
Now that we understand the power that these two models bring, one needs to be wary of the responsibility that this power brings forth. Typical abuse of concurrency and parallelism in the form of blanket code refactoring are often found counterproductive. Patterns become more pertinent in this paradigm, where developers push the limits of computing hardware.
Issues of races, deadlocks, livelocks, priority inversions, two-step dances, and lock convoys typically have no place in a sequential world, and avoiding such issues makes quality patterns all the more important | ||
| --Stephen Toub | ||
The authors wish to put in perspective the modelling/decomposition aspects of the problem, and illustrate the applicability of some of the key patterns, data structures, and synchronization constructs to these so as to aid the programmer to leverage concurrency and parallelism to its full potential. For detailed coverage in terms of patterns and primitive constructs, the authors strongly recommend developers to read Patterns of Parallel Programming by Stephen Toub and Concurrent Programming on Windows by Joe Duffy.
This is the foremost pattern we would cover. The candidate programs that can leverage these are ones that can be easily decomposed into tasks/operations which have little or no dependency. This independence makes parallel execution of these tasks/operations very convenient. We will stray a bit from the conventional examples (that of a ray tracer and matrix multiplication), plus instill a sense of adventure and accomplishment in creating an algorithm, which, in turn, is embarrassingly parallel in nature.
As indicated, the problem statement seems straightforward in terms of having an ability to multiply large numbers (let's push ourselves a bit by further stating astronomically large numbers), which cannot even be represented (64-bit computing limit). We have consciously reduced the scope by restricting ourselves to just one operation (multiplication) for outlining the pattern. Nothing prevents any interested reader who is game to go ahead and implement other operations thereby devising their own BigInteger version with support for all mathematical operations.
Let's start by outlining the algorithm to multiply two three-digit sequences (456 and 789):

The Schönhage-Strassen algorithm depends fundamentally on the convolution theorem, which provides an efficient way to compute the cyclic convolution of two sequences.
Tip
The authors wish to take a disclaimer here: the cyclic convolution computation is not done in the most efficient way here. The prescribed steps include that of taking the Discrete Fourier Transform (DFT) of each sequence, multiplying the resulting vectors element by element, and then taking the Inverse Discrete Fourier Transform (IDFT). In contrast to this, we adopt a naïve and computationally intensive algorithmic way. This results in a runtime bit complexity of O(n2) in Big-O notation for two n digit numbers. The core idea here is to demonstrate the intrinsic parallel nature of the algorithm!
As illustrated, the algorithm to compute the product of two three-digit sequences comprises of three major steps. We will look at the problem decomposition in detail, and interlude the steps with code to see this pattern in action, leveraging some of the core .NET parallelization constructs (specifically, the For method of the Parallel class in TPL-Parallel.For). In this process, you will understand how task decomposition is done effectively, taking into consideration the algorithmic and structural aspects of your application.
We will start off multiplying the two numbers 456 (sequence-1) and 789 (sequence-2) using long multiplication with base 10 digits, without performing any carrying. The multiplication involves three further sub-steps as illustrated.
Step 1.1
As part of the long multiplication, we multiply the least significant digit (9) from sequence-2 with all the digits of sequence-1, producing a sequence 36, 45, and 54.
Step 1.2
We multiply the next least significant digit (8) from sequence-2 with all the digits of sequence-1, producing a sequence 32, 40, and 48.
Step 1.3
Finally, we multiply the most significant digit (7) from sequence-2 with all the digits of sequence-1, producing a sequence 28, 35, and 42.
Add the respective column elements (again without carrying) to obtain the acyclic/linear convolution sequence (28, 67, 118, 93, 54) of sequence 1 and 2.
Perform the final step: that of doing the carrying operation (for example, in the rightmost column, keep the 4 and add the 5 to the column containing 93). In the given example, this yields the correct product, 359,784.
