Chapter 3. Optimization Tips
When you’re programming an application, you generally want the database to respond instantly to anything you do. To maximize its ability to do this, it’s important to know what takes up time.
Tip #21: Minimize disk access
Accessing data from RAM is fast and accessing data from disk is slow. Therefore, most optimization techniques are basically fancy ways of minimizing the amount of disk accesses.
Fuzzy Math
Reading from disk is (about) a million times slower than reading from memory.
Most spinning disk drives can access data in, say, 10 milliseconds, whereas memory returns data in 10 nanoseconds. (This depends a lot on what kind of hard drive you have and what kind of RAM you have, but we’ll do a very broad generalization that is roughly accurate for most people.) This means that the ratio of disk time to RAM time is 1 millisecond to 1 nanosecond. One millisecond is equal to one million nanoseconds, so accessing disk takes (roughly) a million times longer than accessing RAM.
Thus, reading off of disk takes a really long time in computing terms.
Tip
On Linux, you can measure sequential disk access on your machine
by running sudo hdparm -t
/dev/hd. This doesn’t
give you an exact measure, as MongoDB will be doing non-sequential
reads and writes, but it’s interesting to see what your machine can
do.whatever
So, what can be done about this? There are a couple “easy” solutions:
- Use SSDs
SSDs (solid state drives) are much faster than spinning hard disks for many things, but they are often smaller, more expensive, are difficult to securely erase, and still do not come close to the speed at which you can read from memory. This isn’t to discourage you from using them: they usually work fantastically with MongoDB, but they aren’t a magical cure-all.
- Add more RAM
Adding more RAM means you have to hit disk less. However, adding RAM will only get you so far—at some point, your data isn’t going to fit in RAM anymore.
So, the question becomes: how do we store terabytes (petabytes?) of data on disk, but program an application that will mostly access data already in memory and move data from disk to memory as infrequently as possible?
If you literally access all of your data randomly in real time, you’re just going to need a lot of RAM. However, most applications don’t: recent data is accessed more than older data, certain users are more active than others, certain regions have more customers than others. Applications like these can be designed to keep certain documents in memory and go to disk very infrequently.
Tip #22: Use indexes to do more with less memory
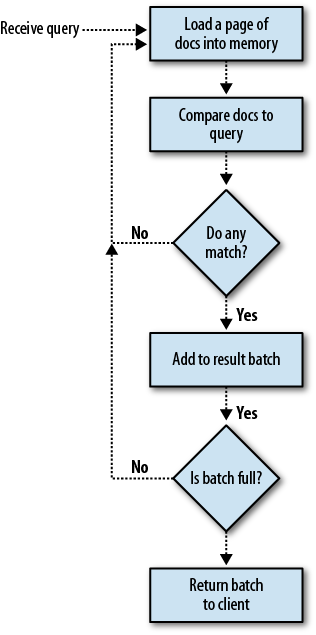
First, just so we’re all on the same page, Figure 3-1 shows the sequence a read request takes.
We’ll assume, for this book, that a page of memory is 4KB, although this is not universally true.
So, let’s say you have a machine with 256GB of data and 16GB of memory. Let’s say most of this data is in one collection and you query this collection. What does MongoDB do?
MongoDB loads the first page of documents from disk into memory, and compares those to your query. Then it loads the next page and compares those. Then it loads the next page. And so on, through 256GB of data. It can’t take any shortcuts: it cannot know if a document matches without looking at the document, so it must look at every document. Thus, it will need to load all 256GB into memory (the OS takes care of swapping the oldest pages out of memory as it needs room for new ones). This is going to take a long, long time.
How can we avoid loading all 256GB into memory every time we do a
query? We can tell MongoDB to create an index on a given field,
xxxx
value. The tree just contains a pointer to the document, not the document
itself, meaning the index is generally much smaller than the entire
collection.

