
![]()
Methods
Methods are the third and last leg of the tripod supporting the entire concept of managed programming, the first two being types and fields. When it comes down to execution, types, fields, and methods are the central players, with the rest of the metadata simply providing additional information about this triad.
Method items can appear in three contexts: a method definition, a method reference (for example, when a method is called), and a method implementation (when a method provides the implementation of another method).
Method Metadata
Similar to field-related metadata, method-related metadata involves definition-specific and reference-specific metadata. In addition, method-related metadata includes the method implementation, discussed later in this chapter, as well as method semantics, method interoperability, and security metadata. (Chapter 15 describes method semantics, Chapter 18 examines method interoperability, and Chapter 17 includes method security.) Figure 10-1 shows the metadata tables involved in the method definition and referencing implementation, and their mutual dependencies. To avoid cluttering the illustration, I have not included metadata tables involved in the other three method-related aspects: method semantics, method interoperability, and security metadata. The MethodSpec table, introduced in version 2.0 of the CLR, is used to define the generic method instantiations. This table will be discussed in Chapter 12.
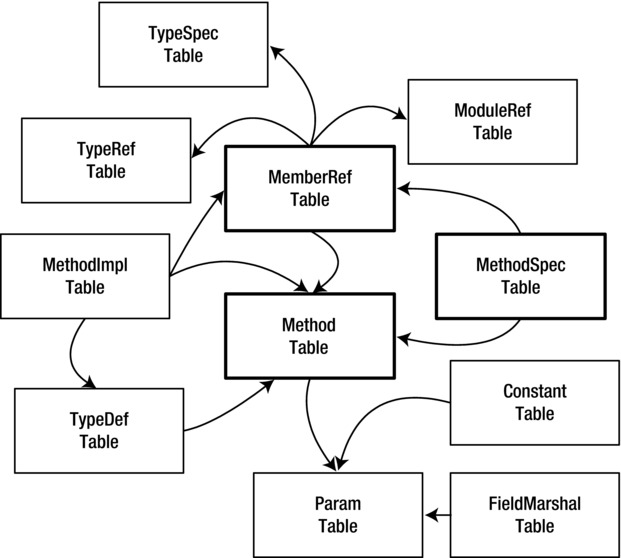
Figure 10-1. Metadata tables related to method definition and referencing
The central table for method definition is the Method table, which has the associated token type mdtMethodDef (0x06000000). A record in the Method table has six entries:
- RVA (4-byte unsigned integer): The RVA of the method body in the module. The method body consists of the header, IL code, and managed exception handling descriptors. The RVA must point to a read-only section of the PE file.
- ImplFlags (2-byte unsigned integer): Implementation binary flags indicating the specifics of the method implementation.
- Flags (2-byte unsigned integer): Binary flags indicating the method’s accessibility and other characteristics.
- Name (offset in the #Strings stream): The name of the method (not including the name of the class to which the method belongs). This entry must index a string of nonzero length no longer than 1,023 bytes in UTF-8 encoding.
- Signature (offset in the #Blob stream): The method signature. This entry must index a blob of nonzero size and must comply with the method definition signature rules described in Chapter 8.
- ParamList (RID in the Param table): The record index of the start of the parameter list belonging to this method. The end of the parameter list is defined by the start of the next method’s parameter list or by the end of the Param table (the same pattern as in method and field lists belonging to a TypeDef).
As in the case of field definition, Method records carry no information regarding the parent class of the method. Instead, the Method table is referenced in the MethodList entries of TypeDef records, indexing the start of Method records belonging to each particular TypeDef.
The RVA entry must be 0 or must hold a valid relative virtual address pointing to a read-only section of the image file. If the RVA value points to a read/write section, the loader will reject the method unless the application is run from a local drive with all security checks disabled. If the RVA entry holds 0, it means this method is implemented somewhere else (imported from a COM library, platform-invoked from an unmanaged DLL, or simply implemented by descendants of the class owning this method). All these cases are described by special combinations of method flags and implementation flags.
The ILAsm syntax for method definition is
<method_def> ::=
.method<flags> <call_conv> <ret_type> <name>(<arg_list>) < impl> {
<method_body> }
where <call_conv>, <ret_type>, and <arg_list> are the method calling convention, the return type, and the argument list defining the method signature.
For example,
. method public instance void set_X(int32value) cil managed
{
ldarg.0
ldarg.1
stfldint32 .this::x
ret
}
Method Flags
The nonterminal symbol <flags> identifies the method binary flags, which are defined in the enumeration CorMethodAttr in CorHdr.h and are described in the following list:
- Accessibility flags (mask 0x0007), which are similar to the accessibility flags of fields:
- privatescope (0x0000): This is the default accessibility. A private scope method is exempt from the requirement of having a unique triad of owner, name, and signature and hence must always be referenced by a MethodDef token and never by a MemberRef token. The privatescope methods are accessible (callable) from anywhere within current module.
- private (0x0001): The method is accessible from its owner class and from classes nested in the method’s owner.
- famandassem (0x0002): The method is accessible from types belonging to the owner’s family—that is, the owner itself and all its descendants—defined in the current assembly.
- assembly (0x0003): The method is accessible from types defined in the current assembly.
- family (0x0004): The method is accessible from the owner’s family.
- famorassem (0x0005): The method is accessible from the owner’s family and from all types defined in the current assembly.
- public (0x0006): The method is accessible from any type.
- Contract flags (mask 0x00F0):
- static (0x0010): The method is static, shared by all instances of the type.
- final (0x0020): The method cannot be overridden. This flag must be paired with the virtual flag; otherwise, it is meaningless and is ignored.
- virtual (0x0040): The method is virtual. This flag cannot be paired with the static flag.
- hidebysig (0x0080): The method hides all methods of the parent classes that have a matching signature and name (as opposed to having a matching name only). This flag is ignored by the common language runtime and is provided for the use of compilers only. The IL assembler recognizes this flag but does not use it.
- Virtual method table (v-table) control flags (mask 0x0300):
- newslot (0x0100): A new slot is created in the class’s v-table for this virtual method so that it does not override the virtual method of the same name and signature this class inherited from its base class. This flag can be used only in conjunction with the virtual flag.
- strict (0x0200): This virtual method can be overridden only if it is accessible from the overriding class. This flag can be used only in conjunction with the virtual flag.
- Implementation flags (mask 0x2C08):
- abstract (0x0400): The method is abstract; no implementation is provided. This method must be overridden by the nonabstract descendants of the class owning the abstract method. Any class owning an abstract method must have its own abstract flag set. The RVA entry of an abstract method record must be 0.
- specialname (0x0800): The method is special in some way, as described by the name.
- pinvokeimpl( <pinvoke_spec> ) (0x2000): The method has an unmanaged implementation and is called through the platform invocation mechanism P/Invoke, discussed in Chapter 18. <pinvoke_spec> in parentheses defines the implementation map, which is a record in the ImplMap metadata table specifying the unmanaged DLL exporting the method and the method’s unmanaged calling convention. If the DLL name in <pinvoke_spec> is provided, the method’s RVA must be 0, because the method is implemented externally. If the DLL name is not specified or the <pinvoke_spec> itself is not provided—that is, the parentheses are empty—the defined method is a local P/Invoke, implemented in unmanaged native code embedded in the current PE file; in this case, its RVA must not be 0 and must point to the location, in the current PE file, of the native method’s body.
- unmanagedexp (0x0008): The managed method is exposed as an unmanaged export. This flag is not currently used by the common language runtime.
- Reserved flags (cannot be set explicitly; mask 0xD000):
- rtspecialname (0x1000): The method has a special name reserved for the internal use of the runtime. Four method names are reserved: .ctor for instance constructors, .cctor for class constructors, _VtblGap* for v-table placeholders, and _Deleted* for methods marked for deletion but not actually removed from metadata. The keyword rtspecialname is ignored by the IL assembler and is displayed by the IL disassembler for informational purposes only. This flag must be accompanied by a specialname flag.
- [no ILAsm keyword] (0x4000): The method either has an associated DeclSecurity metadata record that holds security details concerning access to the method or has the associated custom attribute System.Security.SuppressUnmanagedCodeSecurityAttribute.
