
Chapter 3
Formalizing Examples into Scenarios
We prefer to separate the discovery step of BDD from the formalization and automation steps. Many teams get bogged down in trying to formalize examples too soon, rather than separating that out as a later task that can then be reviewed by the team.
Generating examples should be divergent and exploratory. As the team generates examples, the shape of the desired behavior emerges.
Formalizing examples is convergent. The team takes a single example and converges on a single precise set of words to describe it.
Rushing to formalization too quickly skips over important divergence and exploration.
In this chapter, we look at how to formalize examples into Cucumber scenarios using Cucumber’s Gherkin language.
Moving from Examples to Scenarios
Feature Files as Collaboration Points
As we begin formalizing examples, BDD begins to look more like testing. Let’s see how it relates to other testing activities. In Agile Testing, Lisa Crispin and Janet Gregory described a model for thinking about the various kinds of testing in Agile software development, which they called the “Agile Testing Quadrants,” shown in Figure 3-1.
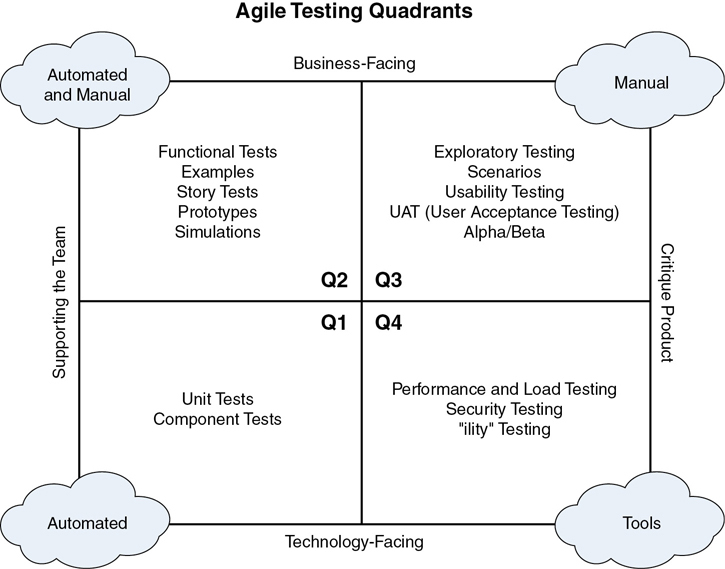
Figure 3-1 The Agile Testing Quadrants
The vertical axis in this model describes whose perspective is taken in the tests. Business-facing tests are tests from the business or customer perspective. They ask questions about whether the system does the functions it ought to do. Technology-facing tests are tests from the developer or team perspective. They ask questions about the implementation: Does the code do what developers intend? Does the system perform well? Is it secure? Of course, customers care about things like performance, but they rarely understand performance tests, and the tests often depend on knowledge of implementation details.
The horizontal axis in the model describes when tests are executed relative to development and what function they serve. Tests that critique the product look at something that already exists in order to ask questions about what it does or how it does it. This is what we traditionally think of as testing. On the other side, tests that support the team are tests used to drive development. These tests are written before the software that will make them pass. They act as specifications for features and code.
As we saw in the dialogue, creating an initial draft of a feature file is the first step toward formalizing the examples harvested from the team conversations. As the team talks about the business domain, they seek to understand what the behavior of the system should be in response to the customer’s needs. They distill these examples into scenarios in the feature file.
Such examples provide structure and focus to specification, but that’s only half the story: Those examples become test scenarios so the team can get automated feedback about the state of the system.
Let’s look at how BDD with Cucumber relates to other kinds of testing an Agile team might do based on the Agile Testing Quadrants model.
Quadrant 1: Technology-facing tests that support the team: Quadrant 1 contains technology-facing tests that support the team as it develops the software. This is what we typically think of as test-driven development, or TDD. In TDD, a developer writes a small unit test describing the next bit of code she’d like to create. She runs the test and confirms that it fails, that it describes something not true of the code right now. Then, she writes just enough code to make the test pass. Assuming all previous tests continue to pass, she either refactors the code to improve its design without changing its behavior or writes the next failing unit test. Quadrant 1 tests are automated; they’re run many, many times in the course of development and must be fast and easy to use.
In the course of making a single Cucumber scenario pass, a developer using TDD will typically write many unit tests. TDD is a small loop inside the bigger BDD loop.
