
5
Towards a Multilingual System for Automatic Irony Detection
5.1. Introduction
In Chapters 3 and 4, we proposed a multilevel annotation scheme for irony and an automatic irony detection system for tweets in French. In this chapter, we shall assess the portability of both the annotation scheme and the automatic detection system for other languages. Two experiments will be presented.
The first experiment consists of testing the portability of the multilevel annotation scheme for irony, described in Chapter 3, for other languages in the same family as French: English and Italian. An annotation campaign is carried out using our scheme, designed to analyze pragmatic phenomena relating to irony in French tweets. The aim of this first experiment is not only to test the performance of the annotation scheme on other Indo-European languages that are culturally similar to French, but also to measure the impact of a set of pragmatic phenomena on the interpretation of irony. Additionally, we shall consider the way in which these phenomena interact with the local context of a tweet in languages belonging to the same family.
The second experiment consists of testing the performance of the feature-based automatic irony detection system (using the SurfSystem and PragSystem models – see Chapter 4) on tweets written in Arabic. For the purposes of this experiment, we constructed the first corpus of ironic and non-ironic tweets in Arabic, studying the performance of features and assessing the algorithms used to classify tweets as ironic/non-ironic.
In what follows, we shall describe our two experiments and the obtained results. Section 5.2 is devoted to the first experiment and includes a description of the corpora used for English and Italian, along with the quantitative results for each level of the annotation scheme in each language. Section 5.3 provides a description of the second experiment, with an overview of the specificities of Arabic and a presentation of the tweet corpus used in this context. We shall then provide the quantitative results obtained through our experiment, comparing them with the results obtained for French as presented in Chapter 4.
5.2. Irony in Indo-European languages
“In linguistics, the Indo-European languages (formerly known as Indo-Germanic or Scythian languages) form a family of closely related languages with shared roots in what is commonly referred to as proto-Indo-European. They possess strong lexical, morphological and syntactic similarities; it is thus supposed that each group of comparable elements evolved from the same original form, now extinct. There are around one thousand languages in this family, currently spoken by approximately three billion people”.1
From this definition, we see that linguists have noted considerable morphological and syntactic similarities between most Indo-European languages. This is encouraging for the purposes of our research, considering the irony phenomenon in different languages within this family. Within this framework, we shall focus on English and Italian.
5.2.1. Corpora
5.2.1.1. Collection of the English corpus
Although other corpora had already been developed (Reyes et al. 2013), we decided to construct our own corpus of ironic and non-ironic tweets in English. The existing corpora were essentially composed of personal tweets (e.g. Don’t worry about what people think. They don’t do it very often), meaning that they were not comparable to the corpus used for research in French. To create our corpus, we followed the same collection procedure used for the French corpus FrIC. We selected a set of themes belonging to the same categories used previously, adapted to language and culture-specific news. For example, for the politics category, we selected Obama, Trump, Clinton, etc.; for artists, we selected keywords including Justin Bieber, Kardashian, Beyoncé, etc. Next, we selected ironic tweets containing these keywords along with the hashtag #ironic or #sarcasm. Non-ironic tweets (e.g. tweets without the #ironic or #sarcasm hashtags) were collected in the same way.
Following collection, we removed all duplicates, retweets and tweets containing images. At the end of the filtering process, we had a corpus of 11,289 tweets, of which 5,173 were ironic and 6,116 were non-ironic. The distribution of these tweets by category is shown in Table 5.1.
Table 5.1. Distribution of tweets in the English corpus
| Themes | Ironic | Non-ironic |
| Economy | 117 | 79 |
| Generic | 311 | 873 |
| Cities or countries | 1,014 | 891 |
| Artists | 472 | 836 |
| Politics | 2,560 | 2,294 |
| Health | 142 | 160 |
| Sports | 557 | 983 |
| Total | 5,173 | 6,116 |
5.2.1.2. Collection of the Italian corpus
For Italian, we made use of two existing resources, annotated as part of the Senti-TUT project2:
- – The Sentipolc corpus used in the Evalita 2014 evaluation campaign3 for sentiment analysis and irony detection in tweets (Basile et al. 2014). The Sentipolc corpus is a collection of tweets in Italian derived from two existing corpora: Senti-TUT (Bosco et al. 2013) and TWITA (Basile and Nissim 2013). It contains tweets using keywords and hashtags on the theme of politics (names of politicians, etc.). Each tweet in Sentipolc is annotated using five mutually exclusive categories: positive opinion, negative opinion, both positive and negative opinion, ironic and objective.
- – The TW-SPINO corpus, containing tweets from Spinoza4, a satirical political blog in Italian. These tweets were selected and reviewed by a team of editors who identified them as being ironic or satirical.
The Italian corpus is made up of 3,079 ironic tweets (806 from Sentipolc and 2,273 from TW-SPINO) and 5,642 non-ironic tweets (from Sentipolc).
5.2.2. Results of the annotation process
To study the portability of our annotation scheme, we focused on annotating a subset of tweets in English and Italian. The aim of this first step was to test the performance of our scheme for other languages, and to compare the statistical results obtained for English, Italian and French.
In this section, we will present the quantitative results obtained from the annotated corpora in English and Italian. Two human annotators worked on each corpus, following a two-step process. In the first step, 100 tweets in each language (50 ironic, 50 non-ironic) were used for training. In the second step, 550 tweets in English and 500 tweets in Italian (80% ironic, 20% non-ironic) were annotated. The first step was essential in order for annotators to become familiar with the annotation scheme and the corpora in question.
