
10
Avoiding Common Design Pitfalls
Chapter 9,“Using Common Design Patterns,” described some common patterns that you might want to use while designing a database. This chapter takes an opposite approach: it describes some common pitfalls that you don't want to fall into while designing a database. If you see one of these situations starting to sprout in your design, stop and rethink the situation so that you can avoid a potential problem as soon as possible.
In this chapter, you will learn to avoid problems with:
- Normalization and denormalization
- Lack of planning and standards
- Mishmash and catchall tables
- Performance anxiety
The following sections describe some of the most common and troublesome problems that can infect a database design.
LACK OF PREPARATION
I've nagged about this in earlier chapters, but it's time to nag again. Database design is often one of the first steps in development. It's only natural for developers to want to rush through the design to get some serious coding done. It gives them something to show management to prove that they aren't only playing computerized mahjong and reading friends' MySpace pages and Facebook posts. Coding is also more fun than working on plans, designs, use cases, documentation, and all the other things that you need to do before you can roll up your sleeves and get to work.
Before you start cranking out tables and code, you need to do your homework. Some things that you need to do before you start wiring up the database are:
- Making sure you understand the problem
- Writing requirements documents to state the problem
- Building use cases to see if you have solved the problem
- Designing a solution
- Testing the design to see if it satisfies the use cases
- Documenting everything
Remember, the time you spend on up-front design almost always pays dividends down the road.
POOR DOCUMENTATION
This is part of preparation but it is so important and underappreciated that it deserves its own section. Many developers think of documentation as busy work or a chore to keep managers who have no real talents off their backs while they build elegant data structures of intricate beauty and complexity.
I confess that occasionally that's a handy attitude, but the real purpose of documentation is to keep everyone on the project focused on the same goals. The documentation should tell people where the project is headed. It should also spell out the project's design decisions so everyone knows how the pieces will fit together.
If the documentation is weak, different people will make different and possibly contradicting assumptions. Eventually, those assumptions will collide and you'll have to resolve the conflict. That will require developers to go back and fix work that they made under the wrong assumptions. That leads to more work, more errors, and copious bickering over whose fault it was.
The real fault was poor documentation.
POOR NAMING STANDARDS
In a sense, naming standards are part of documentation. When done properly, an object's name should give you a lot of information about the object. For example, if I tell you to build an Employees table, you probably know a lot about that table without even being told. You know that it will need name, address, phone number, email address, and Social Security Number information (in the United States, at least). In most companies, it will also need employee ID, hire date, title, salary, and payroll information (such as deductions, bank account for automatic deposit, and so forth). Somehow, it should probably link to a manager and possibly to projects. You got all of that from the single word “Employees.”
Now, suppose I told you to build a People table, but I really want to use the table to hold employee data. You'd probably only put about half of the necessary fields in this table. You'd get the name and address stuff right, but you'd completely miss the business-related fields.
The problems become worse when you start working with multiple related tables and fields. For example, suppose you use employee IDs to link a bunch of tables together, but one table calls the linking field EmpNo, another calls it EmployeeId, and a third calls it Purchaser.
This might seem like a small inconvenience—and in isolation it is—but together a lot of little inconveniences can add up to a real headache. Inconsistent naming makes developers think harder about names than the things they represent, and that makes the team less productive and less accurate.
I have worked on projects where poor naming conventions made small changes take days instead of hours because developers had to jump back and forth through the code to figure out what was happening. Inconsistent naming by itself is unlikely to sink a project, but it is enough to nudge an already leaky ship toward the rocky shoals of disaster.
Pick names for the fields that will be used in more than one table and stick to them so that the same concept gets the same name everywhere. Then use those names consistently. Consistency is more important than following particular arcane formulae to generate names, although I will mention two useful conventions for naming database objects such as tables and fields.
First, don't use keywords such as TABLE, DROP, and INDEX. Though these may make sense for your application and they may be technically allowed by the database, they can make programming confusing. If one of these words really fits well for your project, try adding a word or two to make it even more descriptive. For example, if your database will hold seating assignments and it really makes sense to have a field named Table, try naming it TableNumber or AssignedTable instead.
