
Chapter 2. Entity Framework
In This Chapter
Although it is possible to build ASP.NET Dynamic Data applications with plain ADO.NET data access components, some of its features, such as foreign key templates and filtering, require a modern, LINQ-enabled data access framework such as LINQ to SQL or Entity Framework.
LINQ to SQL was introduced in Visual Studio 2008 and .NET Framework 3.5 as a database-specific implementation of LINQ—Language Integrated Query functionality in C# and Visual Basic. LINQ allows developers to use SQL-like queries directly in the application code as opposed to calling stored procedures or passing SQL statements as strings for execution to a database server. LINQ to SQL was quickly followed by the ADO.NET Entity Framework, released with .NET Framework 3.5 Service Pack 1. LINQ to SQL was designed for simplicity and close integration with Microsoft SQL Server; the Entity Framework was designed for maximum flexibility and multiple database platforms.
Although LINQ-based data access code is much simpler than the traditional code based on ADO.NET, it represents a significant paradigm shift compared to the approach .NET and database developers have been trained to use for over a decade. The ways you retrieve and manipulate data and the way you submit changes and implement business logic are very different with LINQ-based data access frameworks, and using some of the old tricks and habits can lead you in the direction where you are fighting the framework instead of letting it help you.
Because the ASP.NET Dynamic Data relies heavily on LINQ, developers need to have a working knowledge of the underlying data access framework to understand how its web controls work and how to customize them effectively. In this chapter, you are given an overview of the ADO.NET Entity Framework from a pure data access prospective, avoiding the specifics related to ASP.NET web applications in general or Dynamic Data in particular. If you are already familiar with Entity Framework or LINQ to SQL, you can probably skip this chapter.
Understanding Entity Model
The ADO.NET Entity Framework is an Object-relational mapping (ORM) framework developed by Microsoft as part of the .NET Framework. It allows developers to define entities, properties, and associations and map them to the underlying database tables and columns. In version 4.0, you typically create the entities and mappings using the Entity Designer in Visual Studio, which generates the application classes that can be used to query the database with LINQ and manipulate database records in a form of .NET objects.
Creating Entity Model
To get started, you first need to add a new Entity Framework data model to your project (in this chapter, we work with a simple Console Application project template). Select the ADO.NET Entity Data Model item from the Data template category in the Add New Item dialog of Visual Studio, as shown in Figure 2.1.
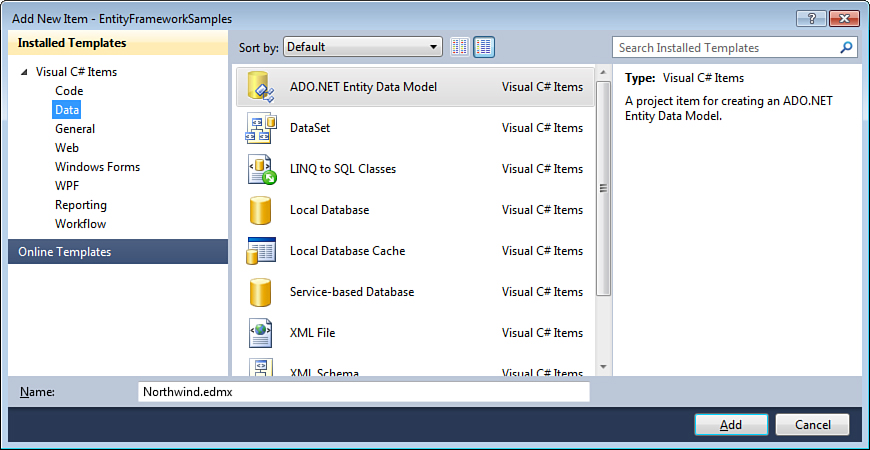
Figure 2.1. Adding ADO.NET Entity Data Model to a project.
After entering the file name and clicking Add, you see the Entity Data Model Wizard shown in Figure 2.2, which prompts you to either generate the model from an existing database or create an empty one. If the database already exists, choose the option to generate the model. You can choose the option to create an empty model if you are lucky enough to be working on a “green field” project for which the database does not yet exist and you want to rely on the Entity Framework to generate the database for you. In this discussion, assume the first scenario and generate the model from the Northwind sample database.
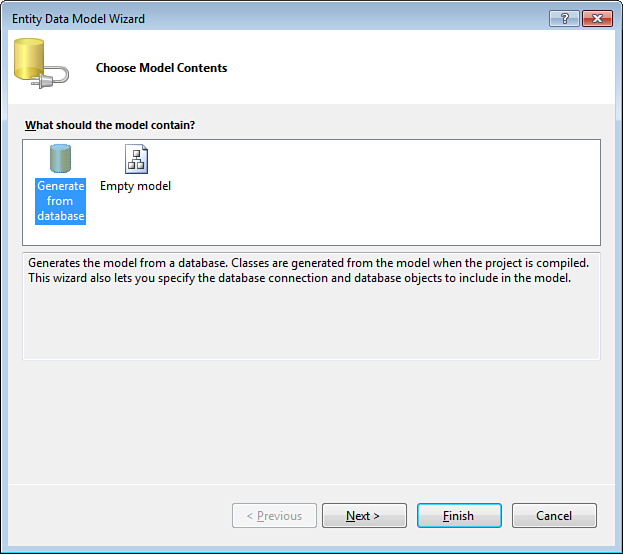
Figure 2.2. Choosing to generate model from database.
After clicking Next on the Choose Model Contents page of the Entity Data Model Wizard, your next step is to choose a connection that will be used to access the database, as shown in Figure 2.3. If you already defined a connection to the Northwind database in Visual Studio’s Server Explorer, you can choose it from the list of available connections. Otherwise, create a new connection that points to your Northwind sample database.
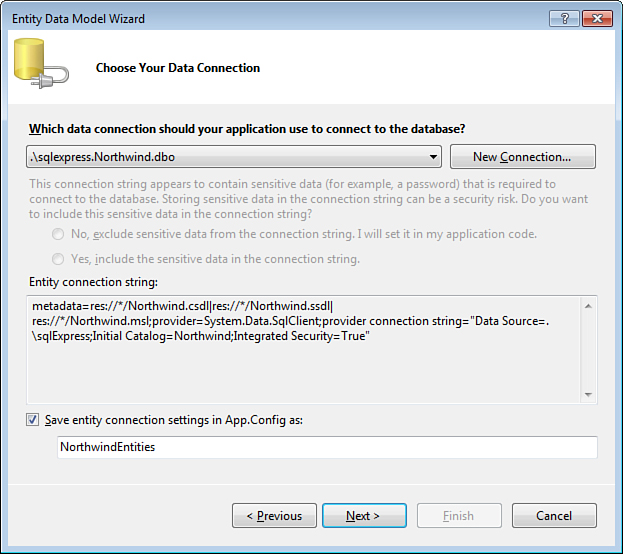
Figure 2.3. Choosing Data Connection.
Notice that the entity connection string includes information about the underlying database provider that will be used to connect to the database. Entity Framework relies on the ADO.NET providers for low-level database connectivity, and you can see the familiar connection information, such as Data Source and Initial Catalog, as part of the “provider connection string.”
Just like with traditional ADO.NET applications, you have the option of storing the Entity Framework connection string in the application configuration file. This is usually a good idea: It avoids specifying the database server name and other connection information explicitly in application code. The Entity Framework does not relieve you from the duty of protecting database credentials. In this example, we are using integrated security and do not need to worry about a username and password in plain text in the configuration file. If you choose to specify database credentials, you need to secure the configuration file appropriately, such as by encrypting the connection string section.
When you have configured the connection and clicked Next on the Choose Your Data Connection page of the Entity Data Model Wizard, you are prompted to select the database objects to include in the model as shown in Figure 2.4. You can choose any number of existing Tables, Views, and Stored Procedures the wizard detects in the database. For now, choose a single table, Products, and click Finish.
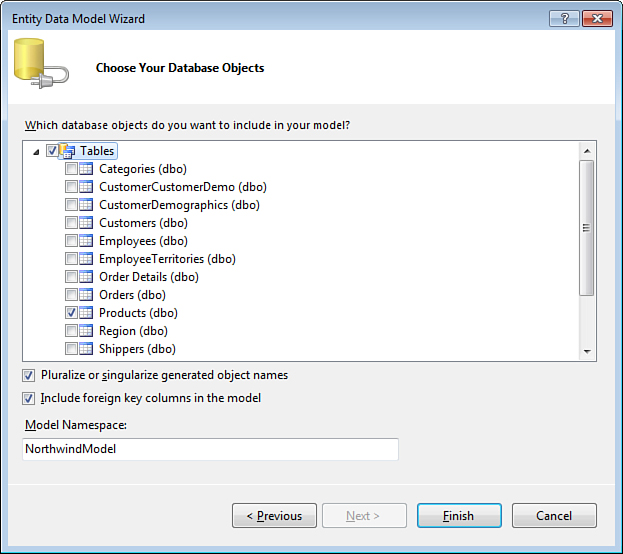
Figure 2.4. Choosing database objects.
Usually you want to accept default values for the remaining options on this page. The option to Pluralize or singularize generated object names instructs the wizard to automatically determine appropriate entity names based on the table names. For databases, such as Northwind, where table names are in plural form (Products), the generated entity name will be singular (Product). This is desirable because in .NET applications, names of classes that represent a single object are usually in singular form, helping to distinguish them from collections that can have multiple items.
The option to Include foreign key columns in the model determines whether columns like SupplierID of the Products table will be available in the application code. This is particularly useful for web applications that have to be stateless and cannot preserve entity objects between requests. The first version of Entity Framework released in .NET 3.5 SP1 did not support this option, and it exists today only for backward compatibility, allowing you to turn it off. Keep this option on unless you are working with a model created using previous versions of the framework.
The Model Namespace setting refers to an internal namespace used by the model itself. It has nothing to do with the namespace of your application classes, and you can safely ignore it, leaving the default value suggested by the tool.
When you click Finish, the Entity Data Model Wizard creates a new EDMX file, adds it to the project, and opens it in an Entity Designer window shown in Figure 2.5.
