
![]()
Metadata Tables Organization
This chapter provides an overview of metadata and how it is structured. It also describes metadata validation. Later chapters will analyze individual metadata items based on the foundation presented here. I understand your possible impatience (“When will this guy quit stalling and get to the real stuff?”) but nevertheless I urge you not to skip this chapter. Far from stalling, I’m simply approaching the subject systematically. It might look the same, but the motivation is quite different, and that’s what matters.
What Is Metadata?
Metadata is, by definition, data that describes data. Like any general definition, however, this one is hardly informative. In the context of the common language runtime, metadata means a system of descriptors of all items that are declared or referenced in a module. The common language runtime programming model is inherently object oriented, so the items represented in metadata are classes and their members, with their accompanying attributes, properties, and relationships.
From a pragmatic point of view, the role played by metadata is similar to that played by type libraries in the COM world. At this general level, however, the similarities end and the differences begin. Metadata, which describes the structural aspect of a module or an assembly in minute detail, is vastly richer than the data provided by type libraries, which carry only information regarding the COM interfaces exposed by the module. The important difference is that metadata is an integral part of a managed module, which means each managed module always carries a complete, high-level, formal description of its logical structure.
Structurally, metadata is a normalized relational database. This means that metadata is organized as a set of cross-referencing rectangular tables—as opposed to, for example, a hierarchical database that has a tree structure. Each column of a metadata table contains either data or a reference to a row of another table. Metadata does not contain any duplicate data fields; each category of data resides in only one table of the metadata database. If another table needs to employ the same data, it references the table that holds the data.
For example, as Chapter 1 explained, a class definition carries certain binary attributes (flags). The behavior and features of methods of this class are affected by the class’s flags, so it would be tempting to duplicate some of the class attributes, including flags, in a metadata record describing one of the methods. But data duplication leads not only to increased database size but also to the problem of keeping all the duplications consistent.
Instead, method descriptors are stored in such a way that the parent class can always be found from a given method descriptor. Such referencing does require a certain amount of searching, which is more expensive, but for typical .NET–based applications, processor speed is not the problem; communication bandwidth and data integrity are.
If this arrangement seems less than efficient to you, think of how you would usually access the metadata if you were the runtime’s class loader. Being a class loader, you would want to load a whole class with all its methods, fields, and other members. And, as I mentioned, the class descriptor (record) carries a reference to the record of the method table that represents the first method of this class. The end of the method records belonging to this class is defined by the beginning of the next class’s method records or (for the last class) by the end of the method table. It’s the same story with the field records.
Obviously, this technique requires that the records in the method table be sorted by their parent class. The same applies to other table-to-table relationships (class-to-field, method-to-parameter, and so on). If this requirement is met, the metadata is referred to as optimized or compressed. Figure 5-1 shows an example of such metadata. The ILAsm compiler always emits optimized metadata.

Figure 5-1. An example of optimized metadata
It is possible, however (perhaps as a result of sloppy metadata emission or of incremental compilation), to have the child tables interleaved with regard to their owner classes. For example, class record A might be emitted first, followed by class record B, the method records of class B, and then the method records of class A; or the sequence might be class record A, then some of the method records of class A, followed by class record B, the method records of class B, and then the rest of the method records of class A.
In such a case, additional intermediate metadata tables are engaged, providing noninterleaved lookup tables sorted by the owner class. Instead of referencing the method records, class records reference the records of an intermediate table (a pointer table), and those records in turn reference the method records, as diagrammed in Figure 5-2. Metadata that uses such intermediate lookup tables is referred to as unoptimized or uncompressed.
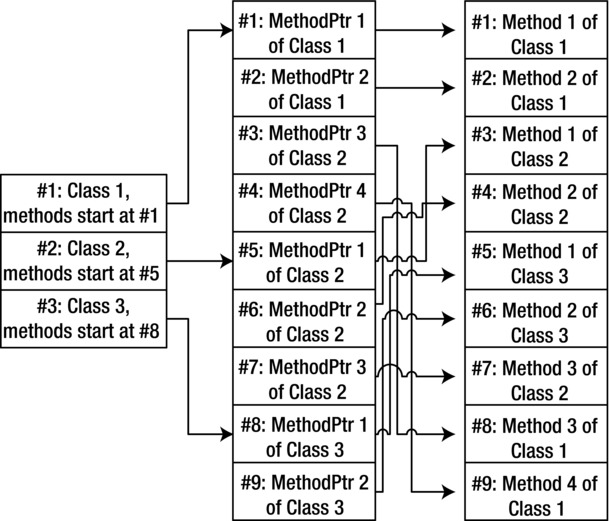
Figure 5-2. An example of unoptimized metadata
Two scenarios usually result in the emission of an uncompressed metadata structure: an “edit-and-continue” scenario, in which metadata and the IL code of a module are modified while the module is loaded in memory, and an incremental compilation scenario, in which metadata and IL code are modified in “installments.”
