
CHAPTER
9
Other Dimensions of Scalability

The majority of this book is dedicated to technical details of designing and building scalable web applications, as these subjects are the main areas of focus for software engineers. In reality, building scalable systems is more than just writing code. Some of the other dimensions of scalability that you need to pay attention to are
![]() Scaling operations How many servers can you run in production? Once you deploy your system to hundreds of servers, you need to be able to manage them efficiently. If you need to hire an additional sysadmin every time you add 20 web servers to your stack, you are not going to be able to scale fast or cheap.
Scaling operations How many servers can you run in production? Once you deploy your system to hundreds of servers, you need to be able to manage them efficiently. If you need to hire an additional sysadmin every time you add 20 web servers to your stack, you are not going to be able to scale fast or cheap.
![]() Scaling your own impact How much value for your customers and your company can you personally generate? As your startup grows, your individual impact should grow with it. You should be more efficient and able to increase your personal contributions by expanding your responsibilities and advising your business leaders.
Scaling your own impact How much value for your customers and your company can you personally generate? As your startup grows, your individual impact should grow with it. You should be more efficient and able to increase your personal contributions by expanding your responsibilities and advising your business leaders.
![]() Scaling the engineering department How many engineers can your startup hire before becoming inefficient? As your company grows, you need to be able to hire more engineers and increase the size of your engineering department without reducing their productivity. That means developing the right culture and structuring your teams and systems in a way that allows parallel development and collaboration at scale.
Scaling the engineering department How many engineers can your startup hire before becoming inefficient? As your company grows, you need to be able to hire more engineers and increase the size of your engineering department without reducing their productivity. That means developing the right culture and structuring your teams and systems in a way that allows parallel development and collaboration at scale.
As you become more senior, you should be able to appreciate these additional facets of scalability. For your applications to be truly scalable, you need to be able to scale the size of your teams, the number of servers you support, and your own personal productivity, minimizing the costs (time and money) at the same time. Let’s now discuss some of the ways in which you can help your startup scale.
Scaling Productivity through Automation
“If you want something to happen, ask.
If you want it to happen often, automate it.” – Ivan Kirigin
A big part of startup philosophy is to scale the value of your company exponentially over time while keeping your costs growing at a much slower rate. That means that the cost of serving the first ten million users should be higher than the cost of serving the second ten million users. Although that may be counterintuitive, the cost of capacity unit should decrease over time. That means your company has to become more efficient as it grows. The cost per user or per transaction or per checkout (or whatever you measure) should decrease as you grow in size.
Modern technology startups manage to achieve incredible customer-to-employee ratios, where tiny technical teams support products used by tens or even hundreds of millions of users. This efficiency constraint makes scalability even more challenging, as it means that you need to design and build systems that become more efficient as they grow. To achieve this level of efficiency, you need to automate everything you can. Let’s have a look at some common areas that can be automated to increase efficiency.
Testing
Testing is the first thing that you should automate when building a scalable web application. Although it took over a decade for businesses and engineers to appreciate automated testing, it is finally becoming a de facto standard of our industry. The main reason why automated testing is a sound investment is that the overall cost of manual testing grows much faster over time than the overall cost of automated testing.
Figure 9-1 shows the overall cost of manual and automated testing. If you decide to depend on manual testing alone, you do not have any up-front investments. You hire testers and they test your application before every release. Initially, the cost is small, but it stacks up very fast. Every time you build a new feature, you need to test that feature, as well as all the previously released features, to make sure that your changes did not break anything else. That, in turn, means that the cost of testing each release is higher than testing any of the previous releases (you become less efficient over time). It also takes longer and longer to release new versions of software because testing cycles become longer as your system grows in size.
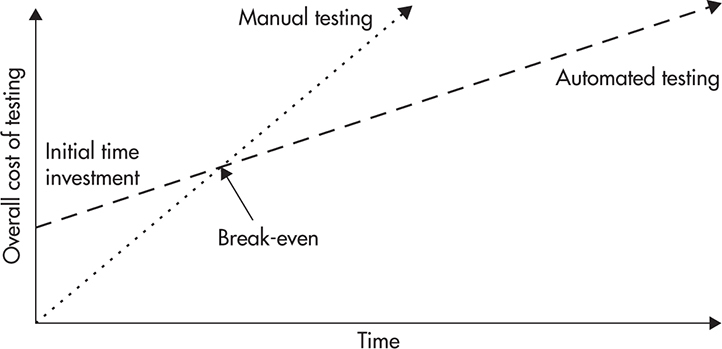
Figure 9-1 Overall cost of manual and automated testing
Automated testing requires an up-front investment, as you need to set up your automated testing suites and deploy continuous integration servers, but it is much cheaper going forward. Once you are done with initial setup, you only create tests for new features. You do not need to spend time on regression testing existing features because this does not cost you anything. As a result, you become more efficient over time because with every release, the ratio of code being tested by existing tests to the new code (which requires tests to be created) increases. Eventually, you reach a break-even point where the overall cost of automated testing is lower than manual testing.
Although it is difficult to measure the costs and benefits of automated testing, I would expect a startup to reach the break-even point after three to six months of development. The benefits of automated testing depend on the volatility of your business, the number of “pivots” (when you decide to change the focus of your business), the size of your team, and the tolerance for defects.
In addition to the time and money spent, automated tests bring confidence to your team and allow you to make rapid changes and refactor aggressively, which is a great advantage when working for a startup. By using automated tests and continuous integration, you can also speed up your development cycles. You do not need to spend days or weeks hardening and testing your code before releasing it. By having a suite of automated tests, you can integrate early and release more often, making you more responsive to market needs.
HINT
With the safety net of automated tests, your teams can become what Robert C. Martin calls fearless engineers. Fearless engineers are not afraid to make changes. They control their software and they have legitimate confidence that bugs are detected before they make their way into production.
Depending on the languages and technologies you work with, you may use different tools to automate your tests. First of all, you want the majority of your tests to be unit tests, which can execute without other components being deployed. Unit tests are the fastest to execute and cheapest to maintain. They don’t cause false positives, and they are easy to debug and fix when making changes.
In addition, you may want to have integration tests, which span multiple components, and some end-to-end tests, which test entire applications via their public interfaces. Two tools that are worth recommending for end-to-end tests are Jmeter and Selenium. Jmeter is great at testing low-level Hypertext Transfer Protocol (HTTP) web services, HTTP redirects, headers, and cookies and it is also a great tool for performance and load testing. Selenium, on the other hand, allows you to remotely control a browser from within your tests. As a result, you can create test cases for complex scenarios like login, purchase, or subscription. Using Selenium, you can automate anything that a manual tester would do and plug it into your automated test suites.
Once you automate your tests, you gain a solid foundation to automate your entire build deployment and release process. Let’s have a look at how you can expand automation in these areas.
Build and Deployment
The next step in increasing your efficiency is to automate your entire build, test, and deployment process. Manual deployments are a time sink in the same way manual testing is. As the number of servers and services grows, more people need to be involved, more servers and services need to be coordinated, and it becomes more difficult to execute a successful deployment. As it becomes more difficult and complex to release software, releases take longer and testing/integration cycles become longer as well. As a result, your releases become larger because more code is developed between releases, leading to even larger and more complex releases. Figure 9-2 shows the vicious cycle of manual releases and the positive cycle of automated releases.
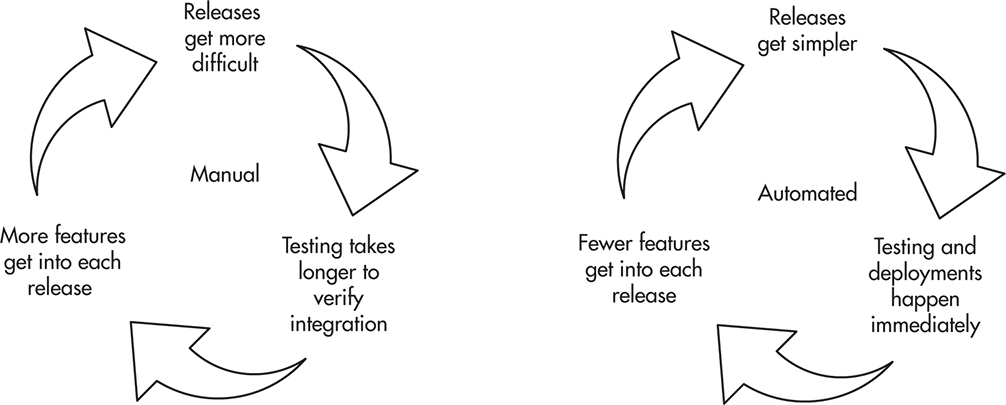
Figure 9-2 Manual deployments vs. automated deployments
The best practice, as of this writing, to break the vicious cycle of manual releases is to automate the entire build, test, and deployment process by adopting continuous integration, delivery, and deployment.
