
Chapter 12. When the Bazaar Sets Out to Build Cathedrals
How ThreadWeaver and Akonadi were shaped by the KDE community and how they shape it in turn
| Principles and properties | Structures | ||
| Versatility | ✓ | Module | |
| ✓ | Conceptual integrity | ✓ | Dependency |
| ✓ | Independently changeable | ✓ | Process |
| Automatic propagation | Data access | ||
| ✓ | Buildability | ||
| ✓ | Growth accommodation | ||
| ✓ | Entropy resistance |
Introduction
The KDE project is one of the biggest Free Software[58] efforts in the world. Over the course of 10 years, its very diverse community of contributors—students, seasoned professionals, hobbyists, companies, government agencies, and others—has produced a vast amount of software addressing a wide variety of issues and tasks, ranging from a complete desktop environment with a web browser, groupware suite, file manager, word processor, spreadsheet, and presentation tools, to highly specialized applications, such as a planetarium tool. The basis of these applications is provided by a collection of shared libraries that are maintained by the project collectively. Beyond their primary intended use by the members of the KDE developer community itself, they are also used by many third-party developers, both commercial and noncommercial, to produce thousands of additional applications and components.
Although the initial focus of the KDE project was to provide an integrated desktop environment for free Unix operating systems, notably GNU/Linux, the scope of KDE has broadened considerably, and much of its software is now available on not just various flavors of Unix, but also on Microsoft Windows and Mac OS X, as well as embedded platforms. This implies that the code written for the KDE libraries has to work with many different tool chains, cope with the various platform peculiarities, integrate with system services flexibly and in extensible ways, and make judicious and careful use of hardware resources. The broad target audience of the libraries also means that they have to provide an API that is understandable, usable, and adaptable by programmers with diverse backgrounds. Someone accustomed to dealing with Microsoft technologies on Windows will have different preconceptions, biases, habits, and tools from an embedded programmer with a Java background or an experienced Mac developer. The goal is to make all programmers able to work comfortably and productively, to allow them to solve the problems at hand, but also (and some say more importantly) to benefit from their contributions should they choose to give back their suggestions, improvements, and extensions.
This is a very agile, very diverse, and very competitive ecosystem, one in which most active contributors are interested in collaborating to improve their software and their skills by constantly reviewing each other’s work. Opinions are freely given, and debates can become quite heated. There are always better ways to do one thing or another, and the code is under constant scrutiny by impressively smart people. Computer science students analyze implementations in college classes. Companies hunt down bugs and publish security advisories. New contributors try to demonstrate their skills by improving existing pieces of code. Hardware manufacturers take the desktop and squeeze it onto a mobile phone. People feel passionately about what they do and how they think things should be done, and one is, in many ways, reminded of the proverbial bazaar.[59] Yet this wild and unruly bunch is faced with many of the same challenges that those in more traditional organizations who are tasked with maintaining a large number of libraries and applications must overcome.
Some of these challenges are technical. Software has to deal with ever-increasing amounts of data, and that data becomes more complex, as do the workflows individuals and organizations require. The necessity to interoperate with other software (Free and proprietary) used in corporations or government administrations means that industry paradigm shifts, such as the move towards service-oriented architecture (SOA), have to be accommodated. Government and corporate mission-critical uses pose stringent security requirements, and large deployments need good automation. Novice users, children, or the elderly have different needs entirely, yet all of those concerns are valid and of equal importance.[60] Much like the rest of the industry, Free Software in general and KDE in particular are coming to terms with pervasive concurrency and increasingly distributed processing. Users rightfully demand easier-to-use, cleaner, and more beautiful interfaces; responsive, well-thought-out, and not overly complex interactions with software; and high reliability, stability, and data safety. Developers expect language-neutral extension points, well-maintained APIs, binary and source compatibility, clean migration paths, and functionality on par with the commercial offerings they are frequently accustomed to from their day jobs.
But even more daunting are the social and coordinative aspects of a larger Free Software project. Communication is key, and it is hampered by time zones, cultural barriers, more or less reflected preferences and prejudices, and also simply by physical distance. Discussions that can be finished in 15 minutes in a stand-up office meeting may take days of arguing on mailing lists to allow the opinions of team members from the other hemisphere to be heard. The process of reaching consensus often is at least as important as the resulting decision itself, to keep the cohesion of the group intact. Naturally, more patience, understanding, and rhetoric wit is necessary to gain a favorable consensus. This is much to ask from people who aced math and physics classes without flinching, but avoid getting a haircut because they do not like the talking to nonprogrammers that such an activity entails. With this in mind, the amicable spirit of the annual Akademy conferences is a wonderful experience (see the next section). We have never seen such a massively diverse group of old and young people from all over the globe, from rivaling countries, countless nations, seemingly different worlds even, and with all shades of skin set aside differences to argue—heatedly, but rationally—about arcane C++ subtleties.
And then, aside from technical and personal aspects, there is a third major influence on how a Free Software project fares: structure. In some ways, structure is inevitable for Free Software groups. Larger and better-known software projects especially need to hold trademarks, receive donations, and organize conferences. The time when this is possible solely through the good will of spouses and weekend trips is usually already over when a project is mentioned publicly for the first time. In some respects, structure (or the lack thereof) determines the fate of the community. An important decision has to be made—whether to go corporately dull or geekily chaotic. The answer is not trivial, because multiple trade-offs are involved: funding versus freedom from external influence; stability of the development process versus attracting the most brilliant cave dwellers;[61] visibility and mind-share versus focus on impressive technical results. Beyond the point where structure is a bare necessity, there are options for the levels of bureaucracy. Some projects do not even have a board of directors, whereas some have dictators who claim to be benevolent. There are examples for successful and unsuccessful communities on both ends of this continuum.
Before we look in detail at two concrete examples of how the technical, social, and structural issues were approached and dealt with by groups within KDE, it seems useful to provide some background on the history of the KDE project in these three areas. The following section will thus describe what KDE is today and how the community arrived at that point.
History and Structure of the KDE Project
KDE, or the K Desktop Environment, was originally conceived out of despair. At a time when FVWM was considered a desktop, Xeyes was a stock inventory item on the screen, and Motif was the toolkit competing with XForms for the higher body count of developer’s brain cells and for lack of sexiness, KDE was founded to achieve a revolutionary goal: to marry the raw power of Unix with a slick, eye-candied user experience. This goal was now considered achievable because the Norwegian startup Trolltech was about to release the first version of its groundbreaking object-oriented GUI toolkit for C++, Qt. Qt set out to allow GUI programming the way it was meant to be: systematic, object-oriented, elegant, easy to learn, well-documented, and efficient. In 1996 Matthias Ettrich, at the time a student at Tuebingen University, first emphasized the potential offered by using Qt to develop a complete desktop environment. The idea quickly attracted a team of about 30 developers, and that group has been growing steadily ever since.
Version 1.0 of KDE was released in 1998. Although nimble in its functionality from today’s point of view, it needs to be measured in relation to the competition: Windows 3.1 did not have memory protection at the time, Apple was struggling to find a new kernel, and Sun swept the sorry remnants of CDE into the gutter. Also, this was before the first Linux hype, and the momentum of Free Software was not yet understood by all in the software industry.
Even in the process of finishing KDE 1, the developers had already redesigned it for 2.0. Some major elements where missing: the component model, the network abstraction layer, the desktop communication protocol, the UI style API, and more. KDE 2 was the first release that was architected, designed, and implemented in a reasonably rational process. Corba was considered for the component model and rejected. This was also the first time the contributor group fluctuated. Interestingly, although some early core developers left, the size of the active KDE development team slowly but steadily grew. KDE e.V., the organization of the KDE contributors, was founded in 1996 and grew to represent the vast majority of the KDE committers by 1998. From the beginning, the organization was meant to support the contributors, but not to influence the technical direction of KDE. The course of development is supposed to be the result of the work of the active developers, not a management team. This idea proved to be one of the most important factors, if not the most important, toward making KDE one of the very few major Free Software projects that are not massively influenced by funding corporate bodies. External funding is not regarded as problematic in KDE, but many other projects that relied too much on it ceased to exist when the major funding sponsor keeled over or lost interest. Because of that, KDE survived many trends and hypes in the Free Software world and continuously maintained its development momentum.
In April 2002, KDE 3 was ready. Since KDE 2 was considered well-designed, version 3 was more evolutionary and matured closer and closer to perfection over five major releases and six years. Important applications that became standard on free desktops have been developed based on the KDE 3 technologies: K3B, the disk burning program; Amarok, one of the slickest music players in general; Kontact, a full personal communication suite. Most interestingly, for the first time these applications use KDE not only as one target desktop, but also as the platform on top of which end-user applications are built. With version 3, KDE started to separate into two things: the desktop and the environment, usually called the platform. But since KDE was still confined to X11, this split was not easily recognized by users. That was the next step.
In 2004, one of the toughest calls in its history had to be made by the KDE team. Trolltech was about to release version 4.0 of Qt, and it was very advanced and very different compared to both previous releases and any other toolkit on the market. Because of the massive changes in the toolkit, going from Qt 3 to Qt 4 was not an adaptation, but a port. The question was whether KDE 4 was going to be a straight port of KDE 3 from Qt 3 to Qt 4 or a major redesign in the process of porting. Both options had many supporters, and it was clear to the vast majority of those involved that, either way, an immense amount of work had to be done. The decision was made in favor of a complete redesign of KDE. Even if it is now accepted that this was the right choice, it was a very risky one, because it meant providing KDE 3 as the main line for an extended period of time in parallel until completing the huge porting effort.
