
CHAPTER
7
Asynchronous Processing

Asynchronous processing and messaging technologies introduce many new concepts and a completely different way of thinking about software. Instead of telling the system what to do step by step, we break down the work into smaller pieces and let it decide the optimal execution order. As a result, things become much more dynamic, but also more unpredictable.
When applied wisely, asynchronous processing and messaging can be very powerful tools in scaling applications and increasing their fault tolerance. However, getting used to them can take some time. In this chapter, I will explain the core concepts behind message queues, event-driven architecture, and asynchronous processing. I will discuss the benefits and the “gotchas,” as well as some of the technologies that can be useful on your journey to asynchronous processing.
By the time you reach the end of the chapter, you should have a good understanding of how messaging and asynchronous processing work. I also hope you’ll be excited about event-driven architecture, an interesting field gaining popularity in recent years.
Core Concepts
Before we dive into asynchronous processing, let’s first start with a brief explanation of synchronous processing and how the two differ. Let’s now look at some examples to explain the difference between synchronous and asynchronous processing.
Synchronous processing is the more traditional way of software execution. In synchronous processing, the caller sends a request to get something done and waits for the response before continuing its own work. The caller usually depends on the result of the operation and cannot continue without it. The caller can be a function calling another function, a thread, or even a process sending a request to another process. It can also be an application or a system sending requests to a remote server. The key point is that in all these cases, the caller has to wait for the response before continuing its execution.
Asynchronous processing, in a nutshell, is about issuing requests that do not block your execution. In the asynchronous model, the caller never waits idle for responses from services it depends upon. Requests are sent and processing continues without ever being blocked.
Synchronous Example
Let’s discuss synchronous processing using an object-oriented programming example of an EmailService. Imagine we have an EmailService interface with a single method, sendEmail, which accepts EmailMessage objects and sends e-mails. In Listing 7-1, you can see how the EmailMessage and EmailService interfaces might look. I do not show the implementation of the service on purpose, because the interface is all that client code should care about.
Listing 7-1 Simple EmailService and EmailMessage interfaces

Whenever you wish to send out an e-mail, you obtain an instance of EmailService and invoke the sendEmail method on it. Then the EmailService implementation can do whatever is necessary to get the job done. For example, it could have an SmtpEmailAdapter allowing it to send e-mails over the Simple Mail Transport Protocol (SMTP) protocol. Figure 7-1 shows how the sequence of calls might appear.
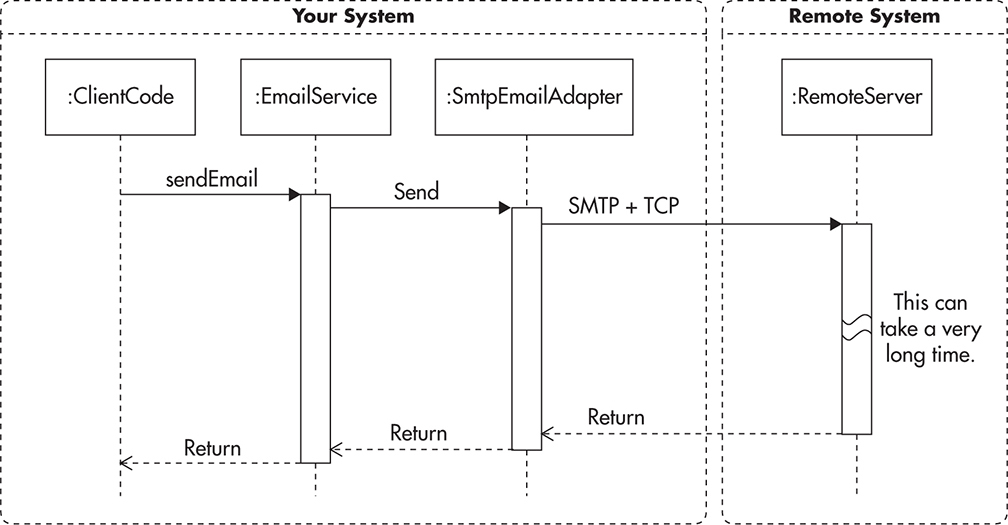
Figure 7-1 Synchronous invocation
The important thing to realize here is that your code has to wait for the e-mail service to complete its task. It means that your code is waiting for the service to resolve Internet Protocol (IP) addresses, establish network connections, and send the e-mail to a remote SMTP server. You also wait for the message to be encoded and all its attachments to be transferred. This process can easily take a few seconds depending on the speed of the SMTP server, network connection, and size of the message. In this context, synchronous processing means that your code has to synchronize its processing with the remote server and all of your processing pauses for the time necessary to complete the sendMail method. Having to stop execution to wait for a response in such a way is also called blocking.
Blocking occurs when your code has to wait for an external operation to finish. Blocking can happen when you read something from a hard drive because the operating system needs time to fetch the data for you. Blocking can also occur when you wait for a user’s input, for example, an automated teller machine (ATM) waiting for you to take your credit card before giving you the money. Blocking can also occur when you synchronize multiple processes/threads to avoid race conditions.
Blocking I/O means blocking input/output. This term is used to describe blocking read and write operations on resources like hard drives, network connections, and user interfaces. Blocking I/O occurs most often when interacting with hard drives and network connections. For example, opening a Transmission Control Protocol/Internet Protocol (TCP/IP) network connection to a remote server can be a blocking operation (depending on your programming model). In such a case, your thread blocks on a synchronous call to open the connection.
Synchronous processing makes it hard to build responsive applications because there is no way to guarantee how long it will take for a blocking operation to complete. Every time you perform a blocking operation, your execution thread is blocked. Blocked threads consume resources without making progress. In some cases, it may take a few milliseconds, but in others, it may take several seconds before you get the result or even find out about a failure.
It is especially dangerous to block user interactions, as users become impatient very quickly. Whenever a web application “freezes” for a second or two, users tend to reload the page, click the back button, or simply abandon the application. Users of a corporate web application that provides business-critical processes are more forgiving because they have to get their job done; they do not have much choice but to wait. On the other hand, users clicking around the Web on their way to work have no tolerance for waiting, and you are likely to lose them if your application forces them to wait.
To visualize how synchronous processing affects perceived performance, let’s look at Figure 7-2. This diagram shows how all blocking operations happen one after another in a sequence.
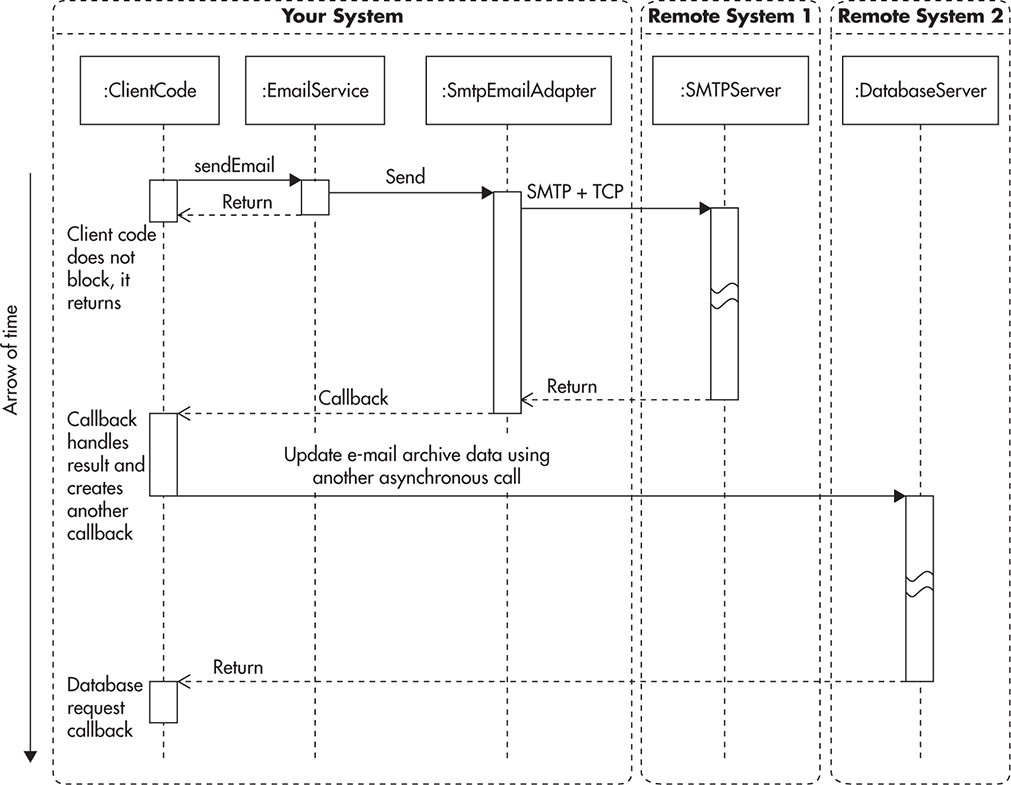
Figure 7-2 Multiple synchronous operations: adding up of execution times
The more blocking operations you perform, the slower your system becomes, as all this execution time adds up. If sending e-mail takes 100 ms and updating a database takes 20 ms, then your overall execution time has to be at least 120 ms because in this implementation, operations cannot happen in parallel.
Now that we have explained what synchronous processing looks like, let’s go through the same example for asynchronous processing.
Asynchronous Example
In a pure fire-and-forget model, client code has no idea what happens with the request. The client can finish its own job without even knowing if the request was processed or not. Asynchronous processing does not always have to be purely fire-and-forget, however, as it can allow for the results of the asynchronous call to be consumed by the caller using callbacks.
A callback is a construct of asynchronous processing where the caller does not block while waiting for the result of the operation, but provides a mechanism to be notified once the operation is finished. A callback is a function, an object, or an endpoint that gets invoked whenever the asynchronous call is completed. For example, if an asynchronous operation fails, callback allows the caller to handle the error condition. Callbacks are especially common in user interface environments, as they allow slow tasks to execute in the background, parallel to user interactions.
Let’s go back the EmailService example and imagine an alternative implementation that is split into two independent components. We still use the EmailService interface to send e-mails from the client code, but there is a message queue buffering requests and a back-end process that sends e-mails. Figure 7-3 shows how the invocation could look in this scenario. As we can see, your code does not have to wait for the message delivery. Your code waits only for the message to be inserted into a message queue.

Figure 7-3 Asynchronous processing of e-mail message
Your code does not know if the e-mail can be delivered successfully, as by the time your code finishes, the e-mail is not even sent yet. It may be just added into the queue or somewhere on its way to the SMTP server. This is an example of asynchronous processing in its fire-and-forget form.
Another important thing to notice here is that we can have independent threads. Client code can execute in a separate process and add messages to the queue at any point in time. On the other hand, the message queue consumer, who sends out e-mails, can work in a separate process and at a different rate. The message consumer could even be shut down or crash and the client code would not know the difference, as long as it can add messages into the queue.
If we wanted to handle results of e-mails being sent by EmailService, we could provide a web service endpoint or other way of notification (some form of callback). This way, every time an SMTP request fails or a bounced e-mail is detected, we could be notified. We could then implement callback functionality that would handle these notifications. For example, we could update the database record of each e-mail sent by marking it as successfully sent or as being bounced back. Based on these statuses, we could then inform our users of failures. Naturally, callback could handle failure and success notifications in any other way depending on the business needs. In Figure 7-4, we can see how the sequence diagram might appear once we include callback functionality. Client code can continue its execution without blocking, but at the same time, it can handle different results of e-mail delivery by providing a callback.
