
Chapter 2. Successful Habits for Production
Success in production starts long before an application is deployed to a production setting. The key is having a system with the simplicity and flexibility to support a wide range of applications using a wide variety of data types and sources reliably and affordably at scale. In short, when you’re ready for production, the system is ready for you.
No doubt doing all this at scale is challenging, but it’s doable, it’s worth it and you can get there from where you are. We’re not talking about having a separate, isolated big data project but, instead, a centralized design and big data system that is core to your business. We also are not promoting the opposite extreme: to entirely do away with traditional solutions such as Relational Database Management Systems (RDBMS) and legacy code and applications. When done correctly, big data systems can work together with traditional solutions. The flexibility and agility possible in modern technologies make it appropriate for the big data system to be the backbone of your enterprise. These qualities of flexibility and agility also make it easier to make the transition to using big data approaches in your mainstream organization.
To plan and build such a system for your business, it can help to see what others have done that led them to success. In our “day jobs” we work with a lot of people who have done this and have overcome the difficulties. Almost all of the customers we deal with at MapR Technologies—more than 90% of them—are in production. This is in fairly stark contrast to the levels we see reported in surveys. For example, a 2018 Gartner report stated that only 17% of Hadoop-based systems were deployed successfully into production, according to the customers surveyed (“Enabling Essential Data Governance for Successful Big Data Architecture”). This made us curious: Why are some people in production successfully and others are not? In this chapter, we report the basic habits we observe in organizations that are winning in production.
Build a Global Data Fabric
One of the most powerful habits of successful data-driven businesses is to have an effective large data system—we call it a data fabric—that spans their organization. A data fabric is not a product you buy. Instead it is the system you assemble in order to make data from many sources available to a wide range of applications developed and managed by multiple users. The data fabric is what houses and delivers data to your applications. This may exist across a single cluster or it may span multiple data centers, on-premises or in a cloud or multicloud, as suggested by Figure 2-1.
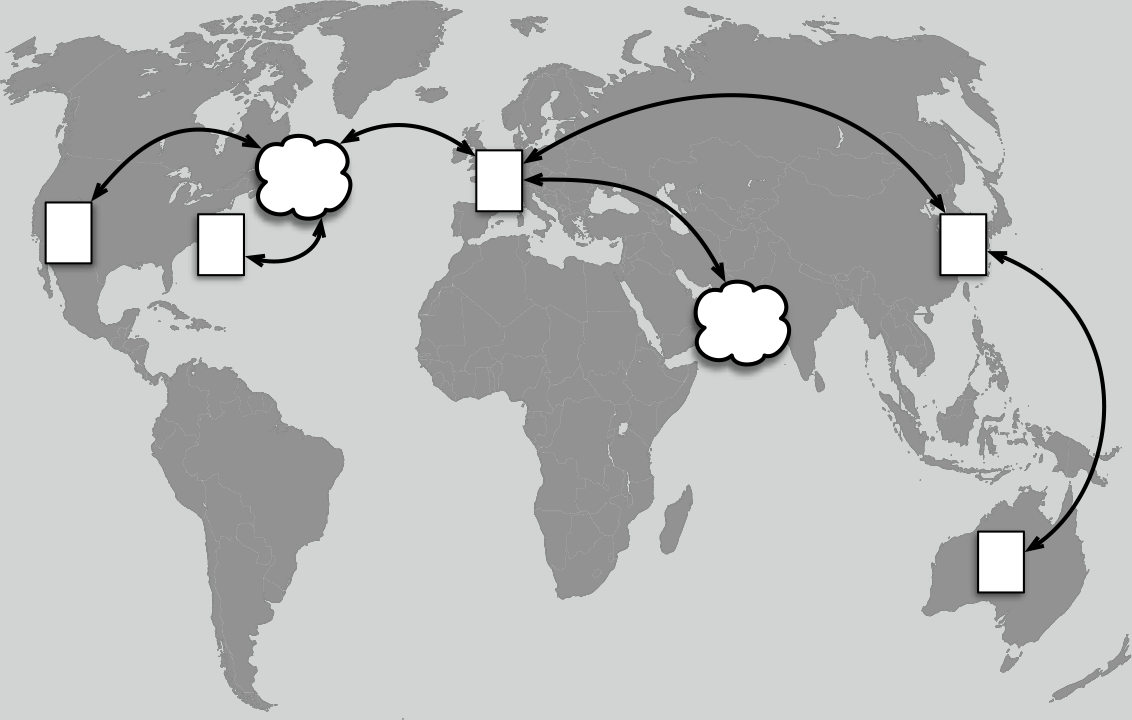
Figure 2-1. Building a unified data fabric across a single cluster or across geo-distributed data centers on-premises or in cloud (or multicloud or a hybrid of cloud/on-premises) is a huge advantage in getting production grade performance from applications in a cost-effective way.
