
Chapter 2: Architectural Overview of Apache ShardingSphere
In this chapter, we will introduce you to Apache ShardingSphere's architecture, which also serves as a gateway to a deeper understanding of what a distributed database is. A thorough introduction of the architecture is essential for you to develop a fundamental understanding of how ShardingSphere is built so that you can better use it in your production environment.
We will guide you through some new concepts that have emerged in the database field, such as Database Mesh, while also sharing with you the driving development concept of our community—Database Plus.
We will start by introducing the typical architecture of a distributed database and then proceed by looking at layers, as ShardingSphere is built on a three-layer logic.
The first layer includes the kernel with critical features working in the background to make sure everything runs properly on your database. These critical features are a transaction engine, a query optimizer, distributed governance, a storage engine, an authority engine, and a scheduling engine.
Next, we will introduce the second layer, which is the one you will probably be most interested in. In this section, we will give an overview of the features that you can choose to use from this layer, and what their functionality is. Example features are data sharding, elastic scaling, a shadow database, and application performance monitoring (APM).
Finally, we will introduce the third layer, which arguably makes ShardingSphere unique: the pluggable ecosystem layer.
After reading this chapter, you will have a fundamental understanding of how Apache ShardingSphere is built and will also have had an overview of each feature.
In this chapter, we will cover the following topics:
- What is a distributed database architecture?
- The Structured Query Language (SQL)-based load-balancing layer.
- Apache ShardingSphere and Database Mesh.
- Solving database pain points with Database Plus.
- An architecture inspired by the Database Plus concept.
- Deployment architecture.
- Plugin platform.
What is a distributed database architecture?
A distributed database consists of three inseparable layers—that is, a load-balancing layer, a compute layer, and a storage layer. A distributed database is a type of database in which data is stored across various physical locations. The data stored in said database is not only physically distributed across locations but is also structured and related to other data according to a predetermined logic. The following diagram illustrates the three-layer architecture of distributed database clusters:
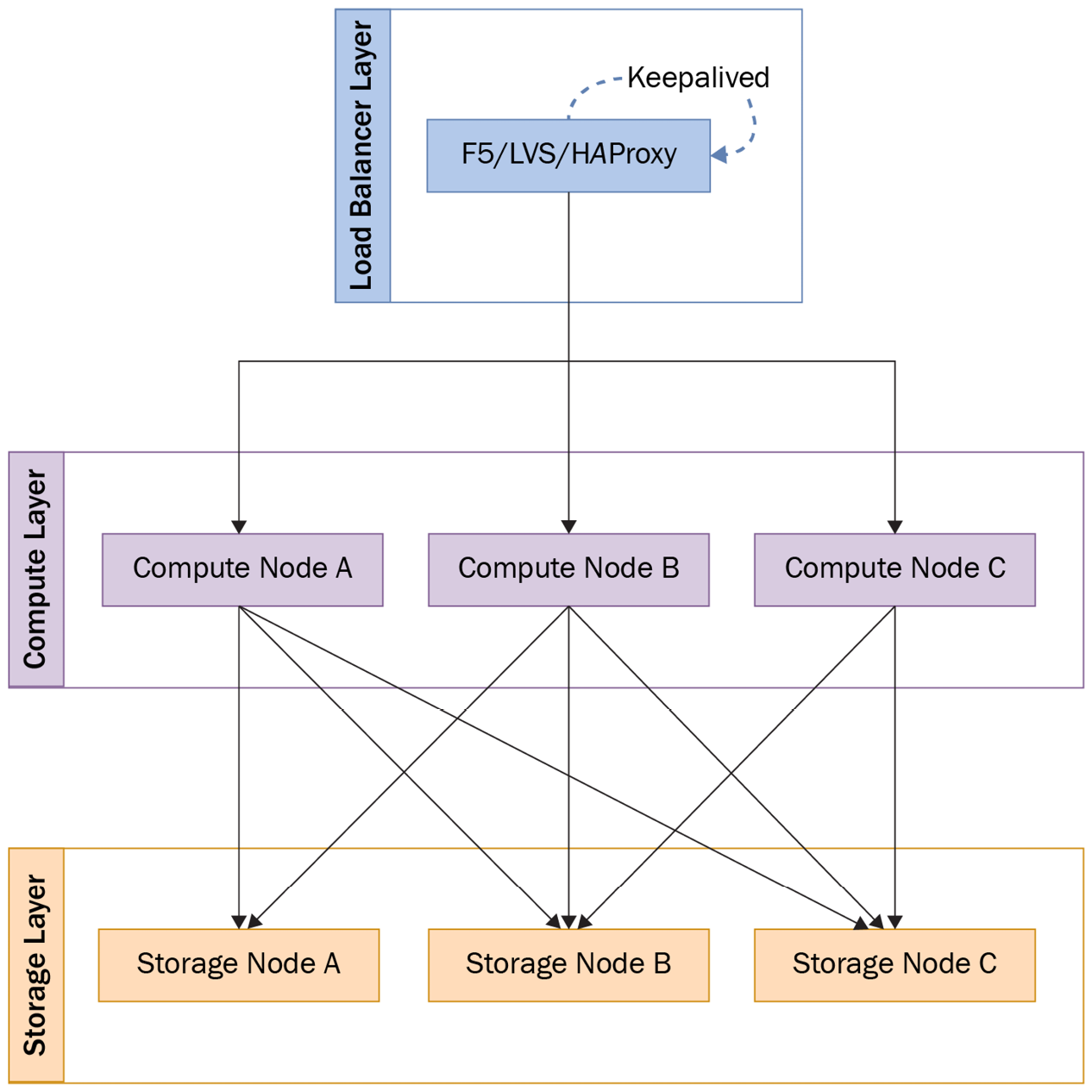
Figure 2.1 – Distributed database cluster architecture
Under the distributed database architecture with storage separated from compute, the stateful storage layer designated for data persistence and push-down computing cannot be expanded as desired. To avoid data loss, it's of great importance to keep multiple copies of data and to adopt a dynamic migration solution to scale out.
