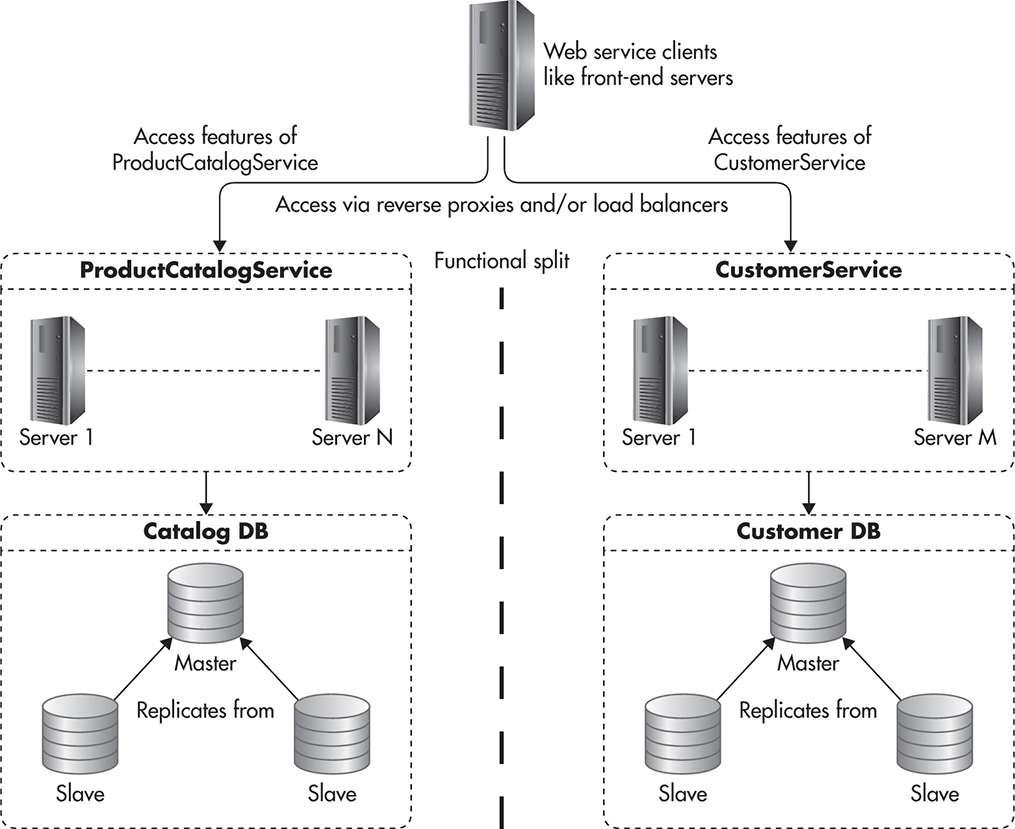
Figure 5-20 Two web services and two databases
By dividing your web service into two highly decoupled services, you could now scale them independently. You could use MySQL replication to scale reads of the ProductCatalogService since the product catalog would be used mainly as a read-only service. Users would search through the data, retrieve product details, or list products in different categories, but they would not be allowed to modify any data in the ProductCatalogService. The only people allowed to modify data in the catalog would be your merchants, and these modifications would happen relatively rarely in comparison to all other types of queries.
On the other hand, CustomerService would require much higher write throughput, as most operations related to user data require writes to persist results of user actions. Each operation, such as adding an item to cart, processing a payment, or requesting a refund, would require writes to the database.
Since your product catalog is mainly read-only and the size is relatively small, you might choose to scale it by adding more read replicas (scaling by adding clones). By keeping all of the products in a single database, you would make your search queries simpler, as you would not need to merge query results across shards. On the other hand, since your user data set was much larger and required many more writes, you could scale it by applying sharding (scaling by data partitioning). You would not depend on replication to scale CustomerService, but you might still want to keep one read replica of each shard just for high-availability and backup purposes. Figure 5-21 shows how your system might look.

Figure 5-21 All three techniques applied
In this scenario, replication would be implemented using MySQL replication and sharding would be implemented in the application layer. The application would need to store user IDs in cookies or sessions so that every request sent to CustomerService could have the user ID (used as the sharding key). Based on the sharding key, the web service could then connect to the correct shard (which is just a regular MySQL database instance) and execute the necessary queries. As you can see, you can mix and match different scalability techniques to help your MySQL-based system grow.
Although application-level sharding is a great way to increase your I/O capacity and allow your application to handle more data, a lot of challenges come with it. Your code becomes much more complex, cross-shard queries are a pain point, and you need to carefully select your sharding key—even then, adding hardware and migrating data can be a challenge.
Replication helps with read throughput and enables higher availability, but it also comes with its own difficulties, especially in terms of ensuring data consistency and recovering from failures. It also forces your application to be aware of replication so that it can handle replication lag correctly and direct queries to the right servers.