When your query includes
xx

So, suppose we do a query that will end up matching a document or two in our collection. If we do not use an index, we must load 64 million pages into memory from disk:
| Pages of data: 256GB / (4KB/page) = 64 million pages |
Suppose our index is about 80GB in size. Then the index is about 20 million pages in size:
| Number of pages in our index: 80GB / (4KB/page) = 20 million pages |
However, the index is ordered, meaning that we don’t have to go through every entry: we only have to load certain nodes. How many?
| Number of pages of the index that must be loaded into memory: ln(20,000,000) = 17 pages |
From 64,000,000 down to 17!
OK, so it isn’t exactly 17: once we’ve found the result in the index we need to load the document from memory, so that’s another size-of-document pages loaded, plus nodes in the tree might be more than one page in size. Still, it’s a tiny number of pages compared with traversing the entire collection!
Hopefully you can now picture how indexes helps queries go faster.
Tip #23: Don’t always use an index
Now that I have you reeling with the usefulness of indexes, let me warn you that they should not be used for all queries. Suppose that, in the example above, instead of fetching a few records we were returning about 90% of the document in the collection. If we use an index for this type of query, we’d end up looking through most of the index tree, loading, say, 60GB of the index into memory. Then we’d have to follow all of the pointers in the index, loading 230GB of data from the collection. We’d end up loading 230GB + 60GB = 290GB—more than if we hadn’t used an index at all!
Thus, indexes are generally most useful when you have a small subset of the total data that you want returned. A good rule of thumb is that they stop being useful once you are returning approximately half of the data in a collection.
If you have an index on a field but you’re doing a large query that
would be less efficient using that index, you can force MongoDB not to use
an index by sorting by {"$natural" :
1}. This sort means “return data in the order it appears on
disk,” which forces MongoDB to not use an index:
> db.foo.find().sort({"$natural" : 1})If a query does not use an index, MongoDB does a table scan, which means it looks through all of the documents in the collection to find the results.
Write speed
Every time a new record is added, removed, or updated, every index affected by the change must be updated. Suppose you insert a document. For each index, MongoDB has to find where the new document’s value falls on the index’s tree and then insert it there. For deletes, it must find and remove an entry from the tree. For updates, it might add a new index entry like an insert, remove an entry like a delete, or have to do both if the value changes. Thus, indexes can add quite a lot of overhead to writes.
Tip #24: Create indexes that cover your queries
If we only want certain fields returned and can include all of these fields in the index, MongoDB can do a covered index query, where it never has to follow the pointers to documents and just returns the index’s data to the client. So, for example, suppose we have an index on some set of fields:
> db.foo.ensureIndex({"x" : 1, "y" : 1, "z" : 1})Then if we query on the indexed fields and only request the indexed fields returned, there’s no reason for MongoDB to load the full document:
> db.foo.find({"x" : criteria, "y" : criteria},
... {"x" : 1, "y" : 1, "z" : 1, "_id" : 0})Now this query will only touch the data in the index, it never has to touch the collection proper.
Notice that we include a clause "_id" :
0 in the fields-to-return argument. The _id
is always returned, by default, but it’s not part of our index so MongoDB
would have to go to the document to fetch the _id.
Removing it from the fields-to-return means that MongoDB can just return
the values from the index.
If some queries only return a few fields, consider throwing these
fields into your index so that you can do covered index queries, even if
they aren’t going to be searched on. For example, z is
not used in the query above, but it is a field in the fields-to-return
and, thus, the index.
Tip #25: Use compound indexes to make multiple queries fast
If possible, create a compound index that can be used by multiple queries. This isn’t always possible, but if you do multiple queries with similar arguments, it may be.
Any query that matches the prefix of an index can use the index. Therefore, you want to create indexes with the greatest number of criteria shared between queries.
Suppose that your application runs these queries:
collection.find({"x" : criteria, "y" : criteria, "z" : criteria})
collection.find({"z" : criteria, "y" : criteria, "w" : criteria})
collection.find({"y" : criteria, "w" : criteria})As you can see, y is the only field that appears
in each query, so that’s a very good candidate to go in the index.
z appears in the first two, and w
appears in the second two, so either of those would work as the next
option (see more on index ordering in Tip #27: AND-queries should match as little as possible as fast as
possible and Tip #28: OR-queries should match as much as possible as soon as
possible).
We want to hit this index as much and as often as possible. If a certain query above is more important than the others or will be run much more frequently, our index should favor that one. For example, suppose the first query is going to be run thousands of times more than the next two. Then we want to favor that one in our index:
collection.ensureIndex({"y" : 1, "z" : 1, "x" : 1})The the first query will be as highly optimized as possible and the next two will use the index for part of the query.
If all three queries will be run approximately the same amount, a good index might be:
collection.ensureIndex({"y" : 1, "w" : 1, "z" : 1})Then all three will be able to use the index for the
y criteria, the second two will be able to use it for
w, and the middle one will be able to fully use the
index.
You can use explain to see how an index is being used on a query:
collection.find(criteria).explain()Tip #26: Create hierarchical documents for faster scans
Keeping your data organized hierarchically not only keeps it organized, but MongoDB can also search it faster without an index (in some cases).
For example, suppose that you have a query that does not use an index. As mentioned previously, MongoDB has to look through every document in the collection to see if anything matches the query criteria. This can take a varying length of time, depending on how you structure your documents.
Let’s say you have user documents with a flat structure like this:
{
"_id" : id,
"name" : username,
"email" : email,
"twitter" : username,
"screenname" : username,
"facebook" : username,
"linkedin" : username,
"phone" : number,
"street" : street
"city" : city,
"state" : state,
"zip" : zip,
"fax" : number
}Now suppose we query:
> db.users.find({"zip" : "10003"})What does MongoDB do? It has to look through every field of every
document, looking for the zip field (Figure 3-4).

