
4
Detection and Security: Achieving Resiliency by Dynamic and Passive System Monitoring and Smart Access Control
Zbigniew Kalbarczyk1, In collaboration with Rakesh Bobba2, Domenico Cotroneo3, Fei Deng4, Zachary Estrada5, Jingwei Huang6, Jun Ho Huh7, Ravishankar K. Iyer1, David M. Nicol8, Cuong Pham4, Antonio Pecchia3, Aashish Sharma9, Gary Wang10, and Lok Yan11
1University of Illinois at Urbana-Champaign, Department of Electrical and Computer Engineering and Coordinated Science Laboratory, Urbana, IL, USA
2Oregon State University, School of Electrical Engineering and Computer Science, Corvallis, OR, USA
3Università degli Studi di Napoli Federico II, Dipartimento di Ingegneria Elettrica e delle Tecnologie dell'Informazione, Naples, Italy
4University of Illinois at Urbana-Champaign, Department of Electrical and Computer Engineering, Urbana, IL, USA
5Rose-Hulman Institute of Technology, Department of Electrical and Computer Engineering, Terre Haute, IN, USA; and University of Illinois at Urbana-Champaign, Department of Electrical and Computer Engineering, Urbana, IL, USA
6Old Dominion University, Department of Engineering Management and Systems Engineering, Norfolk, VA, USA; and University of Illinois at Urbana-Champaign, Information Trust Institute, Urbana, IL, USA
7Samsung Electronics, Samsung Research, Seoul, South Korea
8University of Illinois at Urbana-Champaign, Department of Electrical and Computer Engineering and Information Trust Institute, Urbana, IL, USA
9Lawrence Berkeley National Lab, Berkeley, CA, USA
10University of Illinois at Urbana-Champaign, Department of Computer Science, Urbana, IL, USA
11Air Force Research Laboratory, Rome, NY, USA
In this chapter, we discuss methods to address some of the challenges in achieving resilient cloud computing. The issues and potential solutions are brought about by examples of (i) active and passive monitoring as a way to provide situational awareness about a system and users' state and behavior; (ii) automated reasoning about system/application state based on observations from monitoring tools; (iii) coordination of monitoring and system activities to provide a robust response to accidental failures and malicious attacks; and (iv) use of smart access control methods to reduce the attack surface and limit the likelihood of an unauthorized access to the system. Case studies covering different application domains, for example, cloud computing, large computing infrastructure for scientific applications, and industrial control systems, are used to show both the practicality of the proposed approaches and their capabilities, for example, in terms of detection coverage and performance cost.
4.1 Introduction
Building resilient (i.e., reliable and secure) computing systems is hard due to growing system and application complexity and scale, but maintaining reliability and security is even harder. A resilient system is expected to maintain an acceptable level of service in the presence of internal and external disturbances. Design for resiliency is a multidisciplinary task that brings together experts in security, fault tolerance, and human factors, among others. Achieving resiliency requires mechanisms for efficient monitoring, detection, and recovery from failures due to malicious attacks and accidental faults with minimum negative impact on the delivered service.
Why is design for resiliency challenging?
- Design and assessment: Systems become untrustworthy because of a combination of human failures, hardware faults, software bugs, network problems, and inadequate balance between the cyber and the physical systems, for example, the network and control infrastructures.
- Delivery of critical services: Many systems, including cloud systems, large computing infrastructure, and cyber-physical systems (e.g., for energy delivery, transportation, communications, and heath care) are expected to provide uninterruptable services.
- Interdependencies among systems: Resiliency of one system may be conditioned on the availability of another system, for example, resiliency of a transportation system may depend heavily on the robust operation of an energy delivery infrastructure, or on a human-in-the-decision-loop, such that human intelligence plays a role in system remediation, service restoration, and recovery.
In this chapter, we discuss methods to address some of those challenges.
We will discuss examples of (1) active and passive monitoring as a way to provide situational awareness about a system and users' state and behavior, (2) automated reasoning about system/application state based on observations from monitoring tools, (3) coordination of monitoring and system activities to provide a robust response to accidental failures and malicious attacks, and (4) use of smart access control methods to reduce the attack surface and limit the likelihood of an unauthorized access to the system.
The methods, tools, and techniques we discuss are illustrated by case studies covering different application domains, for example, cloud computing, large computing infrastructure for scientific applications, and industrial control systems. The goal is to show both the practicality of the proposed approaches and their capabilities, for example, in terms of detection coverage and performance cost.
Specific examples encompass dynamic virtual machine monitoring using hypervisor probes, pitfalls of passive virtual machine monitoring, model-based identification of compromised users in large computing infrastructure, and system protection using a combination of attribute-based policies and role-based access control.
This chapter will highlight both cyber and cyber-physical examples that combine research expertise in security and system reliability with human factors, verification, and distributed systems, providing a truly integrated view of the relevant technologies.
4.2 Vision: Using Cloud Technology in Missions
Prolific failures have kept reliability a leading concern for customers considering the cloud [1]. Monitoring is especially important for security, since many attacks go undetected for long periods of time. For example, Trustwave surveyed 574 locations that were victims of cyberattacks [2]. Of those victims, 81% did not detect the attacks themselves; either a customer reported data misuse or a third-party audit uncovered a compromised system. When attacks were detected, the mean detection time was 86 days.
Cloud computing environments are often built on top of virtual machines (VMs) running on top of a hypervisor. A virtual machine is a complete computing system that runs on top of another system. The hypervisor is a privileged software component that manages the VMs. Typically, one can run multiple VMs on top of a single hypervisor, which is often how cloud providers distribute customers across multiple physical servers. As the low-level manager of VMs, the hypervisor has privileged access to those VMs, and this access is often supported by hardware-enforced isolation. The strong isolation between the hypervisor and VMs provides an opportunity for robust security monitoring. Because cloud environments are often built using hypervisor technology, VM monitoring can be used to protect cloud systems.
There has been significant research on virtual machine monitoring [3–8]. Existing VM monitoring systems require setup and configuration as part of the guest OS (operating system) boot process or modification of guest OS internals. In either case, the effect on the guest is the same: At the bare minimum, a VM reboot is necessary to adapt the monitoring system; in the worst case, the guest OS needs to be modified and recompiled. Operationally, these requirements are undesirable for a number of reasons, for example, increased downtime.
In addition to the lack of runtime reconfigurability, VM monitoring is at a disadvantage compared to traditional in-OS monitoring in terms of the information available to the monitors. VM monitoring operates at the hypervisor level, and therefore has access only to low-level hardware information, such as registers and memory, with limited semantic information on what the low-level information represents (e.g., what function is being called when the 0xabcd instruction is executed). In the literature, the hypervisor's lack of semantic information about the guest OS is referred to as the semantic gap.
Given the current technology trends, one may say that virtual machines will be everywhere. Whether in enterprise computing or as the key building block in a cloud, most environments employ VMs to some extent. Consequently, ensuring resilient operation of the cloud in the presence of both accidental failures and malicious attacks is of primary importance.
4.3 State of the Art
The research community has produced a variety of techniques for virtual machine monitoring. Of particular note are the Lares [5] and SIM [7] approaches. Lares uses a memory-protected trampoline inserted by a driver in the guest VM. That trampoline issues a hypercall to notify a separate security VM that an event of interest has occurred. This approach requires modification to the guest OS (albeit in a trusted manner), so runtime adding and removing of hooks is not possible. Furthermore, a guest OS driver and trampoline are needed for every OS and version of OS supported by the monitoring infrastructure. The Secure In-VM Monitoring (SIM) approach uses a clever configuration of hardware-assisted virtualization (HAV) that prevents VM Exits when switching to a protected page inside the VM that performs monitoring. Since SIM does not incur VM Exits, it achieves low overhead. However, this method involves adding special entry and exit gates to the guest OS and hooks are placed in specific kernel locations. In addition to platforms built on top of open-source technology, similar dynamic monitoring solutions also exist in proprietary systems. For example, there are vprobes for VMware ESXi [9].
However, the existing approaches do not support dynamic (i.e., at runtime) addition/removal of monitoring probes. The reason is that hooks are statically inserted into the guest OS. In those systems, in order to support the bare minimum flexibility of application-specific monitoring, one would either have to maintain a set of guest OS kernels or use a scheme that modifies a running kernel from within the guest.
Furthermore, there is lack of techniques that are rooted in hardware invariants [8,10], and hence are enforced by hardware-generated events (e.g., VM Exit). In this context, the invariant is that a properly functioning virtual machine will generate VM Exits on privileged operations (an assumption that is essential for a “trap-and-emulate” VMM). To protect probes, we can use Intel's Extended Page Tables (EPT) or AMD's Nested Page Tables (NPT) and write-protect the pages that contain active probes. This write protection satisfies the security requirement where probes cannot be evaded by actors inside the VM and incurs a performance impact only when pages containing probes are written to (a rare event for code in memory). The existing framework does place the hypervisor at the root of trust, but well-known techniques exist for signing hypervisor code [11–13].
Previous researchers have utilized int3 for VMs in Xenprobes [14], which provides a guest OS kernel debugging interface for Xen VMs. Additionally, xenprobes can use an Out-of-line Execution Area (OEA) to execute the replaced instruction (instead of always executing in place with a single step, such as the hprobe prototype does). The OEA provides a performance boost, but it results in a more complex code base and carries the need to create and maintain a separate memory region for this area. The OEA requires an OS driver to allocate and configure the OEA at guest OS boot, and the number of OEAs are statically allocated at boot, placing a hard upper bound on the number of supported probes (which is acceptable for debugging, but not for dependability monitoring).
Ksplice [15], a rebootless kernel patching mechanism, can be used to provide a basis for VM monitoring. The Linux kernel is also scheduled to incorporate a rebootless patching feature [16]. Ksplice allows for live kernel patching by replacing a function call with a jump to a new patched version of that function. The planned Linux feature will use ftrace10 to switch to a new version of the function after some safety checks. While these techniques can be useful for patches that have been properly tested and worked through a QA cycle, many operators would be uneasy with an untested patch on a live OS. When considering newly reported vulnerabilities, probe-based approaches allow one to quickly deploy an out-of-band monitor to detect the vulnerability without modifying the control flow of a running kernel. This temporary monitoring could even be used to provide a stopgap measure while a rebootless patch is in QA testing: One could use the monitor immediately after a vulnerability is announced and until the patch is vetted and safe to use. A technique such as this would drastically reduce the vulnerable window and alleviate pressure to perform risky maintenance outside of critical windows. It should be noted that while our example focused on a kernel vulnerability, this emergency detector technique can be extended to a user space program.
The next-generation probe-based (or hook-based) active VM monitoring techniques should
- perform application-level hook-based monitoring from the hypervisor, paving the way for cloud-based monitoring as a service (where a cloud provider could give the user a set of probe-based detectors to choose from),
- require no modification of the guest OS, and
- allow adding/removing of monitors/detectors at runtime.
These features are indispensable in any system intended for production use.
4.4 Dynamic VM Monitoring Using Hypervisor Probes
Here we discuss active and passive monitoring as a way of providing situational awareness about the system and users' state and behavior in the context of large computing infrastructure, such as that in cloud computing. (We refer the interested reader to our earlier publication [17] for more details.) Virtual machines provide strong isolation that can be used to enhance reliability and security monitoring [3,8,10,18]. Previous VM monitoring systems require setup and configuration as part of the boot process, or modification of guest OS internals. In either case, the effect on the guest is the same: A VM reboot is necessary to adapt the system. This is undesirable for a number of reasons, such as increased downtime (discussed further in the next section). By using a dynamic monitoring system that requires no guest OS modifications or reboots, we can allow users to respond to new threats and failure modes quickly and effectively.
Monitoring systems can generally be split into two classes: those that perform passive monitoring, and those that perform active monitoring [19]. Passive monitoring systems are polling-based systems that periodically inspect the system's state. These systems are vulnerable to transient attacks that occur between monitoring checks [8]. Furthermore, constant polling of a system can be a source of unnecessary performance overhead. Active monitoring systems overcome these weaknesses since they are triggered only when events of interest occur. However, it is essential to ensure that an active monitoring system's event generation mechanism cannot be circumvented.
One class of active monitoring systems is that of hook-based systems, in which the monitor places hooks inside the target application or OS [5]. A hook is a mechanism used to generate an event when the target executes a particular instruction. When the target's execution reaches the hook, control is transferred to the monitoring system, which can record the event and/or inspect the system's state. Once the monitor has finished processing the event, it returns control to the target system, and execution continues until the next event. Hook-based techniques are robust against failures and attacks inside the target when the monitoring system is properly isolated from the target system.
We find dynamic hook-based systems attractive for dependability monitoring, as they can be easily adapted: Once the hook delivery mechanism is functional, implementation of a new monitor involves merely adding a hook location and deciding how to process the event. In this context, dynamic refers to the ability to add and remove hooks without disrupting the control flow of the target. This is particularly important in real-world use, where monitoring needs to be configured for multiple applications and operational environments. In addition to supporting a variety of environments, monitoring must also be responsive to changes in those environments.
We created the hprobe framework, a dynamic hook-based VM reliability and security monitoring solution. The key contributions of the hprobe framework are that it is loosely coupled with the target VM, can inspect both the OS and user applications, and supports runtime insertion and removal of hooks. Those qualities mean that hprobe is a VM monitoring solution that is suitable for use on an actual production system.
