
Chapter 4. Data Processing
Data applications provide value by processing large volumes of quickly changing raw data to provide customers with actionable insights and embedded analytical tools. There are many ways to approach data processing, from third-party tools and services to coding and deploying bespoke data pipelines. A modern data platform should support all of these options, giving you the power to choose which best meets your needs. In this chapter you will learn how to assess the trade-offs of different data processing methods, providing the necessary understanding to make informed choices about working with the tooling provided by data platforms.
We will start with an overview of design considerations for this space, highlighting the elements you should consider when architecting data processing pipelines as part of a data application. Then we’ll cover best practices and look at some real-world examples of implementing these practices with Snowflake’s Data Cloud.
Design Considerations
Data processing is a sizable task that needs to be done in a way that is very low latency, low maintenance, and does not require manual intervention. A data platform that can meet this challenge will enable product teams to focus on application development instead of managing ingestion processes, and will ensure that users get insights as quickly as possible. The considerations presented in this section will guide you as you consider how to approach data processing.
Raw Versus Conformed Data
Raw data is information stored in its original format. JSON stored as a document is an example of raw data. As mentioned in Chapter 2, relational systems can now store and query this kind of raw, semi-structured data, so it is already in a format that is usable without having to be transformed into a tabular structure. While it is possible to query raw data, the queries are less performant than those run against conformed data.
Conformed data is information that fits a specific schema, requiring transformation of raw data. The motivation to conform data comes from the performance improvements and interoperability advantages of tabular structures. Data that is organized is easier for query engines to work with, resulting in better speed and performance than that achieved by queries run against raw, semi-structured data. In addition, many data analysis tools require structured, tabular data.
The trade-offs of conforming data include time and cost. Translating data from a raw state into a tabular structure requires data pipelines to be developed and maintained. If the data source changes frequently, this will require recurring work to accommodate the new schema. In addition, raw data can be acted on immediately, whereas transforming raw data introduces the delay of data processing.
Understanding how data will be used will help guide the decision of what to conform and what to leave in a raw state. For example, if you launch a new feature for your application that requires a new data source, you might initially choose to leave the data in its raw state. Then, if the new feature proves popular, you could invest the resources to conform the data for better performance.
Data Lakes and Data Warehouses
A key difference between how data warehouses and data lakes handle data is that data warehouses store only conformed data, whereas data lakes contain data in its raw format. That is, a data warehouse transforms all data to a set schema as it is written, while a data lake performs the transformation on an as-needed basis, when the data is read by users. Because data warehouses conform data during ingestion, they can perform additional tasks on the data, such as validation and metadata extraction. For example, JPEG and video files themselves would not undergo an ELT process (described in “ETL Versus ELT”), but information about the content, source, and date of creation could be important to capture.
In legacy data warehouses, data was limited to that which could conform to a rigid schema, owing to the lack of support for unstructured data. If data could not be made to conform to the data warehouse schema, it couldn’t be used. This also meant users were limited to the data that had been curated inside the data warehouse. But with the large amount of variable structured data available today, the industry has made moves to loosen these restrictions to take advantage of the modern data landscape.
Data lakes are at the other extreme. A data lake can ingest data in any form, and it can be tempting to take in data from a broad range of sources without accounting for the complexity of the subsequent transformation process. Because data is transformed when it is read, different users can request different transformations of the same data source, resulting in the need to maintain many different transformations for a single source. This complexity may not be well understood from the outset, so attempts at creating a data lake can result in a large store of data that isn’t usable, giving rise to the moniker “data swamp.”
Data warehouses trade the cost and complexity of transforming the data on load with the benefits of conformed data. Data lakes trade the complexity of managing transformation when the data is accessed for the benefits of being able to quickly onboard new data sources.
Schema Evolution
Changes in the structure of data sources are an inevitability, and data pipelines must be built to address this reality. These changes are most often additive: additional columns available for a structured data source, or new fields in a JSON input.
For conformed data, adherence to a rigid schema makes supporting input data structure changes a heavy lift. Not only do data pipelines and table schemas need to be modified, but there is also a need to handle schema versioning. When data is accessed in its raw format, the issue of schema evolution is significantly reduced.
Far less often, changes can also be destructive, eliminating columns or splitting a single data source into multiple sources. Any such alterations in data sources require downstream schemas to be updated to accommodate the new data format. Such changes require careful planning and rollout regardless of schematization because they affect existing data and consumers of that data.
Other Trade-offs
When setting up a data pipeline for data applications, architects need to consider trade-offs among latency, data completeness, and cost.
