
At this point, you should have a fair understanding of natural language processing . Until now, you have concentrated your efforts on learning language understanding and its associated concepts. NLP is much larger than that, as you have seen with our brief mentions of NLP tasks along the way. So, what else can we expect machines to do with natural languages? Let’s have a look.
After completing this chapter, you will have learned
Concepts behind and usage of four Language APIs other than LUIS
Bing Spell Check API
Text Analytics API
Web Language Model API
Linguistic Analytics API
How Microsoft and others use language-based cognitive models in the real world
Subtasks that each API offers
A detailed explanation of request and response formats for each task’s API
Existing and new usage ideas to inspire your next smart app
The Bing Spell Check API
“bok a ticket”
“whats meaning of athiest”
“whois martin luther king”
“raiders of the lost arc”
Making spelling mistakes is one of the most common user behaviors. Spelling mistakes come in different forms and flavors, from benign and unintentional errors to careless and downright outrageous ones.
You don’t have to be creating a text editor or a word processor to be using spell checking for correcting errors in documents. The market is already saturated with such editors. There are many other areas where spell checking helps. In fact, checking errors in text is sometimes a basic requirement for software to work correctly.
Take, for instance, search. A hearty percentage of websites and mobile apps offer a search textbox, in which users are free to type whatever they want, however they like. Here, users are not bound by any rules for searching; they are so used to using search engines like Google and Bing that they expect the search feature on other websites to just work. Giving users such unrestricted freedom comes with its own set of challenges. For example, it is not uncommon for users to make spelling errors while not even consciously aware of them. Consider a website that allows you to search for movies.
User: “momento”
Website: “No results found for ‘momento.’”
Of course, the website could not find a movie with that name. “Momento” is a common misspelling of “Memento,” and that’s the actual name of the popular Christopher Nolan movie. Is it wise to blame the user for not knowing their spelling? No! A resounding, big no! In turn, it’s shameful for the website to fail to detect such a basic spelling mistake. This situation could be totally avoided by using a simple dictionary-based spell-checker. How about this:
User: “pursuit of happiness”
Website: “No results found for ‘pursuit of happiness.’”
The user would swear that they wrote each word of Will Smith’s 2006 film correctly. Where’s the problem? The actual name of the movie that the user is looking for is “The Pursuit of Happyness.” The problem is not with the user’s search keywords but with the movie title itself. Happyness is a deliberate misspelling of happiness. In any case, the website failed yet again. But it failed this time not because it could not catch a simple dictionary error. It failed because it didn’t know the correct movie name. This is not a trivial problem as we are talking about making the website smarter by having it somehow learn all movie titles.
At any rate, you don’t want to miss out on your users just because your application could not search correctly. Now you see why the ability to handle spelling errors is a basic requirement in some cases. A website that cannot return search results most of the time is bound to lose its most valuable asset: its users. A user who cannot find what they are looking for on a website will, in a matter of seconds, move on to another website to seek answers. In many scenarios , a lost user translates into lost revenue.
Figure 5-1 shows spell check at work on bing.com. If the Bing search results did not take into account spelling mistakes, would its users think twice about going over to Google?
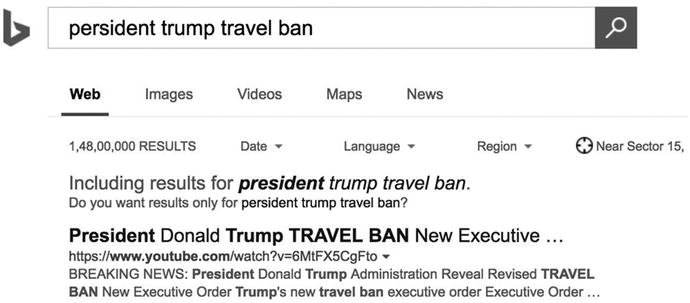
Figure 5-1. Spell check on Bing.com
How can we forget about conversational interfaces? The only way to interact with conversational UIs is to talk to them via text or speech. Where talking is involved, spelling mistakes are bound to happen. The following conversation with a bot could easily qualify for one of the most shameful user experiences.
User: I am feeling unwell. Please help.
Health Bot: What are your symptoms?
User: Head ache, back pain and fever
Health Bot: Have you taken any medicine?
User: Yes. Paracitamole.
Health Bot: Sorry, I couldn’t understand.
User: Paracitamole.
Health Bot: Sorry, I couldn’t understand.
User sighs, then thinks.
User: Parasitamole.
Health Bot: Sorry, I couldn’t understand.
User closes bot app and calls a friend for help instead.
What Is It?
The Bing Spell Check API is an online spell-check service that can scan short to large pieces of text for spelling errors. For each detected error, it provides suggested corrections in decreasing order of confidence score. The API benefits from Bing’s years of experience with user search queries and uses the exact same machine learning models as Bing. It is part of the Microsoft Cognitive Services suite, and is, as you might guess, smarter than the average spell-checker and does much more than just check spelling.
Traditional spell-checkers detect misspellings and provide suggestions for correct spelling using their underlying word dictionaries. Such spell-checkers are fast and small in size. But they usually are not accurate, can recognize only a limited set of proper nouns, and are updated only periodically to support new names and words. These spell-checkers are usually bundled with apps with a small footprint, such as web browsers and text editors.
Slightly more sophisticated spell-checkers can take into account rules of grammar and even additionally suggest grammatical mistakes. You have seen such spell-checkers in word processors such as MS Word, LibreOffice Writer, etc. These are larger in size than simple dictionary-based spell-checkers and are more accurate. Yet all the other restrictions of simple checkers apply.
The Bing Spell Check API works on the principles of machine learning. As you know, with sufficient training an ML model can be taught to understand patterns in data. That’s what has happened with all of the Bing APIs. All of these APIs leverage Bing’s extensively trained models that have learned not just from the engineers who created them but also from millions of users since Bing launched in 2009. Bing APIs provide a way to tap into the wealth of information it has learned and is still learning. You will learn about the Bing Speech API in Chapter 7. All other Bing APIs (Autosuggest, Image Search, News Search, Video Search, and Web Search) are covered in Chapter 8.
