
It’s time to revisit what I’ve written previously, but in a more succinct and more technical way, which will also let me take you on a deeper dive.
For me, the problem was litigation. The solution consisted of deep learning models for text can be used as part of a software system to identify litigation risks in enterprise e-mail messages. In short, the solution was an early warning system to enable prevention. The system provides alerts of risky e-mails in near real-time to corporate (in-house) counsel. With alerts, in-house counsel could investigate further and confer with decision makers on ways to address the legal risks before they are realized as lawsuits.
The example here is employment discrimination, a classification of litigation in the U.S. federal court system. With training data for employment discrimination, a deep learning model was built and tested using three different sources of deep learning models: MetaMind, Indico Data Systems, and TensorFlow. ROC-AUC and t-SNE techniques were used to assess each model’s accuracy.
The test data consisted of e-mail messages in the Enron dataset. Although Enron was known for fraud, the system surfaced four e-mail messages that were True Positives for discrimination. In employment discrimination litigation, like many other business-relevant classifications of litigation, there is a large amount of training data. But for situations where there is only a small amount of training data, this chapter describes a new approach: the formation of a corporate legal data consortium, and the use of blockchain to perform a secure multi-party computation (MPC). With this technique, a deep learning modeler can build a model for a high-value risk, such as a potential violation of the Foreign Corrupt Practices Act, from the aggregate of consortium data.
In 2008, Professor Richard Susskind, of Oxford University, urged lawyers to warn their clients about impending risks instead of managing litigation.1 In enterprises, personnel with legal training generally work in corporate law departments. These in-house legal professionals are potentially privy to possible risks contained in internal documents, including but not limited to e-mails and the documents attached to them (hereinafter, e-mails or test data). As the matter stood, they could only manage the litigation caseload and never saw the risks in time to nip them in the bud. The reason is clear: the daily batches of corporate e-mail are too voluminous for in-house counsel to timely and adequately review.
Yet corporate litigation risk is pervasive and can impact the global economy, so the value of being able to discern risks in near real-time is also clear. A system that enables in-house counsel to mitigate or avoid litigation reduces or avoids costly damages: payouts for settlements and verdicts; attorney fees; discovery costs; expert fees; productivity losses; and the potential for diminutions of brand value and personal reputations. In the United States, the average annual cost of commercial tort litigation during the period 2001–2010, in terms of settlements and verdicts, defense fees, and administrative costs, was $160 billion; and that cost, when divided by the average federal and state caseload for the same period, was between $350,000 and $408,000 per lawsuit. The annual savings of avoiding only one lawsuit per month would range between $4.2 million and almost $4.9 million.2
The current approach to mitigating or avoiding litigation relies in part on post-litigation seminars and on hotlines for whistleblowers. As for hotlines, they will be used to a greater extent only when an enterprise is willing to encourage their use, and enterprises should do so. A recent study has found that the more employees use hotlines, the less likely the enterprise will face litigation and attendant costs.3
Nevertheless, the efficacy of hotlines depends in large part on whether employees use them and how frequently they report to corporate executives or stakeholders. Hotlines are not new, however, and with increasing awareness of the power of Artificial Intelligence, the legal profession now appears to be more willing to try it. For example, in response to a survey in which thousands of attendees of meetings of the Global Pound Conference were asked how dispute resolution can be improved, the top choice of six alternatives, by a significant margin, was “Pre-dispute or pre-escalation processes to prevent disputes.”4
This chapter describes a software system that operates in a way that is very different from hotlines. The system trains a deep learning model with text extracted from complaints in lawsuits filed in the U.S. federal court system, where each lawsuit is filed in a specific classification or label of litigation risk. The labeled text is used to train a deep learning model for each classification of risk.
When deployed, the system ingests copies of all e-mails that an enterprise generates daily, indexes them, processes them overnight, and scores them to the extent that they relate to the model. The next day, the system outputs only the related e-mails to the personnel in the corporate law department previously designated to receive and assess the results.