With virtually infinite availability of compute resources, cloud data platforms can scale out to quickly complete data processing and analysis tasks. But this performance doesn’t come for free: additional, more powerful (and more expensive) compute resources are required. Architects need to consider how to manage this, potentially creating different service tiers to offer latency/cost trade-offs to a wide variety of customers.
Another way to improve latency is by conforming data to enable faster analytical performance. In the cloud, compute resources are more expensive than storage, so it may be a worthwhile trade-off to spend the compute resources to conform the data.
A similar issue arises when considering how often to run data pipelines. For example, running a pipeline every five minutes will provide fresher data than running the pipeline once a day, but depending on the data application use case, it may not be worth the additional compute expense.
Data retention is another important consideration, as the amount of data retained will impact cloud storage costs. Retaining historical data is important in data applications supporting machine learning for model building and testing, and some use cases, such as healthcare or government services, may have strict requirements for keeping historical data.
Another aspect of data completeness relates to how the data is processed. In some cases, applications may want to retain the original data alongside transformed versions, such as for auditing purposes. As we’ve discussed previously, it may not be necessary to conform all fields in a dataset, depending on what is of interest to data users, so there is opportunity to save on costs here while sacrificing completeness.
Best Practices for Data Processing
In this section we will present best practices for designing data processing pipelines when building data applications, highlighting how to take advantage of modern data platforms to build them.
ETL Versus ELT
Extract, transform, and load (ETL) is the process by which legacy data warehouses ingest and transform data. Data is first extracted from its source, then transformed to conform to the data warehouse schema and finally loaded into tables where it is accessible to end users. The conformed data enables performant queries and use of analytical tools requiring structured data.
ETL systems require an investment in development, maintenance, and compute resources to service the underlying data pipelines that perform this process. With many different data sources this can become a significant overhead and often requires staff dedicated to creating and maintaining these systems.
A modern approach to data processing is to move the transformation step to the end, as in data lakes. An extract, load, and transform (ELT) process loads raw data from the source without transforming it, preserving the original format. This not only removes the need to transform all source data, with the associated compute and maintenance costs, but also prevents information loss when converting data from its raw format to a conformed structure. Transformation can then be performed selectively: for example, if a conformed structure is needed to improve query performance or for data visualization tools. In addition, transforming only a subset of the extracted data reduces potential points of failure compared to ETL systems that transform all extracted data.
ELT represents a shift in boundaries in a data warehouse, enabling additional use cases over ETL systems. In legacy ETL systems, data is only loaded after it is transformed, limiting applications to the conformed version of the data. With ELT, applications can access either raw or transformed versions of the data. For example, exploratory data analysis on raw data is a first step in designing machine learning solutions. This provides important insights around potential data issues and their downstream impacts that are not available in ETL systems.
The flexible nature of ELT provides opportunities for performant queries on conformed data alongside less performant raw data queries, enabling a choice in trading off performance for compute expense. In the next section we will discuss how to assess what subset of data to conform.
Schematization
Underlying the trade-offs of ETL versus ELT systems is a difference in when the raw data is schematized. Schema on read is the paradigm of ELT systems, where raw data can be queried in its native format. The schema is applied only when the data is accessed, hence “on read.” Schema on write is the ETL paradigm, where the schema is applied when data is written into the data platform.
The schema-on-read approach offers significantly more flexibility. Because the raw format is always available, it is possible to create a number of derived, conformed versions to meet different business needs while only conforming the subset of data that is of interest.
Snowflake’s VARIANT data type enables schema on read, allowing semi-structured data to be acted on without the delays of transforming data.1 This not only gets data quickly into use, but also provides an opportunity to determine what fields customers are using to identify data that should be conformed.
Schema on read is also preferred by data vendors as it reduces the burden of handling changes in a data source. For example, if a data vendor adds additional fields, a schema-on-write system would need to modify the transformation step to handle these additional columns. In contrast, schema-on-read systems would immediately make this new data available.
Loading Data
Loading is the process by which data is moved from a data source into the data platform, typically into a temporary staging table where it can be further processed. To support different types of data sources, the Snowflake Data Cloud provides two options for loading data: bulk loading and continuous loading.2 Deciding which process is appropriate will depend on the type of data you need to load and the frequency at which the application requires it.
Serverless Versus serverful
The bulk copy approach is a serverful process—that is, one that requires deployment of dedicated compute resources to run the copy job. This is in contrast to Snowflake’s ingestion service, now known as Snowpipe, which is a serverless process. In serverless processes, the compute resources are managed by the platform, not the data application. Serverless processes run immediately, whereas serverful processes incur delays waiting for compute resources to come online.