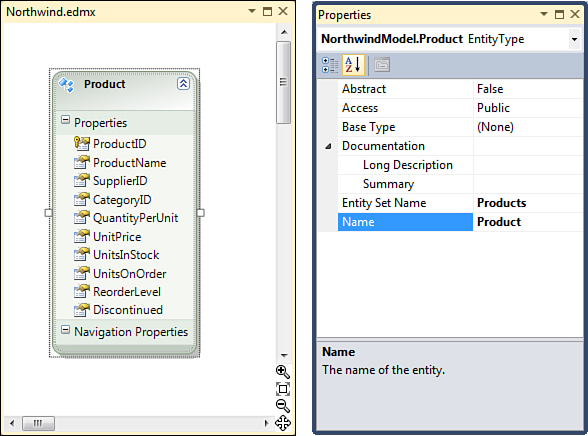
Figure 2.5. Entity Designer and Properties windows.
The diagrams used by the Entity Framework should be familiar to most database developers because they closely resemble database and UML diagrams. The newly created entity, Product, is displayed as a rectangle with a list of scalar properties derived from the columns of the Products table.
The Entity Designer relies on the Properties window of Visual Studio to display and allow you to modify various elements of the model, such as the names of the entity types, their access/visibility, properties, and so on. Explore the new entity model by selecting the entity and its property items in the Entity Designer and observing the information available in the Property Window. Notice that in addition to the names, data types, and other attributes, the Entity Designer also allows you to specify a short Summary and/or a Long Description for every item in the model, making it a reasonably good place to store developer-focused documentation of the data model—even though this information is not available in Dynamic Data applications by default.
The Entity Designer automatically creates a C# file (or Visual Basic file, depending on the type of project you are using) that Solution Explorer hides under the EDMX file. This file contains classes generated from the entity data model, such as the Product entity in this example. After a major cleanup to improve readability, it can be boiled down to the following pseudo-code:
public partial class Product : EntityObject
{
public int ProductID { get; set; }
public string ProductName { get; set; }
public int? SupplierID { get; set; }
public int? CategoryID { get; set; }
public string QuantityPerUnit { get; set; }
public decimal? UnitPrice { get; set; }
public short? UnitsInStock { get; set; }
public short? UnitsOnOrder { get; set; }
public short? ReorderLevel { get; set; }
public bool Discontinued { get; set; }
}
Notice that the Product class closely resembles the Products table it represents. It has properties, such as ProductID and ProductName, with names and types closely matching those of the database columns. However, unlike the Products table, the Product class encapsulates a single row and not the entire table.
ObjectContext and Simple Queries
Another class automatically generated by the Entity Designer is the ObjectContext called NorthwindEntities, shown here in pseudo-code form:
public partial class NorthwindEntities : ObjectContext
{
public ObjectSet<Product> Products { get; }
}
An ObjectContext encapsulates a database connection, allows you to query the database using LINQ (Language Integrated Query), and manipulate data rows using entity classes instead of the general-purpose DataRow objects used with classic ADO.NET. Here is how we can retrieve a list of products for which the number of units in stock dropped below the reorder level:
using (NorthwindEntities context = new NorthwindEntities())
{
var query = from p in context.Products
where p.UnitsInStock < p.ReorderLevel
select p;
foreach (Product p in query)
Console.WriteLine(p.ProductName);
}
The Products property of the NorthwindEntities class encapsulates the Products database table. It returns an ObjectSet of Product instances, which can be used in LINQ queries such as the one in the example just displayed.
Associations
The entity model can also define associations between entities. In the database, relationships are represented as foreign keys, such as the one from the SupplierID column of the Products table referencing the SupplierID column of the Suppliers table. To take advantage of this capability of the Entity Framework, you need to add the Suppliers table to the entity model. The easiest way to do this with an existing database is by using the Update Wizard. Simply right-click the surface of the Entity Designer and choose Update Model from Database.... This brings up an Update Wizard dialog, similar to the one shown in Figure 2.6.
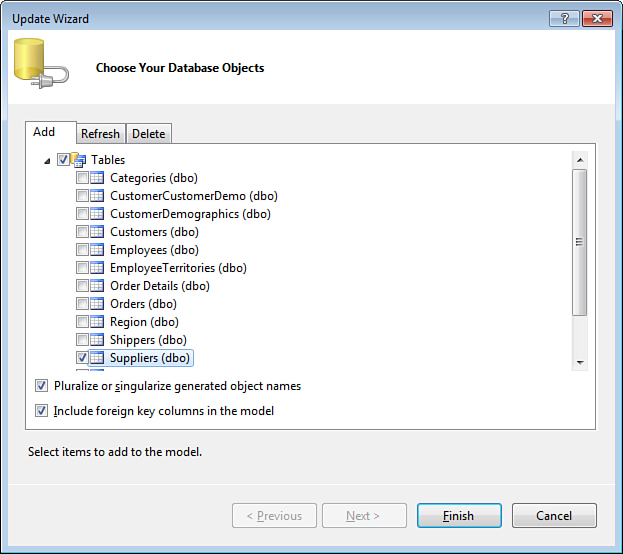
Figure 2.6. Adding database objects to the model.
The Update Wizard is very similar to the Entity Data Model Wizard you used to create the model initially. It uses the connection string stored in the application configuration file to retrieve the list of database tables, views, and stored procedures that exist in the target database but have not been added to the entity model yet. Any tables that were previously included in the model are refreshed automatically, meaning that database schema changes are merged in the model. For this example, add the Suppliers table and click the Finish button.
Note that the Update Wizard uses the pluralization and foreign key column options you selected when creating the model. Avoid changing these options; it results in inconsistently named entity classes and object set properties.
When the Update Wizard finishes updating the model, you see the new entity types, Supplier in this case, displayed in the Entity Designer along with the association (shown as a dotted line) that was created based on the SupplierID foreign key, similar to what is shown in Figure 2.7.
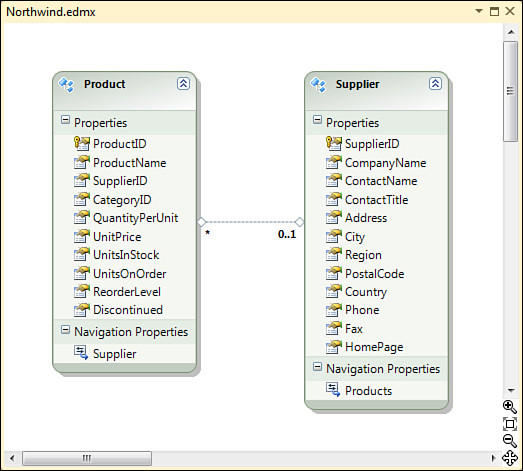
Figure 2.7. Association between entities.
The Entity Framework supports several different types of associations. What we have in this case is a one-to-many association between Supplier and Product entities. In other words, for each Supplier instance there might be zero or more Product instances as indicated by the * symbol on the design surface. The SupplierID property is nullable, so a Product does not have to have a Supplier specified, which is indicated by the 0..1 multiplicity in the model. If the SupplierID column did not allow null values, making a Supplier required for each Product, the multiplicity on the Supplier end of the association would have been 1 instead.
In addition to the associations, the Update Wizard also adds navigation properties to the entities such as the Supplier property in the Product entity. Unlike the underlying scalar property SupplierID, which only stores a key value, the Supplier property returns an instance of the Supplier entity it represents. On the opposite end of this association, the Supplier class has a Products navigation property that returns an EntityCollection of Product instances associated with a particular Supplier. Here is how the generated code looks if you take a look at the NorthwindEntities.Designer.cs:
public partial class Product : EntityObject
{
// ...
public int? SupplierID { get; set; }
public Supplier Supplier { get; set; }
// ...
}
public partial class Supplier : EntityObject
{
public int SupplierID { get; set; }
public EntityCollection<Product> Products { get; set; }
// ...
}
Querying Across Associations
LINQ supports queries that take advantage of associations defined in the model. Here is how you could write a query that returns all Products where the Supplier is located in London:
var query = from p in context.Products
where p.Supplier.City == "London"
select p;
Notice how the Supplier navigation property of the Product entity allows you to filter based on the City property of the Supplier entity. This query could be rewritten to more closely resemble a traditional SQL query, as follows:
var query = from p in context.Products
from s in context.Suppliers
where p.SupplierID == s.SupplierID
&& s.City == "London"
select p;
Although the first version of the query might look strange to someone used to working with SQL statements, it is simply a more elegant and concise way of expressing a join query in LINQ.
Modifying and Saving Entities
To create new and modify existing rows in a database table with the Entity Framework, you need to manipulate the entity instances. In the example that follows, the code retrieves a specific Product instance, updates its UnitsInStock property value, and then submits changes to the database by calling the SaveChanges method of the ObjectContext:
using (NorthwindEntities context = new NorthwindEntities())
{
var query = from p in context.Products
where p.ProductName == "Outback Lager"
select p;
Product outbackLager = query.First();
outbackLager.UnitsInStock += outbackLager.UnitsOnOrder;
context.SaveChanges();
}
The SaveChanges method uses information in the entity model, the primary key definitions in particular, to generate an appropriate UPDATE SQL statement necessary to modify the UnitsInStock field value of the row in the Products table.
To insert a new row into a database table, you need to create a new entity instance and add it to the context as shown next. For newly added entities, the object context automatically generates INSERT SQL statements.
using (NorthwindEntities context = new NorthwindEntities())
{
Product p = new Product() { ProductName = "Mukuzani" };
context.Products.AddObject(p);
context.SaveChanges();
}
LINQ to Entities
Language Integrated Query functionality is not unique to the Entity Framework. It is a general purpose feature of the C# and Visual Basic programming languages that takes advantage of the .NET classes in the System.Linq namespace that define the various query expressions and operations. Entity Framework implements a LINQ flavor, called LINQ to Entities, that allows translating .NET queries into the underlying SQL queries for Microsoft SQL Server and other database engines.
Query Execution
LINQ queries are objects that implement an IQueryable<T> interface and store the query compiled in a form of a LINQ expression:
IQueryable<Product> query = from p in context.Products
where p.Supplier.City == "London"
select p;
Console.WriteLine(query.Expression);
The query is not executed until it is actually accessed by enumeration, as in this example:
foreach (Product p in query)
Console.WriteLine(p.ProductName);
or with one of the LINQ extension methods, such as First.