Our annotation scheme, described in Chapter 3, includes four levels (see Figure 5.1). In level 1, tweets are identified as ironic or non-ironic. Level 2 identifies explicit or implicit contradictions in ironic tweets. Level 3 concerns the category of irony (analogy, hyperbole, etc.), while level 4 relates to markers (negation, punctuation, etc.).
For the English corpus, the annotators used Glozz, the same tool as was used for the French corpus, and annotated tweets using four levels of our scheme. We provided the annotators with an English translation of our annotation guide and the files needed to operate Glozz.
Level 1 of the annotation process (ironic/non-ironic) was already included in our Italian corpus. Manual annotation was only carried out for levels 2 and 3 of the scheme (irony types and categories), following the same guide used for English and French5. Cue annotation (level 4) was carried out automatically, and certain markers were verified manually (negations and emoticons). For this reason, we only provide results for those markers that were manually verified.
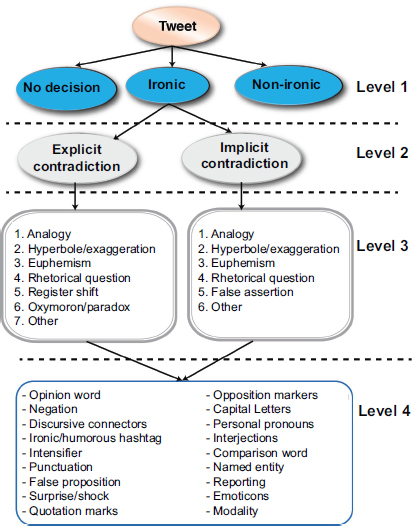
Figure 5.1. Annotation scheme. For a color version of the figures in this chapter see, www.iste.co.uk/karoui/irony.zip
Through this annotation campaign, we were able to analyze the following:
- – presence of markers in ironic tweets;
- – variation in the presence of markers for each irony type (explicit/implicit contradiction) and each category (hyperbole, analogy, paradox, etc.);
- – frequency of irony categories for each type of irony.
5.2.2.1. Quantitative results for ironic/non-ironic annotation
Based on the reference hashtags #ironic and #sarcasm in the English corpus, 440 (80%) of the tweets were ironic and 110 (20%) were non-ironic. The human annotators assessed 427 (77.63%) of the tweets as ironic and 99 (18%) as non-ironic, with the remaining 24 tweets (4.37%) being placed into the “no decision” class (Figure 5.2). These results show that, whatever the language used, a tweet including an irony hashtag is not necessarily ironic, nor is the hashtag a prerequisite for irony.
Unlike the French and English corpora, the Italian corpus was annotated as ironic/non-ironic by humans instead of using hashtags (as part of the Senti-TUT project). This corpus contains 400 ironic tweets and 100 non-ironic tweets, with no tweets in the “no decision” class (Figure 5.2).
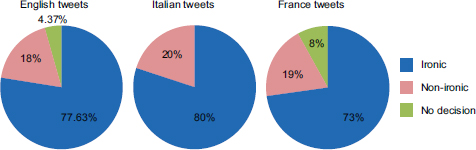
Figure 5.2. Distribution of English, Italian and French tweets
5.2.2.2. Quantitative results for irony type annotation
Table 5.2 shows the total number of annotated tweets and the type of irony trigger in each corpus.
In the English corpus, out of 427 tweets annotated as ironic, 283 featured implicit contradiction and 144 contained explicit contradiction. This indicates that irony is generally expressed implicitly in English (66.28% of cases), as it is in French (73.01%).
In the Italian corpus, however, the majority of ironic tweets featured explicit contradictions (65%). This may stem from the fact that Italian users do not use specific hashtags to indicate irony, perhaps causing them to be more explicit in their expressions.
Table 5.2. Number of tweets annotated by irony type in the French, English and Italian corpora
| Ironic | Non-ironic | No decision | Total | ||
| Explicit | Implicit | – | – | – | |
| French | 394 (19.7%) | 1,066 (53.3%) | 380 (19%) | 160 (8%) | 2,000 |
| English | 144 (26.2%) | 283 (51.45%) | 99 (18%) | 24 (4.35%) | 550 |
| Italian | 260 (52%) | 140 (28%) | 100 (20%) | – | 500 |
5.2.2.3. Quantitative results for irony category annotation
Table 5.3 shows the percentage of tweets belonging to each category of irony, split into explicit/implicit trigger groups6. Significant differences can be seen in terms of the categories of irony found in the French, English and Italian corpora. The results show that:
- – for irony including explicit contradiction, oxymoron/paradox is the most common category for all three languages (French, English and Italian);
- – for irony with implicit contradiction, false assertion and other are the most common categories in French and English. In Italian, the most frequent categories are false assertion, analogy and other;
- – considering the tweets in the other category, we see that the majority are ironic with implicit contradiction. This indicates that the decision task is harder for humans in cases where irony is expressed through an implicit contradiction, whichever language is used.
As the classes are not mutually exclusive:
- – for the English corpus, 35 tweets with explicit contradiction belong to more than one category, and 62 tweets with implicit contradiction belong to more than one category. For explicit contradictions, the most frequent combination is oxymoron/paradox + rhetorical question, while for ironic tweets with implicit contradiction, the most frequent contradiction is metaphor/comparison + other;
- – for the French corpus FrIC, the most frequent combination for explicit contradictions is oxymoron/paradox + hyperbole/exag-geration; for implicit contradictions, the most frequent combination is false assertion + hyperbole/exaggeration;
- – for the Italian corpus, the annotators chose to assign a single category to each tweet, selecting the option which seemed to express irony most strongly.