One major new feature of Qt 4 needs particular emphasis. The GPL and Commercial dual licensing scheme Trolltech was using already for the X11 version was now extended to all target platforms Qt supports, most notably to Windows, Mac OS X, and embedded platforms. KDE 4 thus had the potential to become something relevant beyond the Unix world. Although the Unix desktop remains its home turf, applications developed for KDE can now run on Windows and Mac OS X computers. This possibility was received controversially. One argument against it was that the Free Software community would provide neat applications for those proprietary desktops, thus reducing the incentive to switch away from them to free alternatives. Another one was, “What do we care?” or more politely, “Why should we invest scarce development time in supporting nonfree target systems?” Proponents argued that providing the same applications everywhere would ease the transition for users from proprietary to free operating systems and allow gradual replacements of key applications. In the end the trend was set according to KDE’s long-term mantra of “those who do the work decide.” There was enough interest in the new target platforms to gain the attention of sufficient contributors, so in the end, there was no reason to deprive the KDE users of a capability many obviously longed for.
To become platform-independent, KDE 4 was rearchitected and separated into an application development platform, the desktop built on top of it, and the surrounding applications. Of course the dividing lines are blurry at times.
Given this history, let us look at some of the ways in which a project like KDE tries to deal with issues that go beyond what a single developer, however talented, can solve. How can knowledge and experience be retained and used to maximum effect? Incorporating strategic thinking, how can a large, diverse group make difficult decisions and agree on steering toward the overall destination without jeopardizing the sense of fun? How can we incorporate the idea that decisions are made on equal footing among peers and the other aspects that have made KDE and other Free Software projects so successful? In other words, how to build a cathedral when everyone involved has a tendency to consider themselves, rightfully or not, an architect, and how to fill the role of architect without wearing a funny-looking hat. We start with looking at the contributors because we are convinced that Free Software communities are first and foremost social structures as opposed to technical ones. People are the most scarce and valuable resource we have.
There are different roles to fill for every project, and there is no authority that decides in the recruiting process. Every Free Software project needs a number of poster girls and boys and a large bunch of motivated, skilled, down-to-earth hackers, artists, administrators, writers, translators, and more. The one thing that seems to be a common denominator among all of these trades is that they all require a great deal of self-motivation, skill, and self-guidance. To be able to contribute seems to attract many extraordinary individuals of all ages, from high school students to retirees. What makes them join the project is the fascination of being part of a group that creates tomorrow’s technologies, to meet other people interested in and driving these technologies, and often to do something with a reason, instead of writing throw-away college papers.
A well-functioning Free Software community is about the most competitive environment to be in. Most commercial engineering teams we have encountered are way more regulated, and policies protect the investment employees have made in their position. Not so for Free Software developers. The only criteria for a certain code contribution’s inclusion in the software is its quality and if it is being maintained. For a short while, a mediocre piece of code made by a respected developer may stay in the source code, but in the long term, it will get replaced. The code is out in the open, constantly scrutinized. Even if a certain implementation is of good quality but not close enough to perfection in a few people’s perception, a group of coders will take it on and improve it. Since creation is what motivates most, Free Software developers constantly need to be aware that their creation is made obsolete by the next one. This explains why code written in Free Software projects is often of higher quality than what can be found in commercial projects—there is no reason to hope the embarrassing bits will not be discovered.
Surprisingly, few coders want exterior motivation in the form of recognition from users or the media. Often, they turn away from some piece of work shortly before it is finally released. As with marathon runners, it seems their satisfaction is internal—the knowledge of having reached the finishing line. Sometimes, this is misunderstood as shying away from the public, but on the contrary, it only underlines the disinterest in praise. Because of this set of personal values, in software projects that are really free, it is almost impossible to assign priorities to development goals. Code artists are intrinsically motivated and choose and decide their own individual priorities. Software still gets finished because the most challenging elements attract the highest attention. This coordination from within favors the journey instead of the goal and still leads to results. The chosen path is often different from the one a well-managed commercial software project would have taken, and usually it also incurs fewer compromises of quality versus deadlines. If such compromises are accepted on a regular basis, it is generally a good sign that a Free Software project is in the process of turning into a commercial, or “less Free,” one. Typically, this happens when either a major group of developers spin a company off the project, a funding partner asserts control over major contributors, or the project itself stops innovating and goes into maintenance mode.
Most kinds of structure and organization imposed on a Free Software project are met with resistance. Contributors join KDE for many reasons, but enjoying the bureaucracy of the project is not one of them. People who join a Free Software project usually are very aware of using and protecting their own freedom of choice. At the same time, the necessity of a minimum amount of formal organization is recognized. Although almost all technical challenges are no match for a good team, formal structure is where centrifugal forces are most effective. Many Free Software projects have dissolved because decisions of political scope were forced through by influential team members. Finding a formal structure that solves the problems the project faces once it becomes significant but at the same time does not hinder the further technical development is one of the most (or the single most) important steps KDE had to take in its history. The fact that a very stable and accepted structure was found surely contributed significantly to the long-term stability of the KDE community.
In 1996, KDE founded KDE e.V. as the representation of the KDE contributors. An e.V., or “eingetragener Verein,” is the classical not-for-profit organization in Germany, where most of the KDE contributors were based at the time and where the contributors met. The main force leading to its creation was that a legally capable body representing the project was needed to enter into the Free Qt Foundation. The Free Qt Foundation was an agreement between Trolltech, the makers of Qt, and KDE with the purpose of ensuring that KDE always had access to Qt as a free toolkit. It guaranteed (and still does) that, should Trolltech stop to develop and publish the free version of Qt, the latest released free version can be continued without Trolltech. This agreement was even more important when the free version of Qt was not licensed under the GPL. Today it is, and the foundation is now dealing mostly with resolving copyright subtleties, developer rights, and other similar issues. It was important because many contributors would have hesitated to spend their time on a project that ran the risk of being commercialized, but it also served as an example that KDE as a project must be able to carry legal rights. Later on, the KDE trademark was registered and is held by KDE e.V., which assumed many other responsibilities such as serving as the host of the large annual KDE conference.
Regarding the architecture and design of KDE, the organization is still rather influential, even if it is not supposed to manage the development. Since it is assumed that most of the “accomplished” KDE contributors are members, the KDE e.V.’s opinion weights rather heavy. Also, it is the host of the annual Akademy conference, which for most contributors is the only chance to meet and discuss things in person. It also raises funds, mostly donations and membership fees of sponsors, and thus has the ability to fund (or not fund, in very rare cases) developer activities such as sprints or targeted meetings. Still, the budget the organization spends annually is surprisingly small compared to the effects created by it. The developer meetings are where most of the coordination takes place, which does give the membership a lever. Still, the initiative of groups of contributors gets most things done, not a statement at the general assembly.
Akademy has become an institution that is well-known even outside the KDE community. It is where most of the coordination that really requires in-person meetings takes place. Since neither human resources nor funds can be directly assigned to any development activity, many discussions of broader scope are saved for the conference. It has become a routine to use this annual gathering for decision-making and to only loosely coordinate in the meantime. The conference takes place quite reliably around summer, and contributors to other Free Software projects use that opportunity to coordinate with KDE. One of the decisions made during the 2007 conference was to switch to six-month release cycles, which was suggested and championed by Marc Shuttleworth of Ubuntu.
Akademy is the only global conference KDE organizes. In addition to this large meeting, many small gatherings of subgroups and sprints take place. These meetings are usually more frequent, more local, and more focused, so whereas architectural issues are debated at Akademy, design issues for certain modules or applications are discussed here. Some subgroups, such as the KOffice or Akonadi developers, usually meet at three-month intervals.
This reiterative process of coordinated high- and medium-level reviews has proven to be quite effective and also provides a good understanding of the goals and next actions among the developers. Most attendees express that the annual conference gives them a boost in motivation and in the effectiveness of their development work.
The organization and structure KDE shows today is not the brain child of a group of executives who asked themselves how a Free Software project should be organized. It is the result of an iterative process of trying to find a suitable structure for the main nontechnical goals—to remain free and to ensure the longevity of the project and sustainable growth of the community. Freedom is used here not only in the sense of being able to provide the software for free and as Free Software, but also to be free of dominating influences from third parties. External parties such as companies or governmental groups are regularly present at the conferences, and the project is interested in their findings, experiences, and contributions. However, these stakeholders must be prevented from investing enough resources to be able to determine the outcome of votes in the community. This may seem paranoid, but it actually happened to other projects, and the KDE community is aware of that. So staying active and healthy as a Free Software project is directly related to protecting the freedom of the project itself. The main technical goal, to support the developers and other contributors with funds, materials, organizations, and other resources, are comparatively simple to achieve.
The result is a living, active, vibrant community with an established development process, a stable and healthy fluctuation of contributors, and a lot of fun on the way. And this in turn helps to attract and secure the most important resource for such an environment: new contributors. KDE has succeeded in preventing the typical tendency to create larger and larger formal structures and positions and also does not have any dictators, as benevolent as they might be. KDE is an archetypal Free Software community.