The Bing Spell Check API performs contextual spelling checks on text, meaning it detects errors not based on dictionary rules but how and where a word is used in a sentence. Consider the following sentence:
“Don’t worry. I’ll go home by Uber tonight.”
By the rules of a dictionary, this sentence makes the wrong use of the word “uber.” Uber comes from the German language and means above or beyond. In English, uber must be used either as a prefix (uber-cool, uberstylish) or as an adjective (uber intellectuals). But ask another person and they will tell you that the word as used in the sentence “I’ll go home by…” refers to Uber, a cab-hailing service. You may recap our discussion on pragmatics in Chapter 5: contextual references are so common in natural languages that it would sound artificial and be tiresome to use full sentences all the time.
So, while other spell-checkers will complain about the usage of the word uber, the Bing Spell Check API will not detect any error because it will be aware of the context in which the word is used. In fact, it will warn against the wrong usage of the proper noun Uber as is seen in the following example.
User: “I’ll take an uber tonight.”
Bing Spell Check: “I’ll take an uber Uber tonight.”
Not only can the Bing Spell Check API recognize brands, persons, places, and other proper nouns, it also supports slang and broken words.
“Both knda kinda look the same.”
“Are you going to ch eck check the kitchen?”
“Clerk Clark Kent is Superman.”
“The policemen had guns in there their hands.”
Note
As of writing this book, the Bing Spell Check API supports only English (US) text. Support for more English locales as well as other languages is in the cards for a near future release. Locales in the pipeline are British English (en-GB), Canadian English (en-CA), Australian English (en-AU), New Zealand English (en-NZ), and Indian English (en-IN), plus Chinese and Spanish.
How To Use It
As is the case with other Cognitive Services APIs, Bing Spell Check is also an online REST API that you access via its URL. But first you need an Azure subscription key. Refer the steps in Chapter 2 or Chapter 4 to get a free tier subscription key for the Bing Spell Check API.
Note
In this chapter, we have not written C# code for each service. Instead, we have used the valuable book space to explain in detail the request and response structure for each service. If you wish, you can reuse the C# code in Chapter 2 to call the services covered in this chapter. You are, however, encouraged to first use a REST API client, such as Postman, to try various combinations of request parameters and explore the response received for each Cognitive Services API.
Request
The Bing Spell Check API endpoint is enabled for both GET and POST requests, with only minor differences between the two methods. GET supports more options and should be the method of choice, unless it is not possible to control the request data format, in which case you should use POST (such as when handling data received through an HTML form).
Here is what a sample GET request looks like:
GET /bing/v5.0/spellcheck/?mode=spell&mkt=en-us&text=whois persident trumpp HTTP/1.1
Host: api.cognitive.microsoft.com
Ocp-Apim-Subscription-Key: abc123abc123abc123abc123abc123
Cache-Control: no-cacheEndpoint URL:
https://api.cognitive.microsoft.com/bing/v5.0/spellcheck/
All headers and params except those marked with an asterisk (*) are optional.
Request Headers:
Ocp-Apim-Subscription-Key*: Should be set to your Azure subscription key for the Bing Spell Check API. Please note that the key used in the sample request above is for demonstration purpose only and is invalid.
Request Params:
mode: Can be either Spell or Proof. Bing Spell Check works in two modes:
The Spell mode is optimized for search queries and small sentences. It provides fast and relevant results.
The Proof mode is optimized for long text strings. It is similar to the spell-checker in MS Word.
text*: The text string to be checked for spelling errors. There is virtually no limit on the number characters in Proof mode. In Spell mode, up to nine words are supported.
preContextText: Although the spell-checker automatically understands context, it is possible to manually provide context when the target word or phrase is known in advance. preContextText represents text that comes before the target word/phrase. So “Stephen Spielberg” may be a valid name of a person but “Director Stephen Spielberg” signifies the popular director Steven Spielberg. So “Stephen” becomes a misspelling when used with preContextText “Director.”
postContextText: This parameter is like preContextText, except it provides context after the target word/phrase, such as “inglorious bastards” vs. “inglourious basterds movie.”
mkt: The market your application targets. Optimizes spelling and grammar check based on the target market. This is automatically detected but can be manually overridden by supplying a valid value, such as en-us, pt-br, etc.
A sample POST request looks the following:
POST /bing/v5.0/spellcheck/?mode=spell&mkt=en-us HTTP/1.1Host: api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/x-www-form-urlencodedCache-Control: no-cacheText=Bill+Gatas
Response
Let’s analyze the JSON response received from the GET request:
{"_type": "SpellCheck","flaggedTokens": [{"offset": 0,"token": "whois","type": "UnknownToken","suggestions": [{"suggestion": "who is","score": 1}]},{"offset": 6,"token": "persident","type": "UnknownToken","suggestions": [{"suggestion": "president","score": 1}]},{"offset": 16,"token": "trumpp","type": "UnknownToken","suggestions": [{"suggestion": "trump","score": 1}]}]}
Response Properties:
_type: An internal property that represents the type of Cognitive Services API. Okay to ignore.
flaggedTokens: An array of all detected spelling errors, where each error is a token represented by an object with further properties.
offset: Starting character position of token in the original text.
token: The word that has an error. The value of this property combined with offset can be used to determine the misspelled word to replace in the original text.
type: The type of spelling error.
suggestions: An array of suggested corrections for the misspelled words. Each suggestion is accompanied by a confidence score between 0 and 1. It’s a good idea to filter out suggestions with low scores.
Integration with LUIS
As we mentioned in Chapter 4, Bing Spell Check can be enabled in a LUIS application. Figure 5-2 shows what effect this has on the output received from LUIS.

Figure 5-2. JSON results from a LUIS application before and after enabling Bing Spell Check
Follow these steps to enable spell check in a LUIS application:
On the luis.ai homepage, go to the My Keys page.
In the External Keys section, click the “Add a new key” button. Fill the form as per Figure 5-3.

Figure 5-3. Adding a new external key in LUIS
Now open the LUIS application where you need to enable spell check. Go to the Publish App page.