Quadrant 4: Technology-facing tests that critique the product: Quadrant 4 tests cover what are typically referred to as “nonfunctional requirements,” such as performance, security, scalability, and so on. These tests ask questions about a product or increment of product that already has been developed. Often, such tests require a dedicated, production-like test environment, making them difficult to execute during development. Nonetheless, teams should find ways to get this feedback early and often lest they discover a problem too late to do anything about it. Quadrant 4 tests may be automated. Even when they’re not automated, they’re typically tool-assisted.
Quadrant 4 tests usually address different concerns from Cucumber scenarios. Together, they describe the system more fully.
Quadrant 3: Business-facing tests that critique the product: This is the work typically done by people with “tester” or “QA” in their job title. They look at a product or product increment that already exists and ask questions about whether it does what it ought to do. They look for edge cases, boundary conditions, and defects. Quadrant 3 tests tend to be manual. They ask questions that were not anticipated by automated tests.
Failing Quadrant 3 tests often become new Cucumber scenarios to drive the necessary development to make those tests pass.
Quadrant 2: Business-facing tests that support the team: BDD fits in Quadrant 2. In Quadrant 2, tests address the behavior of the system from the business perspective. Unlike Quadrant 3 tests, however, Quadrant 2 tests are written before the code that makes them pass, and thus are used as a tool to write that code correctly. Quadrant 2 tests are executable examples acting as functional specifications.
Mapping Your Current Testing Activities
Consider the testing activities your team currently does. How do they map to the quadrants? Do you do any testing to support the team, or do all your tests critique the product? If your developers write unit tests but not until after the code exists, you don’t do Quadrant 1 tests—those unit tests aren’t supporting the team during development. If you’re like many Agile teams, you have decent coverage of Quadrant 3, some activity in Quadrant 4, occasional Quadrant 1, and nothing in Quadrant 2.
How Will Adopting BDD Affect Your Testing?
By adopting BDD, you will fill in more of Quadrant 2, allowing testers to do more interesting tests in Quadrant 3 and perhaps dedicate more time to Quadrant 4. In the process, you’ll be investing in creating a foundation and motivation for the adoption of developer-facing TDD to fill in Quadrant 1.
Quadrant 2 tests can create a foundation for moving into Quadrant 1. They build a safety net for the refactoring most teams need to do to make their code more testable in small units. They teach the test-first approach in a way that’s easy to understand, and they create motivation for more attention to be paid to Quadrant 1 because Quadrant 2 tests are inevitably larger and slower. Once teams become accustomed to automated tests supporting their development, they want faster, more granular tests. Eventually, each Quadrant 2 test will drive the development of multiple Quadrant 1 tests as part of developing the code.
In the dialogues, our library team is currently working on Quadrant 2 tests with Cucumber. The scenarios so far test the new ebook search behavior from the user’s perspective. In the next chapter, they’ll begin automating these scenarios. The automation will drive the library website, which is realistic but relatively slow. Raj and Robin might decide they want faster feedback on a part of the ebook search engine as they develop it. This will motivate them to create smaller, faster unit tests for themselves (Quadrant 1).
Growing Quadrant 2 Collaboration Capabilities
A feature file is a Quadrant 2 collaboration point; a springboard for conversation and discovery. The Quadrant 2 test automation that comes later is a nice side effect of growing these feature files as a species of “living documentation.” This is in contrast to a test plan, which is typically a step-by-step description of how a particular feature is going to be verified as having the correct behavior.
The Perils of Misusing Cucumber
Cucumber is a Quadrant 2 collaboration tool. This means that scenarios ought to take the user’s perspective and developers ought to involve product people—business stakeholders, product owners, business analysts—in creating and reviewing scenarios.
Some teams make the mistake of using Cucumber exclusively as a Quadrant 1 developer-facing tool. This leads to unnecessary technical overhead, brittle and slow test scenarios, and eventually unmaintainable feature files. The value is simply not there when treating Cucumber as a developer-facing tool.
In “The World’s Most Misunderstood Collaboration Tool,” Cucumber creator Aslak Hellesoy acknowledges that Cucumber’s unique value is as a collaboration tool, not as a pure test automation tool:
There is a certain amount of ceremony involved with Cucumber. There is both Gherkin and Step Definitions to maintain. This can be justified if it improves collaboration and reduces misunderstandings, but if the tool is used in a vacuum those benefits will obviously never happen.1
The same is true when using Cucumber predominantly as a Quadrant 3 tool by employing the same test-after approach used in many enterprise test tools or other open-source automation tools like Selenium. In this case, scenarios tend to look like manual test plans. They describe how a tester would test a behavior rather than specifying what a user wants the behavior to be.