The following is the serial implementation of this algorithm (it faithfully follows the preceding steps for clarity):
//----------------------------Abstract Factory
public interface INumeric
{
BigNumOperations Operations ();
}
//----------------------------Abstract Product
public abstract class BigNumOperations
{
public abstract string Multiply (string x, string y);
public virtual string Multiply (
string x,
string y,
CancellationToken ct,
BlockingCollection<string> log)
{
return this.Multiply(x, y);
}Note
In the following Power method, we will employ Exponentiation by Squaring Algorithm, which relies on the fact that: x^y == (x*x)^(y/2)
Using this, we will continuously divide the exponent (in this case y) by two while squaring the base (in this case x).That is, in order to find the result of 2^11, we will do [((2*2)*(2*2))*((2*2)*(2*2))] * [(2*2)] * [(2)] or, to put it simply, we will do 2^8 * 2^2 * 2^1.This algorithm achieves O(log n) efficiency!
public string Power (string number, int exponent)
{
int remainingEvenExp = exponent / 2;
int remainingOddExp = exponent % 2;
string result = number;
if (remainingEvenExp > 0)
{
string square = this.Multiply(number, number);
result = square;
if (remainingEvenExp > 1)
{
if (remainingOddExp == 1)
{
result = this.Multiply(
this.Power(square, remainingEvenExp),
number);
}
else
{
result = this.Power(square, remainingEvenExp);
}
}
else
{
if (remainingOddExp == 1)
{
result = this.Multiply(square, number);
}
}
}
return result;
}
// Creates, Initializes and Returns a Jagged Array
public static int[][] CreateMatrix (int rows, int cols)
{
int[][] result = new int[rows][];
for (int i = 0; i < rows; ++i)
result[i] = new int[cols];
return result;
}
}
// ----------------------------Concrete Product-1
public class BigNumOperations1 : BigNumOperations
{
/// <summary>
/// Serial Implementation of Schönhage-Strassen Algorithm
/// <param name="x">String number Sequence-1</param>
/// <param name="y">String number Sequence-2</param>
/// <returns>String Equivalent Product Sequence</returns>
/// </summary>
public override string Multiply (string x, string y)
{
int n = x.Length;
int m = y.Length;
int prodDigits = n + m - 1;
int[] linearConvolution = new int[prodDigits];
int[][] longMultiplication = CreateMatrix(m, prodDigits);
//----------------------------Step-1
for (int i = m - 1; i >= 0; i--)
{
int row = m - 1 - i;
int col = 0;
int iProduct;
for (int j = n - 1; j >= 0; j--)
{
col = i + j;
iProduct = (( int )
Char.GetNumericValue(y[i])) *
(( int ) Char.GetNumericValue(x[j]));
longMultiplication[row][col] = iProduct;
}
}
//----------------------------Step-2
for (int j = prodDigits - 1; j >= 0; j--)
{
int sum = 0;
for (int i = 0; i < m; i++)
{
sum += longMultiplication[i][j];
}
linearConvolution[j] = sum;
}
//----------------------------Step-3
int nextCarry = 0;
int[] product = new int[prodDigits];
for (int i = (n + m - 2); i >= 0; i--)
{
linearConvolution[i] += nextCarry;
product[i] = linearConvolution[i] % 10;
nextCarry = linearConvolution[i] / 10;
}
return (nextCarry > 0 ? nextCarry.ToString() : "") +
new string
(
Array.ConvertAll<int, char>
(product, c => Convert.ToChar(c + 0x30))
);
}
}
// Concrete Factory-1
public class BigNumber1 : INumeric
{
public BigNumOperations Operations()
{
return new BigNumOperations1();
}
} // Concrete Product-2
public class BigNumOperations2 : BigNumOperations
{
public override string Multiply (string x, string y)
{
int n = x.Length;
int m = y.Length;
int prodDigits = n + m - 1;
int[] linearConvolution = new int[prodDigits];
int[][] longMultiplication = CreateMatrix(m, prodDigits);
//----------------------------Step-1
Parallel.For(0, m, i =>
{
int row = m - 1 - i;
int col = 0;
int iProduct;
for (int j = 0; j < n; j++)
{
col = i + j;
iProduct = (( int ) Char.GetNumericValue(y[i]))
* (( int ) Char.GetNumericValue(x[j]));
longMultiplication[row][col] = iProduct;
}
});
//----------------------------Step-2
Parallel.For(0, prodDigits, j =>
{
int sum = 0;
for (int i = 0; i < m; i++)
{
sum += longMultiplication[i][j];
}
linearConvolution[j] = sum;
});
//----------------------------Step-3
//Use code from Concrete Product-1 here...