Heaps and Tables
Logically, metadata is represented as a set of named streams, with each stream representing a category of metadata. These streams are divided into two types: metadata heaps and metadata tables.
Heaps
A metadata heap is a storage of trivial structure, holding a contiguous sequence of items. Heaps are used in metadata to store strings and binary objects. There are three kinds of metadata heaps:
- String heap: This kind of heap contains zero-terminated character strings, encoded in UTF-8. The strings follow each other immediately. The first byte of the heap is always 0, and as a result the first string in the heap is always an empty string. The last byte of the heap must be 0 as well (in other words, the last string in the heap must be zero-terminated just like the others).
- GUID heap: This kind of heap contains 16-byte binary objects, immediately following each other. The size of the binary objects is fixed, so length parameters or terminators are not needed.
- Blob heap: This kind of heap contains binary objects of arbitrary size. Each binary object is preceded by its length (in compressed form). Binary objects are aligned on 4-byte boundaries.
The length compression formula is fairly simple. If the length (which is an unsigned integer) is 0x7F or less, it is represented as 1 byte; if the length is greater than 0x7F but no larger than 0x3FFF, it is represented as a 2-byte unsigned integer with the most significant bit set. Otherwise, it is represented as a 4-byte unsigned integer with two most significant bits set. Table 5-1 summarizes this formula.
Table 5-1. The Length Compression Formula for the Blob
Value Range |
Compressed Size |
Compressed Value (Big Endian) |
|---|---|---|
0–0x7F |
1 byte |
<value> |
0x80–0x3FFF |
2 bytes |
0x8000 | <value> |
0x4000–0x1FFFFFFF |
4 bytes |
0xC0000000 | <value> |
This compression formula is widely used in metadata. Of course, the compression works only for numbers not exceeding 0x3FFFFFFF (1,073,741,832), but this limitation isn’t a problem because the compression is usually applied to such values as lengths and counts.
General Metadata Header
The general metadata header consists of a storage signature and a storage header. The storage signature, which must be 4-byte aligned, has the structure described in Table 5-2.
Table 5-2. Structure of the Metadata Storage Signature
Type |
Field |
Description |
|---|---|---|
DWORD |
lSignature |
“Magic” signature for physical metadata, currently 0x424A5342, or, read as characters, BSJB—the initials of four “founding fathers” Brian Harry, Susan Radke-Sproull, Jason Zander, and Bill Evans (I’d better make that “founders;” Susan might object to be called a father), who started the runtime development in 1998. |
WORD |
iMajorVer |
Major version (1) |
WORD |
iMinorVer |
Minor version (1) |
DWORD |
iExtraData |
Reserved; set to 0 |
DWORD |
iVersionString |
Length of the version string |
BYTE[] |
pVersion |
Version string |
The version string usually contains the textual representation of the CLR version, for example, “v4.0.30319.” The Windows Runtime metadata (.winmd, see Chapter 18 for details) introduced in v4.5 specifically for Windows 8 and later, has version strings starting with “WindowsRuntime”, such as “WindowsRuntime 1.2;Native code 1.2.”
The storage header follows the storage signature, aligned on a 4-byte boundary. Its structure is simple, as described in Table 5-3.
Table 5-3. Metadata Storage Header Structure
Type |
Field |
Description |
|---|---|---|
BYTE |
fFlags |
Reserved; set to 0 |
BYTE |
[padding] |
|
WORD |
iStreams |
Number of streams |
The storage header is followed by an array of stream headers. Table 5-4 describes the structure of a stream header.