Teams Already Doing Lots of Quadrant 3 Testing
If your team does mostly Quadrant 3 testing, where the bulk of your testing is done (manual or automated) after the software has been written, what are your options? Some teams write detailed test plan documents for activities in this quadrant, whereas many teams take a more ad hoc approach. Some teams create many automated tests to verify the software after it has been written, while the vast majority of teams focus on manual testing. BDD with Cucumber has a place for each of these situations.
Jane writes test plans, which is unusual for most Agile teams. However, development teams working in heavily regulated industries, such as in medical device software development, are typically required by regulations to produce detailed documentation and to work within a higher-ceremony process. We find that, even in regulated environments, Cucumber features can frequently replace formal test plans and other artifacts like traceability matrices. (Development teams will often have to negotiate this change with their compliance people. A period of producing both test plans and Cucumber features for the same behavior might be necessary to prove that both artifacts do the same job for regulatory compliance.)
Rather than waiting to hand-write test plan documents after each new piece of functionality is ready to test and then manually testing the functionality, teams using Cucumber can collaboratively define the expected behavior using concrete examples in feature files, and the programmers can implement the functionality to make the scenarios pass. Rather than using a serial, manual, “throw functionality over the wall” process, coders and testers can work together to understand, implement, and verify the requirements.
Teams writing test plans after the fact typically benefit as testers begin to collaborate in all aspects of the development process, including specifying the product behavior, development, testing, and deployment. Testers bring a unique perspective and expertise that’s useful throughout development.
Teams taking a less formal approach by doing all their testing manually with no documentation at all may expect Cucumber to introduce more overhead. As we’ve mentioned, if they don’t also start doing BDD and using Cucumber as a collaboration tool, this is exactly what will happen. Feature files don’t replace manual testing; they supplement it. The subsequent test automation takes away much of the repetitive, manual work from testing, enabling testers to focus more attention on ensuring the whole team is “getting the software right.”
Feature files don’t replace manual testing, and teams may still get value from writing some test plans to augment the feature files by describing things that must be tested manually due to high overhead or complexity in test automation. We’re not saying teams with a more ad hoc specification and testing approach should be writing test plan documents but rather that feature files serve double duty as executable specifications, providing a greater level of rigor for teams currently lacking more rigorous testing efforts.
Another thing to keep in mind is that because feature files are plain text, it is common for teams to store them in their version control system (that is, Subversion, Mercurial, or Git) as part of their source code, giving the team a full version history. This enables teams to document and track changes to their executable documentation and collaborate on changes should there ever be merge conflicts.
Describing Features
Some teams prefer to have the feature description be in the common user story format, “As a [role], I want to … etc.,” rather than a free-form description of the feature. Capturing who, what, and why for a feature is a good idea. However, Cucumber features aren’t user stories; Cucumber features are living documentation of a set of behaviors in the system. A single feature may grow and change over the course of many user stories.
To avoid confusion between Cucumber features and user stories, simply describe the feature. Treat the feature file as living documentation and incorporate the documentation of the feature into the actual feature file. If you can, include information on the user’s role and the benefit or driver for the feature. Also provide any background information on the feature that might be helpful, such as details about the business domain and definitions of any important domain terms.
Using MMFs with BDD Can Keep You from Generating an Excess of Examples
Notice that the team decided to throw away an example instead of adding it to the feature file as a new scenario. That example was not part of the MMF they were working on, so the team was able to postpone covering that example and refocus on the work at hand. Remember, MMFs are a tool to get earlier value and feedback. To achieve this benefit, MMFs need to stay minimal.
Some teams find it difficult to restrict their conversations to appropriate examples, not having a sound understanding of whether they should be digging in to it. Someone proposes an example, with perhaps “what if…happens?” and the team spends an inordinate amount of time digging into a case that ultimately could be deferred until later. MMFs provide a way to avoid that situation. The person facilitating the conversation can say something like, “That sounds like a case we’ll definitely need to cover, but it’s not part of this MMF. Let’s put it on our parking lot or backlog and cover it later.”
Collaborating for Understanding
Someone might say, “This team seems to spend a lot of time in meetings. When do they get the actual work done?” It’s easy to think that typing code into an editor is the actual work of software development and that everything else around it is a distraction from the work. Compounding that perception is the fact that many software developers are much more comfortable spending time with their computers than with other humans, so the coding part of the work also feels more pleasant.