Scroll down to the bottom. Click the “Add key association” button under the External Key Associations section and select the key you entered in step 2.
Finally, check the “Enable Bing spell checker” option and click Publish. Refer to Figure 5-4 for your app’s settings.
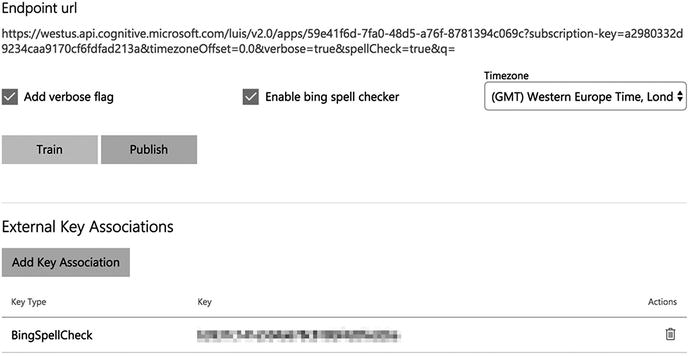
Figure 5-4. Enabling Bing Spell Check in a LUIS application
The Text Analytics API
Data or text is broadly of two types: structured and unstructured. To understand the difference, let’s consider a simple text file with the following content:
I do not believe in a fate that falls on men however they act; but I do believe in a fate that falls on them unless they act.
Such a text file stored on file system would have metadata similar to the following:
Name: Quote.txt
User: Anurag Bhandari
Date created: April 01, 2017
Date modified: April 01, 2017
Size: 125 bytes
Can you guess which one is structured text, out of metadata and file contents? If you said metadata, you were right. Metadata has a structure: fields like name, user, size, etc. are the same in all text files; only the values of these fields change. Can you think of other structured data or text? Hint: spreadsheet, database, log file.
On the other hand, contents of the file are unstructured; they could be any text under the sun. File contents do not have a strict form or structure. This makes unstructured text harder to analyze. Suppose you had 10,000 such text files and were asked to programmatically find the file size using (a) metadata and (b) file contents. Even a child can guess that metadata would be more helpful and quicker in solving such a problem.
Analyzing unstructured text is what text analytics is about. There may be hundreds of problems to be solved that involve analyzing unstructured text. The really hard ones cannot be efficiently solved through traditional programming algorithms. And that’s where machine learning comes handy. Microsoft Cognitive Services’ Text Analytics API provides solutions for four such NLP problems: language detection, key phrase extraction, sentiment analysis, and topic detection. Text analytics is especially useful in accurately determining user or customer responses to your products.
Language Detection
Consider the following conversation with a chatbot.
Bot: Hello. Tell me your problem and I will connect you with the concerned department.
User: J’ai besoin d’aide pour la facturation.
(I need help with billing.)
Bot: Vous connecter avec notre expert en facturation francophone.
(Connecting you with our French speaking billing expert.)
The bot detected the user’s language as French and connected them to a French-speaking support operator from the Billing department. This bot would surely be mind-blowing (and handy) to many users due to its ability to deal with multiple languages. Such a bot would have a big edge over humans, with whom the ability to understand multiple languages is not a given trait.
Given a word, a phrase, or a larger piece of text, the Text Analytics API can detect its natural language through an HTTP call. The longer the piece of text, the more accurate the language detection.
Language detection can be useful in dozens of conversational UI scenarios. It can also be useful in, say, determining the first, second, and third most popular languages used to post replies to a tweet. Such information may be invaluable for a company trying to understand its product’s audience.
Another place where language detection comes in handy is a search engine. Figure 5-5 shows how Microsoft Bing intelligently uses it to filter search results.
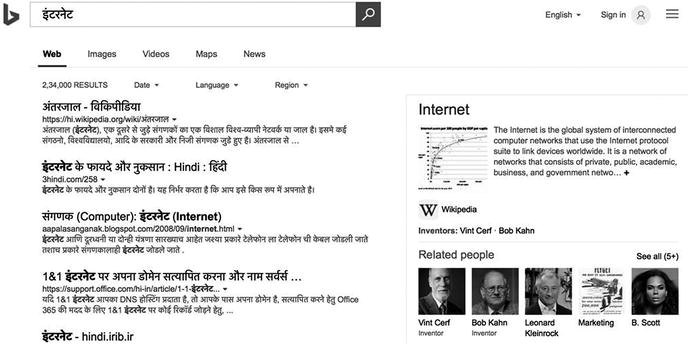
Figure 5-5. Bing uses language detection to smartly filter search results based on the detected language. If the interface language (English in this case) is different from detected language (Hindi in this case), Bing also displays a summary of search keywords in the interface language.
Request
The language detection, key phrase extraction, and sentiment analysis APIs all expect a POST request and share a common JSON body format. An XML body is not supported. The body format allows you to send multiple pieces of text to be analyzed in one go, each piece being a “document.”
Note
This API charges 1 transaction per document submitted. As an example, if you request sentiment for 1,000 documents in a single call, 1,000 transactions will be deducted. This is true for the language detection, key phrase extraction, and sentiment analysis APIs.
POST /text/analytics/v2.0/languages?numberOfLanguagesToDetect=5 HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"documents": [{"id": "1","text": "Hello. Tell me your problem and I will connect you with the concerned department."},{"id": "2","text": "J'ai besoin d'aide pour la facturation."}]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/languages
All params except those marked with an asterisk (*) are optional.
Request Params:
numberOfLanguagesToDetect: An optional query string parameter to specify the maximum number of languages to detect per document. This is helpful for documents that contain text in several languages. The value must be an integer greater than or equal to 1. The default value is 1.
Request Body:
documents*: An array of all documents to be analyzed in one API call. The maximum size of a single document that can be submitted is 10KB, and the total maximum size of submitted input is 1MB. No more than 1,000 documents may be submitted in one call. Rate limiting exists at a rate of 100 calls per minute. It is therefore recommended that you submit large quantities of documents in a single call.
id*: A string that uniquely identifies a document in the list. The same is returned in the API response along with the detected language. It’s up to the developer to specify an id however they like, given that each document’s id is unique. Perhaps the simplest id scheme is 1, 2, 3, 4, etc. GUIDs can be used for more sophisticated id values.
text*: The string to be analyzed.