- reqsecobj (0x8000): This method calls another method containing a security code, so it requires an additional stack slot for a security object. This flag is formally under the Reserved mask, so it cannot be set explicitly. Setting this flag requires emitting the pseudocustom attribute System.Security.DynamicSecurityMethodAttribute. When the IL assembler encounters the keyword reqsecobj, it does exactly that: emits the pseudocustom attribute and thus sets this “reserved” flag. Since anybody can set this flag by emitting the pseudocustom attribute, I wonder what the reason was for putting this flag under the Reserved mask. This flag could just as well been left as assignable.
I’ve used the word implementation here and there rather extensively; perhaps some clarification is in order, to avoid confusion. First, note that method implementation in the sense of one method providing the implementation for another is discussed later in this chapter. Implementation-specific flags of a method are not related to that topic; rather, they indicate the features of implementation of the current method. Second, a Method record contains two binary flag entries: Flags and ImplFlags (implementation flags). It so happens that part of Flags (mask 0x2C08) is also implementation related. That’s a lot of implementations. Thus far, I have been talking about the implementation part of Flags. For information about ImplFlags, see “Method Implementation Flags” later in this chapter.
Method Name
A method name in ILAsm either is a simple name or (in version 2.0 or later) a dotted name or is one of the two keywords .ctor or .cctor. As you already know, .ctor is the reserved name for instance constructors, while .cctor is reserved for class constructors or type initializers. In ILAsm, .ctor and .cctor are keywords, so they should not be single quoted as any other irregular simple name.
The general requirements for a method name are straightforward: the name must contain 1 to 1,023 bytes in UTF-8 encoding plus a zero terminator, and it should not match one of the four reserved method names (.ctor, .cctor, _VtblGap*, _Deleted* ) unless you really mean it. If you give a method one of these reserved names, the common language runtime treats the method according to this name.
Method Implementation Flags
The nonterminal symbol <impl> in the method definition form denotes the implementation flags of the method (the ImplFlags entry of a Method record). The implementation flags are defined in the enumeration CorMethodImpl in CorHdr.h and are described in the following list:
- Code type (mask 0x0003):
- cil (0x0000): The default. The method is implemented in common intermediate language (CIL, a.k.a. IL or MSIL). Yes, I realize that CIL does not sound like a good abbreviation for those familiar with the innards of the Visual C++ compiler, because in that area it traditionally means “C intermediate language.” You can use the il keyword if you don’t like cil. Or don’t use either of them; it is a default flag anyway.
- native (0x0001): The method is implemented in native platform-specific code.
- optil (0x0002): The method is implemented in optimized IL. The optimized IL is not supported in existing releases of the common language runtime, so this flag should not be set.
- runtime (0x0003): The method implementation is automatically generated by the runtime itself. Only certain methods from the base class library (Mscorlib.dll) carry this flag. If this flag is set, the RVA of the method must be 0.
- Code management (mask 0x0004):
- Implementation and interoperability (mask 0x10D8):
- forwardref (0x0010): The method is defined, but the IL code of the method is not supplied. This flag is used primarily in edit-and-continue scenarios and in managed object files, produced by the Visual C++ compiler. This flag should not be set for any of the methods in a managed PE file.
- preservesig (0x0080): The method signature must not be mangled during the interoperation with classic COM code, which is discussed in Chapter 18. As I mentioned in Chapter 1, in versions 4.0 and later this flag should be set on declarations of P/Invoke methods as well.
- internalcall (0x1000): Reserved for internal use. This flag indicates that the method is internal to the runtime and must be called in a special way. If this flag is set, the RVA of the method must be 0.
- synchronized (0x0020): Instruct the JIT compiler to automatically insert code to take a lock on entry to the method and release the lock on exit from the method. When an instance synchronized method is called, the lock is taken on the instance reference (the this parameter). For static methods, the lock is taken on the System.Type object associated with the class of the method. Methods belonging to value types cannot have this flag set.
- noinlining (0x0008): The runtime is not allowed to inline the method—that is, to replace the method call with explicit insertion of the method’s IL code.
Take a look at the examples shown here:
.method public static int32Diff(int32,int32) cil managed
{
...
}
.method publicvoid .ctor( ) runtime internalcall{}
Method parameters reside in the Param metadata table, whose records have three entries:
- Flags (2-byte unsigned integer): Binary flags characterizing the parameter.
- Sequence (2-byte unsigned integer): The sequence number of the parameter, with 0 corresponding to the method return.
- Name (offset in the #Strings stream): The name of the parameter, which can be zero length (because the parameter name is used solely for Reflection and is not involved in any resolution by name). For the method return, it must be zero length.
Parameter flags are defined in the enumeration CorParamAttr in CorHdr.h and are described in the following list:
- Input/output flags (mask 0x0013):
- in (0x0001): Input parameter.
- out (0x0002): Output parameter.
- opt (0x0010): Optional parameter.
- Reserved flags (cannot be set explicitly; mask 0xF000):
- [no ILAsm keyword] (0x1000): The parameter has an associated Constant record. The flag is set by the metadata emission API when the respective Constant record is emitted.
- marshal(<native_type>) (0x2000): The parameter has an associated FieldMarshal record specifying how the parameter must be marshaled when consumed by unmanaged code (interoperation with unmanaged code is described in Chapter 18).
To describe the ILAsm syntax of parameter definition, let me remind you of the method definition form, which is
<method_def> ::=
.method<flags> <call_conv> <ret_type> <name>(<arg_list>) < impl> {
<method_body> }
where
<ret_type> ::= <type> [ marshal(<native_type>)];
<arg_list> ::= [ <arg> [,<arg>*] ];
<arg> ::= [ [<in_out_flag>]* ] <type> [ marshal(<native_type>)]
[<p_name>];
<in_out_flag> ::= in| out| opt
Obviously, <p_name> is the name of the parameter, which, if provided, must be a simple name.
Here is an example of parameter definitions:
.method public static int32 marshal(int) Diff(
[ in] int32 marshal(int) First,
[ in] int32 marshal(int) Second)
{
...
}
This syntax takes care of all the entries of a Param record (Flags, Sequence, Name) and, if needed, those of the associated FieldMarshal record (Parent, NativeType).
To set the default values for the parameters, which are records in the Constant table, you need to add parameter specifications within the method scope:
<param_const_def> ::= .param[<sequence>] = <const_type> [ (<value>) ]
<sequence> is the parameter’s sequence number. This number should not be 0, because a 0 sequence number corresponds to the return type, and a “default return value” does not make sense. <const_type> and <value> are the same as for field default value definitions, described in Chapter 9. For example,
.method public static int32 marshal(int) Diff(
[ in] int32 marshal(int) First,
[ opt] int32 marshal(int) Second)
{
.param[2] = int32(0)
...
}
According to the common language runtime metadata model, it is not necessary to emit a Param record for each return or argument of a method. Rather, it must be done only if you want to specify the name, flags, marshaling, or default value. The IL assembler emits Param records for all arguments unconditionally and for a method return only if marshaling is specified. The name, flags, and default value are not applicable to a method return.
Referencing the Methods
Method references, like field references, translate into either MethodDef tokens or MemberRef tokens. As a rule, a reference to a locally defined method translates into a MethodDef token. However, even a locally defined method can be represented by a MemberRef token; and in certain cases, such as references to vararg methods, it must be represented by a MemberRef token.
The ILAsm syntax for method referencing is as follows:
<method_ref> ::=
[ method] <call_conv> <ret_type> <class_ref>::<name>(<arg_list>)
The method keyword, with no leading dot, is used in the following two cases in which the kind of metadata item being referenced is not clear from the context:
- When a method is referenced as an argument of the ldtoken instruction
- When a method is referenced in an explicit specification of a custom attribute’s owner (see Chapter 16 for more information)
The same rules apply to the use of the field keyword in field references. The method keyword is used in one additional context: when specifying a function pointer as a type of field, variable, or parameter (see Chapter 8). That case, however, involves not a method reference but a signature definition.