Luckily, MySQL and other relational databases are no longer the only way to go when it comes to storing data. Let’s now have a look at alternative technologies that can be used as data stores allowing scalability and high availability.
Scaling with NoSQL
Traditionally, scaling relational databases was the main pain point when scaling web applications. As graduates of computer science courses, we were taught for decades that data should be normalized and transactions should be used to enforce data consistency. Some people would go even further, pushing huge parts of their business logic into the database layer so it would execute as stored procedures or triggers directly on the database servers rather than in the application layer. There was a conviction that relational databases were all there was and all there was ever going to be. If you needed a large-scale database, you needed stronger servers and a bunch of costly software licenses, as there were no alternatives.
Data normalization is a process of structuring data so that it is broken into separate tables. As part of the normalization process, people would usually break data down into separate fields, make sure that each row could be identified by a primary key, and that rows in different tables would reference each other rather than having copies of the same information. Having data in such a form reduces the data size, as there is less redundancy. It also allows for better indexing and searching because data is segregated and smaller in size. Normalization also increases data integrity, as anytime an application needs to update existing data, it only needs to update it in one place (other rows can reference this data, but they would not contain copies of it).
The mind-set that relational database engines were the only way to go began to change in the 2000s with a publication of a few ground-breaking white papers and the increasing popularity of online businesses. Because companies needed to break new scalability records, they needed to look for new, innovative ways to manage the data. Rather than demanding full ACID compliance and expecting databases to run distributed transactions, companies like Amazon, Google, and Facebook decided to build their own simplified data stores. These data stores would not support SQL language, complex stored procedures, or triggers, but what they gave in return was true horizontal scalability and high availability beyond what relational databases could ever offer.
As their platforms proved successful, the world’s largest web startups began publishing computer science white papers describing their innovative technologies. A few famous white papers from Google were Google File System,w44 MapReduce,w1 and BigTable,w28 published in early 2000s. These publications were followed by one of the most famous data store publications, Dynamo, which was a data store designed solely to support the amazon.com checkout process.w39 By 2010, principles and design decisions made by these early pioneers made their way into open-source data stores like Cassandra, Redis, MongoDB, Riak, and CouchDB, and the era of NoSQL began.
NoSQL is a broad term used to label many types of data stores that diverge from the traditional relational database model. These data stores usually do not support the SQL language, thus the term NoSQL.
The reason why these new technologies were so successful at handling ever-growing amounts of data was that they were built with scalability in mind and they were making significant tradeoffs to support this scalability.
The mind shift of the NoSQL era is that when you set out to design a data store, you need to first decide what features are most important to you (for example availability, latency, consistency, ease of use, transactional guarantees, or other dimensions of scalability). Once you decide on your priorities you can then make tradeoffs aligned with what is most important. In the same way, when you are choosing an open-source NoSQL data store, you need to first define the priority order of features that you need and then choose a data store that can satisfy most of them rather than hoping to get everything. If you are hoping to find a “better SQL” in NoSQL, you will be disappointed, as all of the NoSQL data stores make significant sacrifices to support their top-priority features and you need to prepare to make these sacrifices yourself if you want to build a horizontally scalable data layer.
Traditionally, making tradeoffs and sacrifices was not really in the nature of database designers until Eric Brewer’s famous CAP theorem,w23–w25 which stated that it was impossible to build a distributed system that would simultaneously guarantee consistency, availability, and partition tolerance. In this theorem, a distributed system consists of nodes (servers) and network connections allowing nodes to talk to each other. Consistency ensures that all of the nodes see the same data at the same time. Availability guarantees that any available node can serve client requests even when other nodes fail. Finally, partition tolerance ensures that the system can operate even in the face of network failures where communication between nodes is impossible.
HINT
CAP is even more difficult to understand, as the way consistency is defined in CAP is different from the way it was traditionally defined in ACID. In CAP, consistency ensures that the same data becomes visible to all of the nodes at the same time, which means that all of the state changes need to be serializable, as if they happened one after another rather than in parallel. That, in turn, requires ways of coordinating across CPUs and servers to make sure that the latest data is returned. In ACID, on the other hand, consistency is more focused on relationships within the data, like foreign keys and uniqueness.
Since all available nodes need to process all incoming requests (availability) and at the same time they all need to respond with the same data (consistency), there is no way for data to propagate among servers in case of network failure. Figure 5-22 shows a hypothetical data store cluster that conflicts with the CAP theorem. In this example, you can see a network failure separating nodes A and B. You can also see that node C has failed and that multiple clients are reading and writing the same data using different nodes.