The stateless computing layer, on the other hand, is created for distributed query plan generation, distributed transaction, and distributed aggregate calculation, allowing users to horizontally scale computing capabilities. Since computing nodes are scalable, we decided to build the load balancer in front of the database clusters. Naturally, it becomes the centralized point of entry.
In this section, we looked at the concept of distributed databases. This will be useful for understanding the following sections, as Apache ShardingSphere sets out to present a solution allowing the transformation of virtually any of the relational database management systems (RDBMSs) mentioned in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere, into a distributed database system.
The SQL-based load-balancing layer
The network load-balancer layer is now mature enough, as it can distribute and process requests via protocol header identification, weight calculation, and current limiting. Nevertheless, the industry currently still lacks a load-balancer layer suitable for SQL.
Currently, there isn't a load-balancing layer that can understand SQL, which means that a lack of SQL interpretation causes unsatisfactory granularity of request dispatching in any database system. Developing a Smart SQL Load Balancer (LB) solution capable of understanding SQL is the best solution to supplement the database load-balancer layer.
In addition to common load-balancer features such as high performance, traffic governance, service discovery (SD), and high availability (HA), Smart SQL LB also has the capability to parse SQL and calculate query costs.
When it really understands SQL characteristics and query costs, its next move is to label computing nodes and even to tag storage nodes as well. You can use custom labels, of course, such as the following: SELECT && $cost<3, UPDATE && $transaction=true && $cost<10, and (SELECT && GROUP) || $cost>300.
Smart SQL LB can match the executed SQL with a predefined label and distribute the request to the right computing node or storage node. The following diagram shows the features and deployment architecture of Smart SQL LB:

Figure 2.2 – Smart SQL LB deployment architecture
In Figure 2.2, the middle part displays the distributed database cluster architecture with Smart SQL LB, in which the load-balancer layer maintains its HA via organization and management (O&M) methods such as Keepalive and Virtual Internet Protocol (VIP).
The right side of the preceding diagram shows the kernel design of Smart SQL LB. By simulating the target database protocol, it implements the proxy of the load-balancer layer to make accessing Smart SQL LB consistent with directly accessing the target database (MySQL, PostgreSQL, and so on). In addition to the previously mentioned capability to understand SQL, basic features such as dynamic configuration, heartbeat monitors, database discovery, and load balancers are included in node management.
On the left side of the diagram is a configuration example of user-defined labels for the computing node and the storage node. The labels are stored in the Registry Center of Smart SQL LB, and thus the compute layer and the storage layer only need to process the request.
The two layers do not bother with load-balancer-layer capabilities. Thus, the expected return time of a SQL request is quite close to the time the request is sent to the corresponding labeled compute node or storage node. Such improvement solves two pain points in large-scale database clusters, as outlined here:
- Greatly improved system quality of service (QoS) makes the whole cluster run in a much more stable fashion and minimizes the probability of single-node performance waster.
- It effectively isolates transaction computing, analytical computing, and other operations with finer granularity, making cluster resource allocation more reasonable; it's also convenient to customize node hardware resources by following the label description.
In the next section, we will check out how to improve performance and availability thanks to the integration of a load balancer with Sidecar.
Sidecar improves performance and availability
We all agree that performance and availability are at a system's core, rather than fancy-sounding or powerful extra features. Unfortunately, adding the new load-balancer layer may produce a change in both performance and availability.
An additional load balancer increases the network hop count and therefore affects performance to some extent. Concurrently, we also need to build another Virtual Internet Protocol (VIP) or another load balancer designed for the load balancer to fix the HA problem of the load-balancing layer per se, but this method would end up making the system even more complicated. Sidecar is the silver bullet used to solve the problem caused by adding a new load-balancer layer.
A Sidecar model refers to the addition of a load balancer on each application server. Its life cycle is consistent with that of the application itself: when an application starts, so does its load balancer; when an application is destroyed, it will disappear as well.
Now that every application is equipped with its own load balancer, the HA of the load balancer is also ensured. This method also minimizes performance waste because the load balancer and the application are deployed in the same physical container, which means the Remote Procedure Call (RPC) is converted into Inter-Process Communication (IPC).
Along with better performance and HA, Sidecar also has applications loosely coupled to its database software development kit (SDK), and therefore operations (Ops) teams can freely upgrade Sidecar or databases since the design shields the business application from perceiving the upgrade.
Since Sidecar is processed independently of the application, as long as the canary release of Sidecar is guaranteed, it will be completely transparent for application developers. Unlike class libraries dispatched to application programs, Sidecar can more effectively unify online application versions.
The popular Service Mesh concept actually uses Sidecar as its dashboard to process east-west and north-south traffic in the system, and also leverages the Control Panel to issue instructions to the dashboard in order to control traffic or complete transparent upgrades.
The biggest challenge of the model is its costly deployment and administration because it is necessary to deploy each application with Sidecar. Due to the high demand for deployment quantity, it's critical to measure its resource occupancy and capacity.
Tip
Being extremely lightweight is a requisite for a good Sidecar application.
Database Mesh innovates the cloud-native database development path
Kubernetes is a good way to lower Sidecar deployment and management costs. It can put a load balancer and the application image in a Pod or use a DaemonSet to simplify the deployment process. After each Pod starts running, Sidecar can be understood as an inseparable part of the operating system. The application accesses the database through localhost.
For applications, there will always be a database with unlimited capacity that never crashes. Kubernetes is already the de facto standard for cloud-native operating systems, so deploying Sidecar with Kubernetes in the cloud is definitely accepted by the cloud industry.
Along with the success of Service Mesh, the concept of service-oriented, cloud-native, and programmable traffic has revolutionized the Service Cloud market.
