
The section will consist of the introduction of the gradient descent algorithm as an optimization method for linear regression; the corresponding computations will be shown as well as the concept of the learning curve of the model. Later, we will see how to use the specialized functions of the Wolfram Language for machine learning such as Predict, Classify and ClusterClassify, in the case of linear regression, for logistic regression and for cluster search. Adding to this, the different objects and results that these functions generate as well as the metrics to measure the model will be shown for these functions. In each case, we will explain which parts of the model are fundamental for the correct construction using the Wolfram Language. For this part of the book we will use examples of known datasets such as the Fisher's Irises dataset, Boston housing dataset, and the Titanic dataset.
Gradient Descent Algorithm
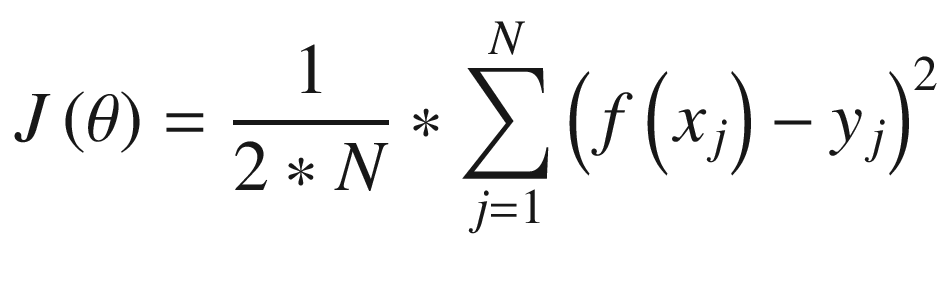

where the summations are obtained from partial derivatives with respect to θ0 and θ1. The term α corresponds to the learning rate, which is a parameter that minimizes error when the learning process is constructed. For more mathematical depth about the method and demonstrations, see the book Artificial Intelligence: A Modern Approach by Stuart Russell and Peter Norvig (2010, Upper Saddle River, NJ: Prentice Hall).
Getting the Data
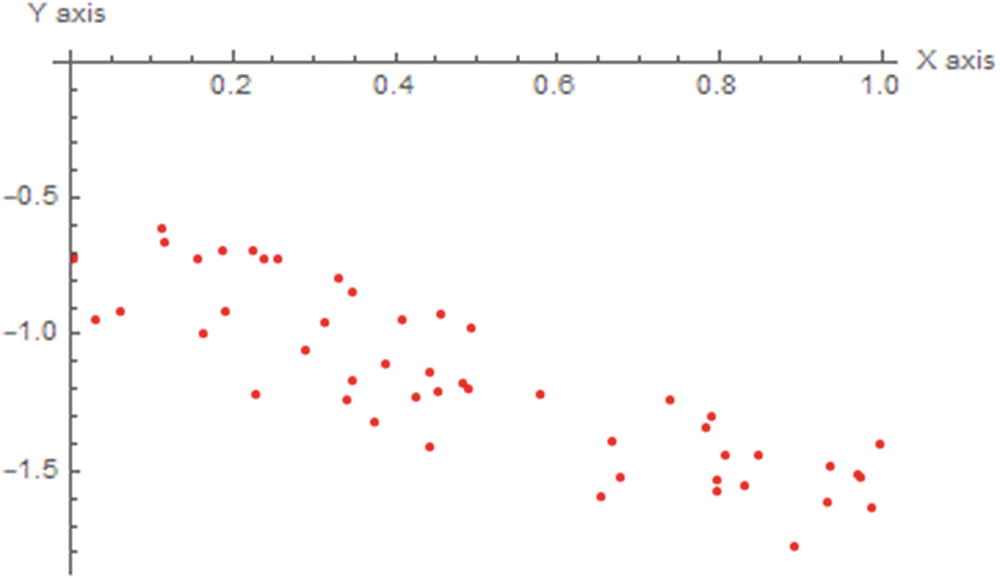
2D scatter plot of the random generated data
Algorithm Implementation
Let us now proceed to the implementation of the algorithm with the Wolfram Language. The algorithm will consist of defining the constants, the number of iterations, and the learning rate. Then we will create two lists containing initial values of zero, in which the values of the coefficients for each iteration will be stored. Later, we will perform the calculation of the coefficients through a loop with Table, which will not end until we reach the number of iterations. In our case, we will establish a number of iterations of 250 with a learning rate of 1.
In[3]:= itt=250;(*Number of iterations*)
α=1;(*Learning rate*)
θ0=Range@@{0,itt};(* Array for values of Theta_0*)
θ1=Range@@{0,itt};(* Array for values of Theta_1*)
Table[{
θ0[[i+1]]=θ0[[i]]-  *Sum[(θ0[[i]]+θ1[[i]]* x[[j]]-y[[j]]),{j,1,Length@x}];
*Sum[(θ0[[i]]+θ1[[i]]* x[[j]]-y[[j]]),{j,1,Length@x}];
θ1[[i+1]]=θ1[[i]]- 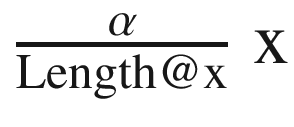 *Sum[( θ0[[i]]+θ1[[i]]*x[[j]]- y[[j]])*x[[j]],{j,1,Length@x}];},{i,1,itt}];
*Sum[( θ0[[i]]+θ1[[i]]*x[[j]]- y[[j]])*x[[j]],{j,1,Length@x}];},{i,1,itt}];
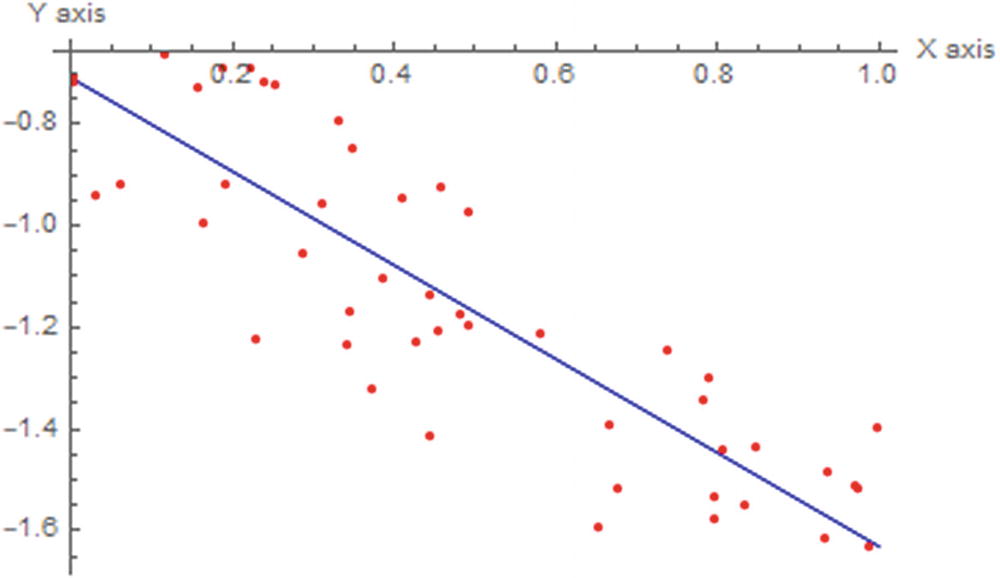
Adjusted line to the data
Since we have built the linear model, we can make a graphical comparison of the variation of the learning rate with the number of iterations and the loss value given by the function J.
 or Sum [expr, {i,imax}].
or Sum [expr, {i,imax}].Below is the graph of loss vs. each interaction for learning rate values of α1=1, α2=0.1, α3=0.01, α4=0.001, and α5=0.001, when repeating the process Figure 8-3.
Multiple Alphas
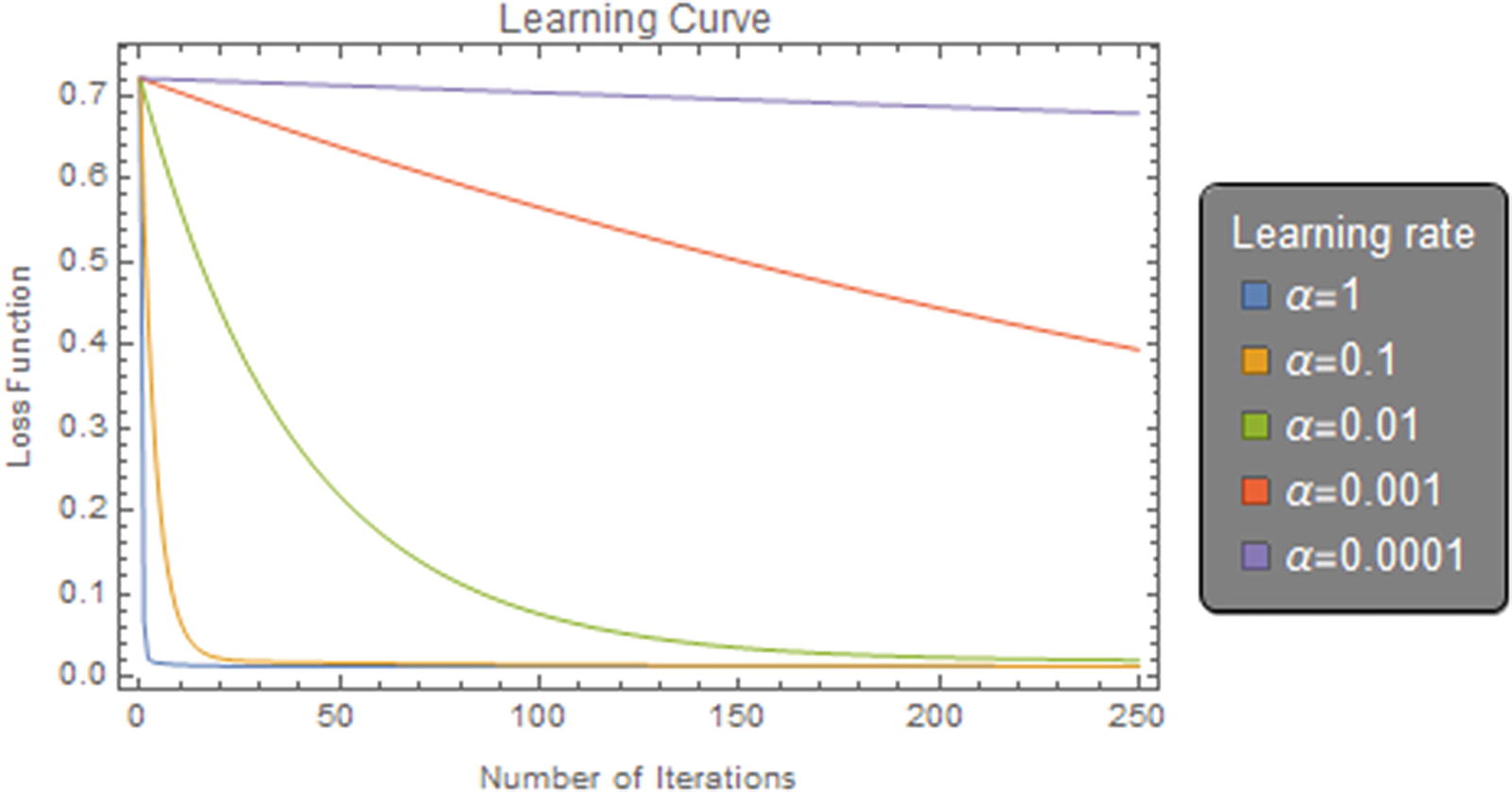
Learning curve for the gradient descent algorithm
In the previous graph (Figure 8-3) we can visualize the size of iterations with respect to cost and how it varies depending on the value of alpha. With a high learning rate, we can cover more ground at each step, but we risk exceeding the lowest point. To know whether the algorithm works, we must see that the loss function is decreasing in each new iteration. The opposite case would be an indicator that the algorithm is not working properly; this can be attributed to various factors such as a code error or an incorrect value of the learning rate. As we see in the graph, adequate values of alpha correspond to small values between a scale of 1 to 10-4. It is not necessary to have to use these same values; you can use values that are within this range. Depending on the form of the data it is possible that the algorithm may or may not converge with different alpha values as the same for the iteration steps. If we choose very small alpha values, the algorithm can take a long time to converge, as we can see for alpha values 10-3 or 10-4.
Linear Regression
Despite being able to build the algorithms to perform a linear regression, the Wolfram Language has a specialized function for machine learning. In the case of a linear regression problems, there is the Predict function. The Predict function can also work with different algorithms, not only regression task algorithms.
Predict Function
The Predict function helps us predict values by creating a predictor function using the training data. It also allows us to choose different learning algorithms, the purpose of which is to be able to predict a numerical, visual, categorical value or a combination. The methods to choose from are decision tree, gradient boosted tree, linear regression, neural network, nearest neighbors, random forest, and gaussian process. For each method, there are options within it; the options vary depending on the algorithm chosen to train the predictor function. Let us look at the linear regression method. The input data for Predict can be in the form of a list of rules, associations, or a dataset.
Boston Dataset