Response
{"documents": [{"id": "1","detectedLanguages": [{"name": "English","iso6391Name": "en","score": 1}]},{"id": "2","detectedLanguages": [{"name": "French","iso6391Name": "fr","score": 1}]}],"errors": []}
Response Properties:
documents: An array of results for each document supplied in the request.
id: Document id specified in the request.
detectedLanguages: An array of language(s) detected in the document text. The number of objects in this array may depend on the numberOfLanguagesToDetect request parameter.
name: Full name of the detected language.
iso6391Name: The two-character language short code as defined by ISO standards body. “en” is for English, “fr” for French, “es” for Spanish, “hi” for Hindi, and so on.
score: Confidence level of detection, 0 being the lowest and 1 highest.
errors: If a supplied document has error(s), the corresponding error will be in this array.
id: The document in which the error was detected.
message: Detailed error message.
Note
Take extra care in specifying request params and body. Wrong values used with either may result in a JSON error response, which usually follows the following format:
{ "statusCode": number, "message": string }where statusCode is the HTTP status code and message is the detailed message string.
Key Phrase Extraction
Sometimes it is desirable to extract just the key words and phrases, the main “talking points,” from a given piece of lengthy, messy text. This information can be used to understand more clearly the context of a news article or a blog entry or a social network post. Once the main talking points of a text are known, one can do a variety of things with that knowledge.
Using extracted key phrases from multiple documents, it’s possible to generate word clouds to easily visualize the most popular key phrases across documents. Figure 5-6 shows a word cloud that illustrates the main talking points in user reviews for the Android version of the popular mobile game Angry Birds Friends.

Figure 5-6. Rovio, creators of the Angry Birds franchise, can see that users are talking mostly about power ups, expensive, tournament, etc. The company can use this information as invaluable feedback to improve its next release.
In a similar fashion, the ability to extract key phrases is crucial to digital advertisement networks, such as Google AdSense and DoubleClick. Such networks use extracted key phrases from web pages where their ads are hosted to display more relevant ads to visitors.
Request
POST /text/analytics/v2.0/keyPhrases HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"documents": [{"id": "1","text": "Tesla will unveil an electric articulated lorry in September, chief executive Elon Musk has said. Additionally, he said an electric pick-up truck would be shown off in around 18-24 months.","language": "en"},{"id": "2","text": "La carta a Cristiano Ronaldo de la víctima de su presunta violación: 'Te dije no, te grité, rogué que parases'","language": "es"}]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/keyPhrases
Request Params:
There are no params for this API.
Request Body:
The JSON request body is like the one you saw in language detection. One additional property in the document object is language. language is an optional property that should be specified for non-English documents. Currently, only English (en), Spanish (es), German (de), and Japanese (ja) languages are supported by this API.
Response
{"documents": [{"keyPhrases": ["electric articulated lorry","September","chief executive Elon Musk","electric pick","Tesla","truck","months"],"id": "1"},{"keyPhrases": ["víctima","Cristiano Ronaldo","carta","presunta violación"],"id": "2"}],"errors": []}
Response Properties:
documents: List of documents supplied in request.
id: The unique document id specified in request.
keyPhrases: An array of all key phrases detected in the corresponding document.
Sentiment Analysis
Sentiment analysis is a process used to determine whether the tone in a piece of text is positive, neutral, or negative. The given text is analyzed to arrive at an overall sentiment score, where 0 means very negative and 1 means very positive.
Sentiment analysis as a product feedback tool has been in use for a considerable amount of time. The big data revolution has allow companies, big and small, to tap into the wealth of user feedback available online in the form of direct comments, Facebook posts/comments, Twitter posts, blogs, and so on. Big data analytics tools and machine learning have enabled exponentially faster analysis of large volumes of data to determine the critical responses of users or customers toward an app or product.
Figure 5-7 shows the kind of visualizations that can be created with the help of sentiment analysis.
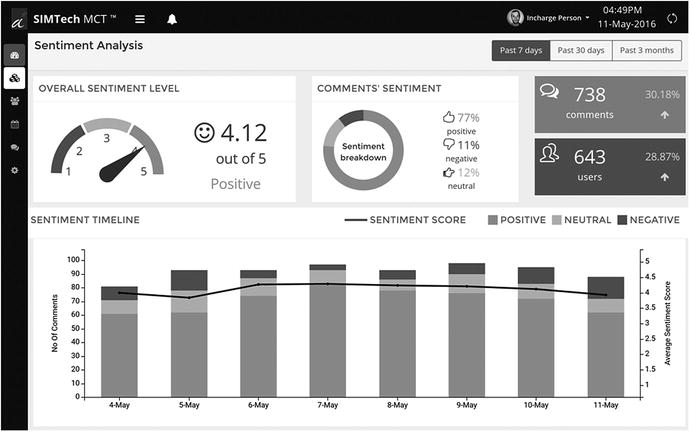
Figure 5-7. Dashboard generated by online tool SIMTech MCT
Note
A sentiment score is generated using classification techniques. The input features to the classifier include n-grams, features generated from part-of-speech tags, and embedded words. The classifier was trained in part using Sentiment140 data. Supported languages are English (en), Spanish (es), French (fr), and Portuguese (pt).
Request
POST /text/analytics/v2.0/sentiment HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"documents": [{"id": "1","text": "You need to change it back! The new graphics are awful! Massive headache after a few minutes of play. Your graphic are what made candy crush different to other match 3 games now its a unplayable as the others. Im out till you fix it","language": "en"},{"id": "2","text": "Great mental exercise and the variation of the levels keeps your interest. Never boring, just frustrating enough to make sure you come back to try again!"}]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/sentiment
Request Params:
There are no params for this API.
Request Body:
Nothing unusual here. The language property, as earlier, is optional.