By using embedded documents, we can create our own “tree” and let MongoDB do this faster. Suppose we change our schema to look like this:
{
"_id" : id,
"name" : username,
"online" : {
"email" : email,
"twitter" : username,
"screenname" : username,
"facebook" : username,
"linkedin" : username,
},
"address" : {
"street" : street,
"city" : city,
"state" : state,
"zip" : zip
}
"tele" : {
"phone" : number,
"fax" : number,
}
}Now our query would look like this:
> db.users.find({"address.zip" : "10003"})And MongoDB would only have to look at _id,
name, and online before seeing that
address was a desired prefix and then looking for zip
within that. Using a sensible hierarchy allows MongoDB not to inspect
every field looking for a match.
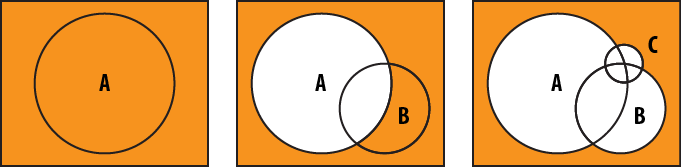
Tip #27: AND-queries should match as little as possible as fast as possible
Suppose we are querying for documents matching criteria
A, B, and
C. Now, let’s say that criteria
A matches 40,000 documents,
B matches 9,000, and
C matches 200. If we query MongoDB with the
criteria in the order given, it will not be very efficient (see Figure 3-5).

If we put C first, then
B, then A, we only
have to look at 200 documents (at most) for the
B and C criteria
(Figure 3-6).

As you can see, this brings down the amount of work quite a bit. If you know that a certain criteria is going to match less documents, make sure that criteria goes first (especially if it is indexed).
Tip #28: OR-queries should match as much as possible as soon as possible
OR-style queries are exactly the opposite of AND queries: try to put the most inclusive clauses first, as MongoDB has to keep checking documents that aren’t part of the result set yet for every match.
If we do it in the same order we were structuring the AND-query in, we have to check documents for each clause (Figure 3-7).
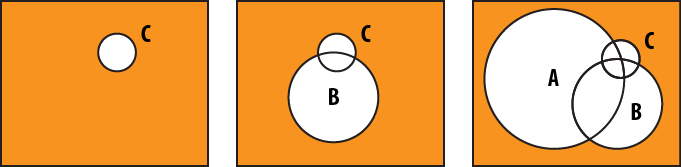
Instead, we match as much of the collection as possible as soon as possible (Figure 3-8).