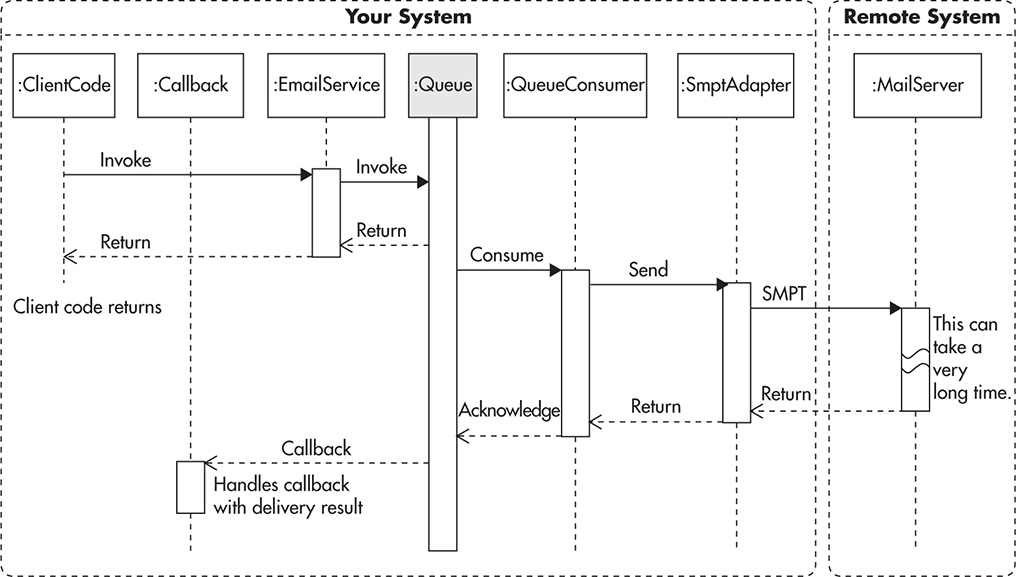
Figure 7-4 Asynchronous call with a callback
This diagram is a great simplification of the actual implementation, but we can see that it already becomes much more complicated than the synchronous version from Figure 7-1. Figure 7-4 looks much more complicated because instead of a single application, we effectively decoupled parts of the call sequence into separate applications. Instead of all the steps happening within a single execution thread, we can have ClientCode, Callback, Queue, and QueueConsumer execute in separate threads. They could also execute on different servers as different processes.
To make it easier to work with asynchronous processing, it is important to provide good frameworks and abstraction layers hiding routing and dispatching of asynchronous calls and callbacks. AJAX is a good example of how asynchronous processing can be made simple to use. If an e-mail message was triggered from JavaScript running in the browser, we could handle its results by providing a callback function declared in place. Listing 7-2 shows an example of the sendEmail invocation with a callback function passed as an argument.
Listing 7-2 Invocation of sendEmail function with a callback function declared in place

The trick here is that JavaScript anonymous functions capture the variable scope in which they are declared. This way, even when the outer function returns, the callback can execute at a later stage, still having access to all the variables defined in the outer scope. This transparent scope inheritance of JavaScript makes it easy to declare callback functions in a concise way.
Finally, let’s consider how asynchronous processing affects perceived performance of the application. Figure 7-5 shows how asynchronous calls are executed. Parallel execution of client code and remote calls can be achieved within a single execution thread. As soon as the sendEmail method returns, client code can allow the user to interact with the page elements. Parallel processing is “emulated” by JavaScript’s event loop, allowing us to perform Nonblocking I/O and achieve the illusion of multithreaded processing.
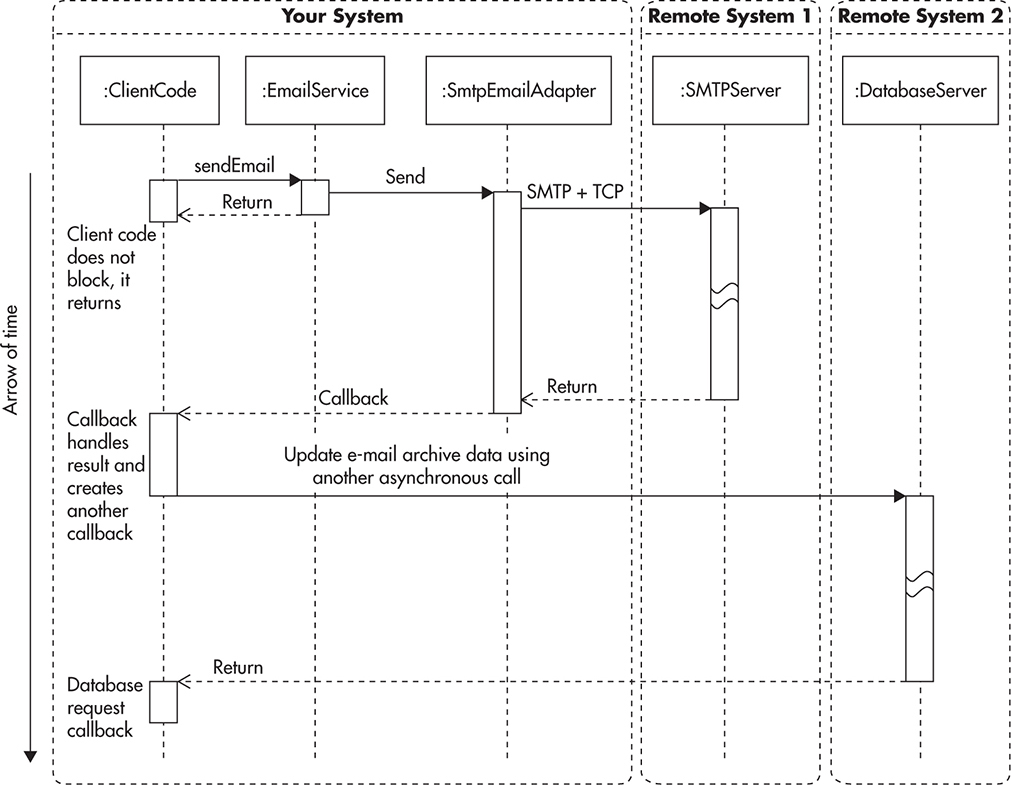
Figure 7-5 Multiple asynchronous operations: execution time hidden from user
Nonblocking I/O refers to input/output operations that do not block the client code’s execution. When using nonblocking I/O libraries, your code does not wait while you read data from disk or write to a network socket. Any time you make a nonblocking I/O call, you provide a callback function, which becomes responsible for handling the output of the operation.
In this case, we create the illusion of instant e-mail delivery. As soon as the user clicks a button, the sendEmail function is called and asynchronous processing begins. The user can be instantly notified that e-mail has been accepted and that she can continue with her work. Even if sending e-mail takes 100 ms and updating the database takes another 20 ms, the user does not have to wait for these steps to happen. If necessary, when the callback code executes, it can notify the user whether her message was delivered.
We have discussed the core concepts of the synchronous and asynchronous models, but let’s further simplify this complicated subject with a quick analogy.
Shopping Analogy
To simplify it even further, you can think of synchronous processing as if you were shopping at a fish market. You approach a vendor, ask for a fish, and wait. The vendor wraps the fish for you and asks if you need anything else. You can either ask for more seafood or pay and go to the next stand. No matter how many things you have to buy, you are buying one thing at a time. You need your fish before you go to the next vendor to get some fresh crab. Figure 7-6 shows such a scenario. Why a fish market? you ask. Just to make it more fun and easier to remember.
Figure 7-6 Synchronous shopping scenario
Continuing our shopping analogy, asynchronous shopping is more like ordering online. Figure 7-7 shows how a sequence of events could look when you order books online. When you place your order, you provide a callback endpoint (the shipping address). Once you submit your request, you get on with your life. In the meantime, the website notifies vendors to send you the books. Whenever books arrive at your home, you have an opportunity to handle the result of your order using your callback functionality (steps 3 and 5). You could collect the books yourself or have someone in your family do it for you. The core difference is that no matter how long it takes to ship the books, you do not have to wait motionless for the books to arrive; you can do other things. It also means that multiple providers can now fulfill parts of your order in parallel without synchronizing on each step.

Figure 7-7 Asynchronous shopping scenario
In addition, if you decided to order the books as a gift for a friend, you would not need to handle the response at all and your order would become a fire-and-forget request.
From a scalability point of view, the main difference between these two approaches is that more agents (processes, threads, or independent systems) can work in parallel at any point in time. This, in turn, means that you can execute each agent on a separate central processing unit (CPU) or even on a separate server.
Message Queues
Now that we have discussed the basic concepts of synchronous and asynchronous processing, let’s have a look at message queues. Message queues are a great tool for achieving asynchronous processing and they can be used in applications that are built in a synchronous fashion. Even if your application or programming language runtime does not support asynchronous processing, you can use message queues to achieve asynchronous processing.
A message queue is a component that buffers and distributes asynchronous requests. In the message queue context, messages are assumed to be one-way, fire-and-forget requests. You can think of a message as a piece of XML or JSON with all of the data that is needed to perform the requested operation. Messages are created by message producers and then buffered by the message queue. Finally, they are delivered to message consumers who perform the asynchronous action on behalf of the producer.
Message producers and consumers in scalable systems usually run as separate processes or separate execution threads. Producers and consumers are often hosted on different servers and can be implemented in different technologies to allow further flexibility. Producers and consumers can work independently of each other, and they are coupled only by the message format and message queue location. Figure 7-8 shows how producers create messages and send them to the message queue. Independently of producers, the message queue arranges messages in a sequence to be delivered to consumers. Consumers can then consume messages from the message queue.

Figure 7-8 Message producers, queue, and consumers
This is a very abstract view of a message queue. We do not care here about the message queue implementation, how producers send their messages, or how consumers receive messages. At this level of abstraction, we just want to see the overall flow of messages and that producers and consumers are separated from each other by the message queue.
The separation of producers and consumers using a queue gives us the benefit of nonblocking communication between producer and consumer. Producers do not have to wait for the consumer to become available. The producer’s execution thread does not have to block until the consumer is ready to accept another piece of work. Instead, producers submit job requests to the queue, which can be done faster, as there is no processing involved.
Another benefit of this separation is that now producers and consumers can be scaled separately. This means that we can add more producers at any time without overloading the system. Messages that cannot be consumed fast enough will just begin to line up in the message queue. We can also scale consumers separately, as now they can be hosted on separate machines and the number of consumers can grow independently of producers. An important feature of the diagram in Figure 7-8 is that there are three distinct responsibilities: producers, message queue, and consumers. Let’s now look at each responsibility in more detail.
Message Producers
Message producers are parts of the client code that initiate asynchronous processing. In message queue–based processing, producers have very little responsibility—all they have to do is create a valid message and send it to the message queue. It is up to the application developer to decide where producers should execute and when they should publish their messages.
Producing a message is referred to as publishing or message publishing. Message producer and message publisher are basically synonyms and can be used interchangeably.
Applications often have multiple producers, publishing the same type of message in different parts of the codebase. All of these messages get queued up together and processed asynchronously.
Going back to our EmailService example, if the e-mail service was implemented with message queues, then producers would be instances of client code that want to send e-mails. Producers could live in the code handling new account creation, purchase confirmation, or reset password. Any time you want to send an e-mail, you would produce a message and add it to the queue. Producers could be implemented in any technology as long as they can locate the message queue and add a valid message to it. Listing 7-3 shows how a sample message could appear. The message format becomes the contract between producers and consumers, so it is important to define it well and validate it strictly.
Listing 7-3 Custom message format; contract between producers and consumers
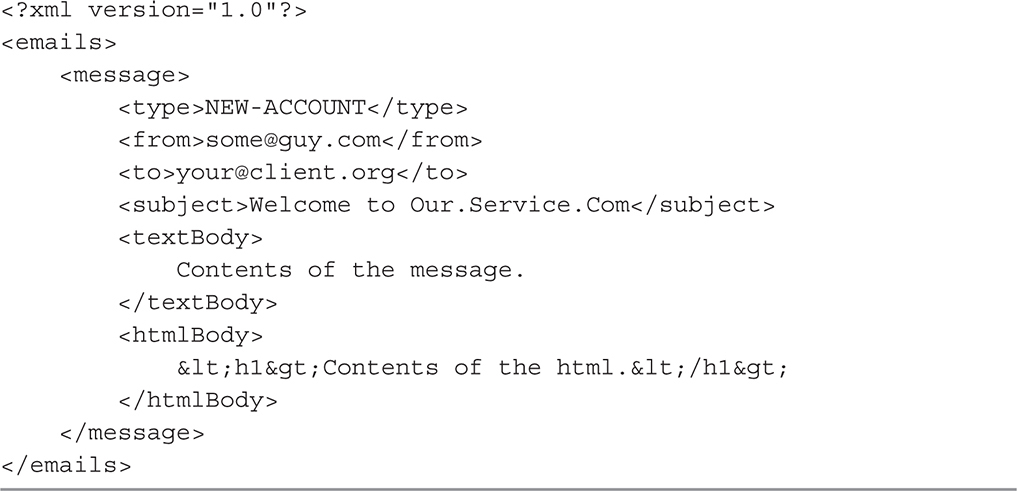
Using a platform-independent format like XML or JSON allows for producers and consumers to be implemented in different technologies and work independently of one another. You could have some PHP code creating e-mails whenever a user subscribes to a new account. You could also have a back-end system written in Java that sends e-mails for every purchase that is processed. Both of these producers could create XML messages and send them to the queue. Producers would not have to wait for e-mails to be delivered; they would simply assume that e-mails will be delivered at some point in time.
HINT
Not having to know how consumers are implemented, what technologies they use, or even if they are available are signs of strong decoupling (which is a very good thing).