Thus, for French and English, the oxymoron/paradox category is one of the most frequent combinations for irony with explicit contradiction. For cases featuring implicit contradiction, the combinations are different for the two languages.
Table 5.3. Distribution of categories for explicit/implicit trigger types in the French (F), English (A) and Italian (I)corpora. The best results are shown in bold
| Analogy | Register shift | Euphemism | Hyperbole | |||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | |
| Explicit | 12% | 17% | 21% | 1% | 6% | 19% | 1% | 1% | 5% | 8% | 2% | 9% |
| Implicit | 2% | 13% | 26% | – | – | – | 1% | 1% | 4% | 10% | 7% | 5% |
| Rhetorical question | Oxymoron/paradox | False assertion | Other | |||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | |
| Explicit | 10% | 15% | 10% | 66% | 81% | 28% | – | – | – | 21% | 6% | 7% |
| Implicit | 14% | 1% | 12% | – | – | – | 56% | 20% | 34% | 32% | 65% | 19% |
5.2.2.4. Quantitative results of the annotation procedure for irony markers
Three statistical studies were carried out for these levels. The first is a quantitative study looking at the first and fourth levels of the annotation scheme, concerning the presence of different markers in ironic and non-ironic tweets (Table 5.4). The second study concerns the second and fourth levels, focusing on the presence of different markers in tweets with explicit versus implicit contradiction (Table 5.4). Finally, our third study relates to the third and fourth levels, specifically the presence of markers in each irony category (Table 5.5).
Table 5.4. Marker distribution in ironic tweets (explicit or implicit) and non-ironic tweets (NIR) in French (F), English (A) and Italian (I), expressed as a percentage. The markers with an asterisk * are those not covered by existing literature. The most frequent cues in each category are shown in bold
| Emoticon | Negation | Discursive connectors | # Humorous* | Intensifier | Punctuation | |||||||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | |
| Explicit | 7 | 2 | 1 | 37 | 58 | 15 | 6 | 41 | 29 | 2 | 14 | - | 22 | 9 | 2 | 51 | 30 | 14 |
| Implicit | 6 | 4 | 7 | 34 | 61 | 9 | 4 | 29 | 16 | 4 | 15 | - | 19 | 12 | 0 | 51 | 28 | 5 |
| NIR | 5 | 10 | 0 | 58 | 75 | 9 | 4 | 13 | 18 | 0 | 0 | - | 11 | 9 | 0 | 28 | 30 | 17 |
| False* proposition | Surprise | Modality | Quotation | Opposition | Capital letters | |||||||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | |
| Explicit | 8 | 0 | - | 3 | 0 | - | 0 | 2 | 3 | 6 | 21 | 3 | 9 | 18 | 4 | 3 | 8 | - |
| Implicit | 54 | 18 | - | 3 | 3 | - | 0 | 2 | 6 | 6 | 21 | 6 | 3 | 11 | 6 | 2 | 6 | - |
| NIR | 0 | 0 | - | 2 | 0 | - | 1 | 6 | 3 | 1 | 10 | 26 | 4 | 14 | 4 | 3 | 3 | - |
| Personal* pronoun | Interjection | Comparison* | Named* entities | Reporting verb | Opinion | URL* | |||||||||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | |
| Explicit Implicit | 31 | 21 | 5 | 14 | 2 | 11 | 8 | 8 | 4 | 97 | 100 | 65 | 1 | 17 | 0 | 48 | 75 | - | 33 | 0 | 10 |
| Implicit | 31 | 24 | 3 | 12 | 0 | 13 | 2 | 12 | 3 | 91 | 97 | 43 | 1 | 14 | 0 | 41 | 74 | - | 29 | 0 | 2 |
| NIR | 30 | 40 | 1 | 2 | 2 | 12 | 4 | 6 | 1 | 82 | 88 | 98 | 3 | 7 | 1 | 35 | 68 | - | 42 | 0 | 44 |
Table 5.4 indicates the percentage of tweets containing markers in the ironic category (making a distinction between explicit/implicit) and the non-ironic category (NIR, in gray).
In French, the intensifier, punctuation and interjection markers were most common in ironic tweets, while quotations were most frequent in non-ironic tweets.
In English, the discursive connectors, quotation, comparison words and reporting verbs were twice as common in ironic tweets than in non-ironic tweets; the reverse is true for personal pronouns. Note that the English corpus does not contain any ironic tweets including URLs, as all tweets of this type were annotated as “no decision”: the annotators were unable to understand the tweet and the content of the web page linked to the URL.
In Italian, most markers were more common in ironic tweets, although some, such as quotations and URLs, occurred more frequently in non-ironic tweets.