Second, don't put special characters such as spaces in table or field names even if the database allows it. Although there are ways to use these sorts of names, it makes working with the database a lot more confusing. Remember, the point of good naming conventions is to reduce confusion.
For some more information on naming conventions, search online for “database naming conventions” or take a look at some of these sites:
https://en.wikipedia.org/wiki/Naming_convention_(programming)http://vyaskn.tripod.com/object_naming.htmwww.geeksforgeeks.org/database-table-and-column-naming-conventions
Picking good names for tables is like a vocabulary test. You need to think of a word or short phrase that sums up as many of the features in the related items as possible so that someone else who looks at your table's name will immediately understand the characteristics that you're trying to record. The following table shows some examples.
| A TABLE THAT HOLDS: | SHOULD BE CALLED: |
|---|---|
| Magazines, newspapers, and comic books | Periodicals |
| Things that your company sells, including physical items and services | Products |
| People who work in your restaurant, including servers, bussers, cooks, and greeters | Employees |
| Things that cost you money, such as groceries, gasoline, and fencing lessons | PersonalExpenses |
| Things that you pay for but that are for work purposes, such as stationery, stamps, and phone calls | BusinessExpenses |
THINKING TOO SMALL
Too often developers design a perfectly reasonable database only to discover during the final project stages that it cannot handle the load being dumped on it. Make some calculations, estimate the database's storage and transaction loads, calculate the likely network traffic, and then multiply by five. For some applications, such as online web applications that can have enormous spikes in load over just a few hours, you might want to multiply by 10 or more.
Be sure you use a realistic model of the users' computers and networks. It's fairly common in software development to give the programmers building a system great big, shiny, powerful computers so they can be more productive. (It takes a lot of horsepower to play those interactive role-playing games quickly so you can get back to work.)
Unfortunately, customers often cannot afford to buy every user a new computer every two years. (Five developers × $3,000 = $15,000. That's not exactly pocket money, but it's small change compared to $2,000 × 200 users, for a total of $400,000.) Make sure your calculations are based on the hardware that the users will really have, not on the dream machine that you are using.
If your customers are “civilians” who download your app or who run it over the Internet, you should assume that the average user's hardware is at least a few years out of date. They may have a decent Internet connection and a few gigabytes of memory, but they may not have the latest solid-state disks and external graphics processing units.
If you don't think your architecture can handle the load, you should probably rethink things a bit. You might be able to buy a more powerful server with more disk space, move to a faster network, or split the data across multiple servers. If those tricks don't work, you might need to consider a three-tier architecture with different middle-tier objects running on separate computers. You might also need to think about moving some of the more intense calculations out of database code and moving them into code running on separate servers. In addition, you might also need to redesign the database to use turnkey records instead of using the database's record-locking tools. Finally, you might even need to split the database into disjoint pieces that can run on different computers.
Recent advances in cloud computing may help with some of these issues. Some cloud platforms can automatically distribute the load and increase compute and storage resources when they are needed. You can build your Pizza Cut app (which figures out the best way to slice a pizza so that the pepperoni is evenly divided among the slices) in a relatively small cloud database. When it becomes massively successful, you can upgrade your service to gain more database space and processing power. If you want to use a cloud database to deal with huge potential growth, then you need to plan that in from the start.
Solving these problems may be difficult, but you should at least plan ahead and be prepared to face them. A sure way to disappoint customers is to get them all excited, release the database, and then tell them they can't use it for four months while you rethink its performance problems.
NOT PLANNING FOR CHANGE
As you design the database, look for places that might have to change in the future. You don't need to build features that might never be needed, but you don't want to narrow the design so those features cannot be implemented later.
In particular, look for exceptions in the data. Customers often think in terms of paper forms, and those are easy to modify. It's easy to cross out headings and scribble in the margins of a paper form. It's a lot harder to do that in a computerized system. (Drawing on the screen with dry erase markers doesn't work very well.)
Whenever you see two or more things that have a lot in common, ask the customers if those are enough or whether you'll sometimes need to add more. Listen for words such as “except,” “sometimes,” and “usually.” Those words often hint at changes yet to come.
For example, suppose a customer says, “This field holds the renter's front binding tension, unless he's goofy-footed.” Here the word “unless” tells you that this one field might not be good enough to hold all of the data. You'd better find out what “goofy-footed” means and change the database accordingly.
