
REST is an architectural style. It is not any strict standard but provides certain guidelines and constraints to be followed. Roy Fielding originally described these constraints in his doctoral dissertation and coined the name Representational State Transfer.
REST relies on stateless, cacheable, and client-server communication protocols such as HTTP. By following the principles of REST and applying it to stateless protocols such as HTTP, developers can build API interfaces that can be used from any device or operating system. Well-designed REST APIs attract developers to build apps that use them. An API interface should be easy to understand and intuitive to the developers. Creating a well-crafted, aesthetically designed REST API is a must-have for the success of any enterprise API program. This chapter looks at the different constraints advocated by REST and how they can be used to design a truly RESTful API interface.
REST Principles
REST is a set of design principles for building scalable web services. Roy Fielding described the following six constraints in his PhD dissertation for building a RESTful architecture:
Uniform interface
Client-server
Stateless
Cache
Layered system
Code on demand
Let’s look at each of these constraints in more detail.
Uniform Interface
A uniform interface helps to define the communication contract between client and the server. It helps to decouple the architecture. Client and server applications can be developed independently as long as they abide by the interface. The interface defines the mechanism and format for interaction—where and how the client can access a server resource. A resource URI identifies resources. Each resource has its own unique URI. However, the physical resources are themselves separate from their representation; for example, the server does not send information about the back-end database storing the product information. Instead, it sends an XML or JSON representation of a product or a collection of products to the client.
Client-Server
The client-server constraint builds a loosely coupled and scalable web architecture. As long as the client and the server follow a uniform interface, they can be developed independently, using any language or technology. The client need not be worried about the database used for the server to store data and assets. Similarly, the server need not be worried about the client implementation technologies or the user interface or user state. It helps to achieve separation of concerns and build simpler and scalable architecture.
Stateless
Statelessness is one of the key principles of a RESTful service. It dictates that a web server is not required to remember the state of the client application. All relevant contextual information should be sent by the client application in the request to the server for all its interactions. The state information can be included as part of the URI as a variable or it can be included as a query parameter, header parameter, or in the body. Once the request is processed by the server, the updated state of the resource is sent back in the response via headers and the body. If the state must span multiple requests, the responsibility of resending the state information lies with the client . This helps to reduce the burden of the server to maintain, update, and communicate the state information of each of its client, thus helping to increase the server scalability. Additionally, even load balancers do not have to worry about the session affinity for stateless systems.
Cache
Caching is yet another REST constraint that increases the scalability and overall performance of the server application. The cache may reside anywhere in the network path between the client and server. It can reside in the server, or an external location like the CDN, or inside the client application itself. By following the caching constraint, the server can specify if a particular response can be cached or not. If the response is cacheable, the server may specify the lifetime of the cached response. Based on the lifetime, the client can decide if it wants to use a cached response or make a separate request to get the live data. Caching the response data can reduce the client-perceived latency and increase the overall availability and reliability of the application.Providing a cached response from the API layer can also reduce the load on the back-end systems, which may not have been originally designed for high loads. Well-managed caching can partially or completely eliminate some client–server interactions, further improving scalability and performance.
Layered Systems
The layered system principle enables a network intermediary to be installed between the client app and the actual back-end server. The layered system can be a proxy or a gateway that acts as a facade for the back-end system. It can be used to implement security, caching, rate limiting, load balancing, and so forth. The client never gets to know if it is connected directly to the source of the service or to an intermediary. The caching and load balancing implemented on the intermediary node can improve the scalability of the system.
Code on Demand
The code-on-demand constraint enables a web server to transfer executable programs to a client. This constraint tends to establish a technology coupling between the client and the web server. The client must be able to understand and execute the code it downloads on demand from the server. This is the only optional constraint for the REST architectural style. Examples of code-on-demand are Java applets, scripts, plug-ins, and Flash.
Designing a RESTful API
Now that you understand the fundamentals of REST principles, let’s look at the various considerations for designing a REST API interface .
A uniform interface is one of the fundamental principles of the RESTful architectural style. Web components interoperate consistently within the uniform interface’s four constraints, which Fielding identified as follows:
Identification of resources
Manipulation of resources through representation
Self-descriptive messages
Hypermedia as the engine of application state (HATEOS)
Identification of Resources
Before we can identify a resource, we need to understand what a resource is. A resource is any web-based concept that can be referenced by a unique identifier and manipulated via the uniform interface. While designing a REST API for a travel portal, your resources could be customer, reservation, ticket, hotel, flight, bus, car, and so forth. A resource can be a single entity or a collection of entities. According to Roy Fielding’s dissertation: “The key abstraction of information in REST is a resource. Any information that can be named can be a resource: a document or image, a temporal service (e.g., today’s weather in Los Angeles), a collection of other resources, a non-virtual object (e.g., a person), and so on.”
A resource is identified by a URI (Uniform Resource Identifier ). A URI provides the name and the network address of a resource. All the information that a server provides can be identified as a resource. For example, the URI http://www.foo.com/v1/customers identifies a resource by name— "customers". To manipulate a resource, the client connects to the server address specified in the URI (in this case www.foo.com ) using a method like GET and access it using the relative path (/v1/customers). If the request is successfully executed, the response is a collection of customers. Again, resources can be related to each other; for example, a customer may have multiple reservations for different dates and hotels in different places. So a reservation is related to the customer as a subresource; for example, http://www.foo.com/v1/customers/12345/reservations .