As we said before, message producers have a lot of freedom and there is not much responsibility on their end.
Let’s now take a closer look at the message queue itself.
Message Broker
The core component of message queue–based asynchronous processing is the queue itself. It is the place where messages are sent and buffered for consumers. A message queue can be implemented in many different ways. It could be as simple as a shared folder with an application allowing you to read and write files to and from it. It could be a component backed by a SQL database (as many homegrown message queues are), or it could be a dedicated message broker that takes care of accepting, routing, persisting, and delivering messages. The message queue could also be a simple thread running within the same application process.
Since the message queue is a distinct component that can have more responsibilities, like permissions control, routing, or failure recovery, it is often implemented as an independent application. In such a case, it is usually referred to as a message broker or message-oriented middleware.
A message broker is a specialized application designed for fast and flexible message queuing, routing, and delivery. Brokers are the more sophisticated way of implementing message queues and usually provide a lot of specialized functionality out of the box. Message brokers are also optimized for high concurrency and high throughput because being able to enqueue messages fast is one of their key responsibilities. A message broker may be referred to as message-oriented middleware (MOM) or enterprise service bus (ESB), depending on the technology used. They all serve similar purpose, with MOM and ESB usually taking even more responsibilities.
A message broker has more responsibilities than producers do. It is the element decoupling producers from consumers. The main responsibility of the message queue is to be available at all times for producers and to accept their messages. It is also responsible for buffering messages and allowing consumers to consume relevant messages. Message brokers are applications, similar to web application containers or database engines. Brokers usually do not require any custom code; they are configured, not customized. Message brokers are often simpler than relational database engines, which allows them to reach higher throughput and scale well.
Because brokers are distinct components, they have their own requirements and limitations when it comes to scalability. Unfortunately, adding a message broker increases infrastructure complexity and requires us to be able to use and scale it appropriately. We will discuss the benefits and drawbacks of using message brokers in a following section, but let’s look at message consumers first.
Message Consumers
Finally, we come to the last component: message consumer. The main responsibility of the message consumer is to receive and process messages from the message queue. Message consumers are implemented by application developers, and they are the components that do the actual asynchronous request processing.
Going back to our EmailSevice example, the consumer would be the code responsible for picking up messages from the queue and sending them to remote mail servers using SMTP. Message consumers, similar to producers, can be implemented in different technologies, modified independently, and run on different servers.
To achieve a high level of decoupling, consumers should not know anything about producers. They should only depend on valid messages coming out of the queue. If we manage to follow that rule, we turn consumers into a lower service layer, and the dependency becomes unidirectional. Producers depend on some work to be done by “some message consumer,” but consumers have no dependency on producers whatsoever.
Message consumers are usually deployed on separate servers to scale them independently of message producers and add extra hardware capacity to the system. The two most common ways of implementing consumers are a “cron-like” and a “daemon-like” approach.
A cron-like consumer connects periodically to the queue and checks the status of the queue. If there are messages, it consumes them and stops when the queue is empty or after consuming a certain amount of messages. This model is common in scripting languages where you do not have a persistently running application container, such as PHP, Ruby, or Perl. Cron-like is also referred to as a pull model because the consumer pulls messages from the queue. It can also be used if messages are added to the queue rarely or if network connectivity is unreliable. For example, a mobile application may try to pull the queue from time to time, assuming that connection may be lost at any point in time.
A daemon-like consumer runs constantly in an infinite loop, and it usually has a permanent connection to the message broker. Instead of checking the status of the queue periodically, it simply blocks on the socket read operation. This means that the consumer is waiting idly until messages are pushed by the message broker into the connection. This model is more common in languages with persistent application containers, such as Java, C#, and Node.js. This is also referred to as a push model because messages are pushed by the message broker onto the consumer as fast as the consumer can keep processing them.
Neither of these approaches is better or worse; they are just different methods of solving the same problem of reading messages from the queue and processing them.
In addition to different execution models, message consumers can use different subscription methods. Message brokers usually allow consumers to specify what messages they are interested in. It is possible to read messages directly from a named queue or to use more advanced routing methods. The availability of different routing methods may depend on which message broker you decide to use, but they usually support the following routing methods: direct worker queue, publish/subscribe, and custom routing rules.12,24
Let’s quickly look at each message routing method.
Direct Worker Queue Method
In this delivery model, the consumers and producers only have to know the name of the queue. Each message produced by producers is added to a single work queue. The queue is located by name, and multiple producers can publish to it at any point in time. On the other side of the queue, you can have one or more consumers competing for messages. Each message arriving to the queue is routed to only one consumer. This way, each consumer sees only a subset of messages. Figure 7-9 shows the structure of the direct worker queue.
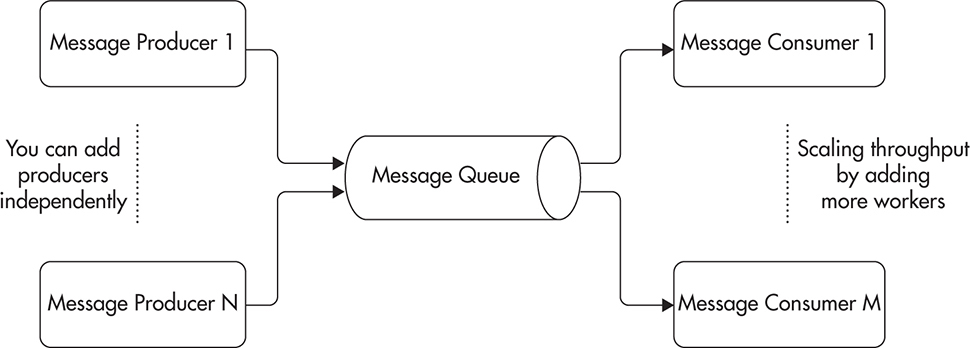
Figure 7-9 Direct worker queue
This routing model is well suited for the distribution of time-consuming tasks across multiple worker machines. It is best if consumers are stateless and uniform; then replacement of failed nodes becomes as easy as adding a new worker node. Scaling becomes trivial as well, as all we have to do is add more worker machines to increase the overall consumer throughput. Please note that consumers can scale independently of producers.
Good examples of this model include sending out e-mails, processing videos, resizing images, or uploading content to third-party web services.
Publish/Subscribe Method
In the publish/subscribe model, messages can be delivered to more than one consumer. Producers publish messages to a topic, not a queue. Messages arriving to a topic are then cloned for each consumer that has a declared subscription to that topic. If there are no consumers at the time of publishing, messages can be discarded altogether (though this behavior may depend on the configuration of the message broker).
Consumers using the publish/subscribe model have to connect to the message broker and declare which topics they are interested in. Whenever a new message is published to a topic, it is cloned for each consumer subscribing to it. Each consumer then receives a copy of the message into their private queue. Each consumer can then consume messages independently from other consumers, as it has a private queue with copies of all the messages that were published to the selected topic.
Figure 7-10 shows how messages published to a topic are routed to separate queues, each belonging to a different consumer.
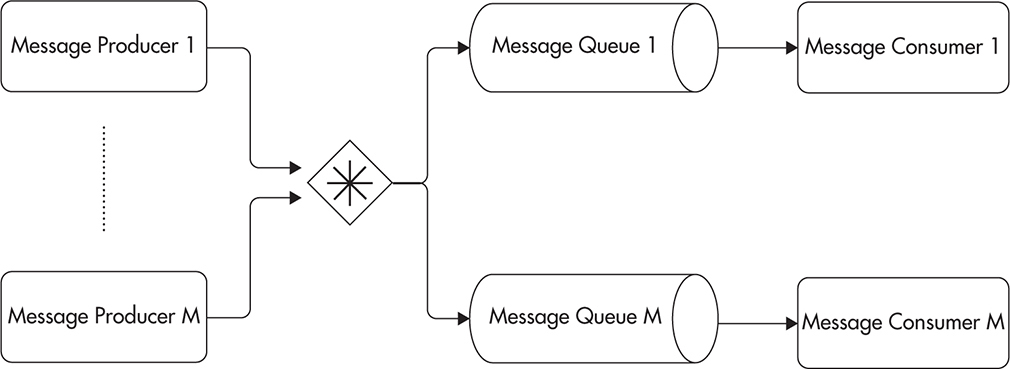
Figure 7-10 Publish/subscribe queue model
A good example of this routing model is to publish a message for every purchase. Your e-commerce application could publish a message to a topic each time a purchase is confirmed. Then you could create multiple consumers performing different actions whenever a purchase message is published. You could have a consumer that notifies shipping providers and a different consumer that processes loyalty program rules and allocates reward points. You would also have a way to add more functionality in the future without the need to ever change existing publishers or consumers. If you needed to add a consumer that sends out a purchase confirmation e-mail with a PDF invoice, you would simply deploy a new consumer and subscribe to the same topic.
The publish/subscribe model is a flexible pattern of messaging. It is also a variation of a generic design pattern called observer1,7 used to decouple components and to promote the open-closed principle (described in Chapter 2). To make it more flexible and scalable, most brokers allow for competing consumers, in which case multiple consumers subscribe to the same queue and messages are distributed among them, rather than a single consumer having to process all of the messages.
Custom Routing Rules
Some message brokers may also support different forms of custom routing, where a consumer can decide in a more flexible way what messages should be routed to its queue. For example, in RabbitMQ you can use a concept of bindings to create flexible routing rules (based on text pattern matching).12 In ActiveMQ you can use the Camel extension to create more advanced routing rules.25
Logging and alerting are good examples of custom routing based on pattern matching. You could create a “Logger Queue” that accepts all log messages and an “Alert Queue” that receives copies of all critical errors and all Severity 1 support tickets. Then you could have a “File Logger” consumer that would simply write all messages from the “Logger Queue” to a file. You could also have an “Alert Generator” consumer that would read all messages routed to the “Alert Queue” and generate operator notifications. Figure 7-11 shows such a configuration.

Figure 7-11 Custom routing configuration
The idea behind custom routing is to increase flexibility of what message consumers can subscribe to. By having more flexibility in the message broker, your system can adapt to new requirements using configuration changes rather than having to change the code of existing producers and consumers.
These are the most common routing methods, but I encourage you to read documentation for your message broker or check out some of the books on messaging.12,24,25 Now that we’ve covered the most important concepts of asynchronous processing and messaging, let’s have a quick look at different messaging protocols and then at the infrastructure to see where message brokers belong.
Messaging Protocols
A messaging protocol defines how client libraries connect to a message broker and how messages are transmitted. Protocols can be binary or text based, they can specify just minimal functionality, or they can describe in details hundreds of features. You should be familiar with the messaging protocols used to transport messages from producers to consumers. As an application developer, you will probably not have to develop your own implementation of any messaging protocol, but it is best to understand the properties of each protocol so that you can choose the best fit for your project. Here, we will look at the three most common protocols in the open-source world: AMQP, STOMP, and JMS.
AMQP (Advanced Message Queuing Protocol) is a well-defined contract for publishing, consuming, and transferring messages, and best of all, it is an industry standard. It is more advanced than STOMP, and it is aimed at enterprise integration and interoperability. Since it is a standardized protocol accepted by OASIS (Organization for the Advancement of Structured Information Standards),w54 integration between different messaging vendors, consumers, and publishers is easier. AMQP includes a lot of features in the protocol specification itself, so things like reliable messaging, delivery guarantees, transactions, and other advanced features are guaranteed to be implemented in the same way by all supporting libraries and servers. Most modern programming languages have stable AMQP clients, and as of this writing both RabbitMQ and ActiveMQ support AMQP as a communication protocol. Considering all of its benefits, I would recommend AMQP as a messaging protocol whenever it is possible.
STOMP (Streaming Text-Oriented Messaging Protocol), on the other hand, is a truly minimalist protocol. In fact, simplicity is one of its main advantages. STOMP is a stateless, text-based protocol similar to HTTP. It supports fewer than a dozen operations, so implementation and debugging of libraries are much easier. It also means that the protocol layer does not add much performance overhead. What can be unpleasant about STOMP is that advanced features have to be implemented as extensions using custom headers, and as a result, interoperability can be limited because there is no standard way of doing certain things. A good example of impaired interoperability is message prefetch count. It allows the consumer to declare how many messages they want to receive from the server without having to acknowledge them. Prefetch is a great way of increasing throughput because messages are received in batches instead of one message at a time. Although both RabbitMQ and ActiveMQ support this feature, they both implement it using different custom STOMP headers. If you talk to ActiveMQ, you have to specify it using the “activemq.prefetchSize” header; when talking to RabbitMQ, you have to set the “prefetch-count” header instead. Obviously, this does not let you create a universal STOMP client library supporting the prefetch feature, as your library will need to know how to negotiate it with every type of message broker, and what is even worse, your code will have to know whether it is talking to RabbitMQ or ActiveMQ. Even though this is a simplistic example, it should demonstrate how important standards are and how difficult it may become to integrate your software using nonstandardized protocols.
