
Most significant development projects involve a relational database.1 The mainstay of most commercial applications is the large-scale storage of ordered information, such as catalogs, customer lists, contract details, published text, and architectural designs.
With the advent of the World Wide Web, the demand for databases has increased. Though they may not know it, the customers of online bookshops and newspapers are using databases. Somewhere in the guts of the application, a database is being queried and a response is offered.
Hibernate is a library (actually, a set of libraries) that simplifies the use of relational databases in Java applications by presenting relational data as simple Java objects, accessed through a session manager, therefore earning the description of being an “Object/Relational Mapper,” or ORM. It provides two kinds of programmatic interfaces: a “native Hibernate” interface and the Jakarta EE2 standard Java Persistence API.
This edition focuses on Hibernate 6. As this sentence is being written, it’s still at Alpha8, so it’s not formally released, but chances are that the actual release is going to be very similar to the code used here.
There are solutions for which an ORM – like Hibernate – is appropriate and some for which the traditional approach of direct access via the Java Database Connectivity (JDBC) API is appropriate. We think that Hibernate represents a good first choice, as it does not preclude the simultaneous use of alternative approaches, even though some care must be taken if data is modified from two different APIs.
To illustrate some of Hibernate’s strengths, in this chapter we take a look at a brief example using Hibernate and contrast this with the traditional JDBC approach.
Plain Old Java Objects (POJOs)
Java, being an object-oriented language, deals with objects. Usually, objects that represent program states are fairly simple, containing properties (or attributes) and methods that alter or retrieve those attributes (mutators and accessors, known as “setters” and “getters,” colloquially). In general, these objects might encapsulate some behavior regarding the attributes, but usually their sole purpose is containing a program state. These are known typically as “plain old Java objects,” or POJOs.
A Rose-Tinted View of Object Persistence
There would be no nasty surprises, no additional work to correlate the class with what the table schema might be, and no performance problems.
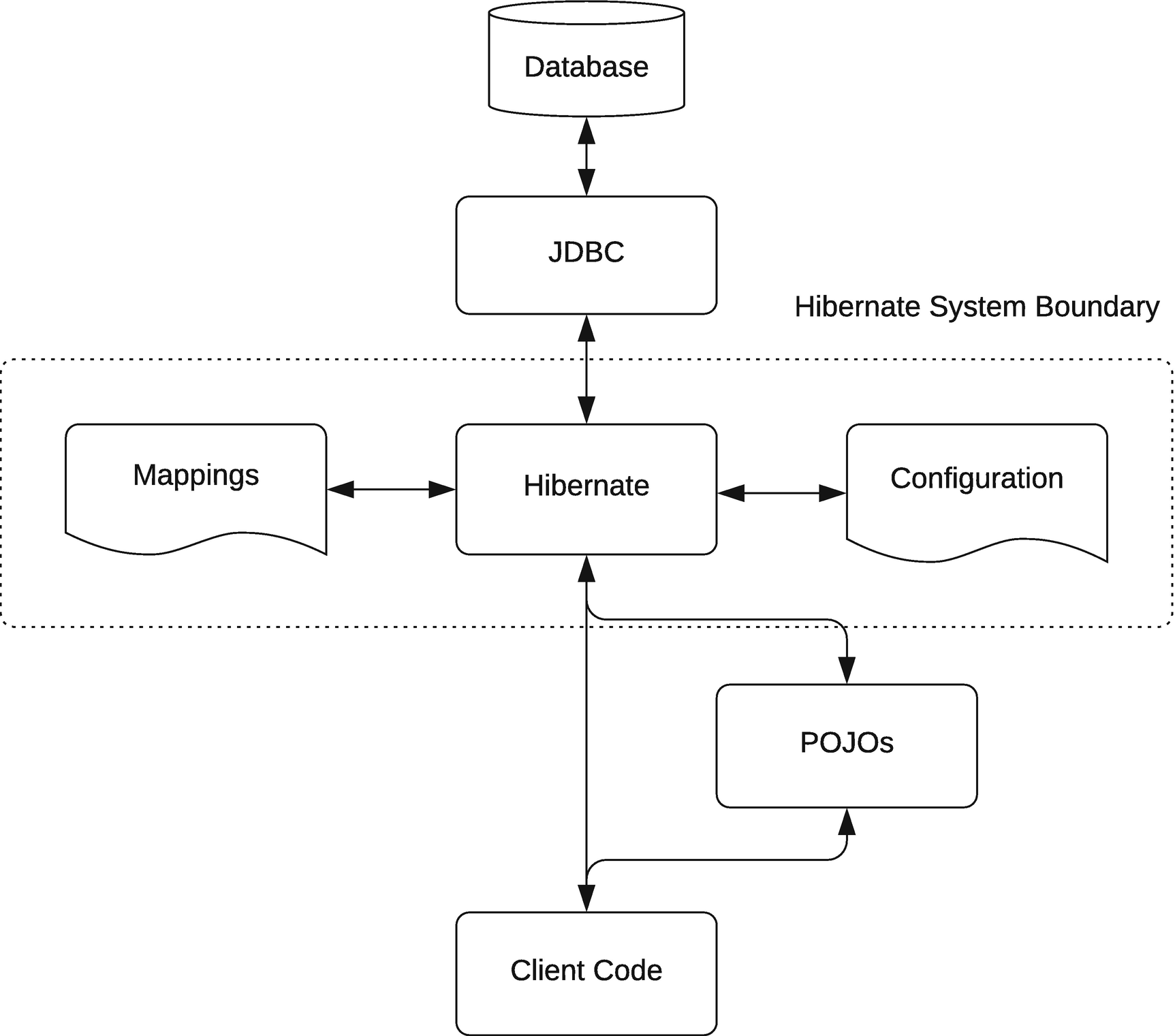
The role of Hibernate in a Java application
Building a Project
