
Chapter 9. Implementing Business Logic
In This Chapter
• Invoking Business Rules in Web Applications
• Business Rules in the Database
Business logic, also known as domain logic, is code that implements a developer’s interpretation of a business domain where the application is intended to solve one or more problems and address opportunities. Because a particular business domain can be described from different points of view, there are different definitions of what constitutes the business logic. This chapter discusses implementation of logic related to real-life entities, such as Customers, Products, and Orders, as well as rules that determine how these entities interact with each other.
The entities and rules are not directly related to any particular software application; instead, they describe the business itself. Similar to how a retailer could be selling products from a brick-and-mortar store directly to customers, accept orders by phone, allow customers to pick products up, or provide a website where customers submit orders that will be shipped to them by mail, different software applications can implement the same business logic as well. A sales clerk at a physical store could use a Windows-based point-of-sale application to sell a product, and a customer could use a Web-based application to place the order online. In both instances, the order needs to be checked to make sure that the product is in stock, order total must be calculated, product inventory needs to be updated, out-of-stock products need to be reordered, and so on.
In part due to the common need to support the same business services through different applications and in part due to their relative stability, there is a wide agreement in the software development industry that separating the business logic from its presentation is beneficial as it allows reusing the business logic in multiple applications. Separation of business logic from presentation is especially important in ASP.NET Dynamic Data applications. Because virtually the entire user interface of a web application can be generated dynamically, embedding the business logic directly in the web pages of the application is not only less attractive but also more cumbersome. To take advantage of the productivity improvements Dynamic Data offers, you as a web developer need to know how to implement business logic outside of the web pages.
Entity Design
Entities are abstractions of things in the business domain. They are implemented as classes in the application and as tables in the database. Although some similarities exist (class properties are similar to table columns for instance), the object-oriented and relational models are very different. The ADO.NET Entity Framework, LINQ to SQL, and other frameworks attempt to bridge the gap between these two radically different ways of representing information by implementing object-relational mapping.
Good entity design requires application of both object-oriented and relational design principles. It would be foolish to try addressing both of these vast topics in this chapter, or even in this book. It is assumed that you already know how to create a class that represents a real-world object or person and use encapsulation and abstraction principles to expose its key attributes as properties. It is also assumed that you know how to create a table to store this information in the database and use normalization techniques to reduce duplication. With these assumptions in mind, this section focuses on practical application of the object-oriented and relational design principles and some of the common pitfalls developers encounter with the Entity Framework.
Measure Impact of Inheritance on Query Performance
Inheritance is one of the most powerful concepts in object-oriented design, allowing a much higher level of reuse and encapsulation than the relational model provides. With the Entity Framework supporting table-per-type, table-per-concrete type, and table-per-hierarchy methods of mapping class hierarchies to database tables, using inheritance in your entity model becomes a very attractive option.
Beware! Although the Entity Framework makes LINQ queries over type hierarchies look deceptively simple, there are significant performance costs associated with the use of inheritance in your conceptual model. Consider the conceptual model shown in Figure 9.1, where you have an abstract base class called User and two concrete classes inheriting from it—Customer and Employee. The Entity Framework allows you to select both Customer and Employee entities by writing a simple LINQ query like this:
var users = from u in context.Users
select u;
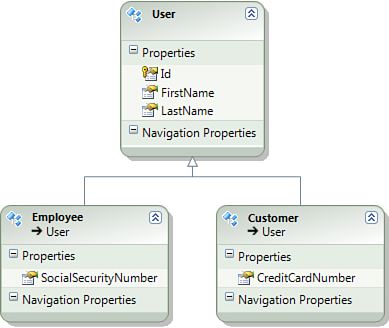
Figure 9.1. Conceptual model with inheritance hierarchy.
You can also select all entities of a particular type by using the OfType LINQ extension method, such as the next query, which returns all entities of Customer type:
var customers = from c in context.Users.OfType<Customer>()
select c;
Although these LINQ queries work with all three types of inheritance mapping, it is important that you understand how each type of mapping is implemented at the database level, how each type of LINQ queries are translated into SQL, and how they affect the performance of your application. If you are considering using inheritance in your entity model, carefully review the tradeoffs described in this section and measure the impact of inheritance on the performance of your system by profiling it. Do not assume that simple LINQ queries will be fast.
Table-per-Concrete Type Mapping
With table-per-concrete type mapping, each concrete class in the inheritance hierarchy gets its own table. The Employees and Customers tables in the database diagram shown in Figure 9.2 include columns for storing not only the concrete types, Employee and Customer, respectively, but also the abstract base type, User. Notice how both of these tables include the FirstName and LastName columns.
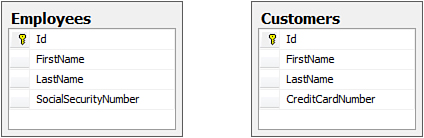
Figure 9.2. Table-per-concrete type mapping.
Because database designers most commonly use this type of entity modeling, table-per-concrete type looks like a good way to extract the commonality into a base class. However, although this type of mapping offers good performance for queries against specific concrete types, it has a significant performance penalty for querying across all base types because it relies on the UNION operator to combine results of multiple queries. Table 9.1 shows the examples.
Table 9.1. SQL Generated with Table-per-Concrete Type Mapping

Examples of SQL queries generated by the Entity Framework in this section show pseudo-code, which was significantly modified to reduce size and make it easy to compare with LINQ code. The Entity Framework does not generate SELECT * SQL statements.
Whereas in plain SQL, the UNION statement has to be used explicitly, with LINQ to Entities, the query looks as if it spans only one table, making it easy to write queries that will perform poorly due to excessive unions.
Table-per-Type Mapping
With table-per-type mapping, each class, regardless of whether it is concrete or abstract, gets its own table in the database. Figure 9.3 shows an example of this type of mapping. As you can see, the User class is mapped to the Users table, with Employee and Customer classes mapped to the Users_Employee and Users_Customer tables, respectively.
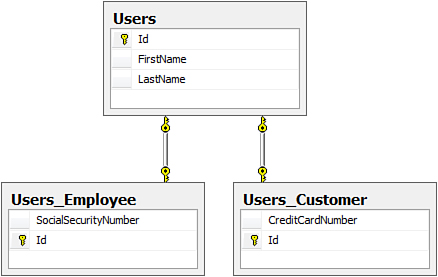
Figure 9.3. Table-per-type mapping.
With table-per-type of mapping, iterating over the entities of the base class User requires an outer join with all other tables in the hierarchy because Entity Framework has to instantiate entities of appropriate type, Customer and Employee. Querying for instances of a derived type Customer will be more efficient as it results in an inner join of the tables where its data is stored.
Table 9.2. SQL Generated with Table-per-Type Mapping
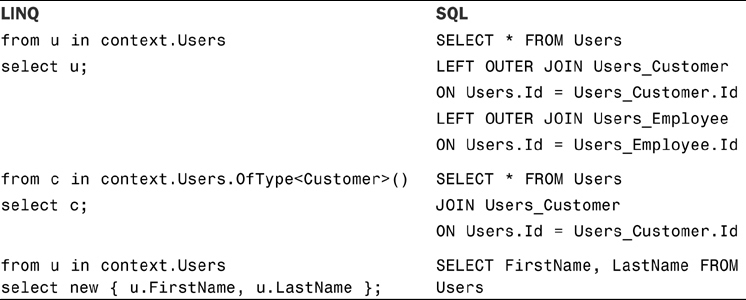
Again, the complexity of the actual SQL statement is hidden from the developer writing the LINQ query, making it easy to write queries that are inefficient due to excessive joins. It is possible to optimize these queries with the help of projections, which can reduce or eliminate joins from the generated SQL; however, as a developer you need to understand what is going on.
Table-Per-Hierarchy Mapping
With table-per-hierarchy mapping, all classes in a given hierarchy are mapped to the same database table, with a particular column storing a discriminator value that determines the entity type. Figure 9.4 shows a table called Users, which stores both Customer and Employee entities, using the UserType column to distinguish between them.
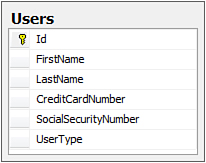
Figure 9.4. Table-per-hierarchy mapping.
The table-per-hierarchy mapping offers a good performance tradeoff between queries across the base types and the queries across the derived types. The SQL generated with this mapping approach is also much closer to the original LINQ code developers write. As you can see in the second example of Table 9.3, the OfType extension method is translated into a straightforward WHERE clause.
Table 9.3. SQL Generated with Table-per-Hierarchy Mapping

This approach is also made attractive by Microsoft SQL Server’s support of Sparse Columns—a storage optimization option for tables with large numbers of nullable columns, which can help storing entities of different types more effective. However, with a small number of types in a hierarchy, the discriminator column might not be selective enough, and the query optimizer might choose to perform a full table scan for each query even if an index covering this column exists. This approach also violates the third form of database normalization, which requires each column to represent a fact about the key, making it unpopular with database designers.
Each of the three O/R Mapping approaches discussed here have different trade-offs, making them appropriate for different scenarios. Theoretically, the table-per-type mapping should work better for shallow hierarchies of significantly different classes, and the table-per-hierarchy mapping should work better for deep hierarchies of classes with small differences. The table-per-concrete type mapping should work better in queries that retrieve objects of leaf types, and the other types of mapping should work better for queries that retrieve information from base classes. However, the only reliable way to determine the best mapping type is through measurement of actual results.
Performance tuning and optimization are best left for later stages of application development, when sufficient information and functionality is available to simulate real-world usage scenarios. However, if you are certain you will need to use class inheritance in your entity model, consider starting with the table-per-hierarchy mapping because it offers the best combination of simplicity and performance.
Keep the Conceptual and Storage Models as Close as Possible
Although being able to fine-tune the object-oriented (conceptual) and the relational (storage) models of your application seems like a good idea, this optimization comes at the cost of a significant increase in effort to maintain the two models and mappings between them. Because the Entity Framework allows this flexibility, it cannot automatically update both models based on a change in one. For instance, if you want to change the name of a particular column in the database, you also have to rename the corresponding property in the conceptual model. The same goes for renaming or deleting tables, changing relationships between them, and so on—all of these common changes have to be done in both models separately.