4.4.1 Design
Hook-Based Monitoring
An illustration of a hook-based monitoring system adapted from the formal model presented in Lares [5] is shown in Figure 4.1. In hook-based monitoring, a monitor takes control of the target after the target reaches a hook. In the case of hypervisor-based VM monitoring, the target is a virtual machine, and the monitor can run in the hypervisor [4], in a separate security VM [5] or in the same VM [7]. Regardless of the separation mechanism used, one must ensure that the monitor is resilient to tampering from within the target VM and that the monitor has access to all relevant state of that VM (e.g., hardware, memory). Furthermore, a VM monitoring system should be able to trigger upon the execution of any instruction, be it in the guest OS or in an application.

Figure 4.1 Hook-based monitoring. A hook is triggered by event e, and control is transferred to the monitor through notification N. The monitor processes e with a behavior B and returns control to the target with a response R.
If a monitoring system can capture all relevant events, it follows that the monitoring system should be dynamic. This is important in the fast-changing landscape of IT security and reliability. As new vulnerabilities and bugs are discovered, one will inevitably need to account for them. The value of a static monitoring system decreases drastically over time unless periodic software updates are issued. However, in many VM monitoring solutions [3,5,7,8], the downtime caused by such software updates is unacceptable, particularly when the schedule is unpredictable (e.g., updates for security vulnerabilities). Dynamic monitors can also provide performance improvement relative to statically configured monitoring; one can monitor just an event of interest, or a general class of events (e.g., a single system call versus all system calls). Furthermore, it is possible to construct dynamic detectors that change during execution (e.g., a hook can be used to add or remove other hooks). Static monitoring systems also present a subtle design flaw: A configuration change in the monitoring system can affect the control flow of the target system (e.g., by requiring a restart).
In line with dynamism and loose coupling with the target system, the detector must also be simple in its implementation. If a system is overly complex and difficult to extend, the value of that system is drastically reduced, as using it requires much effort. In fact, such a system will simply not be used. DNSSEC1 and SELinux2 can serve as instructive examples; they provide valuable security features (e.g., authentication and access control), they were both released around the year 2000, and to this day are still disabled in many environments. Furthermore, a simpler implementation should yield a smaller attack surface [20].
4.4.2 Prototype Implementation
Integration with KVM
The hprobe prototype was inspired by the Linux kernel profiling feature kprobes [21], which has been used for real-time system analysis [22]. The operating principle behind our prototype is to use VM Exits to trap the VM's execution and transfer control to monitoring functionality in the hypervisor. Our implementation leverages HAV, and the prototype framework is built on the KVM hypervisor [23]. The prototype's architecture is shown in Figure 4.2. The modifications to KVM itself make up the Event Forwarder, which is a set of callbacks inserted into KVM's VM Exit handlers. The Event Forwarder uses Helper APIs to communicate with a separate hprobe kernel agent. The hprobe kernel agent is a loadable kernel module that is the workhorse of the framework. The kernel agent provides an interface to detectors for inserting and removing probes. This interface is accessible by kernel modules through a kernel API in the host OS (which is also the hypervisor, since KVM itself is a kernel module) or by user programs via an ioctl interface.

Figure 4.2 Hprobes integrated with the KVM hypervisor. The Event Forwarder has been added to KVM and communicates with a separate kernel agent through Helper APIs. Detectors can be implemented as kernel modules either in the host OS or in user space. In the latter case ioctl functions are used to communicate with the kernel agent.
The execution of an hprobe-based detector is illustrated in Figure 4.3. A probe is added by rewriting the instruction in memory at the target address with int3, saving the original instruction, and adding the target address to a doubly linked list of active probes. This process happens at runtime and requires no application or guest OS restart. The int3 instruction generates an exception when executed. With HAV properly configured, this exception generates a VM Exit event, at which point the hypervisor intervenes (step 1). The hypervisor uses the Event Forwarder to pass the exception to the hprobe kernel agent, which traverses the list of active probes and verifies that the int3 was generated by an hprobe. If it was, the hprobe kernel agent reports the event and optionally calls an hprobe handler function that can be associated with the probe. If the exception does not belong to an hprobe (e.g., it was generated by running gdb or kprobes inside the VM), the int3 is passed back to KVM to be handled as usual. Each hprobe handler performs a user-defined monitoring function and runs in the host OS. When the handler returns, the hypervisor replaces the int3 instruction with the original opcode and puts the CPU in single-step mode. Once the original instruction executes, a single-step exception is generated, causing another VM Exit event [21] (step 2). At this point, the hprobe kernel agent rewrites the int3 and performs a VM Entry, and the VM resumes its execution (step 3). This single-step and instruction-rewrite process ensures that the probe is always caught. If one wishes to protect the probes from being overwritten by the guest, the page containing the probe can be write-protected. Although the prototype was implemented using KVM, the concept will extend to any hypervisor that can trap on similar exceptions. Note that instead of int3, we could use any other instruction that generates VM Exits (e.g., hypercalls or illegal instructions). We chose int3 because it is well-supported and has a single-byte opcode.
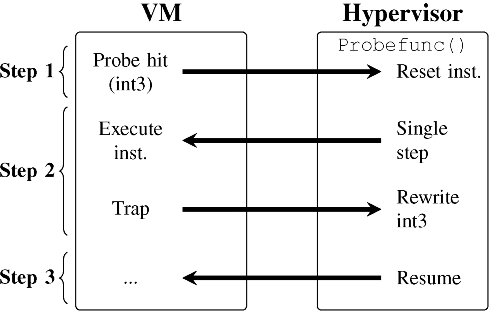
Figure 4.3 A probe hit in the hprobe prototype. Right-facing arrows are VM Exits, and left-facing arrows are VM Entries. When int3 is executed, the hypervisor takes control. The hypervisor optionally executes a probe handler (probefunc()) and places the CPU into single-step mode. It then executes the original instruction and does a VM Entry to resume the VM. After the guest executes the original instruction, it traps back into the hypervisor, and the hypervisor will write the int3 before allowing the VM to continue as usual.
Limitations
This prototype is useful for a large class of monitoring use cases; however, it does have a few limitations:
- Hprobes trigger only on instruction execution. If one is interested in monitoring data access events (e.g., triggering every time a particular address is read from or written to), hprobes will not provide a clean way to do so. One would need to place a probe at every instruction that modifies the data (potentially every instruction that modifies any data, if addresses are affected by user input). More cleanly, one could use an hprobe at the beginning and end of a critical section to turn on and off page protection for data relevant to that critical section, capturing the events in a manner similar to that of livewire [3] but with the flexibility of hprobes.
- Hprobes leverage VM Exits, resulting in nonoptimal performance. However, the simpler, more robust implementation that hprobes offer, with trust rooted in HAV, is worth this trade-off.
- Probes cannot be fully hidden from the VM. Even with clever use of Extended Page Tables (EPT) tricks to hide the existence of a probe when reading from its location, a timing side-channel would still exist, since an attacker could observe that the probed instruction takes longer than expected to complete.
4.4.3 Example Detectors
In this section, we present sample reliability and security detectors built upon the hprobe prototype framework. These detectors are unique to the hprobe framework and cannot be implemented on any other current VM monitoring system.
4.4.3.1 Emergency Exploit Detector
Most system operators fear zero-day vulnerabilities, as there is little that can be done about them until the vendor or maintainer of the software releases a fix. Furthermore, even after a vulnerability is made public, a patch takes time to be developed and must be put through a QA cycle. The challenge is even greater in environments with high availability concerns and stringent change control requirements; even if a patch is available, many times it is not possible to restart the system or service until a regular maintenance window. This leaves operators with a difficult decision: risk damage from restarting a system with a new patch, or risk damage from running an unpatched system.
Consider the CVE-2008-0600 vulnerability, which resulted in a local root exploit through the vmsplice() system call [24,25]. This example represents a highly dangerous buffer overflow, since a successful exploit allows one to arbitrarily execute code in ring 0 using a program that is publicly available on the Internet. Since this exploit involves the base kernel code (i.e., not a loadable module), patching it would require installation of a new kernel followed by a system reboot. As discussed earlier, in many operational cases, a system reboot or OS patch can be conducted only during a predetermined maintenance window. Furthermore, many organizations would be hesitant to run a fresh kernel image on production systems without having gone through a proper testing cycle first.
The vmsplice() system call is used to perform a zero-copy map of user memory into a pipe. At a high level, the CVE-2008-0600 vmsplice() constructs specially crafted compound page structures in user space. A compound page is a structure that allows one to treat a set of pages as a single data structure. Every compound page structure has a pointer to a destructor function that handles the cleanup of those underlying pages. The exploit works by using an integer overflow to corrupt the kernel stack such that it references the compound page structures crafted in user space. Before calling vmsplice(), the exploit closes the pipe, so that when the system call runs, it deallocates the pages, resulting in a call to the compound pages' destructor function. The destructor is set to privilege escalation shellcode that allows an attacker to hijack the system.
The emergency detector works by checking the arguments of a system call for a potential integer overflow. This differs in functionality from the upstream patch, which checks whether the memory region (specified by the struct iovec argument) is accessible to the user program. One could write a probe handler that performs a similar function by checking whether the entire region referred to by the struct iovec pointer + iov_len is in the appropriate range (e.g., by walking the page tables that belong to that process). However, a temporary measure to protect against an attack should be as lightweight and simple as possible to avoid unpredictable side effects. One major benefit of using an hprobe handler is that developing such a detector does not require a deep understanding of the vulnerability; the developer of the emergency detector only needs to understand that there is an integer overflow in an argument. This is far simpler than developing and maintaining a patch for a core kernel function (a system call), especially when reasoning about the risk of running a home-patched kernel (a process that would void most enterprise support agreements).
Our solution uses a monitoring system that resides outside of the VM and relies on a hardware-enforced int3 event. A would-be attacker cannot circumvent this event without having first compromised the hypervisor or modified the guest's kernel code. He or she could do so with a code injection attack that causes a different sys_vmsplice() system call handler to be invoked. However, it is unlikely that an attacker who already has the privileges necessary for code injection into the kernel would have anything to gain by exploiting a local privilege escalation vulnerability. While the proposed emergency detector cannot defeat an attacker who has previously obtained root access, its ease of rapid deployment sufficiently mitigates this risk.
Since no reboot is required and the detector can be used in a “read-only” monitoring mode (only reporting the attack, and otherwise not taking an action), the risk of using this detector on a running production system is minimal. To test the CVE-2008-0600 detector, we used a CENTOS5 VM and the publicly available exploit. As an unprivileged user, we ran an exploit script on the unpatched OS and were able to obtain root access. With the monitor in place, all attempts to obtain root access using the exploit code were detected.
4.4.3.2 Application Heartbeat Detector
One of the most basic reliability techniques used to monitor computing system liveness is a heartbeat detector. In that class of detector, a periodic signal is sent to an external monitor to indicate that the system is functioning properly. A heartbeat serves as an illustrative example of how an hprobe-based reliability detector can be implemented. Using hprobes, we can construct a monitor that directly measures the application's execution. That is, since probes are triggered by application execution itself, they can be viewed as a mechanism for direct validation that the application is functioning correctly. Many applications execute a repetitive code block that is periodically reentered (e.g., a Monte Carlo simulation that runs with a main loop, or an HTTP server that constantly listens for new connections). If one profiles the application, it is possible to identify a period (defined in units of time or using a counter, like the number of instructions) at which this code block is reentered. During correct operation of the application, one can expect that the code block will be executed at the profiled interval.
The hprobe-based application heartbeat detector is built on the principle described in the previous paragraph and illustrated in Figure 4.4. The test detector (i.e., one of the detectors on the left side of Figure 4.2) is a kernel module that is installed in the host OS. An hprobe is inserted at the start of the code block that is expected to be periodically reentered. When the hprobe is inserted, a delayed workqueue5 is scheduled for the timeout corresponding to the reentry period for the code block. When the timeout expires, the workqueue function is executed and declares failure. (If the user desires a more aggressive watchdog-style detector, it is possible to have the hprobe handler perform an action such as restart of the application or VM.) During correct operation (i.e., when the hprobe is hit), the workqueue is canceled and a new workqueue is scheduled for the same interval, starting a new timeout period. This continues until the application finishes or the user no longer desires to monitor it and removes the hprobe. If having an hprobe hit on every iteration of the main loop is too costly, one can ensure that the probe is active for an acceptable time interval; it can be added/removed until a desirable performance is achieved. (The detection latency would still be low, as a tight loop would have a small timeout value.)

Figure 4.4 Application heartbeat detector. A probe is inserted in a critical periodic section of the application (e.g., the main loop). During normal execution, a timer is continuously reset. In the presence of a failure (such as an I/O hang), the timer expires and failure is declared.
We use the open-source Path Integral Quantum Monte Carlo (pi-qmc) simulator [26] as a test application. This application represents a long-running scientific program that can take many hours or days to complete. As is typical with scientific computing applications, pi-qmc has a large main loop. Since Monte Carlo simulation involves repeated sampling and therefore repeated execution of the same functions, we need to run the main loop only a handful of times to determine the time per iteration. After determining the expected duration of each iteration, we set the heartbeat timeout to twice the expected value, set the detector to a statement at the end of the main loop, injected hangs (e.g., SIGSTOP), and crashed the application (e.g., SIGKILL). All crashes (including any VM crashes that occurred after the timer was executed in the hypervisor) were detected.