Currently, cloud-native databases still focus on cloud-native data storage, yet there is no universally acclaimed architecture innovation like Service Mesh that allows adaptors to be smoothly delivered through the internet. Database Mesh, supported by the Sidecar solution consisting of Kubernetes and Smart SQL LB, can definitely innovate cloud-native databases and, at the same time, it can better parse SQL.
The three core features of Database Mesh are the load-balancer layer, which can understand SQL, programmable traffic, and cloud-native. The Database Mesh architecture is shown in the following diagram:

Figure 2.3 – Database Mesh architecture
The Control Panel manages the load balancing layer, the compute layer, and the storage layer; it can even govern all database traffic. The panel involves the Registry Center and Admin Console.
The Registry Center is used for the distributed coordination of SD, metadata storage (such as label definition, and the mapping information of compute nodes and storage nodes), and storage of the operating status of each component in a cluster.
In the Admin Console, node management and observability are the key capabilities of cloud-native distributed databases. They manage the resources of the entire cluster through cloud management and telemetry.
Apart from resource control, the Admin Console allows SQL commands to operate cluster configuration. The SQL used to control distributed clusters is different from the SQL used for database execution, so we created a new type of SQL named Distributed SQL (DistSQL) to manage distributed clusters.
DistSQL is a supplementary SQL. Together with some necessary features such as traffic management and observability, it can also manage labels (such as defining labels and changing the matching relationship between compute nodes and storage nodes, and so on) to change cluster traffic direction. DistSQL is powerful and flexible enough to enable the Control Panel to dynamically modify traffic control and the router of the entire cluster via programming. It's very similar to the Service Mesh dashboard, but Database Mesh is placed at a different layer. Service Mesh, relying on network traffic, does not need to understand SQL semantics, while Database Mesh supplements database traffic cloud-native control.
Actually, the dashboard of Database Mesh is the load-balancer layer that understands SQL, because it receives commands sent by the Control Panel and executes operations such as current limiting, fusing, and label-based routing.
Database Mesh can completely isolate an environment from another, so operation engineers only need to change the network configuration of the dashboard into that of a distributed database, and then adapt it to the right development environment, test environment, or production environment.
Developers only need to develop localhost-oriented database services. It's not necessary to perceive distributed databases after all. Thanks to the cloud-native service functionality provided by Database Mesh, engineers can completely ignore specific database network addresses, which greatly improves their workflow efficiency.
Apache ShardingSphere and Database Mesh
Although Database Mesh and Apache ShardingSphere may sound similar in some aspects, they are not the same. For example, in contrast to Database Mesh, ShardingSphere's Smart SQL LB doesn't intrude into compute or storage nodes, ultimately making it truly adaptable to any kind of database.
However, a combination of Database Mesh and Apache ShardingSphere can improve interaction performance through a private protocol.
Smart SQL LB can generate an abstract syntax tree (AST) via the SQL parser. So, in the future, starting from version 5.1.0, Apache ShardingSphere will open a private protocol: when it receives SQL requests, it can also receive an AST concurrently to improve its performance in the appropriate manner. For example, apart from SQL parsing, in some scenarios such as single-shard routing, it's feasible to identify SQL features and directly access backend database storage nodes without Apache ShardingSphere.
Enhanced Smart SQL LB functions plus a practicable private protocol will make Apache ShardingSphere and Smart SQL LB even more compatible. Eventually, they will present an integrated Database Mesh solution.
Solving database pain points with Database Plus
The kernel design concept of Apache ShardingSphere is Database Plus. The database industry has been expanding rapidly over the last few years, with new players and new solutions being offered with the intent to solve the increasingly widening gap created by the development of internet-related industries.
Some notable examples include MongoDB, PostgreSQL, Apache Hive, and Presto. Their popularity shows us that database fragmentation is an increasingly widespread issue in the database industry, and the relatively recent pouring of venture-capital support has only exacerbated its growth and development. According to DB-Engines (https://db-engines.com/en/), there are more than 350 databases ranked, with many more that didn't even make the list. According to Carnegie Mellon University's (CMU's) Database of Databases (https://dbdb.io/), there currently are 792 different noteworthy database management systems (DBMSs).
Such a large number of DBMSs is telling of the wide spectrum of possible requirements different businesses may have when it comes to choosing their DBMS. However, a coin has two sides, and this database boom is bound to create issues, as described here:
- The upper application layer needs to contact each different type of database with different database dialects. Preserving existing connection pools while adding new ones becomes an issue.
- Aggregating distributed data among separate databases becomes increasingly challenging.
- Another challenge is how to apply the same needs to fragmented databases— such as encryption, for example.
- Database administrators' (DBAs') responsibilities will increase due to maintaining and operating different types of databases in the production environment, which may cause inefficiencies at scale.
We thought of Database Plus in order to build a standardized layer and ecosystem that would be positioned above the fragmented databases, providing unified operation services and hiding database differentiation. This would create an environment where applications are required to only communicate with a standardized service.
Moreover, additional functions are possible to be included with the flow from applications to databases. The resulting mechanism sees this layer—that is, ShardingSphere—acquiring abilities to hijack the traffic, parse all requests, modify the content, and reroute these queries to anticipated target databases.
Because of Database Plus' basic but important idea, ShardingSphere can provide sharding, data encryption, a database gateway, a shadow database, and more.
As mentioned in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere, the core elements of the Database Plus concept are link, enhance, and pluggable, as outlined here:
- Link means connecting applications and databases. In some cases, applications do not need to be aware of the databases' variable differences, even if a given type of database is removed or added to the bottom of this architecture. Applications are not required to be adapted to this change since they would have been communicating with ShardingSphere from the beginning.
- Enhance means to improve the database capability thanks to ShardingSphere. Why would a user prefer to interact through ShardingSphere rather than the original databases?