The resources themselves are conceptually separate from the representations that are returned to the client. For example, the resource may be residing in some database, but when the server responds to a request for a resource, it does not send the database itself; rather it responds with some representation of the resource that represents a record in the database. For example, the record of a resource instance may be represented in XML, JSON, or HTML format, when it is returned to the client. The following is an example of a customer resource representation in JSON format with a reservation subresource:
{"firstName": "Mark","lastName": "Johnson","CustId": "John123","age": 26,"address":{"streetAddress": "28 2nd Street","city": "New York","state": "NY","postalCode": "10021"},"reservations":[{"type": "official","number": "212-555-4321","date": "03-12-2016"},{"type": "personal","number": "646-555-9765","date": "02-06-2015 "}]}
Manipulation of Resources through Representation
Clients modify a representation of a resource. The same exact resource may be represented in different ways for different clients. For example, for a UI client, it might be represented in HTML format; whereas for application clients, it might be represented in either JSON or XML format. The representation is a way for clients to interact with the resource, but it is not the resource itself.
Self-Descriptive Messages
Each message (request/response) must be self-descriptive. That mean that the message may contain additional information to tell the recipient how to process it. Information such as format (JSON/XML), size, payload itself, and other metadata information included in the message can be used by the recipient for processing. An HTTP message provides headers to organize the various types of metadata into uniform fields. For example, Content-Type can he used to specify the format of the message; Content-Length can be used to specify the size of the payload. Many such HTTP headers can be included in the message to describe to the recipient on how they should process the message.
Hypermedia as the Engine of Application State (HATEOAS)
A resources’ state information may include links to other resources. These links provide information on what to do next and how to traverse through other related resources in a meaningful manner; for example, after getting information about the account, you may want to deposit, withdraw, or transfer money. So the response of a RESTful service providing the account information may include links for the next action that the customer may want to do, as follows:
GET /account/12345 HTTP/1.1HTTP/1.1 200 OK{"account_number":"12345","balance":"100.0","currency":"USD","links": [ {"rel": "deposit","href": "http://localhost:8080/account/12345/deposit"},{"rel": "withdraw","href": "http://localhost:8080/account/12345/withdraw"},{"rel": "transfer","href": "http://localhost:8080/account/12345/transfer"}]}
The presence or absence of a link in a resource representation is an important part of resource’s current state.
While designing a REST API interface, you should keep all of these constraints in mind. The next few sections look at how to build a REST API interface by following these constraints.
Resource Identifier Design Using URIs
In a RESTful API , designing the resource is one of the most important tasks for its success. A well-designed resource makes the API intuitive, simple to understand, and easy to use. Let’s look at some of the best practices for designing RESTful APIs.
Resource Naming Conventions
Every resource should have a meaningful name to identify itself. Name a resource using a noun as opposed to a verb or an action. The URI for the resource should refer to a thing rather than an action. Also CRUD function names should not be used in the URI or resource names; for example, while designing resource for a customer’s entity, the resource URI should be named /customersinstead of /getCustomers.
Modelling Resources and Subresources
According to Roy Fielding’s dissertation a resource is “any concept that might be the target of an author’s hypertext reference must fit within the definition of a resource.” It can be single instance of an object or a collection of objects. Even business processes and capabilities can fit the definition of a resource according to Roy Fielding. Resources form the core of REST API design. The starting point of modelling resources is to analyze the current business domain and identify all the relevant objects in it that can be named. The focus for identifying resources and modelling them should be from the consumer’s point of view. It is important to select the right resources and model them at the right level of granularity.
For example, a resource can be a collection of customers in an online store or it can be a single customer. You can identify a collection of ‘customers’ using /customers, while a single instance of a customer can be identified using /customers/{customerId}. Each customer may further have multiple orders. The URI to refer to the subcollection of ‘orders’ is modelled as /customers/{customerId}/orders. A single instance of the order may be identified by /customers/{customerId}/orders/{orderId}. By following a logical grouping or resources and their hierarchy, you can model the resource URI path to access a collection of resources or an individual resource .
Best Practices for Identifying REST API Resources
The following are some of the best practices for identifying resources for RESTful API design.
Resources should not be too fine grained because they lead to chatty communication between the consumer and the provider. Chatty communication degrades overall performance of the app that is using the API; hence, it should be avoided.
Resources should not be too course grained because this leads to APIs that are too difficult to use and maintain.
Resources should be designed such that they do not lead to migration of control flow business logic to the API consumer side; for example, if updates to the customer information requires multiple fields to be updated in a specific sequence that depends on some logic, then the API to update the customer information should be designed so that the client is not responsible for executing the required flow logic. The responsibility of executing the logic should lie with the resource server hosting the resource. Shifting the logic to the consumer side has the risk of putting the resource data in an inconsistent state, especially in the event of failure. Fine-grained APIs that perform CRUD operations may put the business logic on the client side, creating tight coupling between the API consumer and the provider. Any change in business logic at the provider end would require corresponding changes on the API consumer side. They may not be possible in many cases, where consumers do not want to make frequent changes to the applications on their side.
Resource selection should be independent of the underlying domain implementation details. Hence, even a business process can be modelled as a resource if the process involves the operation of multiple low-level resources . For example, the process of setting up a customer in a bank may be modelled as a resource. So there can be a resource created for a customer account setup—such as /accountSetup—that needs to call operations on related resources for entities such as customer and account. By modeling a business process as a resource, the API consumer does not need to apply the business logic in the code.
URI Path Design
Every collection and resource in an API has its own URL. It is recommended to design URLs using an alternate combination of collection/resource path segments, relative to the API entry point. Table 3-1 explains the concept better, with guidelines on how to define the top-level resource and related subresources.