Continuous integration is the first step of the automation evolution. It allows your engineers to commit to a common branch and have automated tests executed on that shared codebase any time that changes are made. Writing automated tests and committing to a shared branch allows your engineers to detect integration issues early. You reduce time spent on merging long-living branches and the effort needed to coordinate releases. By having a stable integration branch with all tests passing (as they are executed for every commit on the integration server), you can deploy to production at any point in time. Continuous integration does not span onto deployment—it only ensures that code can be built and packaged and that tests pass for every commit.
Continuous delivery is the second step in the automation evolution. In addition to running unit tests and building software packages, the continuous delivery pipeline deploys your software to a set of test environments (usually called dev, testing, or staging). A critical feature of that process is that software is built, assembled, and deployed in a reproducible way without any human interaction. That means that any time engineers make a commit to any of the repositories, a set of new builds is triggered; software is deployed to the dev, test, or staging environment; and additional end-to-end test suites are executed to verify correctness of the wider system. As a result, it becomes a business decision whether to deploy code to production or not rather than being an engineering/testing team’s decision. Once the change makes its way through the continuous delivery pipeline, it is ready to be deployed to production. At this stage of evolution, deployment to production usually uses the same automated scripts as deployment to staging environments, and it can be done by a click of a button or issuing a single command, regardless of the complexity of the infrastructure and number of servers.
Continuous deployment is the final stage of the deployment pipeline evolution, where code is tested, built, deployed, and pushed to production without any human interaction. That means that every commit to the shared branch triggers a deployment to production servers without humans being involved. Deployments become cheap and can occur multiple times a day rather than once every couple of weeks.
Figure 9-3 shows an example of a continuous deployment pipeline. It also shows which areas are automated by continuous integration, delivery, and deployment, respectively. Ideally, software would move automatically through the entire pipeline, so that a commit on the integration branch would trigger tests to be executed and a build assembled. Then code would be deployed to dev and testing environments. Automated end-to-end tests would be executed against the testing environment. If all these steps were successful, code would be immediately deployed to production servers, ending the continuous deployment pipeline.
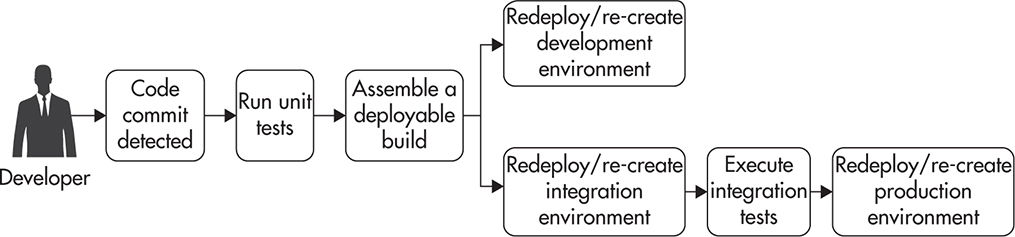
Figure 9-3 Example of a continuous deployment pipeline
While working in different companies over the years, I have witnessed deployments of various sizes and various degrees of automation. For example, in one of the teams that I have worked with, it would take three people up to four hours per week to release software. That is a combined cost of over 300 man-hours per year. That equates to one of our engineers doing nothing but releasing software for two months straight. On the other end of the spectrum, I have seen people deploy software to production with every commit, where a release cycle takes 15 minutes from commit to code being in production.
HINT
Testing and deployments have to be automated if you want to scale. If you need to do more than click a button to create a build, run tests, and deploy software to production, you need to automate further.
The number of tools and platforms that help implement continuous deployment has been increasing in recent years, but it is still a fairly involved process to set up a full-stack, continuous deployment pipeline. Setting up a continuous deployment pipeline is challenging because it requires skills from both ends of DevOps. You need to have Dev’s knowledge of the code and testing tools and Ops’ expertise in setting up servers and deploying software and managing configurations.
Your best bet is to make sure that you have an experienced DevOps engineer on your team to avoid frustration and speed up the initial setup. If you have to learn how to build a continuous deployment pipeline yourself, I would recommend using Jenkins (which is an open-source product) or Atlassian Bamboo (which is a commercial product but with a great feature set) as the tool controlling the pipeline.
In addition to configuring the continuous deployment tool (for example, using Jenkins), you will need to decide how to manage configuration of your servers. The goal is to store server configuration in the source control system to be able to re-create servers at any point in time and track changes. If you want to manage servers at scale, it is absolutely critical to manage their configuration using specialized tools like Chef or Puppet so that you can build server definitions and then create identical instances of these servers at will.
HINT
Having to control more than a dozen servers manually or allowing your servers’ configurations to diverge from one another is a recipe for disaster. Each server type (like a database server or a web server) should have a server definition created using a configuration management tool. This definition should then be used to create all of the instances of a particular server type, ensuring that each and every one of them is identical. By following this process, you can scale the number of servers without affecting the overall management cost. Whether you need to deploy a single server or a hundred servers, your overhead of building a server definition is constant, and deploying to more servers is just a matter of creating more server instances of a particular type.
Once you have server definitions and the continuous deployment tool configured, you are ready to deploy automatically to your servers. To achieve that, you may need to write some custom scripts that will know which servers need to be redeployed in what order. You may also need additional commands, such as purging caches, restarting web servers, or taking servers out of a load balancer.
To be able to deploy to production, your continuous deployment pipeline (and custom scripts) may need to be integrated with your cloud hosting provider to allow server images to be created (for example, Amazon Machine Image [AMI]), new server instances to be built, and servers to be added or removed from load balancers. There is no single right way of doing it, and depending on your infrastructure, skills, and preferences, you may opt for one way or another. For example, if you were hosting your stack on Amazon, you might want to use AMI images for your deployments to also allow auto-scaling and automated server replacement. In such a case, your continuous deployment pipeline might look as follows:
1. Developer commits code to a master branch.
2. Continuous deployment tool is notified by a github web hook.
3. The pipeline starts by checking out the code. Then unit tests are executed; the build is assembled; and test results, documentation, and other artifacts are zipped and pushed to permanent storage (like Amazon S3).
4. On success, a new server instance is created using Amazon API to build a new server image. The instance is restored using the most recent production AMI image for that cluster (let’s say a web service cluster).
5. The instance is then upgraded using configuration management tools to bring its packages up to date and to deploy the latest version of your application. This way, you perform installation, configuration, and dependency assembly only once.
6. Once the instance is ready, you take a snapshot of it as a new AMI image so that it can be used later to create new server instances.
7. As the next step in the pipeline, you deploy the newly created server image in the testing/staging cluster and verify its correctness using end-to-end tests like Selenium or Jmeter.
8. In the next step, you mark the newly created AMI image as production ready and move on to production deployment.
9. You can then redeploy the production web service cluster by updating the load balancer and taking servers out of rotation, one by one, or by doubling the capacity and killing the old instances. Either way, deployment is performed by the Elastic Load Balancer by re-creating all server instances from scratch using the newly created AMI image.
Having a continuous deployment pipeline like this allows you to deliver software extremely fast. You can deploy new features multiple times a day and quickly validate your ideas by running A/B tests on your users rather than having to wait weeks for customer feedback.
The only question that may still remain is “How do you make sure that things don’t break if every commit goes straight to production?” To address this concern, it is best to use a combination of continuous deployment best practices:
![]() Write unit tests for all of your code. Your code coverage should be at least 85 percent to give you a high stability and confidence level.
Write unit tests for all of your code. Your code coverage should be at least 85 percent to give you a high stability and confidence level.
![]() Create end-to-end test cases for all critical paths like sign up, purchase, adding an item to a shopping cart, logging in, or subscribing to a newsletter. Use a tool like Selenium so that you can quickly verify that the most important parts of your system are actually working before deploying code to production hosts.
Create end-to-end test cases for all critical paths like sign up, purchase, adding an item to a shopping cart, logging in, or subscribing to a newsletter. Use a tool like Selenium so that you can quickly verify that the most important parts of your system are actually working before deploying code to production hosts.