If a user deems a result a True Positive, the system allows the user to access the e-mail of interest in its native format. The user may then initiate an internal investigation, conduct e-mail threading (to identify others who may be involved), research internal databases for additional information, and report to a control group executive, who is someone who can make decisions in the name of the enterprise and stands in its shoes.
Since a deep learning model is capable of learning not only from generic examples but also from examples of True Positives that are surfaced when the system is deployed, True Positives can be saved and used to re-train the system. Over time, the model will “learn” and better reflect the culture of the enterprise.
To protect employee privacy, the system would monitor only enterprise computer resources subject to written privacy policies known to and accepted by employees. In connection with e-mail messaging systems, U.S. courts have held that, when such policies are in place, employees have no reasonable expectation of privacy, even when using enterprise systems to communicate with a personal attorney.5
A certain number of labeled examples of appropriate text are required to train a deep learning model. Those examples may be found in the U.S. federal court litigation database known as Public Access to Court Electronic Records (PACER).6 Fortunately, the PACER database is organized into litigation classifications and there is a unique Nature of Suit (NOS) code associated with each classification. In order to initiate a lawsuit in federal court, every person must concurrently complete, sign, and file a Civil Cover Sheet. Along with a complaint, the attorney filing the complaint must review the classifications in the Civil Cover Sheet and comply with the instruction to “Place an ‘X’ in One Box Only.” Accordingly, each lawsuit is mapped to one and only one classification and its associated NOS code.
PACER is a ready source for examples of text typical of each classification and may be searched by specifying only the NOS code. The search will surface case numbers which are active links to the lawsuits filed in that classification. By opening a case link, every document filed in connection with that lawsuit may be accessed.
The first document that tells the story of the risk is the complaint. In PACER, the complaint is usually the first document in the silo of each lawsuit. The facts alleged in each complaint express the filing attorney’s factual basis for asserting that the lawsuit has merit. These facts are the essence of litigation risk.
A deep learning model is binary in nature, so that the system will store, score, and report only the e-mails that match up as being “positive,” that is, are related to a risk. The system will ignore the other e-mails. Thus, the model must be infused with examples of text that is “positive” and “negative” for the risk.
Generally, the complaints filed in each classification contain generic examples of text that are “positive” for that type of litigation risk. The positive training data may also be shaped by adding examples that are more specific to the enterprise. Such examples may be found by using the NOS code and adding the party name to the search.
To create a generic positive training set for Civil Rights: Employment (NOS 442), that is, employment discrimination, the factual allegations in complaints filed in that classification were extracted from PACER. To create a negative training set, more than 40,000 news articles unrelated to the employment discrimination classification were used.
The next step involved creating a numerical structure for each word in the positive and negative datasets. These numerical structures may be called vectors or number strings. The process of converting words into number strings is generally referred to as a “word embedding.” The modern technology for transforming text into number strings was invented in 2013 as word2vec.7 Word2vec was extended in 2014 by “Glove: Global vectors for word representation,” and is referred to as GloVe.8 With GloVe, a deep learning model may “learn” English. Here the Wikipedia 2014 + Gigaword 5 corpus was used. It contains six billion total tokens with a vocabulary of 400,000 words. Each vector has a length of 300.
