
Appendix A
Hints and Pseudocode
Chapter 8 described a data handling task involving acquiring data from spreadsheets, a database, JSON, XML, and fixed-width text files. The formats and layouts of the data are documented in that chapter. In this appendix, we give some extra hints about how to proceed. We recommend trying the exercise first, without referring to this appendix until you need to.
Some of these hints come in the form of “pseudocode.” This is the programmer's term for instructions that describe an algorithm in ordinary English, rather than in the strict form of code in R or another computer language. The actual R code we used can be found in the cleaningBook package.
A.1 Loan Portfolios
Reading, cleaning, and combining the loan portfolios (Section 8.4) is the first task in the exercise, and perhaps the most time-consuming. However, none of the tasks needed to complete this task is particularly challenging from a technical standpoint.
If you have a spreadsheet program such as Excel that can open the file, the very first step in this process might be to use that program to view the file. Look at the values. Are there headers? Can you see any missing value codes? Are some columns empty? Do any rows appear to be missing a lot of values? Are values unexpectedly duplicated across rows? Are there dates, currency amounts, or other values that might require special handling?
Then, it is time to read the two data sets into R and produce data frames, using one of the read.table() functions. We normally start with quote = "" or quote = """ and comment.char = "". You might select stringsAsFactors = FALSE, in which case numeric fields in the data will appear as numeric columns in the data frame. This sets empty entries in those columns of the spreadsheet to NA and also has the effect of stripping leading zeros in fields that look numeric, like the application number. As one alternative, you might set colClasses = "character", in which case all of the columns of the data frame are defined to be of type character. In this case, empty fields appear as the empty string "". Eventually, columns that are intended to be numeric will have to be converted. On the other hand, leading zeros in application numbers are preserved. From the standpoint of column classes, perhaps the best way to read the data in is to pass colClasses as a vector to specify the classes of individual columns – but this requires extra exploration up front to determine those classes.
Pseudocode for the step of reading, cleaning, and combining the portfolio data files might look like this. In this description, we treat the files separately. You might equally well treat them simultaneously, creating the joint data set as you go.
for each of {Beachside, Wilson}
read in file
examine keys and missing values
discard unneeded columns
convert formatted columns (currencies, dates) to R types
ensure categorical variables have the correct levels
construct derived variables
ensure categorical variables levels match between data sets
ensure column names match between data sets
ensure keys are unique across data sets
add an identifying column to each data set
join data sets row-wise (vertically)A.1.1 Things to Check
As you will see, the portfolio data sets are messy, just as real-life data is messy. As you move forward, you will need to keep one eye on the data itself, one eye on the data dictionary, and one eye on the list of columns to construct. (We never said this would be easy.) Consider performing the sorts of checks listed here, as well as any others you can think of. Remember to specify exclude = NULL or useNA = "ifany" in calls to table() to help identify missing values.
- What do the application numbers look like? Do they all have the expected 10 digits? Are any missing? Are there duplicate rows or duplicate application numbers? If so, can rows be safely deleted?
- What do missing value counts look like by column? Are some columns missing a large proportion of entries? Are some rows missing most entries, and, if so, should they be deleted?
- Do the values of categorical variables match the values in the data dictionary? If not, are the differences large or small? Can some levels be converted into others? If two categorical variables measure similar things, cross-tabulate them to ensure that they are associated. At this stage, it might be worthwhile to consider the data from the modeling standpoint. For example, if a large number of categorical values are missing, it might be worthwhile to create a new level called
Missing. If there are a number of values that apply to only a few records each, it might be wise to combine them into anOthercategory. - Are there columns with special formatting, like, for example, currency values that look like
$1,234.56? Convert them to numeric. - Across the set of numeric columns, what sorts of ranges and averages do you see? Are they plausible? For columns that look like counts, what are the most common values? Are there some values that look as if they might be special indicators (999 for a person's age, 99 or
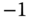 for number of mortgages)? Consider computing the correlation matrix of numeric predictors to see if columns that should carry similar information are in fact correlated.