![]() Use feature toggles to enable and disable selected features instantly. A feature in hidden mode is not visible to the general audience, and disabled features are not visible at all. By using feature toggles, you can quickly disable a new broken feature without redeploying any servers.
Use feature toggles to enable and disable selected features instantly. A feature in hidden mode is not visible to the general audience, and disabled features are not visible at all. By using feature toggles, you can quickly disable a new broken feature without redeploying any servers.
![]() Use A/B tests and feature toggles to test new features on a small subset of users. By rolling out features in a hidden mode and enabling them for a small group of users (let’s say, 2 percent of users), you can test them with less risk. During the A/B testing phase, you can also gather business-level metrics to see whether a new feature is used by users and whether it improves your metrics (for example, increased engagement or user spending).
Use A/B tests and feature toggles to test new features on a small subset of users. By rolling out features in a hidden mode and enabling them for a small group of users (let’s say, 2 percent of users), you can test them with less risk. During the A/B testing phase, you can also gather business-level metrics to see whether a new feature is used by users and whether it improves your metrics (for example, increased engagement or user spending).
![]() Use a wide range of monitoring tools, embed metrics into all of your applications, and configure alerts on critical metrics so that you will be the first to know whenever things break.
Use a wide range of monitoring tools, embed metrics into all of your applications, and configure alerts on critical metrics so that you will be the first to know whenever things break.
Following these best practices will help you implement a continuous deployment pipeline and push changes to production faster without increasing the risk of failures, but no matter how well you test your code, your servers will occasionally fail and you need to be able to handle these failures fast and efficiently. To be able to scale your operations, it is absolutely critical to automate monitoring and alerting. Let’s now have a closer look at how it could be achieved.
Monitoring and Alerting
The main motivation to automate monitoring and alerting of your systems is to increase your availability by reducing mean time to recovery (MTTR). It may seem like a luxury to have automated monitoring, failure detection, and alerting when you run two servers in production, but as the number of servers grows, it becomes absolutely critical to be able to run your operations efficiently. Mean time to recovery is a combination of four components:
MTTR = Time to discover + Time to respond + Time to investigate + Time to fix
Time to discover is the time needed for your business to realize there is a problem with the system. In small companies, failures are often reported by customers or when employees notice that something broke. As a result, things can be broken for hours or even days before anyone reports a problem, resulting in poor user experience and terrible availability metrics. By using automated monitoring, you should be able to reduce the time to discovery to a few minutes.
The second component of MTTR is time to respond. Again, in small companies, it can take hours before the right person responds to the problem. People may not know who to call, they may not have private phone numbers, engineers being called may not have their laptops or passwords necessary to log in to the right servers, or they may just have their phones turned off. As a result, time to respond is unpredictable and it can easily take a few hours before the right person can start looking at a problem. As your company grows, your operations team needs to automate failure notifications so that production issues can be escalated to the right people and so that they can be ready to respond to critical problems within minutes. In addition to automated alerting, you need to develop procedures to define who is on call on which days and how they should react to different types of issues. By implementing clear procedures and automated alerting, you should be able to reduce the time to respond to tens of minutes rather than hours.
The last component of MTTR that you can reduce by monitoring is time to investigate, as time to fix is independent from monitoring and alerting. In small companies, when things break, engineers start logging into production servers, tailing logs, and trying to figure out what exactly broke. In many cases, it is a data store or an external system failure causing alerts through complex knock-on effects, and finding a root cause by traversing logs on dozens of servers can be a very time-consuming process.
To speed up debugging and maintain a clear picture of your “battlefield,” you can introduce metrics and log aggregation. By monitoring internals of your system, you can quickly identify components that are slow or failing. You can also deduce knock-on effects by correlating different metrics. Finally, by aggregating logs, you can quickly search for log entries related to the issue at hand, reducing time to investigate even further.
In addition to reducing MTTR, collecting different types of metrics can help you see trends and gain insight into your business. To get the most out of your monitoring configuration, you should collect four different types of metrics:
![]() Operating system metrics These allow you to see the status of your hardware, network infrastructure, and operating systems. On this level, you collect information like CPU load, memory statistics, number of processes running, network connections, and disk I/O. These metrics are mainly for system admins and DevOps people to estimate capacity and debug performance problems.
Operating system metrics These allow you to see the status of your hardware, network infrastructure, and operating systems. On this level, you collect information like CPU load, memory statistics, number of processes running, network connections, and disk I/O. These metrics are mainly for system admins and DevOps people to estimate capacity and debug performance problems.
![]() Generic server metrics These are all of the metrics that you can get from standard web servers, application containers, databases, message queues, and cache servers. In this level you collect metrics such as the number of database transactions per second, time spent waiting for locks, number of web requests per second, the number of messages in the deepest queue, or a cache hit ratio of your object cache server. These metrics help you gain a much deeper insight into the bottlenecks of each of your components.
Generic server metrics These are all of the metrics that you can get from standard web servers, application containers, databases, message queues, and cache servers. In this level you collect metrics such as the number of database transactions per second, time spent waiting for locks, number of web requests per second, the number of messages in the deepest queue, or a cache hit ratio of your object cache server. These metrics help you gain a much deeper insight into the bottlenecks of each of your components.
![]() Application metrics These are metrics that your application publishes to measure performance and gain insight into what is happening within the application. Examples of application-level metrics can be calls to external systems like databases, object caches, third-party services, and data stores. With every external call, you would want to keep track of the error rate, number of calls, and time it took to execute the call. By having these types of metrics, you can quickly see where the bottlenecks are in your systems, which services are slow, and what the trends of capacity are. On this level, you may also want to collect metrics such as how long it takes for each web service endpoint to generate a response or how often different features are used. The main purpose of these metrics is to allow engineers to understand what their code is doing and what pressures it is facing.
Application metrics These are metrics that your application publishes to measure performance and gain insight into what is happening within the application. Examples of application-level metrics can be calls to external systems like databases, object caches, third-party services, and data stores. With every external call, you would want to keep track of the error rate, number of calls, and time it took to execute the call. By having these types of metrics, you can quickly see where the bottlenecks are in your systems, which services are slow, and what the trends of capacity are. On this level, you may also want to collect metrics such as how long it takes for each web service endpoint to generate a response or how often different features are used. The main purpose of these metrics is to allow engineers to understand what their code is doing and what pressures it is facing.
![]() Business metrics These are metrics that track business events. For example, you may track dollars spent, user account creation, the number of items added to shopping carts, or the number of user logins per minute. The value of such metrics from an engineer’s point of view is that they allow you to verify within seconds whether you have a consumer-affecting problem or not. You can also use them to translate production issues into business impact, like dollars lost or user login failure count. By knowing the business impact of your issues, you can escalate more efficiently and verify recovery of critical systems by observing user activity.
Business metrics These are metrics that track business events. For example, you may track dollars spent, user account creation, the number of items added to shopping carts, or the number of user logins per minute. The value of such metrics from an engineer’s point of view is that they allow you to verify within seconds whether you have a consumer-affecting problem or not. You can also use them to translate production issues into business impact, like dollars lost or user login failure count. By knowing the business impact of your issues, you can escalate more efficiently and verify recovery of critical systems by observing user activity.
Operating web applications at scale without metrics in each of the four categories mentioned earlier is like driving blind. In fact, I would argue that every single service you deploy to production should publish metrics so that you can diagnose and operate it at scale. Let’s now have a look at how monitoring can be done in practice.
Monitoring and alerting are usually implemented by installing a monitoring agent on each of your servers. Each agent is then configured to collect metrics about that server and all of its services. Depending on the role of the server, the agent could have plugins installed to collect metrics from different sources, such as database processes, message queues, application servers, and caches. Each monitoring agent would usually aggregate dozens, hundreds, or even thousands of metrics. Periodically (for example, every minute or every five minutes), the agent would publish its metrics to a central monitoring service, which is usually a cloud service or an internally deployed monitoring server.
Once metrics are published to the monitoring service, they can be recorded so that dashboards and graphs can be drawn. At the same time, the monitoring service can watch the rate of change and values of each of these metrics, and alerts can be sent whenever safety thresholds are breached. For example, you can send a text message to your engineers on call if the number of open connections to your database reaches a certain level (as it may indicate that database queries execute too slowly and connections keep piling up as a result).