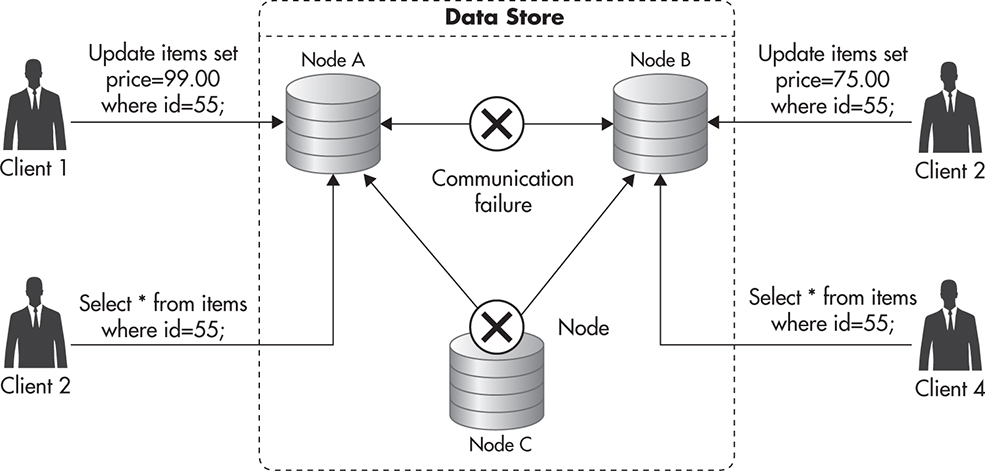
Figure 5-22 Data store conflicting with the CAP theorem
The CAP theorem quickly became popular, as it was used as a justification for tradeoffs made by the new NoSQL data store designers. It was popularized under a simplified label, “Consistency, availability, or partition tolerance: pick two,” which is not entirely correct, but it opened engineers’ eyes to the fact that relational databases with all of their guarantees and features may simply not be able to scale in the way people expected them to. In 2012, Brewer published a white paper titled “CAP 12 Years Later” in which he explained some of the misconceptions about CAP and that tradeoffs are usually made in more subtle ways than sacrificing consistency or high availability altogether. Regardless of its accuracy, the phrase “pick two” became the catchphrase of NoSQL, as it is a powerful way to drive a message that scalable data stores require tradeoffs.
The Rise of Eventual Consistency
As the simplified version of the CAP theorem suggests (pick two), building a distributed data store requires us to relax the guarantees around availability, consistency, or partition tolerance. Some of the NoSQL data stores choose to sacrifice some of the consistency guarantees to make scalability easier. For example, this is what Amazon did with its Dynamo data store.w39 Rather than enforcing full consistency or trying to aim for distributed transactions, Amazon decided that high availability was the most important thing for their online business. Amazon wanted to make sure that you would never get a blank page in the middle of your browsing session and that your shopping cart would never get lost.
Based on these priorities, Amazon then made a series of sacrifices to support their high-availability and scalability needs. They sacrificed complex queries, simplified the data model, and introduced a concept of eventual consistency instead of trying to implement a globally consistent system.
Eventual consistency is a property of a system where different nodes may have different versions of the data, but where state changes eventually propagate to all of the servers. If you asked a single server for data, you would not be able to tell whether you got the latest data or some older version of it because the server you choose might be lagging behind.
If you asked two servers for the exact same data at the exact same time in a globally consistent system, you would be guaranteed to get the same response. In an eventually consistent system, you cannot make such assumptions. Eventually, consistent systems allow each of the servers to return whatever data they have, even if it is some previous stale version of the data the client is asking for. If you waited long enough, though, each server would eventually catch up and return the latest data.
Figure 5-23 shows a scenario where Client A sends an update to Server 1 of an eventually consistent data store. Immediately after that, Clients B and C send queries for that data to Servers 1 and 2. Since the data store is eventually consistent, they cannot be sure if they got the latest data. They know that they got data that was valid at some point in time, but there is no way to know whether the data they got was the freshest or not. In this case, Client B got the latest data, but Client C got a stale response because changes made by Client A have not propagated to Server 2 yet. If Client C waited long enough before sending the request to Server 2, it would receive the same data that Client A has written.