As with a piece of cloth, you can identify or isolate any single fiber of many, and yet together they act as one thing. A data fabric works best when it is under one system of administration and the same security mechanisms.
Edge Computing
Increasingly, it is important to be able to handle large volumes of Internet of Things (IoT) data from many sensors being generated at a high rate. In some cases, this data needs to be moved to data centers; in other cases, it’s desirable to be able to do some edge processing near the data source and then move the results or partially processed data to other data centers. We find customers who need to do this in industries like telecommunications, oil and gas exploration, mining, manufacturing, utilities companies, medical technology, transportation and shipping, online global services, and even smart shops in physical retail locations where real-time interactive engagement with shoppers is the goal.
Note
Because data can come from many small data sources such as IoT sensors, a data fabric needs to extend to the edge, to handle raw data and to support edge applications.
Data Fabric Versus Data Lake
We’ve all heard of the promises of the so-called “data lake”: the idea that we would build a comprehensive and centralized collection of data. The term “data hub” was often used when the focus was on self-service analytics. A data fabric is a new and larger idea, not just a new term for a data lake or data hub. Here’s why that matters.
The power of a data lake was to preserve raw data—structured and unstructured data—and, most important, to see across data silos, but there was a danger of the data lake becoming yet one more huge silo itself. People often assumed that the data lake needed to be built on Hadoop (HDFS), but that automatically limited what you could do, setting up barriers to widespread and facile use, thus increasing the risk of siloing. Due to lack of standard interfaces with HDFS, data must be copied in and out for many processing or machine learning tasks, and users are forced to learn Hadoop skills. A data lake that is difficult to access can fall into disuse or misuse, either way becoming a data swamp. There’s also a need to extend the lake beyond one cluster, to move computing to the edge, and to support real-time and interactive tasks, as we’ve already mentioned.
In contrast, building a data fabric across multiple clusters on-premises or in the cloud and extending it to edge computing gives you the benefits of comprehensive data without forcing everything to a centralized location. A data fabric built with technologies that allow familiar kinds of access (not limited to Hadoop APIs) plus multiple data structures (i.e., files, tables, and streams) encourages use. This new approach is especially attractive for low-latency needs of modern business microcycles. There’s another advantage: The use of a modern data fabric helps because part of the formula for success in a comprehensive data design is social rather than technical. You need to get buy-in from users, and a simpler design with familiar access styles makes that much more likely to happen. A data fabric that is easy to maintain helps you focus on tasks that address the business itself.
This is important, too: your data fabric should let you distribute objects such as streams or tables across multiple clusters. Consider this scenario. A developer in one location builds an application that draws on data from a topic in a message stream. It is important for the developer to be able to focus on goals and Service Level Agreements (SLAs) for the application rather than having to deal with the logistics of where the data originated or is located or how to transport it. It’s a great advantage if stream replication can let you stream live both locally and in a data center somewhere else without having to build that in at the application level, as depicted in Figure 2-2. It’s the same experience for the application developer whether the data is local or in another location. We talk about a data platform with this capability in Chapter 4.
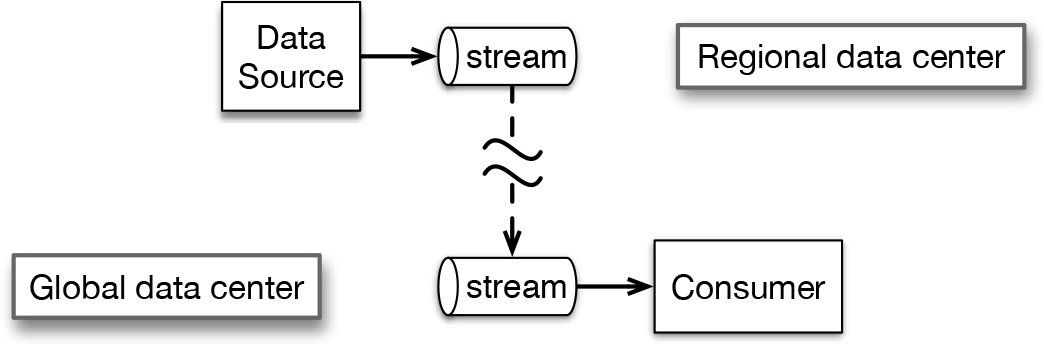
Figure 2-2. With efficient geo-distributed stream replication, the developer can focus on the goals of the application and the insights to be drawn from data rather than having to worry about where data is located. The data source thinks of the stream as local and so does the consumer, even though there may be an ocean between them. A similar advantage could be gained through table replication in a global data fabric.