Boston housing price dataset
Model Creation
We will try to create a model that is capable of predicting housing prices in the Boston area through the number of rooms in the dwelling. To achieve this, the columns of interest correspond to RM (average number of rooms per dwelling) and MEDV (median value of owner-occupied homes), since we want to find out if there is a linear relationship between the number of rooms and the price of the house. Applying a bit of common sense, the houses with the largest number of rooms are larger and therefore have the capacity to store more people, making the price go up.

2D scatter plot
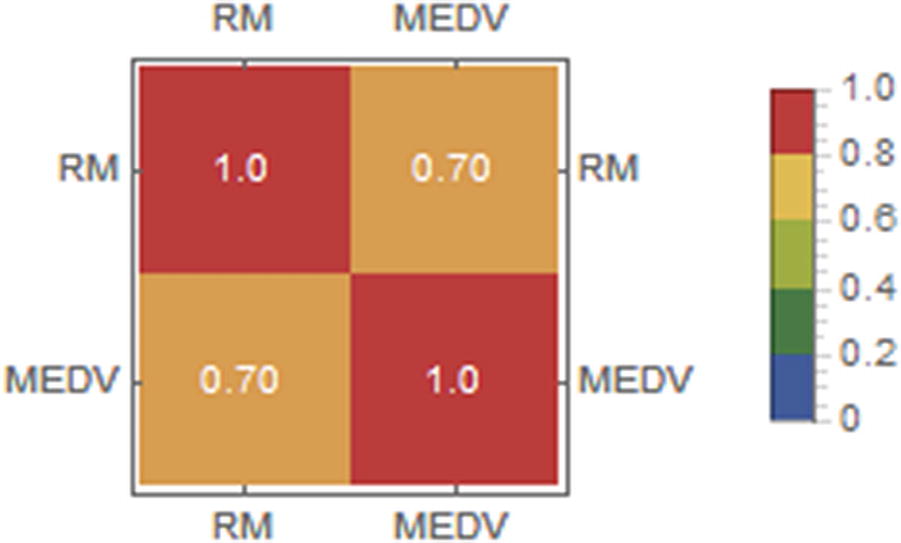
Matrix plot combined with a correlation matrix

PredictorFunction object of the trained model
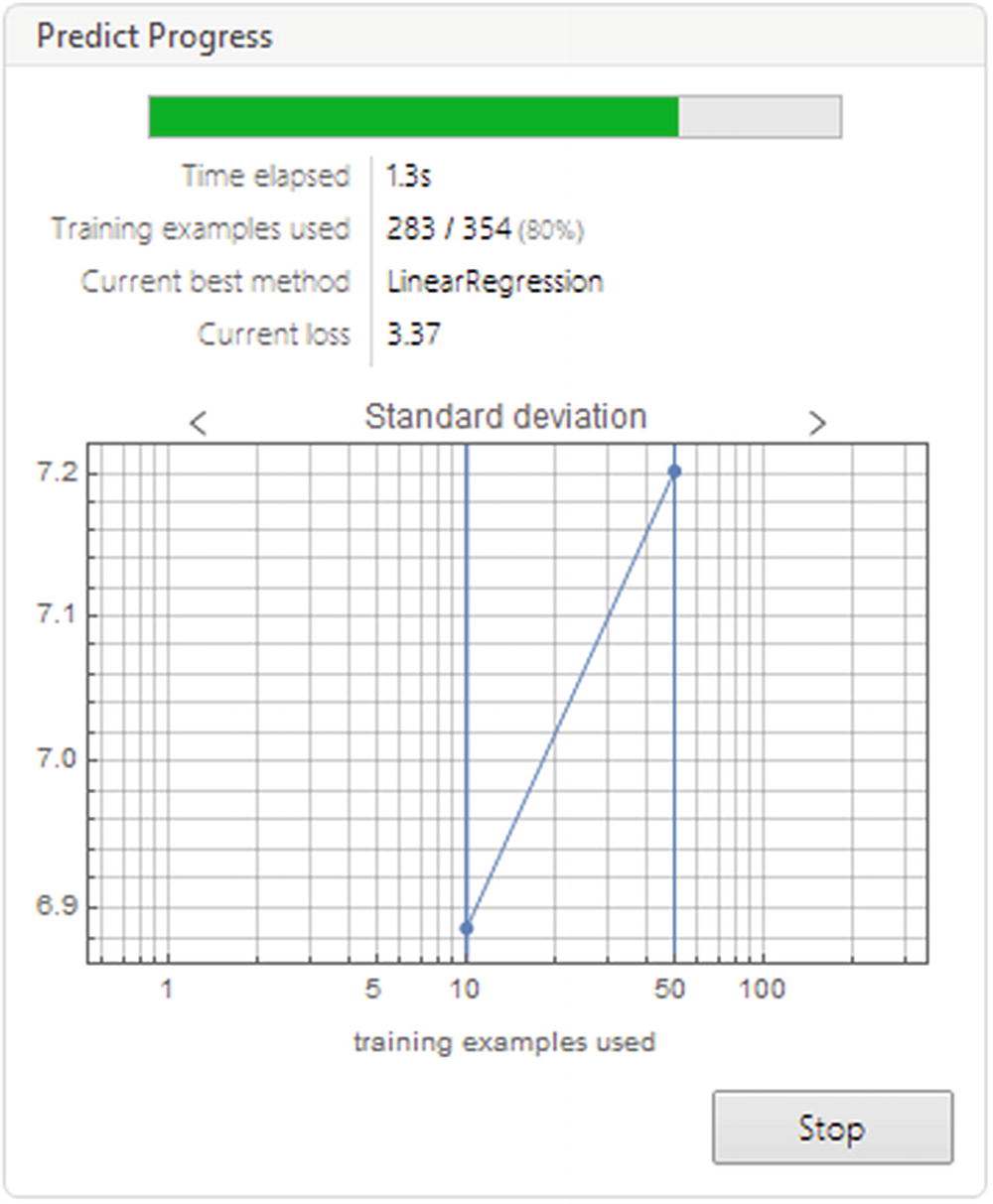
Progress report of the PredictorFunction