for number of mortgages)? Consider computing the correlation matrix of numeric predictors to see if columns that should carry similar information are in fact correlated. - What format are the date columns in? If you plan to do arithmetic on dates, like, for example, computing the number of days between two dates, you will need to ensure that dates use one of the
DateorPOSIXtclasses. If all you need to do is to sort dates, you can also use a text format likeYYYYMMDD, since these text values will sort alphabetically just as the underlying date values would. Keeping dates as characters can save you a lot of grief when you might inadvertently turn aDateorPOSIXtobject into numeric form. The date formats are easier to summarize and to use in plots, however. Examine the dates. Are there missing values? What do the ranges look like? Consider plotting dates by month or quarter to see if there are patterns. - Computing derived variables often involves a table lookup. For example, in the exercise, you can determine each state's region from a lookup into a table that contains state code and region code. The cleaning issue is then a matter of identifying codes not in the table and determining what to do with them.
Once the two loan portfolios have been combined, we can start in on the remaining data sets. In the sections that follow, we will refer to the combined portfolio data set as big. When we completed this step, our big data frame had 19,196 rows and 17 columns; yours may be slightly different, depending on the choices you made in this section.
A.2 Scores Database
The agency scores (Section 8.5) are stored in an SQLite database. The first order of business is to connect to the database and look at a few of its records. Do the extracted records match the descriptions in the data dictionary in Chapter 8? Count the numbers of records. If these are manageable, we might just as well read the entire tables into R, but if there are many millions or tens of millions of records we might be better off reading them bit by bit.
In this case, the tables are not particularly large. Pseudocode for the next steps might look as follows:
read Cscore table into an R data frame called cscore
read CusApp table into an R data frame called cusapp
add application number from cusapp to cscore
add active date from big to cscore
discard records for which ScoreMonth > active date
discard records with invalid scores
order cscore by customer number and then by date, descending
for each customer i, for each agency j
find the first non-missing score and dateWe did not find a particularly efficient way to perform this last step.
A.2.1 Things to Check
As with almost all data sets, the agency scores have some data quality issues. Items to consider include the following:
- What do the application numbers and customer numbers from
cusapplook like? Do they have the expected numbers of digits? Are any duplicated or missing? What proportion of application numbers fromcusappappears inbig, and what proportion of application numbers frombigappears incusapp? Are there customer numbers incscorethat do not appear incusappor vice versa? - Summarize the values in the agency score columns. What do missing values look like in each column? What proportion of scores is missing? Are any values outside the permitted range 200–899?
- The
ScoreMonthcolumn in thecscoretable is inYYYYMMformat, without the day of the month. However, the active date field frombighas days of the month (and, depending on your strategy, might be inDateorPOSIXtformat). How should we compare these two types of date?
In the final step, we merge the data set of scores with the big data set created by combining the two loan portfolios. Recall that duplicate keys are particularly troublesome in R's merge() function – so it might be worthwhile to double-check for duplicates in the key, which in this case is the application number, in the two data frames being merged. Does the merged version of big have the same number of rows as the original? If the original has, say, 17 columns and the new version 26, you might ensure that the first 17 columns of the new version match the original data, with a command like all.equal(orig, new[,1:17]).
A.3 Co-borrower Scores
The co-borrower scores (Section 8.6) make up one of the trickiest of the data sets, because of their custom transactional format (Section 7.4). We start by noting that there are 73,477 records in the data set, so it can easily be handled entirely inside R. If there had been, say, a billion records, we would have needed to devise a different approach. We start off with a pseudocode as follows:
read data into R using scan() with sep = "
"
discard records with codes other than ERS or J01
discard ERS records with invalid scoresAt this point, we are left with the J01 records, which name the application number, and the ERS records, which give the scores. It will now be convenient to construct a data frame with one row for each score. This will serve as an intermediate result, a step toward the final output, which will be a data frame with one row for each application number. This intermediate data frame will, of course, contain an application number field. (This is just one approach, and other equally good ones are possible.) We take the following steps:
extract the application numbers from the J01 records
use the rle() function on the part of the string
that is always either J01 or ERSRecall that each application is represented by a J01 record followed by a series of ERS records. If the data dictionary is correct, the result of the rle() function will be a run of length 1 of J01, followed by a run of ERS, followed by another run of length of 1 of J01, followed by another run of ERS, and so on. So, values 2, 4, 6, and so on of the length component of the output of rle() will give the number of ERS records for each account. Call that subset of length values lens. Then, we operate as follows:
construct a data frame with a column called Appl,
produced by replicating the application numbers
from the J01 records lens times each
add the score identifier (RAY, KSC) etc.