We’re going to use Maven (https://maven.apache.org) to build a project for this book. It’ll be organized as a top-level project with a subproject (or “module”) for every chapter, and we’ll also have a few extra modules to provide common functionality. You can do the same thing with Gradle (https://gradle.org), and there’s no real reason for this book to prefer one over the other, but Maven won the coin toss,4 so Maven it is.
The Top-Level pom.xml
So what is this pom.xml actually doing? It turns out, quite a bit – although almost all of it’s related to common configuration for the rest of the book, so the module pom.xml files are much simpler than they otherwise would be.
The first few lines describe the “parent project,” described as having a groupId of com.autumncode.books.hibernate and an artifact id of hibernate-6-parent. It’s also set to a version of 1.0-SNAPSHOT – none of this is particularly relevant.
We then have a <modules> block, with a single module in it. As we progress through the book, we’ll add modules here for each chapter, and if you look at the source code that accompanies this book, you’ll see a full complement of modules in this section.
Up next is the <properties> block, which we use to set the default compiler version and target (Java 11, which is the current “production” version of Java6), followed by a lot of specific dependency versions, like <h2.version>1.4.200</h2.version>.7
Next, we have a <dependencyManagement> block. This doesn’t actually set up any dependencies, as such: it simply allows us to centralize references for dependencies. Note that modules will inherit the dependencies of the parent project, so we can declare all of our specific dependencies here and the modules can simply use the names, instead of having to include the versions as well. If a new version of Hibernate were to come out, for example, we’d only have to change the version used in <dependencyManagement>, and the change would propagate throughout the whole project.
After <dependencyManagement>, we have dependencies we expect to be common for the entire project. This is a Hibernate book, so it makes sense to have Hibernate itself here, as well as a relatively standard logging framework (Logback (https://logback.qos.ch/), which itself includes Slf4j (www.slf4j.org/) as a transitive dependency), and we also import TestNG (https://testng.org) and H2 (www.h2database.com/), a popular embedded database written in pure Java, as test dependencies.
Lastly, we have a <build> section, which forces Maven to use a recent version of the maven-compiler-plugin, required to set the language version correctly, because while Maven is horribly useful, it’s also designed to support legacy JVMs very well, to the point where you have to tell it specifically to use more recent JVMs.
chapter01/pom.xml
Here, all we do is declare what this module is (chapter01) and include a reference to the parent module. Everything is inherited.