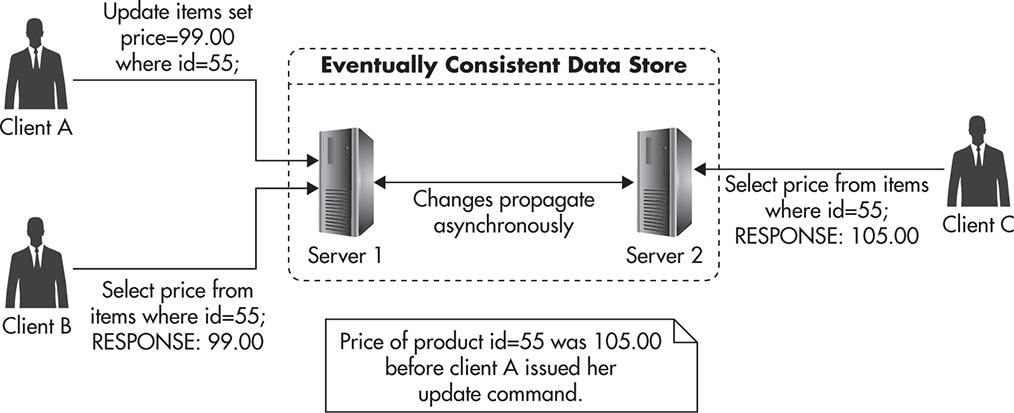
Figure 5-23 Eventual consistency
Some data stores use eventual consistency as a way to increase high availability. Clients do not have to wait for the entire system to be ready for them to be able to read or write. Servers accept reads and writes at all times, hoping that they will be able to replicate incoming state changes to their peers later on. The downside of such an optimistic write policy is that it can lead to conflicts, since multiple clients can update the same data at the exact same time using different servers. Figure 5-24 shows such a conflict scenario. By the time nodes A and B notice the conflict, clients are already gone. Data store nodes need to reach a consensus on what should happen with the price of item id=55.
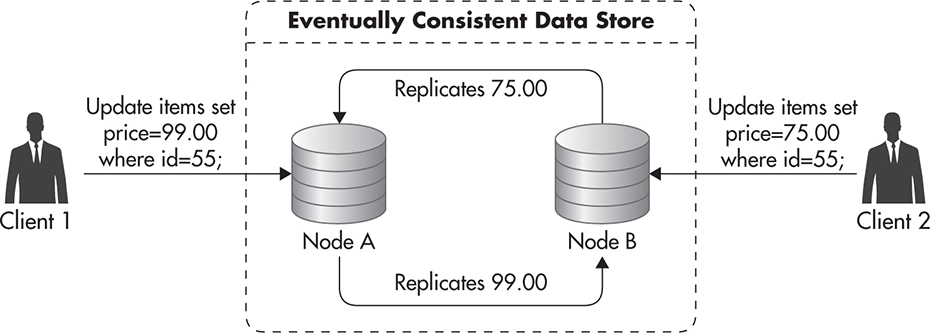
Figure 5-24 Eventual consistency write conflict
There are different ways in which conflicts like this can be resolved. The simplest policy is to accept the most recent write and discard earlier writes. This is usually called “the most recent write wins” and it is appealing due to its simplicity, but it may lead to some data being lost.
Alternatively, some data stores like Dynamo push the responsibility for conflict resolution onto its clients. They detect conflicts and keep all of the conflicting values. Any time a client asks for that data, they would then return all of the conflicted versions of the data, letting the client decide how to resolve the conflict. The client can then apply different business rules to resolve each type of conflict in the most graceful way. For example, with the Amazon shopping cart, even if some servers were down, people would be able to keep adding items to their shopping carts. These writes would then be sent to different servers, potentially resulting in multiple versions of each shopping cart. Whenever multiple versions of a shopping cart are discovered by the client code, they are merged by adding all the items from all of the shopping carts rather than having to choose one winning version of the cart. This way, users will never lose an item that was added to a cart, making it easier to buy.
Figure 5-25 shows how client-side conflict resolution might look. The client created a shopping cart using Server A. Because of a temporary network failure, the client could not write to Server A, so it created a new shopping cart for the same user on Server B. After network failure recovery, both nodes A and B ended up with two conflicting versions of the same shopping cart. To cope with the conflict, they each keep both of the versions and return them to the client in consecutive calls. Then it is up to the client code to decide how to resolve the conflict. In this case, the client decided to merge carts by adding both items and saving the updated cart so that there would be no conflicting versions in the data store.