add the numeric score value
add the score date
insert the active date from big
delete records for which the score date > active dateAt this stage, we have a data set with the information we want, except that some application numbers might still have multiple records for the same agency. A quick way to get rid of the older, unneeded rows is to construct a key consisting of a combination of application number and agency (like, e.g., 3004923564.KSC). Now sort the data set by key, and by date within key, in descending order. We need to keep only the first record for every key – that is, we can delete records for which duplicated(), acting on that newly created key field, returns TRUE.
Following the deletion of older scores, we have a data set (call it co.df) with all the co-borrower scores, arrayed one per score. (When we did this, we had 4928 scores corresponding to 1567 application numbers.) Now we can use a matrix subscript (Section 3.2.5) to assemble these into a matrix that has one row per application number. We start by creating a data frame with the five desired columns: places for the JNG, KSC, NTH, and RAY scores and the application number. It is convenient to put the application number last. Call this new data frame co.scores. Then, we continue as follows:
construct the vector of row indices by matching the
application number from co.df to the application number
from co.scores. This produces a vector of length 4,928
whose values range from 1 to 1,567
construct the vector of column indices by matching the score
id from co.df to the vector c("JNG", "KSC", "NTH",
"RAY"). This produces a vector of length 4,928
whose values range from 1 to 4
combine those two vectors into a two-column matrix
use the matrix to insert scores from co.df into co.scoresA.3.1 Things to Check
As with the other data sets, the most important issues with the co-borrower data are key matching, missing values, and illegal values. You might examine points like the following:
- What do the application numbers look like? Do they have 10 digits? What proportion of application numbers appears in
big? In our experience the proportion of loans with co-borrowers has often been on the order of 20%. Are there application numbers that do not appear inbig? If there are a lot of these we might wonder if the application numbers had been corrupted somehow. - After reading the data in, check that the fields extracted are what you expect. Do the score identifiers all match
JNG, and so on? Are the score values mostly in the 200–899 range? Do the dates look valid? - We expect some scores to be 999 or out of range. What proportions of those values do we see? Are some months associated with large numbers or proportions of illegal score values? Are these any non-numeric values, which might indicate that we extracted the wrong portion of the record?
When the co-borrowers data set is complete, we can merge it to big. Since big already has columns names JNG, KSC, NE, and RAY, it might be useful to rename the columns of our co.score before the merge to Co.JNG and so on. (At this point, you have probably noticed that the NorthEast score is identified by NE in the scores database but by NTH in the co-borrower scores. It might be worthwhile making these names consistent.)
A final task in this step is to add a co-borrower indicator, which is TRUE when an application number from big is found in our co.scores and FALSE otherwise. Actually, this approach has the drawback that it will report FALSE for applications with co-borrowers for which every score was invalid or more recent than the active date (if there are any). If this is an issue, you will need to go back and modify the script by creating the indicator before any ERS records are deleted. This is a good example of why documenting your scripts as you go is necessary.
A.4 Updated KScores
The updated KScores (Section 8.7) are given in a series of JSON messages. For each message, we need to extract fields named appid and record-date, if they exist. We start with pseudocode as follows:
read the JSON into R with scan() and sep = "
"
remove messages in which the string "KScore" does not appear
write a function to handle one JSON message: return appid,
KScore, record-date if found, and (say) "none" if not
apply that function to each messageUsing sapply() in that last command produces a two-row matrix that should be transposed. Using lapply() produces a list of character vectors of length 2 that should be combined row-wise, perhaps via do.call(). In either case, it will be convenient to produce a data frame with three columns. We continue to work on that data frame with operations as follows:
remove rows with invalid scores
add active date from big
remove rows for which KScore date is > active date
keep the most recent row for each application idThis final data set contains the KScores that are eligible to update the ones in big. Presumably, it only makes sense to update scores for which the one is big is either missing, or carries an earlier date than the one in our updated KScore data. When we did this, we found 1098 applications in the updated KScore data set, and they all corresponded to scores that were missing in big. So, all 1098 of these KScore entries in big should be updated. In a real example, you would have to be prepared to update non-missing KScores as well.