This separation of concerns between developers and data scientists on the one hand versus operations and systems administrators on the other is a huge benefit, making all parties more productive. The head of a data science team at one of our customers found this to be extremely valuable. His business deals with a globally distributed online service, and his team’s applications were responsible for collecting metrics and making the data available for business-critical billing. Having taken advantage of stream replication (and thus not having to build these logistics in at the application level), he commented that after just a few months he felt he had “a year of developer time in the bank.” That’s a good situation to be in!
Understand Why the Data Platform Matters
A modern data platform plays an enormous role in either setting up for success in production or, if it lacks the right capabilities, creating barriers. There are a number of things the data platform in a successful production deployment does, but, surprisingly, one of the most important is for the platform to fade from view. What we mean is that a good platform does what needs to be done without getting in the way. Consider the analogy of a professional tennis player about to hit the ball. The player needs to have all attention focused on the ball and on their shot rather than thinking about the racket: has it been strung properly? Is the tension correct? Can the strings withstand the impact? A top player’s racquet is, no doubt, an excellent one, but during a shot, it is like an unconscious extension of the hand and arm. Similarly, if your job is to build and run applications or models or to draw insights, you shouldn’t need to spend a lot of effort and time on dealing with platform issues or with building steps into applications that should have been handled by the platform.
Just as there are a number of common capabilities that essentially all services need for managing containers, network names, and such, there are also common capabilities that almost all services need from a data platform.
The idea that all of container orchestration would be implemented once by Kubernetes is becoming a bog standard design. The same argument applies to factoring out data capabilities into a single data platform that serves as a kind of uber-service for all other services. In contrast, having services implement their own data layer causes a large amount of unnecessary and repetitive effort just as does having every service implement its own container management.
What other roles does the data platform need to fill to build a data fabric that supports development and production? One very important one is ease of data access, for multiple types of data. We have pointed out that one thing that turns a data lake into a swamp is inaccessibility. For example, it is a huge advantage to be able to talk about files, tables, or streams by name and to organize them together in directories. This gives you a coherent way to refer to them in applications, between applications, or between users. Simplicity such as this lessens the chance for errors and reduces duplicated effort. In Chapter 4 we describe a data platform with this capability.
Another key requirement of data access is to not have to copy everything out of the data platform for processing and then copy results back in. That was one of the big problems with Hadoop-based systems, especially for production. It was as though a big wall stood between the data and whatever you wanted to do with it—you had to keep copying it out over the wall to use it and then throw the results back over the wall. That barrier stood in the way of using legacy applications and familiar tools. It required Hadoop specialized skills just to access data. And Hadoop systems couldn’t meet the requirements of real-time or low-latency applications that are so widely needed for the pace of modern business cycles. The ideal production-ready big data platform should be directly accessible via traditional as well as new APIs, be available for development and production applications simultaneously, and support low-latency or real-time applications.
The effective data platform is ubiquitous, letting you use the same platform across data centers on-premises, from IoT edge to center, and to cloud or multi cloud. This ubiquity streamlines your overall organization and architectures, and, as we mentioned in Chapter 1, simplicity such as this reduces risk and generally improves performance. And of course, a good platform is reliable, cost-effective for highly distributed very-large-scale data, supports multitenancy, gives you confidence about security, and provides adequate mechanisms for disaster recovery.
These are the high-level ways in which a data platform supports building a data fabric and helps you get your applications production ready. Keep in mind that as your projects expand or you add new projects or new lines of business, your data platform should support what you are doing without a lot of workarounds or sprawl. Returning to our tennis metaphor, if you find yourself thinking about your racquet too much, that’s a red flag: you should rethink your platform and your architecture, because overly complicated is not inevitable in large-scale systems.
Capabilities and Traits Required by the Data Platform
Happily, there is a pretty strong consensus about what a platform should do and how those capabilities should be accessed. So, here are the first three requirements for a modern data platform:
A data platform must support common data persistence patterns, including files, tables, and streams
The platform must support standard APIs including:
POSIX file access for conventional program access to shared files
HDFS API access for Spark, Hadoop, and Hive
Document-oriented NoSQL
Apache Kafka API for streaming
Performance must be very high, especially for large-scale distributed programs. Input/output (I/O) rates ranging from hundreds of GB/s up to tens of TB/s are not uncommon. Message rates of millions to hundreds of millions per second are not uncommon.
Note that POSIX file access is effectively the same as allowing conventional databases because Postgres, MariaDB, mySQL, Vertica, Sybase, Oracle, Hana, and many others all run on POSIX files.