Information report of the trained model
The information panel (Figure 8-9) includes data type, root mean squared (StandardDeviation), method, batch evaluation speed, loss, model memory, number of examples for training, and training time. The graphics at the bottom of the panel are for standard deviation, model learning curve, and learning curve for the other algorithms. If you hover the cursor pointer over the numerical parameters, it will show the confidence intervals and units. If it’s done by the name of the method, it will show the parameters of the linear regression method. Since we did not select a specific optimization algorithm within the LinearRegression method, Mathematica tries to search through the algorithms for the best one (this can be viewed in the learning curve for all algorithms). We will see how to access these options further down the line.
Every method that can be used in the Predict function has options and suboptions; to see full customization use the Wolfram Language Documentation Center.
Most Common Options for Predict Function
Option | Definition |
|---|---|
Method | Algorithm Possible values: DecisionTree, GradientBoostedTrees, LinearRegression, NearestNeighbors. NeuralNetwork, RandomForest and GaussianProcess. |
PerformanceGoal | Performance optimization Possible values: DirectTraining, Memory, Quality, Speed, TrainingSpeed, Automatic. Combination of values is supported (P PerformanceGoal→ {val1, val2}). |
RandomSeeding | Seed for the pseudorandom number generator Possiblevalues: Automatic. “custom seed,” Inherited (random seed used in previous computations). |
TargetDevice | Specify a device to perform the training or test process Possible values: CPU or GPU. If a GPU is installed, the automatic target device will be the GPU: |
TimeGoal | Time spent for the training process |
TrainingProgressIndicator | Progress report Possible values: Panel, Print, ProgressIndicator, SimplePanel, None. |
Model Measurements

PredictorMeasurements object of the tested model

Report of tested model
This report (Figure 8-11) shows different parameters, such as the root mean square (standard deviation), mean cross entropy, among others. And it shows us a graph of the fit of the model along with the current values and predicted values. We see that the model is good for most cases, with the exception that there are still some outliers that affect performance.
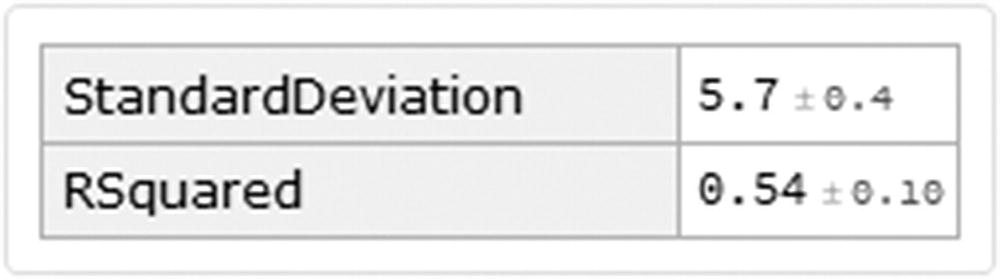
Standard deviation and r-squared values
This gives us a slightly high RMSE value and not a good r-squared value. Remembering that the value of r squared indicates how good the model is for making predictions. These two values would indicate that although there may be a linear relationship between the number of rooms and prices, this is not necessarily explained by a linear regression. These observations are also consistent, remembering that we obtained a correlation value of 0.7.
Model Assessment
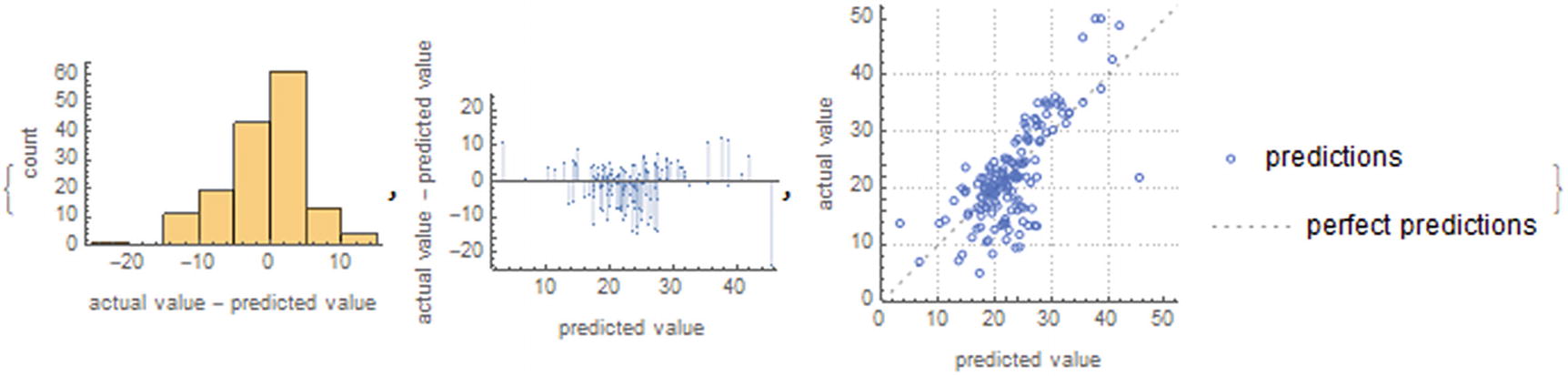
ResidualHistogram, ResidualPlot, and ComparisonPlot
As we can see, there are terms such as L1Regularization, L2Regularization, and OptimizationMethod. The first two terms are associated with regularization methods, and L1 refers to the Lasso regression name and L2 to the Ridge regression name. Regularization is used to minimize the complexity of the model, in addition to reducing the variation; it also improves the precision of the model, solving problems of overfitting. This is accomplished by adding a penalty to the loss function; this penalty is added to the sum of the absolute value of the coefficient 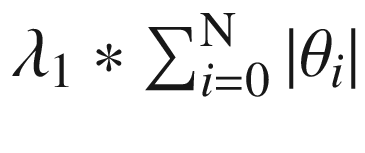 , whereas for L2, it is given by the expression
, whereas for L2, it is given by the expression 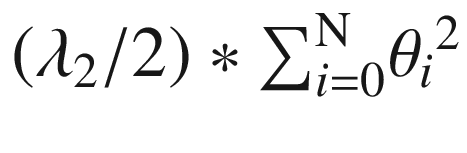 , where the function to minimize is the loss function
, where the function to minimize is the loss function 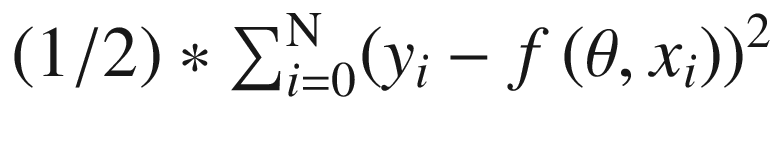 . For more mathematical depth, visit Artificial Intelligence: A Modern Approach. by Stuart Russell and Peter Norvig (2010 Upper Saddle River, NJ: Prentice Hall) and An Introduction to Statistical Learning: With Applications in R by Gareth James, Trevor Hastie, Robert Tibshirani, and Daniela Witten (2017; 1st ed. 2013, Corr. 7th printing 2017 ed.: Springer). The third term is the option of which optimization method we want to choose; the existing methods are NormalEquation, StochasticGradientDescent, and OrthantWiseQuasiNewton. That said, it must be emphasized that when using the vector of coefficients with the L1 and L2 standards, this is known as an Elastic Net regression model. Elastic Net might be used in circumstantces when there is correlation in the parameters. For more theory, use the next reference, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition by Trevor Hastie, Robert Tibshirani, and Jerome Friedman(2nd 2009, Corr. 9th Printing 2017 ed.: Springer).
. For more mathematical depth, visit Artificial Intelligence: A Modern Approach. by Stuart Russell and Peter Norvig (2010 Upper Saddle River, NJ: Prentice Hall) and An Introduction to Statistical Learning: With Applications in R by Gareth James, Trevor Hastie, Robert Tibshirani, and Daniela Witten (2017; 1st ed. 2013, Corr. 7th printing 2017 ed.: Springer). The third term is the option of which optimization method we want to choose; the existing methods are NormalEquation, StochasticGradientDescent, and OrthantWiseQuasiNewton. That said, it must be emphasized that when using the vector of coefficients with the L1 and L2 standards, this is known as an Elastic Net regression model. Elastic Net might be used in circumstantces when there is correlation in the parameters. For more theory, use the next reference, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition by Trevor Hastie, Robert Tibshirani, and Jerome Friedman(2nd 2009, Corr. 9th Printing 2017 ed.: Springer).
Retraining Model Hyperparameters
To see the properties related to an example, type properties after the input data for the Predictorfunction—for example, PF2[“example”, “Properties”].
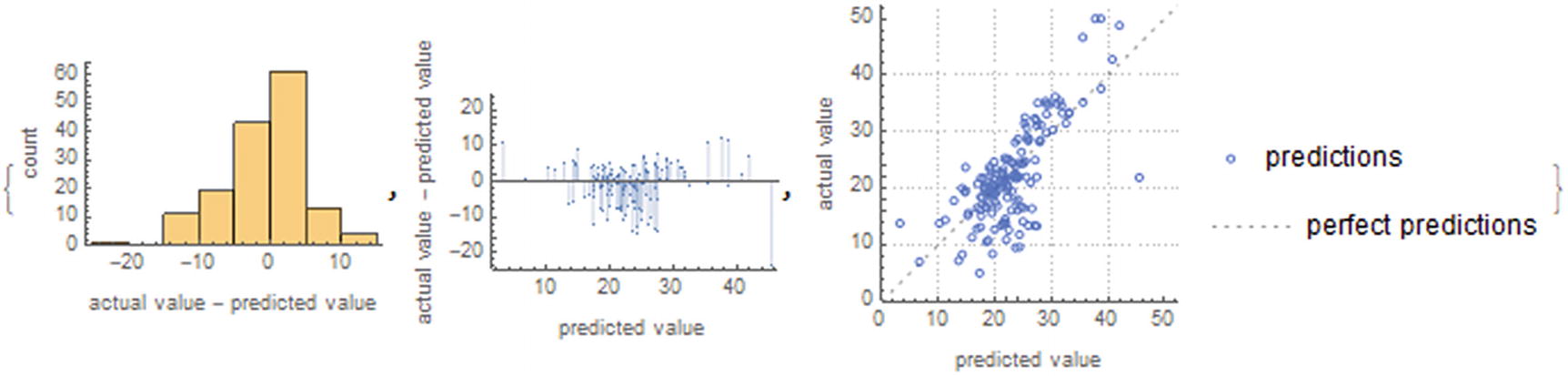
Plots of the retrained model
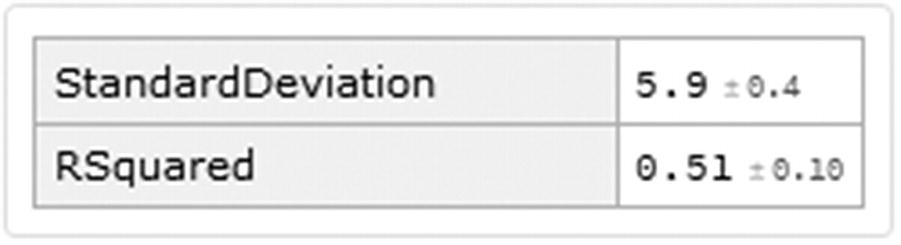
New values for RMSE and r squared
Making observations in the graphs, we see the model merely decrease to a certain degree; this agrees with the new value of r squared, which decreases to 0.51. However, it is still a poor model when it comes to making future predictions. This can be attributed to the optimization choice, the L1 and L2 parameters choice.
Logistic Regression
Logistic regression is a technique commonly used in statistics, but it is also used within machine learning. The logistic regression works considering that the values of the response variable only take two values, 0 and 1; this can also be interpreted as a false or true condition. It is a binary classifier that uses a function to predict the probability of whether or not a condition is met, depending on how the model is constructed. Usually, this type of model is used for classification, since it has the ability to provide us with probabilities and classifications, since the values of the logistic regression oscillates between two values. In logistic regression, the target variable is a binary variable that contains encoded data. For further view visit Introduction to Data Science: A Python Approach to Concepts, Techniques and Applications by Laura Igual, Santi Seguí, Jordi Vitrià, Eloi Puertas, Petia Radeva, Oriol Pujol, Sergio Escalera, Francesc Dantí, and Lluis Garrido (2017 ed.: Springer).
Titanic Dataset
For the following example we will use the titanic dataset , which is a dataset that describes the survival status of the passengers. The variables used are class, age, sex, and survival condition. We will load the data directly as a dataset (Figure 8-16) from the ExampleData and enumerate the rows of the dataset.
This section will be entirely constructed with the use of Query language so that the reader can understand how to use it more deeply inside datasets.
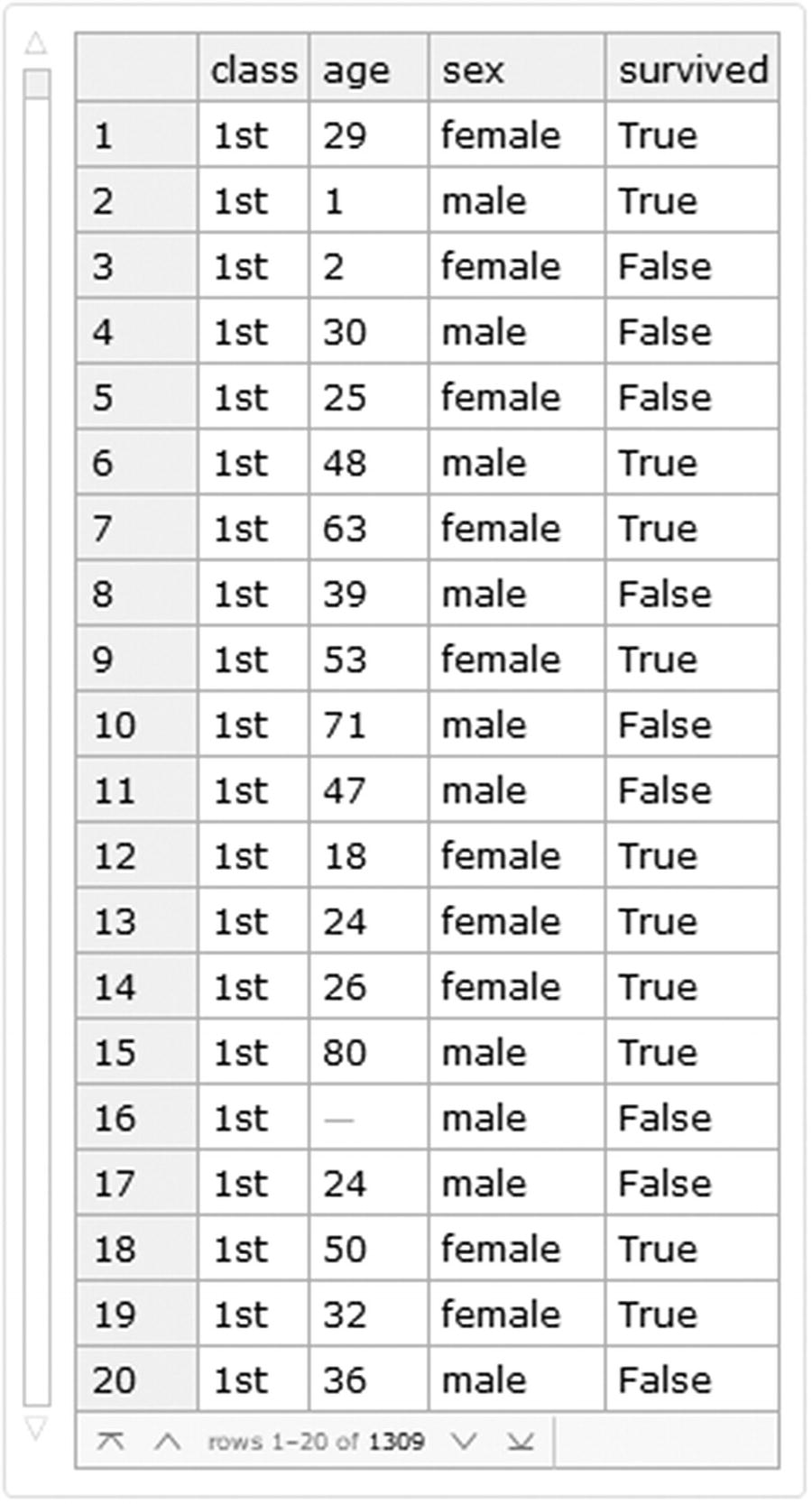
Titanic dataset