That is simply because, admittedly, the link element alone would not be persuasive enough for users to consider using ShardingSphere. Therefore, the enhance element is necessary for ShardingSphere and can provide users with additional and valuable features such as sharding, encryption, and authentication, while at the same time linking databases with applications.
- When it comes to the pluggable element, it is enough to consider that users have diversified needs and issues. They want noticeable care for their needs, which means that user-defined rules and configurations or customization are necessary. However, product sellers or vendors stand in the opposite direction. They prefer to provide standardized products to avoid extra labor, development, or customization costs. The motivating drive has always been to find an answer to the following question: Is there a way to break this deadlock? The community went to work and made ShardingSphere provide application programming interfaces (APIs) for most functionalities. Its kernel workflow basically interacts with these APIs to run. Hence, no matter what the specific implementation is, ShardingSphere can work well while presenting both official and default implementations for each function for an out-of-the-box option together with infinite customization possibilities.
Furthermore, all these functions are pluggable with each other. For example, if you are not looking to implement sharding in your environment for your use case, you can skip its plugin configuration and just provide a data-encryption setting file, and you will get an encrypted database.
Conversely, if you plan to use sharding and encryption functions together, just tell ShardingSphere about this expectation, and it will package these two configurations to build an encrypted sharding database for you. The following diagram presents an overview of the gap created between applications and fragmented databases by new industry needs. As we introduced earlier, the database boom has created a fragmented market that still cannot meet the diversified service requirements brought by a plethora of newly developed applications. Failing to meet fast-changing user needs is what is creating a gap in the industry:

Figure 2.4 – New industry creating a gap between applications and fragmented databases
When it comes to the benefits of Database Plus, we could summarize them with the following points:
- Standardized layer to hide different usages for various databases.
- Noticeably reduce the effect of varying database replacement.
- Supply enhanced functions to solve these annoying problems.
- Assemble different feature plugins for your specific cases.
- Allow users to utilize their customized implementations for most kernel phases.
This innovative idea kicked off with the Apache ShardingSphere 5.x releases. Previously, ShardingSphere defined itself as a sharding middleware layer to help users shard their databases. At that time, it was a lightweight driver, totally different from the present orientation.
Users were vocal in sharing their hopes of ShardingSphere being able to support more valuable features in addition to sharding. To respond to the community's expectations, other excellent features have been added to the development schedules.
On the other hand, the simple combination of various features made the architecture difficult to maintain and hard to keep up with in a sustainable manner. The endeavor to solve these issues required a long-term undertaking. We struggled with these needs and the initial chaos of the project, to finally be able to initiate the Database Plus concept bearing the three characteristic core elements we mentioned previously.
This iterative process sets ShardingSphere apart from other similar sharding products. Citus and Vitess are popular and admittedly excellent products to scale out PostgreSQL or MySQL. Currently, Citus and Vitess are concentrating on sharding and other relevant features, which makes them similar to the older versions of ShardingSphere. The ShardingSphere of today is tracing a new and innovative path, which is bound to drive the database industry toward new heights.
An architecture inspired by the Database Plus concept
Based on the Database Plus concept, ShardingSphere is built according to the architecture that we will introduce you to over the next few sections. We will learn more about this project from both feature architecture and deployment architecture perspectives. Multiple perspectives will allow you to understand how to use the Database Plus concept and deploy it in a production environment.
Feature architecture
Feature architecture elaborates more on the clients, features, and supported databases. It's a catalog of each available component—a dictionary including its clients, functions, layers, and supported databases.
As previously introduced in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere, all components—such as data sharding, data encryption, and all of ShardingSphere's features, including clients—are optional and pluggable. As graphically represented in the following diagram, once you select ShardingSphere for your environment, your next step is to select one or more clients, features, or databases to assemble a database solution that fits your needs:
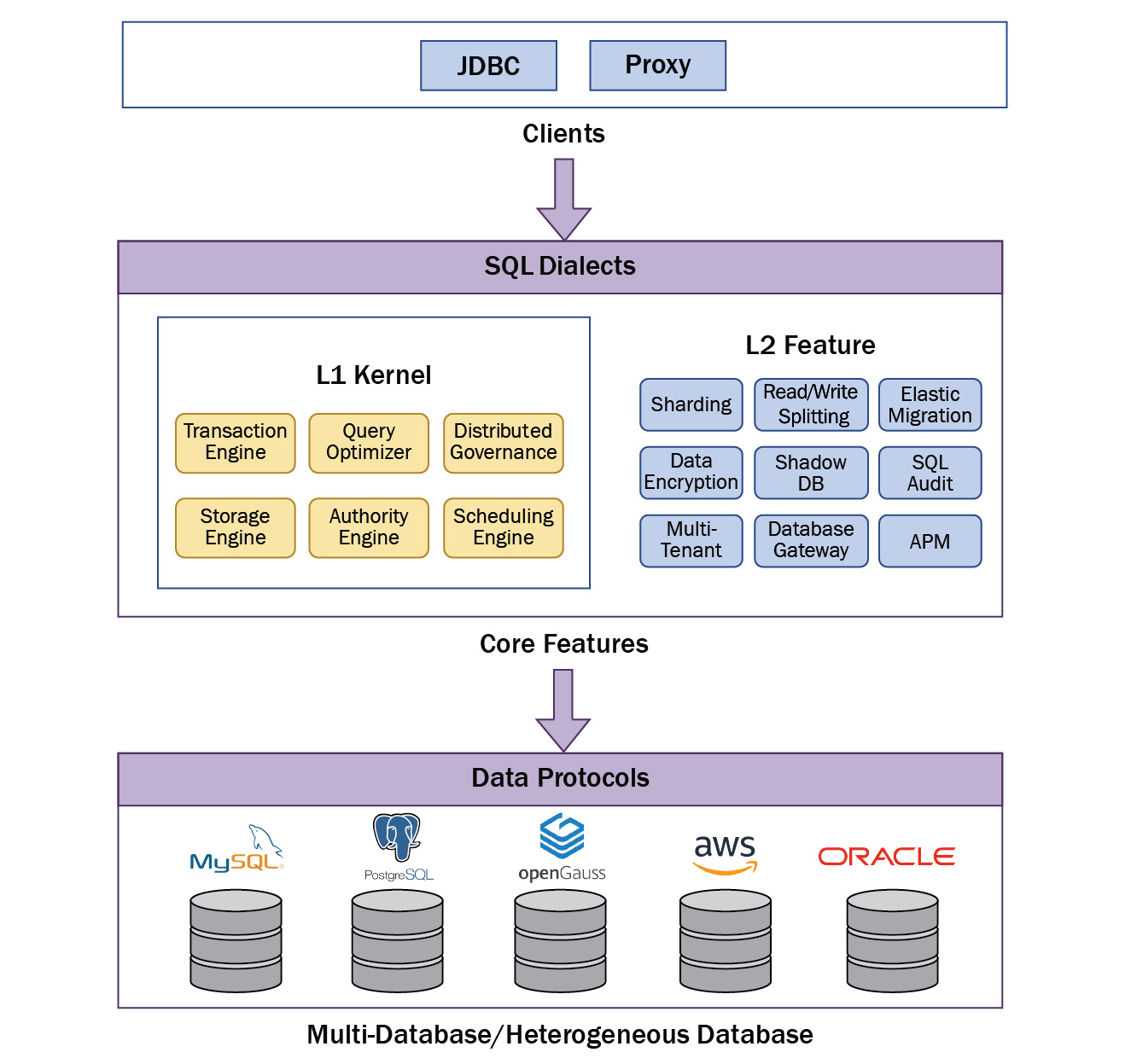