A.4.1 Things to Check
As with the other data sets, the important checks are for keys, missing, duplicated, and illegal values. In this case, we might consider some of the following points:
- Are a lot of records missing application numbers? Examine a few to make sure that it is the data, not the code, at fault. Are any application numbers duplicated? What proportion of application numbers appears in
big? - Are many records missing KScores? That might be odd given the specific purpose of this data set. What do the KScores that are present look like? Are many missing or illegal?
- What proportion of update records carries dates more recent than the active date? If this proportion is very large, it can suggest an error on the part of the data supplier.
A.5 Excluder Files
The Excluder files (Section 8.8) are in XML format. We need to read each XML file and determine whether it has (i) a field called APPID and (ii) a field called EXCLUDE, found under one called DATA. In pseudocode form, the task for the excluder data might look as follows:
acquire a vector of XML file names from the Excluders dir.
use sapply to loop over the vector of names of XML files:
read next XML file in, convert to R list with xmlParse()
if there is a field named "APPID", save it as appid
otherwise set appid to None
if there is a field named "EXCLUDE" save it as exclude
otherwise set exclude to None
return a vector of appid and excludeThe result of this call to sapply() will be a matrix with two rows. It will be convenient to transpose it, then convert it into a data frame and rename the columns, perhaps to Appl and ExcCode. Call this data frame excluder.
A.5.1 Things to Check
- Are there duplicate rows or application numbers? This is primarily just a check on data quality. Presumably, if an application number appears twice in the
excludersdata set, that record will be deleted, just as if it had appeared once. - Do the columns have missing values?
- Are the values in the
ExcCodecolumn what we expect (“Yes,” “No,” “Contingent”)? We can now drop records for whichExcCodeis anything other than Yes or Contingent. - Do the application numbers in
excludermatch the ones in thebig(combined) data set? Do they have 10 digits? If there are records with no application number, or whose application numbers do not appear elsewhere, they can be dropped from theexcluderdata set.
When we are satisfied with the excluder data set, we can remove the matching rows from big. When we did this, our data set ended up with 19,034 rows and between 30 and 40 columns, depending on exactly which columns we chose to save.
A.6 Payment Matrix
Recall from Section 8.9 that every row of the payment matrix contains a fixed-layout record consisting of a 10-digit application number, then a space, and then 48 repetitions of numeric fields of lengths 12, 12, 8, and 3 characters. Those values will go into a vector that will define the field widths. We might also set up a vector of column names, by combining names like Appl and Filler with 48 repetitions of four names like Pay, Delq, Date, and Mo. We pasted those 48 replications together with the numbers 48:1 to create unique and easily tractable names. We also know that the first two columns should be categorical; among the repeaters, we might specify that all should be numeric, or perhaps that the two amounts should be numeric and the date and number of months, character.
With that preparation, we are ready to read in the file, using read.fwf() and the widths, names, and column classes just created. We called that data frame pay.
Our column naming convention makes it easy to extract the names of the date columns with a command like grep("Date", names(pay)). For example, recall that we will declare as “Indeterminate” any record with six or fewer non-zero dates. We can use apply() across the rows of our pay data frame, operating just on the subset of date columns, and run a function that determines whether the number of zero entries is ![]() 6. (Normally, we are hesitant to use
6. (Normally, we are hesitant to use apply() on the rows of a data frame. In this case, we are assured that the relevant columns are all of identical types and lengths.)
Now, we create a column of status values, and wherever the result of this apply() is TRUE, we insert Indet into the corresponding spots in that vector. Our code might look something like the following:
set up pay$Good as a character vector in the pay data frame
apply to the rows of pay[,grep ("Date", names (pay))]
a function that counts the number of entries that are
0 or "00000000"
set pay$Good to Indet when that count is <= 6Our column naming convention also makes it easy to check our work. For example, we might pick out some number haphazardly – say, 45 – and look at the entries in pay for the 45th Indet entry. (This feels wiser than using the very first one, since the first part of the file might be different from the middle part.) In this example, our code might look as follows:
pick some number, like, say, 45
extract the row of pay corresponding to the 45th Indet
-- call that rr
pay[rr, grep ("Date", names (pay))] shows that rowNow we perform similar actions for the other possible outcomes. At this stage, it makes sense to keep the different sorts of bad outcomes separate, combining them only at the end. One bad outcome is when an account is 3 months delinquent. We apply() a function that determines whether the maximum value in any of the month fields is ![]() 3. For those rows that produce
3. For those rows that produce TRUE, we insert a value like bad3 into the pay$Good unless it is already occupied with an Indet value. Again, it makes sense to examine a couple of these records to ensure that our logic is correct.
