
Chapter 3. Implementing APIs
This chapter focuses on actually implementing what’s behind your APIs. You’ve modeled your APIs, but now it’s time to write the code. Here’s how you get started.
Identifying Needs of Clients
Before you start writing code, remember who you’re building APIs for and what they want. Are your APIs primarily for internal developers at your company? Or are they for external developers not employed by your company? Are your APIs for paying customers or for partners?
We’ll discuss this more in Chapter 4, but for now, let’s ask the simple question—who are your clients? Are they other microservices? Are they web frontends? Are they mobile frontends? Your client could be on the other side of the world or on the next rack over in the data center. These are all important considerations. Who’s calling your APIs will have a direct impact on how you design, deploy, and manage them.
Keep these factors in mind as you look at building the code behind your APIs.
Applications Backing APIs
All large applications fall somewhere on a spectrum between monolithic and microservices. A traditional monolithic has multiple business functions in the same codebase. Pricing, orders, inventory, and so on are all included in the same codebase and are deployed as a single large application requiring dozens or hundreds of people working in horizontal (frontend, backend, ops, etc.) teams. These monolithic applications often retroactively add APIs to access functionality contained within the monolith (see Figure 3-1).
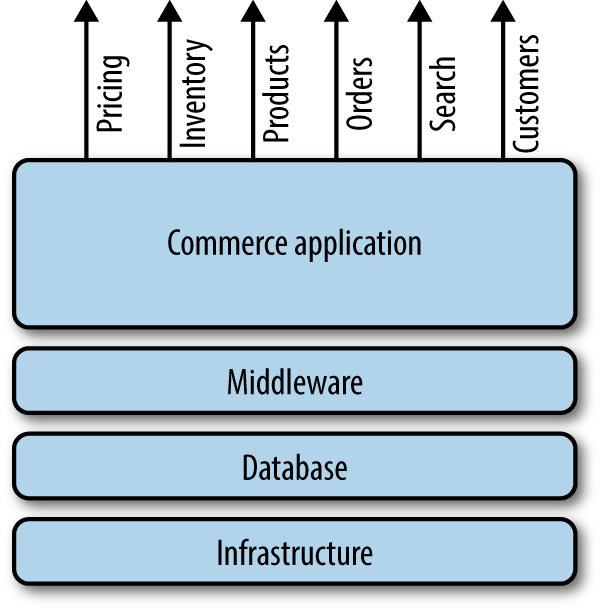
Figure 3-1. Traditional monolithic commerce application
Microservices are individual pieces of business functionality that are independently developed, deployed, and managed by a small team of people from different disciplines. Characteristics of microservices include:
- Single purpose
-
Do one thing and do it well.
- Encapsulation
-
Each microservice owns its own data. Interaction with the world is through well-defined APIs (often, but not always, HTTP REST).
- Ownership
-
A single team of 2 to 15 (7, plus or minus 2, is the standard) people develop, deploy, and manage a single microservice through its life cycle.
- Autonomy
-
Each team is able to build and deploy its own microservice at any time for any reason, without having to coordinate with anyone else. Each team also has a lot of freedom in making its own implementation decisions.
One of the key characteristics of microservices is encapsulation. Small, vertical microservice teams often start by modeling the API and then writing a microservice that implements it (see Figure 3-2).

Figure 3-2. Microservices-based commerce application
The advantage of a microservices-based architecture in this context is that the APIs are more easily able to be consumed independently. The shopping cart microservice team, for example, needs to expose an API that can be called by anybody or anything, internally or externally. An API retroactively bolted on top of a monolithic application is inherently less callable because you’re consuming a small piece of something much larger. There are always going to be dependencies. Going back to the shopping cart example, you may have to call inventory, pricing, and tax as you retrieve your shopping cart. But a shopping cart developed as a standalone microservice will already have those dependencies included. Microservices requires a substantially different approach to development that is ultimately very beneficial for APIs.
For more information about microservices, read Microservices for Modern Commerce, by Kelly Goetsch (O’Reilly).
Handling Changes to APIs
Traditionally, commerce applications have forced all clients to use the same API and implementation versions. In practice, this meant that the monthly or quarterly release to production would require the clients to be updated at the same time, leading to a long weekend for the ops team. When the only client was a website, this was just fine. When it was mobile and web, it became more difficult because an update to the core platform meant you had to redeploy both mobile and web at the same time. But in today’s omnichannel world, there could be dozens of clients, each with their own release cycles (see Figure 3-3). It is not possible to get dozens of clients to push new versions live at the same time. Each client must evolve independently, with its own release cycle.