Regardless of the approach you choose to developing your entity model—database-first, model-first, or code-first—you want to minimize the amount of work you spend on the secondary model. In other words, if you start by developing the database model first, you want to spend the least amount of work on maintaining your conceptual model and application classes. Likewise, if you start by developing the application classes first, you want to spend as little time as possible tweaking the database tables the Entity Framework generates for you.
The best way to keep the conceptual and storage models in sync over the life of the application is to reduce the differences between them. Ideally, you want to be able to regenerate your entire secondary model without having to make any tweaks manually. This could require introducing some of the database principles in the class design or taking object-oriented principles into account when designing the tables. For instance, you might want to sacrifice some of the normalization rules or break some of your DBA’s favorite naming conventions to make the generated classes easier to use in a .NET language.
This advice might feel counter-intuitive and go against the selling points of the O/R mapping frameworks in general and the Entity Framework in particular. It is based on the lessons learned in real-world projects and realization that additional flexibility rarely justifies the added cost of troubleshooting problems caused by modeling mistakes and confusion caused by the differences between the models. Unless your project has an unlimited budget, you want to avoid paying this price until it becomes a true necessity.
Default Property Values
Setting default values of entity properties presents a surprising challenge in the Dynamic Data applications. Although the Entity Framework allows you to specify default values directly in the model, the Dynamic Data metadata API ignores this information. Figure 9.5 shows an example of setting zero as the default value of the UnitsInStock property of the Product entity in the Properties window of Visual Studio.
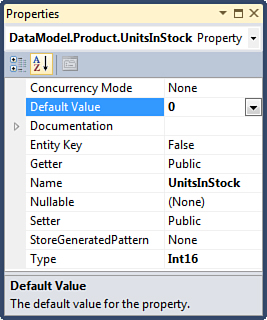
Figure 9.5. Setting default property value with Entity Designer.
Based on this information from the conceptual model, the Entity Designer generates special initialization code that assigns the default value to the backing field of the entity property. Here is how the code looks if you open the generated NorthwindEntities.cs:
[EdmScalarPropertyAttribute(EntityKeyProperty=false, IsNullable=true)]
[DataMemberAttribute()]
public Nullable<global::System.Int16> UnitsInStock
{
get { return _UnitsInStock; }
set
{
OnUnitsInStockChanging(value);
ReportPropertyChanging("UnitsInStock");
_UnitsInStock = StructuralObject.SetValidValue(value);
ReportPropertyChanged("UnitsInStock");
OnUnitsInStockChanged();
}
}
private Nullable<global::System.Int16> _UnitsInStock = 0;
This works great when a new entity is created explicitly, such as in the following unit test, but unfortunately, it has no effect in Dynamic Data insert pages:
[TestMethod]
public void UnitsInStock_IsZeroByDefault()
{
var product = new Product();
Assert.AreEqual((short)0, product.UnitsInStock);
}
The Dynamic Data insert page template does not actually create a new entity instance. Instead, the individual field templates set the initial value of their data controls in Insert mode based on the DefaultValue property of the MetaColumn class describing their respective properties. As you recall from Chapter 7, “Metadata API,” to determine the default property value, the MetaColumn class checks if a DefaultValueAttribute was applied to the property. In other words, the Entity Framework initializes the default property values in code, but Dynamic Data expects this information to be provided via data annotation attributes, forcing you to maintain property default values in two separate places.
The current version of the Dynamic Data provider for Entity Framework ignores the default property values defined in the model. Another possible solution for this problem is to create a custom model provider. More on this in Chapter 13, “Building Dynamic List Pages.”
If you are using the database-first or the model-first approach with Entity Framework, the best solution is to customize the code generator so that it not only generates the initialization code for the backing field, but also applies DefaultValueAttribute to entity properties. As discussed in Chapter 8, “Implementing Entity Validation,” the built-in code generator in the sample DataModel project accompanying this book has already been replaced with a text template (Northwind.tt). Figure 9.6 shows how this text template was modified to automatically generate a DefaultValueAttribute for each property that has a default value defined in the model.
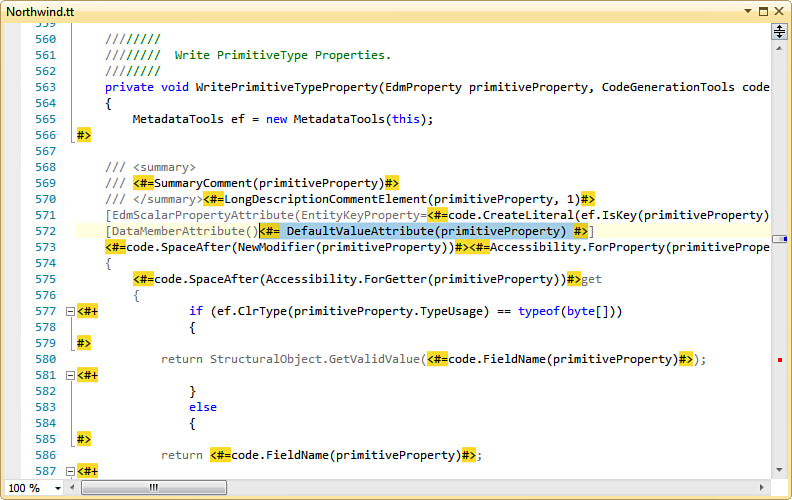
Figure 9.6. Entity Framework text template modified to generate DefaultValueAttribute.
You can locate the part of the text template responsible for generating declarations of primitive properties, such as the UnitsInStock, by searching for the WritePrimitiveTypeProperty method. Notice that in Northwind.tt, the DefaultValueAttribute instances are generated by a helper method with the same name. You can find the complete implementation of this method in the source code accompanying the book. Here is how the modified text template generates the UnitsInStock property:
[EdmScalarPropertyAttribute(EntityKeyProperty=false, IsNullable=true)]
[DataMemberAttribute(), DefaultValue(typeof(global::System.Int16), "0")]
public Nullable<global::System.Int16> UnitsInStock
{
get
{
return _UnitsInStock;
}
set
{
OnUnitsInStockChanging(value);
ReportPropertyChanging("UnitsInStock");
_UnitsInStock = StructuralObject.SetValidValue(value);
ReportPropertyChanged("UnitsInStock");
OnUnitsInStockChanged();
}
}
private Nullable<global::System.Int16> _UnitsInStock = 0;
When writing code by hand, you would typically and rely on the compiler to choose a DefaultValueAttribute constructor that matches the type of default value directly, such as the DefaultValueAttribute(Int16) for the UnitsInStock property. However, generating this code programmatically is challenging. To keep implementation simple, the text template in this sample always generates the DefaultValueAttribute(Type, String) overload.
Property Interaction Rules
Information systems commonly have a requirement to track information regarding important changes in the state of an entity. In the case of the Northwind Traders web application, you might need to keep track of when each particular order was submitted in the SubmittedDate property of the Order entity. Here is a test that illustrates the expected behavior:
[TestMethod]
public void OrderStatus_SetsSubmittedDate()
{
using (new TransactionScope())
using (var context = new NorthwindEntities())
{
var order = new Order();
order.OrderDate = DateTime.Today;
order.OrderStatus = (int)OrderStatus.Submitted;
context.Orders.AddObject(order);
context.SaveChanges();
Assert.IsNotNull(order.SubmittedDate);
Assert.AreEqual(DateTime.Today, order.SubmittedDate.Value.Date);
}
}
This type of logic is an example of business rules that define interaction between different properties of a single entity. This particular rule could have been defined as “Set SubmittedDate to date and time when the OrderStatus changes from Draft to Submitted.”
OnPropertyChanging Partial Methods
The Entity Framework generates a partial OnPropertyChanging method for each property, such as the OnOrderStatusChanging method for the OrderStatus property shown here:
partial void OnOrderStatusChanging(byte? value);
When implemented by a developer, this method receives the new value of the entity property as the parameter and can access the original value through the entity property itself. At first, it looks like an ideal place to implement the code to set the SubmittedDate when the new value of OrderStatus property is Submitted. Unfortunately, this approach does not work in web pages that rely on the EntityDataSource control, such as the page templates in our Dynamic Data web application.
The data source control does not keep the entity object alive between page requests, nor does it serialize the object to the server- or client-side state storage. Instead, it puts the original values of its properties in a hash table and stores the hash table in the ViewState when the page is first rendered. During the post-back, when the data source control needs to save changes, instead of reloading the original entity from the database, it simply creates a brand-new entity object, applies the original values from the ViewState, and calls the AcceptChanges method of its ObjectStateEntry. Then it makes a second pass to apply the current values of the entity properties received from data entry controls on the page. In other words, every OnPropertyChanging partial method is called when any property of the entity changes.
To put this in a specific example, imagine changing the shipping address on an already submitted order. Even though the OrderStatus property itself does not change, the OnOrderStatusChanging method will still be called as if the OrderStatus changed from null to Submitted. Therefore, if we try to set the SubmittedDate in the OnOrderStatusChanging method, it would always store the date of the last change made to the order.
ISavableObject Interface
Instead of implementing the partial OnPropertyChanging methods, rely on the ObjectStateEntry class and explicitly compare the original property values it stores with the current values of the entity properties. This approach is similar to the approach discussed in Chapter 8 to implement validation rules based on property value changes. In fact, you could have implemented this logic in a custom validation method, but mixing the interaction logic, which changes property values, with the validation logic, which verifies them, is not a good idea. You have no control over the order in which the validation methods are called and might end up with validation code for a particular property executing before the code that changes it, leaving the entity in an invalid state.