By having metrics pushed to a central monitoring service from all of your servers, you can visualize them per server or per server group. That also allows you to set alerts per server or per cluster of servers. For example, you could monitor free disk space per server because some servers may run out of disk space faster than others. On the other hand, when monitoring the number of open database connections to your replication slaves, you might be interested in a sum of all the connections across the entire cluster to see the higher-level picture of your system, regardless of which machines are out of rotation or in maintenance.
In addition to metrics gathering via internal monitoring agents and the monitoring service, you can use an external service level agreement (SLA) monitoring service. The advantage of using a third-party SLA monitoring service is that it connects to your services from external networks just like your customers would. As a result, it can detect network outages, routing/virtual private network (VPN) configuration issues, Domain Name Service (DNS) problems, load balancer configuration problems, Secure Sockets Layer (SSL) certificate expiration, and other issues that may be impossible to detect from within your own networks. In addition, some of the SLA monitoring services allow you to measure performance of your services from different locations on the planet and using different devices (simulating mobile network and low-bandwidth connections). As a result, they can provide you with an ocean of valuable data points, allowing you to optimize your user experience and alert on additional types of failures.
Figure 9-4 shows how monitoring and alerting could be implemented. You would have monitoring agents deployed across all of your servers, metrics being pushed to a central monitoring service, and alerting rules being configured within the monitoring service. In addition, an external SLA monitoring service could be utilized to watch performance and availability from the client’s point of view.
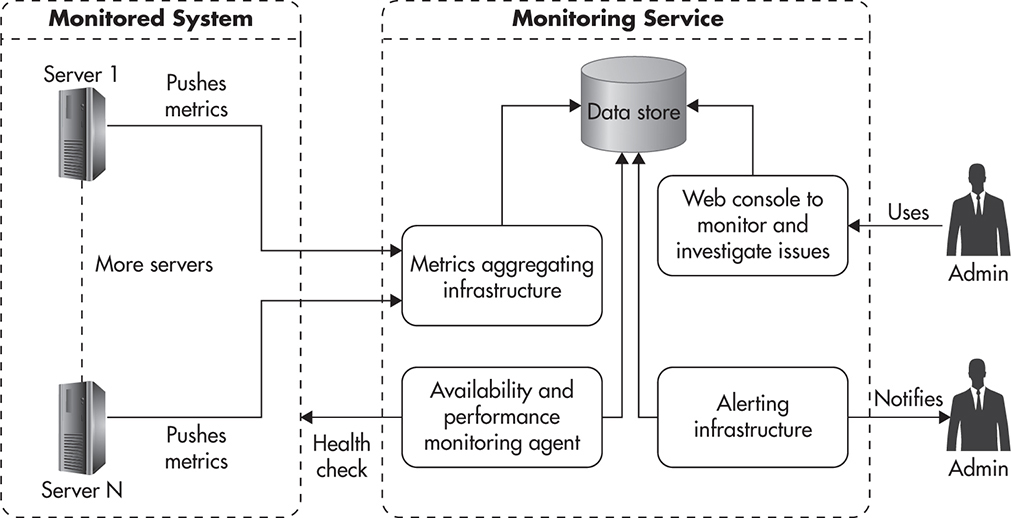
Figure 9-4 Sample monitoring and alerting configuration
As you can imagine, quite a few different components need to be put in place for such a comprehensive monitoring setup to work. You need to install your monitoring agents with plugins for all possible types of services that you want to monitor. You also need to be able to publish arbitrary metrics from your application code to monitor application and business metrics. Then you need to configure all of these agents to publish data to the aggregations service, and on the service side you need to configure graphs, thresholds, alerts, and dashboards. Getting it all to work together and managing all these components at scale can be quite a lot of work—that is why I recommend using a third-party, cloud-based monitoring service rather than deploying your own solution.
The best monitoring service I have seen so far (as of 2014) is Datadog, and I would strongly recommend testing it before committing to a different solution.L5 Some of its advantages are the feature set, ease of integration, and ease of use. Datadog provides plugins to monitor dozens of different open-source servers so that you would not need to develop custom code to monitor things like data stores, message queues, and web servers. In addition, it provides a simple application programming interface (API) and client libraries, so you can start publishing custom metrics from within your application code in a matter of minutes. Finally, it has a user-friendly user interface (UI), allowing you to configure graphs, dashboards thresholds, and alerts with minimal effort.
The competition in monitoring space has been increasing in recent years, and there are quite a few good alternatives that you might want to look at, with Stackdriver, New Relic, and Server Density, to name a few. Some of these providers, like Server Density, provide external SLA monitoring as part of their offering; others don’t. If you need a separate provider for external SLA monitoring, I recommend looking at Pingdom, Moniris, and Keynote.
With monitoring, alerting, and on-call procedures, you should be able to reduce MTTR to tens of minutes. If you wanted to reduce the time needed to investigate and debug issues even further, you might also want to implement a log aggregation and indexing solution.
Log Aggregation
When working with small applications, which run on just a couple of servers, log aggregation is not really necessary. Things usually break on the same server, and you usually have just a handful of log files to tail or grep through to find the root cause of an issue. Unfortunately, as your system grows and the number of servers goes into the dozens (and then the hundreds), you lose the ability to manually search through logs. Even with as few as ten servers it becomes impossible to tail, grep through, and correlate events happening across all of the log files on all of these servers simultaneously. Requests to your front-end layer may cascade to dozens of web service calls, and searching through all of the logs on all the machines becomes a serious challenge. To be able to search through logs and effectively debug problems, you need a way to collect all of your logs in a central location. There are a few common ways of solving this.
First of all, you can log to a data store directly rather than logging to files. The good side of this approach is that you do not have to move the logs once they are written, but the downside is that all of your components become dependent on the availability and performance of the logging data store. Because of this additional coupling, logging directly to a data store is not recommended.
A better alternative is to write to local log files and then have these logs shipped to a centralized log service. In its simplest form, you install log-forwarding agents on each of your servers and configure them to stream logs to a central log server. The main benefit of this approach is its simplicity, as all you need is a log server and log-forwarding agents installed on each of your servers.
There are quite a few open-source products that allow you to stream logs to a centralized log server, and a good example of such a product is Fluentd. Fluentd is easy to work with; it is robust, scalable, and offers a wide range of features. Your log-forwarding agents can tail multiple log files, perform complex filtering and transformations, and then forward logs to a central log server. In addition to having all of the log files on a single server, you can merge events from different sources and standardize time formats to a single time zone, as dealing with logs in multiple time zones and formats can be frustrating.
Streaming all of your logs to a central server is an improvement, but if you store your logs in flat files, it is still going to be time consuming to search through them. The more logs you have, the slower it will become to perform searches. Depending on your needs, you may want to go a step further and use a log-indexing platform to speed up your searches and make log data more available across your company.
Figure 9-5 shows how a complete log aggregation deployment might look. You install a log-forwarding agent on each of your servers with a configuration telling it which logs to forward, how to filter and transform the log events, and where to send them. Then the logs are streamed to a set of search engine servers, where they are persisted and indexed so that you can search through them efficiently. In addition, a log-processing platform provides you with a web-based interface to make searching through logs easier.
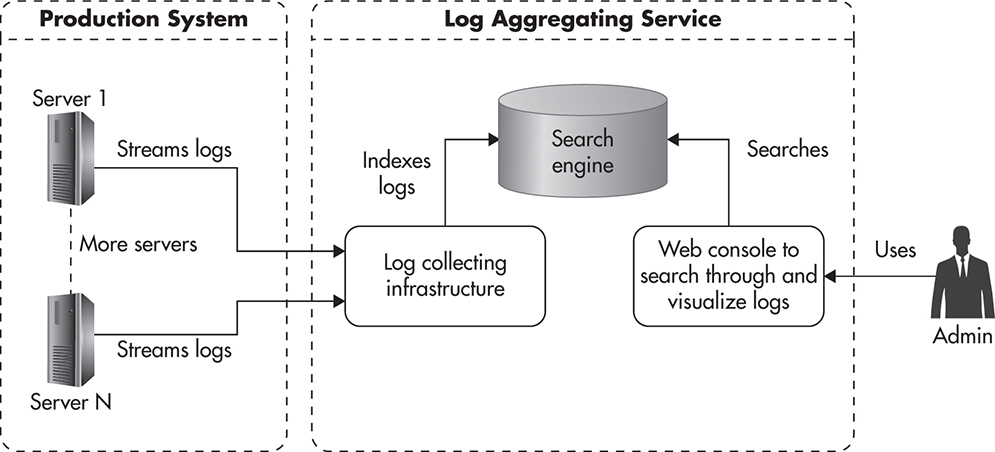
Figure 9-5 Sample log aggregation workflow
Deploying and managing a set of components to allow log aggregation and indexing is a fair amount of work, and I recommend using a hosted solution whenever it is possible and affordable. As of this writing, one of the most famous and most attractive solutions on the market is Splunk, but unfortunately, it is quite expensive and not all startups will get enough value from it to justify the cost. Some cloud vendors have a basic solution for log aggregation, like Amazon CloudWatch Logs or Azure Diagnostics, but they may not provide you with enough flexibility. You can also consider an independent hosted log-processing service like Loggy, which provides good functionality regardless of your hosting platform.