In order to understand how this community functions in practice, how architectural decisions are arrived at, and how the peculiar process influences the outcomes technologically, we will look at two examples in some detail: Akonadi, the personal information management infrastructure layer for KDE 4, and ThreadWeaver, a small library for high-level concurrency management.
Akonadi
The KDE 4 platform, both as a development platform and as a runtime environment for the execution of integrated applications, rests on a number of so-called “pillars.” These key pieces of infrastructure provide the central services that applications expect to have easy and ubiquitous access to on a modern desktop. There is the Solid hardware interaction layer, which is responsible for providing the desktop with information about and notification from the hardware, such as a USB stick becoming available or the network going down. Phonon provides an easy-to-program multimedia layer for playback of various media types and user interface elements for their control. Plasma is a library for rich, dynamic, scalable (SVG-based) user interfaces that go beyond the standard office look.
The personal information of the user—her email, appointments, tasks, journal entries, blog posts and feeds, bookmarks, chat transcripts, address book entries, etc.—contains not only a large amount of primary information (the content of the data). It also weaves a rich contextual fabric from which much about the user’s preferences, social interactions, and work contexts can be learned, and it can be used to make the interaction experience of many applications on the desktop more valuable and interesting, provided that it is readily, pervasively, and reliably accessible. The Akonadi framework aims to provide access to the user’s personal information, the associated metadata, and the relationships between all that data, as well as services that operate on them. It aggregates information from a variety of sources, such as email and groupware servers, web and grid services, or local applications that feed into it, caches that information, and provides access to it. Akonadi thus serves as another pillar of the KDE 4 desktop but, as we shall see, aims to go beyond that.
In the following sections, we will explore the history of this large and powerful framework, the social, technical, and organizational struggles that were and are involved in making it happen, and the vision the authors have for its future. On the way, we will provide some detail on the technical solutions that were found and the reasons why they were chosen.
Background
From the earliest conversations of the initial group of KDE developers about which applications would need to be included in order for a desktop offering to be considered complete by users, email handling, calendering, task list management, and an address book were always considered obvious and important user needs. Consequently, KMail, KAddressbook, and KOrganizer (applications to handle email, contacts, and events and tasks, respectively) were among the first projects to be taken on, and the first usable versions emerged quite quickly. User needs were comparatively simple then, and the standard modes of receiving email were through local mail spools or from POP-3 servers. Mail volume was low, and mail folders were generally stored in the mbox format (one continuous plain text file per folder). HTML content in emails was overwhelmingly frowned upon by the user community that KDE was targeting, multimedia content of any kind was very rare, and encryption and digital signatures were equally exotic. Along similar lines, the custom formats used for address and calendaring data were text-based, and the overall volume of the information to be stored was easily manageable. It was thus relatively straightforward to write basic applications that were already powerful enough to be quickly adopted by other KDE developers and, after the first releases of KDE, also by the user community.
The early and continuous success of the personal information management (PIM) applications would prove to be a double-edged sword in the years to follow. As the Internet and computer use in general skyrocketed, the PIM problem space started to become a lot more complex. New forms of access to email, such as IMAP, and storage of email, such as the maildir format, had to be integrated. Workgroups were starting to share calendars and address books via so-called groupware servers, or store them locally in new standard formats such as vcal/ical or vcard. Company and university directories hosted on LDAP servers grew to tens of thousands of entries. Yet users still expected to use the KDE applications they had come to appreciate under those changed circumstances and get access to new features quickly. As a result, and given the fact that only a few people were actively contributing to the PIM applications, their architectural foundations could not be rethought and regularly cleaned up and updated as new features added, and the overall complexity of the code increased. Fundamental assumptions—that access to the email storage layer would be synchronous and never concurrent, that reading the whole address book into memory would be reasonably possible, that the user would not go back and forth between timezones—had to be upheld and worked around at times, because the cost of changing them would have been prohibitive given the tight time and resource constraints. This is especially true for the email application, KMail, whose codebase subsequently evolved into something rather unpleasant, hard-to-understand, hard-to-extend and maintain, large, and ever more featureful. Additionally, it was a stylistically diverse collection of work by a series of authors, none of whom dared to change things too much internally, for fear of bringing the wrath of their fellow developers upon them should they break their ability to read and write email.
As PIM applications became more and more widely and diversely used, working on these applications became something that was mainly continued by those who had been involved with it for a while out of a sense of dedication and loyalty, rather than an attractor for new contributors. Simply put, there were other places in KDE and Free Software where those wishing to enter the community could do so with a more shallow learning curve and with less likelihood of bloodying their nose by, for example, inadvertently breaking some enterprise encryption feature they would have no way of testing themselves, even if they knew about it. In addition to (and maybe at least partially because of) the technical unattractiveness, the social atmosphere (especially around KMail) was seen as unsavory. Discussions were often conducted rudely, ad hominem attacks were not infrequent, and those who attempted to join the team seldom felt welcome. Individuals worked on the various applications mostly in isolation. In the case of KMail there was even a rather unpleasant dispute over maintainership. All of this was highly unusual within the KDE community, and the internal reputation of this group was thus less than stellar.
As the need for more integration between the individual applications grew, though, and as users were increasingly expecting to be able to use the email and calendaring components from a common shell application, the individuals working on these components had to make some changes. They had to start interacting more, agree on interfaces, communicate their plans and schedules, and think about aspects such as branding of their offerings under the umbrella of the Kontact groupware suite and consistent naming in their areas of responsibility. At the same time, because of commercial interest in the KDEPIM applications and Kontact, outside stakeholders were pushing for a more holistic approach and for the KDEPIM community to speak with one voice, so they could interact with it reliably and professionally. These developments catalyzed a process that would lead the PIM group toward becoming one of the tightest knit, friendliest, and most productive teams within KDE. Their regular meetings have become a model for other groups, and many contributors have become friends and colleagues. Personal differences and past grudges were put aside, and the attitude toward newcomers drastically changed. Today most communication and development talk happens on a combined mailing list ([email protected]), the developers use a common IRC channel (#kontact), and when asked what they are working on will answer “KDEPIM,” not “KMail” or “KAddressBook.”
Personal information management is pivotal in an enterprise context. Widespread adoption of the KDE applications in large organizations has led to a steady demand for professional services, code fixes, extensions, packaging (as part of distributions and specifically for individual use cases and deployments), and the like, which in turn has resulted in an ecosystem of companies offering these services. They have quite naturally hired those people most qualified to do such work—namely the KDEPIM developers. For this reason, the majority of the active code contributors in KDEPIM are now doing it as part of their day jobs. And among those who are not directly paid for their KDE work, there are many who work as C++ and Qt developers full-time. There are still volunteers, especially among the newer contributors, but the core group consists of professionals.[62]
Because of the universal importance of PIM infrastructure for most computer users, be it in a personal or business context, the guiding principle of the technical decision-making process in KDEPIM has become practicability. If an idea cannot be made to work reliably and in a reasonable timeframe, it is dropped. Changes are always scrutinized for their potential impact on the core functionality, which must be maintained in a working state at all times. There is very little room for experimentation or risky decisions. In this, the project is very similar to most commercial and proprietary product teams and somewhat dissimilar from other parts of KDE and Free Software in general. As noted in the introduction, this is not always purely positive, as it has the potential to stifle innovation and creativity.
The Evolution of Akonadi
The KDEPIM community meets quite regularly in person, at conferences and other larger developer gatherings, as well as for small hacking sprints where groups of 5 to 10 developers get together to focus on a particular issue for a few days of intensive discussion and programming. These meetings provide an excellent opportunity to discuss any major issues that are on people’s minds in person, to make big decisions, and to agree on roadmaps and priorities. It is during such meetings that the architecture of a big concerted effort such as Akonadi first emerges and later solidifies. The remainder of this section will trace some of the important decision points of this project, starting from the meeting that brought the fundamental ideas forward for the first time.
When the group met for its traditional winter meeting in January 2005, parts of the underlying infrastructure of KDEPIM were already showing signs of strain. The abstraction used to support multiple backend implementations for contact and calendaring information, KResources, and the storage layer of the email application KMail were built around a few basic assumptions that were starting to no longer hold. Specifically, it was assumed that:
There would be only a very limited number of applications interested in loading the address book or the calendar: namely the primary applications serving that purpose, KAddressbook and KOrganizer. Similarly, there was the assumption that only KMail would need to access the email message store. Consequently there was no, or very limited, support for change notification or concurrent access, and thus no proper locking.
There would be only a very limited amount of data. After all, how many contacts would users typically have to manage, and how many appointments or tasks? The assumption was that this would be in the order of magnitude of “a few hundred.”
That access would be required only by C++ and Qt libraries and KDE applications.
That the various backend implementations would work “online,” accessing the data stored on a server without duplicating a lot of that data locally.
That read and write access to the data would be synchronous and fast enough not to block the caller for a noticeable length of time in the user interface.
There was little disagreement among those present at the 2005 meeting that the requirements imposed by real-world usage scenarios of the current user base, and even more so the probable requirements of future use cases, could not be met by the current design of the three major subsystems. The ever-increasing amounts of data, the need for concurrent access of multiple clients, and more complicated error scenarios leading to a more pressing need for robust, reliable, transactional storage layers cleanly separated from the user interface were clearly apparent. The use of the KDEPIM libraries on mobile devices, transferring data over low-bandwidth, high-latency, and often unreliable links, and the ability to access the user’s data not just from within the applications traditionally dealing with such data, but pervasively throughout the desktop were identified as desirable. This would include the need to provide access via other mechanisms than C++ and Qt, such as scripting languages, interprocess communication, and possibly using web and grid service technologies.