Figure 3-3. Multiple clients, each calling different versions
There are two basic approaches that producers of APIs can take: evolve or version. Let’s start with evolving APIs.
Evolving APIs
Many APIs simply do not change that much, especially if they’re designed by people who understand the domain extremely well. For example, most of the external tax calculators have static APIs. Have a quick look at Avalara’s tax API as an example. The underlying tax rates and sometimes the formulas change, but the actual API you call is fairly static. The response you get back is also fairly static. The US could adopt a VAT-style tax system and the APIs still wouldn’t change. Most APIs you interact with on a day-to-day basis are like this.
Inevitably, APIs need to evolve—but not necessarily change. Let’s say you’re building a customer profile API that allows simple create, read, update, and delete (CRUD) operations. The following code shows the object that the API would need for a new customer to be created.
{"id":"c12345","firstName":"Kelly","lastName":"Goetsch","email":"[email protected]"}
Now let’s say that your business users want to capture your customers’ shoe sizes so they can be targeted with better product offers. Your JSON object would now look like this:
{"id":"c12345","firstName":"Kelly","lastName":"Goetsch","email":"[email protected]","shoeSize":12}
This is an evolution of your API, which should be easily supported without versioning. If the client doesn’t specify the shoeSize parameter, the application shouldn’t break. This goes back to Postel’s law, which states that you should be “liberal in what you accept and conservative in what you send.” When applied to APIs, Postel’s law essentially means you shouldn’t do strict serializations/deserializations. Instead, your code should be tolerant of additional attributes. If shoeSize suddenly appears as an attribute, it shouldn’t break your code. Your code should just ignore it. For example, the serializer we use allows for the following annotation:
// To ignore any unknown properties in JSON input wuthout exception:@JsonIgnoreProperties(ignoreUnknown=true)
If you adopt a strict approach to serialization, any difference in the client and server is going to break the client:
Unhandledexceptionorg.springframework.oxm.jaxb.JaxbUnmarshallingFailureException:JAXBunmarshallingexception:unexpectedelement(uri:"http://yyy.org",local:"xxxResponse").Expectedelementsare<{}xxx>,<{}xxxResponse>;
The approach of having evolving APIs goes back to Bertrand Meyer’s open/closed principle, which he documented in his 1988 book, Object-Oriented Software Construction. In it, he said that software entities (especially APIs) should be “open for extension but closed for modification.” He went on to further say:
A module will be said to be open if it is still available for extension. For example, it should be possible to add fields to the data structures it contains, or new elements to the set of functions it performs.
A module will be said to be closed if it is available for use by other modules. This assumes that the module has been given a well-defined, stable description (the interface in the sense of information hiding).
The majority of APIs you have will fall into this category. Simply add attributes where you can, and don’t break existing functionality.
The major advantage of this approach is that the APIs remain fairly static, allowing clients to code to them more easily. It’s one less dimension for developers to care about. The supplier of the API only has one version of the codebase to support in production at any given time, dramatically simplifying bug fixing, logging, monitoring, etc.
The disadvantage of this approach is that the APIs are fairly locked from the start. Vendors who solely adopt this approach lose the flexibility to radically change the APIs, which is perfectly acceptable in many cases.
For APIs that change more radically and where true A/B testing is necessary, versioning is the preferred approach.
Versioning APIs
With versioning, the provider of the APIs deploys more than one major version of an API to the same environment at the same time. For example, versions 1, 2, and 3 of the pricing API may be live in production all at the same time. All versions can serve traffic concurrently.
While there are many flavors of versioning, a common approach is to guarantee API compatibility at the major version level but continually push minor updates. For example, clients could code to version 1 of an API. The vendor responsible for the implementation of the API can then publish and deploy versions 1.1, 1.2, 1.3, and beyond over time to fix bugs and implement new features that don’t break the published API. Later, that team can publish version 2, which breaks API compatibility with version 1.
Clients (e.g., point of sale, web, mobile, and kiosk) can request a specific major version of an API when making an HTTP request. By default, they should get the latest minor release of a major version. This is often done through a URL (e.g., /Inventory/v2/ or /Inventory?version=v2) or through HTTP request headers (Accept: application/vnd.example.api+json;version=2).
This is great for vendors who are rapidly innovating. It allows them to release minimum viable products. When enough is learned, they can fork the codebase and then offer the old version 1 and have an entirely new breaking API as version 2. The vendor isn’t “locked in” to a specific API, as is the issue with evolving APIs.
The major challenge you’ll have with versioning is persistent data. Here, there are essentially two approaches: you can have one datastore per major API version (Figure 3-4), or you can have one datastore per environment (Figure 3-5).