Table 5.5. Distribution of tweets containing markers by irony category, expressed as percentages for French (F), English (A) and Italian (I)
| Negation | Discursive connectors | # Humorous* | Intensifier | Punctuation | False* assertion | |||||||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | |
| Analogy | 46 | 56 | 2 | 6 | 29 | 8 | 6 | 15 | - | 21 | 10 | 0 | 49 | 24 | 2 | 13 | 8 | - |
| Register shift | 40 | 100 | 3 | 0 | 11 | 3 | 0 | 0 | - | 0 | 0 | 1 | 60 | 44 | 1 | 0 | 0 | - |
| Euphemism | 50 | 67 | 1 | 6 | 0 | 2 | 0 | 0 | - | 50 | 33 | 0 | 72 | 0 | 1 | 44 | 0 | - |
| Hyperbole | 25 | 42 | 1 | 5 | 25 | 2 | 3 | 8 | - | 57 | 38 | 0 | 56 | 21 | 2 | 53 | 46 | - |
| Rhetorical question | 43 | 70 | 2 | 2 | 36 | 3 | 2 | 17 | - | 17 | 9 | 0 | 93 | 86 | 1 | 9 | 3 | - |
| Oxymoron/Paradox | 35 | 59 | 3 | 4 | 43 | 6 | 0 | 14 | - | 21 | 10 | 1 | 49 | 26 | 2 | 11 | 0 | - |
| False assertion | 18 | 57 | 1 | 4 | 25 | 3 | 3 | 7 | - | 10 | 16 | 0 | 29 | 14 | 2 | 95 | 89 | - |
| Other | 26 | 62 | 2 | 5 | 31 | 3 | 5 | 18 | - | 15 | 11 | 0 | 45 | 20 | 2 | 11 | 3 | - |
| Modality | Quotation | Opposition | Personal* pronoun | Interjection | Comparison* | |||||||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | F | A | I | |
| Analogy | 0 | 3 | 2 | 0 | 24 | 1 | 6 | 11 | 2 | 38 | 19 | 2 | 6 | 0 | 3 | 43 | 42 | 3 |
| Register shift | 0 | 11 | 0 | 0 | 44 | 0 | 0 | 11 | 1 | 40 | 33 | 1 | 20 | 0 | 2 | 20 | 6 | 0 |
| Euphemism | 0 | 33 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 22 | 0 | 0 | 6 | 0 | 1 | 0 | 0 | 0 |
| Hyperbole | 0 | 0 | 0 | 8 | 4 | 0 | 2 | 4 | 0 | 29 | 33 | 1 | 18 | 0 | 2 | 0 | 8 | 0 |
| Rhetorical question | 0 | 3 | 0 | 7 | 23 | 1 | 3 | 15 | 1 | 31 | 27 | 0 | 13 | 2 | 1 | 2 | 5 | 0 |
| Oxymoron/Paradox | 0 | 2 | 1 | 5 | 20 | 0 | 12 | 19 | 1 | 32 | 21 | 0 | 15 | 3 | 2 | 2 | 6 | 0 |
| False assertion | 0 | 0 | 0 | 4 | 16 | 1 | 3 | 4 | 1 | 31 | 36 | 1 | 13 | 0 | 1 | 2 | 13 | 1 |
| Other | 0 | 2 | 1 | 8 | 25 | 1 | 2 | 11 | 2 | 29 | 22 | 0 | 10 | 0 | 2 | 1 | 10 | 0 |
| Named* entities | Reporting verb | Opinion | URL* | |||||||||
| F | A | I | F | A | I | F | A | I | F | A | I | |
| Analogy | 100 | 100 | 17 | 2 | 16 | 0 | 41 | 68 | - | 13 | 0 | 1 |
| Register shift | 80 | 100 | 8 | 0 | 22 | 0 | 60 | 68 | - | 0 | 0 | 1 |
| Euphemism | 94 | 100 | 2 | 0 | 33 | 0 | 56 | 67 | - | 22 | 0 | 1 |
| Hyperbole | 88 | 88 | 6 | 3 | 13 | 0 | 84 | 88 | - | 21 | 0 | 1 |
| Rhetorical question | 90 | 97 | 9 | 1 | 17 | 0 | 45 | 73 | - | 25 | 0 | 1 |
| Oxymoron/Paradox | 99 | 100 | 10 | 1 | 19 | 0 | 55 | 75 | - | 11 | 0 | 2 |
| False assertion | 90 | 93 | 8 | 1 | 13 | 0 | 45 | 79 | - | 25 | 0 | 0 |
| Other | 91 | 98 | 6 | 1 | 16 | 0 | 32 | 74 | - | 30 | 0 | 1 |
Table 5.5 indicates the percentage of tweets containing markers in each irony category.
Negation is most common in the euphemism category for French, and in the register shift, euphemism and rhetorical question categories in English.
Intensifiers were most common in the euphemism and hyperbole categories in both French and English.
Punctuation occurred most frequently in the register shift, euphemism and rhetorical question categories in French, and in the register shift and rhetorical question categories in English.
False propositions were most common in the hyperbole and false assertion categories in both French and English. Opposition words occurred most often in the oxymoron/paradox category in French and English.
Personal pronouns were most frequent in the register shift category for French, and in the register shift, hyperbole and false assertion categories for English.
Comparison words occurred most frequently in the analogy category for French and English.
Opinion words were most common in the hyperbole category for both French and English.
For Italian, the percentage of tweets containing markers in each irony category was very low, and tweets were distributed almost equally across different categories (for example, negation is found in all categories at between 1% and 3%, and the frequency of opposition words does not exceed 2%).
This set of quantitative studies show that, whatever the language, the authors of ironic tweets tend to use markers such as opinion words, named entities and negation words in categories including analogy, rhetorical question, oxymoron/paradox, false assertion and other.
5.2.2.5. Quantitative results of the annotation procedure for contradiction relationships
Figure 5.3 shows that the distribution of relationships is almost identical in the French and English corpora. For example, the opposition relationship is most common in ironic tweets in French (69%) and in English (80%). Furthermore, the number of comparison relationships is smaller in both English (20%) and French (14%), while cause/consequence relationships are the least frequent in the two languages (6% for English, and 11% for French). Marker annotation was carried out automatically for the Italian corpus, meaning that contradiction relationships were not noted, given that this must be done manually.