4.4.4 Performance
All of our microbenchmarks and detector performance evaluations were conducted on a Dell PowerEdge R720 server with dual-socket Intel Xeon E5-2660 “Sandy Bridge” 2.20 GHz CPUs (3.0 GHz turbo boost). To obtain runtime measurements, we added an extra hypercall to KVM that starts and stops a timer inside the host OS. This allows us to obtain measurements independent of VM clock jitter. To ensure consistency among measurements, the test VMs were rebooted between two subsequent measurements.
4.4.4.1 Microbenchmarks
We performed microbenchmarks that estimated the latency of a single hprobe, which is the time from execution of int3 by the VM until the VM is resumed (steps 1–3 in Figure 4.3). We ran these microbenchmarks without a probe handler function to determine the lower bound of hprobe-based detector overhead. Since the round-trip latency of an individual VM Exit on Sandy Bridge CPUs has been estimated to take roughly 290 ns [27] and our hypercall measurement scheme induces additional VM Exits, it would be difficult to accurately measure the individual probe latency. Instead, we obtained a mean round-trip latency by repeatedly executing a probed function a large number of times (one million) and dividing by the total time taken for those executions. That approach helped remove jitter due to timer inaccuracies as well as the actual latency of the hypercall measurement system itself. For the test probe function, we added a no-op kernel module to the guest OS that creates a dummy no-op device with an ioctl that calls a noop_func() kernel function that performs no useful work (return 0). First, we inserted an hprobe at the noop_func()'s location. Our microbenchmarking application started by issuing a hypercall to start the timer and then an ioctl against the no-op device. When the no-op module in the guest OS received the ioctl, it called noop_func() one million times. Afterward, another hypercall was issued from the benchmarking application to read the timer value.
For the microbenchmarking experiment, we used a 32-bit Ubuntu 14.04 guest and measured 1000 samples. The mean latency (across samples) was found to be 2.6 μs. In addition to the Sandy Bridge CPU, we have also included data for an older generation 2.66 GHz Xeon E5430 “Harpertown” processor (running the same kernel, KVM version, and VM image), which had a mean latency of 4.1 μs. The distribution of latencies for these experiments is shown in Figure 4.5. The remainder of the benchmarks presented used the Sandy Bridge E5-2660. The hprobe prototype requires multiple VM Exits per probe hit. However, in many practical cases, the flexibility of dynamic monitoring and the reduced maintenance costs resulting from a simple implementation outweigh that cost. The flexibility can increase performance in many practical cases by allowing one to add and remove probes throughout the VM's lifetime. Furthermore, CPU manufacturers are constantly working to reduce the impact of VM Exits; for example, Intel's VT-x saw an 80% reduction in VM Exit latency over its first 6 years [27].

Figure 4.5 Single probe latency. (CPUs' release years are in parentheses.) The E5-2660's larger range can be attributed to “Turbo Boost,” whereby the clock scales from 2.2 to 3.0 GHz. The shaded area is the quartile range (25–75 percentile); whiskers are the minimum/maximum; the center is the mean; and the notches in the middle represent the 95% confidence interval of the mean.
4.4.4.2 Detector Performance
In addition to microbenchmarking individual probes, we measured the overhead of the example hprobe-based detectors presented in the previous section. All measurements in this section were obtained using the hypercall-based timer.
- Emergency Exploit Detector: Our integer overflow detector that protects against the CVE-2008-0600 vmsplice() vulnerability is extremely lightweight. Unless vmsplice() is used, the overhead of the detector is zero since the probe will not be executed. The vmsplice() system call is rare (at least in the open-source repositories that we searched), so zero overhead is overwhelmingly the common case. One application that does use vmsplice() is Checkpoint/Restart in User space (CRIU). CRIU uses vmsplice() to capture the state of open file descriptors referring to pipes. We used the Folding@Home molecular dynamics simulator [28] and the pi-qmc Monte Carlo simulator from earlier as test programs. We ran these applications in a 64-bit Ubuntu 14.04 VM. At each sample, we allowed the application to warm up (load input data and start the main simulation) and then checkpointed it. The timing hypercalls were inserted into CRIU to measure how long it takes to dump the application. This was repeated 100 times for each case with and without the detector, and the results are tabulated in Table 4.1. In the table, we can see that there is a slight difference between the mean checkpoint times (roughly 3.3% for F@H and 1.7% for pi-qmc) and that the variance in the experiment with the detector active is higher for the Folding@Home case. Sys_vmsplice() was called 28 times when Folding@Home was being checkpointed, and 11 times for pi-qmc. We can attribute this difference to the negative cache effects of the context switch when probes are being activated.
- Application Heartbeat Detector: We used the pi-qmc simulator to measure the performance overhead of the application watchdog detector. The pi-qmc simulator allows configuration of its internal sampling, and we utilized this feature to vary the length of the main loop. In order to determine how the detector impacts performance, we measured the total runtime of each iteration of the main loop when the probe was inserted and ran the program for 15 min. The results of our experiments are shown in Figure 4.6.
Table 4.1 CVE-2008-0600 Detector w/CRIU.
| Application | Runtime (s) | 95% CI (s) | Overhead (%) |
| F@H Normal | 0.221 | 0.00922 | 0 |
| F@H w/Detector | 0.228 | 0.0122 | 3.30 |
| F@H w/Naïve Detector | 0.253 | 0.00851 | 14.4 |
| pi-qmc Normal | 0.137 | 0.00635 | 0 |
| pi-qmc w/Detector | 0.140 | 0.00736 | 1.73 |
| pi-qmc w/Naïve Detector | 0.125 | 0.00513 | 11.1 |

Figure 4.6 Benchmarking of the application watchdog detector. The horizontal axis indicates the scaling of an internal loop in the target pi-qmc program. The vertical axis shows a distribution of the completion times for the iterations of the main loop. The boxplot characteristics are the same as in Figure 4.5.
From Figure 4.6, we can see that the detector did not affect performance in a statistically significant way. The reason is that pi-qmc, like many scientific computing applications, does a large amount of work in each iteration of its main loop. However, by setting the threshold of the detector to a conservative value (like twice the mean runtime), one can achieve fault detection in a far more acceptable timeframe than with other methods, like manual inspection. Furthermore, this detector goes beyond checking whether the process is still running; it can detect any fault that causes a main loop iteration to halt (e.g., a disk I/O hang, a network outage when using MPI, or a software bug that does not lead to a crash).
4.4.5 Summary
The hprobe framework is characterized by its simplicity, dynamism, and ability to perform application-level monitoring. Our prototype for this framework uses hardware-assisted virtualization and satisfies protection requirements presented in the literature. We find that compared to past work, the simplicity with which the detectors can be implemented and inserted/removed at runtime allows us to develop monitoring solutions quickly. Based on our experience, this framework is appropriate for use in real-world environments. Through use of our sample detectors, we have found that the framework is suitable for detecting bugs and random faults, and for use as a stopgap measure against vulnerabilities.
4.5 Hypervisor Introspection: A Technique for Evading Passive Virtual Machine Monitoring
While dynamic monitoring (wherein monitoring checks are triggered by certain events, for example, access of specific hardware registers or memory regions) has its advantages, it comes with additional costs in terms of implementation complexity and performance overhead. In consequence, one may ask, why not use passive monitoring (wherein a monitoring check is invoked on a predefined interval, for example, to determine what processes are running every second), which could be less costly?
To address the trade-offs between active and passive monitoring, in this section, we discuss some drawbacks of passive monitoring. In particular, we show that it is possible for a guest VM to recognize the presence of a passive VMI (virtual machine introspection) system and its monitoring frequency through a timing side-channel. We call our technique Hypervisor Introspection (HI). We also present an insider attack scenario that leverages HI to evade a passive VMI monitoring system. Finally, we discuss current state-of-the-art defenses against side-channel attacks in cloud environments and their shortcomings against HI.
We refer the interested reader to our earlier publication [29] for more details on the material covered in this section.
4.5.1 Hypervisor Introspection
We developed a VMI monitor against which to test Hypervisor Introspection, and we used the side-channel attack to evade the passive VMI. The test system was a Dell PowerEdge 1950 server with 16 GB of memory and an Intel Xeon E5430 processor running at 2.66 GHz. The server was running Ubuntu 12.04 with kernel version 3.13. The hypervisor used was QEMU/KVM version 1.2.0, and the guest VMs were running Ubuntu 12.04 with kernel version 3.11.
4.5.1.1 VMI Monitor
In order to test the effectiveness of HI, we implemented a VMI monitor. To do so, we used LibVMI [18]. LibVMI is a software library that helps with the development of VMI monitors. It focuses on abstracting the process of accessing a guest VM's volatile memory. The volatile memory of a VM contains information about the guest VM's OS, such as kernel data structures, which can be examined to determine runtime details such as running processes or active kernel modules.
Because the polling rate of the VMI monitor is directly related to the performance overhead of the monitor, the polling rate must be chosen carefully so as not to introduce an unacceptable decrease in VM performance. We configured the VMI monitor to poll the guest VM every second. This rate introduced only a 5% overhead in VM performance, based on benchmark results from UnixBench.
4.5.1.2 VM Suspend Side-Channel
Because HI revolves around making measurements from a side-channel and inferring hypervisor activity, we first had to identify the actual side-channel to be exploited. We noted that whenever the hypervisor wants to perform a monitoring check on a guest VM, the VM has to be paused so that a consistent view of the hardware state can be obtained. If an observer can detect these VM suspends, then that observer might be able to learn about the monitoring checks performed by the hypervisor. We call this approach the VM suspend side-channel (see Figure 4.7). We came up with two potential methods for measuring the VM suspends: network-based timing measurements and host-based, in-VM timing measurements. Since the network is a noisy medium because of dropped packets and routing inconsistencies, we focused on performing in-VM measurements to detect VM suspends.
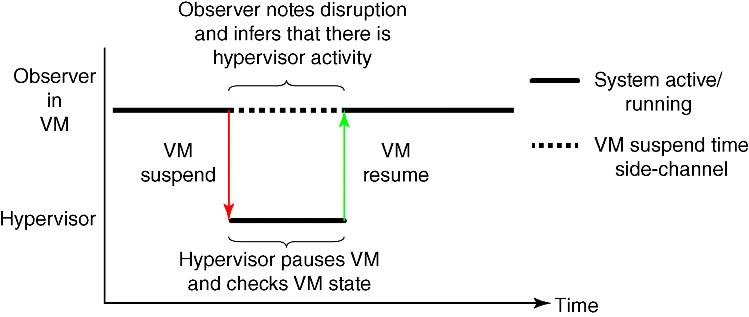
Figure 4.7 Illustration of the VM suspend side-channel in which an observer notes disruptions in VM activity to determine when the hypervisor is performing some action on the VM.
4.5.1.3 Limitations of Hypervisor Introspection
HI has two limitations: the low accuracy of the monitoring intervals it measures, and the difficulty of determining the threshold value for identifying VM suspends. Our testing of HI showed that it is capable of determining monitoring intervals as short as 0.1 s, as we determined by testing HI against increasingly frequent monitoring checks; the maximum frequency resolved by HI was one check every 0.1 s (10 Hz).
Because the threshold value for HI is found through empirical testing, development of HI is not straightforward for any given system. Our testing of HI indicated that threshold values ranging from 5 to 32 ms yielded the same accuracy when we were performing HI and detecting VM suspends. As future work, the threshold value may be correlated with various system specifications, such as kernel version, CPU model/frequency, and system load. After threshold values on various systems are found via empirical testing, a formal relationship between the various system specifications and the threshold value may be derived so that a threshold can be obtained without testing.
4.5.2 Evading VMI with Hypervisor Introspection
This section discusses applications of Hypervisor Introspection to hide malicious activity from a passive VMI system.
4.5.2.1 Insider Attack Model and Assumptions
We present an insider threat attack model in which the insider already has administrator (i.e., root) access to VMs running in a company's public IaaS cloud. The insider knows that he will be leaving the company soon but would like to maintain a presence on the VMs to which he has access. The insider does not have access to the underlying hypervisor hosting the VMs but knows that the company is utilizing some form of passive VMI monitoring. We also assume that the company's VMI monitor is similar to the monitor we implemented, which regularly checks for unauthorized processes. As insiders have full control over their VMs, the company relies on VMI for monitoring, so changes to the VM, such as kernel modifications or creations of new files, are not detected. In this attack model, the insider can utilize HI to detect invocations of the monitor and to hide malicious activities from the VMI monitor.
4.5.2.2 Large File Transfer
Attackers commonly want to exfiltrate data out of the network after compromising a system. The attacker may leverage various tools and protocols to accomplish this, such as secure copy (SCP), file transfer protocol (FTP), the attacker's own custom utility, or any number of other file transfer methods. A passive VMI system may detect attempts at data exfiltration by maintaining a restrictive whitelist of processes that are allowed to run with a network socket open. A restricted VM would have a whitelist with zero or few entries.
For transfer of sufficiently large files via a nonwhitelisted process, the transfer time would be longer than the monitoring interval, and the VMI monitor would detect the file transfer. This scenario is illustrated in Figure 4.8. We tested the effectiveness of our VMI monitor in this scenario by transferring a 250 MB file over TCP from the monitored VM to a coresident VM, and our VMI monitor detected the Python process running with an open socket and signaled an alarm.