The significance of a word embedding tool is that it converts each word in the same classification of documents into a number string (vector) that a computer can process. This approach implements a key insight by the late linguist J. R. Firth. His now-famous observation is that “You shall only know a word by the company it keeps.”9
To create a deep learning model for each risk, the number strings are passed to a bi-directional multi-layer Gated Recurrent Unit-based Recurrent Neural Network (RNN). RNNs process sequential information and have “memory” from previous computations.10
To assess a model’s performance, practitioners typically construct a Receiver Operating Characteristic (ROC) curve and calculate the Area Under the Curve (AUC). The ROC curve plots True Positives on the y-axis with a maximum of 1.0, and False Positives on the x-axis, also with a maximum of 1.0. This space is a 1.0 by 1.0 square such that the maximum AUC score is also 1.0. An AUC score in the eighties or nineties, for example, 0.91, indicates that there are many more True Positives than False.11
In addition, data science practitioners often visualize a model by using t-Distributed Stochastic Neighbor Embedding (“t-SNE”).12 A t-SNE visualization shows whether a decision boundary is well-defined between the text related to the risk (the “positive” dataset) and text unrelated to the risk (the “negative” dataset).13
The next step is to switch from text in PACER (generic and company-specific) to enterprise text, meaning copies of e-mails obtained from a customized cloud environment, hosted Exchange or Office 365. Such test data may consist of the batch of e-mails that an enterprise generated yesterday. Then, each e-mail message is associated with a unique identification (ID) number using dtSearch software.14 A text file is then passed to a GPU where processing using GloVe and the now pre-trained deep learning model takes place. The result is a file with ID numbers and e-mails that have been scored as being “related” to the risk. That file populates a User Interface (UI) as shown below in Figure 9.1.
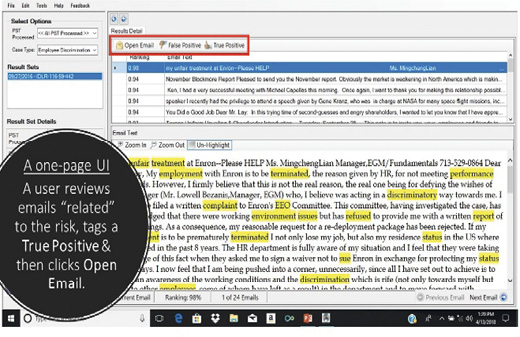
Figure 9.1 A user interface with scored text and subject matter words (highlighted)
Before the UI is presented to a user, the system uses software from dtSearch to access a database containing the words that were initially drawn from the positive dataset in one column and, in another column, only the words that are designated by subject matter experts, that is, experienced litigators, as being relevant to the discrimination risk. Software from dtSearch may be used to access the column with the relevant words and highlight them in UI as a visualization aid for the user.
As Figure 9.1 shows (top rectangle), a user is tasked with making a judgment call and identifying True Positives and False Positives. In addition, a user may also mark/tag an e-mail as True Positive. That tagging places a copy of that e-mail into a database which may be used for re-training the deep learning model at a future date. After deciding that an e-mail is a True Positive, a user can also view that e-mail in its native format and export it to a case management system. Finally, with a True Positive result, an internal investigation may begin.
Besides this functionality, the system is designed to keep the output confidential and limited to the in-house attorney and the client enterprise. It does this by taking advantage of two confidentiality rules: the work-product doctrine and the attorney-client privilege.
For the work-product doctrine to apply, the system must be deployed by members of the corporate law department (or other enterprise personnel under the direction and control of the law department) and then used as defined: “in anticipation of litigation.” The work-product doctrine should also apply when a law department employee concludes that an e-mail is a True Positive, retrieves that e-mail in its native format, and then conducts an internal investigation to determine whether the litigation risk is supported by other information.
If the investigation supports a conclusion that a risk exists and that damages may ensue (or have only recently be incurred), enterprise law department personnel may contact a control group executive, to advise that person of the matter and what may be done about it. Now the attorney-client privilege should apply.
Now for results. An early version of the above-described system was evaluated by two different deep learning providers. They each were given the same positive and negative training data, and the same “test data,” a portion of Enron e-mails from the inbox of Ken Lay, former Chairman and CEO of Enron.
However, before these evaluations, the PACER database was reviewed for statistics about Enron. For the five-year period 1997–2001, the chance of finding an employment discrimination case against an Enron company was very small. During that five-year timeframe, Enron was a named party in PACER 1,339 times. However, Enron was a named party in only 13 employment discrimination lawsuits, which amounts to only about one percent (1 percent).