For another example, suppose the customer says, “The order form must hold two addresses, one for shipping and one for billing. Unless, of course, we're billing a split order.” This says that two address fields (or groups of fields) may not be enough. At this point you probably need to pull the address data into a new table so you can accommodate any number of addresses, including the ones the customer hasn't remembered yet.
For a third example, suppose you're building a coaching tool for youth soccer teams. Figure 10.1 shows your initial design.
Let's review this design and identify any pieces that are likely to change later.
It's often useful to look at fields that allow a single value and ask yourself if they might need to change later. In this design, there are several such fields. It's also particularly useful to look at one-to-one relationships and this design contains some of those, too.
First, do we need to change the one-to-many relationship between Games and GamePlayers to a many-to-many relationship? Probably not. If the group of players is the same in any two games, that's more or less coincidence rather than a more formal arrangement such as an “A team” and a “B team.” (I've known some frighteningly serious youth soccer coaches who might just do that—seriously scary individuals with clipboards yelling at the tops of their lungs at four-year-olds.)
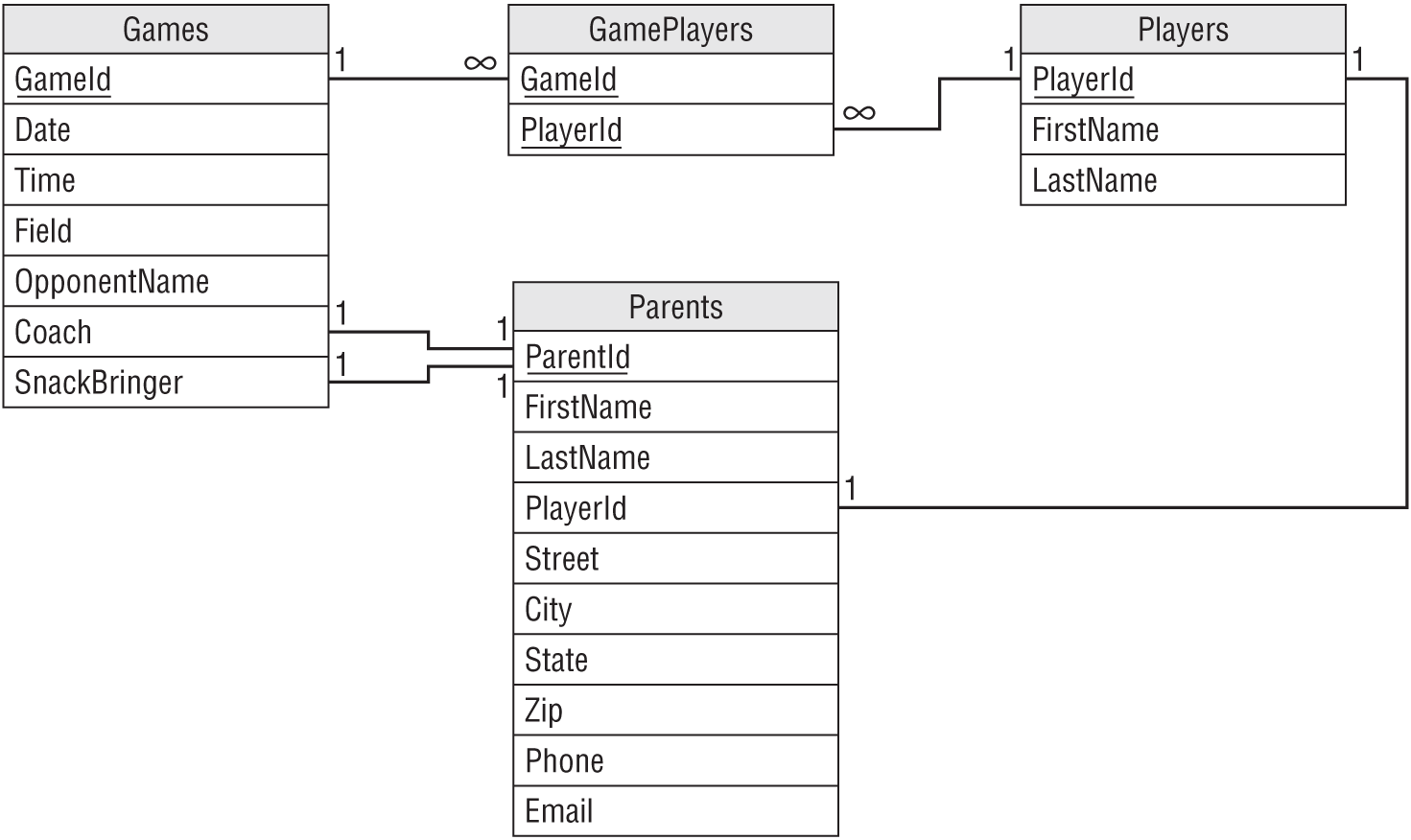
The many-to-one relationship between GamePlayers and Players, together with the Games/GamePlayers relationship, helps model the many-to-many relationship between Games and Players, so it probably shouldn't change.