Instead, change the ObjectContext class in your project so that it notifies the entity objects before they are saved and allows the entity objects to execute property interaction rules before the validation is performed. For example, the Unleashed.EntityFramework assembly in the sample solution accompanying this book defines an interface called ISavableObject (for consistency with the built-in IValidatableObject interface), that entity classes can implement when they require property interaction logic.
interface ISavableObject
{
void BeforeSave(ObjectStateEntry stateEntry);
}
In the Order entity class, you can now implement this interface and have the BeforeSave method get the original value of the OrderStatus property from the ObjectStateEntry, compare it to the current value in the OrderStatus property itself, and set the SubmittedDate property with the system date and time.
partial class Order : ISavableObject
{
public void BeforeSave(ObjectStateEntry stateEntry)
{
byte? oldStatus = (byte)DataModel.OrderStatus.Draft;
if (stateEntry.State == EntityState.Modified)
oldStatus = stateEntry.OriginalValues.Get(() => this.OrderStatus);
if (this.OrderStatus == (byte)DataModel.OrderStatus.Submitted &&
oldStatus == (byte)DataModel.OrderStatus.Draft)
{
this.SubmittedDate = DateTime.Now;
}
}
}
The UnleashedObjectContext class calls the BeforeSave method of each entity object that implements the ISavableObject interface.
partial class UnleashedObjectContext
{
private void BeforeSaveChanges(ObjectStateEntry stateEntry)
{
var savable = stateEntry.Entity as ISavableObject;
if (savable != null)
savable.BeforeSave(stateEntry);
if (stateEntry.State != EntityState.Deleted)
this.Validate(stateEntry);
}
}
As discussed in Chapter 8, the overridden SaveChanges method of the UnleashedObjectContext class calls the BeforeSaveChanges method for every added, modified, or deleted entity before submitting changes to the database. This method receives an ObjectStateEntry that stores both current and original property values of an entity. It checks if the entity implements the ISavableObject interface, calls its BeforeSave method.
When your object context class inherits from the UnleashedObjectContext or has an equivalent functionality, property interaction rules are automatically invoked when an entity object is saved to the database. In other words, whenever a web page changes an Order entity through the NorthwindEntities context, the SubmittedDate is updated automatically based on the value of the OrderStatus property. No changes are required in the web page itself, whether it is a custom page created for editing Order entities or the dynamic Edit page template.
The ISavableObject interface and its BeforeSave method work a lot like the UPDATE triggers in Microsoft SQL Server and other relational database management systems. Although you could have indeed implemented this logic in a database trigger, working at the entity level gives you more flexibility and better tools for implementing business rules. You still have the option of using triggers as an optimization step (see Business Rules in the Database later in this chapter).
Entity Interaction Rules
Complex interaction rules might not be limited by a single entity object or even a single entity type. For example, when an order is fulfilled, the system needs to update the product inventory to decrement the number of items in stock by the number of items shipped to the customer. In the Northwind sample, this means that when the OrderStatus property of the Order entity changes to Fulfilled, values of the Quantity property of the Order_Detail entities need to be subtracted from the UnitsInStock properties of the corresponding Product entities. In other words, the fulfillment business rule spans three classes, Order, Order_Detail, and Product, and fits into the category of entity interaction rules.
There are several different approaches you can take when implementing entity interaction rules with Entity Framework, including (but not limited to):
• Implementing Entity Interaction Rules as BeforeSave Methods
• Implementing Entity Interaction Rules as Entity Methods
• Implementing Entity Interaction Rules as Context Methods
This section discusses these approaches and some of the trade-offs you must take into consideration when choosing how to implement entity interaction rules in your application.
Implementing Entity Interaction Rules in BeforeSave Methods
You can use the BeforeSave “trigger” methods to implement not only property interaction rules, but entity interaction rules as well. For instance, you could change the BeforeSave method of the Order entity class to detect if the OrderStatus property changed from Paid to Fulfilled and update the UnitsInStock property of all Product entities purchased in this Order. The code example that follows illustrates how the implementation could look:
partial class Order : ISavableObject
{
public void BeforeSave(ObjectStateEntry stateEntry)
{
byte? oldStatus = (byte)DataModel.OrderStatus.Draft;
if (stateEntry.State == EntityState.Modified)
oldStatus = stateEntry.OriginalValues.Get(() => this.OrderStatus);
if (this.OrderStatus == (byte)DataModel.OrderStatus.Submitted &&
oldStatus == (byte)DataModel.OrderStatus.Draft)
{
this.ShippedDate = DateTime.Now;
foreach (Order_Detail orderItem in this.Order_Details)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
}
Although this approach is viable for trivial scenarios such as in this example, it quickly becomes overwhelmingly difficult to maintain as the number of rules and their complexity increases. One of the reasons this happens is because the code is guessing what the presentation layer is trying to accomplish. When only the OrderStatus property is changing from Paid to Fulfilled, it is easy to see what is going on, but what if another property of the Order entity changes as well? For example, you could have another business rule tied to the ShipVia property of the Order entity to calculate the shipping fee (the Freight property) depending on the shipping option selected by the customer. If the OrderStatus changes to Fulfilled at the same time with the ShipVia property, does it mean an employee has chosen a different shipper to expedite the customer’s order at no additional cost or that the customer stopped by to pick up the order from our physical store and you need to refund the shipping fee? It is impossible to answer this question in the business layer of the application because it depends on how the presentation layer is implemented.
Implementing complex business rules, such as order fulfillment, in BeforeSave methods (or database triggers for that matter) leads you down the path where you begin thinking about all possible permutations of property changes and what they might mean. Not only does it become difficult to analyze rules upfront, it is just as difficult for someone to learn and maintain the business rules implemented as a mass of if statements later on.
Implementing Entity Interaction Rules as Entity Methods
Alternatively, you can implement a complex business rule as a method in one of the entity classes. For instance, you could implement the order fulfillment rule as the Fulfill method of the Order entity class shown here:
partial class Order
{
public void Fulfill()
{
this.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
this.ShippedDate = DateTime.Now;
foreach (Order_Detail orderItem in this.Order_Details)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
Similar to the code previously implemented in the BeforeSave method, the Fulfill method updates the ShippedDate property with the current date and time, iterates through all child Order_Detail objects, and subtracts their Quantity from the UnitsInStock property of their Products. However, instead of comparing the OrderStatus property with its original value, the Fulfill method itself sets it to Fulfilled.
Note that just like in the previous example, the Fulfill method relies on the lazy loading of related entity objects provided by the Entity Framework. Although it makes implementation of entity interaction rules easy, lazy loading might not be efficient because it results in multiple database calls to retrieve all Order_Detail entities first, followed by their respective Product entities, retrieved one at a time in the foreach loop.
Lazy loading functionality in Entity Framework was designed for desktop applications, where the initial response that users can see is more important than total duration of the operation. The ObjectContext can also be a long-living object in a desktop application, automatically caching previously loaded entities in memory and improving performance of subsequent operations. However, in web applications, where a new ObjectContext is created for each page request and users do not see anything until all data access is complete and the entire page is generated, lazy loading can significantly affect performance for all users of the system. To avoid the performance hit caused by loading the individual Product entities separately, take advantage of the Include method of the ObjectQuery class and load all Order_Detail and Product entities with the order in a single database query.
var order = context.Orders
.Include("Order_Details")
.Include("Order_Details.Product")
.First(o => o.OrderID == orderId);
order.Fulfill();
You need to place code like this, however, in every page that needs to execute the Fulfill business rule, spilling the data access logic into the presentation layer, which is, in most circumstances, not a good idea. One of the reasons to avoid it is that the Entity Framework 4 forces you to hard-code the names of the entity classes and their properties as string literals, which are fragile and prone to typos. Even if you address this problem with string constants, it still means hard-coding the knowledge of all entities and relationships necessary for a particular business rule in the presentation layer, possibly in multiple places where the same method is called.
Implementing Entity Interaction Rules as Context Methods
When performance is important and data access logic needs to be encapsulated, it can be beneficial to implement business rules in methods of the object context class instead of the entity class. Here is how to reimplement the order fulfillment business rule in the NorthwindEntities class:
public partial class NorthwindEntities
{
public void FulfillOrder(int orderId)
{
Order order = this.Orders
.Include("Order_Details").Include("Order_Details.Product")
.First(o => o.OrderID == orderId);
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
foreach (Order_Detail orderItem in order.Order_Details)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
The FulfillOrder method takes OrderID as a parameter and retrieves the Order entity, all of its Order_Detail objects, and the related Product entities in a single roundtrip to the database. When all entities are loaded in the context, the code performs the same steps implemented in the Fulfill method earlier—update OrderStatus and ShippedDate and decrement UnitsInStock.
This version of the FulfillOrder method assumes that the caller does not already have the Order instance loaded from the database, so taking its primary key value as a parameter is the best option. However, if the Order instance is already loaded, you can change or perhaps create an overloaded version of the FulfillOrder method so that it takes an entity instance as a parameter instead. The code sample that follows shows an example of a possible implementation. As you can see, instead of querying the Order entity set, you can query the Order_Details entity set and reduce the number of Include calls to one:
public partial class NorthwindEntities
{
public void FulfillOrder(Order order)
{
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
IQueryable<Order_Detail> orderItems = this.Order_Details
.Include("Product")
.Where(od => od.OrderID == order.OrderID);
foreach (Order_Detail orderItem in orderItems)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
Although the second version of the FulfillOrder feels more “object-oriented” in that it takes an Order object as a parameter instead of a primitive primary key value, your choice of design approach should be driven by the concrete scenarios you need to implement. If the orders will be marked as fulfilled one at a time from an ASP.NET web page, the calling code only has the primary key value stored in the ViewState of the page, and the first version of the FulfillOrder method will work best. The more elegant second version of the FulfillOrder method might work better only in a scenario where multiple orders have already been loaded from the database and the overhead of making an additional database call to retrieve the order instance will not be incurred. In other words, the second style of methods works better for implementing granular business rules that are a part of a larger business process.