Figure 5.3. Distribution by percentage of relationships in ironic tweets with explicit contradiction in French and English
5.2.2.6. Correlation between different levels of the annotation scheme
We also carried out a comparative study of correlations between different levels of the scheme in all three languages: French, English and Italian. The approach previously used in French (see Chapter 3) was applied to the English and Italian results.
We looked at the correlation between irony markers and trigger types (explicit or implicit contradiction) and between irony markers and category. The aim of this study was to analyze the extent to which markers may be used to predict irony in the languages in question.
Applying Cramer’s V (Cohen 1988) to the number of occurrences of each marker, we obtained the following results (all of the correlations are statistically significant):
- – between markers and the ironic/non-ironic class:
- - a strong correlation for French (V = 0.156, df = 14) and Italian (V = 0.31, df = 6);
- - a medium to strong correlation for English (V = 0.132, df = 9);
- – between markers and irony trigger type (explicit or implicit contradiction):
- - a strong correlation for French (V = 0.196, df = 16);
- - a medium to strong correlation for Italian (V = 0.138, df = 5);
- - a medium correlation for English (V = 0.083, df = 12).
We also analyzed correlations by marker (df = 1). The markers with the strongest class correlation (ironic/non-ironic) were:
- – negations, interjections, named entities and URLs for French (0.14 < V < 0.41);
- – negations, discursive connectors and personal pronouns for English (0.12 < V < 0.17);
- – quotations, named entities and URLs for Italian (0.310 < V < 0.416).
The markers most strongly correlated with triggers (explicit/implicit) are:
- – opposition markers, comparison words and false assertions for French (0.140 < V < 0.190);
- – opposition markers and discursive connectors for English (0.110 < V < 0.120);
- – discursive connectors, punctuation and named entities for Italian (0.136 < V < 0.213).
We noted that, in spite of the high frequency of opinion words in ironic tweets in both French and English, the opinion marker is not correlated with the ironic/non-ironic classification or with explicit/implicit triggers (V < 0.06), as many non-ironic tweets also include opinion words.
Finally, we analyzed the correlation between markers and irony categories. According to the results of Cramer’s V test, the most decisive markers were:
- – intensifiers, punctuation, false assertion and opinion word for French, with strong correlation;
- – negation, discursive connectors and personal pronouns for English, with medium correlation;
- – punctuation, interjections and named entities for Italian, with medium correlation.
5.2.3. Summary
These results are encouraging, as they show that our annotation scheme, defined for French, can be applied to other Indo-European languages (English and Italian). The pragmatic phenomena that we identified as being specific to ironic contexts in French are also present when irony is expressed in other languages belonging to the same family. The same trends are present in terms of irony categories and markers, in correlations between markers and the ironic/non-ironic class, and in correlations between markers and trigger type (explicit/implicit).
The results of this portability evaluation for our annotation scheme indicate that, in future, it may be possible to develop an automatic irony detection system in a multilingual context.
We made the first step in this direction by evaluating our automatic detection model for text in Arabic. This investigation is presented below.
5.3. Irony in Semitic languages
“The Semitic languages are a group of languages spoken from ancient times in the Near East, North Africa and the Horn of Africa. The term ‘Semitic’ was coined in 1781, derived from Shem, one of the sons of Noah in the Old Testament. They form a branch of the Afroasiatic language family, present across the northern half of Africa and into the Middle East. The origin and direction of the geographic expansion of these languages is uncertain; they may have expanded from Asia into Africa, or from Africa into Asia. The most widely spoken Semitic languages today are Arabic (approx. 375 million speakers), Amharic (over 90 million), Hebrew (8 million), Tigrinya (6.75 million) and Maltese (400,000 speakers). Other Semitic languages are used in Ethiopia, Eritrea, Djibouti and Somalia, and in the Near East (e.g. neo-Aramaic languages). Arabic is notable for the distinction made between literary Arabic, the lingua franca generally found in writing, and spoken dialects. Literary Arabic includes both Classical Arabic and Modern Standard Arabic. There are many regional variations in spoken (dialectal) Arabic, and not all are mutually comprehensible”. (Adapted from French Wikipedia7)
In the context of our study, we have chosen to focus on Arabic. According to the previous definition, we note that linguists have emphasized the great difference between literal Arabic and dialectal Arabic. A considerable volume of work has been carried out in the field of natural language processing for Arabic, mostly for literary Arabic, and more specifically for Modern Standard Arabic (MSA).
MSA is a modernized and standardized derivative of Classical Arabic8 used in writing and in formal speech in the domains of education, newspapers, and to some extent, TV shows. MSA has a complex linguistic structure with a rich morphology and complex syntax (Al-Sughaiyer and Al-Kharashi 2004, Ryding 2005). Work on automatic processing for Arabic has been ongoing for over 20 years (Habash 2010), and several resources and tools have been developed to handle Arabic morphology and syntax, from superficial to deep analysis (Eskander et al. 2013, Pasha et al. 2014, Green and Manning 2010, Marton et al. 2013). Additionally, many applications have been developed for Arabic NLP (ANLP), including question–answer systems (Bdour and Gharaibeh 2013, Hammo et al. 2002, Abouenour et al. 2012), automatic translation (Sadat and Mohamed 2013, Carpuat et al. 2012), sentiment analysis (Abdul-Mageed et al. 2014) and named entity recognition (Darwish 2013, Oudah and Shaalan 2012). Work has also been carried out in the field of NLP for colloquial Arabic, notably concerning automatic understanding of spontaneous speech (Afify et al. 2006, Biadsy et al. 2009, Bahou et al. 2010), phonetization of the Tunisian dialect (Masmoudi et al. 2014), the construction of domain ontologies for Arabic dialects (Graja et al. 2011, Karoui et al. 2013), morphological analysis (Habash and Rambow 2006, 2007), automatic identification of colloquial Arabic (Alorifi 2008), etc. However, to the best of our knowledge, the problem of automatic irony detection for Arabic, and more specifically in the context of social media, has yet to be addressed.