If sharing your application logs with third parties or running third-party agents on your servers is not an option, you might need to go for a self-hosted, open-source solution. In such a case, I recommend looking at Logstash, which is a feature-rich and scalable log-indexing platform. Logstash uses its own log-forwarding agents to ship logs to the Elasticsearch search engine. It also comes with a web interface called Kibana to let you perform free text searches and visualize your logs in near real time. The only downside of using Logstash is that you need to learn how to configure and operate it. Although the Logstash platform is a solid piece of software, it is not simple. Even a simple deployment requires a lot of configuration steps,L8–L9 and without an experienced sysadmin, it may become more of a burden than a benefit to manage it yourself.
Having automated testing, configuration management, deployments, monitoring, alerting, and keeping all of your logs in a central location should enable you to operate web applications at scale. Let’s now have a look at what can you do to scale your own personal productivity as your startup grows.
Scaling Yourself
The main reason why startups are so attractive is the hope to achieve exponential growth. Growing fast and efficiently is what allows investors and founders to make a profit. To enable this exponential growth, your startup needs you to become more efficient as it grows as well. You need to become more productive and generate more value for your customers and for your business as you go along. Let’s discuss some of the challenges that you may face when working in a startup and how you could approach them to maximize your own productivity and happiness.
Overtime Is Not a Way to Scale
Working under a lot of pressure with limited resources, tight deadlines, and under extreme uncertainty can be nerve wracking, and this is exactly what web startups feel like. Startups are an explosive cocktail of emotions. They are challenging, exhausting, and very rewarding at the same time, but you need to be careful not to fall into a blind race, as working can easily become a thoughtless compulsion.
At first, getting more done by working longer hours feels natural. You push yourself a bit more, work a few extra hours every day, or work over the weekends. It feels like the right thing to do and it feels like a relatively small sacrifice to make, as you are full of energy, motivation, hope, and belief in your future. In addition, it feels good to be needed and to be the hero who saves the day. After all, if working harder is what it takes, then why not do it?
The problem is that in the long run, working overtime is a terrible strategy to scale your productivity. As you work longer hours for extended periods of time, your mental capacity decreases; your creativity drops; and your attention span, field of vision, and ability to make decisions all degrade. In addition, you are likely going to become more cynical, angry, or irritable. You will resent people who work less than you do; you will feel helpless or depressed in the face of an ever-growing pile of work. You may even begin to hate what you used to love doing or feel anxious, with the only way to repress this anxiety being to work even harder. All of these are symptoms of burnout.
Burnout is your archenemy when working for a startup, as it sneaks upon you slowly and by the time it hits you, you are completely blind to it, making you fall even deeper into its grip. It is like a vicious cycle—you work harder, get more tired, you can’t see ways to work smarter, and as a result you end up working even harder. Everyone experiences burnout slightly differently, but from my experience, it is a terrible state to be in and it takes months to fully recover. Again, based on my own experiences, you can expect significant burnout after anything from three to nine months of excessive work (working under high pressure for over 45 to 60 hours a week).
Figure 9-6 shows how productivity changes over time when working excessively. Initially, you experience increased productivity, as you perform at full capacity for more hours. Shortly after that, your productivity begins to decline, diminishing the benefit of working overtime. Finally, if you let it go on for too long, your productivity becomes marginal. You can’t get anything meaningful done even though you spend endless hours working, and eventually you have to give up on the project or quit.

Figure 9-6 Productivity over time
If you are working for a startup, chances are that you are already experiencing burnout. The bad news is that there is no quick and easy cure for it. Working less, exercising more, and spending time with friends and family helps, but recovering fully this way takes months. A quicker way is to take a long holiday (three to six weeks) or leave the project altogether and take a couple of months of light work. It can take a lot of focus and a couple of burnouts in your lifetime before you learn how to recognize early symptoms and how to prevent it altogether by managing yourself.
Rather than continually falling into cycles of hyperproductivity and crashes, it is more efficient and healthier to maintain a more sustainable level of effort. Every person has different limits, depending on their motivation, internal energy, engagement, and personality, but from my personal experience, working more than 50 hours per week is dangerous, and working more than 60 hours per week leads to burnout in a matter of months.
Your time is one of the most precious and nontransferable values you have. You are spending it at a constant rate of 60 minutes per hour, and there is no way to scale beyond that. Instead of trying to work longer hours, you need to find ways to generate more value for your customers, business, and peers within the safety zone of 40 hours per week. Although it may sound like an empty slogan, you truly need to learn to work smarter, not harder.
Managing Yourself
A good way to look at the problem of maximizing your own productivity is to look at your workload as if you were managing a project and all of your potential tasks were parts of this project. When managing a project, you have three “levers” allowing you to balance the project: scope, cost, and time.
Anytime you increase or decrease the scope, cost, or deadline, the remaining two variables need to be adjusted to reach a balance. As you add more work, you need to spend more resources or extend deadlines. As you reduce the time available to deliver your project, you need to reduce scope or add resources. Finally, as you reduce available resources, you need to either cut the scope or extend your deadlines.
Figure 9-7 shows the project management triangle with a few extra notes to help you memorize some of the coping strategies. The first thing that you need to do is to accept the fact that managing a project is about making tradeoffs. You spend more time or money or do less work. It is as simple as that. When you start thinking about work this way, you may be able to find ways to balance your project without working overtime.
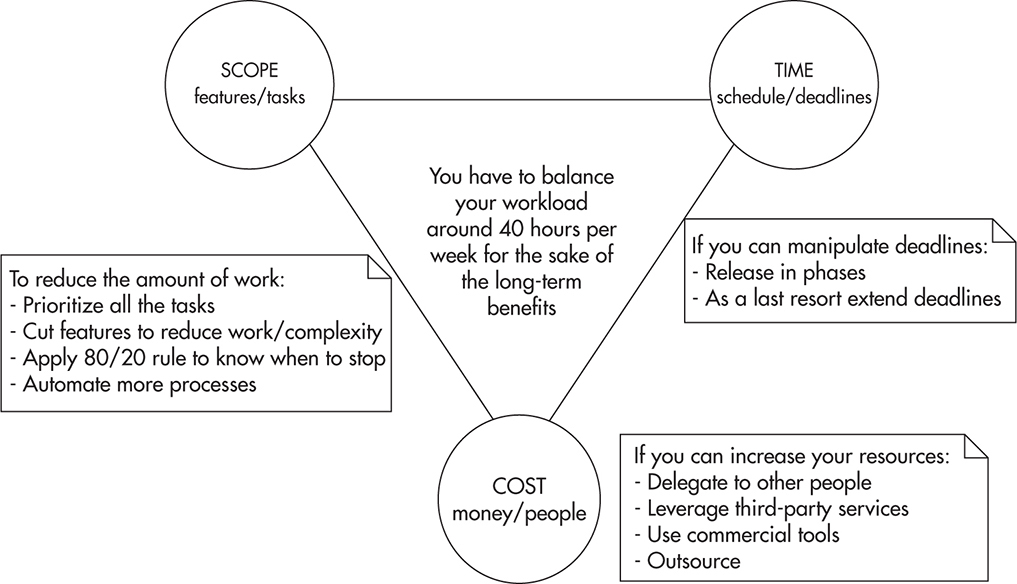
Figure 9-7 Project management levers
HINT
It is important to consider the role of quality in this context. I would suggest that building automated tests and ensuring high-quality code is part of the scope of each feature. You should not try to reduce scope by sacrificing quality if you want to maintain efficiency over the long term. In a way, sacrificing the quality of your code is like borrowing money from Tony Soprano. It may seem like a good idea when you are in a rush and under pressure, but sooner or later you will have to start repaying the vig (excessive weekly interest on a loan).