The last protocol, JMS (Java Message Service), is a Java messaging standard widely adopted across Java-based application servers and libraries. Even though JMS provides a good feature set and is popular, unfortunately, it is a purely Java standard and your ability to integrate with non-JVM (Java Virtual Machine)–based technologies will be very limited. If you develop purely in Java or JVM-based languages like Groovy or Scala, JMS can actually be a good protocol for you. If you have to integrate with different platforms, though, you may be better off using AMQP or STOMP, as they have implementations for all popular languages.
From a scalability point of view, protocols used to transfer messages are not really a concern, so you should make your choice based on the feature set and availability of the tools and libraries for your programming languages.
Messaging Infrastructure
So far we have discussed message queues, brokers, producers, and consumers. We have also described some of the most common messaging protocols. Let’s take a step back now to see how messaging components affect our system infrastructure.
We first looked at infrastructure in Chapter 1. Figure 7-12 shows that same infrastructure from Chapter 1, but with message brokers highlighted for better clarity. The message queuing systems are usually accessible from both front-end and back-end sides of your system. You would usually produce messages in the front end and then consume them in the back end, but it does not have to be this way. Some applications could consume messages in the front end. For example, an online chat application could consume messages to notify the user as soon as a new message arrives in her mailbox. How you use the message broker ultimately depends on your needs and your use cases—it is just another tool in your toolbox.
In Figure 7-12, servers dedicated to message consumers are labeled “Queue Workers.” It is common to see entire clusters of servers dedicated solely to message processing. These machines are often called queue workers, as their sole purpose is to perform work based on queue messages.

Figure 7-12 Message brokers and queue workers in system infrastructure
HINT
If you hosted your servers in the cloud, like Amazon EC2 or another virtualization provider, you could easily select different types of server instances for the queue workers cluster depending on what their bottleneck is (memory, I/O, or CPU).
It is best to isolate queue workers into a separate set of servers so their scalability would not depend on the scalability of other components. The more independent and encapsulated the workers, the less impact and dependency on the rest of the system. An important thing to remember here is that queue worker machines should be stateless just like web application servers and web service machines. Workers should get all of their data from the queue and external persistence stores. Then machine failures and scaling out will not be a problem.
HINT
You may need to use other services to save and retrieve state from to keep your queue workers stateless. For example, if your workers are transcoding videos, your message producer should upload the video binary file into a distributed persistence store (like S3 or a shared FTP, SAN, or NAS). Then it should publish a message to the queue with location of the binary so that any queue worker machine could process the message without having to keep local state.
By having queue workers stateless and isolated to a separate set of machines, you will be able to scale them horizontally by simply adding more servers. Failures will have no impact on you either because new workers can always be added to replace broken ones.
Usually, message brokers provide some built-in functionality for horizontal scalability,12,25 but each broker may have its own gotchas and scalability limitations. There are limitations on the total throughput of a single queue because messages passing through the queue need to be delivered to all connected subscribers. As long as your application is able to distribute messages across multiple queues using simple application-level sharding, you should be able to scale messaging brokers horizontally by adding more message broker servers.
If you require throughput of thousands or tens of thousands of messages per second, RabbitMQ or ActiveMQ should work fine out of the box. If you plan for hundreds of thousands of messages per second, you may need to add custom sharding mechanisms into your application to spread the load among multiple broker instances.
Surprisingly, even in using a cloud-based messaging platform like Microsoft Azure Queues, you may hit scalability limits. For example, as of this writing, Microsoft Azure Queues has a throughput limitation of 2,000 messages per second, per queue,L1 which is a lot. Another Azure product called Service Bus Queues has a hard limit of 100 concurrent connections to a single queue. Depending on your needs, this may be irrelevant, but you simply cannot assume that infinite scalability is available, unless you do some research. Before committing to a messaging solution, always check the most current pricing, required infrastructure, and out-of-the-box scalability guarantees.
HINT
You can think of a message broker as if it was a very “dumb” SQL database engine—an engine that does not allow updates, and the only operation you can perform is to add an item to the end of a table and pop an item from the beginning of a table. A message broker can also be a stand-alone application or an embedded one. It can be connected to using standard protocols and shared libraries. A message broker is just an abstraction of adding messages to the queues and routing them to consumers.
Before you decide which message broker to choose and whether you really have to worry about the broker’s scalability in the first place, prepare the following metrics for your application:
![]() Number of messages published per second
Number of messages published per second
![]() Average message size
Average message size
![]() Number of messages consumed per second (this can be much higher than publishing rate, as multiple consumers may be subscribed to receive copies of the same message)
Number of messages consumed per second (this can be much higher than publishing rate, as multiple consumers may be subscribed to receive copies of the same message)
![]() Number of concurrent publishers
Number of concurrent publishers
![]() Number of concurrent consumers
Number of concurrent consumers
![]() If message persistence is needed (no message loss during message broker crash)
If message persistence is needed (no message loss during message broker crash)
![]() If message acknowledgment is needed (no message loss during consumer crash)
If message acknowledgment is needed (no message loss during consumer crash)
With these metrics, you have an informed approach to discuss your scalability needs with vendors and/or the open-source community. We will look at a few message brokers later in this chapter and discuss their impact on scalability, but before we do that, let’s review the benefits of messaging and motivation for adding this extra complexity to our systems.
Benefits of Message Queues
So far, we have looked at the core concepts and terminology of asynchronous processing and message queues, and you’ve likely deduced that they don’t come for free. You will now need to learn, deploy, optimize, and scale your message queues. Adding new components to your stack usually increases the overall complexity of your system. Since it is so much work, why should you bother? There are a number of benefits to using message queues:
![]() Enabling asynchronous processing
Enabling asynchronous processing
![]() Easier scalability
Easier scalability
![]() Evening out traffic spikes
Evening out traffic spikes
![]() Isolating failures and self-healing
Isolating failures and self-healing
![]() Decoupling
Decoupling
In addition to giving you these benefits, message queues are a specific type of technology. Once you become familiar with them and integrate them into your system, you will find many use cases where a message queue is a perfect fit, making things easier and faster.
Enabling Asynchronous Processing
One of the most visible benefits of using a message queue is the fact that it gives us a way to defer processing of time-consuming tasks without blocking our clients. The message broker becomes our door to the world of asynchronous processing. Anything that is slow or unpredictable is a candidate for asynchronous processing. The only requirement is that you have to find a way to continue execution without having the result of the slow operation.
Good use cases for a message queue could be
![]() Interacting with remote servers If your application performs operations on remote servers, you might benefit from deferring these steps via a queue. For example, if you had an e-commerce platform, you might allow users to create marketing campaigns advertising their products. In such a case, you could let users select which items should be promoted and add requests to the queue so that users would not have to wait for remote service calls to finish. In the background, your system could contact multiple advertising providers like Google AdWords and set up marketing campaigns.
Interacting with remote servers If your application performs operations on remote servers, you might benefit from deferring these steps via a queue. For example, if you had an e-commerce platform, you might allow users to create marketing campaigns advertising their products. In such a case, you could let users select which items should be promoted and add requests to the queue so that users would not have to wait for remote service calls to finish. In the background, your system could contact multiple advertising providers like Google AdWords and set up marketing campaigns.
![]() Low-value processing in the critical path Every application has some critical paths or features that have to work all the time as a matter of top priority. In an e-commerce website, it may be the ability to place orders, search for products, and process payments. It is a common requirement that critical paths have to work 24/7 no matter what else breaks. After all, what kind of e-commerce is it if you cannot place orders or pay for goods? Under such constraints, integrating with a new recommendation engine in checkout could introduce a new point of failure. It could also slow down the checkout process itself. Instead of synchronously sending orders to the recommendation system, you could enqueue them and have them processed asynchronously by an independent component.
Low-value processing in the critical path Every application has some critical paths or features that have to work all the time as a matter of top priority. In an e-commerce website, it may be the ability to place orders, search for products, and process payments. It is a common requirement that critical paths have to work 24/7 no matter what else breaks. After all, what kind of e-commerce is it if you cannot place orders or pay for goods? Under such constraints, integrating with a new recommendation engine in checkout could introduce a new point of failure. It could also slow down the checkout process itself. Instead of synchronously sending orders to the recommendation system, you could enqueue them and have them processed asynchronously by an independent component.
![]() Resource intensive work Most CPU- or I/O-hungry processing like transcoding videos, resizing images, building PDFs, or generating reports are good candidates for a queue-based workflow instead of running synchronously to users’ interactions.
Resource intensive work Most CPU- or I/O-hungry processing like transcoding videos, resizing images, building PDFs, or generating reports are good candidates for a queue-based workflow instead of running synchronously to users’ interactions.
![]() Independent processing of high- and low-priority jobs For example, you could have separate queues dedicated to top-tier customers (high-urgency tasks) and others for low-value customers (less urgent tasks). You could then dedicate more resources to these high-value jobs and protect them from spikes of low-value tasks.
Independent processing of high- and low-priority jobs For example, you could have separate queues dedicated to top-tier customers (high-urgency tasks) and others for low-value customers (less urgent tasks). You could then dedicate more resources to these high-value jobs and protect them from spikes of low-value tasks.
Message queues enable your application to operate in an asynchronous way, but it only adds value if your application is not built in an asynchronous way to begin with. If you developed in an environment like Node.js, which is built with asynchronous processing at its core, you will not benefit from a message broker that much. A message broker does not make already asynchronous systems more asynchronous. What is good about message brokers is that they allow you to easily introduce asynchronous processing to other platforms, like those that are synchronous by nature (C, Java, PHP, Ruby).
Easier Scalability
Applications using message brokers are usually easier to scale due to the nature of deferred processing. Since you produce messages as fire-and-forget requests, for expensive tasks you can publish requests from multiple servers in parallel. You can also process messages in parallel on multiple back-end servers. You can run multiple physical servers dedicated to message queue consumers, and it is usually easy to keep adding more machines as your workload increases.
A good example of parallel back-end processing could be a service resizing images and videos. Figure 7-13 shows how such an application could be assembled. Your front-end application uploads files to a network attached storage (NAS) (1) and then publishes a message for each file to be processed (2). Messages get buffered in the message queue and get picked up by workers at a later stage (3). Each worker consumes a message from a queue and begins the resizing process (which may take some time to complete). Once the file is processed, it can be uploaded back to NAS (4). Workers could also publish a new message to a separate queue to indicate that work has been completed. In such configuration, you can easily add or remove back-end servers whenever demand changes.
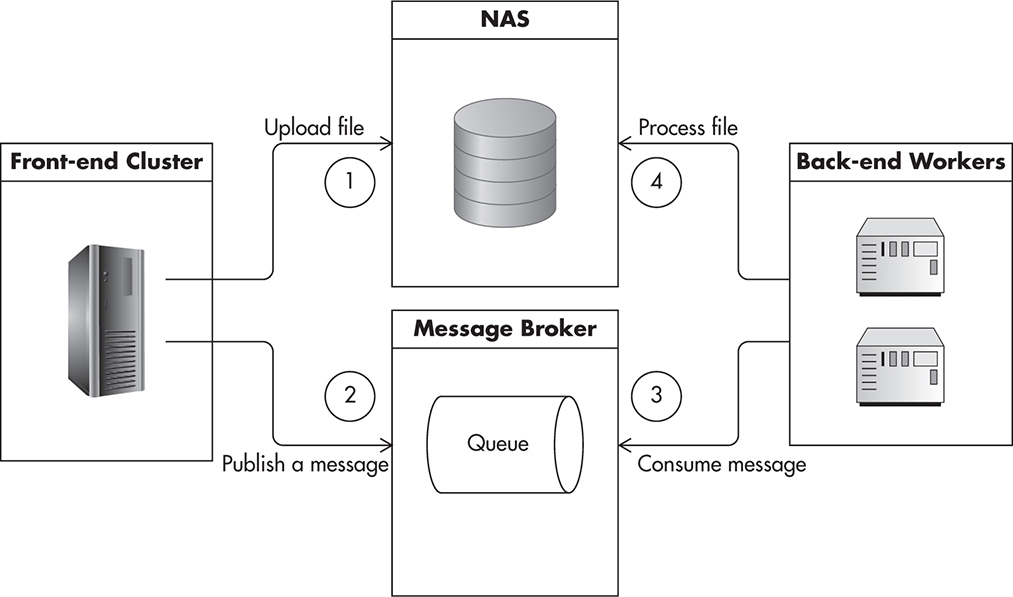
Figure 7-13 Scalability by adding more parallel queue workers
As you can see, by adding more message consumers, we can increase our overall throughput. No matter what the constraint on our queue worker nodes is (disk, memory, CPU, external latency), we can process more messages by simply adding more back-end servers. What gives us even more flexibility is that adding servers does not require publisher configuration changes. Consumers simply connect to the message broker and begin consuming messages; producers do not have to know how many consumers are there or where are they hosted.