Table 3-1. Top-Level Resources and Related Subresources

There may be arbitrary levels of nesting for subresources. However, it is recommended to limit the depth to two or three, if possible, because longer URLs are more difficult to work with.
A URI design that follows a predictable pattern with a hierarchical approach to traverse through the resources eases developer adoption; for example, /stores/{storeId}/products/{productId}. This helps developers to guess the URI for a given resource; and hence, it can make direct calls without going through links.
URI Format
Let’s now look at the recommended format of a URI and learn how this format can be effectively used for designing an API. As per RFC 23964: “a Uniform Resource Identifier (URI) is a compact string of characters for identifying an abstract or physical resource.” This identifier can be realized in one of two ways: as a Uniform Resource Locator (URL) or a Uniform Resource Name (URN) .
URLs (e.g., http://www.foo.com/users/mike ) are used to identify the online location of an individual resource; whereas URNs (e.g., urn:user:mike) are intended to be persistent, location-independent identifiers. The URN functions like a person’s name; whereas a URL is like that person’s street address. In other words, the URN defines an item’s identity (the user’s name is Mike) and the URL provides a method for finding it (Mike can be found at www.foo.com/users/ ).
The syntax of an URI is a hierarchical sequence of components as follows:
scheme:[//authority][/]path[?query][#fragment]:Scheme name: Identifies the protocol (e.g., FTP, HTTP, HTTPS, IRC:)
Authority: Refers to the actual DNS resolution of the server. It consists of the hostname or IP address of the server, optionally along with the port number. The credentials to access the server can also be included as part of the authority as follows: [user:password@]host[:port].
Path: Pertains to a sequence of segments separated by a forward slash (/).
Query: Contains additional identification information that is non-hierarchical in nature and often separated by a question mark (?).
Fragment: Provides direction to a secondary resource within the primary one identified by the authority and path, and separated from the rest by a hash (#).
Naming Conventions for URI Paths
Keep URIs short and simple because this helps you write, remember, and spell it easily. The following are some of the recommended naming conventions for URI paths.
Name a collection resource with a plural noun; for example, http://www.foo.com/api/customers
Name a singular resource with a singular noun; for example, http://www.foo.com/api/customers/customer1234
Name a controller resource using a verb; for example, http://www.foo.com/api/customers/customer1234/register
Avoid using CRUD operation names in URIs. For example, do not use URIs such as http://www.foo.com/api/getcustomers .
Use lowercase letters for naming URIs. Avoid mixed and uppercase letters in URIs. Mixed case is harder to type and read.
Use hyphens instead of a space or an underline. They are more aesthetic and easier to read. Spaces in URLs get transformed into URL encoded %20s, further degrading readability. For example, use URIs such as http://www.foo.com/api/about-us .
Avoid using characters that require URL encoding, such as spaces.
HTTP Verbs for RESTful APIs
Once the resources have been identified, these are next set of questions to ask:
What would a consumer like to do with the resource?
What aspects of the resource would be of interest to a consumer?
The answers to these questions identify the HTTP verbs to be used for each of the identified resources.
HTTP verbs form an important part of a RESTful API design. They identify the actions to be performed on a resource. A consumer’s actions with a resource can be mapped to an HTTP verb in most cases; for example, creating a product can be done using the HTTP verb POST. The primary and most commonly used HTTP verb are POST, GET, PUT, and DELETE. These verbs perform the CRUD operations on the resource as follows:
POST verb creates a new instance of the resource
GET is used to read
PUT is used to update
DELETE is used to delete
There are other verbs—such as HEAD, OPTIONS, TRACE, and CONNECT—in the HTTP 1.1 spec. Let’s look at the detailed usage of these verbs in the design of a REST API interface in the next few sections of this chapter.
GET
The GET verb is used by the client to retrieve information about the requested resource entity identified by the request URI. Requests using GET should only retrieve data and should never modify the data in any way. The GET request is considered safe. GET is a read-only method and does not make any changes to the resource data. Hence, it can be used without risk of data modification or corruption. Also, calling the GET method on a resource once has the same effect as calling it multiple times. Hence, the GET verb is idempotent and safe.
If the request has been executed successfully, the server returns the requested data normally in XML or JSON, depending on the format requested by the client. The HTTP ‘Accept’ header is used by the client to specify the expected format of the response. The request may contain additional HTTP headers that can control the data returned by the server in response to the GET request. For example, if the request message includes headers such as If-Modified-Since, If-Unmodified-Since, If-Range, If-Match, or If-None-Match, it is processed as a conditional GET method. The server responds with the entity only if the conditions described by the header field(s) are satisfied. The conditional GET method is used to reduce unwanted network usage. These conditional headers are inspected by the server to determine if the client is already in possession of some of the data it is requesting. Data is returned only if the condition is satisfied; otherwise, no data is transferred in the response. Thus, conditional GET headers help reduce network traffic.
On successful execution of the GET request, the server responds with HTTP response code of 200 OK. In the event of an error, the server usually responds with the 404 Not Found or 400 Bad Request status code .
The following are examples of GET request for a resource:
GET https://www.foo.com/customersGET https://www.foo.com/customers/{customerId}
POST
The POST verb is normally used to create a new resource. In particular, it is used to create a subresource, which is subordinate to the parent resource identified by the request URI. To create a new resource, send a POST request to the URI of the parent resource and the server takes care of creating the new resource as a subresource of the parent, based on the information provided in the payload. Each new resource created is assigned a name or an ID to uniquely identify it. This identifier may be used to retrieve the resource information using a GET request at a later time.