Figure 3-4. One data store per version

Figure 3-5. One data store per environment
If you have one datastore per major API version, then you need to migrate or continually synchronize the data between major versions. If your client was using version 1 of the order API, and then you start using version 2, you need to physically move or synchronize the data from version 1 to version 2. You can’t just seamlessly switch over to version 2, for example. This is hard to do when you have multiple clients because it requires that you cut all your (potentially dozens of) clients over to the new version of the API at the same time. Facebook has gone so far as to offer an upgrade utility to help developers transition from one version to another.
If you have one datastore per environment, with all API versions hitting the same datastore, you have the problem of “evolving” the objects. Your point-of-sale system could write an order object using version 1 of the API and, five seconds later, your iOS application could try to amend that order using version 2 of the same API. Any API version can write an object, and any API version can update that order at any time. This is by far the most common approach, but it’s hard to do.
Versioning is only used because it offers more freedom to innovate, especially in a fast-changing environment. Evolving APIs are easier to support, but both the clients and the producer of the APIs tend to get locked in over time, slowing the pace of change.
Testing APIs
Testing is obviously important to all software development and must be taken seriously. Fortunately, APIs make testing easy. Before we go further, you must adopt a new mindset.
Traditional commerce applications were one large monolith, often deployed as a single multigigabyte EAR file or something similar. They had frontend and backend code, all contained in one application. The scope of testing was fairly well defined—whatever was in that single archive needed to be tested.
Commerce is now a collection of smaller APIs, often backed by separate microservice teams. You’ll have a team that exposes an inventory API and another that exposes a pricing API. An enterprise could easily expose a catalog of a few hundred individual APIs for any client to consume. The providers of the APIs often have no idea how their APIs will be used by the dozens of clients out there. Think of APIs as LEGO blocks, available for use by anyone in any way.
With that in mind, let’s look at the different methods of testing.
Local Testing
Testing APIs locally is pretty easy. Just download Postman, Advanced REST Client, Insomnia REST Client, or any of the myriad of GUI-based tools that allow you to execute HTTP requests against a REST resource, and see the response (Figure 3-6). You can even use traditional cURL if you’re inclined to use the command line. The purpose of this testing is to verify that uncommitted changes you’ve made locally don’t break the API.

Figure 3-6. Postman HTTP client
Traditionally, local testing was hard because you’d have to run an entire multigigabyte application locally, including the UI, application server and database. There was no way to test out the backend functionality without exercising the frontend. But it’s actually pretty easy to test your APIs if you’re just building APIs. The frontend developers can test their stack independently.
Unit Testing
While local testing is focused on individual developers testing uncommitted changes, unit testing is focused on ensuring that the API you’re working on as a team (often a microservice team) works as expected. The API is the unit you’re testing. An API is really just a contract, if you look at the big picture. When unit testing, you’re verifying that the API is working as advertised.
Unit testing must be 100% automated and baked into your Continuous Integration/Continuous Delivery (CI/CD) pipeline. It should exercise all aspects of the API, including its functionality and especially the HTTP response codes it produces. If you version your APIs, your tests should cover supported versions of your APIs as well.
For example, let’s pretend you have a /Product/{id} HTTP REST resource. When you call it with /Product/12345, you get back the following response:
{"product":{"id":"12345","name":"Test product","description":"Long description..."}}
To test this functionality, you can use any number of frameworks. Let’s use a simple example using REST Assured. It would look something like this:
@Testpublicvoidproduct_resource_returns_200_with_expected_product_name(){when().get("/Product/{id}","12345").then().statusCode(200).body("product.name",equalTo("Test product"));}
You can very easily hook this into any CI/CD pipeline so that each of your APIs is rigorously tested with each code commit.
Load Testing
In addition to testing the functionality of each API, you should also test its scalability limits. Again, you don’t know who’s consuming your API or what they’re doing with it.
Any load testing framework out there can make an HTTP request to test an API. Common frameworks include ApacheBench, Gatling, and JMeter. If your API is backed by a microservice-style application and deployed to a public cloud with auto-scaling, you should have no problems scaling your APIs.
Integration Testing
Once you’ve verified that an individual API works and performs well under load, it then must be tested within the context of other APIs in the ecosystem.
Figure 3-7 shows a fairly common end-to-end flow you’d want to test.