Table 5-4. Metadata Stream Header Structure
Type |
Field |
Description |
|---|---|---|
DWORD |
iOffset |
Offset in the file for this stream. |
DWORD |
iSize |
Size of the stream in bytes. |
char[32 ] |
rcName |
Name of the stream; a zero-terminated ASCII string no longer than 31 characters (plus zero terminator). The name might be shorter, in which case the size of the stream header is correspondingly reduced, padded to the 4-byte boundary. |
Six named streams can be present in the metadata:
- #Strings: A string heap containing the names of metadata items (class names, method names, field names, and so on). The stream does not contain literal constants defined or referenced in the methods of the module.
- #Blob: A blob heap containing internal metadata binary objects, such as default values, signatures, and so on.
- #GUID: A GUID heap containing all sorts of globally unique identifiers.
- #US: A blob heap containing user-defined strings. This stream contains string constants defined in the user code. The strings are kept in Unicode (UTF-16) encoding, with an additional trailing byte set to 1 or 0, indicating whether there are any characters with codes greater than 0x007F in the string. This trailing byte was added to streamline the encoding conversion operations on string objects produced from user-defined string constants. This stream’s most interesting characteristic is that the user strings are never referenced from any metadata table but can be explicitly addressed by the IL code (with the ldstr instruction). In addition, being actually a blob heap, the #US heap can store not only Unicode strings but any binary object, which opens some intriguing possibilities.
- #~: A compressed (optimized) metadata stream. This stream contains an optimized system of metadata tables.
- #-: An uncompressed (unoptimized) metadata stream. This stream contains an unoptimized system of metadata tables, which includes at least one intermediate lookup table (pointer table).
The streams #~ and #- are mutually exclusive—that is, the metadata structure of the module is either optimized or unoptimized; it cannot be both at the same time or be something in between. If no items are stored in a stream, the stream is absent, and the iStreams field of the storage header is correspondingly reduced. At least three streams are guaranteed to be present: a metadata stream (#~ or #-), a string stream (#Strings), and a GUID stream (#GUID). Metadata items must be present in at least a minimal configuration in even the most trivial module, and these metadata items must have names and GUIDs.
Figure 5-3 illustrates the general structure of metadata. In Figure 5-4, you can see the way streams are referenced by other streams as well as by external “consumers” such as metadata APIs and the IL code.
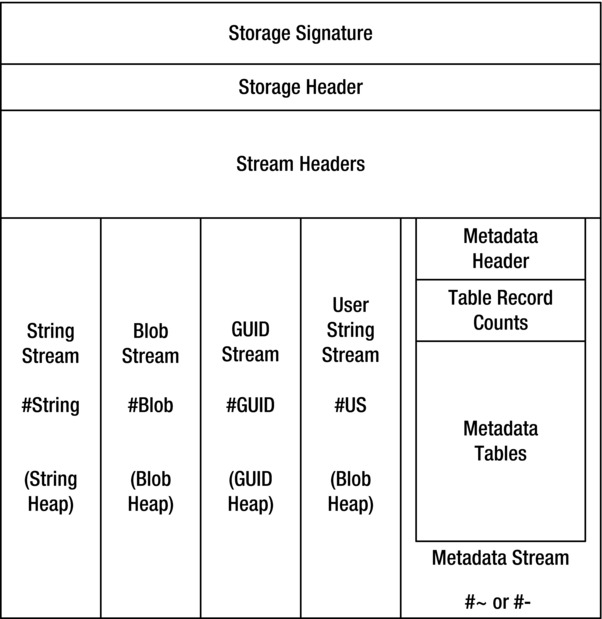
Figure 5-3. The general structure of metadata
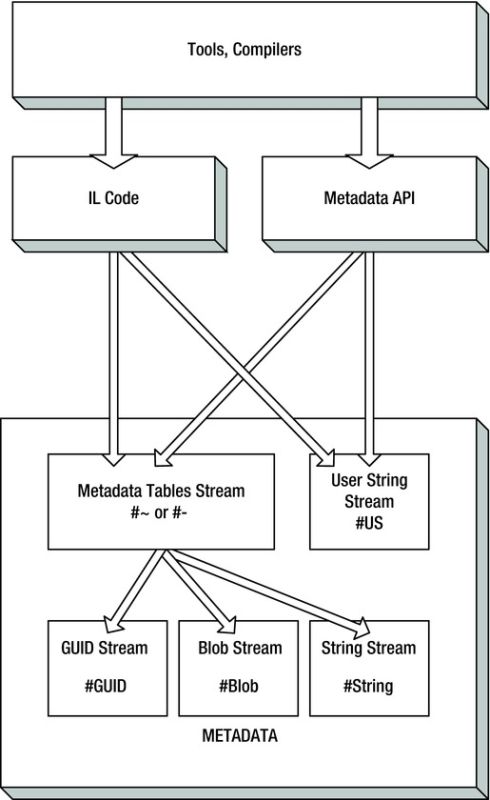
Figure 5-4. Stream referencing
Metadata Table Streams
The metadata streams #~ and #- begin with the header described in Table 5-5.