On successful execution of the POST request, the origin server should respond with a 201 Created status code. The response payload should contain the details of the resource created in a format expected by the client. The response should also contain a 'Location' header to specify the location of the newly created resource. If the resource cannot be created, the server may respond with a 204 No Content status code.
POST is neither safe nor idempotent. It is therefore recommended for non-idempotent resource requests. Making two identical POST requests usually results in two resources containing the same entity.
The following is an example of a POST request to create a 'customer' resource:
POST http://www.foo.com/customers HTTP/1.1{"customers": {"customerId": "12345","customerName": "Brajesh De","Address":{"AddressLine1":"206 Lane 1","AddressLine2":"22 Cross","City":"Bangalore","State":"Karnataka "}}}
PUT
The PUT method is generally used to update an existing resource entity identified by the request URI. If the resource identified by the request URI exists, then the message payload should be considered as the changed version of the existing resource entity. If the resource does not exist, and the URI is capable of being defined as a new resource, the server can create a new resource with the information provided in the message payload. On successful execution of the PUT request, if a new resource is created, the server must respond with a 201 Created status code. If an existing resource is modified, the server must respond with either the 200 OK or the 204 No Content status codes to indicate successful execution of the request. In the event of errors in modifying or creating a PUT request, the server should respond with an HTTP error response status code and an error message that indicates the nature of the problem.
PUT is idempotent but not safe. This means invoking the PUT method multiple times with the same request payload has the same effect on the resource—it continues to exist in the same state. But since the PUT method updates the resource entity , this method is not safe.
The following is an example of a PUT request.
PUT http://www.foo.com/customers/12345 HTTP/1.1{"customers": {"customerId": "12345","customerName": "Brajesh De","Address":{"AddressLine1":"206 Lane 1","AddressLine2":"22 Cross","City":"Bangalore","State":"Karnataka"}}}
The Difference Between PUT and POST
It is recommended to use POST for creating new resources and PUT for updating an already existing resource. Use POST if the server is responsible for creating the resource name or ID and hence is the URI of the new resource. PUT may be used for creating a new resource only when the client is responsible for deciding the new URI (via its resource name or ID) for the resource. A POST verb should be used if the client doesn’t or shouldn’t know the resulting URI of the new resource before creation. If the resource is already created, PUT should be used to update the resource.
DELETE
The DELETE verb is used to delete the resource represented by the request URI.
On successful execution, the server responds with 200 OK or 204 No Content status codes. If the 200 OK status code is returned, it may also contain the representation of the deleted resource. Since additional bandwidth requirements for the response payload may impact the overall performance, it is recommended to respond with HTTP 204 No Content on successful deletion of the resource.
The DELETE verb is idempotent and not safe. The resource is removed or is marked as deleted in the database on successful execution of the DELETE request.
Repeatedly calling DELETE on a resource ends up the same: the resource is gone. However, there is a caveat about DELETE idempotence. Calling DELETE on a resource a second time will often return a 404 (NOT FOUND) since it was already removed and hence can no longer be found. This makes DELETE operations no longer idempotent. However, this is an appropriate compromise if resources are removed from the database instead of being simply marked as deleted.
The following is an example of a DELETE request:
DELETE http://www.foo.com/customers/12345 HTTP/1.1PATCH
The PATCH method was added to HTTP specs in March 2010. This method is similar to the PUT method and can be used to update an existing resource definition. The difference between PUT and PATCH is that PATCH can be used to do a partial update of an existing resource definition; whereas PUT does a complete update. With the PATCH method, only certain attributes of the resource can be specified for update.
The following is an example of a PATCH request:
PATCH http://www.foo.com/customers/12345 HTTP/1.1{"customers": {"Address":{"AddressLine1":"205 Lane 2"}}}
OPTIONS
The OPTIONS verb allows the client to determine the options and/or requirements for interacting with a resource or a server. The OPTIONS verb determines the HTTP methods and headers allowed for interacting with a resource. It indicates to the client the capabilities of a server without actually performing any of the CRUD operations. The client can specify a URL for the OPTIONS method to refer to a specific resource. An asterisk (*) should be used if the client is interested in knowing or testing the capabilities of the entire server. Responses of this method cannot be cached.
This is an optional method that is not always supported by all service implementations. Many popular sites do not support this method; for example, GitHub responds with a 500, Google Maps with 405 Method Not Allowed. If this method is supported, the response should be 200 OK and have an 'Allow' header containing a list of HTTP methods that may be used on this resource.
The OPTIONS method can be used by the client to provide support for cross-origin resource scripting (CORS) implementation. Chapter 7 looks at how to implement CORS for building secure web APIs.
The following is an example of an OPTIONS request:
OPTIONS * HTTP/1.1HEAD
The HEAD method is identical to GET. The difference is that with HEAD method, the server responds only with a response line and headers. The response to the HEAD method does not contain the entity-body. The metainformation contained in the HTTP headers in response to a HEAD request is identical to the information sent in response to a GET request. This gets only the metainformation about the resource entity, without actually transferring the resource entity-body in the response payload. It reduces network bandwidth usage. This method is often used for testing recent modifications, the validity of hypertext links, and accessibility.
Idempotent and Safe Methods
Some HTTP methods can be called multiple times without any change in the result or the state of the resource. This brings in the concept of a method being idempotent and/or safe. An idempotent HTTP method can be called many times without getting a different outcome. It does not matter if the method is called one time or 100 times—the result is going to be the same. A point to note is that idempotency refers to the result of the method execution and not to the resource itself. For example, calling a GET method on a particular resource always gives the same result unless the resource has been changed in some other way. An HTTP method is considered safe if it does not modify the state of the resource. For example, calling a GET or HEAD method on a resource URL never modifies the resource itself; hence, it is considered safe.