Figure 2.5 – ShardingSphere's feature architecture
Now that we have introduced an overall idea of the architecture, the following sections will allow you to have a deeper understanding of the clients, features, and database protocols in order to make informed decisions.
Clients
The top layer is composed of ShardingSphere-Proxy and ShardingSphere-JDBC, which are two products or clients for you to choose from, and they have respectively suitable usages and scenarios. You can choose to deploy one of them or both together. If you remember, we covered these two clients and their deployment patterns in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere. If you need a quick refresher, just remember that ShardingSphere-JDBC is a lightweight Java framework, while ShardingSphere-Proxy is a transparent database proxy.
Introduction to the feature layer
Let's now look at the layer of the architecture that includes the features of Apache ShardingSphere. We will first look at the kernel layer and its corresponding features and then proceed to layer 2 (L2)—the function layer and its features. This is useful for gaining an overview of where features are located before we jump to the deployment architectures in the following section.
L1 kernel layer
If you remember, we first introduced this concept and its definition in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere, in Figure 1.3. This layer is part of the feature layer but focuses on the kernel part, which indicates internal features that are critical but have no direct importance in solving general concerns. They run in the background and support the L2 function layer. Sometimes, their quality determines the performance of these features located in the L2 layer, and in other cases, they notably influence the performance of all clients. Therefore, massive amounts of effort and time were dedicated to their improvement. The following sections will provide you with an understanding of the components of the kernel layer and their functionalities.
Transaction engine
Database transactions are required to satisfy atomicity, consistency, isolation, and durability (ACID) conditions. When considering a single database, transactions can only access and control a single database's resources and are referred to as local transactions. These are natively supported by the overwhelming majority of mature relational databases.
On the other hand, we also have distributed transactions. An increasing number of transactions require the inclusion of multiple service accesses and the respective database resources in the same transaction, thanks to distributed application situations based on microservices.
The transaction engine is designed to deal with local transactions, eXtended architecture (XA)-distributed transactions, and basically available, soft State, eventually consistent (BASE)-distributed transactions.
Query optimizer
The query optimizer attempts to analyze SQL queries and determine the most efficient way to execute a query by considering multiple possible query plans. In a distributed database system, a query optimizer determines the data volume to acquire, transit, and calculate from multiple shards.
Once SQL queries are submitted to the database server and parsed by the parser, it is the right time to pass them to the query optimizer. Since the structure of data and query is not one-to-one, the gap between them is likely to cause inefficient data acquisition.
All the operators in the query optimizer will be used to calculate the cost for each query thanks to the metadata and optimization rules, to subsequently generate various execution plans. The final target of the query optimizer is to find the best execution plan to process a given query in minimal time. Nevertheless, a good enough execution plan is more acceptable. This is because the optimization process to find the best way still takes some time, which might slow performance.
Distributed governance
A distributed system requires individual components to have unified management ability. Distributed governance essentially refers to the ability to manage the state of database storage nodes and the driver or proxy computing nodes, while being able to detect any updates in the distributed environment and synchronize them among all computing nodes online in real time. Furthermore, it will collect the metadata and information of this distributed system and provide advice for this database cluster. By means of machine learning (ML) technology, this distributed governance can learn the history of your database and calculate more beneficial database personalized recommendations.
Additionally, circuit-breaker and traffic-limiting features provided by distributed governance ensure the whole database cluster can serve applications continuously, efficiently, and fluently.
Storage engine
A storage engine concentrates on how to store data in a certain structure. From the previous architecture shown in Figure 2.5, you will see various databases such as MySQL, PostgreSQL, Oracle, Server, Amazon Relational Database Service (Amazon RDS), and so on. Clearly, they are all databases, which means they have the capabilities to store data and calculate queries. In fact, they can be regarded as storage solutions, and the responsibility of the storage engine is to communicate with these storage solutions.