In what follows, we shall present an overview of the specificities of Arabic (section 5.3.1), distinguishing between MSA and colloquial forms. In section 5.3.2, we shall present the corpus and resources used for automatic detection. Section 5.3.3 describes our experiment and results. Finally, in section 5.3.3.3, we compare these results with those obtained for French (presented in Chapter 4).
5.3.1. Specificities of Arabic
Arabic is written from right to left, with ambiguous letter forms that change depending on the position of the letter in a word. Letters may take different forms according to whether they are autonomous (unconnected), initial (at the start of a word), median (within a word) or final (at the end of a word) (see Table 5.6).
Table 5.6. Letters in Arabic according to their position in a word (Habash 2010)
| Autonomou | |||
| Initial | |||
| Median | |||
| Final |
Arabic is characterized by the absence of diacritical signs (dedicated letters for short sounds), complex agglutination, and free word order structure. These characteristics make Arabic particularly difficult to process. For example, (Farghaly et al. 2003) estimate that the average number of ambiguities for a token in standard Arabic may be as high as 19.2, compared to an average of 2.3 in most other languages.
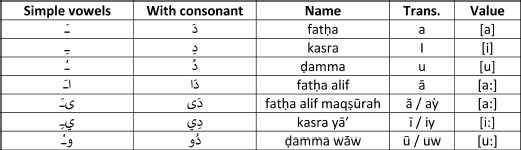
Arabic has 28 consonants, which may be combined with different ling and short vowels, as shown in Table 5.79. Short vowels are represented by diacritical signs in the form of marks above or below letters, such as the fathah (a short diagonal line placed above a letter), the kasrah (a short diagonal line placed below a letter) and the dammah (a small, curl-like sign above a letter). Arabic texts may be full, partial or non-diacritized.
Short vowels are rarely marked explicitly in writing: the associated diacritics are not used in everyday written Arabic, or in general publications. However, texts without diacritics are extremely ambiguous. For example, the word ![]() may be diacritized in nine different ways (Maamouri et al. 2006):
may be diacritized in nine different ways (Maamouri et al. 2006): ![]() (science),
(science), ![]() (flag),
(flag), ![]() (he taught), etc. A non-diacritized word may have different morphological characteristics and, in certain cases, may belong to a different morpho-syntactic category, particularly if it is interpreted out of context.
(he taught), etc. A non-diacritized word may have different morphological characteristics and, in certain cases, may belong to a different morpho-syntactic category, particularly if it is interpreted out of context.
Table 5.7. Types of Arabic diacritics (Wikipedia)
Furthermore, in colloquial Arabic, there are additional sources of ambiguity in terms of understanding. One word may have several meanings according to the dialect being spoken; similarly, a single object may have several names, according to the country or region. For example, the word “suitcase” is written ![]() or
or ![]() in the Tunisian dialect, but
in the Tunisian dialect, but ![]() in the Egyptian dialect. This is an issue in texts published on social networks, blogs, the review sections on online shopping sites, etc., where a variety of words may be used to signify the same thing.
in the Egyptian dialect. This is an issue in texts published on social networks, blogs, the review sections on online shopping sites, etc., where a variety of words may be used to signify the same thing.
In our work, we have chosen to focus on social media texts, specifically tweets, as a form of non-diacritized text combining standard and colloquial Arabic.
5.3.2. Corpus and resources
5.3.2.1. Collection of the first Arabic corpus for irony
Given the absence of an existing corpus of ironic tweets in Arabic, we followed the same procedure as for French and English. Initially, we planned to use the same categories as for the French corpus (politics, economics, health, etc.) with themes specific to the Arab world. However, it rapidly became apparent that the vast majority of ironic tweets concerned political subjects. For this reason, we only collected tweets in the politics category, using a set of five themes: ![]() (Hillary),
(Hillary), ![]() (Trump),
(Trump), ![]() (Al-Sissi: the Egyptian president),
(Al-Sissi: the Egyptian president), ![]() (Mubarak: former Egyptian president) and
(Mubarak: former Egyptian president) and ![]() (Morsi: former Egyptian president).
(Morsi: former Egyptian president).
To construct a corpus of ironic/non-ironic tweets, we harvested examples containing the hashtags ![]() and
and ![]() (translations of #irony and #sarcasm). Tweet (5.1) is an example of an ironic message, while (5.2) is non-ironic.
(translations of #irony and #sarcasm). Tweet (5.1) is an example of an ironic message, while (5.2) is non-ironic.
Tweet (5.2) is written in standard Arabic. Tweet (5.1) combines standard Arabic with a single Egyptian/Tunisian dialect word, ![]() (not).
(not).
| (5.1) |  |
| (Actually, it is obvious that the military coup against President-Elect Morsi was in the best interests of Egypt, and not of ambitions, and now conflicts, regarding the presidency #irony) | |
| (5.2) |  |
| (Life changes, but women never change. That’s what I learned from Hillary Clinton’s tears when she was defeated by Trump) |
After the collection stage, we removed duplicates, retweets and tweets containing images. This filtering process left us with a corpus of 3,479 tweets, of which 1,733 were ironic and 1,746 were non-ironic. The corpus included tweets in both standard and colloquial Arabic, and in the majority of cases, a combination of the two forms. Given that Twitter’s API does not distinguish between standard Arabic and colloquial Arabic or between different dialects, several dialects are present in the corpus, including Egyptian, Syrian and Saudi. Other dialects, such as Tunisian and Algerian, occur less frequently. For the purposes of our study, the hashtags ![]() and
and ![]() (#irony and #sarcasm) were removed.