Response
{"documents": [{"score": 0.0344527179662149,"id": "1"},{"score": 0.796423438202407,"id": "2"}],"errors": []}
Response Properties:
score signifies the overall sentiment of the document text. 0.03 is highly negative, while 0.79 is pretty positive.
Topic Detection
A topic is a brief one-line summary of a given text. It could be one word or multiple related words. Topic detection is not that different from key phrase extraction in that, just like the latter, it provides the main talking point or the highlight of a text. But instead of giving you multiple key phrases, it returns just one topic for the entire text.
Note
This API is designed to work with short text documents, such as user reviews, comments, and other such feedback. It will not work well with long texts, such as book extracts, articles, etc.
Topic detection is especially helpful in making it easier to read long customer reviews about a book, movie, app or product. More than one review text may be assigned the exact same topic, based on their similarity. Normally, key phrase extraction and sentiment analysis are sufficient to get a good idea about the general customer sentiment for a product release. One should additionally go for topic detection to understand feedback in detail, which key phrases cannot provide.
Request
This API expects text documents in a format similar to the other three text analytics APIs. Calling the API, though, is not as straightforward. Topic detection is a time-intensive process. Microsoft mandates you to send at least 100 text documents in a single API call. There is no set limit for the maximum number of text documents, although the max size of 1 document cannot be more than 30KB and the max size of the entire request body must not exceed 30MB. As a reminder, each document in an API call counts as one transaction for billing purposes. You may make up to five API calls every 5 mins.
As topic detection is a time-consuming process, you do not get a response instantly. A request to the API submits the documents to a queue and returns, with an HTTP status code 202, a URL that should be periodically polled to retrieve the results.
POST /text/analytics/v2.0/topics HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"documents": [{"id": "1","text": "I love this product and have no complaints except that I cannot have 2 of them."},...{"id": "100","text": "The sound quality is not as good as my other speakers."}],"stopWords": ["problem", "bug", "feedback"],"topicsToExclude": ["create a ticket", "Amazon Echo"]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/topics
All params except those marked with an asterisk (*) are optional.
Request Params:
minDocumentsPerWord: An integer to specify the minimum number of documents for which a topic word is the same. For example, if you set it to 2, then all topic words that are assigned to only 1 document will be excluded. This param can help you exclude rare topic words.
maxDocumentsPerWord: The opposite of minDocumentsPerWord. Use this to exclude very common topic words.
Request Body:
The document list format remains unchanged. There is no language property in the document object because English is the only supported language. A document whose text is in a language other than English will be ignored. Similarly, documents of a length less than three words will be ignored.
stopWords: List of words that should not be part of detected topics. Helps to exclude words that are common and implicit in a given scenario. For example, if topic detection is being performed on feedback reviews, words such as problem, bug, feedback, etc. will not add any value to a topic. Apart from explicitly specified stop words, the API will also consider their plurals.
topicsToExclude: Similar to the stopWords property. Allows you to specify full topic names to be excluded. Full and partial product names are good candidates for this property.
Response
The immediate response to the above POST request will have an empty body and 202 as its HTTP status code. It will have the following header:
'operation-location': 'https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/operations/<operationId>'The value of the operation-location header is the URL endpoint that will eventually return the results when they are ready. How much time it takes for a request to be processed depends on the number and length of the documents supplied in the original POST request.
This URL must be polled periodically (the recommended duration is once per minute) to check for results.
GET https://westus.api.cognitive.microsoft.com/text/analytics/v2.0/operations/<operationId>Each time the above call will return a JSON response with at least the property status, whose value can be one of notstarted, running, and succeeded. You want to poll until you get succeeded as a status value.
The final response will have the following form:
{"status": "succeeded","operationProcessingResult": {"topics": [{"id": "d8f62239-4ab5-4f95-8067-b2fca96d0c40""score": "7""keyPhrase": “no complaint"},...{"id": "8af50d44-92d0-464f-886a-9690542f259b""score": "2""keyPhrase": “sound quality not good"}],"topicAssignments": [{"topicId": "d8f62239-4ab5-4f95-8067-b2fca96d0c40","documentId": "1","distance": "0.354"},...{"topicId": "8af50d44-92d0-464f-886a-9690542f259b","documentId": "100","distance": "0.758"}],"errors": []}}
Response Properties:
topics: An array of all distinct topics detected for the supplied documents.
id: A unique topic id generated by the API.
score: Number of documents that share this topic.
keyPhrase: The detected topic.
topicAssignments: An array of topic assignments for each document.
topicId: The unique id as seen in the topics array.
documentId: The unique document id that was supplied in the request.
distance: Document-to-topic affiliation score. Between 0 and 1. The lower the score, the higher the affiliation.
Usage Ideas
Election prediction: Performing sentiment analysis on data collected from social media, news articles, public polls, and surveys is not new. But for a very long time, the methodologies used have largely been statistical. With the advent of machine learning, especially deep learning techniques, predicting the winner of an election will produce more accurate results.
Automatic MOM generation. Collecting and articulating the minutes of a meeting (MOM) is a standard activity performed during formal meetings. Techniques such as topic detection and key phrase extraction can be a godsend in automating MOM generation in text-based meetings on platforms such as Slack and IRC.
Call record analysis: As an auditing measure , a user’s call to a call center support executive is usually recorded. Using speech-to-text, the textual transcripts can be generated from these recordings. The transcripts can then be used as documents to perform sentiment analysis and key phrase extraction to better analyze customers’ satisfaction levels.
The Web Language Model (WebLM) API
Creating a language model for machine learning requires a suitably created corpus. As you learned in the previous chapters, the performance of an ML model is as good as its training data (corpus). The larger the corpus, the more the training data, the better the resulting model. Creating a large corpus by hand of the scale required for training is practically infeasible even for large corporations. Publicly available records of European Union court proceedings, translated into several languages, were used to create models for language translation systems . The EU docs are not the only free text that could be used to build language models. There is, of course, the WWW.