Table 3-2 summarizes whether an HTTP method is idempotent and/or safe.
Table 3-2. Idempotent and/or Safe HTTP Methods
HTTP Verb Name | Idempotent | Safe |
|---|---|---|
GET | Yes | Yes |
POST | No | No |
PUT | Yes | No |
DELETE | Yes | No |
HEAD | Yes | Yes |
OPTION | Yes | Yes |
PATCH | No | No |
HTTP Status Code
The HTTP response communicates the status of the request processing. The response contains certain metadata and optional payloads. The Status-Line part of the HTTP response message is used to inform clients of their request processing results in the following format:
Status-Line = <HTTP-Version> SP <Status-Code> SP <Reason-Phrase> CRLFHTTP defines 40 status codes to communicate the execution results of a client's request. The status code is divided into the following five categories.
1xx Informational: Communicates transfer protocol level information.
2xx Success: Communicates that the request from the client was successfully received , understood, and accepted.
3xx: Redirection: Communicates that additional action needs to be taken by the user agent like browser in order to fulfil the request.
4xx Client Error: Indicates errors caused by the client.
5xx Server Error: Indicates that server is aware that an error occurred while processing the request and cannot process it further.
Normally, 2xx and 3xx status codes are treated as success codes. Any 4xx or 5xx status code is treated as an error code.
Table 3-3 lists the most commonly used success codes.
Table 3-3. The Most Commonly Used Success Codes
Status Code | Reason-Phrase | Meaning |
|---|---|---|
200 | OK | Indicates that the request has been processed successfully. |
201 | Created | Indicates that the request has been processed and a new resource has been created successfully. |
202 | Accepted | Indicates that the request has been received by the server and is being processed asynchronously. |
204 | No Content | Indicates that the response body has been purposely left blank. |
301 | Moved Permanently | Indicates that a new permanent URI has been assigned to the client’s requested resource. |
303 | See Others | Indicates that the response to the request can be found in a different URI. |
304 | Not Modified | Indicates that the resource has not been modified for the conditional GET request of the client. |
307 | Use Proxy | Indicates that the request should be accessed through a proxy URI specified in the Location field. |
Table 3-4 lists the most commonly used error codes.
Table 3-4. The Most Commonly Used Error Codes
Status Code | Reason Phrase | Meaning |
|---|---|---|
400 | Bad Request | Indicates that the request had some malformed syntax error due to which it could not be understood by the server. Probable reason is missing mandatory parameters or syntax error. |
401 | Unauthorized | Indicates that the request could not be authorized, possibly due to missing or incorrect authentication token information. |
403 | Forbidden | Indicates that the request was understood by the server but it could not be processed due to some policy violation or the client does not have access to the requested resource. |
404 | Not Found | Indicates that the server did not find anything matching the request URI. |
405 | Method Not Allowed | Indicates that the method specified in the request line is not allowed for the resource identified by the request URI. |
408 | Request Timeout | Indicates that the server did not receive a complete request within the time it was prepared to wait. |
409 | Conflict | Indicates that the request could not be processed due to a conflict with the current state of the resource. |
414 | Request URI Too Long | Indicates that the request URI length is longer than the allowed limit for the server. |
415 | Unsupported Media Type | Indicates that the request format is not supported by the server. |
429 | Too Many Requests | Indicates that the client sent too many requests within the time limit than it is allowed to. |
500 | Internal Server Error | Indicates that the request could not be processed due to an unexpected error in the server. |
501 | Not Implemented | Indicates that the server does not support the functionality required to fulfill the request. |
502 | Bad Gateway | Indicates that the server, while acting as a gateway or proxy, received an invalid response from the back-end server. |
503 | Service Unavailable | Indicates that the server is currently unable to process the request due to temporary overloading or maintenance of the server. Trying the request at a later time might result in success. |
504 | Gateway Timeout | Indicates that the server, while active as a gateway or proxy, did not receive a timely response from the back-end server. |
Resource Representation Design
A REST API resource entity representation is used to convey the state of the resource. The message body of the request/response is used to convey the state of the resource entity. The client sends the resource entity to the server in the request message payload of a POST, PUT, or PATCH message. The server sends the resource entity state in the response message payload for a GET, POST, PUT, or optionally, DELETE request.
A text-based format is normally used to represent the resource state. JSON and XML are the most commonly used text formats for representing the state of the resource entity. JSON is lightweight and provides a simple way to represent a resource. Due to the seamless integration of JSON with the browser’s native runtime environment, JSON is the preferred choice for data representation in the design of a REST API. XML, on the other hand, is verbose, hard to parse, hard to read, and its data model is not compatible with many programing languages. This makes JSON a preferred choice over XML for representing the resource entity for a REST API. Many popular API providers have already moved away from XML to the JSON format. However, if the API consumer base consists of a large number of enterprise customers, you still have to support the XML data format for your APIs.
As a general guideline, it is advisable to support JSON data format by default and provide additional support for the XML format, if required. With support for both JSON and XML formats, how does the client specify the preferred format for the response? There are the following options:
Use the ‘Accept’ header.
Append .json or .xml extensions to the endpoint URL.
Include a query parameter in the URL to specify the response format.
Of the three options, use of 'Accept' header to specify the response message format is most preferred. The following are some of the basic best practices for the JSON format representation of the resource entity.