(#irony and #sarcasm) were removed.
5.3.2.2. Linguistic resources
Our automatic detection approach, described in the previous chapter, makes use of dedicated lexicons to identify opinion words, intensifiers, negations, emotions, etc. To study the portability of our system for Arabic, we looked for existing lexicons (for both standard and dialect forms of the language). Some of the lexicons we found performed well in the context of irony detection; others, less so. We constructed our own lexicons to replace those in the latter category.
The following linguistic resources were used:
- – a lexicon of Arabic discursive connectors based on work by Iskandar (Keskes et al. 2014). This lexicon includes 416 connectors, such as
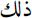 (furthermore) and
(furthermore) and 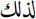 (thus);
(thus); - – a lexicon of 4,501 named entities Keskes et al. (2014), to which we added the entities used for tweet collection, e.g.
 (Clinton);
(Clinton); - – a lexicon of 119 reporting verbs used by Keskes et al. (2014), such as
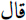 (to say) and
(to say) and 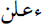 (to announce);
(to announce); - – a lexicon of opinion words, made up of 22,239 negative opinion words and 26,777 positive words. This was obtained by combining two resources: the Arabic Emoticon Lexicon and the Arabic Hashtag Lexicon (dialectal)10 (Saif et al. 2016). These lexicons were used in Task 7 of the SemEval’2016 campaign11,12, and include entries such as
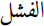 (failure) and
(failure) and 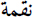 (indignation);
(indignation); - – a lexicon of 681 emoticons, used previously for French;
- – a lexicon of personal pronouns and a lexicon of negation words, which we constructed manually, including terms such as
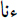 (I),
(I),  (we),
(we),  or
or 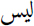 (not/no/isn’t);
(not/no/isn’t); - – a lexicon of 25 intensifiers, translated from a set of intensifiers used for French, including
 (lots) and
(lots) and 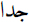 (very).
(very).
5.3.3. Automatic detection of irony in Arabic tweets
In this section, we shall present the features used in the training process and the different algorithms used, focusing on the algorithm that performed best for classification purposes. Finally, we shall present our results.
5.3.3.1. Features used for irony detection
For the French corpus, our system used 30 features, eight of which were obtained using morphosyntactic pre-processing tools such as MElt. In the absence of a satisfactory analyzer for texts in standard and colloquial Arabic, we manually selected a subset of 22 features, which can be extracted without these tools. These were divided into four groups, as shown in Table 5.8.
5.3.3.2. Experiments and results
To classify tweets as ironic/non-ironic, we used all of the features defined above, testing several classifiers using the Weka platform: SMO, Naive Bayes, multinomial logistic regression, linear regression, random tree and random forest. We trained the classifiers using a balanced corpus of 1,733 ironic tweets and 1,733 non-ironic tweets. For the first experiment, 80% of the corpus was used for training and 20% for testing. For the second experiment, we used 10-fold cross-validation. We chose to focus on these two experiments due to the limited size of the corpus (3,466 tweets). The best results were obtained using the random forest classifier with default parameters. These are shown in Table 5.9.
Three feature selection algorithms were applied using Weka with the aim of improving our results: Chi2 and GainRatio (see Table 5.10) to obtain a list of features in decreasing performance order (best to worst), and CfsSubsetEval option to obtain the best feature combination, considering the individual predictive capacity of each feature and the degree of redundancy between features. The last algorithm indicated that the combination of number of emoticons, exclamations, negations, number of interjections, named entities and number of named entities would produce the best results.
Table 5.8. Feature set used for training in Arabic
| Feature groups | Features | Feature type |
| Surface features | Punctuation (.../!/?) | Binary |
| Emoticon | Binary | |
| Number of emoticons | Numerical | |
| Quotation (text in “”) | Binary | |
| Discursive connectors that do not trigger opposition | Binary | |
| Opposition words | Binary | |
| Exclamation (!!/!!!/or more) | Binary | |
| Question (??/???/or more) | Binary | |
| Exclamation + Question (?!/!?) | Binary | |
| Number of words | Numerical | |
| Sentiment features | Interjection | Binary |
| Number of interjections | Numerical | |
| Negative opinion | Binary | |
| Positive opinion | Binary | |
| Number of positive opinions | Numerical | |
| Number of negative opinions | Numerical | |
| Modifier features | Intensifier | Binary |
| Reporting verb | Binary | |
| Negation word | Binary | |
| Contextual features | Personal pronoun | Binary |
| Named entity | Binary | |
| Number of named entities | Numerical |
Table 5.9. Results of ironic/non-ironic classification obtained using random forest and all features. The best results are shown in bold
| Train/test | 10-Fold cross-validation | |||||||
| Precision | Recall | F-measure | Accuracy | Precision | Recall | F-measure | Accuracy | |
| IR | 0.728 | 0.707 | 0.718 | 72.29 | 0.719 | 0.735 | 0.727 | 72.36 |
| NIR | 0.718 | 0.739 | 0.728 | – | 0.729 | 0.713 | 0.721 | – |
Unfortunately, this subset of features identified by the selection algorithms failed to produce better results than those obtained using all features. We thus tested a different approach, adding features one by one in the training process for the random forest classifier (following the order given by the selection algorithm) in order to assess the influence of each feature. In this, we aimed to identify a subset of features, which would maximize performance.