Titanic dataset without missing values
This means that there is no content associated with key 16. If you want to check all keys, use the row list of the missing data.
Data Exploration
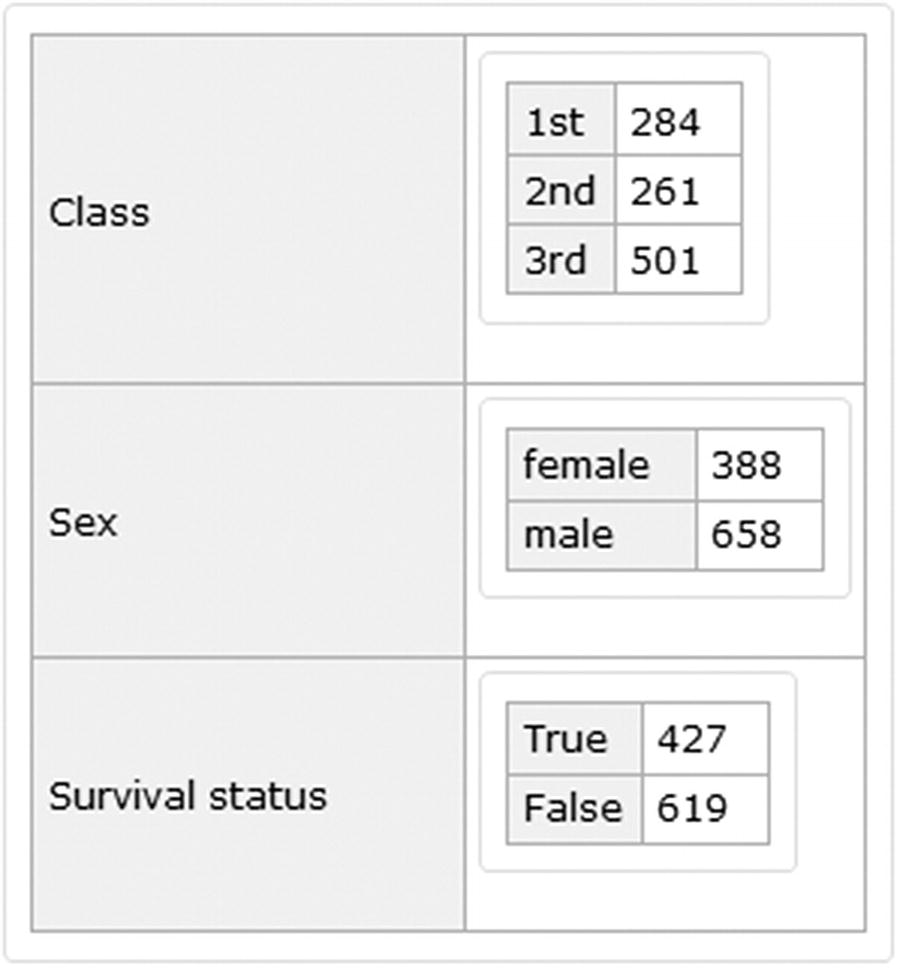
Basic elements count for class, sex, and survival status