JSON should be in a well-formed format, with the variable names and their values enclosed in double quotes.
JSON names should use mixed lowercase and uppercase letters. Special characters should be avoided whenever possible. JSON names like fooName is preferred over foo-Name because it allows the use of the cleaner dot notation for property access in JavaScript.
The 'Content-Type' header in the message should be set to application/json when a JSON format payload is included in the message .
Hypermedia Controls and Metadata
HTTP headers in the request/response convey metadata about the messages and about the resource entity contained in the message. HTTP specification defines a set of standard headers that can be used for various purposes. The specification also allows extension mechanisms to include custom HTTP headers . HTTP headers are classified under four types.
Entity headers : This type of header provides metainformation about the entity body or resource in the message. Information such as the allowed HTTP methods, the media type, size, and location of the resource entity or cache expiration date-time, and so forth, are some of the examples of Entity Header types.
General headers : This type of header provides information that can be applicable for both request and response messages. Caching directive , connection information, message origination date-time, and any message transformation applied on the whole message, are some examples of General Header types.
Client request headers : This type of header is included only in the request message sent by the client or browser to the server. Authorization information, user agent information, information about the character set, encoding, or language that the client can accept, are some examples of information provided by Client Request headers.
Server response headers : This type of header is included only by the server in the response sent to the client. Information about the age of the response generated by origin server, ETag information for caching purposes, the duration for which the server is unavailable for the requesting client, are some examples of Server Response headers.
This section looks at the most commonly used HTTP headers and how they can be used to design a better RESTful interface.
Accept (Client Request Header)
The Accept header is used in the request message to specify the media types that are acceptable by the client for the response. It is a mechanism for the client application or browser to indicate to the server which MIME types it is expecting.
The client can specify a range of media types using an asterisk (*) or multiple media types using comma-separated values. Media ranges can be overridden by specific media ranges or specific media types. If more than one media range applies to a given type, the most specific reference has precedence.
For example,
Accept: text/*, application/xhtml+xml, application/xml;q=0.9, */*has the following precedence:
application/xml;q=0.9
application/xhtml+xml
text/*
*/*
The client can specify its relative preference for a media type using an optional q parameter. The following is an example:
Accept : audio/*; q=0.3, audio/basicThese examples indicate that audio/basic is preferred, but any audio type is also acceptable if it is the best available after a 70% markdown in quality.
If no Accept header field is specified, then it is assumed that the client accepts all media types. If an Accept header field is present but the server cannot send a response that is acceptable according to the Accept field value, then the server should respond with a HTTP status code of 406 Not Acceptable .
Accept-Charset (Client Request Header)
The Accept-Charset request header is used by the client to specify the character sets that it understands and therefore can be included by the server in the response. As with the Accept header, the client can specify multiple charsets in a comma-separated list. A q value on a scale of 0 to 1 can also be included to specify the acceptable quality level for non-preferred character sets.
If the client does not include an Accept-Charset header in the request, it is assumed that any character set is acceptable. If a Accept-Charset header is present but the server cannot send a response that is acceptable according to the Accept-Charset header, then the server should send an error response with the 406 Not Acceptable HTTP status code, though the sending of an unacceptable response is also allowed as per the HTTP specs.
The following is an example of Accept-Charset header:
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8Authorization (Client Request Header)
The Authorization header is used by the client to include authentication information needed to access a server resource. If the server needs authentication and the Authorization header is not present in the request or is having an incorrect value, the server should send an error response with a 401 Unauthorized HTTP status code. The server should also include the WWW-Authenticate header in the response, which indicates the authentication scheme(s) required. The authentication schemes can be basic or digest access.
The following is an example of Authorization header:
Authorization: BASIC Z3Vlc3Q6Z3Vlc3QxMjM=Host (Client Request Header)
The Host request header specifies the server address and the port of the resource requested. A Host without any port information implies the default port. The default port is 80 for HTTP and 443 for HTTPS.
The following is an example of Host header:
Host: http://www.foo.comLocation (Server Response Header)
The Location response header is used by the server to redirect the recipient to a URI other than the request URI for completion. This header is returned by the server in the following two scenarios.
When a new resource is created after the successful execution of a POST or a PUT request. In this scenario, the Location header contains the location information of the newly created resource and the HTTP response status code should be 201 Created.
When the resource has moved temporarily or permanently, or is the result of a request execution is available at a different location. In this scenario, the Location header contains the redirected URI and the HTTP response status code should be 3xx. The Location information is then used by the browser to load a different web page, as specified in the header, thus helping in automatic redirection.
The following is an example of Location header:
Location: http://www.foo.com/http/index.htmETag (Server Response Header)
The ETag (entity tag) response header provides a mechanism for the server to send information about the current state of the entity. It is an alphanumeric string that uniquely identifies a specific version of the resource. If the resource has changed, the ETag value changes. Hence, the ETag value can be compared to determine if the cached resource entity on the client side matches that on the server.
It is a mechanism used for web cache validation that allows a client to make conditional requests. It makes caches more efficient and saves bandwidth because the server does not need to send the full response if the content has not changed.
The following is an example of ETag header:
ETag: "686897696a7c876b7e"Cache-Control (General Header)
The Cache-Control general header field is specifies instructions on caching response information by the client and/or any intermediary along the request/response chain. Directives contained in this header provide information about the cache-ability of the response. It specifies if the response can be cached or not. If yes, can it be cached in public or private cache? It also specifies if the cache can be archived and stored. This header also contains information about the maximum duration for which the response can be cached.