Table 5-5. Metadata Table Stream Header Structure
Size |
Field |
Description |
|---|---|---|
4 bytes |
Reserved |
Reserved; set to 0. |
1 byte |
Major |
Major version of the table schema (1 for v1.0 and v1.1; 2 for v2.0 or later). |
1 byte |
Minor |
Minor version of the table schema (0 for all versions). |
1 byte |
Heaps |
Binary flags indicate the offset sizes to be used within the heaps |
1 byte |
Rid |
Bit width of the maximal record index to all tables of the metadata; calculated at run time (during the metadata stream initialization). |
8 bytes |
MaskValid |
Bit vector of present tables, each bit representing one table (1 if present). |
8 bytes |
Sorted |
Bit vector of sorted tables, each bit representing a respective table (1 if sorted). |
This header is followed by a sequence of 4-byte unsigned integers indicating the number of records in each table marked 1 in the MaskValid bit vector.
Like any database, metadata has a schema. The schema is a system of descriptors of metadata tables and columns; in this sense, it is “meta-metadata.” A schema is not a part of metadata, and it is not an attribute of a managed PE file. Rather, a metadata schema is an attribute of the common language runtime and is hard-coded. It does not change unless there’s a major overhaul of the runtime, and even then it changes incrementally (as it changed between versions 1.0 and 2.0 of the runtime), by adding new tables and leaving the old tables unchanged.
Each metadata table has a descriptor of the structure described in Table 5-6.
Table 5-6. Metadata Table Descriptor Structure
Type |
Field |
Description |
|---|---|---|
Pointer |
pColDefs |
Pointer to an array of column descriptors |
BYTE |
cCols |
Number of columns in the table |
BYTE |
iKey |
Index of the key column |
WORD |
cbRec |
Size of a record in the table |
Column descriptors, to which the pColDefs fields of table descriptors point, have the structure described in Table 5-7.
Table 5-7. Metadata Table Column Descriptor Structure
Type |
Field |
Description |
|---|---|---|
BYTE |
Type |
Code of the column’s type |
BYTE |
oColumn |
Offset of the column |
BYTE |
cbColumn |
Size of the column in bytes |
Type, the first field of a column descriptor, is especially interesting. The metadata schema of the existing releases of the common language runtime identifies the codes for column types described in Table 5-8.
Table 5-8. Metadata Table Column Type Codes
Code |
Description |
|---|---|
0–63 |
Column holds the record index (RID) to another table; the specific code value indicates which table. RID is used as column type when the column can reference records of only one table. The width of the column is defined by the Rid field of the metadata stream header. |
64–95 |
Column holds a coded token referencing another table; the specific code value indicates the type of coded token. Tokens are references carrying the indexes of both the table and the record being referenced. Token is used as a column type when the column can reference records of more than one table. The table being addressed and the index of the record are defined by the coded token value. |
96 |
Column holds a 2-byte signed integer. |
97 |
Column holds a 2-byte unsigned integer. |
98 |
Column holds a 4-byte signed integer. |
99 |
Column holds a 4-byte unsigned integer. |
100 |
Column holds a 1-byte unsigned integer. |
101 |
Column holds an offset in the string heap (the #Strings stream). |
102 |
Column holds an offset in the GUID heap (the #GUID stream). |
103 |
Column holds an offset in the blob heap (the #Blob stream). |
The metadata schema defines 45 tables. Given the range of RID type codes, the common language runtime definitely has room for growth. At the moment, the following tables are defined:
- [0] Module: The current module descriptor.
- [1] TypeRef : Class reference descriptors.
- [2] TypeDef : Class or interface definition descriptors.
- [3] FieldPtr : A class-to-fields lookup table, which does not exist in optimized metadata (#~ stream).