Product product = query.First();
The query object itself does not store the entities retrieved from the database. This is important mainly for performance reasons—every time you access the query by enumerating entities it returns or call one of the LINQ extension methods, a new SQL query is sent to the database engine. If you need to access the query results multiple times, it would be much faster to store the entities the query returns in a list and access the list, which does not trigger the query execution:
List<Product> products = query.ToList();
foreach (Product p in products)
Console.WriteLine(p.ProductName);
Object Identity
A crucial difference exists between Entity Framework and classic ADO.NET in the way they handle rows retrieved from the database. Where ADO.NET treats the rows as values, Entity Framework treats them as objects, so if a particular table row is returned by two different queries, they return the same .NET object. The following code illustrates this example by retrieving the same Product by ProductName and by ProductID:
Product chai1 = (from p in context.Products
where p.ProductName == "Chai"
select p).First();
Product chai2 = (from p in context.Products
where p.ProductID == 1
select p).First();
if (object.ReferenceEquals(chai1, chai2))
Console.WriteLine("chai1 and chai2 are the same object");
This behavior is different from the classic ADO.NET where you would get two different DataRow objects that held the same field values. To implement this functionality, the ObjectContext keeps track of all objects materialized from the data returned by queries, and if a new query returns data for which an object already exists in the context, that object is used and the newly returned data is discarded. Although this might seem counterintuitive from the database point of view (if the Chai product record changed between two queries, isn’t it logical to see the new values?), this is actually consistent with a behavior you would intuitively expect from a .NET object. Consider the following example:
Product chai = (from p in context.Products
where p.ProductName == "Chai"
select p).First();
chai.UnitsInStock += 50;
List<Product> allProducts = (from p in context.Products
select p).ToList();
Console.WriteLine(chai.UnitsInStock);
Here, the code modifies the number of units in stock for the Chai product object and then executes another query that happens to retrieve it again. Because the code holds a reference to the Chai in a local variable, you would not expect an “unrelated” operation to change its UnitsInStock property; the Entity Framework implements this behavior.
Lazy and Eager Loading
By default in version 4 of Entity Framework, a newly created entity model has the Lazy Loading option enabled. This allows you to traverse the navigation properties and query-related entities without actually writing any queries at all.
var query = from p in context.Products
select p;
foreach (Product p in query)
Console.WriteLine(p.ProductName + " " + p.Supplier.CompanyName);
In the preceding example, there is only one explicit query, which returns all products. However, when enumerating the Product objects it returns, the code also prints out the name of the Supplier for each product. The simple act of referencing the Supplier property of a Product instance causes the related Supplier entity to be loaded from the database by the ObjectContext.
Code that takes advantage of lazy loading is very clean and works great when loading of related entities is infrequent. However, a separate query is sent to the database engine every time the Supplier property is referenced. Even though the individual queries can be small and return little data, in a loop, it might be faster to retrieve all Suppliers along with their Products in a single query. This is called eager loading. Entity Framework allows you to do it by calling the Include method and specifying the name of the navigation property that needs to be eager-loaded.
var query = from p in context.Products.Include("Supplier")
select p;
foreach (Product p in query)
Console.WriteLine(p.ProductName + " " + p.Supplier.CompanyName);
This version of the code only executes a single database query at the beginning of the foreach loop. The query retrieves both Product and their associated Supplier entities from the database. No additional requests are sent to the database when the Supplier’s company name is printed out in the loop.
Projections
When a query returns entities, it needs to retrieve values of all of its properties from the database. It is an equivalent of SELECT * SQL statement. When you are only interested in a particular set of columns, you can significantly reduce the amount of data returned and improve performance with the help of projections, or in common terms, by “selecting” only those columns you are interested in. The following code sample only needs the CompanyName and City values of the Supplier entity, so instead of returning an entire entity, it returns instances of an anonymous type that includes just the required properties.
var query = from s in context.Suppliers
select new { s.CompanyName, s.City };
foreach (var item in query)
Console.WriteLine(item.CompanyName + " " + item.City );
An anonymous type is declared in-place, with property names inferred from the names of the Supplier properties that provide the values. It serves as a Data Transfer Object (DTO) that holds Supplier property values in place of the actual Supplier instances. This particular code could be also rewritten to use an explicitly defined DTO class, like so:
class SupplierProjection
{
public string CompanyName;
public string City;
}
var query = from s in context.Suppliers
select new SupplierProjection
{
CompanyName = s.CompanyName,
City = s.City
};
As you can see, the version based on the anonymous type is much more concise and closely resembles the SQL syntax. However, visibility of anonymous types is limited to the methods where they are defined. You need to declare the projection classes explicitly if you need to pass the DTOs to another function for further processing.
Projection objects are not entity instances. They do not participate in the identity management process of the ObjectContext and cannot be used to change the underlying database records.
Sorting
The orderby LINQ keyword can be used to sort query results. Here is how you could sort the list of Products in the order of UnitPrice, from highest to lowest:
var query = from p in context.Products
orderby p.UnitPrice descending
select p;
By default, orderby acts like its counterpart in SQL: Sorting is performed in ascending order. To reverse the sort order for a property, use the descending LINQ keyword after the property name. LINQ also includes the ascending keyword, but like its counterpart in SQL, is rarely used because it is the default.
Multiple properties can be specified as well, separated by comas. If the descending keyword is used with multiple columns specified in the orderby list, it applies only to the property on its immediate left, such as the UnitsOnOrder in the next example:
var query = from p in context.Products
orderby p.UnitsInStock, p.UnitsOnOrder descending
select p;
Grouping
The group..by LINQ operator can be used to group query results by one or more property values. For example, we could get a list of Products grouped by their Suppliers with the LINQ query shown here:
var query = from p in context.Products
group p by p.SupplierID into g
select new{
Supplier = g.FirstOrDefault().Supplier,
Products = g
};
foreach (var group in query)
{
Console.WriteLine("Supplier: " + group.Supplier.CompanyName);
foreach (var product in group.Products)
Console.WriteLine(" " + product.ProductName);
}
The group by operator returns an object that implements the IGrouping<TKey, TElement> interface, where TKey is the type of the property used for grouping, such as the SupplierID in our example, and TElement is the type of entity whose instances are being grouped, which in our example is the Product entity. An IGrouping<TKey, TElement> object is also an IEnumerable<TElement>, so you can access all elements in a group simply by enumerating it. Although it would be possible to have the query return the IGrouping objects directly, it is common to have it return an anonymous type that makes the results easier to understand. In this example, the code “selects” an anonymous type where Supplier property contains a Supplier instance and the Products property contains all of the Product instances offered by that supplier.
Joins
Although LINQ makes many queries that normally require a join in SQL possible with simple traversal of the entity relationships, it also supports joins where the explicit relationships might not exist in the data model. For example, although we have address information for Customers and Suppliers defined in the Northwind data model, there is no explicit relationship connecting them. To cross-reference customers and suppliers located in the same city, we would need to perform a join, as shown here:
var query = from c in context.Customers
join s in context.Suppliers on c.City equals s.City
select new {
c.City,
Customer = c.CompanyName,
Supplier = s.CompanyName
};
foreach (var item in query)
Console.WriteLine(item.City + " " + item.Customer + " " +
item.Supplier);
The example just displayed uses the join keyword, which mimics the JOIN operator introduced by the SQL-92 standard. You can also use syntax that resembles the “old-style” joins as well:
var query = from c in context.Customers
from s in context.Suppliers
where c.City == s.City
select new {
c.City,
Customer = c.CompanyName,
Supplier = s.CompanyName
};
Composing Queries
An additional benefit of having LINQ queries compiled in LINQ expressions is that they can be further modified before execution. This is often beneficial when constructing a query based on options specified by the user.
string city = "London";
bool sortByContactName = true;
var query = from c in context.Customers select c;
if (city != null)
query = from c in query where c.City == city select c;
if (sortByContactName)
query = from c in query orderby c.ContactName select c;
else
query = from c in query orderby c.CompanyName select c;
foreach(Customer c in query)
Console.WriteLine(c.CompanyName + " " + c.ContactName);
In this example, the query returns Customer objects dynamically, based on the values of two variables. The values are hard-coded here for simplicity, but in a real application they would be entered by a user.
LINQ allows any IQueryable to appear in the from part of another query, and this code takes advantage of this to augment the original query with additional operators. Notice that the original query simply returns all customers. If the city parameter is specified, the code adds a where clause to filter customers based on the specified value and replaces the original query. You can also sort the query results based on the value of the sortByContactName variable—by ContactName if it is true or by CompanyName if it is false.
Because of the delayed execution, the final query is sent to the database only once, when the foreach statement enumerates it after all of the query modifications have been made. Composing LINQ queries in this fashion allows you to create the most specific query required for your scenario and helps to ensure its correctness, thanks to the thorough validation performed by the C# compiler.
It is also possible to create LINQ queries dynamically, from strings that contain property names and operators. Chapter 5, “Filter Templates,” provides a detailed discussion on this topic.
SQL Translation
The Entity Framework translates LINQ queries into actual SQL statements based on the information in the data model and sends them for execution to the database server. Because LINQ query syntax is significantly different from SQL syntax, you might find it helpful to see the actual SQL statements your Entity Framework application executes.