Implementing entity interaction rules in object context methods and removing dependency on lazy loading helps improve not only performance, but also correctness of the application. Unless the code reliant on lazy loading explicitly checks that it is enabled, the lazy loading option could be accidentally or intentionally turned off, making an order appear empty when, in fact, its items and products simply have not been loaded from the database.
On the downside, implementing business rules as context methods can feel awkward depending on where you think the method belongs. For instance, if you feel strongly that fulfillment is the behavior of the Order class, moving the Fulfill method to the NorthwindEntities class would mean breaking its encapsulation.
Implementing business rules as context methods works well with simple entity models where the amount of business logic is small. As the size and complexity of the model grows, the number of business rule methods reaches the point where maintaining them in a single class becomes problematic. When that happens, you can start extracting methods into separate classes to group them by entity type to which they apply (table modules) or business process they implement (services). However, it is best to avoid making this design decision too early in the development of the application. Without having a solid understanding of the business domain and required functionality, the premature architecural decisions are often wrong and lead to unnecessary complexity and increased cost.
Validation Rules
As a form of business logic, validation rules are susceptible to many of the same potential problems. As the number of validation rules increases, complexity of the code grows rapidly and, if you are not careful, can have a significant impact on performance of the application as well as your ability to maintain it. Just like with the business logic in general, it helps to keep the validation rules simple and well encapsulated.
To help understand validation rules, they can be separated in two large categories:
• Persistence validation
• Transition validation
Rules in the persistence category determine conditions that an entity must meet to be successfully saved in the database. Most often, validation rules in this category apply to properties entered directly by the users of the application. For instance, a shipping address (ShipAddress, ShipCity, ShipRegion, and other properties) is required for an Order to be accepted by the Northwind Traders.
Transition rules, on the other hand, determine conditions that allow an entity to change from one state to another. For instance, if the Northwind Traders Company requires customers to pre-pay their orders, an Order entity must have OrderStatus of Paid before it can change to Fulfilled. The OrderStatus property is different from the other properties of the Order entity in that it determines its current state.
Entity states might not only have different transition rules; they often have different persistence rules as well. For instance, when saving an Order in Submitted state, you may want to validate that you have enough Products in stock for all items in the order; however, this rule does not apply to Fulfilled orders because you might keep them in your system for years after the boxes have left the warehouse.
Validation Rule Design
To find a reasonable compromise between code reuse, complexity, and performance, without having to do a lot of refactoring later, try the following rules of thumb when designing validation logic in your application:
• Implement persistence validation rules with data annotations
• Make state properties of entities read-only
• Implement state transitions and validation in business rule methods
• Implement state-specific persistence validation in separate validation methods
Implement Persistence Validation Rules with Data Annotations
The validation framework discussed in Chapter 8 offers a great way to implement persistence validation rules by applying pre-built validation attributes or writing custom validation methods for individual properties or entire entities. You can quickly apply the RequiredAttribute to the shipping address properties of the Order entity to ensure that the order is valid before saving it to the database.
Make State Properties of Entities Read-Only
You do not want the users of your application (neither the customers nor the employees) to edit the OrderStatus property directly, even if they initiate the state transition. Customers will submit orders by clicking a Submit button on a check-out page, and a background process handling credit card payments will mark the orders as paid. The best way to ensure that state properties of an entity cannot be changed through the user interface of the application is to make them read-only.
With Entity Framework, you can use the Entity Designer to make the setter of the OrderStatus property internal, as shown in Figure 9.7.
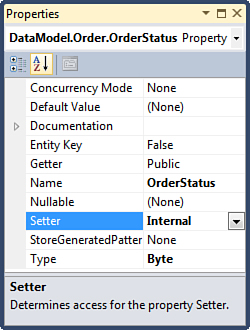
Figure 9.7. Changing visibility of entity property setter.
In the code generated by the Entity Designer, the OrderStatus property now looks similar to the following pseudo-code:
property byte OrderStatus { get; internal set; }
Changing visibility of a property setter to internal makes the property read-only outside of the assembly where its class is defined. As a result, the presentation layer, the WebApplication project in our sample, can continue using a read-only property for display and filtering purposes. However, only the business logic layer, the DataModel project in our sample, can change its value.
Making state properties of entities read-only does not offer bulletproof protection against malicious code. For instance, in a full-trust application, this particular security block can be circumvented using Reflection. However, combined with other security measures, some of which are discussed in Chapter 14, “Implementing Security,” this approach helps to improve security of a well-written application.
Implement State Transitions and Validation in Business Rule Methods
When state properties cannot be modified outside of the business layer, validation of state transition can be separated from validation of entity persistence. You can validate state transitions in the business rule methods, leaving the responsibility for persistence validation to the entities.
For example, because the OrderStatus property is now read-only, you do not need to worry about somebody (a user) or something (incorrect code) changing it from Fulfilled back to Paid when validating the Order entity. To ensure that an order can be fulfilled only once, you can have the FulfillOrder method check that the current OrderStatus is Paid:
public partial class NorthwindEntities
{
public void FulfillOrder(int orderId)
{
Order order = this.Orders
.Include("Order_Details").Include("Order_Details.Product")
.First(o => o.OrderID == orderId);
if (order.OrderStatus != (byte)DataModel.OrderStatus.Paid)
{
throw new ValidationException(
new ValidationResult(
"Order status must be Paid for the order to be fulfilled",
new[] { "OrderStatus" }),
null, order.OrderStatus);
}
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
foreach (Order_Detail orderItem in order.Order_Details)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
Business rule methods should report expected error conditions consistently with the regular validation errors reported when entities are saved to the database. Notice how in the example just shown, the FulfillOrder method throws a ValidationException if the OrderStatus property of the order has an unexpected value. This is important because you want to reuse the existing infrastructure for error handling already implemented in the Dynamic Data web pages.
It is equally as important to ensure that unexpected error conditions are not reported as ValidationException instances. If something unexpected happens, you want the application to fail fast, log detailed information on the server, and display a generic error message to the user without revealing any potentially exploitable technical information about the system. For instance, if the orderId is incorrect and there is no matching order in the database, the LINQ extension method First throws an InvalidOperationException saying, “Sequence contains no elements.” This error should not occur under normal circumstances and needs to be investigated by developers, so wrapping it in a ValidationException would only make the problem harder to notice.
You can read about the Fail Fast approach in an article written by Jim Shore for IEEE and available online at http://martinfowler.com/ieeeSoftware/failFast.pdf. Although it might seem counterintuitive at first, this approach significantly improves quality of applications by allowing developers to discover expected error conditions quickly and implement appropriate logic for handling them in a way that not only looks pretty, but also makes sense from the business standpoint.
Whether or not an error condition is expected during normal execution of the application depends on the perspective of the developer designing on the business layer. For instance, the FulfillOrder method just shown, which takes an OrderID as a parameter, treats an invalid order status value as an expected error condition based on an assumption that this method will be called from an Order web page where the user could click a Fulfill button more than once. This could happen if the user’s network connection is interrupted after the initial Order page is displayed and she clicks the browser’s Back button to fulfill the order again.
However, the overloaded version of the FulfillOrder method shown next, which takes an Order parameter, assumes that the caller is responsible for checking the current order status before trying to fulfill it. If the order is not Paid when the method is called, it throws the InvalidOperationException to indicate that there is a bug in the calling code.
public partial class NorthwindEntities
{
public void FulfillOrder(Order order)
{
if (order.OrderStatus != (byte)DataModel.OrderStatus.Paid)
{
throw new InvalidOperationException(
"Order status must be Paid for the order to be fulfilled");
}
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
IQueryable<Order_Detail> orderItems = this.Order_Details
.Include("Product")
.Where(od => od.OrderID == order.OrderID);
foreach (Order_Detail orderItem in orderItems)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
A simple rule of thumb to decide which type of exception a business rule method should throw is to think about who is responsible for solving the problem. If the error is caused by something the user did and needs to correct in the application, throw a ValidationException. If the error is caused by something a developer did and needs to correct in the code calling the business rule method, throw an InvalidOperationException or an ArgumentException, if the error is associated with a specific method parameter.
Trying to design a comprehensive set of validation checks to a business rule method upfront is not only challenging, but also counterproductive as it often leads to analysis paralysis and over-engineering. Instead, it is normal and desirable to add validation checks to the business rule methods as you continue to learn the business domain and discover new error conditions your application needs to handle gracefully. As long as you continue to create new and maintain existing automated tests that cover most of the business logic in your Entity Framework context and entity classes, the risk of introducing breaking changes remains low throughout the lifetime of your project.
Implement State-Specific Persistence Validation in Separate Validation Methods
When persistence validation rules differ significantly between entity states, you can simplify implementation of the validation logic by creating a separate validation method for each distinct entity state. As an example, consider validation rules for the Order entity.
When the OrderStatus is Draft, the Order entity object represents a shopping cart of a customer shopping on the Northwind Trader’s website. A draft order might be empty; it does not have to have a shipping address or an order date, but for the sake of this example, let’s say that a draft order needs to be associated with a customer because that is how the system retrieves the shopping cart for returning users.
On the other hand, when the OrderStatus is Submitted, the system has to ensure that OrderDate, RequiredDate, and other properties are valid, as well as check that all items in the order have a sufficient number of units in stock. These validation rules are simply not applicable to orders in other states. In particular, for draft orders, you don’t care if the items are in stock because you don’t know how many items the customer is going to order. On the other hand, for fulfilled orders, the items have already been shipped from the warehouse, and it doesn’t make sense to check the current inventory.
Because the declarative validation framework in the DataAnnotations namespace does not support conditional validation, you need to implement state-specific validation rules in validation methods. Although you could create a separate custom validation method for each property, many validation rules apply only to a given entity state, so the same conditional logic will be repeated in multiple validation methods. To reduce code duplication, group validation rules in a smaller number of state-specific methods.