Even if you used Node.js or Erlang, which are asynchronous by nature, you would still benefit from using queues as a way to share the workload among multiple servers.
Evening Out Traffic Spikes
Another advantage of using message queues is that they allow you to transparently even out traffic spikes. By using a message broker, you should be able to keep accepting requests at high rates even at times of increased traffic. Even if your publishing generates messages much faster than consumers can keep up with, you can keep enqueueing messages, and publishers do not have to be affected by a temporary capacity problem on the consumer’s side.
If your front-end application produces messages to be consumed by the back-end cluster, the more traffic you get in the front end, the more messages you will be publishing to the queues. Since front-end code does not have to wait for slow operations to complete, there is no impact on the front-end user. Even if you produce messages faster than consumers can keep processing them, messages still get enqueued quickly. The only impact of the traffic spike is that it takes longer before each message gets processed, because messages “sit” longer in the queues. Figure 7-14 shows how queue consumers work at their full capacity as long as there are messages to be processed. Even when the front-end application produces messages above capacity limits, messages can still be enqueued quickly and processed over time. After the traffic spike is over, consumers eventually catch up with the messages and “drain the queues.”
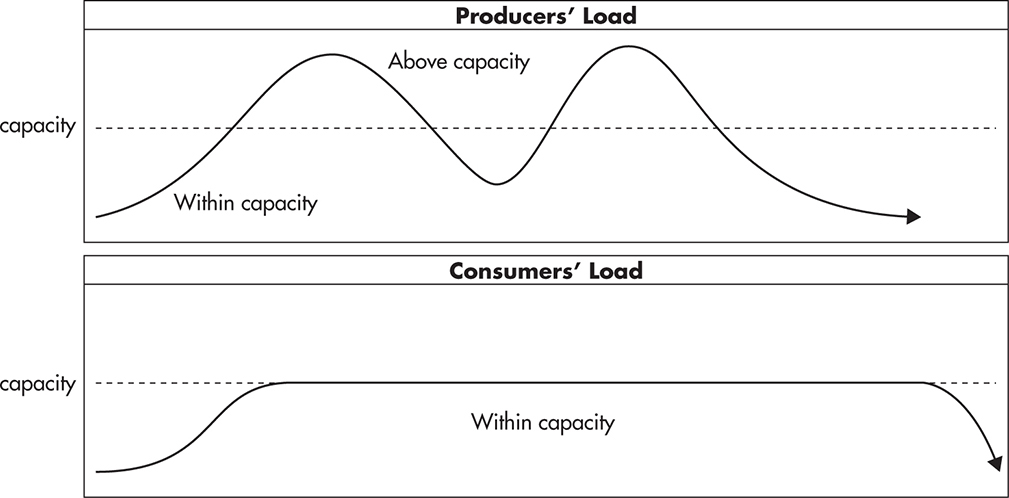
Figure 7-14 Consumers process messages at their full capacity, but don’t get overwhelmed.
This property of evening out spikes increases your availability. Your system is less likely to go down even if you are not able to fully process all of the incoming requests right away. Soon after the spike is over, the system automatically recovers to its normal status.
Isolating Failures and Self-Healing
As was already discussed, message queues allow us to remove functionality from critical paths and to insulate producers from consumers, making a system more robust and fault tolerant. The message broker isolates failures of different parts of your system because publishers do not depend directly on consumers being available. Publishers are not affected by failures happening on the consumers’ side of the queue. Symmetrically, consumers can keep doing their work even if publishers experience technical issues. As long as there are messages in the queue, consumers are not affected in any way by the producers’ failures.
The fact that consumers’ availability does not affect producers allows us to stop message processing at any time. This means that we can perform maintenance and deployments on back-end servers at any time. We can simply restart, remove, or add servers without affecting producers’ availability, which simplifies deployments and server management.
Finally, having multiple queue worker servers makes the system more tolerant to failures and allows it to heal itself to some extent. If you have multiple workers, a hardware failure can be dealt with as a matter of low priority. Instead of breaking the entire application whenever a back-end server goes offline, all that we experience is reduced throughput, but there is no reduction of availability. Reduced throughput of asynchronous tasks is usually invisible to the user, so there is no consumer impact. To recover from failure, you simply add a server replacement and the system “heals” itself automatically by slowly catching up with the queues and draining messages over time.
Surviving failures and self-healing are some of the most important features of truly horizontally scalable systems.
Decoupling
Message queues allow us to achieve some of the highest degrees of decoupling, which can have big impact on the application architecture. I already explained the benefits of decoupling on its own in Chapter 2, but I want to emphasize here how much message queues promote decoupling.
As I mentioned earlier in this chapter, using a message broker allows us to isolate message producers from message consumers. We can have multiple producers publishing messages, and we can also have multiple consumers processing messages, but they never talk to one another directly. They do not even have to know about each other at all.
HINT
Whenever we can separate two components to a degree that they do not know about each other’s existence, we have achieved a high degree of decoupling.
Ideally, we should strive to create publishers that do not care who is consuming their messages or how. All that publishers need to know is the format of the message and where to publish it. On the other hand, consumers can become oblivious as to who publishes messages and why. Consumers can focus solely on processing messages from the queue. Figure 7-15 shows how producers and consumers become unaware of one another. It is best if they do not know what is on the other side of the queue.
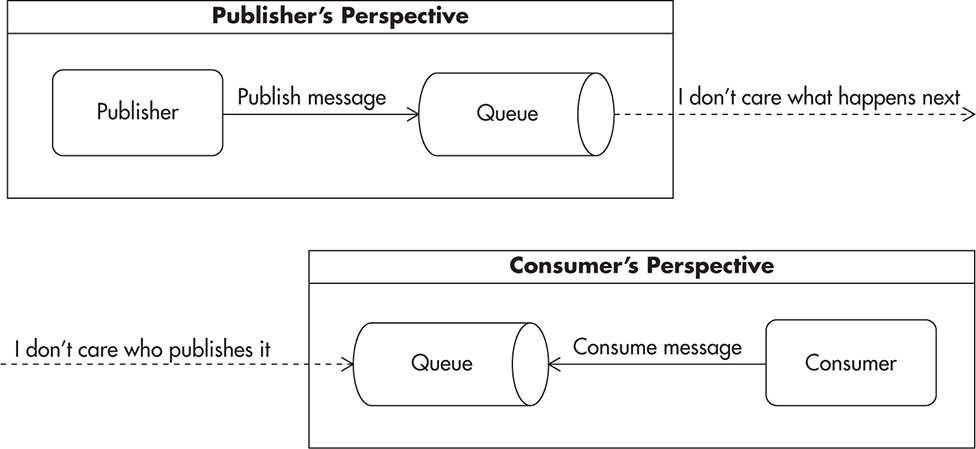
Figure 7-15 Decoupling and isolation of message producers and consumers
Such a high level of decoupling, by use of an intermediate message broker, makes it easier to develop consumers and producers independently. They can even be developed by different teams using different technologies. Because message brokers use standard protocols and messages themselves can be encoded using standards like JSON or XML, message brokers can become an integration point between completely independent applications.
HINT
You can think of a queue as a border. Whatever happens on the other side of that border should be an implementation detail, not known to the code at hand. The queue becomes your single point of interaction and the message format becomes your contract.
Although message queues offer great benefits, remember there is no golden hammer. In the following section, let’s consider some of the common challenges related to messaging.
Message Queue–Related Challenges
As with most technologies, messaging comes with its own set of challenges and costs. Some of the common difficulties and pitfalls you may encounter when working with message queues and asynchronous processing include no message ordering, message requeueing, race conditions, and increased complexity. Let’s look at each in more detail.
No Message Ordering
The first significant challenge developers face when working with message queues at scale is simply that message ordering is not guaranteed. This is caused by the fact that messages are processed in parallel and there is no synchronization between consumers. Each consumer works on a single message at a time and has no knowledge of other consumers running in parallel to it (which is a good thing). Since your consumers are running in parallel and any of them can become slow or even crash at any point in time, it is difficult to prevent messages from being occasionally delivered out of order.
It is difficult to explain messages being consumed out of order, so let’s use a sequence of diagrams. For the sake of simplicity, let’s look at a synthetic example of producers sending multiple message types to a shared queue. Figure 7-16 shows a producer publishing two messages. The first message is sent to create a new user account, and the second message is published to send the user a welcome e-mail. Notice that there are two concurrently running message consumers working in parallel on the same message queue.

Figure 7-16 Producer creates two messages related to the same user.
Each message has an equal chance of being sent to either one of the consumers, as they both arrive at the same logical queue. It is easy to imagine a scenario where each message is sent to a different consumer, as in Figure 7-17. Now, the order of these messages being processed depends on how fast each consumer is and how much time it takes to complete task1 and task2. Either the account can be created first or the e-mail can be created first. The problem that becomes visible here is that e-mail creation could fail if there was no user account present first. It is a classic example of a race condition, as execution of these two tasks in parallel without synchronization may produce incorrect results, depending on the ordering.
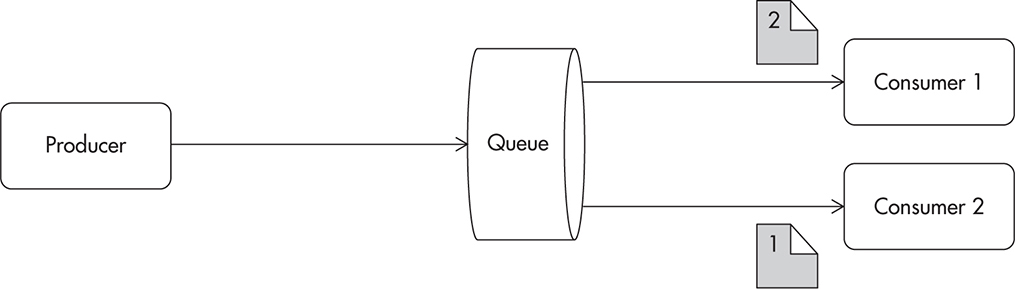
Figure 7-17 Each consumer receives one of the two messages.
To make things worse, there is another possible failure scenario. Consumer 2 can become unavailable or simply crash. In such a situation, messages that were sent to that consumer may have to be returned to the queue and sent to other consumers. Requeueing messages is a strategy used by many message brokers, as it is assumed that the message has not been fully processed until it is “acknowledged” by the consumer. Figure 7-18 shows how a message could be requeued and how it could be delivered out of order to consumer 1.
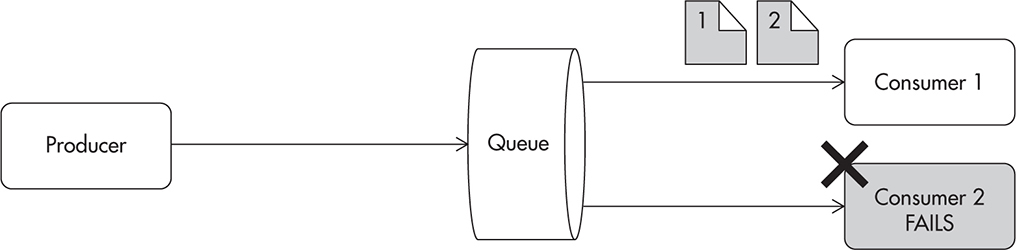
Figure 7-18 Consumer failure causes message to be passed on to another worker.
If that was not bad enough, there is an additional difficulty in this failure scenario. There is no guarantee that consumer 2 did not process the message before the failure occurred. Consumer 2 might have already sent out an e-mail and crashed just before sending the message acknowledgment back to the message broker. In such a situation, message 1 would actually be processed twice.
Fortunately, there are things we can do to make the message ordering problem disappear. Here are three common ways to solve the ordering problem:
![]() Limit the number of consumers to a single thread per queue. Some message queues guarantee ordered delivery (First In First Out [FIFO]) as long as you consume messages one at a time by a single client. Unfortunately, this is not a scalable solution and not all messaging systems support it.
Limit the number of consumers to a single thread per queue. Some message queues guarantee ordered delivery (First In First Out [FIFO]) as long as you consume messages one at a time by a single client. Unfortunately, this is not a scalable solution and not all messaging systems support it.