It is also common that companies have distributed operations that are distant from one another. Even if operations are not geo-distributed, it is common to have a combination of on-premises compute plus cloud compute or to require cloud vendor neutrality. Some companies have a need for edge computing near the source of data on a factory line, on trucks or ships, or in the field. All of these require that the data platform grow beyond a single cluster at a single location to support a bona fide data fabric.
This leads to the next requirement:
Put data where you want it but allow computation where you need it. This includes supporting data structures that span multiple clusters with simple consistency models.
If a data platform is to provide common services to multiple teams, avoiding duplication of effort, and improving access to data, there has to be substantial reuse of the platform. This means that the data platform is going to have to support many applications simultaneously. In large enterprises, that can reach into the hundreds of applications. To do this, it is important to:
Enforce security at the data level using standard user identity management systems and familiar and consistent permission schemes
Support multitenancy by automatically isolating load where possible and providing manual management capabilities to allow additional administrative control over data placement and use of high-performance storage
Operate reliably for years at a time
One fact of life for modern businesses is that they need to explore and (as soon as possible) exploit machine learning and AI to help automate business decisions, particularly high-volume decisions that are difficult for humans to make. Machine learning systems require access to data from a variety of sources and have many particularly stressful I/O patterns. Essentially all emerging machine learning frameworks use standard file access APIs, but they often use certain capabilities such as randomly reading data from very large files that ordinary I/O systems find difficult to support.
Support machine learning and AI development by transparent access to a wide variety of data from other systems and supporting standard POSIX APIs at very high levels of random reads.
Finally, it is common to overlook the fact that there is a lot of ancillary data associated with the analysis of large distributed data. For instance, there are container images, configuration files, processing status tables, core dumps, log files and much more. Using the same data platform for data and for housekeeping makes total sense and simplifies operations tremendously. All that is needed to support this are POSIX APIs, so no bullet point is needed, but a reminder definitely is.
In summary, the data platform plays an essential role in building the data fabric that you will need to move seamlessly to production deployments. It’s not just the need to store data (in a variety of data structures) at scale in a cost-effective way that matters. The role of the effective modern data platform also includes supporting a wide variety of access modes including by legacy applications and using familiar processing tools. And that leads our thinking back to the running of applications and how that can be managed at a production-ready level.
Orchestrate Containers with Kubernetes
When you build a production analytic system, there are two major halves of the problem. One half is the data, for which issues of scale, redundancy, and locality should be handled in a data platform as we have described. But the other half of the problem is the analytics: actually running the software to analyze the data. Analytics applications require a lot of coordination. One reason is that because the data involved is large, analyzing it often requires many computers working together in a well-coordinated fashion. There are probably many small parts of the computation, too. There are tons of non-analytical but data-dependent processes that need to be run as well. Getting large programs and small, I/O-intensive or CPU-intensive, low-latency, and batch to all run together is daunting. You really need to not only develop ways of efficiently orchestrating your analytics and AI/machine learning applications but also of having them coexist with other processes that are essentially “running in the background.”
All of this implies that we need to have an analog of the data platform, what you might call a process platform, to coordinate pieces of applications. Given the increasingly widespread containerization of applications, it’s essential to have a way to coordinate processes running in containers. The good news is that based on their experience building the world’s biggest and most distributed big data production system out there, Google decided to open source Kubernetes. Kubernetes coordinates the execution of programs across a cluster of machines in pretty much the way that is needed for large-scale data analysis.
The way that Kubernetes works is that large-scale services are broken down into subservices that are ultimately composed of tightly bound groups of processes that run inside containers. Containers provide the ability to control most of the environment so that programs with different environmental requirements (such as library versions and such) can be run on the same machine without conflicts. Kubernetes orchestrates the execution of containers arranged as systems across a pool of computers.
Kubernetes purposely does not manage data persistence. Its role is to act as a container orchestration system that only manages where containers run and limits how much memory and CPU is available to a container. You really don’t want to persist state in normal containers. The container is intended to be ephemeral, which is a key aspect of its flexibility; data should (must) outlive the container in order to be useful. The management of persistent data, whether in the form of files, databases, or message streams, is essential for many applications (stateful applications) that will be run in containers. The issue arises because applications generally need to store data to access later or so that other applications can access it later. Purely stateless applications are of only very limited utility. Kubernetes provides methods for connecting to different data storage systems, but some sort of data platform needs to be supplied in addition to Kubernetes itself.
Note
The combination of a modern data platform working in concert with Kubernetes for container orchestration is a powerful duo that offers substantial advantages for production deployments.
Containers managed by Kubernetes can have access to local data storage, but that storage is generally not accessible to other containers. Moreover, if a large amount of data is stored in these local data areas, the container itself becomes very difficult to reprovision on different machines. This makes it difficult to run applications with large amounts of state under Kubernetes, and it is now generally viewed as an anti-pattern to store large amounts of state in local container storage.