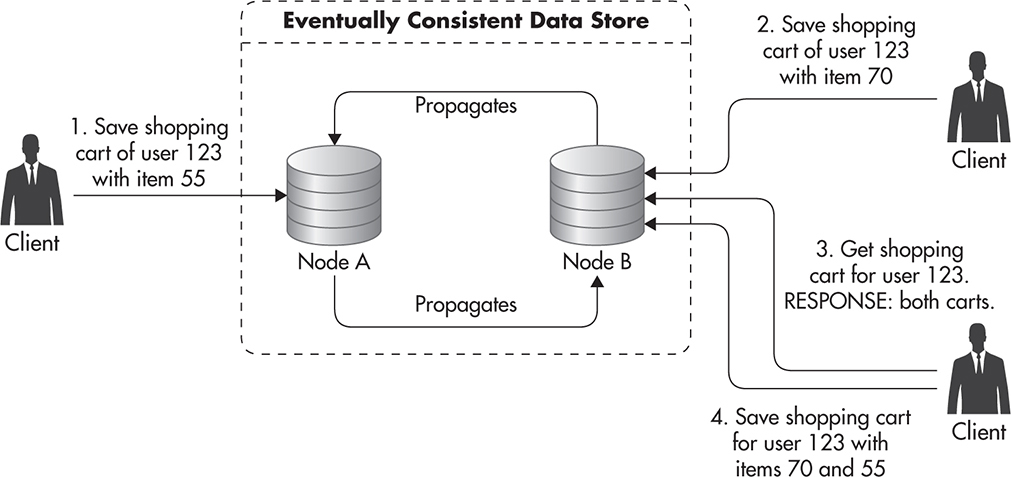
Figure 5-25 Client-side conflict resolution
In addition to the conflict resolution mechanisms mentioned earlier, eventually consistent data stores often support ongoing data synchronization to ensure data convergence. Even when you think of a simple example of an eventually consistent system like MySQL replication, where only one server can accept writes, it can be a challenge to keep all of the copies of the data in sync. Even the smallest human error, application bug, or hardware issue could result in the slave having different data from the master. To deal with edge-case scenarios where different servers end up with different data, some NoSQL data stores, like Cassandra, employ additional self-healing strategies.
For example, 10 percent of reads sent to Cassandra nodes trigger a background read repair mechanism. As part of this process, after a response is sent to the client, the Cassandra node fetches the requested data from all of the replicas, compares their values, and sends updates back to any node with inconsistent or stale data. Although it might seem like overkill to keep comparing all of the data 10 percent of the time, since each of the replicas can accept writes, it is very easy for data to diverge during any maintenance or network issues. Having a fast way of repairing data adds overhead, but it makes the overall system much more resilient to failures, as clients can read and write data using any of the servers rather than having to wait for a single server to become available.
Eventual consistency is a tradeoff and it is usually much more difficult to reason about an eventually consistent system than a globally consistent one. Whatever you read could be some stale version of the data; whatever you write might overwrite data that you did not expect to be there because you read from a stale copy.
Using an eventually consistent data store does not mean that you can never enforce read-after-write semantics. Some of the eventually consistent systems, like Cassandra, allow clients to fine-tune the guarantees and tradeoffs made by specifying the consistency level of each query independently. Rather than having a global tradeoff affecting all of your queries, you can choose which queries require more consistency and which ones can deal with stale data, gaining more availability and reducing latency of your responses.
Quorum consistency means the majority of the replicas agree on the result. When you write using quorum consistency, the majority of the servers need to confirm that they have persisted your change. Reading using a quorum, on the other hand, means that the majority of the replicas need to respond so that the most up-to-date copy of the data can be found and returned to the client.
A quorum is a good way to trade latency for consistency in eventually consistent stores. You need to wait longer for the majority of the servers to respond, but you get the freshest data. If you write certain data using quorum consistency and then you always read it using quorum consistency, you are guaranteed to always get the most up-to-date data and thus regain the read-after-write semantics.
To explain better how quorum consistency works, let’s consider Figure 5-26. In this example, your data is replicated across three nodes. When you write data, you write to at least two nodes (at least two nodes need to confirm persisting your changes before returning the response). That means the failure of Server 2 does not prevent the data store from accepting writes. Later on, when Server 2 recovers and comes back online with stale data, clients would still get the most up-to-date information because their quorum reads would include at least one of the remaining servers, which has the most up-to-date data.

Figure 5-26 Quorum operations during failure
Faster Recovery to Increase Availability
In a similar way in which Dynamo and Cassandra traded some of their consistency guarantees in favor of high availability, other data stores trade some of their high availability for consistency. Rather than guaranteeing that all the clients can read and write all of the time, some data store designers decided to focus more on quick failure recovery rather than sacrificing global consistency.
A good example of such a tradeoff is MongoDB, another popular NoSQL data store. In MongoDB, data is automatically sharded and distributed among multiple servers. Each piece of data belongs to a single server, and anyone who wants to update data needs to talk to the server responsible for that data. That means any time a server becomes unavailable, MongoDB rejects all writes to the data that the failed server was responsible for.
The obvious downside of having a single server responsible for each piece of data is that any time a server fails, some of your client operations begin to fail. To add data redundancy and increase high availability, MongoDB supports replica sets, and it is recommended to set up each of the shards as a replica set. In replica sets, multiple servers share the same data, with a single server being elected as a primary. Whenever the primary node fails, an election process is initiated to decide which of the remaining nodes should take over the primary role. Once the new primary node is elected, replication within the replica set resumes and the new primary node’s data is replicated to the remaining nodes. This way, the window of unavailability can be minimized by automatic and prompt failover.
You could now think that things are great—you have a consistent data store and you only risk a minute of downtime when one of your primary nodes fails. The problem with NoSQL data stores is that they are littered with “gotchas” and you cannot assume anything about them without risking painful surprises. It is not because data store designers are evil, but because they have to make tradeoffs that affect all sorts of things in ways you might not expect.