- [4] Field: Field definition descriptors.
- [5] MethodPtr : A class-to-methods lookup table, which does not exist in optimized metadata (#~ stream).
- [6] Method: Method definition descriptors.
- [7] ParamPtr: A method-to-parameters lookup table, which does not exist in optimized metadata (#~ stream).
- [8] Param: Parameter definition descriptors.
- [9] InterfaceImpl: Interface implementation descriptors.
- [10] MemberRef: Member (field or method) reference descriptors.
- [11] Constant: Constant value descriptors that map the default values stored in the #Blob stream to respective fields, parameters, and properties.
- [12] CustomAttribute: Custom attribute descriptors.
- [13] FieldMarshal: Field or parameter marshaling descriptors for managed/unmanaged interoperations.
- [14] DeclSecurity: Security descriptors.
- [15] ClassLayout: Class layout descriptors that hold information about how the loader should lay out respective classes.
- [16] FieldLayout: Field layout descriptors that specify the offset or ordinal of individual fields.
- [17] StandAloneSig: Stand-alone signature descriptors. Signatures per se are used in two capacities: as composite signatures of local variables of methods and as parameters of the call indirect (calli) IL instruction.
- [18] EventMap: A class-to-events mapping table. This is not an intermediate lookup table, and it does exist in optimized metadata.
- [19] EventPtr: An event map–to–events lookup table, which does not exist in optimized metadata (#~ stream).
- [20] Event: Event descriptors.
- [21] PropertyMap: A class-to-properties mapping table. This is not an intermediate lookup table, and it does exist in optimized metadata.
- [22] PropertyPtr: A property map–to–properties lookup table, which does not exist in optimized metadata (#~ stream).
- [23] Property: Property descriptors.
- [24] MethodSemantics: Method semantics descriptors that hold information about which method is associated with a specific property or event and in what capacity.
- [25] MethodImpl: Method implementation descriptors.
- [26] ModuleRef: Module reference descriptors.
- [27] TypeSpec: Type specification descriptors.
- [28] ImplMap: Implementation map descriptors used for the platform invocation (P/Invoke) type of managed/unmanaged code interoperation.
- [29] FieldRVA: Field-to-data mapping descriptors.
- [30] ENCLog: Edit-and-continue log descriptors that hold information about what changes have been made to specific metadata items during in-memory editing. This table does not exist in optimized metadata (#~ stream).
- [31] ENCMap: Edit-and-continue mapping descriptors. This table does not exist in optimized metadata (#~ stream).
- [32] Assembly: The current assembly descriptor, which should appear only in the prime module metadata.
- [33] AssemblyProcessor: This table is unused.
- [34] AssemblyOS: This table is unused.
- [35] AssemblyRef: Assembly reference descriptors.
- [36] AssemblyRefProcessor: This table is unused.
- [37] AssemblyRefOS: This table is unused.
- [38] File: File descriptors that contain information about other files in the current assembly.
- [39] ExportedType: Exported type descriptors that contain information about public classes exported by the current assembly, which are declared in other modules of the assembly. Only the prime module of the assembly should carry this table.
- [40] ManifestResource: Managed resource descriptors.
- [41] NestedClass: Nested class descriptors that provide mapping of nested classes to their respective enclosing classes.
- [42] GenericParam: Type parameter descriptors for generic (parameterized) classes and methods.
- [43] MethodSpec: Generic method instantiation descriptors.
- [44] GenericParamConstraint: Descriptors of constraints specified for type parameters of generic classes and methods.
The last three tables were added in version 2.0 of the common language runtime. They did not exist in versions 1.0 and 1.1.
I’ll discuss the structural aspects of the various tables and their validity rules in later chapters, along with the corresponding ILAsm constructs.
RIDs and Tokens
Record indexes and tokens are the unsigned integer values used for indexing the records in metadata tables. RIDs are simple indexes, applicable only to an explicitly specified table, and tokens carry the information identifying metadata tables they reference.
RIDs
A RID is a record identifier, which is simply a one-based row number in the table containing the record. The range of valid RIDs stretches from 1 to the record count of the addressed table, inclusive. RIDs are used in metadata internally only; metadata emission and retrieval APIs do not use RIDs as parameters.