Let’s have a closer look at how you can influence the amount of work, cost, and deadlines to make your own workload more sustainable.
Influencing the Scope
“Without data, you’re just another person with an opinion.” –W. Edwards Deming
Influencing the scope of work is usually the easiest way to balance your workload, and it is also an area where the most significant savings can be made. The first step to get better at managing your own workload is to understand that any time you get a new task or an existing task increases in size, you need to reevaluate deadlines, increase available resources, or cut scope elsewhere.
Anything that you decide to do takes time, and by doing one thing you will have less time for the remaining tasks. It may sound obvious, but learning how to prioritize tasks based on their cost and value is the most important skill in managing scope. After all, one of the most important things for a startup to survive is making sure you are building the right stuff. To prioritize tasks efficiently, you need to know their value and their cost. You can then prioritize them based on their relative value/cost ratio.
Task priority = (value of that task) / (overall cost of that task)
The cost component of the equation is usually estimated quite accurately by estimating the time needed to complete the task. Even for larger projects that include financial costs (buy more servers or get additional services), people are usually good at coming up with relatively accurate estimates. The real difficulties begin when you try to estimate the value of each task, as most of the time, people do it based solely on their personal gut feeling rather than past experience or actual data.
This inability to evaluate the true value of features is what leads most companies to develop things that nobody needs. I have witnessed people working their hands to the bone on features that made absolutely no difference, just because they bought into a vision based on someone’s gut feeling without any data or critical validation. In fact, following a vision without validating it is probably one of the most common reasons for startup failures. That is why gathering data and making decisions based on experiments is what the Lean Startup movement is advocating. By designing experiments, gathering data, and making decisions based on this data, you can reduce the risk of building things that nobody needs.
HINT
Following your gut feeling might be a great way to go if you are Richard Branson or Warren Buffett, but in reality, most of us are not. That is why most decisions should be made based on data, not gut feeling.
Changing the decision-making culture of your startup may be difficult, and it is beyond the scope of this book, but I strongly recommend reading more about the Lean Startup philosophy.30,9 Even if you are not able to change the way decisions are made in your organization, you should collect metrics, talk to your customers, run A/B tests, and try to help your business people make sure that you are not building unnecessary things.
Another way to reduce the scope of your work is to follow the 80/20 rule and know when to stop doing things rather than compulsively working for marginal gain. The 80/20 rule is an observation that 80 percent of the value is generated by 20 percent of the effort. Surprisingly, the 80/20 rule applies in many areas of software development:
![]() 80 percent of the features can be built in 20 percent of the overall time.
80 percent of the features can be built in 20 percent of the overall time.
![]() 80 percent of code coverage can be achieved in 20 percent of the overall time.
80 percent of code coverage can be achieved in 20 percent of the overall time.
![]() 80 percent of users use only 20 percent of the features; in fact, studies show that in many systems almost half of the features are never used.L10
80 percent of users use only 20 percent of the features; in fact, studies show that in many systems almost half of the features are never used.L10
![]() 80 percent of the documentation value is in 20 percent of its text.
80 percent of the documentation value is in 20 percent of its text.
![]() 80 percent of the bugs come from 20 percent of the code.
80 percent of the bugs come from 20 percent of the code.
![]() 80 percent of the code changes are made in 20 percent of the codebase.
80 percent of the code changes are made in 20 percent of the codebase.
Although the 80/20 rule is a simplification, by realizing it, you can reduce the time spent on gold plating and make sure that you stop working on the task as soon as it is “complete enough” rather than trying to reach the 100 percent, regardless of the cost. Applying the 80/20 rule is about being pragmatic and considering the cost of your work. You can apply the 80/20 rule in many ways; here are some ideas of how you could apply the 80/20 mind-set to reduce the amount of work that needs to be done:
![]() Negotiate with your stakeholders to reduce the scope of new features to 80 percent and delay the most expensive/difficult parts to future releases. By getting the base functionality out early, you can gather A/B test results before investing more time in their “full” implementation. The minimum viable product mentality can be applied to any feature, and in some cases, it is all that your customers really need.
Negotiate with your stakeholders to reduce the scope of new features to 80 percent and delay the most expensive/difficult parts to future releases. By getting the base functionality out early, you can gather A/B test results before investing more time in their “full” implementation. The minimum viable product mentality can be applied to any feature, and in some cases, it is all that your customers really need.
![]() Keep functionality minimalistic and simple as long as possible. Use A/B testing any time you add new features to make sure that they are used and that they generate the expected value. Code that is not used is a form of technical debt, and features that are not used should be removed to reduce that debt. Remember that less is more, especially in a startup.
Keep functionality minimalistic and simple as long as possible. Use A/B testing any time you add new features to make sure that they are used and that they generate the expected value. Code that is not used is a form of technical debt, and features that are not used should be removed to reduce that debt. Remember that less is more, especially in a startup.
![]() Make sure that you implement only the code that is absolutely necessary without adding nice-to-have parameters, classes, and methods. All this “you ain’t gonna need it” code needs to be tested, documented, understood, and managed. Less is more!
Make sure that you implement only the code that is absolutely necessary without adding nice-to-have parameters, classes, and methods. All this “you ain’t gonna need it” code needs to be tested, documented, understood, and managed. Less is more!
![]() Strive for 85 percent to 90 percent code coverage rather than going for 100 percent coverage at all costs. Some areas of code may be much more difficult to test than others, and the cost of testing this remaining 10 percent may be more than it is worth.
Strive for 85 percent to 90 percent code coverage rather than going for 100 percent coverage at all costs. Some areas of code may be much more difficult to test than others, and the cost of testing this remaining 10 percent may be more than it is worth.
![]() When creating documentation, focus on critical information and the high-level picture rather than documenting everything imaginable. Draw more diagrams, as images are truly worth a thousand words. If you feel that your documentation is complete, you have most likely wasted 80 percent of the time!
When creating documentation, focus on critical information and the high-level picture rather than documenting everything imaginable. Draw more diagrams, as images are truly worth a thousand words. If you feel that your documentation is complete, you have most likely wasted 80 percent of the time!
![]() Don’t fix it if it ain’t broke. Refactor parts of your codebase as you need to modify them, but allow old code to just sit there if it does not need to be changed. Why would you want to refactor a class that no one touched for months? Just to feel better? I know that it sounds harsh, but doing things like that is a compulsion and you simply can’t afford to do that in a startup.
Don’t fix it if it ain’t broke. Refactor parts of your codebase as you need to modify them, but allow old code to just sit there if it does not need to be changed. Why would you want to refactor a class that no one touched for months? Just to feel better? I know that it sounds harsh, but doing things like that is a compulsion and you simply can’t afford to do that in a startup.
![]() Always try to distinguish whether a task at hand belongs to the “I have to do it” or “I want to do it” category, as the second one is a source of huge amounts of extra work. Engineers love to learn and they love to build software—that makes us biased towards building rather than reusing and towards trying new things rather than doing what we already know. As a result, we tend to chase the newest, coolest technologies, frameworks, and patterns rather than using the best tool for the job. In addition, we are smart enough to be able to justify our choices and fool ourselves into believing that the choice we made is truly the best option there is for our company. Practicing self-awareness and watching out for these biases should help you reduce the amount of unnecessary work.
Always try to distinguish whether a task at hand belongs to the “I have to do it” or “I want to do it” category, as the second one is a source of huge amounts of extra work. Engineers love to learn and they love to build software—that makes us biased towards building rather than reusing and towards trying new things rather than doing what we already know. As a result, we tend to chase the newest, coolest technologies, frameworks, and patterns rather than using the best tool for the job. In addition, we are smart enough to be able to justify our choices and fool ourselves into believing that the choice we made is truly the best option there is for our company. Practicing self-awareness and watching out for these biases should help you reduce the amount of unnecessary work.
![]() Don’t scale or optimize until you absolutely have to, and remember that even when you think you have to, you may be falling into an “I want to do it” trap. You should not build horizontal scalability into every project you work on, as most of the time it will be a waste of time. It is estimated that 90 percent of startups that get seed funding fail. The same statistic applies to startups that go through accelerators. Out of the remaining 10 percent that survive, the majority never need to scale beyond a dozen servers, not to mention horizontal scalability. If you work for a startup, you should plan for scalability, but defer complexity and time investments for as long as you can so you can focus on more urgent needs, like making sure that you are building a product that your customers really need.