Although those high-level issues and goals were largely undisputed, the pain of the individual teams was much more concrete and had a different intensity for everyone, which led to disagreement about how to solve the immediate challenges. One such issue was the fact that in order to retrieve information about a contact in the address book, the whole address book needed to be loaded into memory, which could be slow and take up a lot of memory if the address book is big and contains many photos and other attachments. Since access was by way of a library, with a singleton address book instance per initialization of the library and thus per process, a normal KDE desktop running the email, address book, and calendaring applications along with helpers such as the appointment reminder daemon could easily have the address book in memory four or more times.
To remedy the immediate problem of multiple in-memory instances of the address book, the maintainer of that application proposed a client/server-based approach. In a nutshell, there would be only one process holding the actual data in memory. After loading it from disk once, all access to the data would be via IPC mechanisms, notably DCOP, KDE’s remote procedure call infrastructure at the time. This would also isolate the communication with contact data backends (such as groupware servers) in one place, another concern with the old architecture. Lengthy discussion revealed, though, that while the memory footprint issue might be solved by this approach, several major problems would remain. Most notably, locking, conflict resolution, and change notification would still need to be implemented on top of the server somehow. It was also felt that the heavily polymorphic (thus pointer-based) APIs in use for calendaring in particular would make it very hard to serialize the data, which would be needed for the transfer over DCOP. Transferring the data through an IPC interface all the time might also end up being slow, and this was raised as a concern as well, especially if the server was also going to be used for access to email, which had been suggested as an option.
The conclusion of the meeting was that the memory footprint problem might be better solved through a more clever sharing mechanism for both the on-disk cache and the in-memory representation, possibly through the use of memory mapped files. The complexity of changing to a client/server-based architecture was deemed too challenging, and it was felt that the benefits that would come from it were not enough to justify the risk of breaking an essentially working (albeit not satisfactorily) system. As a possible alternative, the Evolution Data Server (EDS) as used by the Evolution team, a competing PIM suite associated with the GNOME project and written in C using the glib and GTK library stack, was agreed to be worth investigating.
The proponents of the data server idea left the meeting somewhat disappointed, and in the following months not much progress was made one way or the other. A short foray into EDS’s codebase with the aim of adding support for the libraries used by KDE for the address book ended quickly and abruptly when those involved realized that bridging the C and C++ worlds, and especially mindsets and API styles, to arrive at a working solution would be inelegant at best and unreliable and incomplete at worst. EDS’s use of CORBA, a technology initially adopted by KDE and then replaced with DCOP for a variety of reasons, was not very appealing either. It should be noted, in all fairness, that the rejection of EDS as the basis for KDE’s new PIM data infrastructure was based on technical judgement as well as personal bias against C, a dislike of the implementation and its perceived maintainability, along with a certain amount of “not invented here” syndrome.
Toward the end of 2005, the problems discussed at the beginning of the year had only become more pressing. Email was not easily accessibly to applications such as desktop search agents or to semantic tagging and linking frameworks. The mail handling application, including its user interface, had to be started in order to access an attachment in a message found in a search index and to open it for editing. These and similar usability and performance issues were adding to the unhappiness with the existing infrastructure.
At a conference in Bangalore, India, where a significant part of the team of developers working on Evolution was located at the time, we had the opportunity to discuss some of these issues with them and ask them about their experiences with EDS. In these meetings it became quickly apparent that they were facing many of the same issues the KDEPIM team had identified, that they were considering similar solutions, and that they did not feel that extending EDS to support mail or porting it away from CORBA were feasible options. The general message from the Evolution team was that if the KDEPIM developers were to build a new infrastructure for PIM data access, they would be interested in sharing it at least in concept, and possibly also in implementation, provided that it wasn’t available solely as a C++ and KDE library.
The possibility to share such a crucial piece of infrastructure across the whole Free desktop in the future, plus the fact that if done right this would be useful to and appreciated by the wider development community beyond KDEPIM, gave new weight to the idea of a client/server design. It would provide an integration point in the form of a protocol or IPC mechanism rather than a library that would need to be linked against, thus opening the door to other toolkits, languages, and paradigms. This scenario of a shared PIM server between KDE and GNOME also seemed more and more realistic in light of the emergence of the DBUS stack as a cross-desktop and cross-platform IPC and desktop bus system, which was at the time actively being adopted by both desktop projects and shared via the Freedesktop.org coordination site.
In an additional interesting instance of cross-project pollination, some developers from the PostgreSQL database project were also present at the conference that year and happened to participate in some of the discussions around this topic. They were interested in it from the perspective of the efficient management of, access to, and ability to query into a large amount of data with a lot of structure, such as the user’s email, events, and contacts. They felt that their expertise and the software they were building could become an important part of such a system. They brought up many interesting aspects related to handling searches efficiently and designing the system with type extensibility in mind, but also related to more operational concerns, such as how to back up such a system and how to ensure its data integrity and robustness.
A few months later, at the annual meeting in Osnabrueck, Germany, the concept of a PIM data server was brought forward again, this time with some additional backing by those working on email. This group had been among those who were more skeptical of the idea the year before and most conscious of the possible performance impact and added complexity.[63] The added perspective beyond the KDE project, the fact that the alternative solutions suggested the year before had not been realised or even tried, and the ever-increasing pressure on the team to address the skeletons in their closet eventually prompted the opponents to rethink their position and seriously consider this disruptive change.
This was helped considerably by a nontechnical aspect that had crystallized through many conversations among the developers over the course of the previous year. It had become clear to the group that their biggest problem was the lack of new developers coming into the project, and that that was largely due to the unwieldy and not-very-pleasant-to-work-on libraries and applications that made up the project. There was quite some fear that the current developers would not be able to contribute forever, and that they would not be able to pass on what they had learned to the next generation and keep the project alive. The solution, it was felt, was to focus as much attention and energy as possible on encoding the combined experience and knowledge of those currently working on KDEPIM into something that would be the basis for the next generation of contributors and upon which others in the KDE project and beyond could build better PIM tools. The goal would be to produce something in the process that would be fun to work on, better documented, less arcane, and more modern. It was hoped that this would attract new contributors and allow creative work in the PIM space again by limiting the unpleasantness and complexity involved to those who wished to make use of the infrastructure form. The client/server approach seemed to facilitate this.
It should be noted that this fundamental decision to rework the whole data storage infrastructure for KDEPIM in a very disruptive way essentially entailed completely rewriting large parts of the system. We quite consciously accepted the fact that this would mean a lot less resources would be available to focus on maintaining the current codebase, keeping it stable and working, and also making it available as part of the KDE 4.0 release somehow, since that would almost certainly happen before such a major refactoring could possibly be finished. As it would turn out, this meant that KDE 4.0 was in fact released without KDEPIM, a somewhat harsh but probably necessary sacrifice in retrospect.
Once the group had agreed on the general direction, they produced the following mission statement:
We intend to design an extensible cross-desktop storage service for PIM data and meta data providing concurrent read, write, and query access. It will provide unique desktop-wide object identification and retrieval.
The Akonadi Architecture
Some key aspects that would remain in the later iterations of the architecture were already present in the first draft of the design produced in the meeting. Chief among those was the decision to not use DBUS, the obvious choice for the IPC mechanism in Akonadi, for the transport of the actual payload data. Instead, a separate transport channel and protocol would be used to handle bulk transfers, namely IMAP. Some reasons for this were that it could control traffic out of band with respect to the data, thus allowing lengthy data transfers to be canceled, for example, since the data pipe would never block the control pipe. Data transfers would have a lot less overhead with IMAP compared to pushing them through an IPC mechanism, since the protocol is designed for fast, streaming delivery of large amounts of data. This was a reaction to concerns about the performance characteristics of DBUS in particular, which explicitly mentioned in its documentation that it was not designed for such usage patterns. It would allow existing IMAP library code to be reused, saving effort when implementing the protocol, both for the KDEPIM team itself and for any future third-party adopters wishing to integrate with Akonadi. It would retain the ability to access the contents of the mail store with generic, non-Akonadi-specific tools, such as the command-line email applications, pine or mutt. This would counter the subjective fear users have of entrusting their data to a system that would lock them in by preventing access to their data by other means. Since IMAP only knows about email, the protocol would need to be extended to support other mime types, but that seemed doable while retaining basic protocol compatibility. An alternative protocol option that was discussed was to use http/webdav for the transport, possibly reusing an existing http server implementation such as Apache, but this approach did not get much support.
A central notion in Akonadi is that it constitutes the one central cache of all PIM data on the system and the associated metadata. Whereas the old framework assumed online access to the storage backends to be the normal case, Akonadi embraces the local copy that has to be made as soon as the data needs to be displayed to the user, for example, and tries to retain as much of the information it has already retrieved as possible, in order to avoid unnecessary redownloads. Applications are expected to retrieve only those things into memory that are actually needed for display (in the case of an email application, the header information of those few email messages that are currently visible in the currently shown folder, for example) and to not keep any on disk caches of their own. This allows the caches to be shared, keeps them consistent, reduces the memory footprint of the applications, and allows data not immediately visible to the user to be lazy-loaded, among other optimizations. Since the cache is always present, albeit potentially incomplete, offline usage is possible, at least in many cases. This greatly increases the robustness against problems with unreliable, low-bandwidth, and high-latency links.