Listing 9.1 shows an example of implementing state-specific validation rules for the Order entity. In this implementation, the Order class has a separate validation method for each value of the OrderStatus property—ValidateDraftOrder, ValidateSubmittedOrder, ValidatePaidOrder, and ValidateFufilledOrder—that are called from a switch statement by the main Validate method. With this approach, the validation rules for Submitted orders, which are quite different from the validation rules for Draft orders, are implemented in two different methods and do not conflict with each other.
Listing 9.1. Partial Order Class with State-Specific Validation Methods
partial class Order : IValidatableObject
{
public IEnumerable<ValidationResult> Validate(ValidationContext context)
{
switch ((DataModel.OrderStatus?)this.OrderStatus)
{
case null:
case DataModel.OrderStatus.Draft:
return this.ValidateDraftOrder(context);
case DataModel.OrderStatus.Submitted:
return this.ValidateSubmittedOrder(context);
case DataModel.OrderStatus.Paid:
return this.ValidatePaidOrder(context);
case DataModel.OrderStatus.Fulfilled:
return this.ValidateFulfilledOrder(context);
default:
Debug.Fail("Unexpected OrderStatus value");
return new ValidationResult[0];
}
}
private IEnumerable<ValidationResult> ValidateDraftOrder(ValidationContext c)
{
if (this.Customer == null && string.IsNullOrEmpty(this.CustomerID))
yield return new ValidationResult(
"The Customer is required", new[] { "Customer" });
}
private IEnumerable<ValidationResult> ValidateSubmittedOrder(ValidationContext c)
{
if (this.OrderDate == null)
yield return new ValidationResult(
"The Order Date is required", new[] { "OrderDate" });
if (this.OrderDate.Value < DateTime.Today)
yield return new ValidationResult(
"The Order Date cannot be in the past", new [] { "OrderDate" });
if (this.RequiredDate != null &&
this.RequiredDate <= this.OrderDate.Value.AddDays(3))
yield return new ValidationResult(
"The Required Date must be greater than Order Date + 3 days",
new[] { "RequiredDate" });
Product product = this.Order_Details
.Where(item => item.Product.UnitsInStock < item.Quantity)
.Select(item => item.Product).FirstOrDefault();
if (product != null)
yield return new ValidationResult(product.ProductName + " is out of stock");
}
private IEnumerable<ValidationResult> ValidatePaidOrder(ValidationContext c)
{
// Validation logic specific to paid orders
return new ValidationResult[0];
}
private IEnumerable<ValidationResult> ValidateFulfilledOrder(ValidationContext c)
{
// Validation logic specific to fulfilled orders
return new ValidationResult[0];
}
}
Validation rules that are shared by all states of an entity can be implemented either declaratively by applying validation attributes or in the main Validate method of the entity class. For complex entities that need to support large number of validation rules, you might want to consider using the Strategy pattern (Design Patterns: Elements of Reusable Object-Oriented Software by Eric Gamma, Richard Helm, Ralph Johnson, and John Vlissides) and moving validation rules specific to a particular state to a separate validation class. However, for simple entities, where the number of rules is relatively small, a simple switch statement showed in this example can do the same job without the overhead of introducing separate validation classes.
Validation of Related Entities
It might be challenging to determine the right place to implement validation logic that requires information from related entities. And although it might seem that the Order_Detail entity should be responsible for validating its Quantity property against the Product’s UnitsInStock, it doesn’t work because an Order_Detail object might not change when the order is submitted. Instead, it is better to validate all Order_Detail objects in a particular order at once when the order status changes to Submitted. Not only does this approach allow you to validate the unchanged Order_Detail objects, it is usually more efficient from the database access standpoint as well. Here is an extract from the ValidateSubmittedOrder method in Listing 9.1 that performs this validation:
Product product = this.Order_Details
.Where(item => item.Product.UnitsInStock < item.Quantity)
.Select(item => item.Product).FirstOrDefault();
if (product != null)
yield return new ValidationResult(product.ProductName + " is out of
stock");
To check for out-of-stock products in an order, the ValidateSubmittedOrder method iterates over all Order_Detail objects of the order, comparing their Quantity with the number of UnitsInStock of the product. If any order item does not have enough product units available, a ValidationResult is returned to indicate an error.
This code relies on the lazy loading, which is enabled by default in the NorthwindEntities class, to access Product entity objects. As you recall from our previous discussion, lazy loading makes writing code easier at the cost of performance. Here is how we could rewrite the Order validation logic to determine if it has any out-of-stock items in a single database request (remember that context is the ValidationContext object passed to the ValidateSubmittedOrder method as a parameter):
var entities = (NorthwindEntities)context.Items[typeof(ObjectContext)];
string productName = entities.Order_Details
.Where(item => item.OrderID == this.OrderID
&& item.Product.UnitsInStock < item.Quantity)
.Select(item => item.Product.ProductName).FirstOrDefault();
if (productName != null)
yield return new ValidationResult(productName + " is out of stock");
Although the new LINQ query looks similar to the previous version, the key difference is that this new version uses the Order_Details property of the NorthwindEntities class, which returns an IQueryable<Order_Detail> instead of the Order_Details property of the Order class, which returns an IEnumerable<Order_Detail>. As a result, instead of using LINQ to Objects and iterating over the lazy-loaded Order_Detail collection in memory of the application, you now use LINQ to Entities to send a single request the database server, query the Order_Details and Products tables, and return the name of the first out-of-stock product.
The ValidateSubmittedOrder method retrieves an instance of the NorthwindEntities object context from the ValidationContext object. As discussed in Chapter 8, the ValidationContext allows the UnleashedObjectContext to pass the ObjectStateEntry object that stores the entity itself to the validation methods. To make the NorthwindEntities object context available as well, the Validate method of the UnleashedObjectContext class was further extended as shown in Listing 9.2.
Listing 9.2. Making ObjectContext Available to Validation Methods
public partial class UnleashedObjectContext
{
private void Validate(ObjectStateEntry stateEntry)
{
object entity = stateEntry.Entity;
var items = new Dictionary<object, object>();
items[typeof(ObjectStateEntry)] = stateEntry;
items[typeof(ObjectContext)] = this;
var context = new ValidationContext(entity, null, items);
var results = new List<ValidationResult>();
if (!Validator.TryValidateObject(entity, context, results, true))
ThrowValidationException(entity, results);
}
}
Entity Deletion Rules
Because persistence validation rules are designed to ensure that entities are saved in a valid state, most of them are not applicable and should not be evaluated when entities are deleted. For example, suppose you have a requirement to prevent deletion of orders after they have been submitted. Even though you implemented a custom validation method that requires the OrderDate not to be in the past, from deletion standpoint, you only care about the value of the OrderStatus property. Evaluating the validation rules for the OrderDate and other properties would prevent deletion of an entity that should have otherwise been allowed.
Because persistence validation rules are not applicable to entity deletion, the BeforeSaveChanges method of the UnleashedObjectContext class validates only added and modified entities. On the other hand, the ISavableObject interface is not bound by the same constraints as the validation logic. The UnleashedObjectContext class calls the BeforeSave method of all entities, including the deleted ones, which allows you to implement validation of entity deletion without introducing conflicts with the validation of entity persistence. Here is how you can implement the BeforeSave method in the Order class to allow deleting only Draft orders:
partial class Order: ISavableObject
{
public void BeforeSave(ObjectStateEntry stateEntry)
{
if (stateEntry.State == EntityState.Deleted &&
this.OrderStatus != (byte)DataModel.OrderStatus.Draft)
throw new ValidationException("Only draft orders can be deleted");
}
}
As you recall from the previous discussion, a good rule of thumb when designing validation logic is to implement persistence validation with data annotations and transition validation with business rule methods. From the validation standpoint, deletion is an odd ball because it can fit in either of these two categories depending on your point of view. It may be helpful, however, to treat entity deletion as a form of state transition. From this point of view, the BeforeSave method becomes a special business rule method that can be used to implement property interaction rules and validation of deletion.
Reusing Entity Validation in Business Rule Methods
Would it be possible or beneficial to reuse the entity validation rules in business rule methods? For instance, you have already implemented validation rules to prevent submitting orders for out-of-stock items. Should the FulfillOrder method also check that all items are in stock before updating the product inventory? Invoking entity validation rules from a business rule method is certainly possible and could be a good idea.
As discussed in Chapter 8, the UnleashedObjectContext class was extended to perform validation of all entities before they are saved in the database. It defines a method called Validate (see Listing 9.2), which takes an ObjectStateEntry as a parameter and validates a single entity object. To make invoking validation rules in business rule methods more clean and convenient, UnleashedObjectContext also provides an overloaded version of this method (shown next) that takes an entity object as a parameter. This method retrieves its ObjectStateEntry from the ObjectStateManager, and calls the main Validate method.
public partial class UnleashedObjectContext
{
protected void Validate(object entity)
{
ObjectStateEntry stateEntry =
this.ObjectStateManager.GetObjectStateEntry(entity);
this.Validate(stateEntry);
}
}
With the new Validate method, you could modify the FulfillOrder business rule method to check the order before trying to fulfill it and ensure that it is valid according to all property- and entity-level validation attributes and coded rules implemented for the Order entity class.
public partial class NorthwindEntities
{
public void FulfillOrder(Order order)
{
this.Validate(order);
if (order.OrderStatus != (byte)DataModel.OrderStatus.Paid)
{
throw new InvalidOperationException(
"Order status must be Paid for the order to be fulfilled");
}
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
IQueryable<Order_Detail> orderItems = this.Order_Details
.Include("Product")
.Where(od => od.OrderID == order.OrderID);
foreach (Order_Detail orderItem in orderItems)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
}
}
Remember that all modified entities go through the mandatory validation before they are persisted in the database in the SaveChanges method that was overidden in the UnleashedObjectContext. Although you could also call the Validate method at the end of FulfillOrder as well to check the modified Order and Product entities, doing so would most likely result in the same validation rules executed two times without any additional changes made to the entities in between. In other words, forcing validation of entity objects at the end of business rule methods is usually redundant and can lead to unnecessary performance problems if validation rules require access to related entities that have to be retrieved from the database.