Pie charts for class, sex, and survival status
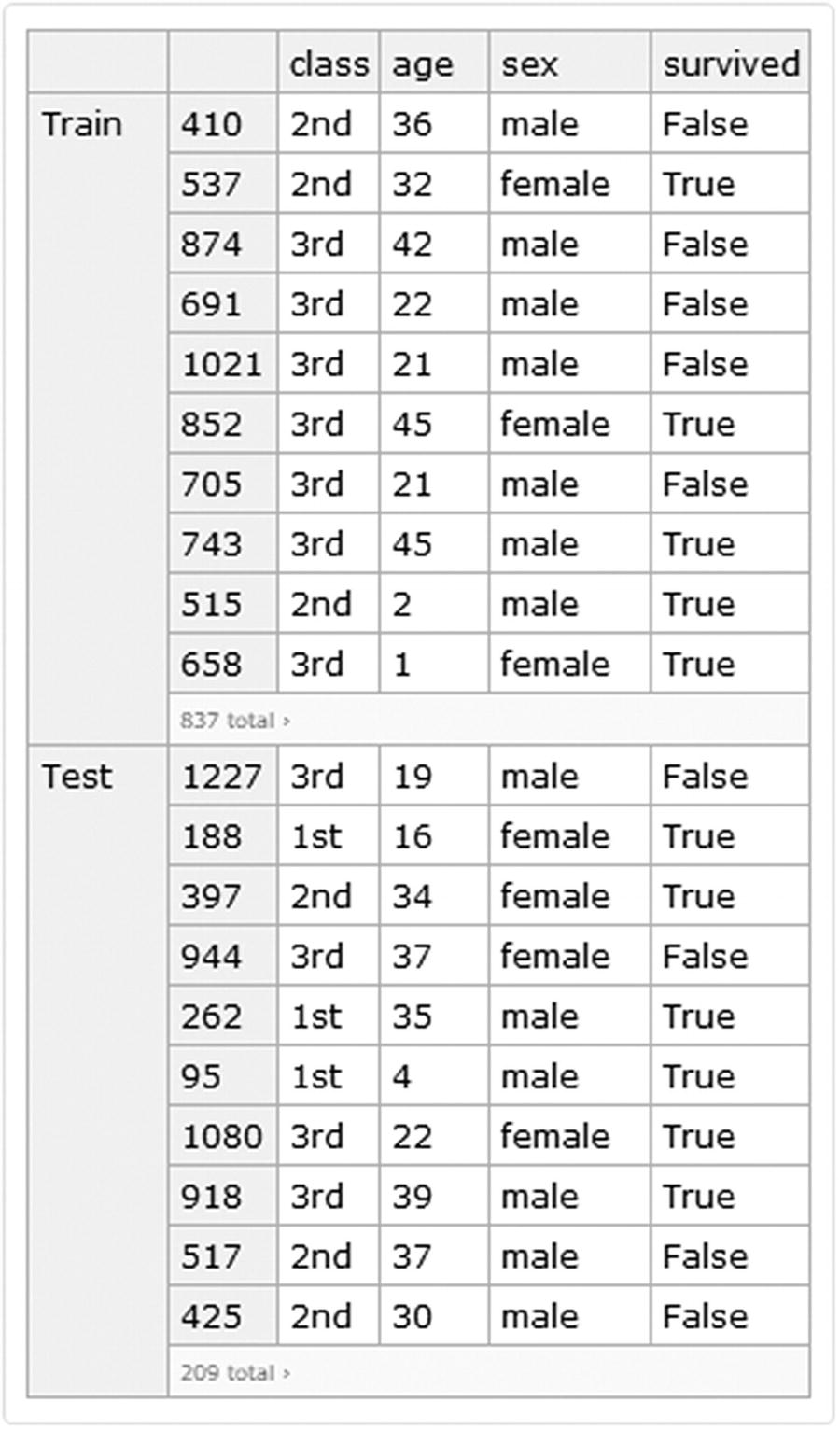
Titanic dataset divided by train and test set
Classify Function
The Classify command is another super function used in the Wolfram Language machine learning scheme. This function can be used in tasks that consist of solving a classification problem. The data that this function accepts are numerical, textual, sound, and image data. The input data of this function can be in the same way as with the Predict function {x → y}. However, it is also possible to enter data as a list of elements, as an association of elements, or as a dataset. In this case we will introduce it as a dataset.
In this case we will extract the data from the dataset format by specifying that the columns input (class, age, sex) pointing to the target (survived). Now let’s build the classifier function (Figure 8-21), with the following options, Method → {LogisticRegression, L1 → Automatic, L2 → Automatic}. When choosing Automatic, we let Mathematica choose the best combination of L1 and L2 parameters. For the OptimizationMethod set the StochasticGradientDescent method. And for performance goal set Quality. Finally, choosing a seed with a value of 100,000 and the CPU unit as the target device.

ClassifierFunction object

Information about the trained classifier function
If you click the arrows above the graphs, three plots will be shown: Learning curve, Accuracy, and Learning curve for all algorithm. If you hover the pointer over the line of the last one, a tooltip appears with the corresponding parameters along with the method used, as shown in Figure 8-23.
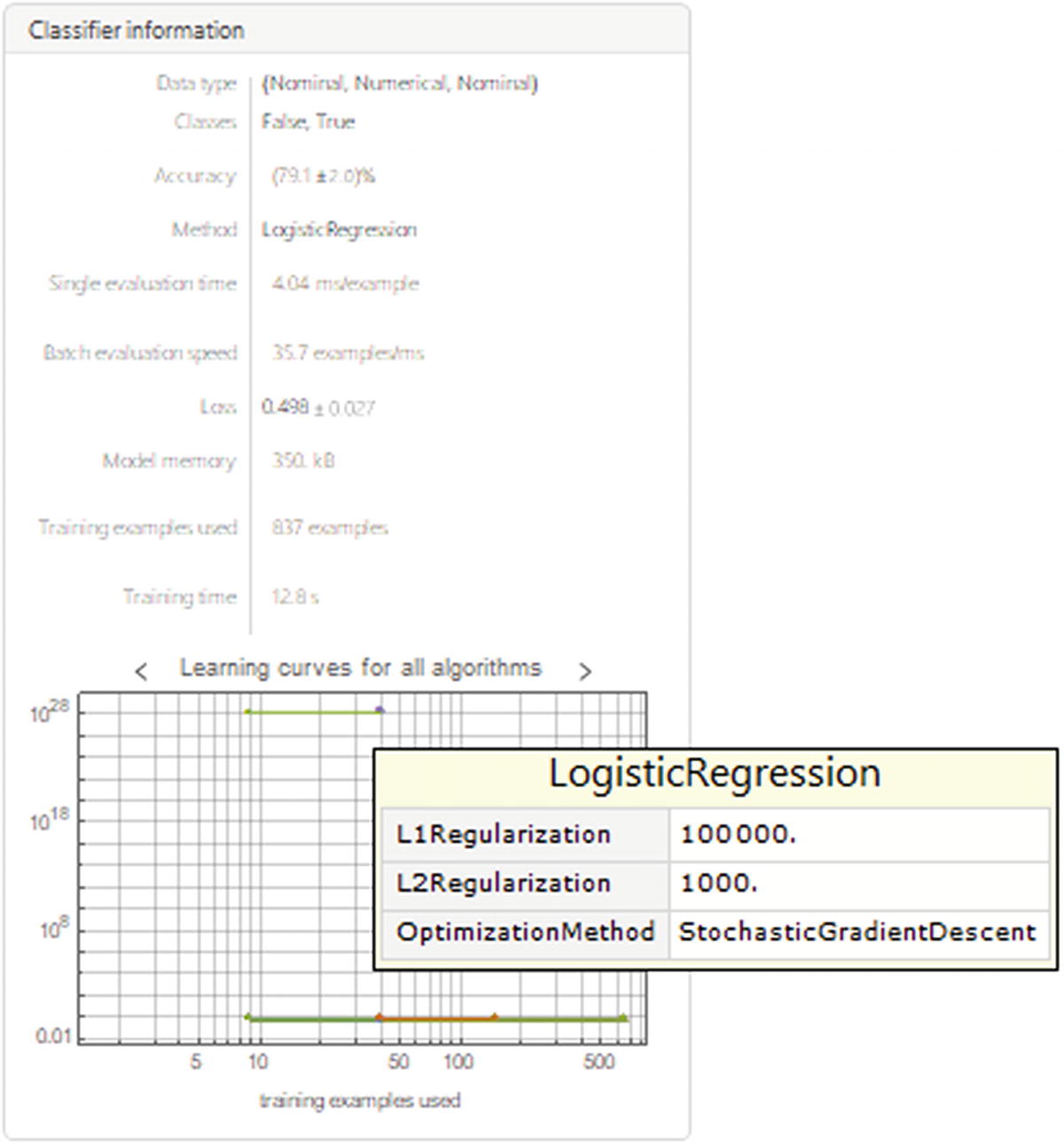
Algorithm specifications tooltip from the method logistic regression
Depending on the method used, properties may vary.
The probabilities of the latter example show that survival status of the passenger may be more inclined to the False status.
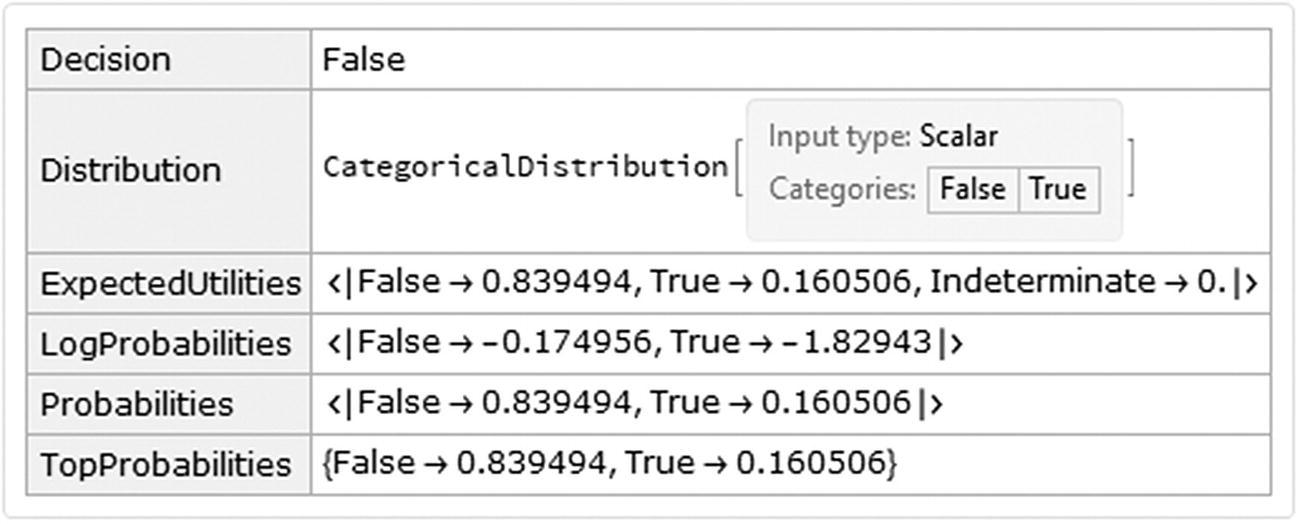
Properties for the classifier function of the trained model
To check the logarithm result, use the Log command, Log[“base”, “number”].
Testing the Model