Figure 3-7. Synthetic integration testing
Repeat this for all the major flows for all the combinations of all the APIs you support. It might take a few minutes to execute the tests, but it’ll be well worth the comfort in knowing that the APIs all work well together.
These integration tests should be executed every time code is checked in, as part of your CI/CD pipeline. If integration testing fails, stop everything and fix it.
Securing APIs
Before you can expose an API, you must secure it. Security starts with authentication: is this developer or application whom he/she/it purports to be? Next, you have to authorize the user: does he/she/it have access to this API? What type of behavior is permitted? Finally, you have to ensure that your users aren’t abusing your APIs in some way. For example, you may want to cap the number of HTTP requests that can be made by any given client. A few thousand HTTP requests may be OK, but are 100 million HTTP requests per hour OK? Probably not.
What’s great about using REST-based APIs is that the underlying stack (TCP, HTTP) is so widely used. There are well-established approaches to solving all of these security issues.
Authentication
Let’s start with authentication. Authentication ensures that a user, whether a human or another system, is who he/she/it purports to be. It’s like having your ID checked at the airport.
At a high level, your client needs to provide a “secret” of some sort (Figure 3-8). That secret can be a username/password or an API key of some sort, which is typically a long string encoded using base64. Keys are best because they’re easier for developers to use, with many SDKs allowing you to supply the key via a configuration file.
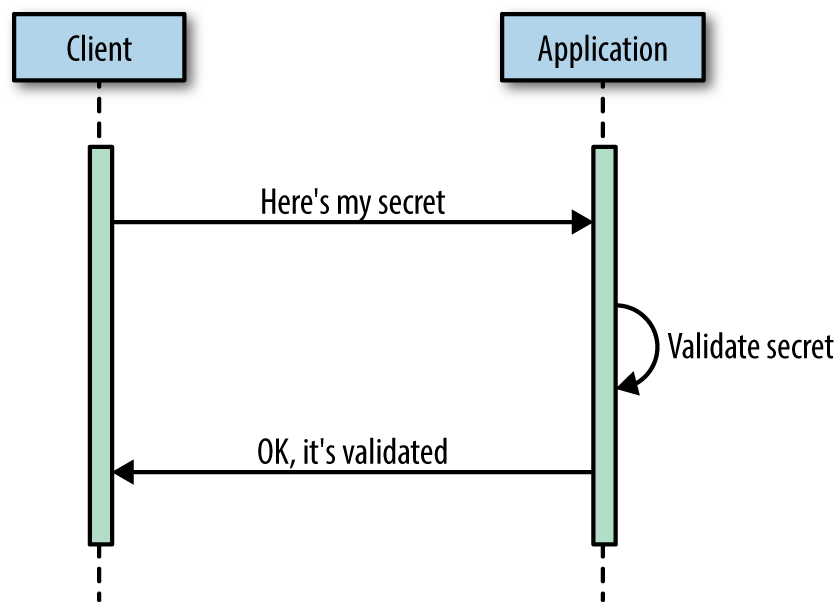
Figure 3-8. Simple authentication flow
Here’s Tesco’s developer documentation for how to pass in a key when making an HTTP GET request for products:
curl -v -X GET"https://dev.tescolabs.com/product/?gtin={string}&tpnb={string}&tpnc={string}&catid={string}"-H"Ocp-Apim-Subscription-Key: {subscription key}"
Note
Never put your secret in a URL as an argument. URLs are public. Your secret should be private. Any number of intermediaries can sniff the URLs you’re browsing, even if you use HTTPS. Your secret is safe if it’s in the request header and you use HTTPS (HTTP + TLS or SSL).
The issue with simply supplying an API key or username/password is that the application now knows your secret. If you have one big monolithic application, it’s fine, as it’s less likely to leak out. But imagine if you have 100 APIs backed by 100 microservices/applications? That creates a whole new set of issues, which we’ll discuss shortly (see Figure 3-9).