Now that we have all the icky project stuff out of the way, let’s circle back around to what Hibernate is designed to do for us.
chapter01/src/main/java/chapter01/pojo/Message.java
You can’t get much simpler than that object; it’s doable, of course, because you could create an object that had no state (therefore, no text field and no accessor or mutator to reference to it), and we could ignore the equals() and hashCode() and toString() as well. Such objects would be useful as actors, objects that act on other objects. But Listing 1-4 is a good example of what most POJOs will look like, in that most Java classes that represent program state will have attributes, accessors, mutators, equals, hashCode, and toString as well.
Hibernate could map Listing 1-4 fairly easily, but it does not follow the idioms you’ll find in most Hibernate entities. Getting there is really simple, though.
chapter01/src/main/java/chapter01/pojo/MessageEntity.java
There are a few changes here. We’ve added an id field (a Long), along with an accessor and a mutator for the id, and we’ve added the id to the standard utility methods (equals(), hashCode(), and toString())… and we’ve added a no-argument constructor. The id field is pretty common for relational mapping, because such fields are much easier to search and refer to when working with the database, but the no-argument constructor is primarily a concession to convenience, because it allows us to create a sort of “blank canvas” object that we can fill in later, through the mutators or by direct field access, if we allow that.
In strict OOP terms, this can be a bad thing, because it means we can legitimately construct an object that lacks legitimate state; consider our poor old MessageEntity. If we define a “valid MessageEntity” as having a valid id field (any number will do, as long as it’s not null) and a populated text field (anything but null), then calling our no-argument constructor creates a MessageEntity that is not valid. In fact, if we call the other constructor, we have similar problems, because we aren’t checking the values of the attributes as we set them.
This is actually a characteristic of the Java Persistence API, or JPA specification, which says that the class must have a public or protected no-argument constructor with no arguments. Hibernate extends the JPA specification, and while it is looser in some requirements than the JPA specification is, it generally follows the constructor requirement (although the constructor can also have package visibility).
We also should not have the class be marked final. There are actually ways around this, but Hibernate by default creates an extension of the class to enable some potentially very useful features (like lazy-loading data in attributes).
You should also provide standard accessors and mutators (like getId() and setId()).
chapter01/src/test/java/chapter01/jdbc/PersistenceTest.java
So what’s going on here? First, we have a simple utility method that returns a Connection; this mostly saves the length of the statement and reduces repetition.
We also have a setup() method , marked with @BeforeClass. This annotation means this method will be invoked before any of the tests in the class are executed. (We could also have used @BeforeTest or @BeforeSuite, but in this case, @BeforeClass is probably the right granularity, assuming we have more functionality to test than we actually do.)
The annotations indicate when the annotated method runs, in context of the test class. @BeforeTest runs before every method annotated with @Test runs. @BeforeClass runs before any test method in the class runs; @BeforeSuite runs before any test in any test class runs. There are also @AfterClass, @AfterTest, and @AfterSuite methods that run at the end of their corresponding phases.
Next, we have another utility method, saveMessage(), which takes message text to save. This will insert a new record in the database table. It requests the generated key from the database so that it can populate a MessageEntity and return it, mirroring convenient behavior (we can now query for that message and test for equivalency, as we see done in the readMessage() test ). It’s functional; it’s not very good, honestly, but it’s not worth improving. Hibernate does this sort of thing far better than we are here, and in less code; we could mirror much of what Hibernate does, but it’s just more effort than it’s worth.
Lastly, we have our actual test: readMessage(). This calls saveMessage() and then reads through all of the “saved messages” – which, given that we’ve taken pains to create a deterministic database state, will be a list of one message. As it reads the messages, it creates MessageEntity objects for each one and stores them in a List, and then we validate the List – it should have one element only, and that element should match the MessageEntity we saved at the beginning of the method.
Whew! That’s a lot of work; there’s some boilerplate, in the acquisition of resources (done with automatic resource management, to handle clean deallocation in the case of exceptions), and the JDBC code itself is pretty low level. It’s also rather underpowered and very manual. We’re still managing the specific resources like Connection and PreparedStatement, and the code’s very brittle; if we added a field, we’d have to look for and modify every statement that would be affected by that field, since we’re manually mapping the data from JDBC into our object.8
We also run into the issue of types with this code. This is a very simple object, after all; it stores a simple numeric identifier with a simple string. However, if we wanted to store a geolocation, we’d have to break the geolocation into its component properties (latitude and longitude, for example) and store each separately, which means your object model no longer cleanly matches your database.