Keeping an eye on costs is important when leveraging serverless processes. It can be tempting to hand over all your jobs to a serverless process, letting the data platform figure out what resources are needed to run the job, but in some cases this can be costly. It is important to understand the workloads that rely on serverless processes, experimenting with running a few jobs and assessing the cost and performance trade-offs compared with a serverful approach.
Batch Versus Streaming
The frequency at which a data pipeline runs will depend on the needs of the data application, considering the trade-off of fresher data for the increased cost of running pipelines more frequently. Underlying data pipeline scheduling is the continuum of batch to stream processing.
Batch processes operate on bulk data, processing a chunk of data on a scheduled basis, such as loading historical transaction data once a day. Streaming processes operate continuously on as little as one event at a time, or at an interval, processing micro-batches of events. Processing clickstream data in real time, as each event is being generated from the source, is an example of stream processing. You can think of stream processing as batch processing with a batch size of 1 (or, in the case of a micro-batch, a small number).
Batch processing
Batch processing is best suited for ingesting large amounts of data from sources that update on a regular schedule and to which the application does not require access in (near) real time. For example, transaction data that is loaded once a day as an input to a marketing recommendation application is well suited for batch processing.
With this approach, batches of data are copied from a data source into the data platform. In Snowflake this is accomplished using a COPY statement in SQL, issued from a virtual warehouse that developers must set up and size appropriately to service the job. This job can be run manually or set up to run on a schedule.
With the copy process, architects need to consider the trade-off of frequency and cost. How often data should be loaded will depend on both how often the data source publishes new data and how soon after this users need this information. More frequent copies will result in users having access to fresh data more regularly, but at the higher cost of more compute resources to schedule the copy jobs.
Appropriately sizing the virtual warehouse to service the copy process is another consideration. Understanding the amount of data in each batch is important to ensure sufficient compute resources are allocated.
Stream processing
Snowflake provides two methods for handling stream processing. For working with data in the cloud, continuous loading with Snowpipe is an alternative method to COPY.3 Snowpipe processes data in micro-batches to surface new data quickly after it becomes available. This enables near-real-time access to data, such as would be required for IoT applications or making real-time recommendations based on clickstream data. Unlike with COPY, Snowpipe manages the compute resources for you, autoscaling as needed.
When processing data from streaming sources such as Apache Kafka,4 Snowflake Streams and Tasks detect data changes and perform transformation on new and updated data. Snowflake STREAM objects provide CDC for underlying tables, enabling stream consumers to take action based on the changes that occurred since the consumer last queried the stream. For example, a STREAM object monitoring a staging table will reflect updates to the table as it receives new data from the source.
Streams can be used as an input to TASK objects—scheduled jobs that can be used to automate data processing steps with SQL statements or stored procedures—and Tasks can be chained, enabling the creation of multistep data pipelines.5