Flags, implementation flags, and parameter-related information (names, marshaling, and so on) are not specified in a method reference. As you know, a MemberRef record holds only the member parent’s token, name, and signature—the three elements needed to identify a method or a field unambiguously. Here are a few examples of method references:
call instance void Foo::Bar(int32,int32)
ldtoken method instance void Foo::Bar(int32,int32)
In the case of method references, the nonterminal symbol <class_ref> can be a TypeDef, TypeRef, TypeSpec, or ModuleRef:
call instance void Foo::Bar(int32,int32) // TypeDef
call instance void[OtherAssembly]Foo::Bar(int32, int32)// TypeRef
call instance void class Foo[]::Bar(int32,int32) // TypeSpec
call void[ .moduleOther.dll]::Bar(int32, int32) // ModuleRef
Method Implementation Metadata
Method implementations represent specific metadata describing method overriding, in which one virtual method’s implementation is substituted for another virtual method’s implementation. The method implementation metadata is held in the MethodImpl table, which has the following structure:
- Class (RID in the TypeDef table): The record index of the TypeDef implementing a method—in other words, replacing the method’s implementation with that of another method.
- MethodBody (coded token of type MethodDefOrRef): A token indexing a record in the Method table that corresponds to the implementing method—that is, to the method whose implementation substitutes for another method’s implementation. A coded token of this type can point to the MemberRef table as well, but this is illegal in the existing releases of the common language runtime. The method indexed by MethodBody must be virtual. In the existing releases of the runtime, the method indexed by MethodBody must belong to the class indexed by the Class entry.
- MethodDecl (coded token of type MethodDefOrRef): A token indexing a record in the Method table or the MemberRef table that corresponds to the implemented method—that is, to the method whose implementation is being replaced by another method’s implementation. The method indexed by MethodDecl must be virtual.
Static, Instance, Virtual Methods
We can classify methods in many ways: global methods vs. member methods, variable argument lists vs. fixed argument lists, and so on. Global and vararg methods are discussed in later sections. In this section, I’ll focus on static vs. instance methods. Take a look at Figure 10-2.
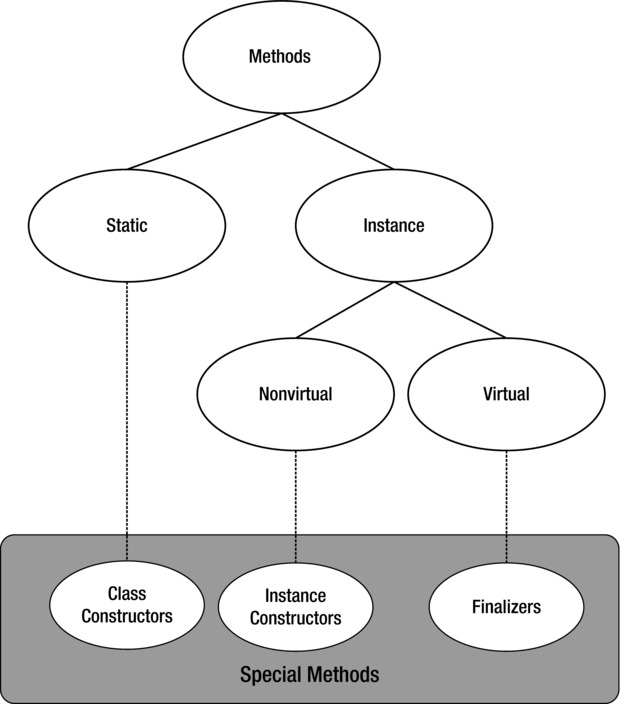
Figure 10-2. Method classification
Static methods are shared by all instances of a type. They don’t require an instance reference (this) and cannot access instance members unless the instance reference is provided explicitly. When a type is loaded, static methods are placed in a separate typewide table.
The signature of a static method is exactly as it is specified, with the first specified argument being number 0.
.method public static void Bar(int32 i, float32 r)
{
ldarg.0// Load int32 i on stack
...
}
Instance methods are instance specific and have the this instance reference as an unlisted first (number 0) argument of the signature.
.method public instance void Bar(int32 i, float32 r)
{
ldarg.0// Load instance pointer on stack
ldarg.1// Load int32 i on stack
...
}
![]() Note Be careful about the use of the keyword instance in specifying the method calling convention. When a method is defined, its flags—including the static flag—are explicitly specified. Because of this, at definition time it’s not necessary to specify the instance calling convention—it can be inferred from the presence or absence of the static flag. When a method is referenced, however, its flags are not specified, so in this case the instance keyword must be specified explicitly for instance methods; otherwise, the referenced method is presumed static. This creates a seeming contradiction: a method when declared is instance by default (no static flag specified), and the same method when referenced is static by default (no instance specified). But static is a flag and instance is a calling convention, so in fact we’re dealing with two different default options here.
Note Be careful about the use of the keyword instance in specifying the method calling convention. When a method is defined, its flags—including the static flag—are explicitly specified. Because of this, at definition time it’s not necessary to specify the instance calling convention—it can be inferred from the presence or absence of the static flag. When a method is referenced, however, its flags are not specified, so in this case the instance keyword must be specified explicitly for instance methods; otherwise, the referenced method is presumed static. This creates a seeming contradiction: a method when declared is instance by default (no static flag specified), and the same method when referenced is static by default (no instance specified). But static is a flag and instance is a calling convention, so in fact we’re dealing with two different default options here.
Instance methods are divided into virtual and nonvirtual methods, identified by the presence or absence of the virtual flag. The virtual methods of a class can be called through the virtual method table (v-table) of this class, which adds a level of indirection to implement so-called late binding. Method calling through the v-table (virtual dispatch) is performed by a special virtual call instruction (callvirt). Virtual methods can be overridden in derived classes by these classes’ own virtual methods of the same signature and name—and even of a different name, although such overriding requires an explicit declaration, as described later in this chapter. Virtual methods can be abstract or might offer some implementation.
If you have a nonvirtual method declared in a class, it does not mean you can’t declare another nonvirtual method with the same name and signature in a class derived from the first one. You can, but it will be a different method, having nothing to do with the method declared in the base class. Such a method in the derived class hides the respective method in the base class, but the hidden method can still be called if you explicitly specify the owning class.
If you do the same with virtual methods, however, the method declared in the derived class actually overrides (replaces in the v-table) the method declared in the base class. This is true unless, of course, you specify the newslot flag on the overriding method, in which case the overriding method will occupy a new entry of the v-table and hence will not really be overriding anything.
To illustrate this point, take a look at the following code from the sample file Virt_not.il on the Apress web site:
.class public A
{
.method public specialname void .ctor()
{
ldarg.0
call instance void[mscorlib]System.Object:: .ctor()
ret
}
.method public void Foo()
{
ldstr"A::Foo"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method publicvirtual void Bar()
{
ldstr"A::Bar"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method public virtual void Baz()
{
ldstr"A::Baz"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
}
.class public B extends A
{
.method public specialname void .ctor()
{
ldarg.0
call instance void A:: .ctor()
ret
}
.method public void Foo()
{
ldstr"B::Foo"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method public virtual void Bar()
{
ldstr"B::Bar"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method publicvirtual newslot void Baz()
{
ldstr"B::Baz"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
}
.method public static void Exec()
{
.entrypoint
newobj instance void B::.ctor() // Create instance of derived class
castclass class A // Cast it to base class
dup // We need 3 instance pointers
dup // On stack for 3 calls
call instance void A::Foo()
callvirt instance void A::Bar()
callvirt instance void A::Baz()
ret
}
If you compile and run the sample, you’ll receive this output:
A:FooB:BarA:BazThe method A::Foo is nonvirtual; hence, declaring B::Foo does not affect A::Foo in any way. So when you cast B to A and call A::Foo, B::Foo does not enter the picture; it’s a different method.
The A::Bar method is virtual, as is B::Bar, so when you create an instance of B, B::Bar replaces A::Bar in the v-table. Casting B to A after that does not change anything: B::Bar is sitting in the v-table of the class instance, and A::Bar is gone. Hence, when you call A::Bar using virtual dispatch, the “usurper” B::Bar is called instead.
Both the A::Baz and B::Baz methods are virtual, but B::Baz is marked newslot. Thus, instead of replacing A::Baz in the v-table, B::Baz takes a new entry and peacefully coexists with A::Baz. Since A::Baz is still present in the v-table of the instance, the situation is practically (oops, almost wrote “virtually”; I should watch it; we can’t have puns in such a serious book) identical to the situation with A::Foo and B::Foo, except that the calls are done through the v-table. The Visual Basic .NET compiler likes this concept and uses it rather extensively.