Forcing validation of entity objects in the beginning of business rule methods can also be redundant. If a business rule method, such as the overload of FulfillOrder that takes OrderID as a parameter, is responsible for retrieving an entity object from the database, you can often assume that the entity object is still valid because it already passed all validation rules last time it was saved to the database. In the FulfillOrder(Order) method, the calling code could have changed the Order entity, making its explicit validation potentially worthwhile. However, in the FulfillOrder(Int32) method, you can safely assume that the Order entity retrieved from the database is still valid, making the explicit revalidation unnecessary.
Although reusing entity- and property-level validation rules in business rule methods helps to improve correctness of your application and its data integrity, it comes at the cost of additional resources required to perform the extra checks. It is usually not a good idea to do this in production code. However, you can benefit from the additional validation in business rule methods during active development and testing of your application by conditionally compiling it. Here is how you could change the FulfillOrder method to validate the Order object only in the Debug configuration of the DataModel project, which defines the DEBUG compiler symbol.
public void FulfillOrder(Order order)
{
#if DEBUG
this.Validate(order);
#endif
// ...
}
You can use the Debug version of the business layer during the initial active development and testing of your application, when finding problems faster is more important than squeezing every bit of performance from the application. When the testing is finished and you are ready to deploy the application to the production environment, it should be safe to assume that the interaction between the presentation and business logic was implemented correctly. At this point, you can deploy the Release version of the business layer, which does not have the additional validation checks and will work faster.
If you do choose to perform additional validation in the release version of the application, it is a good idea to verify that it has no significant effect on the application performance. Remember that CPU and RAM resources of web servers can be increased easily, but additional database access can be costly and limits the application’s ability to scale.
Saving Changes
When implementing business rule methods, such as the FulfillOrder method of the NorthwindEntities context, you might be wondering if saving changes (by calling the SaveChanges method of the ObjectContext) is a good idea. If the SaveChanges method has to be called anyway, why not simply call it from the FulfillOrder method itself?
A business rule method knows how to retrieve and manipulate a specific set of entities. However, it has no way of saving only those entities it modifies. The SaveChanges method of the ObjectContext class saves all changed entities, so calling it in the FulfillOrder method could affect not only the Order and Product entities it modified, but also all other entities that were changed before the method was called. This might produce unexpected side effects further up the call stack, especially when business rule methods can be called from other methods. From the viewpoint of a developer reading the code, it is also easier to understand the code if it is responsible for both creating the ObjectContext and saving changes. Because there is no way to tell if the FulfillOrder method saves changes by reading this code alone, intuitively, you would assume that changes are not saved unless the SaveChanges method is called:
using (var context = new NorthwindEntities())
{
int orderId = // ...
context.FulfillOrder(orderId);
context.SaveChanges();
}
Saving changes inside of business rule methods also makes maintenance of automated tests more difficult. Although the TransactionScope-based approach to enforcing test isolation discussed in Chapter 8 will continue to work, saving changes from a method under test requires additional disk access and makes the test slower. As the number of automated tests increases, their performance becomes more and more important. By keeping saving logic out of business rule methods, you reduce disk access and speed up the tests.
Although there are no hard rules against this, it is usually a good idea to keep the persistence logic out of the business rule methods and entity classes. Instead, it is better to save changes in the business process code, which is usually implemented outside of the Entity Framework context and invoked by the user. For example, a web page or a console application is a better place to save changes.
Managing Transactions
Although the TransactionScope supports hierarchical transactions and you could put one inside of a business rule method, you need to remember that transactions do not apply to changes made in the memory of the application. For instance, you could modify the FulfillOrder method to update the Order and Product entities inside of a TransactionScope:
using (var transaction = new TransactionScope())
{
order.OrderStatus = (byte)DataModel.OrderStatus.Fulfilled;
order.ShippedDate = DateTime.Now;
IQueryable<Order_Detail> orderItems = this.Order_Details
.Include("Product")
.Where(od => od.OrderID == order.OrderID);
foreach (Order_Detail orderItem in orderItems)
orderItem.Product.UnitsInStock -= orderItem.Quantity;
transaction.Complete();
}
However, remember that the Order and Product entities are not saved to the database here; they are merely modified in memory. The TransactionScope in this example encompasses only the query that retrieves the Order_Detail and Product entities from the database. Because Microsoft SQL Server and other database servers already execute SQL queries in transactions by default, using an explicit transaction here would only increase complexity without adding any benefits. Instead, it is better to implement transaction logic in the same place as the persistence logic—outside of the business rule methods, as shown in the following example:
using (var transaction = new TransactionScope())
using (var context = new NorthwindEntities())
{
int orderId = // ...
context.FulfillOrder(orderId);
context.SaveChanges();
transaction.Complete();
}
Invoking Business Rules in Web Applications
Out of the box, Dynamic Data does not provide a way to invoke a custom business rule method from a dynamically generated page. Instead, you need to create a custom page or a custom page template and write code to call the method explicitly. Listing 9.3 shows markup of a custom page that displays an Order entity in a read-only FormView control, with a Fulfill button that users can click to mark the order as fulfilled.
Listing 9.3. Custom Order Page with Fulfill Button (Markup)
<%@ Page Language="C#"
MasterPageFile="~/Site.master" CodeBehind="SamplePage.aspx.cs"
Inherits="WebApplication.Samples.Ch9.EntityMethod.SamplePage" %>
<asp:Content ContentPlaceHolderID="main" runat="server">
<h2>Entry from table <%= ordersTable.DisplayName %></h2>
<asp:ValidationSummary runat="server" />
<unl:UnleashedValidator runat="server" ID="validator"
ControlToValidate="formView" Display="None"/>
<asp:FormView runat="server" ID="formView" DataSourceID="dataSource"
DataKeyNames="OrderID">
<ItemTemplate>
<asp:DynamicEntity runat="server" />
<tr><td colspan="2">
<asp:Button runat="server" Text="Fulfill" OnClick="FulfillButton_Click" />
</td></tr>
</ItemTemplate>
</asp:FormView>
<asp:EntityDataSource ID="dataSource" runat="server"
ConnectionString="name=NorthwindEntities"
DefaultContainerName="NorthwindEntities" EntitySetName="Orders" />
<asp:QueryExtender TargetControlID="dataSource" runat="server">
<asp:DynamicRouteExpression />
</asp:QueryExtender>
</asp:Content>
Most of the code in Listing 9.3 is very similar to the Details page template discussed in Chapter 6, “Page Templates.” (In fact, you could have created it as a custom page template for the Order entity.) The only notable difference here is the Fulfill button, which replaced the usual Edit, Delete, and Show All Items links used by the Details page template. Listing 9.4 shows the code-behind.
Listing 9.4. Custom Order Page with Fulfill Button (Code-Behind)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web.DynamicData;
using DataModel;
namespace WebApplication.Samples.Ch9.ContextMethod
{
public partial class SamplePage : System.Web.UI.Page
{
protected MetaTable ordersTable;
protected void Page_Init(object sender, EventArgs e)
{
this.ordersTable = MetaModel.Default.GetTable(typeof(Order));
this.formView.SetMetaTable(this.ordersTable);
this.dataSource.Include = this.ordersTable.ForeignKeyColumnsNames;
}
protected void FulfillButton_Click(object sender, EventArgs args)
{
using (var context = new NorthwindEntities())
{
int orderId = (int)this.formView.DataKey.Value;
context.FulfillOrder(orderId);
context.SaveChanges();
this.Response.Redirect(
this.ordersTable.GetActionPath(PageAction.Details,
new List<object>(new object[] { orderId })));
}
}
}
}
The FulfillButton_Click method handles the Click event of the Fulfill button. Because the event handler is invoked during a post-back, the original Order entity instance displayed by the page is no longer available. In this example, OrderID is extracted from the DataKey property of the FormView control. Alternatively, if this were a custom page template and the OrderID was available in the URL, you could have obtained it by calling the GetColumnValuesFromRoute method of the MetaTable object discussed in Chapter 7.
If the SaveChanges method completes successfully without any validation or database exceptions thrown, the FulfillButton_Click method redirects the user’s browser to the dynamically generated Details page for the current order. The address of this page is determined by calling the GetActionPath method of the MetaTable object describing the Order entity. This is consistent with the pattern used by the default page templates in Dynamic Data applications that have a distinct page per action. If you prefer to display the updated entity in the same page, you could simply call the DataBind method of the FormView control instead.
Error Handling
As discussed in Chapter 8, the EntityDataSource control catches the exceptions that might be thrown by the SaveChanges method of the NorthwindEntities context class and, by the means of its Exception event, notifies the DynamicValidator controls on the page, enabling them to display the expected validation errors. However, the FulfillButton_Click event handler in Listing 9.4 works with a NorthwindEntities context object directly and currently does not have any error handling logic. If the business rule or the SaveChanges methods throw a ValidationException, the user will see a yellow page of death generated by the ASP.NET runtime.
As of version 4 of the .NET Framework, there is no way to make the EntityDataSource control execute custom code and reuse the error-handling infrastructure the DynamicValidator controls and the field templates provide for Insert, Update, Delete, and Select operations. You have to write your own code to catch and display expected exceptions. The next example shows a new version of the FulfillButton_Click event handler that displays all error messages in the ValidationSummary control at the top of the page.
protected void FulfillButton_Click(object sender, EventArgs args)
{
using (var context = new NorthwindEntities())
try
{
int orderId = (int)this.formView.DataKey.Value;
context.FulfillOrder(orderId);
context.SaveChanges();
this.Response.Redirect(
this.ordersTable.GetActionPath(PageAction.Details,
new List<object>(new object[] { orderId })));
}
catch (Exception e)
{
if (!this.validator.HandleException(e)) throw;
}
}
The new version of the FulfillButton_Click event handler wraps a try/catch block around the FulfillOrder and SaveChanges method calls, which could throw validation exceptions. The catch block intercepts all exceptions and passes them to the HandleException method of the UnleashedValidator (defined at the top of the page in Listing 9.3). If the HandleException method returns false, the code re-throws the exception.