The work of a software development team isn’t creating software, it’s solving people’s problems with software. Thus, understanding the problem and how to best solve it is a critical part of the work. The meetings you’re seeing from the library team in this book are cross-functional collaboration, at the center of what the team’s trying to accomplish.
This is not to say that all meetings are valuable. Meetings have gotten a bad rap for good reason: There are lots of wasteful, ineffective meetings.
In some organizations, we noticed that the word meeting specifically refers to the bad kind of meeting. You might see this in a Daily Scrum. If someone says, “Yesterday, I went to the meeting,” they probably consider that wasted time. If it was valuable, they’ll say something like, “Yesterday, I worked with Ann and Ramu to flesh out the user experience.” Objectively, that collaboration happened in a meeting, but because meeting has come to mean wasting time with other people in a conference room, good meetings are remembered as just getting stuff done.
That’s fine, we have no attachment to the word meeting, but we sure see a lot of value in people collaborating to build the right software. In this book, we’ve tried to illustrate what that collaboration might look like.
In particular, take note of how each meeting has a clear purpose, how it stays focused on that purpose, and how the team transitions between larger and smaller conversations depending on what they’re doing.
BDD Is Iterative, Not Linear
In the previous dialogue Sam confused different mindsets and steps of BDD with phases. He wanted to work on the feature file once, polish it, and move on. There’s a temptation, particularly for development teams used to a waterfall software lifecycle, to mistake BDD for a linear process. They see that BDD involves exploration, formalization, and automation steps and mistake this for a serial process. However, this could not be further from the truth. The reality is that teams using BDD refine and improve their feature files over time as they explore and learn.
At any point, a team may switch from one step to another. They might be formalizing a scenario in their feature file and realize they need to jump back into exploration because they’ve uncovered a case they hadn’t thought about, and need to talk about examples to drive better understanding. The same thing can happen when automating scenarios. While automating one scenario, new scenarios might present themselves or further exploration of examples might need to happen.
It might be confusing in the dialogue where we had the team leave placeholders for the rest of the scenarios. Perhaps you’re wondering, “Shouldn’t we be trying to get the feature file correct and complete as soon as possible?” Most teams tend to create an initial cut of a feature file to use as a conversation starter, then iterate and refine it over time as they learn new things. For a well-understood domain, the first cut of the feature file might be sufficient. Some teams start with the first example and take it through the entire flow of formalizing it as a scenario, then automating the tests as they proceed to implement the actual production code.
Jonah says to “focus on the content for now rather than the syntax, format, or layout.” Does this mean Gherkin isn’t important? No, we’re not saying that at all. Gherkin is important, but there is a time and a place for formalization. Jonah dissuaded the team from formalizing the scenarios in this meeting because formalizing feature files as a group is a brain-numbing activity. It can feel like a group of people all writing an essay together. Better to take that offline, have one or two people work on it, and then return to present the results to the other participants to get their feedback on errors and omissions.
Robin and Raj tried the current catalog search and found a new scenario around “partial matches.” This is typical of the iterative rather than linear nature of BDD. As Robin and Raj were exploring the domain by investigating the current system functionality, they learned something new and incorporated it into their draft of the feature file as a reminder to review it with other team members to get clarity on it.
Finding the Meaningful Variations
Once you have the happy path scenario, how do you come up with the meaningful variations that will make your scenarios expressive and your user story complete without getting buried in noise?
There are some heuristics, a bit of art, and a lot of collaboration in making this work. We tend to go through a series of questions to ourselves like these:
Where are all the places where things could be different in the happy path? In other words, what are the variables/variations?
Which variable is most likely to change?
What’s an example of a change that causes a different outcome? What’s another change that causes a different outcome?
Where are the boundaries of that change? Explore both sides.
What could go wrong? Is there value for one of the variables that breaks something? What should happen?
Repeat for other variables.
Testers are particularly good at identifying possible variations, but you need the product owner perspective to evaluate whether a particular example is relevant and valuable. In exploratory testing, it’s great when testers consider variations no one else has thought of. However, because feature files function as living documentation of the behavior of the system, we don’t want to clutter that documentation with unlikely edge cases.
Occasionally, a variation is worth covering with an automated test but isn’t one the product owner cares about. Cover these variations with developer-facing unit tests.
Gherkin: A Language for Expressive Scenarios
Jonah advised the team early on not to worry too much about the syntax of the Cucumber language, called Gherkin, for feature files. We’re going to provide a guide to the Gherkin keywords and syntax, but first we’ll talk a little about what kind of language Cucumber speaks.