There is an alternative. Figure 2-3 shows a diagram of how several applications might interact. Application 1 reads a file and uses a direct remote procedure call (RPC) to send data to Application 2. Alternatively, Application 2 could read data that Application 1 writes to a message stream. Application 2 produces a log file that is analyzed by Application 3 after Application 2 has exited. If these applications all run in containers, storing these files and the stream locally is problematic.

Figure 2-3. Three applications that communicate using files and a stream. Each of these applications needs to persist data, but none of them should persist it inside their own container.
Figure 2-4 demonstrates a better way to manage this situation. The applications themselves are managed by Kubernetes, whereas the data that the applications create or use is managed by a data platform, preferably one that can handle not only files, but also streams and tables, in a uniformly addressable single namespace.

Figure 2-4. The applications are now run in containers managed by Kubernetes, but the data they operate on is managed by a data platform. This is the preferred way to manage state with Kubernetes.
Note that the output Application 1 writes to a stream can be used not only by Application 2 but also by some other as yet unknown application running on the same platform.
Key requirements of the data platform are that it must do the following:
Abstract away file location so that containers need not worry about where their data is. In particular, there must be a consistent namespace so that containers can access files, streams, or tables without knowing anything about which machines host the actual bits.
Provide sufficient performance so that the applications are the only limiting factor. This might even require collocating data with some containers that demand the highest levels of performance.
Allow access to data no matter where a container is running, even if a container is moved by Kubernetes.
Provide reliability consistent with use by multiple applications.
Pairing a data platform with a container orchestration system like Kubernetes is a great example of success through separation of concerns. Kubernetes does almost nothing with respect to data platforms other than provide hooks by which the data platform can be bound to containers. This works because the orchestration of computation and the orchestration of data storage are highly complementary tasks that can be managed independently.
Extend Applications to Clouds and Edges
The combination of Kubernetes to orchestrate containerized applications and a data platform that can work with Kubernetes to persist state for those applications in multiple structures (i.e., files, tables, streams) is extremely powerful, but it’s not enough if it is able to do so for only one data center. That’s true whether that one location is in the cloud or on-premises. The business goals of many modern organizations drive a need to extend applications across multiple data centers—to take advantage of cloud deployments or multicloud architecture—and to go between IoT edge and data centers. We see organizations in the area of oil and gas production, mining, manufacturing, telecommunications, online video services, and even smart home appliances that need to have computation that is geographically distributed to match how their data is produced and how it needs to be used. Something as fundamental as having multiple data centers as part of advance planning for disaster recovery underlines this need. What’s the best way to handle the scale and complexity associated with multiple required locations and to do so in a cost-effective way?
Let’s break this down into several issues. The first is to realize that the journey to the cloud need not be all at once. It may be preferable for systems to function partly on-premises and partly in cloud deployments, even if the eventual intent is a fully cloud-based system. A second point to keep in mind is that cloud deployments are not automatically the most cost-effective approach. Look at the situations shown in Figure 2-5. A hybrid on-premises plus cloud architecture can have benefits for being able to best optimize compute resources for different workloads in a cost-effective manner.

Figure 2-5. Although cloud deployments may be cost-effective for bursts of computation, base load often is better off in an on-premises data center. For this reason, an efficient hybrid architecture may be optimal. Similarly, optimization sometimes calls for having computation and data in edge locations as well as multiple clouds and on-premises data centers.
What you need to handle all these situations, including edge deployments, is to make sure your data platform is designed to handle geo-distribution of data and computation in a cost-effective way that is reliable and meets SLAs. That means having effective and easily administered ways to mirror data (files, tables and streams) and preferably to have efficient geo-distributed stream and table replication as well. The same platform should extend across multiple centers and be able to interact with Kubernetes across these geo-distributed locations. It’s not just about data storage but also about built-in capabilities to coordinate data functions and computation across these locations securely. This use of edge computing is a basic idea that is described in more detail as one of the design patterns presented in Chapter 5.
The good news is that even though widespread use of Kubernetes in on-premises data centers is a relatively new, it is spreading rapidly. And for cloud deployments, Kubernetes already is, as of this writing, the native language of two of the three major cloud vendors, so using it in the cloud isn’t a problem. The issue is to plan in advance for these cross-location deployments both in your architecture and in the capabilities of your data platform. Even if you start with a single location, this geo-distribution of applications is likely what you will need as you go forward, so be ready for it from the start.