How do you differentiate database middleware from distributed databases? Some people will give the answer that the type of storage and the connection to them are the main factors. If this distributed system is built from scratch (storage, computing nodes, and clients), that means it is born as a distributed database for the new era's needs. Conversely, when the storage is a DBMS and the computing nodes utilize SQL to retrieve data from storage, that is viewed as a database middleware. In other words, the key is the presence or lack of native storage.
When it comes to the storage engine of ShardingSphere, it includes and connects different storage, which implies that the storage could be a DMBS or a key-value (KV) storage. A specific function is taken charge of by the corresponding engine so that other modules are not influenced by the modification or changes of other parts. This design also creates chances for storage replacement.
Authority engine
An authority engine provides user-authentication and privilege-control capabilities for distributed systems. Through the different configuration levels supported by an authority engine, you can use password encryption, schema-level privilege control, table-level privilege control, and more fine-grained privilege customization to provide different degrees of security for your data.
At the same time, a privilege engine is also the basis of data auditing. With the help of a privilege engine, you can easily complete the configuration of audit privileges, thereby limiting the scope of data queries for some users or limiting the number of rows affected by certain SQL.
In addition to the way files are configured, the authority engine also supports the Registry Center or integrates with the user's existing authority system through an API so that architects can flexibly choose a technical solution and customize the authority system that is most suitable for them.
Scheduling engine
A scheduling engine is designed for job scheduling; it is powered by Apache ShardingSphere ElasticJob, which supports an elastic-schedule, resource-assign, job-governance, and job-open ecosystem.
Its features include support for data sharding and HA in a distributed system, scale-out to improve throughput and efficiency, and flexible and scalable job processing thanks to resource allocation. Additional noteworthy highlights include self-diagnosis and recovery when the distributed environment becomes unstable.
It is used for elastic migration, data encryption, data synchronization, online Data Definition Language (DDL), shard splitting and merging, and so on.
L2 function layer
The following sections will provide you with an understanding of the components and functionalities of the function layer. The features of the L2 function layer are supported by background-running components of the L1 function layer that were introduced in the L1 kernel layer section.
Sharding
When we talk about sharding, we refer to splitting data that is stored in one database in a way that allows it to be stored in multiple databases or tables, in order to improve performance and data availability. Sharding can usually be divided into database sharding and table sharding.
Database sharding can effectively reduce visits to a single database and thereby reduce database pressure. Although table sharding cannot reduce database pressure, it can reduce the data amount of a single table to avoid query performance decrease caused by an increase in index depth. At the same time, sharding can also convert distributed transactions into local transactions, avoiding the complexity of distributed transactions.
The sharding module's goal is to provide you with a transparent sharding feature and allow you to use the sharding database cluster like a native database.
Read/write splitting
When we talk about read/write splitting, we refer to splitting the database into a primary database and a replica database. Thanks to this split, the primary database will handle transactions' insertions, deletions, and updates, while the replica database will handle queries.
Recently, databases' throughput has increasingly been facing a transactions-per-second (TPS) bottleneck. For applications with massive concurrent read but smaller simultaneous write, read/write splitting can effectively avoid row locks caused by data updates and greatly improve the query performance of the entire system.
A primary database with many replica databases is able to improve processing capacity thanks to an even distribution of queries across multiple data replicas.
This also means that if we were to expand this setup with multiple primary databases with multiple replica databases, we can enhance not only throughput but also availability. Such advantages are no small feat, and you shouldn't overlook this type of configuration. Remember that under this configuration, the system can still run independently on the occurrence of any database being down or having its disk physically destroyed. The goal of the read/write splitting module is to provide you with a transparent read/write splitting feature so that you can use the primary replica database cluster like a native database.
Elastic migration
Elastic migration is a common solution for migrating data from a database to Apache ShardingSphere or scaling data in Apache ShardingSphere. It's a type of scale-out/-in or horizontal scaling, but not scale-up/-down or vertical scaling.
Considering a hypothetical situation where our business data is growing quickly, then according to widespread database professionals' belief, the backend database could be the bottleneck. How could we prevent or resolve this? Elastic migration could help.
Just add more database instances and configure more shards in Apache ShardingSphere, then migration will be scheduled and a scaling job will be created to do the migration. The scaling job includes four phases: a preparation phase, an inventory phase, an incremental phase, and a switching phase. You will learn more about these phases and the elastic-scaling workflow in Chapter 3, Key Features and Use Cases – Your Distributed Database Essentials, under the An introduction to elastic scaling section. Database connectivity and permissions checks, as well as recording the position of logs, will be done in the preparation phase. Inventory data on current time migration will be done in the inventory phase.
In the event that data is still changing during the inventory phase, the scaling job will synchronize these data changes thanks to the change data capture (CDC) function. The CDC function is based on database replication protocols or write-ahead logging (WAL) logs. This function will be performed in the incremental phase. After the incremental phase is completed, the configuration could be switched by register-center and config-center so that the new shards will be online during the switching phase.
Data encryption
Data security is of paramount importance, both for internet enterprises and ones belonging to more traditional sectors, and data security has always been an important and sensitive topic.
At the core of data-security notions, we find data encryption, but what is it exactly? It is the transformation of sensitive information into private data through the use of encryption algorithms and rules.
If you're thinking about what some potential examples could be, just think of data involving clients' sensitive information, which requires data encryption to be compliant with consumer data protection regulations, for example (such as identification (ID) number, phone number, card number, client number, and other personal information).
The goal of the data-encryption module is to provide a secure and transparent data encryption solution.
Shadow DB
This is a suitable solution for the current popular microservice application architecture. Businesses require multiple services to be in coordination, therefore the stress test of a single service can no longer represent the real scenario.
The industry usually chooses online full-link stress testing—that is, performing stress testing in a production environment. To ensure the reliability and integrity of production data to prevent data pollution, data isolation has become a key and difficult point.
The Shadow DB function is ShardingSphere's solution for isolating the pressure-test data at the database level in a full-link pressure-test scenario.