![]() Build the system to assume that messages can arrive in random order. This may be either easy or difficult depending on the system and on the requirements, but seems the best way out. In the previous example, we could achieve it by changing who publishes which messages. If the front end published a create-account message, then consumer 1 could publish an email-customer message once the account has been created. In this case, message ordering is forced by the application-level workflow. If we decided to go down this route, we would need to make sure that all of our engineers understood the constraints. Otherwise, incorrect message ordering may come as a bitter surprise.
Build the system to assume that messages can arrive in random order. This may be either easy or difficult depending on the system and on the requirements, but seems the best way out. In the previous example, we could achieve it by changing who publishes which messages. If the front end published a create-account message, then consumer 1 could publish an email-customer message once the account has been created. In this case, message ordering is forced by the application-level workflow. If we decided to go down this route, we would need to make sure that all of our engineers understood the constraints. Otherwise, incorrect message ordering may come as a bitter surprise.
![]() Use a messaging broker that supports partial message ordering guarantee. This is the case with ActiveMQ’s message groups, for example.
Use a messaging broker that supports partial message ordering guarantee. This is the case with ActiveMQ’s message groups, for example.
It is best to depend on the message broker to deliver messages in the right order by using a partial message guarantee (ActiveMQ) or topic partitioning (Kafka).w52 If your broker does not support such functionality, you will need to ensure that your application can handle messages being processed in an unpredictable order.
Partial message ordering is a clever mechanism provided by ActiveMQ called message groups. Messages can be published with a special “label” called a message group ID. The group ID is defined by the application developer (for example, it could be a customer ID). Then all messages belonging to the same group are guaranteed to be consumed in the same order they were produced. Figure 7-19 shows how messages belonging to different groups get queued up separately for different consumers. Whenever a message with a new group ID gets published, the message broker maps the new group ID to one of the existing consumers. From then on, all the messages belonging to the same group are delivered to the same consumer. This may cause other consumers to wait idly without messages as the message broker routes messages based on the mapping rather than random distribution. In our example, if both account creation and e-mail notification messages were published with the same message group ID, they would be guaranteed to be processed in the same order they were published.

Figure 7-19 Message groups get assigned to consumers when the first message arrives.
Message ordering is a serious issue to consider when architecting a message-based application, and RabbitMQ, ActiveMQ, and Amazon SQS messaging platform cannot guarantee global message ordering with parallel workers. In fact, Amazon SQS is known for unpredictable ordering of messages because their infrastructure is heavily distributed and ordering of messages is not supported. You can learn more about some interesting ways of dealing with message ordering.w14,w52
Message Requeueing
As previously mentioned, messages can be requeued in some failure scenarios. Dealing with this problem can be easy or difficult, depending on the application needs. A strategy worth considering is to depend on at-least-once delivery instead of exactly-once delivery. By allowing messages to be delivered to your consumers more than once, you make your system more robust and reduce constraints put on the message queue and its workers. For this approach to work, you need to make all of your consumers idempotent, which may be difficult or even impossible in some cases.
An idempotent consumer is a consumer that can process the same message multiple times without affecting the final result. An example of an idempotent operation would be setting a price to $55. An example of a nonidempotent operation would be to “increase price by $5.” The difference is that increasing the price by $5 twice would increase it by a total of $10. Processing such a message twice affects the final result. In contrast, setting the price to $55 once or twice leaves the system in the same state.
Unfortunately, making all consumers idempotent may not be an easy thing to do. Sending e-mails is, by nature, not an idempotent operation, because sending two e-mails to the customer does not produce the same result as sending just a single e-mail. Adding an extra layer of tracking and persistence could help, but it would add a lot of complexity and may not be able to handle all of the failure scenarios. Instead, make consumers idempotent whenever it is practical, but remember that enforcing it across the system may not always be worth the effort.
Finally, idempotent consumers may be more sensitive to messages being processed out of order. If we had two messages, one to set the product’s price to $55 and another one to set the price of the same product to $60, we could end up with different results based on their processing order. Having two nonidempotent consumers increasing the price by $5 each would be sensitive to message requeueing (redelivery), but not to out-of-order delivery.
Race Conditions Become More Likely
One of the biggest challenges related to asynchronous systems is that things that would happen in a well-defined order in a traditional programming model can suddenly happen in a much more unexpected order. As a result, the asynchronous programming is more unpredictable by nature and more prone to race conditions, as work is broken down into much smaller chunks and there are more possible orders of execution.
Since asynchronous calls are made in a nonblocking way, message producers can continue execution without waiting for the results of the asynchronous call. Different message consumers may also execute in a different order because there is no built-in synchronization mechanism. Different parts of an asynchronous system, especially a distributed one, can have different throughput, causing uneven latency in message propagation throughout the system.
Especially when a system is under heavy load, during failure conditions and deployments, code execution may become slower in different parts of the system. This, in turn, makes things more likely to happen in unexpected order. Some consumers may get their messages much later than others, causing hard-to-reproduce bugs.
HINT
You could say that asynchronous programming is programming without a call stack.w11 Things simply execute as soon as they are able to, instead of traditional step-by-step programming.
The increased risk of race conditions is mainly caused by the message-ordering issue discussed earlier. Get into a habit of careful code review, with an explicit search for race conditions and out-of-order processing bugs. Doing so will increase your chance of mitigating issues and building more robust solutions. The less you assume about the state of an asynchronous system, the better.
Risk of Increased Complexity
Systems built as hybrids of traditional imperative and message-oriented code can become more complex because their message flow is not explicitly declared anywhere. When you look at the producer, there is no way of telling where the consumers are or what they do. When you look at the consumer, you cannot be sure under what conditions messages are published. As the system grows and messaging is added ad hoc through the code, without considering the overall architecture, it may become more and more difficult to understand the dependencies.
When integrating applications using a message broker, you must be very diligent in documenting dependencies and the overarching message flow. Remember the discussion about levels of abstraction and how you should be able to build the mental picture of the system (Chapter 2). Without good documentation of the message routes and visibility of how the messages flow through the system, you may increase the complexity and make it much harder for developers to understand how the system works.
Keep things simple and automate documentation creation so it will be generated based on the code itself. If you manage to keep documentation of your messaging in sync with your code, you should be able to find your way through the dependencies.
Message Queue–Related Anti-Patterns
In addition to message queue–related challenges, I would like to highlight a few common design anti-patterns. Engineers tend to think alike, and they often create similar solutions to similar problems. When the solution proves to be successful over and over again, we call it a pattern, but when the solution is repeatedly difficult to maintain or extend, we call it an anti-pattern. A typical anti-pattern is a solution that seems like a good idea at first, but the longer you use it, the more issues you discover with it. By getting familiar with anti-patterns, you should be able to easily avoid them in the future—it is like getting a vaccination against a common design bug.
Treating the Message Queue as a TCP Socket
Some message brokers allow you to create return channels. A return channel becomes a way for the consumer to send a message back to the producer. If you use it a lot, you may end up with an application that is more synchronous than asynchronous. Ideally, you would want your messages to be truly one-way requests (fire-and-forget). Opening a response channel and waiting for response messages makes messaging components more coupled and undermines some of the benefits of messaging. Response channels may also mean that failures of different components on different sides of the message broker may have an impact on one another. When building scalable systems, avoid return channels, as they usually lead to synchronous processing and excessive resource consumption.
Treating Message Queue as a Database
You should not allow random access to elements of the queue. You should not allow deleting messages or updating them, as this will lead to increased complexity. It is best to think of a message queue as an append-only stream (FIFO). It is most common to see such deformations when the message queue is built on top of a relational database or NoSQL engine because this allows secondary indexes and random access to messages. Using random access to modify and delete messages may prevent you from scaling out and migrating to a different messaging broker.
If you have to delete or update messages in flight (when they are in the middle of the queue), you are probably doing something wrong or applying messaging to a wrong use case.
Coupling Message Producers with Consumers
As I mentioned before, it is best to avoid explicit dependency between producers and consumers. You should not hardcode class names or expect messages to be produced or consumed by any particular piece of code. It is best to think of the message broker as being the endpoint and the message body as being the contract. There should be no assumptions or any additional knowledge necessary. If something is not declared explicitly in the message contract, it should be an implementation detail, and it should not matter to the other side of the contract.
For example, a flawed implementation I saw involved serializing an entire object and adding it to the message body. This meant that the consumer had to have this particular class available, and it was not able to process the message without executing the serialized object’s code. Even worse, it meant that the consumer had to be implemented in the same technology as the producer and its deployment had to be coordinated to prevent class mismatches. Messages should not have “logic” or executable code within. Messages should be a data transfer object10 or simply put, a string of bytes that can be written and read by both consumer and producer.
Treat the format of the message as a contract that both sides need to understand, and disallow any other type of coupling.
Lack of Poison Message Handling
When working with message queues you have to be able to handle broken messages and bugs in consumer code. A common anti-pattern is to assume that messages are always valid. A message of death (also known as a poison message) is a message that causes a consumer to crash or fail in some unexpected way. If your messaging system is not able to handle such cases gracefully, you can freeze your entire message-processing pipeline, as every time a consumer crashes, the broker will requeue the message and resend it to another consumer. Even with auto-respawning consumer processes, you would freeze the pipeline, as all of your consumers would keep crashing and reprocessing the same message for infinity.
To prevent that scenario, you need to plan for failures. You have to assume that components of your messaging platform will crash, go offline, stall, and fail in unexpected ways. You also have to assume that messages may be corrupt or even malicious. Assuming that everything would work as expected is the quickest way to building an unavailable system.
HINT
Hope for the best, prepare for the worst.
You can deal with a poison message in different ways depending on which message broker you use. In ActiveMQ you can use dead-letter queue policies out of the box.25 All you need to do is set limits for your messages, and they will be automatically removed from the queue after a certain number of failures. If you use Amazon SQS, you can implement poison message handling in your own code by using an approximate delivery counter. Every time a message is redelivered, SQS increments its approximate delivery counter so that your application could easily recognize messages of death and route them to a custom dead-letter queue or simply discard them. Similarly, in RabbitMQ you get a boolean flag telling you if a message has been delivered before, which could be used to build a dead-letter queue functionality. Unfortunately, it is not as simple to use as having a counter or an out-of-the-box functionality.
Whenever you use message queues, you simply have to implement poison message handling.
Quick Comparison of Selected Messaging Platforms
Choosing a message broker is similar to choosing a database management system. Most of them work for most use cases, but it always pays to know what you are dealing with before making a commitment. This section is a quick overview of three most common message brokers: Amazon Simple Queue Service (SQS), RabbitMQ, and ActiveMQ.
Unfortunately, there is no way to recommend a messaging platform without knowing details of the application use cases, so you may have to do some more research before making your final decision. I recommend reading more25,12,L1–L3 to learn specific details about selected platforms. Here, let’s focus on the strengths and best use cases of each platform, which should empower you with the knowledge necessary to begin your own selection.
Amazon Simple Queue Service
Amazon SQS is known for its simplicity and pragmatic approach. SQS is a cloud-based service provided by Amazon with a public application programming interface (API) and software development kit (SDK) libraries available for most programming languages. It is hosted and managed by Amazon, and users are charged pro rata for the amount of messages they publish and amount of service calls they issue.
If you are hosting your application on Amazon EC2, Amazon SQS, which is a hosted messaging platform, is certainly worth considering. The main benefit of using SQS is that you do not have to manage anything yourself. You do not have to scale it, you do not need to hire additional experts, you do not need to worry about failures. You do not even need to pay for additional virtual server instances that would need to run your message brokers. SQS takes care of the infrastructure, availability, and scalability, making sure that messages can be published and consumed all the time.
If you work for a startup following the Lean Startup methodology, you should consider leveraging SQS to your advantage. Lean Startup advocates minimal viable product (MVP) development and a quick feedback loop.30,9 If SQS functionality is enough for your needs, you benefit in the following ways:
![]() Deliver your MVP faster because there is no setup, no configuration, no maintenance, no surprises.
Deliver your MVP faster because there is no setup, no configuration, no maintenance, no surprises.
![]() Focus on the product and customers instead of spending time on the infrastructure and resolving technical issues.
Focus on the product and customers instead of spending time on the infrastructure and resolving technical issues.
![]() Save money by using SQS rather than managing message brokers yourself.
Save money by using SQS rather than managing message brokers yourself.
Saving time and money in early development stages (first 6 to 12 months) is critical, because your startup may change direction very rapidly. Startup reality is so unpredictable that a few months after the MVP release, you may realize that you don’t need the messaging component at all, and then all the time invested into it would become a waste!