Figure 3-9. Don’t let this happen to you!
Authorization
Once you’ve authenticated your client, you must now authorize that client to perform some action, like retrieve an order or query for inventory availability.
Authentication and authorization are often intermingled, but they’re distinct. Going back to the airport analogy, authorization is scanning your boarding pass when boarding your flight. Your identity has already been validated, but now you need to be authorized to board a particular flight.
With one monolithic application backing your APIs, you can put an API gateway in front of your APIs. Begin by cataloging all your APIs and the HTTP verbs allowed by each (POST, GET, PUT, PATCH, and DELETE). Define which groups or individuals are allowed to access each API, and then within each API, which verb they’re allowed to call. This is fairly simple (see Figure 3-10).

Figure 3-10. Securing your APIs through an API gateway
Now let’s say you have 100 separate microservices, each backed by its own application and development team. A vulnerability in any one of those microservices will expose the secret to the public. The secret will need to be regenerated and all clients using it will need to be updated.
OAuth 2 solves this problem by serving as a trusted intermediary between the client and the applications the client is trying to interact with. The client is able to authenticate once with an OAuth server. The server responds with a temporary access token, which the client sends as an HTTP request header with every request. The microservice/application receiving that temporary access token (such as a product or shopping cart microservice), then consults with the OAuth server, asking what rights the token has (see Figure 3-11).

Figure 3-11. Advanced authentication flow
Access tokens are great because they:
-
Are temporary
-
Can be easily revoked
-
Are granular, allowing for fine-grained access to resources
-
Don’t force each microservice/application to validate identity, as done by the OAuth server
Most API gateways allow you to define authorization policies, with the underlying implementation and enforcement being left to OAuth 2.
Note
Both authentication and authorization are specialized domains that require experts. Hire an external consultant who specializes in this area. It’s not worth doing yourself.
Request Rate Limiting
All your APIs should have throttling in place to ensure that they’re not called too often by any given client, whether maliciously or not. Whether through error or poor architecture, a client can end up calling an API too many times. Establish limits for each type of client. Limit new developers to a thousand requests per hour, for example. But allow your web-based frontend to call your APIs without any limits.
Denial of Service attacks are rampant today. Use your content delivery network or alternate upstream systems to ensure that you’re protected.
If the number of HTTP requests exceeds your policy, respond with an HTTP 429 Too Many Requests response.
Data Validation
As with any application, all inputs must be validated. Since you’re probably using REST APIs, you can use any HTTP-based web application firewall on the market. These firewalls are like traditional network firewalls except that they look more deeply at the HTTP traffic, applying rules that look for malicious behavior, such as cross-site scripting (injecting malicious code that the server then executes), SQL injection (getting the application to arbitrarily execute commands against the database), and the use of special characters or other behavior designed to cause application errors.
Using an API Proxy
APIs should always be protected behind an API proxy of some sort, whether it’s an API load balancer or an API gateway. These proxies sit between your clients and backend, providing a number of valuable functions, including:
-
Load balancing to individual instances of applications running your API
-
Offering authentication and authorization
-
Throttling abusive clients
-
Conversion between representation formats, like XML → JSON
-
Metering of API consumption
-
Logging who’s consuming your APIs and what they do with them
Where an API load balancer differs from an API gateway is aggregation, as seen in Figure 3-12. A web page or screen on a mobile device may require retrieving data from dozens of different APIs. Each of those clients will need data tailored to it. For example, a web page may display 20 of a product’s attributes, but an Apple Watch may only display 1.
You could choose an API to serve as the intermediary.
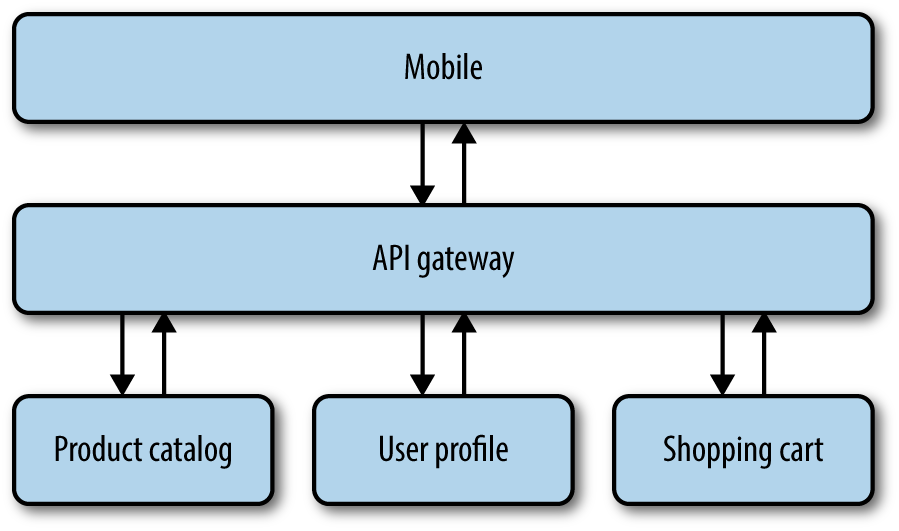
Figure 3-12. Aggregator pattern
The client makes the call to the API gateway, and the API gateway makes concurrent requests to each of the microservices required to build a single response. The client gets back one tailored representation of the data. API gateways are often called “backends for your frontend.”
The issue with API gateways is that they become tightly coupled monoliths because they need to know how to interact with every client (dozens) and every microservice (dozens, hundreds, or even thousands). The very problem you sought to remedy with APIs and microservices may reappear in your pipes if you’re not careful.
Whether you use an API load balancer or gateway, what matters is that you have one or more intermediaries between your clients and backend providing the functions outlined in this section.
Exposing APIs Using GraphQL
GraphQL is a query language specification for APIs that originated at Facebook in 2012, with the specification being open sourced in 2015. Facebook, Twitter, Yelp, GitHub, Intuit, Pinterest, and many others are now using it. GraphQL is analogous to what SQL queries brought to relational databases. Rather than querying the product and SKU tables independently, you can build a SQL query to retrieve data from both tables. GraphQL is the same but for APIs.
Note
GraphQL is a specification, not an implementation.
Let’s say you wanted to render a page showing a given customer’s last five orders, along with the products purchased in each order. Normally, you’d query the orders resource to find the orders belonging to the customer in question. Then you’d query the customer resource to retrieve the customer’s name and other details. Then you’d query the product resource to retrieve the name of the products contained in the orders. To render just one page, you’d hit at least three different resources, retrieving kilobytes or even megabytes of data that is unnecessary to rendering the page (Figure 3-13).