Use Streaming Architecture and Streaming Microservices
Often, the first reason people turn to event-by-event message streaming is for some particular low-latency application such as updates to a real-time dashboard. It makes good sense to put some sort of message queue ahead of this, as a sort of safety measure, so that you don’t drop message data if there is an interruption in the application. But with the right stream transport technology having the right capabilities—as do Apache Kafka or MapR Streams—stream transport offers much more. Streaming can form the heart of an overall architecture that provides widespread advantages including flexibility and new uses for data along with fast response. Figure 2-6 shows how stream transport of this style can support several classes of use cases from real time to very long persistence. We’ve discussed these advantages at length in the short book Streaming Architecture (O’Reilly, 2016).

Figure 2-6. Stream-first architecture for a web-activity-based business. A message stream transport such as Apache Kafka or MapR Streams (shown here as a horizontal cylinder) lies at the heart of an overall streaming architecture that supports a variety of use case types. Group A is the obvious use, for a real-time dashboard. Group B, for archived web activity or Customer 360, is also important. Applications like security analytics (group C) become possible with long-term persistence.
Streaming is not the only way to build a data fabric, but stream-based architectures are a very natural fit for a fabric, especially with efficient stream replication, as mentioned in the previous section. In addition, message stream transport can provide the lightweight connection needed between services of a microservices style of work (see also “Streaming Microservices” by Dunning and Friedman in Springer’s Encyclopedia of Big Data Technologies [2018]). The role of the connector, in this case a message stream, is to provide isolation between microservices so that these applications are highly independent. This in turn leads to a flexible way to work, making it much easier to add or replace a service as well as support agile development. The producers in Figure 2-7, for instance, don’t need to run at the same time as the consumers, thus allowing temporal isolation.

Figure 2-7. Stream transport technologies in the style of Apache Kafka exhibit high performance at scale even with message persistence. As a result, they can help decouple multiple data producers from multiple consumers. This behavior makes stream transport a good connector between microservices.
A microservices style is a good design for deployment to production as well as making development easier and agile. We’ve talked about the importance of flexibility in production, making it easier to make changes and respond to new situations. Microservices is also valuable because being able to isolate services means that you isolate issues. A problem in one service does not necessarily propagate to other services, so the risk (and blast radius) is minimized.
The idea of stream-first architecture is being put to work in real-world situations. We know a customer, for example, who built a stream-based platform used in production to handle the pipeline of processes for finance decisions. This stream-based approach was used mainly because of the need for fast response and agility. But keep in mind that there are many reasons, as we have mentioned, other than just latency to motivate choosing a streaming architecture.
Cultivate a Production-Ready Culture
Using new technologies with old thinking often limits the benefits you get from big data and can create difficulties in production. Here are some pointers on how to have good social habits for success in production.
DataOps