Table 5.10. Results produced by the feature selection algorithms
| Kchi2 | GainRatio | |||
| 0.10578219 | Nb_Named_Entities | 0.1091403 | Named_Entities | |
| 0.08806588 | Named entities | 0.069659 | Nb_Named_Entities | |
| 0.01807329 | Nb_emoticons | 0.0501787 | Nb_Interjections | |
| 0.01788328 | Emoticon | 0.03029 | Nb_Words | |
| 0.01240071 | Nb_Interjections | 0.0245372 | Nb_emoticons | |
| 0.00526265 | Nb_Words | 0.0240979 | Emoticons | |
| 0.00506479 | Interjection | 0.020977 | Interjection | |
| 0.00289741 | Punctuation | 0.0127604 | Question | |
| 0.00289665 | Exclamation | 0.0122677 | Exclamation | |
| 0.00288611 | Nb_PositiveOpinion | 0.0060024 | PositiveOpinion | |
| 0.00209972 | Negation | 0.0046953 | NegativeOpinion | |
| 0.00199026 | NegativeOpinion | 0.0043288 | Nb_PositiveOpinion | |
| 0.00197259 | PositiveOpinion | 0.0032733 | Negation | |
| 0.00118275 | Question | 0.0029279 | Punctuation | |
| 0.00099095 | Personal_pronoun | 0.0016047 | Opposition | |
| 0.00032808 | Opposition | 0.0010676 | Personal_pronoun | |
| 0.00015437 | Intensifier | 0.0007447 | Intensifier | |
| 0.00003629 | DiscursiveConnector-Opposition | 0.0000376 | DiscursiveConnector-Opposition | |
| 0.00000962 | Quotation | 0.0000307 | Exclamation_Question | |
| 0.00000371 | Exclamation_Question | 0.0000295 | Quotation | |
| 0 | Nb_NegativeOpinion | 0 | Nb_NegativeOpinion | |
This approach showed that the use of all features with the exception of reporting verb produced the best results, with an accuracy value of 72.76% compared to 72.36% for all features, an F-measure of 73% instead of 72.70% for the ironic class and an F-measure of 72.50% instead of 72.10% for the non-ironic class (see Table 5.11).
5.3.3.3. Discussion
Although most of the features used here are surface features, the results obtained are very encouraging. Comparing the results obtained for the classification of Arabic tweets into ironic/non-ironic sets with those obtained using the same features in French, we see that the classification algorithms behave differently in the two languages. In French, the SMO classification algorithm was most effective, with an F-measure of 85.70% for the ironic class; in Arabic, the F-measure did not exceed 62.50% using this approach. The random forest classification algorithm performed better for classifying ironic tweets in Arabic, with an F-measure of 73%, but its performance in French was lower than that of the SMO algorithm, with an F-measure of 75.40%.
Table 5.11. Results of tweet classification into ironic (IR)/non-ironic (NIR) obtained using random forest and the best feature combination. The best results are shown in bold
| Train/test | 10-Fold cross-validation | |||||||
| Precision | Recall | F-measure | Accuracy | Precision | Recall | F-measure | Accuracy | |
| IR | 0.723 | 0.696 | 0.709 | 71.57 | 0.724 | 0.736 | 0.730 | 72.76 |
| NIR | 0.709 | 0.736 | 0.722 | – | 0.731 | 0.720 | 0.725 | – |
5.4. Conclusion
In this chapter, we described two experiments. In the first experiment, we studied the portability of our annotation scheme—designed for French—to a multilingual context (English and Italian). We were able to measure the impact of pragmatic phenomena in irony interpretation. The results indicated that our scheme is reliable for French, English and Italian, and the same trends can be seen in terms of irony categories and markers. We notably found correlations between markers and ironic/non-ironic classes, between markers and irony trigger types (explicit/implicit), and between markers and irony categories in all three of the languages considered. These observations are valuable in the context of developing a multilingual automatic irony detection system.
Our second experiment concerned automatic irony detection in a corpus of Arabic tweets. We trained a model using some of the surface features defined for the French corpus. The results of our experiment were encouraging, particularly given (1) the difficulty of processing texts that combine standard Arabic with dialect forms, and (2) the comparable results obtained for other languages. In our work on French, we obtained a precision of 93% for the ironic class; for Arabic, the precision was 72.4%. Other authors working on this problem have obtained precision scores of 30% for Dutch (Liebrecht et al. 2013) and 79% for English (Reyes et al. 2013).
- 1 Adapted from https://fr.wikipedia.org/wiki/Langues_indo-europ%C3%A9ennes.
- 2 www.di.unito.it/tutreeb/sentiTUT.html.
- 3 http://di.unito.it/sentipolc14.
- 4 www.spinoza.it/.
- 5 https://github.com/IronyAndTweets/Scheme.
- 6 The bold values show the highest frequencies.
- 7 https://fr.wikipedia.org/wiki/Langues_s%C3%A9mitiques.
- 8 Classical, Quranic, Arabic is used in literary and religious texts.
- 9 https://fr.wikipedia.org/wiki/Diacritiques_de_l%27alphabet_arabe.
- 10 Available at http://saifmohammad.com/WebPages/ArabicSA.html.
- 11 http://alt.qcri.org/semeval2016/task7/.
- 12 We tested other lexicons, such as the Arabic translation of Bing Liu’s Lexicon and the Arabic translation of MPQA’s Subjectivity Lexicon, but the results of experiments using these lexicons were inconclusive.