The easiest and least obtrusive way to do this with Microsoft SQL Server is by using the SQL Server Profiler, which is as part of the Management Tools—Complete feature you can select during SQL client installation. Alternatively, you can change your application code to do it as well.
var query = from c in context.Customers
where c.City == "London"
orderby c.CompanyName
select c;
ObjectQuery objectQuery = (ObjectQuery)query;
Console.WriteLine(objectQuery.ToTraceString());
The IQueryable objects produced by the C# compiler when compiling LINQ to Entities queries are actually of the type ObjectQuery. This class is provided by the Entity Framework and offers a ToTraceString method that can be used to get the actual SQL statement to which the LINQ query will be translated. The LINQ query in the example just shown is translated into the SQL statement shown next. Although slightly more verbose than a typical hand-written SQL would be, it is recognizable and easy enough to read:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'London' = [Extent1].[City]
ORDER BY [Extent1].[CompanyName] ASC
Notice that the literal 'London' is embedded in this SQL statement only because it was hard-coded in the original LINQ query. If the value comes from a method parameter or a variable, which is normally the case when executing queries in response to user input, the Entity Framework generates parameterized SQL statements.
string city = "London";
var query = from c in context.Customers
where c.City == city
select c;
The modified LINQ query just shown translates into the following SQL statement where the city is no longer embedded in the query itself and instead passed as a parameter:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE [Extent1].[City] = @p__linq__0
Generation of the parameterized SQL is important for two reasons. On one hand, it improves application performance as database servers can reuse the same execution plan with different parameter values. If the parameter values were embedded in the SQL text, each parameter value would make a unique new query for which the server would have to recalculate and cache the execution plan, consuming additional CPU and RAM resources. On the other hand, parameterized SQL statements are immune to SQL injection attacks, very common in applications that generate dynamic SQL statements as strings. Here is an example that illustrates the problem:
string city = "'; drop database Northwind; select '";
string sql = string.Format(
"select * from Customers where City = '{0}'", city);
Console.WriteLine(sql);
Imagine that in the code snippet just shown the value of the city variable is supplied by the user and the application uses it to create a query that returns only the customers in the specified city. With this naïve implementation, a malicious user could enter a specially constructed string that modifies the original SQL statement the developer intended to execute and injects one or more unexpected SQL statements, allowing him to destroy data or get access to restricted information. Following is the SQL statement this code generates. Notice that instead of an innocent SELECT statement, we have a DROP DATABASE injected in an otherwise valid SQL batch:
select * from Customers where City = '';
drop database Northwind;
select ''
However, in the SQL statement generated by the Entity Framework, the city value is passed to the database server as a parameter, making it impossible to modify the original SQL statement and inject a malicious payload. Even if the value was hard-coded in the application like in the first example in this section, the automatic encoding of literal values performed by the Entity Framework would still prevent the injection.
Compiled Queries
It takes a certain amount of CPU and time resources for Entity Framework to translate the LINQ queries into their equivalent SQL statements before they can be executed. When a particular query is executed repeatedly, you can improve application performance by precompiling it, as shown in the following example:
static Func<NorthwindEntities, string, IQueryable<Customer>>
customersByCity =
CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Customer>>(
(context, city) =>
from c in context.Customers
where c.City == city
select c
);
In this code snippet, a familiar LINQ query is compiled with the help of the Compile method of the CompiledQuery class and stored in a static field called customersByCity. The compiled query itself is a lambda expression, which takes an object context as its first parameter, a city as its second, and returns an IQueryable of Customer. Typically, a compiled query like this is stored in a static field of a class that performs the data access and can benefit from compiled queries.
The data access code based on compiled queries is similar to the traditional LINQ queries in that it still needs to create an ObjectContext, like NorthwindEntities in this ongoing example. However, instead of using LINQ queries directly, it calls the Invoke method of one or more of the compiled query objects as shown here:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = customersByCity.Invoke(context, "London");
foreach (Customer c in customers)
Console.WriteLine(c.ContactName);
}
The work required to translate the compiled LINQ query into SQL statement is performed the first time the compiled query is executed. So the program will still take the performance hit the first time the compiled query is executed in an AppDomain; however, all subsequent executions of the compiled query will take advantage of the information cached by the Entity Framework the first time and run faster.
Query composition defeats the caching logic the Entity Framework uses and negates the benefits of query compilation. To keep the benefits of query compilation, you need to compile the entire query and avoid modifying it in any way. As an example, consider the code that follows, which adds an orderby clause to the same compiled query used in the previous sample:
var customers = customersByCity.Invoke(context, "London");
customers = from c in customers
orderby c.ContactName
select c;
foreach (Customer c in customers)
Console.WriteLine(c.ContactName);
The actual LINQ query executed in this sample is different from the compiled query and cannot take advantage of the Entity Framework caching logic.
To avoid doing this by accident, you can change the compiled query to return an IEnumerable instead of an IQueryable.
static Func<NorthwindEntities, string, IEnumerable<Customer>>
customersByCity =
CompiledQuery.Compile<NorthwindEntities, string, IEnumerable<Customer>>(
(context, city) =>
from c in context.Customers
where c.City == city
select c
);
Having a compiled query return an IEnumerable forces any composition done with a compiled query to be done in the application memory after the original query has already been executed instead of modifying the original compiled query before sending it to the database server. If the amount of data returned by the query is small, this approach can yield better performance. On the other hand, if the query returns a large volume of data and requires a lot of post-processing, it might be faster to take a hit on query preparation but let the database server do the heavy lifting instead. You need to measure actual performance to make a good implementation choice.
Extension Methods
C# and Visual Basic syntax covers only a subset of the query operators supported by the Entity Framework. To take full advantage of its querying capabilities, you might need to use one or more of the LINQ extension methods defined in the static class Queryable from the System.Linq namespace. Here is a typical LINQ query, which should look familiar by now:
var customers = from c in context.Customers
where c.City == "London"
select c;
.NET CLR has no special IL instructions for LINQ keywords. Instead, the compiler converts the LINQ syntax into lambda expressions and calls to LINQ extension methods. Here is how this code can be rewritten using extension methods explicitly:
var customers = context.Customers
.Where(c => c.City == "London")
.Select(c => c);
Notice how instead of the where keyword, it’s the Where extension method. c => c.City == "London" is a lambda expression that takes c, an instance of the Customer class, as a parameter and returns a Boolean value that indicates whether a particular customer matches the filter criteria. Where is an extension method defined in the Queryable class for the IQueryable interface. In other words, Queryable.Where takes an IQueryable interface as its first parameter and, in essence, extends the IQueryable interface by adding a Where method to it, hence the term “extension method.”
public static IQueryable<TSource> Where<TSource>(
this IQueryable<TSource> source,
Expression<Func<TSource, bool>> predicate)
You can think of lambda expressions as a kind of shorthand version of anonymous delegates—a compact way of declaring small functions. However, when used with IQueryable, lambda expressions are not compiled directly into IL instructions. Instead, they are parsed into Expression objects and passed to the Entity Framework, which translates them to SQL statements and sends them to database engine for execution.
Where is only one of the many LINQ extension methods available for use with Entity Framework. This list includes methods like Average, Min, Max, Sum, and Count, which have similar names and work like the aggregate functions in SQL. Other methods, such as Any and Contains, also have direct counterparts in SQL with very different names. Any is LINQ’s equivalent of the EXISTS operator, and Contains is an equivalent of the IN operator in SQL. Yet some methods have no direct counterparts in SQL at all, such as the All method, which returns true if all elements of a sequence match the specified criteria.
Table 2.1 provides a summary of the LINQ extension methods. Take a minute to review the list to get an idea of what is available. However, a complete discussion of LINQ operators and extension methods deserves much more time and pages than can be allotted here.
Table 2.1. LINQ Extension Methods



A wealth of reference information about LINQ is available on MSDN. The following page is a great starting point when you are looking for a quick example of a particular extension method or operator:
http://msdn.microsoft.com/en-us/vcsharp/aa336746.aspx
The following provides a complete reference of all LINQ extension methods available, giving you a comprehensive, but more difficult-to-navigate, list:
http://msdn.microsoft.com/en-us/library/system.linq.queryable.aspx
Entity Lifecycle
As you already know, in addition to its formidable querying capabilities, the Entity Framework also helps you implement typical data access scenarios, such as creating a new entity, finding an existing entity, and modifying or deleting it. To do this, the ObjectContext keeps track of all entities throughout their lifecycles—from creation to modification to deletion.
Tracking Changes
When a new entity instance is added to an ObjectContext, the context records its state as Added. The following code shows how to examine entity state changes:
Product p = new Product() { ProductName = "Mukuzani" };
context.Products.AddObject(p);
Console.WriteLine(context.ObjectStateManager.GetObjectStateEntry(p).State);
context.SaveChanges();
Console.WriteLine(context.ObjectStateManager.GetObjectStateEntry(p).State);
The ObjectStateManager property of the ObjectContext class returns the actual object, keeping track of all new entities that have been added to the context or existing entities retrieved from the database. In this code, we use its GetObjectStateEntry method to retrieve an ObjectStateEntry object that represents the newly added Product entity:
[Flags]
public enum EntityState
{
Detached = 1,
Unchanged = 2,
Added = 4,
Deleted = 8,
Modified = 16
}
The State property of the ObjectStateEntry returns an EntityState enumeration value, which for newly created objects has the value Added until we call the SaveChanges method of the ObjectContext, at which point the new entity is submitted to the database and the entity state becomes Unchanged.
In the next example, when an existing Product entity is retrieved from the database, its state is initially Unchanged. Then, as soon as the Category property is assigned, it becomes Modified. After the SaveChanges method is called and the changes are submitted to the database, the entity state becomes Unchanged again:
Product product = context.Products.First(p => p.ProductName=="Mukuzani");
product.Category = context.Categories.First(c => c.CategoryName==
"Beverages");
context.SaveChanges();
In the next scenario, an existing Product entity is deleted, and its state changes from Unchanged to Deleted as soon as the DeleteObject method of the Products entity set is called. At this point, the entity has been marked for deletion but not deleted yet in the database. When the SaveChanges method of the context is called, the row storing the entity is “physically” deleted from the Products table. The deleted Product entity is also removed from the ObjectContext, and trying to get its ObjectStateEntry will result in an InvalidOperationException:
Product product = context.Products.First(p => p.ProductName == "Mukuzani");
context.Products.DeleteObject(product);
context.SaveChanges();
Optimistic Concurrency Control
Most enterprise database applications require access by multiple simultaneous users. When many people have access to the same data records, there is always a chance of two people trying to modify the same record.