If you don’t want a virtual method to be overridden in the class descendants, you can mark it with the final flag. If you try to override a final method, the loader fails and throws a TypeLoad exception.
Instances of unboxed value types don’t have pointers to v-tables. It is perfectly legal to declare the virtual methods as members of a value type, but these methods can be virtually called only from a boxed instance of the value type:
.class public value XXX
{
.method public void YYY( )
{
...
}
.method public virtual void ZZZ( )
{
...
}
}
.method public static void Exec( )
{
.entrypoint
.locals init(valuetype XXX xxx) // Variable xxx is an
// Instance of XXX
ldloca xxx // Load managed ptr to xxx
call instance void XXX::YYY( ) // Legal: access to value
// type member
// by managed ptr
ldloca xxx
callvirt instance void XXX::ZZZ( )// Illegal: virtual call of
// methods possible only
// by object reference.
ldloca xxx
call instance void XXX::ZZZ( ) // Legal: nonvirtual call,
// access to value type member
// by managed ptr.
ldloc xxx // Load instance of XXX.
box valuetype XXX // Convert it to object reference.
callvirt instancevoid XXX::ZZZ( )// Legal
...
}
Explicit Method Overriding
Thus far, I’ve discussed implicit virtual method overriding—that is, a virtual method defined in a class overriding another virtual method of the same name and signature, defined in the class’s ancestor or an interface the class implements. But implicit overriding covers only the simplest cases.
Consider the following problem: class A implements interfaces IX and IY, and each of these interfaces defines its own virtual method called int32 Foo(int32). It is known that these methods are different and must be implemented separately. Implicit overriding can’t help in this situation. It’s time to use the MethodImpl metadata table.
The MethodImpl metadata table contains descriptors of explicit method overrides. An explicit override states which method overrides which other method. To define an explicit override in ILAsm, the following directive is used within the scope of the overriding method:
.override<class_ref>::<method_name>
The signature of the method need not be specified because the signature of the overriding method must match the signature of the overridden method, and the signature of the overriding method is known: it’s the signature of the current method. For example,
.class public interface IX {
.method public abstract virtual int32Foo(int32) { }
}
.class public interface IY {
.method public abstract virtual int32Foo(int32) { }
}
.class public A implements IX,IY {
.method public virtual int32XFoo(int32) {
.override IX::Foo
...
}
.method public virtual int32YFoo(int32) {
.override IY::Foo
...
}
}
Not surprisingly, you can’t override the same method with two different methods within the same class: there is only one slot in the v-table to be overridden. However, you can use the same method to override several virtual methods. Let’s have a look at the following code from the sample file Override.il on the Apress web site:
.class public A
{
.method public specialname void .ctor()
{
ldarg.0
call instance void[mscorlib]System.Object:: .ctor()
ret
}
.method public void Foo()
{
ldstr"A::Foo"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method publicvirtual void Bar()
{
ldstr"A::Bar"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method public virtual void Baz()
{
ldstr"A::Baz"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
}
.class public B extends A
{
.method publicspecialname void .ctor()
{
ldarg.0
call instance void A:: .ctor()
ret
}
.method public void Foo()
{
ldstr"B::Foo"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method public virtual void BarBaz()
{
.override A::Bar
.override A::Baz
ldstr"B::BarBaz"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
}
...
.method publicstatic void Exec()
{
.entrypoint
newobj instance void B:: .ctor()// Create instance of derived class
castclass class A // Cast it to base class
dup // We need 3 instance pointers
dup // On stack for 3 calls
call instance void A::Foo()
callvirt instance void A::Bar()
callvirt instance void A::Baz()
...
ret
}
The output of this code demonstrates that the method B::BarBaz overrides both A::Bar and A::Baz:
A::FooB::BarBazVirtual method overriding, both implicit and explicit, is propagated to the descendants of the overriding class, unless the descendants themselves override those methods. The second half of the sample file Override.il demonstrates this:
...
.class public C extends B
{
.method publicspecialname void .ctor()
{
ldarg.0
call instance void B:: .ctor()
ret
}
// No overrides; let's inherit everything from B
}
.method public static void Exec()
{
.entrypoint
...
newobj instance void C:: .ctor()// Create instance of derived class
castclass class A // Cast it to "grandparent"
dup // We need 3 instance pointers
dup // On stack for 3 calls
call instance void A::Foo()
callvirt instance void A::Bar()
callvirt instance void A::Baz()
ret
}
The output is the same, which proves that class C has inherited the overridden methods from class B:
A::FooB::BarBazB::BarBazILAsm supports an extended form of the explicit override directive, placed within the class scope:
.override<class_ref>::<method_name> with<method_ref>
For example, the overriding effect would be the same in the preceding code if you defined class B like so:
.class public B extends A
{
.method public specialname void .ctor()
{
ldarg.0
call instance void A ::.ctor()
ret
}
.methodpublic void Foo()
{
ldstr"B::Foo"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.method public virtual void BarBaz()
{
ldstr"B::BarBaz"
call void[mscorlib]System.Console::WriteLine(string)
ret
}
.override A::Bar withinstance void B::BarBaz()
.override A::Baz with instance void B::BarBaz()
}
In the extended form of the .override directive, the overriding method must be fully specified because the extended form is used within the overriding class scope, not within the overriding method scope.
To tell the truth, the extended form of the .override directive is not very useful in the existing versions of the common language runtime because the overriding methods are restricted to those of the overriding class. Under these circumstances, the short form of the directive is sufficient, and I doubt that anyone would want to use the more cumbersome extended form. But I’ve noticed that in this industry the circumstances tend to change.
One more note: you probably have noticed that the sample Override.il looks tedious and repetitive: similar constructors of the classes and multiple calls to [mscorlib]System.Console::WriteLine(string). As was discussed in Chapter 3, version 2.0 or later of the ILAsm allows you to streamline the programming by means of defines, typedefs, and the special keywords .this, .base, and .nester. Have a look at the sample Override_v2.il on the Apress web site:
#define DEFLT_CTOR
" .method public specialname void .ctor()
{ ldarg.0; call instance void .base:: .ctor(); ret}"
.typedef methodvoid[mscorlib]System.Console::WriteLine(string) as PrintString
.class public A
{
DEFLT_CTOR
.method public void Foo()
{
ldstr"A::Foo"
call PrintString
ret
}
.method public virtual void Bar()
{
ldstr"A::Bar"
call PrintString
ret
}
.method publicvirtual void Baz()
{
ldstr"A::Baz"
call PrintString
ret
}
}
.class public B extends A
{
DEFLT_CTOR
.methodpublic void Foo()
{
ldstr"B::Foo"
call PrintString
ret
}
.method public virtual void BarBaz()
{
.override .base::Bar
.override .base::Baz
ldstr"B::BarBaz"
call PrintString
ret
}
}
...
.class public C extends B
{
DEFLT_CTOR
// No overrides; let's inherit everything from B
}
.method publicstatic void Exec()
{
.entrypoint
...
newobj instance void C:: .ctor()// Create instance of derived class
castclass class A // Cast it to "grandparent"
dup // We need 3 instance pointers
dup // On stack for 3 calls
call instance void A::Foo()
callvirt instance void A::Bar()
callvirt instance void A::Baz()
ret
}
Not only is sample Override_v2.il easier to read and to type, it is compiled faster (only marginally; you will not notice any effect compiling such small sample). I will leave it to you to modify the Virt_not.il sample in the same way. Just don’t forget that these syntax enhancements are specific to version 2.0 or later and are not supported in versions 1.0 and 1.1.
Method Overriding and Accessibility
Can I override an inaccessible virtual method? For example, if class A has private virtual method Foo, can I derive class B from A and override Foo? I know I cannot call A::Foo, but I don’t want to call it; I want to override it so A calls my own B::Foo. Can I?
“Yes you can,” says C++, “exactly because you are not calling the private method Foo of A.”
“No you cannot,” says C#, “because you have no access whatsoever to the private method Foo of A.”
“Eh?” says Visual Basic.... No, no, I’m just kidding, of course. Actually, VB sides with C#.