The following is an example of Cache-Control header:
cache-control: private , max-age=300, no-cacheContent-Type (General Header)
The Content-Type header specifies the media type of the payload included in the message.
The following is an example of Content-type header:
Content-Type: text/html; charset=ISO-8859-4Header Naming Conventions
Earlier sections looked at the best practices for naming resources and URIs. For good API design, even the HTTP headers should be named according to a convention. This section looks at some of the recommended best practices for naming headers.
HTTP specifications provide names for all standard HTTP headers and their syntax. It also provides extension mechanisms to include custom headers, if required. The following conventions are recommended for naming custom HTTP headers.
Historically, X- has been used as a prefix for naming non-standard custom headers. RFC 6648 has deprecated the use of this convention because it causes more problems than it solves. Hence, do not prefix custom header names with X- or similar constructs.
Name custom headers meaningfully and with the assumption that all custom headers may become standardized, public, commonly deployed, or usable across multiple implementations.
Use hyphens in header names if required; for example, My-Header-Name.
Do not use spaces in header names.
Versioning
Versioning is one of the most important considerations for web API design. Regardless of the approach followed, REST APIs should always be versioned. It helps to develop APIs in an iterative approach.
There are multiple approaches for versioning an API. The following are some questions to ask when thinking about API versioning.
Which versioning approach should be used?
When should a new version of the API be created?
How and where to indicate the version of the API?
How many versions should be maintained?
How long should the older versions of the API be maintained?
What are the deprecation mechanisms for older versions?
This and many other considerations and approaches for API versioning are discussed later in this book .
Querying, Filtering, and Pagination
Enterprises use REST APIs to expose their data and services. The resource collection returned by REST API may be huge. Transmitting the entire payload over the network is heavy on the bandwidth. Additionally, processing an entire collection on the client side would be processor intensive. Since a UI can display only a limited amount of data, this becomes important from UI processing standpoint as well; for example, 20 results per page. Hence, the need arises to be able to query, filter, and paginate the response. The API should provide a mechanism for the consumer to specify the query parameters and filter criteria. They should also be able to specify a range of data to be returned in the response. The range can be in terms of the number of elements, a date and time range, or in terms of offset and a limit.
It is important to note that it is not mandatory to provide support for querying, filtering, and pagination for all REST APIs. This is a resource-specific requirement and by default is not required to be supported on all resources. Consider designing the API to support filtration and pagination only if the number of entities in the resource collection that can be returned by default is high. The API documentation should specify if these complex functionalities are available for any specific service.
Limiting via Query-String Parameters
Filtering and pagination for an API is best implemented by designing the API interface with offset and limit query-string parameters. The offset parameter indicates the beginning item number in a collection and the limit specifies the maximum number of items to return.
The following is an example:
GET http://www.foo.com/products?offset=0&limit=25In this example, the offset value 0 and limit value 25 indicate to return the first 25 items in the list. If the number of items fetched from the back end is more than 25, only the first 25 are returned. To retrieve the next set of items, the client has to make another call with a changed value for offset (=25) and limit (=25). If the number of items in the list is less than 25, all the items are returned in the response. This approach helps implement pagination support in the API.
It is important to understand that offset and limit are query-string parameters and are not dictated by any standards or specifications. Hence, different API providers may implement the same concept by using different parameter names. start, count, page, and rpp (records per page) are other examples of query-string parameters that can be used to implement pagination. An API designer can name them anything to suite the business context.
Filtering
Filtering is an approach to restrict the results returned in the response by specifying additional search criteria. These search criteria must be met on the data returned in the result. The filtering can become complex if the API has to support a complicated set of search criteria. The filtering criteria is based on the resource attribute. The complexity increases if filtering involves a complex combination of comparison operators. However, filtration can be achieved by supporting simple criteria, such as starts-with or contains, and so forth.
The filtering criteria can be specified by using the filter query-string containing a delimiter-separated list of name/value pairs. The delimiters that have conventionally worked are the vertical bar (|) to separate individual filter phrases and a double colon (::) to separate the names and values. This approach supports a wide range of use cases for filtering and also makes the filter criteria user-readable. The following is an example:
GET http://www.foo.com/customers?filter="name::matt|city::delhi"Note that the property names in the name/value pairs match the name of the properties returned by the service in the payload. Wild cards can also be included in the filter values by using the asterisk (*).
Filtering can be implemented for an API by using one of the following approaches.
Map the filter criteria to the back-end database SQL queries and implement filters at the database layer. This would retrieve the data matching the criteria from the data store; the same can be passed to the client with minimal messaging.
Implement filter criteria in the service implementation layer. The service accepts the filter criteria as inputs and applies them on the data fetched from the data store. This may be required when the search criteria is complex or requires some business logic to be executed on the data set returned from the data store.
Implement filter criteria on the API’s intermediary layer. In the event that there is no change to the database or service implementation layer, the filtering is done on the intermediary API node that is generally introduced for creating and exposing REST APIs. Implementation of the filter on the intermediary API node might be complex due to the limited programming support provided by these tools.
When deciding on which of these approaches to adopt, it is recommended to implement filtering as close to the resource data store as possible.
The Richardson Maturity Model
The Richardson Maturity Model defines the levels to assess the maturity of a REST API service. It defines the following four levels (0–3) based on services support for URI, HTTP verbs, and hypermedia.
Level 0: Swamp of POX
Level 1: Resources
Level 2: HTTP verbs
Level 3: Hypermedia controls
Figure 3-1 shows the three core technologies with which Richardson evaluates service maturity. Each layer builds on top of concepts and technologies of the layer below. The higher up the stack an application sits, and the more it employs the technologies in each layer , the more mature it is.