APM
ShardingSphere's APM feature provides metrics and tracing data to a framework or server for implementing the observability of ShardingSphere. It's based on Byte Buddy, which is a runtime code generator used by Java agents, and it's developed this way to support zero intrusion into other modules' code and decoupling it from core functions.
The APM module can be released independently. Currently, it supports exporting metrics data to Prometheus, and Grafana can easily visualize this data through charts. It supports exporting tracing data to different popular open source software (OSS) such as Zipkin, Jaeger, OpenTelemetry, and SkyWalking. It also supports the OpenTracing APIs at the code level. The metrics data includes information about connections, requests, parsing, routing, transactions, and part of the metadata in ShardingSphere.
The tracing data includes the time elapse of parsing, routing, and execution of SQL information alongside the request. The useful data exported by the APM module can provide you with a simple way to analyze ShardingSphere runtime performance. The APM module can also support monitoring the user application using the ShardingSphere-JDBC framework as its backend data access.
Deployment architecture
ShardingSphere provides many practical deployment patterns to solve your cases, but this section will introduce the necessary components with an illustrative and simple one.
Applications are the external visitors, and a computing node, a proxy, is in charge of receiving traffic, parsing SQL, and calculating and scheduling distributed tasks. The registry will persist the metadata, rules, configurations, and cluster status. All the databases will become storage nodes persisting the data and running some calculation jobs.
The following diagram shows one of the three possible deployment architectures you can use with ShardingSphere. These are Proxy, Java database connectivity (JDBC), or hybrid, as mentioned in Chapter 1, The Evolution of DBMSs, DBAs, and the Role of Apache ShardingSphere, under the The architecture possibilities at your disposal section:

Figure 2.6 – ShardingSphere-Proxy deployment architecture
If you have some knowledge of Kubernetes architecture, you will find that it shares similarities with ShardingSphere's architecture. The following diagram gives us an example of Kubernetes architecture, which we can compare with Figure 2.6:

Figure 2.7 – Kubernetes architecture example
As you can see from the preceding diagram, the primary node and proxy work alike. The primary node controls the nodes as represented in Figure 2.7, just as—similarly—proxy visits these databases. etcd, which is a distributed key-value store of a distributed system's critical data, is used to manage the cluster state, and all the primary nodes connect to it. The registry also needs all the proxies to register to it.
These two diagrams will hopefully allow you to understand the similarities between ShardingSphere-Proxy and typical Kubernetes architectures. This will be useful as we proceed to the next section where we will learn about the plugin platform of Apache ShardingSphere.
Plugin platform
Engineers may choose ShardingSphere-JDBC or ShardingSphere-Proxy, but when they use Apache ShardingSphere, they actually call the same kernel engine to process SQL. Though Apache ShardingSphere with its complex structure contains many features, its microkernel architecture is extremely clear and lightweight.
Microkernel ecosystem
The core process of using Apache ShardingSphere is very similar to that of using a database, but ShardingSphere contains more core plugins for users, together with extension points. An overview of the kernel architecture is shown in the following diagram:

Figure 2.8 – Kernel architecture overview
The preceding diagram shows the three layers of the architecture—namely, the innermost microkernel, the pluggable service provider interfaces (SPIs) in the middle, and the pluggable ecosystem placed at the outermost layer.
The microkernel processing workflow involves two standard modules, SQL Parser and SQL Binder. These two modules are developed to identify specific SQL characteristics and then, based on the results, the SQL execution workflow is divided into a simple push-down engine and a SQL federation engine.
The pluggable SPI is the abstract top-level interface of Apache ShardingSphere's core process. The microkernel does not work for rule implementation, and it just calls a class registered in the system that implements an interface step by step. Along with the SQL executor, all SPIs use the decorator design pattern to support feature combinations.
A pluggable ecosystem allows a developer to use pluggable SPIs to combine any desired features. The core features of Apache ShardingSphere (for example, data sharding, read-write splitting, and data encryption) are pluggable SPIs or components of the pluggable ecosystem.
During the microkernel process, SQL Parser converts the SQL you input into an AST Node through the standard lexer and parser processes, and eventually into a SQL statement to extract features, which is actually the core input of the Apache ShardingSphere kernel processer.
SQL statement embodies the original SQL, while SQL binder combines metadata and SQL statement to supplement wildcards and other missing parts in the SQL, to generate a complete AST node that conforms to the database table structure.
The SQL parser analyzes basic information—for example, it checks whether SQL contains related queries and subqueries. SQL binder analyzes the relations between logical tables and physical databases to determine the possibility of cross-database-source operation for the SQL request. When the full SQL can be pushed down to the database storage node after operations such as modifying a logical table or executing information completion, it's time to adopt Simple Push Down Engine to ensure maximum compatibility with SQL. Otherwise, if the SQL involves cross-database association and a cross-database subquery, then SQL Federation Engine is used to achieve better system performance during the process of operating distributed table association.
Simple Push Down Engine
For Apache ShardingSphere, Simple Push Down Engine is an old feature, and it is applicable to scenarios where database native computing and storage capabilities need to be fully reused to maximize SQL compatibility and stabilize query responses. It is perfectly compatible with an application system based on the Share Everything architecture model.
The following diagram clearly illustrates the architecture of Simple Push Down Engine. Following the two standardized preprocesses, SQL Parser and SQL Binder, SQL Router extracts the key fields in SQLStatement (for example, shard key) and matches them with specific DistSQL rules configured by the user to calculate the routing data source:

Figure 2.9 – Simple Push Down Engine architecture
When the data source is clarified, SQL Rewriter rewrites the SQL so that it can be directly pushed down to the database for execution in a distributed scenario. Execution types include logical table name replacement, column supplementation, and aggregate function correction.
SQL Executor checks the transaction status and selects a suitable execution engine to execute the request; then, it sends the rewritten SQL in groups to the data source of the routing result concurrently.