Don’t scale or optimize until you absolutely have to, and remember that even when you think you have to, you may be falling into an “I want to do it” trap. You should not build horizontal scalability into every project you work on, as most of the time it will be a waste of time. It is estimated that 90 percent of startups that get seed funding fail. The same statistic applies to startups that go through accelerators. Out of the remaining 10 percent that survive, the majority never need to scale beyond a dozen servers, not to mention horizontal scalability. If you work for a startup, you should plan for scalability, but defer complexity and time investments for as long as you can so you can focus on more urgent needs, like making sure that you are building a product that your customers really need.
It is especially difficult for engineers to manage scope, as engineers are passionate and optimistic people. We want to get everything done, we want it all to be perfect, and we truly believe it can all be done by tomorrow afternoon. We wish our UIs were beautiful, back ends were optimized, data was consistent, and code was clean. Unfortunately, unless you have unlimited resources or years of time to muck around, you will have to make sacrifices and sometimes you will need to let go of some things for the sake of more important tasks. Be pragmatic.
Influencing the Cost
Another way to balance your workload and allow your startup to scale is to learn how to increase the costs to reduce the amount of work. You can reduce the scope of your own work by delegating tasks and responsibilities to other people, tools, or third-party companies. If you have too much work to do, all of the work truly needs to be done, nothing else can be automated, and deadlines cannot be postponed, you should start looking for ways to delegate.
By delegating tasks to other members of your team, you increase the scalability of your department. If you are the only person who can do a certain task, you are the bottleneck and a single point of failure. By having multiple people on the team equally capable of performing a particular task, work can be distributed more evenly among more people and you stop being the bottleneck. In addition, by having more people working on the same problem, you increase the chances of breakthroughs and innovation in this area. For example, your peer may find a way to automate or optimize part of the workflow that you would never think of.
To be able to easily delegate tasks and responsibilities to other team members, you need to make sure that people are familiar with different tasks and different parts of the application. For that reason, you need to actively share knowledge within the team and collaborate more closely. Here are some of the practices that help in sharing knowledge and responsibility for a project:
![]() Pair programming This is a practice where two engineers work together on a single task. Although it may seem inefficient, pair programming leads to higher-quality designs, fewer bugs, and much closer collaboration. I would not recommend practicing pair programming all the time, but one day a week may be a great way to share knowledge, develop a shared understanding of the system, and agree on best practices. It is also a great way to mentor more junior members of the team, as they can see firsthand how senior engineers think and how they solve problems.
Pair programming This is a practice where two engineers work together on a single task. Although it may seem inefficient, pair programming leads to higher-quality designs, fewer bugs, and much closer collaboration. I would not recommend practicing pair programming all the time, but one day a week may be a great way to share knowledge, develop a shared understanding of the system, and agree on best practices. It is also a great way to mentor more junior members of the team, as they can see firsthand how senior engineers think and how they solve problems.
![]() Ad hoc design sessions These are spontaneous discussions involving whiteboards or pen and paper to discuss problems, brainstorm ideas, and come up with a better solution.
Ad hoc design sessions These are spontaneous discussions involving whiteboards or pen and paper to discuss problems, brainstorm ideas, and come up with a better solution.
![]() Ongoing code reviews This is a practice of reviewing each other’s code. Although code reviews may be associated mainly with code quality, they are a powerful way to increase collaboration and knowledge sharing. Reviewing each other’s code allows engineers not only to provide feedback and enforce best practices, it is also a great way for engineers to stay up to date with changes being made.
Ongoing code reviews This is a practice of reviewing each other’s code. Although code reviews may be associated mainly with code quality, they are a powerful way to increase collaboration and knowledge sharing. Reviewing each other’s code allows engineers not only to provide feedback and enforce best practices, it is also a great way for engineers to stay up to date with changes being made.
Another way to reduce the workload by increasing costs is by buying the services of third-party companies or using commercial tools. A good example of scaling your throughput by third parties is by using third-party monitoring and alerting tools. If you wanted to develop a monitoring and alerting system yourself, it might take you months to get anything useful and scalable built. However, if you decided to deploy an open-source alternative, you might only need days to get it up and running, but you would still incur some ongoing management time costs. If you decided to sign up with a third party, on the other hand, you could convert the time cost of developing and managing the service into a dollars cost. By using a third-party monitoring service, you drastically reduce the initial time cost and trade ongoing time cost for an ongoing money cost. In a similar way, you can reduce your workload or increase your productivity by using more sophisticated commercial tools, hosted data stores, caches, workflow engines, and video conferencing services.
HINT
Engineers love to build software. This love for building new things makes us biased towards developing rather than reusing. Developing things like monitoring services, analytics and alerting platforms, frameworks, or even data stores is just another form of reinventing the wheel. Before you jump into implementation, you should always check what can be used for free and what can be bought.
Although reducing the workload by increasing cost is usually beyond an engineer’s pay grade, it is something that can be presented to the business leaders. Not having to do the work at all is a way to scale, as it allows you to keep 100 percent focused on your customers’ needs.
Influencing the Schedule
The last of the three levers of project management that you may be able to affect is the schedule. In a similar way as with costs, it may be out of your direct control to decide which features can be released by when, but you can usually affect the schedule to some degree by providing feedback to your business leaders. Most of the time, both deadlines and the order of features being released are negotiable and subject to cost considerations. On a very rare occasion you may face a hard deadline when your company schedules a media campaign that cannot be canceled or when your company signs a contract forcing you to deliver on time, but most of the time, things are flexible.
To be absolutely clear, I am not trying to say that you should extend deadlines, as delaying releases is usually a bad idea and it hurts your company. What I am trying to say is that when working in a startup, you are much closer to the decision-making people and you can have a much bigger impact on what gets shipped and when. Rather than passively listening for commands, you should actively provide feedback to your business leaders, letting them know which features are cheap and quick to build and which ones are expensive or risky. As a result, they may understand the costs better and prioritize tasks more accurately.
In addition to providing constant feedback, I recommend releasing in smaller chunks. By reducing the size of each release, you can gain consumer feedback more quickly and decide whether you should keep building what you intended to build or if you should change the direction and build something different. Rapid learning is what Lean Startup methodology is all about. You release often, you gather feedback and data, and then you figure out what your next move is going to be rather than trying to plan it all up front. By developing the product in small pieces, you reduce the risk and the cost of making mistakes, which are an inevitable part of working for a startup.
For example, if you were extending an e-commerce platform to allow external merchants to build their own online stores, you might simply come up with a list of features, plan execution, and then work on that plan for three or six months before releasing it to your customers. By working for three months without any customer feedback, you work as if you were suspended in a vacuum. There is no way of knowing whether your customers will like your features; there is also no way of knowing what other features merchants might need. The larger the release cycle, the higher the risk of building things that customers don’t need.
A better way of approaching such a scenario would be to release a minimal management console as soon as possible and then add features based on your customer feedback. By releasing more quickly, you give yourself an opportunity to interview your customers, run surveys, collect A/B testing data, and ultimately learn. Then, based on this additional information, you can further refine your feature set without the need to implement everything up front. By breaking larger features into smaller pieces, you can also leverage the 80/20 rule, as you will often discover that what you have already built is enough for your customers and further phases of development on a particular feature may not be needed any more.
In addition to splitting features into smaller chunks, you may experiment with mocks, which are especially helpful in early phases of startup development. A mock is a feature that is not really implemented, but presented to users to measure their engagement and validate whether this feature is needed or not.
For example, if you wanted to implement an artificial intelligence algorithm that would automatically tag product pictures uploaded by your merchants, you might need months or years to complete the implementation. Instead of doing that, you could resort to a mock to run a quick and cheap experiment. You could start by selecting a sample of random products in your database. You would then ask your employees to tag the selected images rather than using actual artificial intelligence software. Finally, you could interview your merchants and run A/B tests to measure the impact on search engine optimization and user engagement. By using such a mock and collecting data, your startup could learn more about the true value of the feature in a very quick time (a matter of weeks); then based on this, you could decide whether it is worth building the feature or whether you should build something different.
Depending on your role and the company you are working for, it may be easier to control the scope, costs, or schedules. By looking for tradeoffs and providing feedback to your business leaders, you should be able to balance your workload more efficiently and hopefully avoid working overtime.