With regard to consistency in MongoDB, things are also more complicated than you might expect. You might have read that MongoDB is a CP data store (favoring consistency and partition tolerance over availability), but the way in which consistency is defined is not what you might expect. Since MongoDB replica sets use asynchronous replication, your writes reach primary nodes and then they replicate asynchronously to secondary nodes. This means that if the primary node failed before your changes got replicated to secondary nodes, your changes would be permanently lost.
Figure 5-27 shows how a primary node failure causes some writes to be lost. In a similar way to how Cassandra allowed you to increase consistency, you can also tell MongoDB to enforce secondary node consistency when you perform a write. But would you not expect that to be the default in a CP system? In practice, enforcing writes to be synchronously replicated to secondary nodes is expensive in MongoDB, as writes are not propagated one by one; rather, the entire replication backlog needs to be flushed and processed by the secondary node for a write to be acknowledged.
Figure 5-27 Update lost due to primary node failure
Many of the modern NoSQL data stores support automatic failover or failure recovery in one form or another. No matter which NoSQL data store you choose, you need to study it deeply and resist any assumptions, as practice is usually more complicated than the documentation makes it look.
Cassandra Topology
NoSQL data stores vary significantly, but they use some common patterns to distribute data among multiple servers, replicate information, and handle failures. Let’s have a closer look at Cassandra, which is one of the most popular NoSQL data stores, to see some of these key features.
Cassandra is a data store that was originally built at Facebook and could be seen as a merger of design patterns borrowed from BigTable (developed at Google) and Dynamo (built by Amazon).
The first thing that stands out in the Cassandra architecture is that all of its nodes are functionally equal. Cassandra does not have a single point of failure, and all of its nodes perform the exact same functions. Clients can connect to any of Cassandra’s nodes and when they connect to one, that node becomes the client’s session coordinator. Clients do not need to know which nodes have what data, nor do they have to be aware of outages, repairing data, or replication. Clients send all of their requests to the session coordinator and the coordinator takes responsibility for all of the internal cluster activities like replication or sharding.
Figure 5-28 shows the topology of a Cassandra cluster. Clients can connect to any of the servers no matter what data they intend to read or write. Clients then issue their queries to the coordinator node they chose without any knowledge about the topology or state of the cluster. Since each of the Cassandra nodes knows the status of all of the other nodes and what data they are responsible for, they can delegate queries to the correct servers. The fact that clients know very little about the topology of the cluster is a great example of decoupling and significantly reduces complexity on the application side.
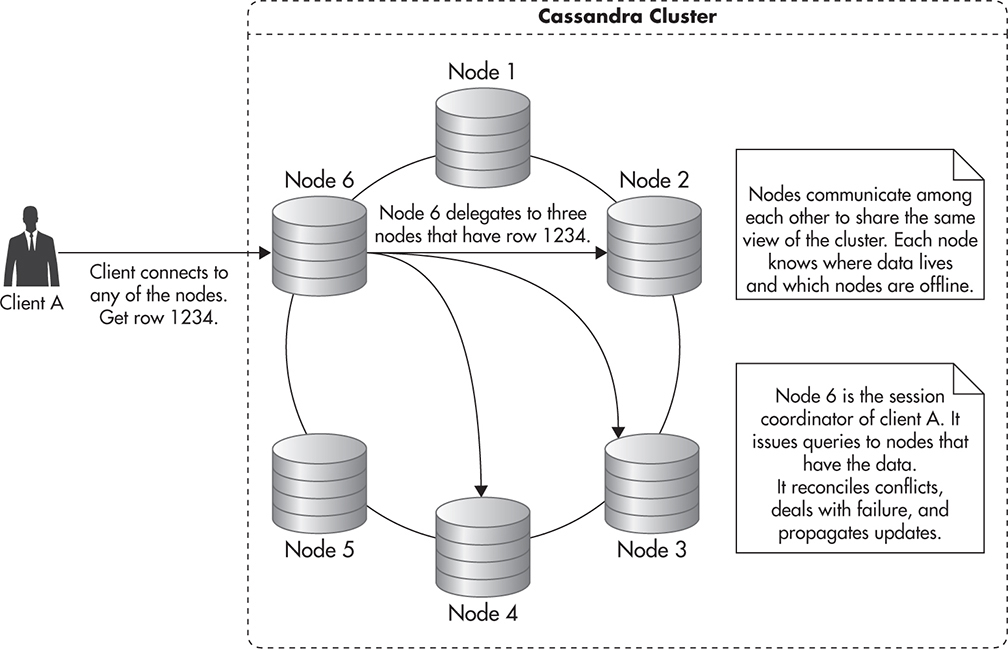
Figure 5-28 Topology of a Cassandra cluster
Although all of the Cassandra nodes have the same function in the cluster, they are not identical. The thing that makes each of the Cassandra nodes unique is the data set that they are responsible for. Cassandra performs data partitioning automatically so that each of the nodes gets a subset of the overall data set. None of the servers needs to have all of the data, and Cassandra nodes communicate among one other to make sure they all know where parts of the data live.