All of this makes using the database directly look more and more flawed, and that’s before factoring in other issues around object persistence and retrieval.
Want to run these tests? It’s really simple: run the Maven lifecycle with mvn build, which will download all of the dependencies for our project (if necessary), compile our “production” classes (the ones in src/main/java), then compile our test classes (the ones in src/test/java), and then execute the tests, dumping any console output (to the console, naturally) and halting on failures. It then builds a jar of our production resources. We can also limit the lifecycle to only doing enough to run the tests with mvn test.
Hibernate As a Persistence Solution
Hibernate fixes almost everything we don’t like about the JDBC solution. We don’t use complex types in this example, so we won’t see how that’s done until later in this book, but it’s easier to do in nearly every metric.9
- 1.
@javax.persistence.Entity: Which marks the class as an entity class to be managed by Hibernate
- 2.
@javax.persistence.Id: Which makes the field to which it applies as a primary key for the database
- 3.
@javax.persistence.GeneratedValue: Which provides information to Hibernate about how the value should be populated
- 4.
@javax.persistence.Column: Which allows us to control aspects of the field in the database
chapter01/src/main/java/chapter01/hibernate/Message.java
The @GeneratedValue here has a strategy of GenerationType.IDENTITY, which specifies that Hibernate will mirror the behavior of our manually created JDBC schema: the keys for each Message will be automatically generated by the database.
The @Column(nullable = false) likewise indicates that the text field can’t store a null in the database. The column name will be derived from the field name, mangled slightly if it matches a reserved word; in this case, our database is fine with a column called text so no mangling occurs, and we can provide an explicit column name if we so desire.
Apart from the annotations and the constructors, the Message and the MessageEntity are very similar.
chapter01/src/test/resources/hibernate.cfg.xml
connection1.driver.class | This is the fully qualified name of the JDBC driver class for the session factory. |
connection.url | This is the JDBC URL used to connect to the database. |
connection.username | The connection’s username, surprisingly enough. |
connection.password | Another surprise – the connection’s password. In an uninitialized H2 database, “sa” and an empty password are sufficient. |
dialect | This property tells Hibernate how to write SQL for the specific database. |
show_sql | This property sets Hibernate to echo its generated SQL statements to a specified logger. |
hbm2ddl.auto | This property tells Hibernate whether it should manage the database schema; in this case, we’re telling it to create on initialization and drop the database when it’s done. |
hbm2ddl.auto is dangerous in production environments. For temporary, or testing, environments, it’s no big deal, but when you’re talking about real data that needs to be preserved, this property can be destructive, a word one rarely wants to hear when talking about valuable data.
The last line tells Hibernate that it has one entity type to manage, the chapter01.hibernate.Message class.
chapter01/src/main/resources/logback.xml
Note that the default logger level is set to info. This tends to create a lot of information on the logger’s output stream (the console); it’s interesting to look at and can be very helpful for diagnostic purposes, but if you want, you can set the logger level to error and reduce the chattiness of Hibernate quite dramatically.
chapter01/src/test/java/chapter01/hibernate/PersistenceTest.java
The first thing to notice is the way we’re accessing resources. In the JDBC version, we had a simple getConnection() that we called whenever we happened to need a Connection; here, we’re creating a reference to a SessionFactory and initializing it before the class’ tests run. The way we build it is … not complex, but it’s verbose for something we’re likely to do over and over again.12
Once we have the SessionFactory, though, the idioms are very straightforward. We create a block for which a Session is in scope – again, with automatic resource management – and then we begin a transaction. (In the JDBC example, we did the same thing, just implicitly.) Then we save() the object, or query for one, as we need.
Once we’ve done something with the database, we commit the transaction.
We’re going to discuss a lot more about the actual configuration and mapping in future chapters; it’s okay if you’re wondering what settings are available, and what operations there are, and why one would want a transaction for a read operation. We’re going to cover all of that.
If you run this code (again, with mvn test or mvn build), you might see a ton of logging output, largely because of the show_sql property being set to true in the Hibernate configuration file.
Summary
In this chapter, we have considered the problems and requirements that have driven the development of Hibernate. We have looked at some of the details of a trivial example application written with and without the aid of Hibernate. We have glossed over some of the implementation details, but we will discuss these in depth in Chapter 2.