Figure 4.8 Illustration of an unauthorized file transfer's detection by the VMI system.
It is possible to transfer a large file over a network without triggering any VMI alarms by splitting the file into chunks and transferring the chunks individually between monitoring checks. This process is illustrated in Figure 4.9. Thus, HI can be used to time the transfer of each chunk to evade the VMI system.

Figure 4.9 Illustration of how a large file can be transferred in chunks by a nonwhitelisted process without triggering the passive VMI monitor.
We implemented this attack by writing a Python script that transfers a chunk of a file each time it is executed. The offset of the current chunk is written to an “offset log” file after each execution, so that the next execution knows which chunk to transfer. We extended our HI kernel module with the user mode helper kernel function that is invoked by the Python script after a suspected VM suspends. With our modified HI kernel module and Python script, we were able to transfer the same 250 MB file without being detected by our VMI monitor.
On our test system, naïve transfer of the entire 250 MB file at once over a TCP connection between two coresident VMs took on average (over 100 tests) 4.905 s, with a standard deviation of 0.414 s. Using our technique with 8 MB chunks, the entire transfer took 32 calls to the Python script, and thus 32 monitoring intervals. Because each monitoring interval is 1 s long, the entire transfer took around 32 s, which is about eight times the transfer time of the naïve method.
We note that the transfer speed of the large file when this method is used depends on the polling frequency of the VMI monitor. Lower polling frequencies lead to longer transfer times because each chunk transfer is triggered by a monitoring check, so chunks would be transferred less frequently. However, after learning the polling frequency through HI, the attacker can increase the chunk size to counteract the delay. Increasing the chunk size is risky, as it may end up triggering the VMI system, so the attacker would likely verify a larger chunk size on his own system before performing the attack. Figure 4.10 shows the trade-offs involved in increasing the chunk size for the file transfer. Increased chunk size leads to a higher detection rate, but the whole file is transferred in fewer monitoring checks.

Figure 4.10 Chunk size versus detection rate in using HI to hide a large file transfer. Note the trade-off between number of monitoring checks (i.e., transfer time) and detection rate.
4.5.3 Defenses against Hypervisor Introspection
In this section, we discuss current state-of-the-art defenses against side-channel attacks in virtual environments and their shortcomings in defending against HI. We also discuss a potential defense against HI that aims to address the shortcomings of the current state-of-the-art defenses.
4.5.3.1 Introducing Noise to VM Clocks
Because HI relies on fine-grained timing measurements to determine occurrences of VM suspends, it follows that reducing the accuracy or granularity of VM clocks could prevent HI from working. Previous research has looked at reducing the granularity or accuracy of time sources to prevent cross-VM side-channel attacks. Although that work aimed to address cross-VM side-channel attacks, much of it is somewhat applicable to the hindering of HI.
Vattikonda et al. explored the possibility of fuzzing timers to reduce the granularity of measurements needed for side-channel attacks [24]. They modified the Xen hypervisor to perturb the x86 RDTSC instruction by rounding it off by 4096 cycles. Because the RDTSC instruction is commonly used to obtain high-resolution times tamps, side-channel attacks may be prevented. An additional benefit of fuzzing the RDTSC instruction is that timing system calls, such as gettimeofday and clock gettime, are fuzzed as well. Although HI relies on one of these system calls for time stamping, the perturbations caused only a 2 μs change in the true RDTSC value. HI needs measurements on the order of milliseconds, so the fuzzing does not perturb the RDTSC value enough to hinder HI.
Li et al. developed a system called StopWatch, in which the VM clock was replaced with a virtual clock that constantly skews [25]. Because the virtual clock depends only on the number of instructions executed, it hid VM suspends from in-VM timing measurements. However, applications with real-time requirements would not be able to use a virtual clock. In addition, StopWatch has a worst-case performance of 2.8× for workloads that require heavy network usage, which might not be acceptable for high-performance workloads.
4.5.3.2 Scheduler-Based Defenses
Recently, scheduling policies have been explored as another means to prevent cross-VM, cache-based, side-channel attacks. Varadarajan et al. proposed using the scheduler to force each process to run for a minimum runtime before another process is allowed to run [30]. If all processes are forced to run for a certain amount of time without being preempted, an attacker would obtain less information from observing a process's cache usage. Adjusting the scheduling policy could prevent part of our HI technique from working if the minimum runtime were greater than the VM suspend threshold. If that were the case, then process scheduling could not be used as one of the events observed for the in-VM timing measurements. However, many other events that occur during normal OS operation could still be observed, such as network operations or memory allocation and deallocation. An attacker could also artificially spawn processes that purposely utilize specific OS operations to increase the frequency of the events and improve the granularity of the measurements needed for HI. Thus, changing the scheduling policy might hinder HI, but it would not altogether block it. Further, enforcing a minimum runtime could degrade performance because CPU-intensive workloads would have to compete with less intensive workloads.
4.5.3.3 Randomized Monitoring Interval
Because HI looks for regular VM suspends to determine when monitoring checks occur, it may seem that simply randomizing the monitoring interval would prevent HI. This is not the case because randomized intervals have a lower bound on the duration between monitoring checks. A patient attacker could use HI to establish the lower bound on the monitoring interval and craft his attacks around that lower bound. Thus, the randomized monitoring interval forces the attacker to be inefficient, but it cannot prevent the attacker from evading the VMI system.
For example, consider a passive VMI system that polls the guest VM on a randomized interval that lasts anywhere from 1 to 10 s, inclusive. Assuming that the monitoring interval is a discrete random variable (i.e., the monitoring interval is an integer), one would expect to observe 10 monitoring checks before the smallest possible interval is seen.
Even if the monitoring interval is a uniform random variable (i.e., the monitoring interval can be a noninteger value), the attacker can transform the problem into the discrete-value case by taking the floor of the observed monitoring interval. In the case of an interval that lasts anywhere from 1 to 10 s, flooring the value leaves 10 possible values. Thus, the expected number of observed monitoring checks before the minimum is obtained is still 10.
The range of the random monitoring intervals is directly related to how difficult it is for an attacker to establish the minimum possible monitoring interval. Because security improves with a lower monitoring interval (and higher monitor frequency), the range of monitoring interval values would remain small in practice to improve security, but that would also make it easier for an attacker to determine the lower bound of the randomized monitoring interval through HI.
We reconfigured our VMI monitor to use a randomized monitoring interval between 0 and 2 s that would change after each monitoring check. We chose this interval because it kept the performance overhead around 5% (based on the same UnixBench benchmarks from earlier), and we expected the lower monitoring intervals (under 1 s) to detect the attack described in the earlier section. We performed the attack 30 times and found that the reconfigured monitor was able to detect the large file transfer 70% of the time.
We were surprised that some large file transfer attacks succeeded against the randomized monitoring defense. Some of the large file transfers went undetected because the randomized intervals that triggered the chunk transfers in those cases were long enough to thwart detection. However, the majority of the large file transfers were detected with randomized monitoring. Based on these tests, we argue that a randomized monitoring interval is sufficient for preventing a large file transfer attack but not a backdoor shell attack. Further, randomized monitoring does not prevent HI from learning that there is a passive VMI system in place, and HI can be used to learn the distribution sampled by the randomized monitor.
4.5.4 Summary
We discussed Hypervisor Introspection as a technique to determine the presence of and evade a passive VMI system through a timing side-channel. Through HI, we demonstrated that hypervisor activity is not perfectly isolated from the guest VM. In addition, we showed an example insider threat attack model that utilizes HI to hide malicious activity from a realistic, passive VMI system. We also showed that passive VMI monitoring has some inherent weaknesses that can be avoided by using active VMI monitoring.
4.6 Identifying Compromised Users in Shared Computing Infrastructures
System monitoring (both dynamic and passive) requires smart and effective techniques that can accurately, and in a timely fashion, detect potential malicious activities in the system. One way to achieve efficiency is to build the detectors based on past data on security incidents. In this section, we discuss a data-driven approach for accurate (with a low false-positive rate) identification of compromised users in a large computing infrastructure.
In the case of shared computing infrastructure, users get remote access by providing their credentials (e.g., username and password) through a public network and using well-established authentication protocols, for example, SSH. However, user credentials can be stolen via phishing or social engineering techniques and made available to attackers via the cybersecurity black market. By using stolen credentials, an attacker can masquerade as a legitimate user and penetrate a system in effect as an insider.
An access to a system performed with stolen credentials is hard to detect and may lead to serious consequences, such as the attackers obtaining root-level privileges on the machines of the system or breach of privacy, for example, e-mail access. Therefore, timely detection of ongoing suspicious activities is crucial for secure system operations. Thus, computing infrastructures are currently equipped with multiple monitoring tools (e.g., intrusion detection systems (IDS) and file integrity monitors) that allow system administrators to detect suspicious activities. However, the need to ensure high coverage in detecting attacks calls for accurate and highly sensitive monitoring, which in turn leads to a large number of false positives. Furthermore, the heterogeneity and large volume of the collected security data make it hard for the security team to conduct timely and meaningful forensic analysis. In this section, we consider credential-stealing incidents, that is, incidents initiated by means of stolen credentials. We refer the interested reader to our earlier publication [31] for more details on the material covered here.
4.6.1 Target System and Security Data
We performed a study of data on credential-stealing incidents collected at the National Center for Supercomputing Applications (NCSA) during the 2008–2010 timeframe. Credential-stealing incidents can occur in virtually any network that is accessible from the Internet (e.g., social networking sites, e-mail systems, or corporate networks that allow VPN access) or from an intranet or a business network managed by an IT department within a corporation. For that reason, the key findings of this study can be used to drive the design of better defensive mechanisms in organizations other than NCSA.
The NCSA computing infrastructure consists of about 5000 machines (including high-performance clusters, small research clusters, and production systems such as mail and file servers) accessed by worldwide users. Figure 4.11 provides a high-level overview of the target system. Users log into the system remotely by forwarding their credentials through the public network via the SSH protocol. Credentials might have been stolen. Thus, an attacker can masquerade as a legitimate user and penetrate the system. The security monitoring tools deployed in the NCSA network infrastructure are responsible for (1) alerting about malicious activities in the system, for example, a login from a blacklisted IP address or the occurrence of suspicious file downloads; and (2) collecting (in security logs) data relevant to detected incidents. An in-depth analysis of the security logs can then be used to identify compromised users.

Figure 4.11 Overview of the target system.
4.6.1.1 Data and Alerts
The log produced by the target machines, which is collected with the syslog protocol, is used to identify the users that access the infrastructure.
In the following, we describe the alerts produced by the monitoring tools when incidents that involve stolen credentials occur. As detailed below, we have assigned to the alerts IDs that are used throughout the remainder of this section.
First, we will discuss alerts that can be triggered when a login violates a user's profile. The detection of potential violations is done by checking login and profile data against rules set in the Simple Event Correlator (SEC):
- Unknown address (A1): A login comes from a previously unknown IP address, that is, the user has never before logged in from that IP, according to his or her profile.
- Multiple login (A2): The same external IP address is used by multiple users to log into the system.
- Command anomaly (A3): A suspicious command is executed by the user.
- Unknown authentication (A10): According to the profile data, the user has never before logged into the system using that authentication mechanism.
- Anomalous host (A11): The login is reported by a node within the infrastructure that has never before been used by the user.
- Last login > 90 days (A12): The last login performed by the user occurred more than 90 days before the current one.
In most cases, the occurrence of a profile alert does not by itself provide definitive proof that a user has been compromised. For example, A1 is raised each time a user (legitimate or not) logs in for the first time from a remote site that is not stored in the profile. In order to increase the chances of correctly detecting compromised users, the analysis of profile alerts is combined with the data provided by the security tools, for example, IDS and NetFlows (Figure 4.11), which are available in the NCSA network infrastructure. The security alerts used in the detection process are as follows:
- HotClusterConn (A4): A node of the computing infrastructure performs a download, although it is expected never to do so. An additional alert (A13) is introduced to indicate that the downloaded file exhibits a sensitive extension, for example, .c, .sh, .bin, or .tgz;
- HTTP (A5) and FTP (A9) sensitive URI: These alerts are triggered upon detection of well-known exploits, rootkits, and malware.
- Watchlist (A7): The user logs in from a blacklisted IP address (the list of suspicious addresses is held by and distributed among security professionals).
- Suspicious download (A14): A node of the computing infrastructure downloads a file with a sensitive extension.
Finally, two further alerts, A6 and A8, were designed by combining profile and security data. Alert A6 is generated whenever the remote IP address used to perform a login is involved in subsequent anomalous activities, such as a suspicious file download. Similarly, the alert A8 is generated if a user responsible for a multiple login is potentially related to other alerts in the security logs.
It should be noted that an event could trigger more than one alert. For example, the download of a file with a sensitive extension, if performed by a node that is not supposed to download any files, can trigger alerts A4, A13, and A14. While the occurrence of a profile alert leads to an initial level of suspiciousness about a user, a set of subsequent notifications, such as command anomalies or suspicious downloads, might actually be the symptoms of ongoing system misuse. Correlation of multiple data sources is valuable to improving detection capabilities and ruling out potential false alarms.