The RID column type codes (0–63) serve as zero-based table indexes. Thus, the type of the column identifies the referenced table, while the value of the table cell identifies the referenced record. This works fine as long as we know that a particular column always references one particular table and no other. Now if we only could combine RID with table identification.
Tokens
Actually, we can. The combined identification entity, referred to as a token, is used in all metadata APIs and in all IL instructions. A token is a 4-byte unsigned integer whose most significant byte carries a zero-based table index (the same as the internal metadata RID type). The remaining 3 bytes are left for the RID.
There is a significant difference between token types and internal metadata RID types, however: whereas internal RID types cover all metadata tables, the token types are defined for only a limited subset of the tables, as noted in Table 5-9.
Table 5-9. Token Types and Their Referenced Tables
Token Type |
Value (RID | (Type << 24)) |
Referenced Table |
|---|---|---|
mdtModule |
0x00000000 |
Module |
mdtTypeRef |
0x01000000 |
TypeRef |
mdtTypeDef |
0x02000000 |
TypeDef |
mdtFieldDef |
0x04000000 |
Field |
mdtMethodDef |
0x06000000 |
Method |
mdtParamDef |
0x08000000 |
Param |
mdtInterfaceImpl |
0x09000000 |
InterfaceImpl |
mdtMemberRef |
0x0A000000 |
MemberRef |
mdtCustomAttribute |
0x0C000000 |
CustomAttribute |
mdtPermission |
0x0E000000 |
DeclSecurity |
mdtSignature |
0x11000000 |
StandAloneSig |
mdtEvent |
0x14000000 |
Event |
mdtProperty |
0x17000000 |
Property |
mdtModuleRef |
0x1A000000 |
ModuleRef |
mdtTypeSpec |
0x1B000000 |
TypeSpec |
mdtAssembly |
0x20000000 |
Assembly |
mdtAssemblyRef |
0x23000000 |
AssemblyRef |
mdtFile |
0x26000000 |
File |
mdtExportedType |
0x27000000 |
ExportedType |
mdtManifestResource |
0x28000000 |
ManifestResource |
mdtGenericParam |
0x2A000000 |
GenericParam |
mdtMethodSpec |
0x2B000000 |
MethodSpec |
mdtGenericParamConstraint |
0x2C000000 |
GenericParamConstraint |
The 22 tables that do not have associated token types are not intended to be accessed from “outside,” through metadata APIs or from IL code. These tables are of an auxiliary or intermediate nature and should be accessed indirectly only, through the references contained in the “exposed” tables, which have associated token types.
The validity of these tokens can be defined simply: a valid token has a type from Table 5-9, and it has a valid RID—that is, a RID in the range from 1 to the record count of the table of a specified type.
An additional token type, quite different from the types listed in Table 5-9, is mdtString (0x70000000). Tokens of this type are used to refer to the user-defined Unicode strings stored in the #US stream.
Both the type component and the RID component of user-defined string tokens differ from those of metadata table tokens. The type component of a user-defined string token (0x70) has nothing to do with column types (the maximal column type is 103 = 0x67), which is not surprising, considering that no column type corresponds to an offset in the #US stream. As metadata tables never reference the user-defined strings, it’s not necessary to define a column type for the strings. In addition, the RID component of a user-defined string token does not represent a RID because no table is being referenced. Instead, the 3 lower bytes of a user-defined string token hold an offset in the #US stream. A side effect of this arrangement is that you cannot have the #US stream much larger than 16MB, or more exactly, all your user-defined strings except the last one must fit into 16MB short of 1B. You can make the last string as long as you like, but it must start at offset below 224, or in other words, below the 16MB boundary.
The definition of the validity of a user-defined string token is more complex. The RID (or offset) component is valid if it is greater than 0 and if the string it defines starts at a 4-byte boundary and is fully contained within the #US stream. The last condition is checked in the following way: the bytes at the offset specified by the RID component of the token are interpreted as the compressed length of the string. (Don’t forget that the #US stream is a blob heap.) If the sum of the offset and the size of compressed length brings us to a 4-byte boundary and if this sum plus the calculated length are within the #US stream size, everything is fine and the token is valid.
Coded Tokens
The discussion thus far has focused on the “external” form of tokens. You have every right to suspect that the “internal” form of tokens, used inside the metadata, is different—and it is.