What about the one-to-one relationship between Parents and Players? This link implies that a parent can have only one player and that might not be a good assumption. What if a parent has two players on the same team? For the younger age brackets, you won't see players of different ages on the same team, but you will find twins on the same team.
This relationship also implies that each player has a single parent (which is unlikely until cloning techniques become more practical). You could add information about a second parent (in fact, that's a very common approach), but if a player's parents are separated and remarried, you might need up to four parents and sometimes you might need to contact any subset of them to figure out if a player will be at a game. It might make the most sense to just allow a player to have any number of parents and not worry about the details. (And don't even think about requiring players to have the same last names as their parents! The combinations, including hyphenated last names, are too numerous to contemplate.)
The first one-to-one relationship between Games and Parents means that one parent will be the coach for that game. Is that a reasonable assumption? Will you ever need to worry about multiple coaches or assistant coaches? For a youth league, it's probably good enough to assume there is only one main coach and not worry about any others, so I wouldn't change that. But this is a good question to ask.
By far the most important piece of information in this database tells who is bringing a game's snacks. The second one-to-one relationship between Games and Parents means one parent will bring snacks for the game. Is that a reasonable assumption? In my experience, there has always been only one snack-bringer per game. As in the case with the coach, you can probably at least assume there is a main caterer and if someone else wants to bring extra cupcakes for a player's birthday, we just won't worry about it. But again, a good question.
One final place to look for these kinds of changes is in the fields within a table. In this design, the field that begs for multiple values is Phone. Lots of people have multiple phones and sometimes you might need to call several of them to track someone down (such as the all-important snack bringer!). I would split the Phone field off into a new table to allow parents to have any number of phone numbers.
Figure 10.2 shows the new and improved design.
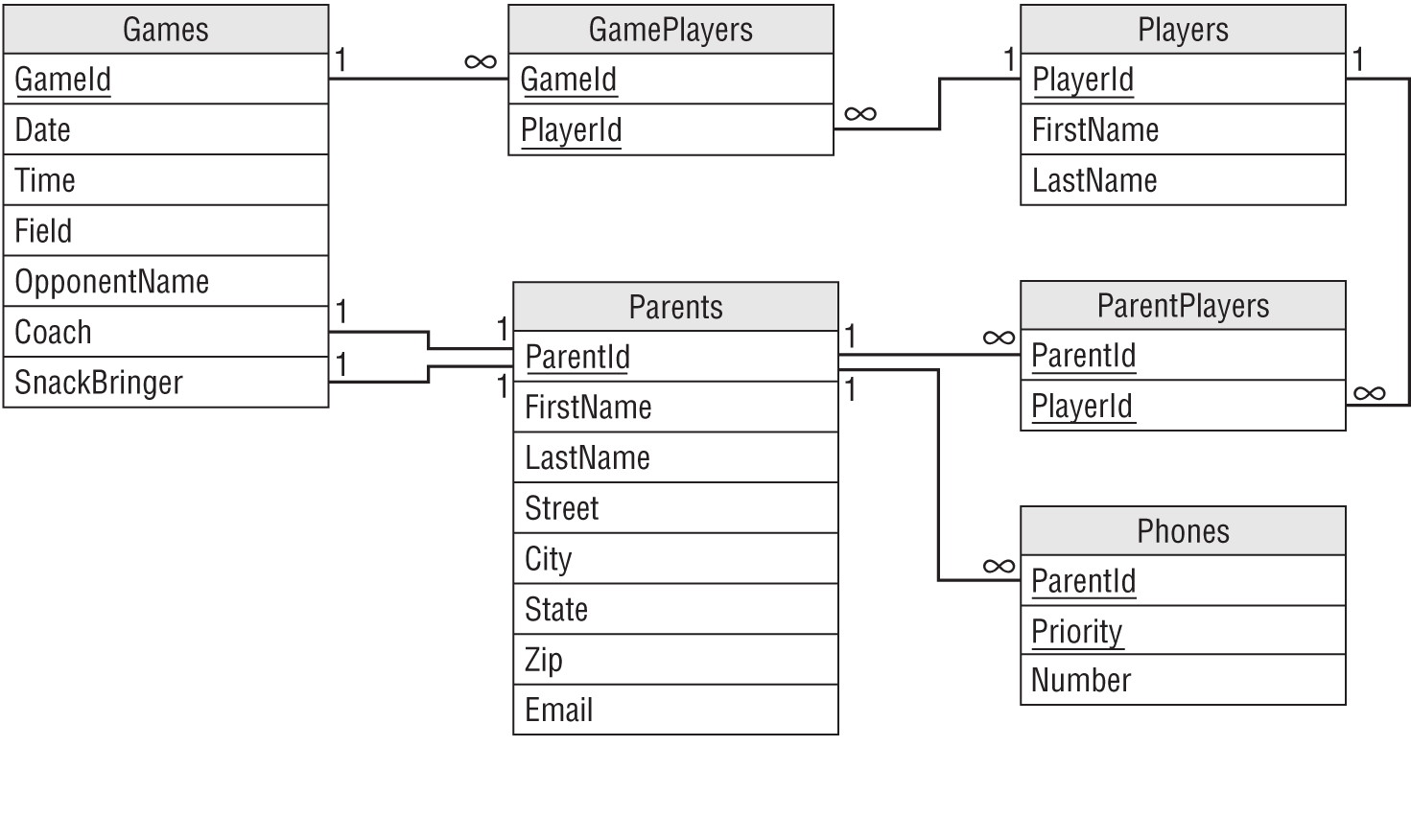
Again, you don't need to use psychic powers to build all of the features that the customer will need in the next 15 years, but keep your eyes open during requirements gathering and try not to close off opportunities for later change.