So what should the common language runtime say in this regard? As usual, it finds some common ground that is acceptable to all languages.
There is the special flag strict (0x0200) that controls the “overridability” of a virtual method. If the method is declared strict virtual, then it can be overridden only by classes that have access to it. A private strict virtual method, for example, cannot be overridden in principle, so it just as well might have been marked final.
If the flag strict is not specified, then the method can be overridden without any regard to its accessibility.
So C# and VB declare their methods strict virtual, C++ declares its methods virtual, and everyone is happy. (Note that C# and VB put the flag strict only on virtual methods with limited accessibility, such as “internal”; this flag is meaningless on public and protected methods, and private virtual methods are forbidden in these languages.)
An interesting thing about this situation is that the explicit overrides are always bound to the accessibility, as if all virtual methods were strict virtual. This creates a regrettable asymmetry between implicit and explicit overriding.
One more note about overriding and accessibility: you cannot override a virtual method with a method that has more restricted accessibility. For example, you cannot override a public method with a family method, but you can override a family method with a public method. This rule works for both implicit and explicit overrides. I leave it to you to figure out the reasoning behind this rule.
Method Header Attributes
The RVA value (if it is nonzero) of a Method record points to the method body. The managed method body consists of a method header, IL code, and an optional managed exception handling (EH) table, as shown in Figure 10-3.
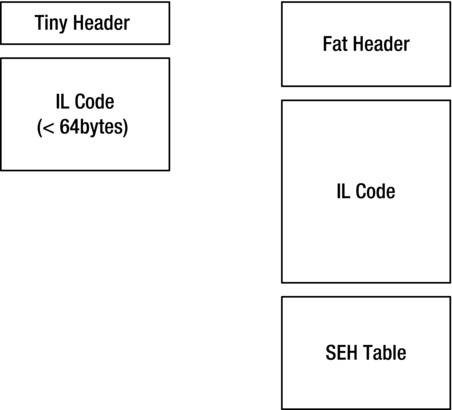
Figure 10-3. Managed method body structure
Two types of method headers—fat and tiny—are defined in CorHdr.h. The first two bits of the header indicate its type: bit 10 stands for the tiny format, and bit 11 stands for the fat format. Why do we need two bits for a simple dichotomy? Speaking hypothetically, the day might come when more method header types are introduced.
A tiny method header is only 1 byte in size, with the first two (least significant) bits holding the type—10—and the six remaining bits holding the method IL code size in bytes. A method is given a tiny header if it has neither local variables nor managed exception handling, if it works fine with the default evaluation stack depth of 8 slots, and if its code size is less than 64 bytes. A fat header is 12 bytes in size and has the structure described in Table 10-1. The fat headers must begin at 4-byte boundaries. Figure 10-4 shows the structures of both tiny and fat method headers.
Table 10-1. The Fat Header Structure
Entry Size |
Description |
|---|---|
The lower 2 bits hold the fat header type code (0x3); the next 10 bits hold Flags. The upper 4 bits hold the size of the header in DWORDs and must be set to 3. Currently used flags are 0x2, which indicates that more sections follow the IL code—that is, an exception handling table is present—and 0x4, which indicates that local variables will be initialized to 0 automatically on entry to method. |
|
WORD |
MaxStack is the maximal evaluation stack depth in slots. Stack size in IL is measured not in bytes but in slots, with each slot able to accept one item regardless of the item’s size. The default value is 8 slots, and the stack depth can be set explicitly in ILAsm by the directive .maxstack <integer> used inside the method scope. Be careful about trying to economize the method runtime footprint by specifying .maxstack lower than the default: if the specified stack depth differs from the default depth, the IL assembler has no choice but to give the method a fat header even if the method has neither local variables nor exception handling table, and its code size is less than 64 bytes. |
CodeSize is the size of the IL code in bytes. |
|
DWORD |
LocalVarSigTok is the token of the local variables signature (token type 0x11000000). Chapter 8 discusses the structure of the local variables signature. If the method has no local variables, this entry is set to 0. |
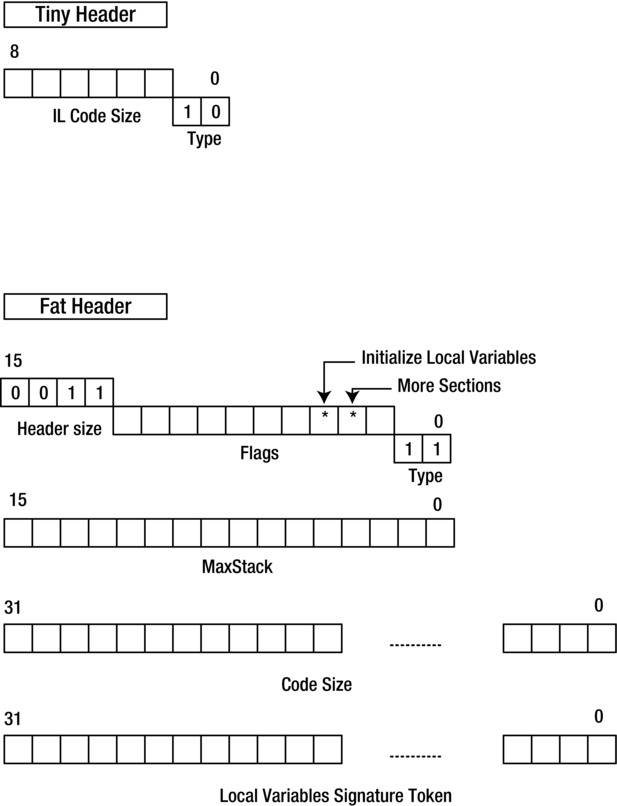
Figure 10-4. The structures of tiny and fat method headers
Local variables are the typed data items that are declared within the method scope and exist from the moment the method is called until it returns. ILAsm allows us to assign names to local variables and reference them by name, but IL instructions address the local variables by their zero-based ordinals.
When the source code is compiled in debug mode, the local variable names are stored in the PDB file accompanying the module, and in this case the local variable names might survive round-tripping. In general, however, these names are not preserved because they, unlike the names of fields and method parameters, are not part of the metadata.
All the local variables, no matter when they are declared within the method scope, form a single signature, kept in the StandAloneSig metadata table (token type 0x11000000). The token referencing respective signature is part of the method header.
Local variables are declared in ILAsm as follows:
.method public void Foo(int32 ii, int32 jj)
{
.locals init(float32 ff, float64 dd, object oo, string ss)
...
}
The init keyword sets the flag 0x4 in the method header, indicating that the JIT compiler must inject the code initializing all local variables before commencing the method execution. Initialization means that for all variables of value types, which are allocated upon declaration, the corresponding memory is zeroed, and all variables of object reference types are set to null. Code that contains methods without a local variable initialization flag set is deemed unverifiable and can be run only with verification disabled.
ILAsm does not require that all local variables be declared in one place; the following is perfectly legal:
.method public void Foo(int32ii, int32jj)
{
.locals init(float32ff, float64dd, object oo, string ss)
...
{
.locals(int32kk, bool bb)
...
}
...
{
.locals(int32mm, float32f)
...
}
...
}
In this case, the summary local variables signature will contain the types float32, float64, object, string, int32, bool, int32, and float32. Repeating init in subsequent local variable declarations of the same method is not necessary because any one of the .locals init directives sets the local variable initialization flag.
It’s obvious enough that there is a redundant local variable slot in the composite signature: by the time you need mm, you don’t need kk anymore, so you could reuse the slot and reduce the composite signature. In ILAsm, you can do that by explicitly specifying the zero-based slot numbers for local variables.
.method public void Foo(int32ii, int32jj)
{
.locals init([0] float32ff, [1] float64dd,
[2] object oo, [3] string ss)
...
{
.locals([4] int32kk, [5] bool bb)
...
}
...
{
.locals([4] int32mm, [6] float32f)
...
}
...
}
Could you also reuse slot 5 for variable f? No, because the type of slot 5 is bool, and you need a slot of type float32 for f. Only the slots holding local variables of the same type and used within nonoverlapping scopes can be reused.