The first evaluation was conducted with a deep learning system provided by MetaMind, a startup founded by Richard Socher, one of the authors of the GloVe paper. Given the training data described above, the MetaMind model was asked to assess approximately 5,000 Enron e-mails by Ken Lay, who had not been directly involved with the Human Resources department. Using MetaMind’s model, the amount of training data was increased in baby steps. The experiment involved only 50 positive training examples at first. It was re-run with 100, 150, 200, and finally 400 examples.
Surprisingly, the MetaMind model trained with only 50 examples produced immediate results. The result was a set of 24 e-mails (out of about 5,000, a fraction of about one-half of one percent) that were scored as being “related” to the risk. In reviewing the top-scoring e-mails, the data showed that while most of the e-mails were False Positives, one was a True Positive. The result was doubly surprising as Enron was known for fraud, not employment discrimination.
Later, the Enron test set was expanded to include other Enron employees, where three e-mails scored almost as high as the first. However, each e-mail presented the same risk, because they were “forwards” of the e-mail first sent to Ken Lay.
Each of these e-mails included the phrase “my unfair treatment at Enron” and read in part as follows:
[M]y employment with Enron is to be terminated, the reason given by HR, for not meeting performance standards. However, I firmly believe that this is not the real reason, the real one being for defying the wishes of my manager . . . , who, I believe was acting in a discriminatory way towards me (Italics added; in the UI, only “terminated” was highlighted.)
In this e-mail, the word “terminated” drew attention to the words that preceded it: “is to be,” common words which were not relevant, but which provided important context. “Is to be terminated” indicated that no job action had yet been taken. And since no other damages had been identified, the e-mail appeared to have been written before damages could be alleged. Because damages are a necessary element of every civil lawsuit, a user would infer that a lawsuit was not yet viable. Thus, the deep learning model had surfaced an e-mail that signaled a potential lawsuit.
Further experiments with a list of sex and race terms added little to the strength of the model. These lists of key words lacked context and were as potentially misleading to users as any list of keywords, a finding first made in 1985.15
The first evaluation ended when MetaMind was acquired in March of 2016 by Salesforce.com. MetaMind was closed in April.
Based on further research, Indico Data Systems, Inc. (“Indico”) was approached and became the second testbed. Indico’s deep learning model was trained with the same training data sourced from PACER and the same test data that came from Enron. The Indico model surfaced the same risky e-mail as the MetaMind model, the one regarding “My unfair treatment at Enron.” That e-mail, which scored 0.86 and 0.88 with MetaMind, received a comparable score from Indico’s model: 0.89.
Then, without being asked to do so, Indico used approximately 75 held-out documents and created a ROC graph with a calculation for the AUC. In an e-mail, Dan Kuster, a data scientist at Indico, reported that the AUC score was 0.967, a high score, and commented that “the classifier is strong.”16
At this point, and rather than continue with Indico, an open-source option was chosen. In November of 2015, prior to these experiments, Google announced the availability of an open-source version of TensorFlow. With TensorFlow, even in its earliest 1.0 version, the results were substantially similar or better.
The next step was a confidential trial with an enterprise listed on the NYSE. After in-house counsel successfully tested the system with Enron e-mails, a production set of e-mails was uploaded from a now-closed employment discrimination case. This batch of e-mails was new to the system, and the results were mixed. The system succeeding in surfacing at least one e-mail that was known to in-house counsel, and at least one e-mail that was previously unknown and which in-house counsel reported was “material.” But the trial ended when the system’s overall accuracy was deemed insufficient to assess the company’s production of two million e-mails per month.
After the trial ended, the challenge was addressed. The “negative” text was combined with 10,000+ Enron e-mails that were curated to avoid the e-mails previously determined to be related to employment discrimination. The model had previously learned English. Now it was learning English in the context of e-mails. The ROC-AUC score went even higher, from 0.967 to 0.997.