Another bad outcome occurs when there are at least two instances of month values equal to 2, and a third is when the delinquency value passes $50,000. In each of these cases, we update the pay$Good vector, ensuring that we only update entries that have not already been set. It is a good idea to check a few of the records for each indicator as we did earlier.
Records that do not get assigned Indet nor one of the bad values are assigned Good. Once we have tabulated the bad values separately, we can combine them into a single Bad value. This way, we can compare the frequencies of the different outcomes to see if what we see matches what we expect.
A.6.1 Things to Check
There are lots of ways that these payment records can be inconsistent. The extent of your exploration here might depend on the time available. But we give, as examples, some of the questions you might ask of this data.
- What do the application numbers look like? Do they have 10 digits? Are any missing? Does every booked record have payment information, and does every record with payment information appear in
big? What is the right action to take for booked records with no payment information – set their response toIndet? - What are the proportions of the different outcomes? Do they look reasonable? For example, if 90% of records are marked
Indetwe might be concerned. - What do the amounts look like? Are they ever negative, missing, or absurd?
- Are the dates valid? We expect every entry to be a plausible value in the form
YYYYMMDDor else a zero or set of zeros. Are they? Are adjacent dates 1 month apart, as we expect? Are there zeros in the interior of a set of non-zero dates? - Are adjacent entries consistent? For example, if month 8 shows a delinquency of 4 months, and month 10 shows a delinquency of 6 months, then we expect month 9 to show a delinquency of 5 months. Are these expected patterns followed?
Once the response variable has been constructed, we can merge big with pay. Actually, since we only want the Good column from pay, we merge big with the two-column data set consisting of Appl and Good extracted from pay. In this way, we add the Good column into big.
A.7 Starting the Modeling Process
Our data set is now nearly ready for modeling, although we could normally expect to convert character columns to factor first. Moreover, we often find errors in our cleaning processes or anomalous data when the modeling begins – requiring us to modify our scripts. In the current example, let us see if the Good column constructed above is correlated with the average of the four scores. This R code shows one way we might examine that hypothesis using the techniques in the book.
> big$AvgScore <- apply (big[,c("RAY", "JNG", "KSC", "NE")],
1, mean, na.rm = T)
> gb <- is.element (big$Good, c("Good", "Bad")) &
!is.na (big$AvgScore)The gb vector is TRUE for those rows of big for which the Good column has one of the values Good or Bad, and AvgScore is present, meaning that at least one agency score was present.
We can now divide the records into groups, based on average agency score. Here we show one way to create five groups; we then tabulate the numbers of Good and Bad responses by group.
> qq <- quantile (big$AvgScore, seq (0, 1, len=6),
na.rm = TRUE)
> (tbl <- table (big$Good[gb], cut (big$AvgScore[gb], qq,
include.lowest = TRUE), useNA = "ifany"))
[420,598] (598,649] (649,696] (696,748] (748,879]
Bad 641 620 514 449 384
Good 607 721 811 926 1067
> round (100 * prop.table (tbl, 2), 1)
[420,598] (598,649] (649,696] (696,748] (748,879]
Bad 51.4 46.2 38.8 32.7 26.5
Good 48.6 53.8 61.2 67.3 73.5We can see a relationship between agency scores and outcome from the tables. The first shows the counts, and the second uses prop.table() to compute percentages within each column. In the group with the lowest average score (left column), there are about as many Bad entries as Good ones. As we move to the right, the proportion of Good entries increases; in the group with the highest average scores, almost 75% of entries are Good ones. This is consistent with what we expect, since higher scores are supposed to be an indication of higher probability of good response.