To allow concurrent access that does not block, the server is designed to keep an execution context (thread) for each connection, and all layers take a potentially large number of concurring contexts into account. This implies transactional semantics of the operations on the state, proper locking, the ability to detect interleavings of operations that would lead to inconsistent state, and much more. It also puts a key constraint on the choice of technology for managing the on-disk persistence of the contents of the system, namely that it supports heavily concurrent access for both reads and writes. Since state might be changed at any time by other ongoing sessions (connections), the notification mechanism that informs all connected endpoints of such changes needs to be reliable, complete, and fast. This is yet another reason to separate the low-latency, low-bandwidth, but high-relevance control information from the higher-bandwidth, higher-latency (due to potential server roundtrips), and less time-critical bulk data transfer in order to prevent notifications from being stuck behind a large email attachment being pushed to the application, for example. This becomes a lot more relevant if the application is concurrently able to process out-of-band notifications while doing data transfer at the same time. Although this might not be the case for the majority of applications that currently exist for potential users of Akonadi, it can be reasonably assumed that future applications will be a lot more concurrency-aware, not least because of the availability of tools such as ThreadWeaver, which is discussed in the next section of this chapter. The high-level convenience classes that are part of the KDE-specific Akonadi access library already make use of this facility.
Another fundamental aspect of Akonadi already present in this first iteration of the design is the fact that the components providing access to a certain kind of storage backend, such as a groupware server, run as separate processes. This has several benefits. The potentially error-prone, slow, or unreliable communication with the server cannot jeopardize the stability of the overall system. Agents[64] can crash without taking down the whole server. If synchronous interaction with the server is more convenient or maybe even the only possible way to get data from the other end, it can block without blocking any other interaction with Akonadi. They can link against third-party libraries without imposing dependencies on the core system, and they can be separately licensed, which is important for those cases where access libraries do not exist as Free Software. They are also isolated from the address space of the Akonadi server proper and thus less of a potential security problem. They can more easily be written by third parties and deployed and tested easily against a running system, using whatever programming language seems suitable, as long as support for DBUS and IMAP is available. The downside, of course, is the impact of having to serialize the data on the way into the Akonadi store, which is crossing process boundaries. This is less of a concern in practice, though, for two reasons. First, it happens in the background, from the user’s perspective, without interrupting anything at the UI level. Second, the data will either be already available locally, in the cache, when the user asks for it, or it will be coming from a network socket that can pass the data onto the Akonadi server socket unparsed, in many cases, and potentially even without copying it. The case where the user asks to see data is one of the few that need to be as fast as possible, to avoid noticeable waiting times. In most cases the interaction between agents and the store is not performance-critical.
From a concurrency point of view, Akonadi has two layers. At the multiprocessing level, each user of Akonadi, generally an application or agent, has a separate address space and resource acquisition context (files, network sockets, etc.). Each of these processes can open one or more connections to the server, and each is represented internally by a thread. The trade-off between the benefits of using threads versus processes is thus side-stepped by using both: processes where the robustness, resource, and security isolation is important, and threads where the shared address space is needed for performance reasons and where the code is controlled by the Akonadi server implementation itself (and thus assumed to be less likely to cause stability problems).
The ability to add support for new types of data to the system with reasonable effort was among one of the first desired properties identified. Ideally, the data management layer should be completely type agnostic, and knowledge about the contents and makeup of the data should be centralized in one place for each kind of data (emails, events, and contacts initially, but later notes, RSS feeds, IM conversations, bookmarks, and possibly many more). Although the desire to achieve this was clear from the start, how to get there was not. Several iterations of the design of the core system itself and the access library API were needed until the goal was reached. We describe the end result a bit further on in this section.
During the initial architecture discussions, the group approached the big picture in a pretty traditional way, separating concerns as layers from the bottom up. As the diagram of the white board drawing from that discussion in Figure 12-1 shows, there would be a storage (persistence) layer at the bottom, with logic to access it on top, a transport and access protocol layer above that, on up to application space.
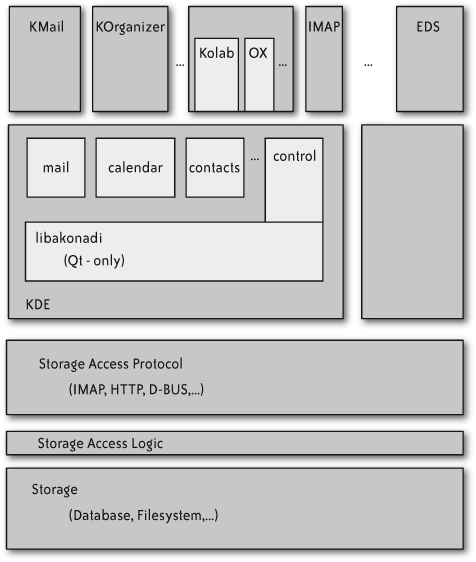
While debating what the API for the applications’ access to the store would look like (as opposed to that used by agent or resources delivering into the system), some were suspicious that there would need to be only one access API, used by all entities interacting with the store, whether their primary focus was providing data or working with the data from a user’s point of view. It quickly emerged that that option is indeed preferable, as it makes things simpler and more symmetric. Any operation by an agent on the data triggers notifications of the changes, which are picked up by all other agents monitoring that part of the system. Whatever the resources need in addition to the needs of the applications—for example, the ability to deliver a lot of data into the store without generating a storm of notifications—is generic enough and useful enough to be worthwhile in one unified API. Keeping the API simple for both application access and resource needs is required anyhow, in order to make it realistically possible for third parties to provide additional groupware server backends and to get application developers to embrace Akonadi. Any necessary special cases for performance or error recovery reasons should be handled under the hood as much as possible. The example of avoiding notification storms is taken care of by a configurable notification compression and update monitoring system, which users of the system can subscribe to with some granularity.
The next version of the high-level architecture diagram that was drawn, shown in Figure 12-2, thus reflects this notion by portraying the layers of the system as concentric rings or parts of rings.

Given the requirements outlined so far, it was fairly obvious that a relational database would make implementation of the lowest (or innermost) layer much easier. At least for the metadata around the actual PIM items, such as retrieval time, local tags, and per folder policies, just to name a few, which are typed, structured, and benefit from fast, indexed random access and efficient querying, no other solution was seriously considered. For the payload data itself, the email messages, contacts, and so on, and their on-disk storage, the decision was less clear cut. Since the store is supposed to be type-independent, a database table holding the data would not be able to make any assumptions about the structure of the data, thus basically forcing it to be stored as BLOB fields. When dealing with unstructured (from the point of view of the database) data, only some of the benefits of using a database can be leveraged. Efficient indexing is basically impossible, as that would require the contents of the data fields to be parsed. Consequently querying into such fields would not perform well. The expected access patterns also do not favor a database; a mechanism that handles continuous streaming of data with a lot of locality of reference might well be preferable. Not using a database for the data items would mean that transactional semantics on the operations on the store would have to be implemented manually. A proposed solution for this was the extension of the principles employed by the maildir standard, which essentially allows lock-free ACID access by relying on atomic rename operations on the filesystem.[65] For the first pass implementation, it was decided that the database would store both data and metadata, with the intent of optimizing this at a later point, when the requirements of searching in particular would be more well defined.
Given that the Akonadi store serves as the authoritative cache for the user’s personal information, it can effectively offer and enforce advanced cache lifetime management. Through the concept of cache policies, very fine-grained control over which items are retained and for how long can be exposed to users to allow a wide variety of usage patterns. On one end of the spectrum—for example, on an embedded device with a bad link and very limited storage—it might make sense to develop a policy to never store anything but header information, which is pretty lightweight, and only download a full item when it needs to be displayed, but to keep already downloaded items in RAM until the connection is severed or power to the memory is shut down. A laptop, which often has no or only unreliable connectivity but a lot more disk space available, might proactively cache as much as possible on disk to enable working offline productively and only purge some folders at regular intervals of days, weeks, or even months. On the other hand, on a desktop workstation, with an always-on, broadband Internet connection or local area network access to the groupware server, fast online access to the data on the server can be assumed. This means that unless the user wants to keep a local copy for reasons of backup or to save network bandwidth, the caching can be more passive, perhaps only retaining already downloaded attachments for local indexing and referencing. These cache policies can be set on a per-folder, per-account, or backend basis and are enforced by a component running in its own thread in the server with lower priority, regularly inspecting the database for data that can be purged according to all policies applicable to it.
Among the major missing puzzle pieces that were identified in the architecture at the 2007 meeting was how to approach searching and semantic linking. The KDE 4 platform was gaining powerful solutions for pervasive indexing, rich metadata handling, and semantic webs with the Strigi and Nepomuk projects, which could yield very interesting possibilities when integrated with Akonadi. It was unclear whether a component feeding data into Strigi for full indexing could be implemented as an agent, a separate process operating on the notifications from the core, or would need to be integrated into the server application itself for performance reasons. Since at least the full text index information would be stored outside of Akonadi, a related question was how search queries would be split up, how and where results from Strigi and Akonadi itself would be aggregated, and how queries could be passed through to backend server systems capable of online searching, such as an LDAP server. Similarly, the strategy for how to divide responsibilities with Nepomuk—for example, whether tagging should be entirely delegated to it—was to be discussed. To some extent, these discussions are still going on, as the technologies involved are evolving along with Akonadi, and the current approaches have yet to be validated in production use. At the time of this writing, there are agents feeding into Nepomuk and Strigi; these are separate processes that use the same API to the store as all other clients and resources. Incoming search queries are expressed in either XESAM or SPARQL, the respective query languages of Strigi and Nepomuk, which are also implemented by other search engines (such as Beagle, for example) and forwarded to them via DBUS. This forwarding happens inside the Akonadi server process. The results come in via DBUS in the form of lists of identifiers, which Akonadi can then use to present the results as actual items from the store to the user. The store does not do any searching or content indexing itself at the moment.