Why can’t the external form also be used as internal? Because the external tokens are huge. Imagine 4 bytes for each token when we fight for each measly byte, trying to squeeze the metadata into as small a footprint as possible. (Bandwidth! Don’t forget about the bandwidth!) Compression? Alas, having the type component occupying the most significant byte, external tokens represent very large unsigned integers and thus cannot be efficiently compressed, even though their middle bytes are full of zeros. We need a fresh approach.
The internal encoding of tokens is based on a simple idea: a column must be given a token type only if it might reference several tables. (Columns referencing only one table have a respective RID type.) But any such column certainly does not need to reference all the tables.
So your first task is to identify which group of tables each such column might reference and form a set of such groups. Let’s assign each group a number, which will be a coded token type of the column. The coded token types occupy a range from 64 to 95, so you can define up to 32 groups.
Now, every group contains two or more table types. Let’s enumerate them within the group and see how many bits you will need for this enumeration. This bit count will be a characteristic of the group and hence of the respective coded token type. The number assigned to a table within the group is called a tag.
This tag plays a role roughly equivalent to that of the type component of an external token. But, unwilling to once again create large tokens full of zeros, you will this time put the tag not in the most significant bits of the token but rather in the least significant bits. Then let’s left-shift the RID n bits and add the left-shifted RID to the tag, where n is the bit width of the tag. Now you’ve got a coded token. For example, an uncoded TypeSpec token 0x1B000123 will be converted into coded TypeDefOrRef token 0x0000048E.
What about the coded token size? You know which metadata tables form each group and you know the record count of each table, so you know the maximal possible RID within the group. Say, for example, that you need m bits to encode the maximal RID. If you can fit the maximal RID (m bits) and the tag (n bits) into a 2-byte unsigned integer (16 bits), you win, and the coded token size for this group will be 2 bytes. If you can’t, you are out of luck and will have to use 4-byte coded tokens for this group. No, don’t even consider 3 bytes—it’s unbecoming.
To summarize, a coded token type has the following attributes:
- Number of referenced tables (part of the schema)
- Array of referenced table IDs (part of the schema)
- Tag bit width (part of the schema, derived from the number of referenced tables)
- Coded token size, either 2 or 4 bytes (computed at the metadata opening time from the tag width and the maximal record count among the referenced tables)
Table 5-10 lists the 13 coded token types defined in the metadata schema of the existing releases of the common language runtime.
Table 5-10. Coded Token Types
Coded Token Type |
Tag |
|---|---|
TypeDefOrRef (64): 3 referenced tables, tag size 2 |
|
TypeDef |
0 |
TypeRef |
1 |
TypeSpec |
2 |
HasConstant (65): 3 referenced tables, tag size 2 |
|
Field |
0 |
Param |
1 |
Property |
2 |
HasCustomAttribute (66): 22 referenced tables, tag size 5 |
|
Method |
0 |
Field |
1 |
TypeRef |
2 |
TypeDef |
3 |
Param |
4 |
InterfaceImpl |
5 |
MemberRef |
6 |
Module |
7 |
DeclSecurity |
8 |
Property |
9 |
Event |
10 |
StandAloneSig |
11 |
ModuleRef |
12 |
TypeSpec |
13 |
Assembly |
14 |
AssemblyRef |
15 |
File |
16 |
ExportedType |
17 |
ManifestResource |
18 |
GenericParam (v2.0+) |
19 |
GenericParamConstraint (v2.0+) |
20 |
MethodSpec (v2.0+) |
21 |
HasFieldMarshal (67): 2 referenced tables, tag size 1 |
|
Field |
0 |
Param |
1 |
HasDeclSecurity (68): 3 referenced tables, tag size 2 |
|
TypeDef |
0 |
Method |
1 |
Assembly |
2 |
MemberRefParent (69): 5 referenced tables, tag size 3 |
|
TypeDef |
0 |
TypeRef |
1 |
ModuleRef |
2 |
Method |
3 |
TypeSpec |
4 |
HasSemantics (70): 2 referenced tables, tag size 1 |
|
Event |
0 |
Property |
1 |
MethodDefOrRef (71): 2 referenced tables, tag size 1 |
|
Method |
0 |
MemberRef |
1 |
MemberForwarded (72): 2 referenced tables, tag size 1 |
|
Field |
0 |
Method |
1 |
Implementation (73): 3 referenced tables, tag size 2 |
|
File |
0 |
AssemblyRef |
1 |
ExportedType |
2 |
CustomAttributeType (74): 5 referenced tables, tag size 3 |
|
TypeRef (obsolete, must not be used) |
0 |
TypeDef (obsolete, must not be used) |
1 |
Method |
2 |
MemberRef |
3 |
String (obsolete, must not be used) |
4 |
ResolutionScope (75): 4 referenced tables, tag size 2 |
|
Module |
0 |
ModuleRef |
1 |
AssemblyRef |
2 |
TypeRef |
3 |
TypeOrMethodDef (76) (v2.0+): 2 referenced tables, tag size 1 |
|
TypeDef |
0 |
Method |
1 |
The coded token type range (64–95) provides room to add another 19 types in the future, should it ever become necessary.