To understand the batch-to-streaming continuum, consider the architecture in Figure 4-1.
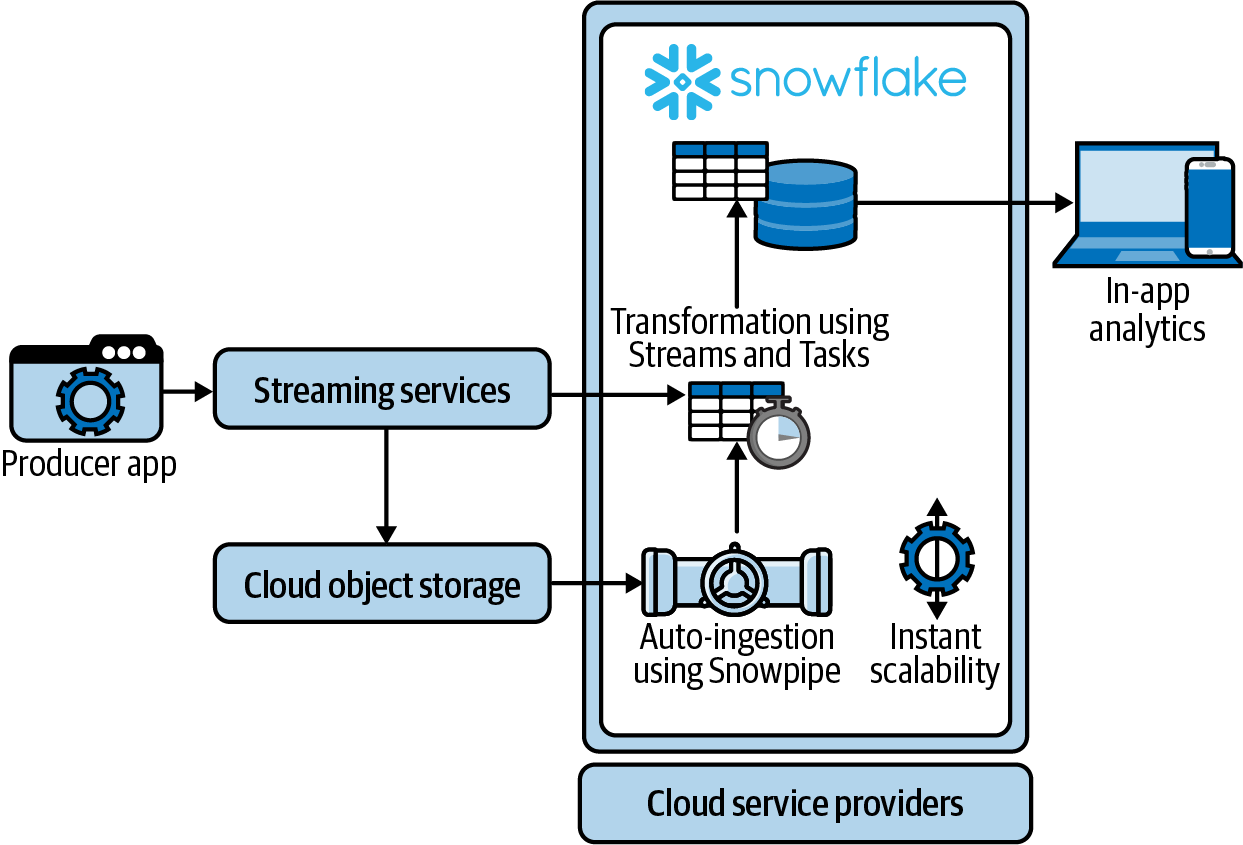
Figure 4-1. Snowflake streaming architecture
Producer applications generate continuous data that is surfaced by streaming services. Depending on data application needs, Snowflake ingests data either directly from the streaming service, processing it in near real time, or via batches published to cloud storage by streaming services.
For example, clickstream events would be ingested directly to enable action to be taken in near real time, such as choosing an ad to display within the application based on customer behavior. In this case data freshness is imperative, making the cost of processing the data continuously worthwhile. Snowflake Streams and Tasks process the data, surfacing it for use by the data application.
On the other hand, application transaction data used to update ad recommendation machine learning models is not needed in near real time and instead can be collected in batches in cloud storage and processed less frequently, such as once a day, by Snowpipe Auto-ingest. The results of the auto-ingest are handed off to Streams and Tasks to run the data pipelines on the bulk data source.
Summary
In this chapter you learned how data pipelines are critical to the success of data applications, which provide value through the ability to deliver fresh insights. From structured, historical data sourced from transaction systems to semi-structured data from devices and applications, data applications must be capable of processing a wide variety of data types.
Scalable, performant data processing leverages both conformed and raw data, selectively conforming data for performance and tool support and using raw data to evaluate new application features, determining if the cost and latency of conforming the data is worthwhile.
A hybrid approach combining the performance of conformed data warehouse tables and the raw data support of data lakes enables data processing systems to be tailored to customer needs while minimizing cost and maintenance overhead. Additionally, providing customers with access to raw data enables new use cases, such as machine learning, and ensures information is not lost as a result of transformation.
To realize these benefits ELT is the preferred approach for most data applications, enabling those applications to deliver fresh insights from both conformed and raw data. ELT systems offer significant flexibility and scalability gains over legacy ETL approaches by being more resilient to changes in data sources and supporting raw data.
When designing data processing systems it is important to consider the batch-to-streaming continuum. Streaming approaches process data in near real time, which is critical for applications such as responding to clickstream data with relevant ad recommendations. Batch approaches trade-off data freshness for lower costs, which is appropriate for cases where data can be consumed less frequently (such as incorporating historical transaction data). In this chapter you learned how Snowflake enables data processing for batch and streaming use cases through COPY, Streams and Tasks, and Snowpipe.
1 https://docs.snowflake.com/en/sql-reference/data-types-semistructured.html
2 https://docs.snowflake.com/en/user-guide/data-load-overview.html
3 https://docs.snowflake.com/en/user-guide/data-load-overview.html#continuous-loading-using-snowpipe
4 https://docs.snowflake.com/en/user-guide/kafka-connector.html
5 https://medium.com/slalom-data-analytics/how-to-automate-data-pipelines-with-snowflake-streams-and-tasks-2b5b77ddff6a