4.6.1.2 Automating the Analysis of Alerts
The timely investigation of alerts is crucial in identifying compromised users and initiating proper recovery actions. However, the analysis can become time-consuming because of the need to correlate alerts coming from multiple sources. In order to automate the alert analysis, we developed a software tool to (1) parse the content of heterogeneous security logs and (2) produce a representation of the security data more suitable for facilitating the Bayesian network approach.
Given the data logs (both syslogs and logs produced by the security tools), the tool returns a user/alerts table, which provides (1) the list of users that logged into the system during the time when the logs were being collected and (2) a set of 14-bit vectors (one for each user), with each bit of the vectors representing one of the alerts introduced in the previous section. Given a user in the system, a bit in the vector assumes value 1 if at least one alert of that type (observed in the security log) has potentially been triggered by that user. In order to illustrate the concept, Table 4.2 shows a hypothetical user/alerts table. For example, a binary vector of [10010000001000] is associated with user_1, which indicates that during the observation period, user_1 was potentially responsible for triggering three alerts: unknown address (A1), HotClusterConn (A4), and anomalous host (A11).
Table 4.2 Example of user/alerts table.
| Alerts | ||||||||||||||
| Users | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 | A13 | A14 |
| user_1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| user_2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ⋮ | ||||||||||||||
| user_N | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
4.6.2 Overview of the Data
Our study analyzed data related to 20 security incidents at NCSA that were initiated using stolen credentials and that occurred during 2008–2010. The NCSA security team comprehensively investigated each incident. The key findings of the investigations are summarized in Ref. [32]. The ground truth, that is, information about the actually compromised users, reports describing the system misuse, and proposed countermeasures, is available for each incident considered in the study. That detailed knowledge makes it possible to validate the effectiveness of the proposed approach. Of the 20 incidents, 3 were detected by means of a third-party notification (i.e., someone outside NCSA reported that anomalous activities had occurred) and 1 incident was a false positive (i.e., the conclusion that the user had been compromised was erroneous).
In order to characterize the ability of each alert Ai (1 ≤ i ≤ 14) to detect compromised users, we estimated the average number of users per day that are flagged as potentially responsible for Ai. We did so by analyzing the logs collected on the day the incident occurred. Figure 4.12 shows the average number of users per day flagged as potentially responsible for each alert considered in our analysis. Note that there is significant variability in the occurrence frequencies of different alerts. For example, the watchlist (A7) alert was observed for only two users during the entire observation period (which spanned the 16 incidents analyzed in this study). In both cases, the user was actually compromised. In the context of our analysis, watchlist is considered a reliable alert, since it has a small number of occurrences (0.125 users/day) and no false positives. On the other end of the spectrum is the HotClusterConn (A4) alert, which has a high occurrence frequency (64 users/day) and a relatively high false-positive rate. (Most of the users flagged as responsible for this alert have not actually been compromised.)

Figure 4.12 Average number of users (per day) flagged as potentially responsible for each alert Ai.
The detection capability is another important feature of the alerts. The detection capability is determined by extracting (from the user/alerts tables generated for the 16 analyzed incidents) the 14-bit vectors for the compromised users. Recall that the actually compromised users (i.e., the ground truth) are known for each incident. There are 20 compromised users in the incident data. Figure 4.13 shows how many compromised users (y-axis) are responsible for the specific alert types (x-axis). Comparison of these data with those presented in Figure 4.12 indicates that the alerts with the largest numbers of potentially responsible users are likely to be observed when the user is actually compromised. For example, around 20 users per day triggered an unknown address (A1) alert (see Figure 4.12); however, while most of these alerts turned out to be false positives, in 14 out of 20 cases (as reported in Figure 4.13), an actually compromised user had triggered the alert. Similarly, the HotClusterConn (A4) alert led to many false positives; nevertheless, it was likely to have been triggered by compromised users (6 out 20 cases).

Figure 4.13 Number of compromised users that triggered an alert Ai.
The inconclusive nature of alerts could suggest that it might be hard to identify compromised users based on the alert data available in the security log. However, our analysis shows that an actually compromised user will be related to more than one alert. In our study, an average of three unique alerts were related to each compromised user for each analyzed incident, such as the joint occurrence of the unknown address, command anomaly, and HotClusterConn alerts. In consequence, it is feasible to correlate multiple alerts by means of statistical techniques in order to distinguish between cases in which unreliable alerts can be discarded and cases in which an alert provides stronger evidence that a user has been compromised.
4.6.3 Approach
We processed security logs to produce (1) the list of users that logged into the system at any time throughout the time interval during which the logs were being collected and (2) the bit vector reporting alerts potentially related to a given user. Using that information, our objective was to estimate the probability that a user was compromised.
4.6.3.1 The Model: Bayesian Network
We have proposed a data-driven Bayesian network approach [33,34] to facilitate identification of compromised users in the target infrastructure. A Bayesian network is a direct acyclic graph in which each node of the network represents a variable of interest in the reference domain. The network makes it possible to estimate the probability of one or more hypothesis variable(s) given the evidence provided by a set of information variables. In the context of this work, the hypothesis variable is “the user is compromised,” while the information variables are the alerts related to the user.
We modeled the problem using a naïve Bayesian network, that is, a network in which a single hypothesis node is connected to each information variable. It was assumed that no connections exist among the information variables. The structure of the network is shown in Figure 4.14. A naïve network estimates the probability of the hypothesis variable by assuming the independence of the information variables. In other words, given a system user, the presence of an alert in a bit vector does not affect the probability of observing the other alerts. A set of vectors (the ones composing the training set described later in the chapter) was used to validate the assumption of independence of information variables. For each combination of the alerts (Ai, Aj) (for i, j ∈ {1, 2, 3,…, 14}), we counted how many vectors in the training set contained Ai, Aj, or both Ai and Aj. Then, the chi-squared test was applied to verify the null hypothesis H0, that is, alerts Ai and Aj are independent of each other. Of the 91 possible combinations of alert pairs, in 28 cases (around 30% of the combinations) the chi-squared test (with a 95% significance level) indicated that H0 had to be rejected. Regardless, in the majority of cases, the assumption of alerts' independence held.
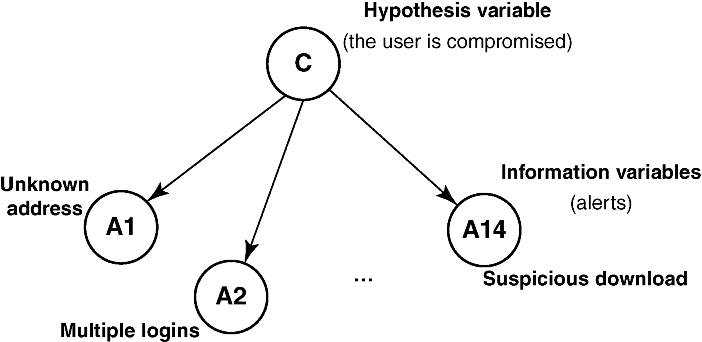
Figure 4.14 Adopted Bayesian network.
It has to be noted that assuming the independence of a pair of dependent alerts leads to overestimation of the statistical evidence provided by the joint occurrence of the alerts. Thus, because the dependencies among the information variables are neglected, it might happen that the a posteriori probability of the hypothesis variable “the user is compromised” is greater than the real value. Consequently, the assumption of alerts' independence makes the analysis more conservative; however, more importantly, it does not compromise the detection capability of the adopted Bayesian network.
4.6.3.2 Training of the Bayesian Network
We used the logs collected for a subset of the available incidents, that is, 5 out of 16, as a training set for the network. Let T denote the adopted training set. T consists of 717 users (and corresponding bit vectors) and includes 6 compromised users. T contains the minimum number of training incidents, ensuring that almost all the alerts are covered by the actually compromised users, as shown in Table 4.3 (where comp_i denotes a compromised user). The strategy taken in this study has two main advantages: (1) It makes it possible to analyze the performance of the Bayesian network with conservative assumptions, that is, only a few training incidents are considered. (2) It does not bias the results, because all the adopted alerts are represented by the training set. Although other criteria might have been adopted, this selection of the training set was reasonable for our preliminary analysis of the performance of the proposed approach.
Table 4.3 Alerts related to the compromised users for the incidents in the training set.
| Alerts | ||||||||||||||
| Users | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A10 | A11 | A12 | A13 | A14 |
| comp_1 | 1 | 1 | 1 | |||||||||||
| comp_2 | 1 | 1 | 1 | 1 | ||||||||||
| comp_3 | 1 | 1 | 1 | 1 | 1 | |||||||||
| comp_4 | 1 | 1 | ||||||||||||
| comp_5 | 1 | 1 | 1 | |||||||||||
| comp_6 | 1 | 1 | ||||||||||||
The training stage makes it possible to tune the network parameters, that is, (1) the a priori probability of the hypothesis variable, and (2) the conditional probability table (CPT) for each information variable Ai. The a priori probability of the hypothesis node C (Figure 4.14) is estimated as P(C) = 6/717 = 0.008. Calculation of CPTs requires additional effort. Four parameters must be estimated for each alert, as shown in Table 4.4. For example, P(Ai|C) denotes the probability that an alert of type Ai is related to a particular user, given that the user is compromised. Similarly, P(Ai|¬C) represents the probability that an alert of type Ai is related to a user, given that the user is not compromised.
Table 4.4 Structure of the CPT for each alert Ai.
| Compromised (C) | ||
| Alert (Ai) | True | False |
| True | P(Ai|C) | P(Ai|¬C) |
| False | P(¬Ai|C) | P(¬Ai|¬C) |
The probability values of the CPTs are estimated as follows. The overall number of users in the training set T is divided into two disjoint subsets: good and compromised. Let G and C denote the two subsets, respectively. Note that |T| = |G| + |C|. For each alert Ai, let Li be the set of users (good or compromised) in the training set T that exhibits that type of alert, for example, all the users in T responsible for a command anomaly alert. P(Ai|C) is the ratio |Li ∩ C|/|C|, that is, the cardinality of the intersection of Li and C divided by the cardinality of C. Similarly, P(Ai|¬C) = |Li ∩ G|/|G|, that is, the cardinality of the intersection of Li and G divided by the cardinality of G. P(¬Ai|C) and P(¬Ai|¬C) are the complement to 1 of P(Ai|C) and P(Ai|¬C), respectively.
Table 4.5 summarizes the obtained results. It can be noted that P(Ai|C) assumes a relatively high value, which depends on the number of compromised users included in the training set T. Furthermore, P(Ai|¬C) is a measure of the quality of the alerts, in terms of the number of false positives they are likely to raise. For example, there is a high chance that an uncompromised user will be responsible for an unknown address (A1) or HotClusterConn (A4) alert. Similarly, the chances of observing a watchlist (A7) alert if the user is not compromised are extremely low.
Table 4.5 Values of P(Ai|C) and P(Ai|¬C) computed for each alert.
| A1 | A2 | A3 | A4 | A5 | A6 | A7 | |
| P(Ai|C) | 0.333 | 0.166 | 0.166 | 0.500 | 0.166 | 0.166 | 0.166 |
| P(Ai|¬C) | 0.042 | 0.022 | 0.012 | 0.303 | 0.021 | 0.001 | 0.001 |
| A8 | A9 | A10 | A11 | A12 | A13 | A14 | |
| P(Ai|C) | 0.166 | 0.001 | 0.166 | 0.166 | 0.001 | 0.500 | 0.833 |
| P(Ai|¬C) | 0.019 | 0.001 | 0.011 | 0.012 | 0.001 | 0.240 | 0.527 |
By means of the proposed Bayesian network, given a user and the related vector of alerts, it is possible to perform the query “What is the probability P(C) that the user will be compromised, given that the user is responsible for 0 or more alerts?” In the following, we analyze how P(C) varies across the incidents and investigate the possibility of using the network as the decision tool.
4.6.4 Analysis of the Incidents
We used the incident data that were not used to train the network to assess the effectiveness of the proposed approach. A list of the incidents is given in the first column of Table 4.6. The analysis consisted in computing the probability P(C) that each user logged into the NCSA machines during the day the given incident occurred. Table 4.6 (the last column) gives the P(C) values computed for the actually compromised users. (Recall that the ground truth is known from the data.) The results of this analysis allow selection of a classification threshold, that is, a value for P(C) that discriminates between compromised and uncompromised users.
Table 4.6 List of the incidents and P(C) values observed for the compromised users.
| Incident | |||
| ID | Date | # Compromised users | P(C) a |
| 1 | May 3, 2010 | 1 | 16.8% |
| 2 | Sep. 8, 2009 | 1 | 99.3% |
| 3 | Aug. 19, 2009 | 2 | 13.5%; 13.5% |
| 4 | Aug.13, 2009 | 1 | 4.3% |
| 5 | Jul. 24, 2009 | 1 | 28.5% |
| 6 | May 16, 2009 | 1 | 0.7% |
| 7 | Apr. 22, 2009 | 1 | 1.2% |
| 8 | Nov. 3, 2008 | 1 | 28.5% |
| 9 | Sep.7, 2008 | 3 | 99.7%; 99.9%; 76.8% |
| 10 | Jul. 12, 2008 | 1 | 44.6% |
| 11 | Jun. 19, 2008 | 1 | 18.1% |
| a Assumed by the compromised users. | |||
4.6.4.1 Sample Incident
Example: Incident #5 (see Table 4.6) occurred on July 24, 2009. On the day the incident occurred, 476 users logged into the system. We estimated P(C) for each bit vector (i.e., user) in the user/alerts table computed for this incident. Figure 4.15 gives a histogram of the numbers of users with respect to the observed P(C) values. For the majority of users (410 out of 476), the computed P(C) is 0.02%. A closer look into the data reveals that none of these users were responsible for alerts observed in the security logs, and hence we can conclude that those users were not compromised.