The following code illustrates this scenario by creating two different instances of the NorthwindEntities context, retrieving two different copies of the same Product entity, making different changes to it and trying to save the changes. Obviously, you wouldn’t write code like this in a real-world application—context1 and context2 simply illustrate the actions performed by two different users running your application on two different computers:
using (NorthwindEntities context1 = new NorthwindEntities())
using (NorthwindEntities context2 = new NorthwindEntities())
{
Product product1 = context1.Products.First(p => p.ProductName == "Chai");
Product product2 = context2.Products.First(p => p.ProductName == "Chai");
product1.UnitsInStock = 50;
product2.UnitsInStock = 20;
context1.SaveChanges();
context2.SaveChanges();
}
When you run this code, you might notice that the second user (represented by context2) submits the changes last and the changes made by the first user are lost.
To prevent data loss, database applications have traditionally relied on record locking. When a user starts editing a particular record, the application would lock it, preventing others from modifying it at the same time. This approach works better when the number of users is small and the number of records is large, thus reducing the chance of contention. However, physical locking can prevent other users not only from changing but also from reading the locked records. This can lead to significant performance degradation and is generally considered a bad practice.
The Entity Framework has built-in support for an alternative strategy, called Optimistic Concurrency Control. When saving modified entities, the ObjectContext generates UPDATE statements with a WHERE clause that ensures that changes are made only if the entity has not changed since the last time it was retrieved from the database. In other words, the framework assumes that chances of contention are low and, optimistically, allows you to modify the entity without locking the record. If somebody else modified the same record in the meantime, you simply get an exception when calling the SaveChanges method.
To take advantage of the optimistic concurrency support, first you need to modify the definitions of the properties in the Entity Designer to set their Concurrency Mode values to Fixed, as shown in Figure 2.8. You need to do this for all properties you want the Entity Framework to check for modifications before saving the entity.
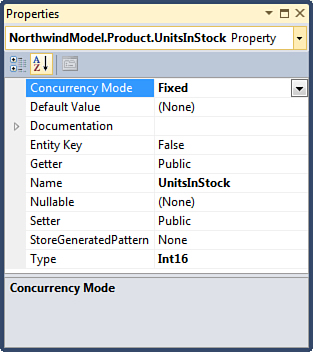
Figure 2.8. Setting Property Concurrency Mode.
When the model has been modified, calling the SaveChanges for context1 in the previous code example generates the following SQL statement:
exec sp_executesql N'update [dbo].[Products]
set [UnitsInStock] = @0
where (([ProductID] = @1) and ([UnitsInStock] = @2))
',N'@0 smallint,@1 int,@2 smallint',@0=50,@1=1,@2=20
It is a dynamic, parameterized update statement that sets the UnitsInStock column to its new value, 50 (specified as the @0 parameter), but only if its current value (specified as the @2 parameter) is still the same as the original value 20 saved when the Product entity was retrieved from the database. If the current value of the UnitsInStock column does not match the original value, no records are updated, and the SaveChanges method of the ObjectContext class throws the OptimisticConcurrencyException.
If you are using Microsoft SQL Server, you can take advantage of the ROWVERSION (formerly known as TIMESTAMP) column type, designed specifically for optimistic concurrency control. When any changes are made to a row, the server automatically updates its ROWVERSION column value. If your entity has a property mapped to a ROWVERSION column, it is the only one whose Concurrency Mode needs to be set to Fixed. Otherwise, you will want to set it for all entity properties and avoid partial data loss.
What does your application need to do when it encounters an OptimisticConcurrencyException? Usually you simply want to let the current user know that somebody else has already changed the record he is trying to modify, let him take note of the changes he was trying to make, and refresh the record to see the other users’ modifications. The following code illustrates this scenario from the pure data access point of view:
Product product = context.Products.First(p => p.ProductName == "Chai");
product.UnitsInStock = 50;
try
{
context.SaveChanges();
}
catch (OptimisticConcurrencyException e)
{
context.Refresh(RefreshMode.StoreWins,
e.StateEntries.Select(s => s.Entity));
}
Notice how after catching an OptimisticConcurrencyException, the code calls the Refresh method of the ObjectContext. This method takes a RefreshMode enumeration, which determines whose changes will be preserved and an IEnumerable of entity objects that need to be refreshed. The RefreshMode.StoreWins value means that changes made by the other users will be preserved. You can also pass the ClientWins value, which would ignore changes of other users and keep the modifications made by the current user. The exception object itself provides a list of entities that failed to save—it is retrieved with the help of the StateEntries property, which returns a collection of the familiar ObjectStateEntry objects, providing access to their entities.
In a web application, however, it is often sufficient to handle the optimistic concurrency errors by simply displaying them to the user and asking him to either refresh the current or go back to the previous page, which automatically discards the changes he made and reloads the latest version of the entity from the database.
Transactions
Transactions help applications to make sure that any changes leave the database in a consistent state. If multiple changes are made as part of a single transaction, the database server ensures that either all of them complete successfully or any incomplete changes are rolled back to the state before the transaction began. By default, database servers, and Microsoft SQL Server in particular, execute each SQL statement in a separate transaction. Although this behavior is sufficient to ensure that any single request leaves the database in a consistent state, when multiple records need to be modified, a transaction that spans multiple requests is required.
As an example, let’s consider a scenario of adding a new product to the Northwind database. Perhaps this is done by an automated inventory import process, reading data from a spreadsheet or a flat file. The file contains a list of products along with their categories, and the process needs to link each new product to an existing category or create a new category if it doesn’t already exist. Here is how to implement it using Entity Framework (the actual values are hard-coded here as an illustration, of course):
Category wines = context.Categories.First(c => c.CategoryName == "Wines");
if (wines == null)
{
wines = new Category() { CategoryName = "Wines" };
context.Categories.AddObject(wines);
}
Product p = new Product() { ProductName = "Mukuzani", Category = wines };
context.Products.AddObject(p);
context.SaveChanges();
Notice that it is possible for this code to create two entities, one for a new Product and one for a new Category. Both of these entities are submitted to the database when the SaveChanges method of the ObjectContext is called. However, if for any reason a new Product cannot be saved (perhaps there is already another product with this name in our database), you don’t want to have an orphaned Category without any Products in it. To implement this requirement, you can submit both the new Category and the new Product as part of a single transaction so that if the new Product cannot be inserted, the new Category is removed as well.
using (TransactionScope transaction = new TransactionScope())
using (NorthwindEntities context = new NorthwindEntities())
{
Category wines = context.Categories
.FirstOrDefault(c => c.CategoryName == "Wines");
if (wines == null)
{
wines = new Category() { CategoryName = "Wines" };
context.Categories.AddObject(wines);
}
Product p = new Product() { ProductName = "Mukuzani", Category = wines };
context.Products.AddObject(p);
context.SaveChanges();
transaction.Complete();
}
In this new version of the code, the TransactionScope class from the System.Transactions assembly and namespace is being used. By creating a new instance of this class, you start a database transaction (think of it as of the BEGIN TRANSACTION statement in SQL for now) and by calling the Complete method, you are committing it (COMMIT TRANSACTION). The TransactionScope class implements the IDisposable interface so that when a transaction scope instance is disposed and the Complete method has not been called, the transaction is automatically rolled back. By placing the TransactionScope instance inside of the using statement you guarantee that if any exceptions are thrown while you are manipulating the Category and Product instances and the Complete method doesn’t get called, the entire transaction will be rolled back (ROLLBACK TRANSACTION) before control leaves this code.
TransactionScope instances can be hierarchical. If your method creates a transaction scope and calls another method that creates its own, by default this second transaction scope becomes a part of the first one, and any changes performed within it are executed as part of the same database transaction. TransactionScope also supports distributed transactions that span multiple databases or servers. Simply place all relevant code inside of a single TransactionScope, and it will automatically escalate the transaction from a single server to the Microsoft Distributed Transaction Coordinator (DTC) to perform a two-phase commit.
Read-Only ObjectContext
Preserving object identity and keeping track of changes are great features when you are writing code that needs to not only retrieve data from the database, but also make changes. However, it requires the ObjectContext to check every database row against the internal dictionary of previously materialized objects and store both original and current values of all entity properties. This comes at the cost of additional CPU resources required to perform the lookup and increased memory consumption to store the additional property values. The tradeoff is usually well justified in a typical rich-client application that retrieves and manipulates a relatively small number of entities at a time. However, web applications and applications working with large numbers of entities in batch mode can increase performance by disabling the change tracking and identity management as shown here:
context.Products.MergeOption = MergeOption.NoTracking;
var chaiQuery = from p in context.Products
where p.ProductName == "Chai"
select p;
The MergeOption property is defined in the ObjectQuery<T> base class and thus can be specified for the Products ObjectSet. It affects all entities returned by the query, which in this case includes only Product entities. The NoTracking value instructs the ObjectContext to bypass the identity and property value tracking for the query results, which can be illustrated by running the following code:
Product chai1 = chaiQuery.First();
Product chai2 = chaiQuery.First();
if (!object.ReferenceEquals(chai1, chai2))
Console.WriteLine("chai1 and chai2 are different objects");
When running this code, notice that chai1 and chai2, initialized by two different executions of the same query, are actually two different objects. Had you not modified the MergeOption for this query, the object context would have detected that the Chai entity had already been retrieved and returned the same entity for both query executions.
Entity Model in Depth
The Entity Model consists of three different sections, each describing a separate aspect of the model. This is best illustrated by opening a newly created EDMX file in a text editor. When stripped of actual content, it looks similar to this:
<?xml version="1.0" encoding="utf-8"?>
<Edmx Version="2.0" xmlns="http://schemas.microsoft.com/ado/2008/10/edmx">
<Runtime>
<StorageModels/>
<ConceptualModels/>
<Mappings/>
</Runtime>
</Edmx>
The EDMX files contain plain XML and work well with most modern source control systems. However, unless you are working on a trivial project with just a handful of tables and only one developer, eventually you will need to look at the EDMX in its raw XML form instead of relying on the Entity Designer. If you have multiple developers on your team, at some point you will need to merge the changes made by different developers at the same time, and even if you are the only developer working with the EDMX, it is always a good idea to review changes made by the Update Wizard in a large model before checking them in. For these reasons, it is important for developers to be familiar with the entity model XML schema, which is why some of its concepts are introduced here.