A pidgin language is a simplified language used for communication between two or more groups that do not have a common language. A key element of a pidgin language is that it develops for a particular shared goal across those language groups, usually trade. It’s not just a new language; it’s a new language optimized for a purpose. Cucumber’s language for describing features is called Gherkin, and Gherkin is a pidgin language for describing the behavior of a software system in a way both humans and their computers can understand.
Gherkin is a simplified language for programmers, testers, and product people to collaboratively describe examples of business scenarios and thus define the expected system behavior. Gherkin provides a small set of terms and sufficient structure to enable your team to write scenarios rich with business domain language with minimal effort. It’s neither a full-fledged programming language like Java nor a complete human language like English, and that’s intentional.
Feature Title and Description
Cucumber features always begin with the Feature keyword (or the equivalent in another human language) and a feature title. This can be followed by text describing the feature. This text can be whatever you like; for example:
Feature: Library patron account reinstatement following full fee payment When a library patron’s card is blocked she cannot check out or renew materials. Payment of all fees reinstates her account.
or as we saw in the dialogue above,
Feature: Search for an ebook by title Library patron searches library catalog for a specific ebook so she can read it on her Kindle
Cucumber treats any text between the feature title and the first Scenario or Back-ground keyword as the description.
Scenarios and Given-When-Then
The core of the Gherkin language is the scenario, a concrete example of a feature in action. Scenarios begin with the Scenario keyword followed by a title and are specified as a sequence of steps that each start with the keyword Given, When, Then, And, or But.
Scenario: Reinstate deactivated account Given a library patron owes $13.05 in unpaid fees and fines When she pays the full amount Then she should have no fines and fees And her library card should be unblocked
A When step describes the main action being taken in the scenario. There should be only one When step per scenario. A Then step asserts something about the state of the system after the When step changes the system state in some way. A Given step sets up the context required to execute the When step.
It’s common to see the same When step used for multiple scenarios in a feature alongside different Given and Then steps—taking the same action in a different context often yields different results. For example:
Scenario: Admins can edit catalog items Given I'm logged in as an administrator When I go to the catalog page Then I should see an edit link by each catalog item Scenario: Non-admins can't edit catalog items Given I'm logged in as a regular user When I go to the catalog page Then I should not see an edit link by any catalog item
The scenario title should be short, usually no more than five or six words, and it should express what makes this scenario different from the others in the feature. Test results will render the scenario titles under the feature title like an outline, so scenario titles need not repeat information already covered by the feature title.
Multiline String Step Arguments
Sometimes a step needs more data than can be provided on a single line. For example:
When I create a catalog item with the description: """ Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut et ipsum turpis, sodales convallis nulla. Vestibulum iaculis sodales felis in ultrices. Vestibulum dapibus lobortis facilisis. Nulla vel orci vel nulla mattis viverra. Nam vitae mauris mattis lectus pellentesque semper non eu diam. Aenean elementum nisi at dui iaculis semper. """
The three double quotes before and after the block of dummy Latin text indicate a multiline string step argument. This value will be passed as a last argument to the matching step definition. (Remember from the earlier dialogue, step definitions are the bits of code that run for each Gherkin step when you run the scenario.)
The colon at the end of the step isn’t required by Cucumber. It’s just a convention we like to use to tell human readers to keep reading for the rest of the step.
Table Step Arguments
Sometimes a step needs more data than can be provided on a single line, and that data can be structured into a table. For example:
Given the following library patrons: | Name | Email | | Chandra Khan | [email protected] | | Denise Jones | [email protected] |
Tables are indicated by pipe characters around the table cells. As with multiline string arguments, the table will be passed as the last argument to the matching step definition, but it will be a Cucumber table object rather than a string.
Sometimes it can be convenient to create a table representing key-value pairs, especially when you need to perform an operation that requires too much data to easily be represented in a sentence-like step. For example:
When I search for a catalog item with advanced search criteria: | Item Type | Book | | Subject | endangered species | | General Notes | history | | Author | McClung | | Publisher | Hamden |
Notice that this table has no header row; each row contains data. Or, more precisely, the table is rotated with headers in the left column and data in the right column.