An awesome thing about the world-wide web is that it contains an infinite amount of text in its billions of web pages . It could form an incredibly large corpus for anybody to train their machine learning language models absolutely free of cost. That’s exactly what Microsoft did with Bing’s indexed web pages. They created vast corpora (plural of corpus) using text read from millions of web pages.
A corpus made using text collected from all over the Web is not suited for such applications as machine translation due to the presence of several anomalies: grammatical errors, slang, profanity, lack of punctuation, and so on. But a corpus made from the Web can give us a general idea about how the common populace uses language. Common patterns can be found in the incorrect usage of words and phrases. This is good enough to use the corpus for creating models to do stuff like predicting the next word in a sequence and breaking up a string of words that lacks spaces. Microsoft calls its language model created in this fashion the Web Language Model or WebLM.
Text may be present in different parts of a web page: body, title, anchor elements, and search queries. There are subtle to visible differences in text extracted from each of these four parts. While the phrase “tryout” may be common in anchor text and search queries, it’s usually present in its more correct form of “try out” in the body part. Thus, Microsoft has created four different models using text from these four parts of a web page:
Bing Anchor Model
Bing Body Model
Bing Query Model
Bing Title Model
Currently, the only language supported by WebLM API is American English.
Note
The WebLM corpus is not as simple as a random collection of zillions of sentences. Instead of plain words and phrases, it contains what are called n-grams. Microsoft calls it Web N-gram Corpus.
An n-gram is a partial sequence of n items derived from a larger, more complete sequence. An item could be a character, a word, or a phrase. Consider the following example sentence:
“Bruno is a good dog.”
n-gram sequences that can be derived from the above complete sequence are
1-gram (unigram) — Bruno, is, a, good, dog
2-gram (bigram) — Bruno is, is a, a good, good dog
3-gram (trigram) — Bruno is a, is a good, a good dog
MS Web N-gram Corpus has up to 5-gram sequences. It’s using these n-grams so that tasks like word breaking and predicting the next word in sequence can be accomplished.
Figure 5-8 shows how Microsoft Bing probably uses WebLM to display search results.
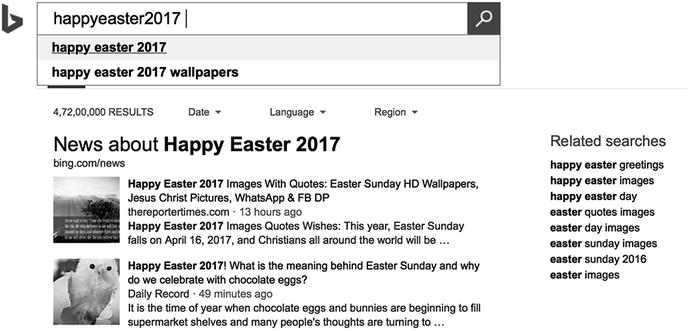
Figure 5-8. Word breaking and next word prediction in action on the Bing search page
Not only was Bing Search able to break the word “happyeaster2017” into “happy easter 2017,” it could also present similar search queries (“happy easter 2017 wallpaper”) by checking its query language model for most common next words.
The WebLM API supports the following four tasks or operations:
Breaking of strings with no spaces into words
Joint probability of a word sequence
Conditional probability of one word succeeding a given sequence of words
Predicting the next word(s) that may follow a given sequence of words
Word Breaking
We know that breaking a contiguous string into individual words is a pretty useful thing. But where can we find instances of such weird strings? In other words, who in their right mind would write words joined together?
You may have seen such strings more than you may realize. Hash tags on social media are a very common example.
#iamfeelinggood #germanyvsargentinafootballlive #EpicFail
The ability to break hash tag strings into individual words can give data analytics systems plenty of otherwise hidden material to analyze. Contiguous strings may also be present in URLs and internal links.
www.example.com/topsellers , www.example.com/tutorial#creatinganewproject
Request
POST /text/weblm/v1.0/breakIntoWords?model=body&text=germanyvsargentinafootballlive&order=5&maxNumOfCandidatesReturned=3 HTTP/1.1
Host: westus.api.cognitive.microsoft.com
Ocp-Apim-Subscription-Key: abc123abc123abc123abc123abc123
Cache-Control: no-cacheEndpoint URL:
https://westus.api.cognitive.microsoft.com/text/weblm/v1.0/breakIntoWords
All params except those marked with an asterisk (*) are optional.
Request Params:
model*: The Bing language model to use. One of anchor, body, query, and title.
text*: The string to be split into individual words. If spaces are already present in the string, they will be maintained as such in the result.
order: The order of n-gram. One of 1, 2, 3, 4, and 5. Default is 5.
maxNumOfCandidatesReturned: Maximum matches to be returned. Default is 5.
This API does not require a request body.
Response
{"candidates": [{"words": "germany vs argentina football live","probability": -12.873},{"words": "g ermany vs argentina football live","probability": -19.08},{"words": "germany vs argentina football l i v e","probability": -19.432}]}
Response Properties:
candidates: An array of all possible matches, limited by themaxNumOfCandidatesReturned request param.
words: Broken-up individual words in a candidate match.
probability: Less negative values represent high confidence.
Joint Probability
Joint probability tells you how often a certain sequence of words occurs together. For example,
here I come => quite probable
hello dude => somewhat probable
Microsoft washing machine => not probable at all
Request
POST /text/weblm/v1.0/calculateJointProbability?model=body&order=5 HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"queries":["but","wide world","natural language processing","natural language dinner"]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/weblm/v1.0/calculateJointProbability
All params except those marked with an asterisk (*) are optional.
Request Params:
model*
order
Request Body:
queries: An array of strings. Each string is a sequence whose joint probability must be calculated. Single word queries are valid.
Response
{"results": [{"words": "but","probability": -2.9},{"words": "wide world","probability": -6.381},{"words": "natural language processing","probability": -6.807},{"words": "natural language dinner","probability": -12.939}]}
Response Properties:
results: An array of results, one for each query specified in a request body.
words: The query sequence from the request.
probability: The lower the negative score, the more common the word or sequence.