TOO MUCH NORMALIZATION
Taken to extremes, too much normalization can lead to a database that scatters related data all over the place for little additional benefit. It can make the design confusing and can slow performance.
When you normalize, think about what a change will cost and what benefits it will provide. Think about how the data will be accessed. If data is only read and written through stored procedures or middle-tier code, that code can help play a role in keeping the data consistent and might allow you to get away with slightly less normalization in the database's tables. Putting every table in fifth normal form or domain/key normal form isn't always necessary to keep the data safe.
I once worked on a project where a certain database developer (who coincidentally had just taken a class in database normalization) wanted to split every data value out into a separate table. For example, a customer record would contain little more than a CustomerId. Then a Values table would hold the actual data in its three fields Id, ValueName, and ValueData. To look up a customer's name, you would search the Values table for a record with Id equal to the customer's ID and ValueName equal to “Name.” In some bizarre otherworldly sense, this table is very normalized and it lets you do some amazing things. For example, you could decide to add a new EarSize field to the customer data without changing the tables at all. However, that design doesn't reflect the structure of the data, so it would be next to impossible to use. (If you really think that you might need to add an EarSize field, then you might consider a NoSQL document database so you can add just about anything at any time.)
INSUFFICIENT NORMALIZATION
Although too much normalization can make the database slower than necessary, poor performance is rarely the reason a software project fails. Much more common reasons for failure are designs that are too complex and confusing to build, and designs that don't do what they're supposed to do. A database that doesn't ensure the data's integrity definitely doesn't do what it's supposed to do.
Normalization is one of the most powerful tools you have for protecting the data against errors. If the database refuses to allow you to make a mistake, then you won't have trouble with bad data later. Adding an extra level of indirection to gather data from a separate table adds only milliseconds to most queries. It's very hard to justify allowing inconsistent data to enter the database to save one or two seconds per user per day.