Another interesting feature of Cassandra is its data model, which is very different from the relational data model used in databases like MySQL. The Cassandra data model is based on a wide column, similar to Google’s BigTable.w28 In a wide column model, you create tables and then each table can have an unlimited number of rows. Unlike the relational model, tables are not connected, each table lives independently, and Cassandra does not enforce any relationships between tables or rows.
Cassandra tables are also defined in a different way than in relational databases. Different rows may have different columns (fields), and they may live on different servers in the cluster. Rather than defining the schema up front, you dynamically create fields as they are required. This lack of upfront schema design can be a significant advantage, as you can make application changes more rapidly without the need to execute expensive alter table commands any time you want to persist a new type of information.
The flip side of Cassandra’s data model simplicity is that you have fewer tools at your disposal when it comes to searching for data. To access data in any of the columns, you need to know which row are you looking for, and to locate the row, you need to know its row key (something like a primary key in a relational database).
Cassandra partitions data based on a row key in a similar way to what we did with MySQL sharding earlier in this chapter. When you send your query to your session coordinator, it hashes the row key (which you provided) to a number. Then, based on the number, it can find the partition range that your row key belongs to (the correct shard). Finally, the coordinator looks up which Cassandra server is responsible for that particular partition range and delegates the query to the correct server.
In addition to automatic data partitioning, Cassandra supports a form of replication. It is important to note, though, that in Cassandra, replication is not like we have seen in MySQL. In Cassandra, each copy of the data is equally important and there is no master–slave relationship between servers. In Cassandra, you can specify how many copies of each piece of data you want to keep across the cluster, and session coordinators are responsible for ensuring the correct number of replicas.
Anytime you write data, the coordinator node forwards your query to all of the servers responsible for the corresponding partition range. This way, if any of the servers was down, the remaining servers can still process the query. Queries for failed nodes are buffered and then replayed when servers become available again (that buffering is also called hinted handoff). So although the client connects to a single server and issues a single write request, that request translates to multiple write requests, one for each of the replica holders.
Figure 5-29 shows how a write request might be coordinated in a cluster with the replication factor equal to three when a quorum consistency level was requested. In such a scenario, the coordinator has to wait for at least two nodes to confirm that they have persisted the change before it can return to the client. In this case, it does not matter to the client whether one of the nodes is broken or down for maintenance, because node 6 returns as soon as two of the nodes acknowledge that they have persisted the change (two out of three is the majority of the nodes, which is enough to guarantee quorum-level consistency).
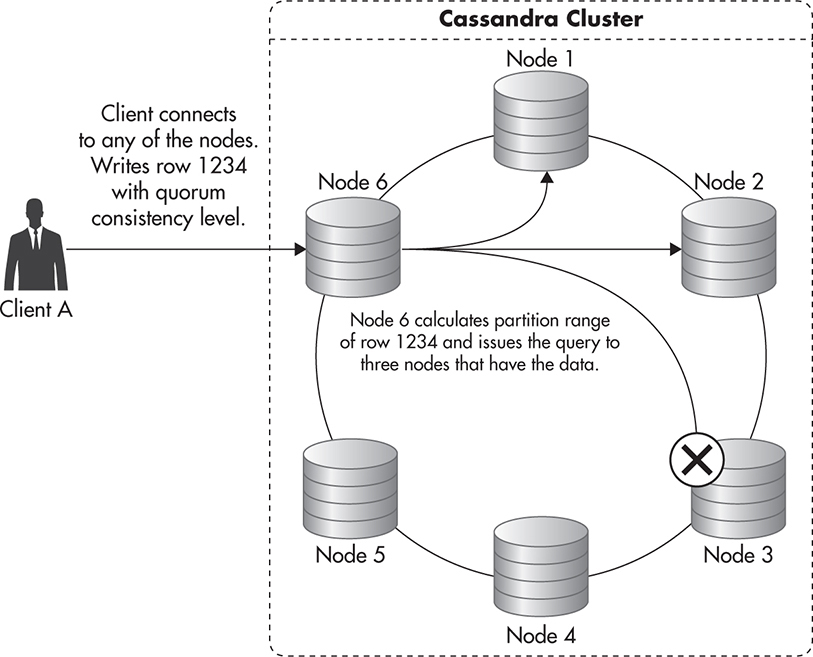
Figure 5-29 Writing to Cassandra
Another extremely valuable feature of Cassandra is how well automated it is and how little administration it requires. For example, replacing a failed node does not require complex backup recovery and replication offset tweaking, as often happens in MySQL. All you need to do to replace a broken server is add a new (blank) one and tell Cassandra which IP address this new node is replacing. All of the data transferring and consistency checking happens automatically in the background. Since each piece of data is stored on multiple servers, the cluster is fully operational throughout the server replacement procedure. Clients can read and write any data they wish even when one server is broken or being replaced. As soon as node recovery is finished, the new node begins processing requests and the cluster goes back to its original capacity.