The storage model describes the database schema as it was captured by the Entity Designer last time when the Update Wizard was used to update model from the database. It includes definitions of tables and their foreign key relationships, as well as views and stored procedures. You can examine the storage model with the help of the Model Browser, a tool window you can open by right-clicking the surface of the Entity Designer and selecting Model Browser from the context menu. Figure 2.9 shows an example of the storage model definition of the Products table.
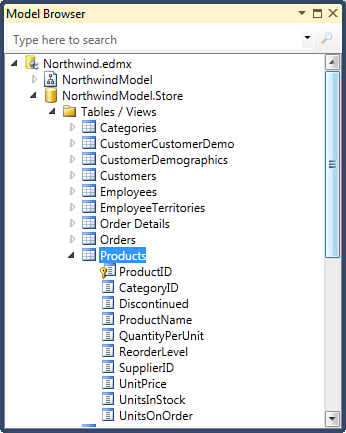
Figure 2.9. Storage model.
The raw XML definition of the Products table looks similar to what’s shown next. The Property elements define the individual columns, and Key element includes PropertyRef elements for all columns in the primary key:
<EntityType Name="Products">
<Key>
<PropertyRef Name="ProductID" />
</Key>
<Property Name="ProductID" Type="int" Nullable="false"
StoreGeneratedPattern="Identity" />
<Property Name="ProductName" Type="nvarchar" Nullable="false"
MaxLength="40" />
<Property Name="SupplierID" Type="int" />
<Property Name="CategoryID" Type="int" />
<Property Name="QuantityPerUnit" Type="nvarchar" MaxLength="20" />
<Property Name="UnitPrice" Type="money" />
<Property Name="UnitsInStock" Type="smallint" />
<Property Name="UnitsOnOrder" Type="smallint" />
<Property Name="ReorderLevel" Type="smallint" />
<Property Name="Discontinued" Type="bit" Nullable="false" />
</EntityType>
The conceptual model describes the entities from the application standpoint. You can also examine the conceptual model using the Model Browser. It displays the conceptual model at the top of the tree view (Figure 2.10 shows an example of the conceptual model generated from the Northwind sample database). However, the Entity Designer, which presents the conceptual model in a UML-like diagram, might be a better option for working with the conceptual model, especially when the number of entities is not large.

Figure 2.10. Conceptual model.
Usually the entities in the conceptual model are closely related to the tables and views in the storage model. However, entity types are higher-level constructs and do not necessarily match the database tables they represent. In particular, the Product entity has a singular name, but the Products table name is plural. It also has navigation properties that allow you to traverse entity relationships without having to immediately resort to joins in LINQ queries.
Following is the raw XML definition of the Product entity. Notice that the XML element names, EntityType, Key, and Property, are similar to those used in the storage model definition. The NavigationProperty element, on the other hand, is used only in the conceptual model:
<EntityType Name="Product">
<Key>
<PropertyRef Name="ProductID" />
</Key>
<Property Name="ProductID" Type="Int32" Nullable="false"
annotation:StoreGeneratedPattern="Identity" />
<Property Name="ProductName" Type="String" Nullable="false"
MaxLength="40" Unicode="true" FixedLength="false" />
<Property Name="SupplierID" Type="Int32" />
<Property Name="CategoryID" Type="Int32" />
<Property Name="QuantityPerUnit" Type="String" MaxLength="20"
Unicode="true" FixedLength="false" />
<Property Name="UnitPrice" Type="Decimal" Precision="19" Scale="4" />
<Property Name="UnitsInStock" Type="Int16" />
<Property Name="UnitsOnOrder" Type="Int16" />
<Property Name="ReorderLevel" Type="Int16" />
<Property Name="Discontinued" Type="Boolean" Nullable="false" />
<NavigationProperty Name="Supplier" FromRole="Product" ToRole="Supplier"
Relationship="NorthwindModel.FK_Products_Suppliers" />
<NavigationProperty Name="Category" FromRole="Product" ToRole="Category"
Relationship="NorthwindModel.FK_Products_Categories" />
<NavigationProperty Name="Order_Details"
FromRole="Product" ToRole="Order_Detail"
Relationship="NorthwindModel.FK_Order_Details_Products" />
</EntityType>
Some database tables, such as the EmployeeTerritories in the Northwind sample database, might not have corresponding entity types at all. The many-to-many association between the Employees and the Territories tables requires a third table, sometimes called a “junction table,” to implement in a relational database system. However, in the conceptual entity model, the many-to-many association between the Employee and Territory entities can be supported directly by their Territories and Employees navigation properties.
The mapping model connects the storage and conceptual models and allows for some degree of differences between them. The Mapping Details tool window shows the mapping information for the entity, currently selected in the Entity Designer or the Model Browser window. Figure 2.11 shows an example of the mapping for the Product entity.

Figure 2.11. Mapping model.
The Mapping Details window shows the database table to which the currently selected entity type is mapped, followed by a list of column mappings, with database columns listed on the left side and the entity properties shown on the right. In this example, the entire entity model is reverse-engineered from an existing Northwind sample database, so the storage and conceptual models are nearly identical, making the mapping very straightforward. However, if you want to customize the conceptual model, you can configure the entity mapping manually.
The underlying XML representation of the mapping model fairly closely matches what the Mapping Details window displays. Following is the mapping of the Product entity type to the Products table of the Northwind database:
<EntityTypeMapping TypeName="NorthwindModel.Product">
<MappingFragment StoreEntitySet="Products">
<ScalarProperty Name="ProductID" ColumnName="ProductID" />
<ScalarProperty Name="ProductName" ColumnName="ProductName" />
<ScalarProperty Name="SupplierID" ColumnName="SupplierID" />
<ScalarProperty Name="CategoryID" ColumnName="CategoryID" />
<ScalarProperty Name="QuantityPerUnit" ColumnName="QuantityPerUnit" />
<ScalarProperty Name="UnitPrice" ColumnName="UnitPrice" />
<ScalarProperty Name="UnitsInStock" ColumnName="UnitsInStock" />
<ScalarProperty Name="UnitsOnOrder" ColumnName="UnitsOnOrder" />
<ScalarProperty Name="ReorderLevel" ColumnName="ReorderLevel" />
<ScalarProperty Name="Discontinued" ColumnName="Discontinued" />
</MappingFragment>
</EntityTypeMapping>
Mapping Entity Type to Multiple Tables
A fairly common problem in database applications is the mismatch between the shape of database tables and entity types. For example, a common database optimization technique is to separate frequently accessed columns from rarely accessed ones by placing them in two separate tables. The idea is to reduce the amount of data that has to be read from disk during table or index scan operations. This scenario can be illustrated by splitting the Customers table from the Northwind database in two—Customer and CustomerAddress:
create table split.Customer(
CustomerID nchar(5) not null primary key,
CompanyName nvarchar(40),
ContactName nvarchar(30) not null,
ContactTitle nvarchar(30)
);
create table split.CustomerAddress(
CustomerID nchar(5) not null primary key,
Address nvarchar(60),
City nvarchar(15),
Region nvarchar(15),
PostalCode nvarchar(10),
Country nvarchar(15),
Phone nvarchar(24),
Fax nvarchar(24)
);
Even though the Customer information is now split in two tables, definition of the Customer entity in the conceptual model does not have to change—it continues to have both contact and address properties. You can map it to two tables instead of one; Figure 2.12 shows how this looks in the Mapping Details window of the Entity Designer. When the entity mapping has been modified, you can continue working with it in the application code as if it were still mapped to a single table:
var query = from c in context.Customers
select c;
foreach (Customer c in query)
Console.WriteLine(c.ContactName + " " + c.Address);
Under the hood, the Entity Framework automatically generates the SQL join queries required to retrieve the customer information from what is now two tables, allowing you to keep a holistic view of the Customer entity in the application code.
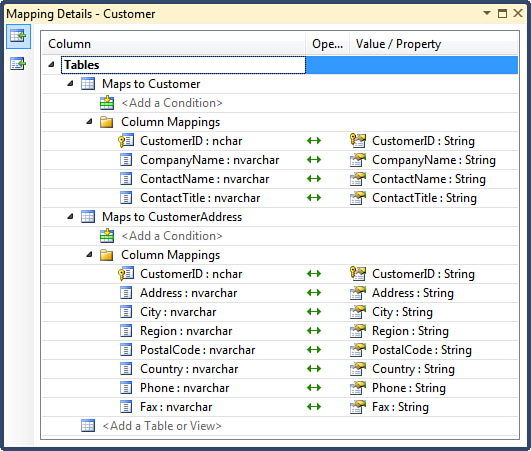
Figure 2.12. Entity type mapped to two separate tables.
Entity Type Inheritance
You can also use class inheritance to model your entities. For example, suppose you need a conceptual model that supports distinguishing visitors of your website from the actual customers who have already placed one or more orders. In this model, User entity type describes all users of an application. Another entity type, Customer, inherits from it and represents customers, a specialized type of users. Figure 2.13 shows how this model looks in the entity designer.
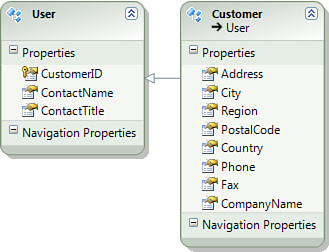
Figure 2.13. Entity type inheritance.