The re-trained deep learning model was then presented with a held-out set of 20,401 Enron e-mails. Re-trained, the system surfaced 25 e-mails related to the risk, a fraction equal to 0.00122, which is about one-eighth of one percent. The 4x improvement was significant. See the t-SNE depiction in Chapter 4 (Figure 4.3).
As you know, a weak model will have some positive training documents in the negative cluster and perhaps some negative documents in the positive cluster. A strong model will not suffer from this “mixing.” With fine-tuning, the “end game” is a t-SNE visualization indicating that the decision-boundary between the positive and negative clusters is free of this confusion. In the context of the training data I was using, I attributed the clear decision boundary to the fact that the quality of the training data was high. I was using attorney-vetted text related to the discrimination risk.
Now the previous “accuracy” objection could be addressed.
A human reviewer might well suggest that the task of finding four True Positives in 20,401 e-mails (a small fraction equal to 0.000196) during a single day is impossible (or with a large team, very expensive), but that finding four True Positives in a set of only 25 related e-mails (a much larger fraction which equates to 4/25 or 16 percent) is possible. But now assume that the system must be able to process two million e-mails per month, as posited by in-house counsel at the NYSE company. Divide 2,000,000 e-mails by 4.3 weeks per month: the result is 465,116 e-mails per week. Then divide 465,116 e-mails per week by 5 days per week: the result is 93,023 e-mails per day. But then, applying the “accuracy” fraction of 25/20,410 = 0.00122, the result is that a TensorFlow model, trained as described, would surface for human review only about 112 e-mails related to the discrimination risk per day. In 2015, the average number of business e-mails a user sent and received per day was 122; and is expected to grow by the end of 2019 to 126 messages per day.17
Combined, three conclusions may be drawn: (1) the savings due to a prevention technology is likely very substantial; (2) the pattern-matching ability of a well-trained deep learning model is a viable filter which enables users to “predict” future lawsuits; and (3) the size of the law department team may be estimated from the amount of enterprise e-mails per month and may result in a high return on investment.
As noted, PACER is a U.S litigation database of nationwide scope. In the context of “civil” litigation (distinct from appellate, bankruptcy, and criminal litigation), there are many business-relevant classifications, for example, insurance, breach of contract, healthcare, fraud, and civil rights-employment. In these categories, there were over a thousand complaints filed in 2018.18 The model-building process for each such PACER classification would be built in the same way as the employment discrimination example described above.
However, a fundamental and previously unsolved problem arises when the amount of data available to train a viable deep learning model is small. While the problem is general, this chapter describes a solution in the context of a specific litigation risk.
For example, consider the matter of a potential violation of the Foreign Corrupt Practices Act (the FCPA). There is no such PACER classification, but it is a high-value, adverse risk to any U.S. enterprise doing business in other countries. An FCPA violation may include monetary losses, for example, fines, penalties, verdicts, or orders for disgorgement of more than $1 billion19; imprisonment for as long as 180 months20; and let’s not forget any damage to company and personal reputations.
The data available to train a deep learning model for FCPA violations is small. From 1977 to 2004, complaints with factual allegations in pleadings were used to file cases but less than 80 complaints were made public. From 2004 to the present, the pleadings have been replaced by non-prosecution agreements, deferred prosecution agreements, administrative orders, or declinations with disgorgements.21
This chapter now describes how blockchain technology can be used to address and solve the small training data problem. The first issue is privacy. In connection with such high-value litigation risks, enterprises do not share the data they gathered in their own internal investigations for the understandable reasons that no enterprise wants competitors or regulatory authorities to know about its potential FCPA violation.
To address this privacy concern and yet solve the “small training data” problem, a Corporate Legal Data Consortium can be formed. Each consortium would be governed by a formal joint venture agreement focused on addressing the risk of the same adverse situation.