Scaling Agile Teams
The final aspect of scalability that I would like to highlight is the challenge of scaling agile teams. As your organization grows, you will need to hire more engineers, managers, product owners, and system administrators to be able to grow your product. Unfortunately, scaling agile is difficult, as you cannot scale an agile team by simply adding people to it. Things that work in teams of eight people do not work as well in larger teams consisting of dozens or hundreds of people.
Adding More People
A good example of things that don’t scale linearly as your team grows is communication. When working in a team of five, you can always get up to speed on what is happening; what changes are being made; what requirements have been discussed; and what designs, standards, and practices were chosen. As you keep adding people to the team, the number of communication paths grows very rapidly, making it impractical for everyone to stay up to date with everyone else at the same time. Figure 9-8 shows how the number of communication paths grows with the size of the team.
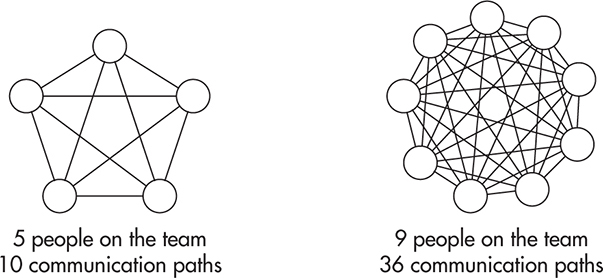
Figure 9-8 Number of communication paths
A common way out of this problem is to create a set of smaller teams of four to nine people and to give each of the teams a set of distinct responsibilities based on their functions. You can have a team of testers, a team of system administrators, a few teams of programmers focusing on different areas, and you can sometimes even see teams of project managers and product owners. It may seem like a good idea to grow this way, but what you inevitably end up with is a culture of handoffs, politics, finger pointing, and hostility among what becomes a set of opposing camps.
The reason why this approach does not work efficiently is that teams are created based on their job function, not an area of product development. As a result, your development and deployment life cycle becomes a pipeline of handoffs where people at every stage care about their own point of view rather than considering the overarching goals. In companies like that, product owners pass requirements to engineers, who then write code and hand over features to testers and sysadmins. Whenever things go wrong, finger pointing begins, stronger and stricter procedures are developed, and progress becomes even more difficult to make as everyone wants to save their own skin.
Luckily, there is a better way to scale software engineering teams: by removing monopolies and creating cross-functional teams.L11 Rather than having teams consisting of only testers or only programmers, you should build teams around products or services. For example, you can have a dedicated team maintaining a checkout functionality, with a designer, web developer, a sysadmin, three back-end engineers, and a couple of front-end ones. As a result, such a team can autonomously design, develop, and deploy features. Ideally, such a team could also gather feedback, analyze metrics, and lead the development of the checkout “product” without having to wait for anyone else.
By reducing dependencies between teams and giving them more autonomy, progress can be made independently. When you think of it, scalability on the organization level is similar to the scalability of your applications. You need to be able to add more workers (servers) to distribute the work among them. Following this analogy, to maximize throughput, your workers need to be able to make decisions locally so that they do not have to wait for other workers. In addition, they need to have the skills, tools, and authority (code and data) to execute with minimal communication overhead.
This model of scaling technology departments by building cross-functional teams can be especially successful in startups embracing service-oriented architecture (or micro-services), as you design your system as a set of loosely coupled UIs and web services, which can then be developed and deployed independently by separate teams. It is best to have teams responsible for an end-to-end product, like a “checkout experience,” including UI, front end, back end, and data stores, but as your applications grow, you may need to create a dedicated team handling the checkout UI and another managing a checkout web service. By splitting the team in two, you can have more people working on the checkout product, but at the same time, you create cross-team dependencies, which can make it more difficult to make progress, as UI guys need to wait for service changes.
Procedures and Innovation
Another important part of scaling your engineering department is to get the right balance among procedures, standards, and autonomy of your teams. As your organization grows, you may want to develop certain procedures to make sure that your organization is aligned and everybody follows best practices. For example, you may require all teams to have an on-call roster to ensure 24-hour support for production issues. You may want every service to have a business continuity plan to be able to recover quickly in case of major disasters and failures. You may also want to develop certain coding standards, documentation standards, branching strategies, agile processes, review processes, automation requirements, schema modeling guidelines, audit trail requirements, testing best practices, and much, much more.
An important thing to keep in mind is that as you develop all of these standards and procedures, you benefit from them, but at the same time, you sacrifice some of your team’s autonomy, flexibility, and ability to innovate.
For example, you may develop a process mandating that every product that goes into production needs to have data replication and a secondary hot standby environment for business continuity. It may be a great idea if all of your systems require 99.999 percent availability, but at the same time, it may slow your teams down significantly. Rather than developing and deploying a lightweight MVP service within a couple of weeks, your people may need to spend an additional month making that service robust enough to be able to meet your business continuity requirements. In some cases, it may be a good thing, but at the same time, it will make experimentation and learning much more expensive, as you will be forced to treat all of your use cases in the same way, regardless of their true requirements.
Procedures and standards are an important part of growing up as a company, but you need to keep them lean and flexible so that they do not have an adverse effect on your productivity, agility, and your culture.
Culture of Alignment
The last, but not least, important facet of scaling technology organizations is to align your teams on common goals and build a good engineering culture. Without alignment, every team will do their own thing. They will lead products in different directions, they will focus on different priorities, and they will ultimately clash against each other as they try to achieve conflicting goals. Anything that you can do as an engineer, a leader, or a business person to align your teams is going to magnify the momentum and increase the overall productivity of your startup.
Figure 9-9 shows how you can visualize alignment across your technology department. When your teams are unaligned, they all pull in different directions. As a result, the overall direction of movement is undefined and uncoordinated. In comparison, by making everyone pull in the same direction, you magnify their strengths, as they do not have to fight each other’s conflicting interests.
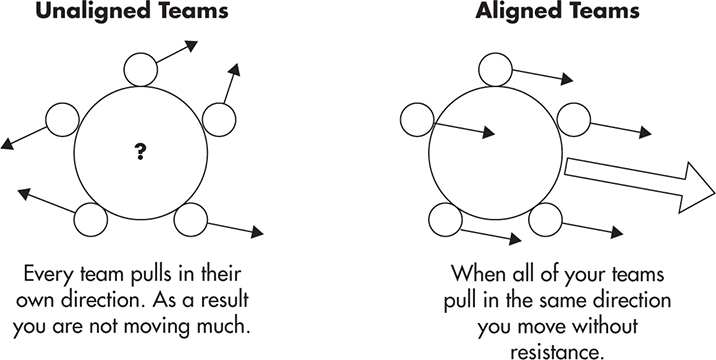
Figure 9-9 Effects of alignment
To align your teams more closely, you can start by developing a culture of humility, respect, and trust, where every engineer’s motto is that “we are all in this together.” To be a good team player, the benefit of the company should always come before the benefit of a team, and the benefit of the team should always come before the benefit of an individual.
Whether you are a CTO, a manager, or an engineer, you can always influence the culture by aiming to work together, learning about others’ needs, seeking compromises, and trying to understand others’ points of view. A good engineering culture is built on foundations of mutual respect, trust, and mindfulness.L11,11 Without a good culture, you end up in a vicious cycle of hiring ever worse engineers, getting bogged down with politics and egos, and fighting obstructionism.
For people to be productive, healthy, and happy, you need to create an environment where everyone can feel safe and accepted, and where people get support from their peers. The good news is that it is in everyone’s capacity to ignite and foster a good engineering culture. You do not have to be a CEO to do this.
Summary
As I have learned over the years, scalability is a deep and difficult subject. I have covered a lot of different topics in this book and although I have just scratched the surface of many of these subjects, I believe that it will help you build a holistic picture of scalability and inspire you to learn more about it.
If you are passionate about scalability from the organizational point of view, I strongly recommend that you learn more about the Lean Startup mentality.30,9 building a good engineering culture,11 and automating processes.4 Each of these subjects is deep as an ocean by itself, and covering it all in this chapter would not be possible.
On a personal level, my final piece of advice to you is to remain pragmatic and never stop learning. Building software, and especially scalable software, is a game of tradeoffs, and there is never a single right way to do things. Learn as much as you can and then decide for yourself what rules are worth following and when to break them.