
Chapter 69. The End of ETL as We Know It
Paul Singman

If you’re as sick of this three-letter term as I am, you’ll be happy to know there is another way.
If you work in data in 2021, the acronym ETL is everywhere.
Ask certain people what they do, and their whole response will be “ETL.” On LinkedIn, thousands of people have the title “ETL developer.” It can be a noun, a verb, an adjective, and even a preposition. (Yes, a mouse can ETL a house.)
Standing for extract, transform, load, ETL refers to the general process of taking batches of data out of one database or application and loading them into another. Data teams are the masters of ETL, as they often have to stick their grubby fingers into the tools and databases of other teams—the software engineers, marketers, and operations folk—to prep a company’s data for deeper, custom analyses.
The good news is that with a bit of foresight, data teams can remove most of the ETL onus from their plate entirely. How is this possible?
Replacing ETL with Intentional Data Transfer
The path forward is with intentional transfer of data (ITD). The need for ETL arises because no one builds their user database or content management system (CMS) with downstream analytics in mind. Instead of making the data team select * from purchases_table where event_date > now() — 1hr every hour, you can add logic in the application code that first processes events and emits them in a pub/sub model (see the following figure).
With no wasted effort, the data team can set up a subscriber process to receive these events and process them in real time (or store them durably in S3 for later use). All it takes is one brave soul on the data team to muster the confidence to ask this of the core engineering squad.
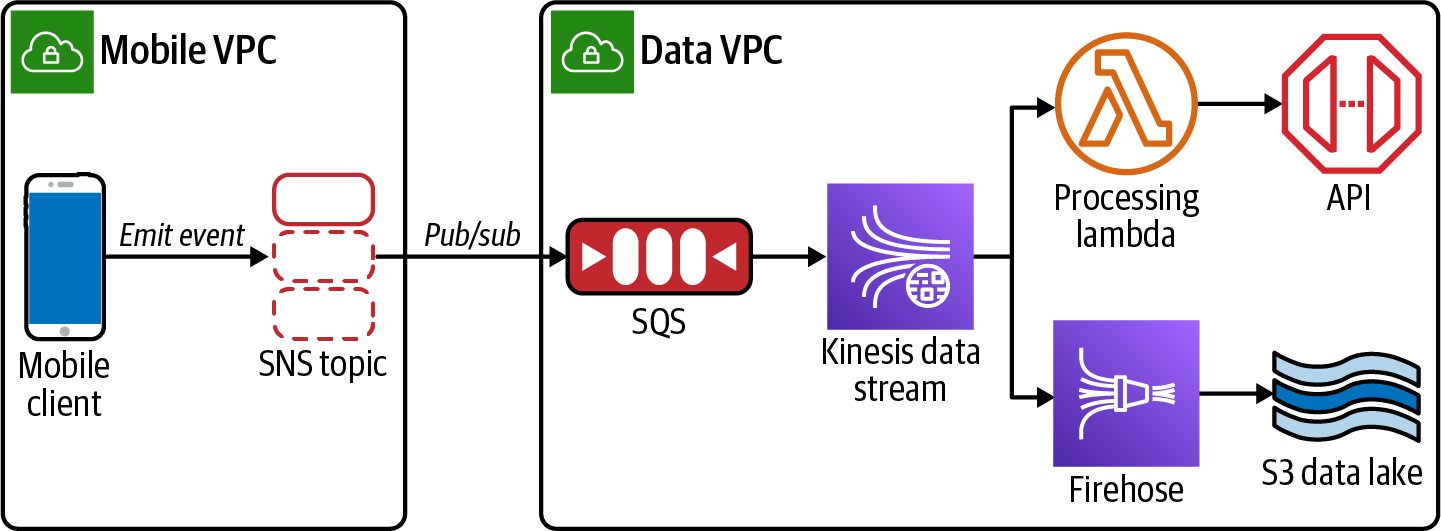
Ten years ago, data teams were beginning to establish their capabilities and needs, and such an ask might have been met with a healthy dose of resistance. A decade later, however, that excuse no longer flies. And if you are on a data team doing solely traditional ETL on internal datasets, it’s time you upped your game.
There are several other benefits to IDT worth noting.
Agreeing on a Data Model Contract
How many times has one team changed a database table’s schema, only to later learn the change broke a downstream analytics report? It is difficult to establish the cross-team communication necessary to avoid these issues when you have ETL scripts running directly against raw database tables.
With IDT, when an event occurs, it will be published with certain fields always present that are previously agreed upon and documented. And everyone knows that any change to this JSON contract needs to be communicated first.
Removing Data Processing Latencies
Most frequently, ETL jobs are run once per day, overnight. But I’ve also worked on projects where they’ve run incrementally every 5 minutes. It all depends on the requirements of the data consumers.
There will always be some latency between an event occurring and the data team receiving it, which introduces tricky edge cases to the data application.
With IDT, however, events are published immediately as they happen. Using real-time services like Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS), and AWS Lambda, they can be responded to immediately.
Taking the First Steps
Moving from ETL to IDT isn’t a transformation that will happen for all your datasets overnight. Taking one dataset to start, though, and setting up a pub/sub messaging pattern for it is extremely doable. My advice is to find a use case that will clearly benefit from real-time data processing—whether it’s a feed of users’ current locations or cancellation events—and then transition it from ETL to the IDT pattern.