If you do not prioritize every dollar and every minute spent, your startup may run out of money before ever finding product-market fit (offering the right service to the right people). SQS is often a great fit for early-stage startups, as it has the lowest up-front time and money cost.
HINT
Any up-front cost, whether it is money or time, may become a waste. The higher the chance of changes, the higher the risk of investment becoming a waste.
To demonstrate the competitiveness of Amazon SQS, let’s have a look at a simple cost comparison. To deploy a highly available message broker using ActiveMQ or RabbitMQ, you will need at least two servers. If you are using Amazon EC2, at the time of writing, two medium-sized reserved instances would cost you roughly $2,000 a year. In comparison, if you used SQS and needed, on average, four requests per message, you would be able to publish and process one billion messages per year for the same amount of money. That is 32 messages per second, on average, throughout the entire year.
In addition, by using SQS you can save hours needed to develop, deploy, manage, upgrade, and configure your own message brokers, which can easily add up to thousands of dollars per year. Even if you assumed that initial time effort to get message brokers set up and integrated would take you a week of up-front work, plus an hour a week of ongoing maintenance effort, you would end up with at least two weeks of time spent looking after your broker rather than looking after your customers’ needs.
Simply put, if you don’t expect large message volumes, or you don’t know what to expect at all, you are better off using SQS. SQS offers just the most basic functionality, so even if you decide to use your own messaging broker later on, you should have no problems migrating away from it. All you need to do when integrating with SQS is to make sure your publishers and consumers are not coupled directly to SQS SDK code. I recommend using thin wrappers and your own interfaces together with design patterns like Dependency Injection, Factory, façade, and Strategy.1,7,10 Figure 7-20 shows how your infrastructure becomes simplified by removing custom messaging brokers and using SQS.

Figure 7-20 Simplified infrastructure depending on Amazon SQS
When it comes to scalability, SQS performs very well. It scales automatically according to your needs and provides really impressive throughput without any preparation or capacity planning. You should be able to publish and consume tens of thousands of messages per second, per queue (assuming multiple concurrent clients). Adding more queues, producers, and consumers should allow you to scale without limits.
It is important to remember that SQS is not a golden hammer, though. It scales well, but it has its limitations. Let’s quickly discuss its disadvantages.
First of all, Amazon had to sacrifice some features and guarantees to be able to scale SQS easily. Some of the features missing in SQS are that it does not provide any complex routing mechanisms and is less flexible than RabbitMQ or ActiveMQ.12,25,L3 If you decide to use SQS, you will not be able to deploy your own logic into it or modify it in any way, as it is a hosted service. You either use it as is, or you don’t use it at all.
Second, SQS has limits on message size, and you may be charged extra if you publish messages with large bodies (tens of kilobytes).
Another important thing to remember is that messages will be delivered out of order using SQS and that you may see occasional redeliveries. Even if you have a single producer, single queue, and single consumer, there is no message-ordering guarantee whatsoever.
Finally, you pay per service call, which means that polling for nonexisting messages counts as a service call; it also means that sending thousands of messages per second may become more expensive than using your own message broker.
If your company is a well-established business and you are not dealing with a huge amount of uncertainty, it may be worth performing a deeper analysis of available platforms and choose a self-managed messaging broker, which could give you more flexibility and advanced features. Although SQS is great from a scalability and up-front cost point of view, it has a very limited feature set. Let’s see now what self-managed brokers can offer.
RabbitMQ
RabbitMQ is a high-performance platform created initially for financial institutions. It provides a lot of valuable features out of the box, it is relatively simple to operate, and it is extremely flexible. Flexibility is actually the thing that makes RabbitMQ really stand out.
RabbitMQ supports two main messaging protocols—AMQP and STOMP—and it is designed as a generic-purpose messaging platform, without preferences towards Java or any other programming language.
The most attractive feature of RabbitMQ is the ability to dynamically configure routes and completely decouple publishers from consumers. In regular messaging, the consumer has to be coupled by a queue name or a topic name. This means that different parts of the system have to be aware of one another to some extent. In RabbitMQ, publishers and consumers are completely separated because they interact with separate endpoint types. RabbitMQ introduces a concept of an exchange.
An exchange is just an abstract named endpoint to which publishers address their messages. Publishers do not have to know topic names or queue names as they publish messages to exchanges. Consumers, on the other hand, consume messages from queues.
Publishers have to know the location of the message broker and the name of the exchange, but they do not have to know anything else. Once a message is published to an exchange, RabbitMQ applies routing rules and sends copies of the message to all applicable queues. Once messages appear in queues, consumers can consume them without knowing anything about exchanges.
Figure 7-21 shows how RabbitMQ takes care of routing and insulates publishers from consumers, both physically and logically. The trick is that routing rules can be defined externally using a web administration interface, AMQP protocol, or RabbitMQ’s REST API. You can declare routing rules in the publisher’s or consumer’s code, but you are not required to do so. Your routing configuration can be managed externally by a separate set of components.
Figure 7-21 RabbitMQ fully decoupling publishers from consumers
If you think about message routing this way, you move closer towards service-oriented architecture (SOA). In SOA, you create highly decoupled and autonomous services that are fairly generic and that can be wired together to build more complex applications using service orchestration and service policies.31 In the context of RabbitMQ, you can think of it as an external component that can be used to decide which parts of the system should communicate with each other and how messages should flow throughout the queues. The important thing about RabbitMQ routing is that you can change these routing rules remotely, and you can do it on the fly, without the need to restart any components.
It is worth noting that RabbitMQ can provide complex routing based on custom routing key patterns and simpler schemas like direct queue publishing and publish/subscribe.
Another important benefit of using RabbitMQ is that you can fully configure, monitor, and control the message broker using its remote REST API. You can use it to create any of the internal resources like hosts, nodes, queues, exchanges, users, and routing rules. Basically, you can dynamically reconfigure any aspect of the message broker without the need to restart anything or run custom code on the broker machine. To make things even better, the REST API provided by RabbitMQ is really well structured and documented. Figure 7-22 shows RabbitMQ’s self-documenting endpoint, so you don’t even need to search for the documentation of the API version you are running to learn all about it.

Figure 7-22 Fragment of RabbitMQ REST API documentation within the endpoint
When it comes to feature comparison, RabbitMQ is much richer than SQS and supports more flexible routing than ActiveMQ. On the other hand, it does miss a few nice-to-have features like scheduled message delivery. The only important drawbacks of RabbitMQ are the lack of partial message ordering and poor poison message support.
From a scalability point of view, RabbitMQ is similar to ActiveMQ. Its performance is comparable to ActiveMQ as well. It supports different clustering and replication topologies, but unfortunately, it does not scale horizontally out of the box, and you would need to partition your messages across multiple brokers to be able to scale horizontally. It is not very difficult, but it is not as easy as when using SQS, which simply does it for you.
If you are not hosted on Amazon EC2 or you need more flexibility, RabbitMQ is a good option for a message broker. If you are using scripting languages like PHP, Python, Ruby, or Node.js, RabbitMQ will allow you to leverage its flexibility and configure it at runtime using AMQP and RabbitMQ’s REST API.
ActiveMQ
The last message broker I would like to introduce is ActiveMQ. Its functionality is similar to RabbitMQ and it has similar performance and scalability abilities. The main difference is that it is written in Java and it can be run as an embedded message broker within your application. This offers some advantages and may be an important decision factor if you develop mainly in Java. Let’s go through some of the ActiveMQ strengths first and then discuss some of its drawbacks.
Being able to run your application code within the message broker or run the message broker within your application process allows you to use the same code on both sides of the border. It also allows you to achieve much lower latency because publishing messages within the same Java process is basically a memory copy operation, which is orders of magnitude faster than sending data over a network.
ActiveMQ does not provide advanced message routing like RabbitMQ, but you can achieve the same level of sophistication by using Camel. Camel is an integration framework designed to implement enterprise integration patterns,10,31–32 and it is a great tool in extending ActiveMQ capabilities. Camel allows you to define routes, filters, and message processors using XML configuration and allows you to wire your own implementations of different components. If you decide to use Camel, you will add extra technology to your stack, increasing the complexity, but you will gain many advanced messaging features.
In addition to being Java based, ActiveMQ implements a common messaging interface called JMS (Java Message Service) and allows the creation of plugins, written also in Java.
Finally, ActiveMQ implements message groups mentioned earlier, which allow you to partially guarantee ordered message delivery. This feature is quite unique and neither RabbitMQ nor SQS has anything like that. If you desperately need FIFO-style messaging, you may want to use ActiveMQ.
We went through some of the most important strengths of ActiveMQ, so now it is time to mention some of its drawbacks.
First, ActiveMQ has much less flexible routing than RabbitMQ. You could use Camel, but if you are not developing in Java, it would add to the burden for your team. Also, Camel is not a simple technology to use, and I would recommend using it only if you have some experienced engineers on the team. There are a few features allowing you to build direct worker queues and persistent fan-out queues, but you don’t have the ability to route messages based on more complex criteria.
The second major drawback in comparison to RabbitMQ is that ActiveMQ cannot be fully controlled using its remote API. In contrast, RabbitMQ can be fully configured and monitored using a REST API. When dealing with ActiveMQ, you can control some aspects of the message broker using the JMX (Java Management Extensions) protocol, but it is not something you would like to use when developing in languages other than Java.
Finally, ActiveMQ can be sensitive to large spikes of messages being published. It happened to me multiple times during load tests that ActiveMQ would simply crash when being overwhelmed by high message rates for extended periods of time. Although it is a stable platform, it does not have access to low-level functions like memory allocation and I/O control because it runs within JVM. It is still possible to run out of memory and crash the broker if you publish too many messages too fast.
Final Comparison Notes
Comparing ActiveMQ and RabbitMQ based on Google Trends,L4 we can see that RabbitMQ has gained a lot of popularity in recent years and both message brokers are pretty much going head to head now (as of this writing). Figure 7-23 shows ActiveMQ and RabbitMQ over the course of the last five years.
Figure 7-23 ActiveMQ and RabbitMQ search popularity according to Google Trends
These trends may also be caused by the fact that RabbitMQ was acquired by SpringSource, which is one of the top players in the world of Java, and that ActiveMQ is being redeveloped from scratch under a new name, Apollo.
Another way to compare brokers is by looking at their high-availability focus and how they handle extreme conditions. In this comparison, ActiveMQ scores the worst of all three systems. It is relatively easy to stall or even crash ActiveMQ by simply publishing messages faster than they can be routed or persisted. Initially, ActiveMQ buffers messages in memory, but as soon as you run out of RAM, it either stalls or crashes completely.
RabbitMQ performs better in such a scenario, as it has a built-in backpressure feature. If messages are published faster than they can be processed or persisted, RabbitMQ begins to throttle producers to avoid message loss and running out of memory. The benefit of that approach is increased stability and reliability, but it can cause unexpected delays on the publisher side, as publishing messages slows down significantly whenever backpressure is triggered.
In this comparison, SQS performs better than both ActiveMQ and RabbitMQ, as it supports very high throughput and Amazon is responsible for enforcing high availability of the service. Although SQS is a hosted platform, you can still experience throttling in some rare situations and you need to make sure that your publishers can handle failures correctly. You do not have to worry about crashing brokers, recovery procedures, or scalability of SQS, though, as it is managed by Amazon.
No matter which of the three technologies you choose, throughput is always finite and the best way to scale is by partitioning messages among multiple broker instances (or queues in the case of SQS).
If you decide to use SQS, you should be able to publish tens of thousands of messages per second, per queue, which is more than enough for most startups. If you find yourself reaching that limit, you would need to create multiple queue instances and distribute messages among them to scale out your overall throughput. Since SQS does not preserve message ordering and has very few advanced features, distributing messages among multiple SQS queues should be as easy as picking one of the queues at random and publishing messages to it. On the consumer side, you would need similar numbers of consumers subscribing to each of the queues and similar hardware resources to provide even consumer power.
If you decide to use ActiveMQ or RabbitMQ, your throughput per machine is going to depend on many factors. Primarily you will be limited by CPU and RAM of machines used (hardware or virtual servers), average message size, message fan-out ratio (how many queues/customers each message is delivered to), and whether your messages are persisted to disk or not. Regardless of how many messages per second you can process using a single broker instance, as you need to scale out, your brokers need to be able to scale out horizontally as well.
As I mentioned before, neither ActiveMQ nor RabbitMQ supports horizontal scalability out of the box, and you will need to implement application-level partitioning to distribute messages among multiple broker instances. You would do it in a similar way as you would deal with application-level data partitioning described in Chapter 5. You would deploy multiple brokers and distribute messages among them. Each broker would have the exact same configuration with the same queues (or exchanges and routing). Each of the brokers would also have a pool of dedicated customers.