From a scalability point of view, Cassandra is a truly horizontally scalable data store. The more servers you add, the more read and write capacity you get, and you can easily scale in and out depending on your needs. Since data is sliced into a high number of small partition ranges, Cassandra can distribute data more evenly across the cluster. In addition, since all of the topology is hidden from the clients, Cassandra is free to move data around. As a result, adding new servers is as easy as starting up a new node and telling it to join the cluster. Again, Cassandra takes care of rebalancing the cluster and making sure that the new server gets a fair share of the data.
As of this writing, Cassandra is one of the clear leaders when it comes to ease of management, scalability, and self-healing, but it is important to remember that everything has its price. The main challenges that come with operating Cassandra are that it is heavily specialized, it has a very particular data model, and it is an eventually consistent data store.
You can work around eventual consistency by using quorum reads and writes, but the data model and tradeoffs made by the designers can often come as a surprise. Anything that you might have learned about relational databases is pretty much invalid when you work with NoSQL data stores like Cassandra. It is easy to get started with most NoSQL data stores, but to be able to operate them at scale takes much more experience and understanding of their internal structure than you might expect.
For example, even though you can read in the open-source community that “Cassandra loves writes”, deletes are the most expensive type of operation you can perform in Cassandra, which can come as a big surprise. Most people would not expect that deletes would be expensive, but it is a consequence of the design tradeoffs made by Cassandra developers. Cassandra uses append-only data structures, which allows it to write inserts with astonishing efficiency. Data is never overwritten in place and hard disks never have to perform random write operations, greatly increasing write throughput. But that feature, together with the fact that Cassandra is an eventually consistent data store, forces deletes and updates to be internally persisted as inserts as well. As a result, some use cases that add and delete a lot of data can become inefficient because deletes increase the data size rather than reducing it (until the compaction process cleans them up).
A great example of how that can come as a surprise is a common Cassandra anti-pattern of a queue. You could model a simple first-in-first-out queue in Cassandra by using its dynamic columns. You add new entries to the queue by appending new columns, and you remove jobs from the queue by deleting columns. With a small scale and low volume of writes, this solution would seem to work perfectly, but as you keep adding and deleting columns, your performance will begin to degrade dramatically. Although both inserts and deletes are perfectly fine and Cassandra purges old deleted data using its background compaction mechanism, it does not particularly like workloads with such a high rate of deletes (in this case, 50 percent of the operations are deletes).
Without deep knowledge of the strengths, weaknesses, and internals of NoSQL data stores, you can easily paint yourself into a corner. This is not to say that NoSQL is not a good way to go or that Cassandra is not a good data store. Quite the opposite—for some use cases, NoSQL is the best way to go, and Cassandra is one of my favorite NoSQL data stores. The point here is that although NoSQL data stores offer horizontal scalability and great optimizations of certain operations, they are not a silver bullet and they always do it at some cost.
Summary
Scaling the data layer is usually the most challenging area of a web application. You can usually achieve horizontal scalability by carefully designing your application, choosing the right data store, and applying three basic scalability techniques: functional partitioning, replication, and sharding.
No matter which data store you choose or which particular techniques you apply, the critical thing to remember is that data store design is all about tradeoffs. There are no silver bullets, and each application may be better suited for a different data store and a different way of scaling. That is why I would strongly suggest you keep an open mind and try to avoid looking for a golden hammer. Rather than shoehorning every application into a single data store, it is better to realize that all of the data stores have pros and cons and mix and match different technologies based on the use case. Functional partitioning of the web services layer and using different data stores based on the business needs is often referred to as polyglot persistence,L37 and it is a growing trend among web applications. Although having multiple data store types adds more complexity and increases maintenance costs, it gives more flexibility and allows you to make tradeoffs independently within each of the web services rather than committing to a single data store.
Before you decide to use any of the NoSQL data stores, I suggest reading at least one book about the selected data store and then explicitly search for gotchas, pitfalls, and common problems that people run into when using that technology. To gain more knowledge on data store scalability techniques, I also recommend reading excellent books on MySQL16 and MongoDB44 and some of the most famous white papers describing different NoSQL data stores.w28,w29,w27,w20,w18,w72,w55
No matter how good our data stores and application designs are, I/O is still a major bottleneck in most systems. Let’s move on to caching in the next chapter, as it is one of the easiest strategies to reduce the load put on the data layer.