This conceptual model can be mapped to the same two tables created earlier, Customer and CustomerAddress. The User entity type is mapped to the Customer table, and the Customer entity type is mapped to the CustomerAddress table. Here is the mapping definition in raw XML form:
<EntitySetMapping Name="Users">
<EntityTypeMapping TypeName="IsTypeOf(NorthwindModel2.User)">
<MappingFragment StoreEntitySet="Customer">
<ScalarProperty Name="ContactTitle" ColumnName="ContactTitle" />
<ScalarProperty Name="ContactName" ColumnName="ContactName" />
<ScalarProperty Name="CustomerID" ColumnName="CustomerID" />
</MappingFragment>
</EntityTypeMapping>
<EntityTypeMapping TypeName="IsTypeOf(NorthwindModel2.Customer)">
<MappingFragment StoreEntitySet="CustomerAddress">
<ScalarProperty Name="Fax" ColumnName="Fax" />
<ScalarProperty Name="Phone" ColumnName="Phone" />
<ScalarProperty Name="Country" ColumnName="Country" />
<ScalarProperty Name="PostalCode" ColumnName="PostalCode" />
<ScalarProperty Name="Region" ColumnName="Region" />
<ScalarProperty Name="City" ColumnName="City" />
<ScalarProperty Name="Address" ColumnName="Address" />
<ScalarProperty Name="CustomerID" ColumnName="CustomerID" />
</MappingFragment>
</EntityTypeMapping>
</EntitySetMapping>
With these conceptual and mapping model definitions, you can easily query all users (this returns both User and Customer entity objects):
var query = from u in context.Users
select u;
On the other hand, if we are interested only in Customers, we can use the OfType extension method, which returns only the entities of a given type:
var query = from c in context.Users.OfType<Customer>()
select c;
Inheritance Mapping
Three different approaches to mapping inheritance hierarchies to database tables exist—table-per-type, table-per-concrete-type, and table-per-hierarchy.
With the table-per-type approach, used in the previous example, each entity type in the conceptual model is mapped to a separate database table. To retrieve a derived entity such as Customer, the Entity Framework performs a SQL join of all tables storing properties of parent entity types.
With the table-per-concrete-type approach, each nonabstract type in the inheritance hierarchy gets its own table with a full set of columns necessary to store properties of the entity type itself and all of its parent types. This allows the Entity Framework to query only one table to retrieve entity of any given type. However, if you query instances of a base type, such as User in the previous example, the Entity Framework has to perform a SQL union of all tables to which the derived entity types are mapped.
With the table-per-hierarchy approach, all entity types derived from a common base are stored in a single table, with one or more columns serving as discriminators that identify the entity type stored in each particular row. This approach results in having columns required to store all properties of all types in a hierarchy in a single table, which could easily become quite wide as the number of entity types increases.
Each of these approaches has unique trade-offs that can have a significant effect on performance and data storage requirements of your application. Assess them carefully before making a decision. See Chapter 9, “Implementing Business Logic,” for a closer look at this advanced topic.
Stored Procedures
Although LINQ to Entities is a very powerful mechanism for creating database queries, you might find yourself in a situation where it is not enough and use of database stored procedures is desirable. The most common reasons for using stored procedures in database applications are performance optimization and security. Both of these reasons are still applicable but not as relevant as in classic ADO.NET applications because Entity Framework generates well-performing and secure SQL code out of the box. When optimizing performance, your first choice should be to simplify and speed-up the LINQ queries. Making sure that LINQ queries take advantage of indexes, return a minimal number of rows, and use projections to limit the size of result sets goes a long way to improve application performance. Although stored procedures are fully supported by the Entity Framework, they require additional effort to implement and maintain, so you should resort to using them for improved performance only after exhausting the LINQ optimization options.
Consider the following LINQ query that returns products that need to be re-ordered:
var query = from p in context.Products
where p.UnitsInStock < p.ReorderLevel
select p;
Similar logic can be implemented using T-SQL in the following stored procedure:
CREATE PROCEDURE dbo.GetProductsToReorder
AS
SELECT * FROM dbo.Products
WHERE UnitsInStock < ReorderLevel;
Code in this example would not benefit from using a stored procedure. Any performance improvement from rewriting it in a stored procedure using raw T-SQL would not be noticeable. It is used here only for simplicity.
Having this procedure defined in the Northwind database, you can import its definition as a function to the model. To do that, open the Update Wizard that was discussed earlier by right-clicking the design surface in Entity Designer and selecting the Update Model from Database item from the context menu. On the Add tab of the Update Wizard, shown in Figure 2.14, expand Stored Procedures, select the GetProductsToReorder stored procedure, and click the Finish button.
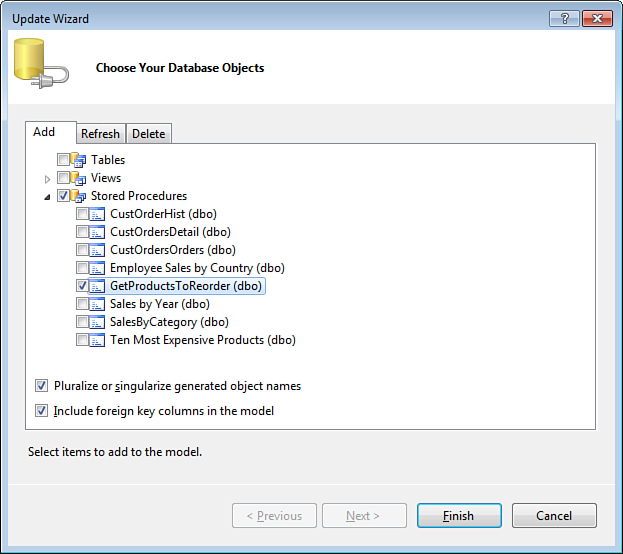
Figure 2.14. Adding stored procedures to the entity model.
When the Update Model wizard closes, the stored procedure is added to the storage section of the entity model shown in Figure 2.15. However, before it can be used in the application code, you must add it as a function import to the conceptual section of the entity model. Right-click the stored procedure in the storage section of the Model Browser and select Add Function Import from the context menu—this opens a dialog similar to that shown in Figure 2.16.
Figure 2.15. Stored procedure in storage section of the entity model.
In the Add Function Import dialog (see Figure 2.16), you can specify the name of the function that will be added to the conceptual model. By default, it will match the name of the stored procedure, but you have the option of changing it. It is common for organizations to use the Hungarian naming convention for stored procedure names, with prefixes such as usp_ to distinguish custom stored procedures from system stored procedures, which have prefix sp_. However, the Hungarian notation is discouraged in .NET applications to improve readability of the code. Function import mapping option in Entity Framework allows you to follow .NET naming conventions in the application code without having to rename the stored procedure.
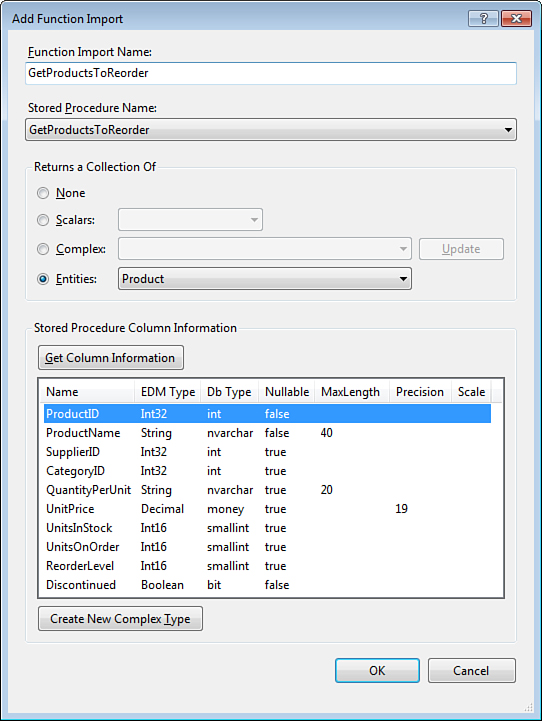
Figure 2.16. Add function import.
In addition to the function name, another design decision you need to make when importing a stored procedure is to specify the type of objects returned by the stored procedure. The Get Column Information button allows you to quickly see the definition of its result set. In this case, the GetProductsToReorder procedure returns a set of Products, and you can have the function return a collection of Product entities. If the set of columns returned by a stored procedure does not match any of the entity types defined in the model, you can choose the option to return a collection of complex (non-entity) objects and have the tool automatically create a new complex type definition. Function imports returning collections of complex objects are similar to LINQ queries that use projection to return sets of anonymous or named objects. Similar to projection, having a stored procedure return a specific set of columns helps to reduce the size of the result set but does not take advantage of the identity tracking, which is only supported for entities.
When you click the OK button in the Add Function Import dialog, the function import is added to the conceptual section of the model. You can find it under Entity Container/Function Imports in the model browser; Figure 2.17 shows an example.
Figure 2.17. Function import in the conceptual section of model browser.
For each function import, the Entity Designer generates a strongly-typed method in the ObjectContext class. Following is an example of using the newly added GetProductsToReorder method to list all products returned by the stored procedure:
using (NorthwindEntities context = new NorthwindEntities())
{
IEnumerable<Product> products = context.GetProductsToReorder();
foreach (Product p in products)
Console.WriteLine(p.ProductName);
}
The generated method returns an IEnumerable and not an IQueryable. Although you can use the familiar LINQ operators to manipulate it further, keep in mind that these operations are performed in the application memory and not by the database server. Instead, it is often best to modify the definition of the stored procedure itself and have it return a more focused result set.
Insert, Update, and Delete Stored Procedures
The Entity Framework also allows you to use stored procedures to perform insert, update, and delete operations instead of generating SQL statements dynamically. When combined with restriction of the application permissions to only read data, this technique can help reduce accidental data corruption and locking due to casual browsing, when developers or administrators use a tool, such as SQL Server Management Studio to interactively explore live data in a production system.
Here’s an example of the stored procedure that inserts a new Product entity into the Products table:
CREATE PROCEDURE [dbo].[Products_Insert]
@ProductName nvarchar(40), @SupplierID int, @CategoryID int,
@QuantityPerUnit nvarchar(20), @UnitPrice money, @UnitsInStock smallint,
@UnitsOnOrder smallint, @ReorderLevel smallint, @Discontinued bit
AS
BEGIN
INSERT INTO Products
(ProductName, SupplierID, CategoryID,
QuantityPerUnit, UnitPrice, UnitsInStock,
UnitsOnOrder, ReorderLevel, Discontinued)
VALUES
(@ProductName, @SupplierID, @CategoryID,
@QuantityPerUnit, @UnitPrice, @UnitsInStock,
@UnitsOnOrder, @ReorderLevel, @Discontinued);
SELECT SCOPE_IDENTITY() as ProductID;
END
Notice that this stored procedure takes a set of parameters, each representing a particular table column, such as ProductName and SupplierID. The stored procedure performs the INSERT statement and a SELECT statement to return the ProductID value of the newly inserted row.