Figure 4.15 Example 1: Histogram of the number of users for the observed P(C) values (incident #5, occurred on July 24, 2009).
In all the other cases, that is, 66 out of 476, at least one alert (in the security log) can be associated with each user. These 66 users are considered potentially compromised. For example, during the day the incident occurred, 33 users triggered a multiple login alert. However, 24 of those alerts were false positives caused by a training class that was using the GPU cluster at NCSA, for which all the users were logged in from the same IP address. Therefore, the presence of the multiple login alert alone does not provide strong enough evidence that a user is compromised, and the Bayesian network returns a small value of P(C) (i.e., 0.21%). The compromised user in incident #5 exhibits a value of P(C) around 28.54% (dotted arrow in Figure 4.15). An unknown address alert, a multiple logins alert, and a command anomaly alert are associated with the user.
We also observed cases in which a large value of P(C) was computed for an uncompromised user. For example, a user that jointly triggered unknown address, multiple login, unknown authentication, and anomalous host alerts resulted in a probability value of 87.73%. Nevertheless, it has to be noted that the number of false indications produced by the Bayesian network is small. In incident #5, only for three uncompromised users was the P(C) value greater than the one computed for the actually compromised user (to the right of the dotted arrow in Figure 4.15). For this incident, the proposed approach would have brought the number of manual investigations of potentially compromised users from 66 down to 4.
4.6.4.2 Discussion
The described analysis was conducted for each incident in the validation set. The analysis results reported in Table 4.6 reveal that P(C), for different incidents, varies across a large range of values.
One can see that in all but two cases (incidents #6 and #7), the P(C) values for the compromised users were relatively large. For incident #6, a single alert, HotClusterConn (with a sensitive extension), was associated with the compromised user. However, this alert, if observed alone, is quite unreliable. As shown in Figure 4.12 (A13), around 43 users per day are potentially responsible for this type of alert. Our Bayesian network returns a very small value for P(C), 0.7%.
As discussed, most of the suspicious users, that is, the ones related to at least one alert, are not actually compromised: P(C) is generally small. This finding suggests that the Bayesian network can be used to remove the noise (false positives) induced by the alerts. In other words, it is feasible to define a classification threshold, that is, (C), that will allow suppression of a significant fraction of false positives while still identifying all compromised users.
4.6.5 Supporting Decisions with the Bayesian Network Approach
In this section, we discuss how our Bayesian network can be used to discriminate between compromised and uncompromised users by means of a classification threshold: if the alerts related to a user result in a value of P(C) greater than the classification threshold, we assume that the user is compromised.
4.6.5.1 Analysis of the Incidents
According to the results provided in Table 4.6, the minimum classification threshold that allows detection of all the compromised users is 0.7% (the value of P(C) observed for the compromised user in incident #6). We used this value to quantify the effectiveness of the Bayesian network approach.
Table 4.7 summarizes the obtained results. Column 1 lists the IDs of incidents in the validation set. (The IDs are the same as in Table 4.6.) For each incident, column 2 reports the number of users that logged into the system during the day the incident occurred, and column 3 provides the number of suspicious users, that is, the ones related to at least one alert.
Table 4.7 Analysis of the incidents with the Bayesian network approach.
| Incident | TH. [≥0.7] | TH. [≥1.2] | TH [≥4.3] | |||||
| ID | #users | #susp | #actn. | ratio | #actn. | ratio | #actn. | ratio |
| 1 | 305 | 252 | 41 | 0.16 | 32 | 0.12 | 19 | 0.07 |
| 2 | 477 | 122 | 29 | 0.23 | 27 | 0.22 | 14 | 0.11 |
| 3 | 353 | 312 | 134 | 0.42 | 39 | 0.12 | 33 | 0.10 |
| 4 | 309 | 203 | 34 | 0.16 | 28 | 0.13 | 13 | 0.06 |
| 5 | 476 | 66 | 11 | 0.16 | 11 | 0.16 | 7 | 0.10 |
| 6 | 491 | 7 | 1 | 0.14 | 0 | 0 | 0 | 0 |
| 7 | 446 | 201 | 41 | 0.20 | 37 | 0.18 | 10 | 0.05 |
| 8 | 447 | 251 | 62 | 0.24 | 50 | 0.20 | 43 | 0.17 |
| 9 | 497 | 422 | 137 | 0.32 | 85 | 0.20 | 58 | 0.13 |
| 10 | 193 | 118 | 9 | 0.07 | 3 | 0.02 | 3 | 0.02 |
| 11 | 380 | 280 | 3 | 0.01 | 3 | 0.01 | 2 | 0.01 |
| avg. | 398 | 221 | 50 | 0.20 | 29 | 0.12 | 19 | 0.07 |
Column 4 gives the number of actionable users, that is, the subset of the suspicious users whose probability of having been compromised is ≥0.7%. For each incident, the ratio between the numbers of actionable and suspicious users quantifies the effectiveness of the proposed approach in reducing the number of false indications/positives. That ratio is reported in column 5. For example, in the worst case (represented by incident #3, in which 134 out of 312 suspicious users are actionable) the tool removed around 58% ((1–134/312)*100%) of false indications. As shown in the last row of Table 4.7, the average ratio (estimated across all the incidents) is around 0.20 when the classification threshold is set to 0.7%. In other words, for the analyzed data set, the Bayesian network approach automatically removed around 80% of false positives (i.e., claims that an uncompromised user was compromised).
The effectiveness of the proposed strategy is bounded by the need to select a relatively low threshold. In fact, 0.7% is a conservative value, which makes it possible to avoid false negatives (wherein actually compromised users are missed). We analyzed how the number of actionable users varies when the value of the classification threshold increases. Results are reported in columns 6 and 7, and in columns 8 and 9, of Table 4.7, for the threshold values 1.2 and 4.3%, respectively. According to Table 4.6, 1.2 and 4.3% are the next two smallest P(C) values observed in the analysis. The compromised user of incident #6 went undetected when the threshold was 1.2%. However, the network removed around 88% of false positives. Similarly, when the classification threshold was set to 4.3%, the compromised users of incidents #6 and #7 were undetected. In that case, the network removed around 93% of false positives.
Analysis results also suggest that the Bayesian network approach can help system administrators by directing them toward the users that are likely to be compromised. After the security logs have been collected, the tool can be used to obtain a list of users exhibiting a particularly large value of P(C), for example, all the users whose probability of being compromised is ≥4.3%. This procedure reduces the work burden of the administrators. As indicated in the last row of Table 4.7, on average, around 19 users out of 398, that is, only 4% of all users that log into NCSA during a normal day of operation, surpass the 4.3% classification threshold. If an actually compromised user is not detected (i.e., the classification threshold is set to a large value), the analyst can decrease the threshold in order to augment the set of possible suspicious users to be investigated.
4.6.5.2 Analysis of the Borderline Cases
We also assess the effectiveness of the network for borderline cases, such as incidents reported by third parties, or for normal days, that is, days on which no incidents occurred. In conducting the analysis, we used 0.7% as the classification threshold. The obtained results are summarized in Table 4.8. The meanings of columns 2, 3, 4, and 5 are the same as in Table 4.7. Furthermore, for each case (when applicable), columns 6 and 7 report the maximum observed P(C) and the P(C) for the compromised user, respectively. The main findings of the analysis are discussed in the following.
Table 4.8 Analysis of the borderline cases with the Bayesian network approach.
| Event | TH. [≥0.7] | |||||
| Type (date) | #users | #susp | #actn. | ratio | P(C)max | P(C)a |
| ex. notif. #1 Apr. 21, 2009 |
386 | 176 | 26 | 0.15 | 4.6% | 0.02% |
| ex. notif. #2 Mar. 18, 2009 |
269 | 179 | 63 | 0.35 | 96.3% | 0.02% |
| ex. notif. #3 Feb.9, 2009 |
289 | 28 | 3 | 0.11 | 1.7% | 0.4% |
| False positive Nov. 3, 2008 |
447 | 251 | 62 | 0.24 | 92.9% | 92.9% |
| norm. day #1 Jun. 30, 2010 |
323 | 227 | 25 | 0.11 | 87.7% | — |
| norm. day #2 Jul. 25, 2010 |
154 | 88 | 28 | 0.32 | 41.7% | — |
| New incident Oct. 29, 2010 |
358 | 159 | 32 | 0.20 | 65% | 9.4% |
| a Assumed by the compromised users (if applicable). | ||||||
External Notifications
Three of the analyzed incidents were missed/undetected by the NCSA monitoring tools and were discovered only because of notifications from external sources, that is, third parties. Our tool was used to analyze the logs collected during the days when the undetected incidents occurred, and for each incident, the bit vectors in the user/alerts table were queried against the network. All compromised users were undetected with the proposed approach. The values of P(C) for the compromised users are 0.02% (external notifications #1 and #2) and 0.4% (external notification #3), which are below the assumed classification threshold of 0.7%. In the first two cases, no alerts in the log seem to have been generated by the compromised users. In the third case, only the command anomaly alert was observed, and this alert, if observed alone, does not provide strong evidence that a user is really compromised. Since the Bayesian network approach relies on the low-level monitoring infrastructure, when no alert is triggered, it is not feasible to identify a compromised user.
False Positive
On November 3, 2008, the NCSA security team was alerted about a login performed by a user that triggered an unknown address, a command anomaly, an unknown authentication, and an anomalous host alert. The user/alerts table obtained from the logs collected during that day confirms the joint occurrence of the alerts. The computed value of P(C) is 92.9%, and hence it is reasonable to assume that the user was compromised. However, system administrators contacted the owner of the account, who confirmed his/her activity and verified that the login was legitimate.
These cases reinforce our earlier finding that alert correlation improves our ability to identify compromised users; however, the deficiencies of the low-level monitoring infrastructure (missing events or false notifications) can produce misleading analysis results.
Normal Days
We queried the network with the user/alerts tables obtained from the logs collected during two normal days of operation, June 30, 2010 and July 25, 2010 (see Table 4.8). The numbers of actionable users, that is, the users whose probability of being compromised was ≥0.7%, were small (25 and 28, respectively). It can be noted that some users exhibited a high P(C). For example, during the normal day #1 (June 30, 2010), the P(C) was 87.7% for one user that jointly exhibited an unknown address, a multiple login, an unknown authentication, and an anomalous host alert. Again, the proposed strategy reduces the number of false indications due to untrusted alerts, but if the user is potentially responsible for multiple alerts, the P(C) will be high even if the user is not actually compromised.
New Incident
We analyzed data collected during an incident that occurred on October 29, 2010. The incident is not included in either the training or the validation data set of the network. During the day when the incident occurred, 358 users logged into NCSA machines. Among them, 159 users raised alerts. The Bayesian network approach allowed us to reduce the initial set of 159 suspicious users to 32 actionable users. The compromised user was correctly included in the actionable set and detected. (Three alerts, that is, unknown address, command anomaly, and HotClusterConn, were raised by the compromised user, and the P(C) was 9.4%).
4.6.6 Conclusion
We discussed a Bayesian network approach to support the detection of compromised users in shared computing infrastructures. The approach has been validated by means of real incident data collected during 3 years at NCSA. The results demonstrate that the Bayesian network approach is a valuable strategy for driving the investigative efforts of security personnel. Furthermore, it is able to significantly reduce the number of false positives (by 80%, with respect to the analyzed data). We also observed that the deficiencies of the underlying monitoring tools could affect the effectiveness of the proposed network.
4.7 Integrating Attribute-Based Policies into Role-Based Access Control
While dynamic (active) and passive monitoring techniques provide runtime awareness of system activities, access control plays an essential role in preventing potentially malicious actors from entering a system at its “entrance gate.”
Toward that end, in this section we discuss a framework that uses attribute-based access control (ABAC) policies to create a more traditional role-based access control (RBAC). RBAC has been widely used but has weaknesses: It is labor-intensive and time-consuming to build a model instance, and a pure RBAC system lacks flexibility to efficiently adapt to changing users, objects, and security policies. In particular, it is impractical to manually make (and maintain) user-to-role assignments and role-to-permission assignments in an industrial context characterized by a large number of users and/or security objects.
Here we discuss a new approach that integrates into RBAC attribute-based policies that were designed to support RBAC model building for large-scale applications. We modeled RBAC in two layers. One layer, called the aboveground level, is a traditional RBAC model extended with environment constraints. It retains the simplicity of RBAC and allows routine operations and policy review. In the second layer, called the underground layer, we focus on how to construct attribute-based policies to automatically create the primary RBAC model on the aboveground level. This second layer adopts the advantages of ABAC, eases the difficulty of RBAC model building (particularly for large-scale applications), and provides flexibility to adapt to dynamic applications. Thus, the proposed approach combines the advantages of RBAC and ABAC.