As discussed in Chapter 8, the UnleashedValidator class inherits from the built-in DynamicValidator and extends error handling to support AggregateException. The HandleException method receives an Exception object as a parameter, iterates over all UnleashedValidator controls on the page, including those in field templates, and attempts to handle the exception by passing it to each validator’s ValidateException method. The HandleException returns true if one or more validators on the page were able to handle the exception by setting their ValidationException properties. For complete details, please refer to the UnleashedValidator source code in the Unleashed.DynamicData project accompanying the book.
Figure 9.8 shows an example of an error message displayed because of the ValidationException thrown in the FulfillOrder business rule method.
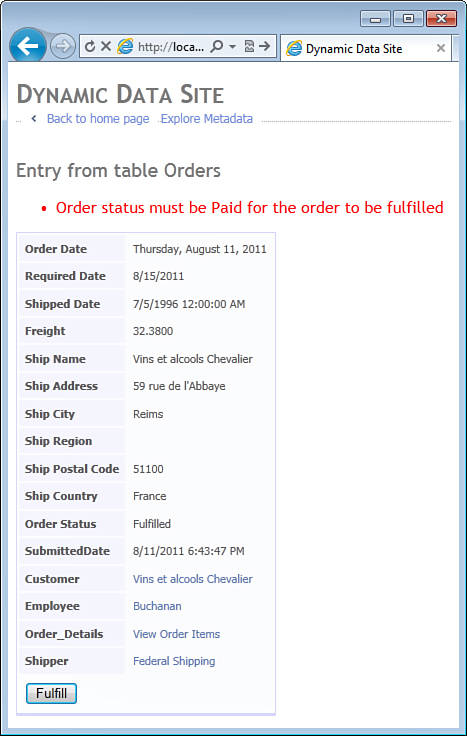
Figure 9.8. Validation error from calling a business rule method.
The read-only field templates do not include validators by default. With less than ten read-only field templates included in a Dynamic Data project out of the box, you can add the UnleashedValidator controls to the field templates and improve display of property-specific errors. However, if you choose to do it, make sure the validators are hidden when there are no errors; otherwise, the increase in the size of generated HTML and JavaScript could have a significant impact on performance of all read-only pages in the application.
Business Rules in the Database
Some of the business logic discussed in this chapter is similar to what you can do with database stored procedures, triggers, and check constraints. It is indeed possible to implement robust business rules directly at the database level; however, doing so has an immediate impact on performance and scalability of the overall system, which are especially important for high-volume web applications.
A system scales up when its performance can be increased by installing faster or additional CPUs and RAM on a single physical computer. On the other hand, a system scales out when its performance can be increased by adding more computers. Scaling up is expensive; the cost of both hardware and software grows exponentially as the number of CPUs and amount of RAM increases beyond typical commodity levels. In practice, this means that performance you can get out of a database server has a practical limit, sometimes called a glass ceiling, which would require unreasonably high costs to break through. Scaling out is much cheaper, as the cost of adding commodity servers to the system grows only linearly. Unfortunately, most relational database management systems that exist today scale up much better than they scale out; in fact, scaling out a database server is nearly impossible without redesigning the system itself.
In general, scalability of an information system can be improved by performing CPU-bound tasks on the application servers (such as a web server in our example) and I/O-bound tasks on the database server. Most of the business rules discussed so far are CPU-bound, or in other words, they only need CPU cycles to execute and do not need to access the database. Therefore, implementing them in the entity classes of the application allows you to scale out the system by adding application servers and leaving the precious resources of the database server available for compiling queries and calculating execution plans.
However, some types of business logic, such as validation of uniqueness or referential integrity, are I/O-bound. They require access to data and can be implemented more efficiently on the database server. Suppose that all products in the Northwind database must have unique names. If you implement this validation logic in the Product entity class, the application would need to send one request to the server to query the Products table for products with a given name, followed by another request to insert a new record. However, if you create a UNIQUE KEY constraint for the Products table in the database, the application only needs to send a single request to insert the new record and can rely on the database server to verify that the ProductName of the new record is unique. Both implementations require the same number of logical operations; however, the database implementation requires fewer server requests, results in less data sent back and forth, and allows the database server to choose the best way to enforce the uniqueness rule.
Integrating Database Validation in Dynamic Data Applications
Here is a T-SQL script you can use to implement validation of the ProductName uniqueness at the database level:
ALTER TABLE [dbo].[Products]
ADD CONSTRAINT [UK_Products]
UNIQUE (ProductName)
Without additional changes, an attempt to create a new Product with a duplicate name through the Dynamic Data web application results in a yellow screen of death, as shown in Figure 9.9.
Figure 9.9. Default error page generated for database exceptions.
Obviously, a yellow page of death is not acceptable in a production-ready web application, and you need to change it to report the error consistently with other validation results implemented in the application code. In particular, you need to catch the appropriate exceptions and rethrow them wrapped inside of ValidationException instances. Here is how you can override the SaveChanges method of the NorthwindEntities class to do this:
public override int SaveChanges(SaveOptions options)
{
try
{
return base.SaveChanges(options);
}
catch (UpdateException e)
{
HandleSqlException(e);
throw;
}
}
The new version of the SaveChanges method puts the call to the base method inside of a try/catch block to intercept database errors reported as instances of the UpdateException class by the Entity Framework. The UpdateException itself provides a very generic error message saying that an error has occurred when trying to save changes; however, the underlying database error is still available through its InnerException property used in the HandleSqlException method shown here:
private static void HandleSqlException(Exception e)
{
SqlException error = e.InnerException as SqlException;
if (error != null)
{
if (error.Number == 547)
HandleReferenceConstraintViolation(error);
else if (error.Number == 2627)
HandleUniqueKeyConstraintViolation(error);
}
}
In this example, Microsoft SQL Server is used, so the inner exception will be of type SqlException defined in the System.Data.SqlClient namespace. You can determine what kind of error has occurred by looking at the SQL error Number, which for the violation of a UNIQUE KEY constraint will be 2627 and for a FOREIGN KEY violation will be 547.
The Microsoft SQL Server documentation does not offer a comprehensive list of error numbers and suggests querying the sys.messages view for details. You might find this impractical for finding an error number based on an error type given the list includes more than 8,000 messages for a single language. It is often easier to find a specific error code by triggering the error condition with a SQL script and getting it from the actual error reported by the SQL Server.
If you are using a database platform other than Microsoft SQL Server, you need to rely on the low-level exceptions, error messages, and error codes provided by your database vendor because the current version of the Entity Framework does not allow accessing this information in a generic fashion.
Error codes, such as 547 and 2627 in the previous example, are difficult to understand and remember. Just like with any hard-coded literals, it is usually a good idea to use constants that encapsulate them instead. Unfortunately, the .NET SQL Client does not offer ready-to-use constants. In this case, they are left as literals because HandleSqlException method is the only place in the sample application where they are being used. They also appear next to the HandleReferenceConstraintViolation and HandleUniqueKeyConstraintViolation methods, which help to explain their meaning.
When you detect an expected database exception, such as the violation of a UNIQUE KEY constraint, you can wrap it in a ValidationException, which the DynamicValidator controls in the application web pages display to the users. Because different database errors require slightly different handling logic, there is a separate method for each expected type of error, such as the HandleUniqueKeyConstraintViolation method shown here:
private static void HandleUniqueKeyConstraintViolation(SqlException error)
{
throw new ValidationException(error.Message);
}
The initial implementation of the unique key violation error handler simply throws a ValidationException with the low-level error message reported by the database. Although this prevents the yellow page of death, the error message is not very helpful and will say something along these lines:
Violation of UNIQUE KEY constraint 'UK_Products'. Cannot insert duplicate
key in object 'dbo.Products'.
This error message contains technical terms, such as the table name, as opposed to the business terms used by the application user interface. It also does not explain what a “duplicate key” means for Products—is it the Product Name alone, a Product Name from a particular Supplier, or perhaps a Product Name within a particular Category? And last, but not least, it reveals the low-level technical details that can help an attacker access the database directly.
Detailed metadata information about database constraints, such as which columns constitute a particular UNIQUE KEY, is available in the SQL Server database itself. You could extract it with the help of the SQL Server Management Objects API provided in the Microsoft.SqlServer.Smo assembly by the SQL Server client. Knowing the database columns, you could then use the Entity Framework mapping schema to determine the entity properties mapped to these columns and then determine their display names with the help of the TypeDescriptor.
As you can imagine, the metadata-driven approach requires a lot of work. In addition to using the metadata APIs for both SQL Server and Entity Framework, you would have to parse the Entity Framework mapping schema (MSL) in raw XML form because it has no public API at this time. Even if you go through all this trouble, the resulting error message you could generate automatically will probably be very technical, dry, and difficult for business users to understand. Instead, you can display a custom error message when a particular database constraint is violated, which is both easier to implement and provides more meaningful messages to the users.