![]() Note The number of local variables declared in a method is completely unrelated to the .maxstack value, which depends only on how many items you might have to load simultaneously for computational purposes. For example, if you declare 20 local variables, you don’t need to declare .maxstack 20; but if your method is calling another method that takes 20 arguments, you need to ensure that the stack has sufficient depth, because you will need at least to load all 20 arguments on the stack to make the call.
Note The number of local variables declared in a method is completely unrelated to the .maxstack value, which depends only on how many items you might have to load simultaneously for computational purposes. For example, if you declare 20 local variables, you don’t need to declare .maxstack 20; but if your method is calling another method that takes 20 arguments, you need to ensure that the stack has sufficient depth, because you will need at least to load all 20 arguments on the stack to make the call.
The number of local variables for any given method cannot exceed 65535 (0xFFFF), because the local variable ordinals are represented in the CLR by unsigned short integers. The same limitation is imposed on the number of method parameters (including the return), for the same reason.
Class constructors, or type initializers, are the methods specific to a type as a whole that run after the type is loaded and before any of the type’s members are accessed. You’ve already encountered class constructors in the preceding chapter, which discussed approaches to static field initialization. That is exactly what class constructors are most often used for: static field initialization.
Class constructors are static, have specialname and rtspecialname flags, cannot use the vararg calling convention, have neither parameters nor a return value (that is, the return type is void), and have the name .cctor, which in ILAsm is a keyword rather than a name. Because of this, only one class constructor per type can be declared. Normally, class constructors are never called from the IL code. If a type has a class constructor, this constructor is executed automatically after the type is loaded. However, a class constructor, like any other static method, can be called explicitly. As a result of such a call, the global fields of the type are reset to their initial values. Calling .cctor explicitly does not lead to type reloading.
Class Constructors and the beforefieldinit Flag
The class constructors are executed before any members (static or instance) of the classes are accessed. Normally, it means that a .cctor is executed right before first access to a static member of the class or before the first class instantiation, whichever comes first.
However, if the class has the beforefieldinit flag set (see Chapter 7), the invocation of .cctor happens on a “relaxed” (as it is called in the Ecma International/ISO standard) schedule—the .cctor is supposed to be called any time, at CLR discretion, prior to the first access to a static field of the class.
In fact, the .cctor invocation schedule in presence of the beforefieldinit flag is anything but “relaxed:” the .cctor is invoked right when the class is referenced, even if no members of the class are ever accessed.
Take a look at the following code (sample Cctors.il on the Apress web site):
.assembly extern mscorlib{ auto}
.assembly cctors {}
.module cctors.exe
.typedef[mscorlib]System.Console as TTY
#define DEFLT_CTOR
" .method public specialname void .ctor()
{ ldarg.0; call instance void .base:: .ctor(); ret;}"
.class public Base
{
DEFLT_CTOR
.method publicvoid DoSomething()
{
ldarg.0
pop
ldstr"Base::DoSomething()"
call void TTY::WriteLine(string)
ret
}
}
.class public/*beforefieldinit*/ A extends Base
{
DEFLT_CTOR
.method public static specialname void .cctor()
{
ldstr"A::.cctor()"
call void TTY::WriteLine(string)
ret
}
}
.class public/*beforefieldinit*/ B extends Base
{
DEFLT_CTOR
.method public static specialname void .cctor()
{
ldstr"B::.cctor()"
call void TTY::WriteLine(string)
ret
}
}
.method publicstatic void Exec()
{
.entrypoint
.locals init(class Base b1)
ldstr"Enter string"
call void TTY::WriteLine(string)
call string TTY::ReadLine()
call bool string::IsNullOrEmpty(string)
brtrue L1// use result of IsNullOrEmpty
// Instantiate class A with .cctor
newobj instance void A:: .ctor()
stloc.s b1
br L2
L1:
// Instantiate class B with .cctor
newobj instancevoid B:: .ctor()
stloc.s b1
L2:
// Use the instance
ldloc.s b1
call instance void Base::DoSomething()
ret
}
This code instantiates either class A or class B, depending on whether you input a nonempty or empty string. The output shows that the class constructor of respective class is executed right before the instantiation of the class:
>cctors.exe
Enter stringB::.cctor()Base::DoSomething()or
>cctors.exe
Enter stringaaa A::.cctor()
Base::DoSomething()But if you uncomment the beforefieldinit flags on declarations of classes A and B and reassemble the code, the output changes:
>cctors.exe
A::.cctor()B::.cctor() Enter string
Base::DoSomething()As you see, the class constructors of both A and B are executed even before the program requests the input string, let alone before either class is accessed. It’s a good thing your class constructors are so harmless; imagine what would happen if the class constructors of A and B were mutually exclusive in some respect. However, without the beforefieldinit flag, the runtime has to check if the .cctor has run every time a member of this class is accessed, and this, of course, means a performance penalty.
The moral of the story is this: avoid using the beforefieldinit flag if you want to run only relevant class constructors, i.e., if you have reasons to suspect your class constructors can step on each other’s toes. To do so in C#, always explicitly specify static constructors for classes that have initialized static fields.
Module Constructors
What happens if you declare a type initializer (.cctor) outside any type scope? What type will it initialize and when?
The answer is simple: as you already know, the global static methods and fields belong to special type (always the first record in the TypeDef table), usually named <Module> and representing current managed module (PE file). Thus, the globally declared type initializer is the module initializer, or module constructor. It is executed upon module load, before any contents of this module are accessed. In this regard, a module constructor is functionally similar to DllMain, called, with reason, DLL_PROCESS_ATTACH. The most common use of the module constructors is the initialization of global fields, but far be it from me to stifle your imagination.
Instance Constructors
Instance constructors, unlike class constructors, are specific to an instance of a type and are used to initialize both static and instance fields of the type. Functionally, instance constructors in IL are a direct analog of C++ constructors. Instance constructors can have parameters but must return void, must be instance, must have specialname and rtspecialname flags, and must have the name .ctor, which is an ILAsm keyword. In the existing releases of the common language runtime, instance constructors are not allowed to be virtual. A type can have multiple instance constructors, but they must have different parameter lists because the name (.ctor) and the return type (void) are fixed.
Note that it is impossible to instantiate a reference type if it does not have an instance constructor. As an exercise, devise a technique to instantiate a reference type that has only private instance constructor(s). If you don’t feel like exercising right now, take a look at sample Privatector.il on the Apress web site.
Usually, instance constructors are called during the execution of the newobj instruction, when a new type instance is created:
.class public Foo
{
.field private int32tally
.method public void .ctor(int32tally_init)
{
ldarg.0 // Load the instance reference
dup // Need two instance references on the stack
call instance void[mscorlib]System.Object:: .ctor()
// Call the base constructor
ldarg.1 // Load the initializing value tally_init
stfld int32Foo::tally// this->tally = tally_init;
ret
}
...
}
.method public static void Exec( )
{
.entrypoint
.locals init(class Foo foo)
// foo is a null reference at this point
ldc.i4 128 // Put 128 on stack as Foo's constructor argument
newobj instance void Foo:: .ctor(int32)
// Instance of Foo is created
stloc.0 // foo = new Foo(128);
...
}
But, as is the case for class constructors, an instance constructor can be called explicitly. Calling the instance constructor resets the fields of the type instance and does not create a new instance. The only problem with calling class or instance constructors explicitly is that sometimes the constructors include type instantiations, if some of the fields to be initialized are of object reference type. In this case, additional care should be taken to avoid multiple type instantiations.
Please note that before calling any instance methods, an instance constructor must call its parent’s instance constructor. This is called instance initialization, and without it any further instance method calls on the created instance of this type are unverifiable. Accessing the instance fields of an unitialized instance is, however, verifiable.
![]() Caution Calling the class and instance constructors explicitly, however possible in principle, renders the code unverifiable. This limitation is imposed on the constructors of the reference types (classes) only and does not concern those of the value types. The CLR does not execute the instance constructors of value types when an instance of the value type is created (for example, when a local variable of some value type is declared), so the only way to invoke a value type instance constructor is to call it explicitly. The only place where an instance constructor of a reference type can be verifiably called explicitly is within an instance constructor of the class’s direct descendant.