}
}
// Concrete Factory-2
public class BigNumber2 : INumeric
{
public BigNumOperations Operations()
{
return new BigNumOperations2();
}
}Note
Now, to really understand the leverage we got from the Parallel.For parallelization construct, we have to do a CPU-intensive operation, which would be best achieved by computing the power (as opposed to the product) utilizing the multiplication algorithm. Imagine solving the wheat and chess problem, or perhaps more, say, 2100,000 (to the power of 100,000) in place of 232. A recursive divide and conquer strategy has been applied to compute the exponential (default implementation of the Power method in the abstract class/product BigNumOperations, which further uses the overridden, concrete Multiply methods of the respective core product implementations).
Can you really compute 2100,000 (given our limit of 64-bit arithmetic operations)? Well, take a look at the following invocation code and result:
public static void Power (string[] args)
{
var bigN1 = new BigNumber1();
var bigN2 = new BigNumber2();
var x = args[0];
int y = Convert.ToInt32(args[1]);
var watch = Stopwatch.StartNew();
var val1 = bigN1.Operations().Power(x, y);
Console.WriteLine(
"Serial Computation of {0} ^ {1}: {2} seconds",
x, y, watch.ElapsedMilliseconds / 1000D);
watch = Stopwatch.StartNew();
var val2 = bigN2.Operations().Power(x, y);
Console.WriteLine(
"Parallel Computation of {0} ^ {1}: {2} seconds",
x, y, watch.ElapsedMilliseconds / 1000D);
Console.WriteLine("Computed Values are {0}!!!",
val1.Equals(val2) ? "EQUAL" : "DIFFERENT");
}

Yes!!! It computed the values, and the parallel implementation took around half the time as compared to the serial one.
Also see how the task granularity seems to utilize the CPU (with all its available cores) to the maximum extent possible in the case of parallel execution (towards the right-hand side of the usage spectrum in all of the four cores):
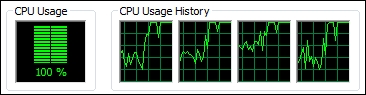
The following is a quick summary of the key applicability of best practices and patterns in this implementation:
- This is a classic case, where data parallelism (applying a single operation to many data elements/inputs) is exploited to the core, and the parallelization construct (
Parallel.For) we have chosen is best suited for this. We could also leverage the synchronization primitiveBarrier(System.Threading.Barrier), which would enable various sub-tasks to cooperatively work in parallel through multiple phases/tasks. ABarrieris recommended when the phases are relatively large in number. - Choose a lock-free task data structure (here, a two dimensional array has been utilized to capture the product sequences from each iteration in step 1). The operations (reads/writes) are atomic if you examine them closely (including step 2). This makes the parallelization process very effective, as there wouldn't be any synchronization penalties (locks, specifically) but a seamless utilization of resources (with the inherent load balancing provided by
Parallel.For). It is best to leaveParallel.Forto calibrate the degree of parallelism (DOP) itself so as to leverage all the available cores, and thereby prevent side-effects because of thread starvation or oversubscription. At best, we could specifyParallelOptionsofParallel.Forto useEnvironment.ProcessorCountso as to explicitly state the usage of one thread per core (a recommended practice in parallelization). The biggest limitation would be in terms of the memory required for array allocation in this case. You would tend to hit theOutOfMemoryexception beyond powers of 100,000 (again, specific to this algorithm and the associated data structures that it employs). - Fine-grained partitioning of tasks, as part of the decomposition process, enables throughput (again, it's a balance that needs to be achieved with careful analysis; any attempt to overdo can swing the performance pendulum to the other side).
- Choose the data representation in string format to represent really big numbers. Of course, you do incur the penalty of data conversion (a necessary evil in this case). You could as well create an extension method for string type to support these big number operations (perhaps, with a validation for legal numbers).