Prior work (e.g., Ref. [35,36]) focused on rule-based automatic user-role assignment, addressing the difficulty of user-role assignment when there is a large, dynamic population of users. We extended this by defining attribute-based policies for both user-role assignment and role-permission assignment. This extension addresses the challenge posed by the large numbers of security objects found in industrial control systems (ICS). Much of the prior research considered only the attributes of users; we considered the attributes of users, roles, objects, and the environment.
We refer the interested reader to our earlier publications [29,37] for more details on the material covered in this section.
4.7.1 Framework Description
In this section, we present the two-layered framework that integrates attribute-based policies into RBAC. Figure 4.16 outlines the architecture of the framework.

Figure 4.16 A two-layered framework integrating attribute-based policies into RBAC.
4.7.2 Aboveground Level: Tables
We use first-order logic to make formal descriptions and follow the convention that all unbound variables are universally quantified in the largest scope. The aboveground level is a simple and standard RBAC model but extended with constraints on attributes of the environment. We use the notion of an environment to represent the context of a user's access, such as the time of access, the access device, the system's operational mode, and so forth. The model is formally described as a tuple,
in which U is a set of users, where a user could be either a human being or an autonomous software agent. R is a set of roles, where a role reflects a job function and is associated with a set of permissions. O is a set of objects, which are the resources protected by access control. OP is a set of operators, which represent a specific type of operations. P is a set of permissions that are defined by legitimate operations, each of which comprises an operator and an object. EP is a set of predefined environment state patterns. We use environment state to model the context of a user's access. Each environment state pattern (called environment pattern hereafter) defines a set of environment states. URAe is the extended user-role assignment relation, which in essence is a mapping from users to roles, and is associated with certain environment patterns. RPAe is the extended role-permission assignment relation, which in essence is a mapping from roles to permissions, and is also associated with certain environment patterns.
4.7.2.1 Environment
We represent the context of an access as an environment and model the environment as a vector of environment attributes, each of which is represented by an environment variable (called an attribute name) associated with an attribute value in a domain. An environment is defined by n attributes. Let vi ∈ Di, i = 1,…, n, be the ith environment variable, where Di is the domain of that environment variable. Then, a vector (v1,…, vn), in which all variables are instantiated, is called an environment state (denoted by s). The set of all possible environment states is denoted by E. The choice of environment attributes (and hence the environment state) is domain-dependent. Environment attributes, particularly the dynamic attributes, are gathered by an access control engine at runtime.
Example (environment state): Assume that the environment is defined by three attributes: mode, access location, and access time. Then, mode = “normal,” access location = “station 1,” and access time = “8:00 a.m. Monday” together is an environment state.
An environment pattern, denoted by e, is treated as a unique pattern in domain EP, but is semantically defined by a first-order logical expression of assertions involving environment attributes. An environment pattern defines a set of environment states in which every environment state satisfies the environment pattern, that is,
Hereafter, we will sometimes directly use e to denote the set of environment states defined by the environment pattern.
4.7.2.2 User-Role Assignments
A particular user-role assignment associates a user, a role, and an environment pattern:
where EP is the set of all environment patterns that have been defined for the system of interest.
The semantics of a user-role assignment, (u, r, e) ∈ URAe, is defined as
which states that if the real environment state s matches the given environment pattern e, then user u is assigned to role r. We assume that the RBAC engine can understand the semantics of each environment pattern as defined.
Basic RBAC models define user-role assignments simply as mappings from users to roles,
We have extended this notion with a dependency on the environment, as a means of integrating certain extended RBAC features of context and constraints. The environment pattern associated with a user-role assignment is the environment-dependent condition that is sufficient for the assignment. This feature can be regarded as constrained user-role assignment. If there are no constraints on user-role assignments, the associated environment patterns are simply empty, so the model becomes the common one. The relation between URAe and URA is given as
Following this formalism, an example user-role assignment with an environment extension may be expressed as follows:
- User id: com:ab:zn1:amy; Role id: manager.zone1; Environment pattern: Device = “Station_1.2” & Time = “Weekday”
- User id: com:ab:zn1:ben; Role id: operator.zone1; Environment pattern: Mode = “emergency”
4.7.2.3 Role-Permission Assignments
A role-permission assignment associates a role, a permission, and an environment pattern. Thus, the set of all such assignments is a subset,
The semantics of a role-permission assignment, (r, p, e) ∈ RPAe, is defined as
which states that if the real environment state s matches the pattern e, then permission p is assigned to role r.
Similar to the approach for user-role assignments, we also extended the common role-permission assignment with environment patterns. The relation between RPAe and RPA is given as
As with user-role assignments, the role-permission assignment may also be organized in tabular fashion.
4.7.3 Underground Level: Policies
The underground level of the RBAC model focuses on the security policies used to construct the aboveground level of the RBAC model. We have attempted to explicitly represent the implicit knowledge used to construct an RBAC model, and to integrate the extensions to standard RBAC models in an attribute-based paradigm.
In the following, we treat all users, roles, permissions, operators, and security objects as “objects” (in the sense of object-oriented design), each of which has certain attributes. The notation obj.attr, or equivalently attr (obj), denotes the attribute attr of object obj.
The attributes needed in RBAC are typically domain-dependent and need to be customized for each specific target system. Some examples of attributes are as follows. The attributes of users may include “ID,” “department,” “security clearance,” “knowledge domain,” “academic degree,” or “professional certificate.” A role may have attributes such as “name”; “type,” reflecting job function types such as “manager,” “engineer,” or “operator”; “security level”; “professional requirements”; and “direct superior roles” and “direct subordinate roles” (if role hierarchy is modeled). Objects may have attributes such “ID,” “type,” “security level,” and “state.” Operators may have attributes such as “name” and “type.” The environment attributes may include “access time,” “access location,” “access application,” “system mode,” and “target value,” among others.
4.7.3.1 Role-Permission Assignment Policy
The role-permission assignment policy is a set of rules. Each rule has the following structure:
rule id {target {role pattern; permission pattern {operator pattern;object pattern;};environment pattern;} condition;decision. }
where all of the patterns and the condition are FOL (first-order logic) expressions; an environment pattern defines a set of environment states; a role pattern defines a set of roles by specifying their common attributes; a permission pattern consisting of an operator pattern and one object pattern defines a set of permissions by specifying their common features with respect to the attributes of the operator and the object in a permission; an operator pattern defines a set of operators (or operation types); each object pattern defines a set of objects; the target defines the range of (role, permission, environment pattern) triples to which this rule applies; and the condition is a logical expression defining a relation among the attributes of the roles, the permissions (operators and objects), and the environment. Rules of this form state that when the condition is true, a role covered by the role pattern can be assigned with a permission covered by the permission pattern in the specified environment pattern.
4.7.3.2 User-Role Assignment Policy
User-role assignment is highly dependent on business rules and constraints. In our view, the task of assigning users to roles can be approached like the role-permission assignment problem, in terms of policies that enforce those rules and constraints. Such policies would be formulated in terms of user and role attributes, and would be crafted to enforce things like separation of duty. However, unlike role-permission assignment, user assignment may have to balance competing or conflicting policy rules against each other. Correspondingly, a complete policy-oriented formulation will need to specify how to combine rules and arrive at a final assignment decision. In what we present below, an attribute-based user-role assignment policy is used only to identify potential assignments. A rule-combining algorithm is used for making the final assignments.
The user-role assignment rule is similar to the role-permission assignment rule and consists of
rule id {target {user pattern;role pattern;environment pattern;} condition;decision. }
where a user/role/environment pattern defines a set of users/roles/environment states by specifying the common attributes; all of the patterns and the condition are expressions in first-order logic; and (unlike the case in the role-permission assignment policy) the decision of a rule marks a (user, role, environment pattern) triple as a potential assignment.
4.7.4 Case Study: Large-Scale ICS
This section explains how the proposed framework might be applied to construction of an RBAC model for an industrial control system (ICS).
Problem: The target application domain of ICS has the following features. There are a very large number of security objects (on the order of millions), among which there are complex relations; on the other hand, many objects and operations applied on them are similar, and there are patterns to follow. Security objects are organized in hierarchical structures. Each role or security object may have a security level. Users dynamically change over time as business changes; security objects also change over time because of device replacement or maintenance. Access to control processes and devices is through some human–machine interfaces and software applications. Each protected point of access to a control system, called a point or control block, contains information about the status of a control process or device and is used to set target control values or control parameters; all those points are important parts of the security objects to be protected by the target access control system. The runtime operation environment (with dynamic attributes), for example, access location and/or access time, is a sensitive and important factor in access control. Different zones have similar structures, that is, roles, operations, and objects are similar in different zones. Zones and devices may have operation “modes.” Finally, control stations play an important role in access control.
A specific challenge we face is that of constructing an RBAC framework that is compatible with the access control mechanisms used in modern ICS, which are a mixture of different mechanisms that include station-based, group-based, attribute-based, and (simplified) lattice-based mechanisms. The underlying reason for the compatibility requirement is the practical need for an incremental transition path. Another major challenge is that of how to define roles and assign fine-grained permissions to roles for a large-scale application effectively, efficiently, and in an automated fashion, as much as possible.
4.7.4.1 RBAC Model-Building Process
In the following, we briefly explain how to apply the proposed framework in building an RBAC model instance for an ICS. More detailed discussion of RBAC for ICS can be found in Ref. [32].
- Identify security objects and object hierarchy: In a plant, security engineers identify devices and points to be protected by RBAC as a set of security objects and organize those objects in hierarchical structures (usually an acyclic graph). In ICS, it is common to find that the control devices and other assets involved in monitoring and controlling the physical process and in overall management of a plant are organized in a hierarchical and modular manner as per ISA-88 and ISA-95 standards. This hierarchical structure that groups objects is called an object hierarchy in this chapter.
- Identify operation types: The types of the operations applied to each security object are identified, for example, a specific type of control parameter may be of type “read” and “reset.” At a minimum, an operation type could be defined by just an operator; in general, an operation type can be defined by a permission pattern.
- Identify role templates: ICS tend to have very well-defined job functions, with well-defined access needs, to monitor and control the physical processes. For example, “Operator” and “Engineer” are very well-understood job functions in the ICS community, even though there might be some variations in their functions across different types of ICS. In the world of electric power, “Operator” is actually a licensed position. Such well-defined job functions with well-defined access needs are good candidates for use in defining “roles.” However, in practice, users who perform such well-defined job functions are limited in scope to either particular subprocesses or particular geographical areas, in accordance with the organization of their plants. In other words, the job functions identified in ICS, such as “Operator” and “Engineer,” perform certain types of operations; the objects to which those operations can apply are dependent on the attributes of the users and those objects. From this point of view, we defined in our previous work [25,32] a role template and proto-permission that leverage some common characteristics of ICS to simplify the creation and management of roles. Here we show how our framework can be used to represent these concepts and realize a manageable RBAC solution for ICS. Unlike a permission that comprises a pair of an operator and an object, a proto-permission consists of an operator and the object type of the operand. Thus, a proto-permission represents just an operation type, rather than a specific operation on a specific object. Proto-permission is a specific form of permission pattern. Unlike a “role” in RBAC, a role template is associated with a set of proto-permissions. A role template tells what types of operations can be performed by a role created from the role template. Let RT denote the set of all role templates, and let PP denote the set of proto-permissions. Every role template has an attribute (or, equivalently, function) of a proto-permission set, denoted by pps; every proto-permission has an attribute (or function) of an operator, and an attribute (or function) of an object type, denoted by objType.
We use the role template to formally represent each well-defined job function in an ICS, and use proto-permissions to represent each allowed operation type associated with a role template. Assume that the plant has a number of basic types of job functions, such as “Operator,” “Engineer,” and “Manager.” They are identified as role templates. Each of them is associated with a set of operation types, for example, “Engineer” has operation type “reset parameter” on objects of type “XYZ”; “Manager” has operation type “view schedule” on “System”; and so forth. All identified operation types should be covered by role templates.
- Identify roles and their privilege ranges: Based on business workflow analysis, a number of roles can be identified for each role template. Each role has an assigned working (access) environment pattern, such as access through station B in zone 1 in daytime. Furthermore, as discussed earlier, in practice each role has access only to a certain range of objects; this range of accessible objects is called the privilege range of the role. Formally,
(4.8)

A privilege range is used to define the boundary of objects for which a role is responsible, and is used as constraints in role-permission assignment. A role has access to an object only if the object is within the role's privilege range. A privilege range can be defined over an object hierarchy. An object hierarchy (denoted by OH) is simply a subset of the power set of all objects considered, that is, OH ⊆ 2O. A node in the object hierarchy is called an object group, which is a subset of the objects, that is, og ∈ 2O. In an object hierarchy, if one object group is a child of another in OH, it means that the former is a subset of the latter.
- Analyze security policies and identify attributes: The security engineers analyze all security policies and requirements applied to the plant and list all of the attributes of users, roles, objects, and the access environment. For example, privilege range is a critical attribute of a role. A particular attribute that needs to be considered is security level. It is common to assign a security object a “security level,” requiring a subject of access to have a corresponding security level.
- Develop attribute-based policies: Security engineers construct the underground level of an RBAC model by developing attribute-based policies for role-permission assignment and user-role assignment.