Caution Calling the class and instance constructors explicitly, however possible in principle, renders the code unverifiable. This limitation is imposed on the constructors of the reference types (classes) only and does not concern those of the value types. The CLR does not execute the instance constructors of value types when an instance of the value type is created (for example, when a local variable of some value type is declared), so the only way to invoke a value type instance constructor is to call it explicitly. The only place where an instance constructor of a reference type can be verifiably called explicitly is within an instance constructor of the class’s direct descendant.
Constructors of the classes cannot be the arguments of the ldftn instruction. In other words, you can’t obtain a function pointer to a .ctor or .cctor of a class.
Class and instance constructors are the only methods allowed to set the values of the static and instance (respectively) fields marked initonly. Methods belonging to some other class, including .ctor and .cctor, cannot modify the initonly field, even if the field accessibility permits. Subsequent explicit calls to .ctor and .cctor can modify the initonly fields as well as the first, implicit initializing calls. Modification of initonly fields by methods other than the type’s constructors renders the code unverifiable.
The value types are not instantiated using the newobj instruction, so an instance constructor of a value type (if specified) should be called explicitly by using the call instruction, even though declaring a variable of a value type creates an instance of this value type.
Interfaces cannot have instance constructors at all; there is no such thing as an interface instance.
Instance Finalizers
Another special method characteristic of a class instance is a finalizer, which is in many aspects similar to a C++ destructor. The finalizer must have the following signature:
.method family virtual instance void Finalize( )
{
...
}
Unlike instance constructors, which cannot be virtual, instance destructors—sorry, I mean finalizers—must be virtual. This requirement and the strict limitations imposed on the finalizer signature and name result from the fact that any particular finalizer is an override of the virtual method Finalize of the inheritance root of the class system, the [mscorlib]System.Object class, the ultimate ancestor of all classes in the Microsoft .NET universe. To tell the truth, the Object’s finalizer does exactly nothing. But Object, full of fatherly care, declares this virtual method anyway, so Object’s descendants could override it, should they desire to do something meaningful at the inevitable moment of their instances’ demise. And at this sad moment, the instances of Object’s descendants must have their own finalizers executed, even if they (instances) are cast to Object. This explains the requirement for the finalizers to be virtual.
The finalizer is executed by the garbage collection (GC) subsystem of the runtime when that subsystem decides that a class instance should be disposed of. No one knows exactly when this happens; the only solid fact is that it occurs after the instance is no longer used and has become inaccessible—but how soon after is anybody’s guess.
If you prefer to execute the instance’s last will and testament—that is, call the finalizer—when you think you don’t need the instance any more, you can do exactly that by calling the finalizer explicitly. But then you should notify the GC subsystem that it does not need to call the finalizer again when in due time it decides to dispose of the abandoned class instance. You can do this by calling the .NET Framework class library method [mscorlib]System.GC::SuppressFinalize, which takes the object (a reference to the instance) as its sole argument—the instance is still there; you simply called its finalizer but did not destroy it—and returns void.
If for some reason you change your mind afterward, you can notify the GC subsystem that the finalizer must be run after all by calling the [mscorlib]System.GC::ReRegisterForFinalize method with the same signature, void(object). You needn’t fear that the GC subsystem might destroy your long-suffering instance without finalization before you call ReRegisterForFinalize; as long as you can still reference this instance, the GC will not touch it. Both methods for controlling finalization are public and static, so they can be called from anywhere.
Variable Argument Lists
Encounters with variable argument list (vararg) methods in earlier chapters revealed the following information:
- The calling convention of these methods is vararg.
- Only mandatory parameters are specified in the vararg method declaration:
.method public static vararg void Print(string Format)
{ ... }
- If and only if optional parameters are specified in a vararg method reference at the call site, they are preceded by a sentinel—an ellipsis in ILAsm notation—and a comma:
call vararg void Print(string, ..., int32, float32, string)
I’m not sure that requiring the sentinel to appear as an independent comma-separated argument was a good idea. After all, a sentinel is not a true element type but is a modifier of the element type immediately following. Nevertheless, such was ILAsm notation in the first release of the common language runtime, and we had to live with it for a while. Version 2.0 or later of ILAsm takes care of this, and the following notations are considered equivalent:
call vararg void Print(string, ..., int32, float32, string)
// works for all versions
call vararg void Print(string, ... int32, float32, string) // works for v2.0+ only
The vararg method signature at the call site obviously differs from the signature specified when the method is defined, because the call site signature carries information about optional parameters. That’s why vararg methods are always referenced by MemberRef tokens and never by MethodDef tokens, even if the method is defined in the current module. (In that case, the MemberRef record corresponding to the vararg call site will have the respective MethodDef as its parent, which is slightly disturbing, but only at first sight.)
Now let’s see how the vararg methods are implemented. IL offers no specific instructions for argument list parsing beyond the arglist instruction, which merely creates the argument list structure. To work with this structure and iterate through the argument list, you need to work with the .NET Framework class library value type [mscorlib]System.ArgIterator. This value type should be initialized with the argument list structure, which is an instance of the value type [mscorlib]System.RuntimeArgumentHandle, returned by the arglist instruction. ArgIterator offers such useful methods as GetRemainingCount and GetNextArg.
To make a long story short, let’s review the following code snippet from the sample file Vararg.il on the Apress web site:
// Compute sum of undefined number of arguments
.method public static vararg unsigned int64
Sum(/* all arguments optional */)
{
.locals init(value class[mscorlib]System.ArgIterator Args,
unsigned int64Sum,
int32NumArgs)
ldc.i80
stloc Sum
ldloca Args
arglist// Create argument list structure
// Initialize ArgIterator with this structure:
call instance void[mscorlib]System.ArgIterator:: .ctor(
valuetype[mscorlib]System.RuntimeArgumentHandle)
// Get the optional argument count:
ldloca Args
call instanceint32System.ArgIterator::GetRemainingCount()
stloc NumArgs
// Main cycle:
LOOP:
ldloc NumArgs
brfalse RETURN// if(NumArgs == 0) goto RETURN;
// Get next argument:
ldloca Args
call instance typedref[mscorlib]System.ArgIterator::GetNextArg()
// Interpret it as unsigned int64:
refanyval[mscorlib]System.UInt64
ldind.u8
// Add it to Sum:
ldloc Sum
add
stloc Sum// Sum += *((int64*)&next_arg)
// Decrease NumArgs and go for next argument:
ldloc NumArgs
ldc.i4.m1
add
stloc NumArgs
br LOOP
RETURN:
ldloc Sum
ret
}
In this code, we did not specify any mandatory arguments and thus took the return value of GetRemainingCount for the argument count. Actually, GetRemainingCount returns only the number of optional arguments, which means that if we had specified N mandatory arguments, the total argument count would have been greater by N.
The GetNextArg method returns a typed reference, typedref, which is cast to a managed pointer to an 8-byte unsigned integer by the instruction refanyval [mscorlib]System.UInt64. If the type of the argument cannot be converted to the required type, the JIT compiler throws an InvalidCast exception. The refanyval instruction is discussed in detail in Chapter 13.
Method Overloading
High-level languages such as C# and C++ allow method overload on parameters only. This means you can declare several methods with the same name within the same class only if the parameter lists of these methods are different. However, you know by now that the methods are uniquely identified by the triad {name, signature, parent} (let’s forget about privatescope methods for now) and that the signature of a method includes the calling convention and the return type. The conclusion I am coming to is...yes! The common language runtime allows you to overload the methods on the return type and even on the calling convention. And, naturally, so does ILAsm.