This doesn't mean you need to put every table in fifth normal form, but there's no excuse for tables that are not in at least third normal form. It's much too easy to normalize tables to that level for anyone to claim that it's not necessary.
If the code needs to parse data from a single field (Hobbies = “sail boarding, skydiving, knitting”), break it into multiple fields or split its values into a new table. If a table contains fields with very similar names (JanPayment, FebPayment, MarPayment), pull the data into a new table. If two rows might contain identical values, figure out what makes them logically different and add that explicitly to the table so that you can make a primary key. If some fields' values don't depend on the entire key, consider spreading the record across multiple tables.
If you use a NoSQL database, then you probably cannot normalize it the way you can with a relational database, but you should still protect it against invalid data. You need to write code that validates the data going into the database to prevent it from becoming inconsistent.
INSUFFICIENT TESTING
This problem is closely related to “Thinking Too Small” and “Too Much Normalization.” Some developers perform little or no testing before releasing a database into the wild. They run through a few tests to check correctness (the better ones go through all of the use cases) and assume that everything will work in the field. Then when customers try to use it under realistic conditions, the whole thing falls apart. They discover bugs that the testers missed and the performance is unacceptable.
Be sure to test the database and any attached applications thoroughly. Fully testing every nook and cranny of a system takes a lot of work, but it's necessary. You need to be sure you exercise every piece of code, every table, and every constraint. You also need to perform load testing to see if the database can handle the expected load.
If you don't find all of the bugs and bottlenecks, sooner or later the user will, guaranteed!
PERFORMANCE ANXIETY
Many developers focus so heavily on performance that they needlessly complicate things. They make a simple solution complicated and harder to build and maintain all in the name of speed. They denormalize tables to avoid using any more tables than necessary, and they build business rules into the database so they don't need to use stored procedures or other code to implement them separately.
Modern hardware and software is pretty fast, however. Often, these CPU-pinching measures save only milliseconds on a one-second query. Think hard about whether a convoluted design will really save all that much time before you make things so complicated that you can't build, debug, and maintain the application. If you're not sure, either run some tests and find out or go with the simpler version and change it later if absolutely necessary. Usually, performance is acceptable, but a database that contains contradictory data is not.
The moral is, you don't need to be stupid about design and ignore obvious chances to improve performance, but don't be so focused on the little things that they cloud the grander design.
First, make it work. Then make it work fast.
MISHMASH TABLES
Sometimes, it's tempting to build tables that contain unrelated values. The classic example is a DomainValues table that contains allowed values for fields in tables scattered throughout the database. For example, suppose the State, Brand, and Medium fields take values from lists. State can take values CA, CT, NV, and so forth; Size can take values Grande, Enorme, Gigantesco, and Intergalattico; and Medium can take values Oil, Acrylic, Pastel, and Crayon. You could build a DomainValues table with fields TableName, FieldName, and Value. Then it would hold records such as TableName = Artwork, FieldName = Medium, Value = Crayon. You would use this magic table to validate foreign keys in all the other tables.
This one-table-to-rule-them-all approach will work, but it's more of a headache than it's worth. The table is filled with unrelated values and that can be confusing. It might seem that having one table rather than several would simplify the database design, but this single table does so many things that it can be hard to keep track of them all. Just think about drawing the database design's ER diagram with this single table connected to dozens of other tables.
Tying this table to a whole bunch of others can make it a chokepoint for the entire system. It can also lead to unnecessary redundancy if multiple tables contain fields that have the same domains.
It's better to use separate tables for each of the domains that you need. In this example, just build separate States, Sizes, and Media tables. Although this requires more tables, the pieces of the design are simpler, smaller, and easier to understand.
Remember the rule that one table should do one clearly defined thing and nothing else. Although this kind of mishmash table has an easily defined purpose, it does not do just one thing.
NOT ENFORCING CONSTRAINTS
When you design a table, you should write down the domains and other constraints for every field. Most database designers can handle that, but it's surprising how often those restrictions don't make it into the actual database.
When you start building the database, go through the list of field constraints and check them off as you implement them. Often, these are as simple as making a field required or writing field-level check constraints for a field.