ClassifierMeasurements object of the classifier function
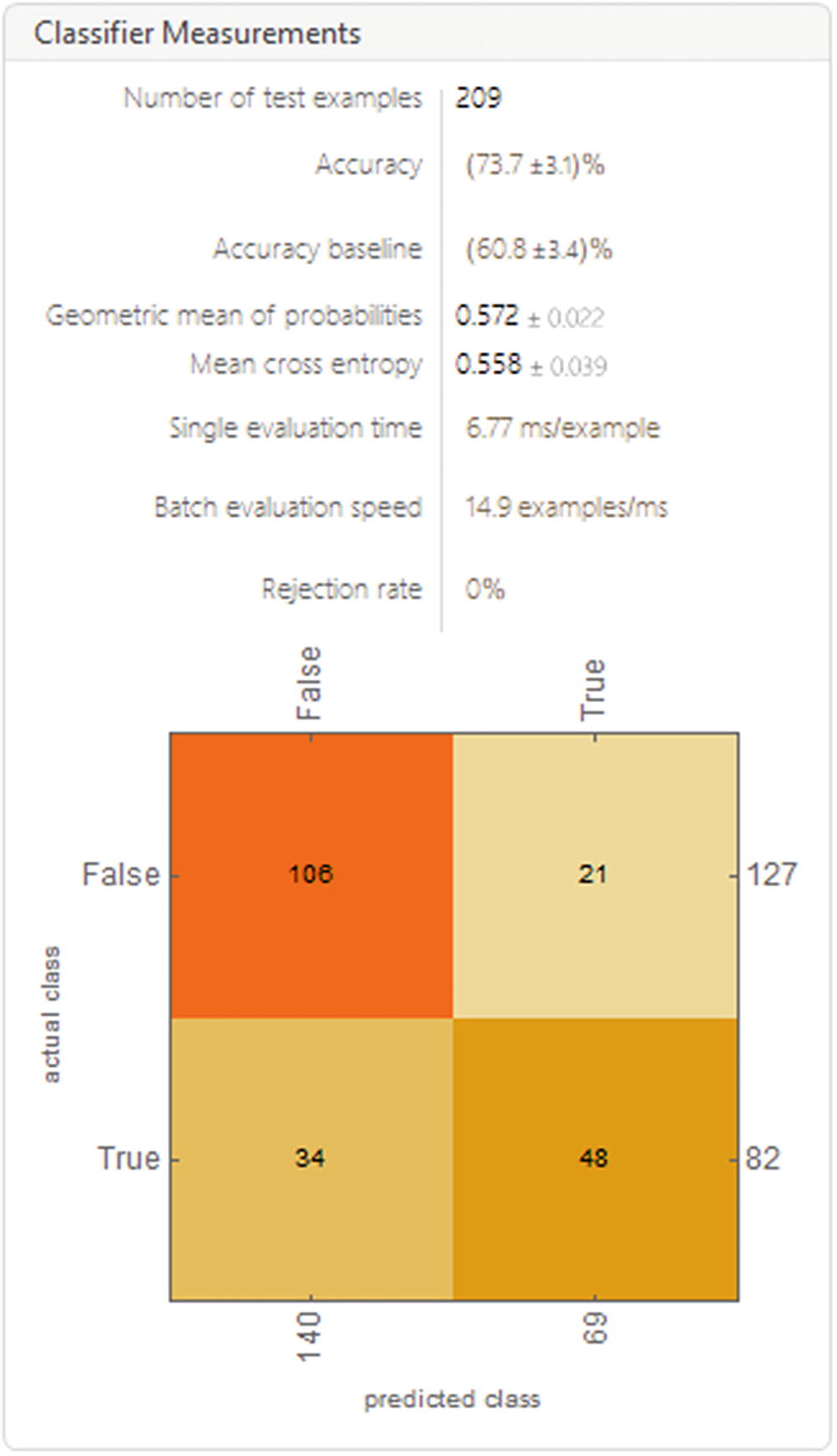
Report of the tested model
The report seen in the figure shows information such as the number of test examples, the accuracy, and the accuracy baseline, among others. It also shows us the confusion matrix, which shows us the prediction results for the classification model, showing the number of correct and incorrect predictions; these being broken down by class in this case return either false or true, which gives us an idea of the errors the model is making and the type of error it is making. Basically, it shows us the true positives and true negatives and false-positives and false-negatives for each class.
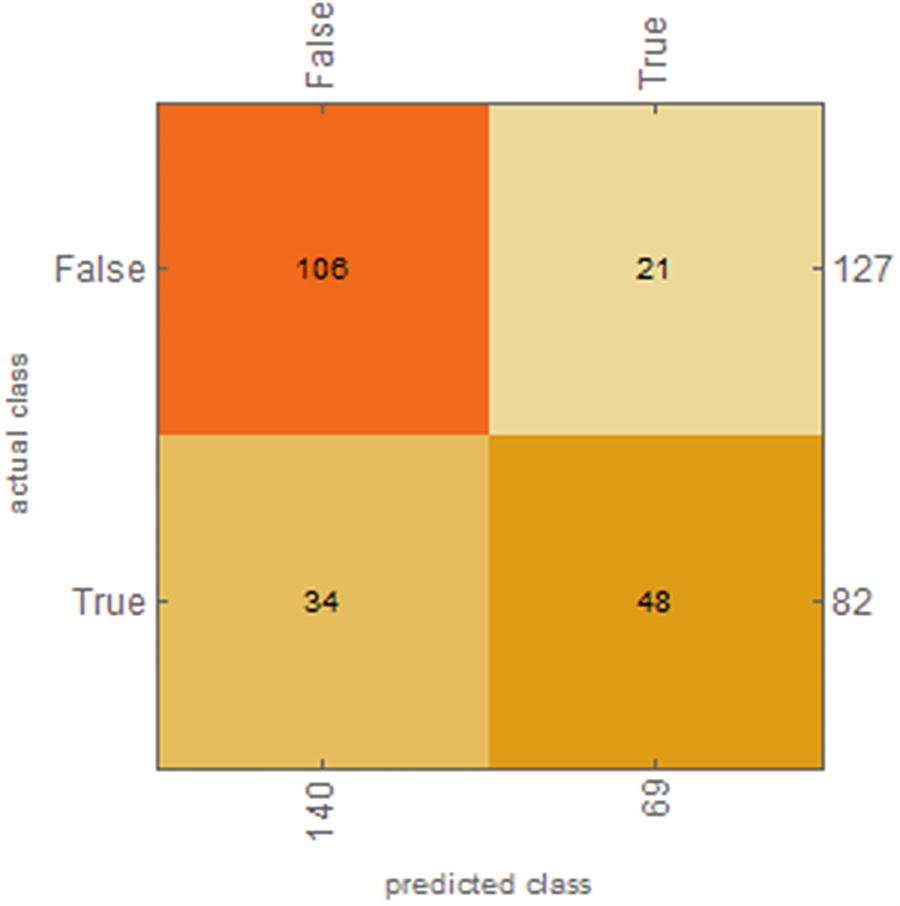
Confusion matrix plot of the tested model
To get the values of the confusion matrix, use CM[“ConfusionMatrix”] or class CM[“ConfusionFunction”].