The API for the KDE-specific C++ access library took a while to mature, mostly because it was not
clear from the start how type-independent the server would end up
being and how much type information would be exposed in the library.
By April 2007, it was clear that the way to extend the access
library to support new types would be to provide so-called
serializer plug-ins. These are runtime-loadable libraries capable of
converting data in a certain format, identified by a mime type, into
a binary representation for storage as a blob in the server and
conversely, capable of restoring the in-memory representation from
the serialized data. This is orthogonal to adding support for a new
storage backend, for example, and the data formats used by it, which
happens by implementing a new resource process (an agent). The
responsibility of the resource lies in converting what the server
sends down the wire into a typed, in-memory representation that it
knows how to deal with, and then using a serializer plug-in to
convert it into a binary datastream that can be pushed into the
Akonadi store and converted back on retrieval by the access library.
The plug-in can also split the data into multiple parts to allow
partial access (to only the message body or only the attachments,
for example). The central class of that library is called
Akonadi::Item and represents a single item in the
store. It has a unique ID, which allows it to be identified globally
on the user’s desktop and associated with other entities as part of
semantic linking (for example, a remote identifier). This maps it to
a source storage location, attributes, a data payload, and some
other useful infrastructure, such as flags or a revision counter.
Attributes and payload are strongly typed, and the methods to set
and get them are templatized. Akonadi::Item
instances themselves are values, and they are easily copiable and
lightweight. Item is parameterized with the type
of the payload and attributes without having to be a template class
itself. The template magic to enable that is somewhat involved, but
the resulting API is very simple to use. The payload is assumed to
be a value type, to avoid unclear ownership semantics. In cases
where the payload needs to be polymorphic and thus a pointer, or
when there is already a pointer-based library to deal with a certain
type of data (as is the case for libkcal, the
library used for events and tasks management in KDE), shared
pointers such as boost::shared_ptr can be used to
provide value semantics. An attempt to set a raw pointer payload is
detected with the help of template specialization and leads to
runtime assertions.
The following example shows how easy it is to add support for
a new type to Akonadi, provided there is already a library to deal
with data in that format, as is frequently the case. It shows the
complete source code of the serializer plug-in for contacts, or
KABC::Addressee objects as the KDE library calls
them:
bool SerializerPluginAddressee::deserialize( Item& item,
const QByteArray& label,
QIODevice& data,
int version )
{
if ( label != Item::FullPayload || version != 1 )
return false;
KABC::Addressee a = m_converter.parseVCard( data.readAll() );
if ( !a.isEmpty() ) {
item.setPayload<KABC::Addressee>( a );
} else {
kWarning() << "Empty addressee object!";
}
return true;
}
void SerializerPluginAddressee::serialize( const Item& item,
const QByteArray& label,
QIODevice& data,
int &version )
{
if ( label != Item::FullPayload
|| !item.hasPayload<KABC::Addressee>() )
return;
const KABC::Addressee a = item.payload<KABC::Addressee>();
data.write( m_converter.createVCard( a ) );
version = 1;
} The typed payload, setPayload, and
hasPayload methods of the Item
class allow developers to use the native types of their data type
libraries directly and easily. Interactions with the store are
generally expressed as jobs, an application of the command pattern.
These jobs track the lifetime of an operation, provide a cancelation
point and access to error contexts, and allow progress to be
tracked. The Monitor class allows a client to
watch for changes to the store in the scope it is interested in,
such as per mime type or per collection, or even only for certain
parts of particular items. The following example from an email
notification applet illustrates these concepts. In this case the
payload type is a polymorphic one, encapsulated in a shared
pointer:
Monitor *monitor = new Monitor( this );
monitor->setMimeTypeMonitored( "message/rfc822" );
monitor->itemFetchScope().fetchPayloadPart( MessagePart::Envelope );
connect( monitor, SIGNAL(itemAdded(Akonadi::Item,Akonadi::Collection)),
SLOT(itemAdded(Akonadi::Item)) );
connect( monitor, SIGNAL(itemChanged(Akonadi::Item,QSet<QByteArray>)),
SLOT(itemChanged(Akonadi::Item)) );
// start an initial message download for the first message to show
ItemFetchJob *fetch = new ItemFetchJob( Collection( myCollection ), this );
fetch->fetchScope().fetchPayloadPart( MessagePart::Envelope );
connect( fetch, SIGNAL(result(KJob*)), SLOT(fetchDone(KJob*)) );
...
typedef boost::shared_ptr<KMime::Message> MessagePtr;
void MyMessageModel::itemAdded(const Akonadi::Item & item)
{
if ( !item.hasPayload<MessagePtr>() )
return;
MessagePtr msg = item.payload<MessagePtr>();
doSomethingWith( msg->subject() );
...
} The First Release and Beyond
When the group congregated in reliably cold and rainy Osnabrueck once more, in January 2008, the first application uses of Akonadi could be presented by their developers, who had been invited to attend. The authors of Mailody, a competitor to the default email application in KDE, had decided some time before that Akonadi could help them build a better application, and they had become the first to try out its facilities and APIs. Their feedback proved very valuable in finding out what was still too complicated, where additional detail was needed, and where concepts were not yet well documented or not well implemented. Another early adopter of Akonadi present at the meeting was Kevin Krammer, who had taken up the interesting task of trying to allow users of the legacy libraries for PIM data in KDE to access Akonadi (as well as the other way around, to access the data stored with the old infrastructure through Akonadi) by providing compatibility agents and resources for both frameworks. The issues he encountered while doing that exposed some holes in the API and validated that at least all of the existing functionality would be possible with the new tools.
A notable outcome of this meeting was the decision to drop backward compatibility with IMAP in the protocol. It had evolved so far away from the original email-only standard that maintaining the ability of the Akonadi server to act as a standard conforming IMAP server for email access was a burden that outweighed the benefits of that feature. The IMAP protocol had served as a great starting point, and many of its concepts remain in the Akonadi access protocol, but it can no longer justifiably be called IMAP. It is possible that this mechanism will return in later versions of the server, probably implemented as a compatibility proxy server.
With the KDE 4.1 release rapidly approaching, the team met again in March 2008 to do a full review of the API before its first public release, which would commit them to keep it stable and binary compatible for the foreseeable future. Over the course of two days, an amazing number of small and large inconsistencies, missing pieces of documentation, implementational quirks, and unhappy namings were identified, and they were rectified in the weeks that followed.
At the time of this writing, the KDE 4.1 release is imminent, and the Akonadi team is excitedly looking forward to the reaction of the many application and library developers in the wider KDE community who comprise its target audience. Interest in writing access resources for various storage backends is increasing, and people have started work on support for Facebook address books, Delicious bookmarks, the MS Exchange email and groupware server via the OpenChange library, RSS blog feeds, and others. It will be fascinating to see what the community will be able to create when data from all of these sources and many others will be available easily, pervasively, and reliably; when it will be efficiently queryable; when it will be possible to annotate the data, link items to each other, and create meaning and context among them; and when they can exploit that richness to make users do more with their software and enjoy using it more.
Two related ideas for optimization remain unimplemented so far. The first is to avoid storing the payload data in blobs in the database by keeping only a filesystem URL in the table and storing the data itself directly on the filesystem, as mentioned earlier. Building on that, it should be possible to avoid copying the data from the filesystem into memory, transferring it through a socket for delivery to the client (which is another process), thus creating a second in-memory copy of it only to release the first copy. This could be achieved by passing a file handle to the application, allowing it to memory map the file itself for access. Whether that can be done without violating the robustness, consistency, security, and API constraints that make the architecture work remains to be seen. An alternative for the first part is to make use of an extension to MySQL for blob streaming, which promises to retain most of the benefits of going through the relation database API while maintaining most of the performance of raw file system access.
Although the server and KDE client libraries will be released for the first time with KDE 4.1, the intent is still to share it with as much of the Free Software world as possible. To this end, a project on Freedesktop.org has been created, and the server will be moved there as soon as that process is finished. The DBUS interfaces have all been named in a desktop-neutral fashion; the only dependency of the server is the Qt library in version 4, which is part of the Linux Standard Base specification and available under the GNU GPL for Linux, Windows, OS X, and embedded systems, including Windows CE. A next major step would be to implement a second access library—in Python, for example, which comes with a lot of infrastructure that should make that possible with reasonable effort, or maybe using Java, where the same is true.
ThreadWeaver
ThreadWeaver is now one of the KDE 4 core libraries. It is discussed here because its genesis contrasts in many ways with that of the Akonadi project, and thus serves as an interesting comparison. ThreadWeaver schedules parallel operations. It was conceived at a time when it was technically pretty much impossible to implement it with the libraries used by KDE, namely Qt. The need for it was seen by a number of developers, but it took until the release of Qt 4 for it to mature and become mainstream. Today, it is used in major applications such as KOffice and KDevelop. It is typically applied in larger-scale, more complex software systems, where the need for concurrency and out-of-band processing becomes more pressing.