Figure 3-1. Richardson’s Maturity Model for REST APIs
Let’s look at each of these levels in detail.
Level 0: Swamp of POX (Plain Old XML)
This is the most basic level of maturity. At this level, the service is characterized as having a single URI that acts as the entry point. HTTP is used as the transport system for remote interactions. The payload content can be described in XML, JSON, YAML, key-value pairs, or any format of your choice. Normally, the POST method is used for sending the request to the server. SOAP and XML RPC are examples of services at Level 0 maturity. Figure 3-2 below shows a client making a request to an appointment service to get the availability of slots for a given date and doctor. The search parameters are sent in plain old XML format using POST request.
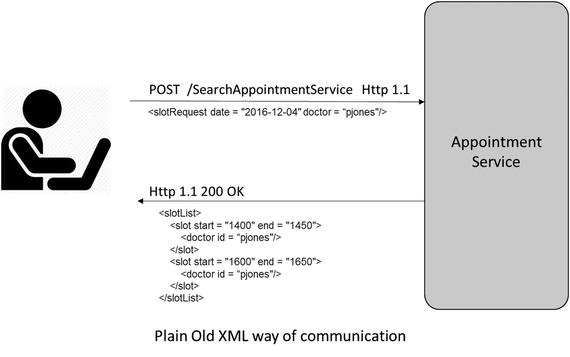
Figure 3-2. Level 0- Plain Old XML way of communication
Level 1: Resources
The first step toward RESTful maturity is the introduction of resources . At this level, instead of having a single URI as an endpoint for all services, you start interacting with individual resources through separate URIs. So instead of going through an endpoint like http://www.foo.com/searchAppointmentService , you start using resource URIs like http://www.foo.com/api/doctors/{doctorId} . Here doctors is a resource and you get access to an individual doctor’s information by using {doctorId}. At this level, you still use POST as the only HTTP method for all of your communication. Figure 3-3 below shows a client making a request to an appointment service to get the availability of slots for a given date and doctor. The URL used to get the slot availability of the doctor is resource oriented.
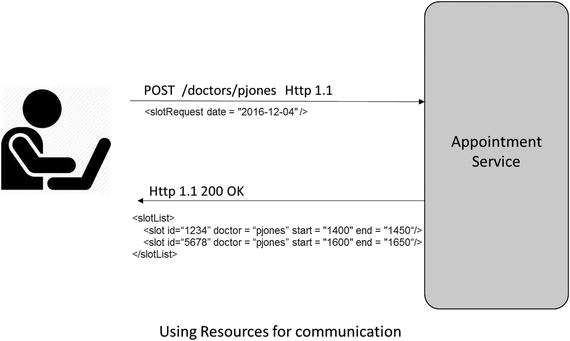
Figure 3-3. Level 1- Using resources for communication
Level 2: HTTP Verbs
At Level 0 and 1, the applications use the POST method for all communication. Level 2 maturity moves toward using the HTTP verbs more closely to how they are used in HTTP itself. To fetch the slot availability of a particular doctor, it should be using the HTTP verb GET at this level. As you’ve seen, the GET verb is safe because it is read-only and does not make any significant changes to the state of the resource. Hence, you can use the GET verb any number of times, in any order, and still get the same result every time, unless the resource has been modified using a different method. If you have to create a new appointment, you can use the POST method. If you want to update an existing appointment, you may use the PUT method.
In addition to the use of HTTP verbs, Level 2 also introduces the use of HTTP response codes to indicate the status of an operation on a resource. If a resource was successfully created, the service returns with HTTP response code 201. If the operation on a resource was successful, the 200 status code is used in the response. If the operation on a resource resulted in an error, an appropriate 4xx or 5xx response code should be used in the response . Figure 3-4 below shows a client making a request to an appointment service to get the availability of slots for a given date and doctor. ‘GET’ Http verb is used to access the resource oriented URL to get the appointment slots of the doctor. Http response code 200 OK is returned to indicate successful response.

Figure 3-4. Level 2- Using resources and verb for communication
Level 3: Hypermedia Controls
This is the final level for REST maturity and it is where HATEOS enters the picture. It addresses the question of what to do next. After receiving the response for a service invocation, what are the next logical steps for the client? At a given node, what are the possible branches for traversal in a tree? This helps the client to be more intelligent and decide or prompt the user for the necessary possible actions.
At Level 3 maturity, the response of a REST service may contain a list of URIs. These URIs are the resources that the client wants to act upon as the next course of action. So rather than the client having to know where to post the next request, the hypermedia controls in the response tells how to do it. Figure 3-5 below shows a client making a request to an appointment service to get the availability of slots for a given date and doctor. The response returned for the GET request contains hyperlinks for the next possible actions that the client can do to book a slot.

Figure 3-5. Using Resource, Verb and HATEOAS for communication
An obvious advantage of hypermedia controls is that it allows the server to change its URI scheme without breaking clients. It also helps client developers expose the protocol. The link gives client developers a hint on what the next possible options are. It may not provide all the information, but it at least gives developers a starting point to think about more information for the API and to look for a similar URI in the API documentation. Currently, there are no absolute standards on how to represent hypermedia controls. It is up to the service implementation team to decide how to implement HATEOS in their service.
As per Martin Fowler's article on Richardson Maturity Model, RMM provides a good way to think of the different elements of a RESTful service, but it is not a definition of levels of REST itself. Roy Fielding has made it clear that Level 3 RMM is a precondition of REST.