For the Entity Framework to take advantage of this stored procedure, it needs to be added to the storage section of the entity model, similar to the GetProductsToReorder stored procedure discussed earlier. However, instead of adding it as a function import to the conceptual model, right-click the Product entity in the Entity Designer and select Stored Procedure Mapping from the context menu. You will see the Mapping Details window similar to that shown in Figure 2.18.
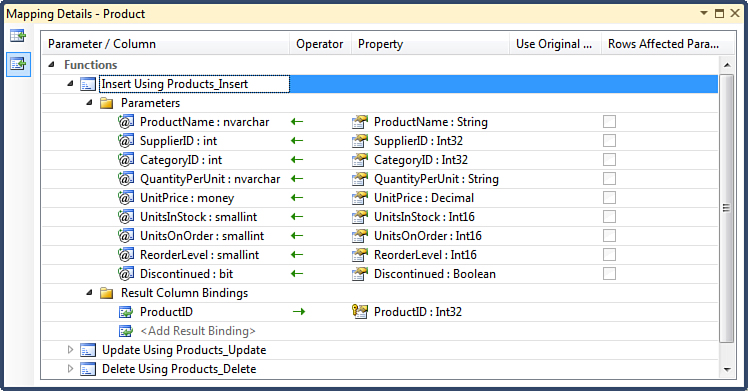
Figure 2.18. Insert function mapping.
The Functions tab of the Mapping window allows you to map the stored procedure parameters (shown on the left) to the entity properties (shown on the right). In this example, the generated ProductID value is mapped in the Result Column Bindings section.
The Update stored procedures are somewhat more complex because they need to implement the optimistic locking normally performed by the Entity Framework. In addition to the primary key value required to uniquely identify the target row and the current values of all fields, the update procedure needs to provide a separate parameter for each entity property that has Concurrency Mode set to Fixed in the entity model. In the following example, the Products_Update procedure provides a separate set of parameters for all properties, one set for the new values, used to update the row, and the other set of old values, used to make sure that the entity has not been modified since it was last retrieved from the database.
The update stored procedure also needs to be added to the model and used to map the Product entity as shown in Figure 2.19. Each property of the Product entity is mapped twice—first to the parameter that receives the “old” value of the entity property as it was originally retrieved from the database and then to the parameter that receives the “new” value that needs to be persisted. Notice that the @RowsAffected output parameter of the stored procedure, which returns the number of rows actually modified by the stored procedure, has a checkbox in the Rows Affected Parameter column. This parameter is used by the Entity Framework to determine if the optimistic locking was performed successfully and throw the OptimisticConcurrencyException if it returns zero.
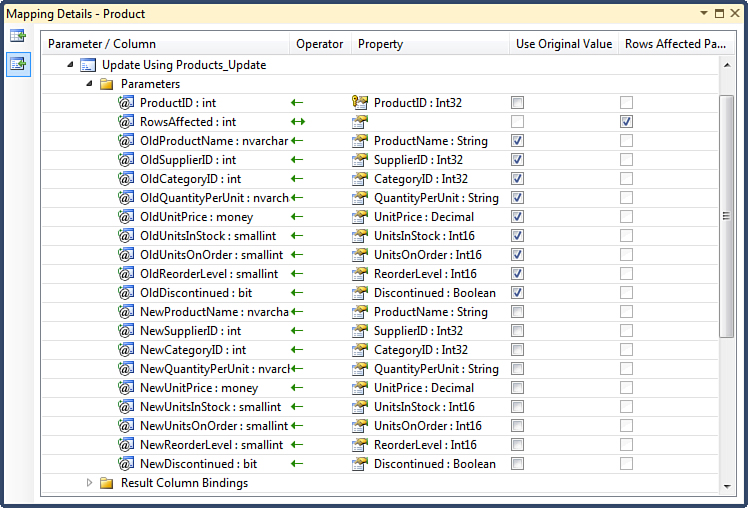
Figure 2.19. Update function mapping.
CREATE PROCEDURE [dbo].[Products_Update]
@ProductID int, @RowsAffected int out,
@OldProductName nvarchar(40), @OldSupplierID int, @OldCategoryID int,
@OldQuantityPerUnit nvarchar(20), @OldUnitPrice money,
@OldUnitsInStock smallint, @OldUnitsOnOrder smallint,
@OldReorderLevel smallint, @OldDiscontinued bit,
@NewProductName nvarchar(40), @NewSupplierID int, @NewCategoryID int,
@NewQuantityPerUnit nvarchar(20), @NewUnitPrice money,
@NewUnitsInStock smallint, @NewUnitsOnOrder smallint,
@NewReorderLevel smallint, @NewDiscontinued bit
AS
BEGIN
UPDATE Products SET
ProductName = @NewProductName,
SupplierID = @NewSupplierID,
CategoryID = @NewCategoryID,
QuantityPerUnit = @NewQuantityPerUnit,
UnitPrice = @NewUnitPrice,
UnitsInStock = @NewUnitsInStock,
UnitsOnOrder = @NewUnitsOnOrder,
ReorderLevel = @NewReorderLevel,
Discontinued = @NewDiscontinued
WHERE
ProductID = @ProductID AND
SupplierID = @OldSupplierID AND
CategoryID = @OldCategoryID AND
QuantityPerUnit = @OldQuantityPerUnit AND
UnitPrice = @OldUnitPrice AND
UnitsInStock = @OldUnitsInStock AND
UnitsOnOrder = @OldUnitsOnOrder AND
ReorderLevel = @OldReorderLevel AND
Discontinued = @OldDiscontinued;
SET @RowsAffected = @@ROWCOUNT;
END
The Delete stored procedures are similar to the update stored procedures in that they also need to implement optimistic locking and make sure that the deleted entity has not been modified since it was last retrieved from the database. However, because there are no new values to persist, their parameter lists are usually much shorter. Here is an example of the delete procedure for the Product entity:
CREATE PROCEDURE [dbo].[Products_Delete]
@ProductID int, @ProductName nvarchar(40), @SupplierID int, @CategoryID
int,
@QuantityPerUnit nvarchar(20), @UnitPrice money, @UnitsInStock smallint,
@UnitsOnOrder smallint, @ReorderLevel smallint, @Discontinued bit,
@RowsAffected int out
AS
BEGIN
DELETE FROM Products
WHERE
ProductID = @ProductID AND
SupplierID = @SupplierID AND
CategoryID = @CategoryID AND
QuantityPerUnit = @QuantityPerUnit AND
UnitPrice = @UnitPrice AND
UnitsInStock = @UnitsInStock AND
UnitsOnOrder = @UnitsOnOrder AND
ReorderLevel = @ReorderLevel AND
Discontinued = @Discontinued;
SET @RowsAffected = @@ROWCOUNT
END
Because there is only one set of parameters, mapping of the delete procedures is also straightforward. If the parameter names match the names of the entity properties, the Entity Designer maps them automatically. You only need to make sure that the RowsAffected parameter has a check mark in the Rows Affected Parameter column.
Although it would be possible to revoke direct data access permissions from an application using Entity Framework and force it to rely strictly on the Select, Insert, Update, and Delete stored procedures, doing so would require an additional effort to implement and take away most of the strengths and productivity improvements offered by the Entity Framework. Stored procedures are a great performance and security optimization option, but when followed to the extreme, this approach defeats most of the reasons to use a LINQ-based framework in the first place.
Summary
The ADO.NET Entity Framework is an ORM framework developed by Microsoft as part of the .NET Framework. It is built on top of the Entity Data Model, which includes a storage model, describing database tables, views, and stored procedures; a conceptual model, describing application entity types and functions; and a mapping model that connects conceptual definitions to their physical implementation in the storage model.
The Entity Framework has first-class design tools in Visual Studio for working with entity data models, including the Entity Designer, Model Browser, and Mapping tool windows as well as the Update Wizard. Together, these tools allow developers to use the database-first approach, where the entity model is reverse-engineered from an existing database, as well as the model-first approach, where the database is generated from an entity data model created from scratch.
Based on the conceptual model, the Entity Framework generates strongly-typed application classes, including entity classes, which encapsulate individual rows of data, and an ObjectContext, which encapsulates a collection of entity sets (tables) and functions (stored procedures). Entity Framework allows using LINQ queries to retrieve entity instances from the database. The LINQ queries are compiled in a form of LINQ expressions. At run time, the LINQ expressions are translated into dynamic, parameterized SQL statements and sent to the underlying database engine for execution. Upon return, the ObjectContext materializes the records returned by the SQL queries are in the form of entity instances, allowing using strongly-typed .NET code to query and manipulate database information.
Entity Framework provides an abstraction layer that allows you to build a holistic view of the information in a conceptual model independent from the underlying storage schema. In particular, a single entity type can be mapped to multiple tables. Entity Framework also supports entity inheritance and allows mapping class hierarchies using table-per-type, table-per-concrete type, and table-per-hierarchy strategies.
The Entity Framework is optimized for rich-client applications that retrieve and manipulate a relatively small number of records at a time. However, by turning off the object tracking options, its performance can be improved for multi-threaded web applications as well as applications working with a large number of records in batch mode. Although the Entity Framework generates high-quality, parameterized SQL code appropriate for most common data access scenarios, it also allows the use of stored procedures to create, read, update, and delete entities/database records.
Entity Framework supports the TransactionScope class from the System.Transactions namespace and optimistic concurrency for conflict detection in multi-user scenarios. It does not support pessimistic locking out of the box; however, implementing it is possible with the help of custom stored procedures.
The Entity Framework represents a long-term strategic investment for Microsoft. As of .NET version 4, it is a powerful framework appropriate for use on most enterprise application projects. It offers significant productivity improvements compared to the classic ADO.NET and has become a recommended choice with some of the new technologies developed by Microsoft, including ASP.NET Dynamic Data. The Entity Framework is under active development. Version 4.1, added support for Code-First approach, making it possible to define entity model directly in application code, as classes. The upcoming version 4.5 will bring significant enhancements to the Entity Designer, including support for enumerated types and multiple diagrams, making developers using the database-first approach, discussed in this chapter, as well as the model-first approach, much more productive.