DataOps extends the flexibility of a DevOps approach by adding data-intensive skills such as data science and data engineering—skills that are needed not only for development but also to deploy and maintain data-intensive applications in production. The driving idea behind DataOps, as with DevOps, is simple but powerful: if you assemble cross-skill teams and get them focused on a shared goal (such as a microservice), you get much better cooperation and collaboration, which in turn leads to more effective use of everyone’s time. DataOps cuts across “skill guilds” to get people working together in a more goal-focused and agile manner for data-intensive projects. Figure 2-8 schematically illustrates the organization of DataOps teams.
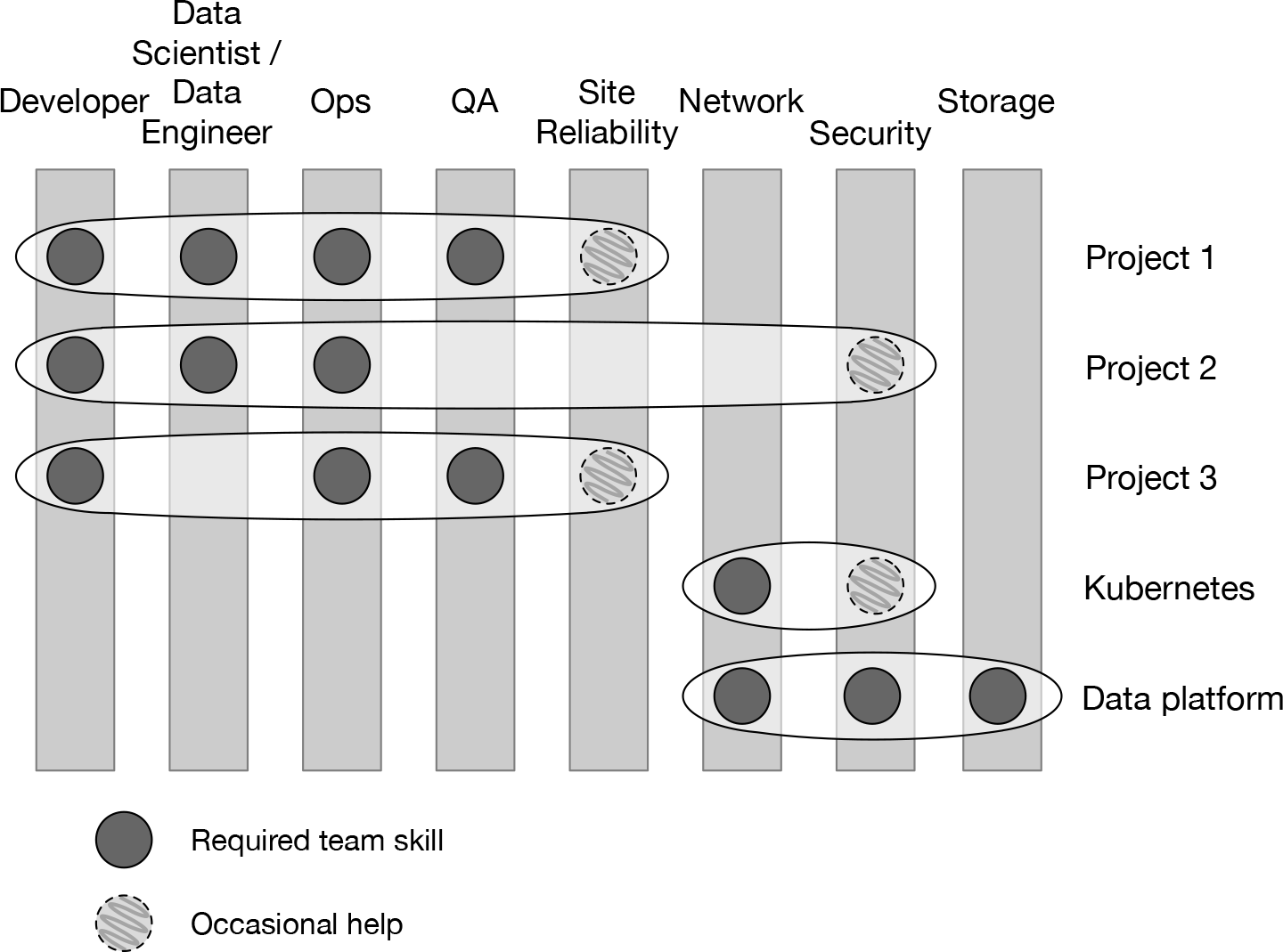
Figure 2-8. A DataOps style of work provides cross-skill teams (horizontal ovals), each focused on a shared goal. This diagram depicts teams for different applications (teams for Projects 1–3) as well as the separate teams for platform-level services (Kubernetes and the data platform). Note how the platform teams have very different skill mix than the other teams.
The key ingredients for DataOps are the right mix of skills, the concept of pulling together toward the common goal as opposed to strict reporting based on departmental divides and much better communication. Better communication is natural in this design because it changes the normal lines of communication and avoids great walls between skills that can be caused by slow-downs waiting for interdepartmental decisions.
A DataOps style of work does not mean having to hire lots of new people for each role. Generally, it involves rearranging assignments to better focus people in cross-functional teams. In some cases, people with particular data skills (such as data scientists or machine learning experts) might be temporarily embedded in an operations/engineering team. The mix of roles will naturally evolve as you go from development teams to production teams. Generally, there are fewer data scientists in a production team than in a development or exploration team.
Making Room for Innovation
A well-designed organizational culture not only provides for agility and flexibility. People also must be free to explore and experiment. A no-fail policy is a no-innovation policy. It’s usually not practical to do unbounded experimentation, but to support innovation you do need to recognize that deliverables can be about more than just products: experience with new technologies and advance testing of new lines of business can be targeted as deliverables.
Remember: IT Does Not Have a Magic Wand
We have seen a pattern of failure where a development group gets the DevOps religion, builds a complex service, and puts it “into production” by slapping an SLA onto it and launching the service but leaves hazily defined critical tasks to the IT department. Commonly, the next thing that happens is that the service turns out to be less reliable than expected, and an IT group gets involved in running it (but that doesn’t help much).
Obviously, one problem here is that you should declare SLAs before you build something if you actually want them to be met, but that isn’t really the ultimate cause of failure here. Some people will respond to these stories by blaming the basic idea of a dev and ops team being fused together into DevOps, but that doesn’t really describe what happened, either.
There is often a deeper issue in these cases. What happens is that when the original team starts building its system, it winds up taking on responsibility for core platform components such as storage, database, or message queuing on top of building the service that it is supposed to focus on. This sounds like the soup-to-nuts kinds of things that DevOps teams do, after all. As the project progresses, however, that core focus becomes more and more elusive because managing a platform as a side hustle doesn’t really work very well. As deadlines loom, more and more development effort is siphoned into operational issues resulting in the design, implementation, and testing of the core service getting short-changed. By the time the service is delivered, the resulting problem is practically inevitable.