If you use ActiveMQ and depend on its message groups for partial message ordering, you would need to use the message group ID as a sharding key so that all of the messages would be published to the same broker, allowing it to enforce ordering. Otherwise, assuming no message-ordering guarantees, you could select brokers at random when publishing messages because from the publisher’s point of view, each of them would be functionally equal.
Messaging platforms are too complex to capture all their differences and gotchas on just a few pages. Having said that, you will need to get to know your tools before you can make really well-informed choices. In this section, I only mentioned the most popular messaging platforms, but there are more message brokers out there to choose from. I believe messaging is still an undervalued technology and it is worth getting to know more platforms. I recommend starting the process by reading about RabbitMQ12 and ActiveMQ,25 as well as a fantastic paper on Kafka.w52
Introduction to Event-Driven Architecture
We have gone a long way since the beginning of this chapter, but there is one more exciting concept I would like to introduce, which is event-driven architecture (EDA). In this section I will explain the core difference between the traditional programming model and EDA. I will also present some of its benefits and how you can use it within a larger non-EDA system.
First of all, to understand EDA, you need to stop thinking about software in terms of requests and responses. Instead, you have to think about components announcing things that have already happened. This subtle difference in the way you think about interactions has a profound impact on the architecture and scalability. Let’s start off slowly by defining some basic terms and comparing how EDA is different from the traditional request/response model.
Event-driven architecture (EDA) is an architecture style where most interactions between different components are realized by announcing events that have already happened instead of requesting work to be done. On the consumer side, EDA is about responding to events that have happened somewhere in the system or outside of it. EDA consumers do not behave as services; they do not do things for others. They just react to things happening elsewhere.
An event is an object or a message that indicates something has happened. For example, an event could be announced or emitted whenever an order in an online store has been placed. In such case, an event would probably contain information about the buyer and items purchased. An event is an entity holding the data necessary to describe what has happened. It does not have any logic; instead, it is best to think of an event as a piece data describing something that has happened in the real world or within the application.
So far the difference between EDA and messaging can still be quite blurry. Let’s have a closer look at the differences between the following interaction patterns: request/response, messaging, and EDA.
Request/Response Interaction
This is the traditional model, resembling the synchronous method or function invocation in traditional programming languages like C or Java. A caller sends a request and waits for the receiver to process the message and return with a response. I described this model in detail earlier in this chapter, so we won’t go into more detail here. The important things to remember are that the caller has to be able to locate the receiver, it has to know the receiver’s contract, and it is temporally coupled to the receiver.
Temporal coupling is another term for synchronous invocation and means that caller cannot continue without the response from the receiver. This dependency on the receiver to finish its work is where coupling comes from. In other words, the weakest link in the entire call stack dictates the overall latency. (You can read more about temporal coupling.w10,31)
In the case of request/response interactions, the contract includes the location of the service, the definition of the request message, and the definition of the response message. Clients of the service need to know at least this much to be able to use the service. Knowing things about the service implies coupling, as we discussed it in Chapter 2—the more you need to know about a component, the stronger is your coupling to it.
Direct Worker Queue Interaction
In this interaction model, the caller publishes messages into the queue or a topic for consumers to react to. Even though this is much more similar to the event-driven model, it still leaves opportunities for closer coupling. In this model, the caller would usually send a message to a queue named something like OrderProcessingQueue, indicating that the caller knows what needs to be done next (an order needs to be processed).
The good side of this approach is that it is asynchronous and there is no temporal coupling between the producer and consumer. Unfortunately, it usually happens that the producer knows something about the consumer and that the message sent to the queue is still a request to do something. If the producer knows what has to be done, it is still coupled to the service doing the actual work—it may not be coupled by the contract, but it is still coupled logically.
In the case of queue-based interaction, the contract consists of the queue location, the definition of the message sent to the queue, and quite often, the expectation about the result of the message being processed. As I already mentioned, there is no temporal coupling and since we are not expecting a response, we also reduce the contract’s scope because the response message is not part of it any more.
Event-Based Interaction
Finally, we get to the event-driven interaction model, where the event publisher has no idea about any consumers being present. The event publisher creates an instance of an event, for example, NewOrderCreated, and announces it to the event-driven framework. The framework can use an ESB, it can be a built-in component, or it can even use a messaging broker like RabbitMQ. The important thing is that events can be published without having to know their destination. Event publishers do not care who reacts or how they react to events.
By its nature, all event-driven interactions are asynchronous, and it is assumed that the publisher continues without needing to know anything about consumers.
The main advantage of this approach is that you can achieve a very high level of decoupling. Your producers and consumers do not have to know each other. Since the event-driven framework wires consumers and producers together, producers do not need to know where to publish their event—they just announce them. On the other hand, consumers do not need to know how to get to the events they are interested in either—they just declare which types of events they are interested in, and the event-driven framework is responsible for routing them to the consumer.
It is worth pointing out that the contract between producer and consumers is reduced to just the event message definition. There are no endpoints, so there is no need to know their locations. Also, since the publisher does not expect responses, the contract does not include them either. All that publishers and consumers have in common is the format and meaning of the event message.
To visualize it better, let’s consider two more diagrams. Figure 7-24 shows how the client and service are coupled to each other in the request/response interaction model. It shows all the pieces of information that the client and service need to share to be able to work together. The total size of the contract is called the contract surface area.
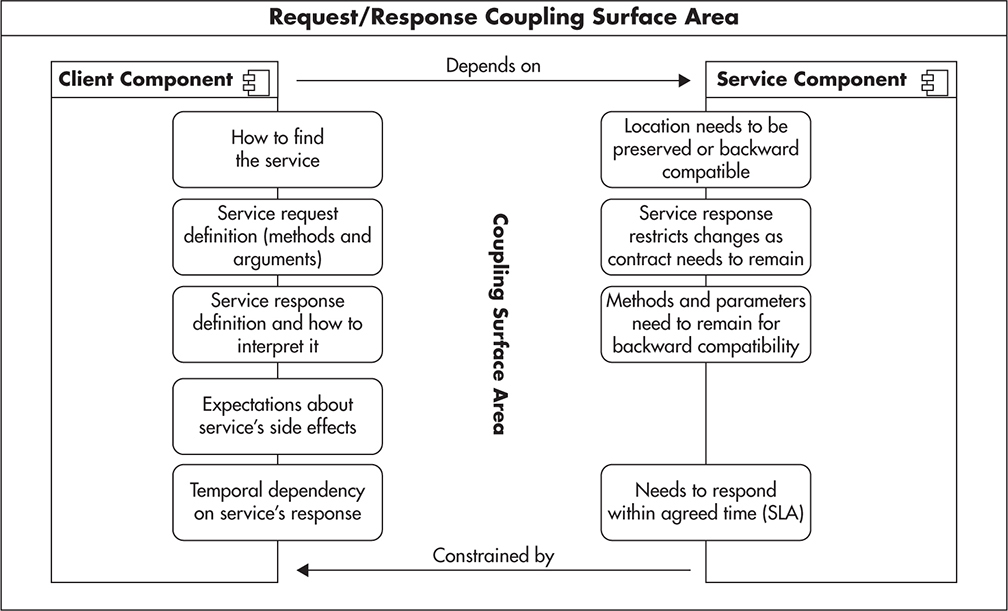
Figure 7-24 Coupling surface area between the service and its clients
Contract Surface Area is the measurement of coupling. The more information components need to know about each other to collaborate, the higher the surface area. The term comes from diagrams and UML modeling as the more lines you have between two components, the stronger the coupling.
In the Request/Response interaction model clients are coupled to the service in many ways. They need to be able to locate the service and understand its messages. Contract of the service includes both request and response messages. The client is also coupled temporally, as it has to wait for the service to respond. Finally, clients often assume a lot about the service’s methods. For example, clients of the createUser service method could assume that a user object gets created somewhere in the service’s database.
On the other side of the contract, the service does not have an easy job adapting to changing business needs as it needs to keep the contract intact. The service is coupled to its clients by every action that it ever exposed and by every piece of information included in request or response messages ever exposed. The service is also responsible for supporting agreed SLA (Service Layer Agreement) which means responding quickly and not going offline too often. Finally service is constrained by the way it is exposed to its clients, which may prevent you from partitioning the service into smaller services to scale better.
In comparison, Figure 7-25 shows EDA interactions. We can see that many coupling factors are removed and that the overall coupling surface area is much smaller. Components do not have to know much about each other, and the only point of coupling is the event definition itself. Both the publisher and consumer have to establish a shared understanding of the event type body and its meaning. In addition, the event consumer may be constrained by the event message, because if certain data was not included in the event definition, the consumer may need to consult a shared source of truth, or it may not have access to a piece of information at all.

Figure 7-25 Coupling surface area between EDA components
In a purely EDA, all the interactions are based on events. This leads to an interesting conclusion that if all of the interactions are asynchronous and all the interactions are carried out using events, you could use events to re-create the state of the entire system by simply replaying events. This is exactly what event sourcing allows us to do.L6–L7,24
Event sourcing is a technique where every change to the application state is persisted in the form of an event. Events are usually stored on disk in the form of event log files or some data store. At the same time, an application is built of event consumers, which process events passed to them. As a result, you can restore the system to an old state (for example, using a daily snapshot) and replay events to reach the same end state.
I have seen EDA with event sourcing in action handling 150,000 concurrently connected clients performing transactions with financial ramifications. If there was ever a crash, the entire system could be recovered to the most recent consistent state by replaying the event log. It also allowed engineers to copy the event log and debug live issues in the development environment by simply replaying the event logs. It was a very cool sight.
In fact, asynchronous replication of distributed systems is often done in a similar way. For example, MySQL replication is done in a similar way, as every data modification is recorded in the binary log right after the change is made on the master server. Since all state changes are in the binary log, the state of the slave replica server can be synchronized by replaying the binary log.16 The only difference is that consumers of these events are replicating slaves. Having all events persisted in a log means that you can add a new event consumer and process historical events, so it would look like it was running from the beginning of time.
The important limitation of event sourcing is the need for a centralized state and event log. To be able to reconstruct the state of the application based on event log alone, you need to be processing them in the same order. You could say that you need to assume a Newtonian perception of time with an absolute ordering of events and a global “now.” Unfortunately, in distributed systems that are spanning the globe, it becomes much harder because events may be happening simultaneously on different servers in different parts of the world. You can read more about the complexity of event sourcing and reasoning about time, L7,39 but for simplicity, you can just remember that event sourcing requires sequential processing of all events.
Whether you use event sourcing or not, you can still benefit from EDA and you can benefit from it even in pre-existing systems. If you are building a new application from scratch, you have more freedom of choice regarding which parts should be developed in EDA style, but even if you are maintaining or extending an existing application, there are many cases where EDA will come in handy. The only trick is to start thinking of the software in terms of events. If you want to add new functionality and existing components do not have to know the results of the operation, you have a candidate for an event-driven workflow.
For example, you could develop a core of your online shopping cart in a traditional way and then extend it by publishing events from the core of the system. By publishing events, you would not make the core depend on external components, you would not jeopardize its availability or responsiveness, yet you could add new features by adding new event consumers later on. The EDA approach would also let you scale out, as you could host different event consumers on different servers.
Summary
We covered a lot of material in this chapter, discussing asynchronous processing, messaging, different brokers, and EDA. To cover these topics in depth would warrant a book dedicated to each. Our discussion here has been simple and fairly high level. The subject matter is quite different from the traditional programming model, but it is really worth learning. The important thing to remember is that messaging, EDA, and asynchronous processing are just tools. They can be great when applied to the right problem, but they can also be a nightmare to work with when forced into the wrong place.
You should come away from this chapter with a better understanding of the value of asynchronous processing in the context of scalability and having gained enough background to explore these topics on your own. All of the concepts presented in this chapter are quite simple and there is nothing to be intimidated by, but it can take some time before you feel that you fully understand the reasoning behind them. Different ways of explaining the same thing may work better for different people, so I strongly encourage you to read more on the subjects. I recommend reading a few books31–32,24–27,12 and articles.L6,w10–w11
Asynchronous processing is still underinvested. High-profile players like VMware (RabbitMQ, Spring AMQP), LinkedIn (Kafka), and Twitter (Storm) are entering the stage. Platforms like Erlang and Node.js are also gaining popularity because distributed systems are built differently now. Monolithic enterprise servers with distributed transactions, locking, and synchronous processing seem to be fading into the past. We are moving into an era of lightweight, innovative, and highly parallel technologies, and startups should be investing in these types of solutions. EDA and asynchronous processing are going through their renaissance, and they are most likely going to become even more popular, so learning about them now is a good investment for every engineer.