Take a look at the following code from sample Overloads.il on the Apress web site:
#define DEFLT_CTOR
" .method public specialname void .ctor()
{ ldarg.0; call instance void .base:: .ctor(); ret}"
.typedef method void[mscorlib]System.Console::WriteLine(string) as PrintString
.class public A
{
DEFLT_CTOR
.method public void Foo()
{
ldstr"instance void Foo"
call PrintString
ret
}
.methodpublic static void Foo()
{
ldstr"static void Foo"
call PrintString
ret
}
.method public vararg void Foo()
{
ldstr"instance vararg void Foo"
call PrintString
ret
}
.method publicstatic vararg void Foo()
{
ldstr"static vararg void Foo"
call PrintString
ret
}
.method public int32Foo()
{
ldstr"instance int32 Foo"
call PrintString
ldc.i4.1
ret
}
.method publicstatic int32Foo()
{
ldstr"static int32 Foo"
call PrintString
ldc.i4.1
ret
}
}
.method public static void Exec()
{
.entrypoint
newobj instance void A:: .ctor() // Create instance of A
dup // We need 3 instance pointers
dup // On stack for 3 calls
call instance void A::Foo()
call instancevararg void A::Foo()
call instance int32A::Foo()
pop
call void A::Foo()
call vararg void A::Foo()
call int32A::Foo()
pop
ret
}
The output proves that all overloads are successfully recognized by the runtime:
instance void Fooinstance vararg void Foo
instance int32 Foo
static void Foo
static vararg void Foo
static int32 FooAs you probably deduced, the same principle applies to the fields: the fields can be overloaded on type, so you can have fields int32 foo and int16 foo in the same class. Unlike methods, the fields cannot be overloaded on the calling convention, because all field signatures have the same calling convention (IMAGE_CEE_CS_CALLCONV_FIELD).
No high-level language (I know of), including C# and C++, supports method overloading on return type or field overloading on type. ILAsm does, because in ILAsm the return type of a method and the type of a field must be explicitly specified when the method or the field is referenced.
Let me reformulate the last statement: the CLR supports overloading on return type/field type and on the method’s calling convention, so ILAsm has to support it also; that’s why in ILAsm the calling convention and return type must be explicitly specified.
Why don’t C# and C++ support method overloading on the return type? Don’t they have linguistic means to specify the type? Yes, they have and they use these means for distinguishing methods overloaded on parameters. I’m talking about casts. Why can C# or C++ distinguish which method Foo to call between
int i = Foo((int)j);
int i = Foo((short)j);
but can’t distinguish between
int i = (int)Foo();
int i = (int)(short)Foo();
with the rightmost cast on the method’s return serving as specification of the method’s return type? I don’t know why.
Global Methods
Global methods, similar to global fields, are defined outside any class scope. Most of the features of global fields and global methods are also similar: global methods are all static, and the accessibility flags for both global fields and methods mean the same.
Of course, one global method worth a special mention is the global class constructor, .cctor. As the preceding chapter discussed, a global .cctor is the best way to initialize global fields. The following code snippet from the sample file Gcctor.il on the Apress web site provides an example:
.field private static string Hello
.method private static void .cctor( )
{
ldstr"Hi there! What's up?"
stsfld string Hello
ret
}
.method public static void Exec( )
{
.entrypoint
ldsfld string Hello// Global fields are accessible
// within the module
call void[mscorlib]System.Console::WriteLine(string)
ret
}
Summary of Metadata Validity Rules
Method-related metadata tables discussed in this chapter include the Method, Param, FieldMarshal, Constant, MemberRef, and MethodImpl tables. The records in these tables have the following entries:
- The Method table: RVA, ImplFlags, Flags, Name, Signature, and ParamList
- The Param table: Flags, Sequence, and Names
- The FieldMarshal table: Parent and NativeType (native signature)
- The Constant table: Type, Parent, and Value
- The MemberRef table: Class, Name, and Signature
- The MethodImpl table: Class, MethodBody, and MethodDecl
Chapter 9 summarized the validity rules for the FieldMarshal, Constant, and MemberRef tables. The only point to mention here regarding the MemberRef table is that, unlike field-referencing MemberRef records, method-referencing records can have the Method table referenced in the Parent entry. The Method table can be referenced exclusively by the MemberRef records representing vararg call sites.
- The Flags entry can have only those bits set that are defined in the enumeration CorMethodAttr in CorHdr.h (validity mask 0xFDF7).
- [run time] The accessibility flag (mask 0x0007) must be one of the following: privatescope, private, famandassem, assembly, family, famorassem, or public.
- The static flag must not be combined with any of the following flags: final, virtual, newslot, or abstract.
- The pinvokeimpl flag must be paired with the static flag (but not vice versa).
- Methods having privatescope accessibility must not have the virtual, final, newslot, specialname, or rtspecialname flag set.
- The abstract, newslot, and final flags must be paired with the virtual flag.
- The abstract flag and the implementation flag forwardref are mutually exclusive.
- [run time] If the flag 0x4000 is set, the method must either have an associated DeclSecurity metadata record that holds security information concerning access to the method or have the associated custom attribute System.Security.SuppressUnmanagedCodeSecurityAttribute. The inverse is true as well.
- [run time] Methods belonging to interfaces must have either the static flag set or the virtual flag set.
- [run time] Global methods must have the static flag set.
- If the rtspecialname flag is set, the specialname flag must also be set.
- The ImplFlags entry must have only those bits set that are defined in the enumeration CorMethodImplAttr in CorHdr.h (validity mask 0x10BF).
- The implementation flag forwardref is used only during in-memory edit-and-continue scenarios and in object files (generated by the MC++ compiler) and must not be set for any method in a managed PE file.
- [run time] The implementation flags cil and unmanaged are mutually exclusive.
- [run time] The implementation flags native and managed are mutually exclusive.
- The implementation flag native must be paired with the unmanaged flag.
- [run time] The implementation flag synchronized must not be set for methods belonging to value types.
- [run time] The implementation flags runtime and internalcall are for internal use only and must not be set for methods defined outside .NET Framework system assemblies.
- [run time] The Name entry must hold a valid reference to the #Strings stream, indexing a nonempty string no more than 1,023 bytes long in UTF-8 encoding.
- [run time] If the method name is .ctor, .cctor, _VtblGap*, or _Deleted*, the rtspecialname flag must be set, and vice versa.
- [run time] A method named .ctor—an instance constructor—must not have the static flag or the virtual flag set.
- [run time] A method named .cctor—a class constructor—must have the static flag set.
- [run time] The Signature entry must hold a valid reference to the #Blob stream, indexing a valid method signature. Chapter 8 discusses validity rules for method signatures.
- [run time] A method named .ctor—an instance constructor—must return void and must have the default calling convention.
- [run time] A method named .cctor—a class constructor—must return void, can take no parameters, and must have the default calling convention.
- No duplicate records—attributed to the same TypeDef and having the same name and signature—should exist unless the accessibility flag is privatescope.
- [run time] The RVA entry must hold 0 or a valid relative virtual address pointing to a read-only section of the PE file.
- [run time] The RVA entry holds 0 if and only if
- the abstract flag is set, or
- the implementation flag runtime is set, or
- the implementation flag internalcall is set, or
- the class owning the method has the import flag set, or
- the pinvokeimpl flag is set, the implementation flags native and unmanaged are not set, and the ImplMap table contains a record referencing the current Method record, and this record contains valid ModuleRef reference.
Param Table Validity Rules
- The Flags entry can have only those bits set that are defined in the enumeration CorParamAttr in CorHdr.h (validity mask 0x3013).
- [run time] If the flag 0x2000 (pdHasFieldMarshal) is set, the FieldMarshal table must contain a record referencing this Param record, and vice versa.
- [run time] If the flag 0x1000 (pdHasDefault) is set, the Constant table must contain a record referencing this Param record, and vice versa.
- [run time] The Sequence entry must hold a value no larger than the number of mandatory parameters of the method owning the Param record.
- If the method owning the Param record returns void, the Sequence entry must not hold 0.
- The Name entry must hold 0 or a valid reference to the #Strings stream, indexing a nonempty string no more than 1,023 bytes long in UTF-8 encoding.
MethodImpl Table Validity Rules
- [run time] The Class entry must hold a valid index to the TypeDef table.
- [run time] The MethodDecl entry must index a record in the Method or MemberRef table.
- [run time] The method indexed by MethodDecl must be virtual.
- [run time] The method indexed by MethodDecl must not be final.
- [run time] If the parent of the method indexed by MethodDecl is not the TypeDef indexed by Class, the method indexed by MethodDecl must not be private.
- [run time] The parent of the method indexed by MethodDecl must not be sealed.
- [run time] The signatures of the methods indexed by MethodDecl and MethodBody must match.
- [run time] The MethodBody entry must index a record in the Method table.
- [run time] The method indexed by MethodBody must be virtual.
- [run time] The parent of the method indexed by MethodBody must be the TypeDef indexed by Class.