The core problem here is that DevOps and DataOps teams shouldn’t be duplicating efforts on building duplicative platforms. This idea is indicated in Figure 2-8. The real lesson of the cloud revolution is that it is a waste of time for application teams to be solving the same platform problems over and over (and doing it poorly because it isn’t their focus). Public clouds have been successful precisely because they draw a sharp line between infrastructure and application. Due to limits of available technology, that line was drawn a tiny bit lower in the stack than it should have been, at least initially. The balance that Google struck with services like storage and tables being part of the platform appears to be where things really ought to be.
The good news is that this is exactly what you can do with modern systems.
Putting It All Together: Common Questions
Now that you’ve seen the ingredients of a formula for success in production—the commonality of a global data fabric, the role of the data platform and technologies like containerization and Kubernetes, the flexibility of streaming microservices and of DataOps—here’s a few thoughts about how to put those concepts to work in the form of some common questions and answers about how to get big data into production.
Can You Manage End-to-End Workloads?
Managing means measuring and controlling. In real-world production systems, however, multitenancy adds the complication that there are lots of workloads active at once, so we need be able to detect and control interactions. Real-world systems also have to deal with ongoing hardware failures and the background loads due to recovery efforts. This means that just managing individual workloads in isolation isn’t sufficient. Realistically, in production you also need to manage these implied workloads at the same time. For instance, if there is a disk or controller failure outage, a competent system will have built-in ways to re-replicate any lost data. That’s great, but that re-replication will cause a load on your system that competes with your applications. You have to plan for both kinds of load and you have to measure and manage both as well as interactions between loads. In an advanced system, the implied loads will be managed automatically; less advanced systems require manual recovery (Kafka, Gluster, Ceph) or lack throttling of recovery loads (HDFS).
Kubernetes helps you orchestrate when and where applications run, the implied use of containerization helps with this by isolating environments in terms of dependencies. Kubernetes is mostly a control mechanism, however, and is limited to controlling the computation side of things.
You also need to have comparable control on the data side of things. Effectively, what you need is Kubernetes, but for data. So, although Kubernetes allows you to control where processes run, avoid too much over-subscription of compute and memory resources and to isolate network access, your data platform should let you control where your data actually is, to avoid oversubscribing storage space and I/O bandwidth and logically isolate data using uniform permission schemes.
But all that control is nearly worthless if you are flying blind. As such, you need to be able to measure. Obviously, you need to know how much data you have and where it is, but you should also be able to get comprehensive data about I/O transfer rates and latency distributions per node, per application and per storage object.
How Do You Migrate from Test to Production?
If you’ve designed and built your organization according to the guidelines we’ve described, you laid the groundwork for this migration long before your application was ready to deploy: you’ve treated data appropriately for in-production status from early on (where that matters) and you are operating within a global data fabric, with much of the logistics handled by your platform.
This means that you have what you need to be able to migrate to production. Keep in mind that this migration is not just a matter of unit testing but also of integration testing—making certain that the various parts of a particular application or interactive processes will work together properly. One way to do that is to have a system that lets you easily light up a production-like environment for testing: Kubernetes, containers, and a data platform that can persist state for applications help with this, particularly if they are all part of the same system that you will use in production. Using a stream as a system-of-record also makes it easier to pretest and stage migration to production because it is so much easier to replay realistic operations for testing.
Can You Find Bottlenecks?
We’ve argued for simplicity in both architecture and technology, for a unified data fabric, and for a unified data platform with the capabilities to handle a lot of the burden of logistics at the platform level rather than application level. This approach helps with finding (and fixing) bottlenecks. A simple system is easier to inspect, and an inspectable system is easier to simplify. Good visibility is important for determining when SLAs are missed and a good historical record should allow you to pinpoint causes. Was it bad design that caused hot-spotting in access to a single table? Was it transient interference with another application that should be avoided by better scheduling or moving loads around? This is important because you should operate with the philosophy that the default state of all software is “broken” and it’s up to you to prove it’s working.
You need to record as much of the function of your system as you can so that you can demonstrate SLA compliance and correct functioning. Your data and execution platforms should help you with this by providing metrics about what might have been slowing you down or interfering with your processes.
To meet this pressure, not only is a simpler system useful but so is having a comprehensive system of record. Having a persisted event stream, change data capture (CDC) for a database, and an audit system for files are various ways to do this. Some of the most successful uses of big data that we have seen record enormous amounts of data that can used to find problems and to test new versions as they are developed.