ThreadWeaver is a job scheduler for concurrency. Its purpose is to manage and arbitrate resource usage in multi-threaded software systems. Its second goal is to provide application developers with a tool to implement parallelism that is similar in its approach to the way they develop their GUI applications. These goals are high-level, and there are secondary ones at a smaller scale: to avoid brute-force synchronization and offer means for cooperative serialization of access to data; to make use of the features of modern C++ libraries, such as thread-safe, implicit sharing, and signal-slot-connections across threads; to integrate with the application’s graphical user interface by separating the processing elements from the delegates that represent them in the UI; to allow it to dynamically throttle the work queue at runtime to adapt to the current system load; to be simplistic; and many more.
The ThreadWeaver library was developed to satisfy the needs of developers of event-driven GUI programs, but it turned out to be more generic. Because GUI programs are driven by a central event loop, they cannot process time-consuming operations in their main thread. Doing so would freeze the user interface until the operation is finished. In some windowing environments, the user interface can be drawn only from the main thread, or the windowing system itself is single-threaded. So a natural way of implementing responsive cross-platform GUI applications is to perform all processing in worker threads and update the user interface from the main thread when necessary. Surprisingly, the need for concurrency in user interfaces is rarely ever as obvious as it should be, although it has been emphasized for OS/2, Windows NT, and Solaris eons ago. Multithreaded programming is more complicated and requires a better understanding of how the written code actually functions. Multithreadings also seems to be a topic well understood by software architects and designers, and badly disseminated to software maintainers and less-experienced programmers. Also, some developers seem to think that most operations are fast enough to be executed synchronously, even reading from mounted filesystems, which is a couple of orders of magnitude slower than anything processed in the CPU. Such mistakes surface only under extraordinary circumstances, such as when the system is under heavy I/O load or, more commonly, a mounted filesystem has been put to sleep to save power or—heavens!—when, all of a sudden, the filesystem happens to be on the network.
The following section will describe the architecture of the library along with its underlying concepts. At the end of the chapter, we will explore how it found its way into KDE 4.
Introduction to ThreadWeaver: Or, How Complicated Can It Be to Load a File?
To convince programmers to make use of concurrency, it needs to be conveniently available. Here is a typical example for an operation performed in a GUI program—loading a file into a memory buffer to process it and display the results. In an imperative program, where all individual operations are blocking, it is of little complexity:
Check whether the file exists and is readable.
Open the file for reading.
Read the file contents into memory.
Process them.
Display the results.
To be user-friendly, it is sufficient to print a progress message to the command line after every step (if the user requested verbose mode).
In a GUI program, things appear in a different light because during all of these steps, it is necessary to be able to update the screen, and users expect a way to cancel the operation. Although it sounds unbelievable, even recent documentation for GUI toolkits mentions the “check for events occasionally” approach. The idea is to periodically check for events while processing the aforementioned steps in chunks and update or abort if necessary. A lot of care needs to be applied in this situation because the application state can change in unexpected ways. For example, the user might decide to close the program, unaware that the program checks for an event in the midst of a call stack of an operation. To put it shortly, this approach of polling has never worked very well and is generally out of fashion.
A better approach is to use a thread (of course). But without a framework to help, this often leads to weird implementations as well. Since GUI programs are event-based, every step just listed starts with an event, and an event notifies its completion. In the C++ world, signals are often used for the notification. Some programs look like this:
The user requests to load the file, which triggers a handler method by a signal or event.
The operation to open and load the file is started and connected to a second method for notification about its completion.
In this method, processing the data is started, connected to a third method.
The last method finally displays the results.
This cascade of handler methods does not track the state of the operation very well and is usually error-prone. It also shows a lack of separation of operations and the view. Nevertheless, it is found in many GUI applications.
This is exactly where ThreadWeaver is there to help. Using jobs, the implementation will look like this:
The user requests to load the file, which triggers a handler method by a signal or event.
In the handler method, the user creates a sequence of jobs (a sequence is a job container that executes its jobs in the order they were added). He adds a job to load the file and one to process its contents. The sequence object is a job itself and sends a signal when all its contained jobs are completed. Up to this point, no processing has taken place; the programmer only declared what needs to be done in what order. Once the whole sequence is set up, the user queues it into the application-global job queue (a lazy initialized singleton). The sequence is automatically executed by worker threads.
When the
done()signal of the sequence is received, the data is ready to be displayed.
Two aspects are apparent. First, the individual steps are all declared in one go and then executed. This alone is a major relief to GUI programmers because it is a nonexpensive operation and can easily be performed in an event handler. Second, the usual issues of synchronization can largely be avoided by the simple convention that the queuing thread only touches the job data after it has been prepared. Since no worker thread will access the job data anymore, access to the data is serialized, but in a cooperative fashion. If the programmer wants to display progress to the user, the sequence emits signals after the processing of every individual job (signals in Qt can be sent across threads). The GUI remains responsive and is able to dequeue the jobs or request cancellation of processing.
Since it is much easier to implement I/O operations this way, ThreadWeaver was quickly adopted by programmers. It solved a problem in a nice, convenient way.
Core Concepts and Features
In the previous example, job sequences have been mentioned. Let us look at what other constructs are provided in the library.
Sequences are a specialized form of job collections. Job collections are containers that queue a set of jobs in an atomic operation and notify the program about the whole set. Job collections are composites, in the way that they are implemented as job classes themselves. There is only one queuing operation in ThreadWeaver: it takes a Job pointer. Composite jobs help keep the queue API minimal.
Job sequences use dependencies to make sure the contained jobs are executed in the correct order. If a dependency is declared between two jobs, it means that the depending job can be executed only after its dependency has finished processing. Since dependencies can be declared in an m:n fashion, pretty much all imaginable control flows of depending operations (which are all directed graphs, since repetition of jobs is not allowed) can be modeled in the same declarative fashion. As long as the execution graph remains directed, jobs may even queue other jobs while being processed. A typical example is that of rendering a web page, where the anchored elements are discovered only once the text of the HTML document itself is processed. Jobs can then be added to retrieve and prepare all linked elements, and a final job that depends on all these preparatory jobs renders the page for display. Still, no mutex necessary. Dependencies are what distinguish a scheduling system like ThreadWeaver from mere tools for parallel processing. They relieve the programmer of thinking how to best distribute the individual suboperations to threads. Even with modern concepts such as futures, usually the programmer still needs to decide on the order of operations. With ThreadWeaver, the worker threads eagerly execute all possible jobs that have no unresolved dependencies. Since the execution of concurrent flow graphs is inherently undeterministic, it is very unlikely that a manually defined order is flexible enough to be the most efficient. A scheduler can adapt much better here. Computer scientists tend to disagree with this thesis, whereas economists, who are more used to analyzing stochastic systems, often support it.
Priorities can be used to influence the order of execution as well. The priority system used is quite simple: of all integer priorities assigned to jobs in the queue, the highest ones are first handed to an available worker thread. Since the job base class is implemented in a way that allows writing decorators, changing a job’s priority externally can be done by writing a decorator that bumps the priority without touching the job’s implementation. The combination of priorities and dependencies can lead to interesting results, as will be shown later.
Instead of relying on direct implementations of queueing behavior, ThreadWeaver uses queue policies. Queue policies do not immediately affect when and how a particular job is executed. Instead, they influence the order in which jobs are taken from the queue by the worker threads. Two standard implementations come with ThreadWeaver. One is the dependencies discussed earlier. The other is resource restrictions. Using resource restrictions, it can be declared that of a certain subset of all created jobs (for example, local filesystem I/O-expensive ones), only a certain amount can be executed at the same time. Without such a tool, it regularly happens that some subsystems get overloaded. Resource restrictions act much like semaphores in traditional threading, except that they do not block a calling thread, and instead simply mark a job as not yet executable. The thread that checked whether the job can be executed is then able to try to get another job to execute.
Queue policies are assigned to jobs, and the same policy object can be assigned to many. As such, they are composed, and every job can be managed by any combination of the available policies. Inheriting specialized policy-driven job base classes would not have provided such flexibility. Also, this way, job objects that do not need any extra policies are in no way affected by a possible performance hit of evaluating the policies.
Declarative Concurrency: A Thumbnail Viewer Example
Another example explains how these different ThreadWeaver concepts play together. It uses jobs, job composites, resource restrictions, priorities, and dependencies, all to render wee little thumbnail images in a GUI program. Let us first look at what operations are required to implement this function, how they depend, and how the user expects to be presented with the results. The example is part of the ThreadWeaver source code.
In this example, it is assumed that loading the thumbnail preview for a digital photo involves three operations: to load the raw file data from disk, to convert the raw data into an image representation without changing its size, and then to scale to the required size of the thumbnail. It is possible to argue that the second and third steps could be merged into one, but that is (a) not the point of the exercise (just like streamed loading of the image data) and (b) would impose the restriction that only image formats can be used where the drivers support scaling during load. It is also assumed that the files are present on the hard disk. Since the processing of each file does not influence or depend on the processing of any other, all files can be processed in parallel. The individual three steps to process one file need to be performed in sequence.