Tables aren’t just useful for setting up data or performing complex operations. They are also good for Then steps where you want to assert about a set of data. The preceding book search step might be followed by a step like this:
Then the results should contain the following catalog item: | Title | Call Number | | LOST WILD AMERICA | Y591.529097 McClung |
Or it could use the key-value table format, depending on what is most expressive in the context of a particular set of scenarios:
Then the results should contain the following catalog item: | Title | LOST WILD AMERICA | | Call Number | Y591.529097 McClung |
Fortunately, we don’t need to compare the actual and expected values ourselves. Cucumber’s table object has a diff method, which will do the comparison and tell us about nonmatching, missing, and surplus values. Cucumber’s online documentation covers tables in detail.2
Gherkin provides a lot of flexibility when specifying data in your steps. For example, you could phrase the same step several different ways:
When I search for call numbers starting with Y591, Y592, Y593, Y594
or
When I search for call numbers starting with: | Y591 | | Y592 | | Y593 | | Y594 |
The first example works nicely if you have only a few values to pass through, while the second makes it easier to pass more values.
Background
When you find yourself reusing the same Given steps in every scenario, you can use a Background section to remove that duplication. Steps in the Background section run before each scenario, just as if they were part of every scenario in the feature. So, for example, the following:
Feature: Administrative functions
Scenario: Admins can edit catalog items
Given I'm logged in as an administrator
When I go to the catalog page
Then I should see an edit link by each catalog item
Scenario: Only certain catalog item fields are editable
Given I'm logged in as an administrator
When I edit a catalog item
Then I should see the following fields:
| Item Type |
| Subject |
| General notes |
| Author |
| Publisher |
becomes
Feature: Administrative functions
Background:
Given I'm logged in as an administrator
Scenario: Admins can edit catalog items
When I go to the catalog page
Then I should see an edit link by each catalog item
Scenario: Only certain catalog item fields are editable
When I edit a catalog item
Then I should see the following fields:
| Item Type |
| Subject |
| General notes |
| Author |
| Publisher |
and runs exactly the same.
Scenario Outlines
When you find yourself reusing the same steps with different data in multiple scenarios, a Scenario Outline block is a great way to remove the duplicated steps and put the focus on the variations in data.
The following scenarios differ only in their data:
Scenario: Search for "BDD with Cucumber" Given I'm on the catalog search page When I search for "BDD with Cucumber" Then I should see "Lawrence and Rayner" in the results Scenario: Search for "cucumber" Given I'm on the catalog search page When I search for "cucumber" Then I should see "Cool as a Cucumber" in the results Scenario: Search for "gherkin" Given I'm on the catalog search page When I search for "gherkin" Then I should see "Origami City: Fold More than 30 Global Landmarks" in the ➥ results
Combining the three scenarios into a scenario outline makes the repeated structure and variations in data more clear:
Scenario Outline: Search Given I'm on the catalog search page When I search for "<query>" Then I should see "<expected result>" in the results Examples: | query | expected result | | BDD with Cucumber | Lawrence and Rayner | | cucumber | Cool as a Cucumber | | gherkin | Origami City: Fold More than 30 Global Landmarks |
For each body row in the examples table, Cucumber replaces the placeholder values in the scenario outline (that is, <query>) with the corresponding values from the table before executing the scenario normally. (No change to the matching step definition is required.)
A scenario outline can be followed by multiple example tables, and tables can have a title. This can be a useful way to group examples and highlight important differences in data.
Use caution with scenario outlines, however. We recommend using them only when you have multiple regular, concrete scenarios that reveal a pattern. Programmers often reach for scenario outlines too early and end up creating features that are unreadable by nonprogrammers. In fact, most scenario outlines we’ve seen in the wild really shouldn’t exist—concrete scenarios would be much more expressive.
Summary
Separate the discovery step of BDD from the formalization and automation steps. Discovery is divergent and exploratory. Formalization is convergent.
It’s often best to formalize a first draft of a scenario with just a couple people and review it with a larger group than to try to write scenarios as a large group.
In the Agile Testing Quadrants, BDD is a Quadrant 2 activity, producing business-facing tests that support development.
BDD is complementary to manual, exploratory testing (which fits in Quadrant 3). It doesn’t completely replace manual testing.
Features and scenarios are formalized using Cucumber’s Gherkin language.
BDD is iterative, not linear. Don’t try to do all the discovery, then all the formalization, then all the automation. Instead, identify some key examples, formalize a few of them, begin automating and implementing them, and then repeat as necessary to complete a user story.
Resources
Crispin, Lisa, and Janet Gregory. Agile Testing: A Practical Guide for Testers and Agile Teams. Hoboken: Pearson Education, Inc., 2009.
Hellesoy Aslak, “The World’s Most Misunderstood Collaboration Tool”: https://cucumber.io/blog/2014/03/03/the-worlds-most-misunderstood-collaboration-tool