Conditional Probability
Conditional probability tells you how common it is for a word to come after a certain sequence of words. For example,
top selling artist => very probable
top selling author => very probable
top selling guy => mildly probable
top selling rat => not probable at all
Possible use cases are
Unscramble a jumbled sentence.
Correctly guess a short search query in which words are incorrectly ordered.
Request
POST /text/weblm/v1.0/calculateConditionalProbability?model=body&order=5 HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"queries":[{"words": "top selling","word": "artist"},{"words": "top selling","word": "rat"},{"words": "game of","word": "thrones"}]}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/text/weblm/v1.0/calculateConditionalProbability
All params except those marked with an asterisk (*) are optional.
Request Params:
model*
order
Request Body:
queries
words: The sequence of words that precede the target word.
word: The target word.
Response
{"results": [{"words": "top selling","word": "artist","probability": -2.901},{"words": "top selling","word": "rat","probability": -5.848},{"words": "game of","word": "thrones","probability": -0.475}]}
Next Word Prediction
You saw earlier in Figure 5-8 how next word prediction works by suggesting the words that may come after the search query. Using this API, it is possible to generate next word suggestions for a certain sequence of words. For example,
new york city
new york times
new york university
Request
POST /text/weblm/v1.0/generateNextWords?model=body&words=Microsoft Windows&order=5&maxNumOfCandidatesReturned=5 HTTP/1.1
Host: westus.api.cognitive.microsoft.com
Ocp-Apim-Subscription-Key: abc123abc123abc123abc123abc123
Cache-Control: no-cacheEndpoint URL:
https://westus.api.cognitive.microsoft.com/text/weblm/v1.0/generateNextWords
All params except those marked with an asterisk (*) are optional.
Request Params:
model*
order
maxNumOfCandidatesReturned
words*: A string that is the sequence of words for which next word suggestions need to be generated. The sequence may contain only one word.
This API does not require a request body.
Response
{"candidates": [{"word": "7","probability": -0.892},{"word": "xp","probability": -0.998},{"word": "currentversion","probability": -1.047},{"word": "server","probability": -1.123},{"word": "8","probability": -1.201}]}
The Linguistic Analysis API
The operations offered by this API deal with analyzing the language structure of a given text. The output of this analysis may be useful in better understanding the meaning and context of text.
The Linguistic Analysis API supports the following three operations:
Sentence separation and tokenization: Breaking text into sentences and tokens.
Part-of-speech tagging: Categorizing each word of a sentence as a grammatical component (noun, verb, adjective, etc.).
Constituency parsing: Breaking text into all possible phrases.
This sort of linguistic analysis is usually done as a first step for other NLP tasks, such as natural language understanding, text-to-speech, machine translations, and so on. Apart from its usefulness as a preliminary step in the field of NLP itself, linguistic analysis has applications in consumer-facing cognitive apps.
To be able to perform the three analyses, a system must be trained using a treebank. A treebank is a corpus that contains a wide collection of POS-tagged words and parsed phrases. Microsoft, for this API, used Penn Treebank 3 to train its systems.
Sentence Separation and Tokenization
Breaking up large pieces of text into individual sentences and tokens is a pretty common requirement in software development. But do we not already know the solution? Consider the following text:
It was nice to meet you. Goodbye and see you again.
The first thing that comes to mind when breaking text into sentences is to split it around the full-stop or dot (.) symbol. Sure, let's do that with the above text. We get two sentences.
Sentence 1: It was nice to meet you.
Sentence 2: Goodbye and see you again.
How about the following text:
He said, “I am going to the concert." And, poof, he was gone!
Splitting it around full-stops gives us the following:
Sentence 1: He said, “I am going to the concert.
Sentence 2: “ And, poof, he was gone!
You surely did not want this. At this point, you no doubt realize that not all sentences end with a full-stop. For example,
How did I do? Was I good?
Are you crazy! I don't have anything to do with this.
What?! Are you out of your mind?
This is where cognitive sentence separation comes handy. You may use the API to extract all sentences from a very long article or book and store them for further analysis. Or you may be simply looking to limit a large piece of text somewhere on your app or website to a few sentences.
Tokenization, or breaking up sentences into individual words and other tokens, is another story. Just like sentence separation, tokenization cannot be simply achieved by always splitting a sentence around white spaces. Stuff like contractions and possessives must be taken care of, among other things. And languages such as Chinese do not always have spaces between words.
The sentence “I don’t have anything to do with Ronnie’s broken glasses, I swear.” contains the following tokens:
I - do - n't - have - anything - to - do – with - Ronnie -’s - broken - glasses - , - I - swear - .
n't is a contraction for not. ’s is a possessive. The dot and comma are punctuation. These are some tokens apart from the usual words that should be detected for a proper further analysis .
Request
POST /linguistics/v1.0/analyze HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"language": "en","analyzerIds": ["08ea174b-bfdb-4e64-987e-602f85da7f72"],"text": "How did I do? Was I good?"}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/linguistics/v1.0/analyze
All params except those marked with an asterisk (*) are optional.
Request Params:
This API doesn't have request params.
Request Body:
language*: The ISO 639-1 two letter code for the language of the text to be analyzed.
analyzerIds*: An array of GUIDs of analyzers to be used (Tokens, POS_Tags, or Constituency_Tree).
text*: The piece of text to be analyzed.
Note
You can use all three analyzers at once on the same piece of text. To get the list of all supported analyzers (three at the time of writing) along with their GUIDs, make a GET call to https://westus.api.cognitive.microsoft.com/linguistics/v1.0/analyzers using the Language Analytics API subscription key.