- Use of alternate algorithm (reverse long multiplication; that is, reversing steps 1.1 through 1.3) to leverage the parallel loop partition counter, which is forward only (as its purpose is only to partition, unlike that of a step counter in a conventional
forloop). Restructuring your algorithm is better than tweaking the code that was originally designed to run serially. - And finally, leverage the abstract factory GoF design pattern to seamlessly support the various implementations (in this case, serial and parallel).
This is a pattern that you generally associate with task parallelism. When there are distinct asynchronous operations that can run simultaneously, you can temporarily fork a program's flow of control with tasks that can potentially execute in parallel. You can then wait for these forked tasks to complete.
In the Microsoft® .NET Framework, tasks are implemented by the Task class in the System.Threading.Tasks namespace. Unlike threads, new tasks that are forked (using the StartNew method) don't necessarily begin executing immediately. They are managed internally by a task scheduler, and run based on a FIFO manner (from a work queue) as cores become available. The Wait (for task) and WaitAll (for task array) method ensures the join operation.
Now, if you try to apply this pattern holistically to our original problem statement (to compute the power of big numbers), you will see the potential to leverage this for executing the tasks within the major phases (Steps 1, 2, and 3) concurrently (by forking off tasks), and have the phases blocking (joining these forked tasks within each phase) to mirror the sequential ordering (steps 1, 2, and 3) as advocated by the algorithm. See the following code that does lock-free parallel implementation of Schönhage-Strassen Algorithm by leveraging the System.Threading.Tasks concurrency construct:
// Concrete Product-3
public class BigNumOperations3 : BigNumOperations
{
public override string Multiply (string x, string y,
CancellationToken ct, BlockingCollection<string> log)
{
int n = x.Length;
int m = y.Length;
int prodDigits = n + m - 1;
int[] linearConvolution = new int[prodDigits];
int[][] longMultiplication = CreateMatrix(m, prodDigits);
var degreeOfParallelism = Environment.ProcessorCount;
var tasks = new Task[degreeOfParallelism];
//----------------------------Step-1
for (int taskNumber = 0;
taskNumber < degreeOfParallelism;
taskNumber++)
{
int taskNumberCopy = taskNumber;
tasks[taskNumber] = Task.Factory.StartNew(
() =>
{
var max =
m * (taskNumberCopy + 1) /
degreeOfParallelism;
var min =
m * taskNumberCopy /
degreeOfParallelism;
for (int i = min; i < max; i++)
{
int row = m - 1 - i;
int col = 0;
int iProduct;
for (int j = 0; j < n; j++)
{
col = i + j;
iProduct =
(( int ) Char
.GetNumericValue(y[i])) *
(( int ) Char
.GetNumericValue(x[j]));
longMultiplication[row][col] =
iProduct;
}
}
});
}
Task.WaitAll(tasks); //Blocking Call
//----------------------------Step-2
for (int taskNumber = 0;
taskNumber < degreeOfParallelism;
taskNumber++)
{
int taskNumberCopy = taskNumber;
tasks[taskNumber] = Task.Factory.StartNew(
() =>
{
var max =
prodDigits * (taskNumberCopy + 1) /
degreeOfParallelism;
var min =
prodDigits * taskNumberCopy /
degreeOfParallelism;
for (int j = min; j < max; j++)
{
int sum = 0;
for (int i = 0; i < m; i++)
{
sum += longMultiplication[i][j];
}
linearConvolution[j] = sum;
}
});
}
Task.WaitAll(tasks); //Blocking Call
//----------------------------Step-3
//Use code from Concrete Product-1 here...
}
}
// Concrete Factory-3
public class BigNumber3 : INumeric
{
public BigNumOperations Operations()
{
return new BigNumOperations3();
}
}The collective sample output along with the preceding code is as follows:

What we have done here in the preceding code is essentially explicit macro-range partitioning with respect to the available cores, and not spinning off in place of micro-range partitioning with respect to the outer loop. This is a strategy which has to be dealt with carefully, as results would vary with the resources available at your disposal. Deliberate calibration can yield much higher throughputs. In this context, we come to the next important pattern.