Because database error messages are application-specific, the sample solution accompanying this book implements them in the NorthwindEntities class (application) and not in the UnleashedObjectContext base class (infrastructure).
static readonly Dictionary<string, ValidationResult> ConstraintErrors =
new Dictionary<string, ValidationResult>()
{
{ "UK_Products", new ValidationResult(
"Product Name must be unique.", new string[] { "ProductName" }) },
{ "FK_Order_Details_Products", new ValidationResult(
"Product is referenced in one or more Orders and"+
"cannot be deleted.") }
};
ConstraintErrors is a static dictionary, defined in the NorthwindEntities class to store constraint names and ValidationResult objects that represent their violation errors. A ValidationResult object allows you to not only provide a meaningful error message, but also associate it with a particular property, such as the ProductName, which the DynamicValidator controls can use to display an asterisk next to the offending field control on the web page. You also need to modify the HandleUniqueKeyConstraint Violation method, as shown next, to take advantage of the new dictionary:
private static void HandleUniqueKeyConstraintViolation(SqlException error)
{
Match match = Regex.Match(error.Message,
"Violation of UNIQUE KEY constraint '(?<Constraint>.+?)'",
RegexOptions.IgnoreCase);
string constraint = match.Groups["Constraint"].Value;
ValidationResult validationResult;
if (ConstraintErrors.TryGetValue(constraint, out validationResult))
ThrowValidationException(null, new [] { validationResult });
}
The new version the HandleUniqueKeyConstraintViolation method uses regular expressions, namely the Regex class from the System.Text.RegularExpressions namespace, to extract the constraint name from the error message. The regular expression pattern includes a capture group called Constraint. Having extracted the name of the constraint from the capture group, the code tries to lookup a ValidationResult object in the ConstraintErrors dictionary and if the lookup was successful, calls the ThrowValidationException method. As you might recall from Chapter 8, this method is defined in the UnleashedObjectContext base class. It takes the entity object as its first parameter, a list of ValidationResult objects, and throws an appropriate exception, either a ValidationException or an AggregateException, depending on the number of validation results.
Detailed discussion of regular expressions could take hundreds of pages. For additional information on this subject, please refer to the following resources:
• http://msdn.microsoft.com/library/hs600312.aspx
• Sams Teach Yourself Regular Expressions in 10 Minutes
Figure 9.10 shows the final version of the UNIQUE KEY error message displayed on the Product insert page. Notice that a custom error message is now displayed at the top of the page, and an asterisk indicates that Product Name is the field that caused the error.
Figure 9.10. Custom error generated for an expected database exception.
Implementing Validation Rules in Triggers
By optimizing LINQ queries and performing validation checks only when they are appropriate in the life cycle of the business entity, such as validating that product inventory is sufficient only when the order status changes from Draft to Submitted, you should be able to reach adequate performance in most validation methods of your application. However, if you find that further optimization is necessary, you can reimplement I/O-bound validation logic in database triggers. Here is a trigger that implements the validation rule for checking product inventory at the database level:
CREATE TRIGGER [Order_CheckOutOfStockProducts]
ON [dbo].[Orders] FOR INSERT, UPDATE AS
BEGIN
SET NOCOUNT ON;
DECLARE @productName NVARCHAR(50);
SELECT @productName = product.ProductName
FROM [Order Details] AS item
JOIN inserted ON item.OrderID = inserted.OrderID
JOIN Products AS product ON item.ProductID = product.ProductID
WHERE inserted.OrderStatus = 1
AND product.UnitsInStock < item.Quantity;
IF @productName <> null
BEGIN
DECLARE @errorMessage NVARCHAR(MAX) = @productName + ' is out of
stock';
RAISERROR (@errorMessage, 11, 0);
END;
END;
Just like the last version of the Order validation logic that was implemented using LINQ in the application code, this T-SQL code executes a single query, joining the Order Details and the Products tables to find order items for products out of stock. The only notable difference in the query logic is the use of the inserted pseudo-table, which in this trigger provides access to the rows of the Orders table that were inserted or updated. The query sets the @productName variable with the name of an out-of-stock product, and the trigger calls the RAISERROR system function if any such products are found.
The first parameter of RAISERROR is the error message that will be reported to the application. The second parameter, severity, indicates the type of error. Severity values between 11 and 16 indicate user errors and throw a SqlException in .NET applications. The third parameter, state, provides additional information about where the error has occurred, and you can simply use zero, if you don’t plan to use it.
Custom validation errors implemented this way can be handled similarly to the built-in errors, such as the UNIQUE KEY and FOREIGN KEY constraint violations discussed earlier. All that is needed is to change the HandleSqlException method of the NorthwindEntities class, as shown next, to handle the SqlException instances thrown by RAISERROR:
private static void HandleSqlException(Exception e)
{
SqlException error = e.InnerException as SqlException;
if (error != null)
{
if (error.Number == 547)
HandleReferenceConstraintViolation(error);
else if (error.Number == 2627)
HandleUniqueKeyConstraintViolation(error);
else if (error.Number >= 50000 && error.Class <= 16)
throw new ValidationException(error.Message);
}
}
The HandleSqlException method wraps all SqlException instances with error codes 50000 and above and severity levels 16 and below in ValidationException instances. These error codes and severity levels distinguish the user errors reported by calling RAISERROR from informational messages and system errors. Informational messages have severity level 10 or lower and do not throw a SqlException. System errors have severity level 17 or higher, and although they also throw SqlException, system errors are not expected during normal execution of the application and thus should not be reported as validation errors.
Triggers and stored procedures described here are more challenging with the code-first approach to development of the entity model. The database management functionality built into the Entity Framework does not support triggers and stored procedures directly, requiring you to manage their source code separately and making database deployment more complex. The database-first and model-first approaches, on the other hand, rely on SQL scripts for database deployment and do not have this problem.
Implementing Business Rules in Stored Procedures
Similar to validation rules, it is possible to optimize business rule methods by re-implementing them in SQL stored procedures. Listing 9.5 shows a stored procedure, which is a T-SQL equivalent of the FulfillOrder business rule method implemented earlier.
Listing 9.5. FulfillOrder Stored Procedure
CREATE PROCEDURE [dbo].[FulfillOrder]
@orderId int
AS
BEGIN
UPDATE Orders SET
OrderStatus = 3,
ShippedDate = GETDATE()
WHERE OrderID = @orderId
AND OrderStatus = 2;
IF @@ROWCOUNT = 0
BEGIN
RAISERROR ('Order status must be Paid for the order to be fulfilled', 11, 0);
RETURN;
END;
UPDATE Products SET
UnitsInStock = UnitsInStock - od.Quantity
FROM Products AS p
JOIN [Order Details] AS od ON p.ProductID = od.ProductID
WHERE od.OrderID = @orderId;
END
The T-SQL version of the FulfillOrder is slightly more efficient as it checks the current order status as part of the UPDATE statement that changes it. The @@ROWCOUNT system variable indicates the actual number of rows affected by the previous statement, allowing this code to determine if the UPDATE statement was successful. Note that unlike throwing an exception in the .NET code, calling RAISERROR in T-SQL does not interrupt the execution of the stored procedure unless it is done from within a TRY block. This is why the FulfillOrder method has a RETURN statement right after RAISERROR; otherwise, the second UPDATE statement, which modifies the UnitsInStock column of the Product table, would be executed even for unpaid orders.
After creating the FulfillOrder stored procedure, you need to import its definition in the NorthwindEntities entity model. As you recall from a discussion in Chapter 2, “Entity Framework,” this requires two steps. First, you need to use the Entity Designer to update the model from the database and create a definition of the stored procedure in the storage model of the EDMX. Second, you need to use the Model Browser to create a function import in the conceptual model, which generates a new method in the NorthwindEntities class when the EDMX file is saved.
Because additional code is required to handle database errors, you do not want the stored procedure method to be called directly by the presentation layer. Instead, you want the function import to have a different name—SqlFulfillOrder—and have internal access so that only the FulfillOrder method can call it and not the web application. Here is how the FulfillOrder method will look after the optimization:
public void FulfillOrder(int orderId)
{
try
{
this.SqlFulfillOrder(orderId);
}
catch (EntityCommandExecutionException e)
{
HandleSqlException(e);
throw;
}
}
Note that the SqlFulfillOrder is called within a try/catch block because Entity Framework reports database errors that occur when calling stored procedures as instances of the EntityCommandExecutionException class. Because the code calling the FulfillOrder method expects only ValidationException, the FulfillOrder method catches the EntityCommandExecutionException instances and passes them to the HandleSqlException method created earlier. In other words, the exception handling code implemented here allows the order status validation now implemented in the T-SQL to continue throwing ValidationException as if it was still implemented in the .NET code.
Side Effects of Stored Procedures
The performance improvement of reimplementing business rule methods as stored procedures comes at a cost of introducing several undesirable side effects in your business layer design:
• Stored procedures persist changes to the database, unlike the business rule methods, which typically modify entity objects in memory and assume that the SaveChanges method of the ObjectContext will be called separately.
• Stored procedures bypass any validation or business rules you implemented in entity classes, executing only those implemented in the stored procedure itself or in the database triggers. For instance, the RangeAttribute applied to the UnitsInStock property of the Product entity class to prevent negative values is ignored.
• Stored procedures ignore state of any entities that were modified in the object context but not saved to the database yet. For instance, the code calling the FulfillOrder method might have changed status of the order to Paid, but in the database it is still stored as Submitted, causing an error in the stored procedure.
• Stored procedures don’t automatically refresh entities in the object context. For instance, the FulfillOrder stored procedure might have changed the UnitsInStock in a particular row in the Products table in the database, but the entity object that represents this row in the application code remains the same, which could lead to optimistic concurrency errors later.
In web applications, where ObjectContext instances are created and destroyed for each incoming request, you might be able to accept the risk of having these side effects. However, they present a significant problem in desktop and console applications, where ObjectContext instances can have a longer life span. If other types of applications reuse your business logic layer, such as the DataModel assembly in this book’s sample, you need to consider the decision to implement business rules as stored procedures very carefully. In many instances, the problems caused by the side effects and overhead of the workarounds you might be forced to implement are not worth the performance improvement you gain by using stored procedures in the first place.
Summary
O/R mapping frameworks, such as the Entity Framework and LINQ to SQL, provide a solid foundation for implementing business logic in your applications. Although good entity design requires solid understanding of both object-oriented and relational design principles, it allows you to create classes that represent real-world entities from your business domain and their interaction rules. Encapsulation of entities and rules in the business layer of the application is essential in Dynamic Data applications that can generate significant portions of the user interface dynamically and cannot have the business logic embedded in the presentation layer.
Although your first choice in implementing business rules should be application code, I/O-bound logic can be optimized to work at the database level. The database servers already validate uniqueness and referential integrity; custom validation and business rules can be implemented in database triggers and stored procedures as well. With a small upfront investment in integration of database error handling, this optimization can be done as needed without affecting the rest of the application.