Let us consider a simple yet general case: (1) A role can perform only the types of operations specified by the proto-permissions of the role's template. (2) There is a privilege range constraint, such that a role can access an object only if that object is within the privilege range of that role. (3) There is a security-level constraint, in that to access an object, the role's security level needs to be greater than or equivalent to the one of the object. This can be represented with the attribute-based policy for role-permission assignment:
rule{target:{} condition:{memberOf(o, r.pr);r.securityLevel >= o.securityLevel; memberOf(pp, r.template.pps)and op = pp.op and o.type = pp.objType;} decision: add(r, p(op,o), phi) in RPAe.} - Create RBAC assignment tables: Use the specified attribute-based policies to create role-permission assignment and user-role assignment in the aboveground level.
This task can be illustrated by considering how the above example rule would be used to make a role-permission assignment. For each pair of role and permission, if the pair or the role's assigned working environment did not match the target of the rule, then this pair would be skipped; otherwise, the condition part of the rule would continue to be evaluated. If the condition is found to be true, then the permission would be assigned to the role in that assigned environment, in the role-permission assignment table of the aboveground level. Consider a role “Engineer Chem Zone1 Daytime” and a permission “reset parameter T” on object “point 1.2.7” (i.e., it represents the seventh point in zone 1 sector 2), in the environment pattern stated in the example rule. This (role, permission) pair is within the target. Assume that object “point 1.2.7” is within the privilege range of the role and the access station. If the role's security level dominates the object's, and the professional domains match, then the permission is assigned to the role in the specified environment pattern. Consider another role, “Engineer Chem Zone2 Daytime,” which has privilege in zone 2 that does not cover “point 1.2.7”; thus, permission would not be granted to it for this role.
- Repeat the process: If the above logical verification and review failed, it would be necessary to go back to an earlier step to revise the RBAC model, and then verify and review it again.
4.7.4.2 Discussion of Case Study
Migration to RBAC from a legacy system could be a great challenge for ICS. The proposed framework could support both building of an RBAC model for ICS and the migration. We highlight some major features as follows.
Expressibility
The proposed framework is general enough to cover the required features of the targeted access control systems in ICS [30]. User groups are modeled by role template, and the types of operations conducted by a user group are modeled by proto-permissions. Station-based access constraints, application access constraints, temporal constraints, “mode” constraints, “parameter range” constraints, and others are modeled as environment constraints.
Support for Role Engineering
Role engineering is widely recognized as difficult. It is an even greater challenge for ICS due to the large-scale and dynamic features of the system. The proposed framework enables automatic user-role assignment and role-permission assignment, through attribute-based polices. This approach could be a great help in overcoming the problems of manual user-role assignment and role-permission assignment for large-scale applications in ICS.
Simplicity
The proposed framework can integrate the existing mechanisms and concepts in ICS uniformly in the form of attribute-based policies, thus avoiding the complexity that would be caused by ad hoc representation and management. Attribute-based policies can express security policies and requirements in a straightforward manner, making them easier to construct and maintain. The simplicity of the aboveground level eases RBAC model review.
Flexibility
The attribute-based policies have the flexibility to adapt to dynamically changing users, objects, security policies and requirements, and even business processes.
Verifiability
The logic representation of the attribute-based policies provides a basis for formal verification of an RBAC model.
4.7.5 Concluding Remarks
We discussed an approach we developed to combine ABAC and RBAC, bringing together the advantages of both models. We developed our model in two levels: aboveground and underground. The aboveground level is a simple and standard RBAC model extended with environment constraints, which retains the simplicity of RBAC and supports straightforward security administration and review. In the underground level, we explicitly represent the knowledge for RBAC model building as attribute-based policies, which are used to automatically create the simple RBAC model in the aboveground level. The attribute-based policies bring the advantages of ABAC: They are easy to build and easy to change for a dynamic application. We showed how the proposed approach can be applied to RBAC system design for large-scale ICS applications.
4.8 The Future
Cloud computing allows users to obtain scalable computing resources, but with a rapidly changing landscape of attack and failure modes, the effort to protect these complex systems is increasing. As we discussed in this chapter, cloud computing environments are built with VMs running on top of a hypervisor, and VM monitoring plays an essential role in achieving resiliency. However, existing VM monitoring systems are frequently insufficient for cloud environments, as those monitoring systems require extensive user involvement when handling multiple operating system (OS) versions. Cloud VMs can be heterogeneous, and therefore the guest OS parameters needed for monitoring can vary across different VMs and must be obtained in some way. Past work involves running code inside the VM, which may be unacceptable for a cloud environment.
We envisage that this problem will be solved by recognizing that there are common OS design patterns that can be used to infer monitoring parameters from the guest OS. We can extract information about the cloud user's guest OS with the user's existing VM image and knowledge of OS design patterns as the only inputs to analysis. As a proof of concept, we have been developing VM monitors by applying this technique. Specifically, we implemented sample monitors that include a return-to-user attack detector and a process-based keylogger detector.
Another important aspect of delivering robust and efficient monitoring and protection against accidental failures and malicious attacks is our ability to validate (using formal and experimental methods) the detection capabilities of the proposed mechanisms and strategies. Toward that end we require development of validation frameworks that integrate the use of tools such as model checkers (for formal analysis and symbolic execution of software) and fault/attack injectors (for experimental assessment).
Further exploration of all these ideas is needed to make Reliability and Security as a Service an actual offering from cloud providers.
References
- 1 Hernandez, P., Skype, AWS outages rekindle cloud reliability concerns, eWeek, Sep. 22, 2015. Available at http://www.eweek.com/cloud/skype-aws-outages-rekindle-cloud-reliability-concerns.html.
- 2 2015 Trustwave Global Security Report, Trustwave Holdings, Inc., 2015. Available at https://www.trustwave.com/Resources/Library/Documents/2015-Trustwave-Global-Security-Report/.
- 3 Garfinkel, T. and Rosenblum, M. (2003) A virtual machine introspection based architecture for intrusion detection, in Proceedings of the 10th Network and Distributed System Security Symposium, pp. 191–206. Available at http://www.isoc.org/isoc/conferences/ndss/03/proceedings/.
- 4 Payne, B.D., Carbone, M.D.P.de A., and Lee, W. (2007) Secure and flexible monitoring of virtual machines, in Proceedings of the 23rd Annual Computer Security Applications Conference, pp. 385–397.
- 5 Payne, B.D. et al. (2008) Lares: an architecture for secure active monitoring using virtualization, in Proceedings of the 2008 IEEE Symposium on Security and Privacy, pp. 233–247.
- 6 Jones, S.T., Arpaci-Dusseau, A.C., and Arpaci-Dusseau, R.H. (2008) VMM-based hidden process detection and identification using Lycosid, in Proceedings of the 4th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, pp. 91–100.
- 7 Sharif, M.I. et al. (2009) Secure in-VM monitoring using hardware virtualization, in Proceedings of the 16th ACM Conference on Computer and Communications Security, pp. 477–487.
- 8 Pham, C., Estrada, Z., Cao, P., Kalbarczyk, Z., and Iyer, R.K. (2014) Reliability and security monitoring of virtual machines using hardware architectural invariants, Proceedings of the 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, pp. 13–24.
- 9 Carbone, M. et al. (2014) VProbes: deep observability into the ESXi hypervisor. VMware Technical Journal, 3 (1). Available at https://labs.vmware.com/vmtj/vprobes-deep-observability-into-the-esxi-hypervisor.
- 10 Jones, S.T., Arpaci-Dusseau, A.C., and Arpaci-Dusseau, R.H. (2006) Antfarm: tracking processes in a virtual machine environment, in Proceedings of the USENIX Annual Technical Conference, pp. 1–14. Available at https://www.usenix.org/legacy/events/usenix06/tech/full_papers/jones/jones.pdf.
- 11 Azab, A.M., Ning, P., and Zhang, X. (2011) SICE: a hardware-level strongly isolated computing environment for x86 multi-core platforms, in Proceedings of the 18th ACM Conference on Computer and Communications Security, pp. 375–388.
- 12 Liu, Z. et al. (2013) CPU transparent protection of OS kernel and hypervisor integrity with programmable DRAM. ACM SIGARCH Computer Architecture News, 41 (3), 392–403.
- 13 Zhou, Z. et al. (2012) Building verifiable trusted path on commodity x86 computers, in Proceedings of the 2012 IEEE Symposium on Security and Privacy (SP), pp. 616–630.
- 14 Quynh, N.A. and Suzaki, K. (2007) Xenprobes, a lightweight user-space probing framework for Xen Virtual Machine, in Proceedings of the 2007 USENIX Annual Technical Conference, Available at https://www.usenix.org/legacy/events/usenix07/tech/full_papers/quynh/quynh.pdf.
- 15 Arnold, J. and Kaashoek, M.F. (2009) Ksplice: automatic rebootless kernel updates, in Proceedings of the 4th ACM European Conference on Computer Systems, pp. 187–198.
- 16 Vaughan-Nichols, S.J., No reboot patching comes to Linux 4.0, ZDNet, March 3, 2015. Available at http://www.zdnet.com/article/no-reboot-patching-comes-to-linux-4-0/.
- 17 Estrada, Z.J., Pham, C., Deng, F., Yan, L., Kalbarczyk, Z., and Iyer, R.K., Dynamic VM dependability monitoring using hypervisor probes, in Proceedings of the 2015 11th European Dependable Computing Conference, pp. 61–72.
- 18 Payne, B.D. (2012) Simplifying Virtual Machine Introspection Using LibVMI, Sandia Report SAND2012-7818, Sandia National Laboratories. Available at http://prod.sandia.gov/techlib/access-control.cgi/2012/127818.pdf.
- 19 Bishop, M. (1989) A model of security monitoring, in Proceedings of the 5th Annual Computer Security Applications Conference, pp. 46–52.
- 20 Manadhata, P.K. and Wing, J.M. (2011) An attack surface metric. IEEE Transactions on Software Engineering, 37 (3), 371–386.
- 21 Krishnakumar, R. (2005) Kernel korner – kprobes: a kernel debugger. Linux Journal, 2005 (133), 1–11.
- 22 Feng, W. et al. (2007) High-fidelity monitoring in virtual computing environments, in Proceedings of the ACM International Conference on Virtual Computing Initiative, Research Triangle Park, NC.
- 23 Kivity, A. et al. (2007) kvm: the Linux virtual machine monitor, in Proceedings of the Linux Symposium, vol. 1, pp. 225–230.
- 24 Vattikonda, B.C., Das, S., and Shacham, H. (2011) Eliminating fine grained timers in Xen, in Proceedings of the 3rd ACM Workshop on Cloud Computing Security, pp. 41–46.
- 25 Li, P., Gao, D., and Reiter, M.K. (2013) Mitigating access-driven timing channels in clouds using StopWatch, in Proceedings of the 43rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks, pp. 1–12.
- 26 Gilbert, M.J. and Shumway, J. (2009) Probing quantum coherent states in bilayer graphene. Journal of Computational Electronics, 8 (2), 51–59.
- 27 Agesen, O. et al. Software techniques for avoiding hardware virtualization exits, in Proceedings of the 2012 USENIX Annual Technical Conference, pp. 373–385. Available at https://www.usenix.org/system/files/conference/atc12/atc12-final158.pdf.
- 28 Larson, S.M. et al. (2002) Folding@ home and genome@ home: using distributed computing to tackle previously intractable problems in computational biology, in Computational Genomics (ed. R. Grant), Horizon Press.
- 29 Wang, G., Estrada, Z.J., Pham, C., Kalbarczyk, Z., and Iyer, R.K. (2015) Hypervisor Introspection: a technique for evading passive virtual machine monitoring, in Proceedings of the 9th USENIX Workshop on Offensive Technologies, Available at https://www.usenix.org/node/191959.
- 30 Varadarajan, V., Ristenpart, T., and Swift, M. (2014) Scheduler-based defenses against cross-VM side-channels, in Proceedings of the 23rd USENIX Security Symposium, pp. 687–702. Available at https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-varadarajan.pdf.
- 31 Pecchia, A., Sharma, A., Kalbarczyk, Z., Cotroneo, D., and Iyer, R.K. (2011) Identifying compromised users in shared computing infrastructures: a data-driven Bayesian network approach, in Proceedings of the IEEE 30th International Symposium on Reliable Distributed Systems, pp. 127–136.
- 32 Sharma, A., Kalbarczyk, Z., Barlow, J., and Iyer, R. (2011) Analysis of security data from a large computing organization, in Proceedings of the IEEE/IFIP 41st International Conference on Dependable Systems and Networks, pp. 506–517.
- 33 Jensen, F.V. (2001) Bayesian Networks and Decision Graphs, Springer, New York, NY.
- 34 Pearl, J. (1988) Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, Morgan Kaufmann, San Francisco, CA.
- 35 Al-Kahtani, M.A. and Sandhu, R. (2002) A model for attribute-based user-role assignment, in Proceedings of the Annual Computer Security Applications Conference. Available at https://www.acsac.org/2002/papers/95.pdf.
- 36 Kern, A. and Walhorn, C. (2005) Rule support for role-based access control, in Proceedings of the 10th ACM Symposium on Access Control Models and Technologies, pp. 130–138.
- 37 Huang, J., Nicol, D.M., Bobba, R., and Huh, J.H. (2012) A framework integrating attribute-based policies into role-based access control, in Proceedings of the 17th ACM Symposium on Access Control Models and Technologies, pp. 187–196.