Figure 3-13. Retrieving customer, order, and product information using separate APIs
There are many solutions to this problem that involve inserting some form of an aggregation layer between your client and the different APIs you need to render (Figure 3-14). While that certainly works and is more elegant than hitting individual APIs, it forces the pages/screens to be rendered to match what data views are available. Now there’s coupling between the different layers.

Figure 3-14. Retrieving customer, order, and product information using an aggregation layer
This is where GraphQL comes in. You can build a simple query that retrieves customer, orders, and products in one single request:
query {customer(id:"25484d8d45") {idfirstNamelastNameorders (last: 5) {iddatePlacedproducts: {displayName}}}}
An intermediary layer then queries the individual APIs (/Customer, /Order, /Product) and exposes the data according to the GraphQL specification:
{"data":{"customer":{"id":"25484d8d45","firstName":"Kelly","lastName":"Goetsch","orders":[{"datePlaced":"2017-06-10T21:33:15.233Z""products":["displayName":"Magformers Construction Set","displayName":"Puzzle Doubles Find It!","displayName":"LEGO Marvel Super Heroes 2"]},{"datePlaced":"2017-08-19T08:07:55.007Z""products":["displayName":"Fast Lane Live Streaming Drone"]},....
The advantages of GraphQL include the following:
-
Each client retrieves exactly the data it needs. This can be especially beneficial in low-bandwidth environments.
-
JSON objects can be retrieved and used as is, without logic on the client side. Everything the client asks for is right there in the response.
-
Your clients can remain independent from how the APIs are defined. There’s no need to build these static intermediary layers.
-
Pairs perfectly with React. GraphQL and React were co-developed and are extensively used together.
APIs are still necessary. But GraphQL is a perfect complement to them.
Final Thoughts
Now that we’ve discussed the mechanics of building an API, let’s explore clients and how they consume APIs.