You can rely on middle-tier objects and user interface code to enforce some of these, but the database is the final authority, so why not take advantage of its capabilities? You might want to allow the middle tier to verify that a flyball team's number of dogs is no more than 3 because it's a possibly changing business rule. It seems unlikely that a team would ever include –1 dogs, however, so let the database enforce that rule at least.
Databases can also often verify field formats. For example, some databases can verify that a phone number string has the format ###-###-####. You might want the user interface to validate this type of format, too, to save round-trips to the database, but there's no reason not to let the database do whatever it can to ensure that garbage doesn't slip into the data.
The database is pretty good at enforcing these simple rules. Let it do its job so it can feel appreciated.
OBSESSION WITH IDs
ID numbers are nice. They are relatively small and efficient, and it's easy to ensure that they are always unique. However, they don't have any real meaning. You can probably recite your name, address, and phone number easily enough, but do you remember your employee ID, utility company account number, and driver's license number? Unless you have a better memory than mine (which is likely, since I have a pretty poor memory) or someone took a shortcut when they defined their keys (in some states, your driver's license number is the same as your Social Security number), you probably don't remember all of these.
It's okay to have some tables with keys that are not artificial IDs, particularly if the data provides a nice unique key readymade for you. Books have International Standard Book Numbers (ISBNs) that uniquely identify them so, if you're tracking books, use ISBN instead of creating a new meaningless number. Products often have stock-keeping unit (SKU) or product numbers that are just as useful as an artificial number. Even keys that include multiple fields can be perfectly fine and give acceptable performance.
Three obvious times when you should create an artificial primary key are when:
- You might need to change the value of the natural key. (You shouldn't change primary key values and some databases won't even let you.)
- The natural key doesn't guarantee uniqueness.
- Adding an automatically generated surrogate key makes integration with other systems easier.
Before you create a new key field, ask yourself whether it's really necessary.
NOT DEFINING NATURAL KEYS
Closely related to obsession with IDs is not defining natural keys. A natural key is a key that you might actually use to search the data. If a table is only there to provide detail for another table, then an ID makes a reasonable link between the two, but if you will be searching a table for natural values such as names or phone numbers, then those might make good keys.
For example, suppose the Addresses table uses CustomerId to link back to Customers records. Typically to look up an address, you will look up the customer's record, and then look at its related address records. It's unlikely that you will know a customer's address and need to look up their name, so you probably don't need to define a key on the Addresses table's Street, City, State, or Zip fields. In the unusual circumstance where you do know the customer's address but not their name, you can still look up the record, it will just take longer.
In contrast, suppose the Customers table uses CustomerId for its primary key. What are the chances that you'll need to look up customers by ID? Unless the ID is something special (such as phone number if you're running a phone company), then that number is meaningless to mere mortals, so you're more likely to look up a customer by name. You can make that faster by making the name a key. It can't be the primary key because it doesn't guarantee uniqueness and you might need to change a customer's name, but making it a non-primary key will make searches by customer name faster. If that's the search you perform the most, this key is a worthwhile addition to the database.
You might also consider using other fields as keys, too. For example, you might want to be able to list customers by city or ZIP Code to prepare mass mailings (postal spam). In that case, making City and ZipCode keys might also be useful if you perform those searches often.
SUMMARY
This chapter described some common mistakes that people make while designing databases. If you don't pay attention to the ideas described in this chapter, you might end up rediscovering the importance of proper planning, documentation, and testing by painful experience.
Some of these lessons I've learned the hard way, some by studying others' mistakes, and some through research. Take my word for it when I say it's a lot easier (and more humorous) to learn about these issues here instead of through firsthand experience.
In this chapter, you learned the importance of:
- Advanced preparation through thorough requirements gathering
- Good design practices such as using naming conventions and making a design before building the database
- Anticipating changes and increased database load
- Using the database's tools to ensure that values are within their allowed domains
- Avoiding artificial keys if they are unnecessary and making natural keys even if they cannot be a primary key
This chapter ends the book's main discussion of general database design topics. The next few chapters explain some practical database implementation issues, paying extra attention to the Microsoft Access and MySQL database management systems.
Before you move on to Chapter 11, however, use the following exercises to test your understanding of the material covered in this chapter. You can find the solutions to these exercises in Appendix A.