ROC curves for each class along with AUC and MCC values

TableForm for the values of Accuracy, Recall, F1Score, Precision, and AccuracyRejectionPlot
To see related metrics about the accuracy, type the following properties: Accuracy (number of correctly classified examples), AccuracyBaseline (accuracy of predicting the common class), and AccuracyRejectionPlot (ARC plot, accuracy rejection curve). However, to find information about probability and the predicted class of the test set, use the following properties: DecisionUtilities (value of the utility function for every example in the test set), Probabilities (probabilities for every example in the test set), and ProbabilityHistogram (histogram of class probabilities).

Probabilities of each class, depending on the class, age, and sex
In the graphs shown in Figure 8-30, clearly it is seen that the probability of survival decreases for males as the age goes up, to even hit values below 20% of chance, whether 1st, 2nd, and 3rd class. This is contrary to the probability of survival for females, where it starts with values above 60% of chance and decreases as age increases too, hitting values above 50% for 1st class.
Data Clustering
The data clustering method is a type of unsupervised learning, as referenced by M. Emre Celebi, and Kemal Aydin in Unsupervised Learning Algorithms (2018; Softcover Reprint of the Original 1st 2016 ed. ed.: Springer). It is generally used to find structures and characteristics of data clusters, where the points to be observed are divided into different groups by which they are compared based on unique characteristics.

2D scatter plot of random data
Clusters Identification

2D scatter plot of the three clusters identified
As we can see, Find Clusters automatically found the clusters and colored them. To explicitly establish the number of clusters to search, we add the desired number as the second argument—that is, in the form FindCluster [“points”, “number of clusters”]. In the previous example we set the method option to automatic. The different methods for finding the clusters are shown here. Agglomerate (which is the algorithm of single linkage clustering), density-based spatial clustering of applications with noise (DBSCAN), NeighborhoodContraction (nearest-neighbor chain algorithm), JarvisPatrick (Jarvis[Dash]Patrick clustering algorithm) , KMeans (k-means clustering), MeanShift (mean-shift clustering), KMedoids (k-medoids partitioning), SpanningTree (minimum spanning tree clustering), Spectral (spectral clustering), and GaussianMixture (Gaussian mixture model).
Choosing a Distance Function
In addition to the method option, there is also the DistanceFunction
, which was given the value of Automatic. This option is used to define how the distance between the points is calculated. In general when we choose automatic, the square Euclidean distance is used ( ∑ (yi − xi)2, SquaredEuclideanDistance). There are also other values for the distance function, EuclideanDistance 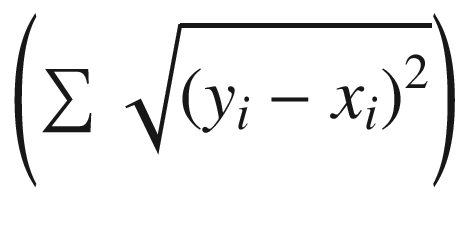 , ManhattanDistance (∑|x _ {i} − y _ {i}|), ChessboardDistance, or ChebyshevDistance (max(|x _ {i} − y _ {i}|)), among others.
, ManhattanDistance (∑|x _ {i} − y _ {i}|), ChessboardDistance, or ChebyshevDistance (max(|x _ {i} − y _ {i}|)), among others.
 , which can be interpreted as the average of the points. For the calculation, we extract the data from each cluster and calculate its arithmetic mean.
, which can be interpreted as the average of the points. For the calculation, we extract the data from each cluster and calculate its arithmetic mean.
2D scatter plot of the three clusters identified with their respective centroids
To make sure the first cluster corresponds to the red points, try using ListPlot to plot the points contained in Clusters[[1, All]], as well as those in the second cluster (blue) and third cluster (green).

2D scatter plot of the three clusters identified with their respective centroids
Identifying Classes
The command returns us that class one contains 174, class two contains 132, class three contains 144. One point to clarify is that why the clusters identified with FindClusters and ClusteringCompnents defer. Well, this is because by setting the automatic option in the distance function, we are telling Mathematica to find the optimal distance function. And depending on the data one function might gather elements in different forms as we will see later on.
K-Means Clustering
At the moment we have seen how to search for clusters in a generic way. In this part we will focus on the K-means method.
The K-means is a technique to find and classify groups (k) of data so that the elements that share similar characteristics are grouped together and in the same way for the opposite case (not similar characteristics). To distinguish whether the data contain similarities or not, the method calculates the distance between the data with respect to a centroid. The elements that have less distance between them will be those that share similarities. This technique is carried out as an iterative process in which the groups are adjusted until they reach a convergence. Basically, the K-means method, which is a simple algorithm, consists of making a classification by means of specific partitions, in different groups, where each point or observation belongs to the group. Clustering is done by minimizing the sum of the distances between each object and the centroid of its group. The k-means clustering technique tries to build the clusters so that they have the least variation within a group. This is done by minimizing the expression  , where Ci represents the i-th cluster, xj represents the points, and ?? represents the centroid of each cluster Ci. The square term of the function is the distance function; the most used is the square Euclidean distance, as in this case. To learn more about the mathematical foundation behind this technique, consult the reference An Introduction to Statistical Learning: With Applications in R by Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. (1st ed. 2013, Corr. 7th printing 2017 ed.: Springer).
, where Ci represents the i-th cluster, xj represents the points, and ?? represents the centroid of each cluster Ci. The square term of the function is the distance function; the most used is the square Euclidean distance, as in this case. To learn more about the mathematical foundation behind this technique, consult the reference An Introduction to Statistical Learning: With Applications in R by Gareth James, Daniela Witten, Trevor Hastie, and Robert Tibshirani. (1st ed. 2013, Corr. 7th printing 2017 ed.: Springer).
Dimensionality Reduction

DimensionReductionFunction object
This calculates the variance of each component , followed by the total to find the proportion of variance explained. Observing that PC1 seems to represent 76% of the data dispersion, and PC2 seems to represent 23%. To obtain the accumulated percentage we add the variations of each component. To view more depth about the proportion of variation refer to An Introduction to Statistical Learning: With Applications in R (James, G., Witten, D., Hastie, T., & Tibshirani, R. ; 1st ed. 2013, Corr. 7th printing 2017 ed.: Springer).