Finally, when execution results of SQL are completed, Result Merger automatically aggregates multiple result sets or rewrites them one more time.
Having acquired an understanding of the Simple Push Down Engine architecture and how it works with SQL, the next step will be understanding ShardingSphere's SQL Federation Engine.
SQL Federation Engine
SQL Federation Engine is a newly developed engine in Apache ShardingSphere, but its development iteration is quite frequent now. The engine is suitable for cross-database associated queries and sub-queries, and its architecture is shown in the following diagram.
It can fully support a multi-dimensional elastic query system applicable to the Share-Nothing distributed architecture model. Apache ShardingSphere will continue to improve the query optimizer model, trying to migrate more SQLs from Simple Push Down Engine to SQL Federation Engine.
Before jumping right into the details of how SQL Federation Engine works and how it is built, take a minute to have a look at the following diagram we prepared to give you an overview of SQL Federation Engine's architecture:
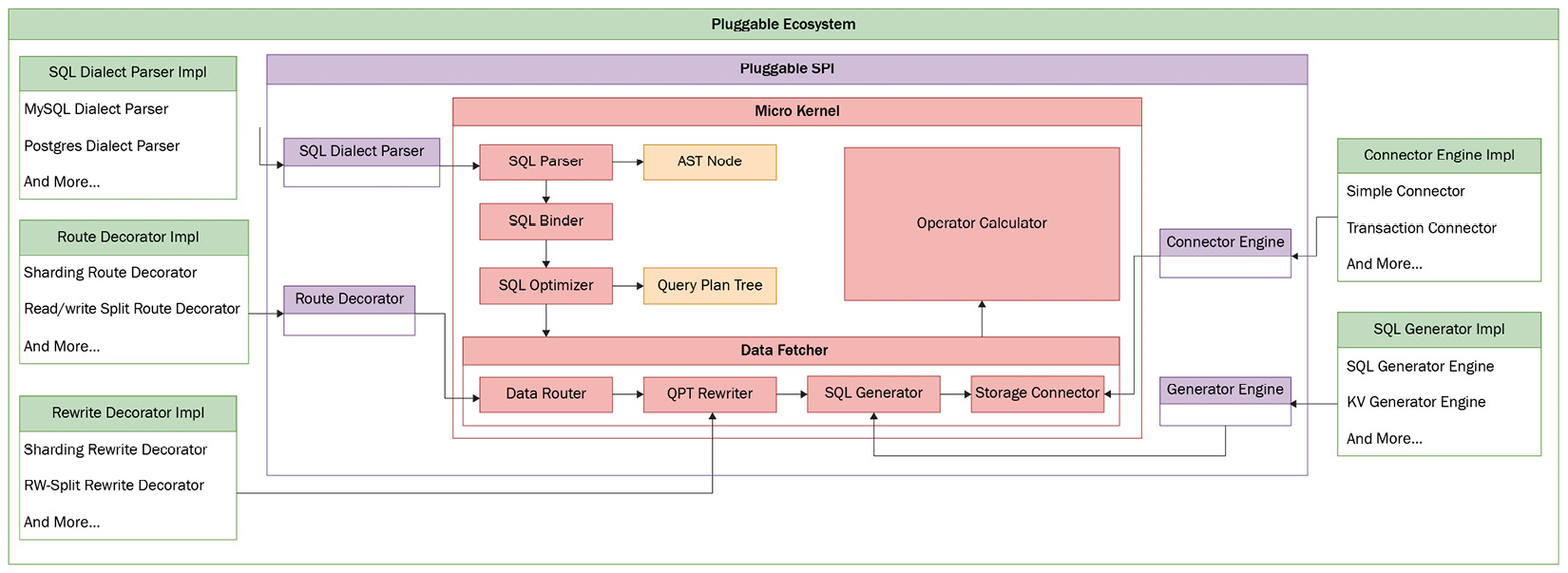
Figure 2.10 – SQL Federation Engine architecture
Compared with Simple Push Down Engine, it is more similar to the core process of databases. The major difference between SQL Federation Engine and Simple Push Down Engine is the SQL optimizer, which optimizes the AST Node by leveraging a rule-based optimizer (RBO) and cost-based optimizer (CBO) to generate a Query Plan Tree.
Therefore, to obtain data from the storage node, it does not rely on the original SQL but instead can leverage the query plan tree, regenerate a new SQL that can be executed on a single data node, and later send this to the storage node according to the routing result.
Before the final SQL is generated, Query Plan Tree Rewriter (QPT Rewriter) modifies the table or the column according to the DistSQL rules configured by the user. It is worth noting that the target data source does not have to be consistent with the SQL dialect input by the user. Instead, it can use the query plan tree to generate a new SQL dialect suitable for storage nodes, such as other database dialects, and even KV.
In the end, it returns the execution result to the compute node of Apache ShardingSphere, and Operator Calculator finishes the final aggregate calculation in the memory until the result set is finally returned.
Both Simple Push Down Engine and SQL Federation Engine showcase how core extension points of Apache ShardingSphere are open to enhanced features. As long as they master the design process of the microkernel architecture, developers can easily add custom functions by implementing core extension points.
Summary
With this chapter, we set out to understand how Apache ShardingSphere is built from an architecture point of view, in order to establish a foundational understanding of how its ecosystem works.
First, we thought it would be necessary to share with you our motivations and some of the recent developments brought to the database industry by Kubernetes and Database Mesh. Having an overview of these concepts allows you to gain an understanding of our Database Plus development concept, Apache ShardingSphere's three-layer architecture, and its components. We then learned about the features, the importance of SQL parsing, and how Apache ShardingSphere is transitioning.
In the next chapter, we will introduce you to potential use cases for Apache ShardingSphere in a professional environment, while introducing its features in a detailed manner.