In such a joint venture, there is one general partner, the deep learning “Modeler.” The limited partners are enterprises that are concerned about potential violations of the FCPA and have relevant data to share.
While the consortium partners would owe fiduciary duties to each other by agreement, including the risk of non-disclosure of the training data that each limited partner would provide, that “glue” is probably insufficient. To ensure that each limited partner’s data is not disclosed to anyone else, each consortium would use blockchain to enable the creation of a deep learning model.
First, each limited partner would identify its own internal training data consisting of, for example, a capstone memo and/or supporting e-mails related to its previous internal FCPA investigations. The text in these documents would then be processed with GloVe to convert the words of these documents into number strings. In contrast to the previous description for building a deep learning model from publicly available text, here the conversion of words into number strings would take place while the documents, and the words in them, remain behind the enterprise’s firewall.
In addition, each limited partner would add an agreed-upon shared secret number, a “Consensus Number,” to the number strings for the documents it intends to put “on chain.” By agreement, the Consensus Number would not be revealed to the Modeler.
Then each limited partner would use an Input Private Key to upload its number strings to an appropriate provider of blockchain for the legal industry, for example, Integra Ledger22 or a blockchain firm that’s already performing secure MPCs for business use cases, for example, Sharemind.23 The limited partners would have the only Input Keys but would not possess an Output Private Key. On the other hand, the Modeler would have no Input Key and would possess the only Output Key.
Once the training data is on-chain, a secure MPC would be performed for the purpose of aggregating the number strings contributed by each limited partner. The Modeler receives only the aggregation, not the ingredients. Since the Modeler receives the aggregation of the data, the Modeler may then overcome the problem of a training set that is otherwise too small.
Before a model may be useful, however, it must be validated. Once a deep learning model for a specific situation has been created, the Modeler would provide it to the limited partners who may they validate it by testing it on the documents in their own previous investigations, including investigations that were not used as inputs. Each limited partner would then describe to the other partners how the model performed. The process would be iterated until the members of the joint venture were satisfied with the model’s efficacy.
Once a model is validated, the limited partners would use it in accordance with the terms of the joint venture agreement. Then, on such terms as the agreement would provide, the joint venture can offer the model to other enterprises that are not part of the consortium. The consortium partners would share in the resulting revenues in accordance with their joint venture agreement.
This use of blockchain to enable the construction of a deep learning model is likely to require a significant up-front commitment. But it has the potential to enable the creation of a deep learning model where the amount of training data is small but the value of preventing a risk is high.
The blockchain solution to the “small training dataset” problem is a roadmap for future work in general. In the litigation context, future work will include implementations, testing, and evaluation of potential FCPA violations and at least two other litigation contexts.
Notes
1 Susskind (2008).
2 Brestoff and Inmon (2015).
3 Stubben and Welch (2018).
4 Barton and Groton (2018).
5 Scott v. Beth Israel Med. Ctr., 17 Misc. 934, 847 N.Y.S.2d 436 (2007); and Holmes v. Petrovich Development, LLC, 191 Cal.App.4th 1047, 119 Cal.Rptr.3d 878 (2011). January 12, 2019. https://scholar.google.com/
6 PACER (2019).
7 Mikolov, Sutskever, Chen, Corrado, and Dean (2013).
8 Pennington, Socher, and Manning (2014).
9 Wikipedia (2018).
10 Young, Hazarika, Poria, and Cambria (2018).
11 Wikipedia (2019).
12 Maaten and Hinton (2008).
13 Linderman and Steinerberger (2017).
14 dtSearch (2018).
15 Blair and Maron (1985).
16 Kuster (2016).
17 The Radicati Group, Inc (2018).
18 United States Courts (2018).
19 Richard (2018).
20 Jessica (2016).
21 Koehler (2018).
22 Integra (2018).
23 Sharemind (2018).