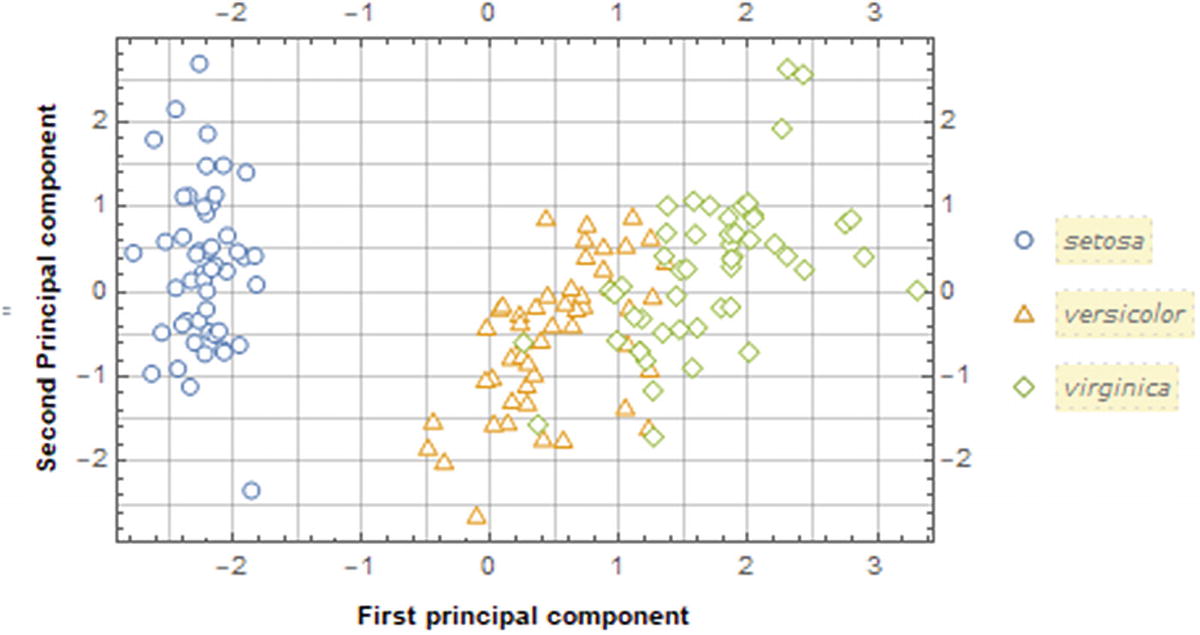
Scatter plot of the two principal components
Applying K-Means
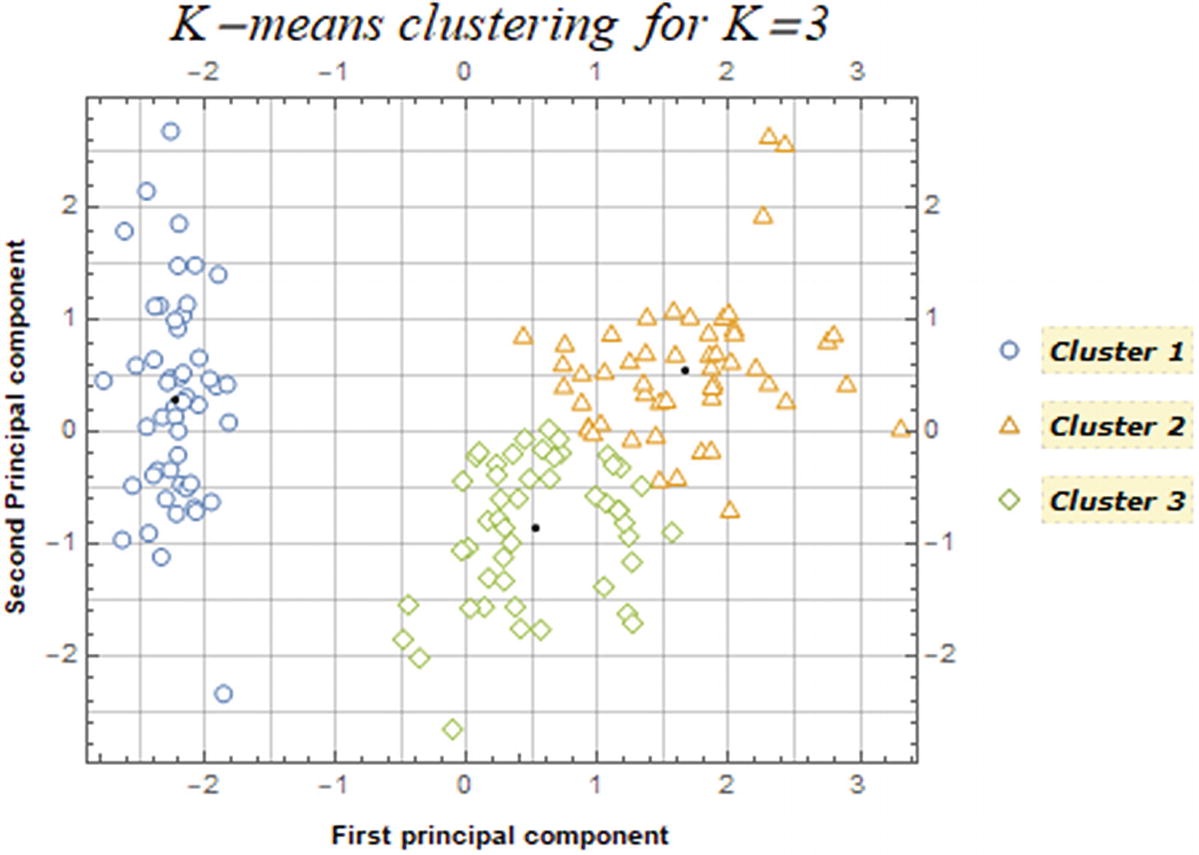
3 clusters identified of the two principal components
In Figure 8-37, it appears that the method clearly identifies the left points as a single cluster (setosa specie), whereas some of the points between clusters 2 and 3 might be misclassified.
Chaining the Distance Function

K-means clustering for K = 3, for different distance functions
As seen in Figure 8-38, the clusters can have different arrangements with different distance functions; one thing to note also is that the clusters centroids change in each of the subfigures (Figure 8-38).
Different K’s

K-means for K from 2 to 5
The spread, or how far apart the points are. This is reflected if the data contains outliers, which can be erroneously classified as part of a cluster, when visually the opposite is observed.
The dimensionality of the data. Given that more information and features are often added to the model, the number of dimensions grows. This type of problem can be solved using data transformation methods, as in the example seen from PCA, but with some restrictions, since the PCA method can have a loss of sensitive information on the features.
The value of k is determined manually, but when there are high values of the cost function, it can be interpreted that the intervariation of the clusters is high, and with low values of the cost function the intervariation of the clusters is low. The last two assumptions can also be attributed to the fact that for lower values of k, many observations can be grouped into large individual clusters, and for high values of k observations they can be a proper group.
Cluster Classify

ClassifierFunction of the cluster classification model
Getting the classifier function (Figure 8-40), we can see the details of the classifier, and we can see the input vector is a numerical vector, the number of classes (three), the method, and the number of training examples.
To correctly use the -means method, the number of clusters needs to be specified; otherwise the command will not execute correctly.
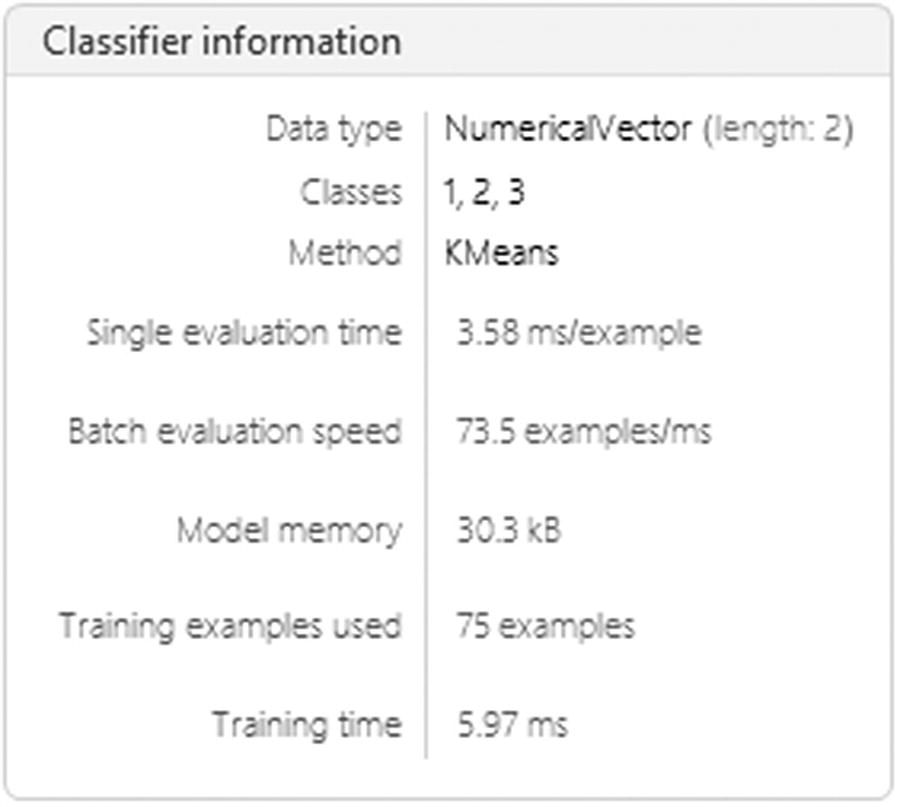
Classifier information for K-means
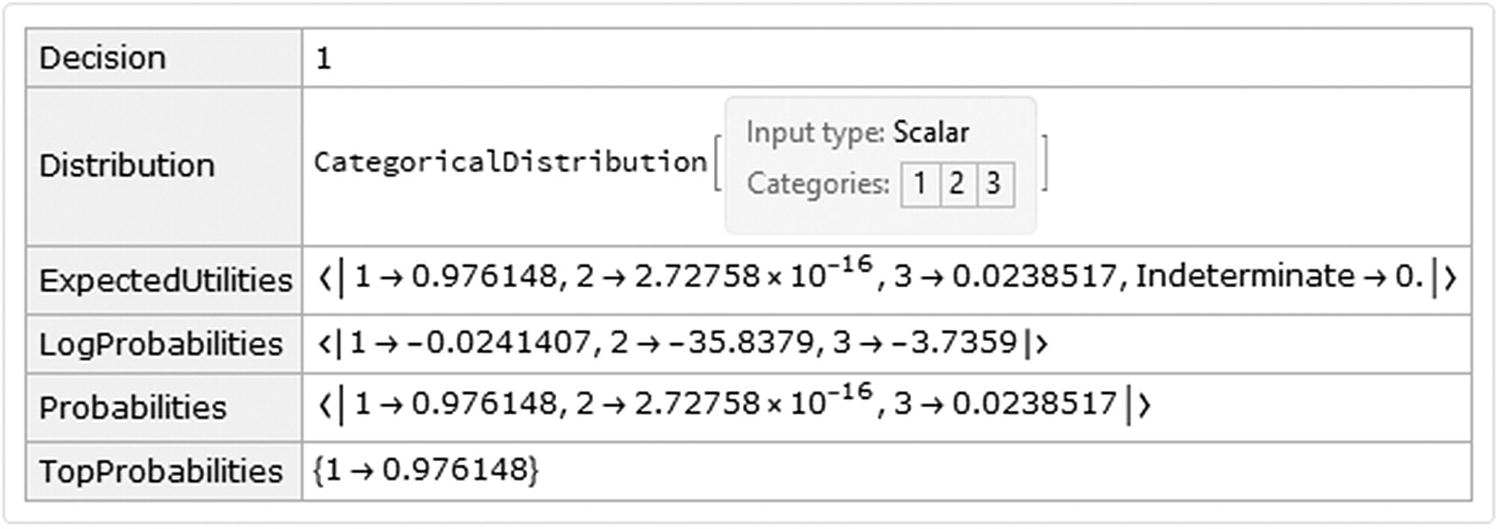
Dataset of the simple example
We can see that the example belongs to the third cluster and that the associated probability is 1 → 0.976148. Let’s look at the rest of the data and plot the cluster classification.

Cluster classification on the example of the iris data for the first two features

Cluster classification on the example of the iris data for the first two features with a probability restriction