Coded tokens are part of metadata’s internal affairs. The IL assembler, like all other compilers, never deals with coded tokens. Compilers and other tools read and emit metadata through the metadata import and emission APIs, either directly or through managed wrappers provided in the .NET Framework class library—System.Reflection for metadata import and System.Reflection.Emit for metadata emission. The metadata APIs automatically convert standard 4-byte tokens to and from coded tokens. IL code also uses only standard 4-byte tokens.
Nonetheless, the preceding definitions are useful to us for two reasons. First, we will need them when we discuss individual metadata tables in later chapters. Second, these definitions provide a good hint about the nature of relationships between the metadata tables.
Metadata Validation
This “good hint,” however, is merely a hint. The definitions in the preceding section provide information about which tables you can reference from a column of a certain type. It does not mean you should reference all the tables you can. Some of the groups of token types listed in Table 5-10 are wider than is actually acceptable. For example, the MemberRefParent group, which describes the tables that can contain the parents of a MemberRef record, includes the TypeDef table. But the metadata emission APIs will not accept a TypeDef token as the parent token of a MemberRef; and even if such metadata were somehow emitted, the loader would reject it.
Metadata emission APIs provide very few safeguards (most of them fairly trivial) as far as metadata validity is concerned. Metadata is an extremely complex system, and literally hundreds of validity rules need to be enforced.
High-level language compilers, such as VB or C# compilers, provide a significant level of protection against invalid metadata emission because they shield the actual metadata specification and emission from programmers. The high-level languages are concept driven and concept based, and it is the compiler’s duty to translate the language concepts to the metadata structures and IL code constructs, so a compiler can be built to emit valid structures and constructs. (Well, more or less.) On the other hand, ILAsm, like other assemblers, is a platform-oriented language and allows a programmer to generate an enormously wide range of metadata structures and IL constructs, only a fraction of which represent a valid subset.
In view of this bleak situation, we need to rely on external validation and verification tools. (Speaking of “validation and verification” is not an exercise in tautology—in the CLR lingo, the term validation is usually applied to metadata and verification to IL code.) One such tool is the common language runtime itself. The loader tests metadata against many of the validity rules, especially those whose violation could break the system. The runtime subsystem responsible for JIT compilation performs IL code verification. These processes are referred to as runtime validation and verification.
PEVerify, a stand-alone tool included in the .NET Framework SDK, offers more exhaustive validation and verification. PEVerify employs two independent subsystems, MDValidator and ILVerifier. MDValidator can also be invoked through the IL disassembler.
You can find information about PEVerify and the IL disassembler in the appendixes. Later chapters discuss various validity rules along with the related metadata structures and IL constructs.
Summary
Now that you know how the metadata is organized in principle, you are ready to examine the particular metadata items and the tables representing them. All further considerations shall concentrate on four metadata streams—#Strings, #Blob, #US, and #~—because the #GUID stream is referenced in one metadata table only (the Module table) and the #- stream (unoptimized metadata) is never emitted by the ILAsm compiler.
Here’s some advice for those of you who wonder whether it would be a good idea to spoof the metadata header to get access to the data beyond the metadata under the pretense of manipulating the metadata: forget it. The CLR loader has safeguards analyzing the consistency of the metadata headers and the metadata itself. If an inconsistency is detected, the loader refuses to open the metadata streams. Tinkering with the metadata headers does not lead to erroneous or unpredictable behavior of the module; instead, it renders the module unloadable, period.
And on this cheerful note, let’s proceed to discussion of the “real” metadata items.