But that is not all. Since this is an example with a graphical user interface, the expectations of the user have to be kept in mind. It is assumed that the user is interested in visual feedback, which also gives him the impression of progress. Image previews should be shown as soon as they are available, and progress information in the form of a reliable progress bar would be nice. The user also expects that the program will not grind his computer to a halt, for example by excessive I/O operations.
Different ThreadWeaver tools can be applied to this problem. First of all, processing an individual file is a sequence of three job implementations. The jobs are quite generic and can be part of a toolbox of premade job classes available to the application. The jobs are (the class names match the ones in the example source code):
A
FileLoaderJob, which loads a file on the file system into an in memory byte arrayA
QImageLoaderJobto convert the image’s raw data into the typical representation of an in-memory image in Qt applications (providing the application access to all available image decoders in the framework or registered by the application)A
ComputeThumbNailJob, which simply scales the image to the wanted size of the preview
All of those are added to a JobSequence,
and each of these sequences is added to a
JobCollection. The composite implementation of
the collection classes allow for implementations that represent the
original problem very closely and therefore feel somewhat natural
and canonical to the programmer.
This solves part one of the problem, the parallel processing of the different images. It could easily lead to other problems, though. With the given declaration of the problem to the ThreadWeaver queue, there is nothing that prevents it from loading all files at once and only then starting to process images. Although this is unlikely, we haven’t told the system otherwise yet. To make sure that only so many file loaders are started at the same time, a resource restriction is used. The code for it looks like this:
#include "ResourceRestrictionPolicy.h"
...
static QueuePolicy* resourceRestriction()
{
static ResourceRestrictionPolicy policy( 4 );
return &policy;
}File loaders simply apply the policy in their constructor or, if generic classes are used, when they are created:
fileloader->assignQueuePolicy( resourceRestriction() );
But that still does not completely arrange the order of the execution of the jobs exactly as wanted. The queue might now start only four file loaders at once, but it still might load all the files and then calculate the previews (again, this is a very unlikely behavior). It needs one more tool, and a bit of thinking against the grain, to solve the problem, and this is where priorities come into play. The problem, translated into ThreadWeaver lingo, is that file loader jobs have lowest priority but need to be executed first; image loader jobs have precedence over file loaders, but a file loader must have finished first before an image loader can be started; and finally, thumbnail computer jobs have highest priority, even if they depend on the other two phases of processing. Since the three jobs are already in a sequence, which will make sure they are executed in the right order for every image, assigning priority one to file loaders, two to image loaders, and three to thumbnail computers finally solves the problem. Basically, the queue will now complete one thumbnail as soon as possible, but will not stop to load the images if slots for file loading become available. Since the problem is mostly I/O bound, this means that the total time until the thumbnails for all images are shown is a little more than the time it takes to load them from the hard disk (other factors aside, such as extremely high-resolution RAW images). In any sequential solution, the behavior would likely be much worse.
The description of the solution might have felt complex, so lightening it up with a bit of code is probably in order. This is how the jobs are generated after the user has selected a couple of hundred images for processing:
m_weaver->suspend();
for (int index = 0; index < files.size(); ++index)
{
SMIVItem *item = new SMIVItem ( m_weaver, files.at(index ), this );
connect ( item, SIGNAL( thumbReady(SMIVItem* ) ),
SLOT ( slotThumbReady( SMIVItem* ) ) );
}
m_startTime.start();
m_weaver->resume();To give correct progress feedback, processing is suspended before the jobs are added. Whenever a sequence is completed, the item object emits a signal to update the view. For every selected file, a specialized item is created, which in turn creates the job objects for processing one file:
m_fileloader = new FileLoaderJob ( fi.absoluteFilePath(), this ); m_fileloader->assignQueuePolicy( resourceRestriction() ); m_imageloader = new QImageLoaderJob ( m_fileloader, this ); m_thumb = new ComputeThumbNailJob ( m_imageloader, this ); m_sequence->addJob ( m_fileloader ); m_sequence->addJob ( m_imageloader ); m_sequence->addJob ( m_thumb ); weaver->enqueue ( m_sequence );
The priorities are virtual properties of the job objects and are set there. It is important to keep in mind that all these objects are set to not process until they are queued, and in this case, until the processing is explicitly resumed. So the whole operation to create all these sequences and jobs really takes only a very short time, and the program returns to the user immediately, for all practical matters. The view updates as soon as a preview image is available.
From Concurrency to Scheduling: How to Implement Expected Behavior Systematically
The previous examples have shown how analyzing the problem completely really helps to solve it (I hope this does not come as a surprise). To make sure concurrency is used to write better programs, it is not enough to provide a tool to move stuff to threads. The difference is scheduling: to be able to tell the program what operations have to be performed and in what order. The approach is remotely reminiscent of PROLOG programming lessons, and sometimes requires a similar way of thinking. Once the minds involved are sufficiently assimilated, the results can be very rewarding.
One design decision of the central Weaver
class has not been discussed yet. There are two very disjunct groups
of users of the Weaver classes API. The internal
Thread objects access it to retrieve their jobs
to process, whereas programmers use it to manage their parallel
operations. To make sure the public API is minimal, a combination of
decorator and facade has been applied that limits the publicly
exposed API to the functions that are intended to be used by
application programmers. Further decoupling of the internal
implementation and the API has been achieved by using the PIMPL
idiom, which is generally applied to all KDE APIs.
A Crazy Idea
It has been mentioned earlier that at the time ThreadWeaver started to be developed, it was not really possible to implement all its ideas. One major obstacle was, in fact, a prohibitive one: the use of advanced implicit sharing features, which included reference counting, in the Qt library. Since this implicit sharing was not thread-safe, the passing of every simple Plain Old Data object (POD) was a synchronization point. The author assumed this to be impractical for users and therefore recommended against using the prototype developed with Qt 3 for any production environments. The developers of the KDEPIM suite (the same people who now develop Akonadi) thought they really knew better and immediately imported a preliminary ThreadWeaver version into KMail, where it is used to this day. Having run into many of the problems ThreadWeaver promised to solve, the KMail developers eagerly embraced it, willing to live with the shortcomings pointed out by its author, even against his express wishes.
The fact that an imperfect version of the library was in active use in KDE served as a motivating factor for quickly porting it to Qt4 when that became usable in beta versions. Thus it was available rather early in the KDE 4 development cycle, if only in a secondary module and not yet as part of KDELibs. Over the course of two years, the author gave a number of presentations on the library, presenting an ever-easier and more complete API as he kept improving it. It was, one could say, a solution looking for a problem. The majority of developers working on KDE needed time to realize that this library was not only academic, but could improve their software significantly given that they make the investment in taking a step back and rethinking some of their architectural structures. There was no concrete need by a group of developers driving the library’s progress; it was progressed by an individual because of his belief in the growing relevance of the problem and the importance of making available a good solution for the KDE 4 platform. Especially following the 2005 Akademy conference in Malaga, Spain, more programs started to use ThreadWeaver, including KOffice and KDevelop, which created enough momentum for it to be integrated into the main KDE 4 set of libraries.
ThreadWeaver represents the case of an alternative solution to a problem that once it had matured to critical point and once the author and the prospective user community agreed that the time had come for it to be adopted by developers in their projects, it was quickly promoted to a cornerstone of KDE 4. After that, the attitudes of community members changed from mild amusement to appreciation and recognition of the effort that had gone into it. This is an example of how efficient this community can be at making technical decisions and adapting its stance when an approach proves itself in practice. There can be no doubt that ThreadWeaver is a much better library now than it would have been if it not taken three to four years of rubbing up against the KDE project until its inclusion. And this includes the rogue premature adoption by the KMail developers. There is also little doubt that applications written for KDE 4 can deal with concurrency a lot better and thus provide a better experience to their users, because it succeeded in the end.
ThreadWeaver will be extended mostly by adding GUI components to visually represent queue activity, and by including more predefined job classes. Another idea is the integration with operating system IPC mechanisms (to allow for host-global resource restrictions, for example), but those are hindered by the requirement to be cross-platform. The approaches taken by the different operating systems are very diverse. With the public availability of the KDE 4 line, it became visible to a large audience. Since ThreadWeaver is not really KDE-specific, the question of where to go next (Freedesktop.org?) is in the air. For now, the focus remains to provide developers of applications and the desktop with a reliable scheduler for concurrency.
[58] Also referred to as open source software.
[60] This is fundamentally different from software that is entirely produced for a market. Free Software can cater to the needs of the blind, for example, without having to justify the considerable effort needed for that with corresponding sales figures and expected returns on the investment. That is one of the reasons why KDE is available in so many more languages than proprietary competitors, for example.
[61] We use that term with a lot of affection. It cannot be denied, though, that many of our dearest friends could do with a tad more exposure to sunlight and healthy food, overall.
[62] This might be surprising, since it goes against the intuitive idea of Free Software being produced largely by students with too much time on their hands, but lately there have been substantiated claims that by now the majority of successful Free Software is in fact written and maintained by professional software engineers. See for example Karim Lakhani, Bob Wolf, Jeff Bates, and Chris DiBona’s Hacker Survey v0.73 at http://freesoftware.mit.edu/papers/lakhaniwolf.pdf (24.6.2002, Boston Consulting Group).
[64] Entities interacting with the Akonadi server and reading and writing its data are referred to as agents. A general example would be a data mining agent. Agents that deal specifically with synchronizing data between the local cache and a remote server are called resources.