Response
[{"analyzerId": "08ea174b-bfdb-4e64-987e-602f85da7f72","result": [{"Len": 13,"Offset": 0,"Tokens": [{"Len": 3,"NormalizedToken": "How","Offset": 0,"RawToken": "How"},{"Len": 3,"NormalizedToken": "did","Offset": 4,"RawToken": "did"},{"Len": 1,"NormalizedToken": "I","Offset": 8,"RawToken": "I"},{"Len": 2,"NormalizedToken": "do","Offset": 10,"RawToken": "do"},{"Len": 1,"NormalizedToken": "?","Offset": 12,"RawToken": "?"}]},{"Len": 11,"Offset": 14,"Tokens": [{"Len": 3,"NormalizedToken": "Was","Offset": 14,"RawToken": "Was"},{"Len": 1,"NormalizedToken": "I","Offset": 18,"RawToken": "I"},{"Len": 4,"NormalizedToken": "good","Offset": 20,"RawToken": "good"},{"Len": 1,"NormalizedToken": "?","Offset": 24,"RawToken": "?"}]}]}]
Note that the result is not an object but an array of objects. This is because this API gives you the option to perform multiple analyses at once on the same text. Each analyzer's result is returned as an object of the root array.
Response Properties:
analyzerId: GUID of the analyzer used for the corresponding result set.
result: The result of the analysis. An array of sentences.
Len: Total number of characters in the sentence.
Offset: Starting position of sentence in the text. Starts from 0.
Tokens: Array of tokens in the sentence.
Len: Number of characters in the token.
Offset: Starting position of token in the sentence.
RawToken: The detected token.
NormalizedToken: The token represented in a format that is safe to be used in a parse tree.
Part-of-Speech Tagging
Remember when you were in school and just starting to learn to identify the grammatical structure of a sentence.
“Subject-verb-object," your teacher would say and then proceed to define subject and object in terms of proper and common nouns. After this you gradually learned to spot adjectives, adverbs, prepositions, and conjunctions in a sentence. Think of that technique to spot grammatical structure taught by your teacher as a simplified version of POS tagging.
Things like nouns and verbs and adjectives are called parts of speech. POS tagging is a common disambiguation technique, something that makes confusing/ambiguous words clearer; it’s used to identify parts of speech in a given sentence based on their respective position and context. That is, for each word in a sentence, POS tagging will tell you what part of speech that word is. Consider the following sentence:
He is going to contest the election.
An interesting thing about the sentence is the word “contest,” which could be a noun or a verb. In this case, it is used as a verb. A POS tagger must smartly detect the context and surrounding words to tag a word correctly. Here is a POS-tagged version of the above sentence:
He (PRP) is (VBZ) going (VBG) to (TO) contest (VB) the (DT) election (NNS).
The following tags were detected:
PRP = pronoun, personal
VBZ = verb, present tense, third person singular
VBG = verb, present participle, or gerund
TO = “to” as preposition or infinitive marker
VB = verb, base form
DT = determiner
NNS = noun, common, plural
A comprehensive list of all possible tags may be found online as well as on Microsoft's documentation for POS tagging.
POS tagging is especially helpful in NLU and language translation.
Request
POST /linguistics/v1.0/analyze HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"language": "en","analyzerIds": ["4fa79af1-f22c-408d-98bb-b7d7aeef7f04"],"text": "He is going to contest the election"}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/linguistics/v1.0/analyze
All params except those marked with an asterisk (*) are optional.
Request Params:
This API doesn't have request params.
Request Body:
language*
analyzerIds*
text*
Response
[{"analyzerId": "4fa79af1-f22c-408d-98bb-b7d7aeef7f04","result": [["DT","VBZ","JJ","."],["PRP","VBP","PRP","."]]}]
Response Properties:
The result is an array of tags in each sentence. Tags are in the same sequence as words in a sentence .
Constituency Parsing
Constituency parsing is used to detect phrases in a given sentence. This is different from the key phrase extraction you saw in the Text Analytics API in that, unlike KPE, constituency parsing does not only return the key phrases but all possible phrases. Such information may be useful to KPE analysis itself.
I want to buy a laptop with graphics card.
How many phrases can you identify in the above sentence?
Let’s see. “I want to buy a laptop,” “buy a laptop,” “a laptop with graphics card,” and “graphics card” are all valid phrases. Can you find more? See Figure 5-9 when you’re done.

Figure 5-9. A parsed tree for the above sentence. Words including and between each pair of nodes in the above binary tree are a valid phrase.
It is important to note that a phrase is not simply any group of words. A phrase is something that may be replaced or moved as a whole in a sentence such that the sentence remains grammatically correct and easy to understand. For example, “I want to buy” and “a laptop with graphics card” are the two main phrases in the above sentence. If we interchange their positions, the sentence remains understandable:
a laptop with graphics card I want to buy
Since “to buy” is not a phrase, changing its position makes the sentence incomprehensible:
to buy I want a laptop with graphics card
Phrases are usually nested within one another and can be hard to find without an understanding of the grammatical structure of the sentence.
Request
POST /linguistics/v1.0/analyze HTTP/1.1Host: westus.api.cognitive.microsoft.comOcp-Apim-Subscription-Key: abc123abc123abc123abc123abc123Content-Type: application/jsonCache-Control: no-cache{"language": "en","analyzerIds": ["22a6b758-420f-4745-8a3c-46835a67c0d2"],"text": "I want to buy a laptop with graphics card."}
Endpoint URL:
https://westus.api.cognitive.microsoft.com/linguistics/v1.0/analyze
All params except those marked with an asterisk (*) are optional.
Request Params:
This API doesn't have request params.
Request Body:
language*
analyzerIds*
text*
Response
[{"analyzerId": "22a6b758-420f-4745-8a3c-46835a67c0d2","result": ["(TOP (S (NP (PRP I)) (VP (VBP want) (S (VP (TO to) (VP (VB buy) (NP (DT a) (NN laptop)) (PP (IN with) (NP (NNS graphics) (NN card))))))) (. .)))"]}]
Response Properties:
The result is an array of parsed sentences . Try to map the rounded brackets format of the parse with Figure 5-9 to see how to interpret it.
Recap
In this chapter, you learned about NLP tasks other than language understanding (NLU), which you learned about in the previous chapter.
To recap, you learned about
The four APIs in the Language category of Cognitive Services: Bing Spell Check, Text Analytics, WebLM, and Linguistics Analysis
Theory and application for each API and all of its operations
A detailed overview of using the APIs
Live implementation examples and new usage ideas
In the next chapter, you will apply your knowledge of LUIS and the Bot Framework to build an enterprise-grade chat bot.